[확률과 통계] 12주차
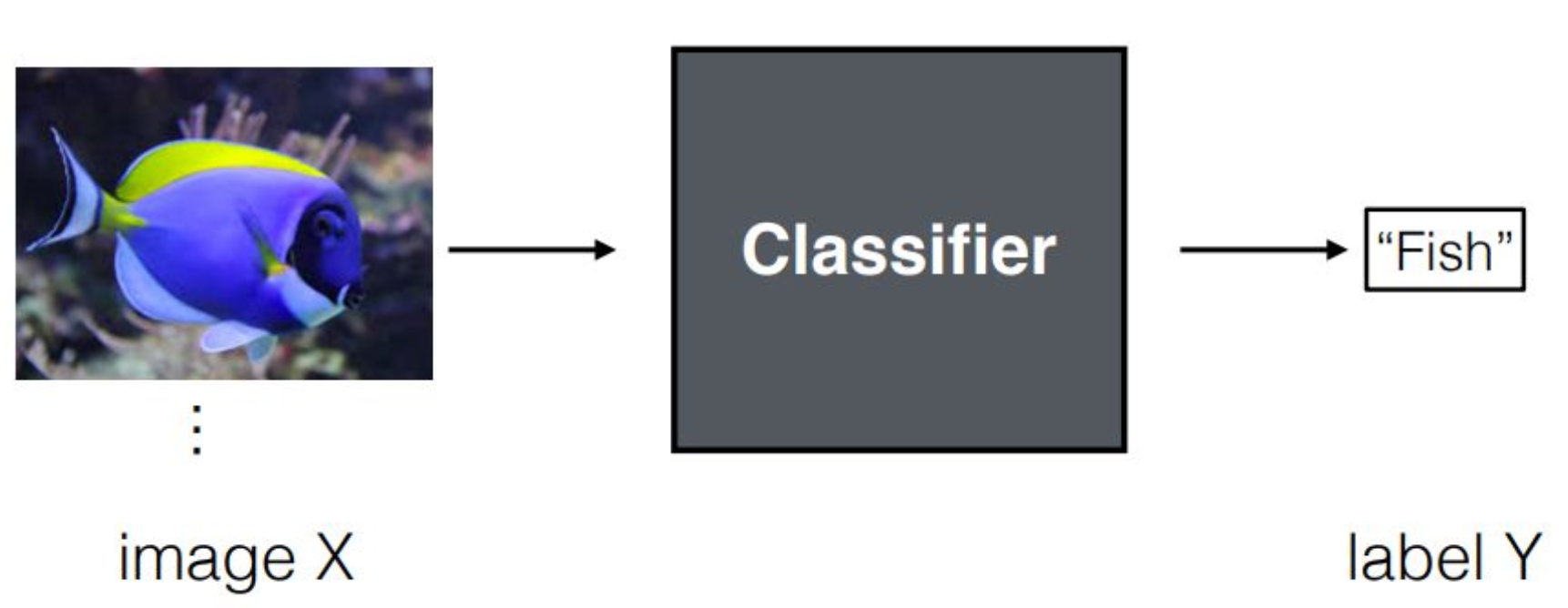
p2. Review : Image Classification
강의 내용
오늘은 GAN을 공부할 예정인데, 그 전에 간단히 리뷰를 해보겠습니다.
이미지 분류(image classification)는
2D 또는 3D 형태의 이미지가 입력으로 들어왔을 때
classifier가 이를 처리하여 최종적으로 레이블을 출력하는 모델을 의미합니다.classifier 역할을 하는 뉴럴 네트워크는
입력 이미지를 컨볼루셔널 연산 등을 통해 처리한 뒤
해당 이미지가 어떤 레이블에 속하는지를 평가하게 됩니다.출력되는 레이블은 경우에 따라
언어 토큰이 될 수도 있고,
전통적인 분류 모델에서는 보통 원핫 벡터 형태로 표현되기도 합니다.예를 들어 클래스가 1,000개라면
1,000차원 벡터 중 특정 클래스의 위치만 1이고
나머지는 모두 0인 원핫 벡터를 사용하여
분류 결과를 표현하게 됩니다.
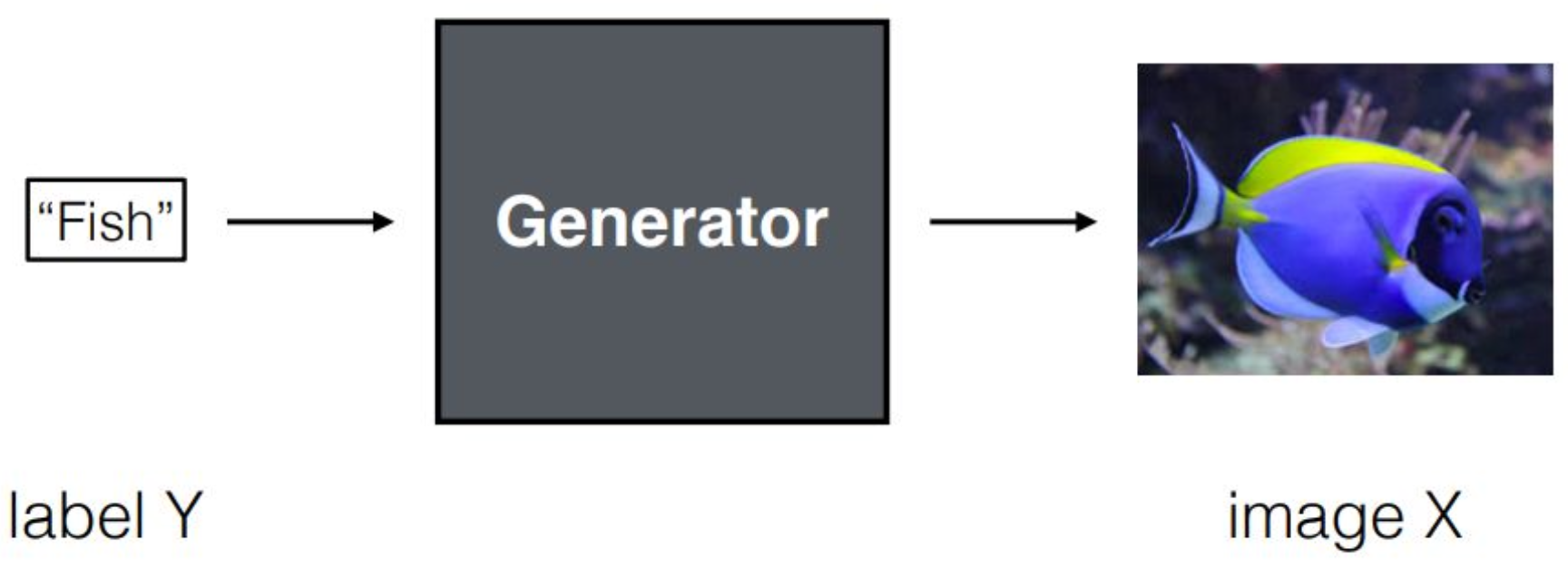
p3. Review : Image Generation
강의 내용
그렇다면 이미지 제너레이션이란 무엇인가를 생각해봅시다.
이전 시간에 VAE를 통해 기본적인 형태의 생성 모델을 경험했지만,
그건 조건이 없는 unconditional 생성이었습니다.VAE에서는 가우시안 랜덤 베리어블을 입력으로 두고
디코더를 통해 이미지를 생성하는 것이 목적이었죠.여기서는 그보다 한 단계 더 나아가
conditional한 이미지 생성 상황을 고려해봅니다.예를 들어 “Fish”라는 언어 토큰 또는 원핫 벡터가 주어졌을 때,
제너레이터는 그 레이블 정보를 활용하여
해당되는 이미지를 생성해야 합니다.생성 모델, 특히 멀티모달 생성 모델은
이미지 분류(classification) 과정을
역방향으로 수행하는 것이라고 이해하시면 됩니다.여기서 중요한 요소는 뉴럴 네트워크 구조입니다.
classifier는
큰 이미지를 convolution layer를 거치며 점차 줄어드는
intermediate feature map으로 변환해
최종적으로 레이블을 출력하는 구조를 갖습니다.VAE의 구조를 자세히 보면 알 수 있듯이
디코더는 이를 역순으로 실행하는 형태를 띱니다.즉, 디코더는
레이블 정보나 레이턴트 벡터를 입력받아
작은 표현을 점차 확대해 나가며
최종적으로 원래 이미지 해상도와 형태를 재구성하도록 설계되어 있습니다.이러한 구조적 차이 때문에
classification과 generation의 역할이 구분되며
제너레이터 아키텍처가 지금과 같은 형태로 발전하게 된 것입니다.이런 역사적·구조적 맥락을 이해하면
생성 모델 아키텍처가 왜 현재의 형태를 띠는지
자연스럽게 이해할 수 있을 것입니다.
p4. Review : Image Generation
고차원 미관측 변수들(high-dimensional unobserved variables)의 모델 $P(\mathbf{X} \mid \mathbf{Y} = y)$
무작위 이미지를 샘플링하는 것 이상의 많은 문제들에 유용하다!
강의 내용
이미지 제너레이션에서는
고차원에서 관측되지 않은 변수 $X$에 대해
주어진 조건 $Y$에 따른 확률 밀도, 즉 conditional probability를 찾는 것이 핵심입니다.여기서 large $Y$는 랜덤 변수이고
small $y$는 그 랜덤 변수의 특정한 결정적 값이라고 이해할 수 있습니다.예를 들어 레이블이 “fish”로 주어졌을 때,
그 조건 $y$에 맞는 데이터 $X$를 생성하려는 것이죠.이를 확률적으로 어떻게 모델링할 것인가가
이미지 생성 모델, 더 나아가 conditional 생성 모델의
핵심 철학이라고 볼 수 있습니다.따라서 $P(X \mid Y)$를 학습한다는 관점에서,
VAE와 동일하게 maximum likelihood estimation을 수행하게 됩니다.$P$에 로그를 취하고
이를 $\theta$라는 파라미터로 parameterization하여
$\log p_\theta$를
최적화를 통해 학습시키는 것,이것이 이미지 생성 모델의 기본적인 목표라고 정리할 수 있습니다.
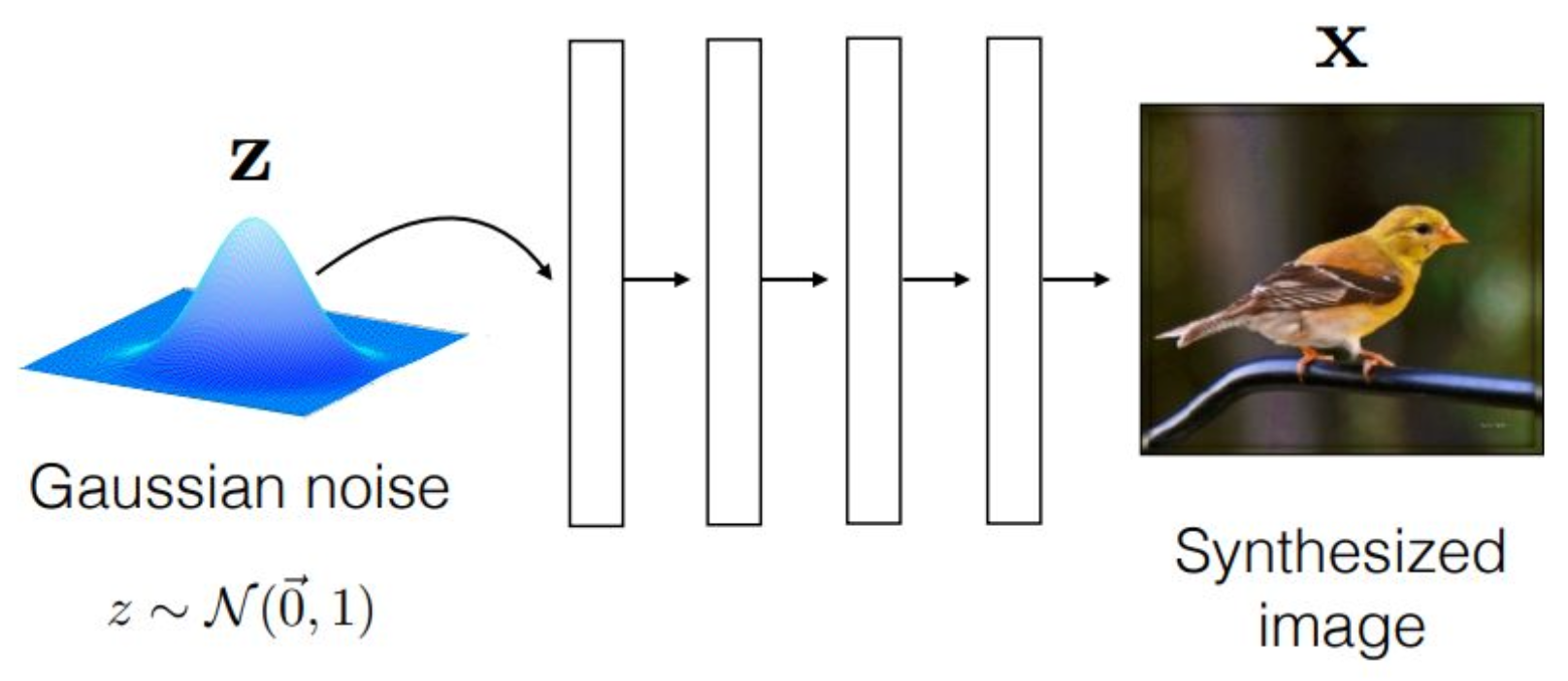
p5. Review : Generative Model
강의 내용
이 내용은 추상적인 레벨에서 생성 모델을 설명한 것이고,
생성 모델이라는 것이 조건부 정보들을
어떻게 처리하는가에 대한 큰 관점을 이야기한 것입니다.다시 돌아가서,
지난번 VAE 설명이 다소 수식 중심으로 바로 들어가
충분한 맥락 없이 진행된 면이 있었기 때문에
오늘은 그 부분을 조금 더 설명하려고 합니다.Generative 모델이라는 것은
기본적으로 다음과 같은 과정을 수행합니다.우선 $z$라는 random variable이 존재합니다.
이는 평균이 $0$, 분산이 $1$인 Gaussian noise를 가정합니다.하얀색 박스로 cascade하게 표현된 구조는
뉴럴 네트워크 레이어들을 여러 번 통과하며
정보가 순차적으로 변환된다는 의미이며,
최종적으로 $x$라는 이미지를 생성하게 됩니다.즉 $z$를 넣었을 때 $x$가 생성되는 부분,
이 부분이 바로 VAE에서 디코더 역할이었습니다.반면 인코더는
이미지를 입력받아 $z$라는 random variable space로
projection하는 역할을 했습니다.그래서 정확하게 말하면,
VAE 자체는 생성 모델이 아닙니다.VAE는 생성 모델을 감싸고 있는
하나의 큰 학습 파이프라인이자 방법론입니다.VAE 내부에서
‘생성 모델’이라고 부를 수 있는 부분은
디코더뿐입니다.이 개념적 차이를 이해하고 계시면
이후의 흐름을 잡는 데 큰 도움이 됩니다.
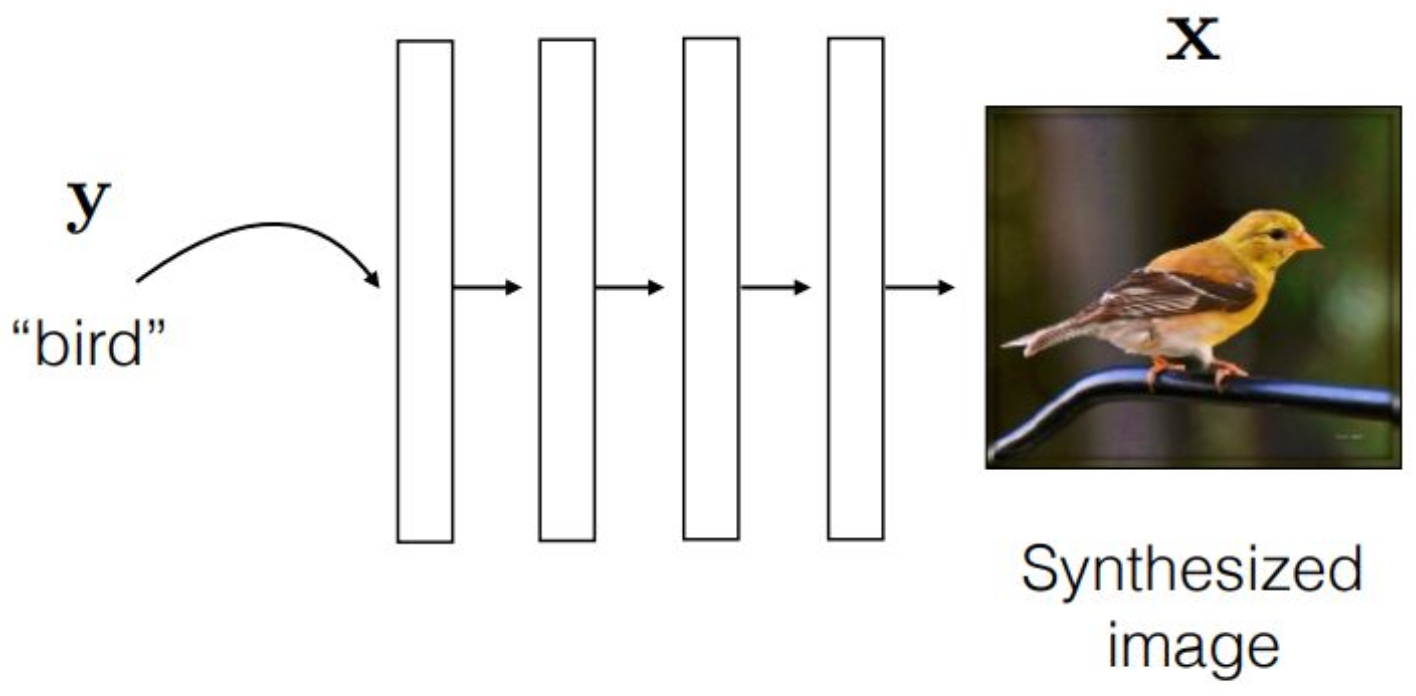
p6. Review : Conditional Generative Model
강의 내용
이 디코더 파이프라인을 기준으로
conditional generative 모델을 생각해 보면,unconditional한 인포메이션이
conditional한 bird라는 레이턴트 인포메이션으로 변하게 되고
뉴럴 네트워크를 통해 이미지가 생성되는 구조임을 알 수 있습니다.이 말은 곧,
conditional VAE 같은 경우를 생각해 보면
(우리가 실제로 conditional VAE를 다루진 않았지만)
VAE를 conditional하게 확장하는 것은 어렵지 않다는 뜻입니다.앞에서 봤던 $z$라는 random variable을
디코더 스트럭처에 넣어 이미지를 생성했었는데,
이제는 $(z, y)$라는 추가적인 정보를 함께 넣어
모델링하면 됩니다.그래서 이 파이프라인을 보면,
VAE를 포함해
Generative Adversarial Network,
뒤에 배울 디퓨전 모델 등
모든 생성 모델들이
conditional한 인포메이션을
어떻게 다루는지를 관통하는 철학을 확인할 수 있습니다.요약하자면,
$z$라는 unconditional한 랜덤성을 부여하고
여기에 $y$라는 추가 정보를 넣어
시맨틱을 더한다는 구조입니다.앞에서 언급했듯,
여기 PPT에서 말하는 $y$는
bird 같은 원핫 벡터 형태의 레이블을
의미하는 것으로 보입니다.
