[빅데이터와 정보검색] 7주차 생성형AI 검색 기초 - 벡터검색과 RAG
p2. 생성형 AI 검색의 정의와 특징
생성형 AI 검색 (Generative AI Search)
대규모 언어 모델(LLM)을 활용하여 사용자의 질문을 이해하고,
관련 정보를 검색한 후 이를 종합하여 자연스러운 맞춤형 답변을 생성하는 검색 기술전통적 검색 vs. 생성형 AI 검색
| 구분 | 전통적 검색 | 생성형 AI 검색 |
|---|---|---|
| 결과 형태 | 링크 목록 | 통합된 자연어 답변 |
| 정보 처리 | 키워드 매칭 | 의미 이해 및 종합 |
| 사용자 경험 | 여러 페이지 방문 필요 | 즉각적인 답변 제공 |
| 상호작용 | 단방향 검색 | 대화형 탐색 |
| 맥락 이해 | 제한적 | 깊은 맥락 파악 |
p3. 생성형 AI 검색의 정의와 특징
생성형 AI 검색의 특징
- 자연어 이해 및 생성
- 복잡한 질문처리
- 맥락기반 해석: 이전 대화 맥락을 고려한 답변 생성
- 자연스러운 표현: 검색결과를 사람이 말하듯 자연스럽게 구성
- 정보 통합 및 종합
- 다중 출처 결합: 여러 웹페이지, 문서의 정보를 하나의 답변으로 통합
- 요약 및 정리: 방대한 정보 중 핵심만 추출하여 제공
- 비교분석: 서로 다른 관점이나 데이터를 비교하여 제시
- 대화형 인터페이스
- 연속적 질문: 추가 질문을 통해 정보를 점진적으로 탐색
- 질문정제: 모호한 질문을 명확히 하거나 추가정보 요청
- 맞춤형 응답: 사용자의 전문성 수준에 맞춘 설명
- 실시간 정보 접근
- 최신 정보 검색: 웹크롤링을 통한 실시간 데이터 확보
- 동적 업데이트: 빠르게 변하는 정보 반영
- 시점인식: 질문의 시간적 맥락 이해
p4. 생성형 AI 검색의 정의와 특징
주요 기술 요소
- LLM : 생성형 AI 검색의 핵심 기술
- 질문의 의도 파악
- 검색 쿼리 최적화
- 정보 종합 및 답변 생성
- 자연스러운 문장 구성
- 검색 증강 생성 (RAG: Retrieval Augmented Generation)
- 외부 지식을 검색하여 LLM의 답변을 보강하는 기술
- 프로세스
- 사용자 질문 분석
- 관련 문서/정보 검색
- 검색된 정보를 컨텍스트로 제공
- LLM이 컨텍스트 기반 답변 생성
- 의미기반 검색
- 단순 키워드 매칭이 아닌 의미기반 검색 수행
- 기술
- 벡터 임베딩
- 유사도 계산: 질문과 문서 간 의미적 거리 측정
- 밀집 검색(Dense Retrieval)을 통한 정확도 향상
p5. 검색증강생성 (RAG: Retrieval Augmented Generation)
LLM의 근본적 한계
- 지식의 시점 고정 (Knowledge Cutoff)
- LLM은 학습 시점까지의 데이터만 알고 있음
- 실시간 정보, 최신 뉴스, 업데이트된 데이터 접근 불가
- 환각 현상 (Hallucination)
- 학습되지 않은 정보에 대해 그럴듯하지만 거짓인 답변을 생성
- 도메인 특화 지식 부족
- 일반적 학습 데이터로는 특정 기업, 산업, 기술의 전문 지식이 부족
- 출처 검증 불가
- 생성된 답변의 근거를 확인할 방법이 없음
p6. 검색증강생성 (RAG: Retrieval Augmented Generation)
- 외부 지식 활용 → Fine Tuning 대비 시간과 비용 감소
- 대규모의 구조화된 지식 베이스(예: 위키피디아)를 모델에 연결
- 주어진 질의에 대한 관련 정보를 지식 베이스에서 검색 및 추출
- 증거 기반 답변 생성으로 Hallucination 완화
- 검색된 지식 정보를 증거로 활용하여 보다 사실에 기반한 답변 생성
- 생성된 답변의 출처를 명시함으로써 신뢰성 향상
- 맥락 이해력 향상
- 외부 지식을 통해 질의의 배경 지식과 맥락 정보를 파악
- 단순한 패턴 매칭이 아닌 추론 능력을 바탕으로 한 답변 생성
➡ LLM 성능 향상 및 신뢰성 확보
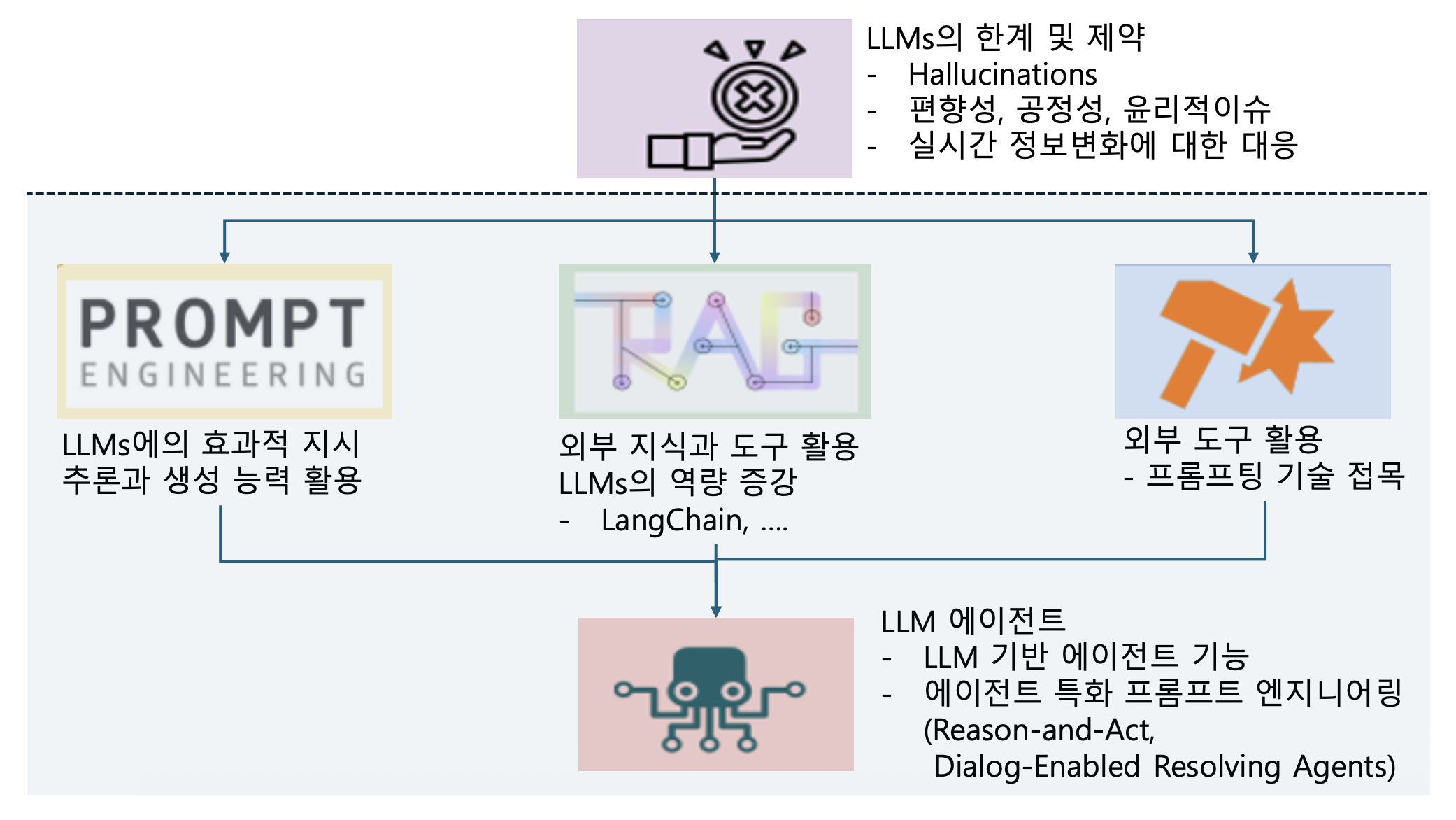
p7. LLM 에이전트
p8. RAG
- RAG의 정의와 원리
- RAG = Retrieval (검색) + Augmented (증강) + Generation (생성)
- 외부 지식 베이스에서 관련 정보를 실시간으로 검색하여,
이를 LLM의 컨텍스트에 추가함으로써 더 정확하고 최신의 답변을 생성하는 기술
- RAG vs Fine-tuning vs Prompt Engineering
| 방식 | 장점 | 단점 | 적합한 경우 |
|---|---|---|---|
| RAG | • 실시간 업데이트 • 비용 효율적 • 출처 제공 | • 검색 품질 의존 • 지연 시간 | 최신 정보, 대용량 문서 |
| Fine-tuning | • 특정 작업 최적화 • 빠른 응답 | • 비용 高 • 업데이트 어려움 | 특정 스타일/형식 학습 |
| Prompt Eng. | • 즉시 적용 • 비용 無 | • 컨텍스트 제한 • 일관성 낮음 | 간단한 작업 |
p9. RAG의 아키텍처 – RAG의 핵심 구성요소
- Retriever : 외부 데이터(문서, DB 등)에서 관련 정보 검색
- 인덱싱 최적화: 청크 크기, 메타데이터, 혼합 검색
- 쿼리 최적화: 쿼리 확장, 변환, 재작성
- 검색 알고리즘: BM25, Dense Retriever, 하이브리드 등
- Augmentation : 검색된 정보를 컨텍스트로 활용해 LLM 입력 확장
- 컨텍스트 재정렬, 요약, 정보 압축
- 중복 제거, 중요도 판단, 스타일/톤 일관성 유지
- Generator : LLM이 검색 정보와 내재 지식을 결합해 응답 생성
- LLM의 프롬프트 설계
- 다중 문서 통합, 대화 이력 반영
- 파인튜닝 / 컨텍스트 학습
p10. RAG 시스템 아키텍처
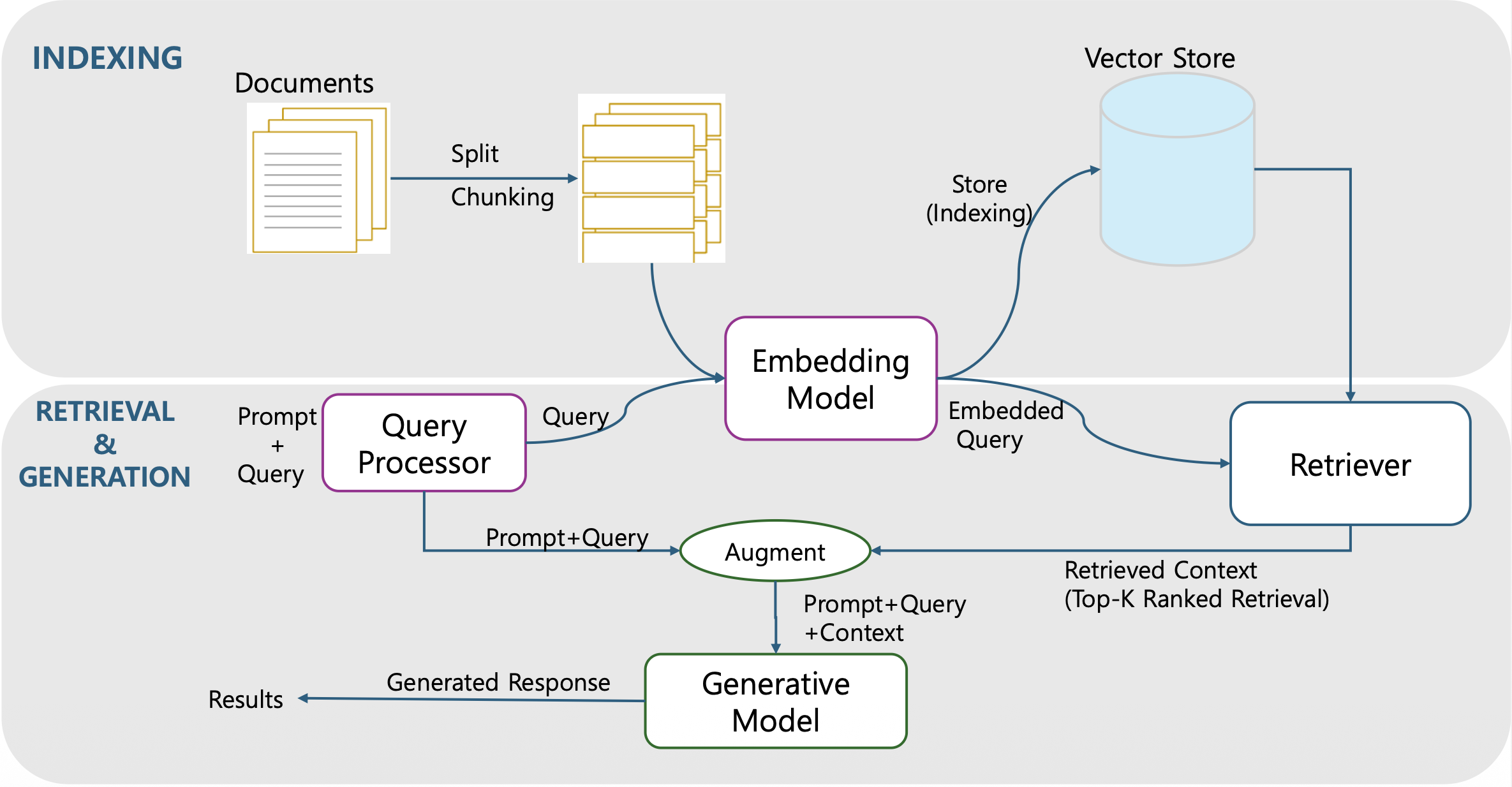
RAG 시스템의 전체 흐름
- RAG는 Indexing 단계와 Retrieval & Generation 단계로 구성된다.
- 문서를 Chunk 단위로 나누고 벡터로 변환해 Vector Store에 저장한다.
- 사용자의 질의를 동일한 임베딩 공간으로 변환한 뒤
벡터 유사도를 이용해 관련 문서를 검색하고 LLM의 입력 컨텍스트로 통합한다.Indexing 단계
- 문서 분할(Splitting/Chunking): 긴 문서를 의미 단위로 분리해 검색 효율을 높인다.
- 임베딩(Embedding): 각 청크를 고차원 벡터로 변환한다.
- 저장(Indexing): 변환된 벡터를 Vector Store(FAISS, Pinecone 등)에 저장한다.
Retrieval & Generation 단계
- Query Processor: 사용자의 질의를 검색 가능한 형태로 변환한다.
- Retriever: 벡터 유사도 기반으로 관련 문서를 찾아 Top-K 문서를 반환한다.
- Augmentation: 검색된 문서를 요약·정제해 LLM 입력 컨텍스트로 결합한다.
- Generative Model: 컨텍스트와 내부 지식을 활용해 사실적이고 문맥적인 답변을 생성한다.
결과 생성 및 반환
- LLM의 응답은 검색 문서에 기반하므로 사실성과 신뢰성이 높다.
- RAG는 이를 통해 지식의 최신성과 정확도를 동시에 확보한다.
