[논문 번역] HopRAG: Multi-Hop Reasoning for Logic-Aware Retrieval-Augmented Generation
논문 출처
Hao Liu, Zhengren Wang, Xi Chen, Zhiyu Li,
Feiyu Xiong, Qinhan Yu, Wentao Zhang.
HopRAG: 논리 기반 멀티홉 추론을 위한 검색 증강 생성(HopRAG: Multi-Hop Reasoning for Logic-Aware Retrieval-Augmented Generation).
베이징대학교¹, 상하이 인공지능 고등알고리즘연구소(Institute for Advanced Algorithms Research)²,
화중과기대학교(Huazhong University of Science and Technology)³.
🔗 원문 링크 (arXiv)
저자
- Hao Liu¹†
- Zhengren Wang¹²†
- Xi Chen³
- Zhiyu Li²*
- Feiyu Xiong²
- Qinhan Yu¹
- Wentao Zhang¹*
(¹Peking University
²Center for LLM, Institute for Advanced Algorithms Research, Shanghai
³Huazhong University of Science and Technology)
†동등 기여자(Equal contribution)이다.
*교신 저자(Corresponding author)이다.
초록 (Abstract)
Retrieval-Augmented Generation(RAG) 시스템은
전통적인 검색기(retriever)가 논리적 관련성보다는
어휘적(lexical) 또는 의미적(semantic) 유사성에 집중하기 때문에
불완전한 검색으로 인해 종종 어려움을 겪는다.
이 문제를 해결하기 위해 우리는 HopRAG을 제안한다.
HopRAG은 그래프 기반 지식 탐색을 통해
검색을 논리적 추론으로 보강하는 새로운 RAG 프레임워크이다.
인덱싱 단계에서 HopRAG은 텍스트 조각들을 정점(vertices)으로 사용하고,
LLM이 생성한 의사 쿼리를 통해 형성된 논리적 연결을 간선(edges)으로 사용하여
문단(passage) 그래프를 구성한다.
검색 단계에서 HopRAG은 retrieve–reason–prune 메커니즘을 사용한다.
먼저 어휘적 또는 의미적으로 유사한 문단들을 시작점으로 삼고,
의사 쿼리와 LLM 추론을 통해 멀티홉 이웃들을 탐색하여
실제로 관련된 문서들을 식별한다.
여러 멀티홉 벤치마크에서 수행한 실험은
HopRAG의 retrieve–reason–prune 메커니즘이
논리적 연결을 기반으로 검색 범위를 확장하고
최종 정답 품질을 향상시킬 수 있음을 보여준다.
1 서론 (Introduction)
“세상에 있는 모든 사람과 모든 것은
누군가의 소개를 통해 여섯 단계 이하의 연결만으로
서로에게 도달할 수 있다.”
— 육촌 이론(Six Degrees of Separation)
Retrieval-augmented generation(RAG)은
대규모 언어 모델(LLMs)이 지식 집약적 작업을 해결하기 위한
표준적인 접근 방식이 되었다
(Guu et al., 2020a; Lewis et al., 2020a; Izacard et al., 2022;
Min et al., 2023; Ram et al., 2023; Liang et al., 2025).
이 접근 방식은 모델이 지닌 고유한 지식 한계와
환각 문제(Zhang et al., 2023)를 효과적으로 해결할 수 있을 뿐만 아니라,
설명 가능성과 정보 출처 추적(Akyürek et al., 2022)을
용이하게 해줄 수 있다.
특히, RAG의 효과성은
방대한 코퍼스에서 관련 문서를 식별하기 위한
검색 모듈의 성능에 달려 있다.
현재 두 가지 주류 검색기 유형이 있다.
하나는 희소 검색기(sparse retrievers)이고
(Jones, 1973; Robertson and Zaragoza, 2009b),
다른 하나는 밀집 검색기(dense retrievers)이다
(Xiao et al., 2024; Wang et al., 2024b; Sturua et al., 2024; Wang et al., 2024c).
희소 검색기는 어휘적(lexical) 유사성에,
밀집 검색기는 의미적(semantic) 유사성에 각각 집중하며,
더 나은 검색 성능을 위해 두 방법이 결합되어 사용되는 경우가 많다
(Sawarkar et al., 2024).
이러한 발전에도 불구하고, 정보 검색의 궁극적 목표는
어휘적 및 의미적 유사성을 넘어, 논리적 관련성을 추구하는 데 있다.
논리 인식(logic-aware) 메커니즘의 부재로 인한
불완전한 검색 문제는 여전히 두드러진 상태로 남아 있다
(Wang et al., 2024a; Shao et al., 2024; Dai et al., 2024; Su et al., 2024a,b).
정밀도(precision) 관점에서는,
검색 시스템이 어휘적 및 의미적으로는 유사하지만
간접적으로만 관련 있는 문단을 반환할 수 있다.
재현율(recall) 관점에서는,
사용자의 쿼리에 필요한 문단들을
모두 검색해 내는 데 실패할 수 있다.
두 경우 모두 결국에는 부정확하거나 불완전한 LLM 응답으로 이어지며
(Chen et al., 2024; Xiang et al., 2024; Zou et al., 2024),
특히 멀티홉 또는 다중 문서 기반의 질의응답 작업처럼
최종 답변을 위해 여러 관련 문단이 필요한 경우에 그렇다.
반면, 생성 모델의 추론 능력은 빠르게 발전하고 있으며,
대표적인 예로 OpenAI-o1(Jaech et al., 2024)과
DeepSeek-R1(Guo et al., 2025)을 들 수 있다.
따라서 자연스럽게 다음과 같은 연구 질문이 제기된다:
“더 발전된 RAG 시스템을 위해,
추론 능력을 검색 모듈에 도입할 수 있을까?”
논리적 구조의 관점에서,
기존 RAG 시스템은 크게 세 가지 유형으로 분류될 수 있다.
첫 번째는 비구조적 RAG(Non-structured RAG)로,
단순히 희소 검색기나 밀집 검색기를 채택한다.
이 방식의 검색은 오직 키워드 매칭이나 의미 벡터 유사성에만 기반하며,
사용자 쿼리와 문단 사이의 논리적 관계를 포착하지 못한다.
두 번째는 트리 구조 RAG(Tree-structured RAG)이다
(Sarthi et al., 2024; Chen et al., 2023; Fatehkia et al., 2024).
이 방식은 단일 문서 내부에서 문단들 간의 계층적 논리를 중심으로 하지만,
계층 구조를 넘어서는 관계나 문서 간 관계는 무시한다.
더 나아가, 서로 다른 수준에 걸쳐 중복된 정보를 도입하기도 한다.
세 번째는 그래프 구조 RAG(Graph-structured RAG)이다
(Soman et al., 2024; Kang et al., 2023; Edge et al., 2024a; Guo et al., 2024).
이 방식은 지식 그래프(KG)를 구성하여 문서를 표현함으로써
논리적 관계를 가장 이상적인 형태로 모델링한다.
이때 엔티티는 정점이며, 이들 간의 관계는 간선이다.
그러나 미리 정의된 스키마에 대한 의존은
표현의 유연성을 제한한다(Li et al., 2024).
또한 지식 그래프를 구축하고 유지·업데이트하는 과정은 어렵고
오류나 누락이 발생하기 쉽다(Edge et al., 2024a).
아울러 지식의 트리플(triplet) 형식은
LLM의 이해를 향상시키기 위해
추가적인 텍스트화 작업이나 파인튜닝을 필요로 한다(He et al., 2024).
지식의 트리플 형식(triplet format)이란
(주어, 관계, 객체)의 세 요소로 정보를 표현하는 방식이다.
예를 들어, (파리, 수도이다, 프랑스)와 같은 구조를 가진다.
이러한 형식은 구조적이지만,
LLM이 이해하기 위해서는 추가적인 텍스트화나
파인튜닝이 필요할 수 있다.
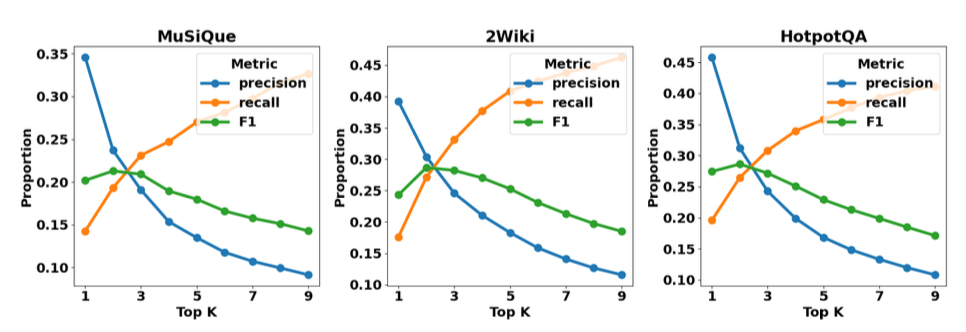
그림 1: (a) MuSiQue, 2WikiMultiHopQA, HotpotQA에서
BGE 밀집 검색기의 top-k 매개변수에 따른
정밀도, 재현율, F1 점수를 나타내며,
심각한 불완전 검색 현상을 드러낸다.
우리의 설정에서 가장 높은 재현율은 0.45에서 포화된다.
(a) Precision, recall and F1 score
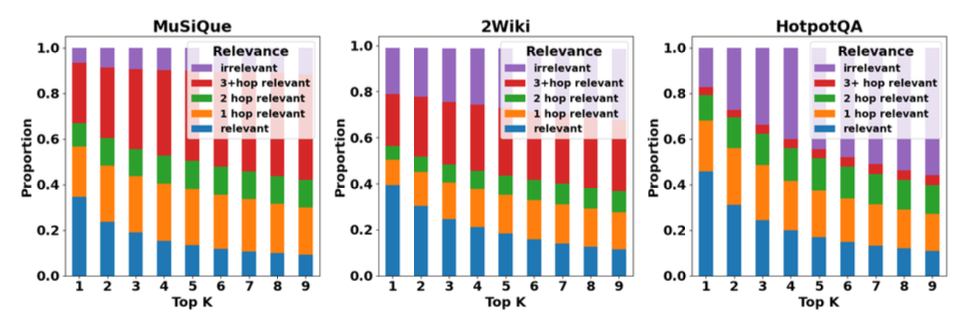
(b) 우리는 검색된 문단들을
쿼리에 대한 논리적 관련성에 따라
관련 있음, 간접적으로 관련 있음, 관련 없음으로 분류한다.
관련 있는 문단은 정확히 정답을 뒷받침하는 사실이며,
간접적으로 관련 있는 문단은 HopRAG을 통해
뒷받침 사실로 여러 홉을 거쳐 도달할 수 있다.
반면 관련 없는 문단은 그렇게 할 수 없다.
검색된 문단 중 상당 비율이
간접적으로 관련 있는 범주에 속한다.
(b) Proportions of passages on relevance
동기(Motivation)
Wang et al.(2024a)에 따르면,
현실 세계의 고도화된 검색 엔진을 사용하더라도
검색된 문단의 약 70%는 해당 환경에서
정답을 직접적으로 포함하지 않는다.
그림 1(a)에 나타난 바와 같이,
우리는 정밀도와 재현율 측면에서
불완전한 검색의 심각성을 확인한다.
스몰월드 이론(the small-world theory)(Kleinberg, 2000)이나
육촌 이론(Guare, 2016)에서 영감을 받아,
우리는 다음과 같이 제안한다.
어휘적으로나 의미적으로 유사한 문단은
간접적으로 관련이 있을 수도 있고
심지어 주의를 흐릴 수도 있지만,
실제로 관련된 정보를 찾기 위한
유용한 시작점이 될 수 있다는 것이다.
그림 1(b)에 나타난 바와 같이,
논리적 관계를 간선으로 하는
문단들로 구성된 그래프를 고려할 때,
검색된 문단의 상당 비율이
실제 정답과 몇 홉 떨어진 범위 안에 존재한다.
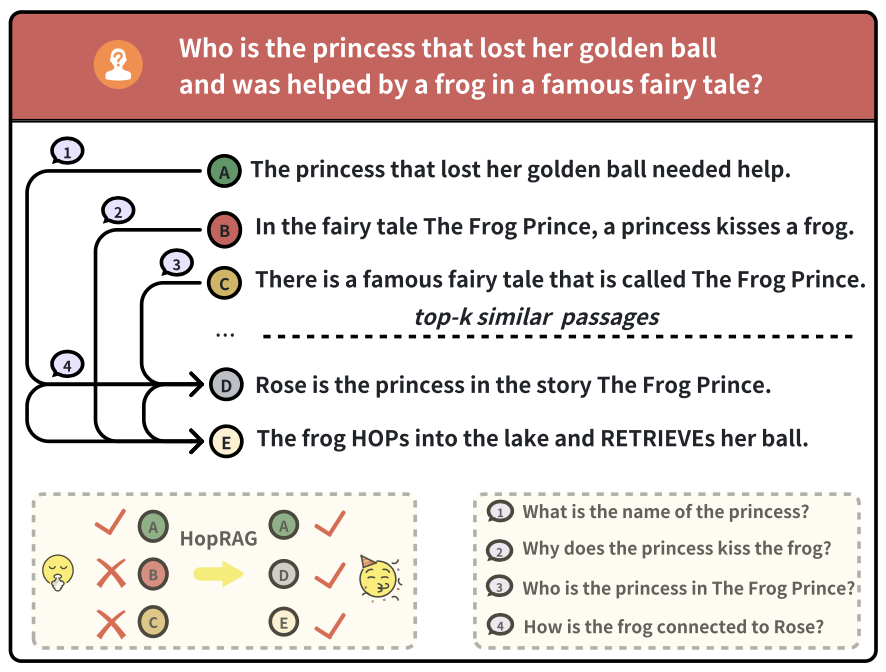
그림 2: 문단들 사이에서의 홉핑(hopping) 시연(Demonstration).
사용자 쿼리에 대해, BGE 밀집 검색기는
top-k 예산 안에서 세 개의 뒷받침 사실 중
하나만을 반환할 수 있다.
그러나 어휘적으로나 의미적으로 유사한 문단들은
서로를 보완한다.
문단들 사이에서 질문을 경로로 하여 홉핑을 수행하면,
검색의 정확성과 완전성이 향상된다.
이러한 관찰을 바탕으로 우리는 HopRAG을 제안한다.
HopRAG은 혁신적인 그래프 기반 RAG 시스템이다.
인덱싱 단계에서 우리는 문단을 정점으로,
논리적 관계를 방향 있는 간선으로 사용하여
그래프 구조의 지식 인덱스를 구축한다.
구체적으로, 문단들은 쿼리 시뮬레이션(query simulation)과
간선 병합(edge merging) 작업을 통해 생성된 의사 쿼리로 연결된다.
예를 들어, 그림 2에서 보여지듯이
의사 쿼리 “왜 공주는 개구리에게 키스를 하는가?”는
문제를 제기하는 문단(raiser passage)과
문제를 해결하는 문단(solver passage)을 연결하며,
논리적 홉을 위한 중심 축 역할을 한다.
검색 단계에서는 추론이 결합된 그래프 탐색을 사용하며,
검색, 추론, 가지치기의 세 단계 패러다임을 따른다.
이 과정은 간접적으로 관련 있는 문단들의
멀티홉 이웃 안에서 실제로 관련 있는 문단을 탐색하며,
이는 인덱스 구조와 LLM 추론의 안내를 동시에 받는다.
기여(Contributions)
우리의 기여는 다음과 같다.
우리는 멀티홉 질의응답 작업에서의
심각한 불완전 검색 현상을 밝혀낸다.
결과에 따르면, 현재 검색된 문단의 60% 이상이
간접적으로 관련 있거나 관련이 없다.
“쓰레기”를 “보물”로 바꾸기 위해,
우리는 간접적으로 관련 있는 문단들을
실제로 관련 있는 문단에 도달하기 위한
디딤돌로 추가적으로 활용한다.우리는 HopRAG을 제안한다.
