[빅데이터와 정보검색] 12주차 RAG의 Multi-Hop 검색문제
p2. Agentic RAG
Agentic RAG 핵심 구성요소
- Query Analysis
- 사용자의 질문의 의도, 복잡도, 필요 정보를 파악
- Planning (계획 수립)
- 쿼리 분석 결과를 바탕으로 실행 계획을 수립
- 계획 수립 전략
- 선형 계획: 간단한 질문에 적합
- 분기 계획 (Branching Planning): 조건부 실행이 필요한 경우
- 병렬 계획: 독립적인 여러 정보 수집
- Agentic RAG의 핵심 패턴인 ReAct 패턴 활용
- Retrieval (검색)
- 적응형 검색 (Adaptive Retrieval)
- 하이브리드 검색 (Hybrid Search)
- 다단계 검색 (Multi-hop Retrieval)
- Self-Reflection (자기 성찰)
- 수집한 정보의 품질과 충분성을 평가
- 관련성(검색결과가 질문과 관련있는 정도),
완전성(정보가 충분한지),
신뢰성(정보 출처와 신뢰성)
- Tool Use (도구 사용): 다양한 도구 통합
p3. Agentic RAG의 사고 과정
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 의사 코드로 본 Agentic RAG 프로세스
def agentic_rag(query):
# 1. 질문 분석
analysis = analyze_query(query)
# "이 질문은 최신 정보가 필요하고, 수치 비교가 포함"
# 2. 전략 수립
strategy = plan_strategy(analysis)
# "먼저 최신 데이터를 검색하고, 그 다음 계산기를 사용"
# 3. 단계별 실행
for step in strategy:
if step.type == "search":
results = search(step.query)
# 4. 결과 평가
if not is_sufficient(results):
# 검색 쿼리 수정 후 재시도
results = search(refine_query(step.query))
elif step.type == "calculate":
results = calculator(step.expression)
# 5. 충분한지 판단
if has_enough_info():
break
# 6. 최종 답변 생성
return generate_answer(query, collected_info)
p4. Planning: ReAct 패턴 활용
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
class ReActPlanner:
def __init__(self, llm):
self.llm = llm
def plan_next_action(self, query, history, observations):
prompt = f"""
현재 상황:
질문: {query}
지금까지의 행동: {history}
관찰 결과: {observations}
다음에 무엇을 해야 할까요?
Thought: [추론 과정]
Action: [search/calculate/aggregate/answer]
Action Input: [구체적 입력]
"""
response = self.llm.generate(prompt)
return self.parse_react_response(response)
def execute_plan(self, query):
history = []
observations = []
max_iterations = 10
