[빅데이터와 정보검색] 10주차 검색에이전트와 LangChain
[빅데이터와 정보검색] 10주차 검색에이전트와 LangChain
p3. 검색 에이전트 개요
- AI 에이전트 정의
- 사용자가 정의한 목표를 달성하기 위해 AI 모델을 활용하여 환경과 상호작용하는 시스템
- 추론(reasoning), 계획(planning), 그리고 외부 도구를 사용한 행동의 실행(execution)을 결합하여 작업을 수행
- 챗봇과의 차이점
- 챗봇
- 사용자의 질문에 반응하여 답변하는 역할
- AI 에이전트
- 챗봇을 넘어서 사용자가 원하는 최종 목표를 달성하기 위해 스스로 계획을 세우고 여러 단계를 거쳐 작업을 완수
- 챗봇
- 검색 에이전트와 기존 검색시스템과의 차이
- 기존 검색
- 사용자가 입력한 키워드에 기반한 정적 정보 제공
- 검색 에이전트
- 사용자의 복잡하고 추상적인 명령을 이해하고, 스스로 계획을 세워 외부 도구를 활용, 능동적으로 정보를 수집하고 처리하여 목표를 달성
- 기존 검색
- 등장 배경 및 중요성
- LLM의 발전과 외부 정보 및 도구 연동 필요성 증가
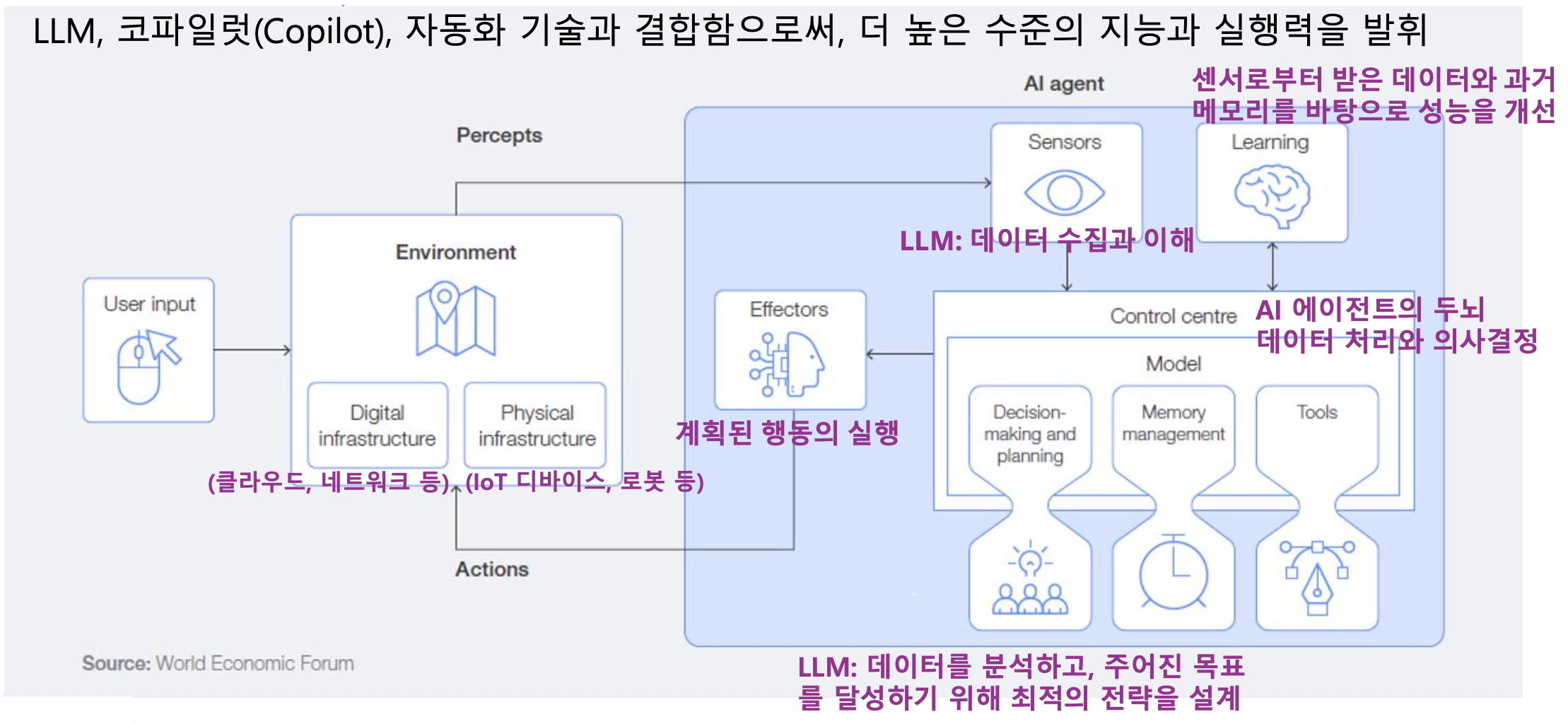
p4. AI 에이전트 아키텍처
AI 에이전트는 환경(Environment), 센서(Sensors), 학습(Learning), 컨트롤 센터(Control Centre),
실행기(Effectors) 로 구성된 구조를 통해 사용자의 요구와 환경 변화에 적응하며 자율적으로 작동
p5. AI 에이전트 아키텍처
AI 에이전트의 핵심 구성 요소
- 센서(Sensors)
- 환경(사용자 입력, 웹 등)으로부터 정보를 수집하는 역할
- 프로세서/추론 엔진(Processor/Reasoning Engine)
- 수집된 데이터를 분석하고 의사 결정을 내리는 핵심 두뇌 역할 (주로 LLM이 담당)
- 액추에이터(Actuators) & 이펙터(Effectors)
- 액추에이터
- 결정된 행동(외부 시스템 호출, 데이터 처리 등)을 실행하는 역할
- 이펙터(Effector)를 움직이게 하는 동력 장치/구동기
- 이펙터(Effector)
- 환경에 직접적인 영향을 미치거나 변화를 일으키는 장치
- 그 자체로 환경과 상호작용하는 도구
- 액추에이터
- 지식베이스/메모리(Knowledge Base/Memory)
- 축적된 경험과 지식을 저장하고 학습하는 공간
p6. AI 에이전트의 핵심 요소기술
- LLM (Large Language Model)
- 에이전트의 중앙 의사 결정자 및 추론 엔진 역할을 수행
- 추론(Reasoning) 및 계획(Planning)
- 복잡한 목표 달성을 위해 필요한 단계들을 스스로 생각하고 계획하는 능력
- 추론: 에이전트가 주어진 정보(프롬프트, 검색 결과, 지식베이스)를 바탕으로 논리적 결론을 도출하거나 문제 해결을 위한 아이디어를 생성
- 계획: 추론을 통해 도출된 아이디어나 목표를 달성하기 위해 필요한 구체적이고 순차적인 행동 단계(Steps)를 수립
- 복잡한 목표 달성을 위해 필요한 단계들을 스스로 생각하고 계획하는 능력
- 도구 사용(Tool Use/Tool Calling)
- 외부 API, 데이터베이스, 기타 시스템과 상호작용하여 정보를 얻거나 작업을 수행하는 기술
- 메모리 및 컨텍스트 관리
- 장기/단기 메모리를 통해 지속적인 학습 및 상황 인식을 유지하는 기술
- 오케스트레이션(Orchestration)
- 전체 작업 흐름을 제어하고 관리하여 목표 달성까지 이끄는 기술
- 요청 목적을 해석하고,
- 어떤 도구를 어떤 순서로 사용할지 계획하고,
- 상태를 유지하며 흐름을 제어
- 전체 작업 흐름을 제어하고 관리하여 목표 달성까지 이끄는 기술
p7. AI 에이전트의 핵심 요소기술
- LLM
- 자연어 이해(NLU): 사용자의 의도 파악
- 자연어 생성(NLG): 자연스러운 응답 생성
- Few-shot Learning: 적은 예시로 학습
- Chain-of-Thought: 단계별 추론
- In-context Learning: 맥락 기반 학습
- 프롬프트 엔지니어링과 도구 사용
- 프롬프트 엔지니어링을 통해 추론과 계획 수립
- CoT, ReACT 등을 사용하여 추론
- 도구를 사용하여 계획 실행: Function Calling 사용
- LLM이 외부 함수/API를 호출하는 메커니즘, 구조화된 출력 생성
- 프롬프트 엔지니어링을 통해 추론과 계획 수립
- 가용 도구 및 프레임워크
- AI 에이전트 개발 프레임워크
- LangChain/LangGraph: 에이전트 개발을 위한 대표적인 오픈소스 프레임워크. 도구 연결, 메모리 관리 등을 모듈화하여 제공
- Microsoft 365 에이전트 툴킷: Microsoft 생태계 내 에이전트 구축 도구
- 검색 및 데이터 처리 도구
- Tavily Search API: AI 에이전트가 실시간 웹 검색을 수행할 수 있도록 돕는 전문 검색 도구
- 기타 API: 웹 크롤링 도구(예: Browserless), 외부 서비스 API(Google Maps, Gmail 등)
- AI 에이전트 개발 프레임워크
p8. AI 에이전트의 핵심 요소기술
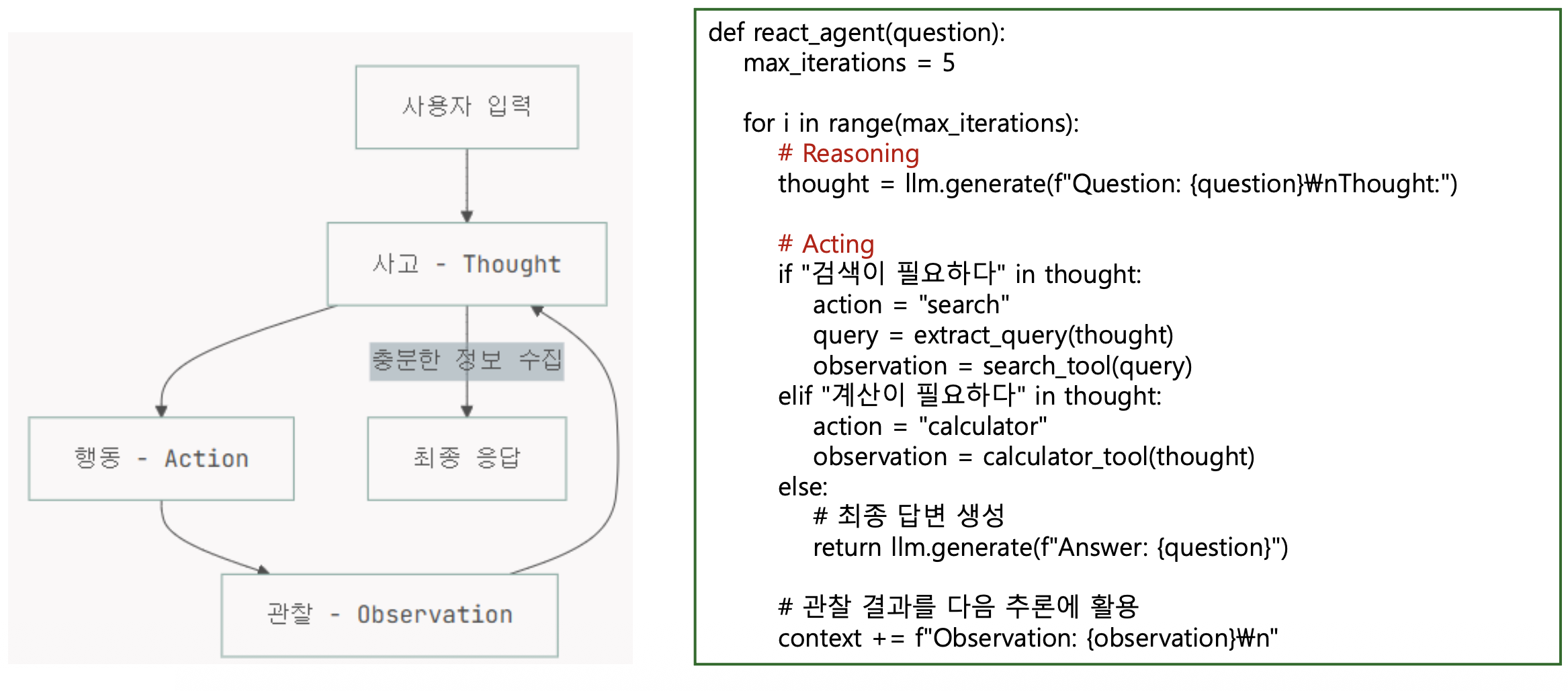
- 프롬프트 엔지니어링을 통한 추론과 실행: ReAct
p9. AI 에이전트의 핵심 요소기술
Planning과 도구사용
- 추론을 통해 결정된 목표를 실행 가능한 작업 목록으로 변환
도구 사용과 밀접하게 연관
- 핵심기법
- 작업 분해(Task Decomposition)
- 크고 복잡한 사용자 요청을 여러 개의 작고 관리 가능한 Sub-tasks으로 나누는 과정
- 예) “2024년 올림픽 개최 도시의 특징과 경제 효과”
→ 1. 개최 도시 검색
→ 2. 도시 특징 검색
→ 3. 관련 경제 보고서 검색
→ 4. 정보 종합 및 답변 생성
- Reflection(반성 및 개선)
- 에이전트가 계획대로 행동한 후 그 결과를 평가하고, 목표 달성에 실패했거나 더 나은 방법이 있다면
기존 계획을 수정하거나 새로운 계획을 수립하는 과정
- 에이전트가 계획대로 행동한 후 그 결과를 평가하고, 목표 달성에 실패했거나 더 나은 방법이 있다면
- LLM-as-a-Planner
- LLM 자체가 계획 수립 엔진 역할 수행
- 현재 상태와 사용 가능한 도구를 바탕으로 다음 행동(JSON, YAML 등 특정 형식의 출력)을 결정하는 접근 방식
- 작업 분해(Task Decomposition)
p10. AI 에이전트의 핵심 요소기술
도구 사용
검색 에이전트가 LLM 학습 데이터만으로는 해결할 수 없는 작업을 수행하기 위해
외부 시스템, API, 데이터베이스 등을 호출하고 활용하는 기술 (Function Calling)- 역할
- 최신성 확보: 실시간 웹 검색 도구를 사용하여 LLM 학습시점 이후의 정보 탐색
- 정확성 및 사실성: 계산, 코드 실행, 데이터베이스 검색과 같은 정밀 작업 수행
- 행동수행: 메일전송, 파일생성, 외부 서비스 예약 등 실제 작업 처리
- 도구 사용의 동작원리 및 매커니즘
- 사용자 요청 접수: LLM에 Prompt 입력
- 도구결정: LLM이 현재 상황과 사용 가능한 도구 목록을 보고 어떤 도구를 사용할지 추론
- 인수생성: 호출할 도구와 필요한 매개변수를 결정하고 정해진 형식으로 출력
- 도구실행: 에이전트 시스템이 LLM이 생성한 형식에 맞춰 실제 외부 도구(API)를 호출
- 결과수신: 도구 실행결과가 에이전트로 반환
- 응답생성 및 반복: LLM이 결과를 바탕으로 사용자에게 최종답변을 생성하거나
다음행동을 계획하여 2~5단계를 반복
p11. AI 에이전트의 핵심 요소기술
주요 도구 유형 및 예시
| 도구 유형 | 설명 | 주요 활용 예시 |
|---|---|---|
| 웹검색도구 | 실시간 인터넷 정보 검색 | 최신 뉴스 검색, 특정 사실 확인 등 (Tavily Search API, Google Search API) |
| 코드 인터프리터 | 파이썬 등 코드 실행 환경 | 복잡한 계산 수행, 데이터 분석, 통계 처리, 그래프 생성 (OpenAI Code Interpreter) |
| 외부 API 연동 | 타 서비스와 상호작용 | 날씨 정보 조회, 주식 시세 확인, 이메일 전송, 예약 시스템 연동 (Gmail API, Weather API) |
| 내부 DB/파일 접근 | 자체 보유 데이터 활용 | 사내 문서 검색(RAG), 개인 파일 읽기/쓰기 |
| 웹 크롤링/파싱 | 특정 웹페이지 정보 추출 | 뉴스 기사 본문 요약, 특정 웹사이트 데이터 수집 (Browserless API) |
p12. AI 에이전트의 핵심 요소기술
도구 사용의 구현방법 및 프레임워크에서의 지원
- Function Calling (함수 호출)
- OpenAI의 GPT 모델 등 대부분의 최신 LLM은