p11. RAG
RAG 시스템 아키텍처
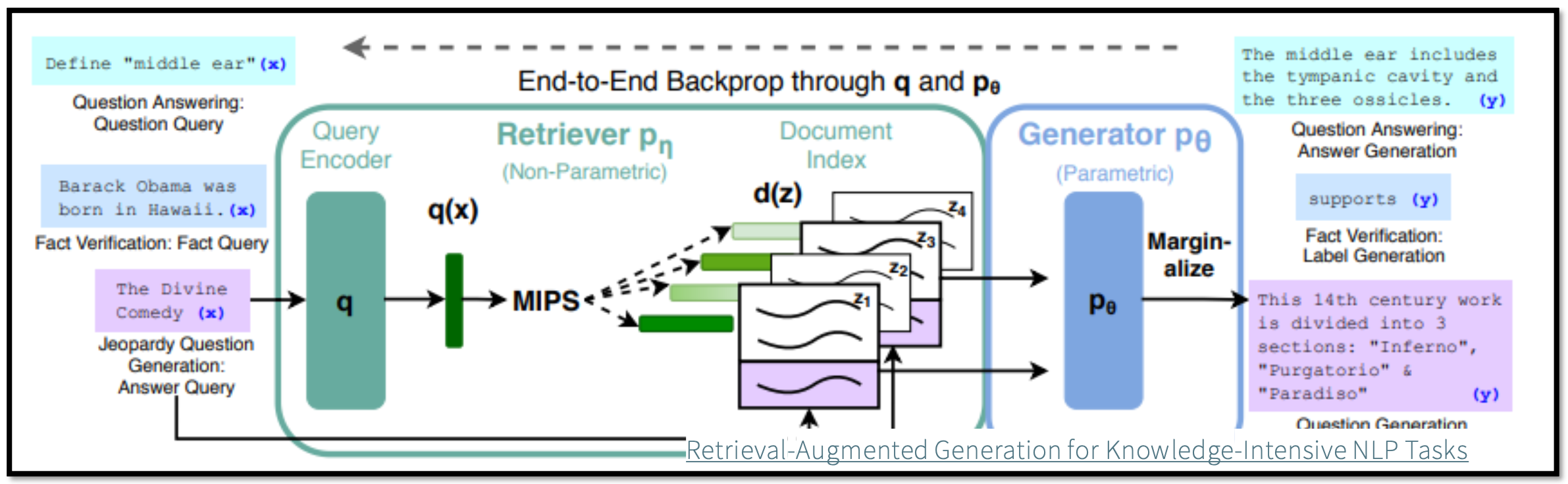
- Query가 입력되면 QueryEncoder를 통과하여 representation(q(x)) 생성
- q(x)와 가장 가까운(InnerProduct기준) {5,10}개의 Passage 탐색
- Passage를 기존 Query와 concat하여 Generator Input으로 사용
- 각 Passage별 생성결과를 Marginalize하여 최종 결과물 도출
p12. RAG
RAG 시스템 아키텍처
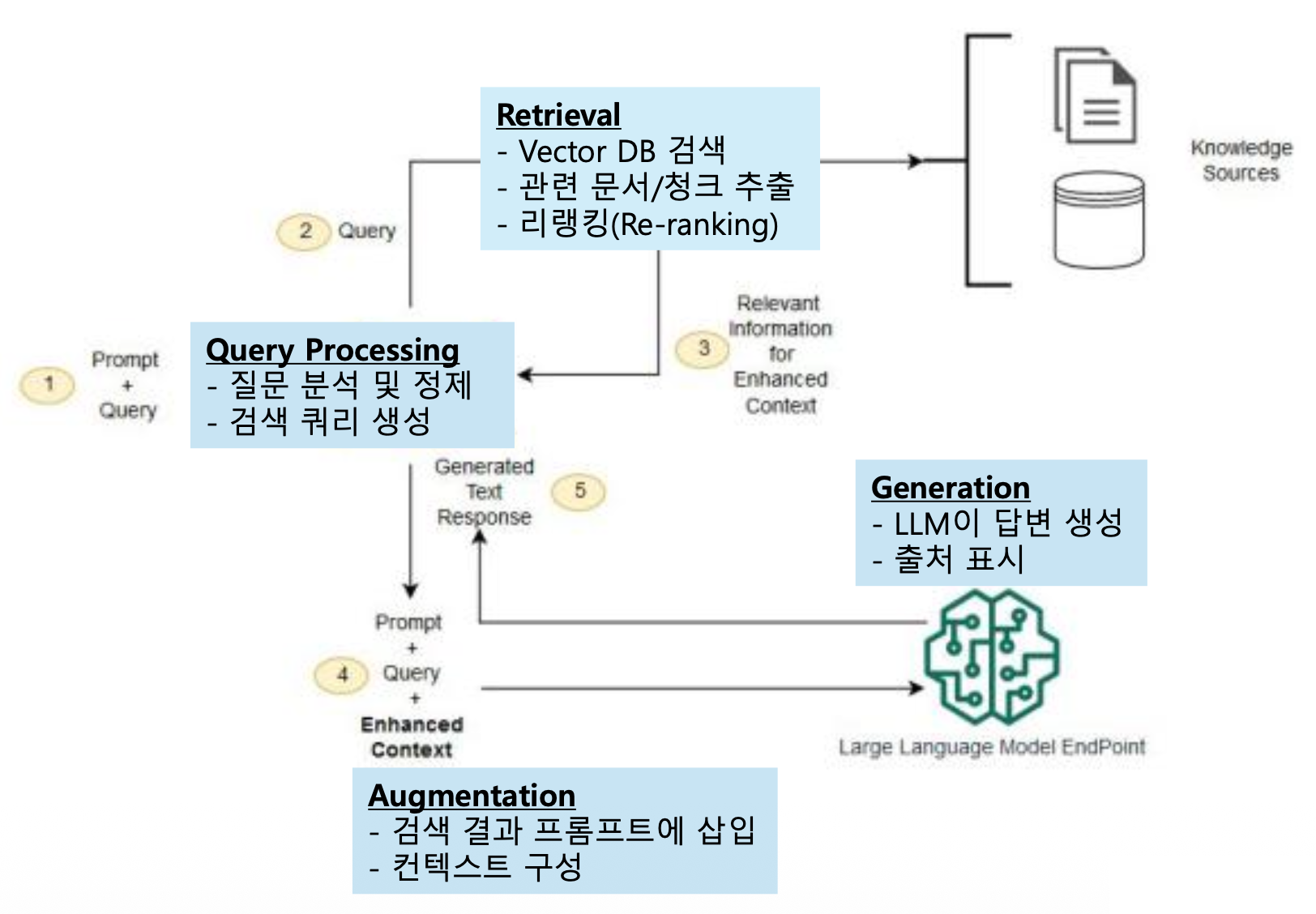
Large Language Models: A Survey
p13. RAG 작동과정
- 사용자의 쿼리가 주어지면 쿼리 인코더가 이를 벡터 형태로 변환.
- 지식 검색기가 인코딩된 쿼리를 바탕으로 외부 지식 베이스에서 관련 정보를 검색.
- 검색된 지식은 지식 증강 생성기의 입력으로 전달.
- 지식 증강 생성기는 검색된 지식을 활용하여 사용자 쿼리에 대한 자연어 답변을 생성.
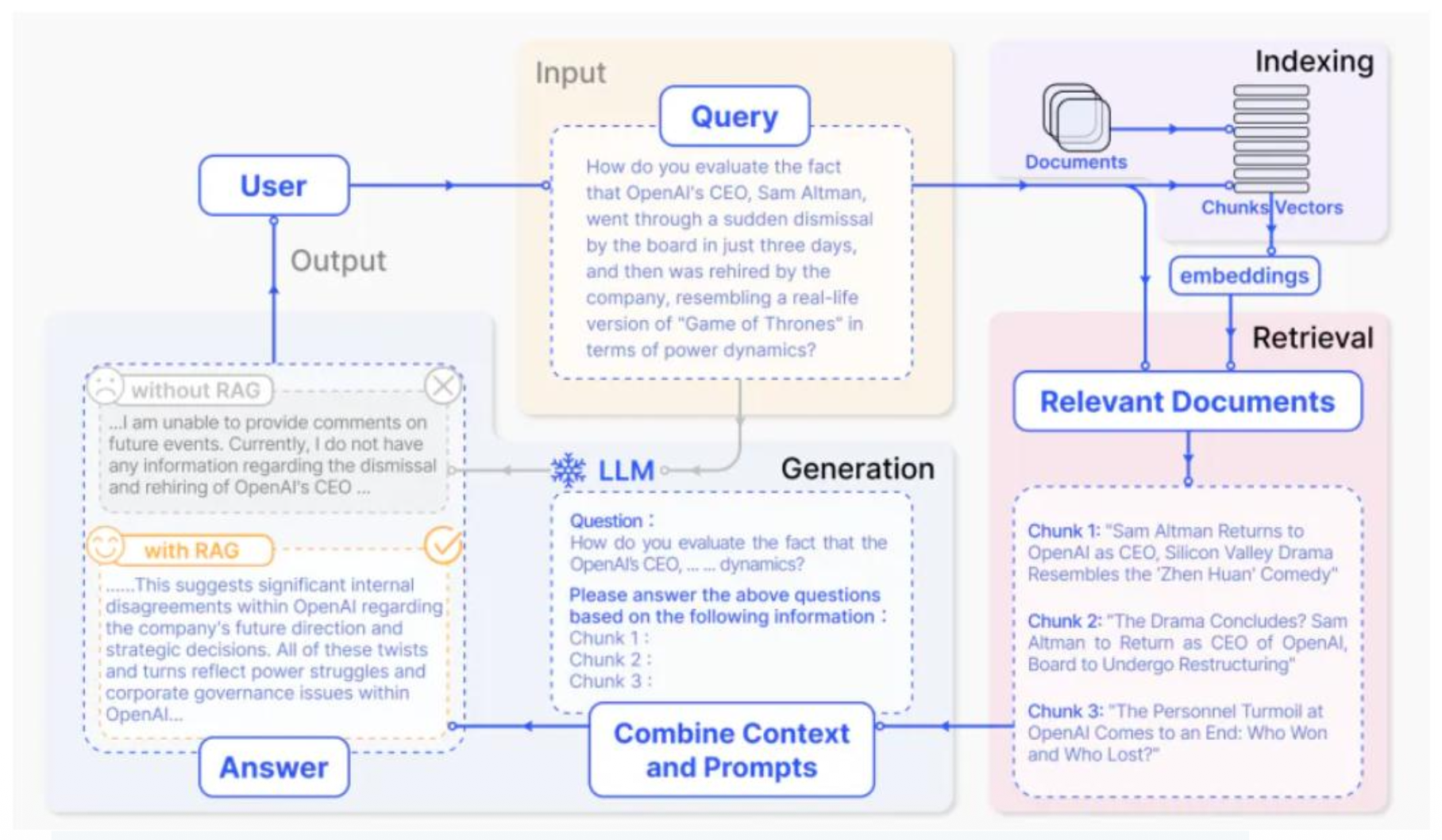
Retrieval-Augmented Generation for Large Language Models: A Survey(2023)
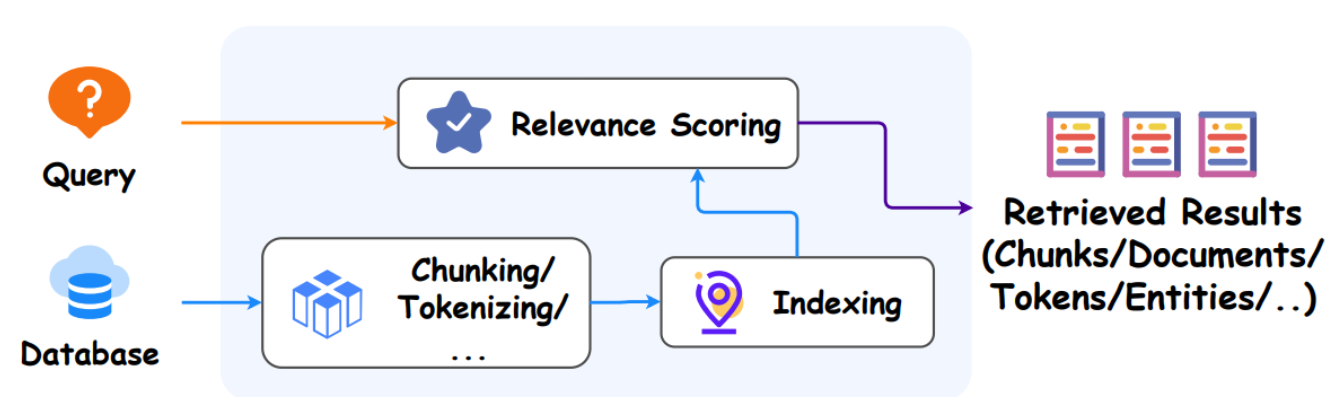
p14. RAG 아키텍처
Retriever Types
- 일반 검색: Sparse Retrievers (SR)
- 적용 용이
- 높은 효율성
- 우수한 성능
- 예: TF-IDF, BM25
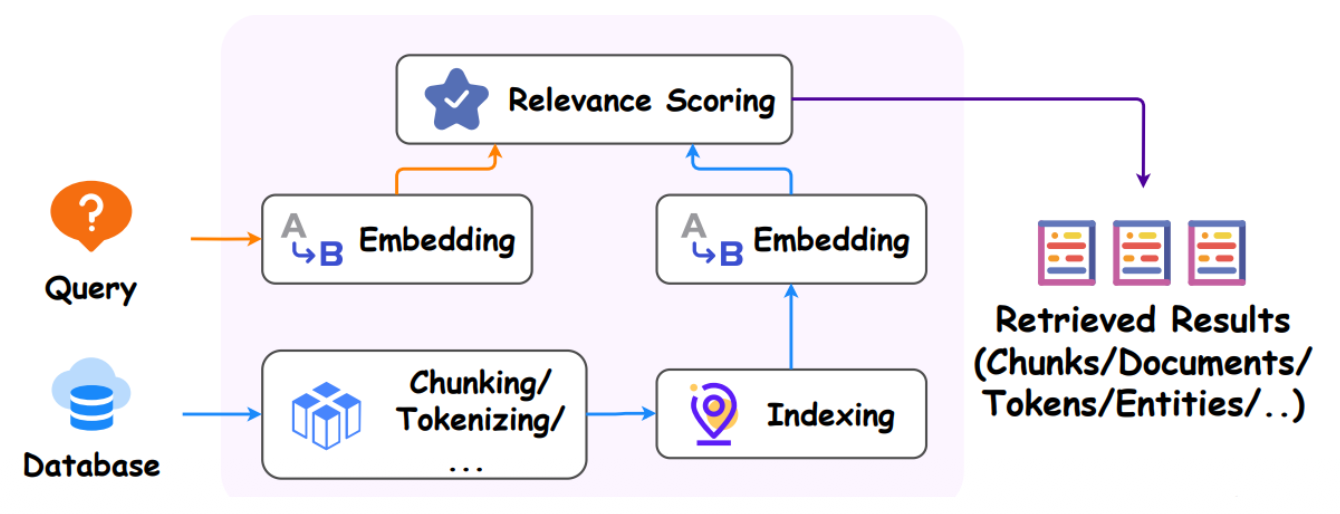
- Dense Retrievers (DR)
- 파인튜닝 허용
- 더 나은 적응력
- 다양한 검색 목적에 맞게 맞춤화 가능
- 예: DPR, Contriever
p15. RAG의 구조적 패러다임
- 전통적 검색과 생성
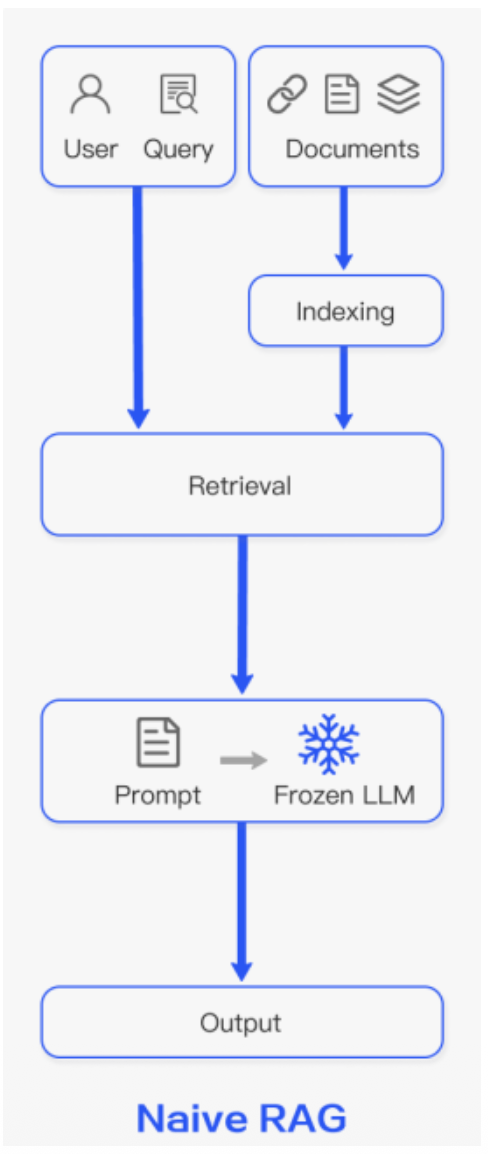
- 검색 품질 향상
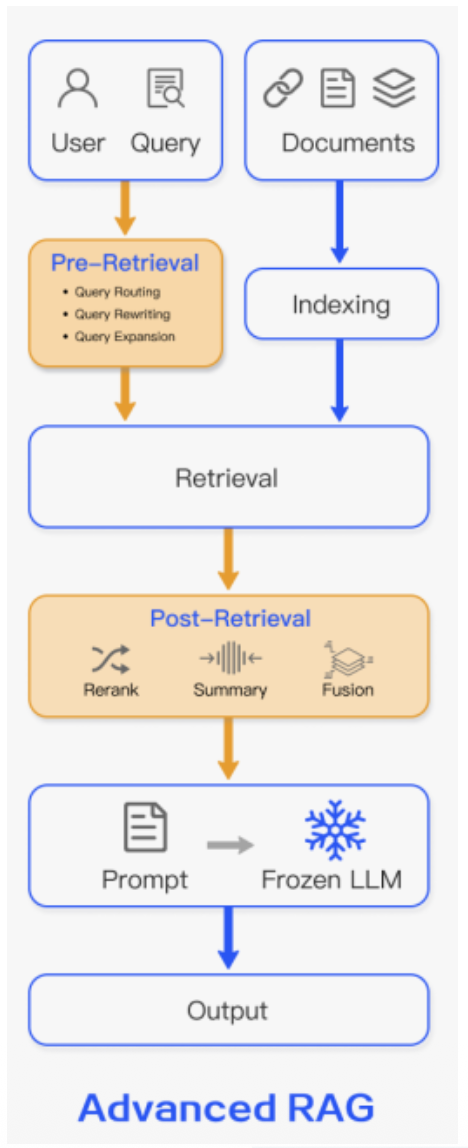
- 유사도 검색 모듈화, 패턴화
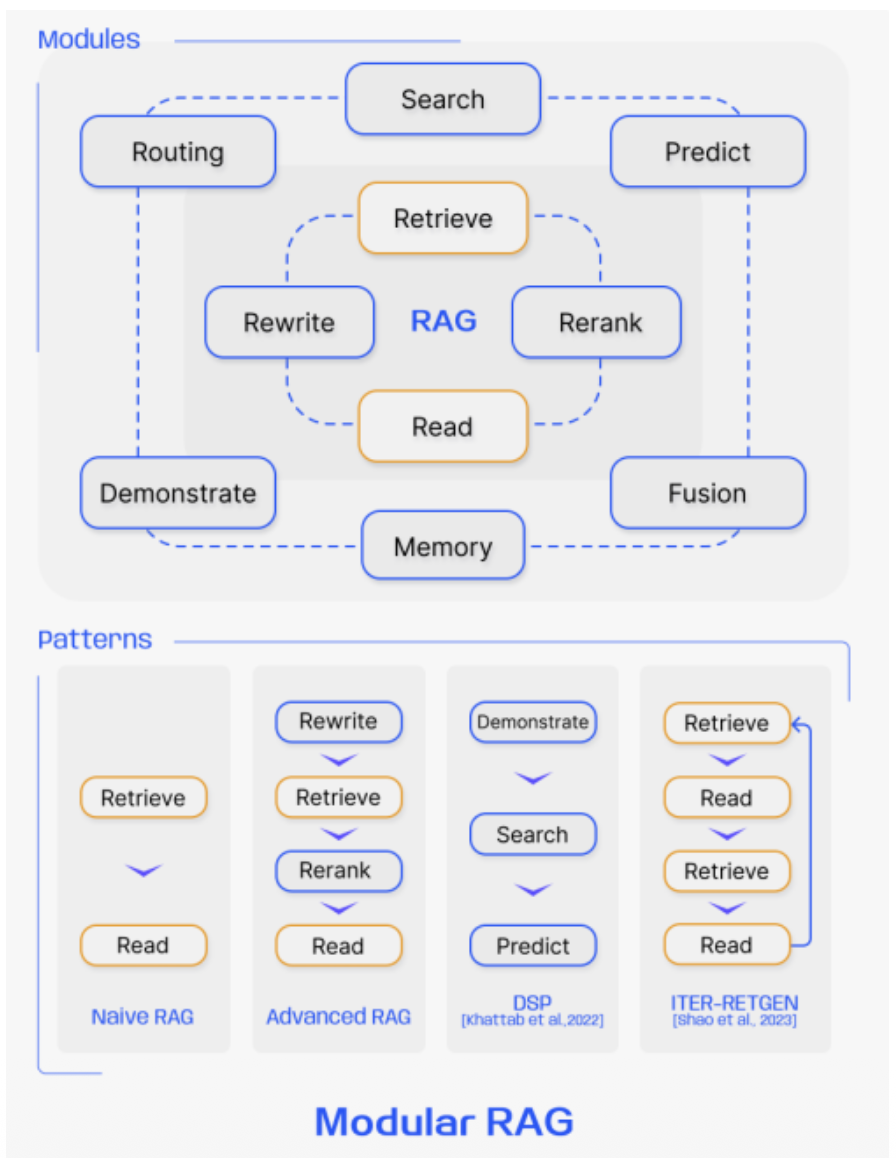
Retrieval-Augmented Generation for Large Language Models: A Survey(2023)
p16. RAG의 구조적 패러다임 변화
- Naïve RAG
- 전통적 “Retrieve-Read” 구조 (인덱싱 → 검색 → 생성)
- Augmentation: 검색된 단일 청크/문서를 프롬프트에 직접 추가
- 장점: 구현이 간단하고 비용 효율적
- 한계: 검색 정확도·재현율(Recall) 부족, 환각·중복 발생, 맥락 통합 어려움
- Advanced RAG
- 검색 대상, 검색 방법, 사전/사후 최적화 도입
- 인덱싱: 슬라이딩 윈도우, 세분화, 메타데이터 활용
- 쿼리 최적화: 쿼리 변환, 확장, 재작성
- 검색 후: 검색 결과 재순위화(rerank), 컨텍스트 압축
- 장점
- 정보 과부하 방지, 핵심 정보 강조, 프롬프트 길이 제약 극복
- 정확도(Precision)와 재현율(Recall)을 향상시켜 LLM 출력 품질 향상
- Augmentation: 최적화된 청크나 여러 소스의 정보를 정제하여 프롬프트에 추가
- 검색 대상, 검색 방법, 사전/사후 최적화 도입
- Modular RAG
- LLM 에이전트, 라우터 등 동적 모듈 사용
- 모듈화 및 유연성 강화
- 다양한 기능 모듈(검색, 생성, 필터링, 평가 등) 조합 가능
- 반복적/적응적 검색, End-to-End 통합 학습 지원
- 특정 도메인/작업에 맞춤화 용이
- Augmentation: 작업 흐름을 제어하며 필요에 따라 정보를 검색하고, 검증하거나, 복합적인 방식으로 증강.