for i in range(max_iterations):
# 다음 행동 결정
action = self.plan_next_action(
query, history, observations
)
if action.type == "answer":
# 충분한 정보 확보
return action.content
# 행동 실행
result = self.execute_action(action)
# 기록
history.append(action)
observations.append(result)
return "최대 반복 횟수 도달"
p5. Retrieval (검색) – Adaptive Retrieval
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
class AdaptiveRetriever:
def retrieve(self, query, context=None):
# 첫 검색
results = self.initial_search(query)
# 결과 평가
quality = self.evaluate_results(results, query)
if quality < THRESHOLD:
# 검색 전략 변경
if quality.issue == "too_broad":
# 더 구체적으로
results = self.search(self.make_specific(query))
elif quality.issue == "outdated":
# 시간 제약 추가
results = self.search(
f"{query} 2024",
filter={"date": "last_6_months"}
)
elif quality.issue == "no_results":
# 쿼리 완화
results = self.search(self.expand_query(query))
return results
p6. 검색 에이전트
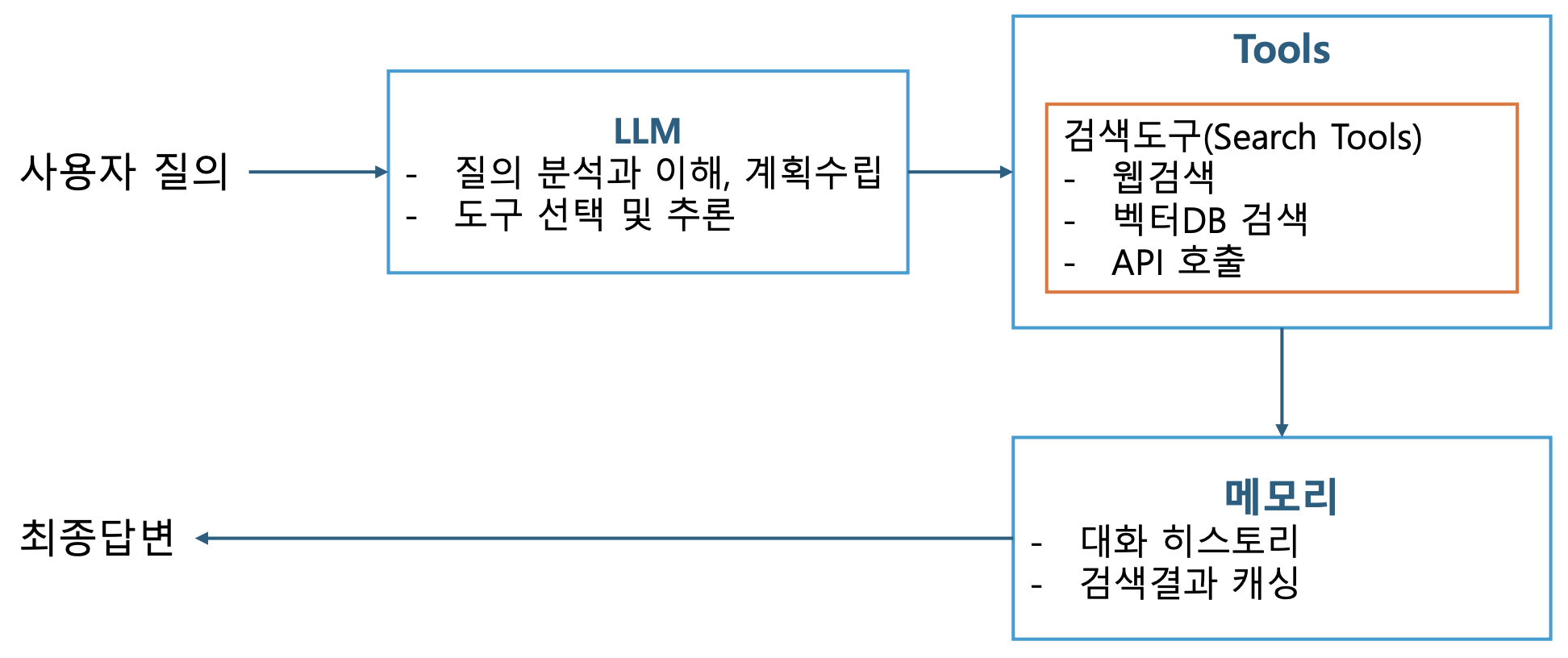
p7. Multi-Hop 검색 개요
Multi-Hop 검색이란 무엇인가?
단일 문서나 지식 베이스의 단일 정보만으로는 답변할 수 없는,
여러 단계(multiple hops)의 추론과 여러 출처의 정보를 조합해야만
최종적인 답변에 도달할 수 있는 복잡한 질의 응답(Question Answering, QA) 문제 및 검색 태스크Single-Hop 검색: 질문에 대한 답이 하나의 검색 결과나 문서 내에 직접적으로 존재
Multi-Hop 검색: 질문을 여러 개의 하위 질문으로 분해하고,
각 하위 질문에 대한 답을 순차적으로 찾은 다음,
이 정보를 결합하고 추론하여 최종 답을 생성해야 함- 첫 번째 검색 결과를 바탕으로 새로운 검색 쿼리를 생성
- 여러 문서에 분산된 정보를 연결
- 중간 추론 단계를 거쳐 최종 답변 도출
p8. Multi-Hop 검색 개요
왜 Multi-Hops 검색이 필요한가?
- 실제 세계의 많은 질문들은 복합적인 추론을 요구
- 정보가 여러 문서에 분산되어 있음
- 질문에 내재된 하위 질문들이 순차적으로 해결되어야 함
- 엔티티 간의 관계나 시간적 순서를 파악해야 함
예)
질문: “BTS의 리더가 졸업한 대학교의 설립 연도는?”
분석:- Hop 1: “BTS의 리더는 누구인가?” → RM(김남준)
- Hop 2: “RM이 졸업한 대학교는?” → 한국예술종합학교
- Hop 3: “한국예술종합학교의 설립 연도는?” → 1993년
질문: “2020년 노벨 화학상 수상자가 발표한 기술이 최초로 상업화된 연도는?”
