[논문] Anomaly detection: A survey
논문 출처
Varun Chandola, Arindam Banerjee, Vipin Kumar.
Anomaly detection: A survey.
University of Minnesota Twin Cities, Minneapolis, MN, United States.
🔗 원문 링크 (ACM DL: 10.1145/1541880.1541882)
저자
- Varun Chandola
- Arindam Banerjee
- Vipin Kumar
(University of Minnesota Twin Cities)
이상 탐지는 다양한 연구 분야와 응용 도메인 전반에 걸쳐
연구되어 온 중요한 문제이다.
많은 이상 탐지 기법들은 특정 응용 도메인을 위해 특별히 개발된 반면,
다른 기법들은 보다 일반적인 성격을 가진다.
이 서베이는 이상 탐지에 관한 연구에 대해
구조적이고 포괄적인 개요를 제공하고자 한다.
우리는 각 기법이 채택하고 있는 근본적인 접근 방식에 기반하여
기존의 기법들을 서로 다른 범주로 묶었다.
각 범주에 대해, 우리는 정상 행동과 이상 행동을 구분하기 위해
해당 기법들이 사용하는 핵심 가정들을 식별하였다.
특정 기법을 특정 도메인에 적용할 때,
이러한 가정들은 해당 도메인에서 그 기법의 효과성을
평가하기 위한 지침으로 사용될 수 있다.
각 범주마다, 우리는 기본적인 이상 탐지 기법을 제시한 후,
해당 범주에 속하는 서로 다른 기존 기법들이
그 기본 기법의 변형임을 보여준다.
이 템플릿은 각 범주에 속하는 기법들에 대해
더 쉽고 간결한 이해를 제공한다.
또한 각 범주에 대해,
우리는 해당 범주에 속하는 기법들의 장점과 단점을 식별한다.
우리는 실제 응용 도메인에서 중요한 이슈이기 때문에
기법들의 계산 복잡도에 대해서도 논의를 제공한다.
우리는 이 서베이가 이 주제에 대해 연구가 수행되어 온
서로 다른 방향들에 대한 더 나은 이해를 제공하고,
한 영역에서 개발된 기법들이
처음에는 의도되지 않았던 도메인들에 어떻게 적용될 수 있는지를
이해하는 데 기여하기를 바란다.
범주 및 주제 분류자: H.2.8 [데이터베이스 관리]: 데이터베이스 응용—데이터 마이닝
일반 용어: 알고리즘
추가 핵심어 및 구문: 이상 탐지, 이상치 탐지
ACM 참고 형식:
Chandola, V., Banerjee, A., 그리고 Kumar, V. 2009.
Anomaly detection: A survey.
ACM Computing Surveys 41, 3, 논문 15 (2009년 7월), 58쪽.
DOI = 10.1145/1541880.1541882
https://doi.acm.org/10.1145/1541880.1541882
1 서론 (Introduction)
이상 탐지는 기대되는 행동에 부합하지 않는
데이터 내의 패턴을 찾아내는 문제를 의미한다.
이러한 기대에 부합하지 않는 패턴들은 서로 다른 응용 도메인에서
이상(anomalies), 이상치(outliers), 불일치 관측값(discordant observations),
예외(exceptions), 이상 현상(aberrations), 놀라운 사건(surprises),
특이성(peculiarities), 또는 오염물(contaminants)로 불리기도 한다.
이들 가운데에서 이상(anomalies)과 이상치(outliers)는
이상 탐지의 맥락에서 가장 일반적으로 사용되는 두 용어이며,
때로는 서로 바꿔 사용되기도 한다.
이상 탐지는 신용카드, 보험, 또는 의료 분야에서의 사기 탐지,
사이버 보안을 위한 침입 탐지, 안전이 중요한 시스템에서의 결함 탐지,
그리고 적의 활동을 감시하기 위한 군사 감시와 같은
다양한 응용 분야에서 폭넓게 활용되고 있다.
이상 탐지가 중요한 이유는 데이터 내의 이상이
다양한 응용 도메인 전반에 걸쳐 의미 있고, 종종 매우 중대하며,
실행 가능한 정보로 전환되기 때문이다.
예를 들어, 컴퓨터 네트워크에서의 비정상적인 트래픽 패턴은
해킹된 컴퓨터가 민감한 데이터를 허가되지 않은 목적지로
전송하고 있음을 의미할 수 있다 [Kumar 2005].
비정상적인 MRI 이미지는 악성 종양의 존재를
나타낼 수 있다 [Spence et al. 2001].
신용카드 거래 데이터에서의 이상은 신용카드 사기 또는 신원 도용을
나타낼 수 있다 [Aleskerov et al. 1997].
또는 우주선 센서로부터의 비정상적인 판독값은
우주선의 어떤 구성 요소에서 결함이 존재함을
의미할 수 있다 [Fujimaki et al. 2005].
데이터에서 이상치 또는 이상을 탐지하는 문제는
이미 19세기부터 통계학 공동체에서 연구되어 왔다 [Edgeworth 1887].
시간이 흐르면서, 다양한 이상 탐지 기법들이
여러 연구 공동체에서 개발되어 왔다.
이들 기법 중 다수는 특정 응용 도메인을 위해 특별히 개발된 반면,
다른 기법들은 보다 일반적인 성격을 가진다.
이 서베이는 이상 탐지에 관한 연구에 대해
구조적이고 포괄적인 개요를 제공하고자 한다.
우리는 이 서베이가, 이 주제에 대해 연구가 수행되어 온
서로 다른 방향들에 대한 더 나은 이해를 가능하게 하고,
한 영역에서 개발된 기법들이, 처음부터 의도되지는 않았던 도메인들에
어떻게 적용될 수 있는지를 이해하는 데 도움을 주기를 바란다.
1.1 이상이란 무엇인가? (What are Anomalies?)
이상이란 명확하게 정의된 정상 행동의 개념에 부합하지 않는
데이터 내의 패턴을 의미한다.
그림 1은 간단한 2차원 데이터셋에서의 이상을 보여준다.
그림 1. 2차원 데이터셋에서의 이상의 간단한 예.
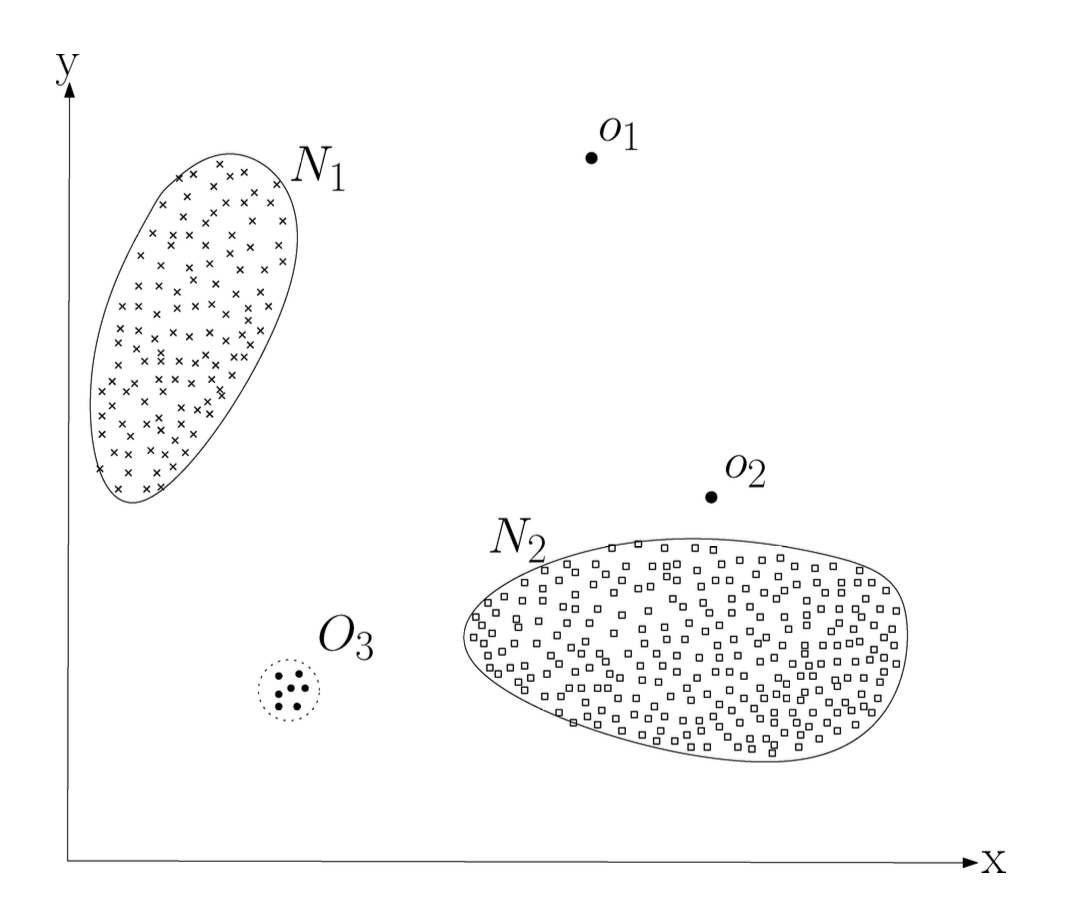
이 데이터는 대부분의 관측값이 이 두 영역에 위치하기 때문에
두 개의 정상 영역 $N_1$과 $N_2$를 가진다.
