[빅데이터와 정보검색] 5주차 LLM의 이해와 프롬프트 엔지니어링
p2. 강의 개요
거대 언어 모델(Large Language Model, LLM)은 폭발적인 성장을 거듦…
단순히 사용자의 간단한 질문에 답변하는 어시스턴트 수준을 넘어,
최근에는 모델 스스로 생각하고 추론하는 능력까지 갖추어….
이러한 추론 능력의 발전과 함께
검색, 컴퓨터 조작, API 호출이나 코드 실행과 같은 다양한 도구를 활용하여
사용자를 대신해 복잡한 작업을 수행하고, 편의성을 크게 향상
- 주제
- LLM의 구조 이해 및 프롬프트 엔지니어링 학습
- 목표
- LLM과 트랜스포머 모델의 핵심 이해
- 검색 관련 다양한 프롬프트 기법 습득 및 활용
p3. LLM의 기본개념
- LLM(Large Language Model)
- 대규모 언어 데이터로 언어의 구조와 의미를 학습한 매우 큰 규모의 인공지능 언어모델
- 인간의 언어를 처리하고 맥락을 이해하며 텍스트 생성, 번역, 요약, 질문에 대한 답변 등 다양한 언어 관련 작업을 수행하는 모델
- 언어모델(Language Model)?
- 언어 모델은 언어 현상을 모델링하고자 단어 시퀀스(문장)에 확률을 할당하는 모델
- 언어 모델은 가장 자연스러운 단어 시퀀스를 찾아내어 생성하는 모델
- 언어를 이루는 구성 요소(글자, 형태소, 단어, 단어열 혹은 문장, 문단 등)를 문맥으로 하여
다음 구성 요소를 예측/생성하는 모델
p4. LLM의 기본개념
- 단어 시퀀스 확률
하나의 단어를 w, 단어 시퀀스를 W라고 한다면, n개의 단어가 등장하는 단어 시퀀스 W의 확률은
\[P(W) = P(w_1, w_2, w_3, w_4, w_5, \ldots, w_n)\]다음 단어의 등장 확률 : n-1개의 단어가 나열된 상태에서 n번째 단어의 확률은
\[P(w_n \mid w_1, \ldots, w_{n-1})\]전체 단어 시퀀스 W의 확률은
\[P(W) = P(w_1, w_2, w_3, w_4, w_5, \ldots, w_n) = \prod_{i=1}^{n} P(w_i \mid w_1, \ldots, w_{i-1})\] \[P(w_1, w_2, w_3, \ldots, w_n) = P(w_1) P(w_2 \mid w_1) P(w_3 \mid w_1, w_2) \cdots P(w_n \mid w_1, \ldots, w_{n-1})\] \[= \prod_{n=1}^{n} P(w_n \mid w_1, \ldots, w_{n-1})\]
단어 시퀀스 확률의 의미
\[P(W)=P(w_1,\ldots,w_n)=\prod_{i=1}^n P(w_i \mid w_1,\ldots,w_{i-1})\]
문장은 단어들의 시퀀스로 표현되며
전체 문장의 확률은 각 단어가 앞 단어들 뒤에 등장할 조건부 확률의 곱으로 정의됨카운팅 기반 확률 추정
\[P(w_n \mid w_1,\ldots,w_{n-1})=\frac{\text{Count}(w_1,\ldots,w_{n-1},w_n)}{\text{Count}(w_1,\ldots,w_{n-1})}\]
전통 언어모델은 확률을 단어 등장 빈도로 계산함희소성(sparsity) 문제
실제 데이터에서는 특정 시퀀스가 거의 등장하지 않아
위 확률이 0이 되는 경우가 매우 많음
이를 해결하기 위해 스무딩·근사화 기법이 필요N-그램 근사와 단순화
\[\text{Bigram: }P(w_n\mid w_{n-1}),\qquad \text{Trigram: }P(w_n\mid w_{n-2},w_{n-1})\]
모든 과거 단어를 조건으로 쓰면 계산량이 폭증하므로
최근 N−1개 단어만 조건으로 사용하는 N-그램 모델을 사용근사 계산의 예
\[P(w_2 \mid w_1)\approx \frac{P(w_1 \cap w_2)}{P(w_1)}\]
엄밀한 bigram 대신 단순 근사로을 사용하기도 하며
이는 계산을 크게 줄이면서도 실용적 성능을 제공함
p5. 언어모델의 발전과정
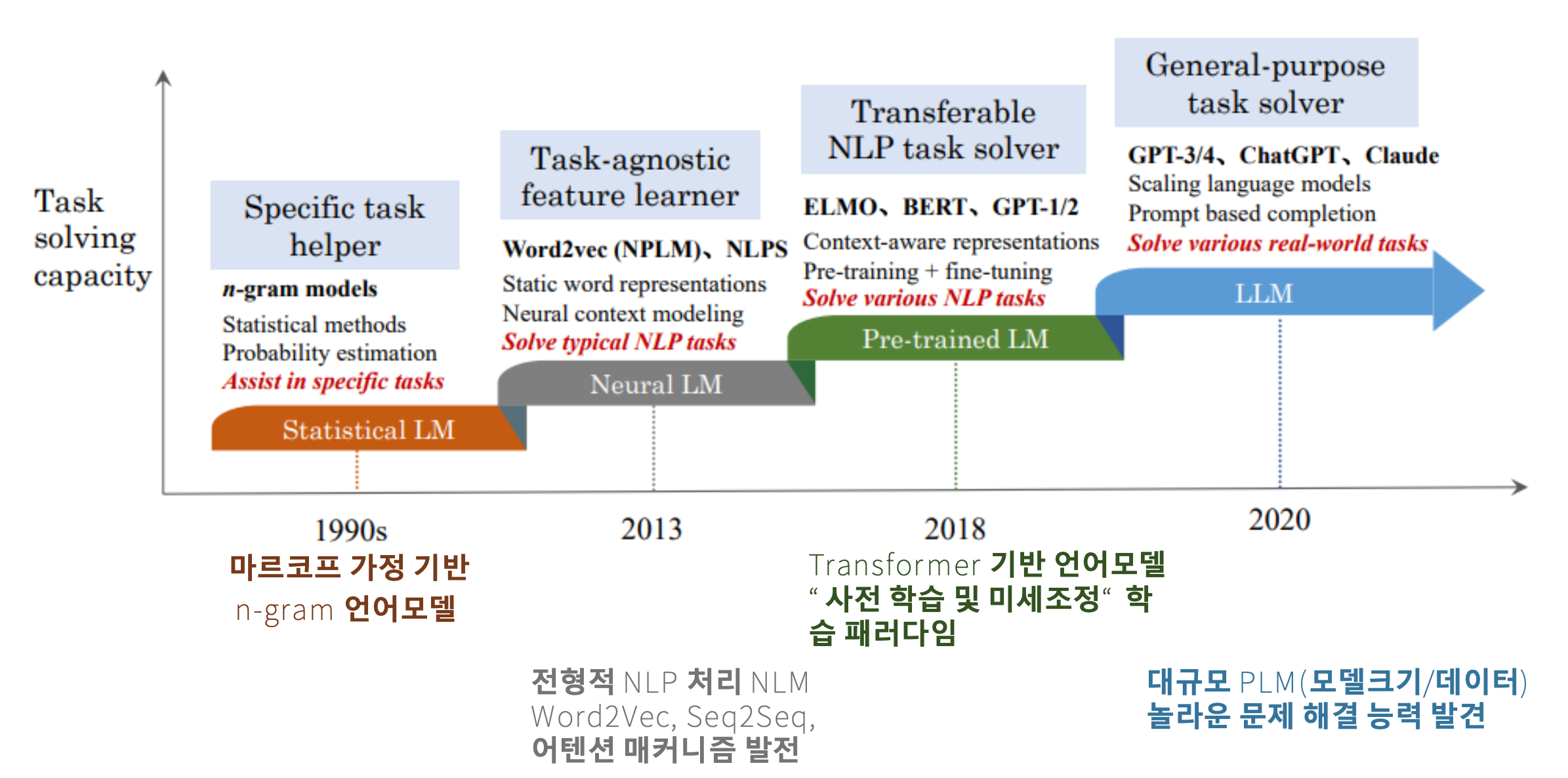
- 특정 작업 보조기 (Specific task helper)
- n-그램 모델 (n-gram models)
- 통계적 방법 (Statistical methods)
- 확률 추정 (Probability estimation)
- 특정 작업 보조 (Assist in specific tasks)
- → 통계적 언어모델 (Statistical LM)
- 작업 비의존적 특징 학습기 (Task-agnostic feature learner)
- Word2vec (NPLM), NLPS
- 정적 단어 표현 (Static word representations)
- 신경망 기반 맥락 모델링 (Neural context modeling)
- 전형적인 NLP 작업 해결 (Solve typical NLP tasks)
- → 신경망 언어모델 (Neural LM)
- 전이 가능한 NLP 작업 해결기 (Transferable NLP task solver)
- ELMO, BERT, GPT-1/2
- 맥락 인식 표현 (Context-aware representations)
- 사전 학습 + 미세조정 (Pre-training + fine-tuning)
- 다양한 NLP 작업 해결 (Solve various NLP tasks)
- → 사전학습 언어모델 (Pre-trained LM)
- 범용 작업 해결기 (General-purpose task solver)
- GPT-3/4, ChatGPT, Claude
- 대규모 언어모델 (Scaling language models)
- 프롬프트 기반 완성 (Prompt based completion)
- 다양한 실제 작업 해결 (Solve various real-world tasks)
- → 대규모 언어모델 (LLM)
- 연대표
- 1990년대: 마르코프 가정 기반 n-그램 언어모델 (n-gram LM)
- 2013년: 전형적 NLP 처리 (NLM, Word2Vec, Seq2Seq, 어텐션 매커니즘 발전)
- 2018년: 트랜스포머 기반 언어모델 (Transformer-based LM)
- “사전 학습 및 미세조정(Pre-training & Fine-tuning)” 학습 패러다임
- 2020년: 대규모 PLM(Pre-trained Language Model, 모델 크기/데이터)
- 놀라운 문제 해결 능력 발견
통계적 언어모델 (Statistical LM, n-gram)
1990년대의 전형적 언어모델로 마르코프 가정에 따라 직전 n−1개의 단어만 보고 다음 단어를 예측함
주 용도는 문자·단어 예측, 음성 통사 태깅 등 특정 Task에 제한됨
“바로 앞의 일정 개수 단어만 사용”하므로 긴 맥락 반영이 어려움신경망 언어모델 (Neural LM)
2013년경 Word2Vec, Seq2Seq, RNN, Attention이 등장하며 단어를 벡터로 임베딩하고 문맥 정보를 학습하기 시작함
정적 단어 임베딩(Word2Vec)과 문맥 기반 표현이 결합되어 Task-agnostic feature learner로 발전
Task는 다양해졌지만 여전히 앱 특화 적용(예: 번역 등)이 많았음사전학습 언어모델 (Pre-trained LM)
2018년 Transformer 기반(BERT, GPT-1/2, ELMo 등) 모델이 등장하며
“사전학습 + 미세조정(fine-tuning)” 패러다임이 확립됨
하나의 거대 LM을 학습시켜 여러 작업에 전이하여 활용 가능해졌음
BERT 공개 이후 NLP 연구 전체가 큰 전환점을 맞음대규모 언어모델 (LLM)
2020년 이후 GPT-3/4, ChatGPT, Claude 등이 등장하면서
범용 작업 해결기(General-purpose task solver)로 진화
단순 NLP를 넘어 검색, 요약, 코드, 번역, 복잡한 의사결정까지 수행
데이터·모델 크기의 폭발적 증가가 능력 향상의 핵심 요인정리
n-gram → Neural LM → Pre-trained LM → LLM으로 발전하며
“국소적 예측 → 맥락 반영 → 전이학습 → 범용 지능”으로 확장됨
각 단계는 이전 모델의 한계를 해결하며 새로운 패러다임을 형성
LLM은 검색·코드 실행·추론·의사결정 등 실세계 문제 해결 능력을 보여줌
p6. 트랜스포머 모델의 이해와 활용
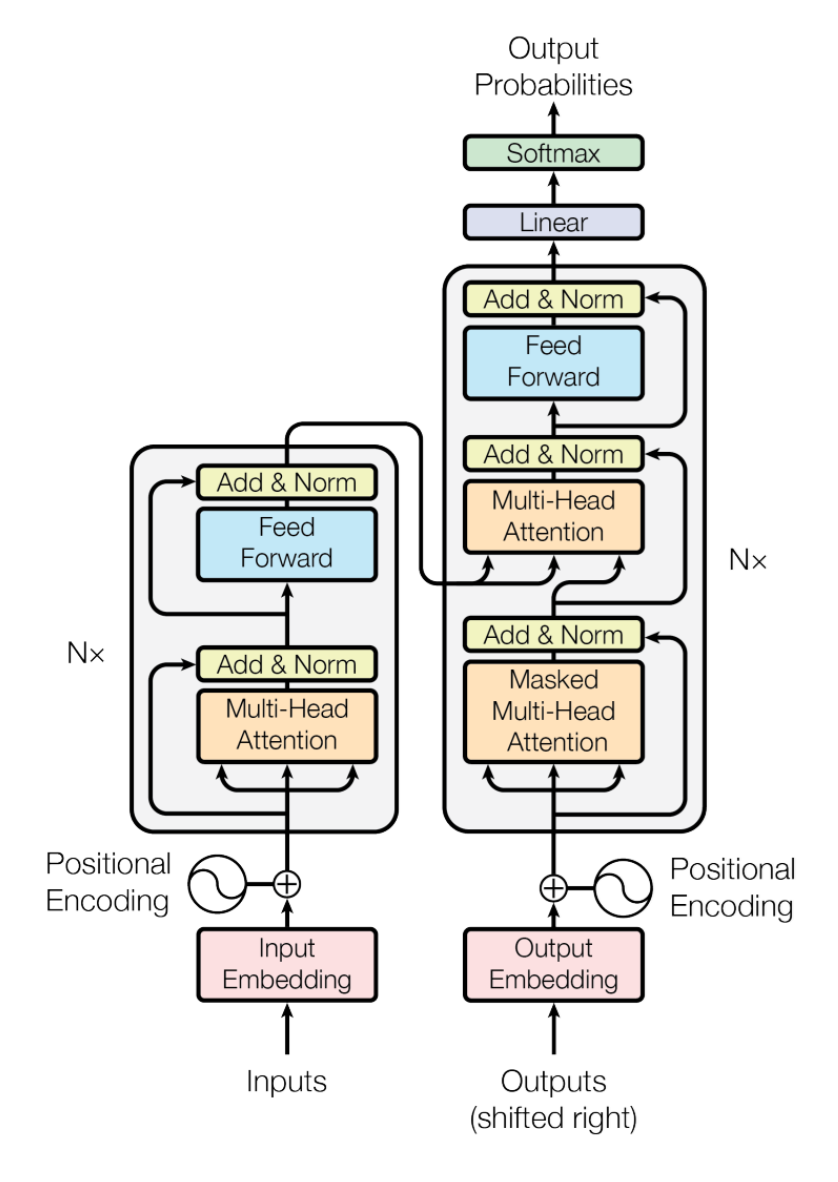
- 병렬처리와 모델 확장 가능한 트랜스포머
- Encoder와 Decoder 연결 구조
- Multi-Head Attention Mechanism으로 병렬처리와 장기 의존성 문제 해결
- 다수의 Encoder 층과 Decoder 층 연결로 모델 용량 확장
- Auto-Regressive Decoding Model
- 최종 비용/손실함수는 softmax 분류기 함수에 대한 교차 엔트로피 (Cross Entropy)를 사용
- 언어모델 매개변수 확장(수백억 또는 수천억 개) → 다양한 LLM 개발의 백본!
Encoder-Decoder 구조
트랜스포머는 Seq-to-Seq(Sequence-to-Sequence) 모델의 확장으로, 입력(소스 언어)을 인코더가 처리하고 출력(타겟 언어)을 디코더가 생성함
인코더는 입력 문장의 맥락(Context Vector)을 벡터로 압축하고, 디코더는 이를 참조해 출력 문장을 점진적으로 생성함
“source → target” 구조가 명확함Multi-Head Attention의 역할
RNN의 한계였던 장기 의존성 문제를 해결하기 위해 도입됨
여러 개의 Attention Head를 병렬로 두어 문맥을 다양한 관점에서 해석할 수 있게 함
이를 통해 병렬 연산이 가능해져 학습 속도가 크게 향상됨모델 용량 확장 (스택 구조)
인코더와 디코더는 단일 블록이 아니라 동일한 층을 여러 번 쌓아 구성됨(논문 기준 6층)
층이 깊어질수록 더 복잡한 문맥과 의미를 학습 가능
“모델 용량 확장”은 결국 매개변수(parameter) 수 증가와 직결되며, 이는 LLM 발전의 핵심 요소Feed Forward와 비선형 변환
각 Attention 블록 뒤에는 비선형 변환(Non-linear projection)을 포함한 Feed Forward 네트워크가 위치
단순한 선형 변환으로는 잡히지 않는 복잡한 패턴을 학습하는 데 필수적인 구조Cross Attention과 Auto-Regressive Decoding
디코더는 자체 입력(이전 단어) + 인코더 출력(Context Vector)을 함께 참조함
이때 인코더의 출력이 디코더 Attention에 연결되는 부분을 Cross Attention이라고 부름
디코더 출력은 Auto-Regressive 방식으로 한 단어씩 순차적으로 생성됨언어모델 매개변수 확장의 의미
수백억~수천억 개의 매개변수로 확장되면서, 트랜스포머는 단순 번역이나 요약을 넘어 범용 LLM 개발의 백본(backbone)으로 자리 잡음
“Source language → Target language” 구조를 기반으로 다양한 작업에 적용할 수 있는 토대가 마련됨
p7. 트랜스포머 모델
동작 과정
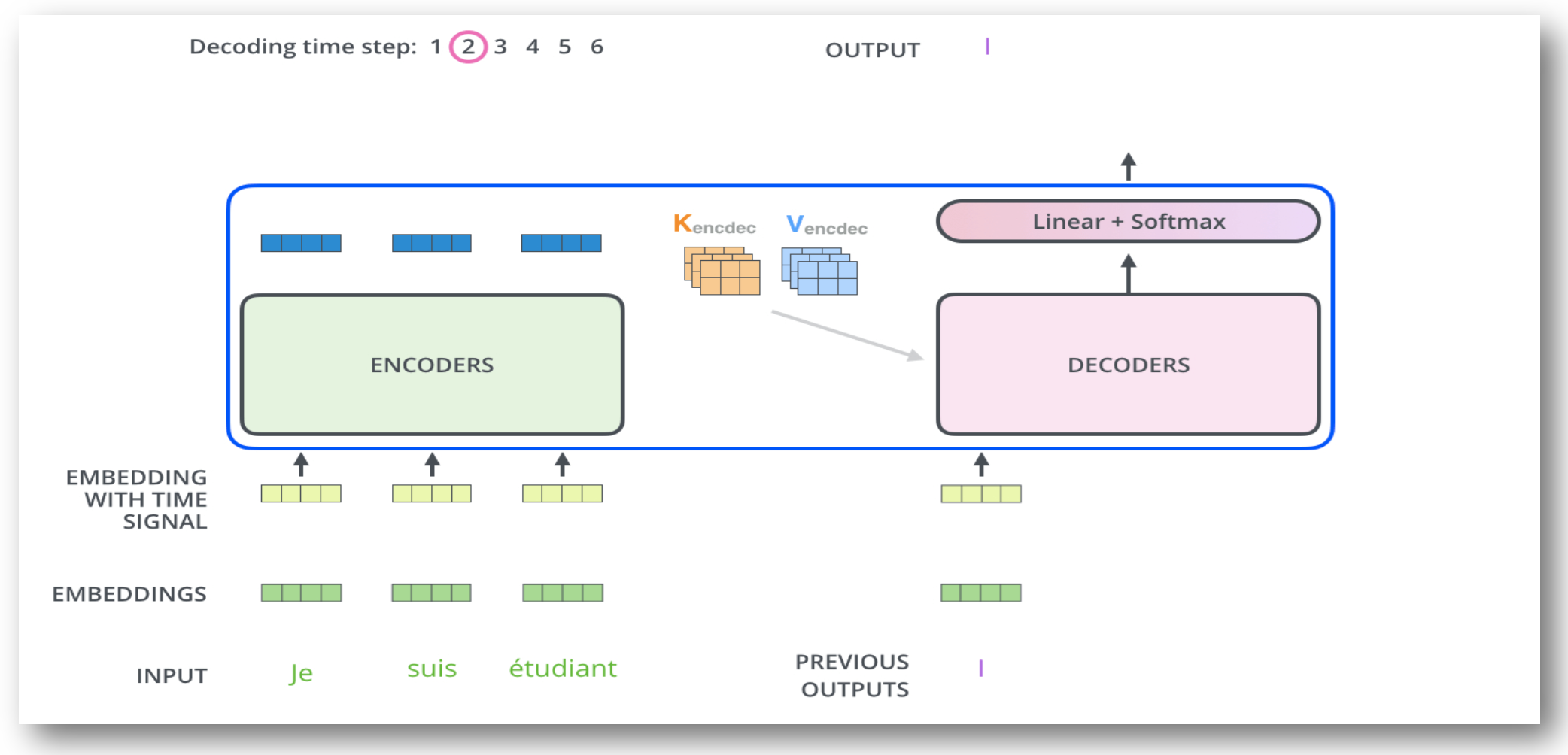
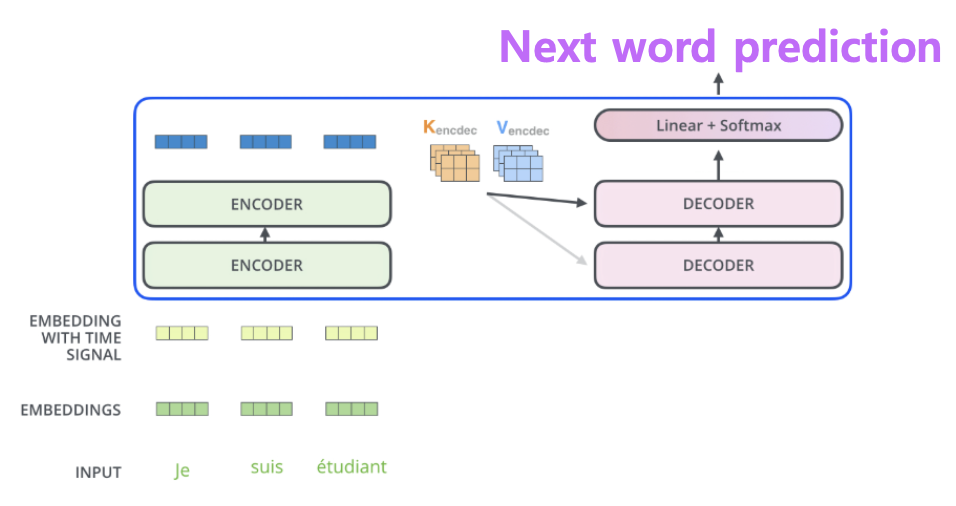
트랜스포머 인코더(Encoder)의 역할
입력 문장(예: Je suis étudiant)은 먼저 임베딩(embedding)과 위치 정보(positional encoding)가 더해져 인코더로 전달됨
인코더는 입력 문장의 모든 단어를 동시에 처리하며, 문맥(Context) 정보를 풍부하게 담은 표현 벡터를 생성함
이렇게 얻은 표현은 이후 디코더가 참조할 수 있도록 Key(K)와 Value(V) 벡터로 변환됨트랜스포머 디코더(Decoder)의 역할
디코더는 이미 생성된 단어(Previous outputs)를 참고하면서 다음 단어를 예측함
인코더에서 전달된 K, V 벡터와 디코더 내부의 Query(Q)를 통해 어텐션(Attention) 연산을 수행함
이를 통해 입력 문장의 중요한 부분에 집중하면서 출력 단어를 순차적으로 생성함Auto-Regressive 방식과 Softmax 출력
디코더는 한 번에 전체 문장을 내놓지 않고, 자동 회귀(Auto-regressive) 방식으로 단어를 하나씩 생성함
예를 들어, 현재 “Je suis étudiant”라는 입력에 대해 첫 출력이 “I”라면, 다음 출력은 이 단어를 포함한 맥락을 바탕으로 예측함
최종적으로 디코더의 출력은 Linear 층을 거쳐 Softmax 분류기에서 확률 분포로 변환되어 가장 적합한 단어가 선택됨핵심 개념 요약
인코더는 입력 문장의 맥락을 벡터로 압축하고
디코더는 이를 바탕으로 출력 문장을 순차적으로 생성함
이 과정은 번역, 요약, 질의응답 등 다양한 NLP 태스크에서 공통적으로 적용됨
p8. 트랜스포머 모델
모델의 구조
- 입력 임베딩 (Input Embedding)
- 입력 시퀀스(문장)의 각 단어를 벡터로 변환
- 포지셔널 인코딩 (Positional Encoding)
- 단어의 순서 정보를 벡터에 추가
- 트랜스포머는 순환 구조가 없으므로, 단어의 위치 정보를 별도로 주입함.