분석:- Hop 1: “2020년 노벨 화학상 수상자는?”
→ Jennifer Doudna, Emmanuelle Charpentier (CRISPR) - Hop 2: “CRISPR 기술이 최초로 상업화된 시점은?”
→ 구체적 연도 검색
p9. Multi-Hop 검색 개요
Multi-Hops 검색의 핵심 문제
- 정보 부족 (Information Gap)
- 초기 검색 결과만으로 최종 답을 알 수 없음
- 어떤 정보로 추가 검색을 해야 하는지 결정 어려움
- 연속적 추론 (Sequential Reasoning)
- 중간 검색 결과를 활용하여 다음 검색 쿼리를 생성
- 이러한 과정을 여러 번 반복하여 일관된 추론 경로를 유지해야 함
- 정보 조합 및 통합 (Information Combination)
- 서로 다른 출처에서 얻은 여러 정보를 정확하고 논리적으로 통합하여
최종 답변을 도출
- 서로 다른 출처에서 얻은 여러 정보를 정확하고 논리적으로 통합하여
p10. Multi-Hop 검색 개요
질문: “찰스 디킨스의 대표적인 소설을 기반으로 한 영화에 출연했던 여배우의 다음 출연작품은?”
| Hop | 단계 (Action) | 중간 검색 쿼리 | 검색 결과 (Snippet/Fact) |
|---|---|---|---|
| 1 | 지정된 인물/작품 식별 | 찰스 디킨스의 대표작 | 결과 1: 대표작은 “올리버 트위스트”, “위대한 유산”, “두 도시 이야기”, “크리스마스 캐럴”, “데이비드 코퍼필드” 등이 있다. |
| 2 | 중간 결과에 기반한 검색 | 영화 “위대한 유산 (Great Expectations, 1998)”에 출연한 여배우 | 결과 2: 기네스 팰트로 (Gwyneth Paltrow), 앤 밴크로프트 (Anne Bancroft), 킴 디킨스 (Kim Dickins) |
| 3 | 최종 정보 검색 | 기네스 팰트로의 다음 작품 | 결과 3: 기네스 팰트로의 영화 “위대한 유산 (1998)” 다음 출연 작품은 “슬라이딩 도어즈 (Sliding Doors, 1998)”와 “퍼펙트 머더 (A Perfect Murder, 1998)” |
| Answer | 정보 통합 | 슬라이딩 도어즈, 퍼펙트 머더 |
p11. Multi-Hop 문제 해결을 위한 핵심 연구 및 방법론
핵심 연구: 추론 경로를 효과적으로 계획하고 실행
- Query Decomposition(쿼리 분해)
- 복잡한 질문을 하위 질문들로 분해하는 과정
- LLM-based decomposition
- Template-based decomposition: 질문 유형별 템플릿 사용
- Dependency graph: 하위 질문들 간의 의존성 파악
- Iterative Retrieval(반복적 검색)
- 각 단계에서 얻은 정보를 바탕으로 다음 검색을 수행
- Chain-of-Thoughts
- Self-Ask: 모델이 스스로 후속 질문 생성
- IRCoT(Interleaving Retrieval with CoT): 검색과 추론을 교차 수행
- Evidence Aggregation(증거수집)
- 여러 검색 결과를 효과적으로 통합하는 방법
- 정보간 모순 해결
- 관련성 높은 정보 선별
- 컨텍스트 윈도우 제약 관리
- 여러 검색 결과를 효과적으로 통합하는 방법
- Reasoning Path Management(추론 경로 관리)
- Beam Search: 여러 후보 경로 동시 탐색
- Pruning: 비효율적인 경로 조기 차단
- Answer Verification: 중간 답변의 신뢰도 평가
p12. Multi-Hop 문제 해결을 위한 핵심 연구 및 방법론
주요 연구 방법론
- Step-by-Step 추론 : Decomposition & ReAct
- 복잡한 질문을 작은 단위의 하위 질문으로 나누고,
각 단계를 순차적으로 해결하는 과정에서 검색 도구(Tool)을 사용 - Decomposition (분해)
- LLM이 질문을 분석하여 논리적인 해결 순서를 포함하는 하위 질문 목록을 생성
- ReAct (Reasoning and Acting)
