[논문 번역] RAPTOR: RECURSIVE ABSTRACTIVE PROCESSING FOR TREE-ORGANIZED RETRIEVAL
논문 출처
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, Christopher D. Manning.
RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval.
Stanford University.
psarthi@cs.stanford.edu 🔗 원문 링크 (arXiv: 2401.18059)
저자
- Parth Sarthi
- Salman Abdullah
- Aditi Tuli
- Shubh Khanna
- Anna Goldie
- Christopher D. Manning
(Stanford University)
초록 (Abstract)
검색 증강 언어 모델(retrieval-augmented language models)은
세계 상태(world state)의 변화에 더 잘 적응하고
롱테일 지식(long-tail knowledge)을 통합할 수 있다.
그러나 기존의 대부분의 방법들은
검색 코퍼스(retrieval corpus)로부터
짧고 연속적인 청크(short contiguous chunks)만을 검색하며,
이로 인해 전체 문서 컨텍스트(overall document context)에 대한
총체적 이해(holistic understanding)가 제한된다.
우리는 텍스트 청크들을
재귀적으로 임베딩하고, 클러스터링하며, 요약하는
새로운 접근법을 소개하며,
상향식(bottom up)으로 서로 다른 요약 수준을 갖는
트리를 구성한다.
추론 시점(inference time)에서
우리의 RAPTOR 모은 이 트리로부터 정보를 검색하며,
서로 다른 추상화 수준(levels of abstraction)에서
긴 문서들(lengthy documents)에 걸친 정보를 통합한다.
통제된 실험(controlled experiments)은
재귀 요약(recursive summaries)을 활용한 검색이
기존의 검색 증강 언어 모델들에 비해
여러 과제들에서 유의미한 성능 향상을 제공함을 보여준다.
복잡하고 다단계 추론(complex, multi-step reasoning)을 포함하는
질의응답 과제(question-answering tasks)에서,
우리는 최신 최고 성능(state-of-the-art) 결과를 보인다;
예를 들어 RAPTOR 검색을 GPT-4의 사용과 결합함으로써,
QuALITY 벤치마크에서
절대 정확도 기준으로 20%의 성능 향상을
달성할 수 있음을 보인다.
1 서론 (Introduction)
대규모 언어 모델(Large Language Models, LLMs)은
다양한 과제에서 인상적인 성능을 보이는
변혁적인(transformative) 도구로 등장하였다.
LLM의 규모가 커짐에 따라,
이들은 파라미터 내부에 사실(facts)을 인코딩함으로써
매우 효과적인 지식 저장소로서
독립적으로(standalone) 동작할 수 있으며
(Petroni et al., 2019; Jiang et al., 2020;
Talmor et al., 2020; Rae et al., 2021;
Hoffmann et al., 2022; Chowdhery et al., 2022;
Bubeck et al., 2023; Kandpal et al., 2023),
또한 모델은 다운스트림 과제에 대한 파인튜닝을 통해
추가적으로 성능을 향상시킬 수 있다
(Roberts et al., 2020).
그럼에도 불구하고,
아무리 큰 모델이라 하더라도
특정 과제에 필요한 충분한 도메인 특화 지식을 포함하지는 못하며,
세계는 계속 변화하여 LLM 내부의 사실들을 무효화한다.
추가적인 파인튜닝이나 편집을 통해
이러한 모델들의 지식을 업데이트하는 것은 어렵고,
특히 방대한 텍스트 코퍼스를 다룰 때 더욱 그러하다
(Lewis et al., 2020; Mitchell et al., 2022).
대안적인 접근법으로,
오픈 도메인 질의응답 시스템에서
처음 제안된 방식(Chen et al., 2017; Yu et al., 2018)은,
텍스트를 청크(문단) 단위로 분할한 후
별도의 정보 검색 시스템에서 대량의 텍스트를 인덱싱하는 것이다.
이후 검색된 정보는 질문과 함께 컨텍스트로서
LLM에 제공되며 (“검색 증강”, retrieval augmentation;
Lewis et al., 2020; Izacard et al., 2022;
Min et al., 2023; Ram et al., 2023),
이를 통해
특정 도메인에 대한 최신 지식을 시스템에 제공하는 것이 쉬워지고,
해석 가능성 및 출처 추적을 용이하게 할 수 있다.
반면, LLM의 파라메트릭 지식은 불투명하며
그 출처를 추적하기가 어렵다 (Akyurek et al., 2022).
그럼에도 불구하고, 기존의 검색 증강 접근법들 역시 결함을 가지고 있다.
우리가 다루는 문제는, 대부분의 기존 방법들이
짧고, 연속적인(contiguous) 텍스트 청크 몇 개만을 검색한다는 점이며,
이는 대규모 담화(discourse) 구조를 표현하고 활용하는 능력을 제한한다는 것이다.
이러한 한계는 특히
텍스트의 여러 부분으로부터의 지식을 통합해야 하는
주제적 질문(thematic questions)에 대해 중요하게 작용한다.
예를 들어, NarrativeQA 데이터셋(Kočiský et al., 2018)에서처럼
하나의 책 전체를 이해해야 하는 경우가 그렇다.
신데렐라 동화를 생각해 보고,
“신데렐라는 어떻게 행복한 결말에 도달했는가?”라는 질문을 고려해 보자.
상위 $k$개로 검색된 짧은 연속 텍스트들만으로는
이 질문에 답하기에 충분한 맥락을 포함하지 못할 것이다.
이를 해결하기 위해, 우리는
텍스트에 대한 고수준(high-level) 정보와
저수준(low-level) 세부 정보를 모두 포착하기 위해
트리 구조를 사용하는 인덱싱 및 검색 시스템을 설계한다.
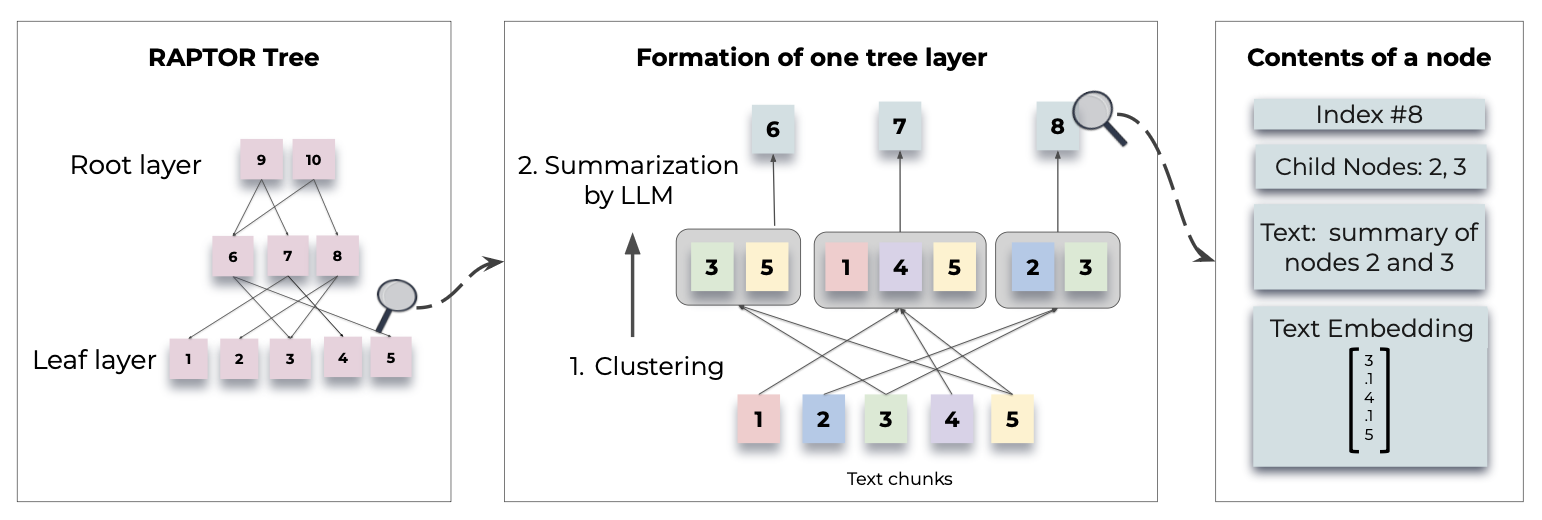
그림 1에 나타난 것처럼,
우리의 시스템인 RAPTOR는 텍스트 청크들을 클러스터링하고,
해당 클러스터들의 텍스트 요약을 생성한 뒤,
이를 반복함으로써 하위에서 상위로(bottom up) 트리를 생성한다.
이 구조는 RAPTOR가
서로 다른 수준에서 텍스트를 대표하는 청크들을
LLM의 컨텍스트에 로드할 수 있도록 하며,
이를 통해 서로 다른 수준의 질문들에 대해
효과적이고 효율적으로 답변할 수 있게 한다.
그림 1: 트리 구성 과정:
RAPTOR는 벡터 임베딩에 기반하여
텍스트 청크들을 재귀적으로 클러스터링하고,
해당 클러스터들의 텍스트 요약을 생성함으로써,
하위에서 상위로(bottom up) 트리를 구성한다.
함께 클러스터링된 노드들은 형제(siblings)이며,
부모 노드는 해당 클러스터의 텍스트 요약을 포함한다.
우리의 주요 기여는
서로 다른 스케일에서의 컨텍스트에 대한 검색 증강을 가능하게 하기 위해
텍스트 요약을 사용하는 아이디어를 제안하고,
긴 문서들의 컬렉션에 대한 실험을 통해
그 효과성을 보여주는 것이다.
UnifiedQA(Khashabi et al., 2020),
GPT-3(Brown et al., 2020), 그리고 GPT-4(OpenAI, 2023)라는
세 가지 언어 모델을 사용한 통제된 실험은
RAPTOR가 기존의 검색 증강 기법들을 능가함을 보여준다.
더 나아가, GPT-4와 결합된 RAPTOR는,
때로는 UnifiedQA와 결합된 경우에도,
세 가지 OA 작업에서 새로운 최신(state-of-the-art) 성과를 달성한다.
이들 작업은,
책과 영화에 대한 자유 텍스트 응답 질문
(NarrativeQA, Kočiský et al. 2018),
전체 텍스트 NLP 논문
(QASPER, Dasigi et al. 2021),
그리고 중간 길이의 지문에 기반한 객관식 질문
(QuALITY, Pang et al. 2022)이다. 1
1 우리는 RAPTOR의 코드를 공식적으로 여기에서 배포한다.
2 관련 연구 (RELATED WORK)
왜 검색(Retrieval)인가?
하드웨어와 알고리즘에 있어서의 최근의 발전들은
모델이 처리할 수 있는 컨텍스트 길이를 실제로 확장시켰으며,
그로 인해 검색 시스템의 필요성에 대한 질문이 제기되고 있다
(Dai et al., 2019; Dao et al., 2022; Liu et al., 2023).
그러나 Liu et al. (2023)과 Sun et al. (2021)이 지적했듯이,
모델들은 범위가 긴(long-range) 컨텍스트를 충분히 활용하지 못하는 경향이 있으며,
컨텍스트 길이가 증가함에 따라 성능이 점차 저하되는 모습을 보인다.
이는 특히 관련 정보가 매우 긴 컨텍스트 안에 포함되어 있을 때 더욱 두드러진다.
더 나아가, 실제적으로 긴 컨텍스트를 사용하는 것은
비용이 많이 들고 속도가 느리다.
이는 지식 집약적인 작업을 위해
가장 관련성 높은 정보를 선택하는 것이 여전히 중요함을 시사한다.
검색 방법(Retrieval Methods)
검색 증강 언어 모델(RALMs)은 여러 구성 요소에서의 개선을 보여 왔다:
검색기(retriever), 판독기(reader), 그리고 종단 간(end-to-end) 시스템 학습
검색 방법들은
TF-IDF(Spärck Jones, 1972)와 BM25(Robertson et al., 1995; Roberts et al., 2020)와 같은
전통적인 용어 기반(term-based) 기법들로부터
딥러닝 기반 전략들(Karpukhin et al., 2020; Khattab & Zaharia, 2020; Sachan et al., 2023)로
전환되어 왔다.
일부 최근 연구들은
방대한 지식을 기억할 수 있는 능력 때문에
대규모 언어 모델을 검색기(retriever)로 사용하는 것을 제안한다
(Yu et al., 2022; Sun et al., 2022).
판독기(reader) 구성 요소에 대한 연구로는,
검색을 위해 DPR과 BM25를 모두 사용하고,
인코더에서 지문들을 독립적으로 처리하는
Fusion-in-Decoder(FiD)(Izacard & Grave, 2022)와,
교차 청크 어텐션(cross-chunked attention)과,
청크 단위 검색(chunkwise retrieval)을 활용하여
검색된 컨텍스트에 기반한 텍스트를 생성하는
RETRO(Borgeaud et al., 2022; Wang et al., 2023)가 포함된다.
DPR(Dense Passage Retrieval)는
질문과 문서를 각각 밀집 벡터(dense vector)로 임베딩한 뒤,
벡터 유사도를 기반으로 관련 문서를 검색하는
신경망 기반 검색 기법이다.주로 bi-encoder 구조를 사용하여
질문 인코더와 문서 인코더를 독립적으로 학습한다.
종단 간(end-to-end) 시스템 학습에 관한 연구에는
검색기와 함께 인코더-디코더 모델을 파인튜닝하는
Atlas(Izacard et al., 2022)가 포함된다.
또한, 개방 도메인(open-domain) 질문 응답을 위해 파인튜닝된
양방향(bidirectional) 마스크드 언어 모델인
REALM(Guu et al., 2020)과,
사전 학습된 시퀀스-투-시퀀스 모델을 신경망 검색기와 통합하는
RAG(Retrieval-Augmented Generation)(Lewis et al., 2020)도 포함된다.
Min et al. (2021)은
다중 정답 검색에서 지문의 다양성과 관련성을 처리하기 위해
트리 디코딩 알고리즘을 사용하는
Joint Passage Retrieval(JPR) 모델을 제안하였다.
Dense Hierarchical Retrieval(DHR)과
Hybrid Hierarchical Retrieval(HHR)은
각각 문서(document) 수준과 지문(passage) 수준 검색을 결합하고,
희소(sparse) 검색과 밀집(dense) 검색 방법을 통합함으로써
검색 정확도의 향상을 보여준다
(Liu et al., 2021; Arivazhagan et al., 2023).
방법들의 다양성에도 불구하고,
모델들의 검색 구성 요소는 주로 표준적인 접근법들에 의존한다.
즉, 코퍼스를 청크화하고 BERT 기반 검색기를 사용하여 인코딩하는 방식이다.