- 인코더 (Encoder)
- 입력 시퀀스의 정보를 압축하여 문맥 정보를 담은 벡터(Context Vector) 생성
- 여러 개의 동일한 인코더 레이어를 쌓아서 구성(논문에서는 6개)
인코더의 최종 출력은 각 디코더 레이어의 Encoder-Decoder Attention 블록으로 연결
- 디코더 (Decoder)
- 인코더의 출력(Context Vector)과 이전 스텝에서 생성된 출력 단어를 입력받아 다음 단어를 예측
- 여러 개의 동일한 디코더 레이어를 쌓아서 구성(논문에서는 6개).
- 선형 변환 및 소프트맥스 (Linear & Softmax)
- 디코더의 최종 출력 벡터를 기반으로 다음 단어의 확률 분포를 계산
입력 임베딩과 위치 정보
트랜스포머는 순환 구조(RNN)가 없기 때문에 단어의 순서를 직접적으로 알 수 없음
이를 해결하기 위해 각 단어를 벡터로 임베딩한 후, 추가적으로 포지셔널 인코딩(Positional Encoding)을 더해 단어의 순서 정보를 반영함
이 과정을 통해 모델은 단어의 의미뿐만 아니라 문장 내 위치까지 학습할 수 있음인코더의 역할
인코더는 입력 시퀀스 전체를 받아 문맥을 담은 컨텍스트 벡터(Context Vector)를 생성함
여러 층의 인코더 레이어를 쌓아 깊은 문맥 표현을 학습하며, 각 층에는 멀티헤드 어텐션과 피드포워드 네트워크가 포함됨
인코더의 최종 출력은 디코더와 연결되어 번역, 요약 등의 작업에서 핵심적인 단서가 됨디코더의 역할
디코더는 인코더의 출력(Context Vector)과 이전에 생성된 단어를 입력으로 받아 다음 단어를 예측함
마스크드 어텐션(Masked Attention)을 사용하여 아직 생성되지 않은 미래 단어는 참조하지 못하도록 함
이렇게 함으로써 자동회귀(Auto-Regressive) 방식으로 문장을 한 단어씩 순차적으로 생성함출력과 확률 분포
디코더의 최종 출력은 선형 변환(Linear)을 거친 뒤 소프트맥스(Softmax)에 입력되어
가능한 모든 단어에 대한 확률 분포로 변환됨
이 확률 분포에서 가장 높은 값을 가진 단어가 실제 출력으로 선택됨전체 구조의 의미
트랜스포머는 입력 임베딩 + 위치 정보 → 인코더 → 디코더 → 확률 분포라는 구조를 가짐
이를 통해 병렬처리와 장기 의존성 학습이 가능해짐
이 아키텍처는 번역, 질의응답, 요약, 텍스트 생성 등 현대 LLM의 기본 골격을 형성함
p9. 트랜스포머 모델
- Input Embedding & Positional Encoding
- 텍스트 시퀀스는 Tokenizer를 통해 토큰으로 분리 후, Vocab Dictionary 내 토큰의 인덱스 ID로 표현하고,
- 각 토큰은 임베딩 모델을 사용하여 고정크기($d_{model}$)의 벡터로 임베딩 (논문에서는 $d_{model}=512$)
- 각 토큰의 임베딩 벡터와 토큰의 위치를 인코딩한 벡터를 더하여 입력 벡터를 구성
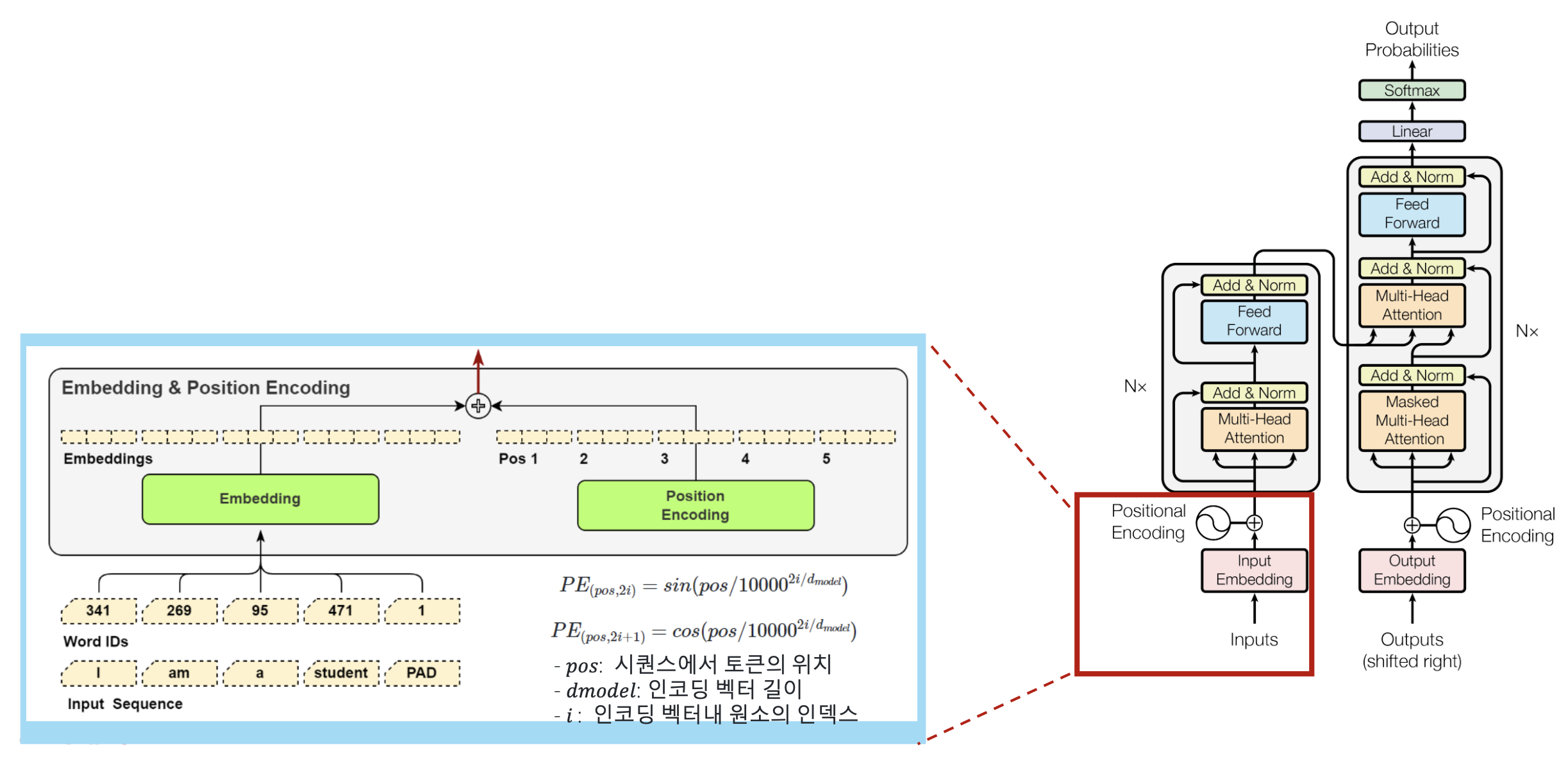
토큰화와 임베딩
입력 문장은 먼저 Tokenizer를 통해 토큰 단위로 분리됨
각 토큰은 Vocab Dictionary에 의해 정수 ID로 변환되고, 이 ID는 다시 임베딩 벡터로 매핑됨
임베딩 벡터의 차원은 고정 크기 $d_{model}$이며, 논문에서는 $d_{model} = 512$로 설정됨포지셔널 인코딩(Positional Encoding)
\[PE_{(pos, 2i)} = \sin \left( \frac{pos}{10000^{2i/d_{model}}} \right)\] \[PE_{(pos, 2i+1)} = \cos \left( \frac{pos}{10000^{2i/d_{model}}} \right)\]
트랜스포머는 RNN과 달리 순차적 구조가 없기 때문에 단어의 위치 정보를 직접 주입해야 함
위치 인코딩은 사인(sin), 코사인(cos) 함수를 이용해 각 위치에 대한 주기적 패턴을 만들어냄여기서 $pos$는 시퀀스 내 토큰의 위치, $i$는 벡터 내 차원의 인덱스를 의미함
입력 벡터 구성
최종 입력 벡터는 임베딩 벡터 + 포지셔널 인코딩 벡터의 합으로 계산됨
이렇게 구성된 입력은 이후 인코더로 전달되어 문맥적 의미를 학습할 수 있게 됨핵심 의의
임베딩은 단어의 의미 표현, 포지셔널 인코딩은 단어의 순서 정보를 담음
두 요소가 결합함으로써 문장의 구조적 의미가 모델에 전달됨
p10. 트랜스포머 모델
- Positional encoding의 조건
- 각 Time Step (문장 내 단어의 위치) 에 대해 고유한 인코딩을 출력해야 함
- 두 Time Step 사이의 거리는 문장의 길이와 상관없이 일관되어야 함
- 값들은 문장의 길이와 상관없이 Bounded 되어야 함
- 논문에서의 설정:
$d_{model} = 512 \quad (i.e., i \in [0, 255])$
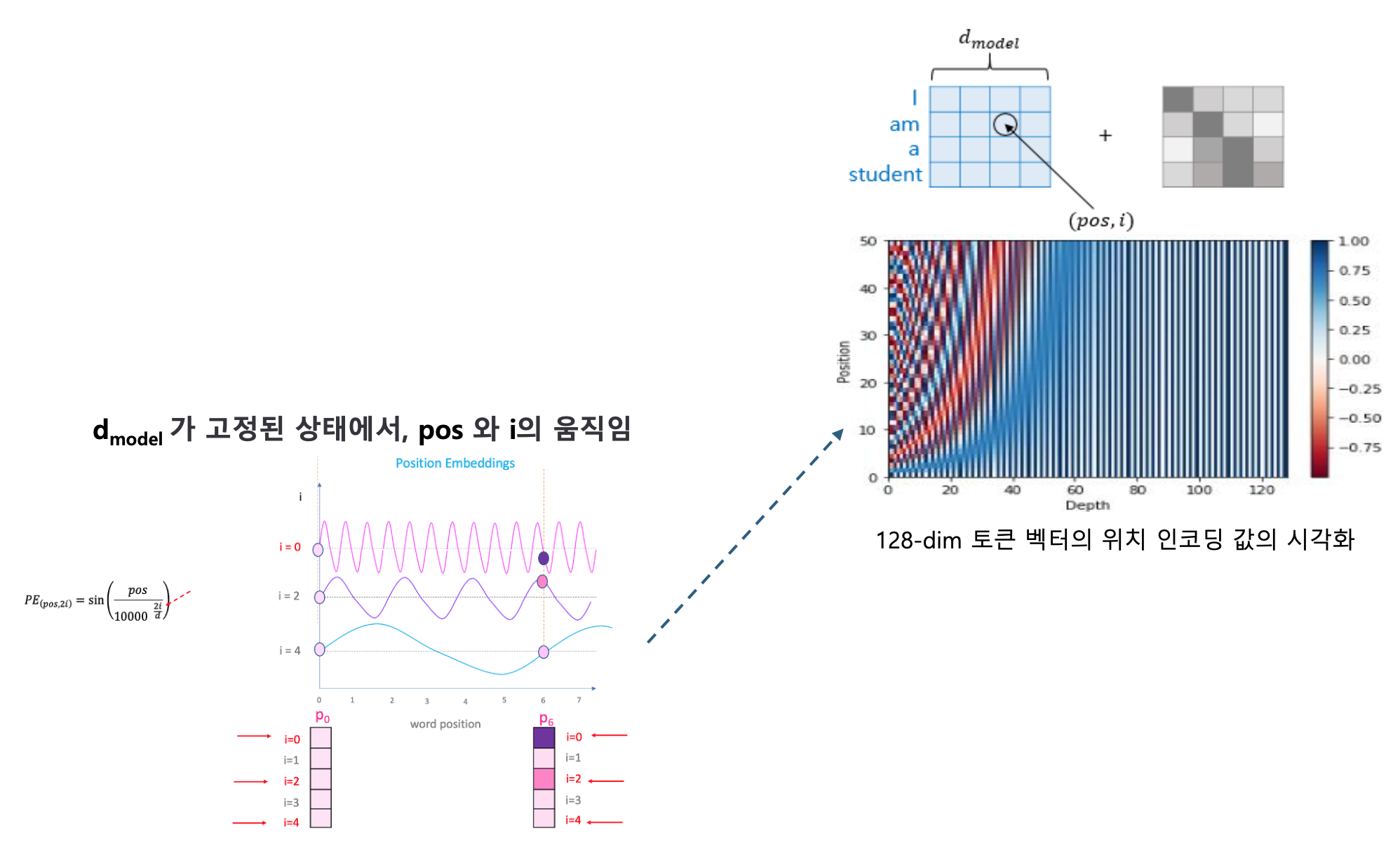
Positional Encoding의 필요성
트랜스포머는 RNN이나 CNN처럼 위치 정보를 구조적으로 반영하지 않음
따라서 단어의 순서 정보를 주입하기 위해 Positional Encoding이 필요함
이 인코딩은 sin, cos 기반 주기 신호를 사용해 단어의 상대적 위치를 학습 가능하게 함Positional Encoding의 조건
각 Time Step마다 고유한 인코딩을 출력해야 함
두 Time Step 간 거리(차이)는 문장 길이와 무관하게 유지되어야 함
인코딩 값은 문장 길이와 관계없이 bounded(제한된 범위) 내에 있어야 함구체적 정의
\[PE_{(pos, 2i)}=\sin\left(\frac{pos}{10000^{2i/d_{model}}}\right)\] \[PE_{(pos, 2i+1)}=\cos\left(\frac{pos}{10000^{2i/d_{model}}}\right)\]
위치 $pos$, 차원 인덱스 $i$, 임베딩 크기 $d_{model}$에 대해 아래와 같이 정의됨논문 기준 $d_{model}=512$이며 $i\in[0,255]$
로터리 포지셔닝(RoPE)
기존 sin/cos 인코딩을 확장한 방식으로, 내적 연산 단계에서 회전 행렬을 적용해 위치 정보를 반영
상대적 위치 정보를 자연스럽게 표현할 수 있고 매우 긴 시퀀스에서도 안정적
LLaMA 등 최신 LLM들이 주로 채택하는 방식긴 Context 처리와 RAG에서의 역할
RAG처럼 수천·수만 토큰을 처리해야 하는 시스템에서는 더 정교한 위치 표현이 필요
RoPE 등은 긴 context에서도 위치 정보를 안정적으로 유지하여
검색 문서와 질의 간 alignment(정렬)을 정확하게 수행하도록 도움의의
Positional Encoding은 단순한 “위치 태그”가 아니라
순서·간격을 연속적으로 반영하는 신호로서
LLM이 긴 문맥, 검색 증강(RAG), 대화 지속성을 처리하는 데 핵심적인 역할을 수행함
p11. 트랜스포머 모델
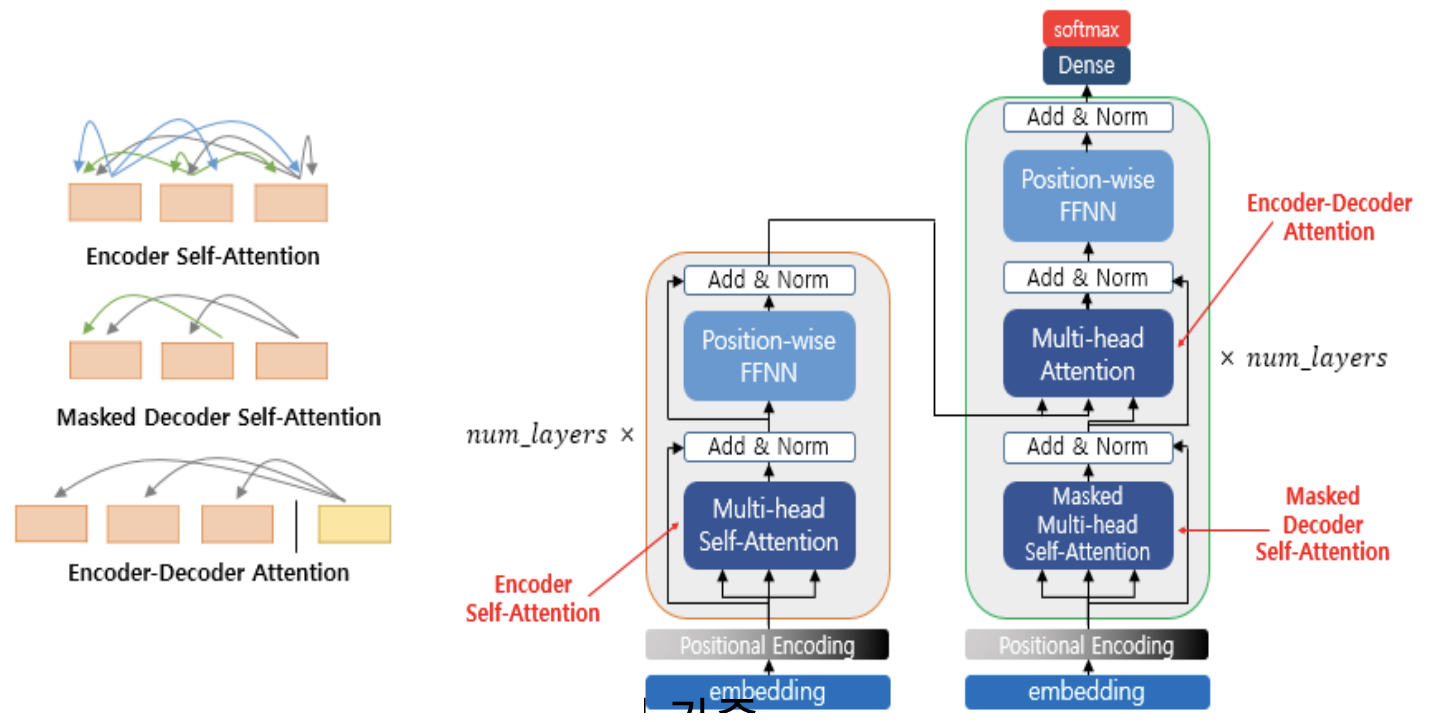
- Transformer의 Attention
- Encoder의 Self-Attention
- Decoder의 Masked Self-Attention
- Decoder의 Encoder-Decoder Attention
- Attention?
- 입력 문장에서 중요한 부분에 집중하는 메커니즘
입력문장의 각 단어 간 연관성을 수치화하고, 문장 내에서 중요한 단어들에게 가중치를 부여
- Self-Attention의 장점
- 문장 내 단어 간 관계를 계산하여 의미적 연관성을 반영
- 문장 내 모든 단어 간 관계를 한 번에 학습
- 병렬 연산 가능 → 연산 속도 향상
- 긴 문장에서도 효율적으로 문맥을 유지
p12. 트랜스포머 모델
Multi-Head Attention Block의 내부 구조
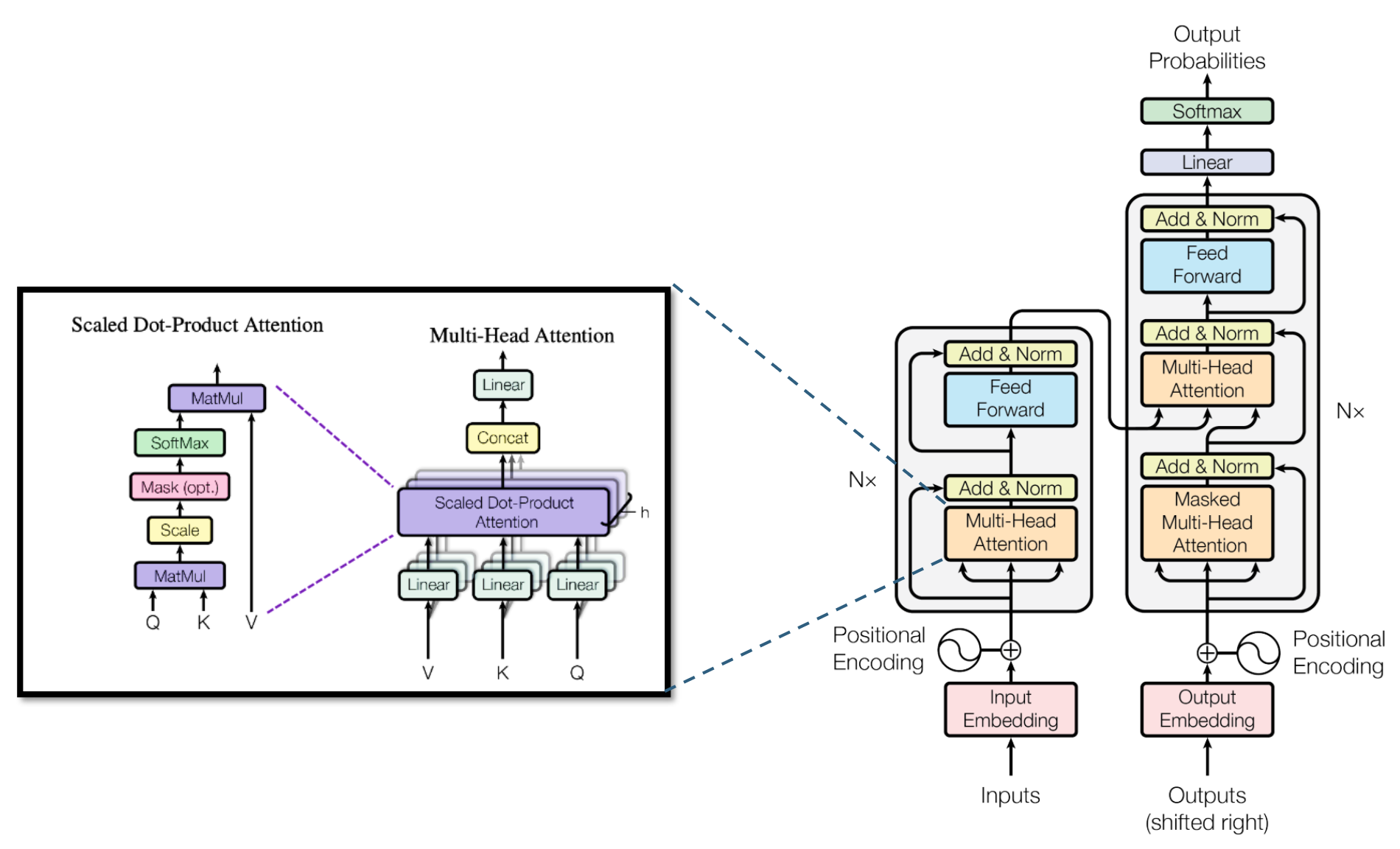
Scaled Dot-Product Attention의 핵심 원리
Query(Q)와 Key(K)의 내적을 통해 단어 간 유사도를 계산함
차원이 커질수록 내적 값이 비정상적으로 커지므로 $\sqrt{d_k}$로 나누어 스케일링
필요 시 Mask를 적용하여 미래 단어를 보지 못하게 하거나 padding 토큰의 영향 제거
Softmax로 가중치 분포를 만든 뒤 Value(V)에 곱해 최종 Attention 출력을 생성Multi-Head Attention의 동작 방식
Q, K, V를 여러 head로 분리해 병렬적으로 Attention을 수행
각 head는 다른 표현 공간에서 정보를 해석하므로 다양한 관점의 문맥 정보를 학습
모든 head의 출력을 Concatenate 후 Linear 변환하여 최종 출력 벡터 생성구조적 특징과 장점
다양한 의미적 관계를 동시에 학습할 수 있어 표현력이 높음
긴 문장에서 단어 간 복잡한 의존성을 정교하게 반영
병렬 연산이 가능하여 계산 효율과 학습 속도 모두 향상됨
p13. 트랜스포머 모델
- Multi-Head Self-Attention
- Self-Attention은 입력 시퀀스의 모든 단어를 다른 모든 단어와 연결하여 상호 연관성을 구하는데,
- Scaled Dot-Product Attention 알고리즘 적용하여 단어간 Attention Score를 계산하되
- Query, Key, Value 벡터를 h개 Head로 분할하여 h개의 AttentionScore를 구한 후 결합(Concat)하여 어텐션 가중치를 구한다. 그리고 어텐션 가중치를 Value 벡터에 적용하여 최종 Attention Value 벡터를 도출함
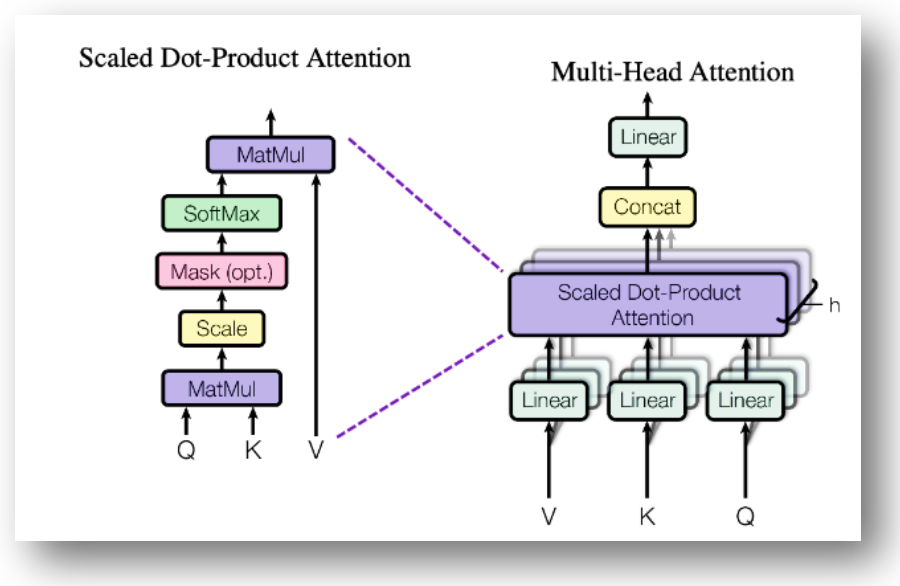
- Q(Query) : 입력시퀀스에서 관련된 부분을 찾으려고 하는 소스 벡터
- K(Key) : 관계의 연관도를 찾기 위해 쿼리와 비교하는 대상 벡터
- V(Value) : 특정 Key에 해당하는 입력 시퀀스의 정보로 가중치를 구하는데 사용

- 입력 문장 내의 단어들끼리 상호 연관성을 구함으로써 “making”이 “difficult”과 가장 연관이 많이 되고 있음을 알아냄
p14. 트랜스포머 모델
- Multi-Head Attention ?