p17. RAG의 구조적 패러다임
주요 Advanced RAG 유형
| 유형 | 검색 단계의 개선 | 증강 프로세스에서의 차이점 |
|---|---|---|
| Pre-Retrieval (Index) | 데이터 전처리(청크 크기, 메타데이터 추가), 인덱스 구조 최적화 | 청크 자체의 품질을 높여 더 정확하고 관련성 높은 컨텍스트를 검색 |
| Post-Retrieval (Reranking) | 검색된 상위 k개 문서에 대해 Reranker 모델을 사용해 재순위 지정 | 가장 관련성 높은 문서만 선별하여 프롬프트에 포함 불필요한 노이즈(Noise) 감소 |
| Query Transformation | 원래 쿼리를 LLM을 이용해 여러 쿼리로 확장 또는 HyDE(Hypothetical Document Embedding) 방식으로 변환 | 사용자의 의도를 더 잘 포착하는 다양한 컨텍스트를 검색하여 Recall(재현율) 향상 |
| Multi-Hop RAG | 한 번의 검색으로 답을 찾기 어려울 때, LLM이 여러 번의 검색·생성을 반복하여 정보를 결합 | 복합적인 추론이 필요한 경우, 단계별 중간 결과를 컨텍스트로 활용하여 최종 답변을 증강 |
p18. RAG의 구조적 패러다임 변화
Modular RAG 유형: LLM 컨트롤러나 에이전트 활용, 동적인 판단 및 제어기능을 추가
| 유형 | 제어/판단 방식 | 증강 프로세스에서의 차이점 |
|---|---|---|
| Fusion RAG | 여러 검색엔진(벡터 검색 + 키워드 검색 등) 결과를 결합하여 사용 | 다양한 검색 소스의 정보를 통합, 컨텍스트 증강 |
| Agentic RAG | LLM이 에이전트 역할, 쿼리 분석 후 적절한 도구(검색, 코드 실행 등) 호출, 그 결과를 증강에 사용 | 단순 검색을 넘어 문제 해결 프로세스 전체를 증강된 컨텍스트로 활용, 복잡한 태스크에 적합 |
| Corrective RAG | LLM 생성 응답을 검증(Validation) 모듈로 평가, 필요하면 재검색을 수행하거나 응답을 수정 | 응답의 신뢰도와 정확성을 높이기 위해 피드백 루프를 통해 증강 과정을 반복 및 개선 |
Naive/Advanced RAG보다 유연하고 지능적인 증강을 제공
p19. Agentic RAG
https://github.com/asinghcsu/AgenticRAG-Survey
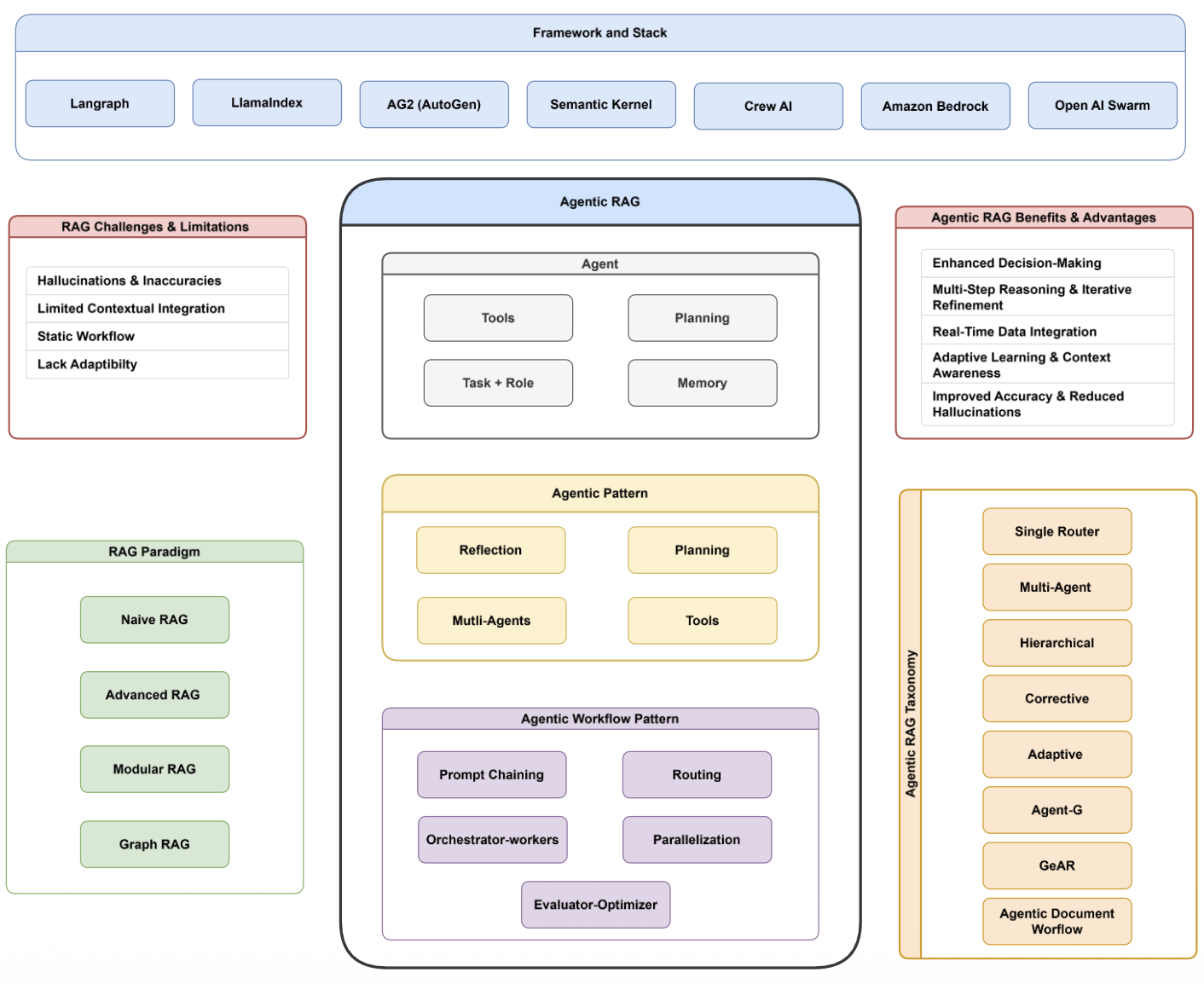
Agentic RAG의 개요
- Agentic RAG는 기존 RAG 한계를 극복하기 위해 에이전트 개념을 도입한 확장형 구조이다.
- 단순 검색–생성을 넘어 도구 활용, 계획, 메모리, 역할 기반의 동적 의사결정을 수행한다.
- 이를 통해 능동적 정보 탐색, 검증, 요약, 추론까지 수행 가능해진다.
기존 RAG의 한계
- 환각 위험 존재
- 검색 문서를 충분히 활용하지 못함
- 검색–생성 절차가 고정된 정적 구조
- 상황에 따른 전략 전환 어려움
Agentic RAG의 핵심 구조
- 도구(Tools): 검색·코드 실행·데이터 분석 등 외부 기능을 호출
- 계획(Planning): 실행 순서 설계 및 정보 탐색 전략 구성
- 역할(Task & Role): 에이전트의 목표와 기능 정의
- 메모리(Memory): 대화 이력 및 검색 결과를 장기적으로 활용
에이전틱 패턴
- 자기반성(Reflection)
- 단계적 추론 및 반복 개선(Planning)
- 다중 에이전트 협력(Multi-Agents)
- 작업에 적합한 도구를 동적으로 선택하여 실행
에이전틱 워크플로우 패턴
- 프롬프트 체이닝
- 라우팅(Routing)
- 오케스트레이터–워커 구조
- 병렬 실행
- 평가–최적화 루프(Evaluator–Optimizer)
Agentic RAG의 장점
- 에이전트의 상황 분석·의사결정 능력 향상
- 다단계 추론 및 반복적 개선 수행
- 최신 정보 통합 가능
- 문맥 변화에 따른 적응적 전략 조정
- 정확도 향상 및 환각 감소
Agentic RAG 분류
- 단일 라우터
- 다중 에이전트
- 계층형 구조
- 교정형(Corrective)
- 적응형(Adaptive)
- Agent-G / GeAR
- 문서형 에이전틱 워크플로우
프레임워크 및 기술 스택
- LangGraph, LlamaIndex, AG2(AutoGen), Semantic Kernel, Crew AI, Amazon Bedrock, OpenAI Swarm
- 모듈형 설계, 에이전트 오케스트레이션, 실시간 데이터 연동, 다중 에이전트 협력 등 지원
요약
- Agentic RAG는 자기반성·도구 활용·계획 기능을 결합한 지능형 검색–생성 구조이다.
- 기존 RAG를 넘어 자율적 의사결정이 가능한 에이전트 기반 검색 시스템으로 진화하고 있다.
p20. RAG의 핵심 구성요소
- 문서처리와 인덱싱(Indexing) 파이프라인(오프라인)
- 데이터 수집
- 문서 파싱 및 청킹
- 청킹전략
- 고정 크기 청킹: 일정한 토큰/문자 수로 분할
- 의미 단위 청킹: 문단, 섹션 단위로 분할
- 슬라이딩 윈도우: 오버랩을 두고 분할
- 문서 구조 기반: 제목, 목차 구조 활용
- 청킹전략
- 임베딩 벡터 생성
- 벡터 DB 저장
- 검색 파이프라인(온라인)
- 쿼리 임베딩
- 유사도 검색
- 리랭킹(선택적)
- 컨텍스트 구성
- 생성 파이프라인
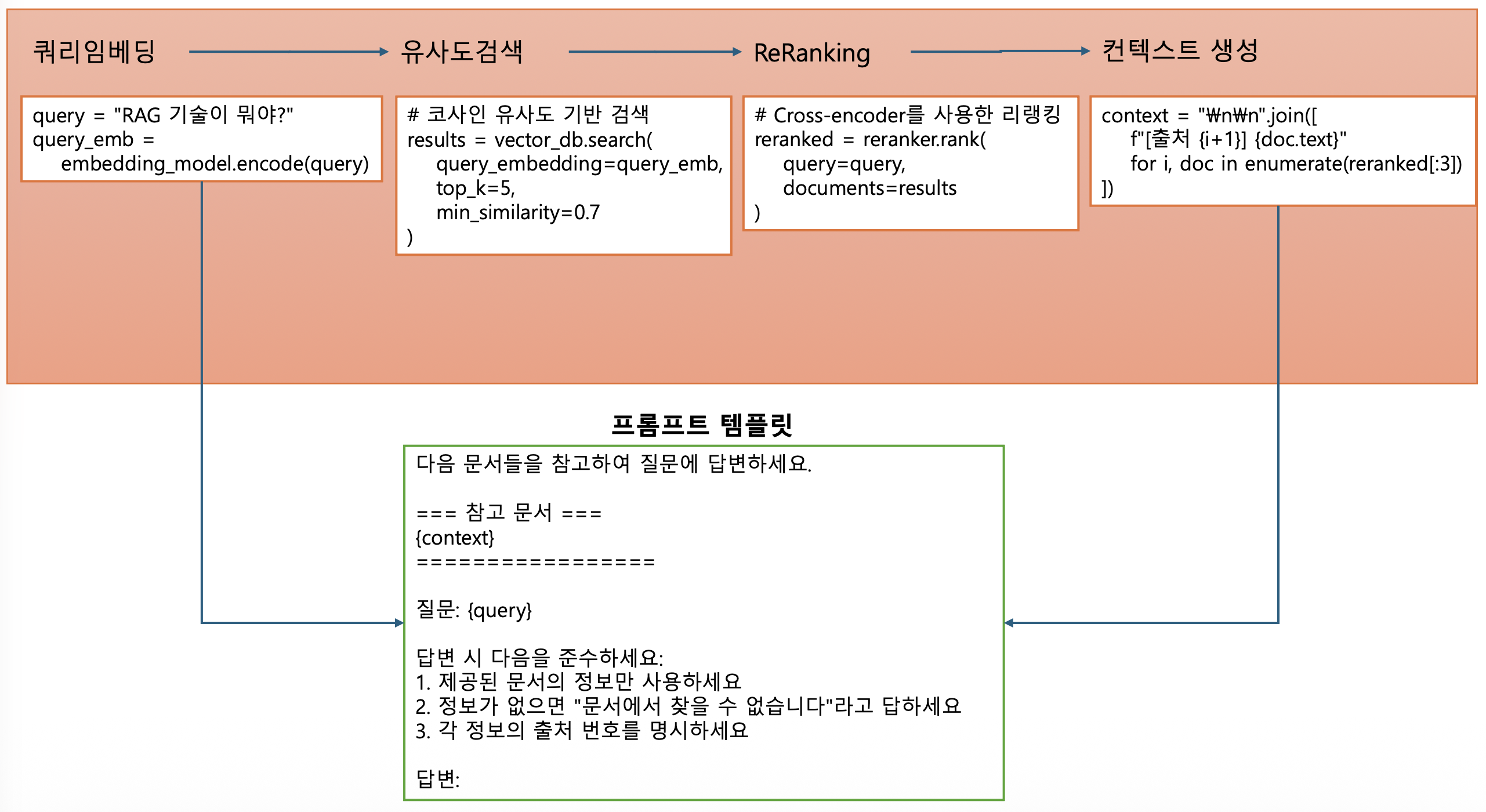
- 프롬프트 템플릿
프롬프트 템플릿
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
다음 문서들을 참고하여 질문에 답변하세요.
=== 참고 문서 ===
{context}
===============
질문: {query}
답변 시 다음을 준수하세요:
제공된 문서의 정보만 사용하세요
정보가 없으면 "문서에서 찾을 수 없습니다"라고 답하세요
각 정보의 출처 번호를 명시하세요
답변:
p21. RAG 구현 과정
RAG (Retrieval-Augmented Generation) 파이프라인
- 기존의 언어 모델에 검색 기능을 추가
주어진 질문이나 문제에 대해 더 정확하고 풍부한 정보를 기반으로 답변 생성 가능
파이프라인은 크게 5단계로 구성
① 데이터 로드: RAG에 사용할 외부 데이터를 필요한 형식으로 변환하여 불러오는 단계
② 텍스트 분할: 불러온 데이터를 작은 크기의 단위(chunk)로 분할하는 과정
③ 인덱싱: 분할된 텍스트를 벡터 형태로 임베딩하고 색인하는 단계 (검색 정확도와 효율을 고려)
④ 검색: 사용자의 질문이나 주어진 context에 가장 적합한 정보를 찾아내는 과정
⑤ 생성: 검색된 정보를 바탕으로 사용자의 질문에 최적 답변을 생성하는 최종 단계
p22~23. RAG 구현 과정

p24. RAG 개발 시 필요한 것
- 데이터
- 다양한 형식의 문서(CSV, JSON, PDF, XML 등)와 DocumentLoader
- DB 및 웹 문서 크롤러
- 문서를 작은 단위로 분할할 Text Splitter
- 임베딩 모델
- 텍스트를 덴스 벡터로 변환할 모델
- Sentence-transformers, OpenAI 임베딩 모델, HuggingFaceEmbeddings 등
- 벡터 데이터 베이스
- 벡터를 저장하는 저장소
- 벡터 유사도 검색 및 메타 데이터 검색 기능 제공
- Pinecone, Qdrant, Chroma, ElasticSearch, FAISS 등
- LLM 애플리케이션 개발 프레임워크
- LangChain / LangGraph
p25. Document Loader
- 다양한 소스에서 문서를 불러오고 처리하는 과정을 담당
- 다양한 소스 지원
- PDF / 웹페이지 / 데이터베이스 등 다양한 소스에서 문서를 불러올 수 있음.
