[논문 번역] Active Retrieval Augmented Generation
논문 출처
Zhengbao Jiang, Frank F. Xu, Luyu Gao, Zhiqing Sun, Qian Liu,
Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, Graham Neubig.
능동 검색 기반 생성(Active Retrieval Augmented Generation).
카네기멜런대학교 언어기술연구소¹, Sea AI Lab², FAIR Meta³.
🔗 원문 링크 (arXiv: 2305.06983)
저자
- Zhengbao Jiang¹*
- Frank F. Xu¹*
- Luyu Gao¹*
- Zhiqing Sun¹*
- Qian Liu²
- Jane Dwivedi-Yu³
- Yiming Yang¹
- Jamie Callan¹
- Graham Neubig¹
(¹Language Technologies Institute, Carnegie Mellon University
²Sea AI Lab
³FAIR, Meta)
*주요 기여자(Lead contributors)이다.
초록 (Abstract)
대규모 언어 모델(LMs)이 언어를 이해하고 생성하는 놀라운 능력에도 불구하고,
LMs는 환각을 일으키고 사실적으로 부정확한 출력을 만들어내는 경향이 있다.
외부 지식 자원으로부터 정보를 검색하여 LMs를 보완하는 것은
하나의 유망한 해결책이다.
대부분의 기존 검색 기반 증강 LMs는
입력에 기반하여 단 한 번만 정보를 검색하는
retrieve-and-generate 방식을 사용한다.
그러나 이것은 긴 텍스트를 생성하는
보다 일반적인 시나리오에서는 한계가 있다.
그러한 경우에는 생성 과정 전체에 걸쳐
지속적으로 정보를 수집하는 것이 필수적이다.
이 연구에서 우리는
능동 검색 기반 생성(active retrieval augmented generation)에 대한
일반화된 관점을 제시한다.
이 방법들은 생성 과정 전반에서 언제, 무엇을 검색해야 하는지를 능동적으로 결정한다.
우리는 FLARE(Forward-Looking Active REtrieval augmented generation)를 제안한다.
이 방식은 다음 문장에 대한 예측을 반복적으로 사용하여 향후 내용을 미리 예상하고,
그 예측된 문장을 관련 문서들을 검색하기 위한 쿼리로 활용하여
만약 낮은 신뢰도의 토큰이 포함될 경우
해당 문장을 재생성하는 일반적(generic) 방법이다.
우리는 FLARE를 4개의 장문 지식 집약적 생성 과제/데이터셋 전반에서
기존 베이스라인들과 함께 종합적으로 테스트하였다.
FLARE는 모든 과제에서 뛰어나거나 경쟁력 있는 성능을 달성하였으며,
이는 우리의 방법1의 효과성을 입증한다.
1코드와 데이터셋은 https://github.com/jzbjyb/FLARE 에서 제공된다.
1 서론 (Introduction)
생성 언어 모델(LMs)은
(Brown et al., 2020; Ouyang et al., 2022; OpenAI, 2023;
Chowdhery et al., 2022; Zhang et al., 2022; Touvron et al., 2023;
Zhao et al., 2023)
그 놀라운 능력으로 인해 자연어처리(NLP) 시스템에서 기초적인 구성 요소가 되었다.
LMs가 훈련 과정에서 일부 세계 지식을 암기하였음에도
(Petroni et al., 2019; Roberts et al., 2020;
Jiang et al., 2020),
여전히 환각을 일으키고 허구의 내용을 만들어내는 경향이 있다
(Maynez et al., 2020; Zhou et al., 2021).
외부 지식 자원으로부터 관련 정보를 조회하는 검색 구성 요소로 LMs를 보완하는 것은
환각 문제를 해결하기 위한 유망한 방향이다
(Khandelwal et al., 2020; Izacard et al., 2022).
검색 기반 증강 LMs는 일반적으로 사용자의 입력에 기반하여 문서를 검색하고,
그 검색된 문서들에 조건부로 완전한 답변을 생성하는
retrieve-and-generate 구성을 사용한다
(Chen et al., 2017; Guu et al., 2020;
Lewis et al., 2020; Izacard and Grave, 2021;
Sachan et al., 2021; Lee et al., 2021;
Jiang et al., 2022; Izacard et al., 2022;
Nakano et al., 2021; Qian et al., 2023;
Lazaridou et al., 2022; Shi et al., 2023).
이러한 단일 시점(single-time) 검색 기반 증강 LMs는
순수한 파라메트릭 LMs보다 우수한 성능을 보이는데,
특히 사실 기반 질의응답(QA)과 같이 단문 지식 집약적 생성 과제에서 그러하다
(Kwiatkowski et al., 2019; Joshi et al., 2017).
이러한 과제에서는 사용자 입력에서 정보 요구가 명확하며,
입력에 기반하여 단 한 번 관련 지식을 검색하는 것만으로 충분하다.
점점 더 강력해지는 대규모 LMs는
장문(long-form) 출력을 생성하는 보다 복잡한 과제들에서도 능력을 보여왔다.
예를 들어 장문 QA
(Fan et al., 2019; Stelmakh et al., 2022),
오픈 도메인 요약
(Cohen et al., 2021; Hayashi et al., 2021; Giorgi et al., 2022),
그리고 연쇄적 사고(chain-of-thought; CoT) 추론
(Wei et al., 2022; Ho et al., 2020; Geva et al., 2021; Hendrycks et al., 2020) 등이 있다.
단문(short-form) 생성과 달리 장문 생성은
입력만으로는 명확하지 않은 복잡한 정보 요구를 수반한다.
사람이 논문, 에세이, 책과 같은 콘텐츠를 작성할 때 점진적으로 정보를 수집하는 것처럼,
LM을 이용한 장문 생성 또한 생성 과정 전반에 걸쳐
여러 조각의 지식을 수집하는 것이 필요하다.
예를 들어 특정 주제에 대한 요약문을 생성할 때,
주제 이름(e.g., Joe Biden)에 기반한 초기 검색은
모든 측면과 세부 내용을 포괄하지 못할 수 있다.
생성 과정에서 필요한 경우 추가 정보를 검색하는 것이 매우 중요하다.
예를 들어 특정 측면(e.g., Joe Biden의 교육 이력)을 생성할 때나,
특정 세부 사항(e.g., Joe Biden의 대통령 선거 출마 발표 날짜)을 생성할 때 그러하다.
생성 과정 전반에 걸쳐 여러 차례 검색하려는 여러 시도가 이루어져 왔다.
이러한 시도들에는 과거 문맥을 수동적으로 사용하여
고정된 간격으로 추가 정보를 검색하는 방식
(Khandelwal et al., 2020; Borgeaud et al., 2022;
Ram et al., 2023; Trivedi et al., 2022)이 포함되는데,
이 방식은 LMs가 향후 무엇을 생성하려 하는지를 정확하게 반영하지 못하거나
부적절한 지점에서 검색을 수행할 수 있다.
멀티홉(multihop) QA 연구들 중 일부는 전체 질문을 하위 질문들로 분해하고,
각 하위 질문을 사용하여 추가 정보를 검색하는 방식을 사용한다
(Press et al., 2022; Yao et al., 2022;
Khot et al., 2022; Khattab et al., 2022).
우리는 다음의 질문을 던진다:
단순하고 일반적인 검색 기반 증강 LM을 만들 수 있는가?
즉, 생성 과정 전반에 걸쳐
언제 무엇을 검색해야 하는지를 능동적으로 결정하며,
다양한 장문 생성 과제에 적용될 수 있는가?
우리는 능동 검색 기반 생성(active retrieval augmented generation)에 대한
일반화된 관점을 제시한다.
우리가 세운 ‘언제 검색할 것인가’에 대한 가설은 다음과 같다:
LMs는 필요한 지식을 갖추지 못한 경우에만 정보를 검색해야 한다.
이는 수동적 검색 기반 LMs에서 발생하는 불필요하거나 부적절한 검색
(Khandelwal et al., 2020; Borgeaud et al., 2022;
Ram et al., 2023; Trivedi et al., 2022)을 피하기 위함이다.
대규모 LMs는 일반적으로 잘 보정되어 있으며(well-calibrated),
낮은 확률/확신(confidence)은 지식 부족을 나타낸다는 관찰
(Kadavath et al., 2022)에 기반하여,
우리는 LMs가 낮은 확률의 토큰을 생성할 때만
검색을 수행하는 능동적 검색 전략을 채택한다.
무엇을 검색할 것인가(what to retrieve)를 결정할 때는
LMs가 미래에 무엇을 생성하려 하는지를 고려하는 것이 중요하다.
능동 검색의 목표는 미래 생성에 이익을 주는 것이기 때문이다.
따라서 우리는 임시 다음 문장(a temporary next sentence)을 생성함으로써
미래를 예측하고, 이를 관련 문서를 검색하기 위한 쿼리로 사용한 뒤,
검색된 문서들에 조건부로 다음 문장을 다시 생성하는 방식을 제안한다.
이 두 가지 측면을 결합하여
우리는 Forward-Looking Active REtrieval augmented generation(FLARE)를 제안한다
(그림 1 참고).
FLARE는 임시 다음 문장을 반복적으로 생성하고,
그 문장이 낮은 확률의 토큰을 포함할 경우 이를 관련 문서 검색을 위한 쿼리로 사용하며,
문장의 끝에 도달할 때까지 다음 문장을 재생성하는 방식으로 동작한다.
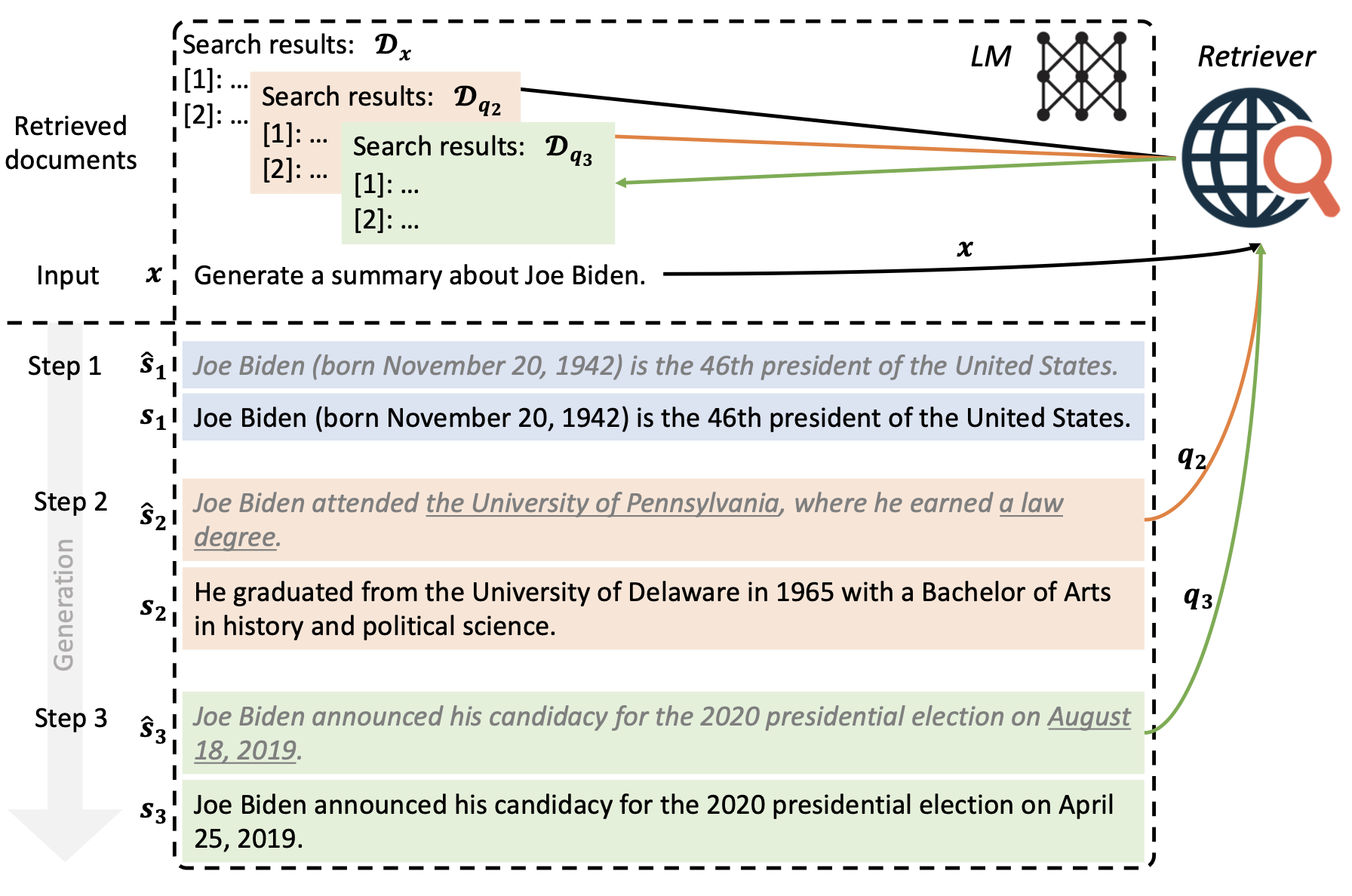
그림 1: 전방향 능동 검색 기반 생성(forward-looking active retrieval augmented generation) (FLARE)의 예시.