- 단일 Attention만 사용하면 하나의 관계만 학습
- 여러 개의 Attention Head를 사용하여 다양한 관계 및 언어 현상/패턴을 학습
- h개의 서로 다른 Attention을 적용한 후 Concat
- 효과
- 여러 관점에서 단어 간 관계 학습 → 더 정밀한 문맥 이해
- 병렬 연산 가능 → 학습 속도 증가
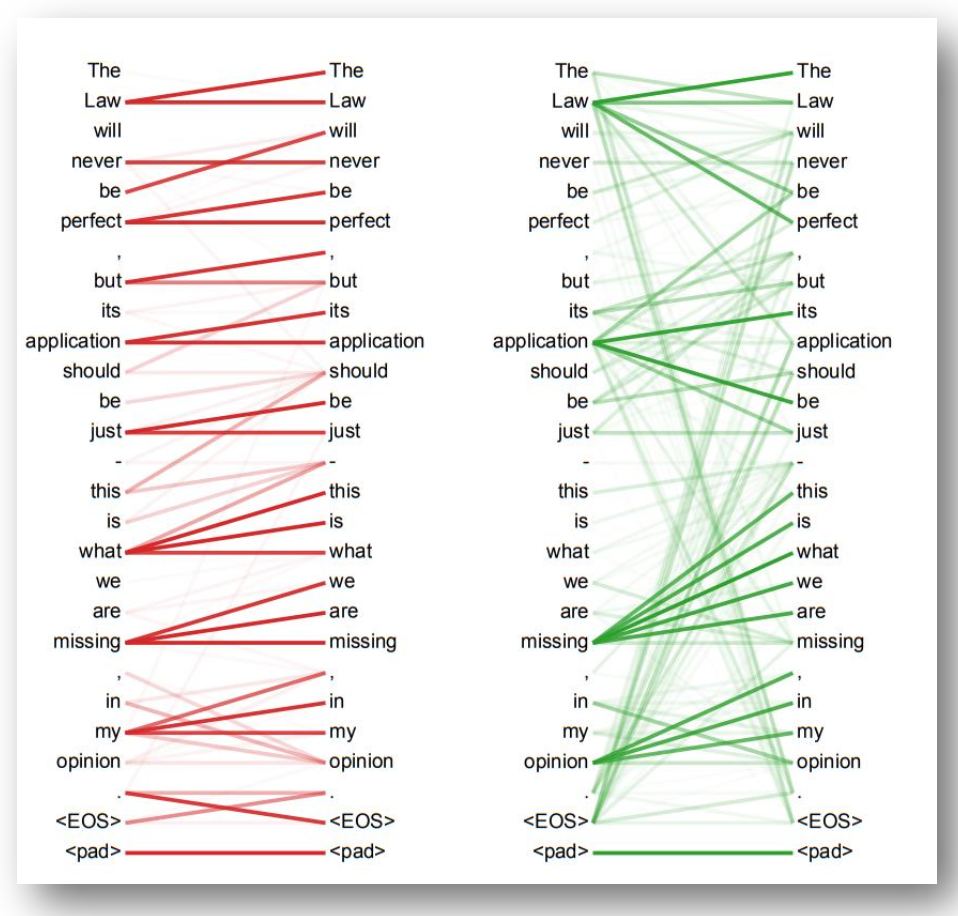
p15. 트랜스포머 모델
- Residual Connection
- 서브층의 입력과 출력을 더하는 것으로 출력과 입력 간의 차이만을 학습
- 모델의 입력값이 점진적으로 변화하며 안정적 학습이 되도록 하기 위해 적용
- Residual Connection 결과에 대한 정규화
- 각 Residual Connection 결과 벡터의 평균 μ과 분산 σ²를 구해 정규화를 수행하며, 학습을 안정적으로 수행하도록 함
- 각 Residual Connection 결과 벡터의 평균 μ과 분산 σ²를 구해 정규화를 수행하며, 학습을 안정적으로 수행하도록 함
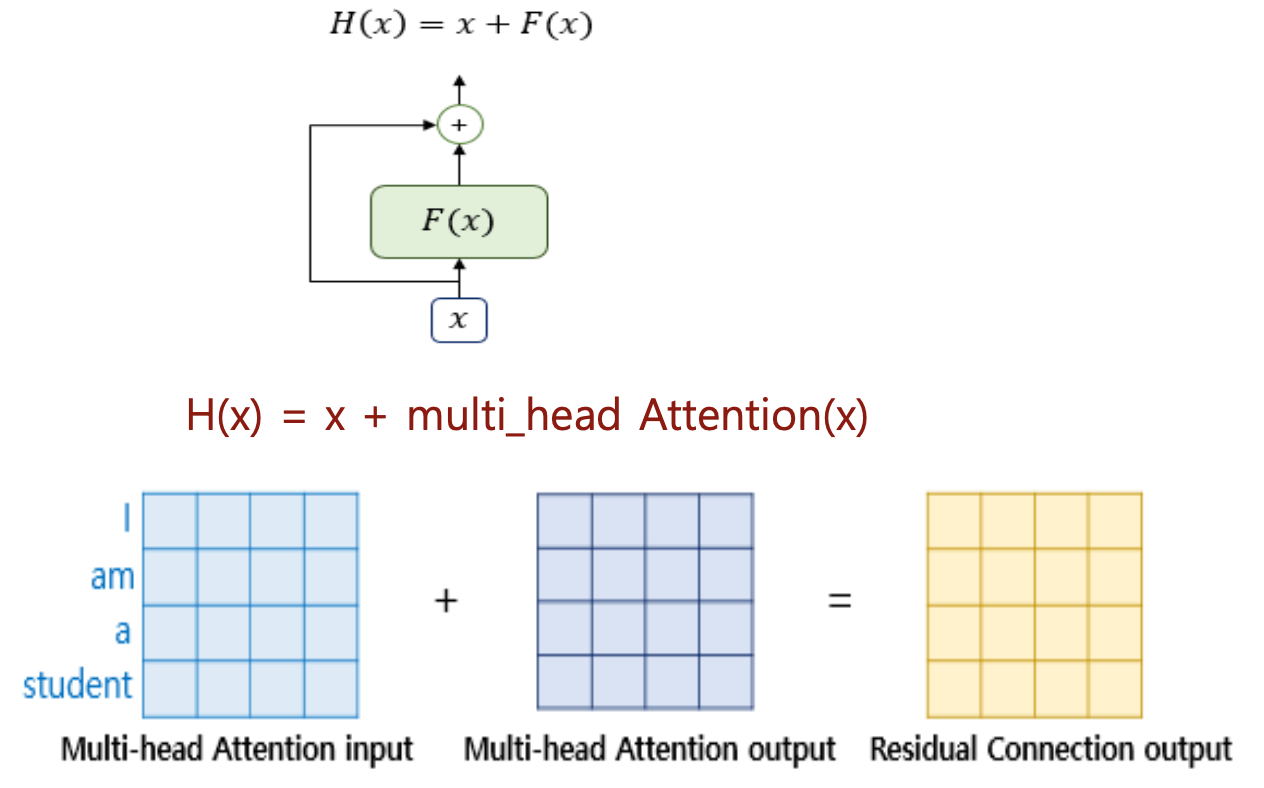
Residual Connection의 필요성
신경망이 깊어질수록 발생하는 기울기 소실 문제를 줄이기 위해 shortcut 경로를 제공
입력을 그대로 더해 정보 손실을 최소화하며, 네트워크는 “차이 F(x)”만 학습하면 됨
이를 통해 학습 안정성과 수렴 속도가 크게 향상됨수식적 해석
\[H(x) = x + F(x)\]
일반적인 학습은 $y = F(x)$ 형태지만, Residual 구조는로 입력을 보존함
$F(x)=0$만 학습하면 $H(x)=x$가 되므로 항등함수를 쉽게 구현 가능
깊은 층에서도 필요하면 특정 층을 “우회”할 수 있어 학습이 안정적임항등함수와 깊은 네트워크
항등함수 $f(x)=x$는 입력을 그대로 전달하는 함수
기존 신경망은 이를 학습하기 어렵지만 Residual 구조에서는 F(x)를 0에 가깝게 만들기만 하면 됨
불필요한 층은 자연스럽게 무시되고, 깊은 네트워크에서도 성능 저하 없이 안정적 학습 가능정규화(Layer Normalization)의 역할
Residual Connection 이후 LayerNorm을 적용하여 출력 분포를 안정화
평균과 분산을 기준으로 정규화해 폭주·불안정 학습을 방지
Transformer에서는 모든 sublayer(Multi-Head Attention, Feed Forward)에 Residual + LayerNorm을 적용해 안정적인 학습을 보장
p16. 트랜스포머 모델
Position-Wise FFNN (Feed-Forward Neural Network)
- 인코더와 디코더에서 공통적으로 갖는 서브층으로 완전 연결 FFNN(Fully-connected FFNN),
동일 가중치를 모든 토큰 위치에 적용 - Attention 가중합 결과를 비선형 연산을 통해 어텐션 결과를 고차원 공간으로 Projection → 추상화 수준 향상
- 개별 토큰의 특징을 심화 학습하는 “미세 조정 장치” 역할
- ReLU 활성화로 하위층에서는 복잡한 단어 내부 패턴 학습(형태소 규칙, 구문특성 등), 상위층에서는 의미론적 관계 등을 학습
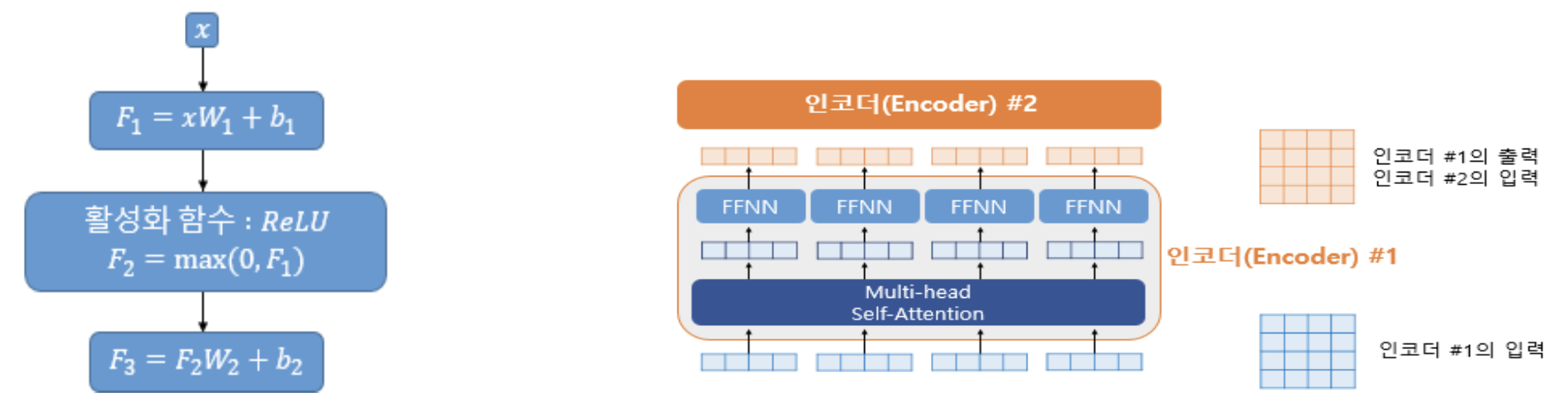
- $X$: 멀티헤드 어텐션 결과 행렬, $(seq_len, d_{model})$의 크기
- $W_1$: 가중치 행렬 $(d_{model}, d_{ff})$의 크기
- $W_2$: 가중치 행렬 $(d_{ff}, d_{model})$의 크기
- $d_{ff}$: 피드 포워드 신경망의 은닉층의 크기 (논문에서는 2048)
Position-Wise FFNN의 의미
“Position-Wise”란 문장 내 모든 토큰 위치마다 같은 FFNN을 독립적으로 적용한다는 뜻
문장의 길이와 무관하게 동일한 구조의 FFNN이 각 단어 벡터에 동일하게 작동하여
위치에 독립적인 일관된 변환을 제공함Projection과 비선형성의 역할
\[F_1 = XW_1 + b_1, \quad F_2 = \text{ReLU}(F_1), \quad F_3 = F_2W_2 + b_2\]
Attention 출력은 단순한 가중 평균이므로 표현력이 제한됨
FFNN은 이를 비선형 함수(ReLU)를 통해 고차원으로 투영하여 더 복잡한 의미·구문 패턴까지 학습하게 함ReLU는 비선형성을 제공하여 단순 선형 조합으로는 포착할 수 없는 언어 특징 학습이 가능
FFNN의 학습 기능
하위층에서는 형태소·어휘 패턴 등 단어 내부 구조적 특징을 학습
상위층에서는 단어 간 의미 관계와 문맥 정보를 학습
따라서 FFNN은 Attention이 만든 정보를 더 정제된 특징 공간으로 변환하는 “미세 조정 장치” 역할 수행차원 확장의 이유 ($d_{ff}$)
Transformer에서는 $d_{ff}=2048$로 설정해 입력 차원 $d_{model}=512$보다 크게 확장
확장했다 다시 축소하는 과정은 더 다양한 특징을 학습하고
불필요한 잡음을 줄여 일반화 성능을 높이는 효과가 있음
p17. 트랜스포머 모델
Decoder Block: Masked Self-Attention
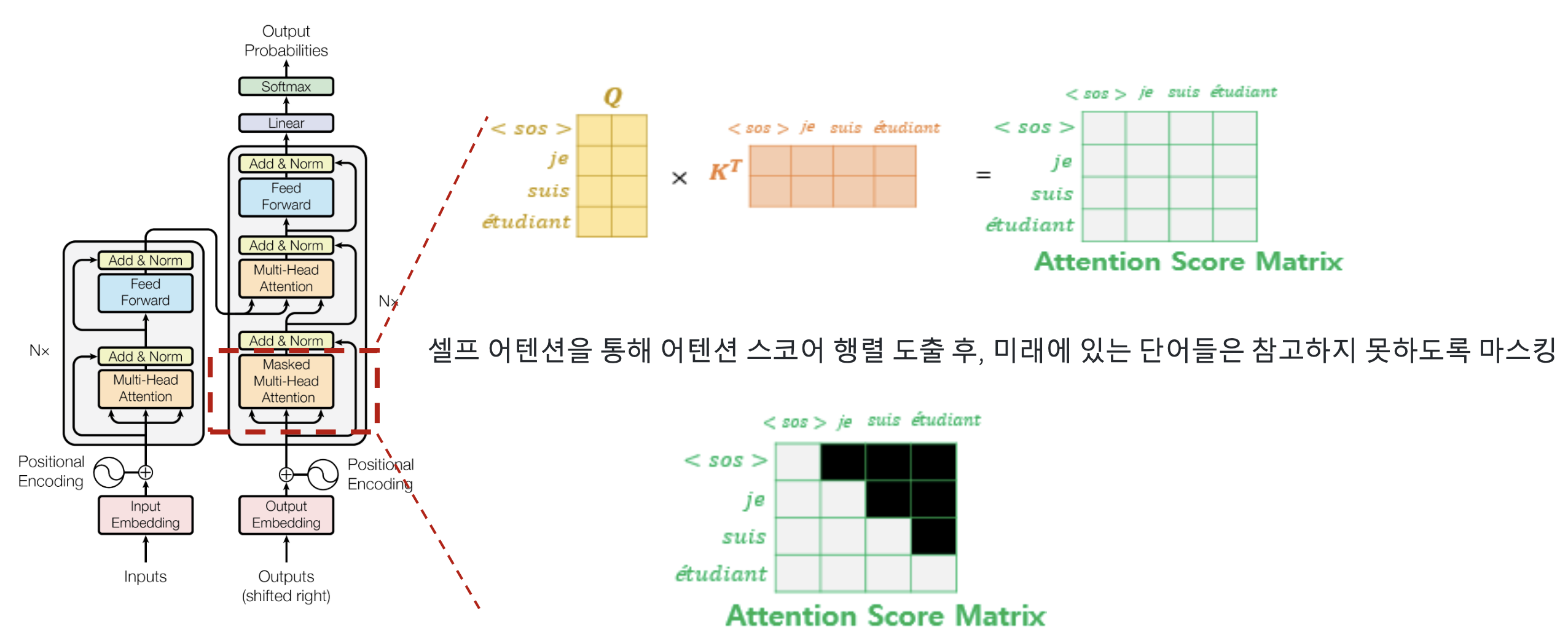
Masked Self-Attention의 필요성
디코더는 텍스트를 한 단어씩 순차적으로 생성해야 하므로
미래 단어를 미리 보면 올바른 학습이 불가능함
따라서 마스크를 적용하여 현재 시점 이전 단어까지만 어텐션 계산수식적 해석
\[\text{Attention}(Q,K,V)=\text{Softmax}\!\left(\frac{QK^T}{\sqrt{d_k}}+M\right)V\]
어텐션 스코어는 Query $Q$와 Key $K$의 내적으로 계산되며
미래 시점의 스코어는 $-\infty$로 마스킹 처리
Softmax에서 $e^{-\infty}=0$이 되어 미래 단어 가중치는 완전히 제거됨여기서 $M$은 마스크 행렬이며 미래 토큰 위치는 $-\infty$를 가짐
훈련 및 추론에서의 역할
훈련 시: 실제 생성 상황과 동일한 조건을 유지하도록 강제
추론 시: 이전까지 생성된 단어만 기반으로 다음 단어를 예측
자연스러운 순차 생성(auto-regressive)을 보장함
p18. 트랜스포머 모델
Decoder Encode-Decoder MSA
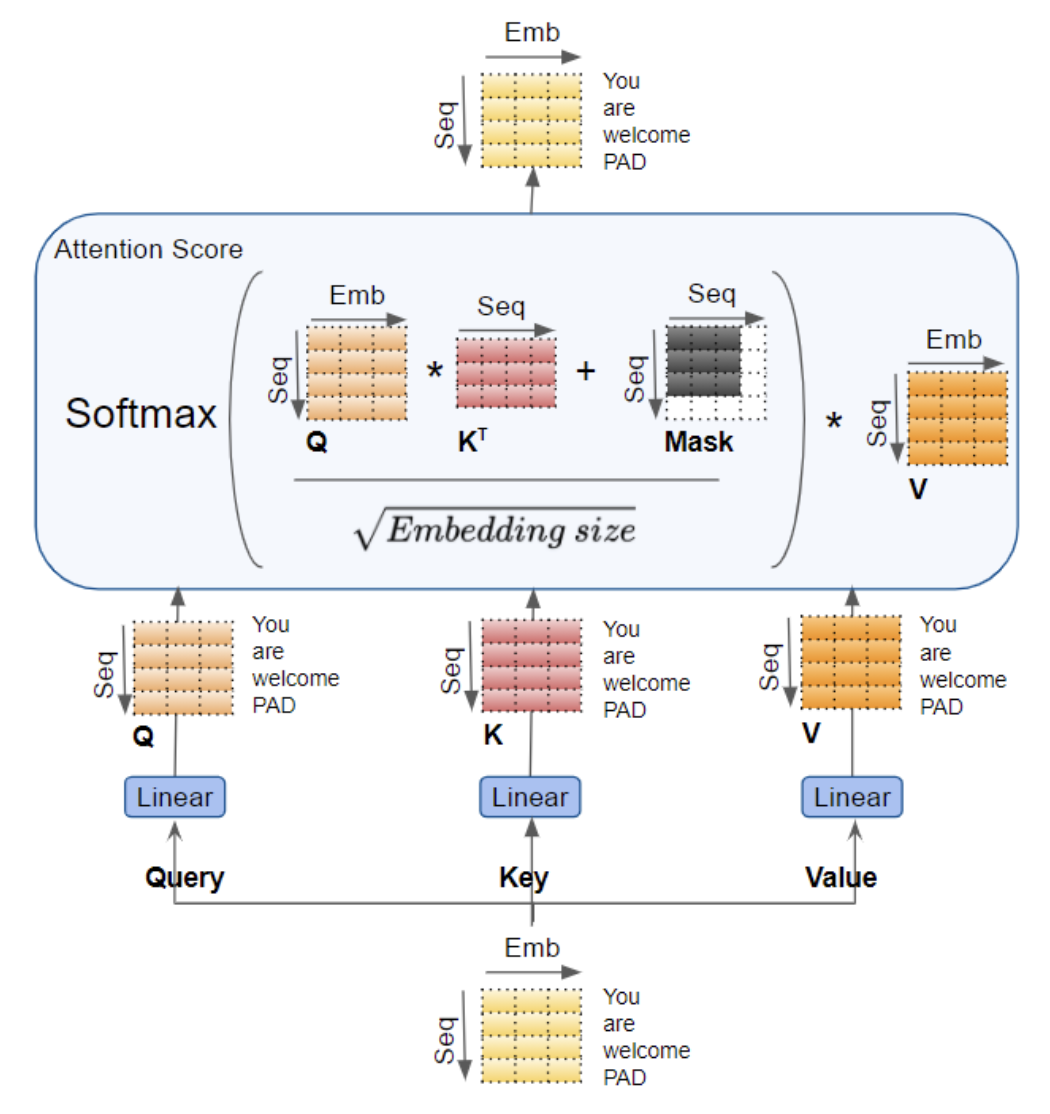
- Query: 디코더의 첫번째 서브층의 결과 행렬
- Key: 인코더의 마지막 층에서 온 행렬
Value: 인코더의 마지막 층에서 온 행렬
- Decoder 입력 시퀀스 데이터의 적절한 위치에 집중할 수 있도록 하기 위함
Encoder-Decoder Attention의 역할
인코더에서 추출된 문맥(Context Vector)을 디코더가 직접 참조하여
출력 단어 생성 시 입력 문장의 의미를 반영하도록 함
Query는 디코더에서, Key와 Value는 인코더에서 오므로
입력–출력 간 상호작용이 자연스럽게 이루어짐Q, K, V의 의미
Query(Q): 디코더의 현재 상태가 “어디를 봐야 하는지”를 질의
Key(K): 인코더가 입력 문장에서 얻어낸 위치·의미 정보
Value(V): Key와 연결된 실제 의미 벡터로, 가중합을 통해 디코더로 전달수식적 해석
\[\text{Attention}(Q,K,V)=\text{Softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V\]
Query–Key 유사도를 구한 뒤 Softmax로 정규화하여
Value 벡터의 가중합으로 최종 Attention 출력을 생성함장점
입력과 출력 사이에 직접 연결을 제공하여 장기 의존성 문제를 완화
기계번역 등에서 어떤 입력 단어가 어떤 출력 단어에 대응되는지
자연스럽게 학습할 수 있음
p19. Linear Layer & Softmax
- Linear Layer
- 쌓아올린 디코더들의 출력 결과를 Logits vector로 Projection
디코더 스택의 최종 출력 벡터를 타겟 어휘 크기(Vocabulary Size)에 맞게 변환
- 구조
- 완전 연결계층으로 구성되며,
- $Logits = W \cdot h + b$
- $W$: 가중치 행렬 (차원: [히든 차원 × 어휘_크기])
- $h$: 디코더 출력 벡터 (예: 512차원)
- $b$: 편향 벡터
- Softmax Layer
- Logits 벡터를 확률 분포로 변환, 최종적으로 분류에 사용할 스코어를 확률로 출력
Linear Layer의 역할
\[\text{Logits} = W \cdot h + b\]
디코더의 최종 출력 벡터는 그대로 사용할 수 없으며
어휘 집합(vocabulary) 크기에 맞도록 차원을 변환해야 함
이를 위해 완전 연결 계층인 Linear Layer를 사용하여
디코더 출력 벡터 $h$에 가중치 $W$를 곱하고 편향 $b$를 더해 logits를 계산함여기서 $W$는 $[\text{hidden dimension} \times \text{vocab size}]$ 형태의 행렬이고
$h$는 디코더 출력 벡터, $b$는 편향 벡터임Softmax Layer의 역할
Linear Layer에서 생성된 logits는 단순한 실수값 벡터이므로
Softmax 함수를 통해 0~1 범위의 확률 분포로 변환해야 함
이렇게 얻어진 확률은 각 단어가 다음 단어로 선택될 가능성을 의미함Next Word Prediction과의 연결
Transformer는 학습 과정에서 “다음 단어 예측(next word prediction)”을 통해 학습되며
Softmax 출력 중 가장 확률이 높은 단어가 실제 다음 단어로 선택됨
이 과정을 반복하면 문장을 한 단어씩 생성할 수 있으며
자연스러운 문장 생성이 가능해짐
p20. 트랜스포머 기반 주요 언어모델 유형
- Encoder-Only Transformer Model
- 대표모델
- BERT (Bidirectional Encoder Representations from Transformers)