- 데이터 변환 및 정제
- LangChain의 module이나 algorithm이 처리하기 쉬운 형태로 변환.
- 효율적인 데이터 관리
- 대량의 문서 데이터를 효율적으로 관리 및 접근 가능하게 함.
- 다양한 소스 지원
- 종류
- WebBaseLoader : 웹페이지 문서를 로드하여 필요한 텍스트를 추출 변환함
- TextLoader : 텍스트 파일을 로드함
- DirectoryLoader : 디렉토리 내의 모든 문서를 로드함.
- CSVLoader : csv파일에서 데이터를 loader
p26. WebBaseLoader
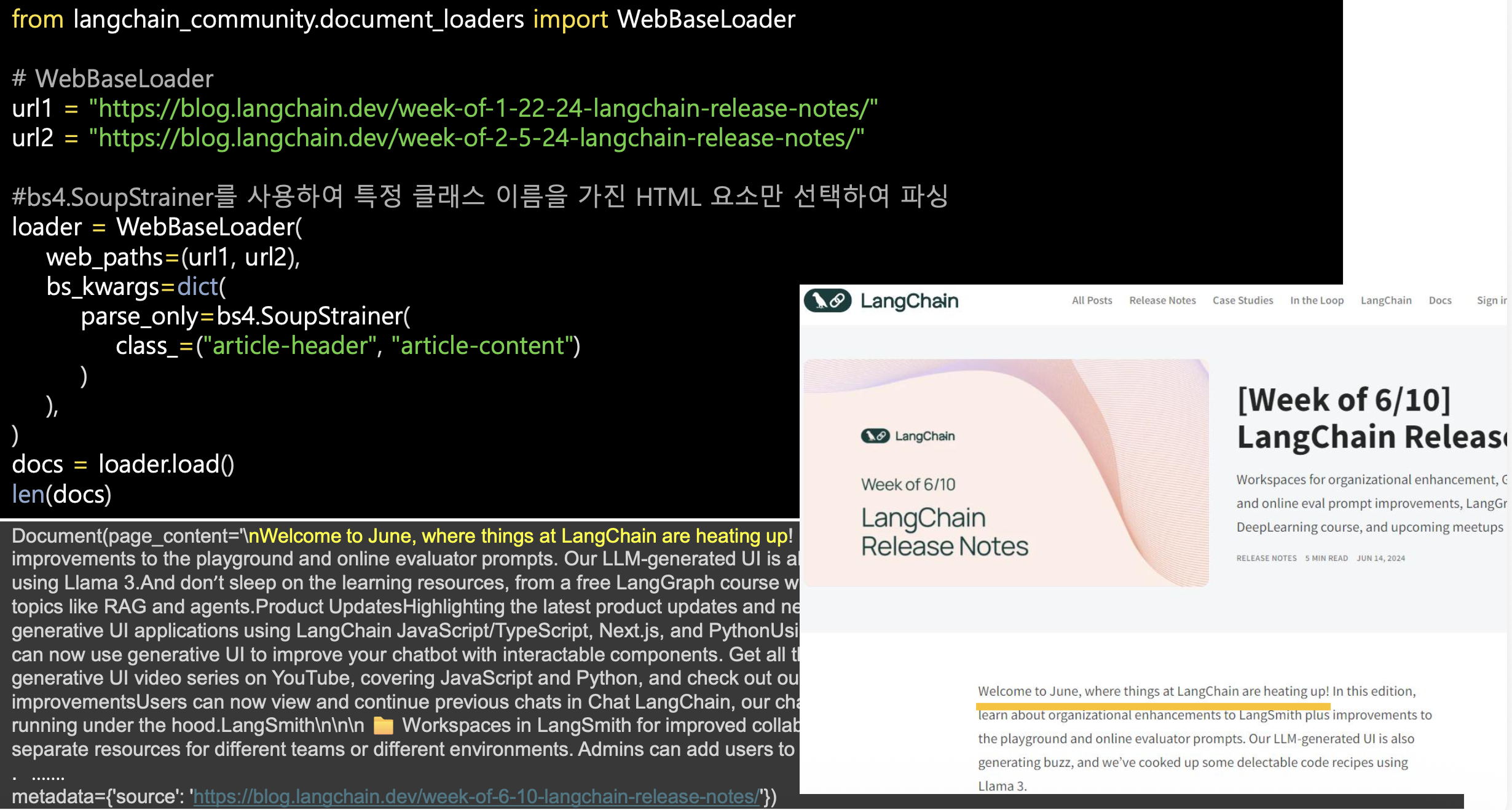
WebBaseLoader의 역할
- WebBaseLoader는 웹페이지 HTML에서 텍스트를 불러와
LLM이 학습·검색할 수 있는 문서 형태로 변환하는 모듈이다.- document_loaders에 포함된 도구로,
HTML 태그·클래스 단위로 특정 영역만 선택적으로 파싱할 수 있다.SoupStrainer를 활용한 선택적 파싱
- bs4.SoupStrainer는 BeautifulSoup이 전체 HTML을 모두 읽지 않고
특정 태그·클래스만 처리하도록 제한해 속도를 높인다.- 코드의 class_=(“article-header”, “article-content”)는
기사 제목과 본문 영역만 추출하도록 지정한 것이다.코드 동작 요약
- url1, url2의 블로그 페이지에서 내용 크롤링
- WebBaseLoader가 지정된 클래스만 파싱
- loader.load()로 문서를 docs에 저장
- len(docs)로 파싱된 문서 개수 확인
활용 예시
- 뉴스·블로그·위키 등에서 필요한 텍스트만 자동 추출해
RAG 인덱싱 단계에 바로 사용 가능하다.- LLM 응용에서 최신 외부 정보를 실시간으로 가져오는 데 유용하다.
p27. PDF Loader
- PyPDFLoader
- PDF 문서 페이지별로 로드, 텍스트를 추출하여 documents list 객체로 반환
- PyMuPDFLoader
- PDF 파일의 페이지를 로드하고, 각 페이지를 개별 document 객체로 추출
- 자세한 메타데이터 추출도 가능
- PyPDFDirectoryLoader
- 특정 폴더에 있는 모든 PDF 파일을 가져옴
- OnlinePDFLoader
- 온라인 PDF 파일 데이터를 가져옴
p28. PyPDFLoader vs. PyMuPDFLoader
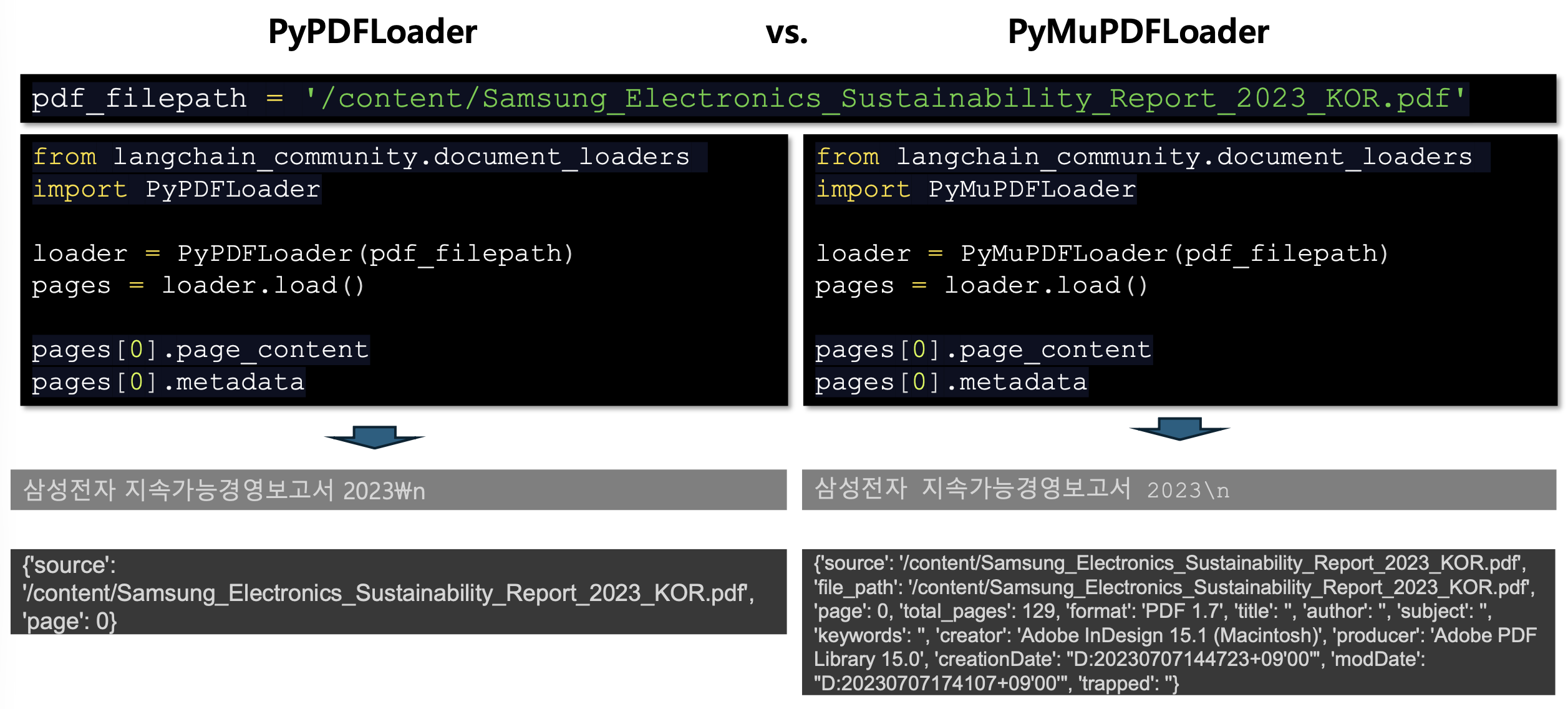
주로 PDF의 메타데이터를 추출하고 관리하는 영역에서 차이가 있음
PyPDFLoader와 PyMuPDFLoader의 공통점
- 두 로더 모두 PDF를 페이지 단위로 로드해 Document 객체로 변환한다.
- page_content로 텍스트를, metadata로 부가 정보를 확인할 수 있다.
PyPDFLoader의 특징
- PyPDF 기반 로더이다.
- 텍스트와 페이지 번호·경로 같은 기본 메타데이터만 제공해
텍스트 분석 중심 작업에 적합하다.- 예: {‘source’: ‘…pdf’, ‘page’: 0}
PyMuPDFLoader의 특징
- PyMuPDF(fitz) 기반 로더이다.
- 전체 페이지 수, PDF 버전, 생성/수정 일자, 제작 도구 등
더 풍부한 메타데이터를 제공한다.- 문서 관리·출처 추적·버전 관리에 유리하다.
- 예: {‘source’: ‘…pdf’, ‘total_pages’: 129, ‘format’: ‘PDF 1.7’, …}
요약 비교
- PyPDFLoader: 단순 메타데이터, 텍스트 분석용
- PyMuPDFLoader: 상세 메타데이터, 문서 구조·출처 관리용
p29. Text Splitter
문서들을 효율적으로 처리하고, 시스템이 정보를 보다 잘 활용할 수 있도록
크고 복잡한 문서를 LLM이 받아들일 수 있는 효율적인 작은 규모의 단위(Chunk) 로 나눔
- 분할의 필요성
- 관련성 높은 정보 검색으로 정확성 향상
- 문서를 세분화함으로써 Query와 연관성이 있는 정보만 가져와 특정 주제나 내용에 초점을 맞춤
- 리소스 최적화(효율성)
- LLM의 입력 토큰 개수가 제한되어 있으므로 전체 문서를 입력하면 비용이 많이 발생
- 많은 정보 속에서 발췌하다 보면 Hallucination 문제를 유발하므로 답변에 필요한 정보만 효율적으로 발췌
- 관련성 높은 정보 검색으로 정확성 향상
- 고려사항
- 텍스트 분리 시 독립적으로 의미를 지닌 단위로 분리: 문장, 구절, 단락 등
- 청크 크기
- LLM 모델의 입력 크기 및 비용 등을 고려하여 최적 크기를 결정
- 단어 수, 문자 수 등을 기준으로 크기를 측정
p30. TextSplitter
CharacterTextSplitter
RecursiveCharacterTextSplitter
tiktoken (token-based chunking)
p31. TextSplitter
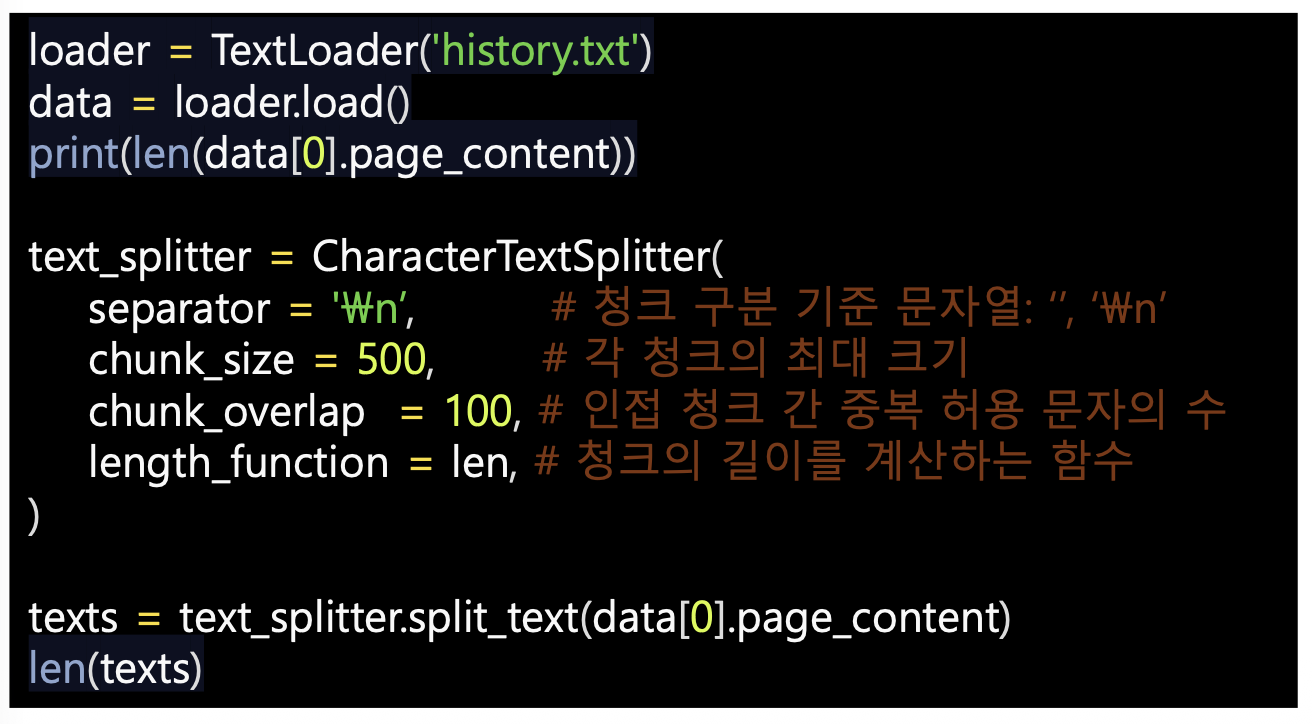
- CharacterTextSplitter
- 문서를 분할구분자 기준으로 나눔
- 문자 중복을 허용하여 문맥을 유지하고 정보손실을 최소화
- RecursiveCharacterTextSplitter
- 텍스트를 재귀적으로 분할, 의미적으로 관련있는 텍스트 조각들로 나눔
- 문자 리스트 [‘\n\n’, ‘\n’, ‘ ’, ‘’] 의 문자를 순서대로 사용하여 텍스트 분할

p32. TextSplitter
- CharacterTextSplitter

- RecursiveCharacterTextSplitter

p33. tiktoken(token-based chunking)
- 텍스트를 토큰 수 기준으로 청크를 나눔
- LLM에 적용된 Tokenizer를 사용하면 모델 입력 토큰 수 조절이 가능
- OpenAI API의 경우, BPE 토크나이저로 만들어진 tiktoken 라이브러리를 지원
- open-source model의 경우 model별 tokenizer 적용
- OpenAI의 tiktoken API 사용
- Parameters
- chunk_size: 각 청크의 최대 길이
- chunk_overlap: 분할된 텍스트 조각들 사이에서 중복으로 포함될 문자 수
- encoding_name: 텍스트를 토큰으로 변환하는 인코딩 방식 (‘cl100k_base’: ada-002 model 사용)
- Parameters

p34. 임베딩 모델
- 임베딩?