HopRAG은 논리 인식 검색 메커니즘을 갖춘
새로운 RAG 시스템이다.
어휘적으로나 의미적으로 유사한 문단들이
서로를 보완함에 따라,
HopRAG은 의사 쿼리를 사용하여
문제를 제기하는 문단과 문제를 해결하는 문단을 연결한다.
유사성 기반 검색을 넘어서,
HopRAG은 검색 과정에서 쿼리를 따라 추론하고 가지치기를 수행한다.
또한 유연한 논리 모델링,
문서 간 조직화,
효율적인 구축 및 업데이트 기능을 제공한다.광범위한 실험은 HopRAG의 효과성을 입증한다.
retrieve-reason-prune 메커니즘은
기존 정보 검색 방식에 비해
정답 지표에서 36.25% 이상,
검색 F1 점수에서 20.97% 더 높은 성능을 달성한다.
여러 소거(ablation) 연구는
추가적으로 가치 있는 통찰을 제공한다.
2 관련 연구 (Related Work)
검색 증강 생성(Retrieval-Augmented Generation)
검색 증강 생성은 외부 지식 근원으로부터
관련 정보를 가져오는 검색 모듈을 통합함으로써
대규모 언어 모델의 성능을 크게 향상시킨다
(Févry et al., 2020; Guu et al., 2020b; Izacard and Grave, 2021;
Zhao et al., 2024; Yu et al., 2025).
검색 모델은 초기의 희소 검색기에서 발전해 왔다.
TF-IDF(Jones, 1973)와 BM25(Robertson and Zaragoza, 2009b)와 같은 초기 방식은
단어 통계와 역색인에 의존하였다.
이후 검색 모델은 의미적 매칭을 위해
신경 표현을 활용하는 밀집 검색기(Lewis et al., 2020b)로 발전하였다.
Self-RAG(Asai et al., 2023)나 FLARE(Jiang et al., 2023)처럼
검색의 필요성과 시점을 결정하는
고도화된 기법들도 중요한 발전을 나타낸다.
그러나 지식 인덱스는 여전히 논리적으로 비구조적이며,
각각의 검색 라운드는
어휘적 또는 의미적 유사성만을 고려하는 방식으로 이루어진다.
트리 및 그래프 기반 RAG(Tree&Graph-structured RAG)
트리와 그래프는 모두 논리적 관계를 모델링하는 데 효과적인 구조이다.
RAPTOR(Sarthi et al., 2023)는
문단을 재귀적으로 임베딩하고, 군집화하며, 요약하여
아래에서 위로 서로 다른 수준의 요약을 갖는 트리를 구성한다.
MemWalker(Chen et al., 2023)는
LLM을 요약 트리를 따라 이동하는
상호작용형 에이전트로 취급한다.
SiReRAG(Zhang et al., 2024)는
유사성 트리와 연관성 트리를 모두 구성하여
유사한 정보와 관련된 정보를 모두 명시적으로 고려한다.
PG-RAG(Liang et al., 2024)는
LLM이 문서 지식을 마인드맵 형태로 조직하고
여러 문서를 통합하도록 유도한다.
GNN-RAG(Mavromatis and Karypis, 2024)는
학습된 GNN을 활용해
밀집한 지식 그래프(KG)의 부분 그래프에서
정답 후보를 검색한다.
쿼리 중심 요약화를 위해,
GraphRAG(Edge et al., 2024b)는
지식 그래프 구축과 재귀적 요약을 포함한
계층적 그래프 인덱스를 구축한다.
이러한 발전에도 불구하고,
트리 구조 RAG는 단일 문서 안의 계층적 논리만을 다룬다.
그래프 구조 RAG는 비용이 많이 들고 시간이 오래 걸리며,
순수 텍스트가 아니라 트리플(triplet) 형식을 반환한다.
반면, HopRAG은 더 가볍고
다운스트림 작업에 친화적인 대안을 제공하며,
유연한 논리 모델링,
문서 간 조직화,
효율적인 구축 및 업데이트를 지원한다.
3 방법 (Method)
이 절에서는 우리의 논리 인식(logic-aware) RAG 시스템인 HopRAG을 소개한다.
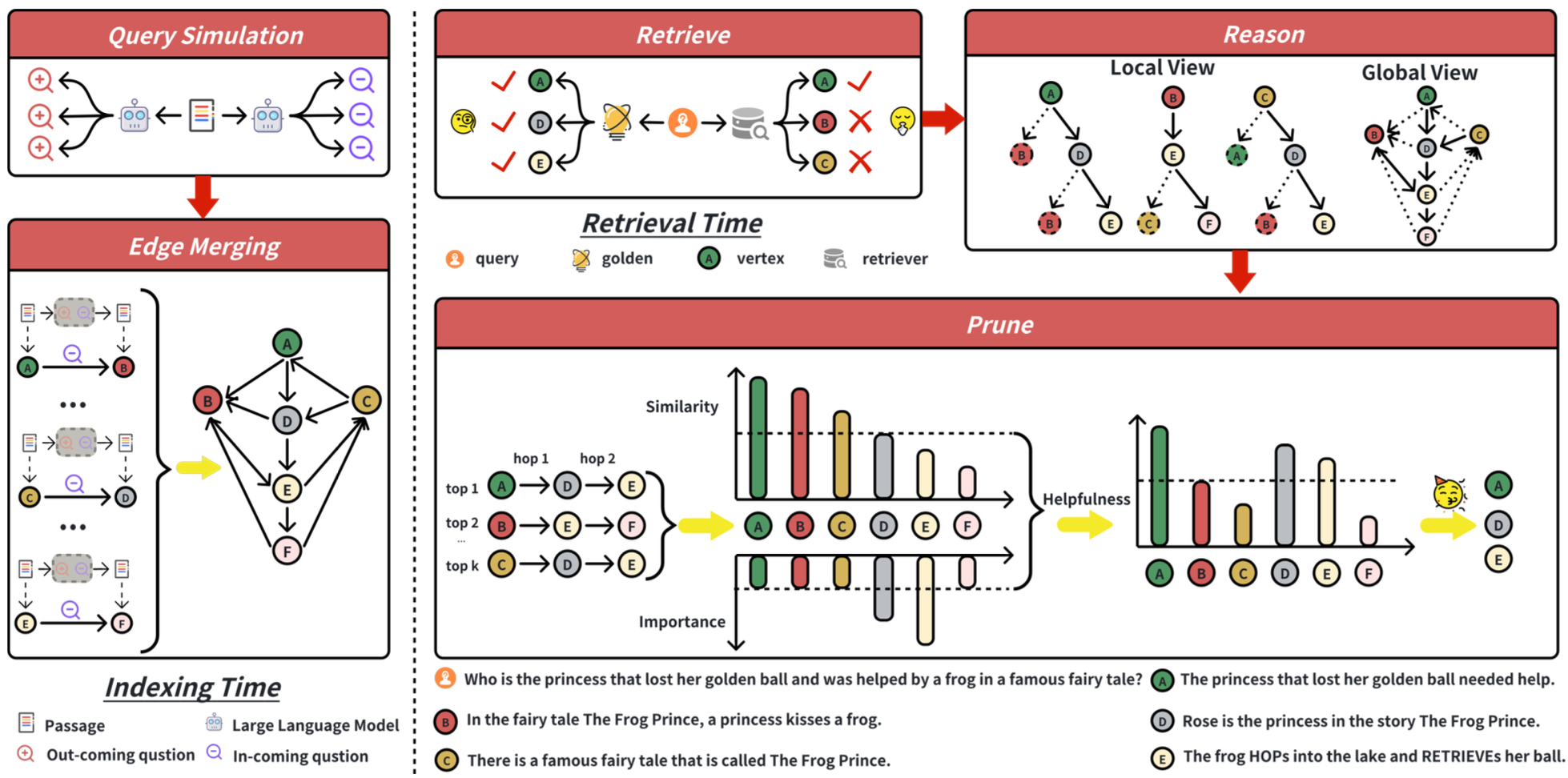
이 시스템의 개요는 그림 3에 제시되어 있다.
그림 3: HopRAG의 작업 흐름.
왼쪽: 인덱싱 단계에서, 먼저 쿼리 시뮬레이션을 활용하여 각 문단에 대한 의사 쿼리를 생성하고,
그 다음 간선 병합을 적용하여 문단들을 방향 있는 논리적 간선으로 연결한다.
오른쪽: 검색 단계에서 우리는 Retrieve-Reason-Prune 파이프라인을 사용한다.
먼저 순수한 유사성 기반 검색을 통해 1차 검색을 수행하고,
그 다음 추론이 결합된 그래프 탐색을 실행하여 주변 이웃을 탐색하며,
마지막으로 텍스트 유사성과 논리적 중요성을 모두 고려하는
새로운 지표 Helpfulness를 사용해 검색을 가지치기한다.
3.1 문제 정의 (Problem Formulation)
문단 코퍼스 $P = \lbrace p_1, p_2, \ldots, p_N \rbrace$ 와
코퍼스 $P$ 안의 여러 문단으로부터 정보를 필요로 하는 쿼리 $q$ 가 주어졌을 때,
과제는 다음과 같다.
(1) 코퍼스 $P$ 의 모든 문단을 저장할 뿐 아니라
문단들 사이의 유사성과 논리까지 모델링하는
그래프 구조 RAG 지식베이스를 설계하는 것.
(2) 간접적으로 관련 있는 문단들로부터
실제로 관련 있는 문단들까지 홉을 수행할 수 있는
검색 전략을 설계하는 것.
마지막으로, 쿼리 $q$ 와
$k$ 개의 문단으로 구성된 컨텍스트
$C = \lbrace p_{i_1}, p_{i_2}, \ldots, p_{i_k} \rbrace$ 를 사용하여
LLM은 응답 $\mathcal{O}$ 를 생성하며, 이는
$\mathcal{O} \sim \mathcal{P}(\mathcal{O} \mid q, C)$ 에 따른다.
3.2 그래프 구조 인덱스 (Graph-Structured Index)
우리는 그래프 구조 인덱스 $G = (\mathcal{V}, \mathcal{E})$ 를 구성한다.
여기서 정점 집합 $\mathcal{V}$ 는 모든 문단을 저장하는 정점들로 이루어져 있으며,
방향 있는 간선 집합 $\mathcal{E} = \lbrace \langle v_i, e_{i,j}, v_j \rangle \mid v_i, v_j \in \mathcal{V} \rbrace \subset \mathcal{V} \times \mathcal{V}$ 는
멀티홉 추론을 위해 문단들 사이의 논리적 관계를 기반으로 구축된다.
$G$ 를 구축하기 위해, 우리는 쿼리 시뮬레이션을 활용하여
논리적 관계를 식별하고,
효율적인 간선 병합(Edge Merging)을 위해 텍스트 유사성을 활용한다.
쿼리 시뮬레이션 (Query Simulation)
문단들 사이의 논리적 관계를 식별하기 위해,
우리는 각 문단에 대해 일련의 의사 쿼리를 생성하고,
이를 사용하여 해당 문단이 다른 문단들과 맺는 관계를 탐색하며
사용자 쿼리와 문단들 사이의 본질적인 간극을 메운다
(Wang et al., 2024c).
구체적으로, 우리는 LLM을 사용하여
각 문단 $p_i$ 에 대해 두 그룹의 의사 쿼리를 생성한다.
(1) 이 문단에서 유래하지만 문단 자체만으로는 답할 수 없는
$m$ 개의 출력(out-coming) 질문
$Q_i^{+} = \bigcup_{1 \le j \le m} \lbrace q_{i,j}^{+} \rbrace$
(2) 답이 그 문단 내부에 존재하는
$n$ 개의 입력(in-coming) 질문
$Q_i^{-} = \bigcup_{1 \le j \le n} \lbrace q_{i,j}^{-} \rbrace$
그림 2에서 보인 바와 같이,
예시 문단이 “Rose is the princess in the story The Frog Prince”일 때,
하나의 입력 질문은 “What is the name of the princess?”일 수 있고,
하나의 출력 질문은 “How is the frog connected to Rose?”일 수 있다.
프롬프트는 부록 A.5에 포함되어 있다.
우리는 $Q_i^{+}$ 와 $Q_i^{-}$ 로부터
개체명 인식 NER(·)을 사용하여 키워드를 추출해
희소 표현을 만들고,
이 질문들을 임베딩 모델 EMB(·)을 사용하여
의미 벡터로 변환해 밀집 표현을 생성한다.
이 과정은 다음과 같은 희소 표현을 만든다.
$K_i^{+} = \bigcup_{1 \le j \le m} \lbrace k_{i,j}^{+} \rbrace$
$K_i^{-} = \bigcup_{1 \le j \le n} \lbrace k_{i,j}^{-} \rbrace$
또한 다음과 같은 밀집 표현도 생성한다.
$V_i^{+} = \bigcup_{1 \le j \le m} \lbrace v_{i,j}^{+} \rbrace$
$V_i^{-} = \bigcup_{1 \le j \le n} \lbrace v_{i,j}^{-} \rbrace$
우리는 출력(out-coming) 트리플들을 다음과 같이 정의한다.
$r_{i,j}^{+} := (q_{i,j}^{+}, k_{i,j}^{+}, v_{i,j}^{+})$
그리고 입력(in-coming) 트리플들은 다음과 같이 정의한다.
$r_{i,j}^{-} := (q_{i,j}^{-}, k_{i,j}^{-}, v_{i,j}^{-})$
각 문단 $p_i$ 는 정점 $v_i$ 안에 저장되며,
그 정점은 출력 트리플들의 집합
$R_i^{+} = \bigcup_{1 \le j \le m} \lbrace r_{i,j}^{+} \rbrace$
및 입력 트리플들의 집합
$R_i^{-} = \bigcup_{1 \le j \le n} \lbrace r_{i,j}^{-} \rbrace$
으로 특징지어진다.
여기에서는 “질문을 어떻게 벡터와 트리플로 바꿔서 그래프에 넣는지”를
예를 들어가며 차근차근 설명한다.
- NER로 키워드를 뽑는 과정
예를 들어, 어떤 문단에 대해 이런 의사 질문이 있다고 하자.
질문 1: “Where does Frodo live?”
질문 2: “Who is the king of Gondor?”개체명 인식(NER)을 적용하면
질문 1에서는 “Frodo”가 인물(entity), “live”와 관련된 장소 개념이 후보가 되고,
질문 2에서는 “king”, “Gondor”가 역할/지명 개체로 추출된다.이때 “Frodo”, “Gondor”, “king” 같은 토큰들이
해당 질문의 핵심 키워드 집합 $k_{i,j}$ 이 된다.
각 질문에 대해 이런 키워드를 모아 놓은 것이
$K_i^{+}$, $K_i^{-}$ 같은 희소 표현이다.즉, 희소 표현은 “어떤 단어(또는 토큰)가 포함되어 있는가”를
중심으로 한 인덱스라고 보면 된다.- EMB로 밀집 벡터를 만드는 과정
같은 질문을 이번에는 임베딩 모델 EMB(·)에 넣는다.
“Where does Frodo live?” → $v_{i,1}^{+}$
“Who is the king of Gondor?” → $v_{i,2}^{+}$이렇게 하면 질문 전체가 하나의 실수 벡터(예: 768차원)로 변환된다.