- LLM이 추론(Reasoning)과 행동(Acting, 즉 Tool 사용)을 교대로 수행하는 프레임워크
- LLM은 현재 상태와 검색 결과를 바탕으로 다음 추론 단계와 사용할 검색 쿼리/도구를 결정
- 복잡한 질문을 작은 단위의 하위 질문으로 나누고,
- 검색 방법론: 그래프 기반 탐색 (Graph-based Exploration)
- 정보 간의 연결성(Relation)을 활용하는 방법
- 문서를 노드(Node)로, 문서 간의 참조나 논리적 연결을 엣지(Edge)로 간주하여
지식 그래프(Knowledge Graph)를 구성하거나, 검색 결과를 그래프처럼 탐색 - Path Retrieval: 에이전트가 단일 키워드 검색 대신,
정보의 흐름을 따라 여러 노드를 점프하며(hop)
최적의 정보 경로(Path)를 찾는 데 중점
- Intermediate Information Extraction (중간 정보 추출)
- 각 단계에서 얻은 검색 결과에서 핵심 엔티티(Key Entity)와 관계(Relation)를 정확하게 추출
- 검색된 스니펫 전체를 다음 단계의 입력으로 사용하는 대신,
LLM이 현재 단계의 답변 정보만을 추출하여 이를 다음 검색 쿼리 생성에 활용 - 불필요/노이즈 정보를 제거하고, 필요한 정보만(예: 기네스 팰트로, 위대한 유산)만을
다음 추론 단계로 전달, 검색의 정밀도와 추론의 효율성을 높임
p13. Multi-Hop 문제 해결을 위한 핵심 연구 및 방법론
Decomposed Retrieval
검색 과정에 최적화, 특히 RAG 환경에서 Vector DB를 활용할 때 효과적
- LLM이 질문을 Q₁, Q₂, Q₃ 등의 하위 쿼리로 분해
- 각 하위 쿼리에 대해 독립적으로 또는 순차적으로 Vector Search 수행
- 각 검색 결과를 모아 최종적으로 하나의 큰 문서 뭉치(Context Block)를 구성
- LLM은 이 통합된 문서 뭉치를 기반으로 최종 답변을 생성
p14. Multi-Hop 문제 해결을 위한 핵심 연구 및 방법론
ReAct (Reasoning and Acting): 추론(Reasoning)과 행동(Acting)을 결합한 프레임워크
- Thought: 현재 상황 분석 및 다음 행동 결정
- Action: 검색 또는 도구 사용
- Observation: 행동 결과 관찰
- (반복) → Final Answer
1
2
3
4
5
6
7
8
9
10
11
Question: "서울대학교를 졸업한 대통령의 재임 기간은?"
Thought 1: 먼저 서울대학교를 졸업한 대통령을 찾아야 함
Action 1: Search["서울대학교 졸업 대통령"]
Observation 1: 이명박, 박근혜 등이 검색됨
Thought 2: 가장 최근 대통령을 확인
Action 2: Search["이명박 재임 기간"]
Observation 2: 2008년 2월 25일 ~ 2013년 2월 24일
Answer: 5년 (2008–2013)

Self-Ask: LLM이 답변에 필요한 중간질문을 스스로 생성하고, 이를 검색엔진에 질의하며 답변을 쌓아가는 방식
- 시작: 복잡한 질문을 입력 받음
- 질문 생성(Ask): “이 질문에 답하기 위해 어떤 중간 사실을 알아야 하는가?”라는 내부 질문을 던짐
- 검색(Search): 생성된 중간 질문을 검색 쿼리로 사용해 외부 검색 도구를 호출
- 답변 포함: 검색 결과에서 얻은 사실(Fact)을 컨텍스트에 추가
- 반복: 모든 중간 질문에 답할 때까지 이 과정을 반복
- 최종 답변(Answer): 모든 중간 사실을 조합하여 최종 질문에 답함
1
2
3
4
5
6
7
8
9
10
11
Question: 2024년 U.S. Open 테니스 남자 단식 우승자의 국적은?
Are follow-up questions needed here: Yes
Follow-up: 2024년 U.S. Open 남자 단식 우승자는 누구인가?
Intermediate answer: Jannik Sinner
Follow-up: Jannik Sinner의 국적은?