사용자 입력 x와 초기 검색 결과 $D_x$으로부터 시작하여,
FLARE는 반복적으로 임시 다음 문장을 생성한다 (회색 이탤릭체로 표시됨).
그리고 그 문장이 낮은 확률의 토큰을 포함하는지 (밑줄로 표시됨) 확인한다.
만약 그렇다면(2단계와 3단계),
시스템은 관련 문서들을 검색하고 그 문장을 다시 생성한다.
FLARE는 추가적인 훈련 없이 추론 단계에서 어떤 기존 LMs에도 적용 가능하다.
GPT-3.5(Ouyang et al., 2022)가 다양한 과제에서 보여준 인상적인 성능을 고려하여,
우리는 text-davinci-003에서 우리 방법의 효과를 검증한다.
우리는 FLARE를 장문 출력을 생성하는 네 가지 다양한 과제/데이터셋에서 평가한다.
이에는 멀티홉 QA(2WikiMultihopQA), 상식 추론(StrategyQA), 장문 QA(ASQA),
오픈 도메인 요약(WikiAsp) (Ho et al., 2020; Geva et al., 2021;
Stelmakh et al., 2022; Hayashi et al., 2021)이 포함된다.
모든 과제에서 FLARE는 단일 시점(single-time) 및
다중 시점(multi-time) 검색 기반 베이스라인들과 비교하여
우수하거나 경쟁력 있는 성능을 달성하였으며,
이는 우리 방법의 효과성과 일반화 성능을 입증한다.
2 검색 기반 생성 (Retrieval Augmented Generation)
우리는 단일 시점(single-time) 검색 기반 생성(retrieval augmented generation)을
형식적으로 정의하고, 능동 검색 기반 생성(active retrieval augmented generation)의
프레임워크를 제안한다.
2.1 표기법과 정의 (Notations and Definitions)
사용자 입력 $x$와 문서 코퍼스 $D = \lbrace d_i \rbrace_{i=1}^{|D|}$
(예: 전체 위키피디아 문서들)이 주어졌을 때,
검색 기반 증강 LMs의 목표는 다음의 답변을 생성하는 것이다:
이는 코퍼스에서 검색된 정보를 활용하여
$m$개의 문장 또는 $n$개의 토큰으로 이루어진 답변을 생성하는 것이다.
검색 기반 LM에서는, LM이 일반적으로 검색기(retriever)와 함께 동작하며,
검색기는 쿼리 $q$에 대해 문서 목록 $D_q = \text{ret}(q)$ 를 검색할 수 있다.
LM은 사용자 입력 $x$와 검색된 문서들 $D_q$ 둘 모두에 조건부로 답변을 생성한다.
우리는 언제 그리고 무엇을 검색할 것인지 결정하는 여러 방법들을 살펴보는 데 초점을 두므로,
기존 연구들 (Ram et al., 2023; Trivedi et al., 2022)을 따라
검색된 문서들을 사용자 입력 앞에 덧붙여 향후 생성에 도움이 되도록 한다.
이 설정은 베이스라인과 우리 방법 모두에 공정한 비교를 제공한다.
\[y = \text{LM}([\;D_q,\; x\;]),\]여기서 $[\;, \;]$는 주어진 순서를 따르는 연결(concatenation)을 의미한다.
2.2 단일 시점 검색 기반 생성 (Single-time Retrieval Augmented Generation)
가장 일반적인 선택은 사용자 입력을 그대로 검색을 위한 쿼리로 사용하고,
전체 답변을 한 번에 생성하는 것이다:
2.3 능동 검색 기반 생성 (Active Retrieval Augmented Generation)
장문 생성을 검색을 통해 보조하기 위해,
우리는 능동 검색 기반 생성(active retrieval augmented generation)을 제안한다.
이는 생성 과정 전반에 걸쳐 언제 그리고 무엇을 검색할 것인지
능동적으로 결정하는 일반적(generic) 프레임워크이다.
이 과정은 검색과 생성이 서로 교차(interleaving)되도록 한다.
형식적으로, 단계 $t$ ($t \ge 1$)에서
검색 쿼리 $q_t$는 사용자 입력 $x$와 이전에 생성된 출력
$y_{<t} = [y_0, \ldots, y_{t-1}]$
둘 모두에 기반하여 구성된다:
여기서 $\text{qry}(\cdot)$는 쿼리 생성(query formulation) 함수이다.
초기 단계($t = 1$)에서 이전 생성은 비어 있으며 ($y_{<1} = \varnothing$),
사용자 입력이 초기 쿼리로 사용된다 ($q_1 = x$).
검색된 문서들 $D_{q_t}$이 주어지면, LM은 다음 검색이 발생하거나
출력이 끝에 도달할 때까지 지속적으로 답변을 생성한다:
여기서 $y_t$는 현재 단계 $t$에서 생성된 토큰을 의미한다.
LM의 입력은 검색된 문서들 $D_{q_t}$,
사용자 입력 $x$, 그리고 이전 생성 $y_{<t}$의 연결(concatenation)이다.
우리는 이전에 검색된 문서들 $\bigcup_{t’ < t} D_{q_{t’}}$을 버리고,
현재 단계의 검색 문서들만을 사용하여
다음 생성이 LM의 입력 길이 제한에 도달하지 않도록 한다.
3 FLARE: 전방향 능동 검색 기반 생성
(FLARE: Forward-Looking Active REtrieval Augmented Generation)
우리의 직관은 다음과 같다.
(1) LMs는 불필요하거나 부적절한 검색을 피하기 위해
필요한 지식을 갖추지 못했을 때에만 정보를 검색해야 한다.
그리고 (2) 검색 쿼리는 미래 생성의 의도를 반영해야 한다.
우리는 능동 검색 기반 생성 프레임워크를 구현하기 위해
두 가지 전방향 능동 검색 기반 생성(FLARE) 방법을 제안한다.
첫 번째 방법은 답변을 생성하는 동안 필요할 때
LM이 검색 쿼리를 생성하도록 프롬프트하며, 검색을 유도하는 지시문을 사용한다.
이 방법을 $ \text{FLARE}_{\text{instruct}} $ 라고 한다.
두 번째 방법은 LM의 생성을 직접 검색 쿼리로 사용하는 방식이며,
$ \text{FLARE}_{\text{direct}} $ 라고 한다.
이 방법은 다음 문장을 반복적으로 생성하여 미래 주제에 대한 통찰을 얻고,
불확실한 토큰이 존재할 경우 관련 문서들을 검색하여 다음 문장을 다시 생성한다.
3.1 검색 지시문을 활용한 FLARE
(FLARE with Retrieval Instructions)
Toolformer(Schick et al., 2023)에서 영감을 받아,
검색이 필요함을 표현하는 가장 직관적인 방법 중 하나는
추가 정보가 필요할 때 “[Search(query)]”를 생성하는 것이다
(Schick et al., 2023).
예를 들어,
“The colors on the flag of Ghana have the following meanings.
Red is for [Search(Ghana flag red meaning)] the blood of martyrs, …”
와 같은 방식이다.
GPT-3.5 모델이 API 접근만을 제공하는 상황에서는,
이러한 동작을 few-shot 프롬프트(Brown et al., 2020)를 통해 유도한다.
구체적으로, 다운스트림(downstream) 작업의 경우
검색 관련 지시문과 예시들을 skill 1로서 프롬프트의 시작 부분에 두고,
그 뒤에 다운스트림 작업의 지시문과 예시들을 skill 2로서 배치한다.
테스트 사례가 주어지면, 우리는 LMs에게 skill 1과 skill 2를 결합하여
작업을 수행하는 동안 검색 쿼리를 생성하도록 요구한다.
프롬프트의 구조는 Prompt 3.1에 제시되어 있으며,
전체 상세 내용은 Prompt D.3에서 확인할 수 있다.

그림 2에서 보인 바와 같이, LM이 “[Search(query)]” (회색 이탤릭체로 표시됨)을 생성하면,
우리는 생성을 중단하고 쿼리 용어를 사용하여 관련 문서들을 검색한다.
검색된 문서들은 다음 검색 쿼리가 생성되거나 출력이 끝에 도달할 때까지
미래 생성을 보조하기 위해 사용자 입력 앞에 덧붙여진다.
추가 구현 상세는 부록 Appendix A에 포함되어 있다.
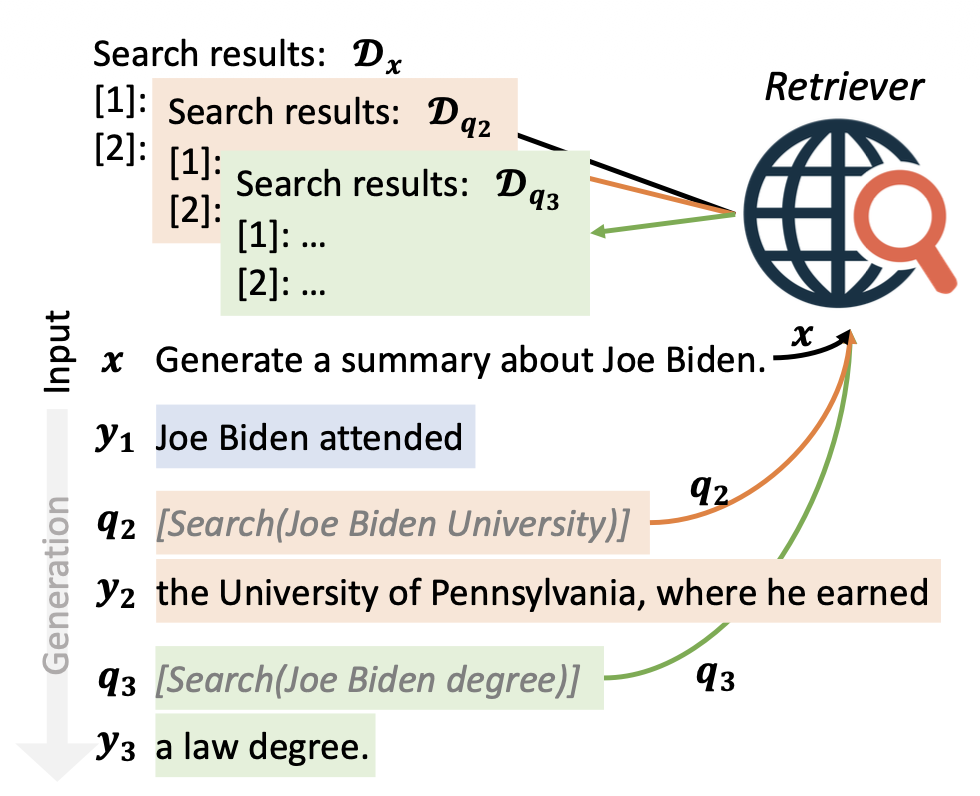
그림 2: 검색 지시문을 사용한 전방-예측(active) 검색 보강 생성($ \text{FLARE}_{\text{instruct}} $)의 예시.
미래 생성을 돕기 위해 관련 정보를 검색하기 위한 검색 쿼리들을
(회색 이탤릭체로 표시된) 반복적으로 생성한다.
3.2 직접 FLARE (Direct FLARE)
우리가 블랙박스 LMs를 미세 조정할 수 없기 때문에,
검색 지시문들을 통해 $ \text{FLARE}_{\text{instruct}} $가 생성한 질의들은
신뢰할 수 없을 수도 있다는 것을 발견했다.