이러한 접근법은 널리 채택되고 있지만,
Nair et al. (2023)은 잠재적인 한계를 지적한다.
연속적인 분할(contiguous segmentation)은
텍스트의 전체적인 의미적 깊이를 포착하지 못할 수 있다는 것이다.
기술 문서나 과학 문서로부터 추출된 스니펫(snippet)들을 읽는 것은
중요한 컨텍스트가 결여되어 있을 수 있으며,
이로 인해 읽기 어렵거나 심지어 오해를 불러일으킬 수도 있다
(Cohan & Goharian, 2017; Newman et al., 2023; Zhang et al., 2023).
컨텍스트로서의 재귀적 요약(Recursive summarization as Context)
요약 기법들은 문서에 대한 압축된 관점을 제공함으로써,
콘텐츠에 대해 보다 집중적인 상호작용을 가능하게 한다
(Angelidis & Lapata, 2018).
Gao et al. (2023)의
요약/스니펫 모델(summarization/snippet model)은
지문들의 요약과 스니펫을 사용하며,
이는 대부분의 데이터셋에서 정답 정확도를 향상시키지만
때로는 손실이 있는 압축 수단이 될 수 있다.
Wu et al. (2021)의
재귀적-추상적 요약 모델(recursive-abstractive summarization model)은
작업 분해(task decomposition)를 활용하여
더 작은 텍스트 청크들을 요약하고,
이후 이를 통합하여 더 큰 섹션들에 대한 요약을 형성한다.
이 방법은 더 넓은 주제들을 포착하는 데에는 효과적이지만,
세부적인(granular) 정보들을 놓칠 수 있다.
LlamaIndex(Liu, 2022)는
인접한 텍스트 청크들을 유사하게 요약하는 동시에
중간 노드들을 유지함으로써 다양한 수준의 세부 정보를 저장하고,
세밀한 정보들을 보존함으로써 이 문제를 완화한다.
그러나 두 방법 모두
인접한 노드들을 그룹화하거나 요약하기 위해
인접성(adjacency)에 의존하기 때문에,
텍스트 내에 존재하는
멀리 떨어진 상호의존성(distant interdependencies)을
여전히 간과할 수 있으며,
이는 우리가 RAPTOR를 통해 찾아내고 그룹화할 수 있는 부분이다.
3 방법(Methods)
RAPTOR 개요
긴 텍스트는 보통 하위 주제들과 계층적 구조를 제시한다는 아이디어에 기반하여
(Cao & Wang, 2022; Dong et al., 2023b),
RAPTOR는
세밀한 정보들에 대한 더 넓은 주제적 이해(thematic comprehension)를 제공하고,
노드들이 텍스트 내의 순서뿐만 아니라
의미적 유사성에 기반하여 그룹화될 수 있도록 하는
재귀적 트리 구조를 구축함으로써,
읽기 과정에서의 의미적(semantic) 깊이와 연결성의 문제를 다룬다.
RAPTOR 트리의 구성(construction)은
전통적인 검색 증강 기법들과 유사하게
검색 코퍼스(retrieval corpus)를
길이 100의 짧고 연속적인 텍스트들(short, contiguous texts)로
분할하는 것에서 시작된다.
한 문장에 의해 100 토큰 제한을 초과하는 경우,
문장 중간에서 잘라내는 대신 문장 전체를 다음 청크로 이동시킨다.
이는 각 청크 내에서 텍스트의 맥락적 및 의미적 일관성
(contextual and semantic coherence)을 보존한다.
이러한 텍스트들은 이후 BERT 기반 인코더인 SBERT
(multi-qa-mpnet-base-cos-v1)를 사용하여
임베딩된다 (Reimers & Gurevych, 2019).
이러한 청크들과 이에 대응하는 SBERT 임베딩들은
우리의 트리 구조에서 리프 노드(leaf nodes)를 형성한다.
유사한 텍스트 청크들을 묶기 위해,
우리는 클러스터링 알고리즘을 사용한다.
클러스터링이 완료되면, 그룹화된 텍스트들을 요약하기 위해
언어 모델(Language Model)을 사용한다.
이렇게 요약된 텍스트들은 이후 다시 임베딩되며,
임베딩, 클러스터링, 요약의 순환 과정은
추가적인 클러스터링이 불가능해질 때까지 계속된다.
그 결과, 원본 문서들에 대한
구조화된 다층(multi-layered) 트리 표현이 형성된다.
RAPTOR의 중요한 특징 중 하나는
계산 효율성(computational efficiency)이다.
이 시스템은
구성 시간(build time)과 토큰 소모(token expenditure)
양쪽 모두에서 선형적으로 확장되며,
이로 인해 크고 복잡한 코퍼스(corpora)를 처리하는 데 적합하다.
RAPTOR의 확장성(scalability)에 대한 포괄적인 논의는
부록 Appendix A를 참조하라.
이 트리 내에서의 질의를 위해,
우리는 두 가지 서로 다른 전략을 도입한다:
트리 순회(tree traversal)와 축약된 트리(collapsed tree)이다.
트리 순회 방법은
트리를 층별(layer-by-layer)로 순회하며,
각 수준에서 가장 관련성 높은 노드들을
가지치기(pruning)하고 선택한다.
축약된 트리 방법은
모든 계층에 걸쳐 노드들을 집합적으로(collectively) 평가하여,
가장 관련성 높은 노드들을 찾는다.
클러스터링 알고리즘(Clustering Algorithm)
클러스터링은 RAPTOR 트리를 구축하는 데에서 핵심적인 역할을 수행하며,
텍스트 조각들을 응집력 있는 그룹들로 조직화한다.
이 단계는 관련된 콘텐츠를 함께 묶어 주며, 이는 이후의 검색 과정을 도와준다.
우리의 클러스터링 접근법의 고유한 특징 중 하나는
고정된 클러스터 수를 요구하지 않으면서
노드들이 여러 클러스터에 속할 수 있도록 하는
소프트 클러스터링(soft clustering)의 사용이다.
이러한 유연성은 개별 텍스트 조각들이 종종
다양한 주제들과 관련된 정보를 포함하고 있으며,
그 결과 이들이 여러 요약들에 포함되는 것이 타당하기 때문에 필수적이다.
우리의 클러스터링 알고리즘은
유연성과 확률적 프레임워크를 모두 제공하는 접근법인
가우시안 혼합 모델(Gaussian Mixture Models, GMMs)에 기반한다.
GMM은 데이터 포인트들이
여러 개의 가우시안 분포들의 혼합으로부터 생성된다고 가정한다.
$N$개의 텍스트 조각들로 이루어진 집합이 주어졌다고 할 때,
각각은 $d$차원의 밀집 벡터 임베딩으로 표현되며,
$k$번째 가우시안 분포에 속한다는 조건 하에서,
텍스트 벡터 $\mathbf{x}$의 가능도(likelihood)는
다음과 같이 표기된다.
전체 확률 분포는
가중 결합(weighted combination)으로 주어지며,
다음과 같이 표현된다.
여기서 $\pi_k$는
$k$번째 가우시안 분포에 대한
혼합 가중치(mixture weight)를 의미한다.
벡터 임베딩의 높은 차원은 고차원 공간에서 유사도를 측정할 때
거리 척도(distance metrics)가 잘 동작하지 않을 수 있기 때문에,
전통적인 가우시안 혼합 모델(GMMs)에 문제가 된다
(Aggarwal et al., 2001).
이를 완화하기 위해,
우리는 차원 축소를 위한 매니폴드 학습 기법인
Uniform Manifold Approximation and Projection(UMAP)을 사용한다
(McInnes et al., 2018).
UMAP에서 최근접 이웃의 개수를 나타내는 n_neighbors 파라미터는
로컬 구조(local structures)와
전역 구조(global structures)를
보존하는 것 사이의 균형을 결정한다.
우리의 알고리즘은 계층적 클러스터링 구조를 생성하기 위해
n_neighbors를 변화시키며,
먼저 전역 클러스터들을 식별한 다음,
이러한 전역 클러스터들 내부에서 로컬 클러스터링을 수행한다.
이러한 두 단계의 클러스터링 과정은
광범위한 주제들로부터 구체적인 세부 사항들에 이르기까지,
텍스트 데이터들 사이의 폭넓은 관계 스펙트럼을 포착한다.
로컬 클러스터의 결합된 컨텍스트가
요약 모델의 토큰 임계값을 초과하게 되는 경우,
우리의 알고리즘은
해당 클러스터 내부에서 재귀적으로 클러스터링을 적용하여,
컨텍스트가 토큰 임계값 내에 유지되도록 보장한다.
최적의 클러스터 수를 결정하기 위해,
우리는 모델 선택을 위해
베이지안 정보 기준(Bayesian Information Criterion, BIC)을 사용한다.
BIC는 모델의 복잡도를 벌점화(penalize)할 뿐만 아니라,
적합도의 우수성(goodness of fit) 또한 보상한다
(Schwarz, 1978).
주어진 가우시안 혼합 모델(GMM)에 대한
BIC는 다음과 같이 정의된다.
여기서 $N$은 텍스트 조각들(또는 데이터 포인트들)의 개수이며,
$k$는 모델 파라미터의 개수이고,
$\hat{L}$은 모델의 가능도 함수의 최대화된 값이다.
GMM의 컨텍스트에서,
모델 파라미터의 개수를 나타내는 값 $k$는
입력 벡터들의 차원과 클러스터의 개수에 의해 결정된다.
BIC에 의해 결정된 최적의 클러스터 수를 바탕으로,
이후 기대-최대화(Expectation-Maximization) 알고리즘을 사용하여
GMM의 파라미터들, 즉 평균(means), 공분산(covariances),
그리고 혼합 가중치(mixture weights)를 추정한다.
GMM에서의 가우시안 가정은,
종종 희소하고 치우친 분포(sparse and skewed distribution)를 보이는
텍스트 데이터의 특성과 완벽하게 일치하지 않을 수 있지만,
우리의 경험적 관찰은
이 모델이 우리의 목적에 대해 효과적인 모델을 제공함을 시사한다.
우리는 GMM 클러스터링을, 연속적인 청크들을 요약하는 방법과 비교하는
소거 실험(ablation)을 수행하였으며,
그에 대한 자세한 내용은 부록 Appendix B에 제시한다.
모델 기반 요약(Model-Based Summarization)
가우시안 혼합 모델을 사용하여 노드들을 클러스터링한 이후,
각 클러스터에 속한 노드들은 요약을 위해 언어 모델로 전달된다.
이 단계는 모델이 큰 텍스트 청크들을
선택된 노드들에 대한 간결하고 일관된 요약으로
변환할 수 있도록 한다.
우리의 실험에서는, 요약을 생성하기 위해
gpt-3.5-turbo를 사용한다.
요약 단계는 잠재적으로 매우 클 수 있는 검색된 정보의 양을
관리 가능한 크기로 압축한다.
우리는 요약으로 인해 발생하는 압축에 대한 통계를
부록 Appendix C에 제공하며,
요약에 사용된 프롬프트는
부록 Appendix D에 제시한다.
요약 모델은 일반적으로 신뢰할 수 있는 요약을 생성하지만,
집중된 주석(annotation) 연구를 통해
요약의 약 4%가 경미한 환각(hallucinations)을
포함하고 있음이 밝혀졌다.
이러한 환각들은 상위 노드(parent nodes)로 전파되지 않았으며,
질의응답 과제(question-answering tasks)에
식별 가능한 영향도 미치지 않았다.
환각에 대한 심층 분석은 부록 Appendix E를 참조하라.
질의(Querying)
이 절에서는 RAPTOR에서 사용되는 두 가지 질의 메커니즘,
즉 트리 순회(tree traversal)와
축약된 트리(collapsed tree)에 대해 자세히 설명한다.
이러한 방법들은 다층 구조의 RAPTOR 트리를 순회하여
관련 정보를 검색하는 서로 다른 방식을 제공하며,
각각 고유한 장점과 트레이드오프를 가진다.
우리는 두 방법 모두에 대한 의사코드(pseudocode)를
부록 Appendix F에 제공한다.
모든 노드들은 SBERT를 사용하여 임베딩된다는 점에 유의하라.
트리 순회(tree traversal) 방법은 먼저,
질의 임베딩에 대한 코사인 유사도를 기준으로
가장 관련성이 높은 상위 $k$개의 루트 노드들을 선택한다.
이렇게 선택된 노드들의 자식 노드들은 다음 계층에서 고려되며,
이 풀(pool)로부터 다시
질의 벡터에 대한 코사인 유사도를 기준으로
상위 $k$개의 노드들이 선택된다.
이 과정은 리프(leaf) 노드에 도달할 때까지 반복된다.
마지막으로, 선택된 모든 노드들로부터의 텍스트가 연결(concatenated)되어
검색된 컨텍스트(retrieved context)을 형성한다.
알고리즘의 단계들은 아래에 개요로 제시되어 있다.
RAPTOR 트리의 루트 계층에서 시작한다.
질의 임베딩과 이 초기 계층에 존재하는 모든 노드들의 임베딩들 사이의
코사인 유사도를 계산한다.가장 높은 코사인 유사도 점수에 기반하여,
상위 $k$개의 노드들을 선택하여,
집합 $S_1$을 형성한다.집합 $S_1$에 속한 요소들의 자식 노드들로 이동한다.
질의 벡터와 이들 자식 노드들의 벡터 임베딩들 사이의
코사인 유사도를 계산한다.질의에 대해 가장 높은 코사인 유사도 점수를 갖는
상위 $k$개의 자식 노드들을 선택하여,
집합 $S_2$를 형성한다.이 과정을 $d$개의 계층에 대해 재귀적으로 계속 수행하여,
집합 $S_1, S_2, \ldots, S_d$를 생성한다.집합 $S_1$부터 $S_d$까지를 연결(concatenate)하여,
질의에 대한 관련 컨텍스트(relevant context)을 구성한다.
각 계층에서 선택되는 노드의 수 $k$와 깊이 $d$를 조정함으로써,
트리 순회 방법은 검색되는 정보의 구체성(specificity)과
범위(breadth)에 대한 제어를 제공한다.
이 알고리즘은 트리의 상위 계층들을 고려함으로써
넓은 관점(broad outlook)에서 시작하며,
하위 계층들을 따라 내려가면서
점진적으로 더 세밀한 세부 사항들에 집중한다.
그림 2: 트리 순회와 축약된 트리 검색 메커니즘의 도식적 설명
트리 순회는 트리의 루트 레벨에서 시작하여,
질의 벡터에 대한 코사인 유사도에 기반해
상위 $k$개(여기서는 top-1)의 노드(들)를 검색한다.
