[빅데이터와 정보검색] 2주차 검색개요 - 색인과 검색랭킹 모델(part1)
p2. 정보 검색 개요
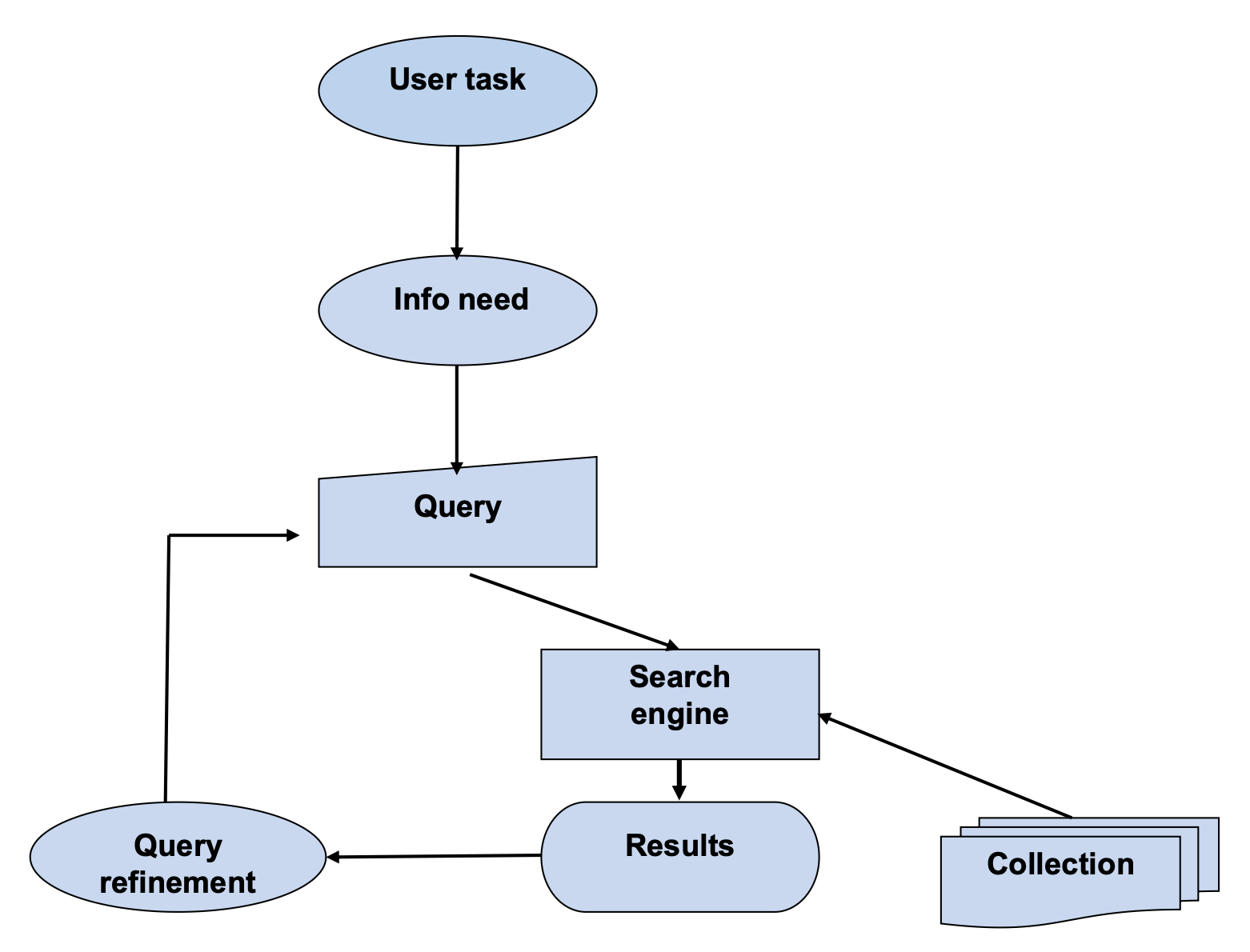
- User task (사용자 과제)
- 사용자가 실제로 수행하려는 작업
- 예: 리포트 작성, 문제 해결, 특정 사실 확인
- Info need (정보 요구)
- 사용자가 과제를 수행하는 과정에서 느끼는 정보의 필요성
- 내적이고 추상적인 개념이며, 명확히 표현되지 않을 수도 있음
- Query (질의)
- 정보 요구를 표현한 구체적 형태
- 검색 엔진에 입력하는 키워드나 문장
- Info need(정보 요구) ↔ Query(질의) 구분 필요
- Search engine (검색 엔진)
- Query를 기반으로 Collection(문서 집합)에서 관련 문서를 검색
- 검색 알고리즘에 따라 결과가 달라짐
- “찾는 방법”에 해당
- Results (검색 결과)
- 검색 엔진이 반환한 문서 집합
- 사용자가 결과를 보고 만족도를 평가
- Query refinement (질의 개선)
- 검색 결과가 만족스럽지 않을 경우 질의를 수정하거나 새로운 키워드 추가
- “얼마나 잘 찾았는지 보고 나서 수정” 과정
- Search engine → Results 과정을 반복
- Collection (문서 집합)
- 검색 대상이 되는 전체 데이터베이스
- 예: 웹 문서, 논문, 뉴스 기사 등
✅ 정리
User task → Info need → Query → Search engine → Results → Query refinement
이러한 순환 과정을 통해 사용자의 정보 요구가 충족된다.
p3. 정보 검색 개요
정보 검색의 핵심 구성요소
- 색인(Indexing) : 수많은 문서를 효율적으로 검색할 수 있도록 구조화 하는 과정
- 전처리
- 토큰화(Tokenization) : 문서를 단어 단위로 쪼개는 과정
- 불용어 제거(Stop Word Removal) : ‘은’, ‘는’, ‘이’, ‘가’, ‘the’, ‘a’ 등 의미없는 단어 제거
- 어간추출(Stemming)/표제어 추출(Lemmatization) : 단어의 원형 복원(예: runs→run, running→run, 먹었다→먹다)
- 키워드 역색인(Inverted Index) : 각 토큰이 어느 문서에서 출현했는지 기록하는 자료구조
- 전처리
- 질의(Query) : 사용자가 찾는 정보의 표현
- 키워드 질의
- 자연어 질의 : ‘인공지능의 최신 연구동향에 대한 논문을 찾아줘’와 같은 자연어 질문
- 랭킹(Ranking) : 문서와 질의간 유사도를 계산하여 질의와 관련된 문서를 중요도 순으로 나열하는 과정
- TF-IDF : 토큰 빈도(문서 내 특정 단어의 출현 빈도)와 역문서 빈도(전체 문서 중 특정 단어가 포함된 문서의 수)를 사용하여 문서 내 용어의 중요도를 평가하는 가장 기본적인 방법
- BM25 : TF-IDF를 개선한 확률적 모델로, 많은 검색 엔진에서 기본 랭킹 알고리즘으로 사용
- 벡터공간 모델(VectorSpaceModel) : 문서와 질의를 고차원 벡터로 표현하고, 두 벡터 간의 코사인 유사도(Cosine Similarity)를 측정하여 랭킹. 최근 워드임베딩, BERT와 같은 딥러닝 기반의 언어 모델을 많이 사용
p4. 정보 검색 개요
정확성(Relevance): 검색된 문서가 사용자의 질의와 얼마나 관련 있는지를 판단하는 주관적인 기준으로 전문가 그룹이 판단
정밀도(Precision): 검색된 문서 중 실제로 관련 있는 문서의 비율
- 재현율(Recall): 전체 관련 문서 중 실제로 검색된 문서의 비율
• F1-점수(F1-score): 정밀도와 재현율의 조화 평균
\[F1 = 2 \times \frac{정밀도 \times 재현율}{정밀도 + 재현율}\]그 외 지표
MAP(Mean Average Precision): 질의에 대한 평균 정밀도를 여러 질의에 대해 평균낸 값
nDCG(normalized Discounted Cumulative Gain): 랭킹 순서를 고려하여 상위 랭크의 중요도를 높게 평가하는 지표
- 쉽게 얘기해서
- 정밀도 는 검색된 문서들 기준으로, 그 안에 관련 있는 문서들 이 얼마나 포함되어 있느냐?