따라서, 우리는 다음 문장을 사용하여
언제 그리고 무엇을 검색할지를 결정하는
보다 직접적인 방식의 순방향(active) 검색을 제안한다.
3.2.1 신뢰도 기반 능동 검색 (Confidence-based Active Retrieval)
그림 1에 나타난 바와 같이, 단계 $t$에서 우리는 먼저 검색된 문서들에 조건화하지 않고
임시 다음 문장 $\hat{s}_t = \text{LM}([\;x,\; y_{<t}\;])$을 생성한다.
그 다음 우리는 검색을 촉발할지 여부를 결정하고
$\hat{s}_t$를 기반으로 질의들을 공식화한다.
만약 LM이 $\hat{s}_t$에 대해 확신(confident)한다면,
추가 정보를 검색하지 않고 이를 받아들인다.
그렇지 않다면, 우리는 $\hat{s}_t$를 사용하여
적절한 문서를 검색하기 위한 검색 질의 $q_t$를 만들고,
그 다음 문장 $s_t$를 다시 생성한다(regenerate).
우리가 반복(iteration)의 기반으로 문장을 사용하는 이유는,
구(phrase)처럼 너무 짧지도 않고
단락(paragraph)처럼 너무 길지도 않은
의미 단위(semantic units)로서 문장이 갖는 중요성 때문이다.
그러나 우리의 접근법은 단락이나 구를 기반으로 사용할 수도 있다.
LM들은 잘 보정되어 있는 경향이 있기 때문에,
낮은 확률/신뢰도는 종종 지식 부족을 나타낸다
(Jiang et al., 2021; Kadavath et al., 2022; Varshney et al., 2022).
우리는 $\hat{s}_t$의 어떤 토큰이라도
임계값 $\theta \in [0,1]$보다 낮은 확률을 가지면 능동적으로 검색을 촉발한다.
$\theta = 0$이면 검색이 전혀 촉발되지 않음을 의미하며,
$\theta = 1$이면 모든 문장에서 검색이 촉발된다.
여기서 질의 $q_t$는 $\hat{s}_t$에 기초하여 공식화된다.
3.2.2 신뢰도 기반 질의 공식화 (Confidence-based Query Formulation)
검색을 수행하는 한 가지 방법은
다음 문장 $\hat{s}_t$를 질의 $q_t$로 직접 사용하는 것이다.
이는 LM이 생성한 가설적 제목(hypothetical titles)이나
단락(paragraphs)을 검색 질의나 증거로 사용하는
기존 방법들과 유사한 취지를 공유한다
(Gao et al., 2022; Sun et al., 2022; Yu et al., 2022; Mao et al., 2021).
우리는 이러한 기법들을 능동적 정보 접근이 필수적인 장문(long-form) 생성으로 일반화한다.
우리는 다음 문장을 사용하여 검색을 수행하는 것이
이전 문맥을 사용하는 것보다 훨씬 더 좋은 결과를 낸다는 것을 발견했으며,
이는 뒤의 하위절 6.2에서 보여진다.
그러나 이는 그 안에 포함된 오류를 지속시킬 위험이 있다.
예를 들어, LM이 “Joe Biden attended the University of Pennsylvania”
라는 문장을 생성했으나,
실제 사실은 그가 University of Delaware에 다녔던 것이라면,
이 잘못된 문장을 질의로 사용하는 것은 오도하는 정보를 검색하게 만들 수 있다.
우리는 그림 3에 나타난 바와 같이
이 문제를 극복하기 위한 두 가지 간단한 방법을 제안한다.
그림 3: 암시적 질의 공식화와 명시적 질의 공식화.
낮은 확률을 가진 토큰들은 밑줄로 표시된다.
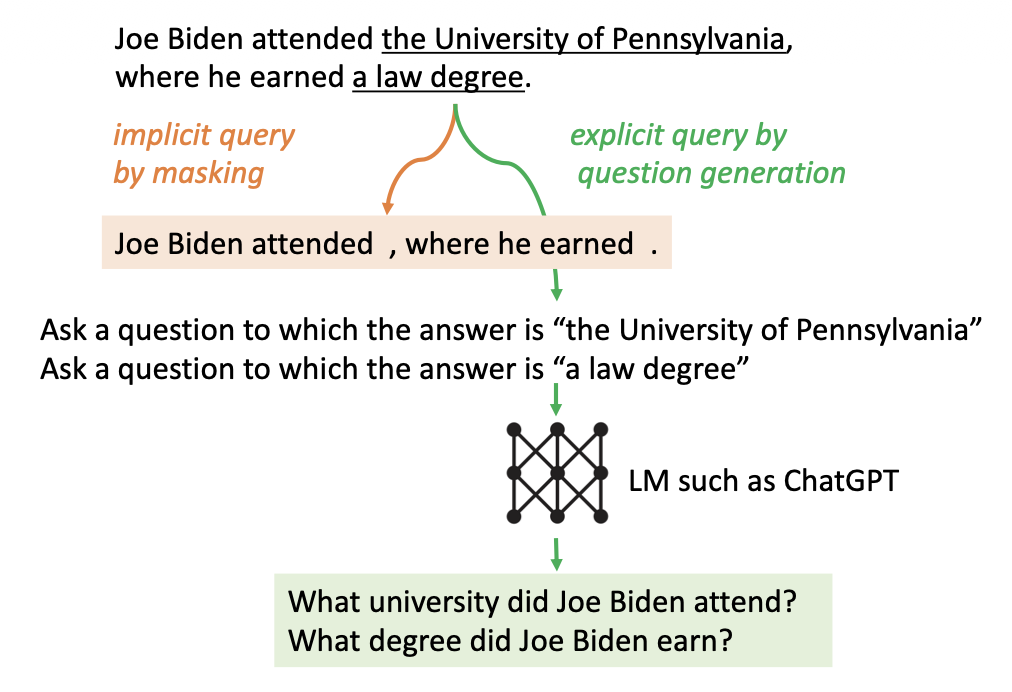
마스킹된 문장을 암시적 질의로 사용하기
첫 번째 방법은 $\hat{s}_t$에서 신뢰도가 낮은 토큰들을
확률이 임계값 $\beta \in [0,1]$ 아래일 때 마스킹한다.
더 높은 $\beta$는 더 공격적인 마스킹을 초래한다.
이 방법은 문장에서 잠재적인 방해 요소들을 제거하여 검색 정확도를 향상시킨다.
명시적 질의로서 생성된 질문들
또 다른 방법은 $\hat{s}_t$에서 신뢰도가 낮은 구간(span)을
직접적으로 겨냥하는 명시적 질문들을 생성하는 것이다.
예를 들어, LM이 “the University of Pennsylvania”에 대해 확신하지 못하는 경우,
“Which university did Joe Biden attend?”와 같은 질문은
관련 정보를 검색하는 데 도움이 될 수 있다.
Self-ask(Press et al., 2022)는 후속 질문(follow-up questions)을
다운스트림 작업 예시들에 수동으로 삽입함으로써 이를 달성했으며,
이는 뒤에 Prompt D.2에서 보이듯 작업별 주석(annotation)이 필요하다.
우리는 이러한 추가 주석 없이
신뢰도가 낮은 구간들을 대상으로 하는 질문을 생성하는 범용적 접근법을 개발하였다.
구체적으로, 우리는 먼저 $\hat{s}_t$에서
확률이 $\beta$ 아래인 모든 구간(span)들을 추출한다.
각 추출된 구간 $z$에 대해,
그 구간으로 대답될 수 있는 질문 $q_{t,z}$를 생성하도록 gpt-3.5-turbo에 프롬프트한다.

우리는 생성된 각 질문을 사용하여 검색을 수행하고,
반환된 문서들을 미래 생성에 도움이 되도록
하나의 랭킹 리스트로 끼워 넣는다(interleave).
요약하면, 질의 $q_t$는 다음과 같이 $\hat{s}_t$를 기반으로 구성된다:
\[q_t = \begin{cases} \varnothing & \text{만약 } \hat{s}_t \text{의 모든 토큰의 확률이 } \ge \theta \text{ 인 경우} \\ \text{mask}(\hat{s}_t) \text{ 또는 } \text{qgen}(\hat{s}_t) & \text{그 외의 경우} \end{cases}\]3.3 구현 세부 사항
Base LM
우리는 가장 발전된 GPT-3.5 LM 중 하나인 text-davinci-003을
그들의 API를 반복적으로 질의(querying)함으로써
우리의 방법을 검증한다.2
2 https://api.openai.com/v1/completions April 23.
문서 코퍼스와 검색기(retrievers)
우리는 검색과 생성의 통합에 초점을 맞추므로,
쿼리를 입력으로 받아 관련 문서 목록을 반환하는
오프더셸프(off-the-shelf) 검색기를 사용한다.
오프더셸프(off-the-shelf)란?
오프더셸프는 “선반에서 바로 가져다 쓰는”이라는 의미로,
추가적인 맞춤 개발 없이 즉시 사용할 수 있는
기존의 완성형 도구·모델·소프트웨어를 의미한다.
즉, 사용자가 별도로 훈련하거나 설계하지 않고
바로 적용할 수 있는 범용 솔루션을 말한다.
주로 Wikipedia의 지식에 의존하는 데이터셋의 경우,
Karpukhin et al. (2020)의 Wikipedia 덤프를 사용하고
BM25(Robertson and Zaragoza, 2009)를 검색기로 사용한다.
오픈 웹의 지식에 의존하는 데이터셋의 경우,
우리는 Bing 검색 엔진3을 검색기로 사용한다.
3 https://www.microsoft.com/en-us/bing/apis/bing-web-search-api
검색된 문서 포맷팅
여러 개의 검색된 문서들은 그들의 순위에 따라 일렬로 정리(linearized)된 뒤,
Prompt D.1을 사용하여 사용자 입력의 맨 앞에 추가된다.
문장 토크나이제이션(sentence-tokenization) 및 효율성과 같은 기타 구현 세부 사항들은
Appendix A에 포함되어 있다.
4 다중 시점 검색 베이스라인들 (Multi-time Retrieval Baselines)
기존의 수동적 다중 시점 검색 증강(passive multi-time retrieval augmented) LMs 역시
우리의 프레임워크(2.3절)를 사용하여 공식화될 수 있다.
이 절에서 우리는 언제 검색하고 무엇을 검색할지에 기반하여
세 가지 베이스라인 범주를 공식적으로 소개한다.
이 베이스라인들은 해당 논문의 정확한 재현이 아니다.
이는 많은 설계 선택들이 다르기 때문에 직접적인 비교가 불가능하게 만들기 때문이다.
우리는 동일한 설정을 사용하여 이를 구현했으며,
유일한 차이는 언제 검색하고 무엇을 검색하는지이다.
이전-윈도우(Previous-window) 접근법은
윈도우 크기를 나타내는 $l$ 토큰마다 한 번씩 검색을 트리거한다.
이전 윈도우에서 생성된 토큰들이 쿼리로 사용된다:
\[\begin{aligned} q_t &= y_{t-1} \quad (t \ge 2), \\ y_t &= [w_{(t-1)l+1}, \ldots, w_{tl}] . \end{aligned}\]이 범주에 속하는 기존 기법들로는 RETRO(Borgeaud et al., 2022),
몇 개의 토큰마다 검색을 수행하는 IC-RALM(Ram et al., 2023),
그리고 모든 토큰마다 검색하는 KNN-LM(Khandelwal et al., 2020)4이 있다.
4 KNN-LM은 현재 디코딩 위치에 대응하는
문맥화된 표현(contextualized representation)을 사용하여
이전 모든 토큰들을 인코딩한 관련 정보를 검색한다.따라서 엄밀히 말하면 $q_t$는 $y_{<t}$가 되어야 한다.
Ram et al. (2023)을 따라 윈도우 크기 $l = 16$을 사용한다.
이전-문장(previous-sentence) 접근법은
매 문장에서 검색을 트리거하고, 이전 문장을 쿼리로 사용하며,
IRCoT(Trivedi et al., 2022)이 여기에 속한다:
질문 분해(Question decomposition) 접근법은
작업별 예시들을 수동으로 주석(annotation) 처리하여
LM이 출력을 생성하는 동안 분해된 하위 질문(sub-questions)을 생성하도록 유도한다.