각 수준에서, 이전 계층의 상위 $k$개 노드들의
자식 노드들로부터 상위 $k$개 노드(들)를 검색한다.
축약된 트리는 트리를 단일 계층으로 축약하고,
질의 벡터에 대한 코사인 유사도에 기반하여
토큰의 개수가 임계값에 도달할 때까지 노드들을 검색한다.
코사인 유사도 검색이 수행되는 노드들은
두 도식 모두에서 강조 표시되어 있다.
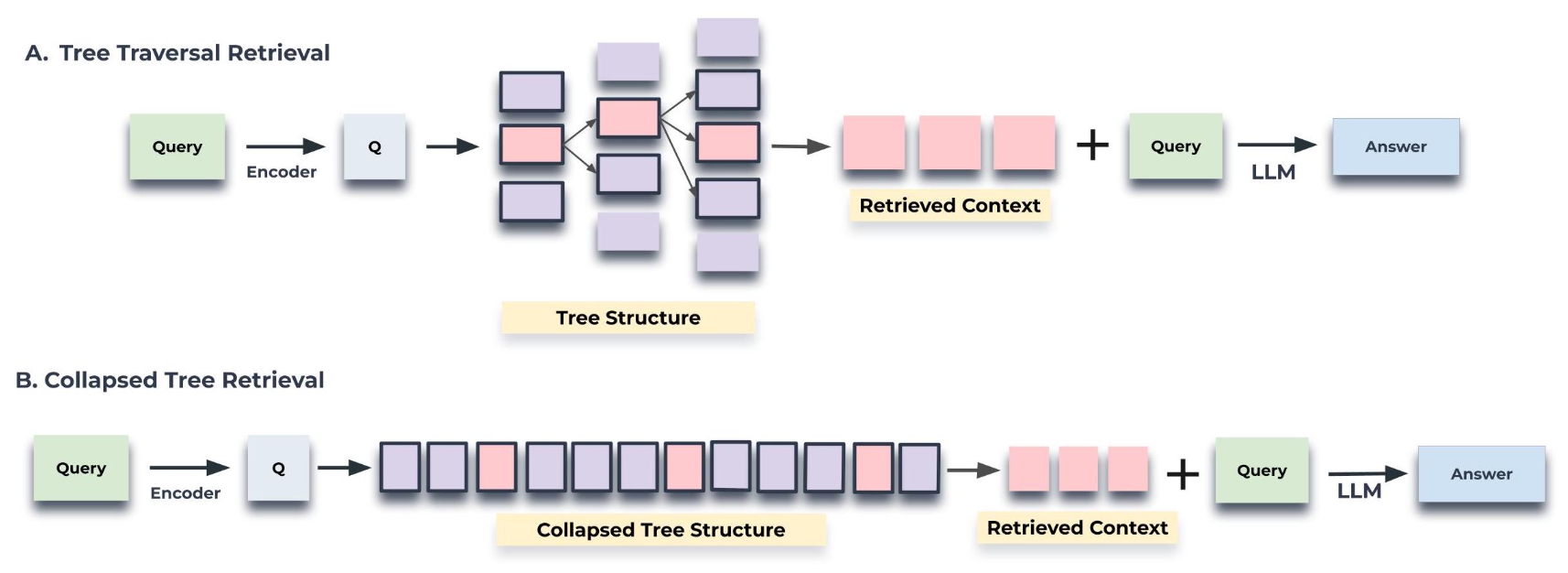
축약된 트리(collapsed tree) 접근법은 그림 2에 나타난 바와 같이,
트리 내의 모든 노드들을 동시에 고려함으로써
관련 정보를 검색하는 더 단순한 방식을 제공한다.
계층별(layer-by-layer)로 이동하는 대신,
이 방법은 다층 구조의 트리를 단일 계층으로 평탄화하여,
본질적으로 모든 노드들을 비교를 위해 동일한 수준으로 가져온다.
이 방법의 단계들은 아래에 개요로 제시되어 있다.
먼저, 전체 RAPTOR 트리를 단일 계층으로 축약한다.
$C$로 표기되는 이 새로운 노드 집합은
원래 트리의 모든 계층으로부터의 노드들을 포함한다.다음으로, 질의 임베딩과 축약된 집합 $C$에 존재하는
모든 노드들의 임베딩들 사이의 코사인 유사도를 계산한다.마지막으로, 질의에 대해 가장 높은 코사인 유사도 점수를 갖는
상위 $k$개의 노드들을 선택한다.
사전에 정의된 최대 토큰 수에 도달할 때까지
결과 집합에 노드들을 계속 추가하되,
모델의 입력 제한을 초과하지 않도록 보장한다.
그림 3: 질의 방법들의 비교
서로 다른 top-$k$ 값들을 사용한 트리 순회와,
서로 다른 컨텍스트 길이를 사용한 축약된 트리를 이용하여,
QASPER 데이터셋의 20개 스토리에 대한 결과를 제시한다.
2000 토큰을 사용하는 축약된 트리는 가장 좋은 결과를 산출하므로,
우리는 주요 결과(main results)를 위해 이 질의 전략을 사용한다.
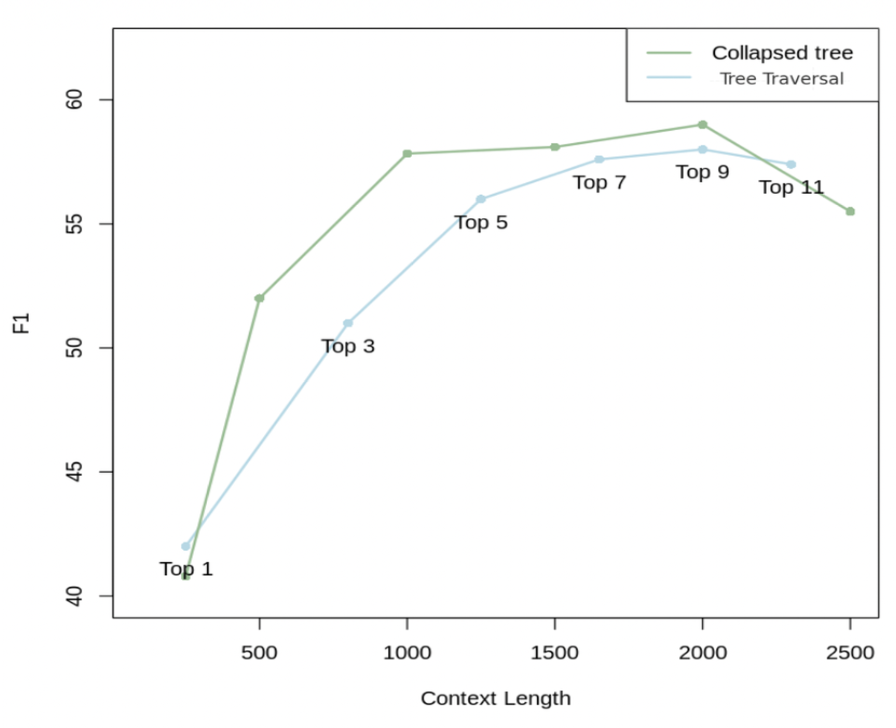
우리는 QASPER 데이터셋의 20개 스토리에 대해
두 가지 접근법 모두를 테스트하였다.
그림 3은 서로 다른 top-$k$ 값들을 사용한 트리 순회와,
서로 다른 최대 토큰 수를 사용한 축약된 트리의 성능을 보여준다.
축약된 트리 접근법은 일관되게 더 나은 성능을 보인다.
우리는 축약된 트리 검색이 트리 순회보다
더 큰 유연성을 제공하기 때문에 더 우수하다고 믿는다;
즉, 모든 노드들을 동시에 검색함으로써 주어진 질문에 대해
올바른 세분성 수준(correct level of granularity)에 있는
정보를 검색해낸다.
이에 비해, 동일한 $d$와 $k$ 값을 사용하여 트리 순회를 수행할 경우,
트리의 각 계층으로부터 선택되는 노드들의 비율은 일정하게 유지된다.
따라서,
고차 주제 정보(higher-order thematic information)와
세밀한 세부 정보(granular details) 사이의 비율은
질문과 무관하게 동일하게 유지된다.
그러나 축약된 트리 접근법의 한 가지 단점은
트리 내의 모든 노드들에 대해
코사인 유사도 검색을 수행해야 한다는 점이다.
하지만 이는 FAISS와 같은
빠른 $k$-최근접 이웃(k-nearest neighbor) 라이브러리를 사용함으로써
더 효율적으로 만들 수 있다 (Johnson et al., 2019).
전반적으로, 축약된 트리 접근법이 지닌 더 큰 유연성과
QASPER 데이터셋의 부분집합에서 보인 우수한 성능을 고려할 때,
우리는 이 질의 접근법을 사용하여 이후의 절차를 진행한다.
구체적으로, 우리는 최대 2000 토큰을 사용하는
축약된 트리를 사용하며, 이는 대략적으로
상위 20개의 노드들을 검색하는 것에 해당한다.
토큰 기반 접근법을 사용하는 것은,
노드들마다 토큰 수가 달라질 수 있기 때문에,
컨텍스트가 모델의 컨텍스트 제약을 초과하지 않도록 보장한다.
UnifiedQA 모델을 사용하는 실험의 경우,
UnifiedQA의 최대 컨텍스트 길이가 512 토큰이므로,
우리는 400 토큰의 컨텍스트를 제공한다.
우리는 RAPTOR와 베이스라인들 모두에 대해
동일한 양의 컨텍스트 토큰을 제공한다.
정성적 연구(Qualitative Study)
우리는 Dense Passage Retrieval(DPR) 방법들과 비교하여
RAPTOR의 검색 과정이 제공하는 이점을 이해하기 위해
정성적 분석을 수행한다.
우리의 연구는 1500단어로 이루어진 신데렐라 동화를 사용한
주제적(thematic)이며 다중 홉(multi-hop) 질문들에
초점을 맞춘다.
그림 4에 나타난 바와 같이, RAPTOR의 트리 기반 검색은
질문의 세부 수준(detail level)에 맞추어
서로 다른 트리 계층들로부터 노드들을 선택할 수 있도록 한다.
이러한 접근법은 DPR에 비해 다운스트림 과제들에 대해
더 관련성이 높고 더 포괄적인 정보를 제공하는 경우가 많다.
RAPTOR와 DPR이 특정 질문들에 대해 검색한 텍스트를 포함한
자세한 논의와 예시를 위해서는, 부록 Appendix G를 참조하라.
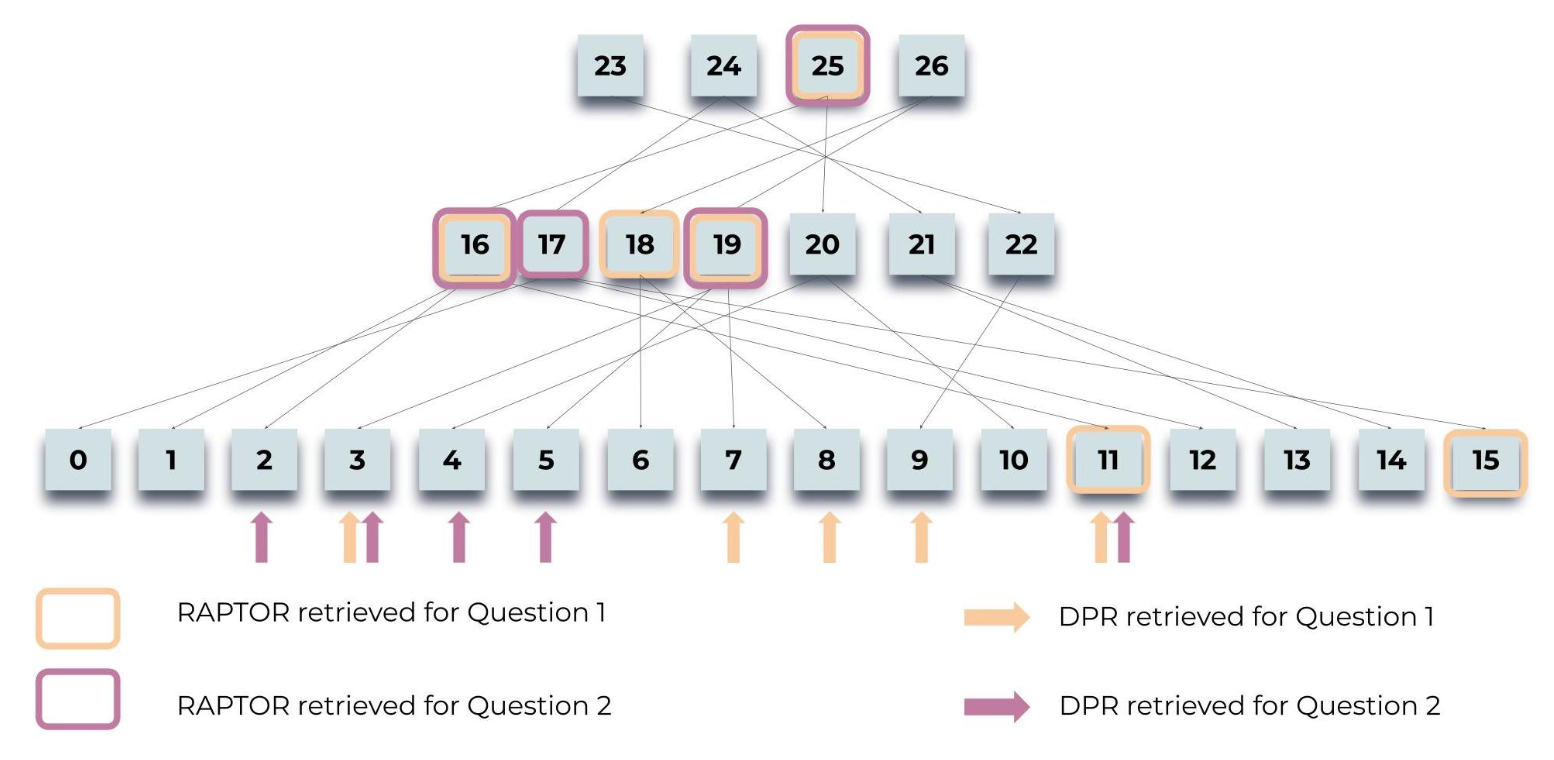
그림 4: 질의 과정(Querying Process):
신데렐라(Cinderella) 이야기와 관련된 두 가지 질문,
즉 “이 이야기의 중심 주제는 무엇인가?”와
“신데렐라는 어떻게 행복한 결말을 맞이했는가?”에 대해
RAPTOR가 정보를 검색하는 방식을 도식적으로 보여준다.
강조 표시된 노드들은 RAPTOR의 선택을 나타내며,
화살표는 DPR의 리프 노드들을 가리킨다.