- 재현율 은 관련 있는 문서들 기준으로, 그 중에서 얼마나 실제로 검색 되었느냐?
- 를 평가하는 것
p5. 인터넷 정보검색 시스템
인터넷에 있는 대량의 정보를 수집하여 사용자의 입맛에 맞게 검색해주는 것
- 검색엔진에게 정보란?
- 관심이 있는 문서의 집합
- 문서란?
- 종류 : 신문기사, 게시판 글, 웹 문서, 상품정보
- 문서의 내용 : 제목, 본문(상품명, 상품설명)
- 문서의 메타정보 : 작성자, 작성일자(가격, 인기도)
- 문서의 형식 : 언어(한글, 영어 …), 파일형식
- 문서의 저장형태 : DB, 웹 문서, 파일서버
- 검색
- 정의 : 관심이 있는 문서들을 획득하기 위하여 하는 행동
- 단순한 질문 : ‘정보검색’이랑 관련(?) 있는 문서는?
- 복잡한 질문 : 문서의 내용에 ‘정보검색’이라는 단어가 들어가는 문서 중에 ‘홍길동’이 ‘최근 1주일’ 이내에 작성한 문서는?
- 비교 : 단순한 질문 vs. 복잡한 질문
p6. 인터넷 정보검색 시스템
- 엄청난 양의 정보
- 2025년 웹 데이터 총량?
- 전 세계적으로 웹에 존재하는 데이터는 181~182 ZB
참고) 데이터 단위
• 1 MB = 1,000 KB
• 1 GB = 1,000 MB
• 1 TB = 1,000 GB
• 1 PB = 1,000 TB
• 1 EB = 1,000 PB
• 1 ZB = 1,000 EB
- 전 세계적으로 웹에 존재하는 데이터는 181~182 ZB
- 하루 또는 매월 생성되는 웹 데이터?
- 약 0.4 ZB /일, 약 12 ZB /월
- 빅데이터
- 구글, 페이스북, 아마존 같은 글로벌 기업들은 PB 또는 EB 단위의 데이터를 저장
- 미래기술
- 인공지능(AI), 사물 인터넷(IoT), 자율 주행차 등은 막대한 양의 데이터를 끊임없이 생성하고 처리
- 2025년 웹 데이터 총량?
- 정확한 검색의 어려움
- Efficiency is not a bottleneck
- Effectiveness is bottleneck
- 낮은 정확률(Precision)
- 낮은 Ranking 성능
- “전 세계적으로 웹에 존재하는 데이터는 181~182 ZB”는 2025년 한 해 동안 생성될(data generated) 데이터의 양(projection)을 말하는 것이다. (참고: Exploding Topics – Data Generated Per Day, IDC Data Growth Report)
- “‘하루 또는 매월 생성되는 웹 데이터: 약 0.4 ZB/일, 약 12 ZB/월’” 또한 생성량(generation) 정보이며, 축적(total stored or existing data)된 전체 웹 데이터량과는 동일한 개념이 아니다. (참고: Exploding Topics – Data Generated Per Day)
- 요약하면, 두 수치는 “미래 생성될 연간/월간 데이터 양” vs “현재 존재 또는 누적된 웹 전체 데이터 저장량”을 혼동한 것이므로, 장표에서는 ‘2025년에 생성될 양’이라는 표현으로 수정하는 것이 정확하다.
p7. 인터넷 정보검색 시스템
색인
- 색인(Indexing) : 수많은 문서를 효율적으로 검색할 수 있도록 구조화 하는 과정
- 문서수집
- 웹서버, DB서버, 파일서버로부터 문서를 수집
- 문서전처리
- 문서의 형식에 따라 문서로부터 내용과 메타정보를 구분하여 텍스트 형태로 추출
- 토큰화(Tokenization) : 문서를 단어 단위로 쪼개는 과정
- 불용어 제거(Stop Word Removal) : ‘은’, ‘는’, ‘이’, ‘가’, ‘the’, ‘a’ 등 의미없는 단어 제거
- 어간추출(Stemming)/표제어 추출(Lemmatization) : 단어의 원형 복원
(예: runs → run, running → run, 먹었다 → 먹다)
- 문서저장
- 색인 및 검색 시 해당 문서의 정보를 바로 제공하기 위해 서버에 특정 형태로 저장
- 역파일 구조(Inverted Index) 생성
- 검색어가 들어왔을 때 해당 검색어가 포함된 문서를 빠르게 찾아주기 위해
각 검색어 토큰이 들어 있는 문서의 리스트를 특정한 자료구조로 구축
- 검색어가 들어왔을 때 해당 검색어가 포함된 문서를 빠르게 찾아주기 위해
- 문서수집
p8. 검색
- 역 파일 구조 탐색
- 검색키워드를 포함하는 문서의 집합을 역파일 구조로부터 가져온다.
- 필터링(filtering)
- 검색키워드를 포함하는 문서들 중에서 검색 조건에 부합되는지 여부를 판단한다.
- 정렬(sorting)
- 최종 선택된 문서들을 정확도 또는 특정 정렬조건에 따라 재정렬한다.
- 기본적으로는 색인된 순서(최근 색인된 문서 우선)로 정렬되어 있다.
- 그룹핑(grouping)
- 검색결과 문서들을 메타정보에 따라 그룹화 한다.
p9. 검색
불리언 연산(boolean) : AND, OR, NOT
자연어 질의 : 형태소 분석, 바이그램
근접 연산 : Near, Order
- 유사어 확장
- 동의어(상하위어) 확장 : 방향성 고려 필요
- 철자 오류 보정
- 다국어 확장
- 구문 확장
- 필드 지정
- 필드의 특성에 따른 추출방법 적용 필요
- 필드 간 중요도 차등 적용 필요
- 질의 보관
- 질의로그 : 사용자의 의도 파악
- 불리언(Boolean) 검색은 정보 검색에서 가장 기본적인 질의 방식으로, 논리 연산자 AND, OR, NOT을 이용한다.