이들 영역으로부터 충분히 멀리 떨어져 있는 점들,
예를 들어 점 $o_1$과 $o_2$,
그리고 영역 $O_3$에 속한 점들은 이상에 해당한다.
이상은 악의적인 활동과 같은 다양한 이유로 데이터에 유입될 수 있는데,
예를 들어 신용카드 사기, 사이버 침입, 테러 활동,
또는 시스템의 고장 등이 있다.
그러나 이러한 모든 이유들은 분석가에게 흥미롭다는
공통된 특성을 가진다.
이상의 흥미로움, 또는 이상이 실제 현실과 갖는 관련성은
이상 탐지의 핵심적인 특징이다.
이상 탐지는 노이즈 제거(noise removal) [Teng et al. 1990] 및
노이즈 수용(noise accommodation) [Rousseeuw and Leroy 1987]과
관련되어 있지만, 이들과는 구별된다.
이 두 접근법은 모두 데이터 내의 원치 않는 노이즈를 다룬다.
노이즈는 분석가에게는 관심의 대상이 아니지만
데이터 분석을 방해하는 역할을 하는
데이터 내의 현상으로 정의될 수 있다.
노이즈 제거는 어떠한 데이터 분석이 수행되기 이전에
원치 않는 객체들을 제거해야 할 필요성에 의해 추진된다.
노이즈 수용은 이상 관측값에 대해 통계적 모델 추정을
면역시키는 것을 의미한다 [Huber 1974].
이상 탐지와 관련된 또 다른 주제로는 새로움 탐지(novelty detection)
[Markou and Singh 2003a, 2003b; Saunders and Gero 2000]가 있다.
이는 데이터에서 이전에 관측되지 않았던
(새롭게 출현한, 새로운) 패턴을 탐지하는 것을 목표로 하는데,
예를 들어 뉴스 그룹에서의 새로운 토론 주제 등이 이에 해당한다.
새로운 패턴과 이상의 차이점은 새로운 패턴은 탐지된 이후에
일반적으로 정상 모델에 통합된다는 점이다.
이러한 관련 문제들에 대한 해법들은 이상 탐지에도 종종 사용되며
그 반대의 경우도 마찬가지이므로, 본 서베이에서도 함께 논의된다.
1.2 도전 과제 (Challenges)
추상적인 수준에서, 이상은 기대되는 정상 행동에 부합하지 않는
패턴으로 정의된다.
따라서 이상 탐지에 대한 직관적인 접근 방식은
정상 행동을 나타내는 영역을 정의하고,
이 정상 영역에 속하지 않는 데이터 내의 모든 관측값을
이상으로 선언하는 것이다.
그러나 겉보기에는 단순해 보이는 이러한 접근 방식은
여러 가지 요인들로 인해 매우 도전적이 된다.
가능한 모든 정상 행동을 포괄하는
정상 영역을 정의하는 것은 매우 어렵다.
또한 정상 행동과 이상 행동 사이의 경계는 종종 명확하지 않다.
따라서 경계에 가까이 위치한 이상 관측값은
실제로는 정상일 수 있으며,
그 반대의 경우도 마찬가지이다.이상이 악의적인 행위의 결과인 경우,
악의적인 공격자들은 이상 관측값이 정상으로 보이도록
스스로를 적응시키는 경우가 많으며,
이로 인해 정상 행동을 정의하는 작업은 더욱 어려워진다.많은 도메인에서 정상 행동은 지속적으로 변화하며,
현재의 정상 행동에 대한 개념은
미래에는 충분히 대표적이지 않을 수 있다.이상의 정확한 개념은 응용 도메인마다 다르다.
예를 들어 의료 도메인에서는 정상 상태로부터의 작은 편차
(예: 체온의 변동)가 이상일 수 있지만,
주식 시장 도메인에서는 유사한 편차
(예: 주식 가치의 변동)가 정상으로 간주될 수 있다.
따라서 한 도메인에서 개발된 기법을 다른 도메인에
적용하는 것은 결코 단순하지 않다.이상 탐지 기법에서 사용되는 모델의 학습 및 검증을 위한
레이블된 데이터의 가용성은 일반적으로 중요한 문제이다.종종 데이터에는 실제 이상과 유사한 특성을 가지는
노이즈가 포함되어 있으며,
이로 인해 이를 구분하고 제거하는 것이 어렵다.
이러한 도전 과제들로 인해, 가장 일반적인 형태에서의
이상 탐지 문제는 해결하기가 쉽지 않다.
실제로, 기존의 대부분의 이상 탐지 기법들은
문제의 특정한 정식화(formulation)만을 해결한다.
이러한 정식화는 데이터의 특성, 레이블된 데이터의 가용성,
탐지하고자 하는 이상의 유형 등과 같은
여러 요인들에 의해 유도된다.
이러한 요인들은 이상이 탐지되어야 하는
응용 도메인에 의해 결정되는 경우가 많다.
연구자들은 통계학, 머신러닝, 데이터 마이닝, 정보 이론,
스펙트럴 이론과 같은 다양한 학문 분야의 개념들을 차용하여,
이를 특정 문제 정식화에 적용해 왔다.
그림 2는 어떠한 이상 탐지 기법에도
공통적으로 연관된 핵심 구성 요소들을 보여준다.
그림 2. 이상 탐지 기법과 연관된 핵심 구성 요소들.
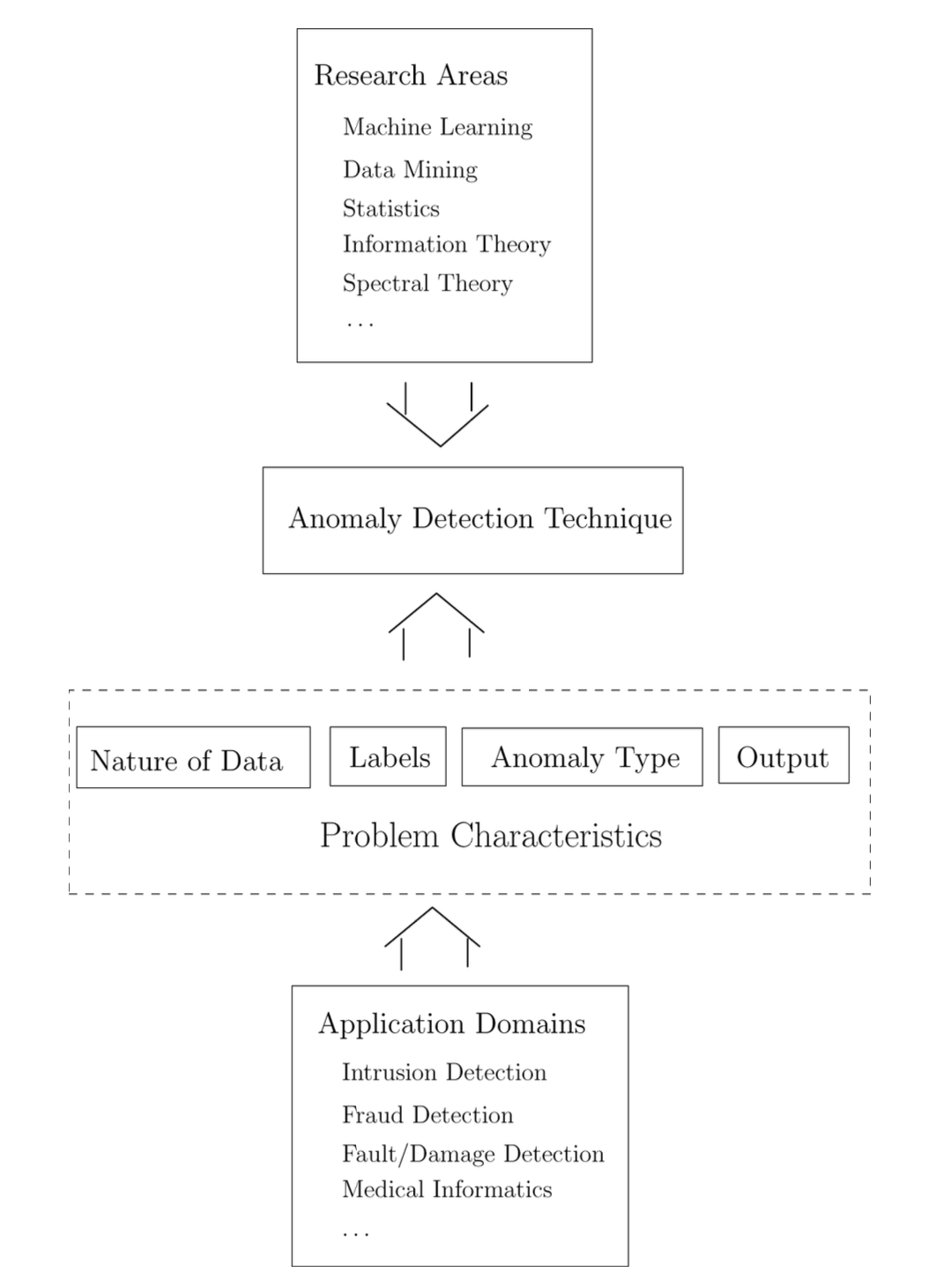
1.3 관련 연구 (Related Work)
이상 탐지는 여러 서베이 논문과 리뷰 논문들뿐만 아니라
서적들의 주제로도 다루어져 왔다.