이 벡터는 질문의 의미를 담고 있어서,
표현은 다르지만 의미가 비슷한 질문끼리는
벡터 공간에서 가깝게 위치하게 된다.이 벡터들을 모아 둔 것이 $V_i^{+}$, $V_i^{-}$ 이고,
밀집 표현은 “질문의 의미를 수치 벡터로 바꾼 결과”라고 이해하면 된다.- 트리플(triplet)로 묶는 이유
각 질문에는
원문 질문 텍스트 $q_{i,j}$,
그 질문에서 추출한 키워드 집합 $k_{i,j}$,
질문의 임베딩 벡터 $v_{i,j}$
가 함께 붙어 있다.이 세 가지를 하나로 묶어
$r_{i,j}^{+} = (q_{i,j}^{+}, k_{i,j}^{+}, v_{i,j}^{+})$
처럼 정의하는데,
이렇게 하면
“질문 문장 자체”,
“검색 인덱싱에 쓸 키워드”,
“유사도 계산에 쓸 벡터”
를 동시에 참조할 수 있게 된다.예를 들어, 나중에 그래프를 탐색할 때
– 키워드만 보고 빠르게 후보 문단을 좁힐 수도 있고,
– 벡터 유사도를 이용해 의미적으로 가까운 문단을 찾을 수도 있으며,
– 필요하면 질문 문장 자체를 LLM에게 다시 넘겨
추론에 활용할 수도 있다.- 문단 정점에 트리플들을 붙이는 의미
문단 $p_i$ 는 그래프에서 하나의 정점 $v_i$ 로 표현되며,
이 정점 옆에 “밖으로 나가는 질문 트리플들($R_i^{+}$)”과
“안으로 들어오는 질문 트리플들($R_i^{-}$)”을 함께 붙여 둔다.이렇게 해 두면,
어떤 문단에서 “어디로 질문이 뻗어나가는지”
그리고 “어떤 질문을 통해 이 문단으로 도착할 수 있는지”
를 그래프 상에서 명시적으로 추적할 수 있다.결국, NER로 뽑은 키워드(희소 표현)와
임베딩 벡터(밀집 표현),
그리고 원래 질문을 묶은 트리플 구조가
멀티홉 논리 탐색을 위한 기본 단위가 되는 것이다.
간선 병합(edge merging)
출력 트리플과 입력 트리플이 주어지면,
우리는 하이브리드 검색을 통해 이 트리플 쌍을 매칭하고
해당 문단들 사이에 방향 간선을 설정한다.
각 소스 정점 $v_s$ 의 출력 트리플 $r_{s,i}^{+}$ 에 대해,
가장 잘 매칭되는 입력 트리플 \(r_{t^{*}, j^{*}}^{-}\) 는 다음과 같이 결정된다:
이후 우리는 다음과 같은 집계된 특징을 갖는
\(\langle v_s,\; e_{s,t^{*}},\; v_{t^{*}} \rangle\) 유향(directed) 간선을 구축한다:
이 표현은 문단 간의 연결을 하나의 “유향(directed) 간선”으로 정의하는 수식이다.
\(\langle v_s,\; e_{s,t^{*}},\; v_{t^{*}} \rangle\) 는
출발 정점 $v_s$ → 도착 정점 $v_{t^{*}}$ 로 이어지는 유향 간선을 의미한다.즉, 문단 $p_s$ 에서 문단 $p_{t^{*}}$ 로 논리적으로 이동(hop)할 수 있음을 나타낸다.
가운데 들어 있는 $e_{s,t^{*}}$ 는 이 간선을 설명하는 “특징(feature) 묶음”이다.
이 특징은 세 부분으로 구성되어 있다:1) \(q_{t^{*}, j^{*}}^{-}\)
도착 문단 쪽에서 생성된 입력 질문(in-coming question)이다.
이 질문이 두 문단을 연결하는 “의미적 경로” 역할을 한다.2) \(k_{t^{*}, j^{*}}^{-} \cup k_{s,i}^{+}\)
두 문단이 공유하거나 결합하는 키워드들의 집합이다.
$s$ 문단의 출력 키워드와 $t^{*}$ 문단의 입력 키워드를 합쳐
두 문단이 어떤 주제적 요소로 이어지는지를 나타낸다.3) \(v_{t^{*}, j^{*}}^{-}\)
도착 문단의 입력 질문을 임베딩했을 때의 의미 벡터이다.
이 벡터는 간선이 표현하는 의미적 방향성을 제공한다.결국 이 유향 간선은
“문단 $v_s$ 에 있는 정보가 질문 \(q_{t^{*}, j^{*}}^{-}\) 을 통해
문단 $v_{t^{*}}$ 로 자연스럽게 이어질 수 있다”는
논리적·의미적 연결을 수학적으로 기록한 것이라고 볼 수 있다.
3.3 추론 증강 그래프 탐색 (Reasoning-Augmented Graph Traversal)
보다 정확하고 완전한 응답을 위해,
HopRAG의 검색 전략은 LLM의 추론 능력을 활용하여
아마도 간접적으로 관련된 문단들의 이웃 영역을 탐색하고,
그래프 구조 내의 논리적 관계에 기반하여
관련 있는 문단들로 홉(hop)한다.
알고리즘 1에서 보여지듯이,
현재 정점 $v_i$ 의 출력 간선 $e_{i,j}$ 위의 질문들에 대해
추론을 수행하고,
가장 유망한 정점 $v_j$ 로 홉(hop)하도록 선택함으로써,
우리는 더 나은 검색 성능을 위한
추론 증강 그래프 탐색을 실현한다.

1. $v_q \leftarrow \text{EMB}(q)$
1번 줄에서는 사용자 쿼리 $q$ 를 임베딩 모델 EMB에 넣어
쿼리의 의미를 담은 벡터 $v_q$ 를 생성한다.
이는 모든 검색·추론 단계에서 기준이 되는 쿼리 표현이다.2. $k_q \leftarrow \text{NER}(q)$
2번 줄에서는 쿼리 내에서 중요한 단어(개체명)를 NER로 추출해
키워드 집합 $k_q$ 를 만든다.
이는 희소 표현 기반 검색에 사용된다.3. $C_{\text{queue}} \leftarrow \text{Retrieve}(v_q, k_q, G)$
3번 줄에서는 쿼리 임베딩 $v_q$ 와 키워드 $k_q$ 를 사용해
그래프 $G$ 로부터 초기 후보 문단들을 검색한다.
검색된 문단들이 먼저 탐색할 후보로 큐에 들어간다.4. $C_{\text{count}} \leftarrow \text{Counter}(C_{\text{queue}})$
4번 줄에서는 초기 검색 결과가 몇 번 등장했는지를 세는
등장 횟수 카운터를 초기화한다.
예를 들면, 어떤 문단이 두 번 검색되었다면 초기 값이 2가 된다.5. for $i \leftarrow 1, 2, \ldots, n_{\text{hop}}$ do
5번 줄부터는 멀티홉 탐색을 수행한다.
총 $n_{\text{hop}}$ 번 반복하며, 한 단계씩 그래프를 확장해 나간다.6. for $j \leftarrow 1, 2, \ldots, |C_{\text{queue}}|$ do
6번 줄에서는 현재 큐에 들어 있는 모든 후보 문단을 대상으로
추론 기반 탐색을 진행한다.
큐의 크기만큼 반복한다는 의미다.7. $v_j \leftarrow C_{\text{queue}}.\text{dequeue}()$
7번 줄에서는 큐에서 가장 앞에 있는 문단 $v_j$ 를 하나 꺼낸다.
이 문단이 이번 단계에서 “현재 탐색할 정점”이 된다.8. $v_k \leftarrow \text{Reason}({ \langle v_j, e_{j,k}, v_k \rangle })$
8번 줄에서는 $v_j$ 에서 나가는 유향(directed) 간선들의 질문 정보를 활용해
LLM에게 “어느 문단으로 이동하는 것이 가장 말이 되는가?”를 판단하게 한다.
Reason 함수는 LLM 기반 추론을 통해 다음으로 이동할 문단 $v_k$ 를 선택한다.9. if $v_k$ not in $C_{\text{count}}$ then
9번 줄에서는 새롭게 발견된 문단인지 확인한다.
즉, $v_k$ 가 지금까지 등장한 적이 있는지 검사한다.10. $C_{\text{queue}}.\text{enqueue}(v_k)$
11. $C_{\text{count}}[v_k] \leftarrow 1$10–11번 줄은 새 문단을 처음 발견한 경우이다.
큐에 새로운 후보로 추가한 뒤, 등장 횟수를 1로 설정한다.12. else
12번 줄은 이미 등장한 적 있는 문단임을 의미한다.
13. $C_{\text{count}}[v_k] \mathrel{++}$
13번 줄에서는 이미 탐색된 문단이면 등장 횟수를 1 증가시킨다.
등장 횟수가 많을수록 해당 문단이 여러 경로에서 의미 있게 등장했다는 뜻이 된다.15–16. 반복 종료
이 두 줄에서는 내부 반복문과 전체 hop 반복을 마무리한다.
17. $C \leftarrow \text{Prune}(C_{\text{count}}, v_q, k_q, \text{top}_k)$
17번 줄에서는 등장 횟수 기반으로 중요한 문단을 우선하고,
쿼리 임베딩 $v_q$ 및 키워드 $k_q$ 와의 유사도를 함께 고려하여
최종적으로 top-k 문단을 선별한다.
불필요한 문단들은 여기서 걸러낸다.18. return $C$
최종 선택된 문단 집합 $C$ 를 반환한다.
이 문단들이 곧 LLM이 답변을 생성할 때 참고하는 최종 컨텍스트가 된다.
검색 단계 (Retrieval Phase)
쿼리 $q$ 에 대해 그래프 상에서 지역 검색을 시작하기 위해,
우리는 먼저 NER(·)과 EMB(·)을 사용하여
쿼리의 키워드 $k_q$ 와 벡터 $v_q$ 를 얻는다.
이는 혼합 검색에서
식 1을 따라 $top_k$ 유사한 유향 간선
\(\langle v_i,\; e_{i,j},\; v_j \rangle\)
을 매칭하는 데 사용될 것이다.
이러한 간선들로부터의 각 정점 $v_j$ 로
너비 우선 지역 검색(breadth-first local search)을 위한
컨텍스트 큐 $C_{queue}$ 를 초기화한다
(Voudouris et al., 2010).
추론 단계 (Reasoning Phase)
그래프 전반의 논리적 관계를 완전히 활용하고
간접적으로 관련된 정점들에서 관련된 정점들로 이동하기 위해,
우리는 너비 우선 지역 검색을 도입한다.
이는 LLM을 사용하여
현재 $C_{queue}$ 안의 각 정점 $v_j$ 에 대해
큐의 뒤쪽에 추가할 가장 적절한 이웃을 선택하는 방식이다.
구체적으로, hop의 각 라운드에서 $C_{queue}$ 안의 각 정점 $v_j$ 에 대해,
우리는 LLM을 사용하여
해당 정점의 모든 출력 유향 간선들로부터 나온 질문들을 기반으로
하나의 간선 $e_{j,k}$ 를 선택하도록 한다.
이때 LLM은 그 질문이
쿼리 $q$ 에 답하는 데 가장 도움이 된다고 판단하며,
해당 간선의 정점 $v_k$ 를 $C_{queue}$ 에 추가한다.
현재의 $C_{queue}$ 안의 각 정점에서 hop을 수행한 이후에는,
우리는 최대 $top_k$ 개의 새로운 정점들로
컨텍스트를 확장할 수 있다.
이 새로운 정점들로부터 다음 hop 라운드를 이어간다.
서로 다른 정점들이 같은 정점으로 hop할 수 있기 때문에,
우리는 방문 횟수가 많은 정점일수록
쿼리 $q$ 에 답하는 데 더 중요하다고 본다.
따라서 각 정점의 방문 횟수를 추적하고 그 중요도를 측정하기 위해
카운터 $C_{count}$ 를 사용한다.
$n_{hop}$ 라운드의 hop을 수행함으로써,
우리는 추론이 보강된 그래프 탐색을 실현하고,
컨텍스트 길이를 최대 $(n_{hop} + 1) \times top_k$ 까지 확장한다.
가지치기 단계 (Pruning Phase)
탐색 동안 너무 많은 중간 정점들을 포함하는 것을 피하기 위해,
우리는 유사성과 논리를 통합하여 순위를 다시 매기고
그 후 탐색 카운터 $C_{count}$ 를 가지치기(prune)하는
새로운 메트릭인 Helpfulness $H(\cdot)$ 를 도입한다.
우리는 $C_{count}$ 안의 각 정점 $v_i$ 에 대해
식 (2)를 따라 $H_i$ 를 계산하고,
가장 높은 $H_i$ 값을 갖는 $top_k$ 개의 정점을 유지한다.
여기서 하이브리드 텍스트 유사도 $SIM(v_i, q)$ 는
식 (1)을 따라 정점 $v_i$ 안의 문단과 쿼리 $q$ 사이의
어휘적 및 의미적 유사도의 평균을 계산한다.
그리고 $IMP(v_i, C_{count})$ 는
식 (3)을 따라 탐색 동안 $C_{count}$ 에서
정점 $v_i$ 의 방문 횟수를 정규화한 값으로 정의된다.
우리는 가장 높은 $H$ 값을 갖는 $top_k$ 개의 정점을 유지하여
$C_{count}$ 를 가지치기하고,
최종 컨텍스트 $C$ 를 얻는다.
4 실험 (Experiments)
4.1 실험 설정 (Experimental Setups)
데이터셋(Datasets)
우리는 HopRAG의 성능을 평가하기 위해
여러 멀티-홉 QA 데이터셋을 수집한다.
우리는 HotpotQA 데이터셋(Yang et al., 2018),
2WikiMultiHopQA 데이터셋(Ho et al., 2020)
그리고 MuSiQue 데이터셋(Trivedi et al., 2022)을 사용한다.
Zhang et al.(2024)과 동일한 절차를 따르며,
이 세 데이터셋 각각의 검증 세트에서
1000개의 질문을 얻는다.
자세한 내용은 부록 Appendix A.2를 참조하라.
베이스라인(Baselines)
우리는 다양한 베이스라인과 HopRAG을 비교한다:
(1) 비구조적(unstructured) RAG – 희소 검색기 BM25(Robertson and Zaragoza, 2009a)
(2) 비구조적 RAG – 밀집 검색기 BGE(Xiao et al., 2024; Karpukhin et al., 2020)
(3) 비구조적 RAG – 질의 분해(query decomposition)를 포함한 밀집 검색기 BGE(Min et al., 2019)
(4) 비구조적 RAG – 재순위(reranking)를 포함한 밀집 검색기 BGE(Nogueira and Cho, 2020)
(5) 트리 구조 RAG – RAPTOR(Sarthi et al., 2024)
(6) 트리 구조 RAG – SiReRAG(Zhang et al., 2024)
(7) 그래프 구조 RAG – GraphRAG(Edge et al., 2024a)
지역(local) 탐색 함수를 포함함
(8) 그래프 구조 RAG – HippoRAG(Gutiérrez et al., 2025)
구조적(structured) RAG 베이스라인의 경우,
우리는 이전 연구(Zhang et al., 2024)와 동일한 설정을 따른다.
평가지표(Metrics)
서로 다른 방법들의 답변 품질을 측정하기 위해,
우리는 exact match(EM) 과 F1 점수를 사용한다.
이 지표들은 생성된 답변과 대응하는 정답 사이의 정확도에 초점을 둔다.
우리는 또한 그래프 기반 방법들을 비교하기 위해
검색(retrieval) 지표들도 사용한다.
SiReRAG(Zhang et al., 2024) 과 RAPTOR(Sarthi et al., 2024) 같은
트리 기반 방법들은 검색 풀 안에 새로운 후보들(예: 요약 노드)을 생성하므로,
이들을 다른 방법들과 검색 지표로 비교하는 것은 공정하지 않을 수 있다.
우리는 HopRAG에 대한 소거 실험과 논의에서
답변 지표와 검색 지표 모두를 보고한다.
자세한 지표 설명은 Appendix A.3을 참조하라.
설정(Settings)
우리는 768차원의 의미(semantic) 벡터를 위해 BGE 임베딩 모델을 사용한다.
고정 크기로 청킹할 때 발생하는 의미 정보 손실을 피하기 위해,
우리는 원본 데이터셋에서 각각 사용된 동일한 청킹 방법을 채택한다.
GPT-4o-mini는 그래프 인덱스를 구축할 때
입력(in-coming) 및 출력(out-coming) 질문을 생성하는 모델이자
그래프 탐색을 위한 추론 모델의 역할을 동시에 수행한다.