Intermediate answer: 이탈리아
So the final answer is: 이탈리아

p15. Multi-Hop 문제 해결을 위한 핵심 연구 및 방법론
IRCoT (Interleaving Retrieval with Chain-of-Thought)
- CoT(Chain-of-Thought)와 검색을 동적으로 교차하여 수행
- 추론 중 필요한 시점에만 검색 수행
- CoT의 중간 단계를 검색 쿼리로 활용
- 검색 결과를 다시 추론에 반영
1
2
3
4
5
6
1. 초기 CoT 생성 시작
2. 외부 지식이 필요한 지점 감지
3. 해당 지점에서 검색 수행
4. 검색 결과를 컨텍스트에 추가
5. 검색된 외부 정보를 다음 추론 단계에 활용하여 추론을 발전시키며 CoT 계속 진행
6. 2–5 반복
1
2
3
4
5
6
7
8
9
10
11
12
13
14
Question: "태양계에서 가장 큰 행성의 위성 중 가장 큰 것의 지름은?"
CoT Step 1: 태양계에서 가장 큰 행성은 목성이다
→ [검색 필요 없음, 기본 지식]
CoT Step 2: 목성의 위성 중 가장 큰 것을 찾아야 한다
→ [검색 트리거] Search["목성 위성 크기 순위"]
→ Observation: 가니메데가 가장 큼
CoT Step 3: 가니메데의 지름을 확인해야 한다
→ [검색 트리거] Search["가니메데 지름"]
→ Observation: 5,268 km
Answer: 5,268 km

p16. Multi-Hop 문제 해결을 위한 핵심 연구 및 방법론
HippoRAG (Hippocampus-Inspired RAG)
- 인간 해마의 기억 메커니즘을 모방한 접근법
- 핵심 구성요소
- Indexing Phase
- 문서를 지식 그래프로 변환
- 엔티티와 관계 추출
- 패러프레이즈를 통한 다양한 표현 저장
- Retrieval Phase
- PPR (Personalized PageRank) 알고리즘 사용
- 쿼리 엔티티에서 시작해 그래프 순회
- 연관성 높은 노드 순차 탐색
- Indexing Phase

p17. Pseudo-code (HippoRAG)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# Pseudo-code
class HippoRAG:
def __init__(self):
self.knowledge_graph = {} # {entity: [related_entities]}
self.entity_passages = {} # {entity: [passages]}
def index(self, documents):
for doc in documents:
entities = extract_entities(doc)
relations = extract_relations(doc)
# 그래프 구축
for entity in entities:
self.knowledge_graph[entity] = relations[entity]
self.entity_passages[entity].append(doc)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
def retrieve(self, query, k_hops=3):
query_entities = extract_entities(query)
# Multi-hop traversal
relevant_passages = []
for hop in range(k_hops):
# PPR로 다음 관련 엔티티 찾기
next_entities = personalized_pagerank(
self.knowledge_graph,
query_entities
)
# 해당 엔티티의 passage 수집
for entity in next_entities:
relevant_passages.extend(
self.entity_passages[entity]
)
return rank_passages(relevant_passages)
p18. Multi-Hop 문제 해결을 위한 핵심 연구 및 방법론
Graph-Based Retrieval
- 문서 간 관계를 그래프로 모델링하여 multi-hop 수행
- Nodes: 문서, 엔티티, 개념
- Edges: 참조 관계, 의미적 유사도, 인용 관계
- 알고리즘: Random Walk with Restart
- 쿼리 관련 노드에서 시작
- 확률적으로 이웃 노드 방문
- 일정 확률로 시작 노드로 복귀
- 방문 빈도 높은 노드를 검색 결과로 반환
- 알고리즘: Subgraph Extraction

1
2
3
4
5
6
7
8
9
10
11
12
13
14
def extract_subgraph(query, graph, max_hops=3):
start_nodes = find_query_entities(query)
subgraph = set(start_nodes)
for hop in range(max_hops):
new_nodes = set()
for node in subgraph:
neighbors = graph.get_neighbors(node)
# 관련성 점수로 필터링
relevant = filter_by_relevance(neighbors, query)
new_nodes.update(relevant)
subgraph.update(new_nodes)
return subgraph
p19. Multi-Hop 문제 해결을 위한 핵심 연구 및 방법론
Multi-Hop 검색 문제를 해결하는 Agent의 일반적인 워크플로우
- 초기화 및 질문 분석 (Initialization & Analysis)
- 입력: 사용자의 복잡한 질문
- LLM 역할: 질문을 분석하여 해결에 필요한 정보 조각과 논리적 순서를 파악(Decomposition)
- 순차적 검색 및 추론 (Sequential Search & Reasoning)
Agent는 각 단계마다 다음 세 가지 행동을 반복
행동 (Action) 설명 LLM/Tool 사용 1. 쿼리 생성
(Query Generation)현재까지의 정보와 다음 하위 질문을 기반으로
가장 최적화된 검색 쿼리를 생성LLM Reasoning:
현재 상태 → 다음 질문 → 검색 쿼리2. 검색 실행
(Search Execution)생성된 쿼리를 사용하여 검색 도구
(웹 검색, 벡터 DB 등)를 호출하고 정보를 가져옴Tool Use (Search):
search(“…query…”)3. 요약 및 상태 업데이트
(Summarize & Update)검색 결과를 분석하고, 다음 단계에 필요한 중간 정보
(Intermediate Fact)를 추출.