- 텍스트를 고차원 벡터 공간의 점으로 변환하는 것
1
2
3
"강아지": [0.8, 0.6, 0.1, ..., 0.3]
"개": [0.79, 0.61, 0.09, ..., 0.31] (유사)
"자동차": [0.1, -0.3, 0.9, ..., -0.2] (다름)
- 임베딩 모델
- 트랜스포머(BERT, RoBERTa 등) 아키텍처 기반, 특히 검색 작업에 특화된 이중 인코더 구조를 사용
- 이중 인코더 구조를 사용
- 쿼리(Q)를 벡터 $v_Q$로 변환하는 Query Encoder와 문서 청크(D)를 벡터 $v_D$로 변환하는 문서 인코더로
Q와 D를 개별적으로 인코딩하고, 벡터 DB에 미리 저장하므로 검색 속도가 빠름
- 쿼리(Q)를 벡터 $v_Q$로 변환하는 Query Encoder와 문서 청크(D)를 벡터 $v_D$로 변환하는 문서 인코더로
- 임베딩 모델의 학습: Contrastive Learning
- “유사한 것은 가깝게, 유사하지 않은 것은 멀리” 벡터 공간에 배치하도록 모델을 학습
- 모델이 쿼리(Q)와 정답 문서(D⁺) 쌍에 대해서는 높은 유사도를,
쿼리와 오답 문서(D⁻) 쌍에 대해서는 낮은 유사도를 출력하도록 학습
p35. 임베딩 모델
RAG 시스템은 속도를 위해 이중 인코더를 사용하여 후보군을 빠르게 검색한 후,
정확도를 위해 크로스 인코더를 사용하여 순위를 재조정하는 하이브리드 파이프라인을 주로 사용
| 특징 | 이중 인코더 (Dual-Encoder) | 크로스 인코더 (Cross-Encoder) |
|---|---|---|
| 구조 | 쿼리와 문서를 각각 인코딩 $(Q \rightarrow v_Q,\ D \rightarrow v_D)$ | 쿼리와 문서를 연결하여 함께 인코딩 $([Q;D] \rightarrow \text{Score})$ |
| 학습/추론 | 분리 인코딩 → 벡터 저장 → 코사인 유사도 | 결합 인코딩 → 단일 점수 출력 (관련도) |
| 속도 | 매우 빠름 (벡터 검색) | 매우 느림 (쿼리당 문서별 인코딩 필요) |
| 정확도 | 높음 (대조 학습으로 충분히 학습) | 최고 (문맥적 상호작용 분석 가능) |
| RAG 활용 | 1단계 검색 (Retrieval): 수십억 개 문서 중 k개 후보군 선별 | 2단계 재순위 지정 (Reranking): k개 후보군 순위 재조정 |
p36. Embedding
- 모델 제공자
- Google, OpenAI, Cohere, Amazon: 상용 임베딩 모델
- Hugging Face: Transformers 라이브러리를 통해 오픈소스 임베딩 모델을 제공
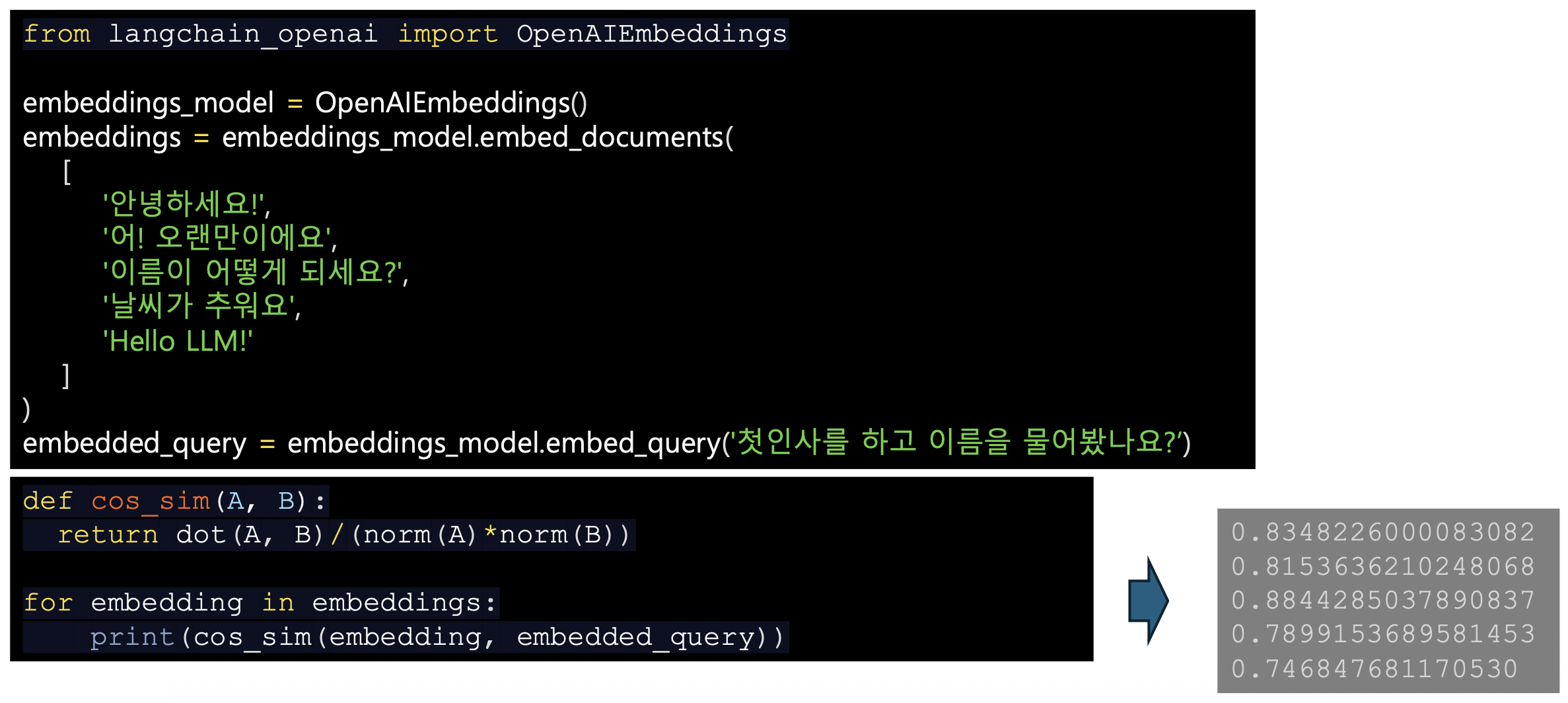
- 임베딩 메소드
- embed_documents
- 입력: 문서 객체의 집합
- 각 문서를 벡터 공간에 임베딩, 대량의 텍스트 데이터를 배치 단위로 처리할 때 사용
- embed_query
- 입력: 단일 텍스트 쿼리
- 쿼리를 벡터 공간에 임베딩
- embed_documents
- 유료 임베딩 모델 (OpenAI, Google, Cohere, Amazon)
- 사용하기 편리하지만 비용 발생
- API 통신을 이용하므로 보안 우려 존재
- 한국어 포함 다국어 임베딩 지원
- GPU 없이도 빠른 임베딩 가능
- 로컬 임베딩 모델 (HuggingFace)
- 무료이지만 다소 어려운 사용
- 오픈소스 모델 사용으로 보안 우수
- 모델마다 지원 언어가 다름
- GPU 없을 시 임베딩 속도 느림
임베딩 모델에 따라 임베딩 벡터의 값과 차원 다르게 표현
용도에 맞는 임베딩 모델 선택이 중요!
p37. OpenAIEmbeddings
- OpenAI의 API를 활용하여, 각 문서를 대응하는 임베딩 벡터로 변환
p38. HuggingFaceEmbeddings
- Hugging Face의 트랜스포머 모델을 사용하여 문서/문장을 임베딩하는 데 사용
- Hugging Face 모델 허브에서 사전 훈련된 임베딩 모델을 다운로드 받아서 적용 가능
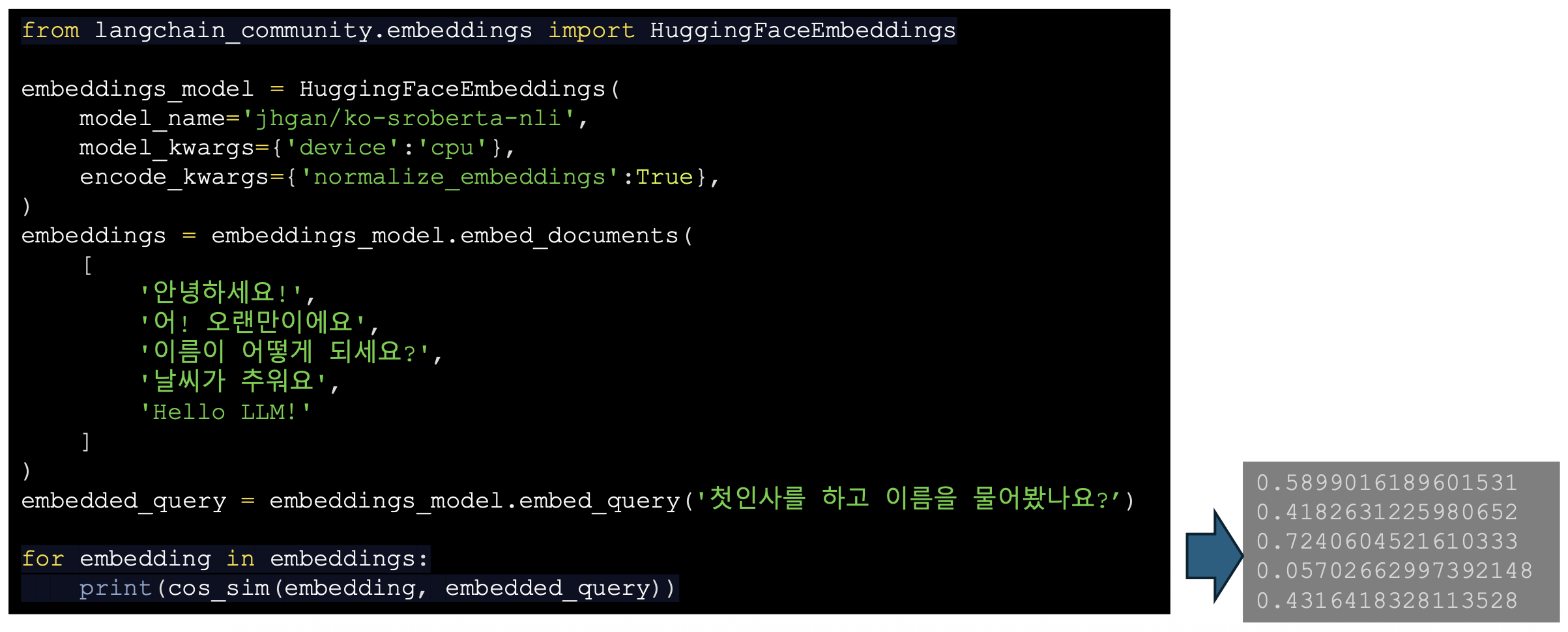
p39. 임베딩 모델
- 임베딩 모델 선택
- 오픈소스: 비용 절감, 데이터 프라이버시, 모델 커스터마이징 측면에서 큰 이점
| 구분 | 모델 예시 | 임베딩 차원 | 특징 및 장점 | 주요 사용 사례 |
|---|---|---|---|---|
| 상용 (API) | OpenAI text-embedding-3-large | 3072 (API로 축소 가능) | 최상위 성능, 다국어 능력 우수, 차원축소 기능으로 비용/속도 최적화 가능, 관리 용이 | 고정밀이 요구되는 전문 지식 기반 RAG, 초기 프로토타이핑, API 종량제 모델에 적합 |
| Cohere Embed v3/v4 | 주로 1024 | 긴 컨텍스트(최대 128K) 처리 강점, 다국어 및 멀티모달 지원 | 긴 법률 문서, 연구 논문 등 장문 검색이 필수인 분야, 긴 텍스트 청크를 기반으로 하는 RAG | |
| 오픈소스 | BAAI BGE-M3 | 1024 | 다기능성 (Dense + Sparse) 지원, 다국어 성능 우수, 하이브리드 검색에 최적화, 커스터마이징 용이 | 고성능/하이브리드 검색이 필요한 복합 RAG, 사내 보안 및 통제 환경 |
| e5 계열 (e5-large, multilingual-e5) | 768 / 1024 | 균형 잡힌 성능과 효율성, SOTA에 근접한 성능을 제공하는 대표적 오픈소스 모델 | 준수한 성능 대비 리소스 효율이 중요한 대규모 인덱싱, 일반적인 RAG | |
| MiniLM 계열 (all-MiniLM-L6-v2) | 384 | 초경량, 고속 추론, 낮은 차원으로 벡터 DB 저장 공간 및 검색 속도 최적화, CPU 환경 적합 | 낮은 지연 시간(Low Latency)이 요구되는 애플리케이션, 리소스 제한적인 환경 |
p40. 임베딩 모델
RAG 개발 시 임베딩 모델 선택 가이드
- 정확도 최우선
- OpenAI / Cohere 같은 상용 API 사용하거나 BGE-M3와 같은 최신 고성능 오픈소스 모델을 선택
- Reranker(재순위 모델)를 추가
- 비용/효율성 최우선
- all-MiniLM-L6-v2 또는 e5-base와 같은 경량 모델을 선택
- 낮은 차원(384d, 768d)을 사용하면 인프라 비용을 크게 절감
- 데이터 프라이버시 / 커스터마이징
- BGE-M3 또는 E5 같은 오픈소스 모델을 자체 서버에 배포
- 자체 도메인 데이터로 파인튜닝하여 보안 및 성능을 확보
- 긴 문서 처리
- Cohere나 컨텍스트 길이가 긴 오픈소스 모델(예: Qwen3-Embedding)을 고려
p41. 유사도 계산
코사인 유사도(Cosine Similarity)
similarity = cosine_similarity(vector1, vector2)
범위: -1 ~ 1 (1에 가까울수록 유사)유클리드 거리(Euclidean Distance)
distance = euclidean_distance(vector1, vector2)
범위: 0 ~ ∞ (0에 가까울수록 유사)내적 (Dot Product)
score = dot_product(vector1, vector2)
| 방식 | 수식 / 정의 | 특징 | 활용 예시 |
|---|---|---|---|
| Cosine Similarity | cos(θ) = (A·B) / (‖A‖‖B‖) | 방향(의미적 유사성)에 민감 | 텍스트 임베딩 기본 |
| Euclidean Distance | d = √Σ(xᵢ - yᵢ)² | 절대 거리 기준 | 이미지 벡터, 위치 기반 |
| Dot Product | A·B = Σ(aᵢbᵢ) | 크기 + 방향 반영 | 신경망 내부 표현 |
| Hamming Distance | bit 간 불일치 수 | 이진 벡터 전용 | 해시 기반 검색 |
Hamming Distance(해밍 거리)의 개요
- 해밍 거리(Hamming Distance)는 두 이진 벡터(binary vectors) 또는 동일 길이 문자열이
서로 얼마나 다른지를 측정하는 거리(metric)이다.- 각 위치(index)의 값을 하나씩 비교하여, 값이 서로 다른 위치(불일치, mismatch)의
개수를 그대로 “거리”로 사용한다.- 예를 들어,
- A = 1011101
- B = 1001001
이 두 벡터를 비교하면 서로 다른 위치가 2개이므로 해밍 거리 = 2이다.Hamming Distance의 특징 및 해석
- 해밍 거리는 연속적인 실수 벡터에는 사용할 수 없고,
오직 0/1 기반 이진 벡터 또는 길이가 동일한 문자열에서만 정의된다.- 따라서 cosine similarity나 euclidean distance와는 완전히 다른 방식의 거리 개념이다.
- LSH(Locality-Sensitive Hashing), SimHash, Bloom filter 등의
해시 기반 고속 검색에서 자주 사용되며,
통신·저장장치에서 오류 검출(Error-Correcting Code)의 핵심 개념으로도 활용된다.
