[빅데이터와 정보검색] 13주차 MultiModal 검색
p2. 멀티모달 AI 개요
왜 멀티모달 AI가 필요할까?
- 인간의 정보 처리 방식
- 인간은 세상을 하나의 감각으로 이해하지 않고, 모든 감각이 통합되어 하나의 경험이 됨
- 기존 AI의 한계
단일 모달 AI의 문제점
텍스트 전용 AI
질문: “이 이미지 속 고양이는 무슨 색인가요?”
AI: “죄송합니다. 이미지를 볼 수 없습니다.”이미지 전용 AI
입력: [고양이 사진]
AI: “고양이” (라벨링만 가능)
추가 질문: “이 고양이의 품종은?”
AI: 답변 불가 (대화 능력 없음)음성 전용 AI
음성: “저기 저 고양이 좀 봐”
AI: 텍스트로 변환만 가능
→ 어떤 고양이인지 확인 불가

p3. 멀티모달 AI 개요
왜 멀티모달 AI가 필요할까?
- 기존 AI의 한계
실제 문제 상황
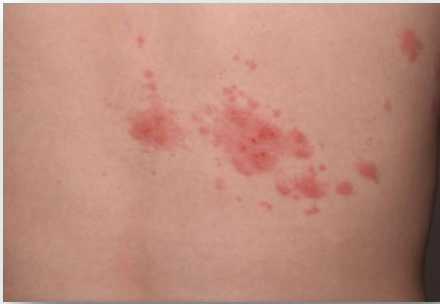
- 사례 1: 의료 진단
환자: “이 부위가 아파요” (음성)- [피부 사진 제시] (이미지)
- “일주일 전부터 시작됐어요” (텍스트)
단일 모달 AI → 부분 정보만 처리
멀티모달 AI → 모든 정보 통합 분석
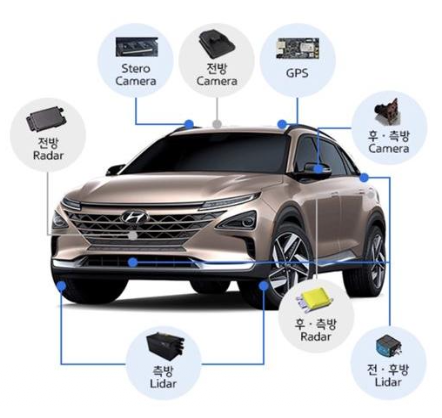
- 사례 2: 자율주행
필요 정보:- 도로 상황 (카메라 영상)
- 장애물까지 거리 (라이다)
- 교통 신호 (이미지 인식)
- GPS 위치 (좌표 데이터)
- 음성 명령 (승객 지시)
→ 모든 정보를 동시에 처리해야 안전!
- 사례 1: 의료 진단
p4. 멀티모달 AI 개요
멀티모달 AI의 정의
멀티모달 AI(Multimodal AI)는
텍스트, 이미지, 음성, 비디오 등 두 가지 이상의 서로 다른 유형의 데이터(모달리티)를
동시에 처리하고 이해하여,
이들을 통합적으로 분석하고 의미 있는 출력을 생성하는 인공지능 시스템
주요 모달리티(Modality) 종류
- 텍스트(Text): 문서, 대화, 코드, 구조화된 데이터
- 이미지(Image): 사진, 스크린샷, 의료 영상, 차트
- 음성(Audio): 대화, 음악, 환경음
- 비디오(Video): 동영상, 애니메이션, 실시간 스트림
- 센서 데이터: 온도, 위치, 가속도, 생체 신호
p5. 멀티모달 LLM의 정의
MM-LLM(Multimodal LLM)
- LLM을 중심으로 다양한 모달리티 작업이 가능하도록 하는 모델
멀티모달 LLM은 텍스트, 이미지, 오디오, 비디오 등 여러 모달리티의 데이터를 동시에 처리하고 이해할 수 있는 AI 모델
- LLM이 제공하는 강력한 언어 생성 기능
- Zero-shot Learning, In-Context Learning과 같은 기능을 지님
- 서로 다른 Modalities를 인식하고 효과적으로 협업추론(collaborative inference) 가능하도록 함
- 주요 학습 과제
- 서로 다른 Modalities를 조율하는 사전 학습(MM Pre-Training)
- 사람의 의도에 맞게 모델을 조절하는 지시 튜닝(MM Instruction Tuning)
p6. MM-LLM의 발전과정
Visual Language (VL) 모델의 발전: 예를 들어 Flamingo는 시각적 데이터와 텍스트를 처리하여
자유 형식의 텍스트를 출력하는 VL 모델 시리즈를 대표자원 효율적인 프레임워크의 도입: BLIP-2는 가벼운 Q-Former를 포함하는 자원 효율적인 프레임워크를
도입하여 모달리티 간 격차를 해소하고 동결된 LLM을 활용IT 기술의 MM 도메인으로의 전환: LLaVA는 데이터 부족 문제를 해결하기 위해 새로운 오픈 소스 MM 지시문
따르기 데이터셋을 소개하며, 이를 통해 MM 지시문 따르기 벤치마크를 제공모듈화된 학습 프레임워크: mPLUG-Owl은 시각적 컨텍스트를 통합하는 새로운 모듈화된 훈련 프레임워크를 제시
다양한 모달리티로의 확장: X-LLM은 오디오를 포함한 다양한 모달리티로 확장되며, Q-Former의 언어 전이성을
활용하여 중국어 등 다양한 언어 컨텍스트에 성공적으로 적용.채팅 중심의 MM-LLM: VideoChat은 비디오 이해 대화를 위한 효율적인 채팅 중심 MM-LLM을 선도하며,
이 분야의 향후 연구 기준을 제시.다양한 모달리티의 지시문 따르기: PandaGPT는 텍스트, 이미지/비디오, 오디오, 열 이미지, 깊이, 관성 측정 장치 등
6가지 다른 모달리티에 걸쳐 지시문을 이해하고 실행할 수 있는 능력을 갖춘 선구적인 범용 모델.
p7. MM-LLM의 발전과정
- 다양한 모달리티의 이해 ➔ 특정 모달리티의 생성 및 임의 모달리티로 변환 가능한 모델로 진화
- 예) MiniGPT-4 ➔ MiniGPT-5 ➔ NExT-GPT로 발전하며 모델의 학습 파이프라인을 지속적으로 정제
인간의 의도와 더 잘 일치하고 모델의 대화 상호작용 능력을 향상
- 예) MiniGPT-4 ➔ MiniGPT-5 ➔ NExT-GPT로 발전하며 모델의 학습 파이프라인을 지속적으로 정제
- 다양한 모달리티를 수용하도록 확장
- BLIP-2 ➔ X-LLM 및 InstructBLIP ➔ X-InstructBLIP으로 발전,
더 높은 품질의 학습 데이터셋을 포함, 모델 아키텍처를 더 효율화하는 방향으로 진화
- BLIP-2 ➔ X-LLM 및 InstructBLIP ➔ X-InstructBLIP으로 발전,
- 보다 효율적인 모델 아키텍처 채택
- VILA 모델: 복잡한 Q-Former 및 P-Former 입력 프로젝터 모듈에서
더 간단하지만 효과적인 선형 프로젝터로 전환
- VILA 모델: 복잡한 Q-Former 및 P-Former 입력 프로젝터 모듈에서
p8. 멀티 모달 AI의 아키텍처
일반적인 멀티모달 AI 아키텍처
인코더, 커넥터, 그리고 LLM으로 구성
- Encoder
- 이미지, 오디오 또는 비디오를 입력받아 특징(features)을 출력
- Connector
- 인코더의 특징들을 처리하여 LLM이 더 잘 이해할 수 있도록 함
- Generator
- 선택적 사용
- 텍스트 외의 더 많은 모달리티 생성을 위해 LLM에 Generator 연결
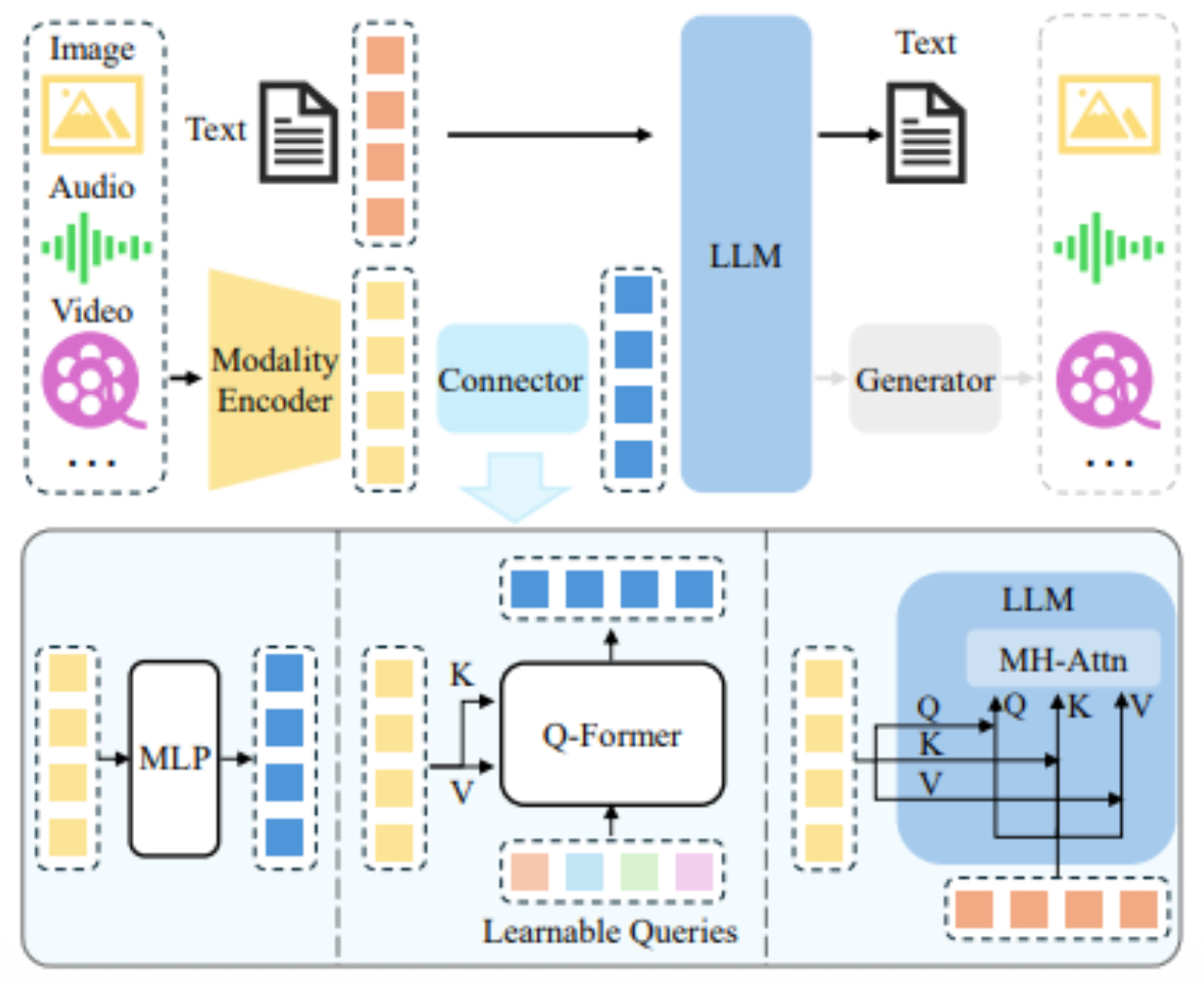
p9. 구성 요소 상세 설명
모달별 인코더 (Modality-Specific Encoders)
각 모달리티를 컴퓨터가 이해할 수 있는 숫자(벡터)로 변환
- 텍스트 인코더 (Text Encoder)
- 기술: 트랜스포머(Transformer)
- 예시: “고양이가 소파에 앉아있다”
단계 1: 토큰화
“고양이가 소파에 앉아있다”
→ [“고양이가”, “소파에”, “앉아있다”]단계 2: 임베딩
“고양이가” → [0.2, 0.8, 0.1, …, 0.5] (768차원)
“소파에” → [0.5, 0.3, 0.9, …, 0.2]
“앉아있다” → [0.7, 0.1, 0.4, …, 0.8]단계 3: 트랜스포머 처리
→ 문맥 이해(셀프 어텐션)
“고양이가” ↔ “앉아있다” (주어-동사 관계)
“소파에” ↔ “앉아있다” (장소-동작 관계)최종 출력:
텍스트_표현 = [0.45, 0.67, 0.23, …, 0.89] (768차원)
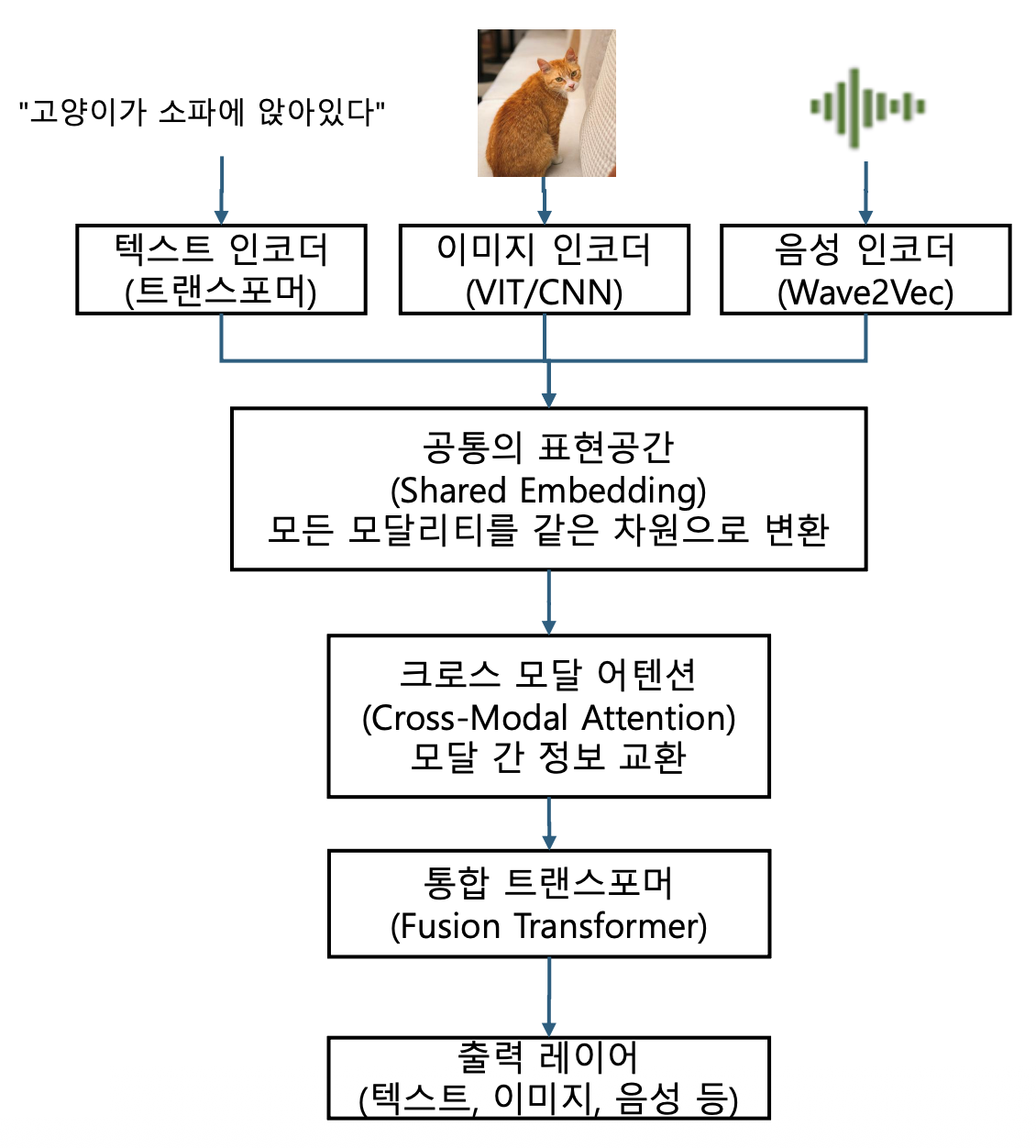
p10. 구성 요소 상세 설명
모달별 인코더 (Modality-Specific Encoders)