주목할 만하게도, RAPTOR의 맥락은
직접적으로 또는 상위 계층 요약들 내에서,
DPR에 의해 검색된 정보를 종종 포괄한다.
4 실험 (Experiments)
데이터셋(Datasets)
우리는 세 가지 질의응답 데이터셋,
즉 NarrativeQA, QASPER, 그리고 QuALITY에 걸쳐
RAPTOR의 성능을 측정한다.
NarrativeQA는 책과 영화 대본의 전체 텍스트를 기반으로 한
질문–답변 쌍들로 구성된 데이터셋으로, 총 1,572개의 문서로 이루어져 있다
(Kociský et al., 2018; Wu et al., 2021).
NarrativeQA-Story 과제는 질문에 정확하게 답변하기 위해
전체 내러티브에 대한 포괄적인 이해를 요구하며,
이를 통해 문학 도메인에서 더 긴 텍스트를 이해하는 모델의 능력을 평가한다.
우리는 이 데이터셋에서의 성능을
표준 BLEU (B-1, B-4), ROUGE (R-L),
그리고 METEOR (M) 지표를 사용하여 측정한다.
우리의 실험에서 사용된 NarrativeQA 평가 스크립트에 대한
추가적인 세부 사항은 부록 Appendix H를 참조하라.
QASPER 데이터셋은 1,585편의 NLP 논문에 걸쳐 5,049개의 질문을 포함하며,
각 질문은 전체 텍스트 내에 내재된 정보를 탐색하도록 구성되어 있다
(Dasigi et al., 2021).
QASPER에서의 답변 유형은
답변 가능/답변 불가능, 예/아니오, 추상적, 그리고 추출형으로 분류된다.
정확도는 표준 F1을 사용하여 측정된다.
마지막으로, QuALITY 데이터셋은 객관식 질문들로 구성되어 있으며,
각 질문에는 평균적으로 약 5,000 토큰 길이의 컨텍스트 문단들이 함께 제공된다
(Pang et al., 2022).
이 데이터셋은 질의응답 과제를 위해 전체 문서에 걸친 추론을 요구하며,
이를 통해 중간 길이 문서들에서의 우리 검색 시스템의 성능을 측정할 수 있도록 한다.
이 데이터셋에는 QuALITY-HARD라는 도전적인 부분집합이 포함되어 있는데,
이는 속도 제한이 있는 설정에서 대다수의 인간 주석자들이 잘못 답변한 질문들을 포함한다.
우리는 전체 테스트 세트와 HARD 부분집합 모두에 대해 정확도를 보고한다.
통제된 베이스라인 비교(Controlled Baseline Comparisons)
우리는 먼저 UnifiedQA 3B를 리더(reader)로 사용하고,
SBERT (Reimers & Gurevych, 2019), BM25 (Robertson et al., 1995; 2009),
그리고 DPR (Karpukhin et al., 2020)을 임베딩 모델로 사용하여,
RAPTOR 트리 구조를 사용한 경우와 사용하지 않은 경우에 대해
세 개의 데이터셋, 즉 QASPER, NarrativeQA, 그리고 QuALITY에서
통제된 비교를 제시한다.
표 1과 표 2에서 보이듯이,
우리의 결과는 RAPTOR가 어떤 검색기(retriever)와 결합되더라도
모든 데이터셋 전반에 걸쳐 해당 검색기 자체보다
일관되게 더 우수한 성능을 보인다는 것을 보여준다. 2
2 표 1과 표 2의 DPR 실험을 위해,
우리는 앞선 실험들의 나머지 부분에서 사용되었던dpr-single-nq-base와는 달리
dpr-multiset-base모델을 사용하였다.이 결정은 Karpukhin et al. (2020)에서 관찰된 성능에 근거한 것으로,
해당 연구에서dpr-multiset-base가 더 우수한 결과를 보였기 때문이다.
표 1: RAPTOR 적용 및 미적용 시 NarrativeQA 성능:
UnifiedQA-3B를 언어 모델로 사용하여, NarrativeQA 데이터셋에서
RAPTOR 적용 여부에 따른 다양한 검색 방법(SBERT, BM25, DPR)의 성능을 비교한다.
RAPTOR는 각 검색 방법에 대한 베이스라인을 상회하는 성능을 보인다.
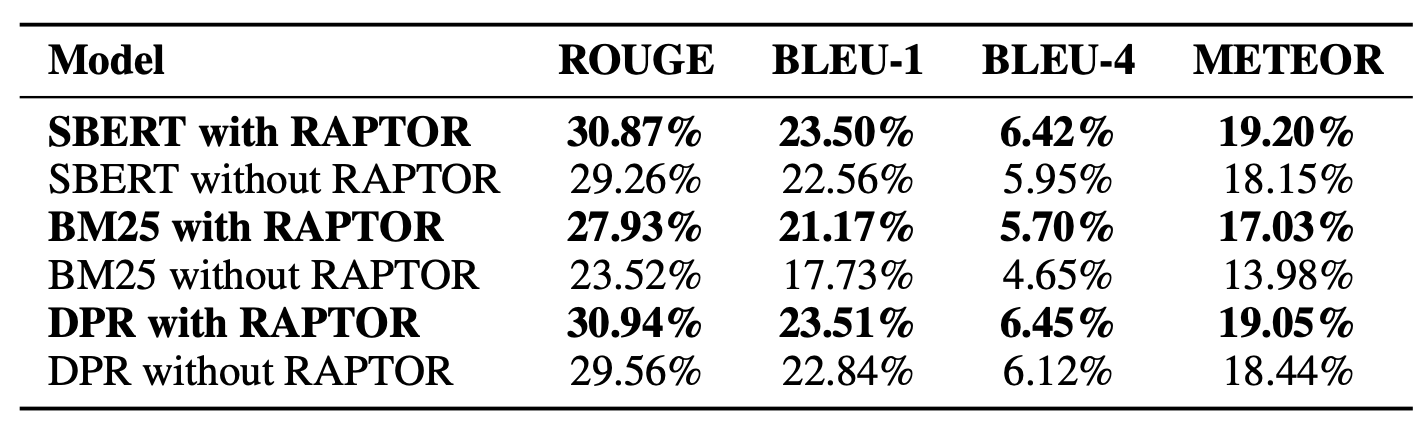
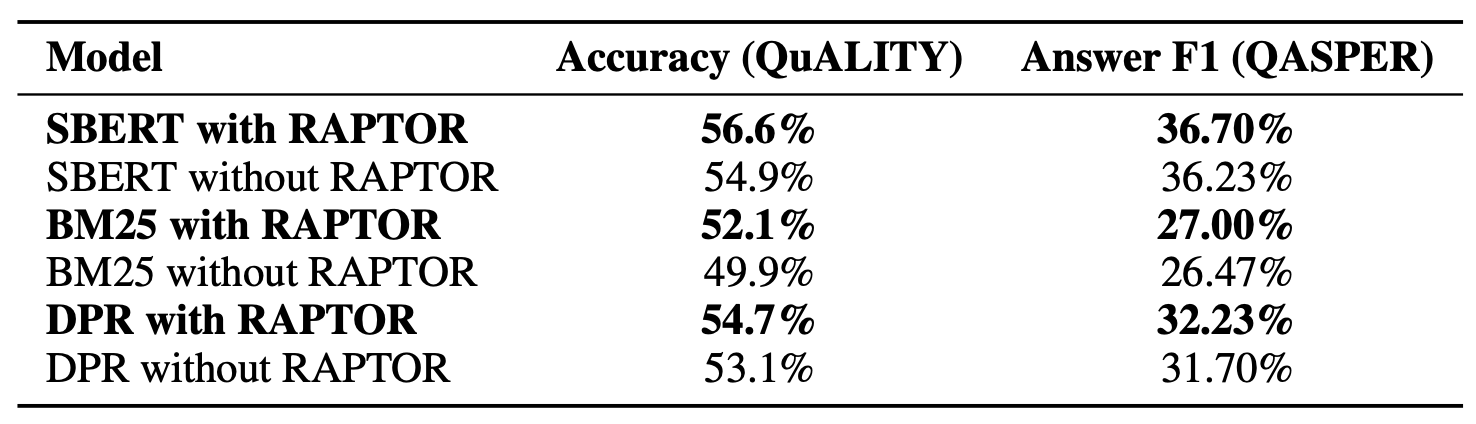
표 2: RAPTOR 적용 및 미적용 시 QuALITY 및 QASPER 성능:
UnifiedQA-3B를 언어 모델로 사용하여,
QuALITY 및 QASPER 데이터셋에서 RAPTOR 적용 여부에 따른
다양한 검색 방법(SBERT, BM25, DPR)의 성능을 비교한다.
RAPTOR는 두 데이터셋 모두에서 각 검색 방법의 베이스라인을 상회하는 성능을 보인다.
SBERT와 결합된 RAPTOR가 가장 좋은 성능을 보이므로,
우리는 이후의 모든 실험에서 이를 사용한다.
이제 우리는 세 가지 서로 다른 LLM, 즉 GPT-3, GPT-4, 그리고 UnifiedQA를 사용하여
RAPTOR를 BM25 및 DPR과 비교한다.
표 3에 나타난 바와 같이, RAPTOR는 QASPER 데이터셋에서
세 가지 언어 모델 모두에 걸쳐 BM25와 DPR을 일관되게 상회하는 성능을 보인다.
RAPTOR의 F1 매치 점수는 각각 GPT-3, GPT-4, UnifiedQA를 사용할 때
53.1%, 55.7%, 36.6%이다.
이 점수들은 DPR을 각각 1.8, 2.7, 4.5 포인트 차이로 상회하며,
각각의 LLM에 대해 BM25를 6.5, 5.5, 10.2 포인트 차이로 능가한다.
QASPER는 NLP 논문 내의 정보를 종합하는 것을 요구하므로,
RAPTOR의 상위 수준 요약 노드들이
단지 가장 유사한 상위 $k$개의 원시(raw) 텍스트 청크만을 추출할 수 있는 방법들보다
더 우수한 성능을 보이는 것은 놀라운 일이 아니다.
이러한 원시 텍스트 청크들은 개별적으로는(in isolation)
올바른 응답을 포함하지 않을 수도 있다.
표 3: QASPER 데이터셋에서의 F-1 점수에 대한 통제된 비교,
세 가지 서로 다른 언어 모델(GPT-3, GPT-4, UnifiedQA 3B)과
다양한 검색 방법을 사용한다.
“Title + Abstract” 열은
논문의 제목과 초록만을 컨텍스트로 사용할 때의 성능을 반영한다.
RAPTOR는 테스트된 모든 언어 모델에 걸쳐
기존 베이스라인인 BM25와 DPR을 상회하는 성능을 보인다.
구체적으로, RAPTOR의 F-1 점수는
DPR보다 최소 1.8%포인트 높고,
BM25보다 최소 5.3%포인트 더 높다.

마찬가지로, 표 4에 나타난 바와 같이 QuALITY 데이터셋에서도
RAPTOR는 62.4%의 정확도를 달성하며,
이는 DPR과 BM25에 비해 각각 2%와 5.1%의 향상이다.
UnifiedQA를 사용하는 경우에도 유사한 경향이 관찰되며,
이때 RAPTOR는 각각 2.7%와 6.7%의 차이로
DPR과 BM25를 상회한다.
표 4: 다양한 검색 방법을 사용하여
두 가지 서로 다른 언어 모델(GPT-3, UnifiedQA 3B)에 대해
QuALITY 개발(dev) 데이터셋에서의 정확도를 비교한다.
RAPTOR는 정확도 기준으로
BM25와 DPR의 베이스라인을 최소 2.0% 상회한다.

마지막으로, 표 6에 제시된 바와 같이 NarrativeQA 데이터셋에서도
RAPTOR는 여러 지표 전반에 걸쳐 뛰어난 성능을 보인다.
ROUGE-L의 경우, RAPTOR는
BM25와 DPR을 각각 7.3포인트와 2.7포인트 차이로 상회한다.
BLEU-1, BLEU-4, METEOR와 같은 다른 지표들에서도
RAPTOR는 BM25를 1.7에서 5.8포인트 범위로,
DPR을 0.7에서 2.1포인트 범위로 각각 능가한다.
표 5: QASPER 데이터셋에서의 다양한 모델들의 F-1 매치 점수 결과

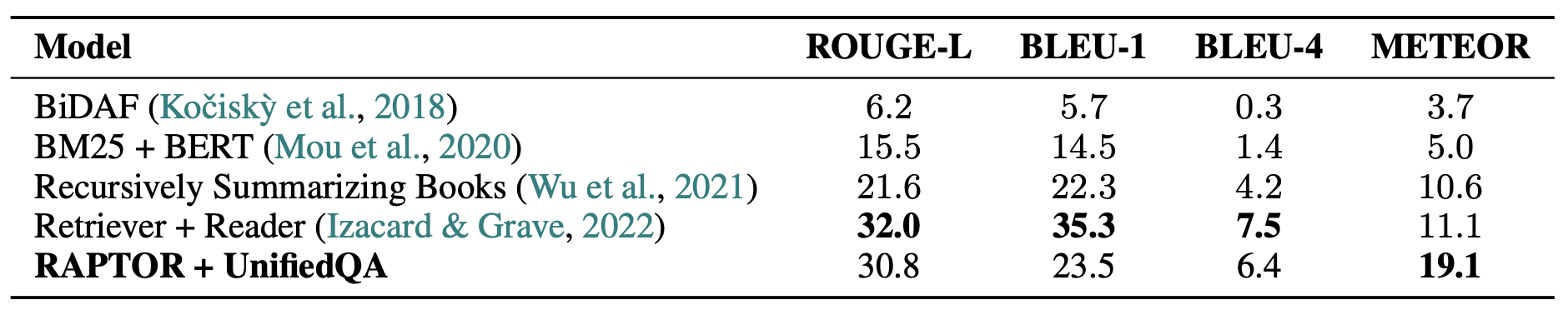
표 6: 여러 모델에 걸친 NarrativeQA 데이터셋에서의 성능 비교,
네 가지 지표인 ROUGE-L, BLEU-1, BLEU-4, 그리고 METEOR에 초점을 둔다.
RAPTOR는 UnifiedQA 3B와 결합되었을 때,
BM25와 DPR과 같은 검색 방법들을 능가할 뿐만 아니라
METEOR 지표에서 새로운 최신 성능(state-of-the-art)을 설정한다.