p7. Review : Conditional Generative Model
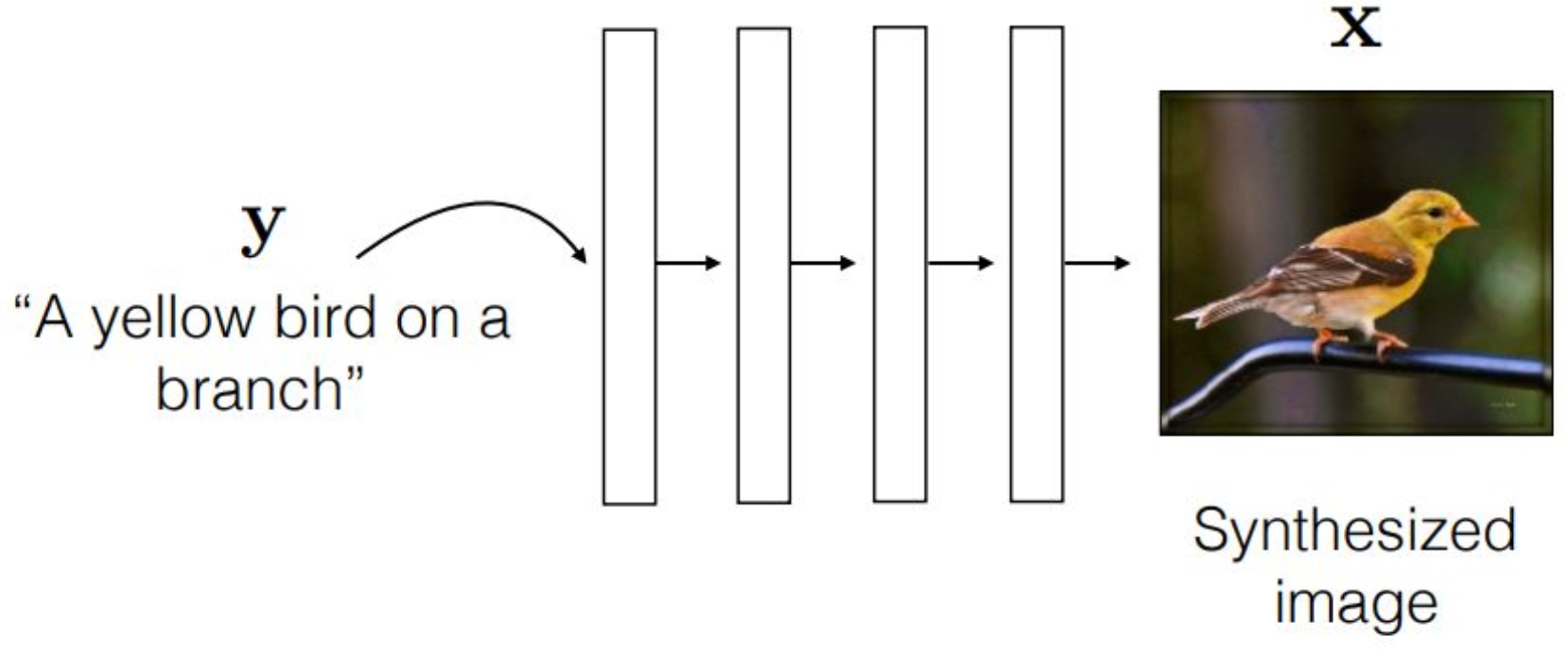
강의 내용
여기에서는 더 정밀한 묘사를 할 수 있습니다.
오브젝트의 종류를 표현할 때,
예를 들어 새, 자동차, 고양이 등을 구분하려면
원핫 벡터가 적절해 보입니다.하지만 ‘새’라는 레이블보다
더 구체적으로 어떤 종류의 새인지까지
묘사해야 할 때는
$y$라는 conditional이
랭귀지 토큰, 즉 문장 형태로 표현되는 것이
중요한 발전이라고 볼 수 있습니다.이런 류의 생성 모델은
우리가 일상적으로 사용하는 것들이기도 합니다.사실 구조적으로만 보면 굉장히 단순합니다.
다만, 잘 발달된 인프라 스트럭처 위에서
대규모 데이터를 넣고
수많은 샘플을 한꺼번에 처리할 수 있는
코어 컴퓨팅, 클라우드 컴퓨팅,
전력 관리, 큐잉, MLops 같은 요소들이
실제로는 핵심입니다.학습 방법론 자체는
GAN, VAE, 디퓨전 모델 모두
철학적으로는 동일한 방향을 가지고 있습니다.이것을 얼마나 스케일러블하게 확장해
프로덕트 단계로 연결할 수 있느냐가
실제 어려운 문제이지,
이론적인 철학 자체는 크게 다르지 않습니다.그래서 이렇게만 보면 너무 쉽지만,
정작 어려운 부분은 엔지니어링에 있습니다.
이론적 파트가 핵심이 아니라는 뜻입니다.이 페이지는
랭귀지 토큰을 이용해
컨디셔닝을 한다고 가정한 경우를
설명하고 있습니다.
p8. Review : Conditional Generative Model
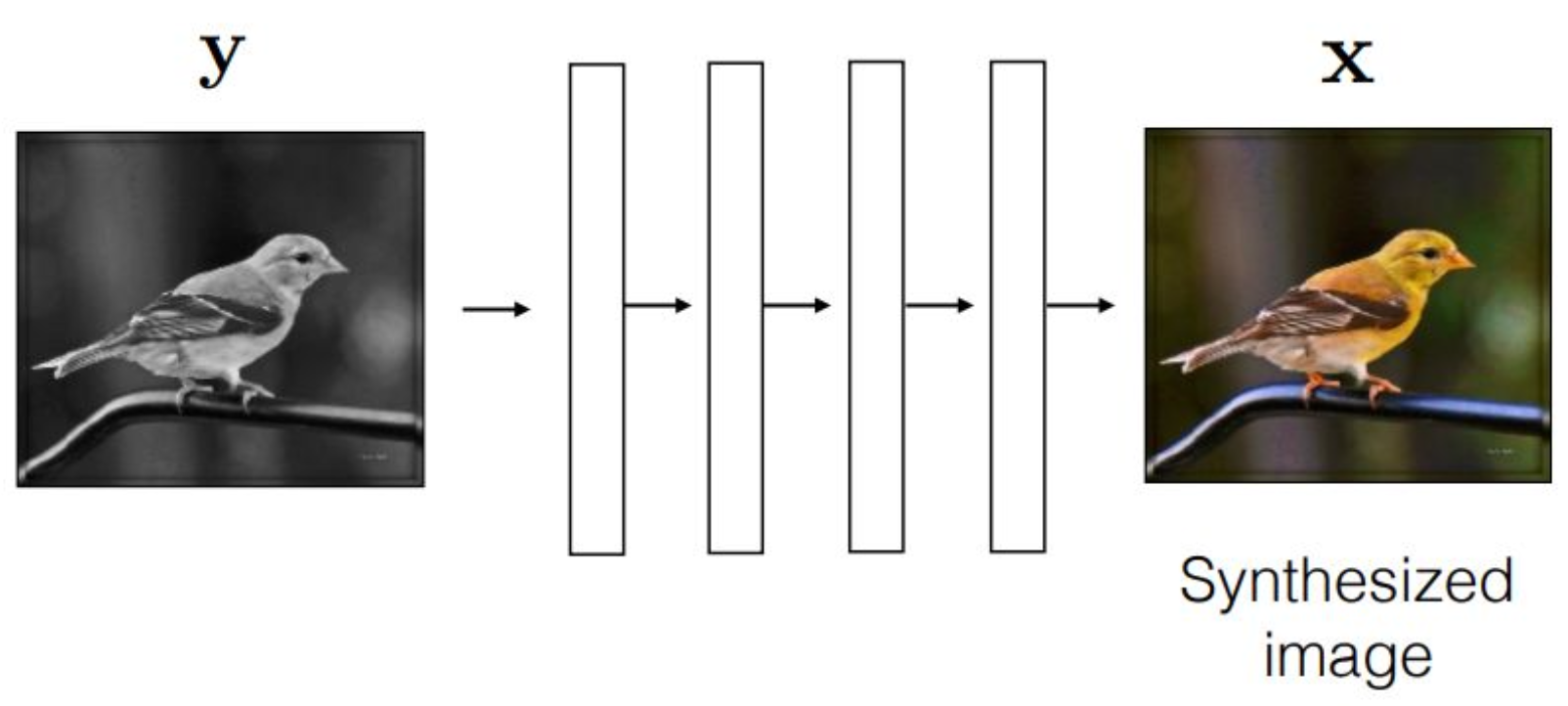
강의 내용
이런 것도 생각해 볼 수 있습니다.
$y$라는 흑백 이미지가 있고,이것은 어떻게 만들었을까요?
오른쪽의 원본 노란색 새 사진을
decolorization, 즉 색 제거 알고리즘을 통해
흑백으로 변환한 것입니다.
이는 deterministic한 알고리즘이 존재해
색 정보를 제거할 수 있습니다.이렇게 색을 제거한 pair를 만들어 놓고
이를 학습시키는 방식입니다.그러면 이 모델의 목적은 무엇일까요?
Colorization, 즉
색이 없는 이미지를 입력하면
색깔이 있는 이미지를 출력하도록 만드는 것입니다.예를 들어,
옛날 필름 시대의 영화나 영상처럼
흑백으로 되어 있는 자료를
AI가 자동으로 colorization 하는 사례들이 많이 있습니다.그런 AI 모델들은
방대한 수의 데이터셋 pair를 이용해
대규모 인프라에서 학습된 결과물이라고 보면 됩니다.결국 $y$와 $x$에 대해
어떤 방식으로 컨디셔닝을 하느냐는
생성 모델이 어떤 목적을 가지고 있고
어떤 테스트 시나리오에서 사용될 것이냐에 따라 달라집니다.생성 모델을 어떻게 훈련해
어디에 적용할 것인가가
곧 컨디셔닝을 어떻게 구성하느냐와 같은 의미입니다.이러한 컨디셔닝을 준비하는 방법은
여러 가지가 존재합니다.
p9. Data Preparation in Conditional Generation

강의 내용
생성 모델의 초창기에는 이런 작업을 굉장히 많이 했습니다.
첫 번째는 Object Labeling입니다.
이런 페어링, 즉 conditional 페어링을 만드는 방식을 많이 사용했습니다.여러분들이 Segmentation에 대해 들어보셨을 텐데요.
예를 들어 사람 이미지를 입력하면
머리는 머리, 팔은 팔처럼 구역을 나누어주는 Segmentation 모델이 있습니다.최근에는 기술이 더 발전해서
이미지를 주면 자동으로 색칠을 해주거나
어떤 영역이 어떤 object인지 표현해주는 기능들이 포함되어 있습니다.삼성 카메라 같은 것을 보면
이미지에서 특정 영역을 선택하면
그 부분을 다른 물체로 채워주거나 제거해주는 기능이 있죠.
그것을 위해서는 흔히 누끼라고 부르는 절단 작업이 필요하고
그 기본에는 Segmentation이 들어갑니다.그래서 많은 초기 생성 모델에는
Segmentation을 기반으로 한 구조가 포함되어 있었고
이 Segmentation 결과를 조건으로 입력해
새로운 이미지를 생성하는 방식이 사용되었습니다.예를 들어,
말 타는 원본 이미지가 있을 때
Object Labeling 알고리즘을 통해
우측의 마스크를 생성합니다.
이렇게 데이터 페어를 만든 뒤 훈련을 진행합니다.그리고 Inference 단계에서는
마스크(Label)를 입력하면
왼쪽의 실제 이미지를 생성하게 되는 구조입니다.이 말 사진뿐 아니라
강아지, 사람 등 다양한 object 형태에서
동일한 방식으로 학습시킬 수 있습니다.우리가 흔히 상상하는 기능도 이런 맥락입니다.
예를 들어 사람이 손으로 말 모양이나 고양이 모양을 대충 그리고
그 모양에 맞는 진짜 이미지를 생성해내는 기능,
이것이 요즘 나오는 생성 모델들—예를 들어 나노바나나 등—에
모두 들어가 있는 능력입니다.지브리풍 변환 같은 것도
사실 이런 조건부 합성의 한 버전으로 이해할 수 있습니다.이처럼 Object Label을 이용해
데이터와 conditional 페어를 만드는 방법이 있었고,두 번째 방법은 Edge Detection입니다.
Edge Detection은 매우 오래된, 고전적이지만 강력한
컨디셔닝 방법론 중 하나입니다.왼쪽에 복잡한 동물이나 자연물 이미지가 있다고 합시다.
여기에 Edge Filter를 적용하면
오른쪽처럼 윤곽만 남게 됩니다.이렇게 만든 pair로 학습을 진행한 다음
Inference 때는 어떻게 될까요?
오른쪽처럼 윤곽(엣지)만 그려주면
모델이 그 안을 자동으로 채워
실제 이미지를 생성해 주는 방식입니다.이것은 앞서 이야기한 object segmentation 기반 생성과
매우 유사한 철학을 갖습니다.세 번째는 텍스트-투-포토이고,
이 부분은 앞에서 이미 설명했습니다.또 하나 매우 중요한 conditional 모델은
비디오 생성입니다.비디오 생성 모델의 철학은 매우 단순합니다.
바로 이전 프레임을 컨디션으로 사용해
다음 프레임을 생성하는 것입니다.
즉, 바로 직전 프레임이 조건 $y$이고
다음 프레임이 생성해야 할 $x$가 되는 구조입니다.이 생성 과정을 여러 번 concatenation 하면
처음 주어진 이미지로부터
시간 순서대로 전체 비디오가 생성됩니다.이것은 비디오 생성 모델의 핵심적인 철학을 보여주며
파이프라인만 놓고 보면
사실 앞에서 소개한 conditional 생성과 동일한 구조입니다.물론 실제 비디오 생성에는
매우 복잡한 엔지니어링이 대거 필요합니다만
철학적 구조는 크게 다르지 않습니다.이러한 방식으로 다양한 형태의
conditional generation을 수행할 수 있습니다.
p10. Challenges?
출력은 고차원(high-dimensional)이며, 구조화된 객체(structured object)이다.
매핑(mapping)에 불확실성이 존재하며, 가능한 출력들이 많다.
강의 내용
이제 그러면, 이런 제너러티브 모델의 문제가 무엇이냐?
라고 하면 여러 가지가 있지만,가장 근본적인 문제 중 하나는
이 매핑에서 발생하는
one-to-one 매핑과
one-to-many 매핑의 문제입니다.이게 무슨 뜻이냐면,
예를 들어 $z$라는 레이턴트 변수가 있고,
어떤 conditional 페어가 주어졌다고 합시다.그런데 매번 생성할 때
똑같은 이미지만 나온다면
그건 생성 모델을 쓰는 의미가 없겠죠.유저는 같은 레이블을 주더라도
생성할 때마다 조금씩 다른 컨텐츠가 나오고
그 결과가 충분히 만족스러운 퀄리티를 가져야 합니다.즉,
컨디션은 동일한데
가능한 아웃풋은 여러 개여야 한다는 것,
이것이 바로 one-to-many correspondence입니다.따라서 conditional 생성 모델의 중요한 특성 중 하나는
반드시 one-to-many correspondence를 유지해야 한다는 점입니다.그래서 생성 모델은
probabilistic한 관점을 채택합니다.
랜덤성을 모델에 포함시켜서
매번 새로운 이미지를 만들 수 있도록 하는 것이죠.이런 철학을 기반으로
conditional generative modeling을 이해할 수 있을 것입니다.
p11. Property of Generative Models?
고차원적이고 구조화된 출력을 모델링한다.