각 모달리티를 컴퓨터가 이해할 수 있는 숫자(벡터)로 변환
- 이미지 인코더 (Vision Encoder)
- 기술: ViT (Vision Transformer) 또는 CNN
- 예시: 고양이가 소파에 앉은 사진

단계 1: 이미지를 패치로 분할
[고양이 사진 224×224 픽셀]
↓
16×16 패치로 분할 → 총 196개 패치 (14×14)패치 1: 왼쪽 위 [16×16 픽셀]
패치 2: 그 옆 [16×16 픽셀]
…
패치 196: 오른쪽 아래단계 2: 각 패치를 벡터로 변환
패치 1 (고양이 얼굴 부분): [픽셀들] → 선형변환 → [0.3, 0.7, 0.2, …, 0.9]
…
패치 67 (소파 부분): [픽셀들] → 선형변환 → [0.8, 0.2, 0.5, …, 0.3]단계 3: 위치 정보 추가
패치 1 + 위치(1) → [0.3, 0.7, …] + [0.01, 0.01, …]
패치 2 + 위치(2) → [0.5, 0.3, …] + [0.02, 0.01, …]단계 4: 트랜스포머 처리
패치 간 어텐션:- “고양이 얼굴” 패치 ↔ “고양이 몸통” 패치 (높은 관계)
- “고양이” 패치들 ↔ “소파” 패치들 (앉아있는 관계)
최종 출력:
이미지_표현 = [0.58, 0.34, 0.91, …, 0.27] (768차원)
p11. 구성 요소 상세 설명
모달별 인코더 (Modality-Specific Encoders)
각 모달리티를 컴퓨터가 이해할 수 있는 숫자(벡터)로 변환
- 음성 인코더 (Audio Encoder)
- 기술: Wav2Vec 2.0, Whisper
- 예시: “고양이가 야옹” (음성)

단계 1: 음성 파형 분석
[음성 신호]
샘플링: 16kHz → 초당 16,000개 샘플
지속 시간: 2초 → 32,000개 샘플단계 2: 프레임 단위로 분할
25ms 프레임, 10ms 이동 → 약 200개 프레임단계 3: 스펙트로그램 변환
각 프레임의 주파수 성분 분석:
프레임 1 (무음): [0.1, 0.1, 0.1, …]
프레임 50 (“고”): [0.3, 0.8, 0.2, …] (특정 주파수 강화)
프레임 100 (“양”): [0.7, 0.4, 0.9, …]
프레임 150 (“이”): [0.2, 0.9, 0.3, …]단계 4: CNN 또는 트랜스포머 처리
프레임 간 관계 학습 → 연속된 소리 패턴 인식최종 출력:
음성_표현 = [0.66, 0.42, 0.78, …, 0.34] (768차원)
p12. 구성 요소 상세 설명
공통 표현 공간 (Shared Embedding Space)
목적: 서로 다른 모달리티를 같은 “언어”로 변환하여 의미적 유사도를 측정
텍스트_표현 [0.45, 0.67, 0.23, …, 0.89] (768차원)
이미지_표현 [0.58, 0.34, 0.91, …, 0.27] (768차원)
음성_표현 [0.66, 0.42, 0.78, …, 0.34] (768차원)→ 모두 같은 차원, 같은 공간에 존재
→ 직접 비교 및 연산 가능!의미적 유사도
텍스트: “고양이”
→ [0.5, 0.8, 0.2, …]
이미지: [고양이 사진]
→ [0.52, 0.79, 0.21, …]
↑ 벡터가 비슷함!텍스트: “강아지”
→ [0.3, 0.6, 0.7, …]
이미지: [고양이 사진]
→ [0.52, 0.79, 0.21, …]
↑ 벡터가 다름!
p13. 구성 요소 상세 설명
크로스 모달 어텐션 (Cross-Modal Attention)
목적: 서로 다른 모달리티 간 정보 교환
- 상황: 이미지 + 텍스트 질문
입력:- 이미지: [고양이가 소파에 앉은 사진]
- 텍스트: “이 동물은 어디에 앉아 있나요?”
단계별 처리:
1. 각 모달 인코딩
이미지 패치들:
패치1 (고양이 얼굴): [0.3, 0.7, 0.2, …]
패치2 (고양이 몸통): [0.5, 0.6, 0.4, …]
패치3 (소파-좌): [0.8, 0.2, 0.5, …]
패치4 (소파-우): [0.7, 0.3, 0.6, …]
…텍스트 토큰들:
“이”: [0.2, 0.5, 0.3, …]
“동물은”: [0.4, 0.7, 0.2, …]
“어디에”: [0.6, 0.3, 0.8, …] ← 위치 질문!
“앉아”: [0.5, 0.8, 0.4, …]
“있나요”: [0.3, 0.6, 0.5, …]
p14. 구성 요소 상세 설명
크로스 모달 어텐션 (Cross-Modal Attention)
목적: 서로 다른 모달리티 간 정보 교환
- 입력:
- 이미지: [고양이가 소파에 앉은 사진]
- 텍스트: “이 동물은 어디에 앉아 있나요?”
단계별 처리
2. 텍스트 → 이미지 크로스 어텐션
“어디에”의 Query 생성:
Query = [0.6, 0.3, 0.8, …] × W_Q = [0.7, 0.5, 0.9]이미지 패치들의 Key 생성:
패치1_Key = [0.3, 0.7, 0.2, …] × W_K = [0.4, 0.6, 0.3]
패치2_Key = [0.5, 0.6, 0.4, …] × W_K = [0.5, 0.7, 0.4]패치3_Key = [0.8, 0.2, 0.5, …] × W_K = [0.8, 0.3, 0.6] ← 소파!
패치4_Key = [0.7, 0.3, 0.6, …] × W_K = [0.7, 0.4, 0.6] ← 소파!어텐션 스코어 계산:
“어디에”_Q · 패치1_K = 0.45 (고양이 얼굴)
“어디에”_Q · 패치2_K = 0.52 (고양이 몸통)
“어디에”_Q · 패치3_K = 0.88 ← 높음! (소파)
“어디에”_Q · 패치4_K = 0.85 ← 높음! (소파)소프트맥스:
확률 = [0.15, 0.18, 0.35, 0.32, …]
↑ ↑
소파에 집중!
p15. 구성 요소 상세 설명
크로스 모달 어텐션 (Cross-Modal Attention)
목적: 서로 다른 모달리티 간 정보 교환
- 입력:
- 이미지: [고양이가 소파에 앉은 사진]
- 텍스트: “이 동물은 어디에 앉아 있나요?”
단계별 처리
3. Value 가중합
“어디에” 토큰의 새로운 표현 =
0.15 × 패치1_Value (고양이 정보 조금)- 0.18 × 패치2_Value (고양이 정보 조금)
- 0.35 × 패치3_Value (소파 정보 많이!)
- 0.32 × 패치4_Value (소파 정보 많이!)
→ “어디에”가 이제 “소파”라는 이미지 정보를 흡수!
4. 이미지 → 텍스트 크로스 어텐션 (반대 방향)
소파 패치의 Query로 텍스트 참조:
패치3_Q · “어디에”_K = 0.82 ← 높음!
패치3_Q · “앉아”_K = 0.76→ 소파 패치가 “위치 질문”과 관련 있음을 인식
p16. 구성 요소 상세 설명
크로스 모달 어텐션 (Cross-Modal Attention)
목적: 서로 다른 모달리티 간 정보 교환
- 입력:
- 이미지: [고양이가 소파에 앉은 사진]
- 텍스트: “이 동물은 어디에 앉아 있나요?”
단계별 처리
3. Value 가중합
“어디에” 토큰의 새로운 표현 =
0.15 × 패치1_Value (고양이 정보 조금)- 0.18 × 패치2_Value (고양이 정보 조금)
- 0.35 × 패치3_Value (소파 정보 많이!)
- 0.32 × 패치4_Value (소파 정보 많이!)
→ “어디에”가 이제 “소파”라는 이미지 정보를 흡수!
4. 이미지 → 텍스트 크로스 어텐션 (반대 방향)
소파 패치의 Query로 텍스트 참조:
패치3_Q · “어디에”_K = 0.82 ← 높음!