METEOR 지표는 기계 번역 및 질의응답과 같은 자연어 생성 과제에서
생성된 문장 $\hat{y}$ 가 정답 문장 $y$ 와 얼마나 의미적으로 유사한지를 평가하는 지표이다.METEOR의 핵심은
두 문장을 단순한 문자열로 비교하지 않고,
단어 수준에서 의미적 대응 관계를 먼저 정의한 뒤 이를 기반으로 점수를 계산한다는 점에 있다.이를 위해 가장 먼저 수행되는 단계가
단어 정렬(alignment)이다.단어 정렬이란,
생성 문장 $\hat{y}$ 의 단어들과
정답 문장 $y$ 의 단어들 중에서
의미적으로 동일하거나 매우 유사하다고 판단되는 단어들을 1:1로 대응시키는 과정을 의미한다.이때 METEOR는
단순한 표면적 일치만을 허용하지 않고,
다음과 같은 점진적인 기준을 사용하여 정렬을 수행한다.(1) 완전 일치(exact match)
두 단어의 표기가 완전히 동일한 경우
(2) 어근 일치(stemming)
형태는 다르지만 동일한 어근을 공유하는 경우
(3) 동의어 매칭(synonym matching)
의미적으로 동일하다고 판단되는 단어 쌍
이러한 기준을 통해,
생성 문장과 정답 문장 사이에서
최대 개수의 단어를 서로 겹치지 않게 1:1로 대응시키는 정렬이 선택된다.이 과정의 결과로 얻어지는
정렬된 단어 쌍의 총 개수를 $m$ 이라고 한다.이후 METEOR는
이 $m$ 값을 기준으로
생성 문장이 정답 문장의 내용을 얼마나 충분히 포함하고 있는지,
그리고 생성 문장의 단어들이 얼마나 정확하게 사용되었는지를
정량적으로 평가한다.구체적으로,
\[\text{Precision} = P = \frac{m}{\mid \hat{y} \mid}\] \[\text{Recall} = R = \frac{m}{\mid y \mid}\]
생성 문장의 단어 수를 $|\hat{y}|$,
정답 문장의 단어 수를 $|y|$ 라고 할 때,
정밀도와 재현율은 다음과 같이 정의된다.METEOR는 재현율을 더 중요하게 반영하기 위해
\[F_{\text{mean}} = \frac{P \cdot R}{\alpha P + (1-\alpha) R}\]
정밀도와 재현율의 가중 조화 평균을 사용한다.
일반적으로 $\alpha = 0.9$ 를 사용하며,
기본 점수는 다음과 같이 계산된다.이후 단어 정렬 결과가 문장 내에서 얼마나 연속적인지를 반영하기 위해
\[\text{Penalty} = \gamma \left( \frac{c}{m} \right)^\beta\]
파편화(fragmentation) 패널티를 적용한다.
정렬된 단어들이 $c$ 개의 연속 구간(chunks)으로 나뉘어 있을 때,
패널티는 다음과 같이 정의된다.여기서 $\gamma$ 와 $\beta$ 는 경험적으로 설정되는 하이퍼파라미터이다.
최종 METEOR 점수는 기본 점수에 패널티를 적용하여 계산된다.
\[\text{METEOR} = (1 - \text{Penalty}) \cdot F_{\text{mean}}\]이와 같이 METEOR는
단어 의미 수준의 일치, 정보 누락 여부, 그리고 단어 순서의 자연스러움을
동시에 고려하여 점수를 산출한다.이러한 특성으로 인해 METEOR 지표는
BLEU와 같은 단순 n-그램 기반 지표보다
인간의 의미적 판단과 더 높은 상관관계를 보이는 것으로 알려져 있다.
최신 기법 시스템과의 비교(Comparison to State-of-the-art Systems)
우리의 통제된 비교 결과를 바탕으로,
우리는 RAPTOR의 성능을 다른 최신(state-of-the-art) 모델들과 비교하여 분석한다.
표 5에 나타난 바와 같이, GPT-4와 결합된 RAPTOR는 QASPER에서
$55.7\%$의 F-1 점수로 새로운 기준을 설정하며,
$53.9\%$의 점수를 기록한 CoLT5 XL을 상회한다.
표 7에 나타난 바와 같이 QuALITY 데이터셋에서 GPT-4와 결합된 RAPTOR는
$82.6\%$의 정확도로 새로운 최신(state-of-the-art) 성능을 달성하며,
기존 최고 성과였던 $62.3\%$를 상회한다.
특히, 이는 QuALITY-HARD에서 CoLISA를 $21.5\%$만큼 상회하는 성능으로,
QuALITY-HARD는 인간이 정답을 맞히는 데 이례적으로 긴 시간이 걸렸던 질문들을 나타내며,
텍스트의 일부를 다시 읽어야 하거나, 어려운 추론을 요구하거나,
또는 그 둘 모두를 요구하는 경우에 해당한다.
표 7: QuALITY 데이터셋에서 전체 테스트 세트와 더 도전적인 하드 하위 집합 모두에 대한 정확도.
RAPTOR와 결합된 GPT-4는 새로운 최신(state-of-the-art) 성능을 달성한다.

NarrativeQA 데이터셋에 대해, 표 6에 제시된 바와 같이,
UnifiedQA와 결합된 RAPTOR는
새로운 최신(state-of-the-art) METEOR 점수를 달성한다.
또한 UnifiedQA를 동일하게 사용하는
Wu et al. (2021)의 재귀적 요약 모델과 비교했을 때,
RAPTOR는 모든 지표에서 이를 상회한다.
Wu et al. (2021)이
트리 구조의 최상위 루트 노드에 있는 요약에만 전적으로 의존하는 반면,
RAPTOR는 중간 계층과 클러스터링 접근법으로부터 이점을 얻으며,
이를 통해 일반적인 주제에서부터 구체적인 세부 사항에 이르기까지
다양한 범위의 정보를 포착할 수 있고,
이는 전반적으로 강력한 성능에 기여한다.
4.1 트리 구조의 기여 (CONTRIBUTION OF THE TREE STRUCTURE)
우리는 RAPTOR의 검색 능력에 대해 각 노드 계층이 기여하는 바를 분석한다.
우리는 상위 노드들이 텍스트에 대한 보다 폭넓은 이해를 요구하는
주제적 질문이나 멀티홉 질문을 처리하는 데에서
중요한 역할을 한다고 가설을 세웠다.
우리는 이 가설을 정량적 및 정성적으로 모두 검증하였다.
정성적 분석은 부록 G에서 제시한다.
상위 계층 노드의 기여를 정량적으로 이해하기 위해,
우리는 QuALITY 데이터셋의 이야기들을 사용하였다.
이러한 각 이야기마다 Section 3에서 설명한 바와 같이
RAPTOR 트리를 구축하였다.
그러나 검색 과정에서는,
우리는 검색 범위를 서로 다른 계층들의 부분집합으로 제한한다.
예를 들어, 우리는 리프 노드에서만 검색하거나
각 상위 계층에서만 검색하는 경우뿐만 아니라,
계층들의 서로 다른 연속적인 부분집합에서도 검색을 수행한다.
우리는 표 8에서 하나의 이야기에 대한 구체적인 결과를 제시하며,
모든 계층을 활용하는 전체 트리 검색이
특정 계층에만 초점을 맞춘 검색 전략들보다
우수한 성능을 보였음을 보여준다.
표 8: QuALITY 데이터셋의 스토리 1에 대해 서로 다른 트리 계층들을 질의할 때의 RAPTOR 성능.
열은 서로 다른 시작 지점(가장 높은 계층)을 나타내며,
행은 질의된 계층의 서로 다른 개수를 나타낸다.

이러한 결과들은 RAPTOR에서 전체 트리 구조의 중요성을 부각한다.
검색을 위해 원문 텍스트와 상위 수준 요약을 모두 제공함으로써,
RAPTOR는 고차원적인 주제 중심 질의부터 세부 지향적인 질문에 이르기까지
더 넓은 범위의 질문들을 효과적으로 처리할 수 있다.
추가적인 스토리에 대한 상세한 결과와 계층 기여도에 대한 소거(ablation) 연구는
부록 I에서 확인할 수 있다.
5 결론 (CONCLUSION)
본 논문에서는 서로 다른 추상화 수준에서의 맥락 정보를 통해
대규모 언어 모델의 파라메트릭 지식을 보강하는
새로운 트리 기반 검색 시스템인 RAPTOR를 제시하였다.
재귀적 클러스터링과 요약 기법을 활용함으로써,
RAPTOR는 검색 코퍼스의 다양한 구간에 걸친 정보를
종합할 수 있는 계층적 트리 구조를 생성한다.
질의 단계에서 RAPTOR는 이러한 트리 구조를 활용하여
보다 효과적인 검색을 수행한다.
통제된 실험 결과, RAPTOR는 전통적인 검색 방법들을
상회할 뿐만 아니라, 여러 질의응답 과제에서
새로운 성능 기준선(benchmark)을 설정함을 확인하였다.
6 재현성 진술 (REPRODUCIBILITY STATEMENT)
질의응답 및 요약을 위한 언어 모델
RAPTOR 실험에서는 네 개의 언어 모델을 사용한다.
질의응답 과제에는 GPT-3와 GPT-4를 사용하고,
요약에는 GPT-3.5-turbo를 사용한다.
gpt-3, gpt-4, gpt-3.5-turbo 모델은 API 호출을 통해 접근할 수 있다(OpenAI API).
질의응답 과제에 사용되는 UnifiedQA는 Hugging Face에서 공개적으로 제공된다.
평가 데이터셋
본 실험에서 사용된 세 가지 평가 데이터셋인 QuALITY, QASPER, NarrativeQA는
모두 공개적으로 접근 가능하다.
이들 데이터셋은 본 연구에서 수행된 검색 및 질의응답 실험이
재현될 수 있음을 보장한다.
소스 코드
RAPTOR의 소스 코드는 공개적으로 제공될 예정이다.
참고문헌 (References)
Charu C. Aggarwal, Alexander Hinneburg, Daniel A. Keim. 2001.
On the surprising behavior of distance metrics in high dimensional space.
(고차원 공간에서 거리 척도의 놀라운 거동에 대하여.)
In Database Theory — ICDT 2001: 8th International Conference, London, UK, January 4–6, 2001 Proceedings, pages 420–434.
Springer.
URL: https://link.springer.com/chapter/10.1007/3-540-44503-x_27Joshua Ainslie, Tao Lei, Michiel de Jong, Santiago Ontañón, Siddhartha Brahma, Yury Zemlyanskiy,
David Uthus, Mandy Guo, James Lee-Thorp, Yi Tay, et al. 2023.
CoLT5: Faster long-range transformers with conditional computation.
(CoLT5: 조건부 계산을 활용한 더 빠른 장거리 트랜스포머.)
arXiv preprint arXiv:2303.09752. URL: https://arxiv.org/abs/2303.09752Ekin Akyurek, Tolga Bolukbasi, Frederick Liu, Binbin Xiong, Ian Tenney, Jacob Andreas, Kelvin Guu. 2022.
Towards tracing knowledge in language models back to the training data.
(언어 모델의 지식을 훈련 데이터로 다시 추적하는 방향을 향하여.)
In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 2429–2446, Abu Dhabi, United Arab Emirates.
Association for Computational Linguistics.
URL: https://aclanthology.org/2022.findings-emnlp.180Stefanos Angelidis, Mirella Lapata. 2018.
Summarizing opinions: Aspect extraction meets sentiment prediction and they are both weakly supervised.
(의견 요약: 측면 추출과 감성 예측의 결합, 그리고 약지도 학습.)
arXiv preprint arXiv:1808.08858.
URL: https://arxiv.org/abs/1808.08858Manoj Ghuhan Arivazhagan, Lan Liu, Peng Qi, Xinchi Chen, William Yang Wang, Zhiheng Huang. 2023.
Hybrid hierarchical retrieval for open-domain question answering.
(오픈 도메인 질의응답을 위한 하이브리드 계층적 검색.)
In Findings of the Association for Computational Linguistics: ACL 2023, pages 10680–10689, Toronto, Canada.
Association for Computational Linguistics.
URL: https://aclanthology.org/2023.findings-acl.679Iz Beltagy, Matthew E. Peters, Arman Cohan. 2020.
Longformer: The long-document transformer.
(Longformer: 장문 문서를 위한 트랜스포머.)
arXiv preprint arXiv:2004.05150.
URL: https://arxiv.org/abs/2004.05150Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican,
George van den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, et al. 2022.
Improving language models by retrieving from trillions of tokens.
(수조 개 토큰으로부터의 검색을 통한 언어 모델 성능 향상.)
In International Conference on Machine Learning (ICML), pages 2206–2240.
PMLR.
URL: https://arxiv.org/abs/2112.04426Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D. Kaplan, Prafulla Dhariwal,
Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, et al. 2020.
Language models are few-shot learners.
(언어 모델은 소수 예제 학습자이다.)
In Advances in Neural Information Processing Systems (NeurIPS), volume 33, pages 1877–1901.
Curran Associates, Inc.
URL: https://proceedings.neurips.cc/paper_files/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdfSébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz,
Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, et al. 2023.
Sparks of artificial general intelligence: Early experiments with GPT-4.
(인공지능 일반 지능의 불꽃: GPT-4를 활용한 초기 실험.)
arXiv preprint arXiv:2303.12712.
URL: https://arxiv.org/abs/2303.12712Shuyang Cao, Lu Wang. 2022.
HIBRIDS: Attention with hierarchical biases for structure-aware long document summarization.
(구조 인식을 위한 계층적 편향을 갖는 어텐션 기반 장문 문서 요약.)
In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics
(Volume 1: Long Papers), pages 786–807, Dublin, Ireland.
Association for Computational Linguistics.
URL: https://aclanthology.org/2022.acl-long.58Danqi Chen, Adam Fisch, Jason Weston, Antoine Bordes. 2017.
Reading Wikipedia to answer open-domain questions.
(위키백과를 읽어 오픈 도메인 질문에 답하기.)
In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics
(Volume 1: Long Papers), pages 1870–1879, Vancouver, Canada.
Association for Computational Linguistics.
URL: https://aclanthology.org/P17-1171Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra,
Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. 2022.
PaLM: Scaling language modeling with pathways.
(PaLM: Pathways를 활용한 언어 모델링 확장.)
arXiv preprint arXiv:2204.02311.
URL: https://arxiv.org/abs/2204.02311Arman Cohan, Nazli Goharian. 2017.
Contextualizing citations for scientific summarization using word embeddings and domain knowledge.
(단어 임베딩과 도메인 지식을 활용한 과학 문서 요약을 위한 인용 맥락화.)
In Proceedings of the 40th International ACM SIGIR Conference on Research and Development
in Information Retrieval, pages 1133–1136.
ACM.