특정 JSON 스키마에 맞춰 함수 호출을 유도하는 기능을 기본으로 탑재
- OpenAI의 GPT 모델 등 대부분의 최신 LLM은
- 프레임워크 지원
- LangChain
- Tools 모듈을 제공하여 다양한 사전 구축 도구를 쉽게 연결 가능하며,
커스텀 도구를 정의하여 사용하는 것이 가능함 - Agent 및 AgentExecutor가 이 도구들을 오케스트레이션
- Tools 모듈을 제공하여 다양한 사전 구축 도구를 쉽게 연결 가능하며,
- LangGraph
- 도구 사용 과정을 그래프의 노드(Node)와 엣지(Edge)로 명시적으로 정의하여,
도구 호출 후 다음 상태로 전환되는 복잡한 흐름을 제어하는 데 효과적
- 도구 사용 과정을 그래프의 노드(Node)와 엣지(Edge)로 명시적으로 정의하여,
- LangChain
p13. AI 에이전트의 핵심 요소기술
도구사용: Function Calling

p14. AI 에이전트의 핵심 요소기술
메모리 및 컨텍스트 관리
- 필요성
- LLM은 한 번의 요청(세션) 내에서만 이전 대화를 기억할 수 있는 ‘제한된 컨텍스트 길이’라는 근본적인 한계를 지님
- 에이전트가 사용자와 장기적으로 상호작용하거나, 여러 작업에 걸쳐 일관된 지식을 유지하려면 이 한계를 극복해야 함
- 정의
- 컨텍스트: 현재 에이전트가 작업을 수행하는 데 필요한 모든 관련 정보 (사용자 입력, 이전 대화 기록, 검색 결과, 시스템 지침 등)
- 메모리: 과거의 상호작용이나 학습된 지식을 저장하고 필요할 때 검색하여 컨텍스트로 주입하는 시스템
- 메모리의 유형: 단기 기억과 장기 기억
- 단기 기억 (Short-Term Memory / STM)
- 현재 진행 중인 대화나 작업 세션 내의 정보를 일시적으로 저장
- 구현방법
- 대화 기록(Chat History): 이전 메시지들을 그대로 프롬프트에 포함시켜 LLM에 전달
- 컨텍스트 창 관리: LLM의 최대 토큰(Context Window) 한도 내에서 최신 대화 내용 위주로 포함되도록 관리
- 장기 기억 (Long-Term Memory / LTM)
- 여러 세션과 작업에 걸쳐 영구적으로 축적되는 지식의 토대
- 사실, 개념, 규칙 등 일반 지식과 에이전트의 경험(일화 기억)을 포함
- 구현 방법: RAG (Retrieval-Augmented Generation, 검색 증강 생성) 기술이 핵심
- 단기 기억 (Short-Term Memory / STM)
p15. AI 에이전트의 핵심 요소기술
- 컨텍스트 관리의 핵심 기술: RAG의 발전
- 기본 RAG: 질문에 대한 관련 문서를 찾아 컨텍스트에 추가하는 기본 방식
- Agentic RAG (에이전틱 RAG): RAG 활동을 수행하기 위해 여러 에이전트나 모듈을 조합
- 질의 재작성: 사용자의 모호한 질문을 명확하게 다듬기 위해 LLM을 사용
- 다중 소스 검색: 여러 데이터베이스나 웹 소스에서 동시에 정보를 가져옴
- 재순위화 (Reranking): 검색된 문서 중 가장 유용한 정보를 선별하여 컨텍스트 품질 향상
- 메모리 관리 메커니즘: 망각과 업데이트 전략
- 압축 (Compression): 너무 길어진 대화 기록을 요약하여 장기 기억에 저장하거나 컨텍스트 창에 맞게 줄임
- 망각/삭제 (Forgetting/Deletion): 관련성이 떨어지거나 오래된 기억은 주기적으로 삭제
- 업데이트 전략: 새로운 정보가 들어왔을 때 기존의 지식과 충돌하지 않도록 지식 베이스를 업데이트
p16. AI 에이전트의 핵심 요소기술
오케스트레이션 기술
- 정의
- 오케스트레이션은 여러 개의 독립적인 AI 구성 요소(LLM, 도구, 메모리 모듈 등)와
프로세스 흐름을 하나의 통일된 시스템으로 조정하고 관리하는 기술
- 오케스트레이션은 여러 개의 독립적인 AI 구성 요소(LLM, 도구, 메모리 모듈 등)와
- 필요성
- 검색 에이전트는 추론, 계획, 도구 사용, 메모리 접근 등 다양한 기술의 복합체로
구성 요소들이 언제, 어떻게 상호작용해야 하는지 통제하는 체계가 필요함
- 검색 에이전트는 추론, 계획, 도구 사용, 메모리 접근 등 다양한 기술의 복합체로
- 핵심원리 및 구성요소
- 오케스트레이션 계층 (Orchestration Layer)
- Routing (라우팅):
사용자의 입력이 들어왔을 때, 어떤 하위 에이전트 또는 모듈로 보낼지 결정
(예: “계산” 관련 질문은 코드 실행 에이전트로, “최신 정보”는 검색 에이전트로 라우팅) - State Management (상태 관리):
현재 에이전트가 어떤 작업을 수행 중인지, 이전 단계의 결과는 무엇인지 등
시스템의 현재 상태를 추적하고 관리 - Control Flow (흐름 제어):
작업의 순서를 정의하고, 조건부 로직(if/else), 반복(loop) 등을 구현하여 작업의 진행을 제어
- Routing (라우팅):
- 오케스트레이터 (Orchestrator)
- 또 다른 LLM이 메타(Meta) 레벨의 오케스트레이터 역할을 수행하며,
- 전체 작업 흐름을 내려다보며 다음 단계의 행동을 지시
- 오케스트레이션 계층 (Orchestration Layer)
p17. AI 에이전트의 핵심 요소기술
오케스트레이션 패턴 및 프레임워크
- Chain(체인) 기반 오케스트레이션
- 미리 정의된 고정된 순서로 일련의 작업(프롬프트, 도구 호출 등)을 순차적으로 실행
- 선형적인 흐름에 적합
- 장단점: 구현이 단순하고 예측 가능성이 높으나, 유연성이 떨어지며 동적인 상황변화에 대처하기 어려움
- 프레임워크: LangChain Expression Language (LCEL)
- Agent(에이전트) 기반 오케스트레이션
- LLM이 스스로 추론(Reasoning)하고 계획(Planning)하여
동적으로 다음 행동(Action)을 결정하는 방식으로, ReAct (Reasoning and Acting) 패턴이 대표적 - 높은 자율성과 유연성을 가지며, 복잡하고 예측 불가능한 문제 해결에 적합하지만
비결정적 특성으로 인해 결과의 일관성이 떨어질 수 있음 - 프레임워크: LangChain의 AgentExecutor
- LLM이 스스로 추론(Reasoning)하고 계획(Planning)하여
- Graph(그래프) 기반 오케스트레이션
- 작업 흐름을 노드(상태 또는 행동)와 엣지(전환 조건)로 구성된 방향성 그래프로 정의
- 체인 방식보다 유연하고, 에이전트 방식보다 흐름 제어가 명시적이어서
복잡한 워크플로우를 안정적으로 구축 가능 - Reflection(반성)과 Loop(반복) 구현에 매우 강력
- 프레임워크: LangGraph, Microsoft Autogen (멀티 에이전트 협업)
p18. AgenticRAG
- 전통적 RAG의 한계
- 검색품질 문제: 컨텍스트 창 제한, 노이즈 포함
- 단순선형 처리로 복잡한 질문처리 한계: 질문의 복잡도나 유형을 고려하지 않고, 단일 검색으로 충분하지 않은 경우 존재
- 적용성 부족: 검색 실패시 대안 전략부재, 추가정보가 필요한지 판단불가
→ 반복적 탐색, 질문유형에 따른 검색전략 사용, 품질평가, 다중소스 통합 등을 위해 AgenticRAG 등장
- Agentic RAG
- ‘추론하고 행동하는(Agentic)’ AI 에이전트 기술을 RAG 파이프라인에 도입 → 능동적인 정보 탐색 및 처리 가능
전통적인 RAG 흐름에 에이전트의 ‘계획(Planning)’ 및 ‘도구 사용(Tool Use)’ 능력을 통합
- 핵심 구성 요소(1)
- 오케스트레이터 에이전트 (Orchestrator Agent): 전체 프로세스를 관리(주로 LLM)
- 목표 달성을 위해 하위 에이전트와 도구를 언제 호출할지 결정
- 검색 에이전트 (Retrieval Agent): 데이터베이스, 웹 검색 도구 등을 사용하여 정보를 탐색하는 전문 에이전트
- 평가/반성 에이전트 (Evaluation/Reflection Agent): 검색된 정보의 유용성, 정확성을 판단하고, 부족할 경우 오케스트레이터에게 피드백을 제공하여 재시도(Loop)를 유도
- 도구 (Tools): 벡터 DB, 웹 검색 API, 코드 인터프리터 등
- 오케스트레이터 에이전트 (Orchestrator Agent): 전체 프로세스를 관리(주로 LLM)
p19. Agentic RAG의 사고 과정
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 의사 코드로 본 Agentic RAG 프로세스
def agentic_rag(query):
# 1. 질문 분석
analysis = analyze_query(query)
# "이 질문은 최신 정보가 필요하고, 수치 비교가 포함"
# 2. 전략 수립
strategy = plan_strategy(analysis)
# "먼저 최신 데이터를 검색하고, 그 다음 계산기를 사용"
# 3. 단계별 실행
for step in strategy:
if step.type == "search":
results = search(step.query)
# 4. 결과 평가
if not is_sufficient(results):
# 검색 쿼리 수정 후 재시도
results = search(refine_query(step.query))
elif step.type == "calculate":
results = calculator(step.expression)
# 5. 충분한지 판단
if has_enough_info():
break
# 6. 최종 답변 생성
return generate_answer(query, collected_info)
p20. AgenticRAG
AgenticRAG 핵심 구성요소(2)
- Query Analysis: 사용자의 질문의 의도, 복잡도, 필요 정보를 파악
- Planning(계획수립)
- 쿼리 분석 결과를 바탕으로 실행 계획을 수립
- 계획 수립 전략
- 선형계획: 간단한 질문에 적합
- 분기계획(Branching Planning): 조건부 실행이 필요한 경우
- 병렬 계획: 독립적인 여러 정보 수집
- Agentic RAG의 핵심 패턴인 ReAct 패턴 활용
- Retrieval(검색)
- 적응형 검색(Adaptive Retrieval)
- 하이브리드 검색(Hybrid Search)
- 다단계 검색(Multi-hop Retrieval)
- Self-Reflection(자기 성찰)
- 수집한 정보의 품질과 충분성을 평가
- 관련성(검색결과가 질문과 관련있는 정도)
완전성(정보가 충분한지?)
신뢰성(정보 출처와 신뢰성)
- Tool Use (도구 사용): 다양한 도구 통합
p21. Planning: ReAct 패턴 활용
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
class ReActPlanner:
def __init__(self, llm):
self.llm = llm
def plan_next_action(self, query, history, observations):
prompt = f"""
현재 상황:
질문: {query}
지금까지의 행동: {history}
관찰 결과: {observations}
다음에 무엇을 해야 할까요?
Thought: [추론 과정]
Action: [search/calculate/aggregate/answer]
Action Input: [구체적 입력]
"""
response = self.llm.generate(prompt)
return self.parse_react_response(response)
def execute_plan(self, query):
history = []
observations = []
max_iterations = 10
for i in range(max_iterations):
# 다음 행동 결정
action = self.plan_next_action(
query, history, observations
)
if action.type == "answer":
# 충분한 정보 확보
return action.content
# 행동 실행
result = self.execute_action(action)
# 기록
history.append(action)
observations.append(result)
return "최대 반복 횟수 도달"
p22. Retrieval (검색) – Adaptive Retrieval
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
class AdaptiveRetriever:
def retrieve(self, query, context=None):
# 첫 검색
results = self.initial_search(query)
# 결과 평가
quality = self.evaluate_results(results, query)
if quality < THRESHOLD:
# 검색 전략 변경
if quality.issue == "too_broad":
# 더 구체적으로
results = self.search(self.make_specific(query))
elif quality.issue == "outdated":
# 시간 제약 추가
results = self.search(
f"{query} 2024",
filter={"date": "last_6_months"}
)
elif quality.issue == "no_results":
# 쿼리 완화
results = self.search(self.expand_query(query))
return results
p23. Retrieval (검색) – 하이브리드 검색 (Hybrid Search)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
class HybridSearcher:
def __init__(self, vector_db, bm25_index):
self.vector_db = vector_db
self.bm25_index = bm25_index
def search(self, query, alpha=0.5):
# 의미 검색 (Vector Search)
semantic_results = self.vector_db.search(query, top_k=20)
# 키워드 검색 (BM25)
keyword_results = self.bm25_index.search(query, top_k=20)
# 점수 결합
combined = self.reciprocal_rank_fusion(
semantic_results,
keyword_results,
alpha=alpha
)
return combined[:10] # Top 10 반환
def reciprocal_rank_fusion(self, results1, results2, alpha=0.5):
"""RRF 알고리즘으로 결과 결합"""
scores = {}
k = 60 # RRF 상수
for rank, doc in enumerate(results1):
scores[doc.id] = scores.get(doc.id, 0) + alpha / (k + rank + 1)
for rank, doc in enumerate(results2):
scores[doc.id] = scores.get(doc.id, 0) + (1 - alpha) / (k + rank + 1)
return sorted(scores.items(),
key=lambda x: x[1],
reverse=True)
p24. Retrieval (검색) – 다단계 검색 (Multi-hop Retrieval)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
class MultiHopRetriever:
def retrieve(self, query, max_hops=3):
results = []
current_query = query
for hop in range(max_hops):
# 현재 쿼리로 검색
hop_results = self.search(current_query)
results.extend(hop_results)
# 다음 검색이 필요한지 판단
need_more = self.assess_information_gap(
query, results
)
if not need_more:
break
# 다음 쿼리 생성
current_query = self.generate_followup_query(
query, results
)
return self.deduplicate_and_rank(results)
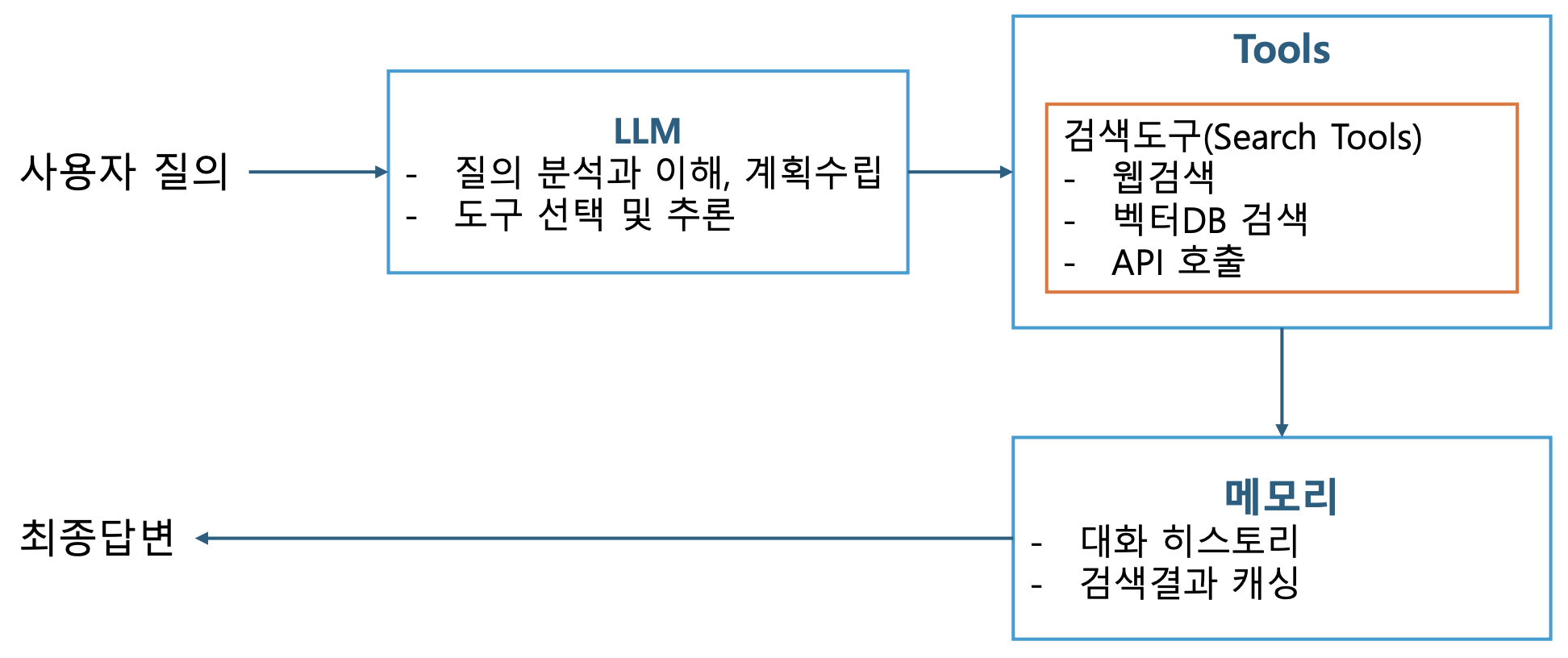
p25. 검색 에이전트
p26. 검색 에이전트
필수 구성요소
- LLM
- OpenAI GPT-4, …
- Anthropic Claude
- Google PaLM
- 오픈소스 모델(Llama, Mistral 등)
- 도구
- 검색도구
- SerpAPI: Google 검색
- DuckDuckGo: 프라이버시 중심 검색
- Wikipedia: 백과사전 정보
- ArXiv: 학술 논문 검색
- 벡터 저장소
- 유틸리티 도구
- Calculator: 수학 계산
- Python REPL: 코드 실행
- Requests: HTTP 요청
- 검색도구
- 메모리
- ConversationBufferMemory: 전체 대화 저장
- ConversationSummaryMemory: 요약 저장
- ConversationBufferWindowMemory: 최근 N개 메시지만 저장
- VectorStoreMemory: 벡터 기반 관련 메모리 검색
p27. LangChain을 이용한 검색 에이전트
- LangChain ?