패치3_Q · “앉아”_K = 0.76→ 소파 패치가 “위치 질문”과 관련 있음을 인식
양방향 정보 흐름
텍스트 “어디에” ↔ 이미지 “소파” 패치들- 텍스트가 이미지의 특정 영역(소파)을 이해
- 이미지가 질문의 의도(위치 질문)를 이해
- 두 정보가 통합됨
p17. 구성 요소 상세 설명
통합 트랜스포머 (Fusion Transformer)
목적: 통합된 정보로 최종 추론
- 입력:
- 이미지: [고양이가 소파에 앉은 사진]
- 텍스트: “이 동물은 어디에 앉아 있나요?”
입력: 크로스 어텐션을 거친 통합 표현들
[텍스트 토큰들 + 이미지 정보]
[이미지 패치들 + 텍스트 정보]↓ 추가 트랜스포머 레이어들
- 최종 통합 이해:
“질문은 ‘어디에’를 묻고 있고,
이미지에서 동물(고양이)이 소파 위에 있으므로
답변은 ‘소파’ 또는 ‘소파에’가 적절하다”
p18. 구성 요소 상세 설명
출력 레이어 (Output Layer)
- 작업에 따라 다른 출력 생성
텍스트 생성 (VQA - Visual Question Answering)
통합 표현 → 디코더 → “소파에 앉아 있습니다”
분류 (Image Classification)
통합 표현 → Softmax → [고양이: 0.95, 강아지: 0.03, …]
이미지 생성 (Text-to-Image)
텍스트 표현 → Diffusion 모델 → [생성된 이미지]
p19. 구성 요소 상세 설명

p20. 멀티모달 AI의 특징
- 상호보완성 (Complementarity)
- 한 모달의 약점을 다른 모달이 보완
- 맥락 인식 (Context Awareness)
- 주변 정보를 종합적으로 고려
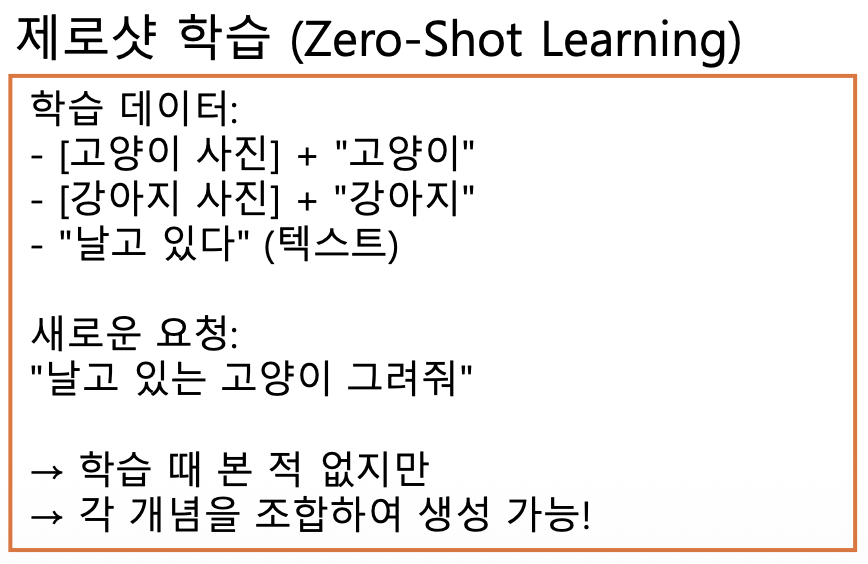
- 제로샷 학습 (Zero-Shot Learning)
- 학습하지 않은 조합도 이해 가능
- 전이 학습 (Transfer Learning)
- 한 모달에서 배운 지식을 다른 모달에 적용
p21. 멀티모달 AI의 특징



p22. 기술적 특징
- 어텐션 메커니즘
- 중요한 정보에 집중
- 모달 간 관계 학습
- 대규모 사전학습
- 수억~수십억 개의 데이터로 학습
- 일반적인 세상 지식 획득
- 종단간 학습 (End-to-End)
- 입력에서 출력까지 하나의 모델
- 별도의 파이프라인 불필요
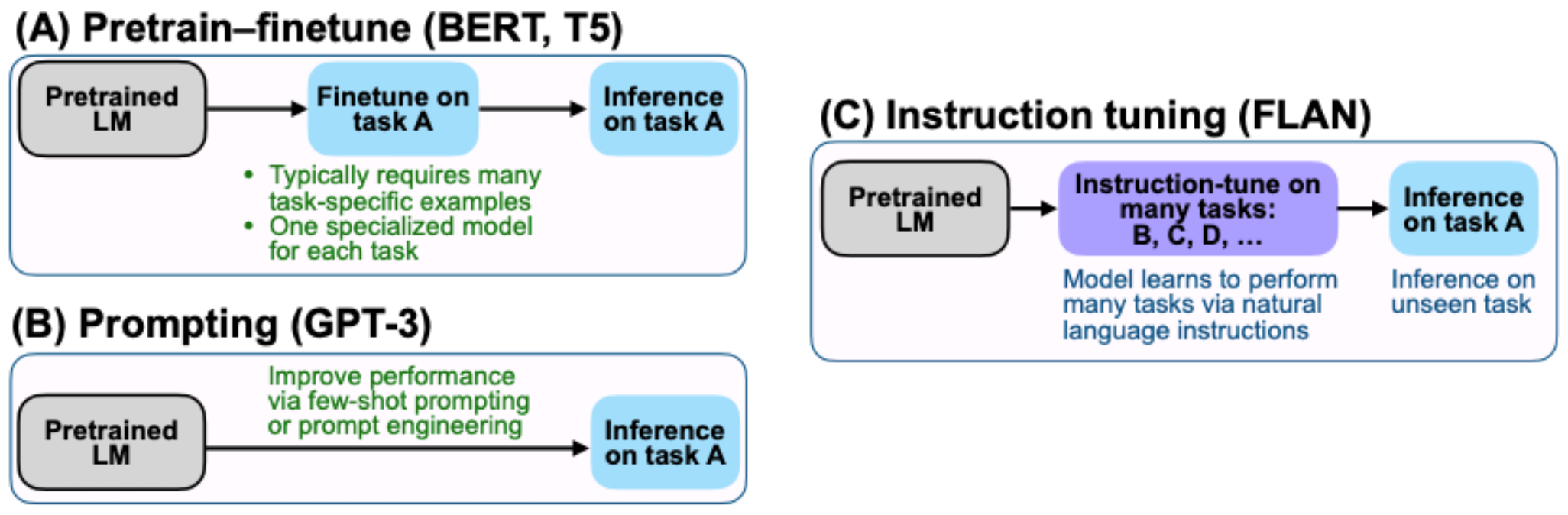
p23. MM-LLM Instruction Tuning
- SFT(Supervised Fine-tuning)
- Prompt Engineering
- Instruction Tuning using RLHF
- 특정 task에 잘 대응하도록 학습시키기 보다는, unseen tasks에 대해서도 견고하게 대응하도록 일반화
p24. CLIP
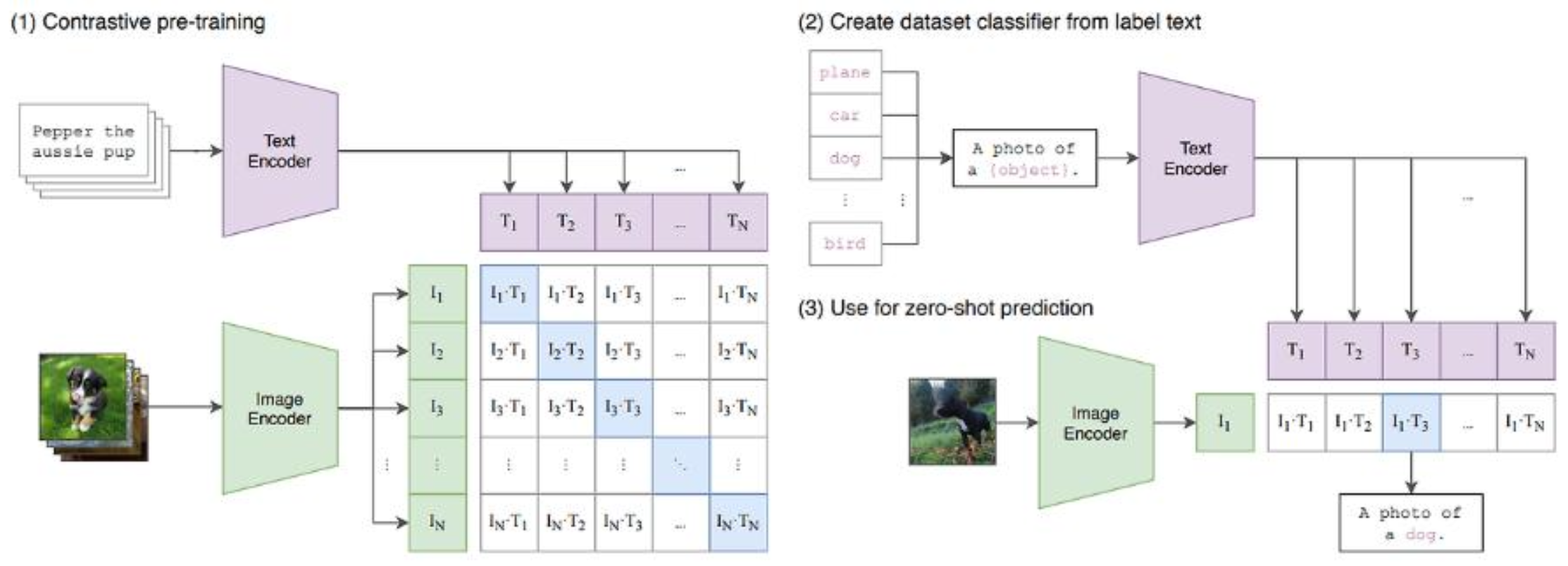
- 학습과정
- 배치 사이즈 N에 대해 N개의 (image, text) 쌍을 구성
- 텍스트는 Text Encoder를 이용해 벡터 값으로 표현, 이미지는 Image Encoder를 이용해 벡터 값으로 표현
- N개의 텍스트 벡터와 N개의 이미지 벡터 사이의 코사인 유사도를 계산
- 유사도 값을 이용해 Cross Entropy loss 값을 계산해 최적화
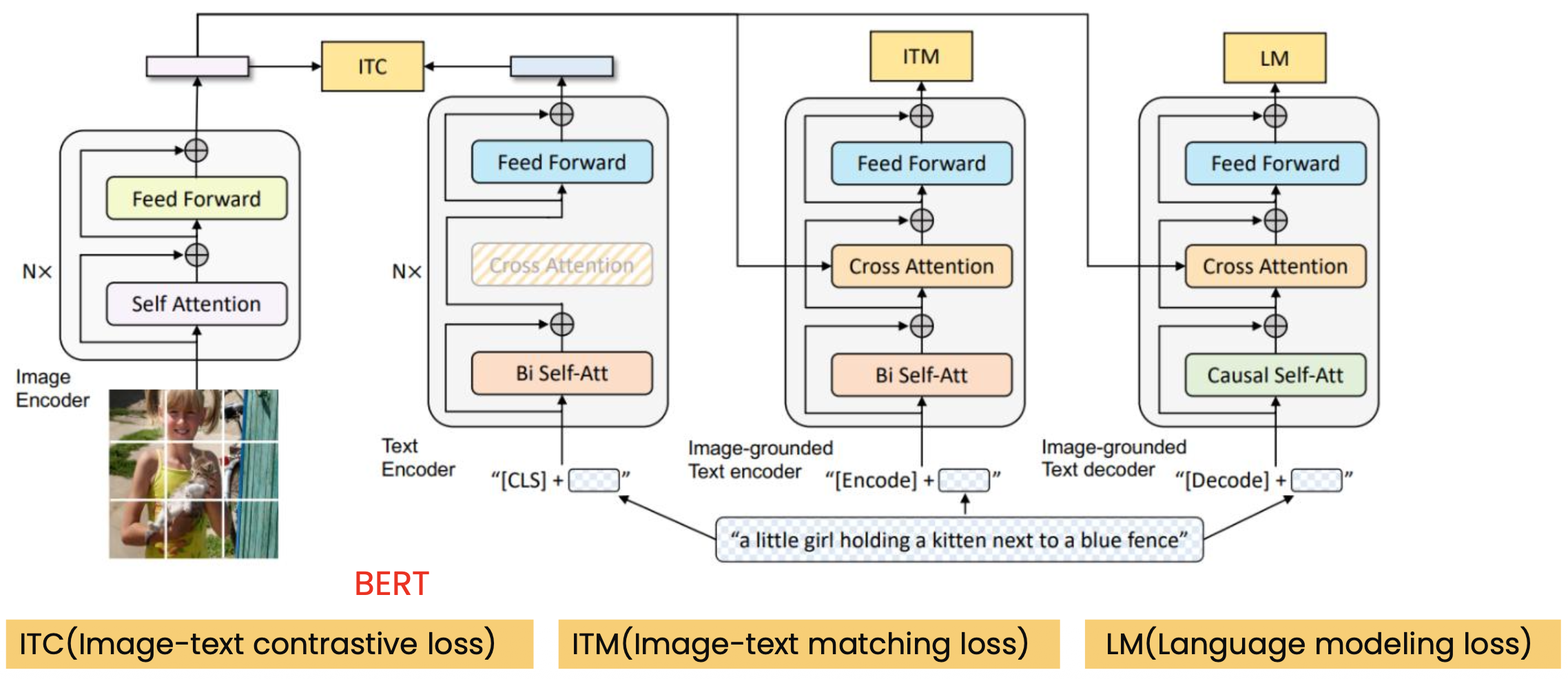