예를 들어, self-ask(Press et al., 2022)는 이 범주에 속하는 방법으로,
Prompt D.2에서 보이듯 예시(exemplar) 안에 하위 질문들을 수동으로 삽입한다.
테스트 사례(test case)에서는
모델이 하위 질문을 생성할 때마다 동적으로 검색이 트리거된다.
앞서 언급된 접근법들은 생성 중에 추가 정보를 검색해 올 수 있다.
그러나 이러한 방법들은 다음과 같은 뚜렷한 단점들을 가진다:
(1) 이전에 생성된 토큰들을 쿼리로 사용하는 것은
LM이 미래에 생성하려는 내용을 반영하지 못할 수 있다.
(2) 고정된 간격으로 정보를 검색하는 방식은
부적절한 지점에서 검색이 발생할 수 있어 비효율적일 수 있다.
(3) 질문 분해(question decomposition) 기반 접근법은
작업(task)별 프롬프트 엔지니어링이 필수적이므로,
새로운 작업에 대한 일반화 성능을 제한한다.
5 실험 설정 (Experimental Setup)
우리는 FLARE의 효과를 few-shot in-context 학습
(Radford et al., 2019; Brown et al., 2020; Liu et al., 2023)을 사용하여
4개의 다양한 지식-집약적 작업에서 평가한다.
우리는 이전 연구(Trivedi et al., 2022)를 따라
실험 비용 때문에 각 데이터셋에서 최대 500개의 예시만 부분 샘플링한다.
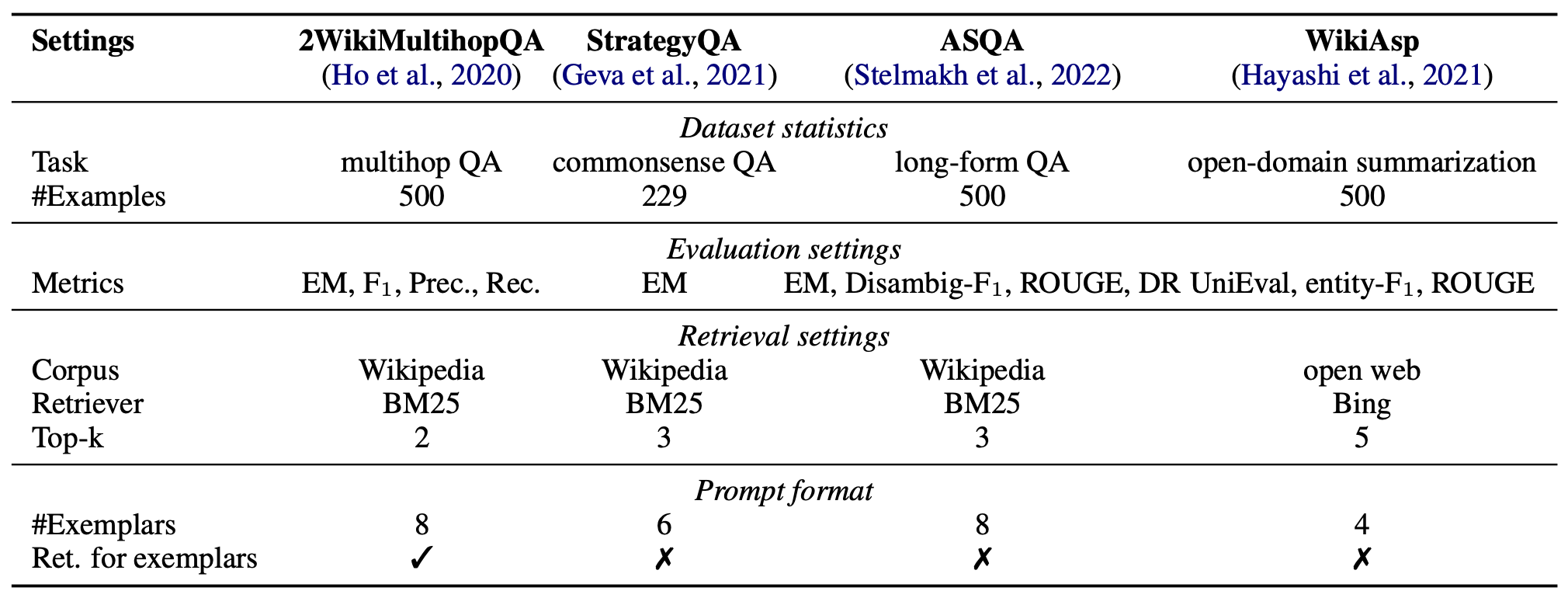
데이터셋, 측정 지표, 그리고 설정은 부록 B의 표 7에 요약되어 있다.
FLARE의 하이퍼파라미터는 개발 세트를 기준으로 선택되며
표 9에 나열되어 있다.
특별히 명시되지 않은 경우, FLARE는 $ \text{FLARE}_{\text{direct}} $를 의미한다.
멀티홉 QA(Multihop QA)
멀티홉 QA의 목표는 정보 검색과 추론을 통해 복잡한 질문에 답하는 것이다.
우리는 2WikiMultihopQA (Ho et al., 2020)를 사용하며,
이는 Wikipedia 문서들이 출처가 되는,
구성(composition), 비교(comparison), 또는 추론(inference)을 요구하는
2-홉(2-hop)의 복잡한 질문들을 포함한다.
예: “Why did the founder of Versus die?”
우리는 Wang et al. (2022)를 따라
연쇄적 사고(chain-of-thought)와 최종 답을 모두 생성한다.
실험 설정의 세부사항은 Appendix B에 포함되어 있다.
우리는 정규표현식을 사용하여 출력에서 최종 답을 추출하고,
정확 일치(EM), 그리고 토큰 수준 F₁, 정밀도, 재현율을 이용하여
참조 답(reference answer)과 비교한다.
EM(Exact Match)
EM은 모델이 생성한 최종 답이
참조 답(reference answer)과 글자 단위로 완전히 동일한지를 평가하는 지표이다.
공백, 구두점, 대소문자 등을 정규화한 뒤,
정확히 같은 문자열이면 1점, 그렇지 않으면 0점을 부여한다.
즉, 답을 정확히 맞췄는지 여부만 판단하는 가장 엄격한 평가 방식이다.
상식 추론(Commonsense reasoning)
상식 추론은 답변을 생성하기 위해 세계 지식과 상식적 지식을 필요로 한다.
우리는 StrategyQA(Geva et al., 2021)를 사용하며,
이는 군중 지성으로 수집된 예/아니오 질문들로 구성된 데이터셋이다.
예: “배가 물에 가라앉을까? (Would a pear sink in water?)”
우리는 Wei et al. (2022)를 따라
연쇄적 사고(chain-of-thought)와 최종 예/아니오 답변을 모두 생성한다.
실험 설정의 세부사항은 Appendix B에 포함되어 있다.
우리는 최종 답변을 추출하고
정확 일치(exact match)를 사용하여 정답(gold answer)과 비교한다.
장문 QA(Long-form QA)
장문 QA(Long-form QA)는 복잡한 정보를 요구하는 질문들에 대해
포괄적인(comprehensive) 답변을 생성하는 것을 목표로 한다
(Fan et al., 2019; Stelmakh et al., 2022).
우리는 입력이 여러 해석이 가능한 모호한 질문들이며
출력은 그 모든 해석을 포함해야 하는
ASQA(Stelmakh et al., 2022)를 테스트베드로 사용한다.
예를 들어
“Where do the Philadelphia Eagles play their home games?”라는 질문은
도시(city), 스포츠 컴플렉스(sports complex),
혹은 경기장(stadium)을 묻는 것일 수 있다.
우리는 많은 경우에서
해당 질문의 어느 측면이 모호한지 사람조차 식별하기 어렵다는 것을 발견했다.
따라서 우리는 또 다른 설정(ASQA-hint)을 만들었는데,
이는 LMs가 답변을 생성할 때
방향을 잃지 않도록 돕는 간단한 힌트를 제공한다.
위 사례의 힌트는 다음과 같다:
“This question is ambiguous in terms of which specific location or venue is being referred to.”
실험 설정의 세부사항은 Appendix B에 포함되어 있다.
우리는 Stelmakh et al. (2022)의 평가지표를 사용하며,
여기에는 EM, RoBERTa 기반 QA 점수(Disambig-F₁),
ROUGE(Lin, 2004),
그리고 Disambig-F₁과 ROUGE를 결합한 전체 점수(DR)가 포함된다.
Disambig-F₁
Disambig-F₁은 모델이 애매하거나 다의적인 질문에서
정답 의미 집합과 동일한 의미를 선택했는지를 평가하는 지표라 한다.
정답 의미 집합을
$G = \lbrace g_1, g_2, \ldots \rbrace$ 라 하고,
모델이 생성한 의미 집합을
$P = \lbrace p_1, p_2, \ldots \rbrace$ 라 할 때,
Precision과 Recall은 다음과 같이 정의된다:
\(\text{Precision} = \frac{|P \cap G|}{|P|}, \qquad \text{Recall} = \frac{|P \cap G|}{|G|}\)
최종 점수는
\(\text{Disambig-F1} = \frac{2 \cdot \text{Precision} \cdot \text{Recall}} {\text{Precision} + \text{Recall}}\) 로 계산된다.
즉, 모델이 선택한 의미가 정답 의미와 얼마나 일치하는지를
F₁ 방식으로 평가하는 지표라 한다.ROUGE
ROUGE는 생성된 문장이 정답 문장과 얼마나 유사한지 측정하는
전통적 텍스트 유사도 지표라 한다.
특히 ROUGE-L은 두 문장 간의 최장 공통 부분수열(LCS)을 기반으로 계산한다.
정답 시퀀스를 $X$, 생성 시퀀스를 $Y$라 할 때,
\(\text{Precision}_{LCS} = \frac{LCS(X, Y)}{|Y|}, \qquad \text{Recall}_{LCS} = \frac{LCS(X, Y)}{|X|}\)
ROUGE-L은 다음과 같이 계산된다:
\(\text{ROUGE-L} = \frac{(1 + \beta^2)\,\text{Precision}_{LCS}\,\text{Recall}_{LCS}} {\text{Recall}_{LCS} + \beta^2\,\text{Precision}_{LCS}}\)
일반적으로 $\beta = 1$을 사용한다.
이는 생성 문장이 정답과 구조적으로 얼마나 겹치는지를 평가하는 지표라 한다.DR (Disambig-F₁ + ROUGE)
DR은 Disambig-F₁과 ROUGE-L을 결합한 종합 점수라 한다.
두 지표를 동일 비중으로 반영하기 위해 일반적으로 다음과 같이 계산한다:
\(\text{DR} = \frac{\text{Disambig-F1} + \text{ROUGE-L}}{2}\)
DR은 모델이
의미적 정확성(Disambig-F₁)과 텍스트적 유사성(ROUGE-L)
두 측면을 모두 얼마나 충족하는지를 평가하는 균형 잡힌 지표라 한다.
개방형 도메인 요약(Open-domain summarization)
개방형 도메인 요약(Open-domain summarization)의 목표는
오픈 웹에서 정보를 수집하여 특정 주제에 대한 종합적인 요약을 생성하는 것이다
(Giorgi et al., 2022).
우리는 WikiAsp(Hayashi et al., 2021)를 사용하며,
이는 Wikipedia의 20개 도메인에 걸친 개체들에 대해
측면 기반(aspect-based) 요약을 생성하는 것을 목표로 한다.
예를 들어, “Echo School(Oregon)에 대해
학업(academics), 역사(history) 측면을 포함한 요약을 생성하라.”
와 같은 형태이다.
실험 설정 세부 사항은 Appendix B에 포함되어 있다.
평가지표로는 ROUGE,
개체 기반 F₁(named entity-based F₁),
그리고 사실적 일관성(factual consistency)을 측정하는 UniEval
(Zhong et al., 2022)을 사용한다.
6 실험 결과
우리는 먼저 4개의 작업/데이터셋에 걸친 전체 결과를 보고하고,
4절(section 4)에서 소개된 모든 베이스라인(baseline)들과 FLARE의 성능을 비교한다.