p42. 벡터 데이터베이스
- 벡터 데이터베이스(Vector Database, Vector DB)
- RAG(검색 증강 생성) 시스템에서 외부 지식을 저장하고 검색하는 핵심 인프라
- 고차원 벡터의 저장, 인덱싱 및 유사도 검색에 최적화
| 특징 | 설명 |
|---|---|
| 벡터 스토리지 | 텍스트, 이미지, 오디오 등 복잡한 데이터를 수치화한 임베딩 벡터와 해당 벡터의 메타데이터를 함께 저장 |
| 유사도 검색 (ANN) | 모든 벡터와의 비교 검색(O(N))이 아닌 Approximate Nearest Neighbor(근사 최근접 이웃) 알고리즘(예: HNSW, IVF)을 사용하여 수십억 개의 벡터 중 가장 유사한 벡터를 초고속으로 검색 |
| 확장성 | 대규모 데이터셋과 쿼리 부하에 대응하기 위해 수평 확장(Horizontal Scaling)을 기본적으로 지원 |
| 필터링 | 벡터 검색과 함께 메타데이터(예: 작성자, 날짜, 카테고리) 기반으로 필터링이 가능 |
p43. 벡터 데이터베이스
상용 vs. 오픈소스 벡터 DB
- 상용 벡터DB
- Pinecone, Vertex AI Vector Search (Google), Azure AI Search (Microsoft),
Amazon OpenSearch Service (w/ k-NN) (AWS) 특징: 완전 관리형(Fully Managed), 클라우드 기반 서비스
- 장점
- 인프라 관리 부담 해소: 설치 확장, 백업, 모니터링 등 운영 오버헤드가 없음
- 고가용성 및 성능 보장: 안정적인 서비스 가능
- 전문지원: SLA(서비스 수준 계약) 기반의 기술지원
- Time-to-Market
- 단점
- 비용: 벡터수, 차원, 쿼리량에 따라 비용 증가
- 벤더 종속성
- 커스터마이징 제한: 인덱싱 알고리즘, 하부 인프라 등의 세부적인 제어 불가능
- 데이터 주권/보안 우려
- 주요 활용 예: 실시간성이 중요한 프로덕션 환경, 빠른 Prototyping, 인프라 운영 인력 부족 시
- Pinecone, Vertex AI Vector Search (Google), Azure AI Search (Microsoft),
p44. 벡터 데이터베이스
- 주요 상용 벡터 DB 특징 요약
| 구분 | 주요 서비스 | 핵심 특징 | 하이브리드 검색 | 적합한 사용자 |
|---|---|---|---|---|
| 전용 벡터 DB | Pinecone (대표적) | 벡터 검색에 최적화된 아키텍처 다양한 LLM/임베딩 API와 연동용이 클라우드 agnostic (AWS, GCP 등 선택 가능) | 메타데이터 필터링 및 희소 벡터(Sparse) 지원 | 고성능 및 낮은 지연 시간이 필수적인 RAG 개발자, 자체 DB 운영을 원치 않는 기업 |
| 클라우드 통합 | Vertex AI Vector Search (Google) | Google Cloud 서비스와 긴밀한 통합 강력한 ML 플랫폼(Vertex AI)의 일부 | 메타데이터 필터링 지원 | Google Cloud를 주력으로 사용. ML Ops 환경을 통합하려는 기업 |
| Azure AI Search (Microsoft) | 기존 Full-Text Search 기능과의 강력한 결합. Microsoft 생태계(Azure, OpenAI) 통합 | 네이티브 하이브리드 검색 (Full-Text + Vector) 강력 지원 | Microsoft Azure를 사용하거나, 하이브리드 검색을 중요하게 생각하는 기업 | |
| Amazon OpenSearch Service (w/ k-NN) (AWS) | 로그 및 검색 기능 중심. 벡터 검색을 기존 검색 엔진 기능에 추가 통합 | - | AWS를 사용하며, 기존 OpenSearch 클러스터에 벡터 기능을 추가하려는 기업 |
p45. 벡터 데이터베이스
- 오픈소스 벡터 DB
Milvus, Qdrant, Weaviate, Chroma, pgvector (PostgreSQL 확장), FAISS, ElasticSearch
- 특징
- 자유로운 라이선스, 자체 구축 및 운영 필요 (Self-hosted)
- 장점
- 비용 절감
- 최대 유연성 및 통제: 소스코드 수정 및 커스터마이징 가능
- 데이터 프라이버시: 민감한 기업 내부 데이터를 외부에 전송하지 않고 관리
- 단점
- 운영 복잡성
- 기술지원
- 활용사례
- 대규모 데이터 인프라를 이미 보유한 기업
- 높은 수준의 데이터 보안이 요구되는 금융/공공 기관
- 도메인 특화된 기능을 개발해야 하는 경우
p46. 벡터 데이터베이스
Indexing 알고리즘
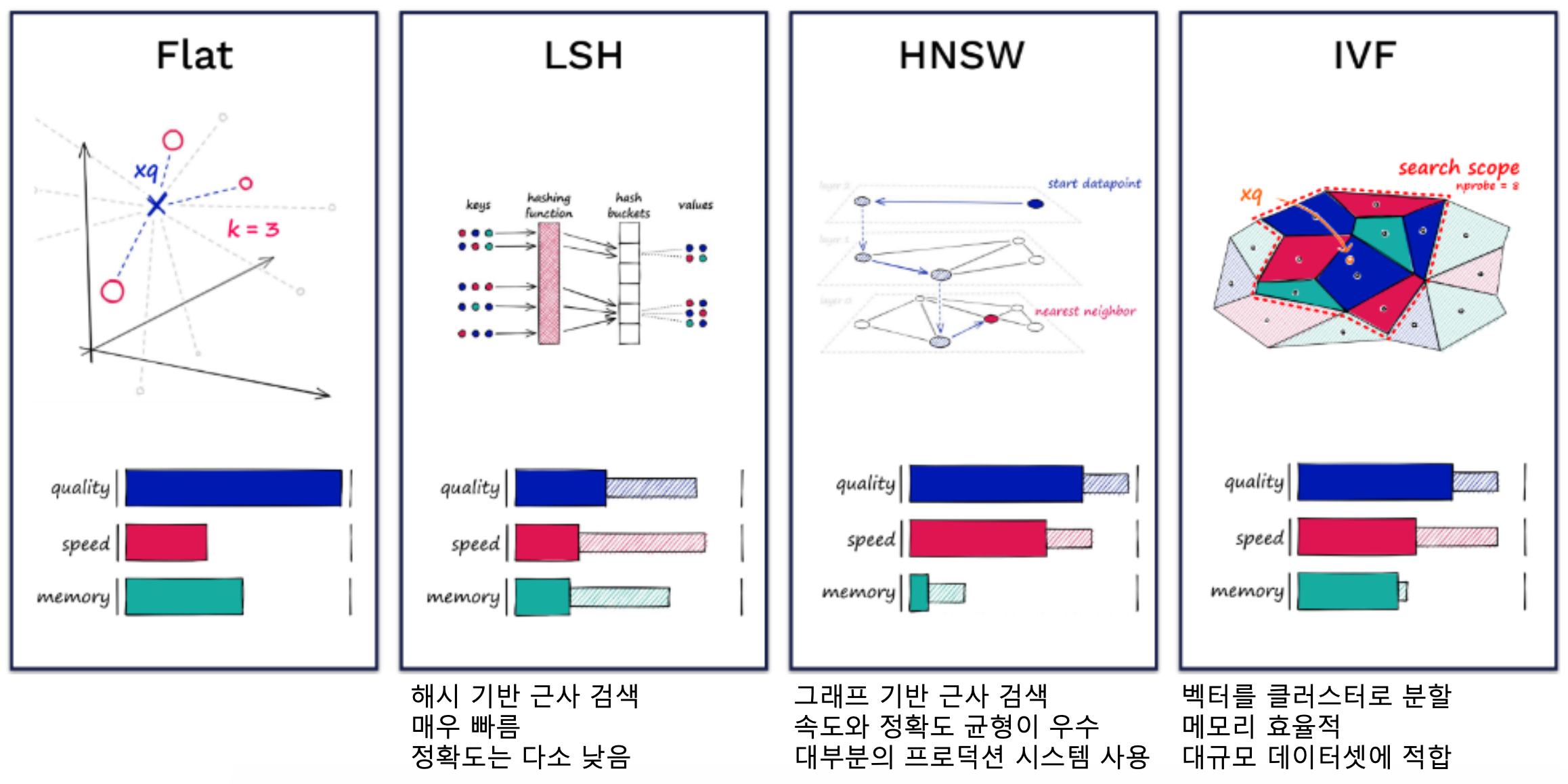
- Flat Index (No optimization)
- Indexing 기법 없이 벡터를 저장하는 방법
- 저장된 모든 벡터들과 유사도를 계산, 가장 높은 유사도를 지닌 벡터를 찾는 방법
- 10000~50000개 정도의 벡터에서 적당한 성능과 높은 확장성
- PQ (Product Quantization)
- 원벡터를 균등하게 몇 개의 서브 벡터로 쪼개고,
각 서브 벡터들을 Quantization하여 크기를 줄임 - 빠르고 정확도가 높고, 큰 데이터 셋에서 사용하기 좋은 기법
- 원벡터를 균등하게 몇 개의 서브 벡터로 쪼개고,
- LSH (Locality-Sensitive Hashing)
- 벡터들을 Hashing 함수를 이용해 Bucket에 매핑하는 방법
- 유사도 검색과 색인을 모두 동일한 Hashing 함수를 사용하여
같은 Bucket에 있는 벡터들과 비교 및 탐색 - Bucket에 있는 데이터들 사이에서만 유사도 검색을 하므로 검색속도가 빠름
PQ(Product Quantization)은
“고차원 벡터를 여러 조각(sub-vector)으로 나누고,
각 조각을 가장 가까운 코드워드(codeword)의 ID로 치환해
벡터 전체를 아주 작은 정수들의 조합으로 압축하는 방법”이다.아래는 128차원 벡터를 기준으로 PQ가 어떻게 동작하는지,
그리고 코드북(codebook)이 실제로 어떤 구조인지까지
모두 포함한 설명이다.(예시: PQ 전체 흐름)
128차원 임베딩 벡터 예시
예: [0.12, 0.98, -0.33, … , 0.44]PQ는 이 벡터를 4개의 sub-vector로 나눈다.
• 구간1: 차원 0~31
• 구간2: 차원 32~63
• 구간3: 차원 64~95
• 구간4: 차원 96~127각 구간마다 “코드북(codebook)”이 존재한다.
예: 구간1 코드북 = K=256개의 32차원 codeword(1) 코드북(Codebook)이란 무엇인가?
- 코드북은 “이 sub-vector 영역에서 자주 등장하는 패턴을 압축한 벡터 사전(dictionary)”이다.
- 즉, 코드북의 각 codeword는 32차원 대표 벡터이며,
sub-vector가 어떤 패턴인지에 따라 가장 가까운 codeword의 ID를 사용한다.(예: 구간1의 Codebook_1, K=8일 때)
Codebook_1 = [ c1 = [ 0.12, -0.01, 0.88, ..., 0.42 ] # 32D c2 = [-0.44, 0.92, -0.10, ..., 0.03 ] # 32D c3 = [ 1.22, 0.14, -0.75, ..., 0.50 ] ... c8 = [-0.91, 0.33, 0.29, ..., -0.20 ] ]
- 실제 PQ에서는 K=256 또는 K=512를 사용하므로
256개(또는 512개)의 32차원 벡터가 코드북 하나를 구성한다.(2) 코드북은 어떻게 생성되는가? (직관적 설명)
- 예를 들어 100만 개의 128차원 벡터가 있다고 하자.
- 각 128D 벡터를 4개 sub-vector(32D씩)로 나눈다.
- sub-vector 1만 모아놓고 k-means 클러스터링(K clusters)을 실행한다.
→ 그 K개의 중심(centroid)이 바로 Codebook_1의 codewords가 된다.- 같은 방식으로 구간 2, 구간 3, 구간 4도 각각 따로 k-means를 실행한다.
즉:
(3) 코드북의 실제 사용 예시
아래 입력 벡터 x를 보자:
이것을 4개 sub-vector로 나누면:
이제 각 sub-vector에 대해 “가장 가까운 codeword ID”를 찾는다.
예:
최종 PQ 코드 =
즉, 원래 128차원 벡터가
정수 4개로 압축된 것이다.(4) 검색은 lookup table로 어떻게 빨라지는가?
쿼리 벡터 q 역시 4개 sub-vector로 나눈다:
각 q_i에 대해 다음을 미리 계산한다:
이제 어떤 데이터 벡터의 PQ 코드가 [17, 201, 88, 9]라면
근사 거리는 즉시 계산된다:
approx_distance = DistTable_1[17] + DistTable_2[201] + DistTable_3[88] + DistTable_4[9]→ 128차원 실수 연산 없이,
정수 lookup 4번만으로 거리 계산 완료
(10~100배 이상 빠름)(5) PQ 요약
- 코드buk = 각 sub-vector 공간의 대표 패턴을 모아둔 “벡터 사전”
- 코드워드 = k-means로 얻은 centroid(대표 벡터)
- PQ 코드 = 각 sub-vector가 가장 가까운 codeword의 인덱스
- 검색 = 128D 연산 대신 “정수 lookup 조합”으로 근사 거리 계산
- 목표 = 정확한 클러스터 보존이 아니라
메모리 절약 + 고속 근사 검색LSH(Locality-Sensitive Hashing)은
“유사한 벡터가 같은 해시 결과(또는 비슷한 해시 결과)를 얻을
확률을 높이는 해시 함수로, 벡터를 0/1 비트열로 매핑하는 기법”이다.아래는 Random Hyperplane LSH를 기준으로
(1) 해싱 단계
(2) 해싱 이후 실제 탐색 단계에서 어떤 계산이 이루어지는지
를 구체적으로 정리한 내용이다.(1) 해싱 단계
D차원 공간에 랜덤 초평면(hyperplane) L개를 만든다.
각 초평면은 방향 벡터 w₁, w₂, …, w_L 로 정의된다.주어진 벡터 x에 대해, 각 w_i와 내적 후 부호(sign)를 취한다. 예: sign(x · w₁) → 1
sign(x · w₂) → 0
sign(x · w₃) → 1
sign(x · w₄) → 1
sign(x · w₅) → 0이 0/1 결과를 이어 붙여
예: 10110 과 같은 L비트 해시 코드가 된다.이 해시 코드를 key로 사용해
해시 테이블의 bucket 에 x를 삽입한다.이렇게 하면, “비슷한 방향을 가진 벡터들”은
같은 초평면에 대해 비슷한 부호 패턴을 가지므로
같은 bucket(또는 아주 비슷한 코드의 bucket)에 들어갈 확률이 높아진다.(2) 해싱 이후 탐색 절차에서 어떤 계산이 이루어지는가?
이제 쿼리 벡터 q가 들어왔을 때
LSH 기반으로 근사 최근접 이웃(ANN)을 찾는 과정을 단계별로 보면 다음과 같다.
- 쿼리 벡터 q의 해시 코드 계산
- 데이터 삽입 때와 똑같이
w₁, …, w_L와 q의 내적을 계산하고 부호를 취한다.- 예: sign(q · w₁) → 1
sign(q · w₂) → 0
sign(q · w₃) → 1
sign(q · w₄) → 1
sign(q · w₅) → 0- 결과: q의 해시 코드 H(q) = 10110
- 1차 후보 집합: 같은 bucket 조회
- 해시 테이블에서 key = 10110 인 bucket을 찾는다.
- 이 bucket 안에는,
“H(x) = 10110” 인 데이터 벡터들이 저장되어 있다.- 이들을 1차 후보(candidate set)로 가져온다.
- 필요 시 인근 버킷도 함께 탐색 (Hamming 거리 기반)
만약 10110 버킷에 벡터가 너무 적거나,
더 많은 후보가 필요하다면,
“해시 코드가 조금 다른” 버킷도 함께 조회한다.이때 “조금 다르다”는 것은
해시 코드 사이의 Hamming 거리(서로 다른 비트 수)가 작음을 의미한다.- 예:
- Hamming 거리 1인 패턴들:
00110, 11110, 10010, 10100, 10111- Hamming 거리 2까지 허용하면
비트가 2개 다른 패턴들도 포함된다.- 구현 상으로는
“H(q)와 Hamming 거리가 ≤ r 인 코드 집합”에 해당하는
bucket들을 생성해서 순차적으로 조회하는 방식이 사용된다.- 2차 계산: 후보들에 대해 실제 거리 계산
위에서 모은 후보 벡터 집합 C에 대해서는
더 이상 해시 코드만 보지 않고,
실제 원본 벡터 공간에서 거리(유클리드 거리, 코사인 거리 등)를 계산한다.예: 후보 집합 C = {x₁, x₂, …, x_M}
각 후보에 대해: distance(q, xᵢ) =
- 유클리드 거리: $ | q - x_i |_2 $
- 또는 코사인 거리: $ 1 - \frac{ q \cdot x_i }{ | q | \, | x_i | } $
이 단계는
“LSH가 줄여준 후보 집합 C에 한해서만”
원래 고차원 거리 계산을 수행하므로,
전체 N개(예: 100만 개)를 비교하는 것보다 훨씬 싸다.- 후보 정렬 및 Top-k 반환
계산된 distance(q, xᵢ)를 기준으로
오름차순 정렬 후 상위 k개를 반환한다.이 k개는
“LSH가 제공한 근사 최근접 이웃(Approximate Nearest Neighbors)”
이라고 볼 수 있다.요약하면, 해싱 이후 탐색 단계에서 실제로 이루어지는 계산은:
- q의 해시 코드 H(q)를 구한다.
- H(q)와 동일하거나 Hamming 거리가 작은 버킷들을 조회한다.
- 그 버킷들 안에 있는 후보 벡터들에 대해서만
실제 거리(유클리드/코사인)를 계산한다.- 거리 기준으로 Top-k를 선택한다.
(3) 여러 개의 해시 테이블을 사용하는 경우(LSH의 강화)
실제 시스템에서는 “충분한 재현율(recall)”을 얻기 위해
해시 테이블 1개만 쓰지 않고
여러 개의 독립적인 해시 테이블을 사용한다.- 예:
- 테이블 A: 랜덤 초평면 집합 {w₁, …, w_L}
- 테이블 B: 다른 랜덤 초평면 집합 {u₁, …, u_L}
- 테이블 C: 또 다른 집합 {v₁, …, v_L}
- 삽입 시:
- 각 벡터 x에 대해
테이블 A, B, C 각각에 해시해서
해당 버킷에 x를 넣어둔다.- 쿼리 q에 대해: 1) 각 테이블에서 H_A(q), H_B(q), H_C(q) 코드 계산
2) 각 테이블에서 해당 코드(및 인근 코드)의 버킷을 조회
3) 모든 테이블에서 나온 후보들을 합집합으로 모은 뒤
최종 후보 집합 C에 대해 실제 거리 계산이렇게 여러 테이블을 쓰면:
- “유사한 벡터를 최소 한 테이블에서는 같은 버킷에 넣을 확률”이 올라가고
- 너무 많은 후보가 하나의 테이블에 몰리는 현상을 줄여
속도·정확도 간 트레이드오프를 조절하기 쉽다.(4) LSH vs PQ 관점에서 검색 단계 비교
- PQ:
- 쿼리 q의 sub-vector와 각 코드북 간 거리 테이블을 미리 계산
- 데이터는 정수 ID 조합 [i₁, i₂, …]로 저장
- 검색 시 “lookup table 합산”으로 근사 거리 계산 후
필요하면 상위 일부에 대해만 정확한 거리 재계산- LSH:
- 쿼리 q의 해시 코드 H(q)를 계산
- 같은 코드 또는 Hamming 거리가 작은 코드의 버킷만 조회
- 그 안에 있는 후보들에 대해서만
실제 거리(유클리드/코사인)를 계산하고 Top-k 선택둘 다 “전체 데이터와 직접 거리 계산하는 비용”을 줄이는 방식이지만,
- PQ는 “연속 공간을 코드북으로 양자화하여 거리 계산 자체를 근사”
- LSH는 “해시 버킷으로 후보를 좁힌 뒤 원래 거리를 계산” 라는 점에서 검색 단계의 계산 방식이 다르다.
p47. 벡터 데이터베이스
HNSW (Hierarchical Navigable Small World graph)
탐색 가능한 작은 세계(NSW) 그래프 구조를 계층적으로 구성하여,
방대한 데이터셋에서 쿼리 벡터와 가장 유사한 벡터를 빠르게 찾아내는 것을 목표로 함작은 세계 (Small World): 임의의 두 노드 사이의 거리가 매우 짧은 그래프를 의미
계층 구조 (Hierarchy): 그래프를 여러 레벨(층)으로 나누어 검색 속도와 정확도를 조절
- 상위 레벨: 매우 희소한 그래프 → 전역 탐색 (빠르게 후보 집합을 찾음)
- 하위 레벨: 상세(밀집) 그래프 → 지역적으로 정확한 최근접 탐색
HNSW 그래프 구조: HNSW 인덱스는 다중 레벨 그래프(Multilayer Graph)와 진입점(Entry Point)으로 구성
다중 레벨 그래프 (Multilayer Graph)
새로운 벡터(v)가 인덱스에 삽입될 때, 무작위로 레벨 L이 할당
- 레벨 0 (Base Layer)
- 모든 벡터 노드를 포함하며, 가장 촘촘하게 연결되어 정확한 지역 검색 수행
모든 탐색은 최종적으로 이 레벨에서 마무리
- 모든 벡터 노드를 포함하며, 가장 촘촘하게 연결되어 정확한 지역 검색 수행
- 상위 레벨 (L > 0)
- 벡터의 부분 집합만을 포함한 매우 희소한 그래프
→ 노드 수가 적고 연결이 성기기 때문에 빠른 전역 탐색을 위해 사용
- 벡터의 부분 집합만을 포함한 매우 희소한 그래프
- 연결 제한 (M)
- 각 노드가 갖는 최대 이웃의 개수로, M 값이 클수록 정확도는 높아지지만, 메모리 사용량과 인덱스 구축 시간 증가
진입점 (Entry Point, E)
- 인덱스에서 가장 높은 레벨에 있는 임의의 노드를 진입점으로 설정. 모든 검색은 이 E 노드에서 시작
1) HNSW 전체 개념
- HNSW는 벡터를 그래프 형태로 저장하고
그 그래프 위를 걸어가며(탐색하며) 가장 가까운 벡터를 빠르게 찾는 알고리즘이다.- “Small World 그래프 + 계층 구조” 를 결합하여
전역 탐색 → 지역 정밀 탐색 방식으로 동작한다.2) Small World란?