p25. BLIP(Bootstrapping Language-Image Pre-training)
- VLP(Vision-Language Pre-training)
- 모델 관점: encoder-based(Understanding)과 encoder-decoder based(Generation 중심)
- 데이터 관점: 웹으로부터 수집가능한 대량의 image-text 쌍 데이터를 활용하여 학습
- BLIP model
- Multimodal mixture of Encoder-Decoder(MED)
- 유기적으로 transfer learning을 진행할 수 있는 모델구조로 3개의 objective functions을 학습
- unimodal encoder: image embedding과 text embedding 간의 contrastive learning
- image-grounded text encoder: image-text matching 최적화
- image-grounded text decoder: image-conditioned language modeling을 최적화
- 유기적으로 transfer learning을 진행할 수 있는 모델구조로 3개의 objective functions을 학습
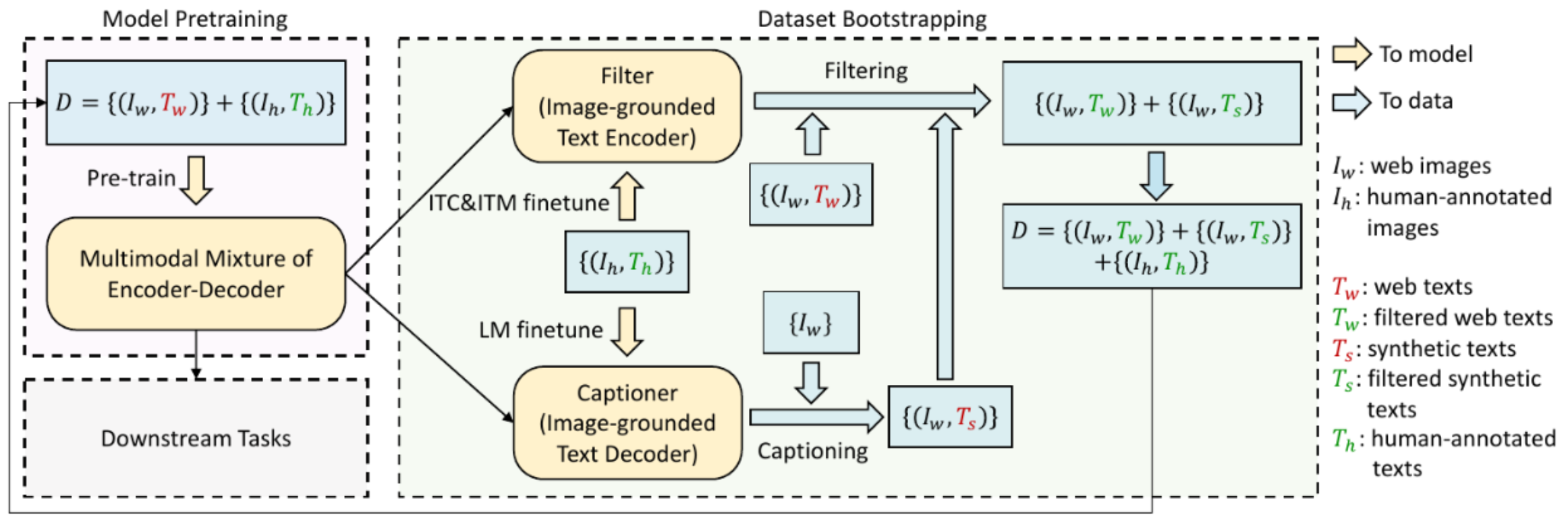
- Captioning and Filtering(CapFilt)
- Noisy한 image-text pair로부터 dataset을 bootstrapping할 수 있는 방법 제시
- synthetic model(decoder)인 captioner와 understanding model(encoder)인 filter를 사용하여
original web caption과 synthetic caption 중 noisy한 샘플을 없애는 작업 수행
- Multimodal mixture of Encoder-Decoder(MED)
p26. BLIP(Bootstrapping Language-Image Pre-training)
- System Architecture: MED(Multimodal mixture of Encoder-Decoder)
p27. BLIP(Bootstrapping Language-Image Pre-training)
- System Architecture: CapFilt
p28. BLIP
- 주요 장점
- 성능이 좋은 image encoder와 text encoder, 그리고 text decoder 전반을 융합하여 다양한 task에 높은 performance로 적용 가능한 구조를 만들고자 한 것
- 단점
- end-to-end로 네트워크를 학습해야 하는 방법론에서는 벗어나지 못해 학습 과정이 복잡
- 즉, modality gap을 줄이기 위해 수행해야 하는 학습 과정이 복잡해짐
p29. BLIP2
- frozen pre-trained image and text network를 효율적으로 사용하면서
Q-former를 통해 modality gap을 줄일 수 있는 방법을 제시- 학습은 representation learning stage와 text generative learning stage로 구분
- 성능
- Flamingo보다 zero-shot VQA 성능: 8.7%가 높았으며
- 54배 적은 parameter 수로 이를 충족
p29. BLIP2