그 후, 우리의 방법에서 다양한 설계 선택의 효과를
연구하기 위해 소거 실험(ablation study)을 수행한다.
6.1 베이스라인과의 비교
전체 결과(Overall results)
모든 작업/데이터셋에 걸친 FLARE와
베이스라인(baseline)의 전체 성능은 그림 4에 보고된다.
FLARE는 모든 작업/데이터셋에서 모든 베이스라인을 능가하며,
이는 FLARE가 생성 과정 전반에 걸쳐 추가 정보를 효과적으로 검색할 수 있는
범용적(generic) 방법임을 나타낸다.
그림 4: FLARE와 베이스라인(baselines)을 모든 작업/데이터셋에 걸쳐 비교한 결과.
각 데이터셋의 주요 평가지표(primary metric)를 보고하며,
2WikiMultihopQA, StrategyQA, ASQA에는 EM을,
WikiAsp에는 UniEval을 사용한다.
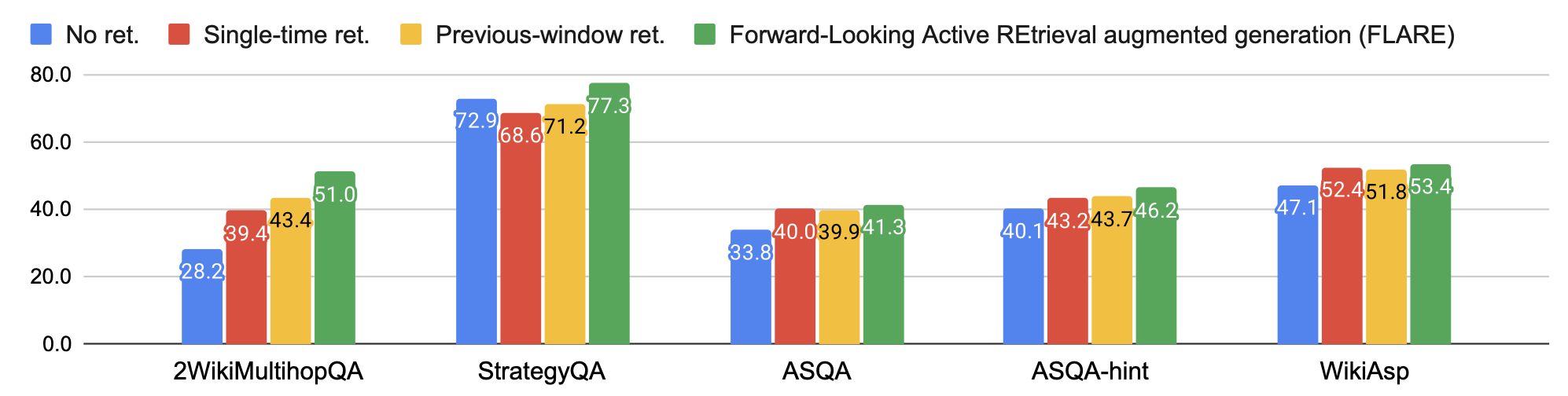
여러 작업 중에서도, multihop QA가 가장 큰 성능 향상을 보인다.
이는 해당 작업이 명확하게 정의되어 있으며,
2-hop 추론 과정을 통해 최종 답을 생성하는 구체적 목표를 가지고 있어,
LLM이 주제에 맞는(on-topic) 출력을 생성하기가 더 쉽기 때문이다.
반면, ASQA와 WikiAsp는 보다 개방형(open-ended) 특성을 가지므로,
생성과 평가 모두에서 난이도가 높아진다.
ASQA-hint에서의 성능 향상은 ASQA보다 더 크게 나타나는데,
이는 애매한 측면(ambiguous aspects)을 식별하는 것이 많은 경우 인간에게조차 어려우며,
일반적인 힌트(generic hint)를 제공하면
LLM이 주제에서 벗어나지 않도록 안내할 수 있기 때문이다.
베이스라인과의 철저한(thorough) 비교
2WikiMultihopQA에서의 모든 베이스라인의 성능은 표 1에 보고된다.
표 1: 2WikiMultihopQA에서의 FLARE와 베이스라인 비교.
이전-윈도우(Previous-window)(Borgeaud et al., 2022; Ram et al., 2023),
이전-문장(previous-sentence)(Trivedi et al., 2022),
그리고 질문 분해(Question decomposition)(Press et al., 2022; Yao et al., 2022)
방법들은 공정한 비교를 위해 다시 구현되었다.
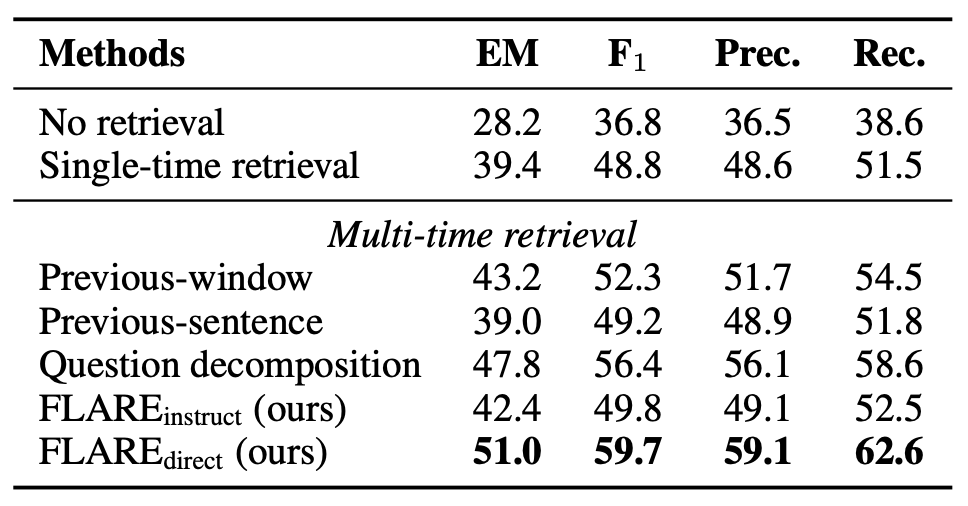
FLARE는 모든 베이스라인을 큰 폭으로 능가하며,
이는 전방향적(active) 미래 정보 탐색이 매우 효과적임을 확인시켜 준다.
대부분의 멀티타임 검색(multi-time retrieval) 기반 접근법은
싱글타임 검색(single-time retrieval)을 능가하지만, 그 차이는 서로 다르다.
이전 문장을 사용한 검색의 향상은 비교적 작으며, 우리는 그 이유가 주로
이전 문장이 종종 2WikiMultihopQA에서
다음 문장에 나타나는 개체나 관계와 다른 내용을 설명하기 때문이라고 가정한다.
반면 이전-윈도우 접근법은 문장의 전반부를 사용하여
후반부 생성을 위해 유용할 수 있는 정보를 검색할 수도 있다.
모든 베이스라인 중에서,
질문 분해 접근법(Press et al., 2022)이 가장 좋은 성능을 보인다.
이는 놀라운 일이 아닌데,
수동으로 주석된(decomposed) 하위 질문(sub-questions)을 포함한
in-context 예시들(Prompt D.2)이
LM이 향후 생성될 토픽/의도에 맞는 하위 질문을
생성하도록 안내하기 때문이다.
FLARE는 이 베이스라인을 능가하며,
이는 효과적인 미래 인지 검색(future-aware retrieval)에
수동 예시 주석(manual exemplar annotation)이
필수적이지 않음을 나타낸다.
$ \text{FLARE}_{\text{instruct}} $와 질문 분해 간의 격차는 크며,
이는 작업-일반적 검색 지시(task-generic retrieval instructions)와 예시를 통해
LM에게 검색 쿼리를 생성하도록 가르치는 것이 도전적임을 보여준다.
우리는 다른 데이터셋들에 대한 모든 평가지표를 표2에 보고한다.
표 2: StrategyQA, ASQA, ASQA-hint, 그리고 WikiAsp에서 FLARE와 베이스라인들의 비교.
D-F1은 Disambig-F1을,
R-L은 ROUGE-L을,
E-F1은 개체(entity) 기반 F1을 의미한다.
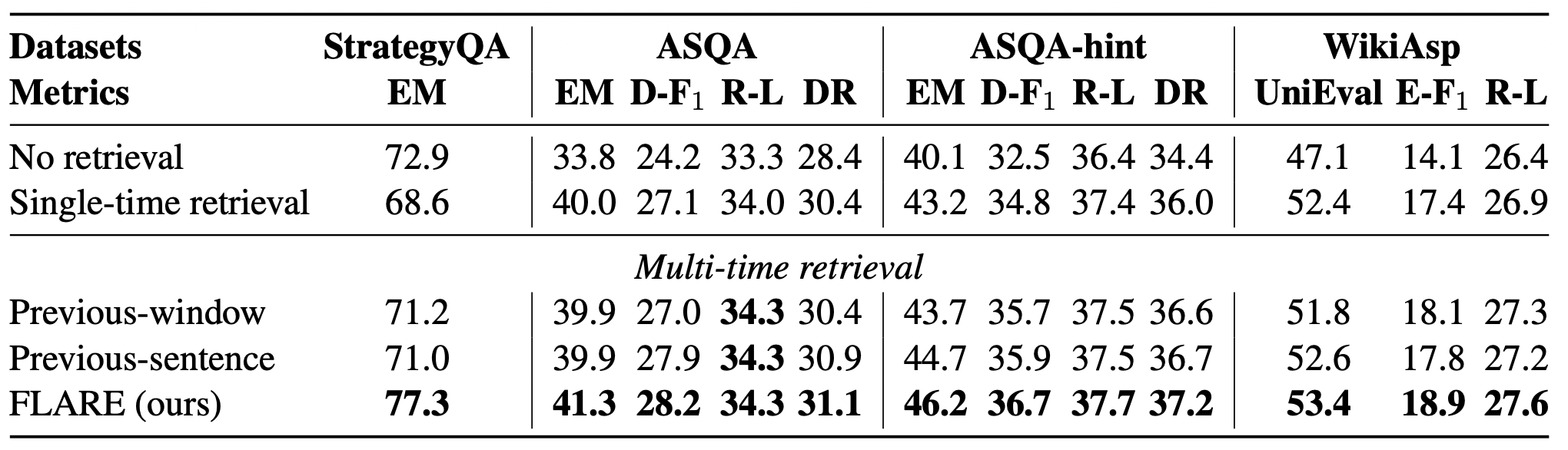
FLARE는 모든 평가지표에 대해 베이스라인보다 우수한 성능을 보인다.
이전 윈도우(previous-window)를 사용한 검색은
ASQA에서 단일 시점(single-time) 검색보다 성능이 떨어지는데,
이는 이전 윈도우가 미래 의도를 정확하게 반영하지 못하기 때문이라고
우리는 가설을 세운다.
우리가 사실성(factuality) 평가에 중점을 두기 때문에,
사실 기반 콘텐츠를 강조하는 평가지표(예: EM, Disambig-F₁, UniEval)가
모든 토큰을 기준으로 계산되는 평가지표(ROUGE-L)보다 더 신뢰할 수 있다.
6.2 소거 실험(Ablation Study)
전방향(forward-looking) 검색의 중요성
우리는 먼저 전방향 검색이 과거 문맥 기반 검색보다 더 효과적임을 검증한다.
2WikiMultihopQA와 ASQA-hint에서 소거 실험을 수행하여,
이전 문장을 사용할 때와 다음 문장을 사용할 때의 검색 성능을 비교한다.
구체적으로, 두 방식 모두 매 문장마다 검색을 수행하며
이전/다음 문장 전체를 그대로 쿼리로 사용한다.
표 3에 나타난 바와 같이,
다음 문장을 사용하여 검색하는 방식이
이전 문장을 사용하는 것보다 명확하게 더 우수한 성능을 보였으며,
이를 통해 우리의 가설이 확인된다.