- ELECTRA
- 문장내에서 단어들의 양방향 문맥을 이해
- 주로 텍스트 분류, 질의응답, 검색 등에 사용
- 대표모델
- Decoder-Only Transformer Model
- 대표 모델
- GPT Family
- PaLM Family
- LLaMA Family
- Auto-Regressive Model로 언어 생성에 강점
- GPT-3는 1750억 개의 파라미터를 사용
- 대표 모델
- Encoder-Decoder Transformer Model
- 대표모델
- T5 (Text-To-Text Transfer Transformer)
- BART (Bidirectional and Auto-Regressive Transformers)
- 모든 NLP 작업을 텍스트 변환 문제로 통합
- 다양한 NLP 작업에서 높은 성능
- 대표모델
p21. GPT 모델 시리즈 개요
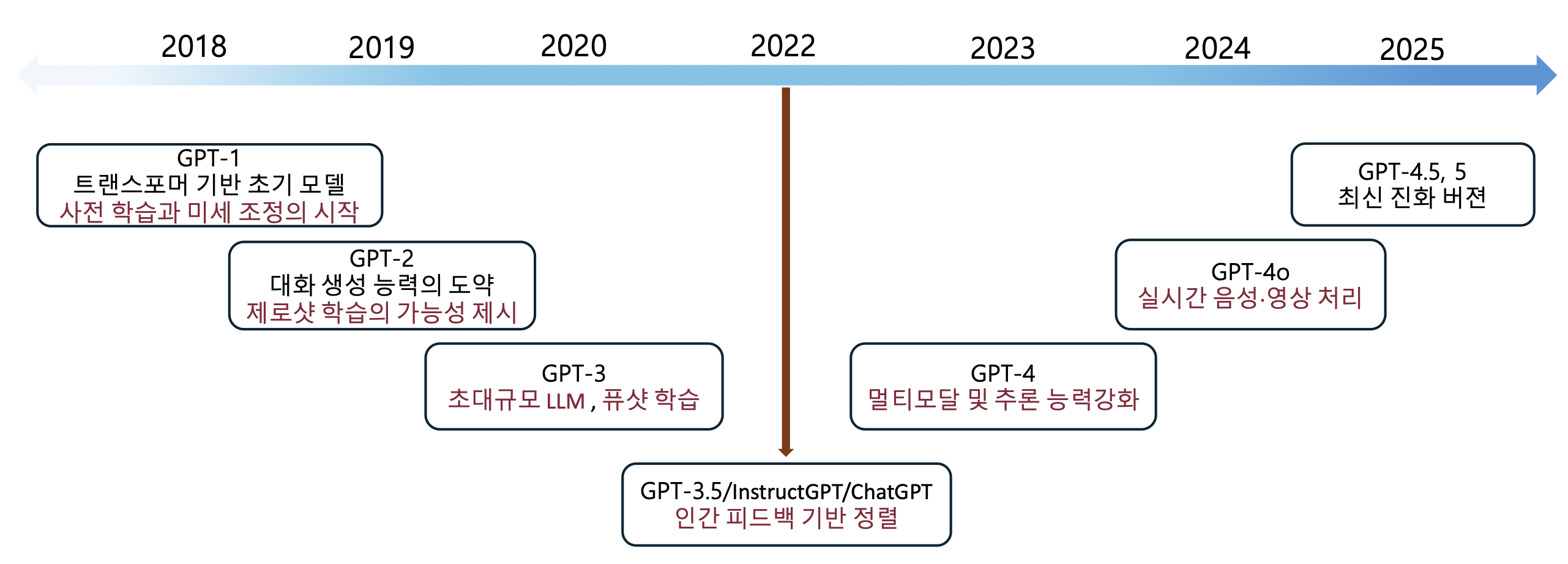
GPT 모델의 발전과정
- (2018) GPT-1
- 트랜스포머 기반 초기 모델
- 사전 학습과 미세 조정의 시작
- (2019) GPT-2
- 대화 생성 능력의 도약
- 제로샷 학습의 가능성 제시
- (2020) GPT-3
- 초대규모 LLM, 퓨샷 학습
- (2022) GPT-3.5 / InstructGPT / ChatGPT
- 인간 피드백 기반 정렬
- (2023) GPT-4
- 멀티모달 및 추론 능력 강화
- (2024) GPT-4o
- 실시간 음성·영상 처리
- (2025) GPT-4.5, 5
- 최신 진화 버전
- (2018) GPT-1
발전의 방향
- 모델 규모 증가 → 효율성 최적화 (예: GLaM의 MoE 구조)
- 단순 텍스트 → 멀티모달(이미지·음성) 처리 확장
- 범용 성능 → 도메인 특화(의료, 법률 등) 및 안전성 강조
p22. GPT 계열 모델 발전 동향
| 세대 | 출시 시기 | 주요 특징 | 기술적 진보 | 활용 범위 |
|---|---|---|---|---|
| GPT1 | 2018 | Transformer 기반 언어 모델 최초 공개 | - 대규모 비지도 사전학습(Pre-training) - 소규모 지도학습(Fine-tuning) 수행 | 자연어이해 중심 실험 수준 |
| GPT2 | 2019 | 대규모 파라미터(1.5B)로 강력한 생성 능력 확보 | - 단일 모델로 다수의 언어 작업 수행 가능성 제시 - Zero-shot, Few-shot 학습 능력 초기 구현 | 텍스트 생성, 요약, 번역, 질의응답 |
| GPT3 | 2020 | 175B 파라미터로 상식 추론·언어 이해 도약 | - 파라미터 수 급증 → 범용 언어 능력 확보 - Prompt 기반 학습(지시문 학습) 부상 | 창작, 코딩, 질의응답, 대화형 시스템 |
| GPT3.5 | 2022 | 실용화 단계 진입 (서비스 기반) | - 인간 피드백 강화학습(RLHF) 적용 - 안전성·대화 품질 개선 | 실시간 대화, 교육, 고객지원 |
| GPT4 | 2023 | 멀티모달 AI로 진화(텍스트+이미지 입력 지원) | - 복합 추론 능력 향상 - 안전성·사실성 강화 - 도메인 전문성 확장 | 멀티모달 분석, 전문 분야 조언, 복합 추론 |
| GPT-4o | 2024 | ‘Omni’ 모델 – 실시간 멀티모달 대화 지원 | - 음성·이미지·텍스트 처리 - 실시간 상호작용 가능 - 속도·비용 효율성 개선 | 음성 비서, 실시간 분석, 인터랙티브 에이전트 |
| GPT5 | 2025 | 범용 AGI에 한 걸음 더 접근 | - 장기 추론 및 계획 능력 향상 - 에이전트화(지속적 맥락 기억·자율행동) - 다중 작업 협업 능력 강화 | 자율적 업무 처리, 고차원 의사결정 지원 |
p23. GPT 모델 시리즈 개요
- 공통 기술적 진화 방향
- 모델 규모 증가 → 지능 수준 상승, 효율성 최적화(예: GLaM의 MoE 구조)
- Prompt 학습 → Zero/Few-shot 추론 발전
- 단순 텍스트 → 멀티모달(이미지·음성) 처리 확장
- GPT-4부터 텍스트 외 이미지·음성 등 다양한 입력을 통합적으로 처리하는 단계로 진입
- 범용 성능 → 도메인 특화(의료, 법률 등) 및 안전성 강조
- 인간 피드백 기반 학습으로 대화 품질, 사용자 친화성, 사실성 개선
- 한각 문제 감소를 위한 자기검증(self-checking) 메커니즘 도입
- 실시간 대화형 AI → 지능형 에이전트화
- GPT-4o 이후 실시간 상호작용 및 다중 작업 수행이 가능해지며, “도구적 AI”에서 “자율적 에이전트”로 진화
- 한계와 미래 과제
- 한각 문제: 신뢰성 향상을 위한 자기검증 메커니즘 필요
- 계산 비용: 에너지 효율적인 학습 알고리즘 개발
- 윤리적 문제: 편향 완화와 오용 방지 체계 구축
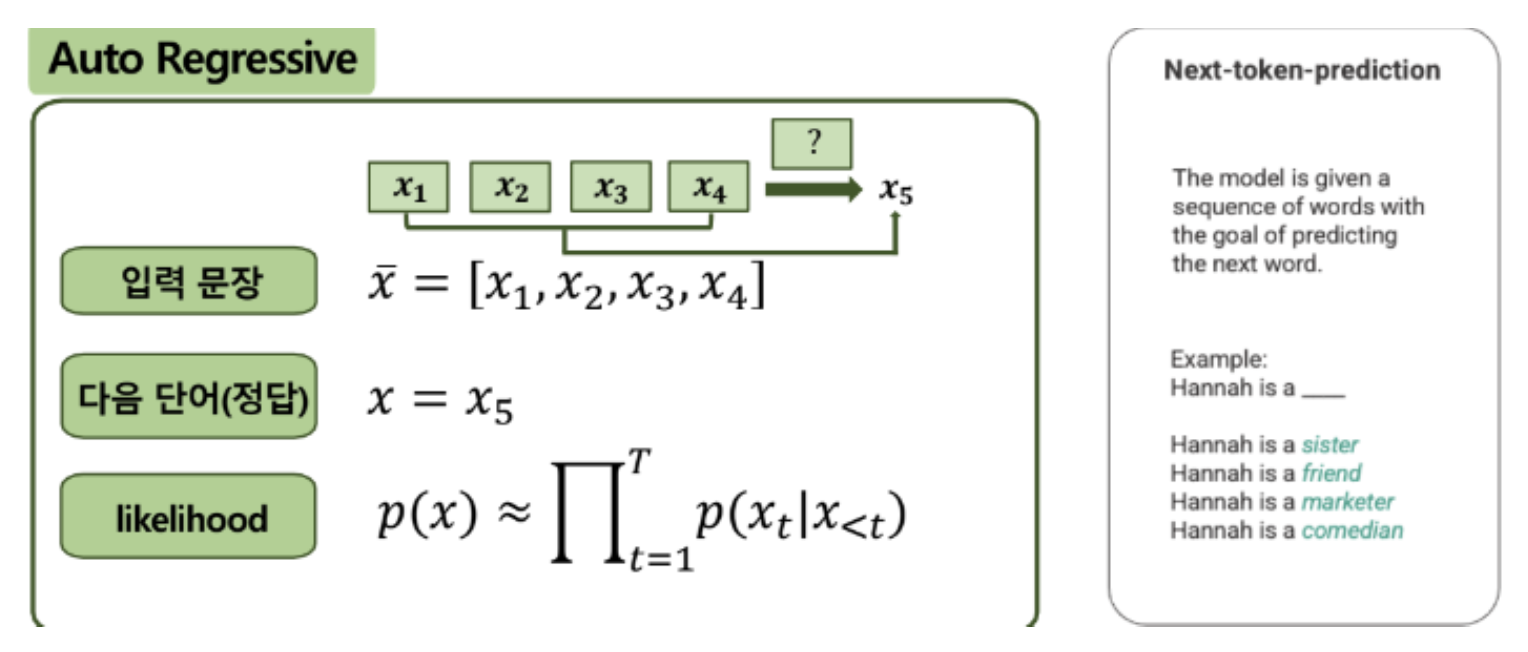
p24. GPT(Generative Pre-trained Transformer)
- GPT?
- 2018년 오픈 AI에서 개발한 언어모델로 GPT-n 시리즈로 발전
- 트랜스포머 아키텍처 기반으로 Decoder 구조만을 사용하는 Autoregressive Language 모델
- 한번에 한 토큰을 예측하고, 이를 다시 입력에 추가하여 계속 다음 텍스트를 예측하는 모델
p25. InstructGPT / ChatGPT 개요
- LLMs은 학습 가능한 파라미터 수를 증가시키는 쪽으로 발전
- 실제로 학습 가능한 파라미터 수가 증가할수록 모델 성능이 증가하고,
- LLM은 이제 몇 개의 예시를 주면 다양한 NLP task를 수행할 수 있음
- 그러나, public NLP datasets에 대한 객관적인 성능은 향상되었으나, 인간의 의도를 잘 반영하고 있지 못하고(misaligned), 다음의 문제점들이 드러남
- Making up facts
- Generating biased or toxic text
- Simply not following user instructions
- 왜?
- 기존의 LLMs의 Objective는 오로지 “주어진 문서의 다음에 나올 토큰을 예측”하는 것에 집중
- 이는 “사용자의 지시에 안전하게 따르고 도움을 줄 것”이라는 objective가 아님
p26. InstructGPT / ChatGPT 개요
- 문제 해결을 위한 관련 사후 학습 연구
- 정렬(alignment), 인간 피드백 기반 학습
- 지시를 따르도록 언어 모델 학습시키기
- 언어 모델의 해로움 측정 (evaluating harms)
- 해로움을 줄이기 위해 언어 모델 행동 수정하기
- 강화학습에 있어서의 문제제기
- AI가 생성한 글의 점수를 매기는 것이 가능한가?
- 점수 등 지표가 있어야 손실함수를 만들 수 있다.
- 주관적/상황에 따라 달라지기 때문에 지표와 손실함수를 정의하기 어렵다.
- 따라서 사람이 직접 피드백을 통해 점수를 제공할 수 있는 체계를 만든다.
p27. InstructGPT / ChatGPT 개요
RLHF (Reinforcement Learning from Human Feedback)
- 지시, 대화 데이터에 대한 지도학습과 강화학습으로 LLM을 추가학습함으로써
- 사용자의 지시, 대화에 따라 사용자의 의도를 반영하여 응답할 수 있는 human-aligned LLM 도출
학습과정
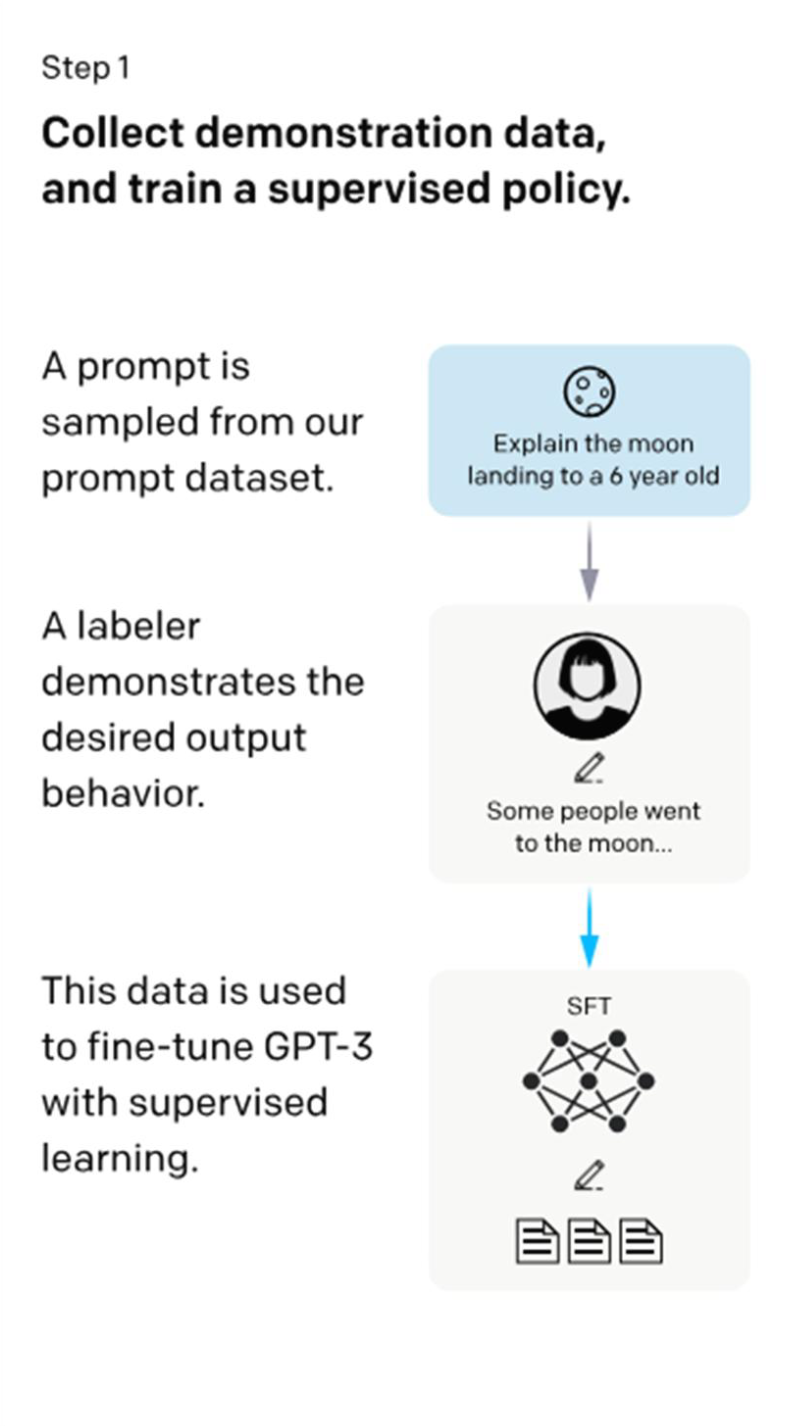
- Step1: supervised fine-tuning (SFT)
- 입력 prompt에 대한 답변을 human labeler 40명이 작성해 training dataset 구축 (데이터 13,000개)
- 어떻게 답변하는 것이 바람직한지 모범 답안을 제시함 (demonstrations of the desired behavior)
- Training dataset으로 GPT-3 (1750억 파라미터)를 지시문에 따라 생성할 수 있도록 supervised fine-tuning
- 사람의 선호를 보상 신호로 활용해 모델을 사전학습
- 입력 prompt에 대한 답변을 human labeler 40명이 작성해 training dataset 구축 (데이터 13,000개)
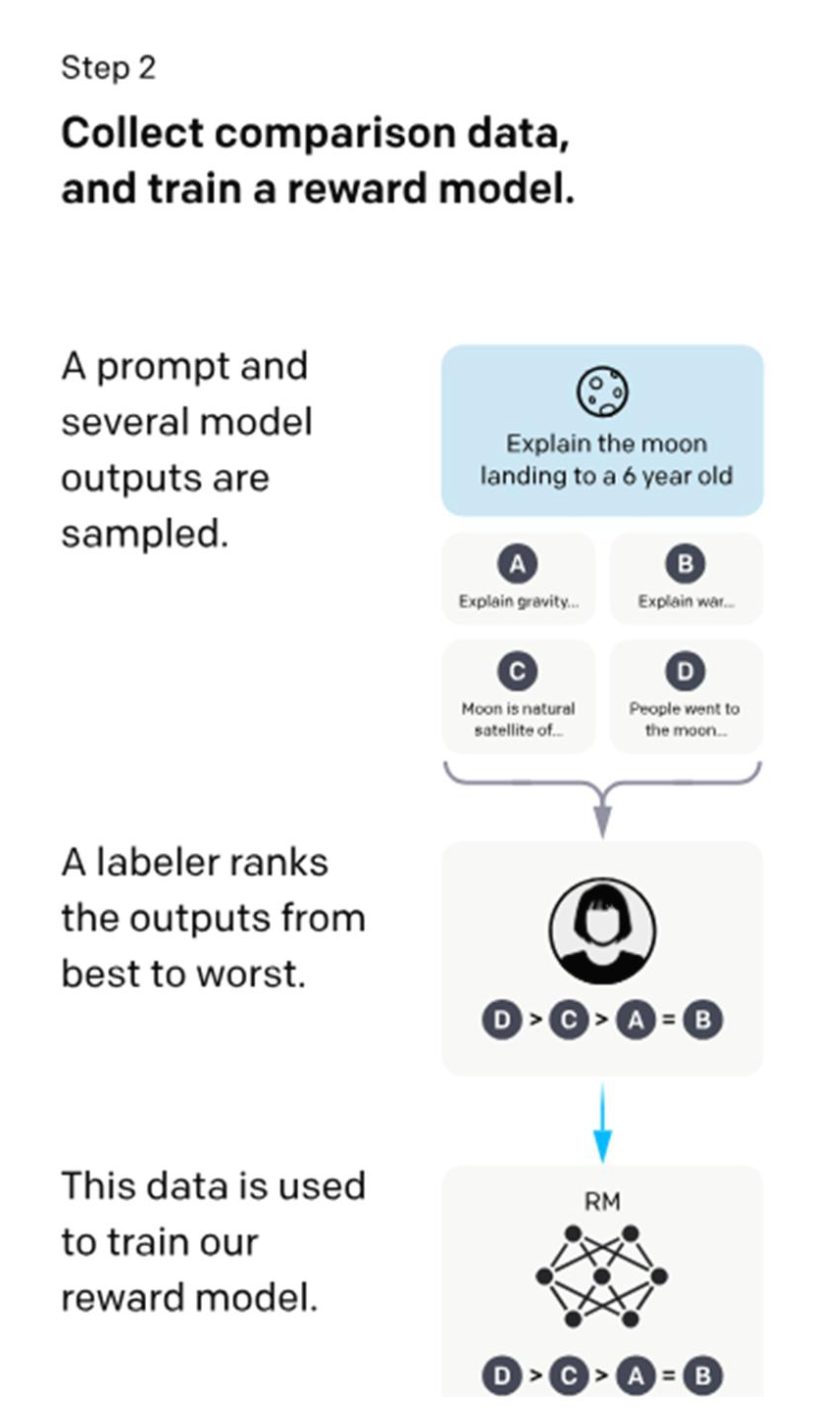
- Step2: reward model (RM) training
- 여러 버전의 model output (한 번에 4~6개)에 대해 human labeler가 선호도 순위를 매긴 preference dataset 구축 (데이터 33,000개)
- Preference dataset으로 reward model 학습
- Reward model은 사람이 선호하는 output을 예측해 점수(reward)를 출력함
- Step3: reinforcement learning via PPO algorithm on the reward model
- RM을 이용해 supervised policy (Step 1에서 학습시킨 모델)을 fine-tuning (데이터 31,000개)
- 최종 모델로 fine-tuning 해가는 과정에서 Step1의 모델과 너무 다르지 않도록 penalty를 줌
p28. RLHF 학습 과정
- 1단계: 시연 데이터를 수집하고, 지도 정책(supervised policy)을 학습한다.
- 프롬프트 데이터셋에서 하나의 프롬프트가 샘플링된다.
- 라벨러가 원하는 출력 행동을 직접 시연한다.
- 이 데이터는 GPT-3를 감독 학습(supervised learning)으로 파인튜닝하는 데 사용된다.
- 2단계: 비교 데이터를 수집하고, 보상 모델(reward model)을 학습한다.
- 하나의 프롬프트와 여러 개의 모델 출력이 샘플링된다.
- 라벨러가 출력들을 가장 좋은 것부터 가장 나쁜 것까지 순위를 매긴다.
- 이 데이터는 보상 모델을 학습하는 데 사용된다.
- 3단계: 강화학습을 통해 보상 모델에 맞추어 정책(policy)을 최적화한다.