- AND : 두 검색어를 모두 포함하는 문서를 검색 (교집합)
- 예:
정보 AND 검색→ 두 단어가 모두 포함된 문서만 검색- OR : 두 검색어 중 하나라도 포함하는 문서를 검색 (합집합)
- 예:
정보 OR 데이터→ 두 단어 중 하나라도 포함된 문서를 검색- NOT : 특정 검색어가 포함된 문서를 제외 (차집합)
- 예:
검색 NOT 광고→ ‘검색’은 포함하지만 ‘광고’는 포함하지 않는 문서 검색- 불리언 연산은 단순하고 직관적이지만, 검색 결과가 지나치게 많거나 적을 수 있어 정밀도(precision)와 재현율(recall)의 균형 조절이 어려운 단점이 있다.
p10. 랭킹
- Boolean
- 해당 키워드가 나오면 1, 나오지 않으면 0
- Boolean Queries 연산자: AND, OR, NOT
- 문서에 나타나는 검색키워드의 가지수(등장 여부)가 해당 문서의 가중치를 결정
- TF*IDF
- TF : 문서에 해당 키워드가 몇 번 나오는가?
- IDF : 1/DF (DF = 해당 키워드가 몇 개의 문서에 나오는가?)
- 문서에 나타나는 검색 키워드의 TF*IDF 값의 합이 해당 문서의 가중치를 결정
- 가중치 응용
- 카테고리 정보, 문서의 길이 정보 등 추가적인 정보 적용
- 두 개 이상의 검색필드에 검색 시 필드 별 가중치의 합산
검색에서 랭킹이 필요한 이유
- 검색 결과가 여러 개일 때 단순 나열하면 원하는 정보를 빠르게 찾기 어렵다.
- 따라서 관련성이 높은 문서를 상위에 배치하는 “랭킹” 과정이 필수적이다.
- 이는 사용자가 가장 유용한 정보를 먼저 확인하도록 해 검색 효율을 높여준다.
본문에 명기된 랭킹 방법의 장단점
- Boolean 검색: 단순하고 명확하지만 관련성의 강약을 구분하지 못한다.
- TF*IDF: 단어 빈도·희소성을 반영해 중요도를 계산하지만
의미나 맥락을 파악하지 못하고 문서 길이에 영향을 받을 수 있다.가중치 응용의 의미
- TF*IDF 외에 문서의 추가 속성에 가중치를 부여해 랭킹을 정교하게 만드는 방식이다.
- 예: 문서 카테고리, 제목/본문/태그처럼 필드별 중요도 차등 적용
- 여러 필드에서 검색할 때 가중치를 합산해 더 정확한 랭킹을 만들 수 있다.
p11. 색인
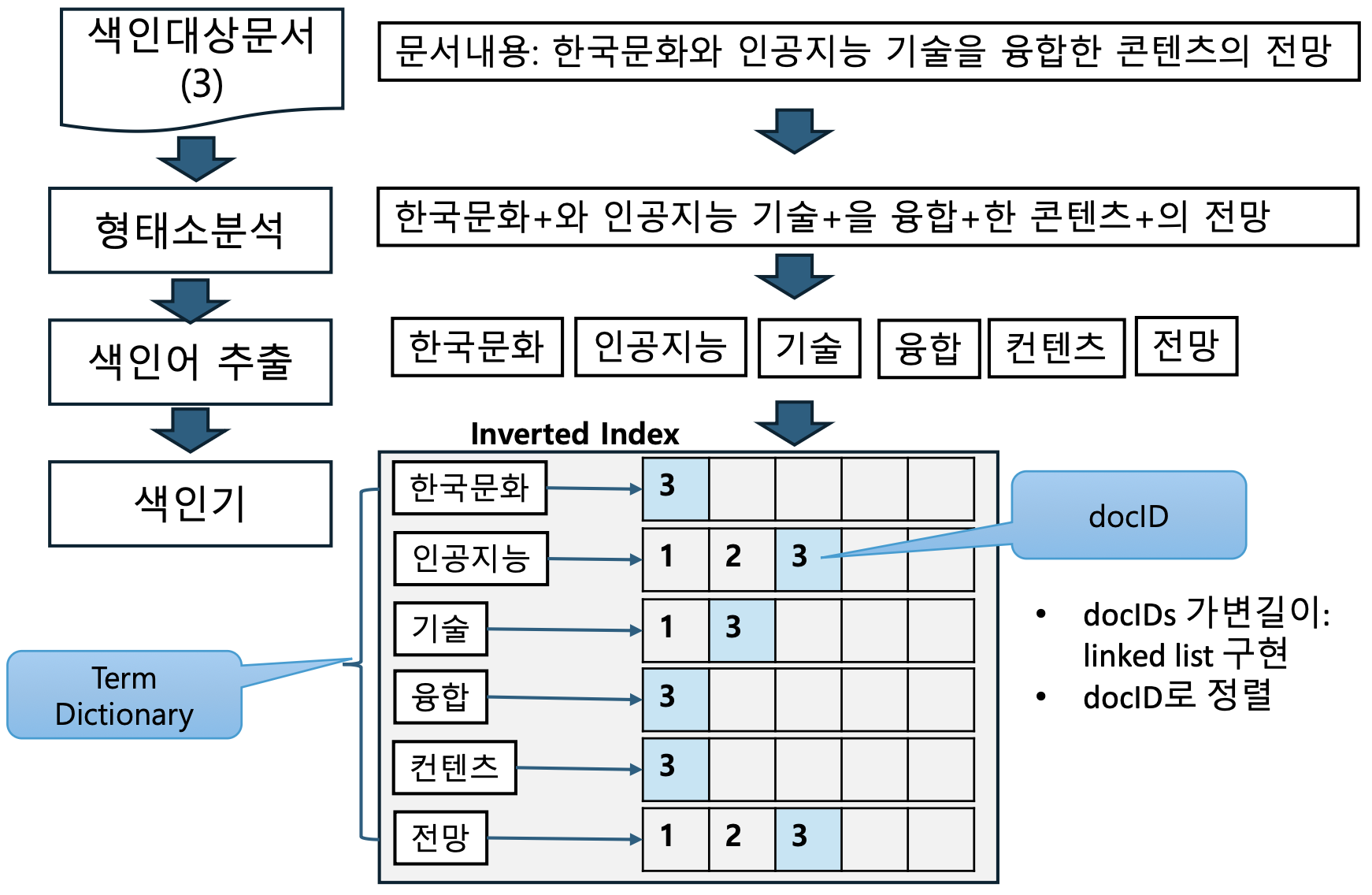
- 색인 대상 문서 예시
- Doc#1: 인공지능 기술의 발전과 일자리 전망은
- Doc#2: 인공지능 시대의 핵심 ‘합성 데이터’, 세 가지로 알아보는 장단점과 전망은?
- Doc#3: 한국문화와 인공지능 기술을 융합한 콘텐츠의 전망
- 형태소 분석
- 문장을 형태소 단위로 분해하여 의미 단위로 나눔
- 색인어 추출
- 불필요한 조사·어미 등을 제거하고 핵심 단어만 남김
- 색인기 구축
- 추출된 색인어를 이용해 역파일(Inverted Index) 생성
- 각 단어가 어떤 문서에 등장했는지를 문서 ID와 함께 기록
색인어 추출 전략의 중요성
- 어떤 기준으로 색인어를 뽑느냐에 따라 검색 품질이 크게 달라진다.
- 보통 명사만 사용하지만, 필요하면 동사·형용사 등도 포함해야 한다.
- 즉, 데이터 특성과 검색 목적에 맞는 색인어 전략을 직접 설계해야 한다.