이 정보를 에이전트의 메모리(Memory)에 저장하고,
추론 경로를 업데이트LLM Reasoning / Tool Use
(Extraction):
검색 결과 → 핵심 답변 추출
- 종료 조건 및 최종 답변 생성
- 종료 조건: 모든 하위 질문에 대한 답을 찾았거나, 더 이상 유효한 검색 경로를 찾을 수 없을 때
- 최종 생성: 에이전트는 기억에 저장된 모든 중간 정보를 논리적으로 연결하여 사용자 질문에 대한 완전하고 일관된 최종 답변을 생성
p20. Multi-Hop 문제 해결을 위한 핵심 연구 및 방법론
추론 경로의 동적 계획 및 검증 (Dynamic Planning & Verification)
검색 경로를 동적으로 계획하고 오류를 검증
Recursive RAG / Advanced ReAct
- 개념:
- Multi-Hop 문제를 해결하는 Agent가 검색, 추론, 행동을 반복할 뿐만 아니라,
- 이전 단계의 결과를 바탕으로 다음 단계를 재귀적으로(Recursively) 최적화
- Agent의 역할:
- 계획 (Planning): 현재의 지식 상태를 기반으로 다음 검색 행동(쿼리, 도구)을 결정
- 실행 (Execution): 검색 도구를 사용
- 평가/수정 (Correction):
- 검색된 정보가 이전 단계의 결과와 모순되거나 질문에 답하기에 불충분한지 평가
- 만약 불충분하다면, 계획 단계로 되돌아가 새로운 쿼리를 생성하거나 검색 전략을 변경 (Self-Correction)
- 장점:
- 한 번의 잘못된 추론(오류 전파)로 인해 전체 과정이 실패하는 것을 방지하며,
불확실한 검색 환경에서 Robustness를 크게 향상
- 한 번의 잘못된 추론(오류 전파)로 인해 전체 과정이 실패하는 것을 방지하며,
- 개념:
p21. Multi-Hop 문제 해결을 위한 핵심 연구 및 방법론
추론 경로의 동적 계획 및 검증 (Dynamic Planning & Verification)
검색 경로를 동적으로 계획하고 오류를 검증
Verify-then-Answer (검증 후 답변)
- 개념:
- Multi-Hop 추론 과정에서 얻은 모든 중간 사실과 최종 답변에 대해
사실 검증(Fact Verification) 단계를 추가하는 방법
- Multi-Hop 추론 과정에서 얻은 모든 중간 사실과 최종 답변에 대해
- 작동과정:
- Agent가 최종 답변 초안을 생성
- LLM은 이 답변의 모든 구성 요소를 분해하고, 각각을 별도의 검증 쿼리로 변환
- 이 검증 쿼리를 사용하여 추가적인 검색을 수행하고
답변의 사실적 정확도를 교차 확인
- 장점:
- 사실적 정확도가 중요한 분야에서
RAG 시스템의 환각(Hallucination) 문제를 줄이고
답변의 신뢰도를 높이는 데 좋음
- 사실적 정확도가 중요한 분야에서
- 개념:
p22. Multi-Hop 문제 해결을 위한 핵심 연구 및 방법론
요약
- Agentic RAG에서의 실용적 Multi-Hop 해결책
실무 환경에서 Multi-Hop 문제를 해결하는 Agentic RAG 시스템은 다음 세 가지 구성 요소를 핵심적으로 결합
- Decomposition: 복잡한 질문을 하위 질문으로 분해하는 LLM의 능력 (Self-Ask)
- Sequential Retrieval: 각 하위 질문에 대해 순차적으로 외부 정보를 검색하고
컨텍스트를 쌓는 도구 활용 (Decomposed Retrieval) - Self-Correction: 검색된 중간 정보의 정확성과 충분성을 스스로 판단하고,
필요 시 검색/추론 계획을 동적으로 수정하는 능력 (Advanced ReAct / Verification)
p23. 주요 고려사항
주요 고려사항
- 검색 깊이 제어
- 최대 Hop 수 제한
- 조기 종료 조건 설정
- 신뢰도 임계값 활용
- 컨텍스트 관리
- 각 hop의 결과를 효율적으로 요약
- 중요한 정보만 다음 단계로 전달
- 컨텍스트 윈도우 크기 관리