URL: https://dl.acm.org/doi/abs/10.1145/3077136.3080740Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc Le, Ruslan Salakhutdinov. 2019.
Transformer-XL: Attentive language models beyond a fixed-length context.
(고정 길이 문맥을 넘어서는 주의 기반 언어 모델 Transformer-XL.)
In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics,
pages 2978–2988, Florence, Italy.
Association for Computational Linguistics.
URL: https://aclanthology.org/P19-1285Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, Christopher Ré. 2022.
FlashAttention: Fast and memory-efficient exact attention with IO-awareness.
(입출력 인식을 활용한 빠르고 메모리 효율적인 정확 어텐션.)
In Advances in Neural Information Processing Systems, volume 35, pages 16344–16359.
URL: https://arxiv.org/abs/2205.14135Pradeep Dasigi, Kyle Lo, Iz Beltagy, Arman Cohan, Noah A. Smith, Matt Gardner. 2021.
A dataset of information-seeking questions and answers anchored in research papers.
(연구 논문에 기반한 정보 탐색 질문·응답 데이터셋.)
In Proceedings of the 2021 Conference of the North American Chapter of the Association
for Computational Linguistics: Human Language Technologies, pages 4599–4610, Online.
Association for Computational Linguistics.
URL: https://aclanthology.org/2021.naacl-main.365Mengxing Dong, Bowei Zou, Yanling Li, Yu Hong. 2023.
CoLISA: Inner interaction via contrastive learning for multi-choice reading comprehension.
(대조 학습을 활용한 다지선다 독해를 위한 내부 상호작용: CoLISA.)
In Advances in Information Retrieval: 45th European Conference on Information Retrieval (ECIR 2023),
pages 264–278, Dublin, Ireland.
Springer.
URL: https://link.springer.com/chapter/10.1007/978-3-031-28244-7_17Zican Dong, Tianyi Tang, Lunyi Li, Wayne Xin Zhao. 2023.
A survey on long text modeling with transformers.
(트랜스포머 기반 장문 텍스트 모델링에 대한 서베이.)
arXiv preprint arXiv:2302.14502.
URL: https://arxiv.org/abs/2302.14502Tianyu Gao, Howard Yen, Jiatong Yu, Danqi Chen. 2023.
Enabling large language models to generate text with citations.
(대규모 언어 모델이 인용을 포함한 텍스트를 생성하도록 하는 방법.)
arXiv preprint arXiv:2305.14627.
URL: https://arxiv.org/abs/2305.14627Mandy Guo, Joshua Ainslie, David Uthus, Santiago Ontanon, Jianmo Ni,
Yun-Hsuan Sung, Yinfei Yang. 2022.
LongT5: Efficient text-to-text transformer for long sequences.
(장문 시퀀스를 위한 효율적인 텍스트-투-텍스트 트랜스포머 LongT5.)
In Findings of the Association for Computational Linguistics: NAACL 2022,
pages 724–736, Seattle, United States.
Association for Computational Linguistics.
URL: https://aclanthology.org/2022.findings-naacl.55Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, Mingwei Chang. 2020.
Retrieval augmented language model pre-training.
(검색 증강 언어 모델 사전학습.)
In International Conference on Machine Learning, pages 3929–3938.
PMLR.
URL: https://doi.org/10.48550/arXiv.2002.08909Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya,
Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks,
Johannes Welbl, Aidan Clark, et al. 2022.
Training compute-optimal large language models.
(계산 효율적으로 최적화된 대규모 언어 모델 학습.)
arXiv preprint arXiv:2203.15556.
URL: https://arxiv.org/abs/2203.15556Gautier Izacard, Edouard Grave. 2022.
Distilling knowledge from reader to retriever for question answering.
(질의응답을 위한 리더에서 리트리버로의 지식 증류.)
arXiv preprint arXiv:2012.04584.
URL: https://arxiv.org/abs/2012.04584Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni,
Timo Schick, Jane Dwivedi-Yu, Armand Joulin, Sebastian Riedel, Edouard Grave. 2022.
Few-shot learning with retrieval augmented language models.
(검색 증강 언어 모델을 활용한 소수샷 학습.)
arXiv preprint arXiv:2208.03299.
URL: https://arxiv.org/abs/2208.03299Zhengbao Jiang, Frank F. Xu, Jun Araki, Graham Neubig. 2020.
How can we know what language models know?
(언어 모델이 무엇을 알고 있는지 어떻게 알 수 있는가?)
Transactions of the Association for Computational Linguistics, 8:423–438.
URL: https://arxiv.org/abs/1911.12543Jeff Johnson, Matthijs Douze, Hervé Jégou. 2019.
Billion-scale similarity search with GPUs.
(GPU를 활용한 수십억 규모 유사도 검색.)
IEEE Transactions on Big Data, 7(3):535–547.
URL: https://arxiv.org/abs/1702.08734Nikhil Kandpal, Haikang Deng, Adam Roberts, Eric Wallace, Colin Raffel. 2023.
Large language models struggle to learn long-tail knowledge.
(대규모 언어 모델은 롱테일 지식 학습에 어려움을 겪는다.)
In International Conference on Machine Learning, pages 15696–15707.
PMLR.
URL: https://proceedings.mlr.press/v202/kandpal23a/kandpal23a.pdfVladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu,
Sergey Edunov, Danqi Chen, Wen-tau Yih. 2020.
Dense passage retrieval for open-domain question answering.
(오픈 도메인 질의응답을 위한 밀집 패시지 검색.)
In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing,
pages 6769–6781, Online.
Association for Computational Linguistics.
URL: https://aclanthology.org/2020.emnlp-main.550Daniel Khashabi, Sewon Min, Tushar Khot, Ashish Sabharwal,
Oyvind Tafjord, Peter Clark, Hannaneh Hajishirzi. 2020.
UnifiedQA: Crossing format boundaries with a single QA system.
(단일 질의응답 시스템으로 형식 경계를 넘는 UnifiedQA.)
In Findings of the Association for Computational Linguistics: EMNLP 2020,
pages 1896–1907, Online.
Association for Computational Linguistics.
URL: https://aclanthology.org/2020.findings-emnlp.171Omar Khattab, Matei Zaharia. 2020.
ColBERT: Efficient and effective passage search via contextualized late interaction over BERT.
(BERT 기반 맥락화된 지연 상호작용을 활용한 효율적이고 효과적인 패시지 검색.)
In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval,
pages 39–48.
URL: https://arxiv.org/abs/2004.12832Tomáš Kočiský, Jonathan Schwarz, Phil Blunsom, Chris Dyer,
Karl Moritz Hermann, Gábor Melis, Edward Grefenstette. 2018.
The NarrativeQA reading comprehension challenge.
(NarrativeQA 독해 이해 챌린지.)
Transactions of the Association for Computational Linguistics, 6:317–328.
URL: https://arxiv.org/abs/1712.07040Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020.
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.
(지식 집약적 자연어 처리 과제를 위한 검색 증강 생성.)
Advances in Neural Information Processing Systems, 33:9459–9474.
URL: https://doi.org/10.48550/arXiv.2005.11401Jerry Liu. 2022.
LlamaIndex.
URL: https://github.com/jerryjliu/llama_indexNelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, Percy Liang. 2023.
Lost in the Middle: How Language Models Use Long Contexts.
(중간에서 길을 잃다: 언어 모델은 긴 문맥을 어떻게 사용하는가.)
arXiv preprint arXiv:2307.03172.
URL: https://arxiv.org/abs/2307.03172Ye Liu, Kazuma Hashimoto, Yingbo Zhou, Semih Yavuz, Caiming Xiong, Philip Yu. 2021.
Dense Hierarchical Retrieval for Open-Domain Question Answering.
(오픈 도메인 질의응답을 위한 밀집 계층적 검색.)
In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 188–200, Punta Cana, Dominican Republic.
Association for Computational Linguistics.
URL: https://aclanthology.org/2021.findings-emnlp.19Leland McInnes, John Healy, James Melville. 2018.
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction.
(차원 축소를 위한 UMAP: 균일 다양체 근사 및 사영.)
arXiv preprint arXiv:1802.03426.
URL: https://arxiv.org/abs/1802.03426Sewon Min, Kenton Lee, Ming-Wei Chang, Kristina Toutanova, Hannaneh Hajishirzi. 2021.
Joint Passage Ranking for Diverse Multi-Answer Retrieval.
(다양한 다중 답변 검색을 위한 공동 패시지 랭킹.)
In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6997–7008.
Association for Computational Linguistics.
URL: https://aclanthology.org/2021.emnlp-main.560Sewon Min, Weijia Shi, Mike Lewis, Xilun Chen, Wen-tau Yih, Hannaneh Hajishirzi, Luke Zettlemoyer. 2023.
Nonparametric Masked Language Modeling.
(비모수적 마스크드 언어 모델링.)
In Findings of the Association for Computational Linguistics: ACL 2023, pages 2097–2118, Toronto, Canada.
Association for Computational Linguistics.
URL: https://aclanthology.org/2023.findings-acl.132Eric Mitchell, Charles Lin, Antoine Bosselut, Christopher D. Manning, Chelsea Finn. 2022.
Memory-Based Model Editing at Scale.
(대규모 메모리 기반 모델 편집.)
In International Conference on Machine Learning, pages 15817–15831. PMLR.
URL: https://proceedings.mlr.press/v162/mitchell22a/mitchell22a.pdfXiangyang Mou, Mo Yu, Bingsheng Yao, Chenghao Yang, Xiaoxiao Guo, Saloni Potdar, Hui Su. 2020.
Frustratingly Hard Evidence Retrieval for QA over Books.
(도서 기반 질의응답에서 매우 어려운 근거 검색.)
In Proceedings of the First Joint Workshop on Narrative Understanding, Storylines, and Events, pages 108–113.
Association for Computational Linguistics.
URL: https://aclanthology.org/2020.nuse-1.13Inderjeet Nair, Aparna Garimella, Balaji Vasan Srinivasan, Natwar Modani, Niyati Chhaya, Srikrishna Karanam, Sumit Shekhar. 2023.
A Neural CRF-Based Hierarchical Approach for Linear Text Segmentation.
(선형 텍스트 분할을 위한 신경망 CRF 기반 계층적 접근법.)
In Findings of the Association for Computational Linguistics: EACL 2023, pages 883–893, Dubrovnik, Croatia.
Association for Computational Linguistics.
URL: https://aclanthology.org/2023.findings-eacl.65Benjamin Newman, Luca Soldaini, Raymond Fok, Arman Cohan, Kyle Lo. 2023.
A Controllable QA-Based Framework for Decontextualization.
(탈맥락화를 위한 제어 가능한 질의응답 기반 프레임워크.)
arXiv preprint arXiv:2305.14772.
URL: https://arxiv.org/pdf/2305.14772.pdfOpenAI. 2023.
GPT-4 Technical Report.
(GPT-4 기술 보고서.)
arXiv:2303.08774.
URL: https://arxiv.org/abs/2303.08774Richard Yuanzhe Pang, Alicia Parrish, Nitish Joshi, Nikita Nangia, Jason Phang, Angelica Chen, Vishakh Padmakumar, Johnny Ma, Jana Thompson, He He, Samuel Bowman. 2022.
QuALITY: Question Answering with Long Input Texts, Yes!
(QuALITY: 긴 입력 텍스트를 사용하는 질의응답.)
In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 5336–5358, Seattle, United States.
Association for Computational Linguistics.
URL: https://aclanthology.org/2022.naacl-main.391Fabio Petroni, Tim Rocktäschel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, Alexander H. Miller, Sebastian Riedel. 2019.
Language Models as Knowledge Bases?
(언어 모델은 지식 베이스인가?)
arXiv preprint arXiv:1909.01066.
URL: https://arxiv.org/abs/1909.01066Jack W. Rae, Sebastian Borgeaud, Trevor Cai, Katie Millican, Jordan Hoffmann, Francis Song, John Aslanides, Sarah Henderson, Roman Ring, Susannah Young, et al. 2021.
Scaling Language Models: Methods, Analysis & Insights from Training Gopher.
(언어 모델 스케일링: Gopher 학습에서의 방법, 분석 및 통찰.)
arXiv preprint arXiv:2112.11446.
URL: https://arxiv.org/abs/2112.11446Ori Ram, Yoav Levine, Itay Dalmedigos, Dor Muhlgay, Amnon Shashua, Kevin Leyton-Brown, Yoav Shoham. 2023.
In-Context Retrieval-Augmented Language Models.
(문맥 내 검색 증강 언어 모델.)
arXiv preprint arXiv:2302.00083.
URL: https://arxiv.org/abs/2302.00083Nils Reimers, Iryna Gurevych. 2019.
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks.
(시암 BERT 네트워크를 이용한 문장 임베딩: Sentence-BERT.)
In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982–3992, Hong Kong, China.
Association for Computational Linguistics.
URL: https://aclanthology.org/D19-1410Adam Roberts, Colin Raffel, Noam Shazeer. 2020.
How Much Knowledge Can You Pack Into the Parameters of a Language Model?
(언어 모델의 파라미터에는 얼마나 많은 지식을 담을 수 있는가?)
In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 5418–5426.
Association for Computational Linguistics.
URL: https://aclanthology.org/2020.emnlp-main.437Stephen Robertson, Hugo Zaragoza. 2009.
The Probabilistic Relevance Framework: BM25 and Beyond.
(확률적 관련성 프레임워크: BM25와 그 이후.)
Foundations and Trends in Information Retrieval, 3(4):333–389.
URL: https://doi.org/10.1561/1500000019Stephen E. Robertson, Steve Walker, Susan Jones, Micheline M. Hancock-Beaulieu, Mike Gatford. 1995.
Okapi at TREC-3.
(TREC-3에서의 Okapi.)
NIST Special Publication, 109:109.
URL: https://www.microsoft.com/en-us/research/publication/okapi-at-trec-3/Devendra Singh Sachan, Mike Lewis, Dani Yogatama, Luke Zettlemoyer, Joelle Pineau, Manzil Zaheer. 2023.
Questions Are All You Need to Train a Dense Passage Retriever.
(질문만으로도 밀집 패시지 검색기를 학습할 수 있다.)
Transactions of the Association for Computational Linguistics, 11:600–616.
URL: https://aclanthology.org/2023.tacl-1.35Gideon Schwarz. 1978.
Estimating the Dimension of a Model.
(모델의 차원 추정.)
The Annals of Statistics, pages 461–464.
URL: https://projecteuclid.org/journals/annals-of-statistics/volume-6/issue-2/Estimating-the-Dimension-of-a-Model/10.1214/aos/1176344136.fullKaren Spärck Jones. 1972.
A Statistical Interpretation of Term Specificity and Its Application in Retrieval.