Hodge와 Austin [2004]는 머신러닝 및 통계적 도메인에서 개발된
이상 탐지 기법들에 대한 포괄적인 서베이를 제공한다.
수치 데이터뿐만 아니라 기호 데이터에 대한
이상 탐지 기법들의 폭넓은 리뷰는
Agyemang 등 [2006]에 의해 제시되었다.
신경망과 통계적 접근법을 사용하는 새로움 탐지(novelty detection)
기법들에 대한 포괄적인 리뷰는 각각 Markou와 Singh [2003a] 및
Markou와 Singh [2003b]에서 제시되었다.
Patcha와 Park [2007], 그리고 Snyder [2001]는
사이버 침입 탐지를 위해 특별히 사용되는
이상 탐지 기법들에 대한 서베이를 제시한다.
이상치 탐지에 관한 상당한 양의 연구는
통계학 분야에서 수행되어 왔으며,
여러 서적들 [Rousseeuw and Leroy 1987;
Barnett and Lewis 1994; Hawkins 1980]과
다른 서베이 논문들 [Beckman and Cook 1983;
Bakar et al. 2006]에서 검토되어 왔다.
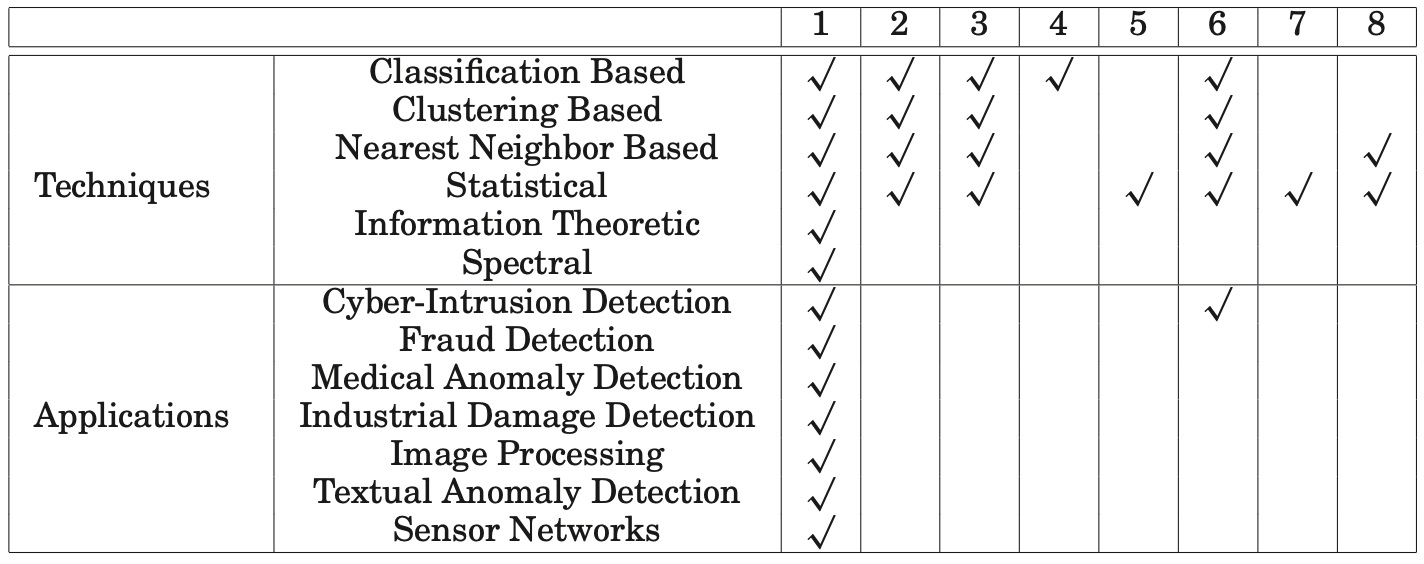
표 1은 본 서베이와 다양한 관련 서베이 논문들에서
다루고 있는 기법들의 집합과 응용 도메인들을 보여준다.
표 1. 본 서베이와 다른 관련 서베이 논문들의 비교.
1—본 서베이,
2—Hodge와 Austin [2004],
3—Agyemang 등 [2006],
4—Markou와 Singh [2003a],
5—Markou와 Singh [2003b],
6—Patcha와 Park [2007],
7—Beckman과 Cook [1983],
8—Bakar 등 [2006]
1.4 우리의 기여 (Our Contributions)
이 서베이는 여러 연구 분야와 응용 도메인에 걸쳐 있는
이상 탐지 기법들에 관한 방대한 연구에 대해
구조적이고 폭넓은 개요를 제공하고자 하는 시도이다.
기존의 대부분의 이상 탐지 서베이들은 특정 응용 도메인에
초점을 맞추거나 단일 연구 분야에 초점을 맞춘다.
Agyemang 등 [2006]과 Hodge와 Austin [2004]는
이상 탐지를 여러 범주로 나누고 각 범주별로 기법들을 논의하는
두 개의 관련 연구이다.
본 서베이는 이 두 연구를 기반으로 하여
여러 방향에서 논의를 상당히 확장한다.
우리는 Agyemang 등 [2006]과 Hodge와 Austin [2004]에서 논의된
네 가지 범주에 더하여, 정보 이론적 기법과 스펙트럴 기법이라는
두 가지 이상의 범주를 추가한다.
총 여섯 개의 각 범주에 대해, 우리는 기법들을 논의할 뿐만 아니라
해당 범주에 속한 기법들이 이상의 본질에 대해
어떠한 고유한 가정을 하고 있는지도 식별한다.
이러한 가정들은 해당 범주의 기법들이 언제 이상을 탐지할 수 있고
언제 실패하는지를 결정하는 데 있어 중요하다.
각 범주마다 우리는 기본적인 이상 탐지 기법을 제시한 후,
그 범주에 속한 서로 다른 기존 기법들이
그 기본 기법의 변형임을 보여준다.
이 템플릿은 각 범주에 속한 기법들에 대해 더 쉽고 간결한 이해를 제공한다.
또한 각 범주에 대해 우리는 기법들의 장점과 단점을 식별한다.
아울러 실제 응용 도메인에서 중요한 문제이기 때문에,
기법들의 계산 복잡도에 대한 논의도 제공한다.
기존의 일부 서베이들이 이상 탐지의 다양한 응용을 언급하고는 있지만,
본 서베이에서는 이상 탐지 기법들이 사용되어 온 응용 도메인들에 대해
보다 상세한 논의를 제공한다.
각 도메인마다 우리는 이상의 개념, 이상 탐지 문제의 서로 다른 측면들,
그리고 이상 탐지 기법들이 직면하는 도전 과제들을 논의한다.
또한 각 응용 도메인에서 적용되어 온 기법들의 목록도 제공한다.
기존의 서베이들은 가장 단순한 형태의 이상을 탐지하는
이상 탐지 기법들을 주로 논의한다.
우리는 단순한 이상과 복잡한 이상을 구분한다.
이상 탐지의 응용에 대한 논의는
대부분의 응용 도메인에서 흥미로운 이상들은 본질적으로 복잡한 반면,
대부분의 알고리즘 연구는 단순한 이상에 초점을 맞추어 왔음을 드러낸다.
1.5 구성 (Organization)
이 서베이는 세 부분으로 구성되어 있으며, 그 구조는 그림 2를 밀접하게 따른다.
2절에서는 문제의 정식화(formulation)를 결정하는 여러 측면들을 식별하고,
이상 탐지와 관련된 풍부함과 복잡성을 강조한다.
우리는 단순한 이상과 복잡한 이상을 구분하고,
복잡한 이상의 두 가지 유형, 즉 맥락적 이상과 집합적 이상을 정의한다.
3절에서는 이상 탐지가 적용되어 온
서로 다른 응용 도메인들을 간략하게 설명한다.
이후의 절들에서는 이들이 속한 연구 분야를 기준으로
이상 탐지 기법들의 분류를 제공한다.
대부분의 기법들은 분류 기반 기법(4절), 최근접 이웃 기반 기법(5절),
군집화 기반 기법(6절), 통계적 기법(7절)으로 분류될 수 있다.
일부 기법들은 정보 이론(8절)이나 스펙트럴 이론(9절)과 같은
연구 분야에 속한다.
각 기법 범주에 대해 우리는 학습 단계와 테스트 단계에서의
계산 복잡도 또한 논의한다.
10절에서는 다양한 맥락적 이상 탐지 기법들을 논의한다.
11절에서는 기존의 여러 기법들의 한계와 상대적 성능에 대한 논의를 제시한다.
12절에는 결론적 논평이 포함되어 있다.
2 이상 탐지 문제의 다양한 측면 (Different Aspects of an Anomaly Detection Problem)
이 절에서는 이상 탐지의 서로 다른 측면들을 식별하고 논의한다.
앞서 언급한 바와 같이, 문제의 구체적인 정식화(formulation)는
입력 데이터의 성격, 레이블의 가용성 또는 비가용성,
그리고 응용 도메인에 의해 유도되는 제약 조건과 요구 사항과 같은
여러 서로 다른 요인들에 의해 결정된다.