- frozen pre-trained image and text network를 효율적으로 사용하면서
Q-former를 통해 modality gap을 줄일 수 있는 방법을 제시- 학습은 representation learning stage와 text generative learning stage로 구분
- 성능
- Flamingo보다 zero-shot VQA 성능: 8.7%가 높았으며
- 54배 적은 parameter 수로 이를 충족
p30. BLIP2
- BLIP2: 2 step의 pre-training 과정을 통해 vision과 language의 alignment
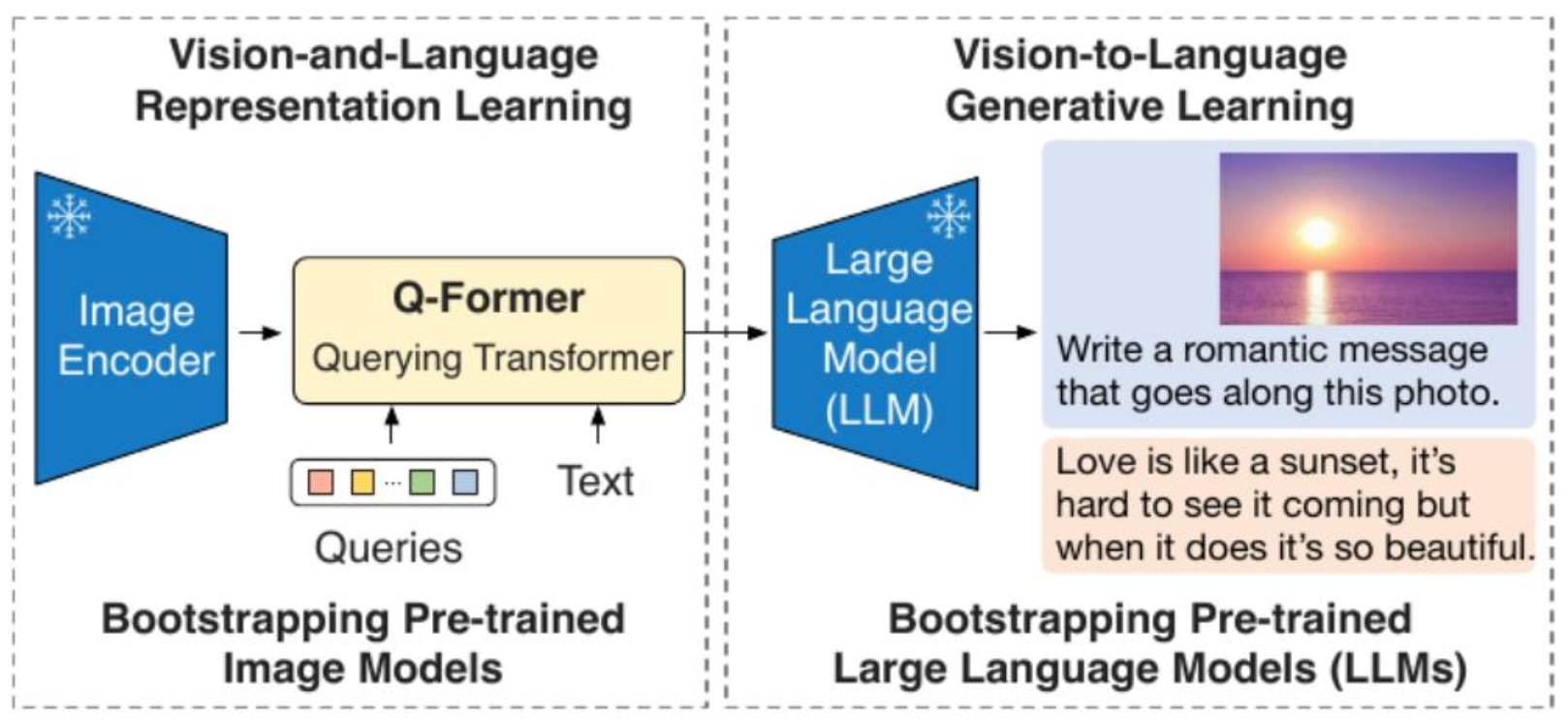
- vision model과 language model의 generic하고 compute-efficient한 방법을 제시하여,
pre-trained vision model과 language model을 직접 건드리지 않고 bootstrapping
(학습 과정에서 Image encoder와 LLM은 frozen 상태로 guidance로 사용)
p31. BLIP2
- BLIP2: 2 step의 pre-training 과정을 통해 vision과 language의 alignment
- Image encoder에서는 입력 이미지 resolution과 상관 없이 고정된 크기의 output feature를 추출
Q-former(Querying Transformer)
- cross-modal alignment (이미지 표현과 언어표현 사이의 적절한 매칭 관계)
- 기존의 cross-attention layer를 단일 module로 구현하여 scalability를 높임
- image encoder에서 나온 embedding에서 LLM에 유용하게 사용될 수 있는 embedding을 추출해내고,
이를 통해 LLM 성능을 높이고자 함
p32. BLIP2
Vision-Language Representation Learning
- Q-Former(Querying Transformer)
- Vision modality와 language modality 사이의 modality gap을 bridge하는 모듈
- 이미지에서 표현되는 feature들을 text에 연관짓는 작업 수행
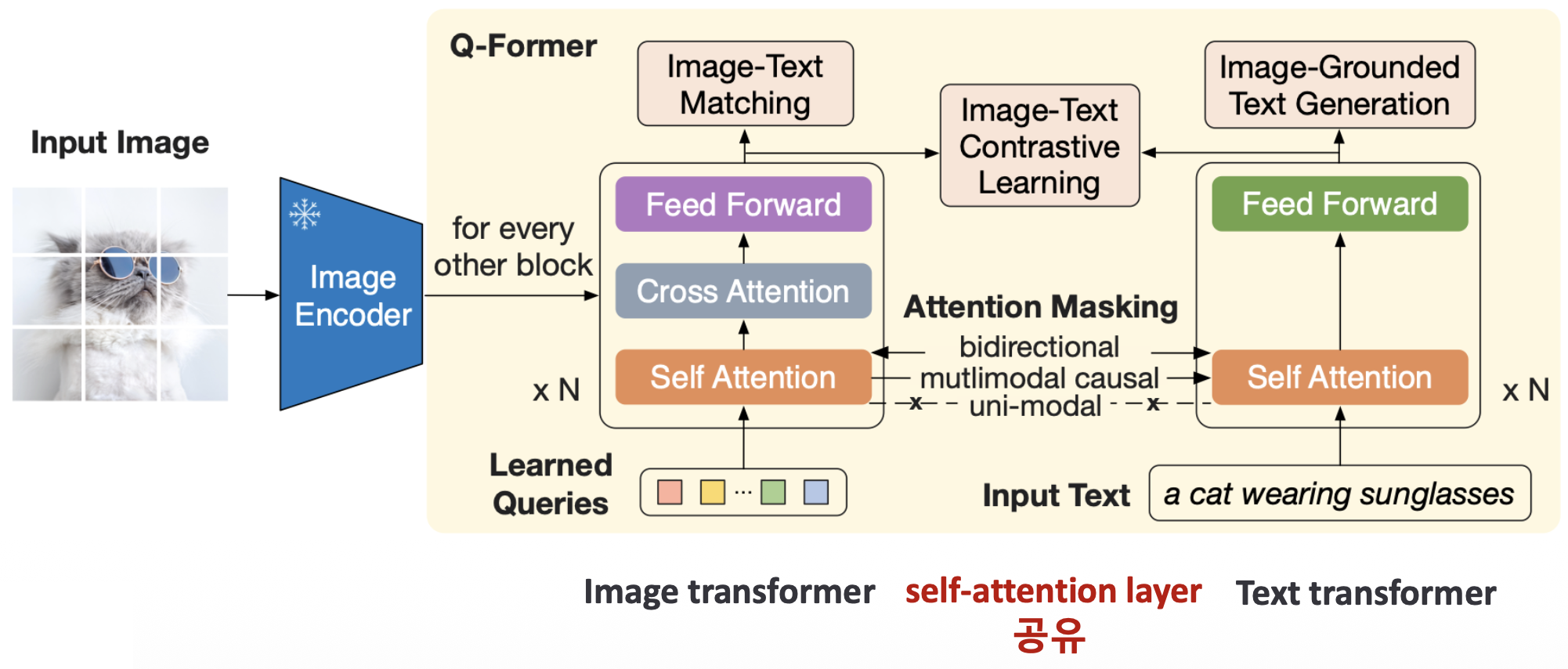
p33. BLIP2
- Query-text 간의 상호작용을 조절하기 위한 attention masking strategy
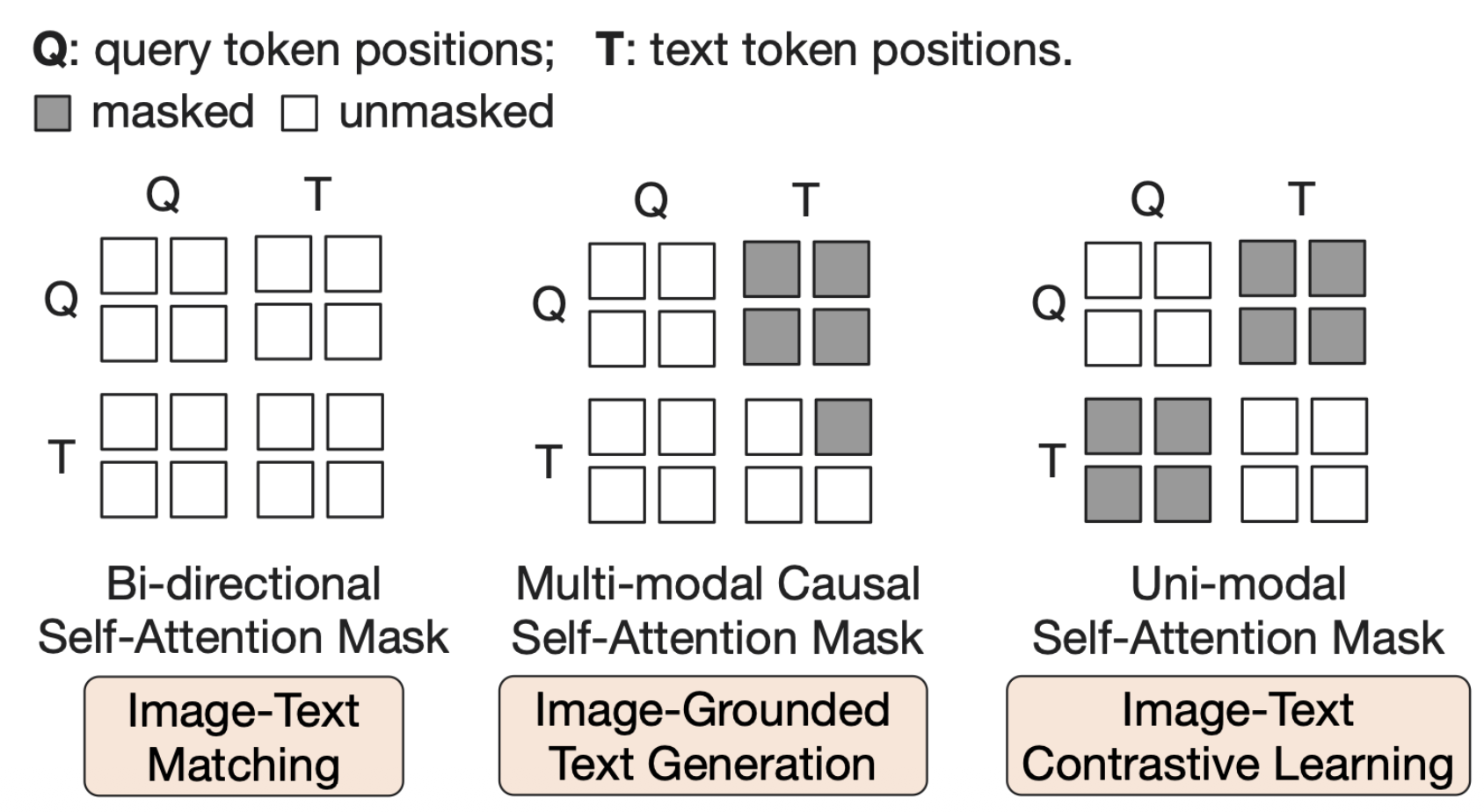
p34. BLIP2
Vision-Language Generative Learning
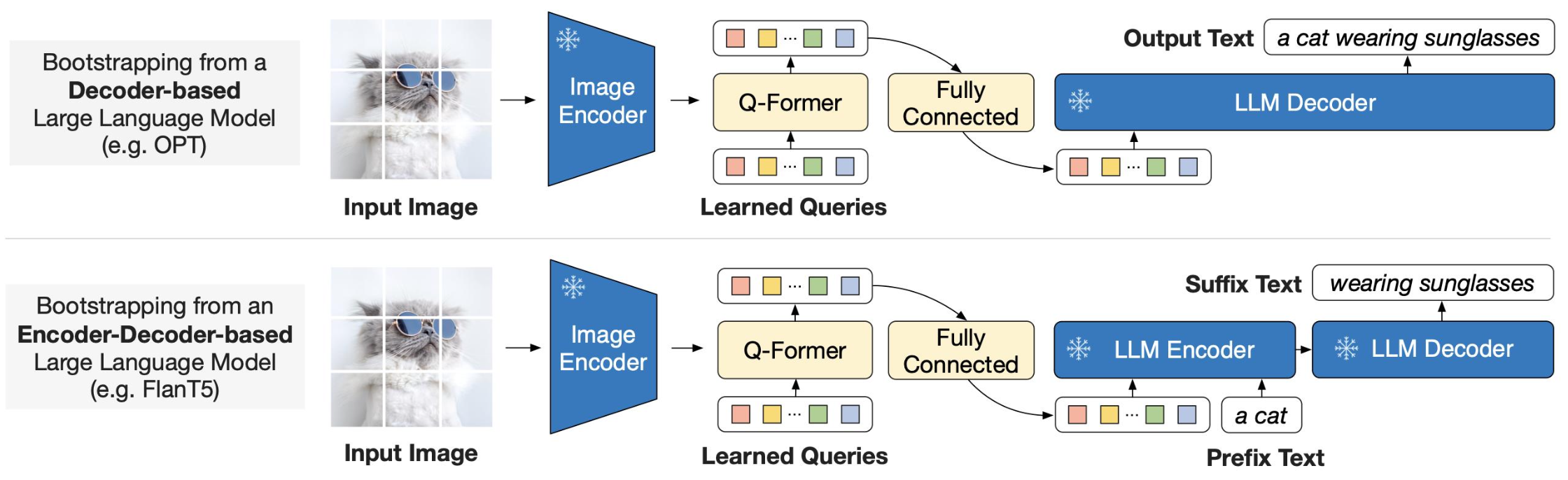
p35. MMIR
MMIR TASK
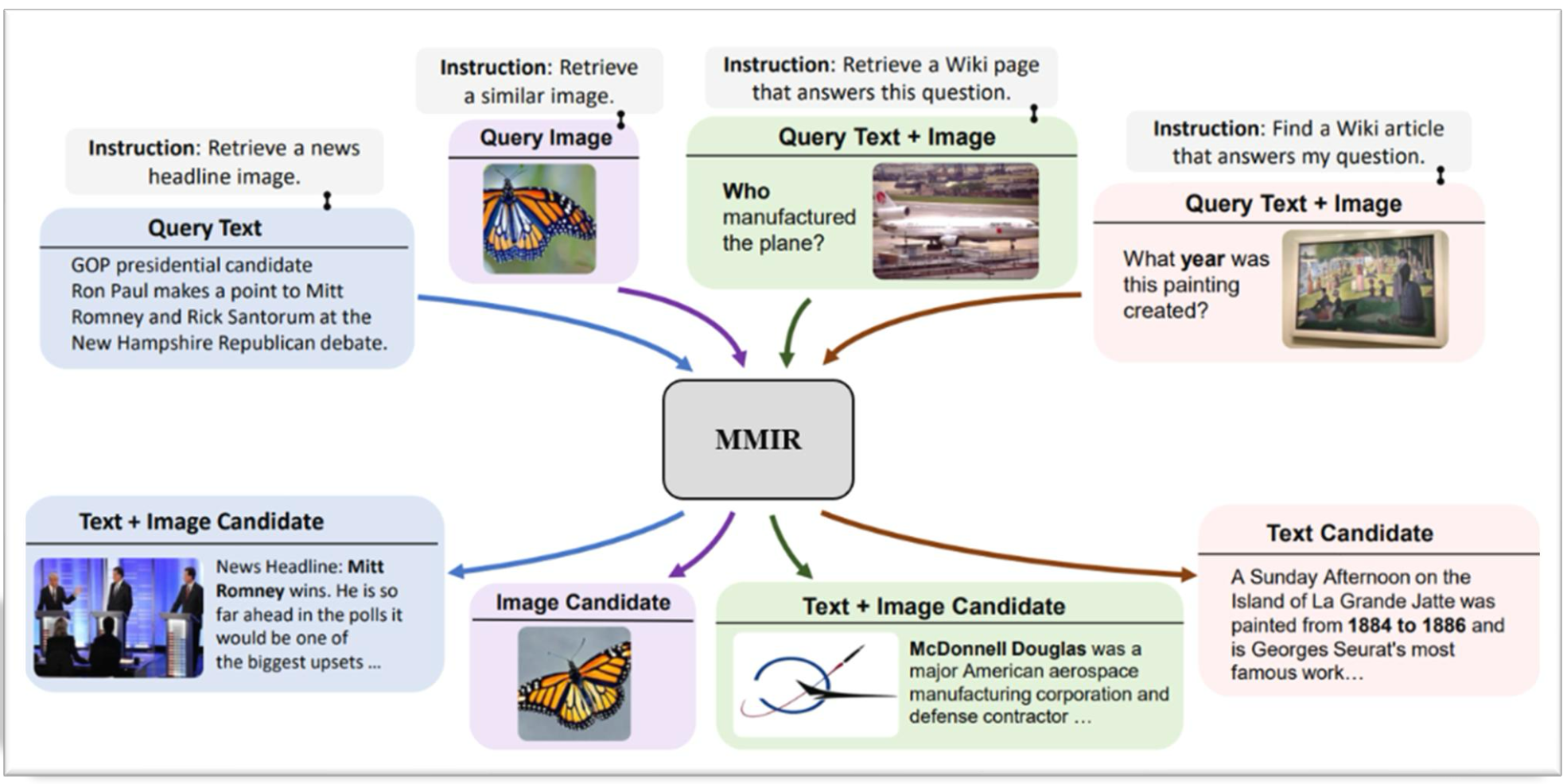
UniIR : Training and Benchmarking Universal Multimodal Information Retrievers
p36. MMIR
- MMIR Dataset and Benchmark : M-BEIR
- ECCV 2024에서 소개, 8개의 Task을 커버하는 10개 데이터 셋으로 구성
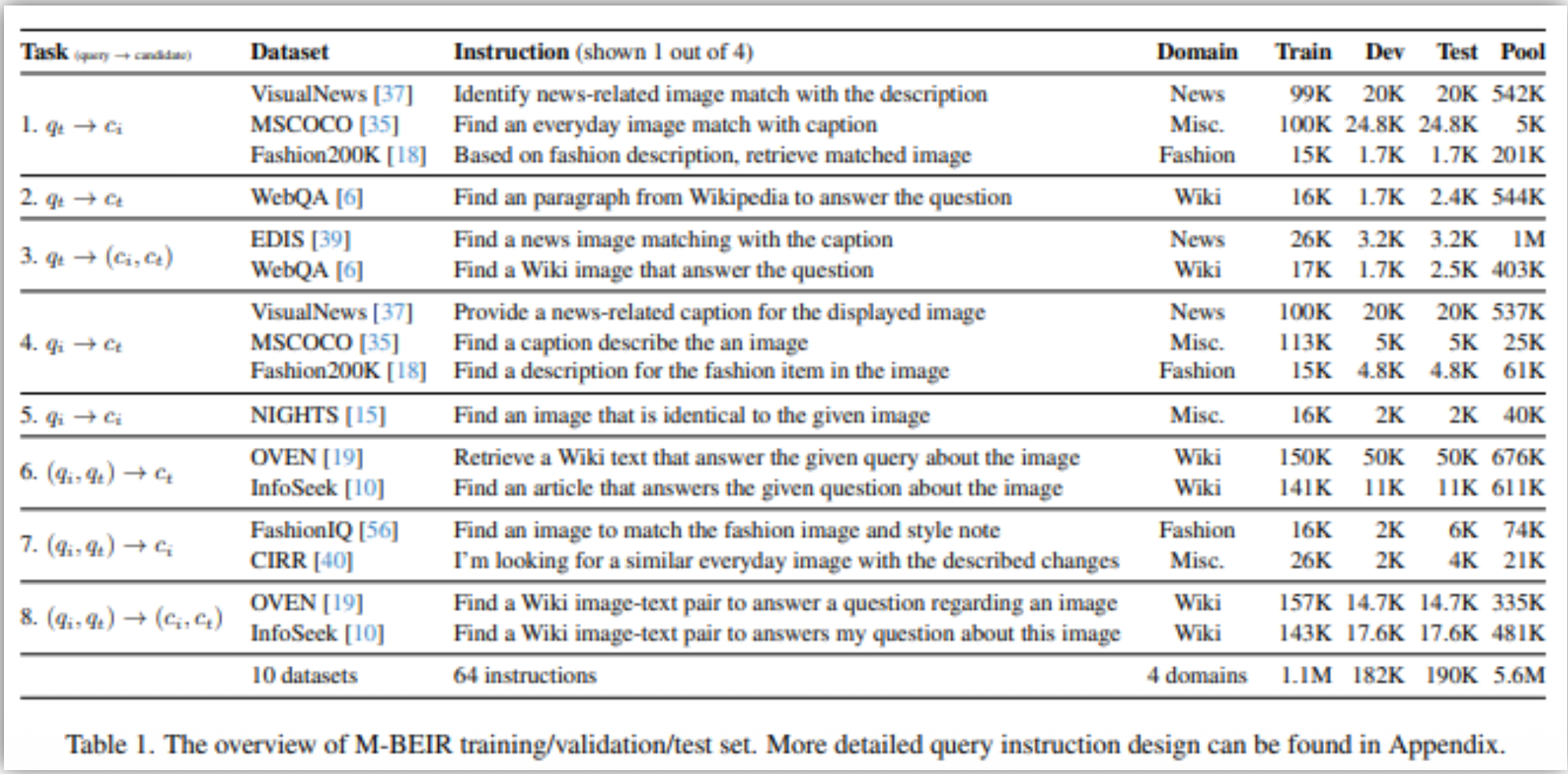
p37. MMIR
- M-BEIR 샘플 예시

p38. MMIR - UniIR