표 3: 검색을 위해 이전 문장을 사용하는 경우와
다음 문장을 사용하는 경우의 일대일(head-to-head) 비교한 결과
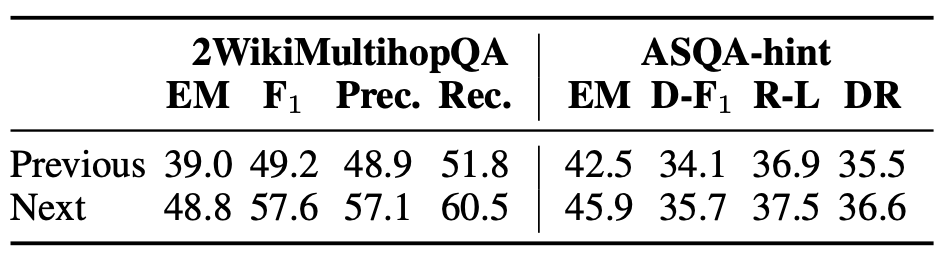
우리는 이전-윈도(previous-window) 접근법도 실행하는데,
서로 다른 개수의 과거 토큰들을 질의로 사용한다.
표 4에서 보이듯, 과거의 너무 많은 토큰들(> 32)을 사용하는 것은 성능을 저해하며,
이는 이전 문맥(previous context)이
향후 생성의 의도(intent of future generations)와
관련이 없을 수도 있다는 우리의 가설을 더욱 확증해준다.
표 4: 서로 다른 개수의 토큰들을 질의로 사용한 이전-윈도(previous-window) 접근법.
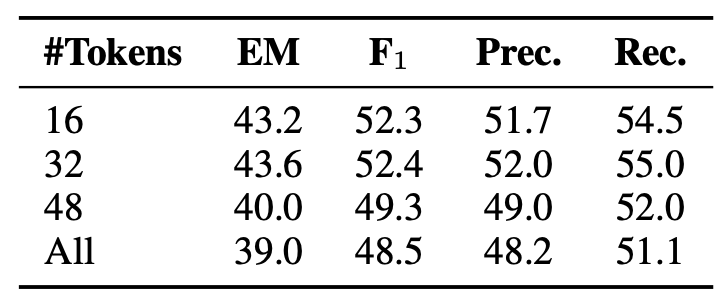
능동적(active) 검색의 중요성
다음으로, 능동적 검색 임계값 θ가 성능에 어떤 영향을 미치는지를 조사한다.
우리의 방법을 “검색을 전혀 하지 않는 경우”에서 “모든 문장에서 검색하는 경우”로 전환하기 위해,
검색을 언제 트리거할지를 결정하는 신뢰도 임계값 θ를 0에서 1까지 조정한다.
그 후, 검색이 활성화된 단계/문장의 비율을 계산하고
이에 기반하여 성능을 평가한다.
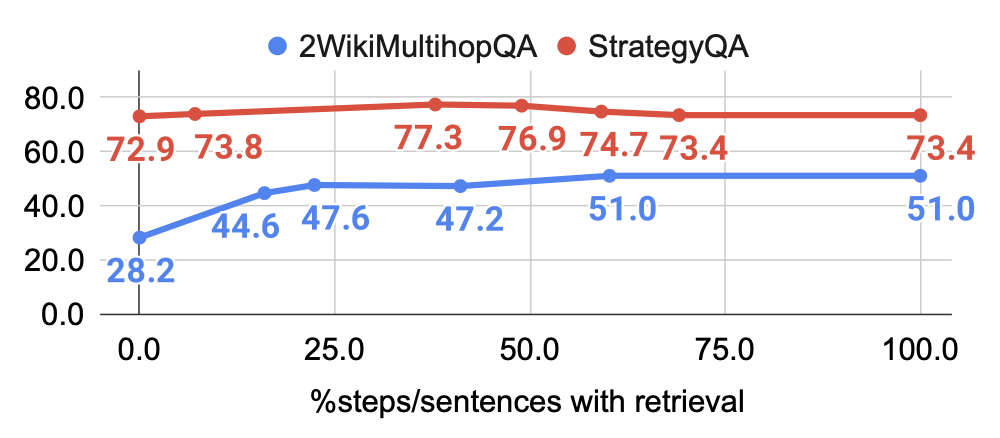
그림 5에서 보이듯, 2WikiMultihopQA에서는
검색 비율이 60%를 초과하면 성능이 평탄해지며,
이는 언어모델이 충분히 확신(confident)하는 경우에는
추가 검색이 필요하지 않음을 의미한다.
StrategyQA에서는 검색 비율이 50%를 넘어서면 성능이 감소하는데,
이는 불필요한 검색이 노이즈를 유발하여
원래의 생성 과정을 방해할 수 있음을 나타낸다.
우리는 전체 문장의 약 40%~80%에서 검색을 트리거하는 것이
작업/데이터셋 전반에서 좋은 성능을 보인다는 사실을 확인하였다.
그림 5: 2WikiMultihopQA와 StrategyQA에서
검색이 활성화된 단계/문장의 비율에 따른 FLARE의 성능(EM).
다양한 쿼리 구조화(formulation) 방법의 효과성
우리는 확률 마스킹을 통한 암묵적(implicit) 쿼리 생성과
질문 생성(question generation)을 통한 명시적(explicit) 쿼리 생성을 연구한다.
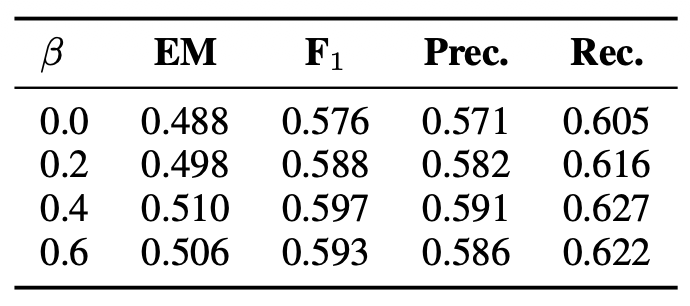
표 5에서는 FLARE가 서로 다른 마스킹 임계값 $ \beta $를 사용할 때의 성능을 비교한다.
완전한 문장 그대로로 검색을 수행하는 것(즉, $ \beta = 0 $)은
낮은 확률을 가진 토큰들을 마스킹하는 것보다 성능이 떨어지며,
이는 낮은 신뢰도의 오류 토큰들이 검색기(retriever)를 방해할 수 있다는
우리의 가설을 확인해 준다.
표 5: 2WikiMultihopQA에서 마스킹 임계값 $ \beta $에 따른 FLARE의 성능.
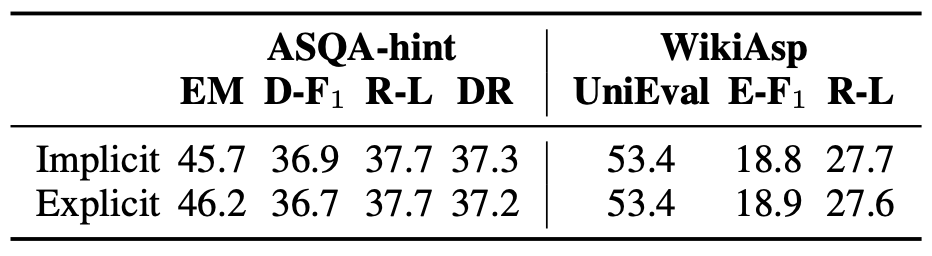
우리는 또한 표 6에서 암묵적 쿼리 구조화 방식과
명시적 쿼리 구조화 방식을 비교한다.
두 방식의 성능은 유사하며,
두 방법 모두 정보 요구(information needs)를 효과적으로 반영할 수 있음을 나타낸다.
표 6: FLARE에서 암시적 쿼리 구성 방식과 명시적 쿼리 구성 방식을 비교한 결과
7 관련 연구(Related Work)
우리는 단일 시점(single-time) 및 다중 시점(multi-time) 검색 기반 LMs에 대한
광범위한 논의는 2.2절과 4절을 참조한다.
이는 본 논문과 가장 밀접하게 관련된 분야이다.
반복적(iterative) 및 적응형(adaptive) 검색
반복적 검색(iterative retrieval)과 결과 정제(refinement)는
텍스트 및 코드 생성 작업에서 연구되어 왔다
(Peng et al., 2023; Zhang et al., 2023; Zemlyanskiy et al., 2022; Yu et al., 2023).
FLARE는 생성 및 검색 전략의 세분성(granularity)측면에서
이들 기존 방법과 구별된다.
적응형 검색(adaptive retrieval)은
질문 빈도(question popularity)
또는 생성 확률(generation probabilities)에 기반하여
단일 시점(single-time) 검색 상황에서 연구되어 왔다
(Mallen et al., 2022; Li et al., 2023).
반면, 본 논문은
능동적인 정보 접근(active information access)이 필요한
장문(long-form) 생성에 초점을 맞춘다.
브라우저 기반 강화 LM들(Browser-enhanced LMs)
WebGPT(Nakano et al., 2021)와 WebCPM(Qin et al., 2023)은
LM이 브라우저와 상호작용하도록 학습시켜 사실성을 강화한다.
이는 강화학습(reinforcement learning) 또는 지도학습(supervised training)을 통해 이루어지며,
생성 이전에 여러 개의 쿼리를 트리거할 수 있는 구조를 갖는다.
FLARE는 텍스트 기반 검색기(text-based retrievers)에 구축되어 있지만,
브라우저와 결합될 경우 검색 품질을 향상시킬 잠재력이 있다.
8 결론 (Conclusion)
장문 생성을 검색 증강과 함께 보조하기 위해,
우리는 생성 도중 언제 무엇을 검색할지 결정하는 능동 검색 증강 생성 프레임워크를 제안한다.
이 프레임워크는 전방향(forward-looking) 능동 검색으로 구현되며,
다가올 문장에 신뢰도가 낮은 토큰(low-confidence tokens)이 포함되어 있을 경우
그 문장을 사용해 관련 정보를 검색하고, 다음 문장을 다시 생성한다.
4개의 작업/데이터셋에 대한 실험 결과는 제안된 방법의 효과성을 입증한다.
향후 연구 방향으로는 능동 검색을 위한 더 나은 전략을 개발하고,
능동적 정보 통합을 수행할 수 있는 효율적인 언어 모델 구조를 개발하는 것이 포함된다.
9 한계점 (Limitations)
우리는 Wizard of Wikipedia(Dinan et al., 2019)와
ELI5(Fan et al., 2019) 데이터셋에서도 실험을 수행했으며,
FLARE가 유의미한 성능 향상을 제공하지는 못한다는 점을 발견한다.
Wizard of Wikipedia는 지식 집약적 대화 생성 데이터셋으로,
출력 길이가 상대적으로 짧다(평균 약 20 토큰).
따라서 여러 개의 서로 다른 정보 조각을 검색할 필요가 크지 않을 수 있다.
ELI5(Fan et al., 2019)는 개방형 질문에 대해
심층적인 장문 답변을 요구하는 장문 QA 데이터셋이다.
Krishna et al. (2021)에서 언급된 바와 같이,
검색 및 평가 과정에서 생성 결과를 정교하게 정합(grounding)하는 데 어려움이 있어,
단일 시점(single-time) 검색과 FLARE 모두 검색을 사용하지 않는 경우에 비해
유의미한 성능 향상을 제공하지는 못한다.
엔지니어링 관점에서 보면,
생성과 검색을 단순하게 엮는(interleaving) 방식은 오버헤드와 생성 비용을 증가시킨다.
LLM은 검색이 일어날 때마다(각 검색마다) 여러 번 활성화되어야 하며,
캐싱이 없는 구현에서는 검색 이후 이전 활성화를 매번 다시 계산해야 한다.
이 문제는, 검색된 문서들 $D_{q_t}$와 입력/생성 $(x / y_{<t})$을
독립적으로 인코딩할 수 있는 특수한 구조적 설계를 통해 잠재적으로 완화될 수 있다.
감사의 글 (Acknowledgements)
본 연구는 싱가포르 국방과학기술청(Singapore Defence Science and Technology Agency)과
IBM 박사과정 펠로십(IBM PhD Fellowship)의 연구비 지원을 일부 받았다.
우리는 Chunting Zhou, Amanda Bertsch, Uri Alon, Hiroaki Hayashi,
Harsh Trivedi, Patrick Lewis, Timo Schick, Kaixin Ma,
Shuyan Zhou, Songwei Ge에게 유익한 논의와 실험에 대한 도움을 제공해 준 것에 대해 감사한다.