우리는 두 개의 리더(reader) 모델인 GPT-4o와 GPT-3.5-turbo를 사용하여,
20개의 검색 후보와 $n_{hop} = 4$ 인 컨텍스트가 주어졌을 때
응답을 생성한다.
세부 설정은 Appendix A.4를 참조하라.
표 1: 우리는 여러 데이터셋에 대해 일련의 베이스라인들과 비교하여 HopRAG을 테스트하며,
추론 모델로 GPT-4o와 GPT-3.5-turbo를 사용하고 상위 20개의 문단을 사용한다.
여기에서는 GPT-3.5-turbo로 측정한 QA 성능 지표 EM과 F1 점수를 보고하고,
GPT-4o로 측정한 결과는 표 2에 제시하며, 최고 점수는 굵게 표시되고
두 번째로 높은 점수는 밑줄로 표시된다.
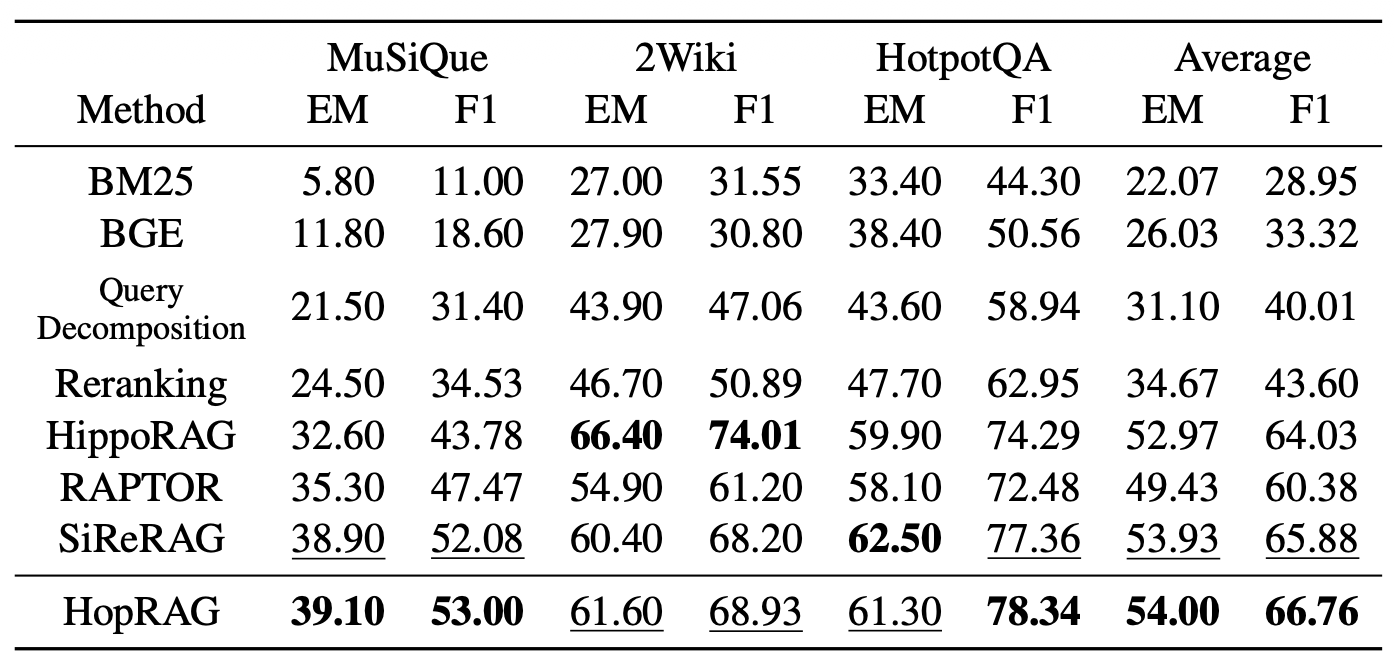
표 2: 여기에서는 GPT-4o와 상위 20개의 문단을 사용하여 QA 성능 지표 EM과 F1 점수를 보고하며,
최고 점수는 굵게 표시되고 두 번째로 높은 점수는 밑줄로 표시된다.
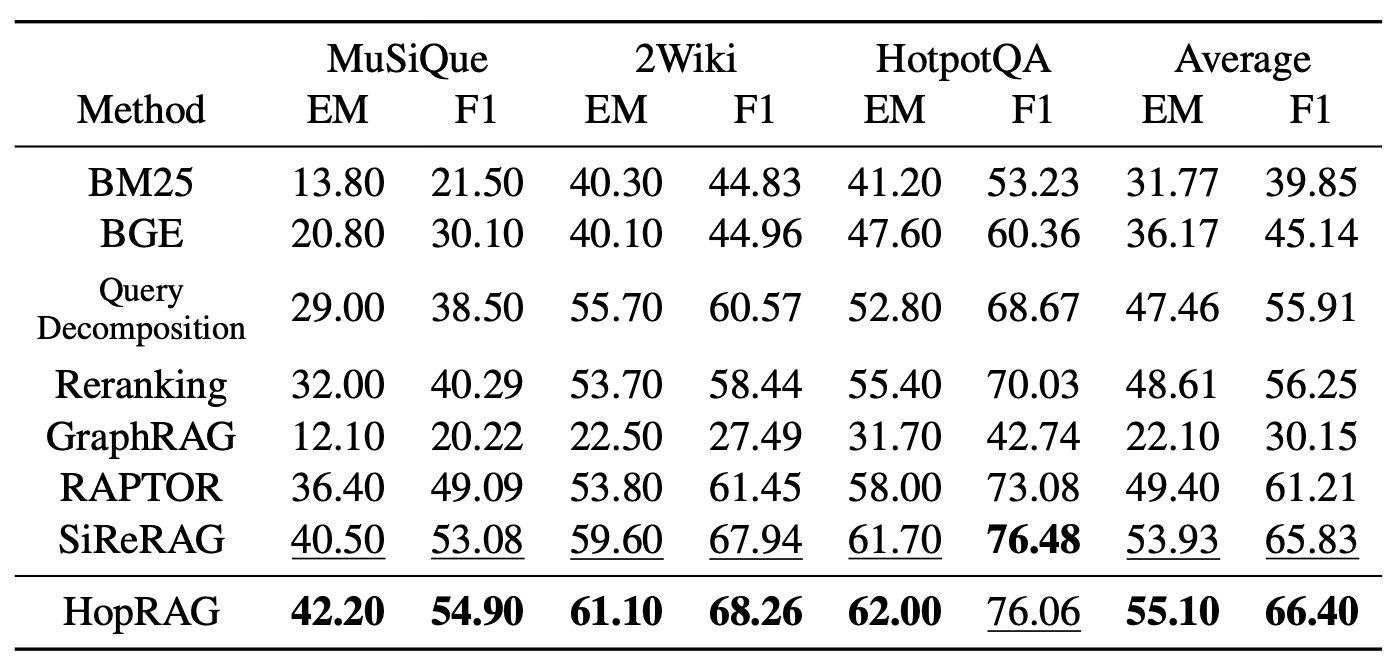
4.2 주요 결과 (Main Results)
주요 결과는 표 1과 표 2에 제시되어 있다.
우리는 거의 모든 설정에서 HopRAG이 가장 좋은 성능을 보인다는 것을 관찰한다.
예외적으로, HotpotQA에서는 SiReRAG과 비교했을 때,
그리고 2WikiMultiHopQA에서는 HippoRAG과 비교했을 때 예외가 존재한다.
전체적으로, HopRAG은 고밀집 검색기(BGE)보다 약 76.78% 더 높은 성능을 달성하고,
쿼리 분해(query decomposition)보다 48.62%,
리랭킹(BGE)보다 36.25%,
RAPTOR보다 9.94%,
HippoRAG보다 3.08%,
SiReRAG보다 1.11% 더 높은 성능을 보인다.
이러한 결과는 HopRAG이 다중 단계 질의응답(multi-hop QA)을 처리하기 위해
텍스트 유사성과 논리적 관계를 모두 포착하는 데 강점을 지니고 있음을 보여준다.
구체적으로, BM25, BGE, 그리고 쿼리 분해를 적용한 BGE는
유사성만을 기반으로 하기 때문에 만족스럽지 않은 결과를 낳는다.
또한 리랭킹을 적용한 BGE는 후보들 사이의 논리적 연관성을 포착할 수 없다.
GraphRAG는 그래프 검색을 위해 유사성 대신 엔티티들 사이의 연관성을 고려하고,
RAPTOR는 문단들 사이의 계층적 논리 관계에 초점을 맞추지만
그 외 종류의 연관성은 포착할 수 없다.
따라서 이 두 방법은
쿼리 중심 요약(query-focused summarization)에는 더 적합하지만,
(Zhang et al., 2024)에서 보고된 바와 같이
멀티-홉 QA 작업에서는 가장 경쟁력 있는 방법이라고 볼 수 없다.
HippoRAG의 관점에서 보면,
이 방법은 가장 많은 간선을 가진 정점들과 같은
관련성 신호들을 우선시하며,
유사성을 명시적으로 모델링하지 않는다.
반면에 우리의 설계인 HopRAG은
간선을 구성할 때 유사성과 논리적 관계를 직접 통합한다.
비록 HopRAG이 상위 20개의 후보 문단이 있는 시나리오에서
SiReRAG보다 작은 폭으로만 성능을 앞서긴 하지만,
우리의 일반적인 그래프 구조는
추가적인 요약 및 명제(proposition) 집계 노드를 도입하지 않으며,
SiReRAG과 비교했을 때 더 빠른 검색을 위한
효율적인 그래프 탐색을 가능하게 한다.
논의에서 우리는 HopRAG이
더 작은 컨텍스트 길이로도 경쟁력 있는 결과를
달성할 수 있음을 보일 것이다.
정량적 점수 외에도,
부록 A.6에서 HopRAG과 GraphRAG을 비교하는 사례 연구도 제시한다.
4.3 소거 실험과 논의 (Ablations and Discussion)
HopRAG의 견고성을 확인하고 더 많은 통찰을 제공하기 위해,
우리는 $top_k$, $n_{hop}$ 을 변화시키고
탐색(traversal) 모델에 대한 소거 실험을 수행한다.
표 3: 우리는 여러 데이터셋에서 GPT-3.5-turbo를 사용하여
HopRAG의 $top_k$ 하이퍼파라미터에 대한 강건성을 테스트한다.
$top_k$ 값을 2에서 20까지 변화시키고,
정답 품질 지표와 검색 지표를 모두 보고하며,
최고 점수는 굵게, 두 번째 점수는 밑줄로 표시한다.
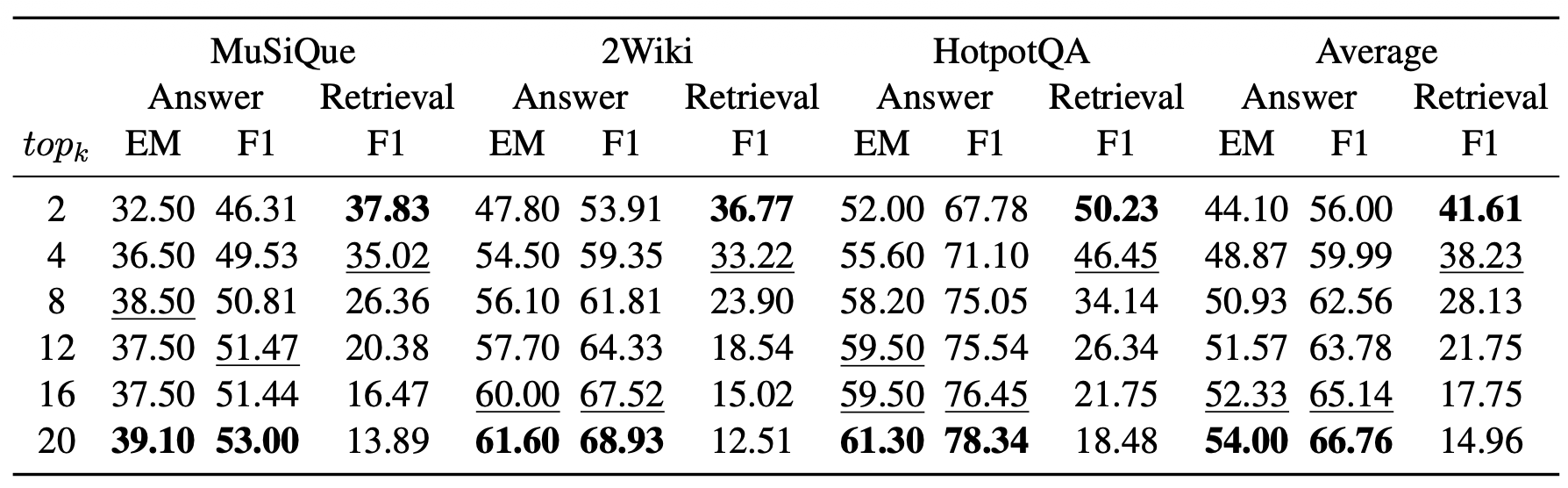
$top_k$ 의 효과
간접적으로 관련된 문단들에서
진정으로 관련 있는 문단들로 더 빠르게 hop 하는 데 있어
우리 방법의 효율성을 보여주기 위해,
우리는 더 작은 $top_k$ 값을 사용하여
GPT-3.5-turbo 기반의 QA 성능과 검색 성능을
모두 평가함으로써 강건성을 테스트한다.
이는 표 3에서 볼 수 있다.
결과로부터, 상위 12개의 후보만 사용하더라도
HopRAG의 QA 성능은
20개의 후보를 사용하는 HippoRAG 또는 RAPTOR와
여전히 비슷한 수준임을 알 수 있다.
이는 제한된 컨텍스트 길이 안에서
더 많은 정보를 효율적으로 검색하도록 설계된
우리의 그래프 탐색 방식의 효과를 강조한다.
한편, $top_k$ 가 증가함에 따라
검색 F1 점수가 점차 감소하는데,
이는 과도한 중복 정보가 포함되기 때문이다.
반대로, 정답 품질은 전반적으로 향상되며,
이는 GPT-3.5-turbo가 확장된 컨텍스트를
효율적으로 처리하고 추론하는 강력한 능력을 갖기 때문이다.
MuSiQue 데이터셋에서 단 하나의 예외만 존재한다.
표 4: 우리는 여러 데이터셋에서 GPT-3.5-turbo와 상위 20개 문단을 사용하여
HopRAG의 하이퍼파라미터 $n_{hop}$ 의 효과를 테스트한다.
$n_{hop}$ 값을 1에서 4까지 변화시키고,
정답 성능 지표와 검색 성능 지표를 표 8에 보고하며,
여기에서는 검색 성능 지표만 보고한다.
검색 성능 지표로는
검색 F1 점수와 탐색 과정에서 호출된 LLM의 평균 호출 횟수를 계산하여
비용을 측정한다 (낮을수록 더 좋다).
가장 높은 점수는 굵게 표시하고, 두 번째로 높은 점수는 밑줄로 표시한다.

$n_{hop}$ 의 효과
추론이 보강된 그래프 탐색에서
하이퍼파라미터 $n_{hop}$ 의 영향을 평가하기 위해,
우리는 $n_{hop}$ 값을 1에서 4까지 변화시키며
이에 대응하는 검색 성능과 비용을 평가한다.
비용은 그래프 탐색 동안 발생하는 LLM 호출의 총량으로 측정된다.
표 4에 제시된 결과는
$n_{hop}$ 이 증가함에 따라 검색 성능이 향상되는 경향을 보이며,
이는 탐색 중 더 많은 정점이
추론 및 가지치기를 위해 방문되기 때문이다.
그러나 $n_{hop}$ 증가에 따라 LLM 호출로 인한 비용과 지연도 증가하므로
성능과 비용 사이의 트레이드오프가 생긴다.