(용어 특이성의 통계적 해석과 검색에서의 적용.)
Journal of Documentation, 28(1):11–21.
URL: https://doi.org/10.1108/eb026526Simeng Sun, Kalpesh Krishna, Andrew Mattarella-Micke, Mohit Iyyer. 2021.
Do Long-Range Language Models Actually Use Long-Range Context?
(장거리 언어 모델은 실제로 장거리 문맥을 사용하는가?)
In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 807–822.
Association for Computational Linguistics.
URL: https://aclanthology.org/2021.emnlp-main.62Zhiqing Sun, Xuezhi Wang, Yi Tay, Yiming Yang, Denny Zhou. 2022.
Recitation-Augmented Language Models.
(암송 증강 언어 모델.)
arXiv preprint arXiv:2210.01296.
URL: https://arxiv.org/abs/2210.01296Alon Talmor, Yanai Elazar, Yoav Goldberg, Jonathan Berant. 2020.
oLMpics — on what language model pre-training captures.
(oLMpics — 언어 모델 사전학습이 무엇을 포착하는가.)
Transactions of the Association for Computational Linguistics, 8:743–758.
URL: https://arxiv.org/abs/1912.13283Boxin Wang, Wei Ping, Peng Xu, Lawrence McAfee, Zihan Liu, Mohammad Shoeybi, Yi Dong, Oleksii Kuchaiev, Bo Li, Chaowei Xiao, et al. 2023.
Shall we pretrain autoregressive language models with retrieval? a comprehensive study.
(검색을 활용해 자기회귀 언어 모델을 사전학습해야 하는가? 포괄적 연구.)
arXiv preprint arXiv:2304.06762.
URL: https://arxiv.org/abs/2304.06762Jeff Wu, Long Ouyang, Daniel M. Ziegler, Nisan Stiennon, Ryan Lowe, Jan Leike, Paul Christiano. 2021.
Recursively Summarizing Books with Human Feedback.
(인간 피드백을 활용한 재귀적 도서 요약.)
arXiv preprint arXiv:2109.10862.
URL: https://arxiv.org/abs/2109.10862Adams Wei Yu, David Dohan, Minh-Thang Luong, Rui Zhao, Kai Chen, Mohammad Norouzi, Quoc V. Le. 2018.
QANet: Combining Local Convolution with Global Self-Attention for Reading Comprehension.
(독해 이해를 위한 지역 합성과 전역 셀프-어텐션 결합: QANet.)
arXiv preprint arXiv:1804.09541.
URL: https://arxiv.org/abs/1804.09541Wenhao Yu, Dan Iter, Shuohang Wang, Yichong Xu, Mingxuan Ju, Soumya Sanyal, Chenguang Zhu, Michael Zeng, Meng Jiang. 2022.
Generate rather than retrieve: Large Language Models are strong context generators.
(검색보다 생성: 대규모 언어 모델은 강력한 문맥 생성기이다.)
arXiv preprint arXiv:2209.10063.
URL: https://arxiv.org/abs/2209.10063Shiyue Zhang, David Wan, Mohit Bansal. 2023.
Extractive is not faithful: An investigation of broad unfaithfulness problems in extractive summarization.
(추출 요약은 충실하지 않다: 추출 요약에서의 광범위한 비충실성 문제 분석.)
In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2153–2174, Toronto, Canada.
Association for Computational Linguistics.
URL: https://aclanthology.org/2023.acl-long.120
A 트리 구축 과정의 확장성 및 계산 효율성 (SCALABILITY AND COMPUTATIONAL EFFICIENCY OF THE TREE-BUILDING PROCESS)
RAPTOR의 트리 구축 과정의 계산 효율성과 비용 효율성을 평가하기 위해,
우리는 소비자용 노트북에서 실험을 수행하였으며,
구체적으로는 RAM 16GB를 갖춘 Apple M1 Mac을 사용하였다.
이러한 실험들은 일반적인 하드웨어 환경에서 RAPTOR의 확장성과
실행 가능성을 입증하는 것을 목표로 하였다.
우리는 문맥 길이를 12,500 토큰에서 78,000 토큰까지 변화시키고,
초기 분할 및 임베딩 단계부터 최종 루트 노드의 구축에 이르기까지
트리 구축 과정을 완료하는 데 필요한 시간과 토큰 소모량을 모두 측정하였다.
토큰 소모량(Token Expenditure)
우리는 초기 문서 길이와 트리 구축 과정 동안
소모된 총 토큰 수 사이의 관계를 경험적으로 조사하였다.
이때 트리 구축 과정에서의 총 토큰 수에는
프롬프트 토큰과 생성(completion) 토큰이 모두 포함된다.
문서 길이는 분석된 세 가지 데이터셋, 즉 QuALITY, QASPER,
그리고 NarrativeQA 전반에 걸쳐 상당히 크게 달랐다.
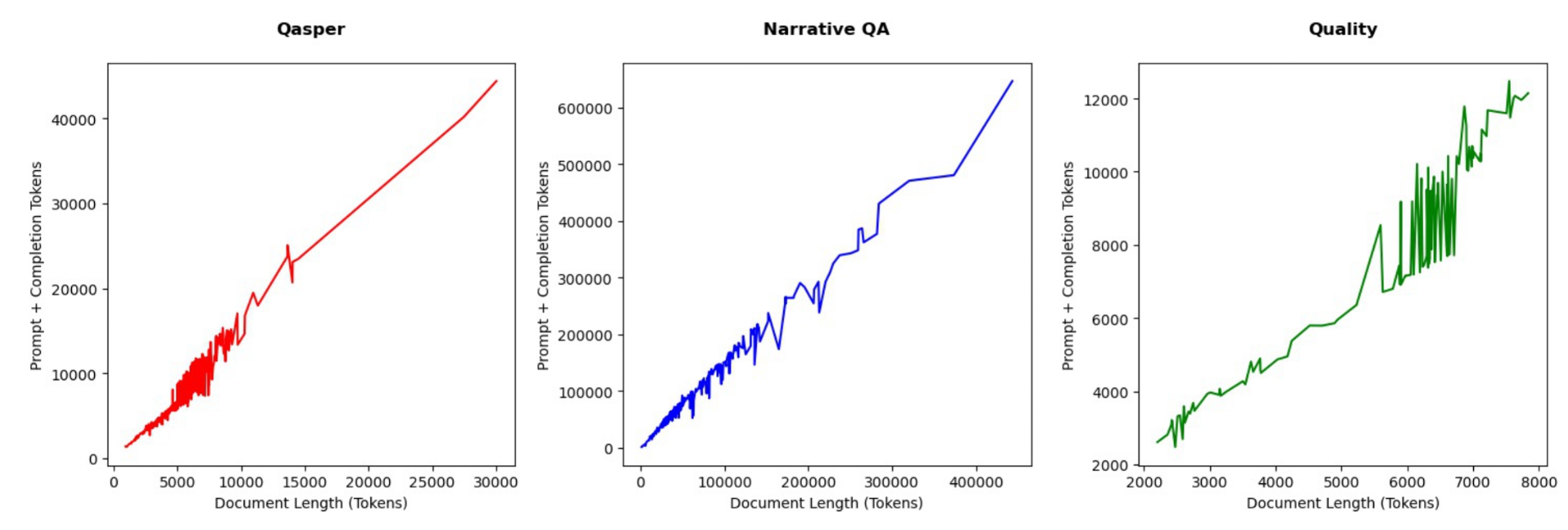
그림 5는 초기 문서 길이와 총 토큰 소모량 사이에
명확한 선형 상관관계가 있음을 보여주며,
RAPTOR가 문서의 복잡도나 길이와 무관하게
선형적인 토큰 스케일링을 유지함을 강조한다.
그림 5: QASPER, NarrativeQA, 그리고 QuALITY에 대해 문서 길이의 함수로서의 토큰 비용.
RAPTOR 트리 구축 비용은 각 데이터셋에 대해 문서 길이에 따라 선형적으로 스케일된다.
구축 시간(Build Time)
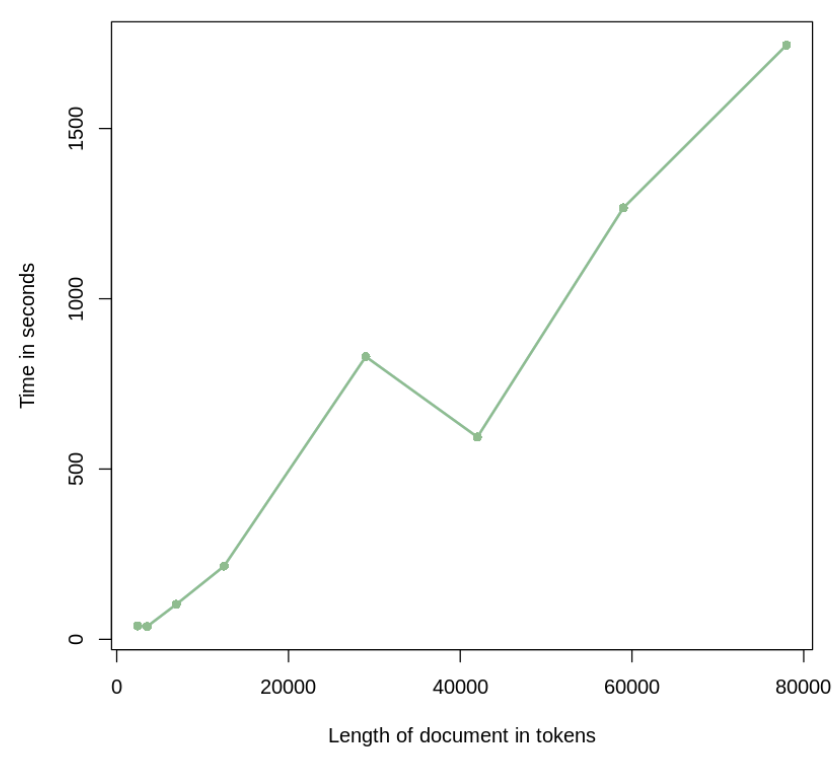
우리는 그림 6에 나타난 바와 같이, 문서 길이와 구축 시간 사이에서도
일관된 선형 추세가 존재함을 경험적으로 관찰하였다.
이는 RAPTOR가 시간 측면에서도 선형적으로 스케일링됨을 시사하며,
서로 다른 길이를 갖는 대규모 코퍼스를
효율적으로 처리하기 위한 실용적인 해법임을 의미한다.
그림 6: 최대 80,000 토큰에 이르는 문서들에 대해, 문서 길이의 함수로 나타낸 구축 시간.
RAPTOR 트리 구축 시간은 각 데이터셋에 대해 문서 길이에 따라 선형적으로 스케일링된다.
결론(Conclusion)
전반적으로, 우리의 경험적 결과는 RAPTOR가
소모되는 토큰 수와 구축 시간 모두의 측면에서 선형적으로 스케일링됨을 보여준다.
입력 텍스트의 복잡도와 분량이 증가하더라도,
트리를 구축하는 비용은 예측 가능하고 선형적으로 증가한다.
이는 RAPTOR가 계산적으로 효율적이며,
대규모이면서도 다양한 코퍼스를 처리하는 데 적합함을 입증한다.
B RAPTOR에서의 클러스터링 메커니즘에 대한 소거 연구 (ABLATION STUDY ON CLUSTERING MECHANISM IN RAPTOR)
우리의 RAPTOR 접근법에서 클러스터링 메커니즘의 효과성을 평가하기 위해,
우리는 QuALITY 데이터셋에 대해 소거 연구를 수행하였다.
이 연구는 표준 클러스터링 방법과 대비하여,
연속적인 청크들의 균형 잡힌 트리 스타일 인코딩 및 요약을 사용하는 방식과
RAPTOR의 성능을 비교한다.
B.1 방법론 (METHODOLOGY)
이 소거 연구에서의 두 구성 모두
검색에서의 일관성을 유지하기 위해
SBERT 임베딩과 UnifiedQA를 사용하였다.
RAPTOR의 경우,
우리는 일반적으로 사용하는 클러스터링 및 요약 과정을 적용하였다.
반면, 대안적인 설정에서는
연속적인 텍스트 청크들을 재귀적으로 인코딩하고 요약함으로써
균형 잡힌 트리를 생성하는 방식을 사용하였다.
우리는 RAPTOR에서 관측된 평균 클러스터 크기를 기반으로
이 설정에 대한 윈도우 크기를 결정하였으며,
이는 약 6.7개의 노드였다.
따라서 우리는 7개의 노드로 구성된 윈도우 크기를 선택하였다.
축약된 트리 접근법은 두 모델 모두에서 검색을 위해 적용되었다.
B.2 결과 및 논의 (RESULTS & DISCUSSION)
소거 연구의 결과는 표 9에 제시되어 있다.
이 소거 연구의 결과는
최근성 기반(recency-based) 트리 접근법에 비해
RAPTOR의 클러스터링 메커니즘을 사용할 때
정확도가 향상됨을 명확하게 보여준다.
이러한 결과는
RAPTOR의 클러스터링 전략이
요약을 위해 동질적인 내용을 포착하는 데 더 효과적이며,
그로 인해 전체 검색 성능을 향상시킨다는
우리의 가설을 뒷받침한다.
표 9: RAPTOR를 최근성 기반 트리 접근법과 비교한 소거 연구 결과

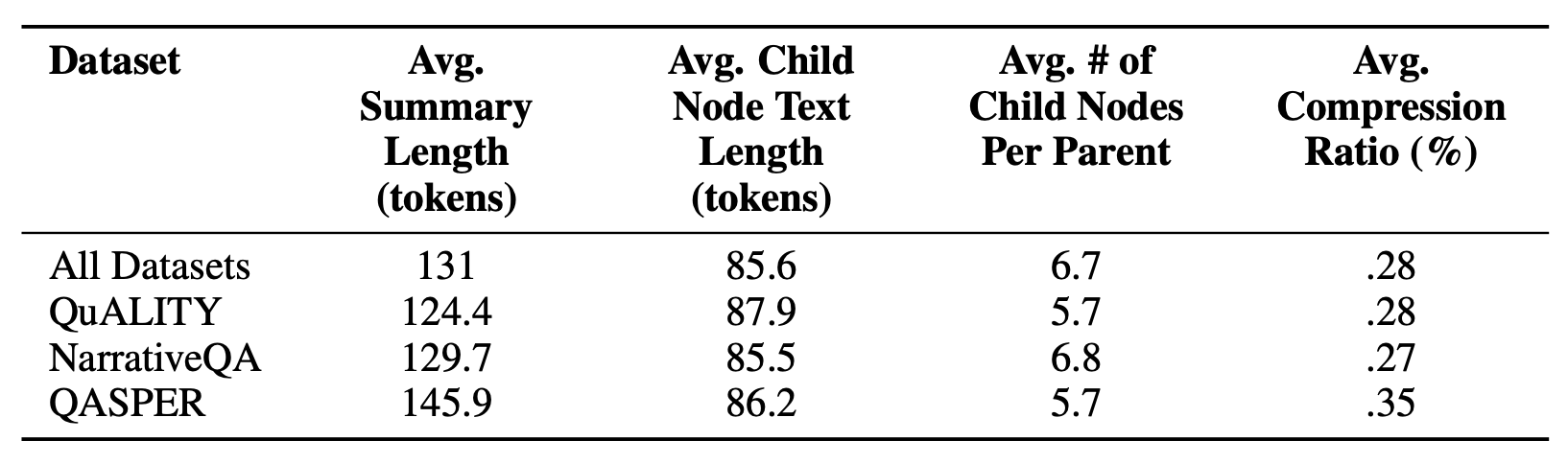
C 데이터셋 통계 및 압축 (DATASET STATISTICS AND COMPRESSION RATIOS)
모든 데이터셋에 걸쳐 요약 길이를
자식 노드 길이들의 합으로 나눈 평균 비율은 0.28이며,
이는 72%의 압축률을 나타낸다.