이 절은 문제 도메인 내의 풍부함을 드러내며,
광범위한 이상 탐지 기법들이 필요한 이유를 정당화한다.
2.1 입력 데이터의 성격 (Nature of Input Data)
어떠한 이상 탐지 기법에서든 핵심적인 측면 중 하나는 입력 데이터의 성격이다.
입력은 일반적으로 데이터 인스턴스들의 집합이며,
이는 object, record, point, vector, pattern, event, case,
sample, observation, 또는 entity라고도 불린다
[Tan et al. 2005, Chapter 2].
각 데이터 인스턴스는 속성들의 집합을 사용하여 기술될 수 있으며,
이 속성들은 variable, characteristic, feature, field,
또는 dimension이라고도 불린다.
이러한 속성들은 binary, categorical, 또는 continuous와 같은
서로 다른 유형을 가질 수 있다.
각 데이터 인스턴스는 하나의 속성만을 가질 수도 있고(univariate),
여러 개의 속성을 가질 수도 있다(multivariate).
다변량 데이터 인스턴스의 경우, 모든 속성이 동일한 유형일 수도 있고,
서로 다른 데이터 유형들의 혼합일 수도 있다.
속성의 성격은 이상 탐지 기법의 적용 가능성을 결정한다.
예를 들어, 통계적 기법의 경우, 연속형 데이터와 범주형 데이터에 대해
서로 다른 통계적 모델이 사용되어야 한다.
마찬가지로, 최근접 이웃 기반 기법의 경우에도
속성의 성격이 사용될 거리 척도를 결정한다.
종종 실제 데이터 대신, 인스턴스들 간의 쌍별(pairwise) 거리가
거리 행렬 또는 유사도 행렬의 형태로 제공되기도 한다.
이러한 경우에는, 원래의 데이터 인스턴스를 필요로 하는 기법들,
예를 들어 많은 통계적 기법이나 분류 기반 기법들은 적용될 수 없다.
입력 데이터는 또한 데이터 인스턴스들 사이에 존재하는
관계에 기반하여 분류될 수 있다
[Tan et al. 2005].
기존의 대부분의 이상 탐지 기법들은 레코드 데이터 또는 포인트 데이터를 다루며,
이 경우 데이터 인스턴스들 사이에는 어떠한 관계도 가정되지 않는다.
일반적으로, 데이터 인스턴스들은 서로 연관될 수 있다.
그 예로는 시퀀스(sequence) 데이터, 공간(spatial) 데이터,
그리고 그래프 데이터가 있다.
시퀀스 데이터의 경우, 데이터 인스턴스들은 선형적으로 정렬되어 있으며,
예를 들면 시계열 데이터, 유전체 서열, 단백질 서열 등이 이에 해당한다.
공간 데이터의 경우, 각 데이터 인스턴스는 이웃한 인스턴스들과 연관되어 있으며,
예를 들면 차량 교통 데이터나 생태 데이터가 이에 해당한다.
공간 데이터가 시간적(순차적) 요소를 함께 가질 경우,
이는 시공간 데이터(spatio-temporal data)라고 불리며,
그 예로는 기후 데이터가 있다.
그래프 데이터의 경우, 데이터 인스턴스들은
그래프 내의 정점으로 표현되며, 간선을 통해 다른 정점들과 연결된다.
이 절의 후반부에서는, 이와 같은 데이터 인스턴스들 간의 관계가
이상 탐지에 있어 중요해지는 상황들을 논의할 것이다.
2.2 이상 유형 (Type of Anomaly)
이상 탐지 기법의 중요한 측면 중 하나는 탐지하고자 하는 이상이 지니는 성격이다.
이상은 다음의 세 가지 범주로 분류될 수 있다.
2.2.1 점 이상 (Point Anomalies)
개별 데이터 인스턴스가 나머지 데이터에 비추어 보아 이상하다고 간주될 수 있다면,
그 인스턴스는 점 이상(point anomaly)이라 불린다.
이는 가장 단순한 형태의 이상이며,
이상 탐지 연구의 대부분이 이 유형에 초점을 맞추고 있다.
예를 들어, 그림 1에서 점 $o_1$과 $o_2$, 그리고 영역 $O_3$에 속한 점들은
정상 영역의 경계 밖에 위치하므로, 정상 데이터 점들과 다르다는 점에서
점 이상에 해당한다.
실제 사례로 신용카드 사기 탐지를 고려해 보자.
데이터 집합이 한 개인의 신용카드 거래 내역에 해당한다고 하자.
단순화를 위해, 데이터가 오직 하나의 특징,
즉 사용 금액(amount spent)만으로 정의된다고 가정하자.
해당 개인의 정상적인 지출 범위에 비해
사용 금액이 매우 큰 거래는 점 이상이 될 것이다.
2.2.2 맥락적 이상 (Contextual Anomalies)
데이터 인스턴스가 특정한 맥락에서는 이상이지만
그 외의 경우에는 그렇지 않다면, 이를 맥락적 이상이라 부른다
(조건부 이상이라고도 불린다 [Song et al. 2007]).
맥락이라는 개념은 데이터 집합의 구조에 의해 유도되며,
문제 정식화(formulation)의 일부로 명시되어야 한다.
각 데이터 인스턴스는 다음의 두 가지 속성 집합을 사용하여 정의된다.
(1) 맥락 속성 (Contextual attributes)
맥락 속성은 해당 인스턴스의 맥락 (또는 이웃)을 결정하는 데 사용된다.
예를 들어, 공간 데이터 집합에서는 위치의 경도와 위도가 맥락 속성이 된다.
시계열 데이터에서는 시간이 맥락 속성으로 작용하여
전체 시퀀스에서 인스턴스의 위치를 결정한다.
(2) 행동 속성 (Behavioral attributes)
행동 속성은 인스턴스의 비맥락적 특성을 정의한다.
예를 들어, 전 세계 평균 강우량을 설명하는 공간 데이터 집합에서
각 위치에서의 강우량은 행동 속성에 해당한다.
이상 행동은 특정 맥락 내에서의 행동 속성 값들을 사용하여 결정된다.
하나의 데이터 인스턴스는 어떤 맥락에서는 맥락적 이상일 수 있으나,
행동 속성의 관점에서 동일한 데이터 인스턴스가
다른 맥락에서는 정상으로 간주될 수 있다.
이러한 성질은 맥락적 이상 탐지 기법에서
맥락 속성과 행동 속성을 식별하는 데 핵심적이다.
맥락적 이상은
시계열 데이터 [Weigend et al. 1995; Salvador and Chan 2003]와
공간 데이터 [Kou et al. 2006; Shekhar et al. 2001]에서
가장 흔히 연구되어 왔다.
그림 3은 최근 몇 년간의 월별 기온을 나타내는
온도 시계열 데이터의 한 예를 보여준다.
해당 지역에서 겨울($t_1$ 시점) 동안의 $35^\circ\mathrm{F}$는 정상일 수 있으나,
여름($t_2$ 시점) 동안의 같은 값은 이상이 될 것이다.
그림 3. 온도 시계열에서의 맥락적 이상 $t_2$.
시간 $t_1$에서의 온도는 시간 $t_2$에서의 온도와 동일하지만,
서로 다른 맥락에서 발생하므로 이상으로 간주되지 않는다.
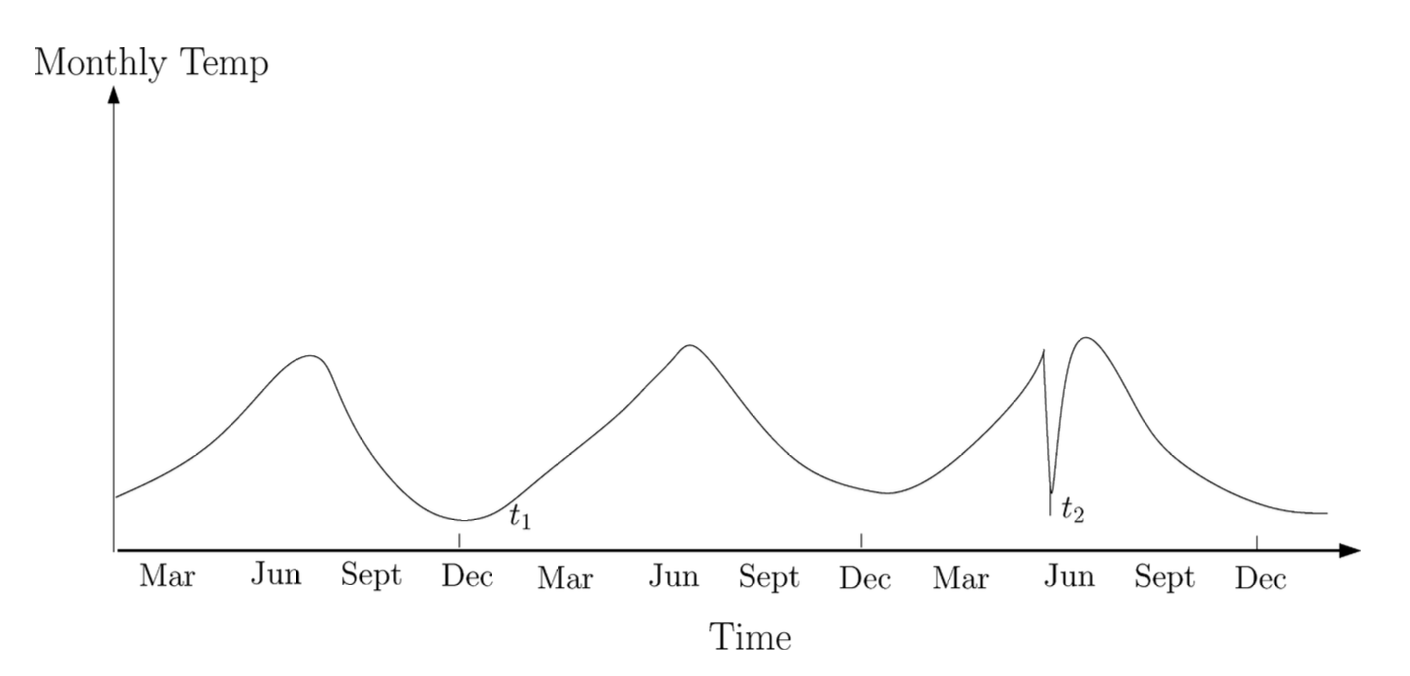
유사한 예는 신용카드 사기 탐지에서도 찾을 수 있다.