- 아무 두 노드도 몇 번만 점프하면 연결될 정도로 탐색 효율이 좋은 구조.
- SNS의 “6단계 이론(6 degrees)”처럼, 멀리 있는 노드도 적은 단계로 접근할 수 있다.
3) 왜 계층 구조를 쓰는가?
- 상위 레벨: 노드 수가 적어서 “대략적인 방향”을 빠르게 파악할 수 있음.
- 하위 레벨: 노드가 많고 촘촘해서 “정밀 검색” 수행 가능.
4) 새 벡터 삽입 시 일어나는 일
- 새 벡터 v는 무작위로 레벨 L을 부여받으며,
L부터 0까지 모든 레벨에 삽입된다.- 각 레벨의 노드와 연결될 때 최대 M개의 이웃만 유지한다.
5) M(이웃 수 제한)의 동작 원리
- 각 노드는 “가까운 이웃 M개”만 유지한다.
- M을 초과하면 먼 이웃은 잘라내는(pruning) 구조.
- 이유: 그래프가 너무 복잡해지면 탐색이 느려지므로
가장 중요한 근접 연결만 유지해 Small World 특성을 보존한다.6) 레벨별 M 값의 차이
- 높은 레벨일수록 M이 작음 → 희소 연결 유지 (전역 탐색 최적)
- 낮은 레벨일수록 M이 큼 → 촘촘 연결 유지 (정밀 탐색 최적)
7) Entry Point
- 항상 가장 높은 레벨의 노드 하나를 Entry Point로 삼아 탐색을 시작한다.
- 높은 레벨은 노드가 적기 때문에 전역적인 위치를 빠르게 좁힐 수 있다.
요약하면,
HNSW는 “멀리서 방향 잡고 → 가까워질수록 세밀한 탐색”을 수행하는 구조이며,
레벨·M·Small World 특성을 조합하여 매우 빠르고 안정적인 벡터 검색을 가능하게 한다.
p48. 벡터 데이터베이스
HNSW (Hierarchical Navigable Small World graph)
탐색 알고리즘
시작: entry_point와 현재 그래프의 최상위 레벨에서 시작
- 상위 레벨에서 greedy search
- 현재 노드에서 인접 노드들 중 쿼리와 거리(또는 유사도)가 더 나은 노드가 있으면 그 쪽으로 이동
- 더 이상 개선 불가할 때까지 반복 → 로컬 최적점 도달
- 하위 레벨로 내려가기
- 해당 레벨에서 탐색 후보 집합(efSearch)을 이용한 beam-like search
(best-first 후보 유지)를 실행 - 하위 레벨 시작점은 상위 레벨에서의 최종 노드(로컬 최적점)
- 해당 레벨에서 탐색 후보 집합(efSearch)을 이용한 beam-like search
- 최저 레벨 (0) 에서 최종 Top-K 반환. 선택적으로 re-ranking 수행
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
function search(query, efSearch, entry_point, max_level):
cur_node = entry_point
# greedy search on upper levels (max_level .. 1)
for level in range(max_level, 0, -1):
improved = True
while improved:
improved = False
for neighbor in cur_node.neighbors[level]:
if dist(query, neighbor.vector) < dist(query, cur_node.vector):
cur_node = neighbor
improved = True
# at level 0: do best-first search with efSearch
candidates = priority_queue()
visited = set()
add cur_node to candidates
top_candidates = best_first_search(query, candidates, efSearch)
return top_candidates.topK()
(HNSW 탐색 알고리즘 전체 흐름 + greedy search + beam search 직관 설명)
1) 탐색 시작 – Entry Point에서 최상위 레벨 탐색
- 검색은 항상 가장 높은 레벨의 Entry Point에서 시작한다.
- 이 레벨은 노드가 적으므로
“대략 어느 방향으로 가야 하는지” 빠르게 파악할 수 있다.2) 상위 레벨에서의 Greedy Search (탐색 단순화 버전)
- 현재 노드에서 인접 노드들을 확인하며
쿼리와 더 가까운 노드가 있으면 즉시 이동한다.- “더 가까운 노드가 없을 때까지” 반복 → 지역 최적점 도달.
- 이 방식은 상위 레벨에서 매우 빠르게 전역적인 방향을 잡아준다.
3) 레벨을 내려가며 탐색 정밀도를 높임
- 상위 레벨에서 찾은 ‘최종 노드’가
하위 레벨의 시작점이 된다.- 레벨이 내려갈수록 노드가 많아지고 연결이 촘촘해지므로
보다 정확한 위치로 좁혀간다.4) Level 0(최하위 레벨)에서의 정밀 탐색: Best-first / Beam-like Search
- Level 0은 모든 노드를 포함하므로
여기서는 greedy로는 부족하고 더 정밀한 탐색이 필요함.- HNSW는 efSearch 크기만큼 후보를 유지하며 탐색을 확장하는
best-first(beam-like) 탐색을 수행한다.
- 더 좋은 후보가 생길 때 후보 큐(priority queue)를 갱신
- 방문한 노드는 visited에 기록하여 중복 탐색 방지
5) 최종 Top-K 반환 + 선택적 re-ranking
- Level 0의 best-first 탐색 결과에서
가장 가까운 K개를 최종 반환.- 필요 시 이 Top-K에 대해 실제 거리 재측정(re-ranking)을 수행할 수도 있음.
6) 전체 탐색 흐름 요약
7) 직관적 비유
- 높은 레벨에서는 “한국 지도”처럼 큰 범위를 한번에 훑고
- 중간 레벨에서는 “서울 지도”처럼 더 좁혀 보고
- Level 0에서는 “강남역 골목길 지도”처럼 세밀하게 탐색하는 느낌.
즉, HNSW 탐색은
멀리서 방향 잡고 → 가까워질수록 확대해서 정밀 탐색하는 과정으로 이해하면 된다.
p49. 벡터 데이터베이스
IVF (Inverted File index)
- 클러스터링을 통해 검색 범위를 축소함으로써 검색 효율을 높이는 방법: Clustering + Inverted File
- 대규모 벡터 집합의 ANN(근사 최근접 탐색)을 위해 데이터를 여러 버킷(list)으로 군집화
(e.g. k-means 등을 적용해 N개 클러스터 구성) - 검색 쿼리가 주어지면, 쿼리가 포함된 cluster를 찾고,
해당 cluster의 inverted list 내 벡터들에 대해 유사도 검색 수행
- 대규모 벡터 집합의 ANN(근사 최근접 탐색)을 위해 데이터를 여러 버킷(list)으로 군집화
- IVFADC
- IVF에 Product Quantization (PQ) 을 결합해
검색 메모리와 계산 비용을 줄인 기법의 표준
- IVF에 Product Quantization (PQ) 을 결합해
- 알고리즘
- 전체 벡터들을 nlist개의 군집(버킷)으로 나눈다 (코어 센트로이드 $C_i$)
- 각 벡터 $x$는 그 벡터가 속한 centroid의 버킷에 저장
(또는 residual을 PQ로 압축하여 저장) - 검색 시 쿼리 $q$에 대해 가장 가까운 nprobe개의 centroid를 선택 — 해당 버킷들만 탐색
- 버킷 내 벡터는 PQ 코드(또는 원본 벡터)로 저장되어 있음
- 최고 효율의 거리 계산(ADC)으로 Top-K를 빠르게 구함
- 필요하면 Top-L 후보를 re-rank (원본 벡터 거리 계산 또는 cross-encoder)하여 최종 Top-K 반환
IVF (Inverted File Index)
IVF는 “대규모 벡터를 여러 버킷(list)으로 먼저 나눠 두고,
검색 시 전체가 아니라 관련된 버킷만 탐색하는 방식”이다.Clustering + Inverted Lists 구조
- 전체 벡터를 nlist개의 클러스터로 나누고
각 centroid에 소속된 벡터들을 “inverted list(버킷)” 형태로 저장한다.예시
1,000만 개의 이미지 임베딩을 nlist = 1,000개 클러스터로 나누면
평균적으로 각 버킷에는 1만 개씩 저장된다.검색 쿼리가 들어오면 전체 1,000만 개와 비교하는 대신,
“q가 가장 가까운 centroid 3~5개(nprobe)”의 버킷만 확인하면 된다.
즉, 전체의 0.3~0.5%만 검사해도 충분하다.인덱싱 단계(벡터 저장)
- 벡터 x는 가장 가까운 centroid Cᵢ의 inverted list에 저장된다.
예시
centroid #57이 x와 가장 가깝다면,
x는 “list 57”에만 넣으면 된다.
나중에 검색 시 list 57만 보면 되므로 계산량이 크게 줄어든다.검색 단계(query q)
- q와 모든 centroid 간 거리 계산
- 가장 가까운 nprobe개의 centroid 선택
- 선택된 centroid들의 inverted list만 탐색
- 각 리스트 내 벡터들에 대해 유사도/거리 계산 수행
예시
q와 centroid들을 비교했더니
#10, #88, #514가 가장 가깝다면
IVF는 오직 list 10, 88, 514만 탐색한다.전체 1,000만 → 30,000개(3개 리스트)로 대폭 축소.
IVFADC (IVF + PQ 결합)
- IVF는 “탐색 범위 축소” 역할
- PQ(Product Quantization)는 “벡터 압축 + 빠른 근사 거리 계산” 역할
- 두 기술을 결합한 형태가 IVFADC이며, 현대 벡터 DB(Faiss)의 표준 구조다.
예시
128D 벡터 1개는 원래 512 bytes지만
PQ로 압축하면 8 bytes로 줄어든다.inverted list에 저장할 메모리가 64배 절약되며
거리 계산도 lookup table로 매우 빨라진다.Residual 기반 PQ 저장
- IVFADC에서는 원본 벡터 x를 그대로 저장하지 않고
“residual = x − centroid”를 PQ로 압축해서 저장하기도 한다.예시
centroid가 [1.0, 0.5]인데 x=[1.2,0.6]이면
residual=[0.2,0.1]을 PQ로 양자화하여 저장.residual은 분포가 더 좁아 PQ 정확도가 올라간다.
검색 시 ADC (Asymmetric Distance Computation)
- PQ로 압축된 벡터는
쿼리 q의 sub-vector와 코드북 간 사전 계산 테이블로
빠르게 근사 거리를 구한다.예시
list 57에 PQ 코드 [17, 201, 9, 88]으로 저장된 벡터가 있다면
q의 lookup table에서
Dist1[17] + Dist2[201] + Dist3[9] + Dist4[88]
과 같이 정수 ID 4개만으로 거리 계산이 끝난다.Re-ranking 단계
- 근사 검색(IVF + PQ)으로 Top-L 후보를 구한 뒤
이 L개에 대해서만 “정확한 거리” 또는 cross-encoder를 이용해
최종 Top-K를 재정렬할 수 있다.예시
PQ 근사 Top-100 → 이 100개만 원본 벡터 거리로 재측정
→ 최종 Top-10 반환
(전체 1,000만 개를 재측정할 필요 없음)요약 예시
대규모 도서관에서 원하는 책을 찾는 과정에 비유하면:
IVF = “먼저 장르(centroid)부터 찾는다.”
→ 문학/과학/IT/요리 등 큰 카테고리 중 몇 개만 보면 됨PQ = “책 내용을 1줄 요약(ID)만 보고 빠르게 비교한다.”
IVFADC =
장르로 먼저 후보를 좁히고(IVF)
그 안에서 요약본(PQ 코드)으로 빠르게 비교하는 방식대규모 벡터 검색에서 메모리·속도·정확도를 모두 잡기 위해
가장 널리 쓰이는 구조가 IVFADC이다.
p50. 벡터 데이터베이스
p51. 벡터 데이터베이스: Retrieval
Retrieval Algorithms
- 유사도 기반 검색
- MMR (Maximal Marginal Relevance) 검색 기법
- 쿼리에 대한 적합한 항목을 검색하면서 동시에 중복을 최소화 하는 방법
- 관련성과 다양성의 사이의 균형을 맞추어 검색 결과의 품질을 향상하는 알고리즘
- 검색 쿼리에 대한 문서들의 관련성은 최대화
- 검색된 문서들 사이의 중복성은 최소화
(매우 유사한 항목들만 검색되는 상황 방지)
- 동작
Greedy 방식으로 하나씩 선택.
\[MMR = \lambda \cdot Rel(d, Q) - (1 - \lambda) \cdot \max_{d' \in S} Sim(d, d')\]
각 단계에서 아직 선택되지 않은 문서 중에서
다음의 수식의 값을 최대화하는 문서를 선택- $\lambda$: 관련성 vs. 다양성 trade-off 조절 ($0 \le \lambda \le 1$).
$\lambda = 1$이면 단순 관련성(다양성 고려 없음),
$\lambda = 0$이면 오직 다양성에만 초점. - $Rel(d, Q)$: 쿼리와 문서의 관련도 (예: cosine similarity)
- $Sim(d_i, d_j)$: 문서 간 유사도 (예: cosine similarity)
- $S$: 이미 선택된 문서 집합
- $\lambda$: 관련성 vs. 다양성 trade-off 조절 ($0 \le \lambda \le 1$).
MMR 선택 절차
① 초기: $S = \lbrace\rbrace$
② 첫 항목은 보통 가장 관련도 높은 문서(또는 MMR 식으로 선택).
③ 반복: 남은 문서 중 MMR score 최대인 문서를 $S$에 추가.
④ 종료: $|S| = $ 원하는 개수 $K$.
p52. 벡터 데이터베이스
Chroma
- 임베딩 벡터를 저장하기 위한 오픈소스 소프트웨어
- 임베딩 및 메타데이터 저장: 임베딩 데이터뿐만 아니라 관련된 메타데이터를 효율적으로 저장
- 문서 및 쿼리 임베딩: 텍스트 데이터를 벡터 공간에 매핑하여 임베딩 생성
- 임베딩 검색: 사용자 쿼리에 기반하여 가장 관련성이 높은 임베딩을 검색할 수 있음
- Chroma 벡터 저장소 생성 & 유사도 기반 검색
- Chroma.from_texts: 분할된 텍스트를 임베딩하고 벡터 저장소에 저장하는 메서드
- similarity_search() 메서드
1
2
3
4
5
6
7
8
9
embeddings_model = OpenAIEmbeddings()
db = Chroma.from_texts(
texts, # chunks로 분할된 텍스트
embeddings_model, # 텍스트 임베딩에 사용할 모델
collection_name='history', # 저장소 이름
persist_directory='./db/chromadb', # 데이터 저장 위치
collection_metadata={'hnsw:space': 'cosine'} # l2 is the default, 색인과 검색 알고리즘 지정
)
docs = db.similarity_search(query="누가 한글을 창제했나요?")
‘hnsw:space’의 의미
- hnsw: 이 컬렉션이 HNSW 인덱스를 사용한다는 뜻
- space: HNSW가 “벡터 간 거리를 어떤 방식으로 계산할지” 지정하는 옵션
- 즉, 거리(metric) 종류를 지정하는 파라미터
예:
hnsw:space = 'cosine'→ 코사인 거리 기반으로 HNSW 탐색hnsw:space = 'l2'→ 유클리드 거리(L2) 기반 탐색(기본값)요약:
space = “HNSW가 어떤 거리 함수를 사용할지 지정하는 설정”이다.
p53. 벡터 데이터베이스
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
loader = TextLoader('history.txt')
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250,
chunk_overlap=50,
encoding_name='cl100k_base'
)
texts = text_splitter.split_text(data[0].page_content)
embeddings_model = OpenAIEmbeddings()
db = Chroma.from_texts(
texts,
embeddings_model,
collection_name='history',
persist_directory='./db/chromadb',
collection_metadata={'hnsw:space': 'cosine'} # l2 is the default
)
query = '누가 한글을 창제했나요?'
docs = db.similarity_search(query)
print(docs[0].page_content)
조선은 1392년 이성계에 의해 건국되어, 1910년까지 이어졌습니다. 조선 초기에는 세종대왕이 한글을 창제하여 백성들의 문해율을 높이는 등 문화적, 과학적 성취가 이루어졌습니다. (후략)
p54. 벡터 데이터베이스
- Chroma
- 유사도 기반 검색 vs. MMR 검색
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
embeddings_model = OpenAIEmbeddings()
db = Chroma.from_texts(
texts, # chunks로 분할된 텍스트
embeddings_model, # 텍스트 임베딩에 사용할 모델
collection_name='history', # 저장소 이름
persist_directory='./db/chromadb', # 데이터 저장 위치
collection_metadata={'hnsw:space': 'cosine'} # l2 is the default, 색인과 검색 알고리즘 지정
)
query = '카카오뱅크의 환경목표와 세부추진내용을 알려줘?'