복합어 처리
- “한국문화” 같은 복합어를 그대로만 색인하면 검색 성공률이 낮아질 수 있다.
- 이를 보완하기 위해 “한국”, “문화”, “한국문화”를 모두 색인어로 넣는 경우가 많다.
- 이렇게 하면 단일어 검색과 복합어 검색 모두 대응할 수 있다.
Inverted Index 저장 방식
- 색인어에 연결되는 문서 수는 가변적이라 linked list 구조가 기본적으로 사용된다.
- 하지만 linked list는 노드마다 메모리 할당이 발생해 성능이 저하될 수 있다.
- 실제 구현에서는 linked list 기반이되, 배열처럼 일정 크기 블록을 미리 확보하고
부족하면 2배 단위로 확장하는 방식으로 메모리 부담을 줄인다.검색 과정
- 검색은 색인의 역과정이며
형태소 분석 → 색인어 추출 → Inverted Index 조회
순서로 관련 문서를 찾는다.색인과 검색의 일관성
- 색인 시 사용한 형태소 분석·색인어 전략을 검색 시에도 동일하게 적용해야 한다.
- 둘이 다르면 검색 결과가 왜곡되거나 누락될 수 있다.
p12. 색인
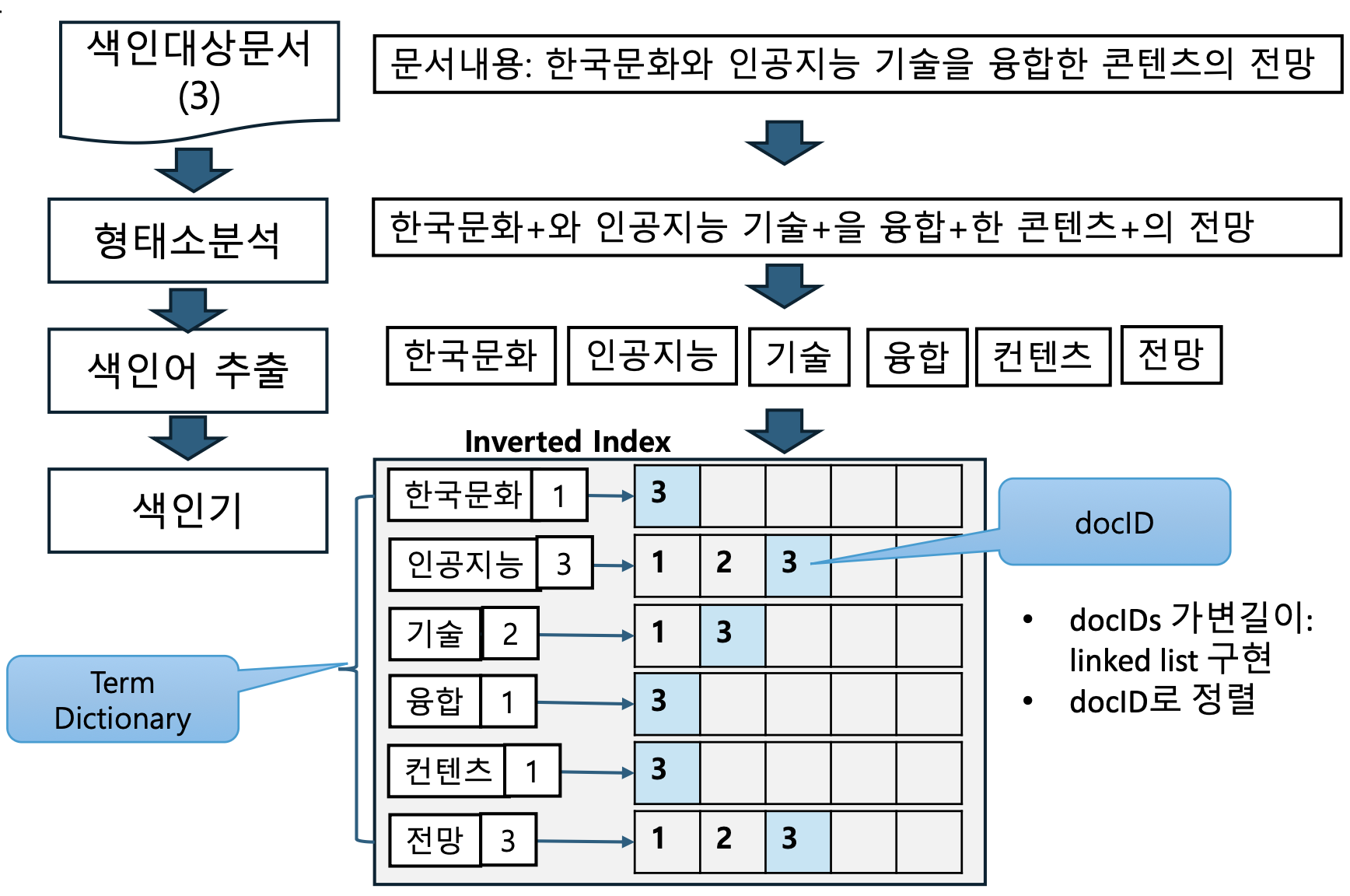
단어별 문서 수 저장의 의미
- 기존 색인에서는 단어마다 “등장 문서 목록(docID 리스트)”만 유지했다.
- 이번 장표에서는 여기에 그 단어가 등장한 전체 문서 수를 함께 저장한다.
왜 문서 수가 중요한가?
- 어떤 단어가 적은 문서에서만 등장한다면, 그 단어는 더 특별하고 구별력 있는 단어가 된다.
- 예: “인공지능” → 관련 문서 수 = 3 (Doc#1, Doc#2, Doc#3)
- 이런 정보는 그 단어의 희소성(sparsity) 을 알려주며,
검색 랭킹 산정에서 중요한 단서가 된다.랭킹 활용
- 문서 수가 적을수록 해당 단어는 특징도가 높다고 판단해
검색 결과에서 가중치를 더 높게 부여할 수 있다.
p13. 색인
- 색인 용어의 결정
- 출현빈도가 높은 용어는 부적합
- 일상적인 용어는 문서의 주제와 특별한 관련이 없음
- 출현빈도가 아주 낮은 용어는 거의 사용되지 않는 용어로 부적합
- 출현빈도가 높은 용어는 부적합
- Zipf의 법칙
- 대량의 텍스트에 사용된 어구의 빈출 순위와 빈도를 집계하면,
빈출 순위가 r번째인 빈도는 빈출 순위 첫 번째 빈도를 1/r한 값이 되는 법칙(제타 분포) - 자연어 텍스트에서 단어의 빈도가 그 순위에 반비례한다는 것을 의미
$frequency(rank \ r) \propto \frac{1}{rank \ r}$
- 순위 × 출현 빈도 = 상수
- 대량의 텍스트에 사용된 어구의 빈출 순위와 빈도를 집계하면,
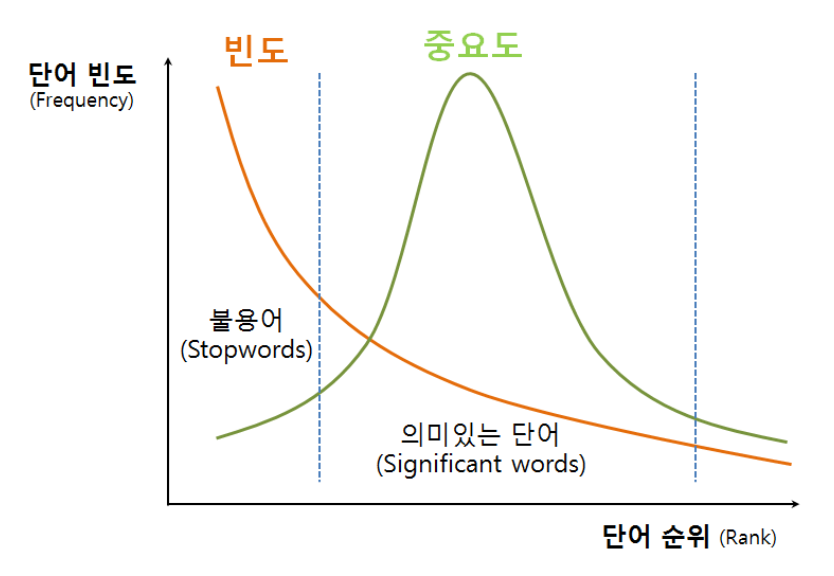
- 빈도가 너무 높은 단어는 거의 모든 문서에 등장하는 불용어와 같아, 검색에 도움이 되지 않으므로 제외한다.