신용카드 도메인에서의 맥락 속성은 구매 시점의 시간일 수 있다.
어떤 개인이 보통 주당 쇼핑 비용으로 100 달러를 지출하지만
크리스마스 주간에는 그 금액이 1000 달러에 이른다고 가정하자.
7월의 어느 주에 1000 달러의 새로운 구매가 발생한다면,
이는 시간이라는 맥락에서 개인의 정상 행동에 부합하지 않으므로
맥락적 이상으로 간주될 것이다.
반면, 크리스마스 주간에 같은 금액이 사용된다면 정상으로 간주될 것이다.
맥락적 이상 탐지 기법을 적용할지의 여부는
목표 응용 도메인에서 맥락적 이상이
얼마나 의미 있는지에 따라 결정된다.
또 다른 핵심 요인은 맥락 속성의 가용성이다.
일부 경우에는 맥락을 정의하는 것이 비교적 명확하므로,
맥락적 이상 탐지 기법을 적용하는 것이 타당하다.
그러나 다른 경우에는 맥락을 정의하는 것이 쉽지 않아,
이러한 기법을 적용하기가 어려워진다.
2.2.3 집합적 이상 (Collective Anomalies)
서로 관련된 데이터 인스턴스들의 집합이
전체 데이터 집합에 비추어 이상한 경우,
이를 집합적 이상이라 한다.
집합적 이상에 포함된 개별 데이터 인스턴스들은
그 자체로는 이상이 아닐 수 있으나,
집합으로 함께 나타난다는 점에서 이상이 된다.
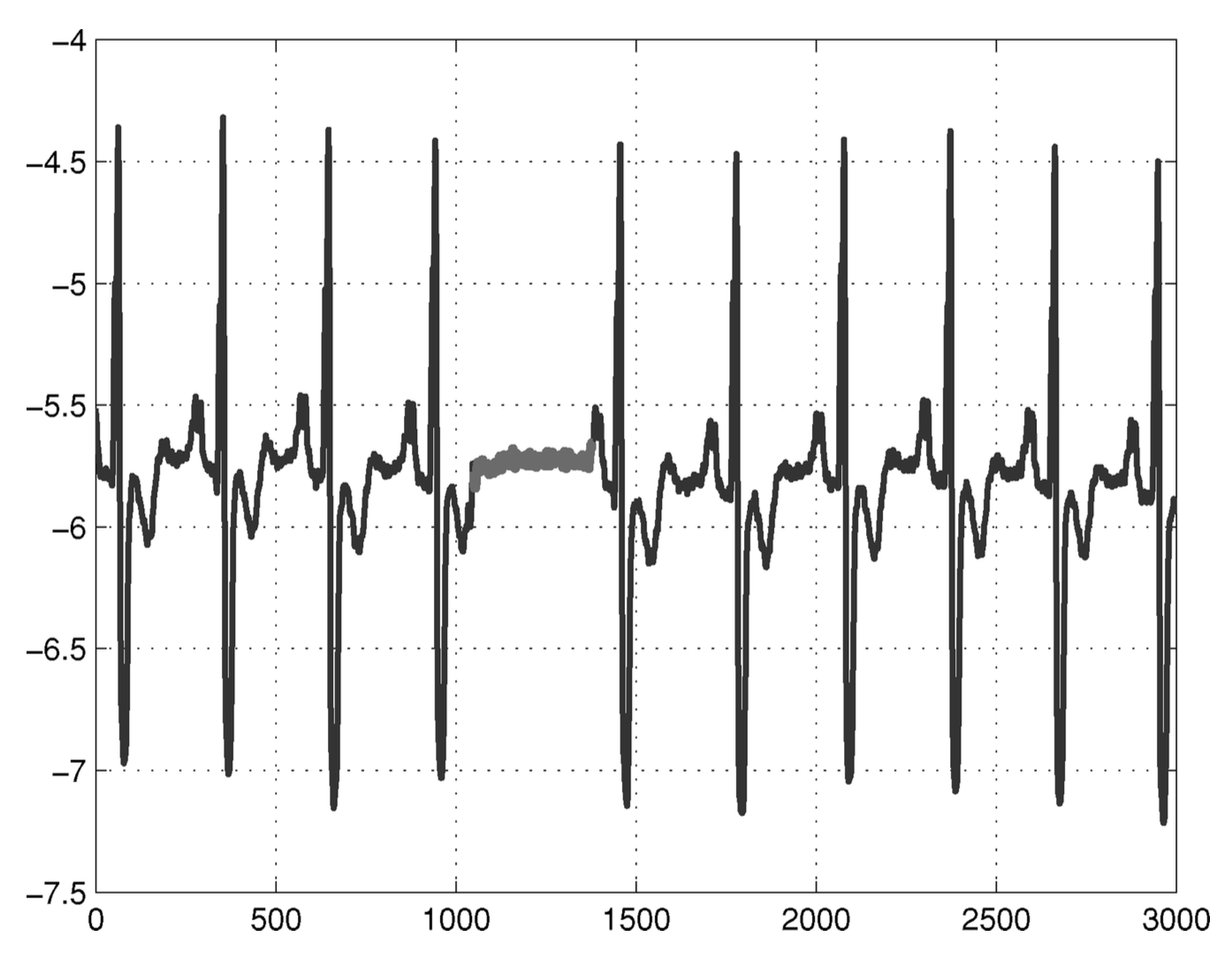
그림 4는 사람의 심전도 출력 예시를 보여준다
[Goldberger et al. 2000].
강조된 구간은 비정상적으로 긴 시간 동안
같은 낮은 값이 지속되기 때문에 이상으로 간주된다
(이는 조기 심방 수축 Atrial Premature Contraction에 해당한다).
해당 낮은 값 자체는 그 자체만으로는 이상이 아님에 유의해야 한다.
그림 4. 인간 심전도 출력에서 심방 조기 수축(Atrial Premature Contraction)에
대응하는 집단 이상(collective anomaly).
또 다른 예로, 아래와 같이 컴퓨터에서 발생하는 일련의 동작 시퀀스를 고려해 보자.
… http-web, buffer-overflow, http-web, http-web, smtp-mail, ftp,
http-web, ssh, smtp-mail, http-web, ssh, buffer-overflow, ftp,
http-web, ftp, smtp-mail, http-web …
강조된 사건들의 시퀀스(buffer-overflow, ssh, ftp)는
원격 머신에 의한 전형적인 웹 기반 공격 이후
ftp를 통해 호스트 컴퓨터에서 원격 목적지로
데이터가 복사되는 과정을 나타낸다.
이 사건들의 집합은 이상에 해당하지만,
각각의 개별 사건은 시퀀스 내의 다른 위치에서 발생할 경우 이상이 아니다.
집합적 이상은 시퀀스 데이터 [Forrest et al. 1999; Sun et al. 2006],
그래프 데이터 [Noble and Cook 2003],
그리고 공간 데이터 [Shekhar et al. 2001]에서 연구되어 왔다.
점 이상은 어떤 데이터 집합에서도 발생할 수 있는 반면,
집합적 이상은 데이터 인스턴스들 사이에 관계가 존재하는
데이터 집합에서만 발생할 수 있다.
반면, 맥락적 이상의 발생은 데이터 내에 맥락 속성이 존재하는지에 의존한다.
점 이상이나 집합적 이상도 맥락을 기준으로 분석될 경우 맥락적 이상이 될 수 있다.
따라서 점 이상 탐지 문제나 집합적 이상 탐지 문제는
맥락 정보를 포함시킴으로써 맥락적 이상 탐지 문제로 변환될 수 있다.
집합적 이상을 탐지하는 기법들은 점 이상 및 맥락적 이상 탐지 기법과는
매우 다르며, 별도의 상세한 논의가 필요하다.
따라서 우리는 이 서베이에서는 이를 다루지 않기로 하였다.
집합적 이상 탐지 분야의 연구에 대한 간략한 검토를 위해서는
이 서베이의 확장판을 참조하기 바란다 [Chandola et al. 2007].