- LangChain은 대규모 언어 모델(LLM)을 활용한 애플리케이션 개발을 위한 프레임워크
- 핵심 기능
- 프롬프트 관리 및 최적화
- 체인(Chain) 구성을 통한 복잡한 워크플로우 구현
- 데이터 소스 연결 및 통합
- 에이전트를 통한 자율적 작업 수행
- 메모리 관리
p28. LangChain을 이용한 검색 에이전트
LangChain 개발환경 설정
- 필요 패키지 설치
1 2 3 4 5 6 7 8 9 10 11
# 기본 LangChain 설치 pip install langchain langchain-community langchain-openai # 검색 도구 pip install google-search-results duckduckgo-search wikipedia # 벡터 저장소 pip install chromadb faiss-cpu # 유틸리티 pip install python-dotenv requests beautifulsoup4
- 환경변수 설정
1 2 3
# .env 파일 생성 OPENAI_API_KEY=your_openai_api_key SERPAPI_API_KEY=your_serpapi_key
p29. LangChain을 이용한 검색 에이전트
- 기본 임포트
1 2 3 4 5 6 7 8 9
from langchain.agents import initialize_agent, Tool, AgentType from langchain_openai import ChatOpenAI from langchain.memory import ConversationBufferMemory from langchain.prompts import MessagesPlaceholder from dotenv import load_dotenv import os # 환경 변수 로드 load_dotenv()
p30. 간단한 검색 에이전트
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
from langchain.agents import load_tools, initialize_agent, AgentType
from langchain_openai import ChatOpenAI
# LLM 초기화
llm = ChatOpenAI(
model="gpt-4",
temperature=0
)
# 도구 로드
tools = load_tools(
["serpapi", "llm-math"],
llm=llm
)
# 에이전트 초기화
agent = initialize_agent(
tools=tools,
llm=llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
# 실행
response = agent.run(
"2024년 노벨 물리학상 수상자는 누구이며, 그들의 주요 업적은 무엇인가요?"
)
print(response)
p31. 커스텀 검색 도구 생성
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
from langchain.tools import Tool
from langchain.utilities import DuckDuckGoSearchAPIWrapper
# DuckDuckGo 검색 래퍼
search = DuckDuckGoSearchAPIWrapper()
# 커스텀 도구 정의
search_tool = Tool(
name="웹검색",
func=search.run,
description="최신 정보나 실시간 데이터가 필요할 때 유용합니다. "
"뉴스, 날씨, 최신 이벤트 등을 검색할 수 있습니다."
)
# Wikipedia 도구
from langchain.utilities import WikipediaAPIWrapper
wikipedia = WikipediaAPIWrapper()
wiki_tool = Tool(
name="위키피디아",
func=wikipedia.run,
description="역사적 사실, 인물 정보, 개념 설명 등 "
"검증된 백과사전 정보가 필요할 때 사용합니다."
)
# 도구 리스트
tools = [search_tool, wiki_tool]
p32. 메모리를 포함한 에이전트
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
from langchain.memory import ConversationBufferMemory
from langchain.prompts import MessagesPlaceholder
# 메모리 초기화
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True
)
# 에이전트 생성
agent = initialize_agent(
tools=tools,
llm=llm,
agent=AgentType.CHAT_CONVERSATIONAL_REACT_DESCRIPTION,
memory=memory,
verbose=True,
agent_kwargs={
"memory_prompts": [
MessagesPlaceholder(variable_name="chat_history")
],
"input_variables": ["input", "agent_scratchpad", "chat_history"]
}
)
# 대화형 실행
print(agent.run("파이썬이 언제 만들어졌나요?"))
print(agent.run("그 언어의 창시자는 누구인가요?")) # 이전 맥락 기억
p33. 벡터 저장소를 활용한 RAG 에이전트
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import TextLoader
from langchain.chains import RetrievalQA
# 문서 로드 및 분할
loader = TextLoader("knowledge_base.txt")
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
texts = text_splitter.split_documents(documents)
# 벡터 저장소 생성
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(
documents=texts,
embedding=embeddings,
persist_directory="./chroma_db"
)
# 검색 도구 생성
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
knowledge_tool = Tool(
name="지식베이스",
func=RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever
).run,
description="내부 문서나 지식베이스에서 정보를 검색할 때 사용합니다."
)
p34. 커스텀 에이전트 타입
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
from langchain.agents import BaseSingleActionAgent
from langchain.schema import AgentAction, AgentFinish
class CustomSearchAgent(BaseSingleActionAgent):
"""커스텀 검색 에이전트"""
tools: list
llm: ChatOpenAI
def plan(self, intermediate_steps, **kwargs):
"""다음 행동 계획"""
# 커스텀 로직 구현
user_input = kwargs["input"]
# LLM을 사용한 의사결정
# …
return AgentAction(
tool="웹검색",