불확실성을 모델링한다; 가능한 출력들의 전체 분포를 모델링한다.
p12. Image-to-Image Translation
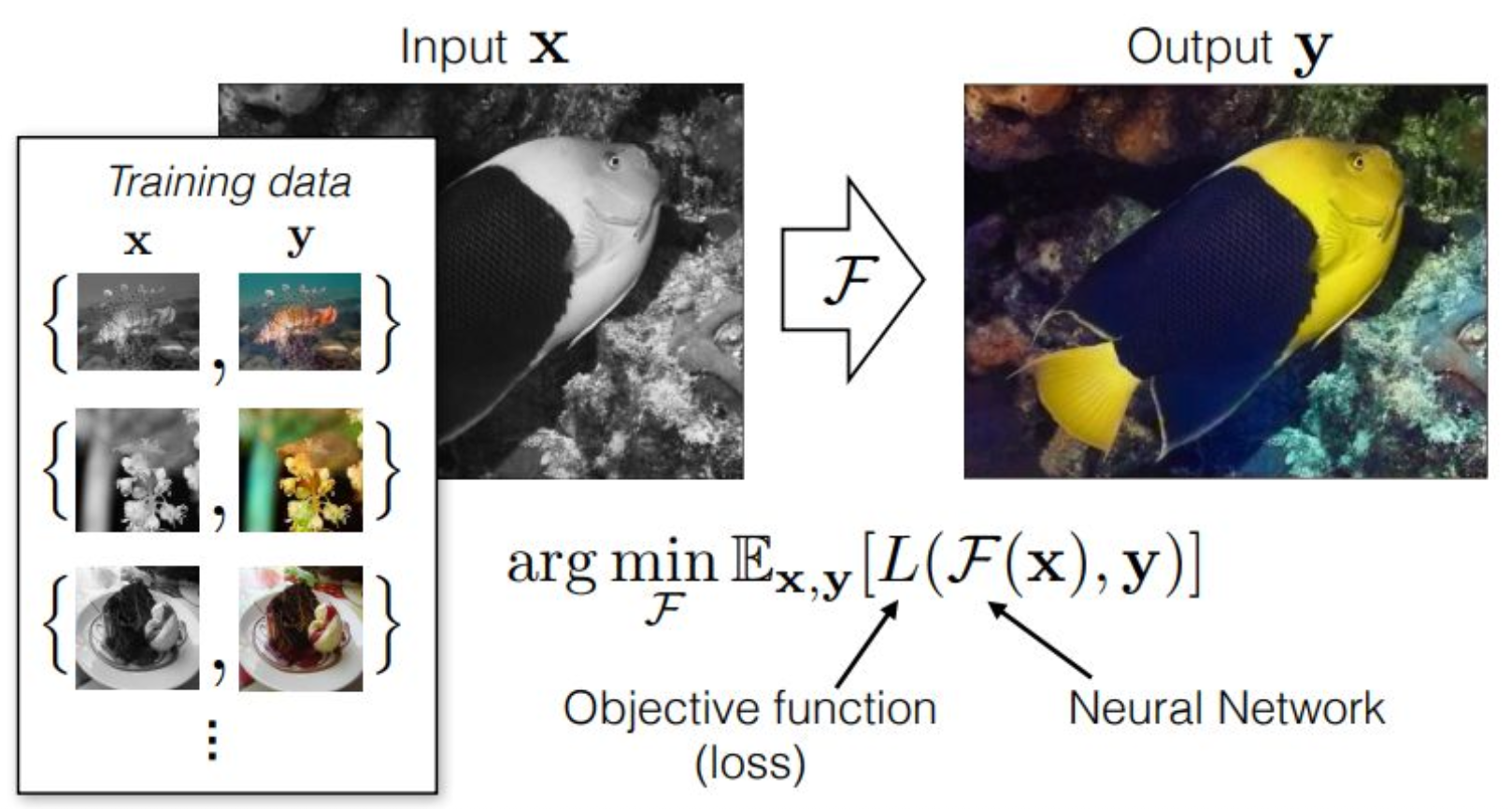
강의 내용
그래서 이제
전통적인 관점의 Image-to-Image Translation을 한 번 생각해봅시다.앞에서 제가 pair를 만든다고 말씀드렸죠.
이것을 단순히 Generative Model의 관점이 아니라,
혹은 Generative Model이라고 하더라도
좀 더 제너럴한 형태로,
수학적인 공식을 통해 문제를 정의하고 싶다는 겁니다.Training Data는
black, 즉 decolorized된 이미지와
color가 있는 이미지를
$x, y$ pair로 구성하게 됩니다.그러면 우리가 목표로 하는 바는 무엇이냐 하면,
Image-to-Image Translation에서는
다음과 같은 수학적 목표식을 설정하게 됩니다.$F$는 neural network를 의미하고,
$L$은 objective function을 의미합니다.neural network $F$가 입력 $X$를 통과시키고,
그 출력과 정답 $Y$의 차이를
$L$을 통해 measure한 뒤,
그 기대값을 최소화하는
그런 function, 즉 neural network를 찾는 것이
Image-to-Image Translation의 목표입니다.
p13. Image-to-Image Translation
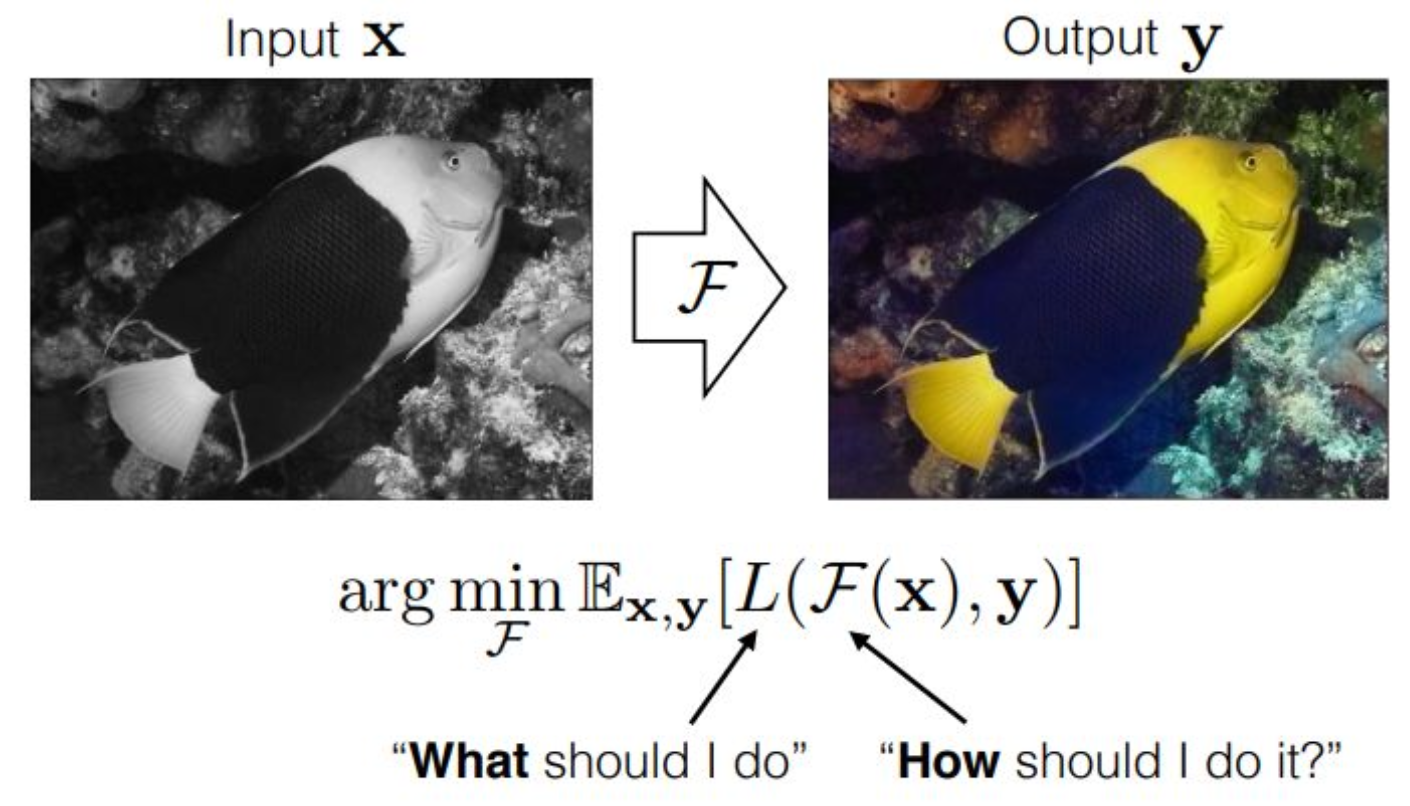
강의 내용
조금 더 관점적으로 해석을 해보자면,
$F$라는 것은
우리가 $x$를 어떻게 $y$로 만들 것이냐,
즉 How should I do it?
이 질문에 대한 방식을 묘사하는 것이라고 볼 수 있습니다.반면에 $L$이라는 것은
방법은 알겠는데,
우리가 무엇을 줄여야 하느냐,
어떤 기준으로 줄여야 하느냐에 대한
질문에 대응하는 요소라고 보시면 될 것 같습니다.그래서 $F$라는 neural network를 통과한 output이 만들어지면,
$L$은
예를 들어 $L2$ distance 같은 것을 사용한다면,
$x$가 $y’$로 매핑되었을 때
true $y$와의 거리를 줄이는 방향으로 학습시키고,
그렇게 해서 color가 생성되도록 만드는 것입니다.
p14. Image-to-Image Translation : Objective Function
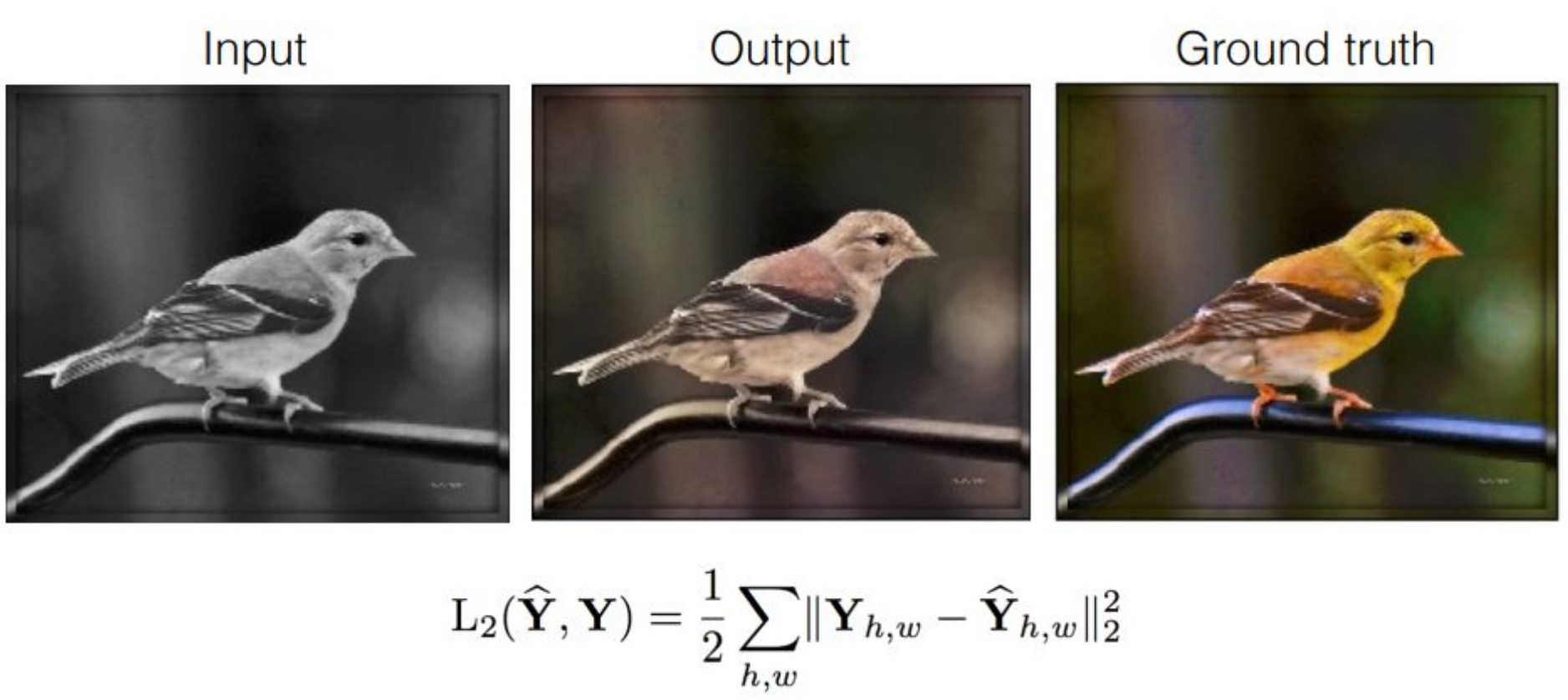
강의 내용
여러 가지 Loss Function을 고려해 볼 수 있는데,
여기에서는 $L2$라는 Euclidean Distance를 고려했을 때의
결과물을 생각해 볼 수 있을 것 같습니다.
그리고 이것이 최적이라는 뜻은 아니고,
이런 식의 출력이 많이 관찰되는 일반적인 형태라는 의미입니다.Neural Network을 잘 설계하면
Output이 ground truth와 비슷하게 나올 수도 있지만,
보통은 Neural Network의 크기를 키워도
이런 output regime에 빠지게 됩니다
(즉, 모델이 특정한 출력 방식 또는 출력 패턴에 갇히는 현상).$Y’$라는 target이 존재하고,
$Y$는 Neural Network가 만들어 내는 것이라고 해봅시다.$h$와 $w$는 이미지의 X축, Y축 위치를 뜻하는 좌표이고,
이 수식이 설명하는 바는
각각의 픽셀 단위로 $L2$ distance를 구하고
이를 제곱하여 모두 더하는 과정입니다.그러면 두 이미지가 얼마나 다른지
픽셀 공간에서 정량적으로 표현할 수 있게 되겠죠.Input을 넣고 Neural Network를 통과했을 때
Output이 가운데 그림처럼 나오고,
ground truth는 오른쪽 그림처럼 나온다고 가정해 봅시다.이 Output은 노란색이 아니므로
결과가 제대로 생성되지 않았다고 볼 수 있습니다.이처럼 $L2$ loss 기반으로
deterministic하게 생성 모델적 성질 없이 학습되는 모델들은
색의 차이가 크게 발생하고,
pixel space 위에서 optimization이 잘 되지 않는 문제가 발생합니다.colorization 방법론에서
생성 모델을 많이 사용하는 이유도
바로 이러한 문제가 있기 때문입니다.앞에서는 conditional 항에 대한 예제를 설명드렸으니,
이제 실제로 deep neural network를 사용해
이러한 문제를 어떻게 학습시키는지
이어서 살펴보도록 하겠습니다.
p15. Image-to-Image Translation : Objective Function
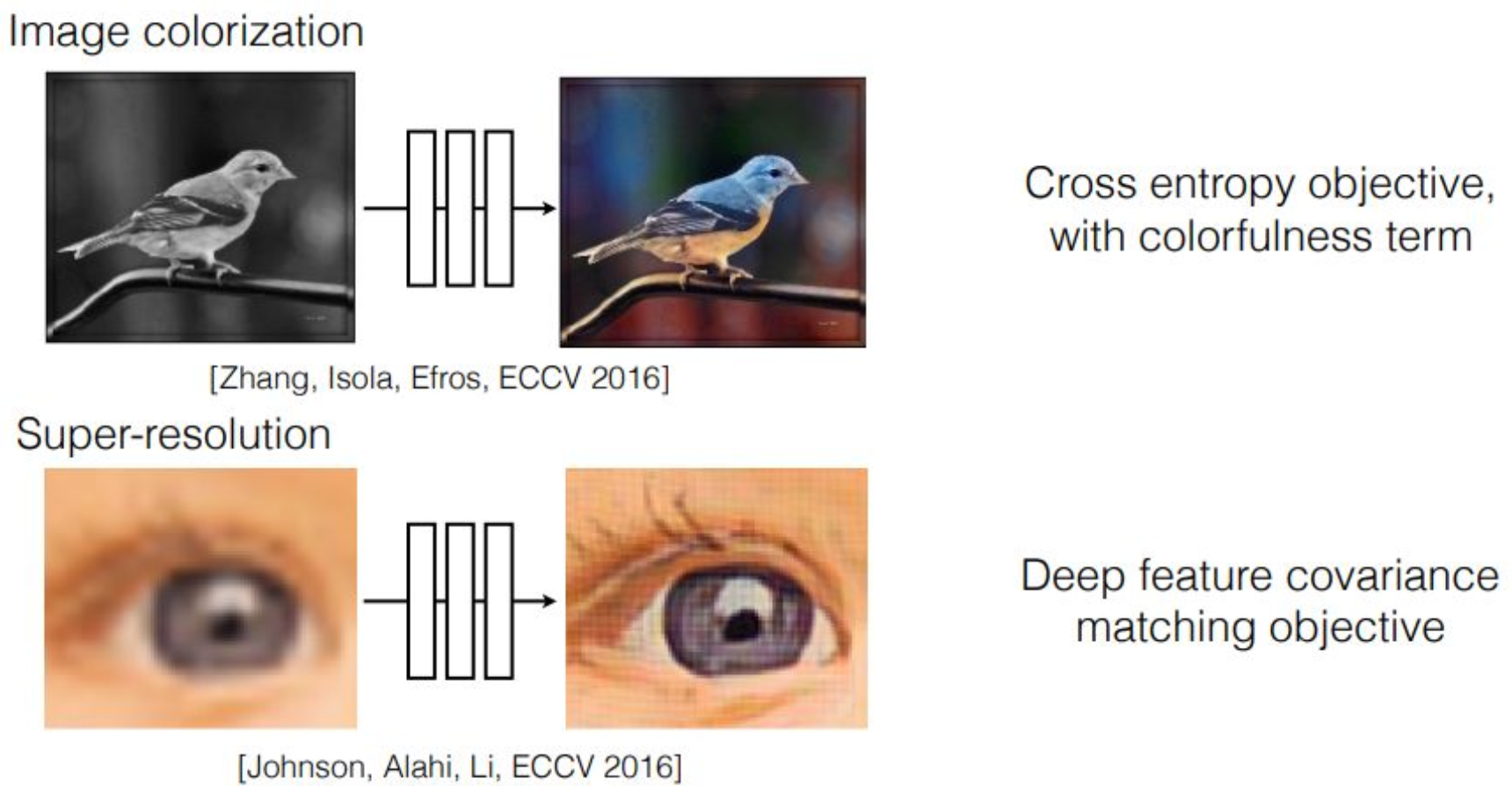
강의 내용
이렇게 페어링을 만드는 작업 중에는
Colorization, 즉 컬러를 채우는 경우가 있고,
Super Resolution이라는 중요한 컴퓨터 비전 task도 있습니다.conditioning을 줄 때,
해상도가 낮아진 이미지를
해상도가 높은 이미지로 변환해야 한다는 것은
결국 부족한 정보를 채워 넣는 과정입니다.이러한 종류의 문제는
image-to-image translation에서 매우 흔히 등장하며,
생성 모델들이 이 task를 잘 수행하기 때문에
실제로 많은 경우 생성 모델을 사용해 해결합니다.제가 요즘 예로 자주 드는 Nano Banana 모델도 마찬가지인데,
유명한 교수님이 Nano Banana 모델을 이용해
super resolution 실험을 해본 적이 있습니다.화질이 좋지 않은 카메라로 촬영된 이미지를 입력한 뒤
“super resolution을 해줘”라고 요청하면,전광판의 글자처럼
흐릿해서 잘 보이지 않는 요소들에 대해
모델이 새로운 정보를 만들어내어
보다 선명한 이미지를 생성합니다.이러한 생성 모델들은
모두 이와 같은 image-to-image translation 프레임워크 안에서
해석할 수 있다고 보시면 됩니다
(특히 컴퓨터 비전 관점에서 바라볼 때).물론 생성 모델은 컴퓨터 비전 외 다양한 분야에 사용되지만,
이미지 예제를 기준으로 보면
이런 식의 활용을 자연스럽게 떠올릴 수 있습니다.
p16. Motivation : GANs
강의 내용
그렇다면 지금까지의 내용이 GAN과 어떤 연관이 있는가,
생성 모델과 어떤 관계가 있는가를 생각해 보면,
사실 직접적인 연결은 다소 약했습니다.이는 여러분이 전체 문맥을 충분히 접하지 못했기 때문에
그 배경을 설명하기 위해 앞의 내용을 다룬 것입니다.오늘 우리의 목표는 무엇이었느냐 하면,
바로 Generative Adversarial Network(GAN)를 정의하는 것이었습니다.이제 본격적으로 GAN이라는 생성 모델을 정의해 보겠습니다.