우리는 $n_{hop}$ 이 증가함에 따라
LLM 추론이 필요한 $C_{queue}$ 내의 새로운 정점의 수가
빠르게 감소한다는 점을 관찰한다.
서로 다른 정점들이 동일한 중요한 정점으로 hop할 수 있기 때문에,
각 hop 라운드에서의 실제 큐 길이는 $top_k$ 보다 작다.
구체적으로,
4번째 라운드에서 평균 큐 길이는 2.60,
5번째 라운드에서 평균 큐 길이는 1.23으로 나타난다.
이는 세 개의 데이터셋 모두에서
그래프 구조의 지역 영역이 대체로 4번의 hop 안에 충분히 탐색되므로
추가 hop이 필요 없음을 시사한다.
우리는 표 1과 표 2에서 $n_{hop}=4$ 로 설정하였다.
또한 $n_{hop}$ 변화에 따른 정답 성능도 평가하였으며,
전체 결과는 부록 A.8에 제시되어 있다.
표 5: 우리는 추론 모델에 대한 소거 실험을 수행하는데, 탐색 과정에서의 추론 모델을 대상으로 하며
추론 모델로 GPT-3.5-turbo를 사용하고 상위 20개의 문단을 사용한다.
우리는 다섯 가지 시나리오를 비교한다:
희소 검색기(BM25), 밀집 검색기(BGE),
HopRAG(비-LLM), HopRAG(Qwen2.5-1.5B-Instruct),
HopRAG(GPT-4o-mini).
그리고 정답 지표와 검색 지표를 모두 보고하며,
가장 높은 점수는 굵게 표시되고 두 번째로 높은 점수는 밑줄로 표시된다.
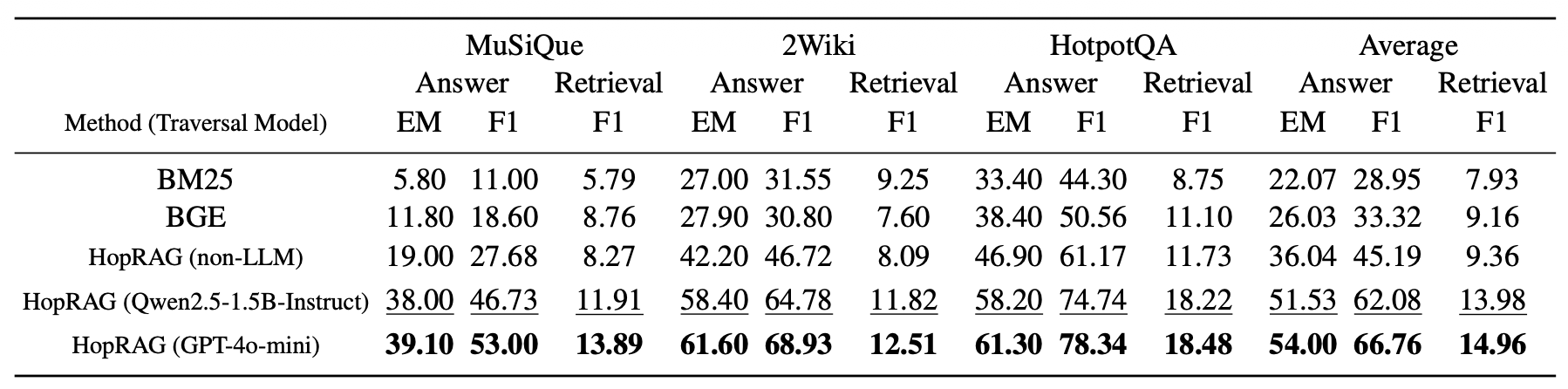
탐색(traversal) 모델에 대한 소거 연구(ablation)
검색 중의 더 적은 계산 오버헤드를 갖는 시나리오들에 대해
HopRAG을 일반화하기 위해, 우리는 다음의 결과들을 보완한다:
(1) 탐색 모델 Qwen2.5-1.5B-Instruct를 사용한 HopRAG,
(2) 알고리즘 1에서의 추론 단계를 유사도 매칭으로 대체한
비-LLM 그래프 탐색을 사용하는 HopRAG
표 5는 그래프 탐색에서 LLM의 추론 능력을 사용하지 않더라도,
HopRAG이 BM25보다 45.84% 높고
밀집 검색기(BGE)보다 25.43% 더 높은 성능을 달성할 수 있음을 보여준다.
이는 HopRAG이 논리 기반 검색을 위해
텍스트 유사성과 논리적 관계를 포착하는 데 효과적임을 입증한다.
LLM(GPT-4o-mini)의 추론 능력을 도입하면
비-LLM 버전보다 약 45.78% 더 높은 평균 점수를 달성할 수 있으며,
탐색 모델로 Qwen2.5-1.5B-Instruct를 사용하는 경우
더 적은 비용과 더 높은 효율성으로 유사한 결과를 생성한다.
우리는 부록 A.7에서 검색 효율성에 대한 추가 분석을 제공한다.
5 결론
이 논문에서 우리는 논리 인식 검색 메커니즘을 갖춘
새로운 RAG 시스템인 HopRAG을 소개하였다.
HopRAG은 의사 쿼리를 통해 관련 문단들을 연결하며,
이를 통해 간접적으로 관련된 문단들의 다중 hop 이웃 안에서
진정으로 관련된 문단들을 식별할 수 있게 한다.
이는 검색의 정밀도와 재현율을 모두 크게 향상시킨다.
광범위한 실험을 다중 hop QA 벤치마크,
즉 MuSiQue, 2WikiMultiHopQA, HotpotQA에서 수행한 결과,
HopRAG은 기존 RAG 시스템과 최신 베이스라인들을 능가함을 보여준다.
구체적으로, HopRAG은 기존 정보 검색 방식과 비교했을 때
정답 정확도가 36.25% 이상 높았으며,
검색 F1 점수 역시 20.97% 향상되었다.
이는 논리적 추론을 검색 모듈에 통합하는 접근법의 효과를 강조한다.
더 나아가, 소거(ablation) 연구는
하이퍼파라미터와 모델의 민감도에 대한 통찰을 제공하며,
검색 성능과 계산 비용 간의 트레이드-오프 관계를 드러낸다.
HopRAG은 추론 기반 지식 검색을 향한 길을 열어준다.
향후 연구는 HopRAG을 QA 태스크를 넘어
더 넓은 도메인으로 확장하는 것,
더 복잡한 시나리오에서도 낮은 계산 비용으로 동작할 수 있도록
색인 및 탐색 전략을 최적화하는 것을 포함한다.
감사의 글 (Acknowledgments)
이 연구는 중국 국가 중점 연구개발 프로그램(2024YFA1014003),
중국 국가자연과학재단(92470121, 62402016),
CAAI–Ant Group 연구기금,
그리고 베이징대학교 고성능 컴퓨팅 플랫폼의 지원을 받았다.
제한사항 (Limitations)
HopRAG의 이점에도 불구하고,
현재의 평가는 멀티-홉 또는 멀티-문서 QA 태스크에 초점을 맞추고 있다.
HopRAG을 다른 데이터셋에 적용할 때 발생할 수 있는
성능 변동의 위험을 줄이기 위해,
우리는 더 넓은 범위의 도메인에 걸친
일반화(generalization) 가능성을 탐색해야 한다.
또한, 더 정교한 질의 시뮬레이션(query simulation)과
간선 병합(edge merging) 전략은
추가적인 성능 향상을 가져올 수 있다.
마지막으로, 비록 우리가
‘육촌 이론(six degrees of separation)’과
‘스몰월드 네트워크(small-world networks)’의 개념에서 영감을 받았지만,
우리 단말 그래프의 정점 차수 분포(the degree distribution of our passage graph vertices)는
멱법칙(power-law) 특성을 보이지 않는다.
마지막 문장은 “왜 스몰월드·육촌 이론을 참고했는데
실제 그래프는 멱법칙(power-law) 형태를 띠지 않는가?”에 대한 설명이다.일반적으로 육촌 이론이나 스몰월드 네트워크는
노드들 간의 연결 구조가 특정 패턴을 보인다고 가정한다.
그중 하나가 정점 차수 분포가 멱법칙 형태를 나타낸다는 점이다.
즉, 소수의 노드는 매우 높은 연결수를 갖고,
대부분의 노드는 낮은 연결수를 갖는 불균형 구조가 나타난다.그러나 HopRAG에서 구성한 문단 그래프(passage graph)에서는
이러한 멱법칙적 분포가 관찰되지 않았다.이는 곧
“HopRAG의 그래프 구조는 스몰월드 네트워크나 육촌 이론의
이상적인 네트워크 모델과는 구조적으로 다르다”는 의미이며,
두 이론은 어디까지나 직관적 비유일 뿐,
HopRAG 그래프가 동일한 분포 특성을 따라야 한다는 뜻은 아니다.
한편으로는 이러한 이론들이
단지 동기 부여와 직관적 비유로만 작용하고,
다른 한편으로는 더 적절한 차수 분포 전략을 탐구하는 것이
흥미로운 연구 주제가 될 것이다.
우리는 이러한 연구 문제들을 향후 과제로 남긴다.
윤리적 영향 (Ethics Impact)
우리의 작업에서, 우리는 두 가지 주요한 윤리적 고려사항을 인정한다.
첫째, 우리는 논문과 코드의 작성 과정을 향상시키기 위해 AI 도우미를 활용하였다.
우리는 AI 도우미가 명확성과 간결성을 향상시키는 도구로 사용되었음을 보장하며,
최종적인 내용과 아이디어는 인간 저자들에 의해 개발되고 검토되었다.
둘째, 우리는 실험에서 여러 개의 오픈소스 데이터셋과
GPL v3 라이선스 하에 제공되는 하나의 오픈소스 도구인
Neo4j Community Edition(Webber, 2012)을 사용하였다.
우리는 이들의 출처와 한계에 대해 투명하게 밝히며,
데이터 소유권과 사용자 프라이버시를 존중한다.
참고문헌(References)
Ekin Akyurek, Tolga Bolukbasi, Frederick Liu, Binbin Xiong, Ian Tenney, Jacob Andreas, Kelvin Guu. 2022.
Towards tracing knowledge in language models back to the training data.
(언어 모델의 지식을 훈련 데이터로 다시 추적하는 방향을 향하여.)
In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 2429–2446, Abu Dhabi, United Arab Emirates.
Association for Computational Linguistics.Akari Asai, Zeqiu Wu, Yizhong Wang, et al. 2023.
Self-rag: Learning to retrieve, generate, and critique through self-reflection.
(Self-RAG: 자기 성찰을 통해 검색·생성·비평을 학습하기.)
arXiv:2310.11511.Howard Chen, Ramakanth Pasunuru, Jason Weston, Asli Celikyilmaz. 2023.
Walking Down the Memory Maze: Beyond Context Limit through Interactive Reading.
(기억 미로를 따라 걷기: 상호작용적 읽기를 통한 컨텍스트 한계 극복.)
arXiv preprint, arXiv:2310.05029.Jiawei Chen, Hongyu Lin, Xianpei Han, Le Sun. 2024.
Benchmarking large language models in retrieval-augmented generation.
(검색 증강 생성에서 대형 언어 모델을 벤치마크하기.)
In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 17754–17762.Sunhao Dai, Chen Xu, Shicheng Xu, Liang Pang, Zhenhua Dong, Jun Xu. 2024.
Unifying bias and unfairness in information retrieval: A survey of challenges and opportunities with large language models.
(정보 검색에서의 편향과 불공정을 통합하기: 대형 언어 모델이 제공하는 도전과 기회의 조사.)
arXiv preprint, arXiv:2404.11457.Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Jonathan Larson. 2024a.
From Local to Global: A Graph RAG Approach to Query-Focused Summarization.
(로컬에서 글로벌로: 질의 중심 요약을 위한 그래프 RAG 접근법.)
arXiv preprint, arXiv:2404.16130 [cs].Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Jonathan Larson. 2024b.
From local to global: A graph rag approach to query-focused summarization.
(로컬에서 글로벌로: 질의 중심 요약을 위한 그래프 RAG 접근법.)
arXiv preprint, arXiv:2404.16130.Masoomali Fatehkia, Ji Kim Lucas, Sanjay Chawla. 2024.
T-rag: Lessons from the llm trenches.
(T-RAG: LLM 실전에서 얻은 교훈들.)
Preprint, arXiv:2402.07483.Thibault Févr y, Livio Baldini Soares, et al. 2020.
Entities as experts: Sparse memory access with entity supervision.
(전문가로서의 엔티티: 엔티티 감독을 통한 희소 메모리 접근.)
In EMNLP.John Guare. 2016.
Six degrees of separation.
(육촌 이론.)
In The Contemporary Monologue: Men, pages 89–93. Routledge.Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. 2025.
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.
(DeepSeek-R1: 강화학습을 통해 LLM의 추론 능력을 장려하기.)
arXiv preprint, arXiv:2501.12948.Zirui Guo, Lianghao Xia, Yanhua Yu, Tu Ao, Chao Huang. 2024.
LightRAG: Simple and Fast Retrieval-Augmented Generation.
(LightRAG: 단순하고 빠른 검색 증강 생성.)
arXiv preprint, arXiv:2410.05779.Bernal Jiménez Gutiérrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, Yu Su. 2025.
Hippograg: Neurobiologically inspired long-term memory for large language models.
(HippoRAG: 신경생물학에서 영감을 받은 LLM용 장기 기억 메커니즘.)
Preprint, arXiv:2405.14831.Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, Mingwei Chang. 2020a.
Retrieval augmented language model pre-training.
(검색 증강 언어 모델 사전훈련.)
In International Conference on Machine Learning, pages 3929–3938. PMLR.Kelvin Guu, Kenton Lee, Zora Tung, et al. 2020b.
REALM: retrieval-augmented language model pretraining.
(REALM: 검색 증강 언어 모델 사전훈련.)
In ICML.Xiaoxin He, Yijun Tian, Yifei Sun, Nitesh V. Chawla, Thomas Laurent, Yann LeCun, Xavier Bresson, Bryan Hooi. 2024.
G-Retriever: Retrieval-Augmented Generation for Textual Graph Understanding and Question Answering.
(G-Retriever: 텍스트 그래프 이해 및 질문응답을 위한 검색 증강 생성.)
arXiv preprint, arXiv:2402.07630.Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, Akiko Aizawa. 2020.
Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps.
(추론 단계를 포괄적으로 평가하기 위한 멀티홉 QA 데이터셋 구성.)
Preprint, arXiv:2011.01060.Gautier Izacard, Edouard Grave. 2021.
Leveraging passage retrieval with generative models for open domain question answering.
(생성 모델을 활용한 패시지 검색 기반의 오픈 도메인 질문응답.)
In EACL.Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane Dwivedi-Yu, Armand Joulin, Sebastian Riedel, Edouard Grave. 2022.
Few-shot learning with retrieval augmented language models.
(검색 증강 언어 모델을 활용한 소수샘플 학습.)
arXiv preprint, arXiv:2208.03299.Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. 2024.
Openai o1 system card.
(OpenAI o1 시스템 카드.)
arXiv preprint, arXiv:2412.16720.Zhengbao Jiang, Frank F. Xu, Luyu Gao, et al. 2023.
Active retrieval augmented generation.
(능동 검색 증강 생성.)
arXiv:2305.06983.Karen Sparck Jones. 1973.
Index term weighting.
(색인 용어 가중치.)
Information Storage and Retrieval, 9(11): 619–633.Minki Kang, Jin Myung Kwak, Jinheon Baek, Sung Ju Hwang. 2023.
Knowledge graph-augmented language models for knowledge-grounded dialogue generation.
(지식 그래프 증강 언어 모델을 이용한 지식 기반 대화 생성.)
Preprint, arXiv:2305.18864.Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, Wen-tau Yih. 2020.
Dense passage retrieval for open-domain question answering.
(오픈 도메인 질문응답을 위한 밀집 패시지 검색.)
Preprint, arXiv:2004.04906.Jon Kleinberg. 2000.