2.3. 데이터 레이블(Data Labels)
데이터 인스턴스와 연관된 레이블은
해당 인스턴스가 정상(normal)인지 이상(anomalous)인지를 나타낸다.
정확하면서도 모든 유형의 행동을 대표할 수 있는 레이블된 데이터를 획득하는 것은
종종 비용이 매우 많이 드는 작업이라는 점에 유의해야 한다.
레이블링은 보통 인간 전문가에 의해 수작업으로 수행되며,
따라서 레이블된 학습 데이터 셋을 얻기 위해서는 상당한 노력이 요구된다.
일반적으로, 가능한 모든 유형의 이상 행동을 포괄하는
이상 데이터 인스턴스에 대한 레이블 집합을 얻는 것은
정상 행동에 대한 레이블을 얻는 것보다 더 어렵다.
더 나아가, 이상 행동은 종종 본질적으로 동적이어서
예를 들어 새로운 유형의 이상이 발생할 수 있으며,
이 경우에는 이에 대한 레이블된 학습 데이터가 존재하지 않는다.
항공 교통 안전과 같은 특정한 경우에는
이상 인스턴스가 재앙적인 사건으로 이어질 수 있으며,
따라서 이러한 이상은 매우 드물게 발생한다.
레이블의 가용 정도에 따라,
이상 탐지 기법은 다음의 세 가지 모드 중 하나로 동작할 수 있다.
2.3.1. 지도 학습 기반 이상 탐지(Supervised Anomaly Detection)
지도 학습 모드에서 학습되는 기법들은 정상 클래스와 이상 클래스 모두에 대해
레이블이 부여된 인스턴스를 포함하는 학습 데이터 셋의 가용성을 가정한다.
이러한 경우의 전형적인 접근법은
정상 대 이상 클래스를 구분하는 예측 모델을 구축하는 것이다.
관측되지 않은 새로운 데이터 인스턴스는
이 모델과 비교되어 어느 클래스에 속하는지가 결정된다.
지도 학습 기반 이상 탐지에서는 두 가지 주요 문제가 발생한다.
첫째, 학습 데이터에서 이상 인스턴스의 수는
정상 인스턴스에 비해 훨씬 적다.
이와 같은 클래스 불균형으로 인해 발생하는 문제들은
데이터 마이닝과 머신러닝 문헌에서 다루어져 왔다
[Joshi et al. 2001, 2002; Chawla et al. 2004; Phua et al. 2004;
Weiss and Hirsh 1998; Vilalta and Ma 2002].
둘째, 특히 이상 클래스에 대해
정확하고 대표성 있는 레이블을 얻는 것은 일반적으로 어렵다.
이를 해결하기 위해,
정상 데이터 셋에 인위적인 이상을 주입하여
레이블된 학습 데이터 셋을 얻는 다양한 기법들이 제안되었다
[Theiler and Cai 2003; Abe et al. 2006; Steinwart et al. 2005].
이 두 가지 문제를 제외하면,
지도 학습 기반 이상 탐지 문제는 예측 모델을 구축하는 문제와 유사하다.
따라서 본 서베이에서는 이 범주의 기법들을 다루지 않는다.
2.3.2. 반지도 학습 기반 이상 탐지(Semisupervised Anomaly Detection)
반지도 학습 모드에서 동작하는 기법들은
학습 데이터에 정상 클래스에 대해서만 레이블이 존재한다고 가정한다.
이상 클래스에 대한 레이블을 필요로 하지 않기 때문에,
이러한 기법들은 지도 학습 기법보다 더 폭넓게 적용 가능하다.
예를 들어, 우주선 고장 탐지 문제에서 [Fujimaki et al. 2005],
이상 시나리오는 사고를 의미할 수 있는데, 이는 모델링하기가 쉽지 않다.
이러한 기법에서의 전형적인 접근법은 정상 행동에 해당하는 클래스를 모델링하고,
이 모델을 사용하여 테스트 데이터에서 이상을 식별하는 것이다.
이상 인스턴스만을 학습에 사용할 수 있다고 가정하는
제한된 수의 이상 탐지 기법들이 존재한다
[Dasgupta and Nino 2000; Dasgupta and Majumdar 2002;
Forrest et al. 1999].
그러나 이러한 기법들은 일반적으로 잘 사용되지 않는데,
그 이유는 데이터에서 발생할 수 있는
모든 가능한 이상 행동을 포괄하는
학습 데이터 셋을 얻는 것이 어렵기 때문이다.
2.3.3. 비지도 학습 기반 이상 탐지(Unsupervised Anomaly Detection)
비지도 학습 모드에서 동작하는 기법들은 학습 데이터를 필요로 하지 않으며,
따라서 가장 널리 적용 가능한 방법들이다.
이 범주에 속하는 기법들은 테스트 데이터에서 정상 인스턴스가
이상 인스턴스보다 훨씬 더 빈번하다는 암묵적인 가정을 둔다.
이 가정이 성립하지 않을 경우,
이러한 기법들은 높은 오경보율(high false alarm rate)을 겪게 된다.
많은 반지도 학습 기법들은 레이블되지 않은 데이터 셋의 일부를
학습 데이터로 사용함으로써 비지도 학습 모드로 적응시킬 수 있다.
이러한 적응은 테스트 데이터에 아주 적은 수의 이상만이 존재하며,
학습 과정에서 얻어진 모델이 이 소수의 이상에 대해 강인하다는 것을 가정한다.
2.4. 이상 탐지의 출력 (Output of Anomaly Detection)
어떠한 이상 탐지 기법에 있어서도 중요한 측면 중 하나는
이상이 어떤 방식으로 보고되는가이다.
일반적으로, 이상 탐지 기법에 의해 생성되는 출력은
다음 두 가지 유형 중 하나이다.
2.4.1. 점수 (Scores)
점수 기반 기법은 테스트 데이터에 있는 각 인스턴스에 대해
그 인스턴스가 이상으로 간주되는 정도에 따라
이상 점수(anomaly score)를 할당한다.
따라서 이러한 기법의 출력은 이상들의 순위가 매겨진 목록이다.
분석가는 상위 몇 개의 이상만을 분석할 수도 있고,
임계값(cutoff threshold)을 사용하여 이상을 선택할 수도 있다.
2.4.2. 레이블 (Labels)
이 범주에 속하는 기법들은
각 테스트 인스턴스에 레이블(normal 또는 anomalous)을 할당한다.
점수 기반 이상 탐지 기법은 분석가가 도메인 특화 임계값을 사용하여
가장 관련성이 높은 이상들을 선택할 수 있도록 해준다.
이와 달리, 테스트 인스턴스에 이진 레이블을 제공하는 기법들은
분석가가 그러한 선택을 직접적으로 수행하도록 허용하지는 않지만,
각 기법 내부의 매개변수 선택을 통해 간접적으로 제어될 수 있다.
3. 이상 탐지의 응용 (Applications of Anomaly Detection)
이 절에서는 이상 탐지의 여러 응용 분야를 논의한다.
각 응용 도메인에 대해 우리는 다음의 네 가지 측면을 논의한다.
— 이상(anomaly)의 개념.
— 데이터의 성격.
— 이상을 탐지하는 것과 관련된 도전 과제.
— 기존의 이상 탐지 기법들.
3.1 침입 탐지 (Intrusion Detection)
침입 탐지는 컴퓨터 관련 시스템에서의 악의적인 활동
(침입, 침투, 그리고 기타 형태의 컴퓨터 남용)을
탐지하는 것을 의미한다 [Phoha 2002].
이러한 악의적인 활동 또는 침입(intrusions)은 컴퓨터 보안 관점에서 흥미롭다.
침입은 시스템의 정상적인 행동과 다르며,
따라서 이상 탐지 기법은 침입 탐지 도메인에 적용 가능하다.
이 도메인에서 이상 탐지의 핵심적인 도전 과제는 데이터의 방대한 양이다.
이상 탐지 기법은 이러한 대규모 입력을 처리하기 위해 계산적으로 효율적이어야 한다.
더 나아가 데이터는 일반적으로 스트리밍 방식으로 들어오기 때문에
온라인 분석을 요구한다.
대규모 입력으로 인해 발생하는 또 다른 문제는 오경보(false alarm) 비율이다.
데이터의 양이 수백만 개의 데이터 객체에 달하기 때문에
소수 퍼센트의 오경보만으로도 분석가에게는 분석이 감당하기 어려울 수 있다.
정상 행동에 해당하는 레이블 데이터는 일반적으로 가용하지만,
침입에 대한 레이블은 그렇지 않다.
따라서 이 도메인에서는 반지도(semi-supervised) 및 비지도(unsupervised)
이상 탐지 기법이 선호된다.
Denning [1987]은 침입 탐지 시스템을
호스트 기반(host-based) 침입 탐지 시스템과
네트워크 기반(network-based) 침입 탐지 시스템으로 분류하였다.
3.1.1 호스트 기반 침입 탐지 시스템 (Host-Based Intrusion Detection Systems)
이러한 시스템(시스템 호출 침입 탐지 시스템이라고도 불림)은
운영체제의 시스템 호출 트레이스(system call traces)를 다룬다.