- 빈도가 너무 낮은 단어는 거의 사용되지 않아 검색 결과에 의미 있는 기여를 하지 못하므로 역시 제외한다.
- 실제로는 소수의 단어가 전체 빈도의 대부분을 차지하는 경향이 있으며, 이는 Zipf의 법칙으로 설명된다.
p14. 검색
- Query Optimization
- Query 처리의 최적 순서는 ?
- 여러 개의 질의어를 포함한 Query의 경우 어떤 순서로 ?
- 가장 작은 집합에서 시작해서, 계속해서 잘라내기
“Start with smallest set, then keep cutting further”
- 가장 작은 집합에서 시작해서, 계속해서 잘라내기
- 예) Query: “인공지능” and “기술” and “전망”
Dictionary에 문서 빈도를 유지함으로써 처리 효율 도모
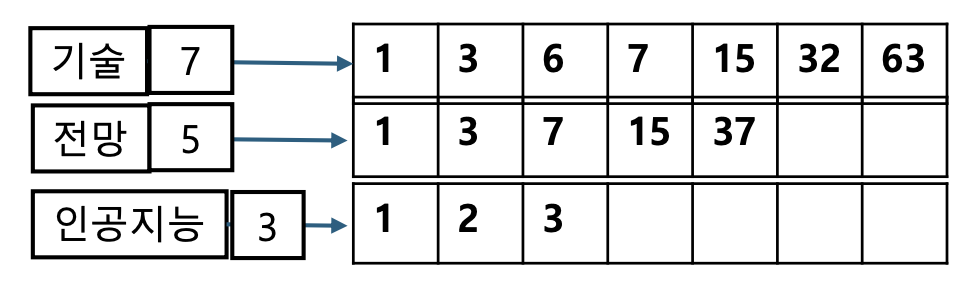
(인공지능 and 전망) and 기술
가장 작은 집합부터 시작하는 이유
- 여러 질의어가 AND 조건으로 묶이면, 각 단어는 해당 단어를 포함하는 문서 집합과 연결된다.
- 이때 문서 수가 가장 적은 집합을 먼저 사용하면 처리해야 할 후보 문서 수가 크게 줄어든다.
- 작은 집합으로 먼저 필터링하면 이후 교집합 연산 범위가 좁아져 전체 계산 비용이 급감한다.
- 결국 AND 검색의 전체 속도가 크게 향상된다.
큰 집합부터 시작했을 때의 비효율성
- 문서 수가 많은 집합부터 시작하면 초기 단계에서 너무 많은 후보를 처리해야 한다.
- 이후 교집합을 아무리 취해도, 처음에 큰 집합을 모두 탐색한 비용은 그대로 발생한다.
- 예:
- “기술” → 7개
- “전망” → 5개
- “인공지능” → 3개
- “기술”(7개)부터 시작하면 7개 전부 확인 후 다시 5개, 3개와 비교해야 한다.
- 반대로 “인공지능”(3개)부터 시작하면 처음부터 처리량이 작아 훨씬 효율적이다.
p15. Phrase Query와 위치 색인
- “합성 데이터”와 같이 Query가 구문으로 주어진 경우
- 다음의 문장들이 검색될까?
- “합성한 데이터로 학습하기”, “데이터를 합성하여 학습하였다”
- <term: docs> 형식의 색인만으로는 충분하지 않음
- Biword Index 구성하기
- 텍스트에서 연속해서 출현하는 Terms의 쌍을 phase로 색인하는 방법
- 품사 정보와 언어학적 패턴을 활용하여 biwords 추출하여 색인
- 예1) “합성하다 데이터”, “데이터 학습하다”, “데이터 합성하다”, “합성하다 학습”
- 예2) “합성 데이터”, “데이터 학습”, “데이터 합성”, “합성 학습”
- biwords를 dictionary의 term으로 사용
- 품사 정보와 언어학적 패턴을 활용하여 biwords 추출하여 색인
- 텍스트에서 연속해서 출현하는 Terms의 쌍을 phase로 색인하는 방법
- Query가 2단어보다 더 많은 단어로 되어 있다면?
- 구문을 2단어씩 쪼개서 Boolean Query 처리 → 문제는?
Biword Index의 개념
- 텍스트에서 연속된 두 단어(2-gram) 를 하나의 색인어(term)로 저장하는 방식이다.
- 예: “합성 데이터로 학습” → “합성 데이터”, “데이터로 학습” 이 biword로 추출된다.
Biword Index를 사용하는 이유
- 단일 단어 색인만으로는 “합성 데이터” 같은 정확한 구문 검색이 어렵다.
- 단어 단위 색인만 있으면 “합성”과 “데이터”가 서로 떨어져 있어도 검색될 수 있기 때문이다.
- 연속된 단어 조합을 색인하면 구문 단위 검색(phrase query) 을 정확히 처리할 수 있다.
- 하지만 3-gram, 4-gram처럼 길이를 늘리면 vocabulary가 폭발적으로 증가해 비효율적이다.
- 그래서 2-gram(Biword) 이 색인 크기와 검색 정확도 사이에서 가장 실용적인 절충안이다.
장단점
- 장점: 연속된 구문 검색을 빠르고 정확하게 지원하며, Boolean 검색보다 더 정밀하다.
- 단점: 연속된 단어 쌍 전체를 색인해야 하므로 색인 크기가 증가하고 저장 공간 부담이 커진다.
또한 긴 구문 검색은 추가 처리가 필요하다.
p16. Phrase Query와 위치 색인
- Biword 색인의 문제 및 Issue
- False positives
- Query
- “Stanford university palo alto” → “stanford university” and “university palo” and “palo alto”
- False positives
- Term Dictionary의 크기
False positives 문제
- Biword 색인은 연속된 두 단어를 모두 색인어로 저장하므로,
Query가 분해될 때 실제 구문과 관계없는 bigram이 포함될 수 있다.- 예: Query = “Stanford university palo alto”
- 분해 → “stanford university”, “university palo”, “palo alto”
- 이 중 “university palo”는 실제 문장 구조와 관계없지만 후보에 포함되어 false positives 를 만든다.