The small-world phenomenon: An algorithmic perspective.
(스몰월드 현상: 알고리즘 관점.)
In Proceedings of the thirty-second annual ACM symposium on Theory of computing, pages 163–170.Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020a.
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.
(지식 집약적 NLP 작업을 위한 검색 증강 생성.)
Advances in Neural Information Processing Systems, 33:9459–9474.Patrick S. H. Lewis, Ethan Perez, Aleksandra Piktus, et al. 2020b.
Retrieval-augmented generation for knowledge-intensive NLP tasks.
(지식 집약적 NLP 작업을 위한 검색 증강 생성.)
In NeurIPS.Zijian Li, Qingyan Guo, Jiawei Shao, Lei Song, Jiang Bian, Jun Zhang, Rui Wang. 2024.
Graph Neural Network Enhanced Retrieval for Question Answering of LLMs.
(LLM의 질문응답을 위한 그래프 신경망 기반 향상 검색.)
arXiv preprint, arXiv:2406.06572.Xun Liang, Simin Niu, Zhiyu Li, Sensen Zhang, Hanyu Wang, Feiyu Xiong, Jason Zhaoxin Fan, Bo Tang, Shichao Song, Mengwei Wang, et al. 2025.
Saferag: Benchmarking security in retrieval-augmented generation of large language model.
(SaferAG: 대형 언어 모델의 검색 증강 생성에서 보안 벤치마킹.)
arXiv preprint, arXiv:2501.18636.Xun Liang, Simin Niu, Sensen Zhang, Shichao Song, Hanyu Wang, Jiawei Yang, Feiyu Xiong, Bo Tang, Chenyang Xi, et al. 2024.
Empowering large language models to set up a knowledge retrieval indexer via self-learning.
(자가 학습을 통해 지식 검색 인덱서를 구축하도록 대형 언어 모델을 강화하기.)
arXiv preprint, arXiv:2405.16933.Costas Mavromatis, George Karypis. 2024.
Gnnrag: Graph neural retrieval for large language model reasoning.
(GNN-RAG: 대형 언어 모델 추론을 위한 그래프 신경 기반 검색.)
arXiv preprint, arXiv:2405.20139.Sewon Min, Weijia Shi, Mike Lewis, Xilun Chen, Wen-tau Yih, Hannaneh Hajishirzi, Luke Zettlemoyer. 2023.
Nonparametric masked language modeling.
(비모수 마스크드 언어 모델링.)
In Findings of the Association for Computational Linguistics: ACL 2023, pages 2097–2118, Toronto, Canada.Sewon Min, Victor Zhong, Luke Zettlemoyer, Hannaneh Hajishirzi. 2019.
Multi-hop reading comprehension through question decomposition and rescoring.
(질문 분해 및 재점수를 통한 멀티홉 독해.)
In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 6097–6109, Florence, Italy.Rodrigo Nogueira, Kyunghyun Cho. 2020.
Passage re-ranking with bert.
(BERT를 이용한 패시지 재순위화.)
Preprint, arXiv:1901.04085.Qwen Development Team. 2025.
Qwen 2.5 Speed Benchmark.
(Qwen 2.5 속도 벤치마크.)
https://qwen.readthedocs.io/en/stable/benchmark/speed_benchmark.html
Accessed: 2025-5-4.Ori Ram, Yoav Levine, Itay Dalmedigos, Dor Muhlgay, Amnon Shashua, Kevin Leyton-Brown, Yoav Shoham. 2023.
In-context retrieval-augmented language models.
(문맥 내 검색 증강 언어 모델.)
arXiv preprint, arXiv:2302.00083.Stephen Robertson, Hugo Zaragoza. 2009a.
The Probabilistic Relevance Framework: BM25 and Beyond.
(확률적 관련성 프레임워크: BM25 및 그 너머.)
Foundations and Trends® in Information Retrieval, 3(4):333–389.Stephen E. Robertson, Hugo Zaragoza. 2009b.
The probabilistic relevance framework: BM25 and beyond.
(확률적 관련성 프레임워크: BM25 및 그 너머.)
FTIR, 3(4):333–389.Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, Christopher D. Manning. 2024.
RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval.
(RAPTOR: 트리 기반 검색을 위한 재귀적 추상 처리.)
arXiv preprint, arXiv:2401.18059 [cs].Parth Sarthi, Salman Abdullah, Aditi Tuli, et al. 2023.
Raptor: Recursive abstractive processing for tree-organized retrieval.
(RAPTOR: 트리 구조 검색을 위한 재귀적 추상 처리.)
In ICLR.Kunal Sawarkar, Abhilasha Mangal, Shivam Raj Solanki. 2024.
Blended rag: Improving rag (retriever-augmented generation) accuracy with semantic search and hybrid query-based retrievers.
(Blended RAG: 의미 기반 검색과 하이브리드 질의 기반 검색기를 통해 RAG 정확도 향상.)
arXiv preprint, arXiv:2404.07220.Rulin Shao, Jacqueline He, Akari Asai, Weijia Shi, Tim Dettmers, Sewon Min, Luke Zettlemoyer, Pang Wei Koh. 2024.
Scaling retrieval-based language models with a trillion-token datastore.
(1조 토큰 데이터스토어로 검색 기반 언어 모델 확장.)
arXiv preprint, arXiv:2407.12854.Karthik Soman, Peter W Rose, John H Morris, Rabia E Akbas, Brett Smith, Braian Peetoom, Catalina Villouta-Reyes, Gabriel Cerono, Yongmei Shi, Angela Rizk-Jackson, Sharaf Israni, Charlotte A Nelson, Sui Huang, Sergio E Baranzini. 2024.
Biomedical knowledge graph-optimized prompt generation for large language models.
(대형 언어 모델을 위한 생의학 지식 그래프 기반 프롬프트 최적 생성.)
Preprint, arXiv:2311.17330.Saba Sturua, Isabelle Mohr, Mohammad Kalim Akram, Michael Günther, Bo Wang, Markus Krimmel, Feng Wang, Georgios Mastrapas, Andreas Koukounas, Nan Wang, et al. 2024.
juma-embeddings-v3: Multilingual embeddings with task lora.
(juma-embeddings-v3: Task LoRA 기반 다국어 임베딩.)
arXiv preprint, arXiv:2409.10173.Hongjun Su, Howard Yen, Mengzhou Xia, Weijia Shi, Niklas Muennighoff, Han-yu Wang, Haisu Liu, Quan Shi, Zachary S. Siegel, Michael Tang, et al. 2024a.
Bright: A realistic and challenging benchmark for reasoning-intensive retrieval.
(BRIGHT: 추론 집약적 검색을 위한 현실적이고 어려운 벤치마크.)
arXiv preprint, arXiv:2407.12883.Hongjun Su, Howard Yen, Mengzhou Xia, Weijia Shi, Niklas Muennighoff, Han-yu Wang, Haisu Liu, Quan Shi, Zachary S. Siegel, Michael Tang, Ruoxi Sun, Jinsung Yoon, Sercan O. Arik, Danqi Chen, Tao Yu. 2024b.
Bright: A realistic and challenging benchmark for reasoning-intensive retrieval.
(BRIGHT: 추론 집약적 검색을 위한 현실적이고 어려운 벤치마크.)
Preprint, arXiv:2407.12883.Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, Ashish Sabharwal. 2022.
Musique: Multi-hop questions via single-hop question composition.
(Musique: 단일 홉 질문 결합을 통한 멀티홉 질문 생성.)
Preprint, arXiv:2108.00573.Christos Voudouris, Edward PK Tsang, Abdullah Alsheddy. 2010.
Guided local search.
(가이드된 로컬 서치.)
In Handbook of metaheuristics, pages 321–361. Springer.Fei Wang, Xingchen Wan, Ruoxi Sun, Jiefeng Chen, Sercan O. Arik. 2024a.
Asterix rag: Overcoming imperfect retrieval augmentation and knowledge conflicts for large language models.
(Asterix RAG: 불완전한 검색 증강과 지식 충돌을 극복하기 위한 방법.)
arXiv preprint, arXiv:2410.01776.Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, Furu Wei. 2024b.
Multilingual e5 text embeddings: A technical report.
(다국어 E5 텍스트 임베딩: 기술 보고서.)
arXiv preprint, arXiv:2402.05672.Zhengran Wang, Qinhan Yu, Shida Wei, Zhiyu Li, Feiyu Xiong, Xiaoxing Wang, Simin Niu, Hao Liang, Wentao Zhang. 2024c.
QAEncoder: Towards aligned representation learning in question answering system.
(QAEncoder: 질문응답 시스템에서 정렬된 표현 학습을 향해.)
arXiv preprint, arXiv:2409.20434 [cs].Jim Webber. 2012.
A programmatic introduction to neo4j.
(Neo4j에 대한 프로그래밍적 소개.)
In Proceedings of the 3rd Annual Conference on Systems, Programming, and Applications: Software for Humanity, SPLASH ’12, pages 217–218.Chong Xiang, Tong Wu, Zexuan Zhong, David Wagner, Danqi Chen, Prateek Mittal. 2024.
Certifying robust rag against retrieval corruption.
(검색 손상에 대해 견고한 RAG를 인증하기.)
arXiv preprint, arXiv:2405.15556.Shizao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff, Defu Lian, Jian-Yun Nie. 2024.
C-pack: Packaged resources to advance general chinese embedding.
(C-pack: 범용 중국어 임베딩을 위한 패키지 리소스.)
Preprint, arXiv:2309.07597.Zhilin Yang, Peng Qi, Saizheng Zhang, Yousha Bengio, William W. Cohen, Ruslan Salakhutdinov, Christopher D. Manning. 2018.
Hotpotqa: A dataset for diverse, explainable multi-hop question answering.
(HotpotQA: 다양한 설명 가능한 멀티홉 질의응답을 위한 데이터셋.)
Preprint, arXiv:1809.09600.Qinhau Yu, Zhiyou Xiao, Binghui Li, Zhengren Wang, Chong Chen, Wentao Zhang. 2025.
Mram-bench: A beyondtext benchmark for multimodal retrieval-augmented multimodal generation.
(MRAM-bench: 멀티모달 검색 증강 생성용 BeyondText 벤치마크.)
arXiv preprint, arXiv:2502.04176.Nan Zhang, Prafulla Kumar Choubey, Alexander Fabri, Gabriel Bernadett-Shapiro, Rui Zhang, Prasenjit Mitra, Caiming Xiong, Chen-Sheng Wu. 2024.
Sirerag: Indexing similar and related information for multihop reasoning.
(SireRAG: 멀티홉 추론을 위한 유사/관련 정보 인덱싱.)
Preprint, arXiv:2412.06206.Yue Zhang, Yafu Li, Leyang Cui, Deng Cai, Lemao Liu, Tingchen Fu, Xinting Huang, Enbo Zhao, Yu Zhang, Yulong Chen, Longyue Wang, Anh Tuan Luu, Wei Bi, Freda Shi, Shuming Shi. 2023.
Siren’s Song in the AI Ocean: A Survey on Hallucination in Large Language Models.
(AI 바다의 사이렌의 노래: 대형 언어 모델 환각(hallucination)에 관한 조사.)
arXiv preprint, arXiv:2309.01219 [cs].Penghao Zhao, Hailin Zhang, Qinhan Yu, Zhengren Wang, Yunteng Geng, Fangcheng Fu, Ling Yang, Wentao Zhang, Bin Cui. 2024.
Retrieval-augmented generation for ai-generated content: A survey.
(AI 생성 콘텐츠를 위한 검색 증강 생성: 조사.)
arXiv preprint, arXiv:2402.19473.Wei Zou, Runpeng Ge, Binghui Wang, Jinyuan Jia. 2024.
Poisonedrag: Knowledge poisoning attacks to retrieval-augmented generation of large language models.
(PoisonedRAG: 대형 언어 모델의 검색 증강 생성에 대한 지식 오염 공격.)
arXiv preprint, arXiv:2402.07867.
A 부록 (Appendix)
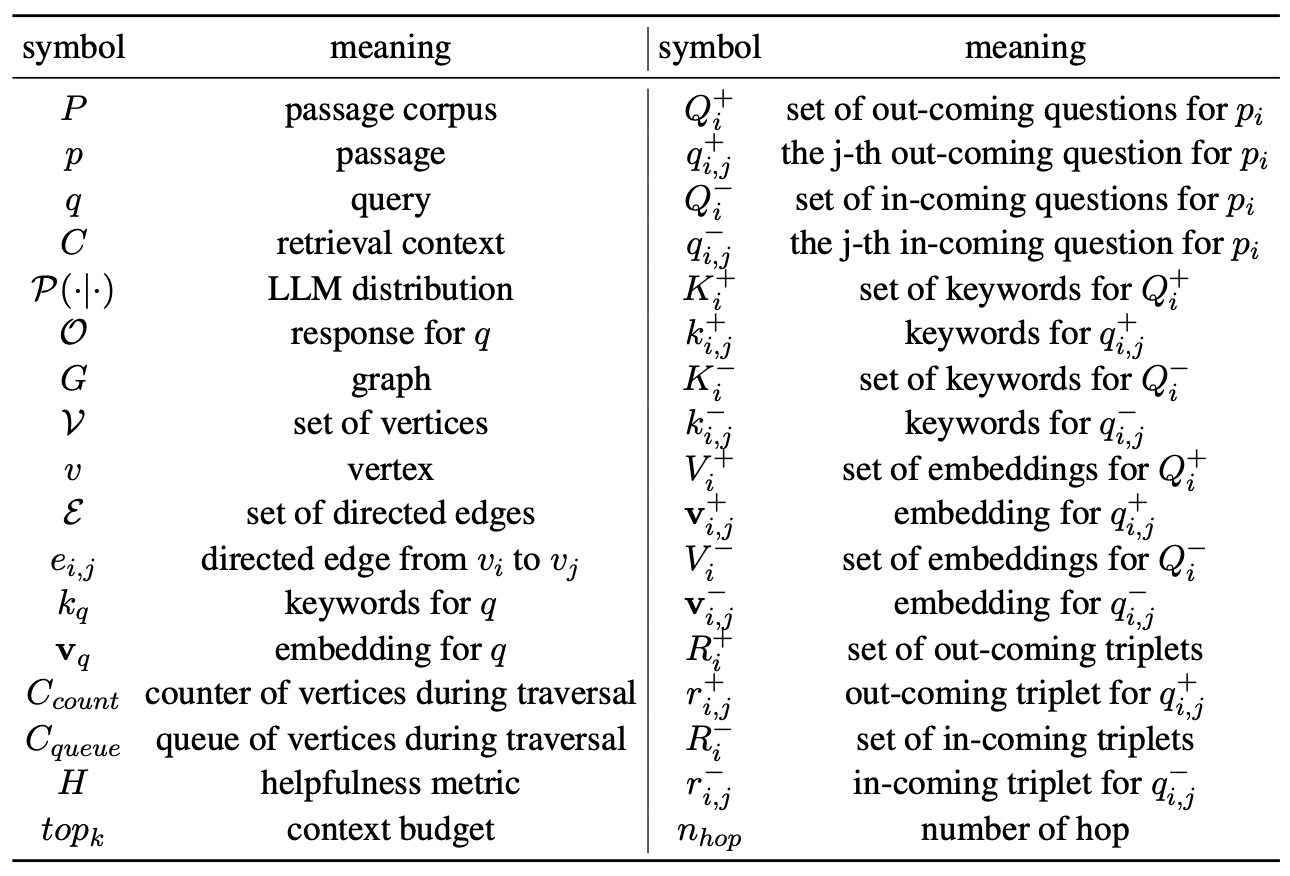
A.1 기호(Symbols)
기호들과 그에 대응하는 의미들은 표 6에 나열되어 있다.
표 6: 기호와 의미의 표
A.2 데이터셋(Datasets)
표 7은 해당하는 문단(passage) 풀과 함께 우리 데이터셋의 기본 통계를 보여준다.
표 7: 데이터셋 통계.