tool_input=user_input,
log="검색을 수행합니다."
)
@property
def input_keys(self):
return ["input"]
p35. 에이전트 체인 구성
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
from langchain.chains import SequentialChain, LLMChain
from langchain.prompts import PromptTemplate
# 1단계: 질의 분석 체인
analysis_template = """
다음 질문을 분석하여 필요한 정보를 파악하세요:
질문: {question}
분석 결과:
"""
analysis_chain = LLMChain(
llm=llm,
prompt=PromptTemplate(template=analysis_template, input_variables=["question"]),
output_key="analysis"
)
# 2단계: 검색 전략 수립 체인
strategy_template = """
분석 결과를 바탕으로 검색 전략을 수립하세요:
분석: {analysis}
검색 전략:
"""
strategy_chain = LLMChain(
llm=llm,
prompt=PromptTemplate(template=strategy_template, input_variables=["analysis"]),
output_key="strategy"
)
# 순차 체인 구성
chain = SequentialChain(
chains=[analysis_chain, strategy_chain],
input_variables=["question"],
output_variables=["analysis", "strategy"],
verbose=True
)
p36. LangChain

p37. 랭체인(LangChain)이란?

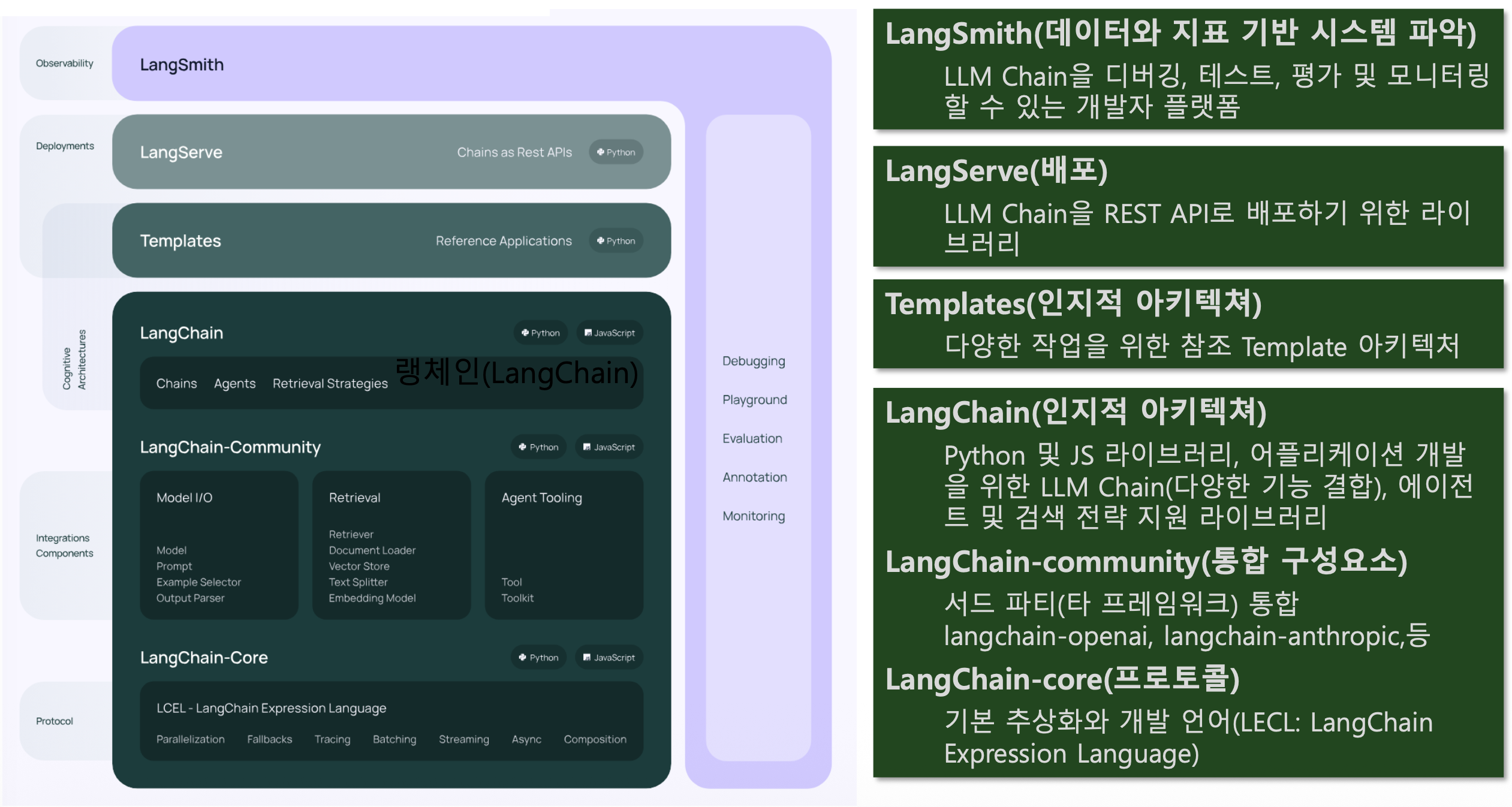
p38. 랭체인 프레임워크 구조
p39. 랭체인(LangChain) 개요
LangChain 패키지의 주요 모듈
- Chains
- LLM 관련 도구, 전처리 등 기능 제공
- LCEL(LangChain Expression Language) 활용
- Model I/O(Input/Output)
- 모델의 입출력 관리 모듈
- 전세계 언어 관련 모델과 상호작용할 수 있는 블록 방식 기능 제공
- Prompt Template
- 사용자의 입력 변수를 사용하여 완전한 프롬프트 문자열을 만드는 데 사용되는 템플릿 제공
- Agents
- 에이전트(작업 주체)가 LLM을 활용하여 어떤 작업을 수행할지 선택
- Retrieval
- 언어 생성에 문서를 참고하며, 문서를 텍스트 벡터 형식으로 저장하여 최적화
- Memory
- 언어 생성에서 과거의 상호작용 기록이 필요한 경우 이를 메모리 형태로 관리
- Callbacks
- 로깅, 모니터링, 스트리밍(ChatGPT와 같이 실시간 답변 생성) 등
LLM 애플리케이션의 다양한 단계와 연결하는 기능 제공
- 로깅, 모니터링, 스트리밍(ChatGPT와 같이 실시간 답변 생성) 등
p40. 랭체인 설치 및 OpenAI LLM 사용 환경 설정
- Langchain과 langchain-openai 라이브러리 패키지 설치
1 2
!pip install langchain !pip install langchain-openai
- 3rd Party 통합을 위한 패키지 설치
1 2
!pip install langchain-community langchain-core !pip install --upgrade langchain
- OpenAI 의존성 패키지 import
1
from langchain_openai import ChatOpenAI
- PromptTemplate, LLMChain import
1
from langchain import PromptTemplate, LLMChain
- OpenAI 인증키 등록
1 2
import os os.environ['OPENAI_API_KEY'] = 'OPENAI_API_KEY'
p41. LangChain의 구성요소
- Model I/O
- Prompts
- ChatModels
- LLMs
- PromptTemplates
- OutputParsers
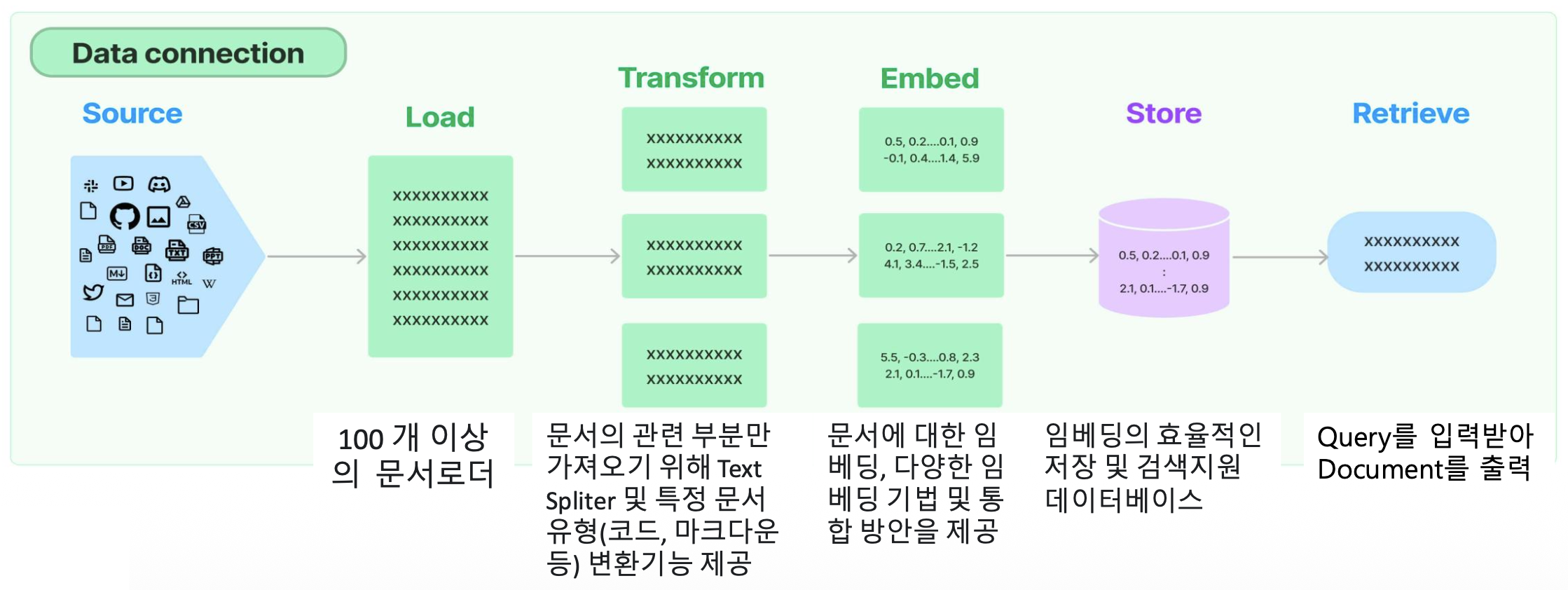
- Retrieval
- Document Loaders
- Text Spliters
- Embedding Models
- Vector Stores
- Retrievers
- Indexing
- Composition
- Tools
- Agents
- Chains
p42. LangChain 구성요소
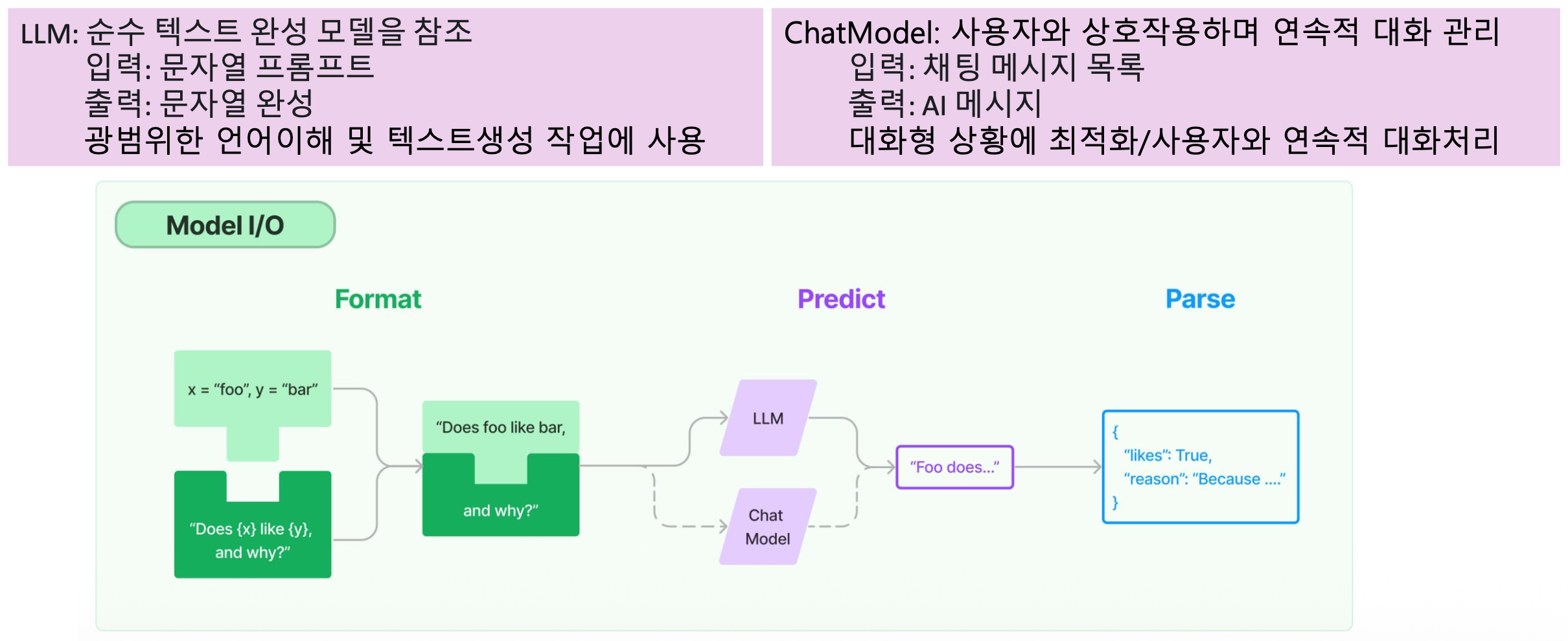
- Model I/O: 언어 모델 애플리케이션의 핵심 요소는 모델
- LangChain의 언어 모델은 두 가지 형태로 제공
p43. LangChain 구성요소
Retrieval
- 검색증강생성 기법(RAG: Retrieval Augmented Generation)
- LLM 애플리케이션에서 모델 학습 데이터가 아닌 사용자별 데이터 사용 시
- 외부 데이터를 검색한 후 생성 단계를 수행하고, 언어모델(LLM)으로 전달
- RAG 애플리케이션을 위한 빌딩 블록 제공
p44. LangChain 구성요소
Composition
다른 시스템(예: 외부 API 및 서비스) 또는 LangChain Primitive를 결합한 상위 수준 구성 요소
- Tools
- LLM 및 기타 구성 요소가 다른 시스템과 상호 작용할 수 있는 인터페이스를 제공
- 예: Wikipedia, 계산기, Python REPL 등
- Ref) https://python.langchain.com/v0.1/docs/modules/tools/
- Agents
- 언어 모델을 사용하여 수행할 일련의 작업을 결정
- 언어모델은 수행할 작업과 순서를 결정하는 추론 엔진으로 사용
- Runtime executor
- Agent 호출, Agent가 선택한 도구 실행, 작업 출력을 Agent에 다시 전달하고 반복하는 역할
- Ref) https://python.langchain.com/v0.1/docs/modules/agents/
- 언어 모델을 사용하여 수행할 일련의 작업을 결정
- Chains
- LCEL을 사용하여 LLM, 도구 또는 데이터 전처리 단계 등 일련의 호출 지원
- Ref) https://python.langchain.com/v0.1/docs/modules/chains/
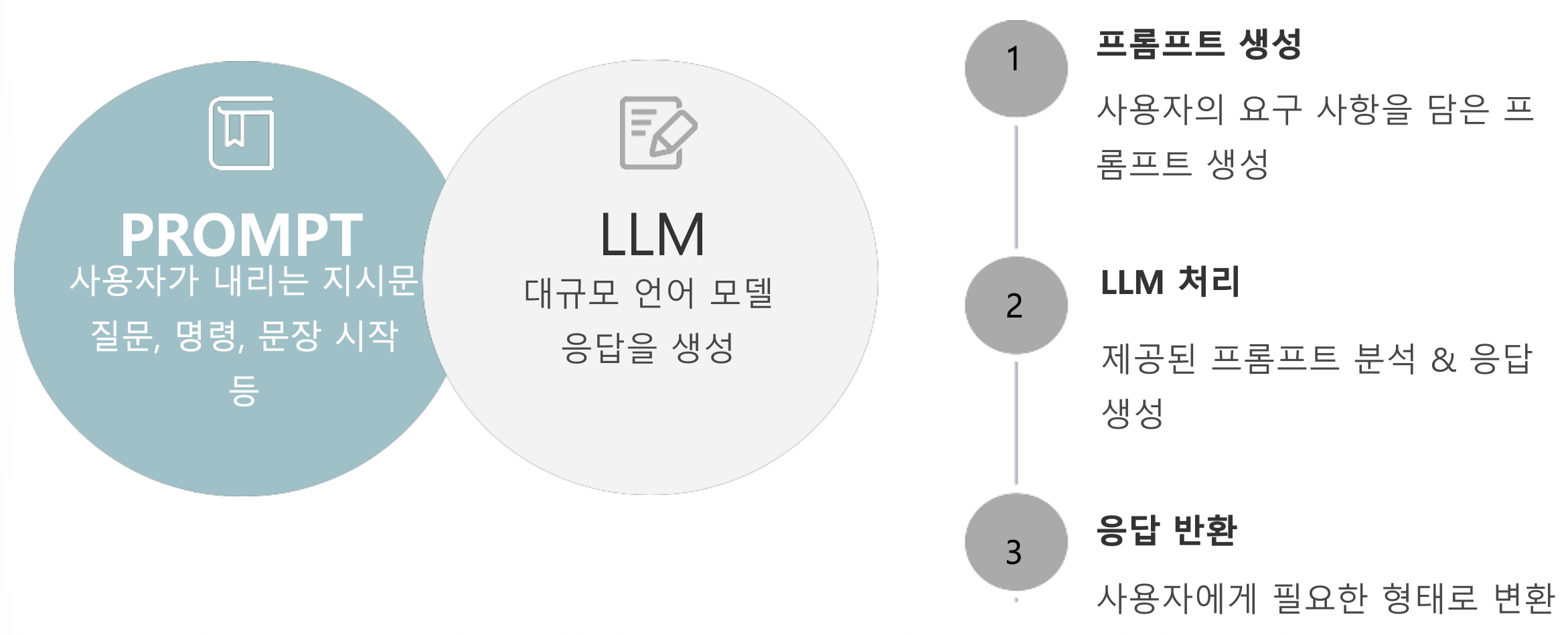
p45. LLM 체인 만들기
기본 LLM 체인
p46. LLM 체인 만들기
기본적으로 사용하는 클래스와 메서드
- ChatOpenAI
- 모델을 불러오는 클래스
- ChatPromptTemplate
- prompt 템플릿을 제공해주는 클래스
- ChatPromptTemplate.from_template()
- 문자열 형태의 템플릿을 인자로 받아, 해당 형식에 맞는 프롬프트 객체를 생성
- StrOutputParser
- 모델 출력값을 문자열 형태로 파싱하여 최종 결과를 반환
- invoke
- chain을 실행하는 메서드
p47. 가장 간단한 LLM 실행 예시
(1) 기본 LLM 실행
1
2
3
4
5
6
from langchain_openai import ChatOpenAI
# 가장 간단한 LLM 실행
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
llm.invoke("지구의 자전 주기는?")