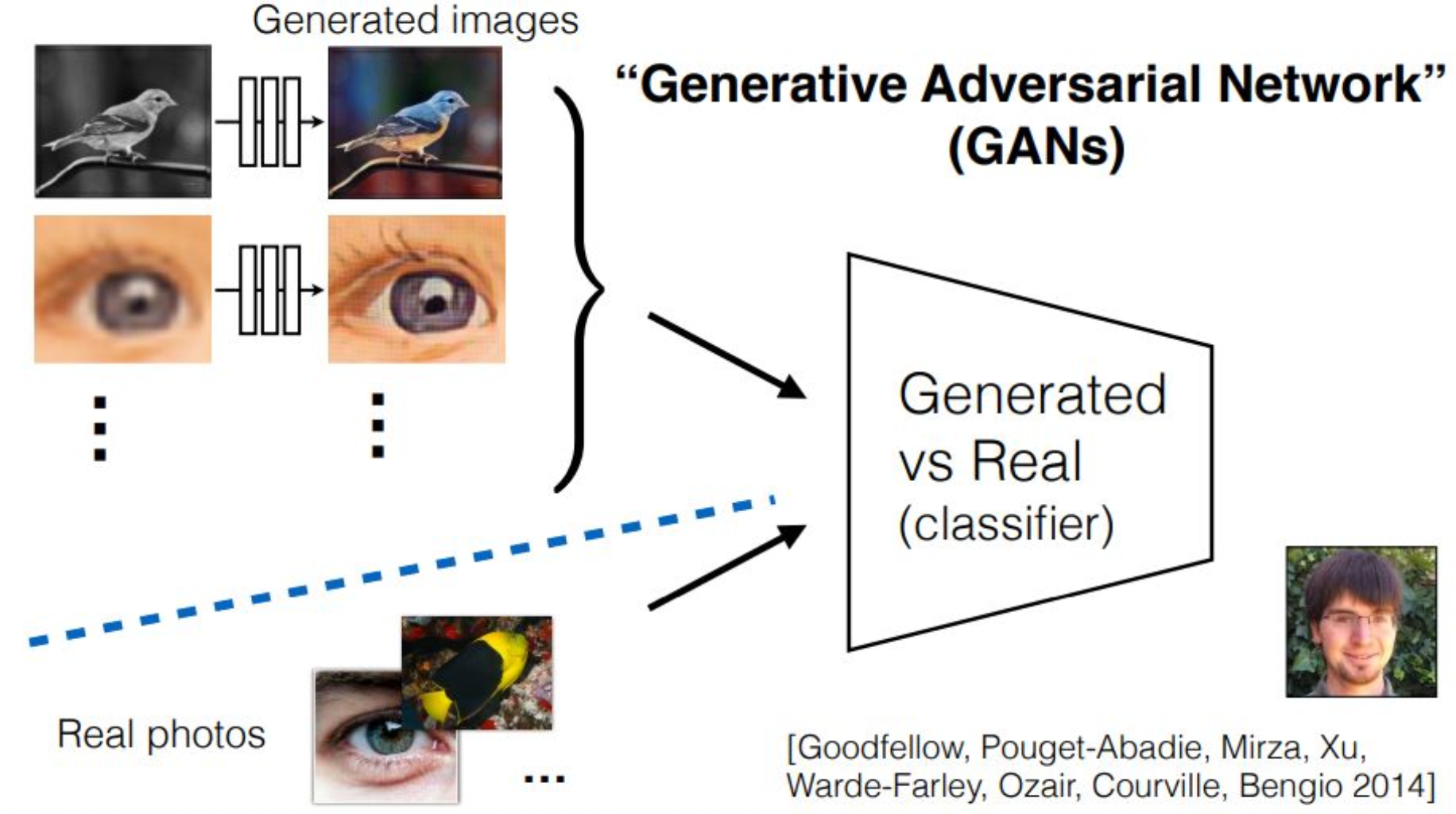
왼쪽 그림을 보면
y라는 페어와 x라는 페어가 존재하고
우리는 이러한 페어들을 모두 생성할 수 있다고 했습니다.이렇게 만들어진 페어링을 생성된 데이터라고 한다면
이에 대응되는 실제 이미지(real photos)를
별도로 준비해 둡니다.왼쪽의 경우
x에서 y로 가는 명확한 가이드라인이 존재하고
이를 하나의 세트로 볼 수 있습니다.하지만 이것은 어디까지나 one-to-one correspondence이고
앞에서 설명했듯이
생성 모델은 이런 구조와는 성격이 다릅니다.단순한 알고리즘으로 학습을 진행하게 되면
동일한 블랙 이미지가 입력될 때마다
항상 같은 색의 정보 분포를 가진
동일한 이미지만 출력될 것입니다.그러나 우리는 그런 결과를 원하지 않기 때문에
단순히 페어링만 학습하는 것이 아니라
전체 데이터셋 기준에서
real photos와 generated photos를 비교하게 됩니다.개념적으로는 다소 복잡하지만
뒤에서 수학적으로 조금 더 정리해 보겠습니다.결론적으로 Generative Adversarial Network(GAN)란
가짜 이미지들의 집합과
진짜 이미지들의 집합을
서로 구별하려는 classifier(판별기, discriminator)가 포함된
생성 모델이라고 이해할 수 있습니다.GAN은 2014년에 Ian Goodfellow가 제안한 모델이며
한동안 생성 모델의 흐름을 강하게 주도했던
중요한 모델 중 하나였습니다.
p17. Actor-critic Perspective
강의 내용
이제 조금 더 깊게 들어가서
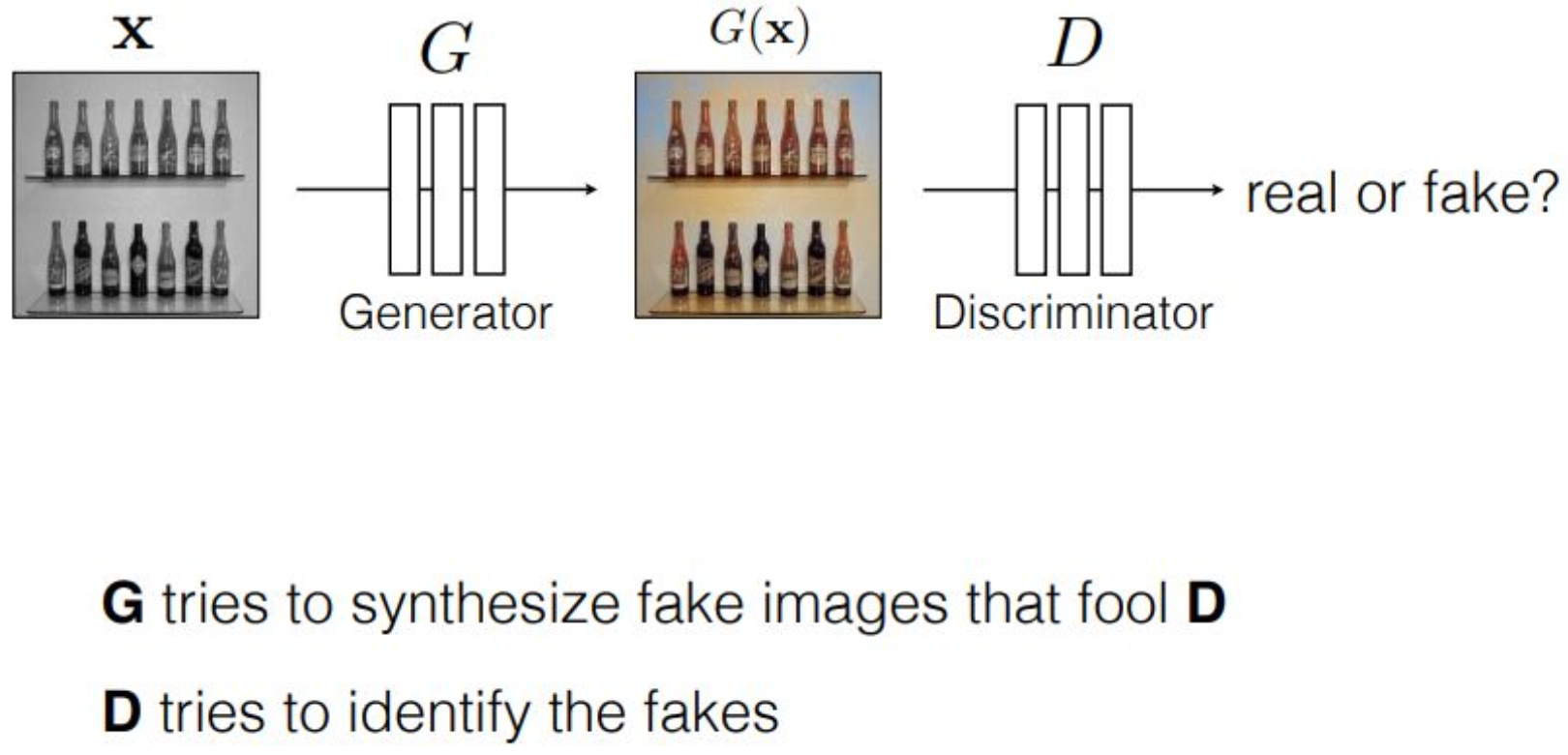
GAN이라는 모델이 실제로 어떻게 작동하는지 생각해 보겠습니다.먼저 x라는 이미지 또는 어떤 조건(condition)이
G라는 generator 신경망에 입력됩니다.generator의 목적은
새로운 이미지를 생성하는 것입니다.
그래서 generator는 G(x)라는 출력 이미지를 만들어 내고,
그 뒤에는 또 하나의 신경망이 존재합니다.바로 discriminator,
혹은 critic이라고도 불리는 신경망입니다.이 신경망의 역할은
generator가 만든 데이터가
진짜 이미지인지 가짜 이미지인지
판별하는 것입니다.만약 generator가 만들어 낸 이미지가
discriminator 입장에서 보기에는
가짜라고 판단된다면,
discriminator는 generator에게
일종의 벌, 즉 negative signal을 전달합니다.generator는 이러한 negative signal을
더 이상 받지 않도록
discriminator를 속일 수 있는
더 그럴듯한 이미지를 만들어야 합니다.이렇게 generator와 discriminator는
생성된 이미지 G(x)를
공통의 자원으로 삼아
서로 반대 목표를 가지고 경쟁하게 됩니다.수학적으로는 이것을
min-max 게임, 또는 zero-sum 게임이라고 합니다.예를 들어 게임이론에서 자주 등장하는
죄수의 딜레마와 같은 시나리오처럼,
GAN에서도 두 신경망이
서로의 입장을 고려하며
최적의 전략을 찾아가는 구조를 갖습니다.아래 영어 표현에서 보듯이,
G는 D를 속일 수 있는 가짜 이미지를 생성하는 것이 목표이고,
D는 그 이미지가 진짜인지 가짜인지
정확히 구별하는 것이 목표입니다.흔히 드는 예로,
범죄 조직이 위조지폐를 만들면
경찰이 그것을 판별하기 위해 검사하는 과정이 있습니다.
이 관계가 generator와 discriminator의 관계와 유사합니다.이렇게 보면
actor-critic 관점에서도
두 모델이 서로 상반된 목표를 가지며
경쟁적으로 학습되는 구조임을 확인할 수 있습니다.흥미로운 점은
GAN 구조를 VAE 관점에서 보면
일종의 뒤집힌 형태라는 것입니다.원래 VAE에서는
인코더가 데이터를 입력받아 latent variable을 출력하고,
디코더가 latent variable을 입력받아 이미지를 출력합니다.그런데 GAN에서는
generator가 latent variable을 입력받아 이미지를 출력하므로
VAE의 디코더와 역할이 비슷합니다.또한 discriminator는
데이터를 입력받아
어떤 latent-like representation을 출력하므로
VAE의 인코더와 유사한 구조처럼 보입니다.즉, 인코더와 디코더가
서로 뒤집혀 연결된 형태라고 이해할 수 있습니다.
p18. Role of discriminator : critic
강의 내용
이제 discriminator의 목적과 훈련 방식을
조금 더 정제된 형태로 설명해 보겠습니다.먼저 위의 구조를 떠올려 봅시다.
generator가 존재하고,
generator가 생성한 데이터인
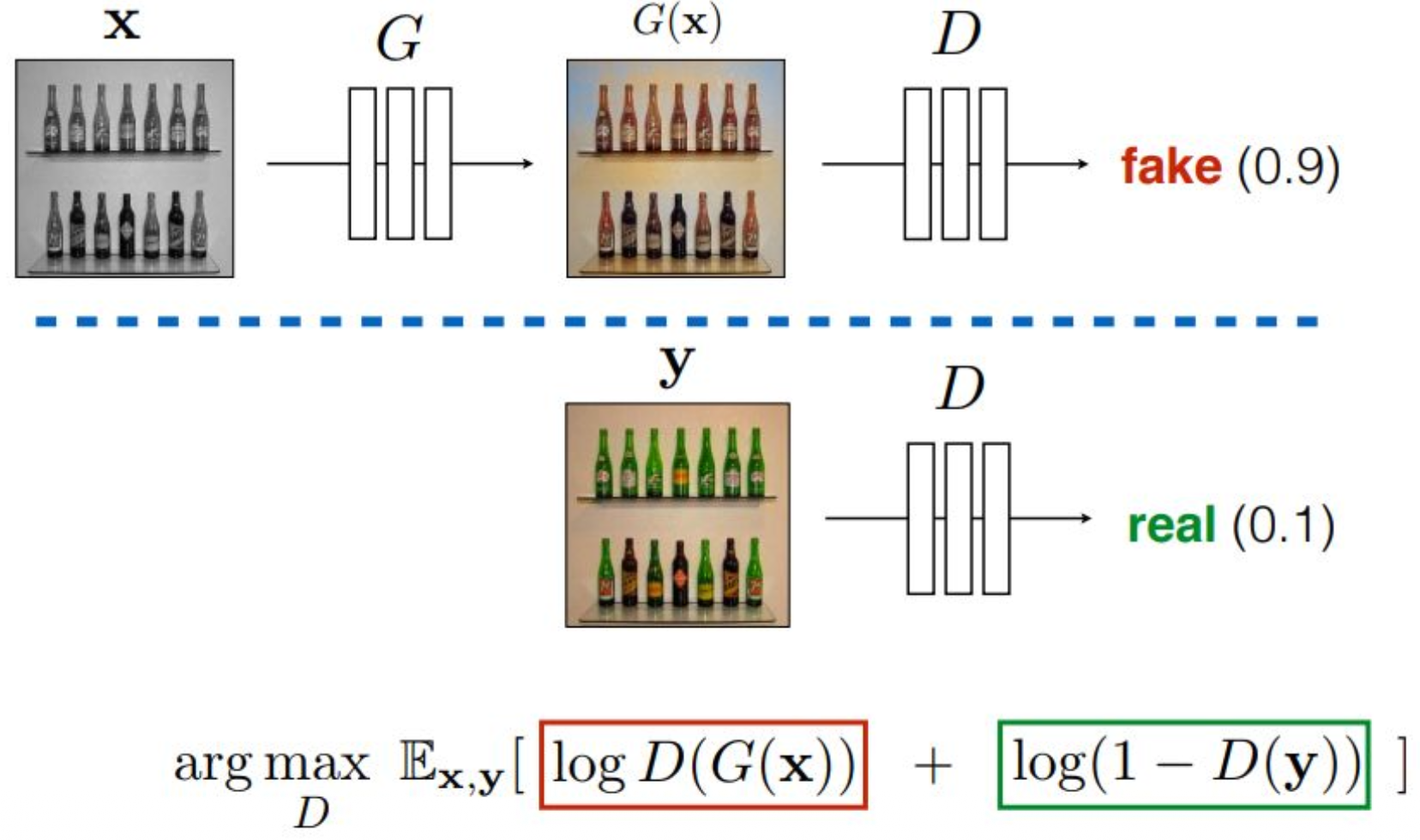
G(x)를 discriminator에 입력합니다.아래와 같은 objective function을 고려한다고 가정하면,
discriminator의 출력이 클수록
해당 입력을 fake라고 판단하는 것이고,
discriminator의 출력이 작을수록
real이라고 판단하는 것입니다.그러므로 discriminator 입장에서는
fake 이미지가 들어왔을 때
자신의 출력값을 크게 만들도록 학습해야 하고,
real 이미지가 들어왔을 때는
출력값을 0에 가깝게 만들도록 학습해야 합니다.예를 들어, 아래 표현에서
1 - D(y)를 maximizing하는 것은
D(y)를 최대한 작게 만드는 효과를 갖습니다.
이는 real 데이터에 대한 discriminator의 목표입니다.반면, G(x)를 D에 넣어
maximizing log D(G(x))을 하게 되면
discriminator의 출력이 최대한 커지도록
(즉 fake를 확실히 fake라고 구분하도록)
학습됩니다.이 두 가지 목표를 동시에 만족시키는
discriminator의 파라미터 θ를 찾는 것이 훈련의 목적입니다.그런데 이러한 학습 방식은
고전적인 머신러닝 알고리즘에서는 보기 드문 형태입니다.이유는 매우 간단합니다.
최적화가 굉장히 불안정하기 때문입니다.학습을 진행하다 보면
종종 수렴되지 않고
발산하는 현상이 나타날 수 있습니다.discriminator와 generator의 표현력이나
파라미터 규모의 균형이 조금만 깨져도
학습이 망가지는 경우가 많습니다.GAN이 잘 학습되기만 하면
훈련 후에는 discriminator를 버리고
generator에 입력을 넣기만 하면
바로 이미지를 생성할 수 있습니다.하지만 학습 과정은 매우 까다롭습니다.
예를 들어 log D(⋅) 형태의 loss는
미분 시 문제가 발생할 수 있습니다.log x의 도함수는 1/x인데,
x가 0에 가까워지면 기울기가 폭발적으로 커집니다.즉 gradient explosion이
아주 쉽게 발생하는 구조라는 뜻입니다.이런 문제 때문에
이 objective function을
그대로 사용하는 것이 쉽지 않습니다.그러나 본질적인 목적만 요약하면,
discriminator는 다음을 학습합니다.