- 새로운 프롬프트가 데이터셋에서 샘플링된다.
- 정책이 출력을 생성한다.
- 보상 모델이 출력에 대해 보상을 계산한다.
- 이 보상은 정책을 업데이트하는 데 사용된다.
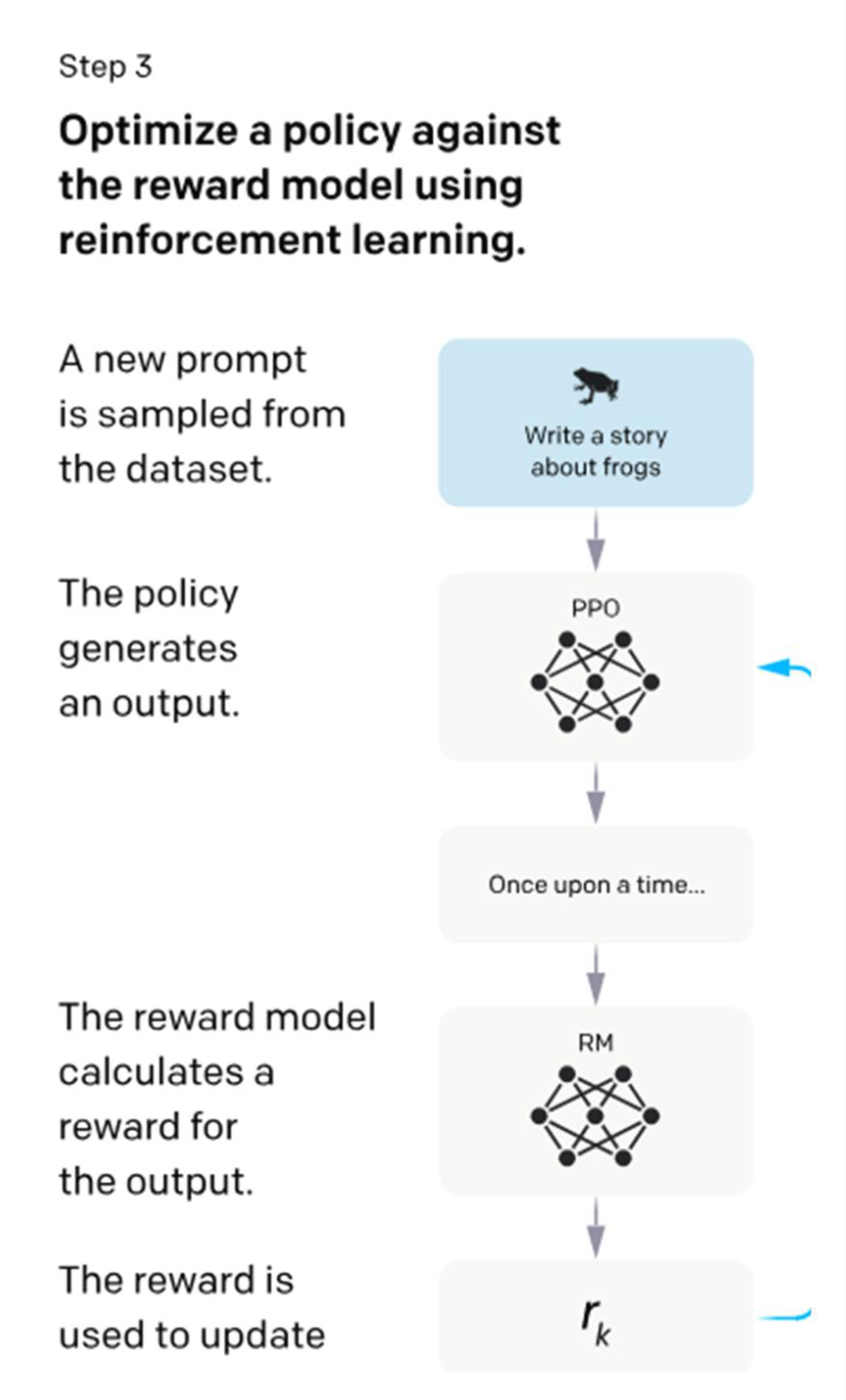
RLHF의 핵심 개념
RLHF(Reinforcement Learning from Human Feedback)는 사람의 선호도를 활용해
언어 모델을 사람 의도에 더 잘 맞도록 조정(alignment)하는 학습 기법임
기존 LLM이 단순히 다음 토큰을 예측하는 데 집중했다면
RLHF는 사람이 원하는 출력 방식을 반영하여
모델을 더 안전하고 유용하며 신뢰 가능한 방향으로 이끌어 줌세 단계의 의미
Step 1 — Supervised Fine-Tuning(SFT):
사람이 직접 작성한 고품질 예시를 모델이 모방하도록 지도학습으로 미세조정함Step 2 — Reward Model 학습(RM):
모델이 생성한 여러 답변을 사람이 비교·선호도 순위로 매기면
이를 학습해 “좋은 출력 ↔ 나쁜 출력”을 구분하는 보상 모델을 구축함Step 3 — 정책 최적화(RL, PPO 등):
Reward Model을 기준으로 강화학습을 수행하여
모델의 정책(policy)이 반복적으로 개선되도록 최적화함효과와 한계
효과: 사용자의 의도에 맞게 반응하며
유해·편향 출력이 감소하고 보다 유용한 응답을 생성함
한계: 사람의 피드백이 주관적일 수 있으며
데이터를 수집하는 데 많은 비용·노력이 필요하다는 점이 존재함
따라서 RLHF는 완벽한 정답이라기보다
모델과 사람 사이의 간극을 줄이기 위한 실용적·효율적 방식으로 이해할 수 있음
p29. Instruction Following을 위한 데이터셋 구축 예시
인스턴스 포맷팅(instance formatting)과, 지시문(instruction) 형식의 인스턴스를 구축하기 위한 세 가지 서로 다른 방법을 나타낸 그림
- (a) 작업(Task) 데이터셋 포맷팅
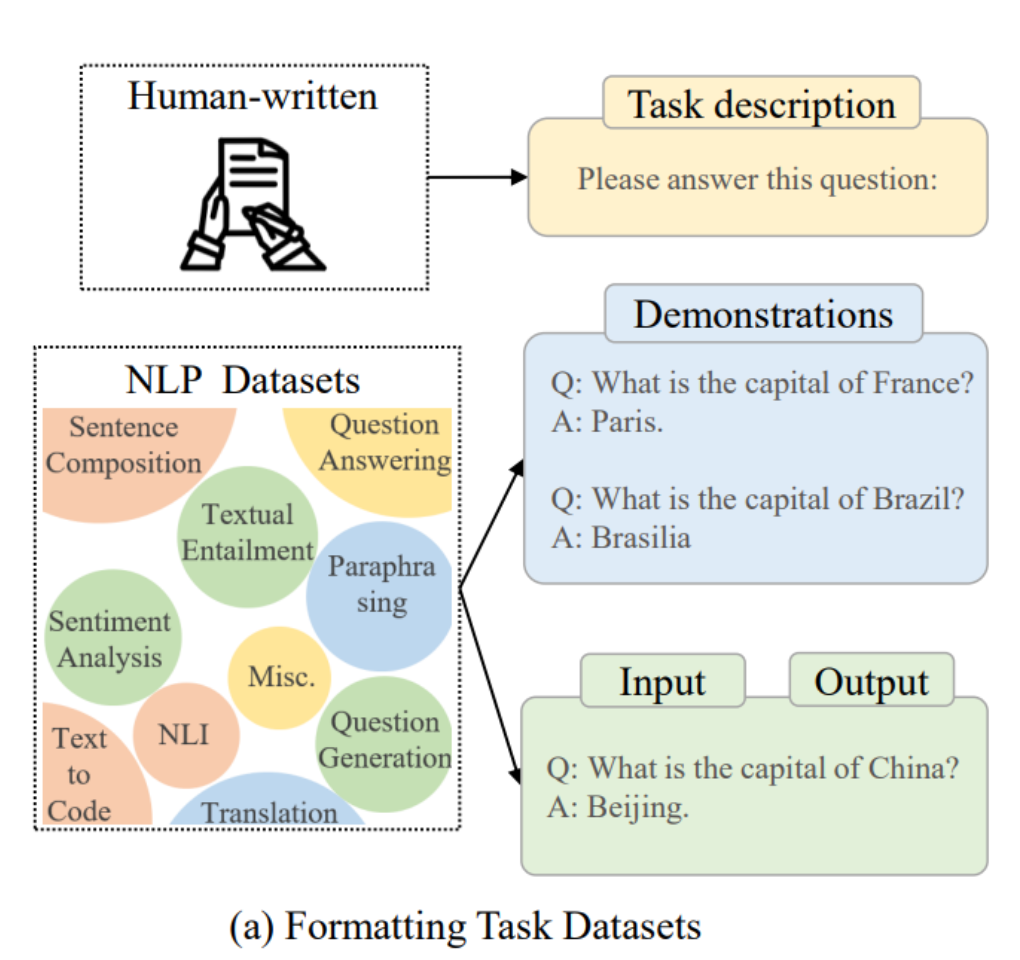
- 사람이 직접 작성 (Human-written)
- 작업 설명(Task description)
- 이 질문에 답해주세요:
- 작업 설명(Task description)
- NLP 데이터셋
문장 구성(Sentence Composition), 질문 응답(Question Answering), 텍스트 함의(Textual Entailment), 의역하기(Paraphrasing), 감정 분석(Sentiment Analysis), 자연어 추론(NLI), 번역(Translation), 질문 생성(Question Generation) 등
- 시연(Demonstrations)
- Q: 프랑스의 수도는 무엇입니까?
A: 파리 - Q: 브라질의 수도는 무엇입니까?
A: 브라질리아
- Q: 프랑스의 수도는 무엇입니까?
- 입력(Input), 출력(Output)
- Q: 중국의 수도는 무엇입니까?
A: 베이징
- Q: 중국의 수도는 무엇입니까?
- 시연(Demonstrations)
- 사람이 직접 작성 (Human-written)
- (b) 일상 대화 데이터 포맷팅
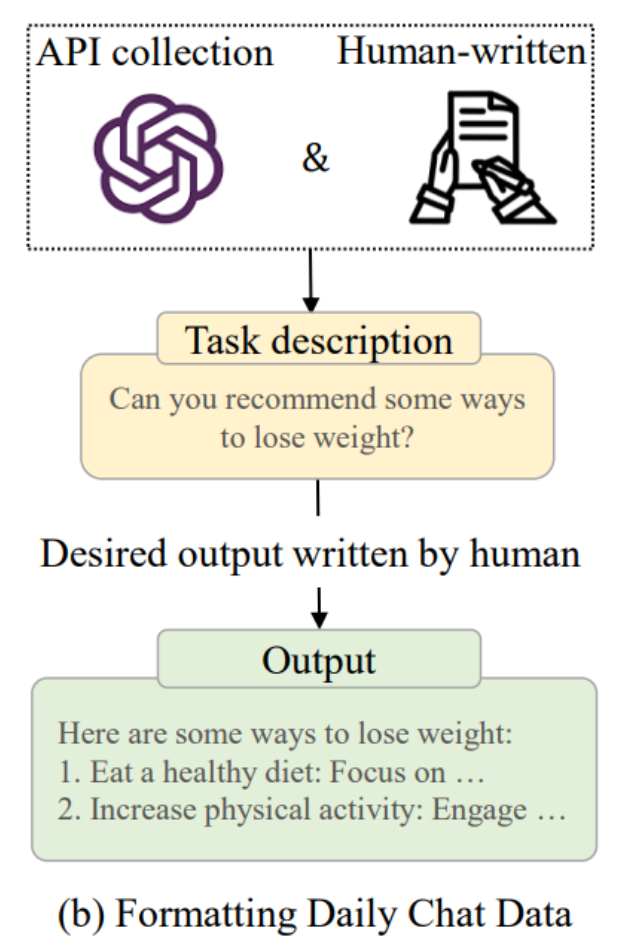
- API 수집 또는 사람이 직접 작성(Human-written)
- 작업 설명(Task description)
- 다이어트를 할 수 있는 몇 가지 방법을 추천해줄 수 있나요?
- 사람이 작성한 원하는 출력(Desired output)
- 건강한 식단을 유지하세요: ~에 집중
- 신체 활동을 늘리세요: ~에 참여
- (c) 합성(Synthetic) 데이터 포맷팅
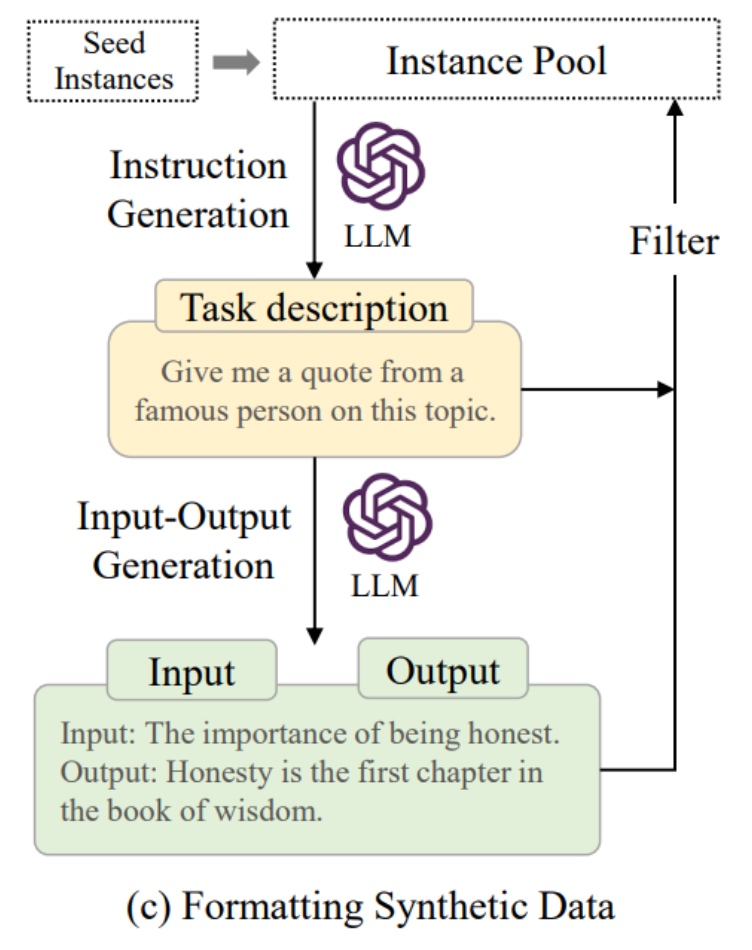
- 시드 인스턴스(Seed Instances)를 기반으로 LLM이 지시문(Instruction)을 생성
- 작업 설명(Task description) 예시: 이 주제에 대해 유명인의 명언을 알려주세요.
- LLM이 입력-출력(Input-Output) 생성
- 입력: 정직함의 중요성
- 출력: 정직은 지혜의 책에서 첫 장이다.
- 인스턴스 풀(Instance Pool)에 저장된 후 필터(Filter) 과정을 거침
데이터셋 구축의 필요성
- 대규모 언어 모델은 단순한 인터넷 텍스트 학습만으로는
사용자의 지시를 정확히 따르기 어려움- 따라서 사람이 만든 질문–응답, 실제 대화, 합성 데이터 등을 활용해
Instruction Following 능력을 강화하는 추가 학습이 필요함세 가지 접근 방식의 차이점
(a) Task Datasets:
기존 NLP 벤치마크·데이터셋을 재활용해 질문–답변 형태의
입력–출력 쌍으로 변환하여 학습함
구조화된 패턴과 규칙 기반 작업에 강함(b) Daily Chat Data:
실제 사용자 대화나 API 기반 대화 데이터를 수집하여 학습함
현실적·일상적 질문에 대응하는 능력을 향상시키며
자연스러운 응답 생성 능력을 강화함(c) Synthetic Data:
사람이 만든 seed 예시를 기반으로
모델이 스스로 다양한 입력–출력 예시를 생성하도록 함
이후 자동/수동 필터링을 통해 품질을 보정하여 학습에 사용함
대규모 확장이 가능하며 비용 효율적임종합적 효과
세 접근법을 결합하면
구조화된 과제 해결 능력(Task Datasets),
실제 대화 적응력(Daily Chat),
데이터 확장성(Synthetic Data)을 동시에 확보할 수 있음
특히 Synthetic Data는 사람이 모든 데이터를 직접 만들 필요가 없어
비용·시간 측면에서 큰 이점을 가짐
이러한 조합 덕분에 LLM은
사용자 지시 이해력, 상황 적응력, 일관된 응답 품질을 전반적으로 향상시키게 됨
p30. 성능
- 평가: Aligned Model 정의 요소
- Likert, Helpful, Truthfulness, Harmlessness / Bias
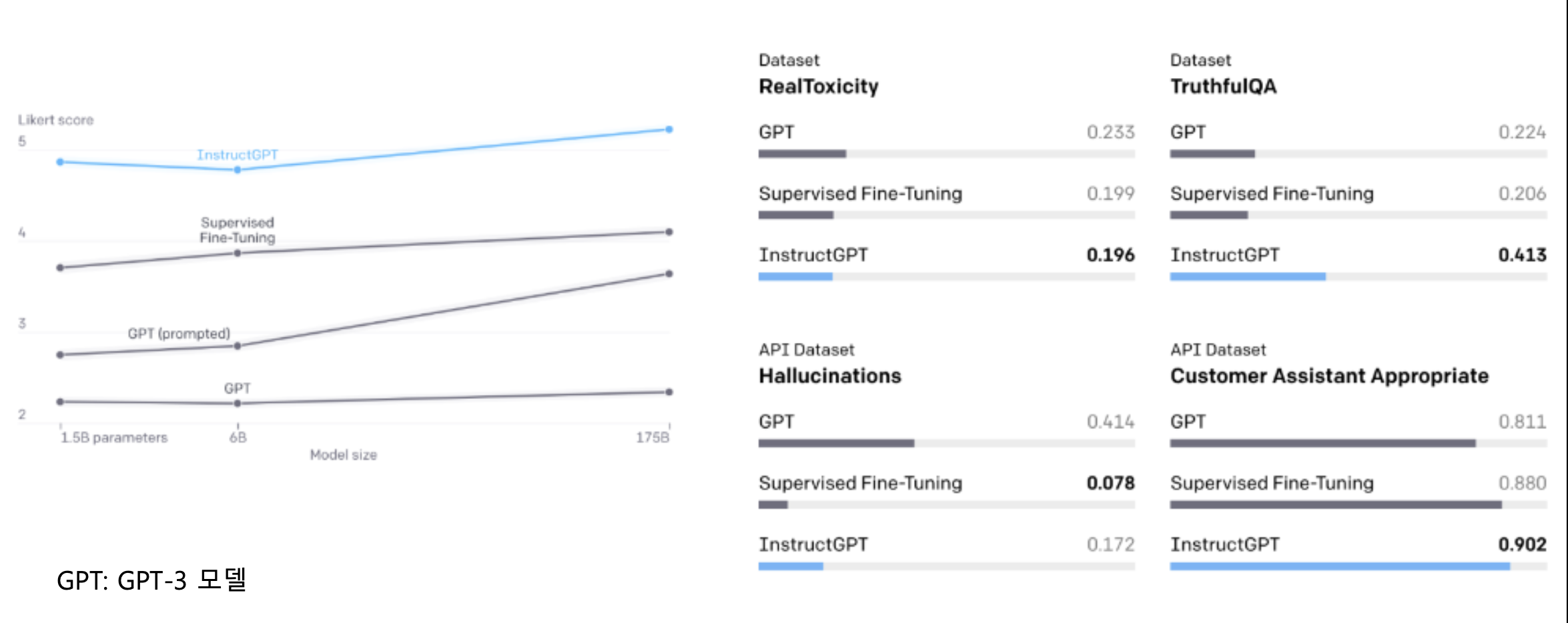
Alignment의 핵심 목표
- LLM은 단순한 다음 토큰 예측기가 아니라
인간의 지시와 의도에 부합하는 모델로 정렬되어야 함- 이를 평가하기 위해 Truthfulness(진실성), Harmlessness(무해성),
Bias 억제 등 인간 중심 가치 지표가 사용됨- 유창성만이 아니라 사람이 원하는 방향으로 행동하는 것이 핵심
InstructGPT의 성능 향상 포인트
- 독성(Toxicity) 감소 → 불필요하게 공격적·해로운 응답을 줄임
- 진실성(TruthfulQA) 향상 → 사실 오류를 줄이고 정확한 정보 제공
- 환각(Hallucination) 억제 → 근거 없는 허위 정보 생성 감소
- 고객 응대 적절성(Customer Assistant Appropriate) 향상 →
실제 서비스·상담 환경에서 더 자연스럽고 도움이 되는 응답 제공Likert Score의 의미
- Likert scale은 사용자가 모델 출력이 얼마나 유용·만족스러운지를
평가하는 품질 지표- GPT-3 대비 InstructGPT에서 Likert 점수가 상승했다는 것은
모델이 실제 사용자 관점에서 더 도움이 되는 방향으로 정렬되었음을 의미결론적 시사점
- InstructGPT는 Performance + Alignment를 동시에 끌어올린 사례
- 단순히 파라미터 수를 늘리는 것이 아니라
인간 피드백 기반 학습(RLHF) 과 지도 학습(SFT) 이
실질적인 품질 향상에 결정적임을 보여줌
p31. LLM 구축 방법
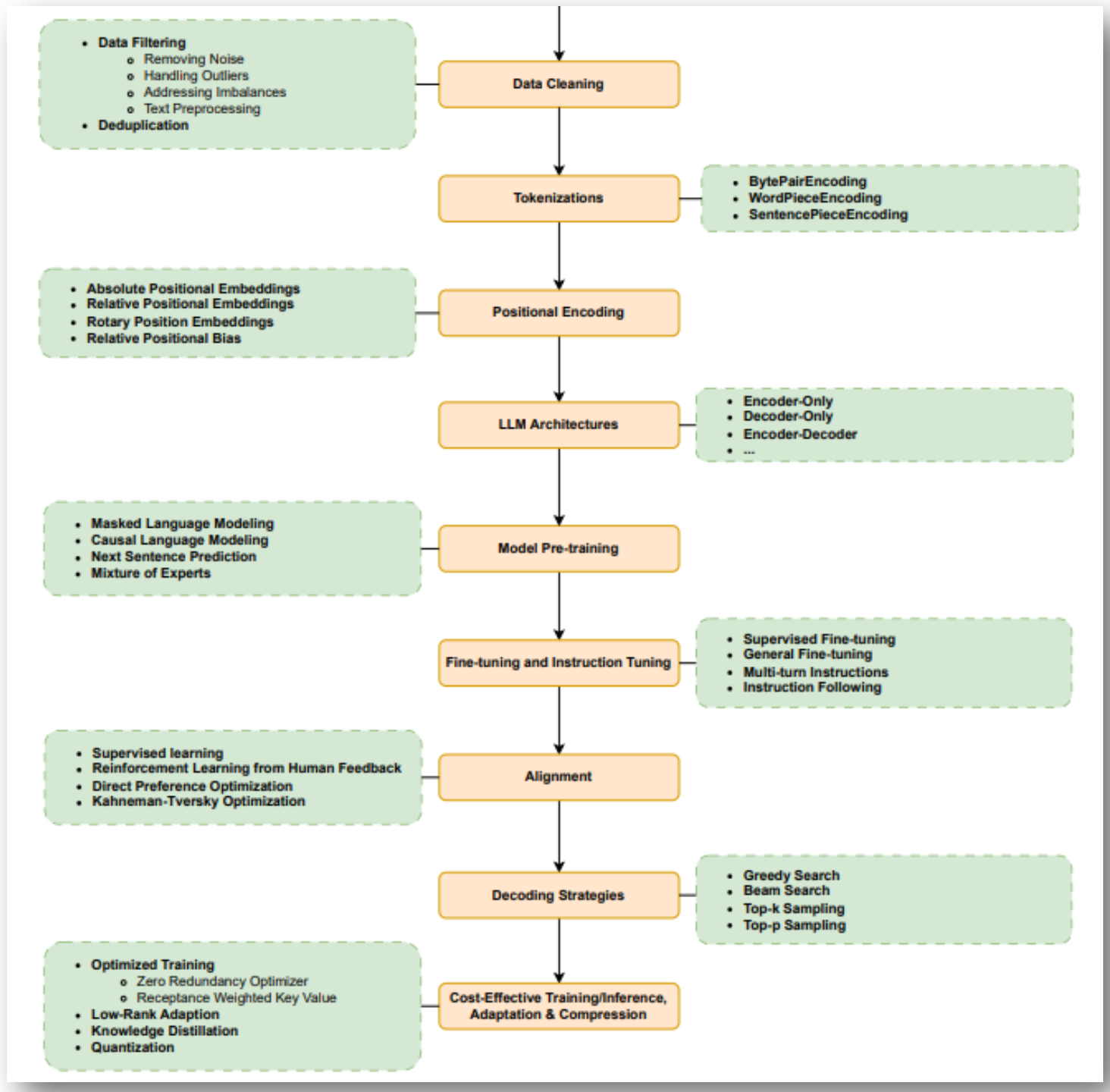
- 데이터 정제 (Data Cleaning)
- 데이터 필터링 (Data Filtering)
- 노이즈 제거 (Removing Noise)
- 이상치 처리 (Handling Outliers)
- 불균형 보정 (Addressing Imbalances)
- 텍스트 전처리 (Text Preprocessing)
- 중복 제거 (Deduplication)
- 데이터 필터링 (Data Filtering)
- 토크나이즈 (Tokenizations)
- 바이트쌍 인코딩 (Byte Pair Encoding)
- 워드피스 인코딩 (WordPiece Encoding)
- 센텐스피스 인코딩 (SentencePiece Encoding)
- 위치 인코딩 (Positional Encoding)
- 절대 위치 임베딩 (Absolute Positional Embeddings)
- 상대 위치 임베딩 (Relative Positional Embeddings)
- 회전 위치 임베딩 (Rotary Position Embeddings)
- 상대 위치 편향 (Relative Positional Bias)
- LLM 아키텍처 (LLM Architectures)
- 인코더 전용 (Encoder-Only)
- 디코더 전용 (Decoder-Only)
- 인코더-디코더 (Encoder-Decoder)
- 모델 사전학습 (Model Pre-training)
- 마스크드 언어 모델링 (Masked Language Modeling)
- 인과적 언어 모델링 (Causal Language Modeling)
- 다음 문장 예측 (Next Sentence Prediction)
- 전문가 혼합 (Mixture of Experts)
- 파인튜닝 및 지시 튜닝 (Fine-tuning and Instruction Tuning)
- 지도 학습 파인튜닝 (Supervised Fine-tuning)
- 일반 파인튜닝 (General Fine-tuning)
- 다중 턴 지시 (Multi-turn Instructions)
- 지시 따르기 (Instruction Following)
- 정렬 (Alignment)
- 지도 학습 (Supervised Learning)
- 인간 피드백 기반 강화학습 (Reinforcement Learning from Human Feedback)
- 직접 선호 최적화 (Direct Preference Optimization)
- 카너먼-트버스키 최적화 (Kahneman-Tversky Optimization)
- 디코딩 전략 (Decoding Strategies)
- 탐욕적 탐색 (Greedy Search)
- 빔 서치 (Beam Search)
- Top-k 샘플링 (Top-k Sampling)
- Top-p 샘플링 (Top-p Sampling)
- 비용 효율적 학습/추론, 적응 및 압축 (Cost-Effective Training/Inference, Adaptation & Compression)
- 최적화된 학습 (Optimized Training)
- 제로 중복 최적화기 (Zero Redundancy Optimizer)
- 가중 키-값 기법 (Repactance Weighted Key Value)
- 저랭크 적응 (Low-Rank Adaption)
- 지식 증류 (Knowledge Distillation)
- 양자화 (Quantization)
- 최적화된 학습 (Optimized Training)
데이터 정제와 중복 제거의 중요성
- LLM의 성능은 훈련 데이터 품질에 크게 좌우됨
- 노이즈나 중복 데이터가 포함되면 편향(bias)·과적합(overfitting)이 발생
- 따라서 Data Filtering, Deduplication은 학습의 출발점이자 핵심 단계
위치 인코딩(Positional Encoding)의 역할
- Transformer는 순차 구조가 없으므로 입력 토큰의 순서를 직접 알 수 없음
- 이를 해결하기 위해 Absolute / Relative / Rotary 위치 임베딩이 사용됨
- 특히 RoPE는 긴 문맥(long context) 처리에서 필수적이며
RAG에서도 긴 문서 embedding에 폭넓게 활용됨사전학습과 전문가 혼합(Mixture of Experts)
- Masked LM은 문맥 이해를 위한 양방향 학습(BERT 계열)
- Causal LM은 다음 토큰 예측을 통한 생성 능력 학습(GPT 계열)
- Mixture of Experts는 여러 전문가 모듈 중 일부만 활성화하여
연산 효율과 확장성을 극대화하는 기술Alignment의 필요성
- 단순히 언어 예측만 잘하는 것은 안전·유용한 모델을 만들기에 부족
- RLHF는 인간 피드백을 반영해 모델을 인간 의도에 맞게 정렬시킴
- 최근에는 강화학습 없이 선호를 직접 최적화하는 DPO 방식도 연구됨
디코딩 전략과 최종 성능
- Greedy Search는 반복적 출력 위험
- Beam Search는 다양성 부족 가능
- Top-k / Top-p 샘플링은 무작위성·창의성·다양성을 확보
모델 최적화와 경량화
- 초대규모 모델은 비용이 커서
Quantization, LoRA(저랭크 적응), Knowledge Distillation 같은
경량화·최적화 기법이 실제 서비스 배포의 핵심 기술로 사용됨
p32. 데이터 전처리
Fig. 7: 대규모 언어 모델(LLM, Large Language Models)의 사전학습을 위한 전형적인 데이터 전처리 파이프라인을 보여줌.