Term Dictionary의 크기 문제
- 텍스트에 등장하는 모든 bigram을 vocabulary에 넣으면
단어 종류가 많을수록 dictionary 크기가 폭발적으로 증가한다.- 저장 공간이 커지고 검색 효율도 떨어지며 관리가 어려워진다.
Dictionary 크기 해결 방안
- 모든 bigram을 넣지 않고 유의미한 bigram만 선택하는 필터링을 적용한다.
- 예: 단어 A와 B가
- 개별적으로 자주 등장하는 빈도
- 둘이 함께 등장하는 빈도
를 비교해, 함께 등장하는 비율이 충분히 높은 경우에만 bigram을 vocabulary에 추가한다.- 이렇게 하면 불필요한 bigram은 제거하고, 실제 의미 있는 구문만 색인할 수 있다.
p17. 검색
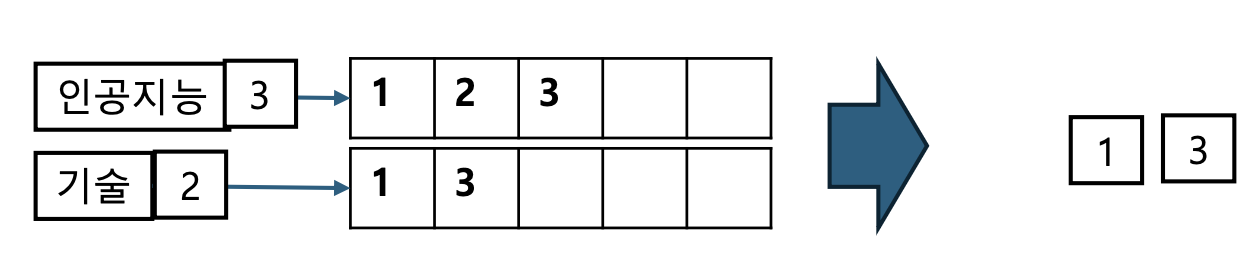
- Boolean Query Processing
- Query: “인공지능” and “기술”
- “인공지능”을 포함하고 있는 문서 리스트와 “기술”을 포함하고 있는 문서 리스트를 가져오고
- 두 문서 리스트에 공통적으로 등장하는 문서를 찾는다
- Query: “인공지능” and “기술”
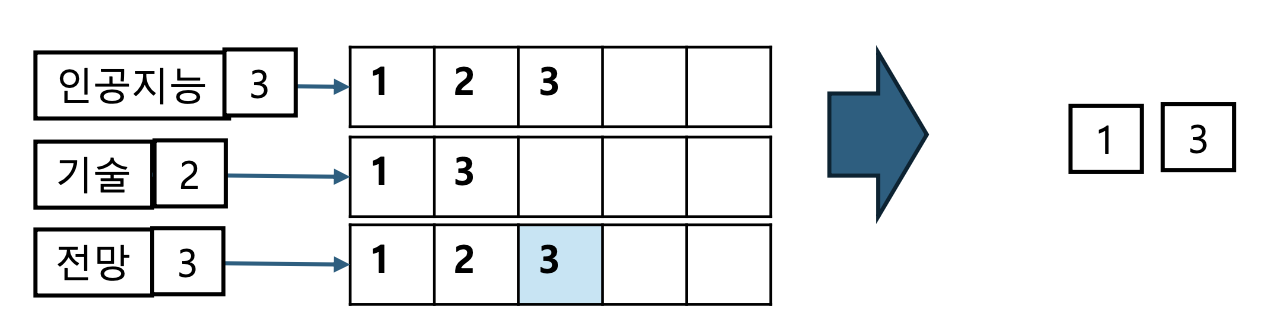
- Query: “인공지능” and “기술” and “전망”
Boolean Query의 기본 개념
- “AND, OR, NOT” 연산으로 검색 결과를 결합하는 가장 기본적인 검색 방식이다.
- 예:
- “인공지능 AND 기술” → 두 단어 모두 포함한 문서
- “인공지능 OR 기술” → 둘 중 하나라도 포함한 문서
- “인공지능 NOT 기술” → “인공지능” 포함 + “기술” 제외
교집합 연산 과정
- 각 단어는 자신의 posting list(해당 단어가 등장하는 문서 집합)를 가진다.
- AND 연산은 두 posting list의 교집합을 구하는 과정이다.
- 예:
- “인공지능” = {1, 2, 3}, “기술” = {1, 3}
- 교집합 = {1, 3}
여러 단어 Query 처리
- “인공지능 AND 기술 AND 전망”처럼 3개 이상이면
posting list를 순차적으로 교집합한다.- 이때 가장 문서 수가 적은 리스트부터 처리하는 것이 가장 효율적이다.
장점과 한계
- 장점: 구현이 단순하고 직관적이며 빠르다.
- 한계: 단순 포함 여부만 판단해 관련성(Relevance) 을 반영하지 못한다.
대규모 문서 집합에서는 교집합 연산 비용이 커질 수 있다.
p18. Phrase Query와 위치 색인
- 위치 색인(Positional Indexing): 표준적으로 사용
각 색인어에 대해 색인어의 토큰이 출현했던 위치를 색인
<Term, # of term을 포함한 문서의 수;
doc1: position1, position2, …;
doc2: position1, position2, …;
etc.>
<인공지능: 9934;
1: 7, 18, 72, 84, 231;
2: 3, 149;
3: 17, 190, 430, 544;
5: 1, 25, 39, …?> - Phrase query 프로세싱
- doc:position lists를 모아서 근접검색(Proximity Search)
- 근접검색: 단어들간의 상대적 거리나 순서를 고려하여 검색하는 방법
- doc:position lists를 모아서 근접검색(Proximity Search)
- 위치색인 크기
- 위치 색인을 하지 않는 대비 2~4배
- 원래 텍스트 크기의 35~50% 정도
옵셋(offset)이란?
- 위치 색인에서 옵셋은 문서 안에서 단어가 등장한 정확한 위치 번호를 의미한다.
- 예: “인공지능 기술의 전망”
- 인공지능 = 1
- 기술 = 2
- 전망 = 4
- 이 정보를 기록해두면 이후 구문 검색(phrase) 이나 근접 검색(proximity) 에 활용할 수 있다.
옵셋 간 근접 여부 확인
- 두 단어가 같은 문서에 등장하는 것만으로는 구문 검색을 수행할 수 없다.
- 예: “인공지능 기술” 검색
- 인공지능(1), 기술(2) → 연속하므로 매칭
- 인공지능(1), 기술(10) → 멀리 떨어져 있으므로 매칭 아님
- 따라서 검색 시 위치(옵셋)의 거리와 순서를 체크하여 정확한 구문 매칭을 수행한다.
위치 색인의 크기가 2~4배 커지는 이유
- 일반 역색인은 단어 → 문서 ID 목록만 저장한다.
- 위치 색인은 단어 → (문서 ID + 위치 정보들) 을 모두 저장해야 한다.
- 위치 정보가 추가되므로 데이터 양이 크게 늘어나 보통 2~4배 증가한다.