# 유사도 기반 검색
docs = db.similarity_search(query)
print(len(docs))
print(docs[0].page_content)
# MMR(Maximal Marginal Relevance) 기반 검색
mmr_docs = db.max_marginal_relevance_search(query, k=4, fetch_k=10)
print(len(mmr_docs))
print(mmr_docs[0].page_content)
k
- 최종적으로 반환할 결과(Top-k)의 개수
- 여기서는 가장 관련성이 높은 결과 4개만 최종 반환
fetch_k
- 우선 더 많은 후보를 가져온 뒤
MMR(Maximal Marginal Relevance)로 중복되지 않게 다양성을 고려하여 재선정할 때
처음에 가져오는 후보 개수- 여기서는 먼저 10개 후보를 가져온 후, 그중에서 MMR로 4개를 선택
p55~56. 벡터 데이터베이스
- FAISS
- Facebook AI Research에서 개발
- 벡터의 압축된 표현을 사용함으로써 메모리 사용량을 최소화하고 검색 속도를 극대화
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.vectorstores.utils import DistanceStrategy
embeddings_model = HuggingFaceEmbeddings(
model_name='jhgan/ko-sbert-nli',
model_kwargs={'device': 'cpu'},
encode_kwargs={'normalize_embeddings': True},
)
vectorstore = FAISS.from_documents(
documents,
embedding=embeddings_model,
distance_strategy=DistanceStrategy.COSINE
)
docs = vectorstore.similarity_search(query)
print(len(docs))
print(docs[0].page_content)
mmr_docs = vectorstore.max_marginal_relevance_search(query, k=4, fetch_k=10)
print(len(mmr_docs))
print(mmr_docs[0].page_content)
MMR 작동 과정
- 주어진 쿼리에 대해 유사도가 높은 문서들을 fetch_k 만큼 검색
- 해당 문서 집합에서 첫 번째 문서를 선택, 나머지 문서들과의 MMR 점수를 계산
- MMR 점수가 가장 높은 문서를 다음으로 선택하고 k개의 문서를 선택할 때까지 반복
p57. 벡터 데이터베이스: Retrieval
Retrieval Algorithms
- 유사도 기반 검색
- RRF(Reciprocal Rank Fusion): 하이브리드 검색의 최종 순위 생성 알고리즘
- 여러 개의 독립적인 검색기법의 결과를 결합하여,
각 방법의 장점을 살리고 단점을 보완하여 단일한 최종 순위를 생성 - 하이브리드 검색의 문제점
- 각 검색 방법은 서로 다른 점수와 순위를 도출하는데,
단순히 점수를 합치면 스케일이 달라 결과가 편향될 가능성이 존재함 - RRF는 순위(Rank)를 기반으로 점수의 스케일 문제를 해결
- 각 검색 방법은 서로 다른 점수와 순위를 도출하는데,
- 동작
- 각 검색 방법에서 얻은 순위(r)를 사용하여, 최종적으로 각 문서(d)에 대한 융합 점수(RRFscore)를 계산
- \[RRFscore(d) = \sum_{i=1}^{N} \frac{1}{k + r_i(d)}\]
- RRFscore(d): 문서 d의 최종 융합 점수
- N: 사용된 검색 방법의 총 개수 (예: 키워드 검색, 벡터 검색)
- rᵢ(d): 검색 방법 i에서 문서 d가 받은 순위 (1부터 시작)
- k: 하이퍼파라미터 (일반적으로 60으로 설정)로 상위 순위의 영향력을 조절하는 매개변수
- 여러 개의 독립적인 검색기법의 결과를 결합하여,
p58. 주요 벡터 DB 비교
| 구분 | Pinecone | Milvus | Qdrant | Weaviate | Chroma | FAISS | Elasticsearch |
|---|---|---|---|---|---|---|---|
| 오픈소스 여부 | 상용 (클로즈드 소스) | 오픈소스 (Apache 2.0) | 오픈소스 (Apache 2.0) | 오픈소스 (BSD-3-Clause) | 오픈소스 (MIT) | 오픈소스 (MIT, 라이브러리) | 오픈소스 (Apache 2.0/ Elastic License) |
| 핵심 특징 | 완전 관리형, 벡터 검색 전용, 서버리스 | 클라우드 네이티브 분산 아키텍처, 대규모 처리 | Rust 기반, 고성능, 필터링 & 하이브리드 | 내장 벡터화, GraphQL API, 지식 그래프 지향 | Python 네이티브, 간편한 로컬 개발 및 프로토타이핑 | 순수 벡터 검색 라이브러리, GPU 가속 | 기존 검색 엔진, 벡터 검색 기능 통합 |
| 하이브리드 검색 지원 방법 | Sparse-Dense 벡터 통합 (SDA), Metadata 필터링 | Sparse-Dense 통합, Metadata 필터링, RRF(ReciprocalRankFusion) | Vector + Payload 필터 (가장 강력), Sparse-Dense 통합 | Vector + Keyword (BM25) 통합, RRF | Metadata 필터링 (Keyword/Structured) | 외부 시스템 통합 필수 (자체 지원 X) | Native BM25 + HNSW 통합 (RRF 사용), 가장 성숙한 하이브리드 |
| 주요 인덱싱 지원 | HNSW, IVF | HNSW, IVF_FLAT, ANNOY, DISKANN 등 다양 | HNSW (주력) | HNSW | HNSW (기본) | IVF, PQ, HNSW 등 매우 다양 (라이브러리) | HNSW (8.x 버전부터) |
| 확장성 | 최고 수준 (완전 관리형, 수평 확장 유제한) | 최고 수준 (클라우드 네이티브, 분산형 아키텍처) | 매우 좋음 (클러스터 및 샤딩 지원) | 좋음 (모듈형 아키텍처, 수평 확장 지원) | 낮음 (주로 로컬/소규모 POC, 엔터프라이즈 기능 부족) | 높음 (대용량 데이터셋 처리 가능, 라이브러리 레벨) | 좋음 (Elasticsearch 클러스터 확장성 활용) |
| QPS (처리량) | 매우 높음 (파드 추가로 확장 용이), 낮은 지연시간 | 매우 높음 (분산 구조), 고성능 | 높음 (Rust 기반, 메모리 효율) | 준수함 (대규모 시 성능 저하 가능성 있음) | 낮음 (단일 인스턴스 기준) | 매우 높음 (순수 검색, GPU 가속 시 극대화) | 준수함 (통합 검색 부하 고려) |
| 장점 | 운영 오버헤드 無, 빠른 구축, 엔터프라이즈 기능, SLA 보장 | 유연한 배포(K8s), 다양한 인덱스 선택지, 대규모 데이터에 최적화 | 고성능 필터링, Rust 기반 안정성과 속도, 개발자 친화적 API | 내장 벡터화, 객체지향 API 지향, LLM 에코시스템 통합 용이 | 가장 쉬운 시작, LLM 프레임워크와의 긴밀한 통합, 경량 | 극도의 검색 속도, 메모리 효율성, 임베딩 모델 무관 | 기존 키워드 검색 통합, 성숙한 운영 인프라, 강력한 분석 기능 |
| 단점 | 높은 비용, 벤더 종속성, 커스터마이징 제약 | 초기 설정 및 운영 복잡성 학습 곡선 | 대규모 분산 환경에선 Milvus 대비 약간 열세 | 데이터 구조 변경 시 성능 영향 가능성, 재색인 필요 | 대규모 서비스 부족, 기본 기능만 제공 | DB 기능 부재(CRUD, Metadata 관리 X), 검색 후 데이터 재구성 필요 | 순수 벡터 DB 대비 성능 최적화가 어려움, 리소스 소모가 큼 |
| 주요 활용 사례 | 실시간 개인화, 엔터프라이즈 RAG 프로젝트, 보안 위협 탐지 | 초거대 이미지/비디오 분석, 대규모 분산 RAG, 계량 분석 | 고성능 추천 시스템, 복잡한 메타데이터 필터링이 필요한 RAG | 내장형 검색 엔진, 지식 그래프 기반 Q&A 시스템 | RAG 프로토타입, 로컬/테스트 환경의 실험 개발 및 실행 | 검색 엔진의 백엔드 라이브러리로 임베딩 검색 모듈 구현 | 통합 검색 플랫폼 (로그, 메타데이터, 벡터), 기존 Elastic 사용자 |
| 커뮤니티 규모 | 중간~대형 (주로 상용 사용자) | 대형 (가장 활발한 오픈소스 커뮤니티 중 하나) | 중간~대형 (빠르게 성장 중) | 중간~대형 (활발한 개발 및 문서화) | 중간 (LLM 개발자에게 인기) | 매우 큼 (AI/ML 분야의 표준 라이브러리) | 매우 큼 (전통적인 검색 엔진 시장 주도) |
p59. Retriever
벡터 저장소에서 문서를 검색하는 도구
- Vector Store Retriever
- 대량의 텍스트 데이터에서 관련된 정보를 효율적으로 검색 가능
- MultiQueryRetriever
- Vector Store Retriever의 한계를 극복하기 위해 고안된 방식
- 쿼리의 의미를 다각도로 포착, 더욱더 관련성이 높고 정확한 정보를 제공
- 사용자의 입력 문장을 다양한 관점으로 Paraphrasing함
- ContextualCompression
- 검색된 문서 중에서 쿼리와 관련된 정보만을 추출하여 반환
- 답변의 품질을 높이고 비용을 줄일 수 있음
p60. Retriever
Vector Store Retriever
사전 준비: 문서 임베딩을 벡터스토어에 저장
단일 문서 검색
→ 유사도가 가장 높은 것MMR 검색
→ lambda_mult: 유사도와 다양성 중요도 결정유사도 점수 임계값 기반 검색
→ 유사도가 임계값 이상인 문서만을 대상으로 추출메타데이터 필터링 사용한 검색
- 메타데이터의 특정 필드에 대해서 기준을 설정하여 필터링
- 예: ‘format’: ‘PDF 1.4’처럼 특정 형식이나 조건 만족 기준
p61. Retriever
Multi Query Retriever
- 사용 방법
- MultiQueryRetriever 설정
from_llm을 통해 기존 벡터 저장소 검색도구와 LLM 모델을 결합하여 인스턴스 생성
- 로깅 설정
- 생성되고 실행되는 쿼리들에 대한 정보를 로그로 기록하고 확인 가능
- 문서 검색 실행
get_relevant_documents메서드를 사용하여 쿼리에 대한 Multi Query 기반의 문서 검색 진행
- 결과 확인
- 검색을 통해 반환된 고유 문서들의 수를 확인
- MultiQueryRetriever 설정
p62. Retriever
Contextual compression
- 구성과 동작방식
- LLMChainExtractor 설정
LLMChainExtractor.from_llm(llm)을 사용하여 문서 압축기를 설정- 언어모델을 사용하여 문서 내용을 압축 (질의에 관련된 내용만 추출)
- ContextualCompressionRetriever 설정
base_compressor에 LLMChainExtractor 인스턴스를,
base_retriever에 기본 검색기 인스턴스를 제공
- 압축된 문서 검색
Compression_retriever.get_relevant_documents(question)함수를 사용하여
주어진 쿼리에 대한 압축된 문서들을 검색- 기본 검색기를 통해 얻은 문서들은 문서 압축기를 사용하여
내용을 압축 및 가장 관련된 내용만 추려냄
- 결과 출력
- LLMChainExtractor 설정
p63. Generation
Generation의 단계
- Retrieval
- MMR을 사용하든, 일반적인 similarity search를 사용하든 문서를 검색
- Prompt
- Context 부분에 문서를 넣어줌
- Model
- Model을 초기화
- Formatting Docs
- 검색된 문서를 포맷팅
- Chain Execution
- LLM chain 구성 및 실행
- Run
- Invoke를 사용하여 체인을 실행
p64. Generation
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# Retrieval
retriever = vectorstore.as_retriever(
search_type='mmr',
search_kwargs={'k': 5, 'lambda_mult': 0.15}
)
docs = retriever.get_relevant_documents(query)
# Prompt
template = '''Answer the question based only on the following context:
{context}
Question: {question}
'''
prompt = ChatPromptTemplate.from_template(template)
# Model
llm = ChatOpenAI(
model='gpt-3.5-turbo-0125',
temperature=0,
max_tokens=500,
)
def format_docs(docs):
return '\n\n'.join([d.page_content for d in docs])
# Chain
chain = prompt | llm | StrOutputParser()
# Run
response = chain.invoke({'context': (format_docs(docs)), 'question': query})
response
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
카카오뱅크의 환경목표는
‘더 나은 세상을 만들어 나가는데 앞장서겠습니다’입니다.
이를 위해 카카오뱅크는 다음과 같은 환경방침을 수립하여 운영하고 있습니다:
- 전사 환경경영 정책 수립
- 녹색 구매 지침 수립
- 환경 지표 설정 및 성과 관리
- 자원 사용량 관리 (용수, 폐기물, 에너지 등)
- 기후변화를 포함한 환경 리스크 관리체계 마련
- Scope 1&2&3 온실가스 배출량 모니터링
- 탄소 가격 도입을 통한 환경 비용 관리
- 신재생 에너지 사용 확대
- 녹색채권 발행 기반 마련
- 환경경영 조직 및 관리 체계 구축
- 환경영향평가 체계 구축
- 구축을 통한 환경 리스크 및 성과 관리
이를 통해 카카오뱅크는 환경을 보호하고
지속 가능한 경영을 추구하고 있습니다.
p65. Legal Query RAG(LQ-RAG)’ 프레임워크 (출처 : 인공지능신문)
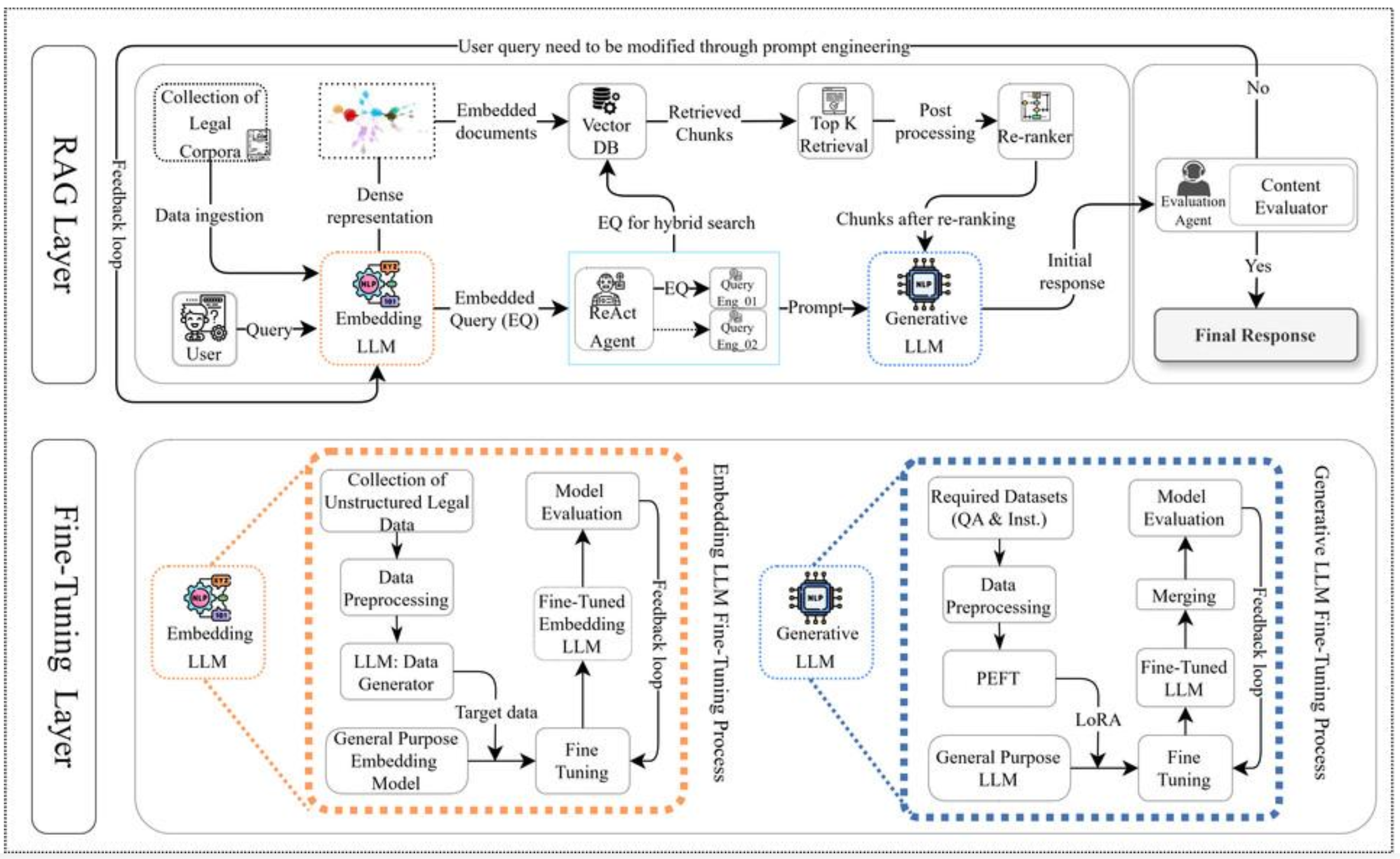
Legal Query RAG(LQ-RAG)의 개요
- LQ-RAG는 법률 질의에 특화된 RAG 구조이며
법률 문서의 복잡성과 정확성을 위해 임베딩 LLM과 생성 LLM을 각각 정교하게 파인튜닝한다.- 사용자의 질의를 받아 관련 법률 데이터를 검색하고
신뢰할 수 있는 답변을 생성하는 전체 파이프라인을 포함한다.RAG Layer (상단 구조)
- 사용자 질의는 임베딩 LLM을 통해 벡터 표현으로 변환된다.
- 변환된 쿼리는 Vector DB에서 유사 법률 문서 Top-K를 검색한다.
- 검색된 문서 조각은 Re-ranker로 재정렬되어
품질 높은 근거가 Generative LLM에 전달된다.- 생성된 초안 답변은 Evaluation Agent가 검증하고
필요 시 Feedback Loop을 통해 검색·생성 단계를 다시 조정한다.- 최종적으로 검증된 답변만 사용자에게 반환된다.
Fine-Tuning Layer (하단 구조)
- LQ-RAG는 임베딩 LLM 파인튜닝과 생성 LLM 파인튜닝의 두 과정으로 구성된다.
Embedding LLM Fine-Tuning
- 비정형 법률 데이터를 수집·전처리해 일반 임베딩 모델을 파인튜닝한다.
- 데이터 생성기(LLM Generator)와 Feedback Loop을 활용하여
법률 도메인에 최적화된 임베딩 모델을 구축한다.- 최종 임베딩 모델은 RAG 단계에서 정확한 법률 문서 검색을 수행한다.
Generative LLM Fine-Tuning
- QA·지시문 기반 법률 데이터를 활용해 생성 모델을 파인튜닝한다.
- PEFT·LoRA 등 경량 파인튜닝 기법을 적용해 효율적으로 학습한다.
- 병합과 평가 단계를 거쳐 법률 질의에 특화된 생성 LLM을 완성한다.
핵심 특징 요약
- 법률 특화 쿼리 임베딩으로 정확한 법률 용어 매칭 가능
- ReAct Agent 기반 하이브리드 검색으로 검색 품질 향상
- Feedback Loop을 통한 검색·생성의 반복 개선
- 목표: 근거 기반의 정확한 법률 질의응답 시스템 구현
출처: 인공지능신문 (https://www.aitimes.kr)