- real 이미지는 real이라고 판단하기
- fake 이미지는 fake라고 판단하기
즉 discriminator는
real에 대한 기준점을 먼저 학습해야
fake를 구분할 수 있습니다.그래서 real을 얼마나 잘 학습하는지가
매우 중요한 요소가 됩니다.
p19. Role of generator : actor
강의 내용
이제 actor인 generator의 역할을
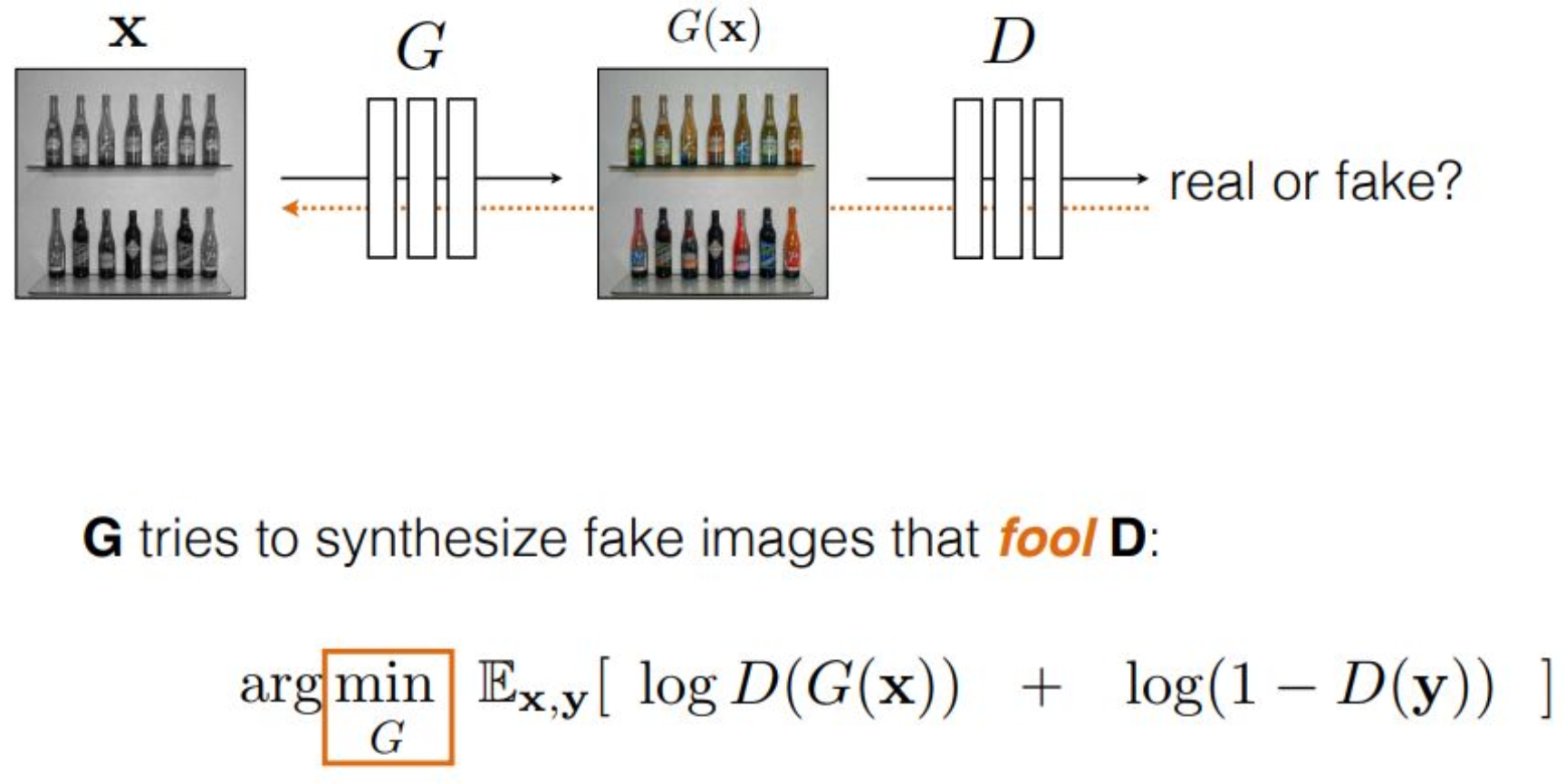
조금 더 정제된 형태로 설명해 보겠습니다.앞에서 object function은
discriminator에 대해 argmax를 취해
fake일 때 출력이 커지고,
real일 때 출력이 작아지도록
discriminator가 학습된다고 했습니다.그렇다면 generator는
이와 반대 방향으로 학습을 하면 됩니다.즉, fake 샘플을 real처럼 보이도록 속이고,
real 샘플이 fake처럼 보이게 속이는 것이 아니라
(real 샘플 영역에는 G가 개입할 수 없으므로),
generator가 할 수 있는 유일한 개입 지점,
즉 자신이 만들어 낸 샘플에 대한 부분만 속이는 것입니다.다시 말해,
object function 안에서
generator가 영향을 줄 수 있는 항은
첫 번째 term뿐입니다.generator는 자신이 생성한 데이터를
discriminator에게 전달하기 전에
최대한 real처럼 보이도록 만들어야 합니다.그렇게 잘 속이면
discriminator는 혼란을 느끼게 됩니다.원래라면 fake 데이터가 들어오면
출력값이 크게 올라가야 하는데,
generator가 속이기에 성공하면
discriminator의 출력이 낮아지게 되고,discriminator는
“내가 배운 기준에서는 이게 fake인데
왜 real처럼 보이지?”
와 같은 교란 상태가 됩니다.그래서 generator가 discriminator를
fool한다고 표현하는 것입니다.흥미로운 점은,
generator와 discriminator가 사용하는
objective function의 모양은 동일하다는 것입니다.차이는 단 하나,
discriminator는 argmax를 취해 그 값을 키우려 하고,
generator는 argmin을 취해 그 값을 줄이려 한다는 점입니다.즉, expectation 내부의 동일한 항을
두 네트워크가 공통의 자원으로 공유하면서
서로 반대 방향으로 최적화를 수행합니다.discriminator는 그 값을 크게 만들려 하고,
generator는 그 값을 작게 만들려 하며,
이렇게 두 모델이 서로 경쟁하며 싸우는 구조가
GAN의 핵심적인 학습 방식입니다.
p20. Min-max game : Game theory
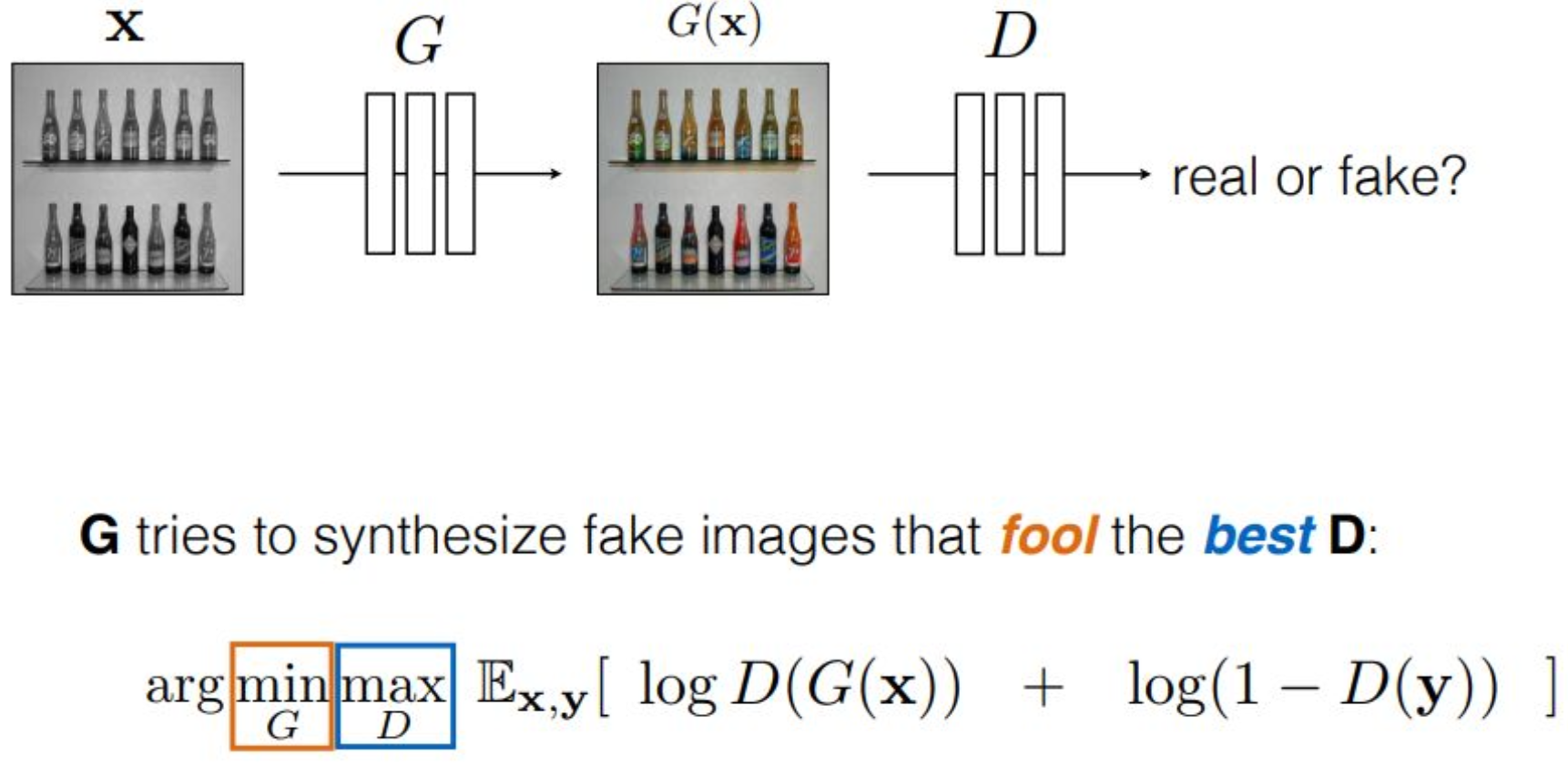
강의 내용
그래서 이러한 방식으로 min-max game으로 고려한 것입니다.
그런데 우리의 목표가 무엇일까요?
생성 모델입니다.이 Generative Adversarial Network의 목표는 무엇이어야 할까요?
잘 판별하는 것이 목표일까요?
아니면 잘 생성하는 것이 목표일까요?생성하는 것이 목표가 되어야 합니다.
그렇다면 이 게임은 최종적으로 discriminator가 지도록 설계되어야 합니다.
discriminator는
generator가 좋은 퀄리티의 샘플을 만들어 내도록
독려하고 도와줘야 하는 역할은 있지만,
마지막 순간에는 generator가 승리하도록 만들어야 합니다.그것이 이렇게 표현되어 있는 것입니다.
mathematical operation을 수행할 때는
오른쪽에 있는 것을 먼저 처리합니다.그래서 $D$가 maximization을 먼저 합니다.
$D$가 최대한 잘 판별한 것,
즉 최대 판별을 수행한 것에 대해
generator가 그것을 최소화하는 방향으로 학습되는 것입니다.네가 아무리 최대로 노력하더라도
나는 그것을 줄이겠다
라고 objective function이 설정되어 있는 셈입니다.이 전체 구조가
모든 GAN 모델, Adversarial Training의
핵심 철학이라고 볼 수 있습니다.이것을 단순히 생성 모델에 국한된 것으로 볼 수도 있지만,
실제로는 신뢰성과 관련된 여러 문제들과도 연결되기 때문에
매우 중요한 개념입니다.예를 들어 이런 상황을 생각해볼 수 있습니다.
여러분, Adversarial Attack이라는 것을 들어본 적이 있을 것입니다.
Adversarial Attack이라는 것이 존재합니다.
classifier에 이미지를 넣었을 때,
앞의 예시를 보며 이야기해 봅시다.classifier에 생선 사진을 넣으면
생선 레이블이 나와야 합니다.그런데 Adversarial Attack이란 무엇이냐면,
이 classifier를 최대한 속일 수 있는 생성 모델이
이미지의 픽셀 레벨에 아주 작은 값,
$0.00001$을 넣었을 때
이미지의 output 값을 바꿔버릴 수 있다는 것입니다.이러한 방식을 min-max 게임 형식으로 forging하여
GAN의 트레이닝 objective를 그대로 사용합니다.사람의 눈으로 볼 때는 구별이 불가능합니다.
왜냐하면 픽셀 레벨의 $0.00001$은
인간의 눈으로 구별할 수 없기 때문입니다.하지만 데이터로는 다르게 작용합니다.
Neural Network는 보통 long bit도 사용하기도 하지만
근본적으로 double bit precision을 사용하기 때문에
$0.00001$ 같은 값도 정확히 표현됩니다.그리고 그 값이 이러한 min-max operation을 통해
이미지에 injection되고,
classifier를 속일 수 있는 방식으로 생성될 수 있습니다.이런 것을 Adversarial Attack이라고 부릅니다.
사람 눈에는 전혀 구별되지 않으며
실제로 $L2$ norm 같은 기준으로도 구별하기 어렵습니다.그래서 최근에 나온 classifier들도
Adversarial Attack을 수행하면 모두 공격당합니다.이는 매우 큰 문제입니다.
공격자가 이미지에 악성 코드를 삽입하고
그 이미지를 인터넷에 유포한 뒤,
누군가 그것을 classifier나 서비스에 업로드하면
output 값을 완전히 뒤집어버리는 것입니다.생명과 관련된 문제도 발생할 수 있습니다.
예를 들어 테슬라 이미지 classifier에서
어떤 대상을 detection한다고 가정해봅시다.만약 테슬라 센서에 adversarial 픽셀을 주입한다면
사람을 표지판이라고 잘못 판단할 수도 있습니다.그래서 보안 이슈 측면에서 매우 큰 문제이며
아직도 해결되지 않았습니다.Neural Network 구조의 한계 때문에
근본적인 해결이 어려우며,
접근 자체를 막도록 wrapping하는 방식만 존재합니다.생성 모델의 min-max 게임 구조를 통해
이런 흥미로운 문제들이 만들어질 수 있습니다.다시 돌아가서,
우리가 하고자 하는 것은
최대한 노력하는 discriminator를 속일 수 있는 generator를 만드는 것입니다.그것이 목표이며,
이를 $\arg\min_G\, \max_D$
objective function으로 표현합니다.
p21. Min-max game : Game theory
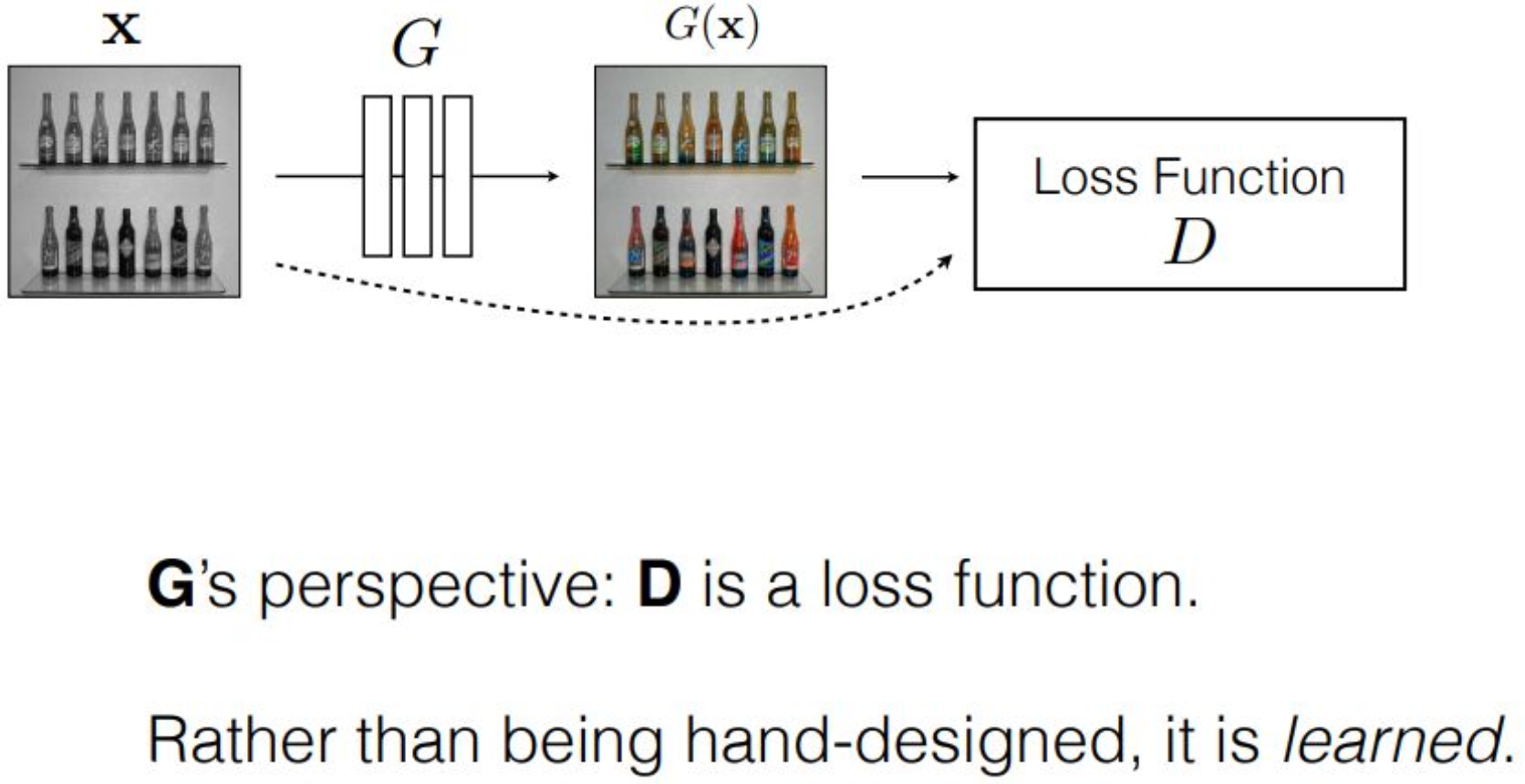
강의 내용
G의 입장에서 보면 D는 loss function입니다.
왜냐하면 $G(x)$가 D의 input으로 들어가기 때문에
$\log D(\cdot)$가 G 입장에서는 loss function처럼 작동합니다.앞에서 설명했듯이
Neural Network의 output이
어떤 objective function으로 래핑되는 구조를 고려했는데,
모양이 동일하게 나타납니다.그래서 generator 입장에서 보면
D는 loss function이라고 할 수 있습니다.그런데 이것이 조금 흥미로운 지점입니다.