# llm.invoke("지구의 자전 주기는?").content # 출력 내용만 가져옴
1
2
3
4
5
6
7
8
AIMessage(content='지구의 자전 주기는 약 24시간입니다. 이는 하루 동안 지구가 자전하는 시간을 의미하며,
이에 따라 낮과 밤이 생기게 됩니다. 지구의 자전 주기는 항상 일정하지는 않고
다양한 외부 요인에 의해 조금씩 변할 수 있습니다.',
response_metadata={'token_usage': {'completion_tokens': 100, 'prompt_tokens': 16,
'total_tokens': 116}, 'model_name': 'gpt-3.5-turbo-0125',
'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None},
id='run-00a6deca-1c25-4c06-8a6f-a069c1fcc1bc-0',
usage_metadata={'input_tokens': 16, 'output_tokens': 100, 'total_tokens': 116})
(2) Prompt Template 도입
1
2
3
4
5
6
7
from langchain.prompts import ChatPromptTemplate
# prompt template 생성
prompt = ChatPromptTemplate.from_template(
"You are an expert in astronomy. Answer the question. <Question>: {input}"
)
prompt
1
2
3
4
ChatPromptTemplate(input_variables=['input'],
messages=[HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['input'],
template='You are an expert in astronomy.
Answer the question. <Question>: {input}'))])
(3) Chain으로 연결
1
2
3
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
chain = prompt | llm
chain.invoke({"input": "지구의 자전 주기는?"})
1
2
3
4
5
AIMessage(content='지구의 자전 주기는 약 24시간 입니다. 이는 하루 동안 지구가 한 번 자전하는 주기를 의미합니다.',
response_metadata={'token_usage': {'completion_tokens': 42, 'prompt_tokens': 30, 'total_tokens': 72},
'model_name': 'gpt-3.5-turbo-0125', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None},
id='run-83e54510-b44e-4b46-b4cf-2943803ff896-0',
usage_metadata={'input_tokens': 30, 'output_tokens': 42, 'total_tokens': 72})
p48. StrOutputParser 도입
1
2
3
4
5
6
7
8
9
10
11
# StrOutputParser 도입
prompt = ChatPromptTemplate.from_template(
"You are an expert in astronomy. Answer the question. <Question>: {input}"
)
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
output_parser = StrOutputParser()
chain = prompt | llm | output_parser
chain.invoke({"input": "지구의 자전 주기는?"})
1
2
지구의 자전 주기는 약 24시간입니다. 이는 하루 동안 지구가 자전하는 시간을 의미합니다. 지구는
자전하면서 자전축 주위를 도는데, 이러한 운동으로 하루가 끝나면 다시 일출이 일어나게 됩니다.
p49. 순차적인 체인 연결
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 순차적인 체인 연결
prompt1 = ChatPromptTemplate.from_template("translates {korean_word} to English.")
prompt2 = ChatPromptTemplate.from_template(
"explain {english_word} using oxford dictionary to me in Korean."
)
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
chain1 = prompt1 | llm | StrOutputParser()
chain2 = (
{"english_word": chain1}
| prompt2
| llm
| StrOutputParser()
)
chain2.invoke({"korean_word": "미래"})
1
미래: 사람이나 사물이나 사건의 뒤에 따라오는 시기.
p50. Prompt Template
- Prompt Template
- 언어 모델에 대한 프롬프트를 생성하기 위해 미리 정의된 레시피
- LangChain은 프롬프트 템플릿을 생성하고 작업할 수 있는 도구를 제공
- PromptTemplate의 유형
- PromptTemplate
- PromptTemplate은 문자열 프롬프트에 대한 템플릿을 생성하는 데 사용
- 기본적으로 템플릿 작성에는 Python의 str.format 구문을 사용
- ChatPromptTemplate
- 각 채팅 메시지는 content와 추가적인 매개변수 role이 연결됨
- OpenAI Chat Completions API에서 채팅 메시지는 AI Assistant, Human, System과 연결
- Message Prompt Templates
- AIMessagePromptTemplate: AI assistant 메시지용
- SystemMessagePromptTemplate: 시스템 메시지용
- HumanMessagePromptTemplate: 사용자 메시지용
- ChatMessagePromptTemplate: 임의의 역할(role)을 가진 메시지용
- MessagesPlaceholder: 여러 개의 메시지를 리스트로 처리할 때 사용
- FewShotPromptTemplate
- Few-shot을 위해 사용하는 Prompt Template
- PipelinePromptTemplate
- 여러 개의 프롬프트를 조합해서 최종 프롬프트를 만들어야 할 때 사용
- PromptTemplate
p51. Prompt Template
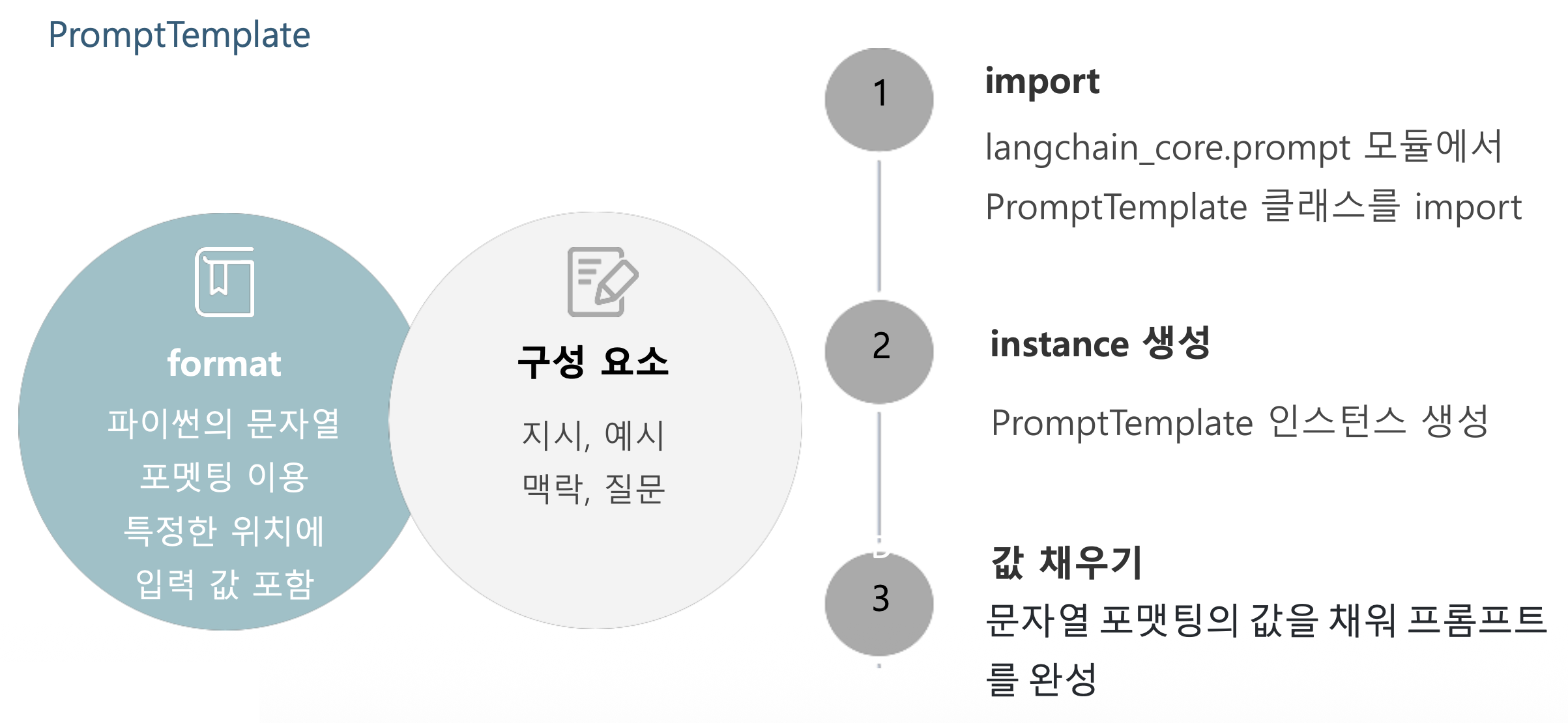
p52. PromptTemplate
- PromptTemplate: 프롬프트 템플릿을 정의할 수 있는 Template
- PromptTemplate.from_template: 문자열 template으로부터 PromptTemplate 인스턴스를 생성
- PromptTemplate.format: 템플릿을 채우는 메서드
1
2
3
4
5
6
from langchain_core.prompts import PromptTemplate
template_text = "안녕하세요, 제 이름은 {name}이고, 나이는 {age}살입니다."
prompt_template = PromptTemplate.from_template(template_text)
filled_prompt = prompt_template.format(name="홍길동", age=30)
filled_prompt
1
안녕하세요, 제 이름은 홍길동이고, 나이는 30살입니다.
p53. Prompt Template
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 문자열 템플릿 결합
combined_prompt = (
prompt_template
+ PromptTemplate.from_template("\n\n아버지를 아버지라 부를 수 없습니다.")
+ "\n\n{language}로 번역해주세요."
)
combined_prompt.format(name="홍길동", age=30, language="영어")
llm = ChatOpenAI(model="gpt-3.5-turbo-0125")
chain = combined_prompt | llm | StrOutputParser()
chain.invoke({"age": 30, "language": "영어", "name": "홍길동"})
1
Hello, my name is Hong Gil-dong and I am 30 years old.\n\nI cannot call my father "father."
p54. Chat Prompt Template
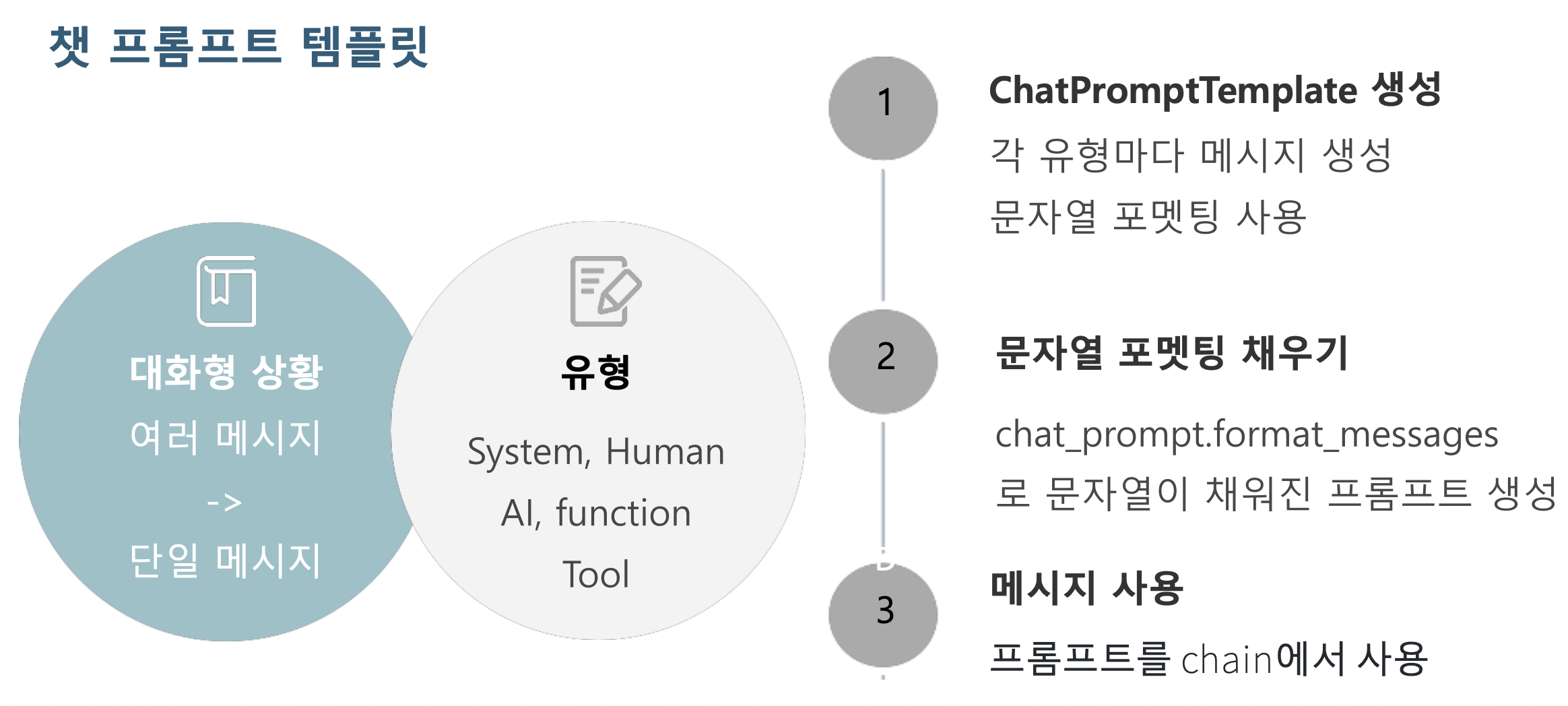
p55. ChatPromptTemplate
- ChatPromptTemplate
- 대화형 상황에서 여러 메시지 입력을 기반으로 단일 메시지 응답을 생성하는 데 사용
- ChatPromptTemplate.from_messages
- 메시지 리스트(혹은 튜플)를 기반으로 프롬프트를 구성함
- ChatPromptTemplate.format_messages
- 사용자의 입력을 프롬프트에 동적으로 삽입하여,
최종적으로 대화형 상황을 반영한 메시지 리스트를 생성
- 사용자의 입력을 프롬프트에 동적으로 삽입하여,
1
2
3
4
5
6
7
8
9
from langchain_core.prompts import ChatPromptTemplate
chat_prompt = ChatPromptTemplate.from_messages([
("system", "이 시스템은 천문학 질문에 답변할 수 있습니다."),
("user", "{user_input}"),
])
messages = chat_prompt.format_messages(user_input="태양계에서 가장 큰 행성은 무엇인가요?")