- 원시 말뭉치 (Raw Corpus)
- 인터넷, 논문, 코드 저장소 등에서 수집된 대규모 데이터
- 필터링 및 선택 (Filtering & Selection)
- 언어 필터링 (Language Filtering)
- 지표 기반 필터링 (Metric Filtering)
- 통계적 필터링 (Statistic Filtering)
- 키워드 필터링 (Keyword Filtering)
- 중복 제거 (De-duplication)
- 문장 단위 (Sentence-level)
- 문서 단위 (Document-level)
- 데이터셋 단위 (Set-level)
- 개인정보 축소 (Privacy Reduction)
- 개인식별정보 탐지 (Detect Personally Identifiable Information, PII)
- 개인식별정보 제거 (Remove PII)
- 토크나이즈 (Tokenization)
- 기존 토크나이저 재사용 (Reuse Existing Tokenizer)
- 센텐스피스 (SentencePiece)
- 바이트 단위 BPE (Byte-level BPE)
- 사전학습 준비 완료 (Ready to Pre-train!)
- 정제, 중복 제거, 개인정보 제거, 토큰화 과정을 거쳐 학습 가능한 데이터로 변환됨
데이터 전처리의 중요성
- LLM 성능은 모델 구조뿐 아니라 데이터 품질에 크게 좌우됨
- 노이즈 제거·중복 문서 제거·개인정보 보호는 잘못된 패턴 학습을 방지
- 전처리는 단순 준비가 아니라 모델의 안전성과 신뢰성을 보장하는 핵심 단계
중복 제거(De-duplication)의 필요성
- 동일 문장이 반복되면 과적합(overfitting) 위험 증가
- Sentence-level / Document-level / Set-level 중복 제거는
- 데이터의 다양성과 균형을 확보하기 위한 전략
개인정보 보호(Privacy Reduction)
- 웹 크롤링 기반 데이터에는 PII(개인식별정보)가 포함될 수 있음
- PII가 포함되면 모델이 민감한 정보를 그대로 출력할 위험
- 따라서 탐지(detect) → 제거(remove)를 통해 안전한 학습 데이터셋 구축
토크나이즈(Tokenization)의 역할
- LLM은 텍스트를 토큰 단위로 나누어 처리
- SentencePiece, Byte-level BPE 등은 희귀 단어·다국어 처리에 강력
- 토크나이즈는 인간 언어를 모델이 이해 가능한 벡터 표현으로 바꾸는 다리 역할
최종 단계: Ready to Pre-train
- 노이즈 제거 → 중복 제거 → 개인정보 보호 → 토큰화 과정을 통과한 데이터는
- 대규모 사전학습(pre-training)에 적합하며 학습 효율성과 안정성이 높아짐
p33. LLM의 Capabilities
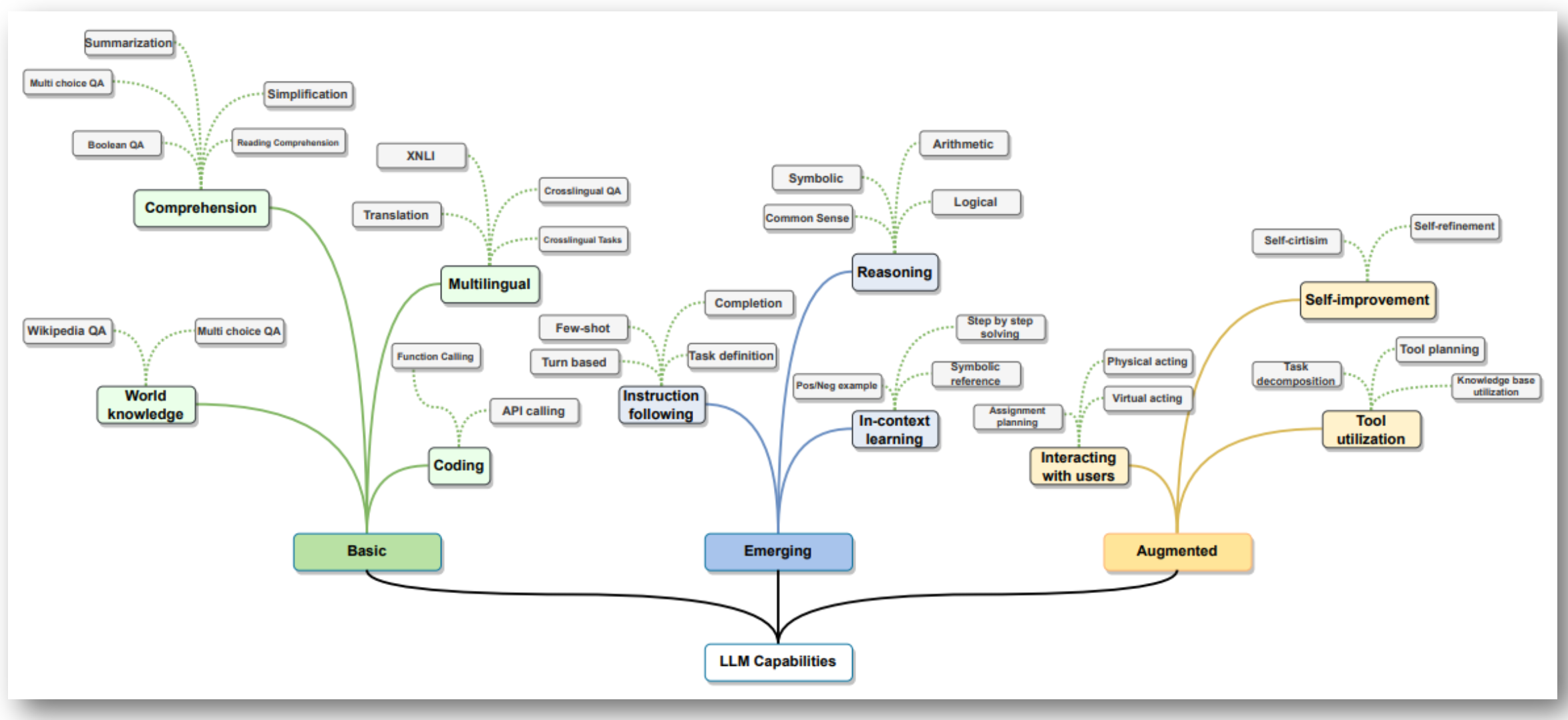
- 기초 기능 (Basic)
- 이해 (Comprehension): 요약(Summarization), 객관식 질의응답(Multi choice QA), 참/거짓 질의응답(Boolean QA), 단순화(Simplification), 독해(Reading Comprehension)
- 세계 지식 (World knowledge): 위키피디아 질의응답(Wikipedia QA), 객관식 질의응답(Multi choice QA)
- 코딩 (Coding): API 호출(API calling), 함수 호출(Function Calling)
- 다국어 (Multilingual): 번역(Translation), XNLI, 교차 언어 질의응답(Crosslingual QA), 교차 언어 작업(Crosslingual Tasks)
- 발현 기능 (Emerging)
- 지시 따르기 (Instruction following): 작업 정의(Task definition), 완성(Completion), 퓨샷(Few-shot), 턴 기반(Turn based)
- 추론 (Reasoning): 상징적(Symbolic), 상식(Common Sense), 산술(Arithmetic), 논리(Logical)
- 맥락 내 학습 (In-context learning): 단계별 해결(Step by step solving), 상징적 참조(Symbolic reference), 과제 계획(Assignment planning), 긍/부정 예시(Pos/Neg example)
- 증강 기능 (Augmented)
- 사용자와 상호작용 (Interacting with users): 물리적 행동(Physical acting), 가상 행동(Virtual acting)
- 도구 활용 (Tool utilization): 작업 분해(Task decomposition), 도구 계획(Tool planning), 지식 기반 활용(Knowledge base utilization)
- 자기 개선 (Self-improvement): 자기 비판(Self-criticism), 자기 정제(Self-refinement)
기초 기능
- LLM이 기본적으로 수행할 수 있는 언어 처리 능력
- 요약, 번역, 질의응답, 코드 실행 등 사람이 추가 지시를 하지 않아도 가능한 범용 기능
- ‘이해’는 텍스트 의미 파악·질문 답변 포함
- ‘다국어’는 다양한 언어 간 번역·질의응답 수행 가능
발현 기능
- 사전 학습되지 않은 새로운 작업을 예시 몇 개로 수행하는 Few-shot learning
- 입력 맥락만으로 새로운 작업을 학습하는 In-context learning
- 상식적·논리적 추론을 통해 단순 텍스트 처리 이상의 고차원 작업 수행
증강 기능
- LLM이 외부 도구를 활용하고 스스로 개선하는 능력
예: 외부 API 호출, 데이터베이스 검색 등의 ‘도구 활용’- 모델이 스스로 오류를 검토하고 수정하는 ‘자기 개선’
- 지능형 에이전트(Agent)로 발전하는 핵심 요소
p34. 자연어처리 성능향상 기술요소
- LLM 활용에 기반이 되는 Foundation Model
- 대규모 모델 학습을 위한 Mixture-of-Experts
- 적은 계산 비용으로 대규모 모델 학습을 가능하게 하는 효율적인 구조
- 트랜스포머 모델의 Feed-Forward Network(FFN) 계층을 다수의 FFN으로 구성된 MoE Layer로 대체, 입력 토큰마다 선택적으로 특정 Expert들을 활성화해 연산을 수행하는 모델 구조
- 빠르고 효율적인 학습을 위한 FP8 Training
- LLM의 학습 속도와 효율을 더 높이기 위한 낮은 정밀도 학습이 주목
- 초기 32비트(Float32)에서 시작하여 Bf16과 같은 16비트 → 최근에는 8비트(FP8)
- 메모리 사용량 감소와 함께 계산 속도 향상되는 이점
- 대규모 모델 학습을 위한 Mixture-of-Experts
- 데이터 처리 및 품질 향상
- 라벨링 및 데이터 증강(Data Augmentation): 적은 데이터로 모델 성능을 높이는 기법
- 노이즈 제거(Noise Reduction): 철자 오류 수정, 중복 데이터 제거
- 멀티모달 데이터 활용(Multimodal Learning): 텍스트 뿐만 아니라 이미지, 음성을 함께 처리
- 고품질의 Instruction Data 생성
p35. 자연어처리 성능향상 기술요소
- 모델 최적화 및 학습 기법
- Transfer Learning: 사전학습 된 모델을 활용하여 새로운 작업에 적은 데이터로 적용
- In context Learning: 적은 학습 데이터로 성능을 유지하는 기법
- Knowledge Distillation: 대형 모델의 지식을 작은 모델로 전이하여 경량화
- 사람의 지시를 잘 따르기 위한 Instruction Tuning과 심층 추론을 위한 Reasoning Model
- 사람의 선호를 학습하는 Preference Learning
- 하드웨어 및 시스템 지원
- GPU/TPU 가속 (Hardware Acceleration): 대규모 NLP 모델 학습 속도 향상
- 분산 학습 (Distributed Training): 여러 장비에서 병렬 학습 수행
- 경량화 모델 (Edge AI, Mobile AI): 모바일 및 임베디드 환경에서도 NLP 활용 가능
- 보안 및 윤리적 고려
p36. LLM의 특징 및 장점
- 방대하고 광범위한 지식 활용
- 방대한 양의 텍스트 데이터를 학습하여 다양한 분야의 지식을 습득
- 학습한 지식을 바탕으로 사용자의 질문에 폭넓고 심도 있는 답변 가능
- 뛰어난 언어 이해 및 생성 능력
- 단어 간의 관계와 문맥을 고려하여 자연스러운 언어 이해 가능
- 문법적으로 정확하고 의미 있는 문장 생성 능력
- 전이학습 및 다양한 태스크 수행 능력
- 텍스트 분류, 질의응답, 요약, 번역, 문장 생성 등 다양한 NLP 태스크 처리 가능
- 하나의 모델로 여러 태스크를 수행할 수 있어 범용성이 높음
- 한 분야에서 학습한 지식을 다른 유사 태스크에 활용하는 등 전이 학습이 가능
- 사용자 친화적인 인터페이스
- 자연어로 된 사용자 입력을 이해하고 응답할 수 있어 접근성이 좋음
- 챗봇, 가상 어시스턴트 등으로 활용되어 사용자 경험 향상
- 다양한 분야에서의 활용
- 고객 서비스, 콘텐츠 제작, 교육, 의료 등 다양한 산업 분야에서 활용 가능
- 사람과 기계 간의 상호작용을 향상시키고 업무 효율성 증대에 기여
p37. LLM의 단점
- 편향성과 공정성 문제
- 학습 데이터에 내재된 편향성을 그대로 반영할 수 있음
- 성별, 인종, 종교 등에 대한 고정관념이나 차별적 표현을 생성할 위험 존재
- 사실 관계 오류 가능성 (Hallucination)
- 방대한 데이터를 학습하지만, 항상 정확한 정보를 제공하지는 않음
- 잘못된 정보나 허위 정보를 진실로 간주하고 전파할 수 있음
- 일관성 문제
- 동일한 입력에 대해 일관된 답변을 생성하지 않을 수 있음
- 모델의 확률적 특성상 생성 결과가 매번 달라질 수 있어 신뢰성 저하
- 윤리적 문제
- 악용 가능성이 존재하며, 책임 소재 파악이 어려울 수 있음
- 모델의 출력 결과에 대한 통제와 검증 체계 마련 필요
개인정보 보호 및 기업내 데이터 활용의 어려움
- 새로운 정보의 반영 (실시간적 변화 등)
p38. 프롬프트 엔지니어링
- 기본 프롬프트 엔지니어링 기법
- Few-shot prompting
- 역할부여(Role Playing) prompting
- 제약 조건 기반 prompting
- 출력형식제어 prompting
- 고급 프롬프트 엔지니어링 기법
- Prompt Chaining
- Chain-of-Thought (CoT), MultiModal CoT
- Generate Knowledge Prompting
- Automatic CoT (Auto-CoT)
- Self-consistency CoT
- Meta Prompt
- AutomaicPromptEngineer (APE)
- RAG (Retrieval Augmented Generation)
- ReAct (Reason + Act)
- Function Calling
p39. 프롬프트 엔지니어링
In-Context Learning
모델 파라미터를 업데이트하며 학습하는 것이 아니고,
새로운 문제나 도메인에 모델을 적용할 때 (Inference 시) 잘 해보자는 접근방법으로,
프롬프트를 잘 구성하여 원하는 Task를 수행하는 방법즉, 프롬프트 내 맥락적 의미(in-context)를 모델이 이해하고(learning),
이에 따라 답변을 생성하는 방법임.
p40. 기본 프롬프트 기법
기본 프롬프트 구조
- 지시 (Instruction)
- 모델에게 수행할 태스크를 명확히 알려주는 부분
- “주어진 영화 리뷰의 감성을 긍정 또는 부정으로 분류하시오.”
- “당신은 영화 리뷰 분석 전문가입니다. 리뷰의 감성을 판단해주세요.”
- “다음 리뷰가 긍정적인지 부정적인지 결정하세요.”
- 모델에게 수행할 태스크를 명확히 알려주는 부분
- 컨텍스트 (Context)
- 태스크 수행에 필요한 배경 정보나 자료
- “감성 분류는 ‘긍정’ 또는 ‘부정’ 둘 중 하나로만 응답해야 합니다.” (규칙 제시)
- “긍정적인 리뷰는 영화에 대한 만족감, 칭찬, 추천 등의 내용을 포함합니다. 부정적인 리뷰는 실망감, 비판, 불만족 등의 내용을 포함합니다.” (개념 정의)
- (Few-shot 예시 - 아래 ‘입력 데이터’와 ‘출력 형식 지시’ 포함하여 구성)
- 태스크 수행에 필요한 배경 정보나 자료
- 입력 데이터 (Input Data)
- 모델이 처리해야 할 실제 데이터
- 간단한 텍스트 분류 또는 정보 추출 프롬프트 작성 및 모델 출력 확인 (예: 분석할 텍스트)
- “리뷰: 영상미는 뛰어났지만 스토리가 좀 아쉬웠어요.” (모델이 분류할 실제 리뷰)
- “사용자 리뷰: 이 영화 정말 인생 영화입니다!”
- 출력 형식 지시 (Output Indicator)
- 원하는 출력의 시작이나 형식을 알려주는 표시
- “감성:”
- “분류 결과:”
- “판단:”
- 원하는 출력의 시작이나 형식을 알려주는 표시
p41. 기본 프롬프트 예시
[지시]
아래의 문단을 읽은 뒤, 그 속에서 사실에 근거한 주장들을 뽑아내고,
이후 해당 주장들의 사실 여부를 확인할 수 있도록 검색 엔진에 던질 질문들을 만들어줘.[문단]
톰 크루즈는 니콜 키드먼과 재혼했다. 그들에게 3명의 자녀가 있으며,
그는 현재 니콜 키드먼과 이혼한 상태이다.
나는 여기서 검색 엔진에 어떤 질문을 검색해야 사실 여부를 확인할 수 있을까?[요청]
여기서 사실에 근거한 주장들을 뽑아주고, 사실 여부 확인할 수 있는 질문들을 만들되,
질문을 만들 때에는 SEARCH(“query”) 형식으로 만들어줘.
Chat GPT 답변
- 추출된 주장들
- 톰 크루즈는 니콜 키드먼과 재혼했다.
- 그들에게 3명의 자녀가 있다.
- 그는 현재 니콜 키드먼과 이혼한 상태이다.
- 검색 질문들
- 톰 크루즈와 니콜 키드먼의 재혼 여부 확인
- SEARCH(“Tom Cruise remarried Nicole Kidman”)
- SEARCH(“Tom Cruise Nicole Kidman remarriage”)
- 톰 크루즈와 니콜 키드먼의 자녀 수 확인
- SEARCH(“Tom Cruise Nicole Kidman three children”)
- SEARCH(“Tom Cruise Nicole Kidman children”)
- SEARCH(“Tom Cruise Nicole Kidman family”)
- 톰 크루즈와 니콜 키드먼의 이혼 상태 확인
- SEARCH(“Tom Cruise Nicole Kidman divorce”)
- SEARCH(“Tom Cruise Nicole Kidman current relationship status”)
- SEARCH(“Tom Cruise Nicole Kidman divorced”)
이러한 질문들을 검색 엔진에 입력하면, 해당 주장들의 사실 여부를 확인할 수 있는 정보를 찾을 수 있습니다.
p42. 프롬프트 엔지니어링 기법
Few-Shot Prompting
- 문맥 내 학습(In Context Learning)을 사용한 프롬프트팅 기법
새로운 문제나 도메인에서 원하는 작업의 성공적인 작업 수행 예시를 제공하여
새로운 문제에 대해 원하는 수행결과를 생성하는 기법다음의 예시에서와 같이 주어진 텍스트에서 속성과 속성에 대한 의견을 추출해줘
예시1: 내 두피 상태에 맞춤형으로 원하는 향과 헤어케어에 도움이 되었다.
→<두피, 맞춤형이다>, <향, 원한다>, <헤어케어, 도움된다>예시2: 브랜드 이미지가 좋고 아파트 주변 조경이 맘에 든다.
→<브랜드 이미지, 좋다>, <주변 조경, 좋다>텍스트: 롯데캐슬이란 상호가 왠지 고급스럽게 느껴짐
- Chat GPT 답변
<상호, 고급스럽다>
- Chat GPT 답변
Your task is to answer in a consistent style.
**
**: Teach me about patience. ** **: The river that carves the deepest valley flows from a modest spring; the grandest symphony originates from a single note; the most intricate tapestry begins with a solitary thread. **
**: Teach me about resilience. - Chat GPT 답변
**
**: The mighty bamboo bends but does not break under the fiercest winds; the persistent water erodes even the hardest stone over time; the small seedling that pushes through the concrete crack reaches for the sun.