침입은 트레이스 내의 이상한 부분 시퀀스(anomalous subsequences),
즉 집합적 이상(collective anomalies)의 형태로 나타난다.
이러한 이상 부분 시퀀스는 악성 프로그램, 비인가된 행동,
그리고 정책 위반으로 이어진다.
모든 트레이스는 동일한 알파벳에 속하는 이벤트들을 포함하지만,
정상 행동과 이상 행동을 구분하는 핵심 요인은
이벤트들의 동시 발생(co-occurrence)이다.
그림 5. 세 개의 운영체제 시스템 호출 트레이스로 구성된 샘플 데이터 집합.

데이터는 순차적인 성격을 가지며,
알파벳은 그림 5에 나타난 것처럼 개별 시스템 호출들로 구성된다.
이러한 호출은 프로그램에 의해 생성될 수도 있고
사용자에 의해 생성될 수도 있다. [Hofmeyr et al. 1998; Lane and Brodley 1999].
알파벳의 크기는 일반적으로 크다
(SunOS 4.1x 운영체제의 경우 183개의 시스템 호출).
서로 다른 프로그램은 이러한 시스템 호출을 서로 다른 순서로 실행한다.
각 프로그램에 대한 시퀀스의 길이는 서로 다르다.
그림 5는 운영체제 시스템 호출 시퀀스의 예시 집합을 보여준다.
이 도메인 데이터의 중요한 특성은
데이터가 프로그램 수준이나 사용자 수준과 같이
서로 다른 수준에서 프로파일링될 수 있다는 점이다.
호스트 기반 침입 탐지에 적용되는 이상 탐지 기법은
데이터의 순차적 특성을 처리할 수 있어야 한다.
또한 점 이상(point anomaly) 탐지 기법은 이 도메인에서는 적용 가능하지 않다.
기법들은 시퀀스 데이터를 모델링하거나 시퀀스 간의 유사도를 계산해야 한다.
이 문제에 사용된 다양한 기법들에 대한 설문은 Snyder [2001]에 제시되어 있다.
호스트 기반 침입 탐지에 대한 이상 탐지의 비교 평가 결과는
Forrest et al. [1999]와 Dasgupta and Nino [2000]에 제시되어 있다.
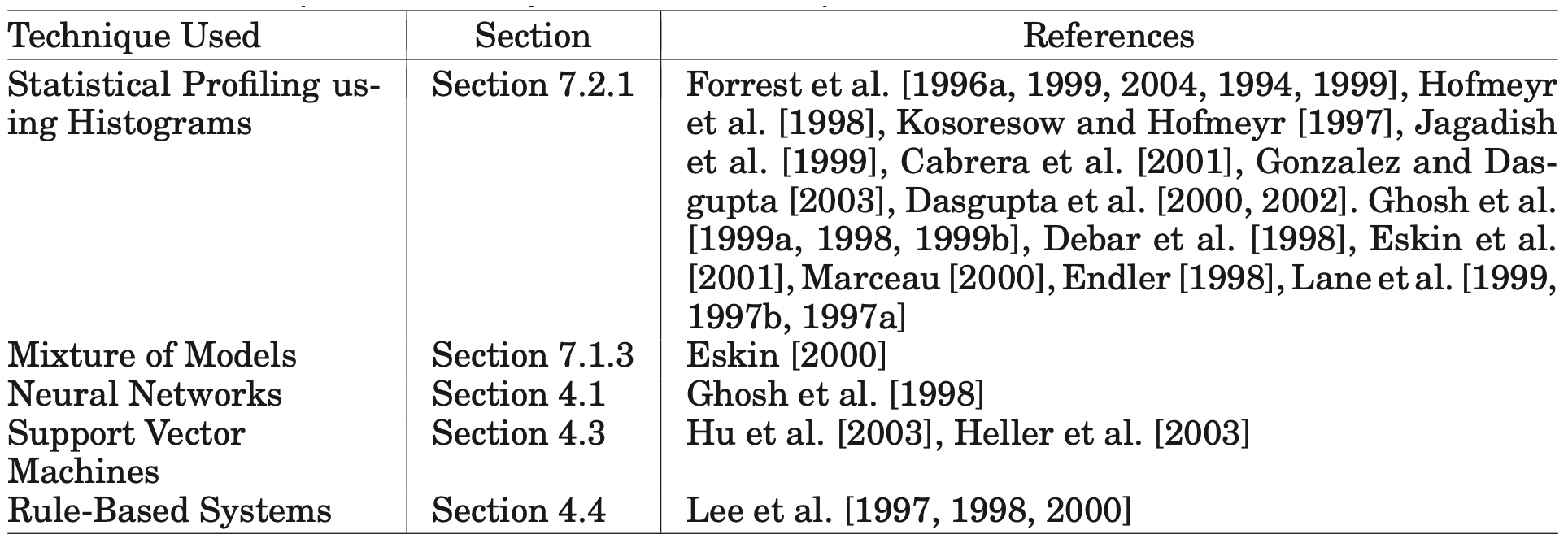
이 도메인에서 사용된 일부 이상 탐지 기법은 표 2에 나타나 있다.
표 2. 호스트 기반 침입 탐지에 사용되는 이상 탐지 기법의 예시.
3.1.2 네트워크 기반 침입 탐지 시스템 (Network Intrusion Detection Systems)
이러한 시스템은 네트워크 데이터에서 침입을 탐지하는 것을 다룬다.
침입은 일반적으로 이상한 패턴(점 이상)의 형태로 발생하지만,
일부 기법은 데이터를 순차적으로 모델링하여
이상한 부분 시퀀스(집합적 이상)를 탐지한다
[Gwadra et al. 2005b, 2004].
이러한 이상이 발생하는 주된 이유는
외부 해커가 정보 탈취 또는 네트워크 교란을 목적으로
비인가 접근을 얻기 위해 공격을 수행하기 때문이다.
일반적인 설정은 인터넷을 통해 전 세계와 연결된
대규모 컴퓨터 네트워크이다.
침입 탐지 시스템에 사용 가능한 데이터는
패킷 수준 트레이스, CISCO net-flows 데이터 등과 같이
서로 다른 세분화 수준(granularity)을 가질 수 있다.
데이터는 시간적 측면을 가지지만,
대부분의 기법은 이러한 순차적 측면을 명시적으로 처리하지 않는다.
데이터는 일반적으로 고차원이며,
범주형 속성과 연속형 속성이 혼합되어 있다.
이 도메인에서 이상 탐지 기법이 직면하는 도전 과제는
침입자가 기존의 침입 탐지 솔루션을 회피하기 위해
네트워크 공격을 지속적으로 적응시키면서
이상의 성격이 시간에 따라 계속 변화한다는 점이다.
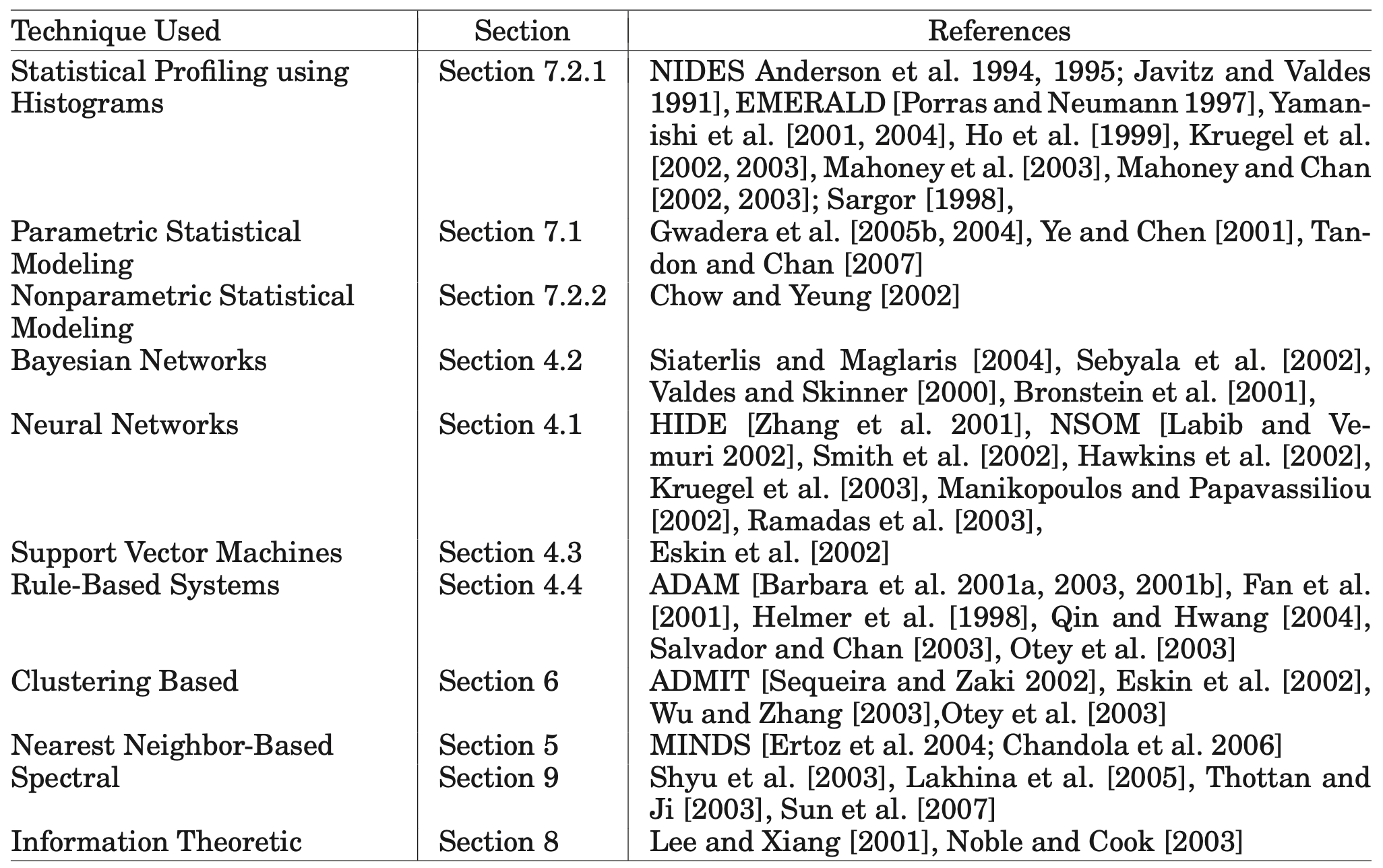
이 도메인에서 사용되는 일부 이상 탐지 기법은 표 3에 나타나 있다.