messages
1
2
[SystemMessage(content='이 시스템은 천문학 질문에 답변할 수 있습니다.’),
HumanMessage(content='태양계에서 가장 큰 행성은 무엇인가요?')]
1
2
chain = chat_prompt | llm | StrOutputParser()
chain.invoke({"user_input": "태양계에서 가장 큰 행성은 무엇인가요?"})
1
태양계에서 가장 큰 행성은 목성입니다. 목성은 질량과 부피 모두에서 가장 큰 행성으로 알려져 있습니다
p56. LangChain 모델
모델 유형
- LLM
- 단일 요청에 대한 복잡한 출력 생성
- Input: 텍스트 문자열
- Output: 텍스트 문자열
- 광범위한 언어 이해 및 텍스트 생성 작업에 사용
- 단일 요청에 대한 복잡한 출력 생성
- Chat Model
- 사용자와의 상호작용을 통한 연속적인 대화 관리
- Input: 메시지의 리스트
- Output: 하나의 메시지
- 대화형 상황에 최적화되어, 사용자와의 연속적인 대화를 처리
- 사용자와의 상호작용을 통한 연속적인 대화 관리
p57. LangChain 모델
LLM 하이퍼 파라미터
- Temperature
- 다양성을 조정
- 값이 작으면 일관된 출력 / 크면 예측하기 어려운 출력
- Max Tokens
- 생성할 최대 토큰 수 지정
- Top p
- 상위 P%의 토큰만을 고려
- Frequency Penalty
- 등장한 단어나 구절이 다시 등장할 확률을 감소
- Presence Penalty
- 단어의 존재 유무에 따라 선택 확률을 조정
- Stop Sequences
- 특정 단어나 구절이 등장할 경우 생성을 멈춤
p58. LangChain 모델
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 모델 생성 단계에서 주기
params = {
"temperature": 0.7,
"max_tokens": 100,
}
kwargs = {
"frequency_penalty": 0.5,
"presence_penalty": 0.5,
"stop": ["\n"]
}
model = ChatOpenAI(model="gpt-3.5-turbo-0125", **params, model_kwargs=kwargs)
question = "태양계에서 가장 큰 행성은 무엇인가요?"
response = model.invoke(input=question)
print(response)
1
2
3
4
5
6
7
# 모델 호출 단계에서 주기
params = {
"temperature": 0.7,
"max_tokens": 10,
}
response = model.invoke(input=question, **params)
print(response.content)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# LLM 모델 파라미터를 추가로 바인딩(bind 메소드)
# 특수한 상황에서만 일부 파라미터를 다르게 적용
prompt = ChatPromptTemplate.from_messages([
("system", "이 시스템은 천문학 질문에 답변할 수 있습니다."),
("user", "{user_input}"),
])
model = ChatOpenAI(model="gpt-3.5-turbo-0125", max_tokens=100)
messages = prompt.format_messages(user_input="태양계에서 가장 큰 행성은 무엇인가요?")
before_answer = model.invoke(messages)
print(before_answer)
chain = prompt | model.bind(max_tokens=10)
after_answer = chain.invoke({"user_input": "태양계에서 가장 큰 행성은 무엇인가요?"})
print(after_answer)
1
2
3
4
5
content=
'가장 큰 행성은 목성입니다. 목성은 태양계에서 가장 크고 질량이 가장 큰 행성으로, 지름은 약 14만 2000km에 달합니다.’
content=
'태양계에서 가장 큰'
p59. 출력 파서(OutputParser)
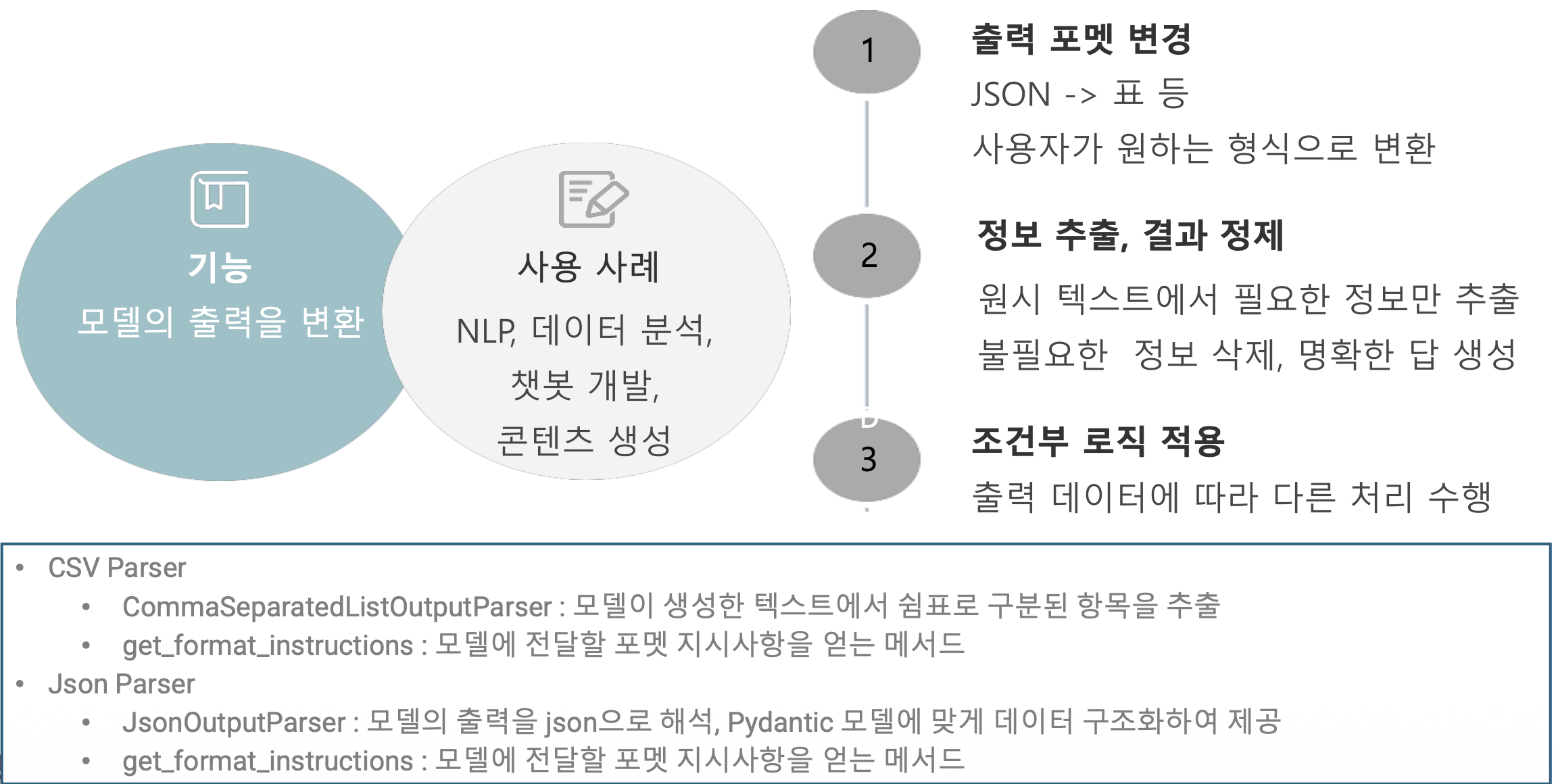
p60. 출력 파서(OutputParser)
1
2
3
4
5
from langchain_core.output_parsers import CommaSeparatedListOutputParser
output_parser = CommaSeparatedListOutputParser()
format_instructions = output_parser.get_format_instructions()
print(format_instructions)
1
Your response should be a list of comma separated values, eg: `foo, bar, baz` or `foo,bar,baz`
1
2
3
4
5
6
7
8
9
prompt = PromptTemplate(