- UniIR
- 2024 ECCV에 발표
- 다양한 검색 태스크를 하나의 모델에서 수행
- Instruction-Guided Multimodal Retriever
- 사전 학습된 CLIP 또는 BLIP 모델을 기반으로 하며,
두 가지 융합 메커니즘(fusion mechanisms) 을 실험
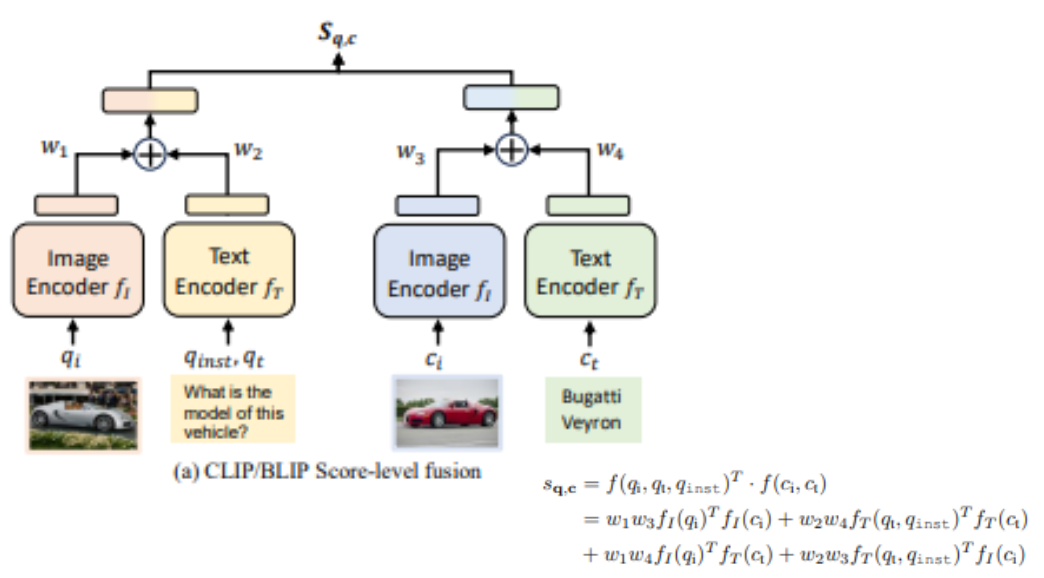
- 개별 인코더(fᵢ, fₜ)를 사용하여 이미지와 텍스트를 각각 벡터로 인코딩
- 질의(q)와 후보(c)의 유사도 점수(S(q,c))를 모달리티 내 및 모달리티 간 유사도 점수의 가중 합으로 계산
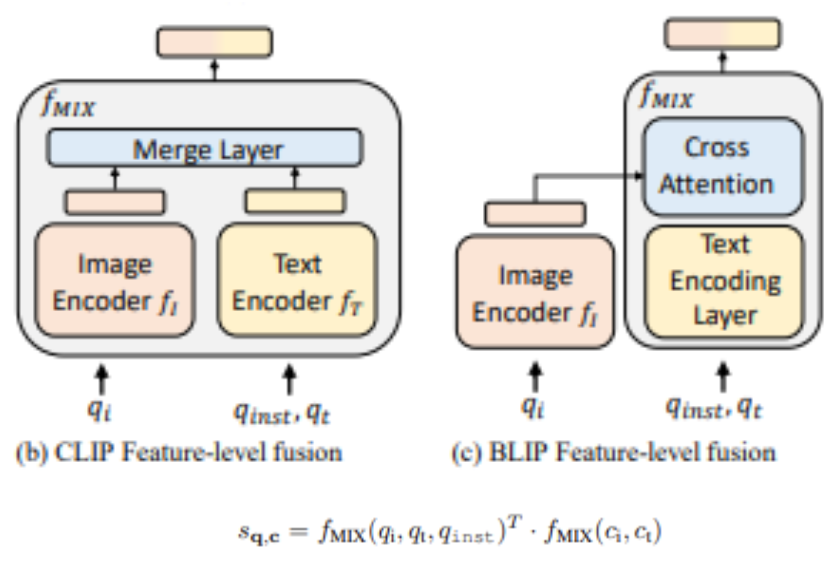
- 인코딩 단계에서 특징을 통합
- Mixed-modality Transformer 또는 Cross-Attention 레이어를 활용하여
다중 모달 질의 또는 후보에 대해 단일의 종합적인 특징 벡터를 계산
p39. MMIR - UniIR
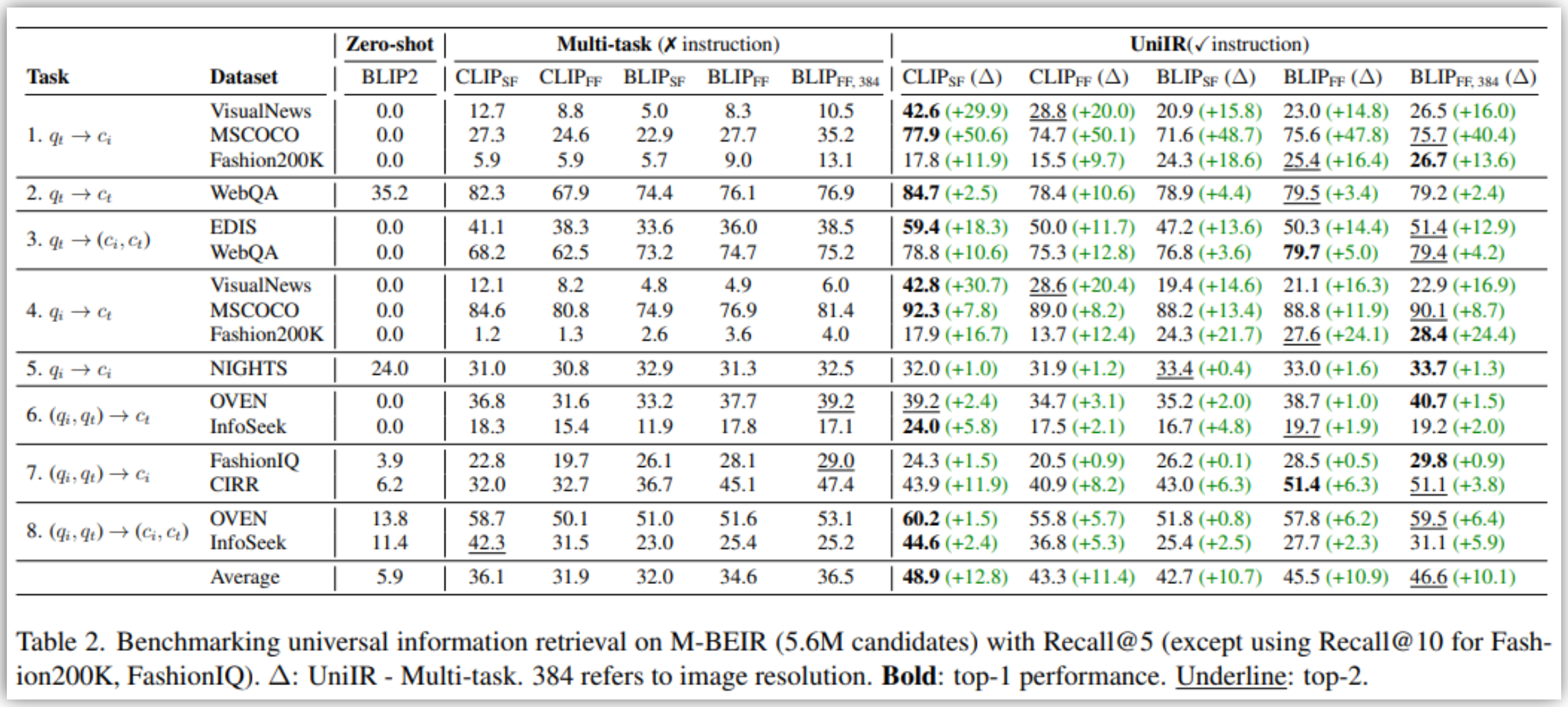
주요 실험 결과
- Instruction Tuning의 중요성
- UniIR 모델(q_inst 포함)이
다중 작업 미세조정 모델(Multi-task fine-tuned baseline, q_inst 미포함) 모델에 비해
M-BEIR에서 훨씬 우수한 성능 - Instruction Tuning은 모델이 검색 의도를 정확히 이해하도록 도와,
의도치 않은 모달리티의 후보를 검색하는 오류 감소에 결정적 - 미학습 작업(Unseen Tasks) 에 대한 일반화 능력(Zero-shot Generalization) 향상
- UniIR 모델(q_inst 포함)이
- 다중 작업 훈련(Multi-task Training)의 효과
- UniIR(BLIP)의 경우, 단일 작업(Single-task) 훈련 대비
Recall@5 기준 평균 +9.7% 성능 향상 - 특히 복합 이미지 검색 작업인 CIRR(Task 7) 에서
UniIR(BLIP_FF)은 단일 작업 모델 대비 48.6% 큰 폭의 개선
- UniIR(BLIP)의 경우, 단일 작업(Single-task) 훈련 대비
- 최적 모델 및 융합 방식
- 실험 결과, CLIP 기반의 점수 수준 융합(CBLIP_FF) 모델이 전반적으로 가장 경쟁력 있는 성능
- BLIP 기반의 특징 수준 융합(BLIP_FF) 모델 또한 단일 작업 모델을 크게 능가
p40. MMIR - UniIR
p41. MMIR-VISTA
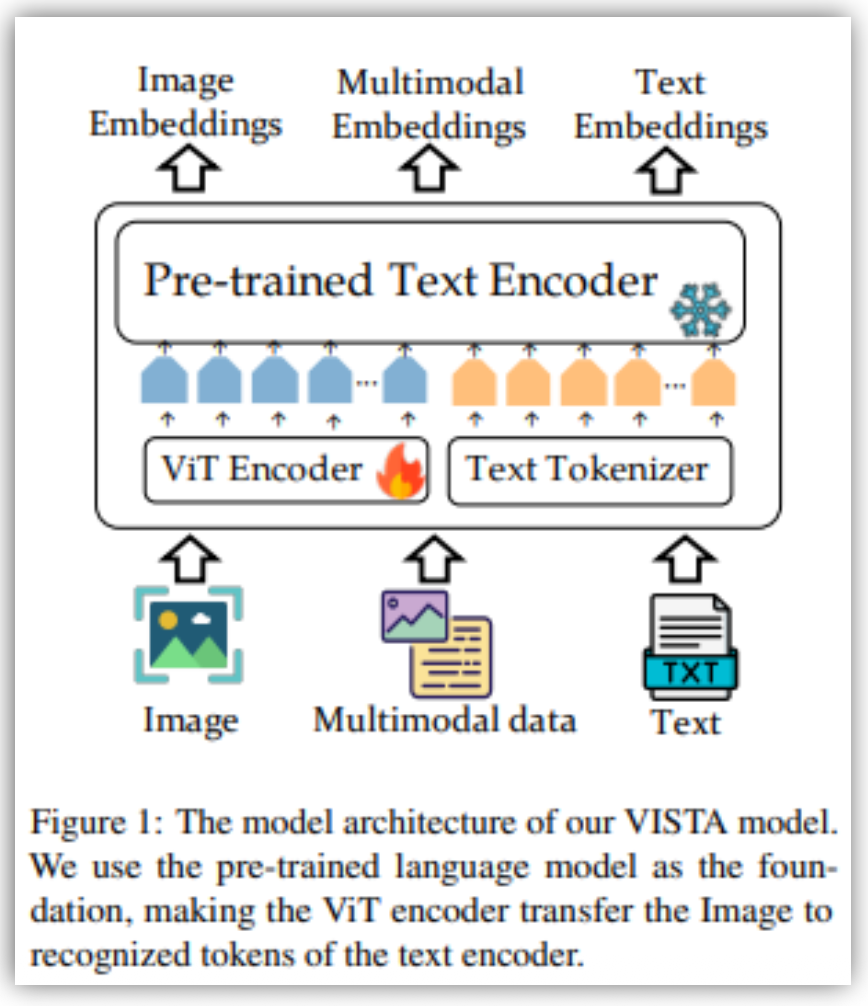
VISTA (Visualized Text Embedding For Universal Multi-Modal Retrieval)
- 텍스트 인코더를 기반으로 비주얼 정보를 인코딩하는 구조
비주얼 토큰 임베딩 도입하여 이미지 이해 능력을 확장
- 다단계 학습 과정
- 1단계: 비주얼 토큰 임베딩을 텍스트 인코더와 정렬하고,
- 2단계: 생성된 구성 이미지-텍스트 데이터를 통해 다중 모달 표현 기능을 개발.
이를 통해 모델은 텍스트와 이미지를 효과적으로 통합
VISTA: Visualized Text Embedding For Universal Multi-Modal Retrieval ACL 2024
p42. MMIR-VISTA
- VISTA 데이터 생성 프로세스