앞에서 Image-to-Image Translation을 할 때
$L$을 pixel-wise L2 distance로 정의했었는데,
여기서는 loss function이 움직이는 형태가 됩니다.G의 입장에서 보면
D가 계속 학습되면서 바뀌고
그 바뀐 D를 기준으로 최적화를 해야 하기 때문에
시간에 따라 변하는 loss function이라고 볼 수 있습니다.실제로 훈련을 진행할 때는
어떤 방식으로 학습을 수행할까요?앞으로 GAN 코드도 보게 될 텐데,
코드 implementation을 통해 확인할 수 있습니다.Maximum D를 취한 다음 Minimum G를 취하는 과정은
수학적으로는 명확하게 정리되어 있지만
코드 레벨에서 그대로 구현하여 학습시키는 것은
사실상 거의 불가능합니다.Maximizing D를 어떻게 할 것인가라는 문제가 있습니다.
우선 $G$는 처음 initialization 상태가 어떨까요?
Neural Network를 처음 만들면
파라미터들은 쓰레기 값으로 채워져 있습니다.그러면 아무리 속이려 해도 의미가 없습니다.
서로 발전하면서 표현이 형성되어야 합니다.수식은 이러한 구조를 묘사하고 있지만
실제로는 두 Neural Network가 중첩된 구조를 가진 상태에서
하나는 gradient ascent,
하나는 gradient descent를 번갈아 반복하게 됩니다.discriminator는
objective function을 maximizing하는 것이므로
기본적인 gradient descent가 아니라
gradient ascent를 수행합니다.원래 gradient descent는
loss function 값을 줄이는 방향으로 업데이트하지만
discriminator는 그 반대 방향으로 이동하여
objective function을 키우는 방식으로 업데이트합니다.그래서 먼저 discriminator를 업데이트하고
그 다음 generator를 업데이트합니다.generator를 업데이트할 때는
objective function을 줄이는 것이 목적이므로
gradient descent를 수행합니다.즉, generator를 고정한 채
discriminator만 gradient descent 또는 ascent로 한 번 업데이트하고,이후 discriminator를 고정한 채
generator가 gradient descent를 수행하며이 과정을 무한 반복하는 구조입니다.
그런데 이렇게 학습하면
뭔가 불안정하다는 생각이 들지 않을까요?
이를 어떻게 컨트롤할 수 있을까요?큰 블랙박스 모델이
gradient ascent와 descent를 번갈아 수행한다고 해서
우리가 원하는 방향으로 수렴할 것이라고 믿는 것은
사실상 무모한 일입니다.그래서 실제로 많은 어려움이 발생했고
이러한 방식은 잘 동작하지 않았습니다.많은 사람들이 최적화를 시도하며 결과를 얻어냈지만
이 방식으로 product를 만드는 경우는 거의 없습니다.요즘의 Image 생성 모델은
실제로 product화가 활발하게 이루어지고 있습니다.이것이 가능한 이유는
Diffusion Model 시대가 도래했기 때문입니다.이러한 모델을 한 번 훈련하는 데에는
막대한 비용이 필요합니다.예를 들어 H100 GPU 20만 장을 사용하여 훈련한다고 하면
전기료만 해도 1초에 얼마나 나올지 상상하기 어렵습니다.인프라 유지보수 인력의 인건비,
장비 임대료 등
다양한 비용이 모두 얽혀 있습니다.그런데 그렇게 막대한 비용을 들여 훈련했는데
결과가 수렴하지 않고 이상한 값이 나온다면
그 비용은 어떻게 해야 할까요?이런 문제는 매우 심각합니다.
작은 규모에서는 큰 문제가 아니지만
의미 있는 semantic을 갖는
사람 수준의 스케일로 모델이 커지면objective function 설계의 작은 디테일 차이 하나가
엄청난 비용 손실로 이어질 수 있습니다.실제 경험을 통해 확인한 부분입니다.
따라서 대규모 시스템에서는
이러한 부분이 매우 중요합니다.이런 이유로 GAN 모델은
실제 산업 현장에서
잘 사용되지 않는 모델이 되었습니다.한편 adversarial attack 관련 연구는 계속되지만
GAN 자체는 학습 안정성 문제 때문에
널리 사용되지는 않습니다.다시 돌아가서
gradient ascent와 gradient descent를
번갈아 수행한다고 했었는데여기에 또 하나의 규칙이 존재합니다.
여러 시행착오를 통해 밝혀진 사실인데
ascent 한 번, descent 한 번이라는
1:1 업데이트 규칙을 적용하면
대부분 트레이닝 스킴이 전부 붕괴합니다.수많은 파라미터 조절과 시도를 해봐도
1:1 업데이트로는
트레이닝 전체가 collapse됩니다.그래서 일반적으로는
discriminator를 5번 업데이트하고
generator를 1번 업데이트하는 식으로
반복합니다.또한 중요한 점은
representation power라는 개념입니다.특정 metric을 사용하면
representation power의 비율을 정의할 수 있고
이를 적절히 조절해야 합니다.학습 데이터와
학습 아키텍처에 따라
적절한 비율을 찾는 과정이 필요합니다.안정적인 GAN 학습을 위해서는
일종의 warmup처럼
최적의 비율을 찾는 과정을
최소 10번 정도 반복해야 합니다.이 정도가 되어야
끝까지 학습을 돌렸을 때
결과가 제대로 나올 것이라는 판단이 가능합니다.그래서 생성 모델 연구자들은
이러한 instability 문제 때문에
많은 고통을 겪어왔습니다.이러한 치명적 단점이 존재한다는 것입니다.
그 원인은 무엇일까요?
min-max 게임 구조에는
이론적인 솔루션이 존재하지 않기 때문에
numerical한 방식으로만 접근할 수 있었고명확한 해결 방법 없이
간접적인 방식으로
마치 기도하듯 학습하는 구조였기 때문입니다.이런 배경을 고려해야 합니다.
VAE나 GAN은
이러한 성격이 강한 모델들입니다.수학적 constraint가 명확하지 않고
neural network에 모든 것을 맡기는 구조입니다.이전에 배웠던 variation equation에서도
upper bound를 학습한다고 했는데
원래는 정확하게 계산해야 하지만
복잡성 때문에 생략하는 구조였고이런 구조적 특징 때문에
instability와 퀄리티 저하가 존재합니다.반면 앞으로 배우게 될
Normalizing Flow나 Diffusion 모델은
mathematical constraint를 더욱 명확하게 설정해
사람이 이해하기 쉽고
코드로 다루기 용이하게 설계되었습니다.이러한 설계 철학을 기반으로 만들어졌기 때문에
실제 훈련과 퀄리티 평가에서
다른 모델들보다 더 좋은
퀄리티와 안정적인 트레이닝 landscape를 보여줍니다.이처럼 엔지니어링적인 배경 문제 또한 존재합니다.
이러한 내용은 PPT만으로는 이해하기 어려운 부분입니다.
p22. Conditional GANs
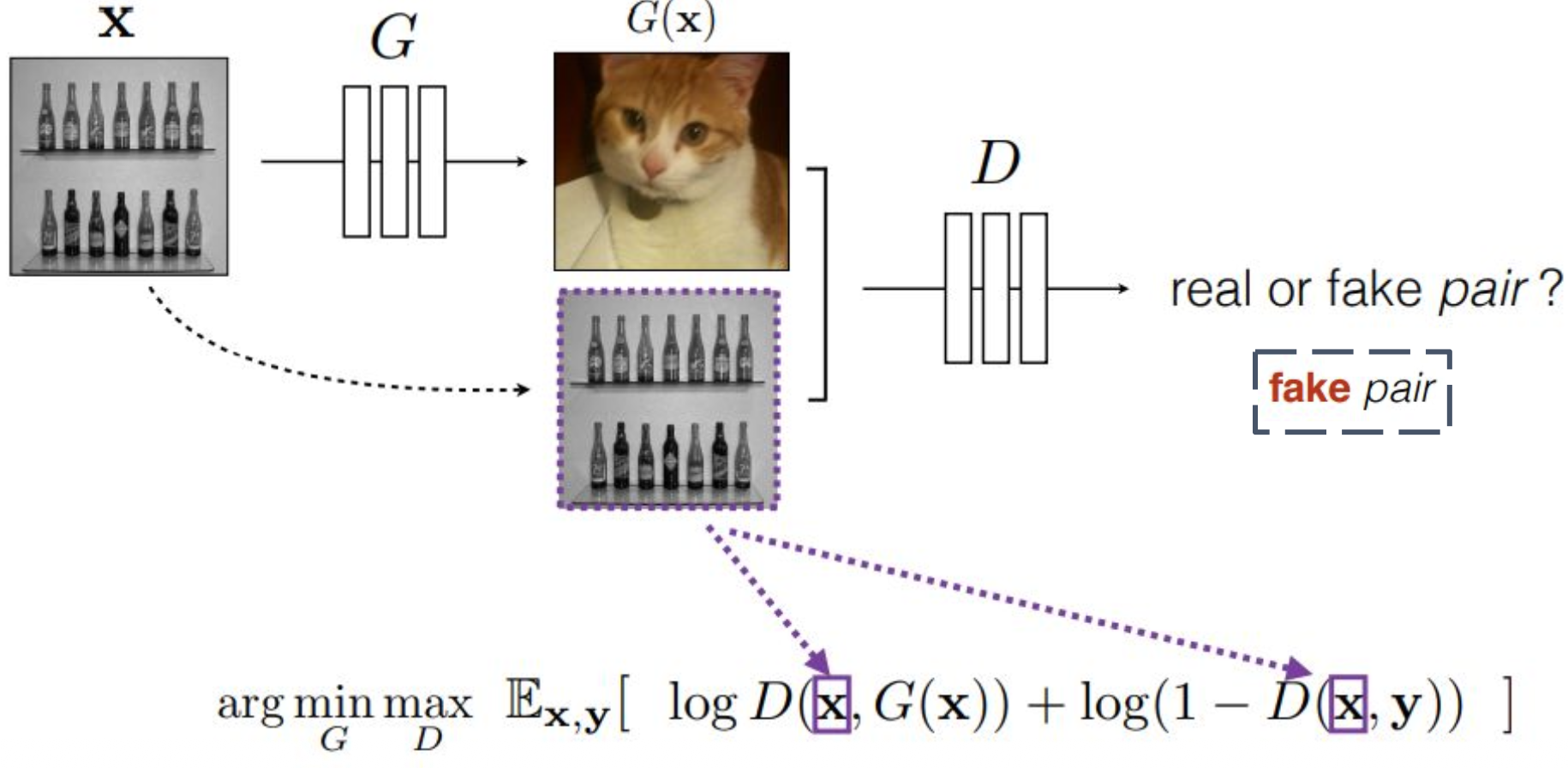
강의 내용
conditional GAN은 어떻게 동작하는지 한번 생각해보겠습니다.
$x$라는 input 이미지(조건 이미지)가 있다고 할 때
$G(x)$는 $G$가 생성한 fake 데이터입니다.conditional GAN에서는
discriminator가
조건 이미지와 fake 이미지의 pair를
input으로 받습니다.real 데이터의 경우에는
조건 이미지와 target real 이미지의 pair를
discriminator의 input으로 넣어
학습을 진행합니다.그리고 argmin, argmax 구조는 동일하게 유지됩니다.
real과 fake에 대해
앞에서 설명한 것과 마찬가지로
discriminator output이 1에 가까우면 fake로,
0에 가까우면 real로 판별합니다.즉, 기존 GAN 구조에
conditioning만 추가적으로 입력되는 형태라고 보면 됩니다.
p23. Conditional GANs
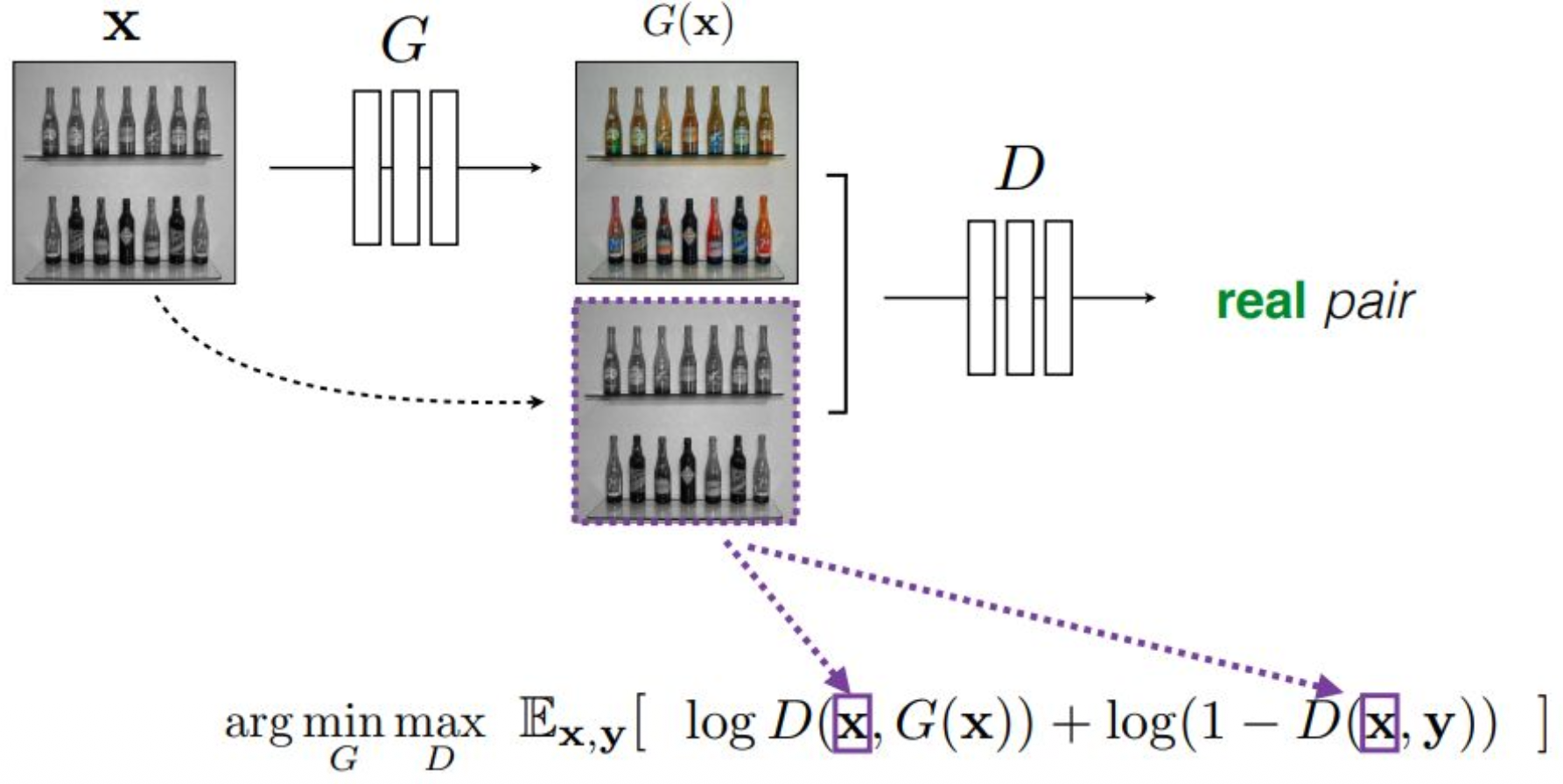
p24. Conditional GANs for Image Translation
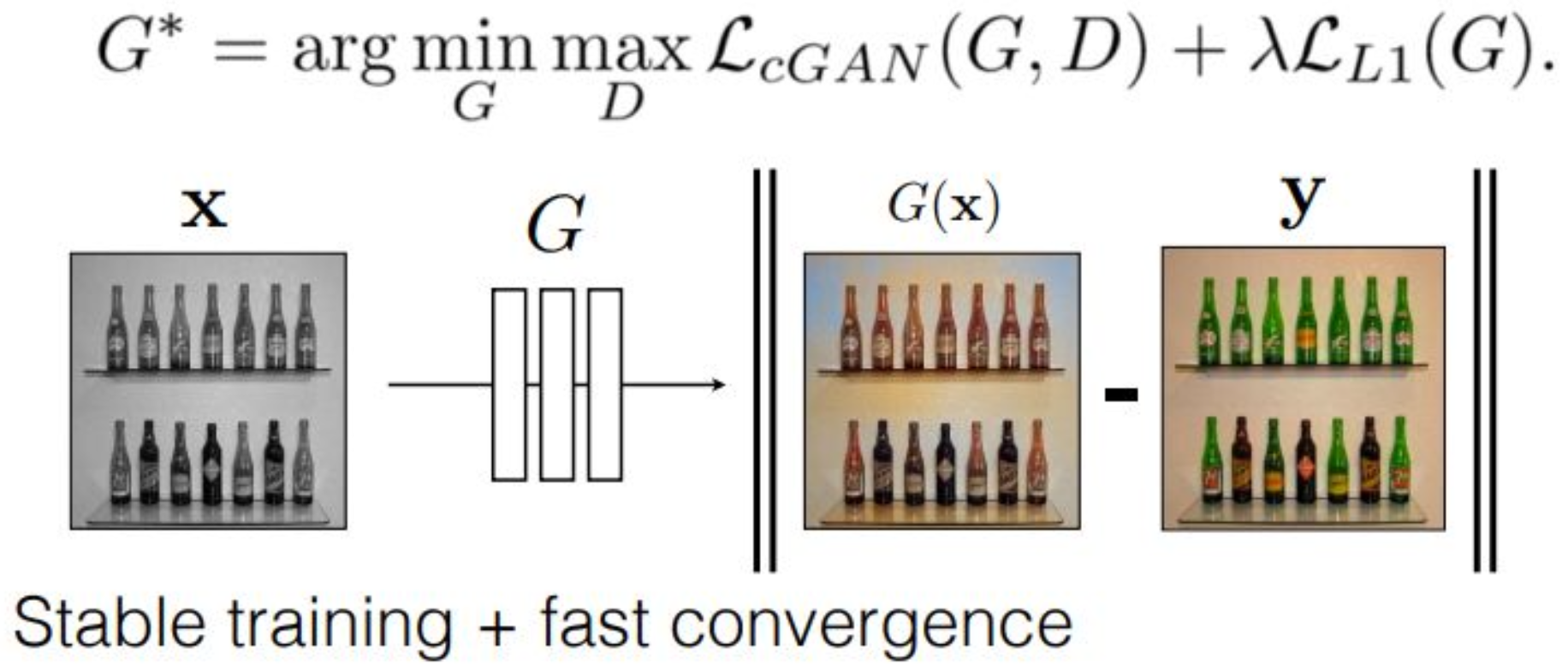
강의 내용
앞에서 말씀드렸듯이
GAN은 generator와 discriminator가
gradient descent와 ascent를 번갈아 수행하기 때문에
학습이 매우 unstable해지는 문제가 있습니다.엔지니어들은 이러한 불안정성을
어쨌든 해결할 방법을 찾아야 합니다.그래서 Image Translation 같은 경우에는
뒤에 $\mathcal{L}_{L1}$이라는 항을 추가하게 됩니다.이것을 regularization term이라고 부르며,
생성된 데이터 $G(x)$와
target 데이터 $y$가
L1 distance 관점에서 서로 가까워지도록
추가적인 제약을 주는 역할을 합니다.즉,
generator와 discriminator가
서로 다른 방향으로 diverge되려 할 때
이 regularization term이 개입하여
최대한 divergence를 억제하는 구조입니다.이를 적용하면
학습이 안정(stable)해지고
수렴 속도도 빨라지는 효과가 있습니다.