- 오류처리
- 잘못된 중간 답변 감지, 백트래킹 매커니즘, Alternative Path 탐색
- 성능 최적화
- 병렬 검색, 캐싱전략, 검색결과 재사용 등
p24. 평가지표
평가 지표
- 정확도 지표
- Exact Match, F1-score, hop-wise accuracy(각 단계별 정확도)
- 효율성 지표
- 평균 hop수, 검색횟수, 응답시간
- 추론 품질
- Path validity(추론 경로의 논리성)
- Evidence coverage(필요한 증거 수집 여부)
- Reasoning coherence(추론의 일관성)
p25. RAG의 Multi-hop 문제에서 중요한 이슈
- 검색 단계의 이슈
- 추론 단계의 이슈
p26. RAG의 Multi-hop 문제에서 중요한 이슈 — 검색 단계
검색(Retrieval) 단계의 주요 이슈
- 중간 쿼리 생성 및 오류 전파(Intermediate Query Generation and Error Propagation)
- 문제: Multi-Hop 질문에 답하기 위해 LLM은 중간 단계의 브릿지 엔티티(Bridge Entity)를 파악하고,
이를 포함하는 다음 검색 쿼리를 생성해야 함
(예: “찰스 디킨스의 대표작” → 위대한 유산) - 이슈: 만약 LLM이 첫 번째 단계에서 잘못된 브릿지 엔티티를 추론하여 잘못된 쿼리를 생성하면,
이후의 모든 검색 단계가 잘못된 경로를 따르게 되어 최종적으로 오답을 산출
- 문제: Multi-Hop 질문에 답하기 위해 LLM은 중간 단계의 브릿지 엔티티(Bridge Entity)를 파악하고,
- 정보의 단절 및 낮은 재현율(Discontinuity of Information and Low Recall)
- 문제: Multi-Hop 질문은 여러 독립적인 문서에 분산된 정보를 연결해야 함
- 이슈:
- 일반적인 벡터 검색 시스템은 Semantic Similarity에 기반하여 문서를 검색
- 그러나 Multi-Hop에서는
“A와 B의 연결”을 직접 설명하는 문서가 아니라,
“A에 대한 사실”과 “B에 대한 사실”을 담은 문서를 각각 검색해야 함- 이때, LLM이 생성한 중간 쿼리가 정확하더라도
데이터베이스 내에서 정보 연결의 고리(Chain)를 이루는 문서가 없거나,
검색 시스템의 Top-K 결과 안에 포함되지 못하면(낮은 재현율), Multi-Hop 과정이 중단될 위험
- 이때, LLM이 생성한 중간 쿼리가 정확하더라도
- 노이즈 및 불필요한 컨텍스트 증가
- 문제: 여러 단계의 검색을 통해 문서가 누적되면서 컨텍스트 창에 입력되는 정보의 양이 급격히 증가
- 이슈:
- 각 단계에서 불필요하거나 관련 없는 노이즈 정보가 함께 딸려 들어오며,
이 노이즈가 누적되면 LLM의 집중력을 저해하여
최종 추론 단계에서 중요한 사실을 놓치거나, 성능 저하(Context Window Pressure)를 유발
- 각 단계에서 불필요하거나 관련 없는 노이즈 정보가 함께 딸려 들어오며,
p27. RAG의 Multi-hop 문제에서 중요한 이슈 — 추론 및 생성 단계
추론 및 생성(Generation) 단계의 주요 이슈
- 복잡한 논리적 통합(Complex Logical Synthesis)
- 문제: Multi-Hop은 서로 다른 출처의 사실 A, B, C를 정확한 순서와 논리에 따라 결합하여 최종 답변을 도출
- 이슈:
- LLM은 복잡한 논리 구조를 추론하고 생성하는 데 어려움을 겪을 수 있으며
- 특히 컨텍스트가 길거나 정보가 모호할 경우, 논리의 비약이나 오류적인 결합이 발생
- 모순 및 불일치 해결(Conflict and Inconsistency Resolution)
- 문제: 서로 다른 문서 A와 B가 동일한 사실에 대해 상반된 정보(예: 인물의 출생 연도가 다름)를 제공 가능
- 이슈:
- Multi-Hop RAG 시스템은 모순된 정보를 탐지하고,