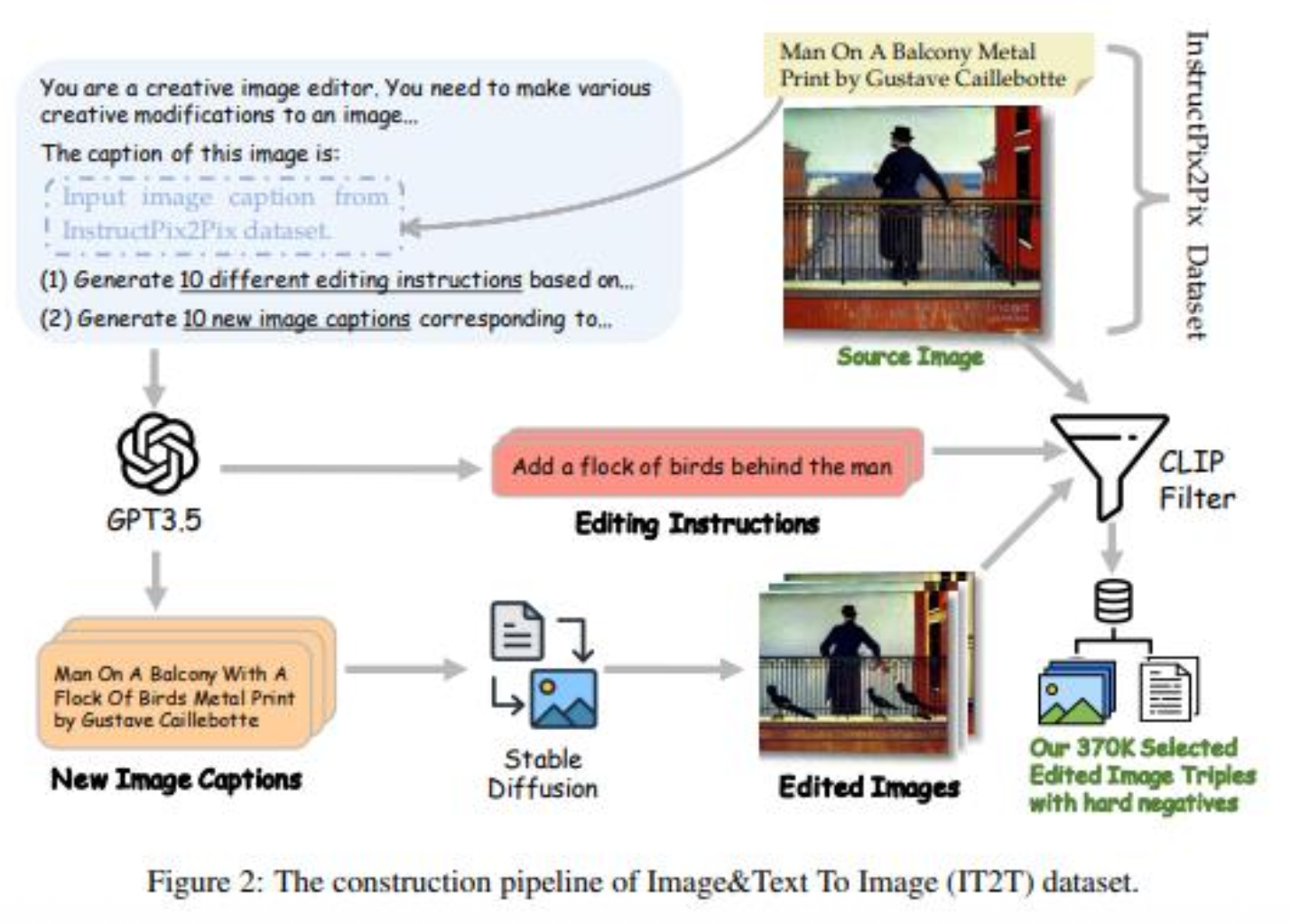
p43. MMIR : E5-V
E5-V
- Universal Embeddings with Multimodal Large Language Models (MLLMs)
- MLLM 기반 범용 임베딩 모델 E5-V
- MLLM의 강력한 시각 및 언어 이해 능력을 활용하여 텍스트 및 이미지를 위한 범용적이고 효율적인 임베딩 모델(E5-V)을 제안
- 특히, 텍스트 전용 학습만으로 다중 모달 성능을 달성하는 혁신적인 학습 전략을 제시
- 연구동기
- CLIP 계열 모델의 한계: 대규모 이미지-텍스트 쌍으로 학습되지만, 텍스트 임베딩만으로 쿼리 시 이미지의 복잡한 뉘앙스를 포착하는 데 한계
- MLLM의 임베딩 활용 미흡: MLLM은 시각·언어 이해에 있어 강력한 성능을 보여주지만, 주로 생성(Generation) 작업에 초점이 맞춰져 있어 효율적인 표현 학습(Representation Learning), 즉 임베딩 생성에 대한 탐구가 부족
- 다중 모달 학습의 비효율성: 기존 방식은 대규모의 정렬된 이미지-텍스트 쌍 데이터셋이 필수적이며, 이는 데이터 수집 및 모델 훈련에 막대한 비용과 시간이 소요
- E5-V의 목표
- MLLM을 활용하여 단일 벡터 공간에 텍스트와 이미지를 통합하는 범용 임베딩 모델을 구축
- 텍스트 쌍 데이터만으로 학습하여 다중 모달 임베딩 성능을 달성하는 효율적인 학습 패러다임을 제시
E5-V: Universal Embeddings with Multimodal Large Language Models
p44. MMIR : E5-V
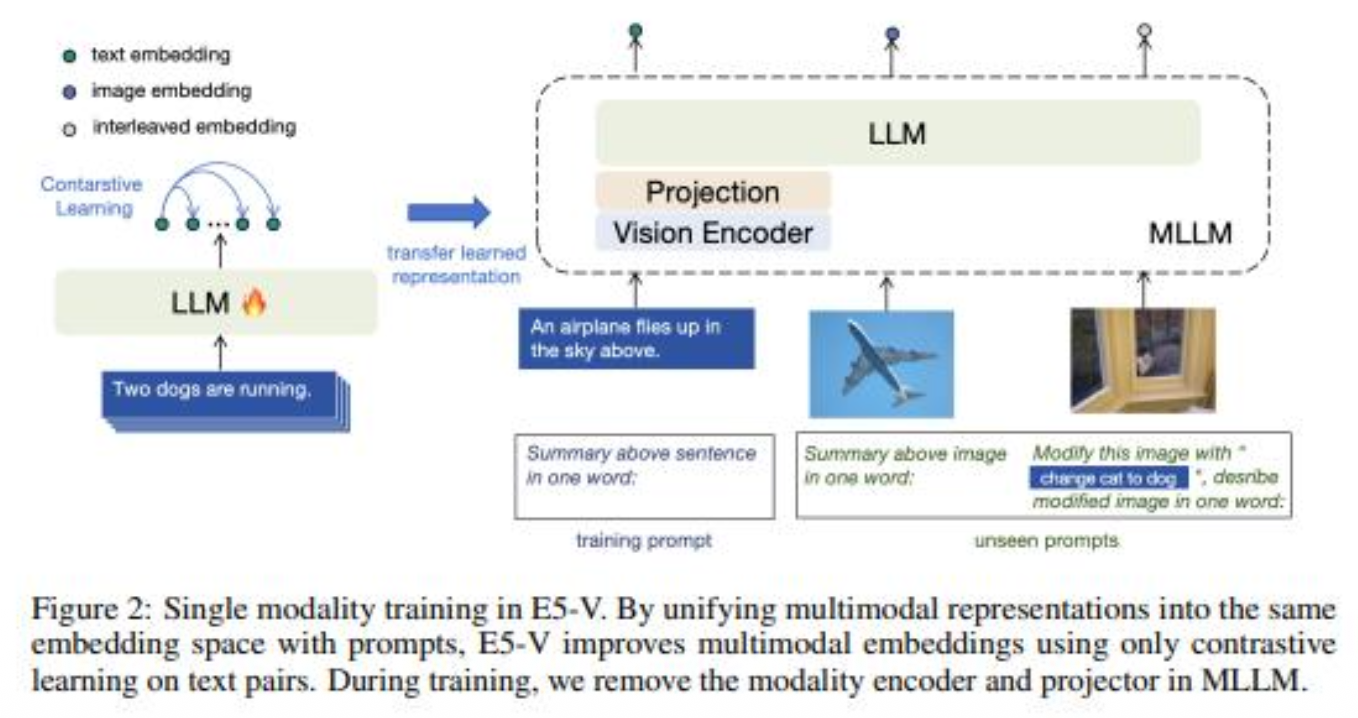
E5-V의 핵심
프롬프트 기반의 표현 방법을 사용하여 MLLM이 모달리티 간 간극(modality gap)을 제거하고 단일 모드 훈련을 통해 다중 모드 임베딩을 생성할 수 있도록 하는 것
- 아키텍처 (MLLM Adaptation)
- 기반 모델: MLLM (예: LLaVA-NeXT, Phi3, LLaVA 1.6)을 기반으로 사용
- 프로젝션 레이어 (Projection Layer):
MLLM의 마지막 계층 출력 토큰(주로 CLS 토큰 또는 마지막 토큰)을
고정된 차원의 임베딩 벡터로 변환하는 선형 레이어를 추가 - 단일 입력/출력 (Single I/O):
MLLM이 텍스트와 이미지를 모두 입력으로 받아 단일 임베딩 벡터를 출력하도록 구조화
- 학습 전략: 단일 모달리티 학습 (Single Modality Training)
- 모델을 이미지-텍스트 쌍이 아닌 텍스트-텍스트 쌍 데이터셋에 대해서만 대조 학습(Contrastive Learning) 수행
- 원리
- MLLM은 사전 학습 과정에서 이미 텍스트와 이미지 간의 강력한 의미적 연결(Semantic Alignment) 을 학습
- E5-V는 이 사전 학습된 MLLM의 능력을 활용하여, 텍스트 쌍 학습을 통해 텍스트 공간의 구조를 강화하면
이 구조가 MLLM 내부의 시각-언어 공간에 전이되어 이미지 임베딩 성능까지 자동으로 향상된다는 가설을 증명
- 대조 학습(Contrastive Learning)
- 학습 과정에서는 텍스트 쌍이 입력으로 제공되고
대조 손실 값을 최소화하는 방식으로 모델을 학습 - 입력 텍스트 쌍 각각에 대해 긍정적인 쌍과 부정적인 쌍이 제공되며,
모델이 긍정적인 짝은 더 가깝게, 부정적인 짝은 더 멀게 위치시키도록 학습