template="List five {subject}.\n{format_instructions}",
input_variables=["subject"],
partial_variables={"format_instructions": format_instructions},
)
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
chain = prompt | llm | output_parser
chain.invoke({"subject": "popular Korean cuisine"})
1
['Bibimbap', 'Kimchi', 'Bulgogi', 'Japchae', 'Tteokbokki']
p61. LCEL(LangChain Expression Language)
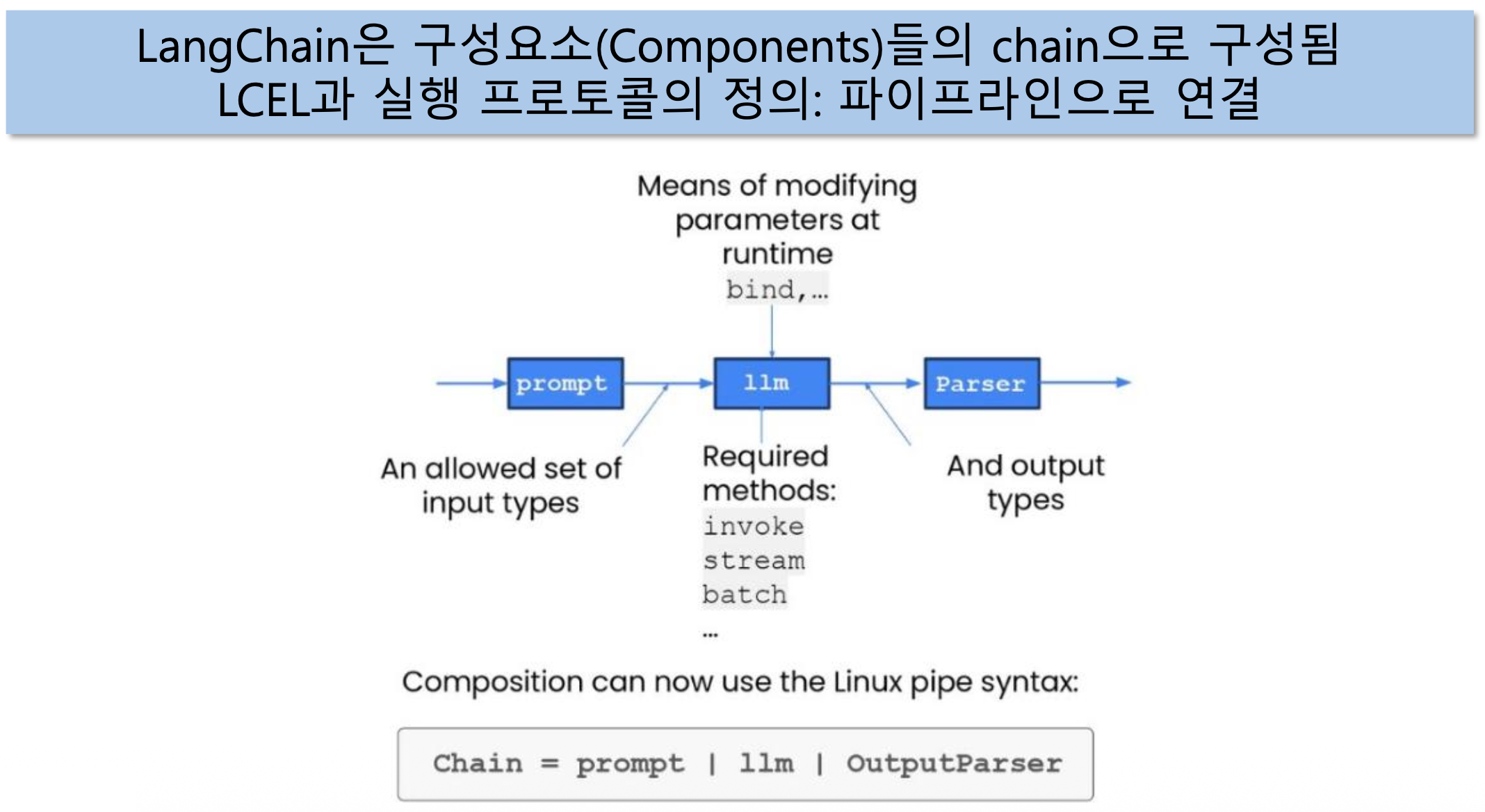
p62. LCEL (LangChain Expression Language)
Interface: 컴포넌트 실행 프로토콜을 구현
- 일반적인 메서드:
invoke(ainvoke)stream(astream)batch(abatch)
- 일반 속성:
input_schema,output_schema - Common I/O
| Component | Input Type | Output Type |
|---|---|---|
| Prompt | Dictionary | PromptValue |
| ChatModel | Single string, list of chat messages or a PromptValue | ChatMessage |
| LLM | Single string, list of chat messages or a PromptValue | String |
| OutputParser | The output of an LLM or ChatModel | Depends on the parser |
| Retriever | Single string | List of Documents |
| Tool | Single string or dictionary, depending on the tool | Depends on the tool |
p63. LangChain Agents
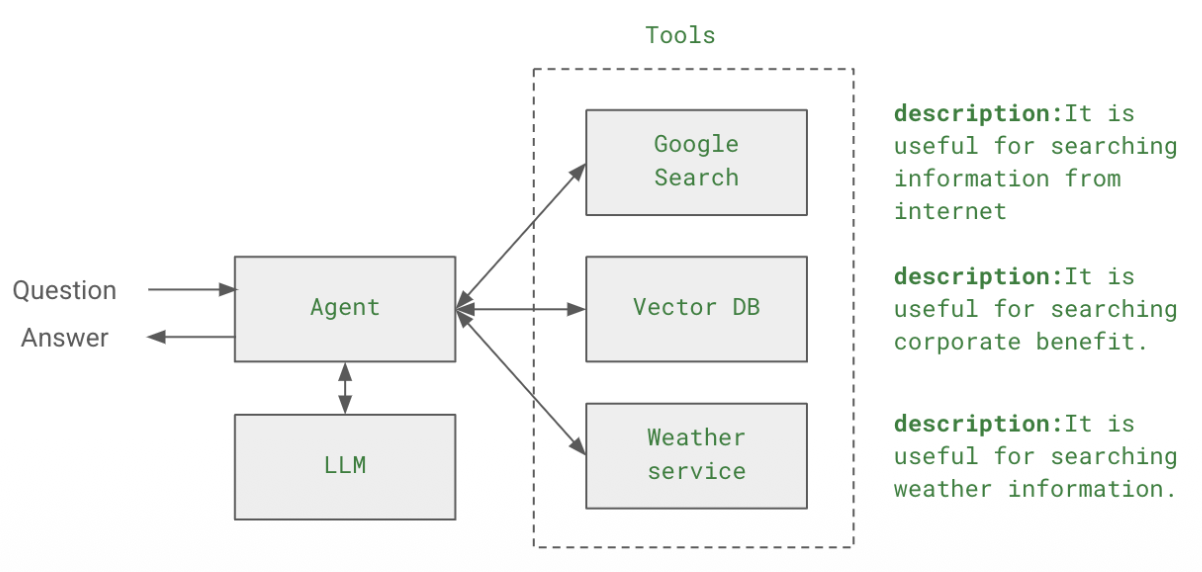
Agent
- LLM과 코드의 결합 (Combination of LLM and code)
- LLM이 수행할 단계와 호출할 액션을 추론함 (LLM reason about what steps to take and call for actions)
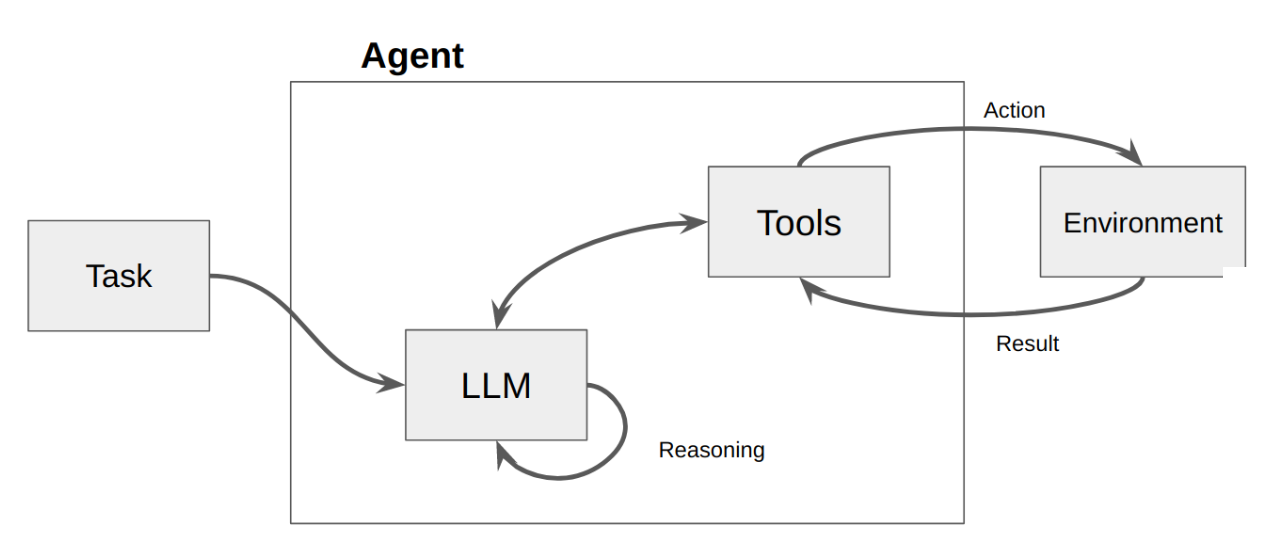
p64. LangChain Agents
Tools
- LangChain에서 LLM의 역량을 확장하기 위해 활용할 수 있는 함수와 서비스들
- 사용 가능한 Tools
- Search tools
- Math tools
- SQL tools
- 코드를 실행할 수 있는 tools
- 사용자 정의 함수를 실행하는 tools
- 위키피디아 라이브러리 등
p65. LangChain Agents
Agents
- LLM과 코드의 조합으로 어떤 작업을 어떤 단계와 순서로 수행할지 결정
- LLM을 통해 어떤 단계들을 거치고, Actions를 호출할 것인지 추론
- Agent Loop
- 사용할 tool을 선택 → tool의 결과를 관찰(observation) → 종료 조건이 만족할 때까지 반복
- 종료 조건
- LLM이 결정하고 코드에서 Hard Coding 됨
- Schema
AgentAction, AgentFinish, Intermediate Steps - Agent
다음 단계에 수행할 역할을 결정하며, Prompt, LLM, output parser로 실행됨 - AgentExecutor
Agent의 “런타임 Agent 호출, 선택한 작업 실행, 출력을 Agent로 전달” 반복하는 역할 - Tools
Agent가 호출할 수 있는 함수. - Toolkits
특정 목표를 달성하기 위해 여러 개의 Tools를 toolkit을 통해 제공
p66. LangChain Agents
1
!pip install wikipedia
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(
temperature=0, # 창의성 0으로 설정
model_name='gpt-4', # 모델명
)
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
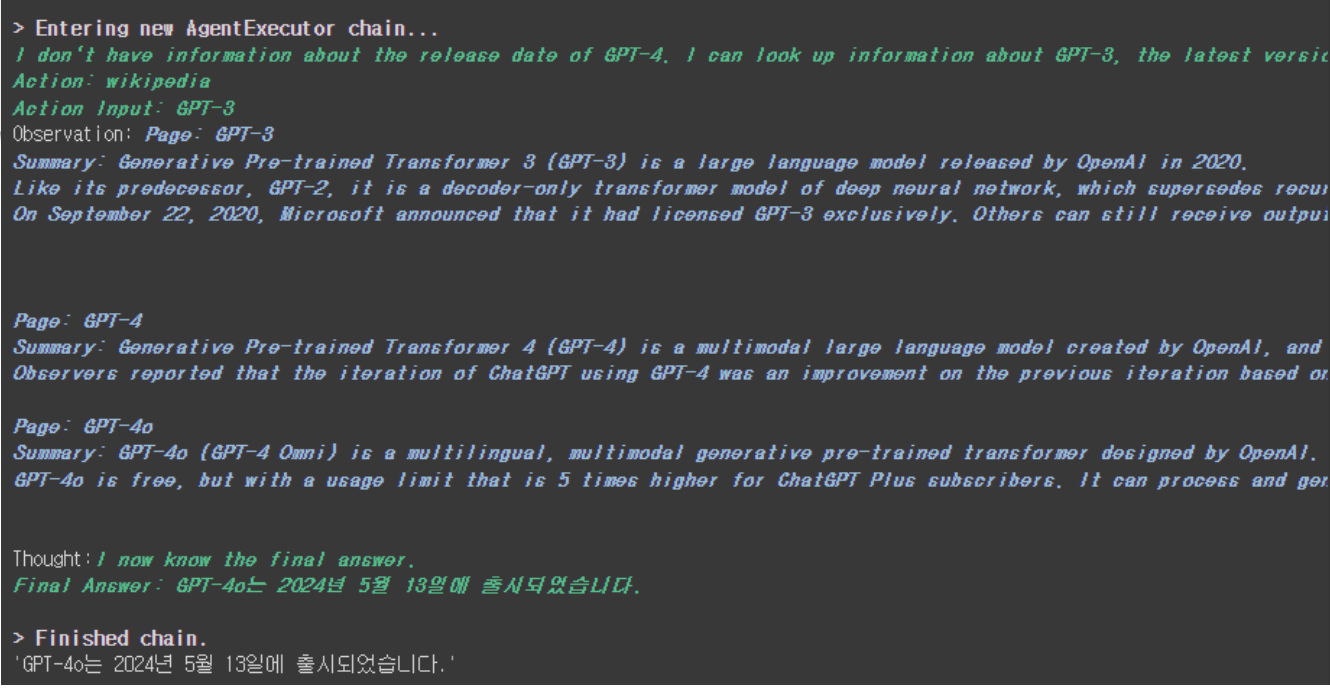
tools = load_tools(["wikipedia", "llm-math"], llm=llm) # llm-math의 경우 나이 계산을 위해 사용
agent = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
description='위키피디아에서 정보를 검색하고 계산이 필요할 때 사용',
verbose=True
)
agent.run("gpt-4는 언제 출시되었어?")
이 기사는 저작권자의 CC BY 4.0 라이센스를 따릅니다.