원래 텍스트 대비 35~50% 크기라는 의미
- 위치 색인 전체 용량을 원문 텍스트 용량과 비교하면
약 35~50% 정도의 추가 저장 공간이 필요하다는 의미이다.- 예: 원문이 1GB라면 위치 색인은 약 350MB~500MB 수준
p19. Boolean 검색
- Boolean Queries
- 문서의 포함 또는 제외 여부를 결정
- 검색 결과의 순위화 또는 그룹화에 대한 사용자 요구
- 질의와 각 문서의 근접성(proximity) 측정 필요
- 사용자에게 제시된 문서가 단일문서인지, 질의의 다양한 측면을 다루는 문서그룹인지 결정 필요
Boolean Query의 한계와 필요성
- Boolean 검색은 AND / OR / NOT 으로 문서가 “질의어를 포함하는지 여부”만 판단한다.
- 결과가 단순히 포함 / 미포함(binary)으로 나오기 때문에,
문서가 얼마나 관련성이 높은지는 알 수 없다.- 따라서 실제 검색에서는 관련성 기반 순위화(ranking) 가 반드시 필요하다.
근접성(Proximity)의 의미
- 예: 질의어가 “인공지능 기술 전망”일 때
세 단어가 문서 안에서 서로 가까이 등장할수록 실제로 주제가 더 일치한다고 본다.- Boolean 검색만 사용하면 단어가 멀리 떨어져 있어도 결과에 포함되므로,
이를 보완하기 위해 단어 간 거리(옵셋 기반)를 활용한 근접성 평가가 필요하다.단일문서 vs 문서그룹 제시 기준
- 단일문서로 제시
- 질의가 매우 구체적일 때
- Top-1 문서의 점수가 압도적으로 높을 때
- 특정 출처/작성자/도메인 등 메타데이터 조건이 명확할 때
- 문서그룹으로 제시
- 질의가 광범위하거나 모호할 때
- 상위 문서들이 서로 다른 주제·관점을 포함할 때
- 점수 차이가 작아 어느 문서 하나를 확정하기 어려울 때
20. 색인 – Scalable Index 구성
- 예시 데이터 셋: Reuters newswire (part of 1995 and 1996)
Reuters Newswire 데이터셋
- 로이터 통신사가 배포한 뉴스 기사 모음으로, 정보검색(IR)·자연어처리(NLP) 분야의 대표적인 벤치마크 데이터셋이다.
- 1995~1996년 뉴스 기사를 포함하며, 문서 분류·색인·검색 알고리즘 평가에 자주 활용된다.
- 문서는 주로 경제·금융·정치 등 시사 이슈를 다루며 문서 ID, 카테고리 라벨, 본문 텍스트로 구성된다.
- 대표적으로
Reuters-21578,RCV1이 많이 사용되며, 여기서는 그 중 1995~1996년 시기 일부 데이터셋을 의미한다.
21. 색인 – Scalable Index 구성
| symbol | statistic | value | 설명 |
|---|---|---|---|
| N | documents | 800,000 | 뉴스 문서 80만 개 |
| L | avg. # tokens per doc | 200 | 문서(뉴스) 1개당 평균 200개 토큰 |
| M | terms (= word types) | 400,000 | 고유한 term 약 40만 개 |
| avg. # bytes per token (incl. spaces/punct.) | 6 | 토큰 1개당 평균 6바이트 (공백/구두점 포함) | |
| avg. # bytes per token (without spaces/punct.) | 4.5 | 구두점 제외 시 토큰 1개당 평균 4.5바이트 | |
| avg. # bytes per term | 7.5 | term 1개당 평균 7.5바이트 | |
| non-positional postings | 100,000,000 | 위치 고려 없는 postings 약 1억 개 |
Posting이란?
- posting은
(term, docID)형태의 튜플로, 특정 단어가 어떤 문서에 등장했는지를 나타내는 최소 단위이다.- 필요하면 빈도(frequency)나 위치(position) 같은 추가 정보도 포함될 수 있다.
- 예: “인공지능”이 Doc3에 등장 →
(인공지능, Doc3)Non-positional postings란?
- 단어가 문서 어디에 등장했는지는 기록하지 않고,
(term, docID, frequency)정도만 저장하는 방식이다.- 예: “인공지능”이 Doc1에서 3번 등장 →
(인공지능, Doc1, f=3)- 위치 정보를 저장하지 않으므로 phrase query에는 한계가 있지만,
Boolean 검색이나 TF–IDF 검색에는 충분하다.왜 1억 개의 non-positional postings이 되는가?
- 전체 문서 수: 800,000
- 문서당 평균 토큰 수: 200
- 전체 토큰 수:
800,000 × 200 = 160,000,000- 같은 문서 내에서 중복되는 term들은 하나의
(term, docID)posting으로 합쳐지므로
최종 posting 수는 약 1억 개 수준이 된다.
p22. 색인 – Scalable Index 구성

의사코드의 의미
- 1~2행: 출력 파일과 dictionary(색인어 → postings list)를 초기화한다.
- 3~4행: 메모리가 허용되는 동안 토큰 스트림에서 단어를 하나씩 읽는다.
- 5~6행: 단어가 dictionary에 없으면 새로운 postings list를 생성한다.
- 7행: 이미 dictionary에 있다면 기존 postings list를 가져온다.
- 8~9행: postings list가 꽉 차면 블록 크기를 2배로 확장한다.
- 10행: postings list에 현재 단어가 등장한 문서의 docID를 추가한다.
- 11~12행: 메모리가 부족해지면 dictionary를 정렬하고 디스크에 저장한다.
- 13행: 마지막으로 출력 파일 핸들을 반환한다.
2배 확장 방식의 의미
- postings list를 linked list로만 구현하면 노드마다 메모리 할당이 발생해 비효율적이다.
- 실제 구현은 linked list 기반이지만, 내부는 배열처럼 여유 블록을 미리 확보한다.
- 공간이 부족해지면 기존 배열 크기를 2배로 증가시켜 추가 메모리를 얻는다.
- 이렇게 하면 메모리 재할당 횟수가 줄고, 동적 확장도 가능하다는 장점이 있다.
SPIMI 핵심 포인트
- SPIMI는 “메모리가 허락하는 만큼 한 번에 인덱스를 만든 뒤 디스크에 저장하는” 방식이다.
- term마다 postings list가 동적으로 확장되며, 이 과정을 반복해 대규모 인덱스를 완성한다.