- 학습 과정에서는 텍스트 쌍이 입력으로 제공되고
- 프롬프트 설계
- E5-V는 텍스트와 이미지 입력을 올바로 표현하기 위해 특정 프롬프트를 사용
- 예) 이미지에 대해
"image: <image> \n Summary above image in one word:"와 같은 프롬프트를 사용하여
이미지의 의미를 간결하게 요약하도록 모델에 지시
p45. MMIR : E5-V
멀티모달 임베딩 통합(Unifying Multimodal Embeddings)
- E5-V는 멀티모달 입력을 동일한 임베딩 공간으로 통합하여 모달리티 간극(Modality Gap)을 제거

p46. MMIR : E5-V
- 단일 모달리티 학습(Single Modality Training)
- 단일 모달리티 학습은 텍스트 쌍을 사용하여 대조적 학습을 수행하며, 시각적 입력을 사용하지 않음
- 학습 데이터로는 NLI 데이터셋의 문장 쌍을 사용
- 단일 모달리티 학습 효과
- 학습 비용을 크게 절감
- 텍스트 쌍만을 사용하여 학습함으로써 입력 크기를 줄이고, 학습시간 단축
p47. 실제 서비스 사례
- GPT-4V (Vision) – OpenAI
- 이미지 + 텍스트 동시 처리
- 시각적 질문 답변
- 차트/그래프 분석
- 문서 이해
- Claude 3 (Anthropic)
- PDF, 이미지 분석
- 긴 문서 처리
- 복잡한 시각 추론
- Gemini (Google)
- 텍스트, 이미지, 음성, 비디오
- 실시간 멀티모달 처리
- 긴 컨텍스트 이해
p48. 실제 서비스 사례
비주얼과 관련된 프롬프트를 분석하여 사용자에게 가장 유용한 답변을 제공
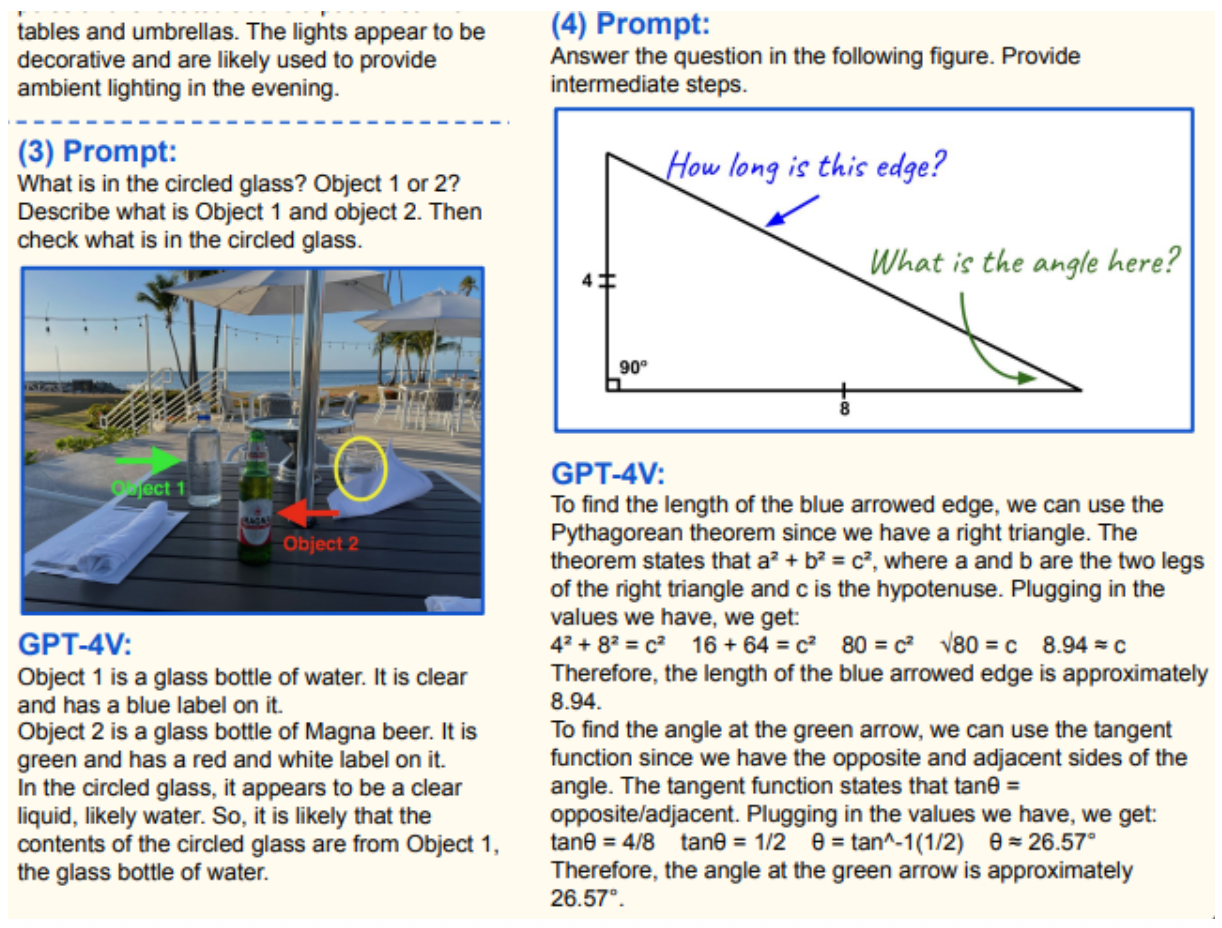
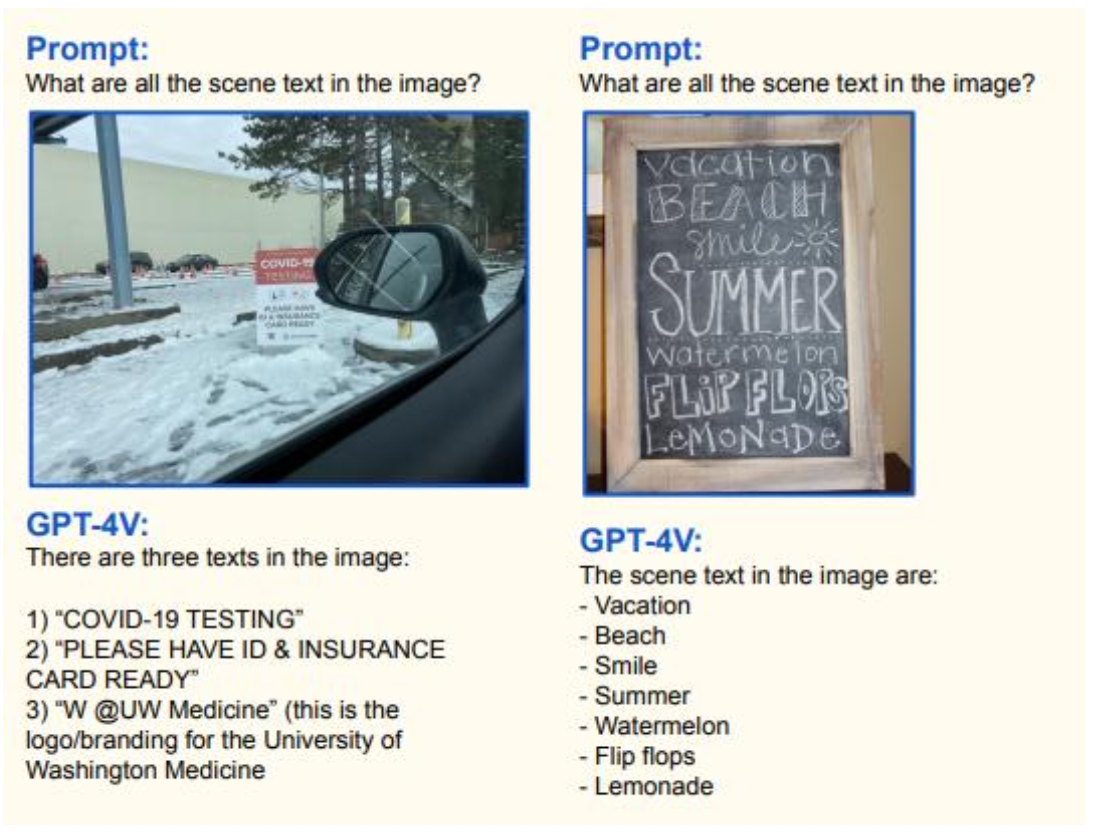
각 이미지의 텍스트, 숫자, 데이터를 인식하고 이 정보를 기반으로 출력을 생성
p49. 실제 서비스 사례
다국어 지원

문서이해: 논문 분석과 요약 정리

p50. 실제 서비스 사례
- 비디오 분석

p51. 실제 서비스 사례 : 구글 DeeVid AI
p52. 참고문헌
- MM-LLMs: Recent Advances in MultiModal Large Language Models
- 2024.5.28
- A Survey on Multimodal Large Language Models
- 2024.4.1
- Visual Instruction Tuning
- 2023.4.17
- Learning Transferable Visual Models From Natural Language Supervision
- 2021.2.26
- BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
- 2022.2.15
- BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
- 2023.7.15
VISTA: Visualized Text Embedding For Universal Multi-Modal Retrieval
- UniIR : Training and Benchmarking Universal Multimodal Information Retrievers
- E5-V: Universal Embeddings with Multimodal Large Language Models