참고문헌(References)
Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George van den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, Diego de Las Casas, Aurelia Guy, Jacob Menick, Roman Ring, Tom Hennigan, Saffron Huang, Loren Maggiore, Chris Jones, Albin Cassirer, Andy Brock, Michela Paganini, Geoffrey Irving, Oriol Vinyals, Simon Osindero, Karen Simonyan, Jack W. Rae, Erich Elsen, and Laurent Sifre. 2022. 수조 개의 토큰에서 검색하여 언어 모델을 향상시키기. In International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA, volume 162 of Proceedings of Machine Learning Research, pages 2206–2240. PMLR.
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Hennigan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. 언어 모델은 퓨샷 학습자들이다. Advances in Neural Information Processing Systems 33, NeurIPS 2020.
Danqi Chen, Adam Fisch, Jason Weston, Antoine Bordes. 2017. 위키백과를 읽어 오픈 도메인 질문에 답하기. ACL 2017, Vancouver, Canada, Long Papers, pages 1870–1879.
Aakansha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Ben Hutchinson, Reza Pope, James Bradbury, Jacob Austin, Michael Isard, Guy Gur-Ari, Pengcheng Yin, Toju Duke, Asmelash Lezsyka, Sanjay Ghemawat, Sunipa Dev, Henryk Michalewski, Xavier Garcia, Vedant Misra, Kevin Robinson, Liam Fedus, Denny Zhou, Daphne Ippolito, David Luan, Heyoatenk Liam, Barret Zoph, Alexander Spiridonov, Ryan Sepassi, David Dohan, Shivani Agrawal, Mark Omernick, Andrew M. Dai, Tharamalayam Sankaranarayana Pillai, Marie Pellat, Aitor Lewkowycz, Erica Moreira, Rewon Child, Oleksandr Polozov, Katherine Lee, Zongev Zhou, Xuezhi Wang, Brennan Saeta, Mark Diaz, Orhan Firat, Michele Catasta, Jason Wei, Kathy Meier-Hellstern, Douglas Eck, Jeff Dean, Slav Petrov, Noah Fiedel. 2022. Pathways를 사용한 확장 가능한 언어 모델링. CoRR, abs/2204.02311.
Nachshon Cohen, Oren Kalinsky, Yftah Ziser, Alessandro Moschitti. 2021. Wikisum: 인간 평가에 효율적인 요약 데이터셋. ACL/IJCNLP 2021, Short Papers, pages 212–219.
Emily Dinan, Stephen Roller, Kurt Shuster, Angela Fan, Michael Auli, Jason Weston. 2019. 위키피디아의 마법사: 지식 기반 대화형 에이전트. ICLR 2019.
Angela Fan, Yacine Jernite, Ethan Perez, David Grangier, Jason Weston, Michael Auli. 2019. ELI5: 장문 질문 응답. ACL 2019, Long Papers, pages 3558–3567.
Luyu Gao, Xueguang Ma, Jimmy Lin, Jamie Callan. 2022. 레이블 없이 밀집 검색을 제로샷으로 수행. CoRR, abs/2212.10496.
Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot, Dan Roth, Jonathan Berant. 2021. 아리스토텔레스는 노트북을 사용했는가? 암시적 추론 전략을 조사하는 질문 답변 벤치마크. TACL, 9:346–361.
John M. Giorgi, Luca Soldaini, Bo Wang, Gary D. Bader, Kyle Lo, Lucy Lu Wang, Arman Cohan. 2022. 오픈 도메인 다중 문서 요약의 도전 과제 탐구. CoRR, abs/2212.10526.
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, Ming-Wei Chang. 2020. REALM: 검색 증강 언어 모델 사전학습. CoRR, abs/2002.08909.
Hiroaki Hayashi, Prashant Budania, Peng Wang, Chris Ackerson, Raj Neervannan, Graham Neubig. 2021. Wikiasp: 다중 도메인 요약을 위한 다면적 요약 데이터셋. Transactions of the Association for Computational Linguistics, 9:211–225.
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, Jacob Steinhardt. 2020. 대규모 멀티태스크 언어 이해 측정. CoRR, abs/2009.03300.
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, Akiko Aizawa. 2020. 풍부한 추론 단계를 평가하기 위한 멀티홉 QA 데이터셋 구성. COLING 2020, Barcelona, Spain.
Gautier Izacard, Edouard Grave. 2021. 생성 모델을 활용한 오픈 도메인 질문 응답을 위한 패시지 검색 레버리지. EACL 2021, pages 874–880.
Gautier Izacard, Patrick S. H. Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane Dwivedi-Yu, Armand Joulin, Sebastian Riedel, Edouard Grave. 2022. 검색 증강 언어 모델을 통한 퓨샷 학습. CoRR, abs/2208.03299.
Zhengbao Jiang, Jun Araki, Haibo Ding, Graham Neubig. 2021. 언어 모델이 무엇을 알고 있는지 어떻게 알 수 있는가? 질문 응답을 위한 언어 모델의 보정. TACL, 9:962–977.
Zhengbao Jiang, Luyu Gao, Jun Araki, Haibo Ding, Zhiruo Wang, Jamie Callan, Graham Neubig. 2022. 단일 트랜스포머에서의 검색과 읽기의 종단 간 학습. CoRR, abs/2212.00227.
Zhengbao Jiang, Frank F. Xu, Jun Araki, Graham Neubig. 2020. 언어 모델이 무엇을 알고 있는지 어떻게 알 수 있는가? TACL, 8:423–438.
Mandar Joshi, Eunsol Choi, Daniel S. Weld, Luke Zettlemoyer. 2017. TriviaQA: 거대하고 거리 기반으로 감독된 독해 데이터셋. ACL 2017, pages 1601–1611.
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Hennigan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, Scott Johnston, Sherel El Showk, Andy Jones, Nelson Elhage, Tristan Hume, Anna Chen, Yuntao Bai, Sam Bowman, Stanislav Fort, Deep Ganguli, Danny Hernandez, Josh Jacobson, Jackson Kernion, Shauna Kravec, Liane Lovitt, Kamal Ndousse, Catherine Olsson, Sam Ringer, Dario Amodei, Tom Brown, Jack Clark, Nicholas Joseph, Ben Mann, Sam McCandlish, Chris Olah, Jared Kaplan. 2022. 언어 모델은 (대체로) 무엇을 알고 있는가? CoRR, abs/2207.05221.
Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick S. H. Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, Wen-tau Yih. 2020. 오픈 도메인 질문 응답을 위한 밀집 패시지 검색. EMNLP 2020, pages 6769–6781.
Urvashi Khandelwal, Omer Levy, Dan Jurafsky, Luke Zettlemoyer, Mike Lewis. 2020. 암기를 통한 일반화: 최근접 이웃 언어 모델. ICLR 2020.
Omar Khattab, Keshav Santhanam, Xiang Lisa Li, David Hall, Percy Liang, Christopher Potts, Matei Zaharia. 2022. 도메인 검색-예측: 지식 중심 NLP를 위한 검색과 언어 모델 구성. CoRR, abs/2212.14024.
Tushar Khot, Harsh Trivedi, Matthew Finlayson, Yao Fu, Kyle Richardson, Peter Clark, Ashish Sabharwal. 2022. 복합 작업 해결을 위한 모듈형 접근. CoRR, abs/2210.02406.
Kalpesh Krishna, Aurko Roy, Mohit Iyyer. 2021. 장문 질문 응답의 장벽. North American Association for Computational Linguistics.
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur P. Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Lilon Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, Slav Petrov. 2019. 자연 질의: 질문 응답 연구를 위한 벤치마크. TACL, 7:452–466.
Angeliki Lazaridou, Elena Gribovskaya, Wojciech Stokowiec, Nicola Grigorev. 2022. 퓨샷 프롬프팅을 통해 오픈 도메인 질문 응답을 확장하는 인터넷-증강 언어 모델. CoRR, abs/2203.05115.
Haejun Lee, Akhil Kedia, Jongwon Lee, Ashwin Paranjape, Christopher D. Manning, Kyoung-Gu Woo. 2021. 오픈 도메인 질문 응답을 위해 단 하나의 모델만 필요하다. CoRR, abs/2112.07381.
Patrick S. H. Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, Douwe Kiela. 2020. 지식 중심 NLP 작업을 위한 검색 증강 생성. NeurIPS 2020.
Junyi Li, Tianyi Tang, Wayne Xin Zhao, Jingyuan Wang, Jian-Yun Nie, Ji-Rong Wen. 2023. 웹은 언어 모델을 개선하는 굴 껍질일 수 있다. CoRR, abs/2305.10998.
Chin-Yew Lin. 2004. ROUGE: 자동 요약 평가 패키지. Text Summarization Branches, Barcelona, Spain.
Pengfei Liu, Weijie Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, Graham Neubig. 2023. 사전, 프롬프트, 그리고 예측: 자연어 처리에서 프롬프트 방법의 체계적 조사. ACM Comput. Surv., 55(9):195:1–195:35.
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Hannaneh Hajishirzi, Daniel Khashabi. 2022. 신뢰할 수 없는 언어 모델인가? 파라메트릭 및 비파라메트릭 방법의 효율성 및 한계를 조사하기. CoRR, abs/2212.10511.
Yuning Mao, Pengcheng He, Xiaodong Liu, Yelong Shen, Jianfeng Gao, Jiawei Han, Weizhu Chen. 2021. 오픈 도메인 질문 응답을 위한 생성-증강 검색. ACL/IJCNLP 2021, Volume 1: Long Papers, pages 4089–4100.
Joshua Maynez, Shashi Narayan, Bernd Bohnet, Ryan McDonald. 2020. 추상 요약에서의 사실성 및 신뢰성에 대하여. ACL 2020, pages 1906–1919.
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, Xu Jiang, Karl Cobbe, Tyna Eloundou, Gretchen Krueger, Kevin Button, Matthew Knight, Benjamin Chess, John Schulman. 2021. Webgpt: 인간 피드백으로 보조된 브라우저 기반 질문-응답. CoRR, abs/2112.09332.
OpenAI. 2023. GPT-4 기술 보고서. CoRR, abs/2303.08774.
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, Ryan Lowe. 2022. 인간 피드백을 통한 지침 따르기 언어 모델 훈련. CoRR, abs/2203.02155.
Baolin Peng, Michel Galley, Pengcheng He, Hao Cheng, Yujia Xie, Yu Hu, Qiuyuan Huang, Lars Liden, Zhou Yu, Weizhu Chen, Jianfeng Gao. 2023. 사실 확인하고 시정하기: 외부 지식 및 자동화된 피드백으로 대규모 언어 모델 개선. CoRR, abs/2302.12813.
Fabio Petroni, Tim Rocktäschel, Sebastian Riedel, Patrick S. H. Lewis, Anton Bakhtin, Yuxiang Wu, Alexander H. Miller. 2019. 언어 모델은 지식 기반인가? In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3–7, 2019, pages 2463–2473.
Olf Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A. Smith, Mike Lewis. 2022. 언어 모델에서의 구성성 학습 측정. arXiv preprint arXiv:2210.03052.
Hongqinq Qian, Yutao Zhu, Zhicheng Dou, Haoqi Gu, Xinyu Zhang, Zheng Liu, Ruofei Lai, Zhao Cao, Jian-Yun Nie, Ji-Rong Wen. 2023. Webbrain: 대규모 웹 코퍼스를 기반으로 정확한 기사 쿼리 생성 학습. CoRR, abs/2304.03453.
Yujia Qin, Zihan Cai, Dian Jin, Lan Yan, Shihao Liang, Kunlun Zhu, Yankai Lin, Xu Han, Ning Ding, Huadong Wang, Ruobing Xie, Fanhao Qi, Zhiyuan Liu, Maosong Sun, Jie Zhou. 2023. Webcpm: 장문 질문 응답을 위한 대화형 웹 검색. CoRR, abs/2305.06849.
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever. 2019. 언어 모델은 감독되지 않은 멀티태스크 학습자이다. OpenAI Blog, 1(8).
Ori Ram, Yoav Levine, Itay Dalmedigos, Dor Muhlgay, Amnon Shashua, Kevin Leyton-Brown, Yoav Shoham. 2023. 문맥 내 검색-증강 언어 모델. arXiv preprint arXiv:2302.00083.
Adam Roberts, Colin Raffel, Noam Shazeer. 2020. 언어 모델의 파라미터 안에 얼마나 많은 지식을 담을 수 있는가? EMNLP 2020, pages 5418–5426.