우리는 서로 다른 데이터셋에 대한 그래프 구조의 기본 통계를 보고하고,
우리의 효율적인 그래프 구조가 탐색 친화적임을 보여준다.
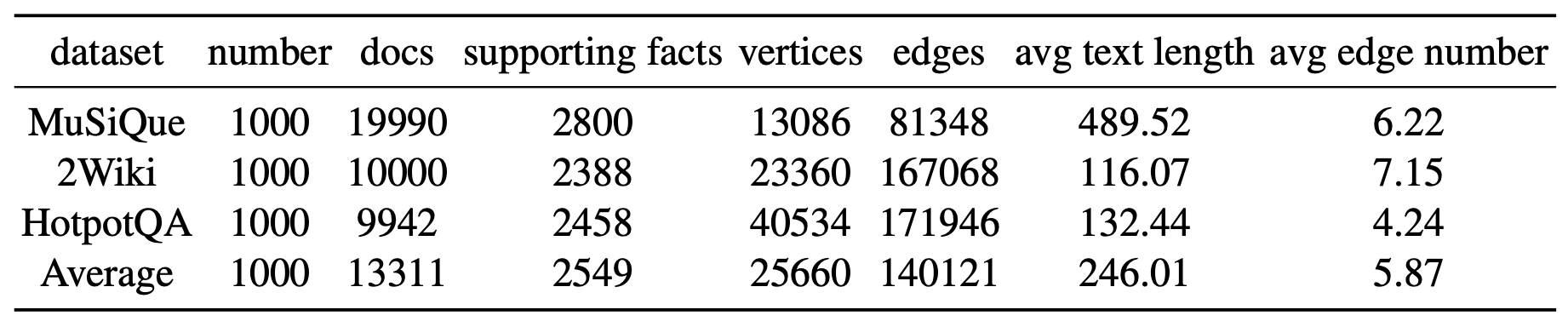
지식 그래프와 비교했을 때, 우리의 그래프 구조 인덱스는
덜 밀집되어 있으며 더 효율적으로 구성된다.
우리가 각 문단 텍스트를 정점(vertex)에 넣기 때문에,
모든 문단을 포괄하는 데 더 적은 정점을 사용할 수 있고,
이는 데이터베이스의 공간 복잡도를 낮춘다.
각 정점당 평균 유향(directed) 간선의 수는 단지 5.87에 불과하며,
이는 그래프 탐색의 시간 복잡도를 낮춘다.
A.3 지표(Metrics)
우리의 실험에서, 우리는 주로 모든 방법들을 비교하기 위해
Exact Match(EM)와 F1 점수를 보고한다.
Exact Match(EM)
Exact Match(EM) 지표는 예측들이 정답 중 하나와 정확히 일치하는 비율을 측정한다.
이는 다음과 같이 정의된다:
\[EM = \frac{\lvert \{ p \mid p = g \} \rvert}{\lvert P \rvert}\]여기서 $p$ 는 예측된 답을 나타내고,
$g$ 는 해당하는 정답을 나타내며,
$P$ 는 모든 예측들의 집합을 의미한다.
F1 점수
F1 점수는 정밀도(precision)와 재현율(recall)의 조화 평균이며,
예측과 정답 사이의 평균 중첩 정도를 측정한다.
정밀도 $P$ 와 재현율 $R$ 은 다음과 같이 정의된다:
\[P = \frac{\lvert A \cap \hat{A} \rvert}{\lvert \hat{A} \rvert}, \qquad R = \frac{\lvert A \cap \hat{A} \rvert}{\lvert A \rvert}\]여기서 \(\lvert A \cap \hat{A} \rvert\) 는 예측 $\hat{A}$ 와 정답 $A$ 사이에서 일치하는 토큰의 수를 의미하며,
\(\lvert \hat{A} \rvert\) 와 \(\lvert A \rvert\) 는 각각 예측 답변과 정답 답변의 토큰 수를 나타낸다.
F1 점수는 다음과 같이 계산된다:
\[F1 = \frac{2 \cdot P \cdot R}{P + R}\]우리의 소거(ablation) 연구에서, 우리는 HopRAG의 민감도를 테스트하기 위해
검색(retrieval) F1 점수도 보고하며, 이는 다음과 같이 계산된다.
검색을 위한 정밀도(P)와 재현율(R)은 다음과 같이 계산된다:
\[P = \frac{\lvert Ret \cap Rel \rvert}{\lvert Ret \rvert}, \qquad R = \frac{\lvert Ret \cap Rel \rvert}{\lvert Rel \rvert}\]여기서 $Ret$ 은 검색 과정에서 검색된 문단들의 집합을 나타내며,
$Rel$ 은 정답을 지지하는 관련 문단들의 집합을 나타낸다.
검색 F1 점수는 정밀도와 재현율의 조화 평균으로 계산되며,
다음과 같이 정의된다:
A.4 설정(Settings)
문서를 일정한 크기로 청크(chunk)로 나누면서 발생하는 의미 손실을 피하기 위해,
우리는 각 문서를 각 데이터셋의 supporting facts(지원 사실)에 대응하는 방식으로 청크한다.
구체적으로, HotpotQA와 2WikiMultiHopQA에서는 각 문서를 문장 단위로 청크하는데,
이는 이 두 데이터셋의 supporting facts의 최소 단위가 문장이기 때문이다.
각 청크의 임베딩 표현을 얻기 위해, 우리는 bge-base 모델을 사용한다.
키워드를 추출하기 위해, 우리는 파이썬 패키지 PaddleNLP의 품사 태깅 기능을 사용하여
엔티티를 추출하고 필터링한다.
우리의 방법에서는, Neo4j 그래프 데이터베이스를 사용해
정점(vertices)을 저장하고 간선(edges)을 구축한다.
간선을 구축할 때, 우리는 prompt engineering 기법을 사용하여
LLM에게 각 정점이 가진 정보를 포괄하도록 적절한 수의 질문을 생성하도록 지시하며,
최소한 2개의 in-coming 질문과 4개의 out-coming 질문이 필요하다.
그래프 구조가 지나치게 복잡하고 조밀해지는 것을 방지하기 위해,
우리는 정점의 수를 $n$이라 할 때 $O(n \cdot \log(n))$ 개의 간선만을 유지한다.
우리는 reasoning-augmented graph traversal(추론이 결합된 그래프 탐색)을 위해 GPT-4o-mini를,
그리고 주요 실험에서 2048 max tokens 및 0.1 temperature 설정으로
GPT-4o와 GPT-3.5-turbo를 추론(inference)에 사용한다.
희소(sparse) 및 밀집(dense) 검색기(retrievers)를 위해,
우리는 Neo4j 데이터베이스를 사용하여 정점(vertex) 단위의 검색을 수행한다.
이 설정을 통해, 비구조적(unstructured) 베이스라인들의 검색 엔진을 HopRAG과 정렬(alignment)시켜,
우리의 그래프 구조 인덱스가 얼마나 효과적인지 공정하게(fairly) 보여줄 수 있다.
쿼리 분해(query decomposition)를 위해,
우리는 GPT-4o-mini를 사용하여 하나의 질의를 여러 개의 서브 쿼리로 분해하는데,
각 서브 쿼리는 single-hop 질의여야 한다.
$m$개의 서브 쿼리가 있을 때,
우리는 각 서브 쿼리에 대해 BGE를 이용한 밀집 검색을 수행하여
각 서브 쿼리당 $top_k / m$ 개의 후보를 독립적으로 추출하고,
이 후보들을 모두 결합해 최종 컨텍스트를 구성한다.
재순위화(reranking) 베이스라인에서는
bge-reranker-base를 사용하여
밀집 검색기로부터 얻은 $2 * top_k$ 개의 후보들을 순위화하고,
그중 상위 $top_k$만을 최종 컨텍스트로 유지한다.
구조적(structured) 베이스라인 방법들은
각각의 논문에서 언급된 특정 오픈소스 프로젝트에 의존하여 구현된다.
A.5 프롬프트들 (Prompts)
들어오는(in-coming) 질문들을 생성하는 데 사용된 프롬프트는 그림 4에 제시되어 있다.
나가는(out-coming) 질문들을 생성하는 데 사용된 프롬프트는 그림 5에 제시되어 있다.
추론이 보강된(reasoning-augmented) 그래프 탐색을 위한 프롬프트는 그림 8에 제시되어 있다.
그림 4: 들어오는(in-coming) 질문들을 생성하기 위한 프롬프트.
당신은 질문을 잘 만들고 중국어와 영어에 모두 능숙한 기자이다.
당신의 작업은 뉴스 기사 또는 전기적 텍스트에서 연속된 몇 개의 문장을 기반으로
질문을 생성하는 것이다.
그러나 질문에 대한 답은 반드시 이러한 특정 문장들에서만 나와야 한다.
즉, 당신은 텍스트의 몇 개 문장에서 역으로 질문을 생성해야 한다.당신은 전체 문서가 아니라 몇 개의 문장에만 접근할 수 있다.
이 연속된 문장들에 집중하여, 답이 오직 이 문장들에서만 나오도록
관련된 질문을 만들어야 한다.요구사항:
각 질문에는 특정 뉴스 요소들(시간, 장소, 사람) 또는
모호성을 줄이고 맥락을 명확히 하며
스스로 완결성을 갖추도록 하는 다른 핵심 특성들이 포함되어야 한다.문장의 중요한 부분을 생략하거나 공백을 남기고 질문을 만들 수 있지만,
문장의 같은 부분에 대해 여러 개의 질문을 해서는 안 된다.
문장의 모든 부분에 대해 질문을 만들 필요는 없다.어떤 부분을 생략하는 경우, 생략되지 않은 정보는
문맥적 일관성이 깨지지 않는 한 질문에 포함되어야 한다.서로 다른 질문들은 문장들 안의 서로 다른 측면에 초점을 맞추어야 하며,
다양성과 대표성을 확보해야 한다.모든 질문들은 주어진 문장들의 핵심 내용을 모두 포괄해야 하며,
표현 방식은 표준화되어야 한다.질문은 객관적이고 사실 기반이며 세부 지향적이어야 한다.
예를 들어, 사건이 언제 발생했는지,
주제와 관련된 개인 정보 등은 문장들 안의 정보에서만 답할 수 있도록 해야 한다.어떤 문장의 정보가 이전 질문에서 이미 언급되었다면,
다시 묻지 않아야 한다.
문장의 정보는 반드시 질문들 안에서 모두 다루어져야 하며,
문장이 길다면 모든 정보를 포괄하기 위해 질문 수가 증가해야 한다.
질문 수에는 상한이 없지만, 반복은 피해야 한다.### 문장 리스트 예시
[“그들의 여덟 번째 스튜디오 앨범 "(How to Live) As Ghosts"는 2017년 10월 27일에 발매될 예정이다.”]### 답변 예시
```json
{“Question List”:[“그들의 여덟 번째 앨범 이름은 무엇인가?”,”‘(How to Live) As Ghosts’ 앨범은 언제 발매될 예정인가?”]}
```### 문장 리스트
{sentences}당신의 응답은 불필요한 이스케이프, 줄바꿈, 공백 없이
JSON 형식을 엄격하게 따르도록 해야 한다.
또한 JSON 및 리스트 형식 자체를 제외한
다른 모든 큰따옴표는 작은따옴표로 바꾸어야 한다
(예: “(How to Live) As Ghosts” 대신 ‘(How to Live) As Ghosts’).최종 출력 형식은 다음과 같아야 한다:
```json
{“Question List”:[”<Question 1>”,”<Question 2>”,…..]}
```
그림 5: 나가는(out-coming) 질문을 생성하기 위한 프롬프트.
당신은 통찰력 있는 질문을 만들어내는 능력이 뛰어나고
두 개의 언어에 모두 능숙한 기자이다.
당신의 작업은 뉴스 기사 또는 전기적 텍스트의
연속된 몇 개의 문장을 기반으로 후속 질문(follow-up questions)을 생성하는 것이다.후속 질문이란, 답변이 주어진 문장들 안에는 없지만
문장 이전 또는 이후의 맥락,
동일한 사건을 다루는 다른 문서들,
혹은 주어진 문장 안의 논리적·인과적·시간적 확장에서
추론될 수 있는 질문을 의미한다.당신은 전체 문서가 아니라 몇 개의 문장만 볼 수 있다.
이 연속된 문장들을 읽은 뒤,
해당 문장들 안에 답이 포함되어 있지 않은
관련된 후속 질문을 생성해야 한다.
독자가 이 문장들을 읽고 난 뒤
‘다음에 무엇을 궁금해할까?’를 예측할 수도 있지만,
질문의 답변은 가능한 한 간결해야 하므로
객관적인 질문에 집중하는 것이 좋다.요구사항:
각 질문에는 모호성을 줄이고 자족성을 보장하기 위해
특정 뉴스 요소(시간, 장소, 인물) 또는
기타 중요한 특징들이 포함되어야 한다.서로 다른 후속 질문들은
주어진 문장들이 표현하는 전체 사건의
다양한 객관적 측면에 초점을 맞추어야 하며,
다양성과 대표성을 확보해야 한다.
객관적 질문을 우선시하라.주어진 문장을 기반으로,
인과관계, 병렬성, 순차성, 사건 전개,
연결성 및 기타 논리적 요소들을 포함하는
세부 사항에 대한 질문을 생성하라.
탐구 가능한 영역의 예시는 다음과 같으나 이에 제한되지는 않는다:
사건의 배경, 정보, 이유, 영향, 중요성, 발전 방향,
혹은 관련 인물들의 관점 등.질문은 객관적이고 사실 기반이며
세부 지향적이어야 한다.
예를 들어, 사건이 언제 발생했는지,
혹은 특정 인물의 정보 등을 물을 수 있다.
단, 질문에 대한 답은 주어진 문장들 안에 포함되어 있지 않아야 한다.가능한 한 반복 없이 많은 질문을 생성해야 한다.
단, 질문의 답은 주어진 문장들 안에 나타나면 안 된다.
질문 수에는 상한이 없지만,
질문의 중복은 피해야 한다.### 문장 예시
[“그들의 여덟 번째 스튜디오 앨범 "(How to Live) As Ghosts"는 2017년 10월 27일에 발매될 예정이다.”]### 답변 예시
```json
{“Question List”:[“그들의 여덟 번째 스튜디오 앨범은 누구의 작품인가?”,”‘(How to Live) As Ghosts’ 앨범 제작에는 얼마나 시간이 걸렸는가?”,”이 앨범의 발표는 음악계에 어떤 영향을 미쳤는가?”]}
```### 뉴스 문장 리스트
{sentences}당신의 출력은 불필요한 이스케이프, 줄바꿈, 공백 없이
JSON 형식을 엄격하게 따라야 한다.
또한 JSON 및 리스트 형식 자체를 제외한
텍스트 내의 모든 큰따옴표는 작은따옴표로 바꾸어야 한다
(예: “(How to Live) As Ghosts” → ‘(How to Live) As Ghosts’).최종 출력 형식은 다음과 같아야 한다:
```json
{“Question List”:[“<Question 1>”,”<Question 2>”,”<Question 3>”,…..]}
```
그림 8: 추론이 보강된 그래프 탐색을 위한 프롬프트.
당신은 주어진 주요 질문(main question)에 답해야 하는
질문-응답 로봇이다.
주요 질문은 여러 개의 정보 조각을 포함하며,
추가(auxiliary) 질문도 함께 제공된다.
당신의 임무는 주요 질문에 답하는 것이다.
그러나 주요 질문에는 당신이 모를 수 있는 많은 정보가 포함되므로,
필요하다면 보조 질문(auxiliary question)을 사용하여
필요한 정보를 추론할 기회를 갖게 된다.다만 보조 질문이 항상 유용한 것은 아니므로,
보조 질문과 주요 질문의 관계를 평가하여
그것을 사용할지 말지를 결정해야 한다.보조 질문이 주요 질문에 완전히 무관한지,
간접적으로 관련 있는지,
혹은 주요 질문을 답하는 데 필수적인지를
판단해야 하며,
세 결과 중 하나만 선택하여 답해야 한다.주요 질문을 구성하는 문장들은
여러 배경 정보 문장을 포함하고,
주요 질문에 답하기 위해서는
다양한 정보 결합과 추론 과정이 필요하다.