- Chat GPT 답변
p43. 기본 프롬프트 엔지니어링 기법
역할 부여 (Role Playing) 프롬프트
- 모델에게 특정 역할(예: 전문 연구원, 비평가, 요약 전문가)을 부여하는 기법
역할 부여를 통해 모델의 응답 스타일과 내용 제어
- 주요목적
- 모델 응답의 스타일과 톤을 특정 역할에 맞게 조정
- 특정 역할의 전문성이나 관점을 반영한 정보를 획득
- 사용자의 의도를 모델에게 더 명확하게 전달
- 예시
- “블록체인 기술에 대해 설명해 줘.” vs.
- “당신은 블록체인 기술 전문가입니다. 블록체인 기술의 핵심 원리를 비전공자도 이해할 수 있도록 쉽게 설명해주세요. 설명 대상: 블록체인 기술”
- “당신은 전통적인 금융 시장의 분석가입니다. 블록체인 기술이 기존 금융 시스템에 미칠 잠재적 영향을 대해 분석해 주세요. 분석 대상: 블록체인 기술과 기존 금융 시스템의 관계”
- 실습
p44. 기본 프롬프트 엔지니어링 기법
제약 조건 기반 프롬프트
- 모델의 응답을 사용자의 의도에 더욱 정확하게 맞추고 통제하기 위한 기법 중 하나
- 출력의 길이, 스타일, 포함/제외해야 할 내용 등 구체적인 제약 조건 명시
- 부정적 제약 (Negative Constraints): 모델이 하지 말아야 할 것을 명시
- 제약 조건 충돌 관리
- LLM은
- 생성될 응답의 형태, 내용, 길이에 대한 구체적인 제한을 설정
- 제약 조건 기반 프롬프트 작성 방법
모델이 명확하게 인식하고 따를 수 있도록 지시를 구체적으로 작성- 명확한 지시: 제약 조건을 포함하는 지시사항을 프롬프트의 시작 부분이나 모델이 태스크를 수행하기 직전에 명확하게 제시
- 구체적인 수치/기준 제시: 길이 제한이라면 몇 글자/단어/문장인지, 키워드인지 등을 정확하게 명시
- 강조 표현 (선택 사항): 중요한 제약 조건의 경우, 대문자 사용, 볼드체(마크다운 환경), 특정 기호 등을 사용
- 부정적 제약 활용: “무엇을 하지 마세요”라는 형태의 부정적 제약도 유용
- 예시 활용 (Few-shot): 제약 조건을 따르는 예시를 함께 제공
p45. 기본 프롬프트 엔지니어링 기법
다음 제품에 대한 소개 글을 작성해 줘. 소개 글은 반드시 50자 이상 100자 이하로 작성해야 해.
제품: 최신 스마트 워치 “TechTime Pro”다음 제품에 대한 소개 글을 작성해 줘. 소개 글에는 “혁신적인 디자인”과 “오래가는 배터리”라는 키워드를 반드시 포함해야 해.
제품: 최신 스마트 워치 “TechTime Pro”다음 제품에 대한 소개 글을 작성해 줘. 소개 글에는 “방수 기능” 또는 “운동 추적” 기능에 대한 내용은 절대 언급하지 않아야 해.
제품: 최신 스마트 워치 “TechTime Pro”당신은 제품 마케터입니다. 다음 제품에 대한 짧은 홍보 문구를 작성해 주세요. 홍보 문구는 “30자 이내”여야 하며, “스마트”, “시간”, “디자인” 이 세 단어를 모두 포함해야 합니다. 또한, 가격에 대한 언급은 절대 하지 마세요.
제품: 최신 스마트 워치 “TechTime Pro”홍보 문구:
p46. 기본 프롬프트 엔지니어링 기법
- 출력 형식 제어 기법
- 모델이 생성하는 응답이 특정 구조나 포맷을 따르도록 유도
- 출력 형식 제어 기법
- 명확한 지시: 원하는 출력 형식을 텍스트로 명확하게 설명 (예: “응답은 JSON 형식으로 작성해 줘.”)
- 출력형식 지시어 사용 (예: “결과:”, “JSON Output:”)
- Few-shot 예시
- 구조화된 템플릿 제공 (구조화된 출력 요구: JSON, XML, 마크다운 테이블 등)
- 단계별 사고 과정 유도 (Chain-of-Thought Prompting, CoT)와 출력형식 제어 결합
- 모델이 특정 정보를 추출하거나 결론을 내리기까지의 추론 과정을 보여주고, 최종 결과를 특정형식으로 요약하여 제공
예시:
당신은 문서 분석 전문가입니다. 다음 문단에서 보고서의 발행 연도와 프로젝트 비용을 추출하세요.
정보 추출 과정을 단계별로 설명해주세요. 각 단계는 짧은 문장으로 작성합니다. 모든 추출 과정 설명이 끝난 후, 추출된 최종 정보를 마크다운 테이블 형식으로 요약해서 보여주세요.
— 문단: 최근 발행된 보고서에 따르면, 2023년에 착수된 이 프로젝트의 총 비용은 150만 달러였습니다. 연구 결과는 긍정적이며, 향후 추가 투자가 기대됩니다.
— 단계별 추출 과정:
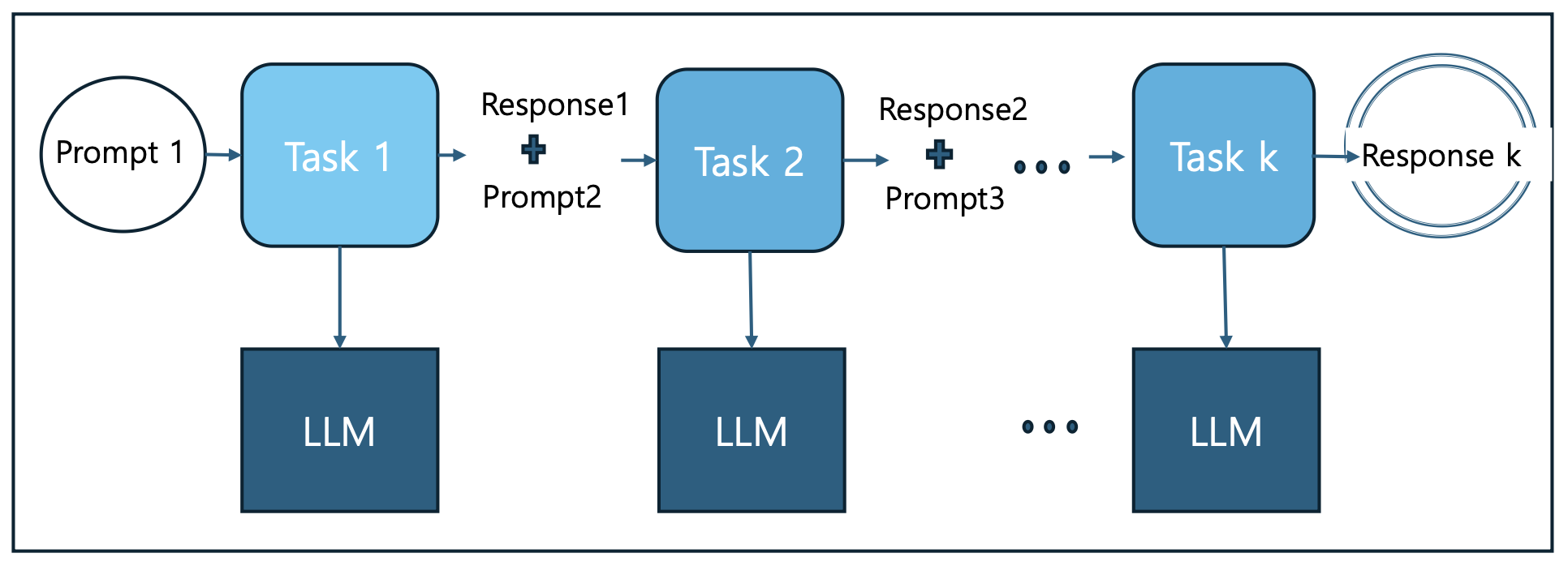
p47. 고급 프롬프트 엔지니어링 – Prompt Chaining
- Prompt Chaining:
복잡한 문제를 해결하거나 분석할 때 사용하는 방법으로
작업을 하위 작업으로 분할하여 이전 단계의 결과를 다음 단계의 입력으로 연속적으로 사용하여
프롬프트 작업의 연쇄를 만드는 기법
p48. 고급 프롬프트 엔지니어링 - CoT
- 복잡한 문제 해결 과정에서 단계별 추론을 사용하여 답변 퀄리티를 높이는 기법
- 모델이 sufficiently large LLM(충분히 큰 LLM)에서만 작동하며,
CoT 설계 시 질문을 단계별로 분해하고, 각 단계에서 필요한 정보와 추론 과정을 명시하는 것이 핵심임
Standard Prompting
Model Input
Q: Roger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 tennis balls. How many tennis balls does he have now?
A: The answer is 11.Q: The cafeteria had 23 apples. If they used 20 to make lunch and bought 6 more, how many apples do they have?
Model Output
❌ 잘못된 답변: A: The answer is 27.
Chain-of-Thought Prompting
Model Input
Q: Roger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 tennis balls. How many tennis balls does he have now?
A: Roger started with 5 balls. 2 cans of 3 tennis balls each is 6 tennis balls. 5 + 6 = 11. The answer is 11.Q: The cafeteria had 23 apples. If they used 20 to make lunch and bought 6 more, how many apples do they have?
Model Output
✅ 올바른 답변: A: The cafeteria had 23 apples originally. They used 20 to make lunch. So they had 23 - 20 = 3. They bought 6 more apples, so they have 3 + 6 = 9. The answer is 9.
p49. Multi-Modal CoT
- 텍스트와 비전을 2단계 프레임워크로 통합
- 첫 번째 단계: 다중 모드 정보를 기반으로 한 이론적 근거 생성 단계
모델에 텍스트와 이미지를 모두 제공, 텍스트와 이미지가 어떻게 관련되어 있는지 설명하는 근거 생성 - 두 번째 단계: 답변 추론
첫 번째 단계에서 생성한 정보적 근거를 사용하여 질문에 대한 정답을 추론
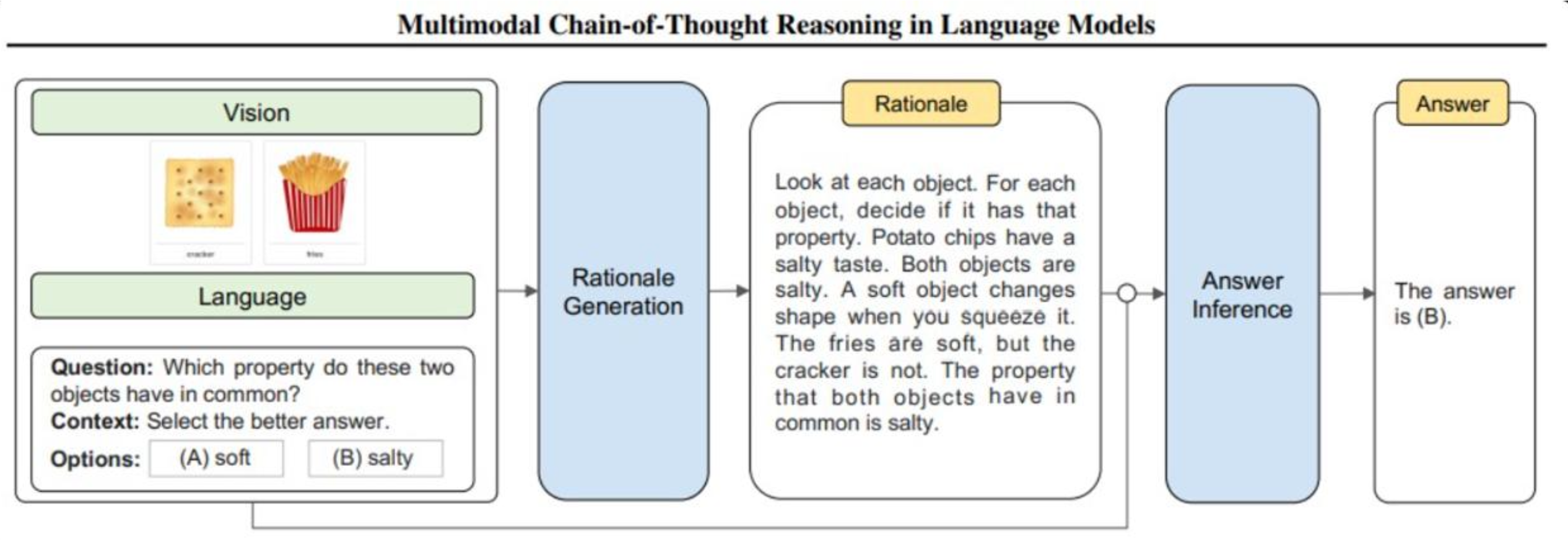
- 첫 번째 단계: 다중 모드 정보를 기반으로 한 이론적 근거 생성 단계
멀티모달 추론의 필요성
- 전통적 LLM은 텍스트 입력에 주로 의존
- 실제 문제에서는 이미지·텍스트가 함께 주어지는 경우가 많음
- Multi-Modal CoT는 다중 모드를 동시에 처리해 더 정교한 추론을 수행
2단계 프레임워크의 의미
- 근거 생성 단계: 텍스트–이미지 간 관계를 명시적으로 해석
예: 감자튀김·크래커 모두 짠 음식이라는 근거 제시- 추론 단계: 생성된 근거를 바탕으로 최종 답 도출
예: “둘 다 짠 음식 → 정답은 salty”장점과 응용
- 정답만 제공하는 것이 아니라 추론 과정(reasoning)을 투명하게 공개
- 모델의 설명가능성(Explainability) 향상
- 교육, 의료 영상 분석, 멀티모달 질의응답 등 다양한 분야에 응용 가능
p50. Generate Knowledge Prompting
- Generate Knowledge Prompting:
- 모델로부터 답을 얻기 전에 Few-shot Prompting으로 모델이 직접 관련 정보를 가져오도록 한 다음,
이를 질문과 함께 활용해서 답을 생성하는 방법
- 모델로부터 답을 얻기 전에 Few-shot Prompting으로 모델이 직접 관련 정보를 가져오도록 한 다음,
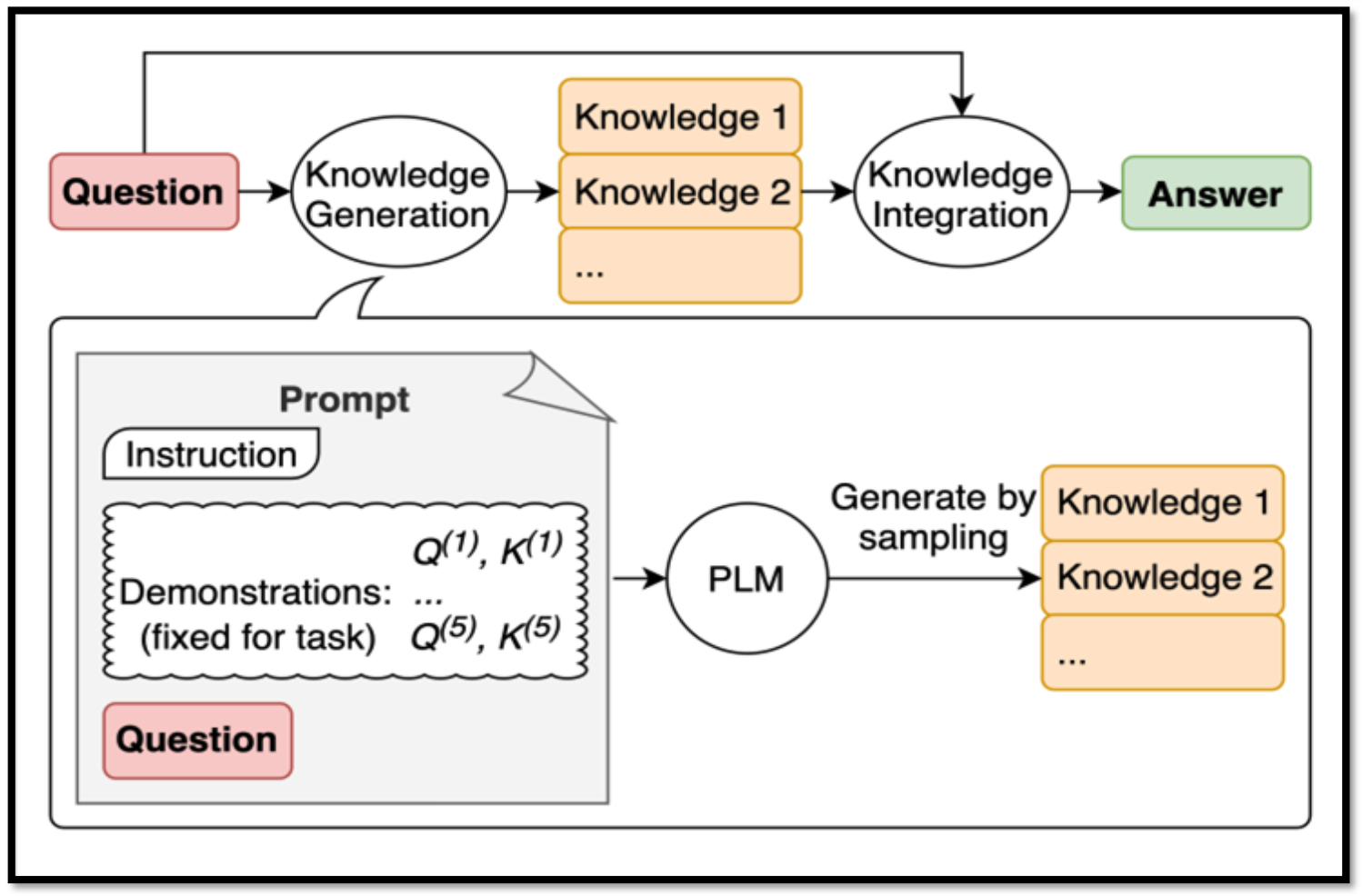
지식 생성 단계 (Knowledge Generation)
- 질문 입력 전에 모델이 먼저 관련 지식을 스스로 생성
예: “태양계의 가장 큰 행성은?” → “목성은 가장 큰 행성”과 같은 사전 지식 생성지식 통합 단계 (Knowledge Integration)
- 생성된 지식을 질문과 결합해 최종 답을 도출
- 단순 질의 이해에 그치지 않고 사전 지식을 적극 활용해 정확도를 향상
Few-shot Prompting과의 관계
- Few-shot 예시는 모델이 어떤 방식으로 지식을 생성·활용해야 하는지에 대한 가이드 역할
- 이를 통해 새로운 질문에도 더 합리적인 답변 생성 가능
활용 의의
- 지식이 부족한 질문에도 대응할 수 있어 추론 능력 강화
- 단순 검색을 넘어 맥락적 이해·지식 확장이 필요한 상황에서 특히 유용
p51. 고급 프롬프트 엔지니어링 - Meta Prompt
Meta Prompt
- 정의
- 일반적인 프롬프트가 LLM에게 “이것을 번역해 줘”, “이 질문에 답해 줘”와 같이 특정 작업을 직접 수행하도록 지시하는 것이라면,
메타 프롬프트(Meta Prompt)는 LLM에게 프롬프트 자체에 대한 작업을 수행하거나, 모델의 전반적인 행동 방식/규칙을 정의하도록 지시하는 프롬프트 - 즉, 모델의 ‘사고(思考)’나 ‘프롬프트 처리 방식’, ‘역할’ 등에 대한 지시를 담고 있으며,
사용자의 최종 태스크를 직접적으로 수행하는 것이 아니라 다른 프롬프트의 생성이나 모델의 상위 레벨 행동을 제어하는 데 관여
- 일반적인 프롬프트가 LLM에게 “이것을 번역해 줘”, “이 질문에 답해 줘”와 같이 특정 작업을 직접 수행하도록 지시하는 것이라면,
- 주요 목적 및 사용 사례
- 프롬프트 생성 (Prompt Generation)
- 특정 태스크에 대한 다양한 프롬프트 후보를 만들도록 모델에게 요청할 때 사용
- 모델 행동 방식 정의 및 제어 (Controlling Model Behavior)
- 모델에게 특정 역할(페르소나)을 부여하거나, 안전 지침, 응답 규칙 등 대화 전반에 걸쳐 지켜야 할 사항들을 설정할 때 사용
- 태스크 수행 방식 지시 (Instructing Task Approach)
- 복잡한 태스크를 해결하기 위해 모델에게 “정보를 이렇게 분석하고, 저렇게 종합하여 결론을 내려라”는 식으로 문제 해결 접근 방식을 지시할 때 사용
- 프롬프트 생성 (Prompt Generation)
p52. 고급 프롬프트 엔지니어링
1
2
3
4
5
6
7
8
9
10
11
12
meta_prompt_system_message = """
You are a helpful and friendly AI assistant. However, you are not a medical professional.
Whenever the user asks about health issues, medical conditions, symptoms, or treatments,
you must first state clearly that "I am an AI and cannot provide medical advice. Please
consult a qualified healthcare professional for any health concerns."
Before providing any general information, start your response with this exact sentence.
For other types of questions, answer normally.
"""
# --- 사용자 질문 예시 ---
user_question_health = "요즘 계속 피곤하고 두통이 있어요. 왜 그런 걸까요?"
user_question_other = "오늘 날씨는 어떤가요?"
1
2
3
4
5
6
7
8
9
--- 사용자 질문: 요즘 계속 피곤하고 두통이 있어요. 왜 그런 걸까요?
--- 모델 응답: 저는 AI이며 의료 조언을 제공할 수 없습니다. 건강 문제에 대해서는 자격을 갖춘 의료 전문가와 상담하시기
바랍니다. 일반적으로 피곤함과 두통은 다양한 원인으로 인해 발생할 수 있습니다. 스트레스, 수면 부족, 탈수, 과도한
카페인 섭취 또는 심지어 감기와 같은 감염이 원인일 수 있습니다. 하지만 정확한 원인은 전문가의 진단이 필요합니다.
건강을 잘 챙기세요!
--- 사용자 질문: 오늘 날씨는 어떤가요?
--- 모델 응답: 오늘의 날씨는 지역에 따라 다를 수 있습니다. 구체적인 지역을 알려주시면 더 정확한 정보를 제공해드릴 수
있습니다. 또는, 기상청 웹사이트나 날씨 앱을 통해 최신 날씨 정보를 확인하시는 것도 좋은 방법입니다!
메타 프롬프트(Meta Prompt)의 의미
- 일반적인 프롬프트는 모델에게 “번역해 줘”, “요약해 줘” 등 특정 작업을 직접 수행하라고 지시한다.
- 그러나 메타 프롬프트는 모델에게 작업 수행 방식, 규칙, 행동 원칙을 정의하도록 지시하는 상위 레벨의 프롬프트다.
- 즉, 사용자의 질문에 바로 답하는 것이 아니라, 모델이 앞으로 어떤 태도로 답해야 하는지를 설정하는 역할을 한다.
안전성과 일관성 확보
- 슬라이드의 예시처럼, 건강 문제와 같은 민감한 주제에서는 모델이 직접 의료 조언을 제공하는 것이 위험하다.
- 따라서 “AI는 의료 전문가가 아니며, 의료 조언을 줄 수 없다”라는 문장을 반드시 먼저 출력하게 하여 안전한 응답을 보장한다.
- 이런 방식은 모델이 민감한 질문에 일관되게 반응하도록 만들며, 사용자 신뢰성을 높인다.
응답 차별화의 효과
- 건강 관련 질문에는 사전 정의된 경고 문구를 반드시 포함시켜야 하며, 이후 일반적인 설명을 제공한다.
- 반면, 건강과 무관한 일반적인 질문(예: 날씨)에는 평소처럼 정상적인 답변을 제공한다.
- 이를 통해 상황별 응답 차별화가 가능해지고, 모델의 응답 품질과 책임성을 동시에 강화할 수 있다.
p53. 고급 프롬프트 엔지니어링
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# --- 메타 프롬프트 작성 ---
# 프롬프트 생성 대상 태스크 정의
target_task_description = "주어진 영화 리뷰의 감성을 '긍정' 또는 '부정'으로 분류하시오."
# 프롬프트 후보 생성을 요청하는 메타 프롬프트
meta_prompt_for_prompt_generation = f"""
당신은 대규모 언어 모델을 위한 프롬프트 작성 전문가입니다. 다음 태스크를 가장 잘 수행할 수 있는 다양하고 효과적인
한국어 프롬프트들을 5개 생성해주세요. 각 프롬프트는 사용자가 영화 리뷰 텍스트 뒤에 붙여 모델에게 감성 분류를
요청할 때 사용될 것입니다.