p23. 색인 – distributed Indexing
- 입력 문서 집합을 splits 단위로 분할
- Master: 유휴 상태의 파서(parser) 머신에 split을 할당
- Parser: 문서를 읽고 (term, doc) 쌍을 생성
- Inverter: 모든 (term, doc) 쌍(=postings)을 수집하여 정렬한 뒤 postings list에 기록
Map-Reduce의 개요
- map: 입력 → list(k, v)
- reduce: (k, list(v)) → 출력
색인 구축 과정
- map: 문서 집합 → list(termID, docID)
- reduce: (<termID1, list(docID)>, <termID2, list(docID)>, …)
→ (postings list1, postings list2, …)
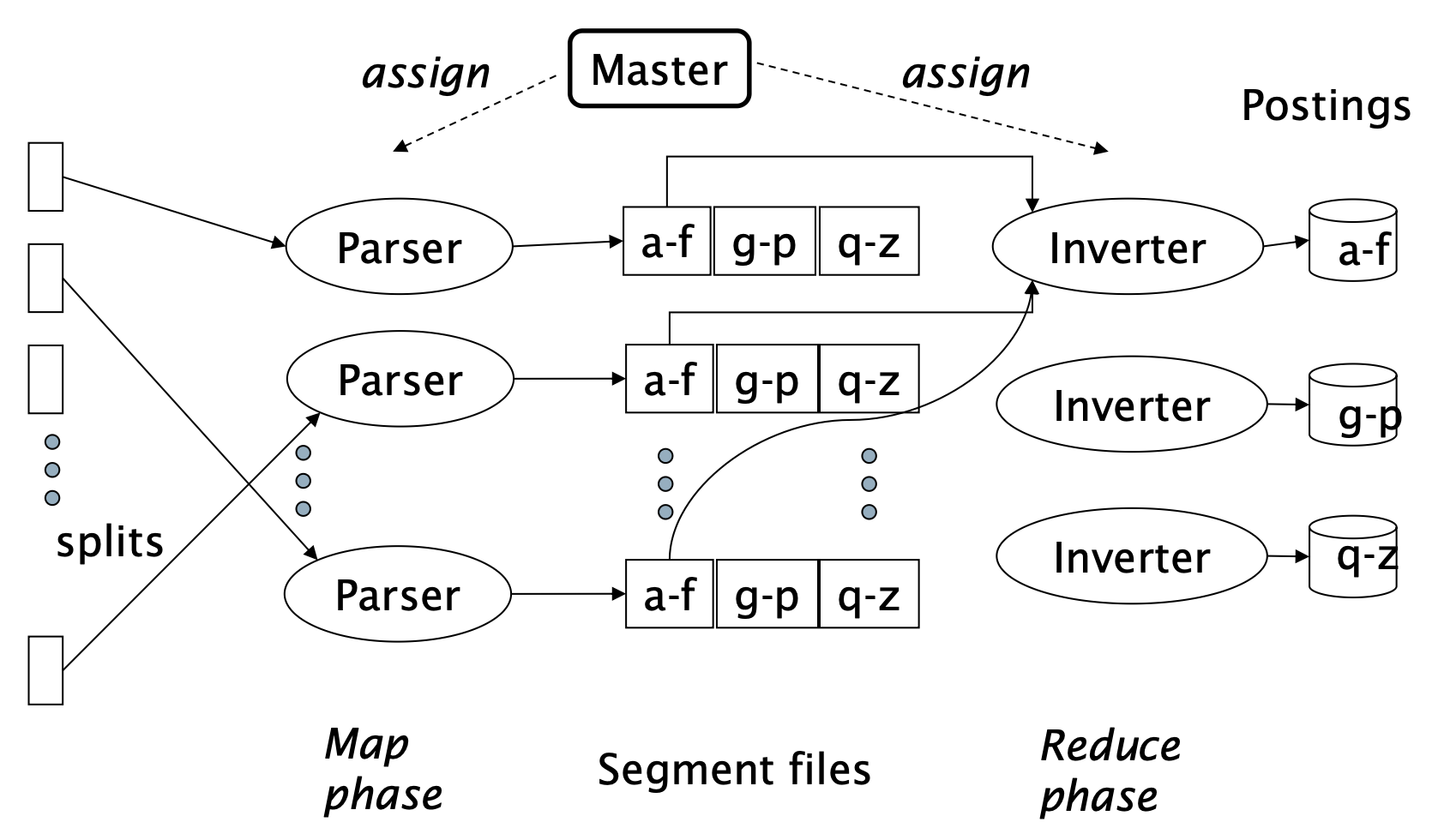
Map-Reduce란 무엇인가?
- 대규모 데이터를 분산해 처리하는 대표적 모델이다.
- Map 단계: 데이터를 분할(splits)하고 각 조각에서
(key, value)를 생성한다.- Reduce 단계: 같은 key를 모아 집계·정리한다.
- 예: 단어 빈도 세기 — map은
(단어, 1)생성, reduce는 동일 단어의 값을 합산한다.색인(distributed indexing) 과정
- 대량 문서를 여러 split으로 나눠 병렬 처리한다.
- Master가 idle 상태의 Parser 노드에게 작업을 분배한다.
- Parser는 문서를 읽어
(term, docID)쌍을 생성해 segment files에 저장한다.- 이후 Inverter가 이 데이터를 모아 정렬하고 term별로 묶어 최종 postings list를 만든다.
그림 속 구성요소 설명
- Master: 전체 문서를 관리하며 split 단위로 parser에게 작업을 할당한다.
- Parser: 문서를 받아
(term, docID)형태로 변환한다.- Segment files: term을 알파벳 구간(a–f, g–p, q–z 등)으로 나눠 저장해 샤딩 및 병렬 처리를 가능하게 한다.
- Inverter: 같은 term들의
(term, docID)를 모아 정렬·그룹화하여 postings list를 구축한다.
p24. 색인 – 동적 색인
- 정적 문서 집합 색인 대비 동적으로 변화하는 문서 색인은?
- 문서들은 시간이 지남에 따라 추가되고, 삽입됨
- 문서들은 삭제되거나 수정되기도 함
- 색인 문서의 변화는 dictionary, postings lists의 수정 요구
- dictionary에 이미 있는 용어에 대한 posting lists 업데이트
- 새로운 용어의 사전에 추가
- 간단한 접근방법
- 색인 업데이트 전략: 보조 색인 활용
- 대규모 주(Main) 색인을 유지
- 새로운 문서는 소규모 보조(Auxiliary) 색인에 추가
- 검색 시, 두 색인에서 동시에 검색하고 결과를 병합
- 문서 삭제 처리
- 삭제된 문서는 무효화 비트 벡터(invalidation bit-vector)로 표시
- 검색 결과 출력 시, 이 비트 벡터를 이용해 삭제된 문서를 필터링
- 주기적인 재색인
- 주기적으로 보조 색인을 주 색인에 통합하여 하나의 주 색인으로 재색인
- 색인 업데이트 전략: 보조 색인 활용
동적 색인의 개념
- 실제 문서 집합은 계속 변하기 때문에 색인도 이에 맞춰 업데이트되어야 한다.
- 새로운 문서는 추가되고, 오래된 문서는 삭제·수정되므로 정적인 색인은 현실에 적합하지 않다.
보조 색인(Auxiliary Index)의 역할
- 대규모 메인 색인(Main Index) 은 그대로 유지한다.
- 새로 추가되는 문서는 보조 색인(Aux Index) 에만 반영한다.
- 검색 시에는 메인 + 보조 색인을 함께 조회해 최신 결과를 구성한다.
- 주기적으로 보조 색인을 메인 색인에 합쳐 재구성(merge)한다.
삭제 처리 방식
- 삭제된 문서를 색인에서 즉시 제거하지 않고,
무효화 비트 벡터(invalidation bit-vector) 로 표시한다.- 검색 결과 출력 시 bit-vector를 참고해 삭제된 문서를 걸러낸다.
- 비트 연산(bit masking) 기반이라 매우 빠르고 효율적이다.
정리
- 메인 색인은 안정성 유지, 보조 색인은 빠른 업데이트 담당.
- 일정 주기로 두 색인을 통합해 새로운 메인 색인을 만든다.
- 이런 구조가 동적 색인을 효율적으로 유지하는 핵심 전략이다.