그러나 어떤 문장들이 실제로 필요한지
당신은 알지 못한다.
당신의 임무는
주어진 보조 질문이
주요 질문을 답하는 데 필요한지,
간접적으로만 도움이 되는지,
혹은 완전히 무관한지 평가하는 것이다.결과 1: [완전히 무관]
보조 질문이 없어도 주요 질문에 답할 수 있거나,
보조 질문 안의 정보가 주요 질문의 답과
전혀 관계가 없다고 판단되는 경우이다.결과 2: [간접적으로 관련 있음]
보조 질문이 주요 질문과 비슷한 주제를 다루지만,
주요 질문을 답하는 데 필요한 핵심 정보는 제공하지 않는 경우이다.
즉, 보조 질문은 관련된 주제를 다루지만
주요 질문을 해결하는 데 직접적 기여를 하지 않는다.결과 3: [관련 있고 필수적임]
보조 질문이 주요 질문의 하위 질문 역할을 하며
주요 질문을 해결하는 데 반드시 필요한 정보를 제공하는 경우이다.
보조 질문을 사용하지 않으면
주요 질문에 답할 수 없다면
이 범주에 속한다.예시 1 — 완전히 무관한 경우:
주요 질문: “뉴잉글랜드 레볼루션에서 레프트백으로 뛰는 Donnie Smith는
22개 팀으로 구성된 어떤 리그에 속하는가?”
보조 질문: “대통령의 연두교서(State of the Union) 연설의 목적은 무엇인가?”
→ 보조 질문이 주요 질문과 전혀 관계없음.
→ 응답 형식: ```json { “Decision”:”Completely Irrelevant” } ```예시 2 — 간접적으로 관련 있는 경우:
주요 질문: 동일
보조 질문: “이 리그가 해당 지역의 세컨드 팀들에게 어떤 중요성을 갖는가?”
→ 유사한 주제를 다루지만,
주요 질문(어느 리그에 속하는가)을 해결하는 데
직접적인 정보를 주지 않음.
→ 응답 형식: ```json { “Decision”:”Indirectly Relevant” } ```예시 3 — 관련 있고 필수적인 경우:
주요 질문: 동일
보조 질문: “Donnie Smith는 어떤 리그에서 뛰는가?”
→ 보조 질문이 주요 질문의 핵심 하위 질문이며
주요 질문을 해결하는 데 필수적임.
→ 응답 형식: ```json { “Decision”:”Relevant and Necessary” } ```당신의 응답은 불필요한 이스케이프, 줄바꿈, 공백 없이
JSON 형식을 엄격하게 따라야 한다.
또한 JSON 및 리스트 형식을 제외한
모든 큰따옴표는 작은따옴표로 바꾸어야 한다.
예: “(How to Live) As Ghosts” → ‘(How to Live) As Ghosts’최종 출력 형식은 다음과 같다:
```json
{“Decision”:”<Completely Irrelevant | Indirectly Relevant | Relevant and Necessary>”}
```주요 질문, 보조 질문 입력 형식은 다음과 같다:
Main Question: {query}
Auxiliary Question: {question}
A.6 사례 연구 (Case Study)
우리는 그림 7(a)에서 그래프 구조를, 그림 6(a)에서 두 개의 정점을 가진 하나의 예시 간선을 보여준다.
그림 6: 그래프 구조에서의 탐색 시연
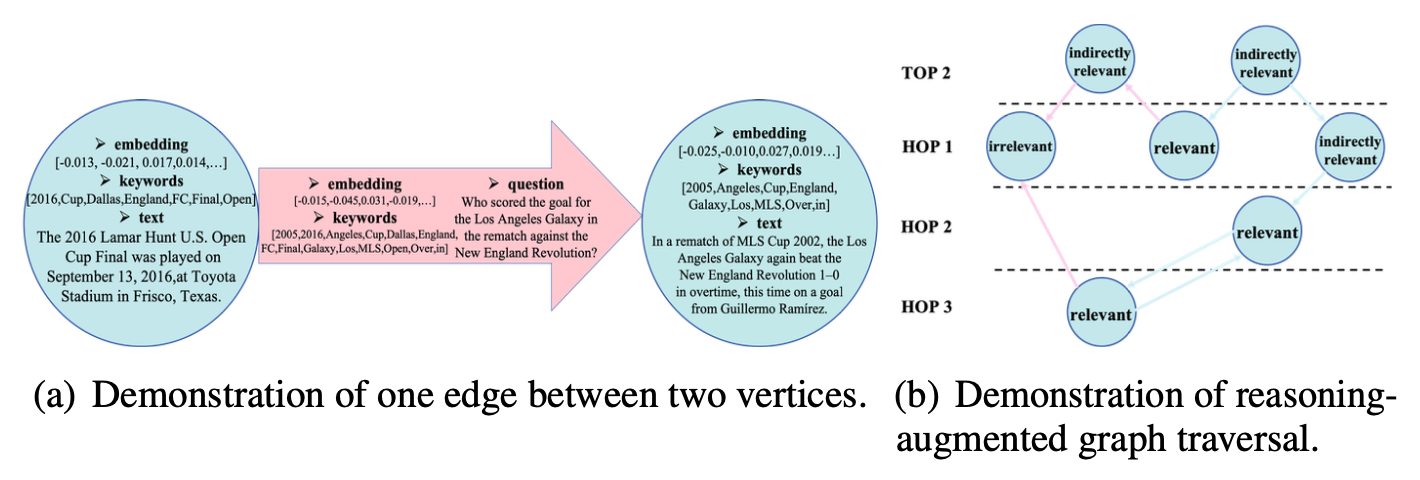
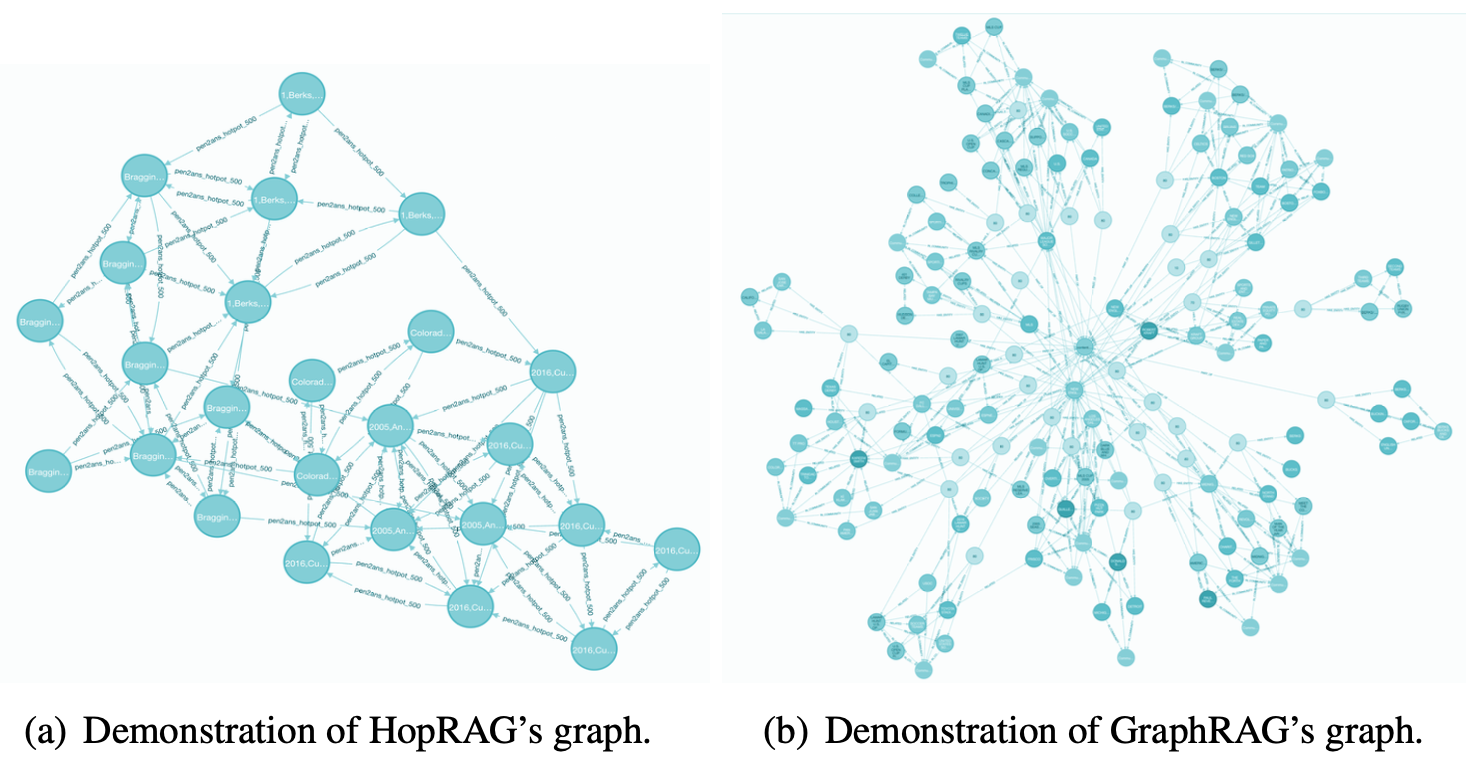
그림 7: HopRAG와 GraphRAG의 시각화
쿼리
“Donnie Smith who plays as a left back for New England Revolution belongs to what league featuring 22 teams?”
(뉴잉글랜드 레볼루션에서 레프트 백으로 뛰는 Donnie Smith는 22개 팀으로 구성된 어떤 리그에 속하는가?)
를 예시로 사용하여 우리는 질적 분석을 수행한다.
이 멀티-홉 질문(정답: Major League Soccer)에 대해, HotpotQA 코퍼스는 세 개의 관련 문장을 포함한다:
(1) “Donald W. Donnie Smith (born December 7, 1990 in Detroit, Michigan) is an American soccer player who plays as a left back for New England Revolution in Major League Soccer.”;
(2) “Major League Soccer (MLS) is a men’s professional soccer league, sanctioned by U.S. Soccer, that represents the sport’s highest level in both the United States and Canada.”;
(3) “The league comprises 22 teams in the U.S. and 3 in Canada.”
밀집 검색기(BGE)를 사용하면 첫 번째 문장은 쉽게 검색할 수 있지만,
뒤의 두 사실은 $top_k$가 30이어도 문맥에서 검색될 수 없다.
그러나 우리의 그래프-구조 인덱스에서는,
이 세 정점이 논리적으로 연결되어 있으며,
이는 Figure 6(b)에 제시되어 있다.
탐색 동안, LLM은 의미적으로 유사하지만 간접적으로 관련된 정점들에서 시작하여
최대 3홉(hop) 이내에 모든 supporting facts에 도달할 수 있다.
이 질의와 그 문단들을 시연(demonstration)에 사용하여,
우리는 HopRAG의 그래프 인덱스와 GraphRAG을 시각화하여
독자들이 그 차이점과 혁신성을 파악하도록 한다.
그림 7에 나타난 바와 같이, HopRAG과 GraphRAG의 주요 차이는 다음과 같다.
정점(vertices)
GraphRAG은 텍스트 청크의 정보를 요약하기 위해 LLM을 사용한 다음,
그래프 안에 추가 정점들(예: 사건, 조직, 사람)을 생성한다.
반면 HopRAG은 원본 청크를 정점에 직접 저장하며,
이로 인해 요약 과정에서의 LLM 환각(hallucination),
엔티티 추출 과정에서의 정보 손실,
불필요하게 밀집된 그래프 구조(중복된 정점들로 인한)를 방지한다.간선(edges)
GraphRAG은 “부분(part of)” 또는 “관련됨(related)” 같은
사전에 정의된 관계로 정점들을 연결한다.
반면 HopRAG은 간선에 in-coming 질문들과 그 키워드 및 임베딩을 유연하게 저장하여,
이들이 추론-증강 그래프 탐색(reasoning-augmented graph traversal)을 안내할 뿐 아니라
간선 검색(edge retrieval)도 용이하게 한다.인덱스(index)
GraphRAG은 LLM 요약본을 위한 임베딩을 생성하고 저장하는 반면,
HopRAG은 정점과 간선 모두에 대해 희소 및 밀집 인덱스를 생성한다.
이 인덱스는 더 정밀하고 효율적인 정보 검색을 가능하게 한다.
요약하면, HopRAG의 그래프 구조는
추가 정점을 생성하지 않고도 논리적 관계를 발굴할 수 있을 뿐 아니라,
추론 기반 지식 검색(reasoning-driven knowledge retrieval)의 길을 열어 준다.
A.7 검색 효율성(Retrieval Efficiency)
우리는 검색 효율성에 대한 보다 포괄적인 분석을 보완하고,
추가적인 속도 향상을 위한 최적화 전략들을 함께 제시한다.
HopRAG의 검색에서의 주요 지연은
검색-증강 그래프 탐색 동안의 LLM 추론 시간에서 발생한다.
로컬에 배포된 Qwen2.5-1.5B-Instruct를
탐색 모델로 사용하는 HopRAG이 경쟁력 있는 성능을 보여주므로,
우리는 이 시나리오에서의 검색 효율성에 초점을 맞춘다.
우리의 주요 실험에서 사용된 하이퍼파라미터
$n_{\text{hop}} = 4$ 및 $top_k = 20$에 따르면,
각 질문은 LLM을 38.53회 호출해야 한다.
각 LLM 호출은 평균 5.87개의 간선(edge) 중 하나를 선택하며,
약 500개의 입력 토큰, 20개의 출력 토큰을 가진다.
(Qwen Development Team, 2025)에 따르면,
Qwen2.5-1.5B-Instruct의 출력 토큰 속도는
BF16 및 Transformer를 사용할 때 약 40.86 tokens/s이다.
따라서 각 질문에 대해 LLM 추론으로 인해 발생하는
추가 지연 시간은 다음과 같다:
그러나 검색 효율성을 향상시키기 위한 많은 최적화 전략들이 존재한다.
vLLM 및 GPTQ-Int4 기법을 사용하면
각 질문의 추가 지연 시간은 다음과 같이 줄어든다:
게다가, 멀티스레딩과 같은 병렬성 기법은
모든 질의에 대한 총 실행 시간을 더욱 감소시킬 수 있다.
A.8 $n_{\text{hop}}$에 대한 논의(Discussion Results on $n_{\text{hop}}$)
논의에서 우리는 하이퍼파라미터 $n_{\text{hop}}$이 1에서 4까지 변함에 따라,
답변 성능(answer performance)과 검색 성능(retrieval performance)이 함께 증가하며,
탐색 동안 LLM을 호출하는 비용 역시 증가한다는 것을 확인한다.
다섯 번째 hop에서의 평균 큐 길이가 단지 1.23에 불과하므로,
우리는 4가 이상적인 $n_{\text{hop}}$라고 믿는다.
전체 결과는 표 8에 제시되어 있다.
표 8: 우리는 GPT-3.5-turbo와 상위 20개의 문단들을 사용하여
하이퍼파라미터 $n_{\text{hop}}$이 HopRAG에 미치는 영향을 시험한다.
$n_{\text{hop}}$을 1에서 4까지 변화시키며 답변(answer) 메트릭과 검색(retrieval) 메트릭을 모두 보고한다.
답변 메트릭의 경우, answer EM과 F1 점수를 보고한다.
검색 메트릭의 경우, F1 점수와 함께 탐색(traversal) 중 LLM 호출 평균 횟수를 보고하여
비용(cost)을 측정한다 (낮을수록 더 좋다).
최고 점수는 굵게 표시되며, 두 번째로 좋은 점수는 밑줄로 표시된다.