표 3. 네트워크 기반 침입 탐지에 사용되는 이상 탐지 기법의 예시.
3.2. 사기 탐지 (Fraud Detection)
사기 탐지는 은행, 신용카드 회사, 보험 기관, 이동통신 회사, 주식 시장 등과
같은 상업적 조직에서 발생하는 범죄 활동을 탐지하는 것을 의미한다.
악의적인 사용자들은 해당 조직의 실제 고객일 수도 있고,
고객으로 가장하고 있을 수도 있다
(이는 신원 도용(identity theft)으로도 알려져 있다).
이러한 사용자들이 조직이 제공하는 자원을
허가되지 않은 방식으로 소비할 때 사기가 발생한다.
조직들은 경제적 손실을 방지하기 위해
이러한 사기를 즉각적으로 탐지하는 데 관심이 있다.
Fawcett와 Provost [1999]는
이러한 도메인에서의 사기 탐지를 위한 일반적인 접근법으로
활동 모니터링(activity monitoring)이라는 용어를 도입하였다.
이상 탐지 기법의 전형적인 접근법은
각 고객에 대해 사용 프로파일을 유지하고,
편차를 탐지하기 위해 해당 프로파일을 모니터링하는 것이다.
사기 탐지의 구체적인 응용 사례 중 일부는 아래에서 논의된다.
3.2.1. 신용카드 사기 탐지 (Credit Card Fraud Detection)
이 도메인에서 이상 탐지 기법은 사기성 신용카드 신청이나
사기성 신용카드 사용(신용카드 도난과 연관됨)을 탐지하는 데 적용된다.
사기성 신용카드 신청을 탐지하는 것은
보험 사기를 탐지하는 것과 유사하다 [Ghosh and Reilly 1994].
데이터는 일반적으로 사용자 ID, 사용 금액,
연속적인 카드 사용 간의 시간 간격 등과 같은
여러 차원에 걸쳐 정의된 기록들로 구성된다.
사기는 일반적으로 거래 기록(포인트 이상)에 반영되며, 이는 고액 결제,
사용자가 이전에 구매한 적이 없는 물품의 구매, 높은 구매 빈도 등과 대응된다.
신용카드 회사들은 완전한 데이터를 보유하고 있으며,
라벨이 부여된 기록 또한 가지고 있다.
또한 데이터는 신용카드 사용자에 따라 서로 다른 프로파일로 구분된다.
따라서 이 도메인에서는 프로파일링 및 클러스터링 기반 기법이 일반적으로 사용된다.
무단 신용카드 사용을 탐지하는 것과 관련된 과제는
사기성 거래가 발생하는 즉시 온라인으로 사기를 탐지해야 한다는 점이다.
이 문제를 해결하기 위해 이상 탐지 기법은
두 가지 서로 다른 방식으로 적용되어 왔다.
첫 번째 방식은 by-owner로 알려져 있으며,
각 신용카드 사용자는 자신의 신용카드 사용 이력에 기반하여 프로파일링된다.
새로운 거래는 사용자의 프로파일과 비교되며,
프로파일과 일치하지 않을 경우 이상으로 표시된다.
이 접근법은 사용자가 거래를 할 때마다 중앙 데이터 저장소를 질의해야 하므로
일반적으로 비용이 많이 든다.
또 다른 접근법인 by-operation은
특정 지리적 위치에서 발생하는 거래들 가운데서 이상을 탐지한다.
by-user와 by-operation 기법 모두 문맥적 이상을 탐지한다.
첫 번째 경우 문맥은 사용자이며, 두 번째 경우 문맥은 지리적 위치이다.
이 도메인에서 사용되는 일부 이상 탐지 기법은 표 4에 나열되어 있다.
표 4. 신용 카드 사기 탐지를 위해 사용되는 이상 탐지 기법의 예시

3.2.2. 이동전화 사기 탐지 (Mobile Phone Fraud Detection)
이동전화/셀룰러 사기 탐지는 전형적인 활동 모니터링 문제이다.
이 작업은 대규모 계정 집합을 스캔하고,
각 계정의 통화 행위를 조사하여,
계정이 오용된 것으로 보일 때 경보를 발생시키는 것이다.
통화 활동은 다양한 방식으로 표현될 수 있으나,
일반적으로 통화 기록으로 기술된다.
각 통화 기록은 연속형(예: CALL-DURATION)과
이산형(예: CALLING-CITY) 특성을 모두 포함하는 특성 벡터이다.
그러나 이 도메인에는 본질적인 원시 표현 방식이 존재하지 않는다.
통화는 원하는 세분화 수준에 따라 시간 기준으로,
예를 들어 통화 시간대나 통화 일자, 또는 사용자나 지역 기준으로 집계될 수 있다.
이상은 높은 통화량이나 가능성이 낮은 목적지로의 통화에 대응된다.
이동전화 사기 탐지에 적용된 일부 기법은 표 5에 나열되어 있다.
표 5. 이동 전화 사기 탐지를 위해 사용되는 이상 탐지 기법의 예시

3.2.3. 보험 청구 사기 탐지 (Insurance Claim Fraud Detection)
재산·상해 보험 산업에서 중요한 문제 중 하나는 보험 청구 사기이며,
예를 들어 자동차 보험 사기가 있다.
개인이나, 청구인과 제공자들로 구성된 공모 집단은
허가되지 않거나 불법적인 청구를 위해 청구 처리 시스템을 조작한다.
이러한 사기를 탐지하는 것은
관련 기업들이 재정적 손실을 피하기 위해 매우 중요하다.
이 도메인에서 이용 가능한 데이터는 청구인들이 제출한 문서들이다.
기법들은 이 문서들로부터 범주형 특성과 연속형 특성을
모두 포함하는 다양한 특성들을 추출한다.
일반적으로 손해 사정인과 조사관들이
이러한 청구들을 사기 여부에 대해 평가한다.
이렇게 수작업으로 조사된 사례들은 보험 사기 탐지를 위한
지도 및 준지도 기법에서 라벨이 부여된 인스턴스로 사용된다.
보험 청구 사기 탐지는 종종 일반적인 활동 모니터링 문제로 처리된다
[Fawcett and Provost 1999].
신경망 기반 기법 또한 이상 보험 청구를 식별하는 데 적용되어 왔다
[He et al. 2003; Brockett et al. 1998].
3.2.4. 내부자 거래 탐지 (Insider Trading Detection)
이상 탐지 기법의 또 다른 최근 응용은
내부자 거래(Insider Trading)의 조기 탐지이다.
내부자 거래는 주식 시장에서 발견되는 현상으로,
정보가 공개되기 전에 내부 정보를 이용하거나 (또는 유출하여)
불법적인 이익을 취하는 행위를 말한다.
내부 정보는 다양한 형태를 가질 수 있다 [Donoho 2004].
이는 진행 중인 인수·합병에 대한 지식, 특정 산업에 영향을 미치는 테러 공격,
특정 산업에 영향을 미치는 입법 예정 사항,
또는 특정 산업의 주가에 영향을 미칠 수 있는 모든 정보를 포함할 수 있다.
내부자 거래는 시장에서의 이상 거래 활동을 식별함으로써 탐지될 수 있다.
이용 가능한 데이터는 옵션 거래 데이터, 주식 거래 데이터,
뉴스 등과 같은 여러 이질적인 출처로부터 제공된다.
데이터는 지속적으로 수집되기 때문에 시간적 연관성을 가진다.
이러한 시간적 및 스트리밍 특성은
일부 기법들에서 활용되어 왔다 [Aggarwal 2005].
이 도메인에서의 이상 탐지 기법은 사람이나 조직이
불법적인 이익을 취하는 것을 방지하기 위해,
가능한 한 조기에 온라인 방식으로 사기를 탐지해야 한다.
이 도메인에서 사용되는 일부 이상 탐지 기법은 표 6에 나열되어 있다.
표 6. 내부자 거래 탐지를 위해 사용되는 서로 다른 이상 탐지 기법들의 예시