태스크: {target_task_description}
생성해야 할 프롬프트의 특징:
- 간결하고 명확해야 합니다.
- 다양한 표현 방식을 사용해주세요.
- 결과는 '긍정' 또는 '부정'으로 명확히 분류되도록 유도해야 합니다.
---
생성된 프롬프트들:
"""
1
2
3
4
5
6
7
8
9
10
11
12
--- 메타 프롬프트 실행 결과 (프롬프트 후보 생성)
--- LLM이 생성한 프롬프트 후보군:
1.이 영화 리뷰의 감정을 판단해 주세요.
감정이 긍정적이면 '긍정', 부정적이면 '부정'으로 분류해 주세요: [리뷰 텍스트]
2.다음 영화 리뷰를 바탕으로 감성을 분석해 주세요.
결과는 '긍정' 또는 '부정' 중 하나로 명시해 주세요: [리뷰 텍스트]
3.주어진 영화 리뷰에 대한 감정이 어떤지 평가해 주세요.
긍정적인 느낌이면 '긍정', 부정적인 느낌이면 '부정'으로 표시해 주세요: [리뷰 텍스트]
4.이 영화 리뷰를 읽고 감정을 분류해 주시기 바랍니다.
긍정적이면 '긍정', 부정적이면 '부정'으로 답변해 주세요: [리뷰 텍스트]
5.다음 영화 리뷰에 대해 감성을 결정해주세요.
긍정적일 경우 '긍정', 부정적일 경우 '부정'이라고 적어주세요: [리뷰 텍스트]
p54. 고급 프롬프트 엔지니어링
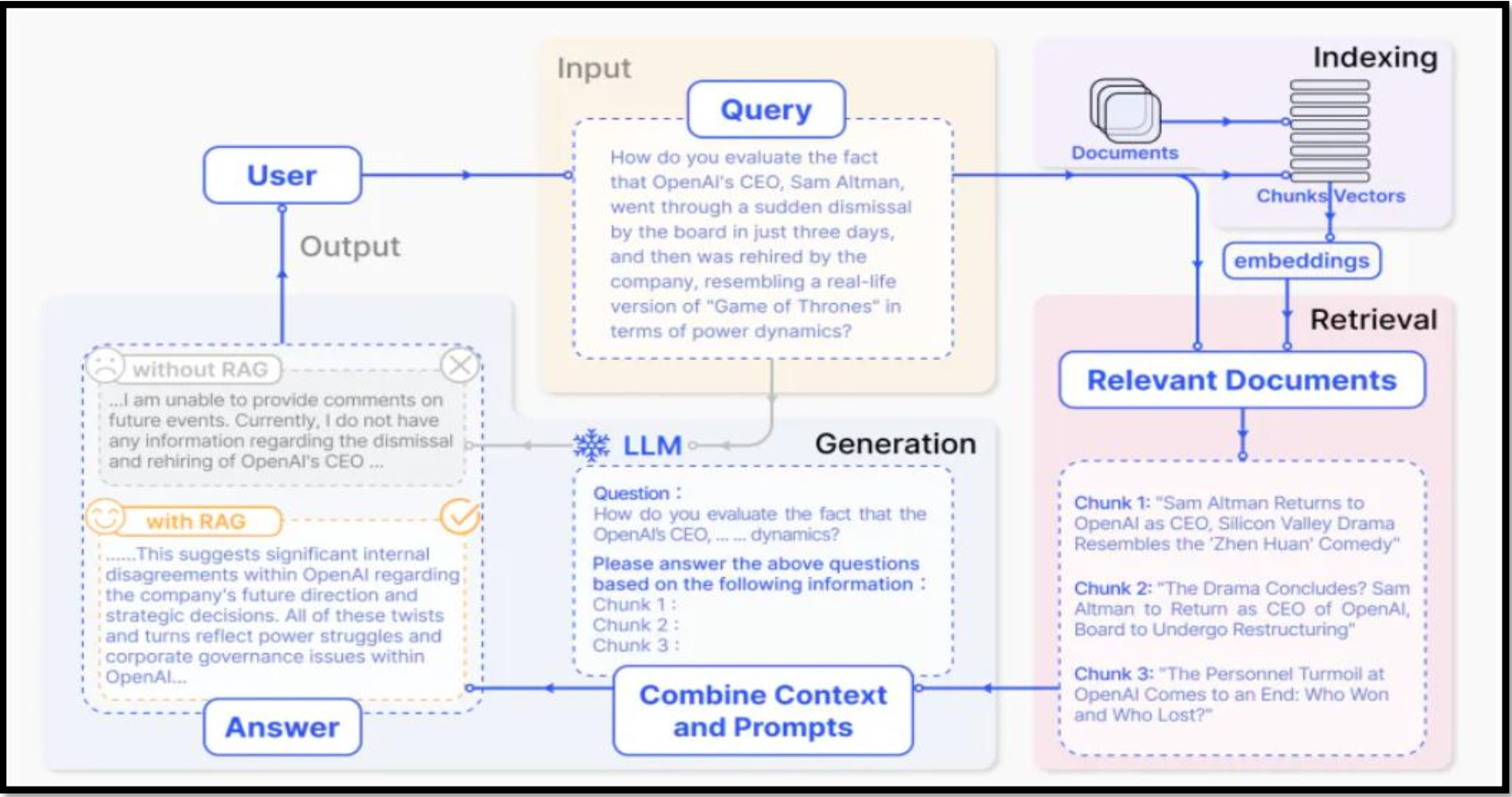
- RAG (Retrieval Augmented Generation):
- 언어모델 외부에서 가져온 정보로 모델의 정확성과 신뢰성을 향상시키는 기술
- 작업과 관련된 데이터/문서를 외부 지식베이스를 연결하여 검색한 결과를 LLM의 문맥으로 Prompt에 제공,
모델의 정확성과 신뢰성 향상시키는 기법
p55. ReAct (Reason + Act)
- ReAct (Reason + Act):
- 언어모델이 문제를 해결하는 과정에서 추론과 행동을 결합하는 기법
- 작업을 위해 언어모델이 추론 추적과 행동을 생성함으로써 행동계획을 생성, 유지 및 조정하는 동시에
외부 환경과의 상호작용을 통해 사실적 응답으로 이어지는 정보검색으로 추론에 추가 정보를 통합함 - 질의응답과 사실검증 (FEVER) 등의 언어이해 작업에서 뛰어난 성능을 보임
- 질문 (Question) : 사용자가 요청한 작업이나 해결해야 할 문제
- 사고 (Thought) : 취할 행동 식별, 행동 계획의 생성/유지/조정 방법을 언어모델에 제시
- 행동 (Action) : 사전 허용/정의된 API 등 외부 환경(예: 검색 엔진)과 모델의 실시간 상호 작용
- 관찰 (Observation) : 행동을 수행한 결과 출력
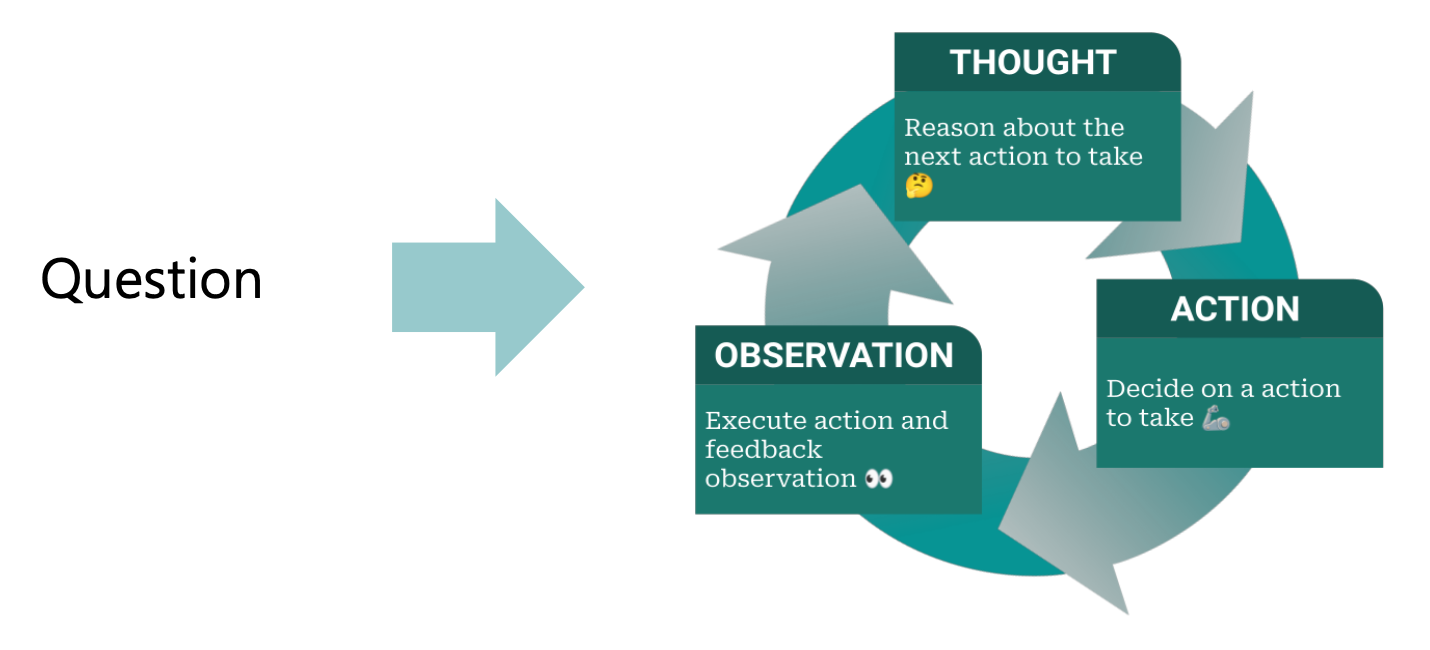
ReAct의 핵심 아이디어
- 전통적인 언어모델은 단순히 입력된 질문에 대한 답변을 생성하는 데 그쳤다.
- 그러나 ReAct는 추론(Reasoning)과 행동(Action)을 결합하여, 모델이 스스로 생각한 계획(Thought)을 실행(Action)하고 그 결과를 다시 반영(Observation)하는 순환 구조를 만든다.
- 이를 통해 모델은 단순한 텍스트 생성기를 넘어 능동적으로 환경과 상호작용하며 문제를 해결하는 에이전트 역할을 수행할 수 있다.
작동 방식
- 질문(Question) 단계에서 사용자가 해결하고자 하는 문제를 입력한다.
- 모델은 이를 기반으로 사고(Thought) 단계를 거쳐 어떤 행동을 취할지 결정한다.
- 이후 행동(Action) 단계에서 외부 도구(API, 검색 엔진 등)를 사용해 필요한 정보를 수집하거나 계산을 수행한다.
- 마지막으로 관찰(Observation) 단계에서 실행 결과를 받아들여 이를 다시 추론에 반영한다.
- 이러한 순환 과정을 통해 모델은 점진적으로 문제를 해결하며, 단순히 지식을 출력하는 것을 넘어 사실 확인과 실제 응용이 가능해진다.
응용 분야
- 질의응답(QA)과 사실 검증(Fact Verification): 모델이 검색 엔진과 같은 외부 환경을 활용하여 사실성을 보완하고 잘못된 정보를 줄인다.
- 복잡한 의사결정 문제 해결: 단순한 답변 생성이 아니라 여러 단계의 행동과 추론을 결합하여 최적의 결론을 도출한다.
- 지능형 에이전트: 일정 관리, 웹 브라우징, 데이터 수집 등 다양한 실세계 작업을 수행할 수 있는 기반을 제공한다.
p56. ReAct 예시
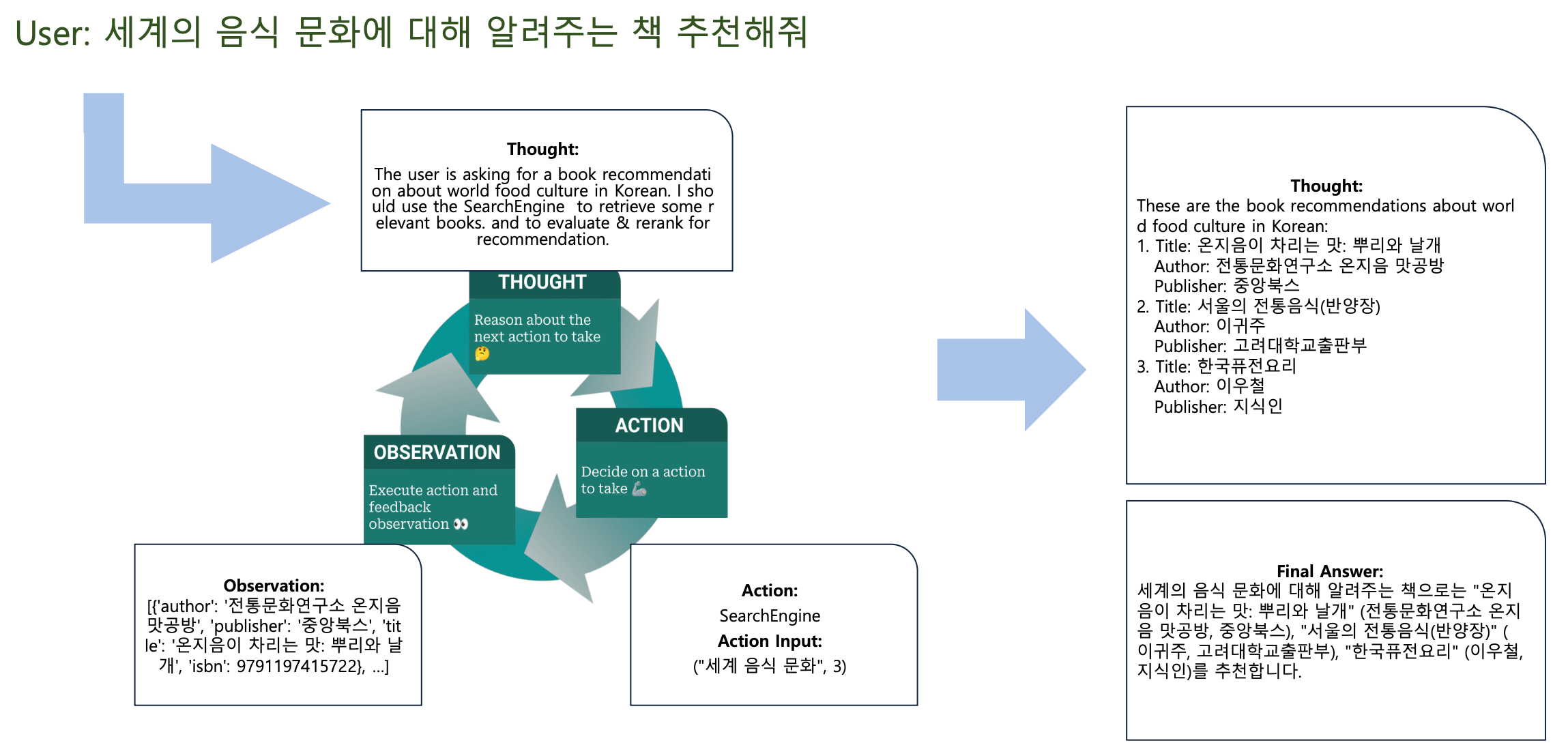
- User 요청
- 세계의 음식 문화에 대해 알려주는 책을 추천해줘
- Thought (1차 사고)
- The user is asking for a book recommendation about world food culture in Korean.
- I should use the SearchEngine to retrieve some relevant books, and to evaluate & rerank for recommendation.
- Action (행동)
- SearchEngine
- Action Input: (“세계 음식 문화”, 3)
- Observation (관찰)
- [{‘author’: ‘전통문화연구소 온지음 맛공방’, ‘publisher’: ‘중앙북스’, ‘title’: ‘온지음이 차리는 맛: 뿌리와 날개’, ‘isbn’: 9791197415722}, …]
- Thought (2차 사고)
- These are the book recommendations about world food culture in Korean:
- 온지음이 차리는 맛: 뿌리와 날개
- Author: 전통문화연구소 온지음 맛공방
- Publisher: 중앙북스
- 서울의 전통음식(반양장)
- Author: 이규전
- Publisher: 고려대학교출판부
- 한국퓨전요리
- Author: 이우철
- Publisher: 지식인
- 온지음이 차리는 맛: 뿌리와 날개
- These are the book recommendations about world food culture in Korean:
- Final Answer (최종 답변)
- 세계의 음식 문화에 대해 알려주는 책으로는
- 온지음이 차리는 맛: 뿌리와 날개 (전통문화연구소 온지음 맛공방, 중앙북스),
- 서울의 전통음식(반양장) (이규전, 고려대학교출판부),
- 한국퓨전요리 (이우철, 지식인)
을 추천합니다.
- 세계의 음식 문화에 대해 알려주는 책으로는
p57. 고급 프롬프트 엔지니어링
Function Calling
- 정의
- LLM API가 제공하는 기능으로 코드에 정의된 함수(Function)들의 설명을 LLM에게 제공하면,
LLM은 사용자의 질의를 분석하여 어떤 함수가 사용자의 의도에 가장 적합한지 판단하고,
해당 함수를 호출하는 데 필요한 인자(Arguments)를 구조화된 형식(일반적으로 JSON)으로 생성해 주는 기능
- LLM API가 제공하는 기능으로 코드에 정의된 함수(Function)들의 설명을 LLM에게 제공하면,
- 목표
- LLM의 정적 지식 한계 극복: LLM의 학습 시점 이후의 실시간 정보, 개인화된 정보,
또는 방대한 외부 데이터베이스에 접근 가능 - 외부 시스템과의 상호작용: 이메일 보내기, 알림 설정, 데이터베이스 수정 등 실제 환경에서 ‘행동’을 수행할 수 있는 기반을 마련
- 안정적인 도구 사용 인터페이스: ReAct의 텍스트 파싱 기반 Action 식별보다 훨씬 안정적이고 오류 발생 가능성이 낮은
구조화된 인터페이스(JSON)를 통해 도구 사용을 지시
- LLM의 정적 지식 한계 극복: LLM의 학습 시점 이후의 실시간 정보, 개인화된 정보,
- 작동 원리 (구현 관점)
- 실제 함수를 프로그램 내에 정의하고 구현
- 함수 설명 (Schema) 생성: 정의한 실제 함수의 이름, 기능 설명,
그리고 함수가 필요로 하는 인자들의 이름과 데이터 타입, 설명 등을 JSON Schema 형태로 정의 - LLM 호출 (User Query + Function Schemas): 사용자의 질의와 함께 2단계에서 준비한 함수 설명 리스트를 LLM API에 전달
- 모델의 판단 및 함수 호출 결정: LLM은 사용자의 질의와 함수 설명을 모두 검토
- 개발자의 코드에서 함수 호출 실행
- 실행된 함수의 결과를 다시 LLM에게 전달하기 위해 새로운 API 호출을 수행
- 이때 이전 대화 기록과 함께 ‘함수 호출 결과를 나타내는 특별한 메시지 타입’으로 함수의 반환값을 전달
- 함수 실행 결과를 LLM에 전달
- LLM의 최종 응답 생성
- 실습: 코드 참조
p58. 고급 프롬프트 엔지니어링
OpenAI 에서의 Function Calling
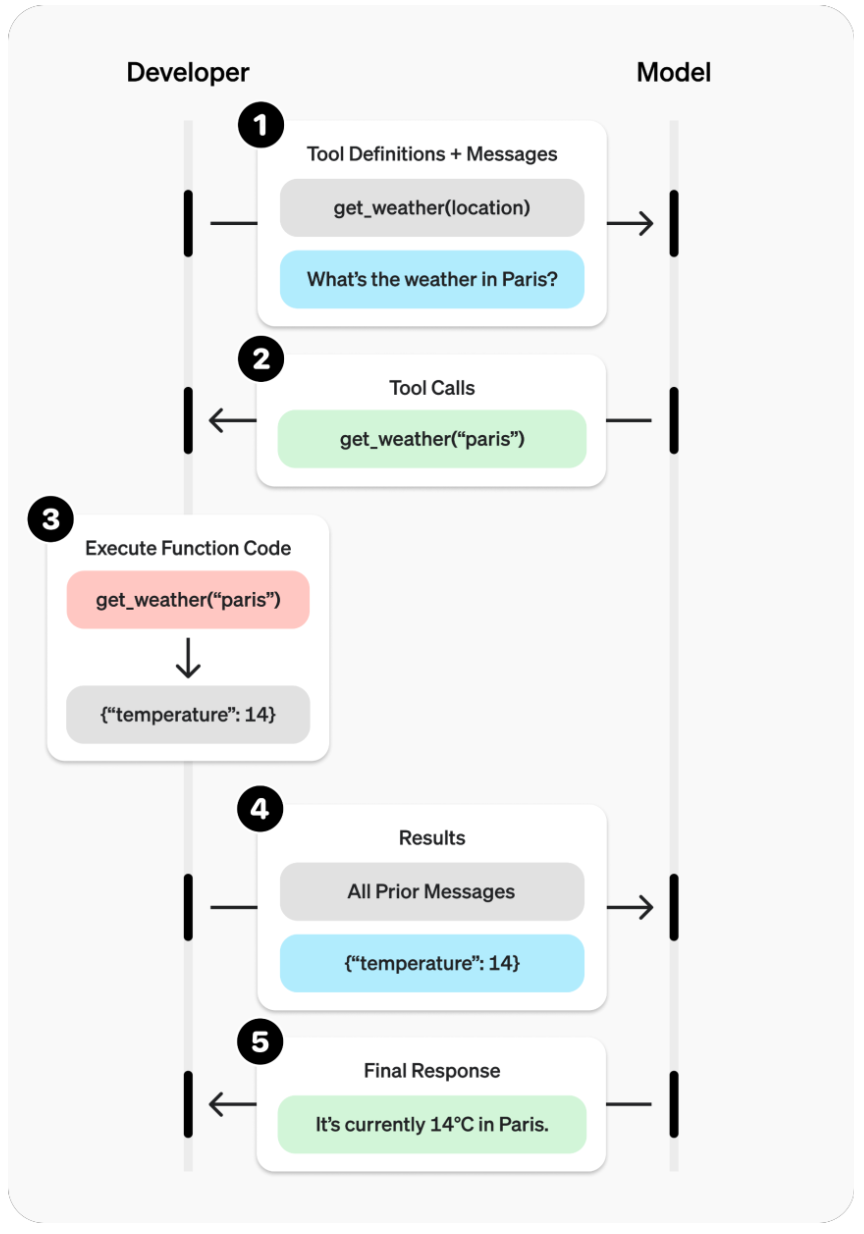
- OpenAI 에서의 Function Calling ?
- OpenAI의 Function Calling은 모델이 사용자의 질문을 분석하여 적절한 함수를 선택하고,
필요한 인자(argument)를 구조화된 형식으로 생성해 실행한 뒤, 그 결과를 다시 종합하여
최종 응답을 반환하는 과정으로 동작
- OpenAI의 Function Calling은 모델이 사용자의 질문을 분석하여 적절한 함수를 선택하고,
- 절차
- Tool Definitions + Messages
- 예:
get_weather(location) - 사용자 질문: “What’s the weather in Paris?”
- 예:
- Tool Calls
- 모델이 생성:
get_weather("paris")
- 모델이 생성:
- Execute Function Code
- 함수 실행:
get_weather("paris") - 반환:
{"temperature": 14}
- 함수 실행:
- Results
- 모든 이전 메시지와 함께 결과 전달:
{"temperature": 14}
- 모든 이전 메시지와 함께 결과 전달:
- Final Response
- 최종 응답: “It’s currently 14°C in Paris.”
- Tool Definitions + Messages
p59. ReAct vs. Function Calling
| 구분 | ReAct | Function Calling |
|---|---|---|
| 유형 | 프롬프트 엔지니어링 기법 (패턴) | 모델의 기능/API |
| 작동 방식 | 사고-행동-관찰 사이클 반복을 프롬프트로 유도 | 사용자의 의도 파악 → 정의된 함수 호출 JSON 생성 |
| 투명성 | 높음 (Thought 단계 명시적) | 낮음 (함수 호출 결정 내부 과정 불투명) |
| 출력 형식 | 자유로운 텍스트 (Thought, Action, Observation) | 구조화된 형식 (주로 JSON) |
| 유연성 | 프롬프트 내에서 다양한 액션 정의 가능 | 미리 정의된 함수 목록 내에서만 호출 가능 |
| 주요 용도 | 복잡한 추론, 다단계 문제 해결, 사고 과정 분석 | 외부 시스템(API, 데이터베이스) 연동, 특정 기능 호출 |
| 구현 복잡성 | 프롬프트 설계 복잡성, 출력 파싱 필요 | 모델 설정 및 함수 정의 필요, 출력 파싱 및 실행 로직 구현 필요 |