가장 신뢰할 수 있는 출처를 판단하여 모순을 해결해야 함 - LLM이 출처의 신뢰도를 자동으로 평가하는 데 실패할 경우
환각(Hallucination)이나 잘못된 정보 제공으로 연결될 위험
- Multi-Hop RAG 시스템은 모순된 정보를 탐지하고,
- “Lost in the Middle” 현상
- 문제: LLM은 컨텍스트 창의 시작 부분이나 끝 부분에 있는 정보는 잘 활용하지만,
중간 부분에 있는 정보를 소홀히 하는 경향(Lost in the Middle) - 이슈:
- Multi-Hop RAG에서 핵심적인 브릿지 엔티티나 중간 사실이
누적된 컨텍스트의 중간에 위치할 경우,
LLM이 이를 무시하고 답변에서 누락시키거나 잘못 해석할 위험 존재
- Multi-Hop RAG에서 핵심적인 브릿지 엔티티나 중간 사실이
- 문제: LLM은 컨텍스트 창의 시작 부분이나 끝 부분에 있는 정보는 잘 활용하지만,
p28. RAG의 Multi-hop 문제에서 중요한 이슈 — Decomposition & Dynamic Planning
오류 전파 및 논리적 통합 이슈 해결: Decomposition & Dynamic Planning
- 연구 논문: Least-to-Most Prompting
- Denny Zhou, et al.,
“Least-to-Most Prompting Enables Complex Reasoning in Large Language Models”, 2022 - LLM에게 복잡한 문제를 스스로 하위 문제로 분해하고,
이 하위 문제들을 순차적으로 해결하도록 유도하여 Multi-Hop 추론을 구조화
- Denny Zhou, et al.,
- 연구 논문: Active Retrieval (ActiveRAG)
- Zhengbao Jiang, et al.,
“Active Retrieval-Augmented Generation”, EMNLP 2023 - LLM이 검색을 수행할지 여부
검색 내용을 어떻게 결정할지
를 동적으로 판단하고,
검색 결과가 만족스럽지 않을 경우 스스로 쿼리를 수정하는 동적 제어 전략을 제시
- Zhengbao Jiang, et al.,
p29. RAG의 Multi-hop 문제에서 중요한 이슈 — Context & Verification
노이즈 및 불일치 해결: Context & Verification
- 연구 논문: RAG with Multi-Hop Knowledge and Reasoning
- Hao Liu, et al.,
“HopRAG: Multi-Hop Reasoning for Logic-Aware Retrieval-Augmented Generation”, 2025 ACL - RAG 시스템을 위한 Multi-Hop 검색 전용 지식 구조(Knowledge Structure) 구축 및 활용
- Hao Liu, et al.,
- 연구 논문: Chain-of-Verification (CoVe)
- Tal Schuster, et al.,
“Chain-of-Verification Reduces Hallucination in Large Language Models”, 2023 CoVe는 LLM이 생성한 답변의 사실적 정확도를 높여
Multi-Hop 추론 과정에서 발생하는 모순 및 오류 결합 문제를 해결하는 방법론- 초안 답변 및 검증 계획:
LLM은 질문에 대한 초안 답변을 생성한 후,
답변의 핵심 주장들을 검증하기 위한 별도의 검증 질문(Verification Questions) 목록을 생성 - 독립적 검증 (Independent Verification):
각 검증 질문을 별도로 검색 도구에 질의하여 정보를 바탕으로,
해당 주장의 사실 여부를 참(True) 또는 거짓(False) 으로 판단 - 수정 및 최종 답변:
LLM은 검증 단계를 통해 얻은 피드백(어떤 주장이 틀렸는지)을 바탕으로
최종 답변 수정 & 재작성
- 초안 답변 및 검증 계획:
- Tal Schuster, et al.,