보충 자료
이 장표는 conditional GAN을 이용한 이미지 변환 과정을 설명한 것이다.
먼저 입력 이미지 $x$가 주어지면, 생성기 $G$는 이를 입력받아 $G(x)$라는 출력 이미지를 생성한다.
이후 생성된 이미지 $G(x)$와 실제 타깃 이미지 $y$를 비교하여, 두 이미지 간의 차이를 최소화하도록 학습이 이루어진다.상단의 수식은 생성기 $G$와 판별기 $D$가 서로 경쟁하는 구조를 나타낸다.
판별기 $D$는 진짜 이미지와 생성된 이미지를 구분하기 위해 최대한 정확히 판별하려 하고,
생성기 $G$는 판별기를 속이기 위해 진짜와 유사한 이미지를 생성하려 한다.
이러한 경쟁 관계는 일반적으로 min-max 문제로 표현된다.또한 기본적인 GAN 손실인 $L_{\text{cGAN}}(G, D)$에 더하여
$\lambda \, \mathcal{L}_{L1}(G)$ 항이 추가되어 있다.
여기에서 L1 정규화 항은 다음과 같이 정의된다.
\(\mathcal{L}_{L1}(G) = \mathbb{E}\left[\lVert y - G(x) \rVert_1 \right]\)
이 항은 생성된 이미지가 실제 이미지 $y$와 픽셀 단위에서 가까워지도록 유도하는 역할을 한다.이러한 L1 항을 추가함으로써 학습의 안정성이 크게 향상되고,
모델이 더 빠르게 수렴할 수 있게 된다.
따라서 장표 하단에는 “Stable training + fast convergence”라는 문구가 제시되어 있다.정리하면, 입력 이미지 $x$는 생성기 $G$를 거쳐 $G(x)$로 변환되고,
이 결과는 실제 이미지 $y$와 L1 기준으로 비교되며,
동시에 판별기 $D$는 진짜와 가짜를 판별하는 과정에 참여한다.
이러한 구성은 안정적이고 실용적인 이미지 변환 모델을 구현하기 위한 구조라고 할 수 있다.
p25. Conditional GANs

강의 내용
이것은 앞에서 말씀드렸던 것처럼
블랙 앤 화이트 이미지를 컬러로 변환하는
그런 예제들입니다.이는 18년도쯤에 발표된 논문들의 결과 수준인데
지금은 그보다 훨씬 더 높은 퀄리티가 가능해졌습니다.colorization뿐만 아니라
다양한 conditional한 생성 작업을
하나의 파운데이션 모델에서 모두 처리할 수 있으며
이러한 획기적인 모델들이 이미 많이 존재합니다.
p26. Edges2Cats
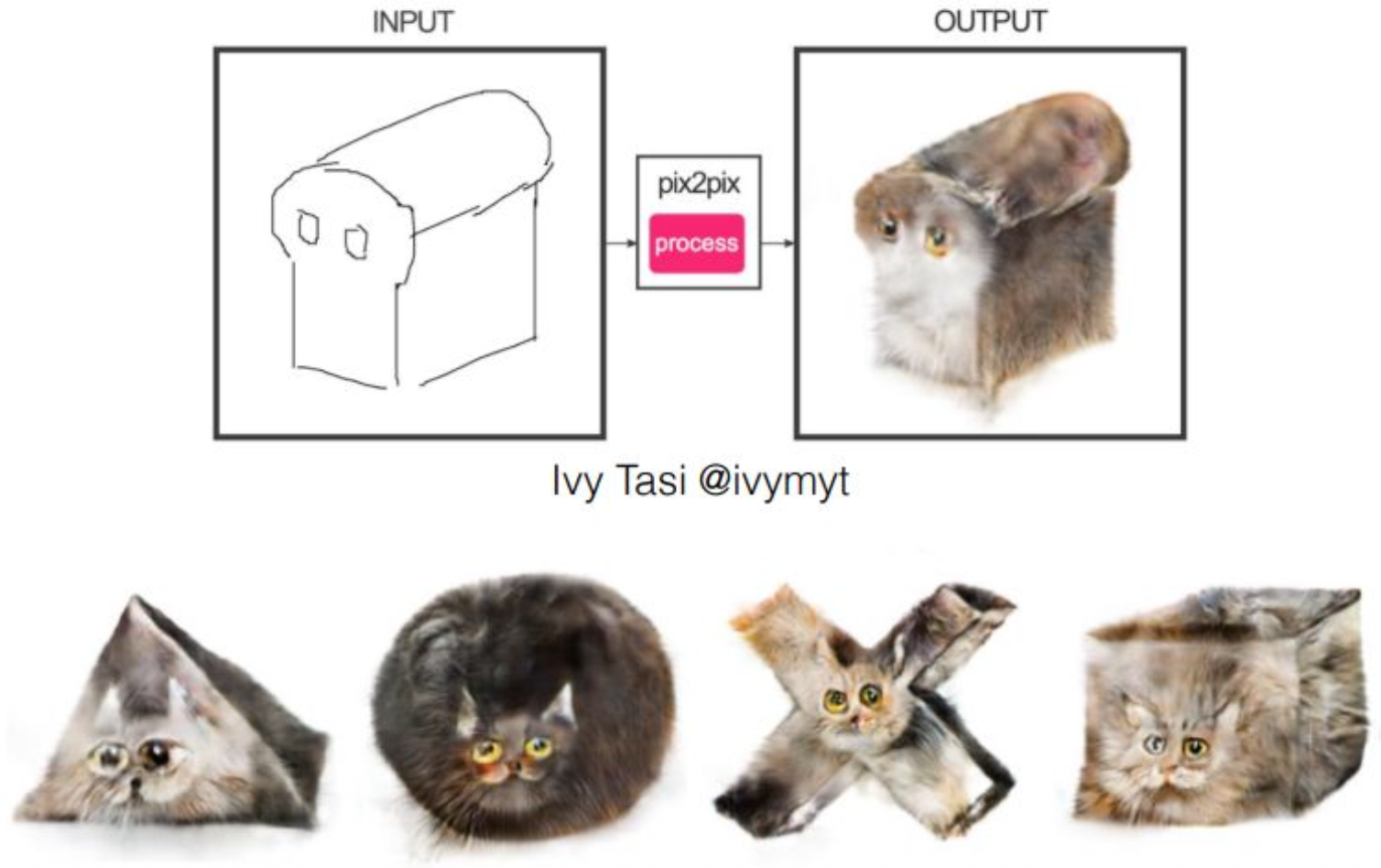
강의 내용
앞에서 보았던 Edge Detection으로 훈련된 모양들이
실제로 어떤 방식으로 결과물을 만들어내는지
생각해볼 수 있습니다.기본적으로 이런 방식을 사용합니다.
고양이 사진을 충분히 학습시켜 놓고,
전혀 다른 형태, 예를 들어 식빵처럼 생긴 모양을
엣지 형태로 discriminator와 generator에 입력하여
생성을 수행하도록 합니다.하지만 훈련은 고양이 이미지로 이루어졌기 때문에
모델은 어떻게든 자신이 학습했던
고양이의 형태적 특징을
입력된 엣지 구조에 맞추어 배치하여 표현합니다.흥미로운 점은,
해당 모양을 보면 눈이 있어야 할 것 같은 위치가 존재하는데
실제로 생성된 이미지에도 눈이 나타난다는 것입니다.단순히 동그라미로 표현된 엣지를 주었을 때
반드시 눈이 채워지는 것은 아니지만
학습 과정에서 고양이 얼굴의 기하학적 구조상
눈이 항상 그 위치에 있었기 때문에
모델은 그 확률을 반영하여 눈을 생성합니다.이러한 원리는 다른 형태의 입력에서도 동일하게 작동하며
다소 엉뚱한 모양이라도
재미있고 그럴듯한 방식으로 표현이 이루어집니다.
p27. Pix2Pix : Labels to Facades
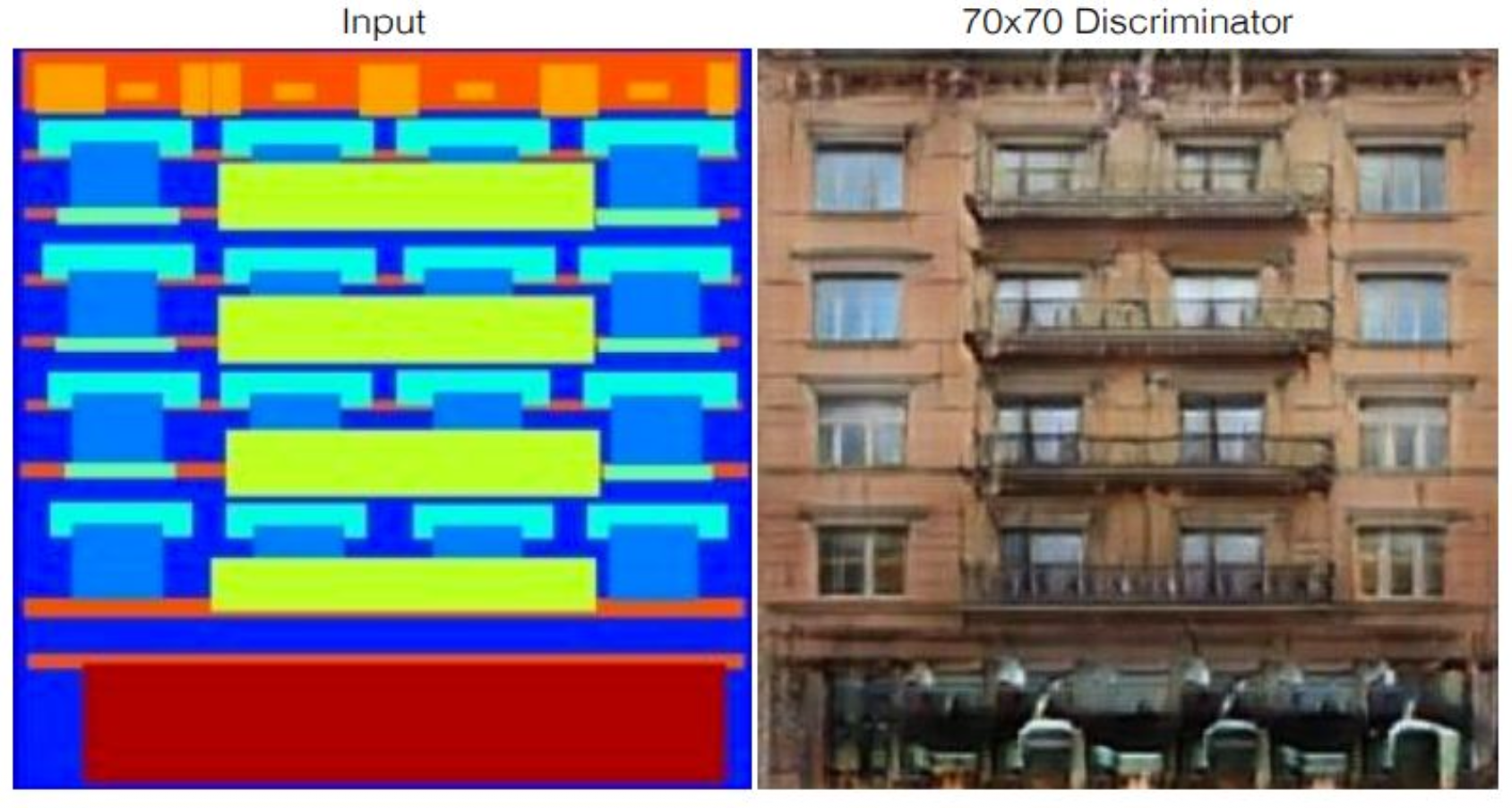
강의 내용
이것은 Pix2Pix라는 유명한 Image Translation 생성 모델입니다.
왼쪽에 있는 층, 창문, 틀처럼
계단식(cascaded)으로 구성된 input 이미지에 대해
레이블링을 제공하면
오른쪽과 같은 결과를 생성해주는 구조입니다.방이나 가구처럼 각지고 정형화된 대상들은
생성 품질이 더 좋습니다.
정형화된 구조적 틀이 존재하기 때문입니다.생성 모델을 훈련하다 보면
(그리고 현대 생성 모델들도 마찬가지인데)
자연에 존재하는
각지고 규칙적인 natural object에 대해서는
이미지 생성 품질이 더욱 높습니다.반면,
정형화되지 않았거나
데이터 수집이 어려운 자연 객체의 형태를
생성하도록 하면생성 모델을 평가하는 메트릭인
FID(Fresh Inception Distance) 점수가
압도적으로 떨어집니다.사람이 보기에는 괜찮아 보일 수 있어도
수치적으로는 품질 저하가 크게 나타납니다.이렇게 모델들은
정형화된 구조를 잘 생성합니다.그렇다면 어떤 것을 특히 잘 생성할까요?
사람의 얼굴을 매우 잘 생성합니다.
눈, 코, 입처럼 정형화된 위치가 존재하고
기하학적으로 뒤틀리면 안 되는 구조이기 때문입니다.
예를 들어 입이 코 위치에 있으면 안 되겠죠.그래서 AI가 생성한 사람 얼굴을 보면
약간 이질적인 느낌이 드는 경우가 있습니다.
흔히 평균 이미지 같다라고 표현하곤 합니다.이는 결국
기하학적 패턴들을 확률적으로 정형화하는 과정에서
평균적 형태로 수렴하기 때문입니다.
이러한 패턴들은 convolution filter에 흔적으로 남게 됩니다.큰 모델의 convolution filter들을 관찰해보면
기하학적 위치에 따라
서로 다른 필터들이 배치되는 것을 확인할 수 있습니다.이러한 모든 현상은
실제로 매우 흥미로운
확률적, 통계적 특성에서 비롯된 것입니다.
p28. GANs vs VAEs
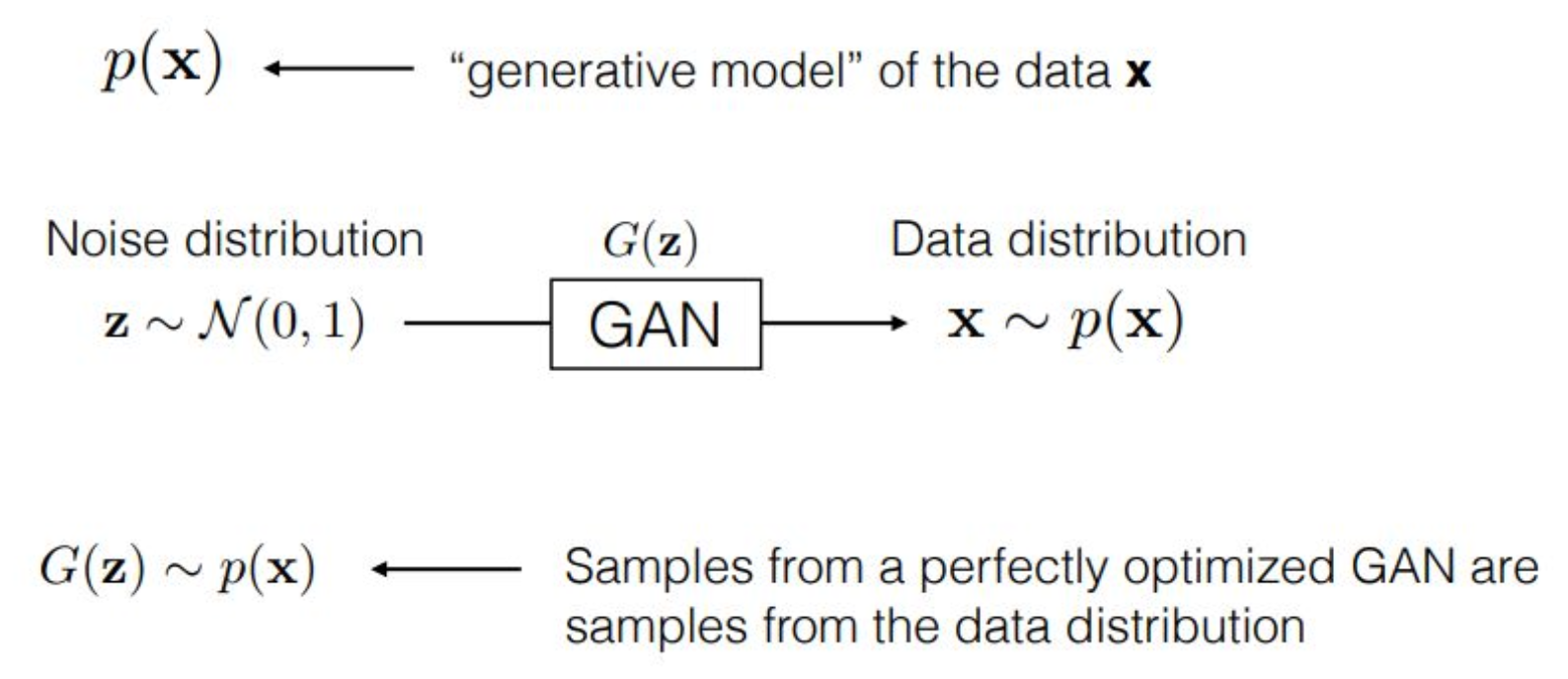
강의 내용
그러면 마지막으로 GAN과 VAE를 비교해보도록 하겠습니다.
GAN은 무엇이었을까요?