Stephen E. Robertson, Hugo Zaragoza. 2009. 확률적 검색 프레임워크: BM25 그리고 그 이후. Found. Trends Inf. Retr., 3(4):333–389.
Devendra Singh Sachan, Siva Reddy, William L. Hamilton, Chris Dyer, Dani Yogatama. 2021. 오픈 도메인 질문 응답에서 다중 문서 검색 및 훈련의 종단 간 훈련. NeurIPS 2021, pages 25968–25981.
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, Thomas Scialom. 2023. Toolformer: 언어 모델이 스스로 도구 사용을 가르친다. CoRR, abs/2302.04761.
Weijia Shi, Sewon Min, Michihiro Yasunaga, Mingqiong Xie, Rich James, Mike Lewis, Luke Zettlemoyer, Wen-tau Yih. 2023. REPLUG: 검색-증강 블랙박스 언어 모델. CoRR, abs/2301.12652.
Ivan Stelmakh, Yi Luan, Bhuwan Dhingra, Ming-Wei Chang. 2022. ASQA: 사실 기반 질문이 장문 응답을 필요로 한다. EMNLP 2022, Abu Dhabi, United Arab Emirates, pages 8273–8288.
Zhiqing Sun, Xuezhi Wang, Yi Tay, Yiming Yang, Denny Zhou. 2022. 검색-증강 언어 모델. CoRR, abs/2210.01296.
Hugo Touvron, Thibaut Lavril, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurélien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample. 2023. Llama: 오픈 및 효율적인 기초 언어 모델. CoRR, abs/2302.13971.
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, Ashish Sabharwal. 2022. 지식 집약적 다중 단계 질문을 위한 체인-오브-생각 검색. CoRR, abs/2212.10509.
Neeraj Varshney, Man Luo, Chitta Baral. 2022. 인간처럼 외부 지식을 효율적으로 활용하는 오픈 도메인 QA? CoRR, abs/2211.12707.
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V. Le, Ed H. Chi, Denny Zhou. 2022. 자기 일관성이 언어 모델에서 체인-오브-생각 추론을 향상시킨다. CoRR, abs/2203.11171.
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed H. Chi, Quoc Le, Denny Zhou. 2022. 체인-오브-생각 프롬프팅이 대규모 언어 모델에서 추론을 유도한다. CoRR, abs/2201.11903.
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, Yuan Cao. 2022. React: 언어 모델에서 추론과 행동을 시너지화하기. CoRR, abs/2210.03629.
Wenhao Yu, Dan Iter, Shuohang Wang, Yichong Xu, Mingxuan Ju, Soumya Sanyal, Chenguang Zhu, Michael Zeng, Meng Jiang. 2022. 검색이 아닌 생성: 대규모 언어 모델은 강력한 문맥 생성자이다. CoRR, abs/2209.10063.
Wenhao Yu, Zhihan Zhang, Zhenwen Liang, Meng Jiang, Ashish Sabharwal. 2023. 플러그-앤드-플레이 검색 피드백을 통한 대규모 언어 모델 개선. CoRR, abs/2305.14002.
Yury Zemlyanskiy, Michiel de Jong, Joshua Ainslie, Panupong Pasupat, Peter Shaw, Linlu Qiu, Sumit Sanghai, Fei Sha. 2022. 생성-그리고-검색: 시맨틱 파싱을 위한 검색 개선을 위해 예측 활용하기. COLING 2022, pages 4946–4951.
Fengji Zhang, Bei Chen, Yue Zhang, Jin Liu, Daoguang Zan, Yi Mao, Jian-Guang Lou, Weizhu Chen. 2023.
Repocoder: 반복적인 검색과 생성을 통한 저장소 수준 코드 자동완성.
CoRR, abs/2303.12570.Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, Todor Mihaylov, Myle Ott, Sam Shleifer, Kurt Shuster, Daniel Simig, Punit Singh Koura, Anjali Sridhar, Tianlu Wang, Luke Zettlemoyer. 2022.
OPT: 오픈 사전학습 트랜스포머 언어 모델.
ArXiv, abs/2205.01068.Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, Ji-Rong Wen. 2023.
대규모 언어 모델에 대한 조사(Survey).
CoRR, abs/2303.18223.Ming Zhong, Yang Liu, Da Yin, Yuning Mao, Yizhu Jiao, Pengfei Liu, Chenguang Zhu, Heng Ji, Jiawei Han. 2022.
텍스트 생성을 위한 통합 다차원 평가자를 향하여.
In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7–11, 2022, pages 2023–2038.
Association for Computational Linguistics.Chunting Zhou, Graham Neubig, Jiatao Gu, Mona Diab, Francisco Guzmán, Luke Zettlemoyer, Marjan Ghazvininejad. 2021.
조건부 신경 시퀀스 생성에서 환각된(hallucinated) 콘텐츠 탐지.
Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 1393–1404, Online.
A FLARE 구현 세부사항 (FLARE Implementation Details)
$ \text{FLARE}_{\text{instruct}} $ 구현 세부사항
우리는 언어 모델이 검색과 다운스트림 작업 관련 기술을 효과적으로 결합하여
작업을 수행하는 동안 의미 있는 검색 질의를 생성할 수 있음을 발견했다.
그러나 두 가지 문제가 있다:
(1) 언어 모델은 필요한 것보다 더 적은 검색 질의를 생성하는 경향이 있다.
(2) 과도한 검색 질의 생성은 답변 생성 과정을 방해하고 성능에 부정적인 영향을 줄 수 있다.
우리는 각각의 문제를 두 가지 방법을 사용하여 해결한다.
첫째, 언어 모델이 “[Search(query)]”를 생성할 가능성을 높이기 위해
토큰 “[“의 로짓(logit)을 2.0 증가시킨다.
둘째, 언어 모델이 검색 질의를 생성할 때마다
우리는 그것을 사용하여 관련 정보를 검색하고,
해당 질의를 즉시 생성 과정에서 제거한 뒤,
다음 몇 개의 토큰을 생성하되 “[“을 금지하기 위해
토큰 “[“의 로짓에 큰 음수 값을 추가한다.
FLARE의 초기 질의
FLARE는 사용자 입력 $x$ 를 초기 질의로 사용하여 문서를 검색하고,
첫 번째 문장 $\hat{s}_1 = \text{LM}([\mathcal{D}_x, x])$을 생성함으로써 반복 생성 과정을 부트스트랩한다.
다음 단계들에서는, 검색된 문서 없이 임시적인 forward-looking 문장이 생성된다.
문장 토크나이즈(Sentence tokenization)
각 단계 $t$ 에서, 우리는 대부분의 문장보다 더 긴 64개의 토큰을 생성하고,
NLTK sentence tokenizer5를 사용하여 첫 번째 문장을 추출하고 나머지는 버린다.
5 https://www.nltk.org/api/nltk.tokenize.PunktSentenceTokenizer.html
효율성(Efficiency)
6.2절에서 보인 바와 같이,
다운스트림 작업에 따라 평균적으로 문장의 30% ∼ 60%에서 검색이 트리거된다.
비교하자면, KNN-LM (Khandelwal et al., 2020)은 모든 토큰마다 검색을 수행하고,
RETRO 또는 IC-RALM (Borgeaud et al., 2022; Ram et al., 2023)은
4∼32개의 토큰마다 검색을 수행하며,
IRCoT (Trivedi et al., 2022)은 모든 문장마다 검색을 수행한다.
그러나 단일 시점 검색(single-time retrieval)과 비교하면,
검색과 생성을 교차(interleaving)시키는 나이브한 구현 방식은 실제로 오버헤드를 증가시키며,
이에 대해서는 한계점 논의 부분(9절)에서 논의한다.
B 데이터셋과 설정 (Datasets and Settings)
데이터셋, 측정 지표, 그리고 실험 설정은 표 7에 요약되어 있다.
표 7: 서로 다른 작업들의 데이터셋 통계와 실험 설정.
Multihop QA
“Why did the founder of Versus die?”에 대해, 우리가 생성하려는 출력은
“The founder of Versus was Gianni Versace.
Gianni Versace was shot and killed on the steps of his Miami Beach mansion
on July 15, 1997. So the answer is shot.”
이다.
우리는 Trivedi et al. (2022)의 Prompt D.4에 나열된 8개의 예시(exemplars)를
in-context learning에 사용하고,
BM25를 검색기(retriever)로, Wikipedia 문서를 검색 코퍼스로 사용한다.
Trivedi et al. (2022)에서의 관찰과 유사하게,
우리는 예시들에 대해 검색 결과를 포함시키는 것이 성능을 향상시킨다는 것을 발견했다.
그 결과, 우리는 각 예시의 입력 $x$ 를 사용하여 여러 문서를 검색한 후,
Prompt D.1의 형식으로 그것들을 추가한다.
우리는 검색 문서 수를 늘리는 것이 성능을 증가시키는 경우가 많다는 것을 발견했다.
따라서 우리는 text-davinci-003의 입력 길이 제한 내에
들어갈 수 있는 최대 문서 수를 사용한다.
2Wiki-MultihopQA의 경우 이 수는 2이다.
Commonsense Reasoning
“Would a pear sink in water?”에 대해 우리가 생성하려는 출력은:
“The density of a pear is about 0.6g/cm³, which is less than water.
Objects less dense than water float.
Thus, a pear would float.
So the final answer is no.” 이다.
우리는 Wei et al. (2022)의 Prompt D.5에 나열된 6개의 예시,
Wikipedia 코퍼스에서의 BM25,
그리고 실험을 수행하기 위해 검색된 문서 3개를 사용한다.
Long-form QA
“Where do the Philadelphia Eagles play their home games?”에 대해
우리가 생성하려는 출력은 다음과 같다:
“We need to consider the different possible locations or venues
that could be considered the home field of the Philadelphia Eagles.
These include the city, the sports complex, or the stadium.
Therefore, this question has 3 interpretations and the answers are:
(1) The city is Philadelphia.
(2) The sports complex is the South Philadelphia Sports Complex.
(3) The stadium is the Lincoln Financial Field stadium.”
원래 설정(ASQA)과 힌트가 포함된 설정(ASQA-hint) 모두에서,
우리는 8개의 예시(exemplars)를 수동으로 주석(annotation)하며
(Prompt D.6 및 D.8),
Wikipedia 코퍼스에서 BM25를 사용하고,
실험 수행을 위해 검색된 문서 3개를 사용한다.
Open-domain Summarization
원래 WikiAsp 데이터셋은
다중 문서 요약(multi-document summarization)을 위해 설계되었으며
시스템들에 대한 참고 문헌(reference) 목록을 제공한다.
우리는 관련된 참고 문헌들을 제거하고,
대신 공개 웹에서 정보를 수집하도록 변경하여
이를 오픈 도메인 설정으로 변환하였다.
예를 들어 “Generate a summary about Echo School (Oregon)
including the following aspects: academics, history.”에서는
우리가 생성하려는 출력은 다음과 같다:
“# Academics.
In 2008, 91% of the school’s seniors received their high school diploma…
# History.
The class of 2008 was the 100th class in the school’s history.”
여기서 ‘#’은 측면(aspects)을 표시하기 위해 사용된다.
우리는 Prompt D.10에서와 같이 4개의 예시를 수동으로 주석하고,
Bing 검색 엔진을 사용해 오픈 웹에서 5개의 문서를 검색한다.
정보 누수를 피하기 위해, 우리는 Bing의 검색 결과에서
표 8에 나열된 여러 Wikipedia 관련 도메인들을 제외한다.
C Hyperparameters
다양한 데이터셋에서의 FLARE의 하이퍼파라미터는 표 9에 나열되어 있다.
D Prompts and Few-shot exemplars
여러 문서를 선형화(linearize)하는 데 사용된 프롬프트는 Prompt D.1에 나와 있다.
self-ask(Press et al., 2022)에 사용된 프롬프트는 Prompt D.2에 나와 있다.
서로 다른 작업/데이터셋의 프롬프트와 예시들은
각각 Prompt D.3, D.4, D.5, D.6, D.8, D.10에 나와 있다.

표 8: Bing의 검색 결과에서 제외된 Wikipedia 관련 도메인들.

표 9: 서로 다른 데이터셋에서의 FLARE 하이퍼파라미터.