앞에서는 이해를 돕기 위해 conditional 생성 모델을 예로 들었지만
원래 GAN의 초기 형태는 unconditional 모델이었습니다.$z$라는 Gaussian distribution이 입력되면
$x$라는 데이터가 출력되며
Gaussian distribution에서 data distribution으로
매핑을 수행하는 것이 generator의 역할입니다.그리고 이 구조는
min-max 게임을 통해 학습이 이루어집니다.
p29. GANs vs VAEs

강의 내용
그러면 생성 퀄리티를 살펴보겠습니다.
이 예시는 상당히 오래된 논문에서 나온 것으로,
16년도나 17년도 논문에서 제시됐던 그림으로 기억합니다.VAE의 경우 blurry한 형태가 많이 나타나는데,
이는 reconstruction loss의 upper bound를 무시하고
approximation된 형태를 사용했기 때문에 발생하는 현상입니다.
즉, 정보가 상당 부분 손실된 형태라고 볼 수 있습니다.뉴럴 네트워크 구조가 아무리 잘 구성되더라도
VAE의 경우 일정 수준 이상의 blur를 피하기 어렵습니다.예시를 보면
얼굴처럼 정형화된 패턴이 존재하는 영역은 비교적 잘 생성되지만
배경은 고주파수(high-frequency) 영역이기 때문에
재현이 어렵습니다.실제 사진에서도 배경은 매우 다양하게 나타납니다.
어떤 경우에는 빨간색 배경일 수도 있고
또 어떤 경우에는 단순한 실내 공간일 수도 있습니다.
그래서 얼굴 부분은 명확하게 표현되는데
배경은 고주파수 특성 때문에 대부분 소실됩니다.반면 GAN은 이러한 문제를 어느 정도 해결할 수 있습니다.
다만 앞에서 언급했듯이
GAN의 경우 훈련 품질이 충분히 확보되고
warmup 단계를 거쳐
안정적인(truly stable) 트레이닝이 이루어진 상황을 가정해야
이러한 고품질 샘플이 나옵니다.
이 수준에 도달하는 것이 결코 쉽지 않습니다.VAE는 샘플 퀄리티가 다소 낮아질 수는 있으나
상대적으로 학습이 어렵지 않습니다.이와 같이
두 모델의 차이를 이해하시면 될 것 같습니다.
p30. Theory : Global Convergence of Critic

강의 내용
글로벌 컨버전스와 관련된 수학적 논의가 있지만
이 부분은 생략하도록 하겠습니다.
보충 자료
명제 1. G가 고정되었을 때, 최적의 판별기 D는
\[D_G^*(x) = \frac{p_{\text{data}}(x)}{p_{\text{data}}(x) + p_g(x)}\]증명
\[V(G, D) = \int_x p_{\text{data}}(x) \log(D(x)) \, dx + \int_z p_z(z) \log(1 - D(g(z))) \, dz\]\[= \int_x p_{\text{data}}(x) \log(D(x)) + p_g(x) \log(1 - D(x)) \, dx\]임의의 $(a, b) \in \mathbb{R}^2 \setminus {0, 0}$ 에 대해,
함수 $y \mapsto a\log(y) + b\log(1-y)$ 는
$[0,1]$ 에서 $\frac{a}{a+b}$ 일 때 최대값을 가진다.
판별기(discriminator)는
$\text{Supp}(p_{\text{data}}) \cup \text{Supp}(p_g)$ 밖에서 정의될 필요가 없으며,
이것으로 증명이 완료된다. □이 정리는 “G(Generator)를 고정했을 때, 어떤 D가 가장 좋은가?”를 알려준다.
즉, 생성 모델 G가 이미 정해져 있다면,
판별기 D는 어떤 값을 출력해야
전체 GAN 목적함수 $V(G, D)$ 가 최대가 되는지를
정확히 계산한 결과이다.핵심 아이디어는 다음과 같다.
1) GAN의 목적함수 $V(G,D)$ 는
데이터 분포와 생성 분포가 함께 등장하는
로그 형태의 합이다.2) 이 적분을 $x$별로 바라보면,
각 $x$에 대해
$p_{\text{data}}(x)\log(D(x)) + p_g(x)\log(1 - D(x))$
를 최대화하는 문제가 된다.3) 이는 일반적인 형태
$a\log(y) + b\log(1-y)$
의 최대화 문제와 동일하다.4) 이 함수는 $y = \frac{a}{a+b}$ 일 때 최대가 된다.
여기서 $a = p_{\text{data}}(x)$, $b = p_g(x)$ 로 두면
각 $x$마다 최적의 판별기 출력은\[D^*(x) = \frac{p_{\text{data}}(x)}{p_{\text{data}}(x) + p_g(x)}\]이 된다.
즉, 판별기의 최적 출력은
“이 $x$가 진짜 데이터일 확률의 정규화된 비율” 이다.
다시 말해, 데이터와 생성 분포의 상대적 확률비로
진짜 여부를 판단하는 것이 최적이라는 뜻이다.마지막 문장에 따르면,
판별기는 $p_{\text{data}}$ 또는 $p_g$ 가 0인 구간에서는
정의될 필요가 없다.“두 분포가 실제로 존재하는 영역(지원집합)에서만 의미가 있으며,
그 바깥에서는 $V(G,D)$ 에 아무 영향도 없다.”이렇게 해서 최적 판별기 공식이 도출되며,
이는 GAN 이론의 가장 핵심적인 기반 공식이다.
p31. Theory : Global Convergence of Distribution

p32. Theory : Global Convergence of Distribution
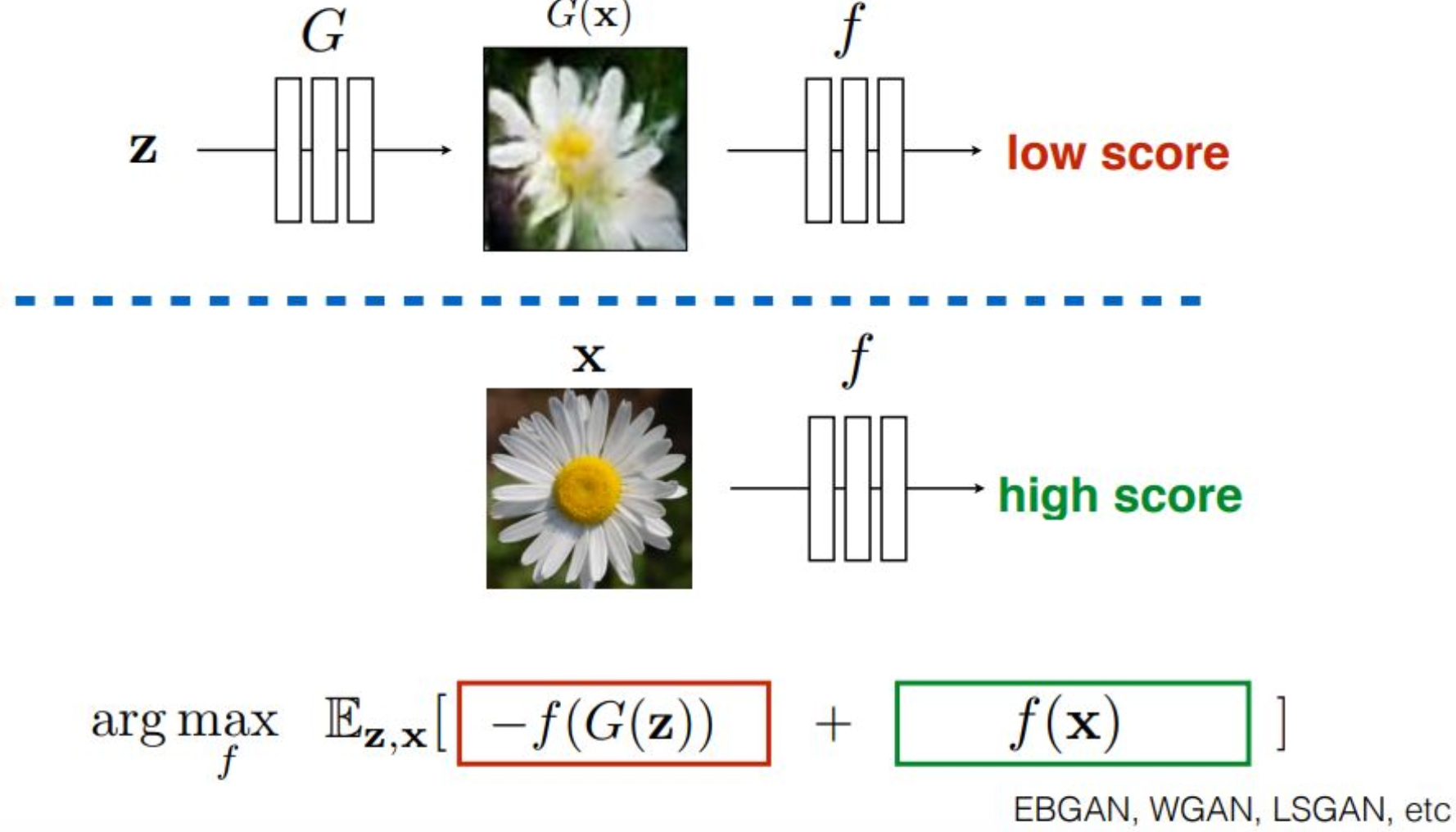
p33. Theory : Global Convergence of Distribution
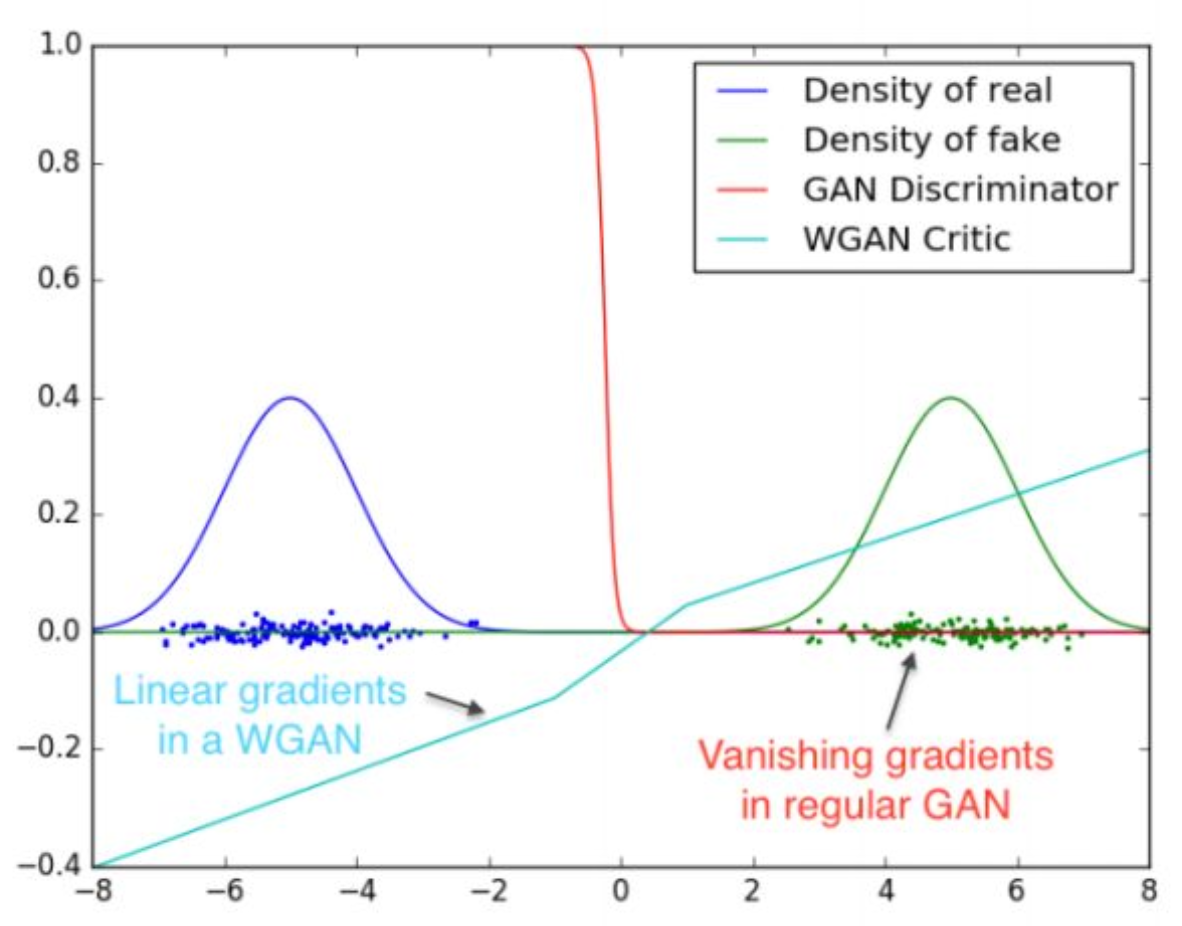
강의 내용
오늘은 이 정도로 내용을 마무리해도 될 것 같습니다.
이 그림에 대해 간단히 말씀드리면,앞에서 log function을 사용해 훈련한다고 했었는데
바닐라 형태의 GAN을 그대로 훈련할 경우
log를 미분하는 과정에서 심각한 문제가 발생합니다.빨간색 선으로 표시된 GAN discriminator 곡선은
log function에 결합된 discriminator loss 항을
그래프로 표현한 것입니다.특정 상황에서는 loss가 0이 되어
vanishing gradient 현상이 나타나는 것을 보여줍니다.또한 GAN의 변형·확장 버전들도 존재합니다.
예를 들어
GAN을 수학적으로 일반화한 구조인 Wasserstein GAN, F-GAN 등이 있습니다.KL divergence의 일반화된 형태를 기반으로 한
Wasserstein distance를 사용하는 GAN에서는
critic(discriminator) function이
gradient vanishing 문제를 겪지 않습니다.GAN의 instability 문제를 해결하기 위해
수학자들, AI 연구자들이
오랫동안 다양한 접근을 시도해 왔습니다.하지만 이후
Normalizing Flow, Diffusion 등
새로운 생성 모델 구조가 등장하면서
GAN 중심의 연구는 많은 부분에서 넘어갔다고 볼 수 있습니다.아무리 노력을 해도
GAN의 instability는 완전히 해결되지 않았습니다.그럼에도 불구하고
GAN은 매우 중요한 역할을 했고
지금의 Diffusion 모델을 포함한
현대 생성 모델 연구에 많은 유산을 남겼습니다.다만 현재 관점에서,
특히 프로덕트 관점에서는
GAN은 거의 사용되지 않는 모델이라고 보시면 됩니다.그래도 한 시대를 대표하는 패러다임이었고
중요한 개념들을 많이 소개한 모델이기에
강의에서 다루었습니다.오늘 메인 콘텐츠는 여기까지 하겠습니다.
이제 질문을 받겠습니다.
질문 있으실까요?(질문)
아까 정형화된 데이터에 대해 말씀해주셨는데,
요즘 physics generative 모델들도 잘 되는 것 같더라구요.
그것도 정형화된 데이터인가요?(답변)
physics 데이터라고 하면 어떤 것을 말할까요?
제가 실제로 physics 데이터를 많이 다루고 있어서,
그 예를 들어 말씀드리겠습니다.보통 physical이라 하면 로봇 등을 떠올리지만
physics AI, physical AI를
그 일부로 볼 수도 있습니다.예를 들어
스프링에 매달린 진자 운동 데이터를 생각해봅시다.진자 운동은 주기성을 갖고 움직이죠.
이런 데이터는 정형성을 갖고 있다고 볼 수 있습니다.
왜냐하면 방정식에 따라 움직이기 때문입니다.드론을 예로 들어도 마찬가지입니다.
드론에는 많은 센서가 달려 있지만
물리적으로 불가능한 센서값은 존재할 수 없습니다.드론은 물리적 구조가 고정되어 있고
쿼드콥터라면 네 개의 날개가 회전하는 방식에 따라
회전 각도가 정해지며
이는 모두 물리 방정식을 따릅니다.따라서 이런 데이터는
학습이 매우 잘 됩니다.방정식으로 설명할 수 있고
그 방정식을 넘어서는 관측이 존재하지 않기 때문입니다.반면
정형화되지 않은 데이터,
물리적으로 설명되지 않는 데이터의 경우
탐색 공간이 커지기 때문에
당연히 학습이 더 어려워집니다.여기서 한 가지 더 말씀드리면
physics를 알아야 합니다.데이터만 가지고 방정식을 역추적하기는 어렵고
예를 들어
코사인, 사인 함수 기반의 진동 데이터를 학습한다고 하면
핵심은 방정식의 coefficient를
neural network가 학습하도록 하는 것입니다.즉,
방정식으로 생성된 데이터를 학습하는 것이 아니라
그 방정식 자체의 계수를 학습시키는 쪽이
훨씬 정형화된 데이터 처리가 가능합니다.이런 관점은
physical AI나 robotics AI에도
유사하게 적용할 수 있습니다.(질문)
Adversarial Attack 관련해서,
생성된 공격 데이터를 파인튜닝으로 추가 학습하면
문제 해결에 도움이 될까요?(답변)
질문을 약간 정리해보면,
공격 데이터를 추가 학습하여
robustness를 높일 수 있느냐는 의미로 이해됩니다.네, 가능합니다.
Adversarial Attack을 연구하면
자연스럽게 방어 메커니즘도 함께 발전합니다.현실 세계에서도
공격 의도가 없어도
자연 이미지에 공격과 유사한 패턴이 존재할 수 있습니다.이런 관점에서
공격 데이터를 추가 학습하고
robustness를 강화하는 접근은
딥러닝에서는 data augmentation에 해당하며
이를 파인튜닝으로 해석할 수도 있습니다.예를 들어
블러, 안개 등의 degraded image를
공격적 노이즈처럼 생성하여
모델이 강건하게 작동하도록 만들 수 있습니다.다만 accuracy를 일부 희생해야 할 수도 있고
다양한 케이스를 모두 학습시키기 어렵다는 문제가 있습니다.그럼에도 불구하고
아예 대응하지 못하는 것보다는 훨씬 낫습니다.이런 방법들은
논문 단위로 살펴보면 좋습니다.
실제로 attack–defense 연구는
논문을 통해 체계적으로 이해하는 것이 바람직합니다.강의 형식에서는 모든 논문을 다룰 수 없기 때문에
핵심 아이디어만 소개드리지만관련 논문 리스트를 정리해
LMS에 제공해드릴 테니
한 번 읽어보며
적용 가능성을 판단해보시면 좋겠습니다.옛날 논문도 많이 포함될 텐데
분야 발전의 중요한 흐름을 만드는
필러 역할을 했던 연구도 많습니다.그런 논문들을 살펴보는 것도 도움이 됩니다.
오늘 강의는 여기서 마무리하겠습니다.