평균적으로 요약 길이는 131 토큰이며,
자식 노드의 평균 길이는 86 토큰이다.
아래에는 세 개의 모든 데이터셋에 대한 상세 통계가 제시되어 있다:
표 10: 데이터셋 전반에 걸친 평균 요약 길이 및 자식 노드 길이에 대한 통계
D 요약 프롬프트 (SUMMARIZATION PROMPT)
표 11은 요약을 위해 사용된 프롬프트를 보여준다.
표 11: 요약을 위한 프롬프트

E 환각 분석 (HALLUCINATION ANALYSIS)
우리 RAPTOR 모델 내에서 생성된 요약의 품질과 정확성을 평가하기 위해,
우리는 생성된 요약에서의 환각에 초점을 맞춘 분석을 수행하였다.
요약들은 gpt-3.5-turbo에 의해 생성되었으며,
이후 환각의 발생 비율을 정량화하고,
이러한 부정확성이 상위(parent) 노드로 전파되는지 여부를 검토하며,
질의응답(QA) 작업에 미치는 영향을 평가하기 위해 주석이 달렸다.
E.1 방법론 (METHODOLOGY)
우리는 40개의 이야기 전반에 걸쳐 150개의 노드를 무작위로 샘플링하고,
이들에 대해 환각 여부를 평가하였다.
이 샘플링 전략은 서로 다른 맥락 전반에서 모델 성능에 대한 폭넓은 관점을 제공한다.
각 노드는 수작업으로 주석되었으며,
환각을 포함하는지 여부가 판정되었다.
E.2 결과 (FINDINGS)
샘플링된 150개의 노드 중,
4%(6개 노드)가 어떤 형태의 환각을 포함하고 있었다.
가장 흔하게는,
이러한 환각은 모델이 요약 대상 텍스트에는 존재하지 않는
훈련 데이터로부터의 사소한 정보를 추가하거나,
요약을 생성하는 과정에서 일부 정보를 잘못 외삽(extrapolating)함으로써 발생하였다.
예시:
자식 노드들의 텍스트:
“그리고 당신은 나와 함께 내 사람들에게 올 건가요?
우리는 여기에서 그들 사이에서 살 수도 있고,
당신은 위대한 전사가 될 거예요—아, 요르가 죽으면
당신은 어쩌면 족장이 될 수도 있겠죠.
내 전사만큼 강한 이는 없으니까요…”
하지만 당신의 아버지는 그것을 허락하지 않을 거예요—
요르, 나의 아버지이자 갈루스의 대족장은
그것을 허락하지 않을 거예요.
왜냐하면 나와 마찬가지로 당신은 cos-ata-lo이기 때문이에요.
오, 코-탄, 우리가 그럴 수만 있다면!…
브래들리는 그녀가 영어로 말하고 있다는 것을 알아차렸다—
코-탄의 영어와 마찬가지로 어눌한 영어였지만,
그만큼이나 매력적이었다.
해당 노드의 부모에서 발견된 요약:
주인공인 Bradley는
Co-Tan으로부터 그녀의 사람들과 함께 남아 위대한 전사가 되라는 요청을 받고 있으나,
그는 이를 거절하고 자신의 나라로 돌아가야 한다.
산타 모니카 출신의 Tom Billings가 도착하여,
Bowen J. Tyler, Jr.라는 이름의 남자를 찾기 위해 왔다고 말한다.
Co-Tan의 여동생인 Ajor는
Tom의 나라로 가서 낯설고 놀라운 것들을 볼 가능성에 대해 흥분한다…
여기서의 환각은,
요약이 Jr. Ajor와 Co-Tan이 자매라고 서술하고 있으나,
원문 텍스트에서는 이를 명시적으로 언급하거나 암시하지 않는다는 점이다.
모든 부모 노드를 검토한 결과,
환각이 더 상위 계층으로 전파되지는 않는다는 것을 발견하였다.
전반적으로, 환각은 사소한 수준이었으며 텍스트의 주제적 해석을 변경하지 않았다.
E.3 QA 작업에 대한 영향
우리의 결과에 따르면,
환각은 QA 작업의 성능에 식별 가능한 영향을 미치지 않았다.
이는 우리 RAPTOR 아키텍처에서
요약 구성 요소에 있어 환각이 주요한 우려 사항이 아님을 시사한다.
F 검색 방법을 위한 의사코드


G 정성적 분석
RAPTOR의 검색 과정을 정성적으로 검토하기 위해,
우리는 동화 신데렐라의 1,500단어 버전에 대한
주제 중심의 다중 홉(multi-hop) 질문들에 대해 이를 테스트한다.
우리는 RAPTOR가 검색한 컨텍스트를
Dense Passage Retrieval(DPR)이 검색한 컨텍스트와 비교한다.
본 논문의 그림 4는 두 개의 질문에 대해
RAPTOR의 트리 구조 내에서 이루어지는 검색 과정을 상세히 보여준다.
각 질문에 대해 RAPTOR가 선택한 노드들은 강조 표시되어 있으며,
같은 질문에 대해 DPR이 선택한 리프 노드들은 화살표로 표시되어 있다.
이 비교는 RAPTOR의 트리 구조가 가지는 장점을 보여준다.
RAPTOR는 해당 질문에 요구되는 세분화 수준에 따라
서로 다른 계층들로부터 노드들을 선택한다.
더 나아가, DPR에 의해 검색될 정보는
대부분의 경우 RAPTOR에 의해 검색된 컨텍스트 안에 포함되는데,
이는 리프 노드로서 직접 포함되거나,
또는 상위 계층의 요약의 일부로서 간접적으로 포함된다.
우리가 처음으로 검토하는 질문은
“신데렐라는 어떻게 해피엔딩을 맞이하는가?”이며,
이는 다양한 텍스트 구간들로부터 정보를 종합함으로써
가장 잘 답할 수 있는 멀티-홉 질문이다.
언어 모델이 신데렐라 이야기 자체에 대해 이미 알고 있을 가능성을 통제하기 위해,
우리는 답변을 생성할 때 검색된 정보에만 전적으로 의존하도록 지시하였다.
표 13은 이 질문에 대해 RAPTOR와 DPR이 각각 검색한 텍스트를 보여준다.
RAPTOR의 컨텍스트는 신데렐라가 행복에 이르는 여정을 간결하게 설명하는 반면,
DPR의 리프 노드들은 주로 그녀의 초기 변신에 초점을 맞춘다.
표 12: 동화 신데렐라에 관한 질문들에 대해
RAPTOR와 DPR이 검색한 텍스트로부터의 관련 발췌문
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
질문: 이야기의 중심 주제는 무엇인가?
RAPTOR
요정 대모는 신데렐라의 누더기를 변신시켜 무도회에 갈 수 있도록 도와준다…
신데렐라는 무도회에서 왕자를 매혹시킨다…
그녀는 시간을 잊고 어둠 속에서 혼자 집으로 달려가야 한다.
왕자는 신데렐라를 찾지 못하고 그녀를 찾아 나선다…
신데렐라는 자신의 자매들을 용서하고 언제나 매우 친절하게 대했으며,
왕자는 유리 구두를 찾아낸 것을 매우 기뻐할 만한 충분한 이유가 있었다.
DPR
두 마리의 생쥐는 하인으로 변했고, 네 마리의 메뚜기는 흰 말로 변했다.
다음으로 요정은 신데렐라의 누더기를 만졌고, 그것들은 뾰족 레이스로 장식된
화려한 비단 예복으로 변했다…
아아! 시계가 열한 시를 쳤다.
그녀는 마차를 찾지 못했고, 오직 호박만 있었으며,
쥐와 생쥐는 그녀를 보자 재빨리 달아났다.
그동안 그녀의 고운 옷은 누더기로 변했고, 그녀는 혼자 집으로 달려가야 했다…
사람들은 무도회에 매우 아름다운 공주가 있었고 왕자가 그녀를 매우 기뻐했다고 말했다.
그들은 그것이 신데렐라인 줄 알지 못했다.
질문: 신데렐라는 어떻게 행복한 결말을 맞이하는가?
RAPTOR
신데렐라의 이야기는 그녀의 대모인 요정이 지팡이로 호박을 화려한 마차로 변신시켜
신데렐라가 무도회에 갈 수 있도록 해주는 것을 포함한다.
그러나 신데렐라는 시계가 열한 시를 치기 전에 집으로 돌아와야 하며,
그렇지 않으면 그녀의 드레스는 다시 누더기로 변하게 된다…
신데렐라는 무도회에서 왕자를 매혹시키지만,
왕자가 그녀가 누구인지 알아내기 전에 떠난다…
왕자는 잃어버린 유리 구두의 주인을 찾았고, 그것이 신데렐라의 것임을 알아낸다.
신데렐라는 자신의 자매들을 용서했고, 왕자는 그녀를 찾은 것을 기뻐했다.
DPR
시계가 열한 시를 쳤다…
왕자는 다시 신데렐라를 놓치자 매우 놀랐고,
무도회를 떠나 그녀를 찾아 나섰다…
요정은 신데렐라의 누더기를 만졌고, 그것들은 뾰족 레이스로 장식된
화려한 비단 예복으로 변했다…
그녀의 낡은 신발은 다이아몬드처럼 빛나는 매력적인 유리 구두 한 켤레가 되었다.
“이제 무도회에 가렴, 내 사랑,” 요정은 말했다.
“그리고 마음껏 즐기거라.
하지만 기억해라, 시계가 열한 시를 치기 전에 반드시 방을 떠나야 한다.
그렇지 않으면 너의 드레스는 원래의 누더기로 돌아갈 것이다.”
표 13: 동화 신데렐라에 대한 질문들을 위해
RAPTOR와 DPR에 의해 검색된 텍스트의 관련 발췌문
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
질문: 이야기의 중심 주제는 무엇인가?
RAPTOR
요정 대모는 신데렐라의 누더기를 변신시켜 무도회에 갈 수 있도록 도와준다…
신데렐라는 무도회에서 왕자를 매혹시킨다…
그녀는 시간을 잊고 어둠 속에서 혼자 집으로 달려가야 한다.
왕자는 신데렐라를 찾지 못하고 그녀를 찾아 나선다…
신데렐라는 자신의 자매들을 용서하고 언제나 매우 친절하게 대했으며,
왕자는 유리 구두를 찾아낸 것을 매우 기뻐할 만한 충분한 이유가 있었다.
DPR
두 마리의 생쥐는 하인으로 변했고, 네 마리의 메뚜기는 흰 말로 변했다.
다음으로 요정은 신데렐라의 누더기를 만졌고, 그것들은 뾰족 레이스로 장식된
화려한 비단 예복으로 변했다…
아아! 시계가 열한 시를 쳤다.
그녀는 마차를 찾지 못했고, 오직 호박만 있었으며,
쥐와 생쥐는 그녀를 보자 재빨리 달아났다.
그동안 그녀의 고운 옷은 누더기로 변했고, 그녀는 혼자 집으로 달려가야 했다…
사람들은 무도회에 매우 아름다운 공주가 있었고 왕자가 그녀를 매우 기뻐했다고 말했다.
그들은 그것이 신데렐라인 줄 알지 못했다.
질문: 신데렐라는 어떻게 행복한 결말을 맞이하는가?
RAPTOR
신데렐라의 이야기는 그녀의 대모인 요정이 지팡이로 호박을 화려한 마차로 변신시켜
신데렐라가 무도회에 갈 수 있도록 해주는 것을 포함한다.
그러나 신데렐라는 시계가 열한 시를 치기 전에 집으로 돌아와야 하며,
그렇지 않으면 그녀의 드레스는 다시 누더기로 변하게 된다…
신데렐라는 무도회에서 왕자를 매혹시키지만,
왕자가 그녀가 누구인지 알아내기 전에 떠난다…
왕자는 잃어버린 유리 구두의 주인을 찾았고, 그것이 신데렐라의 것임을 알아낸다.
신데렐라는 자신의 자매들을 용서했고, 왕자는 그녀를 찾은 것을 기뻐했다.
DPR
시계가 열한 시를 쳤다…
왕자는 다시 신데렐라를 놓치자 매우 놀랐고,
무도회를 떠나 그녀를 찾아 나섰다…
요정은 신데렐라의 누더기를 만졌고, 그것들은 뾰족 레이스로 장식된
화려한 비단 예복으로 변했다…
그녀의 낡은 신발은 다이아몬드처럼 빛나는 매력적인 유리 구두 한 켤레가 되었다.
“이제 무도회에 가렴, 내 사랑,” 요정은 말했다.
“그리고 마음껏 즐기거라.
하지만 기억해라, 시계가 열한 시를 치기 전에 반드시 방을 떠나야 한다.
그렇지 않으면 너의 드레스는 원래의 누더기로 돌아갈 것이다.”
이렇게 검색된 정보의 차이는
후속 태스크(downstream tasks)에 유의미한 영향을 미친다.
GPT-4에 RAPTOR의 컨텍스트를 제공했을 때,
다음과 같은 상세한 답변을 생성한다:
“신데렐라는 왕자가 잃어버린 유리 구두의 주인을 찾아 나서
그것이 신데렐라의 것임을 발견할 때 해피엔딩을 맞이한다.
그들은 결국 결혼하여,
신데렐라의 삶을 더 나은 방향으로 변화시킨다.”
반면, DPR의 컨텍스트를 사용했을 때 GPT-4는 다음과 같이 말한다:
“주어진 컨텍스트에 기반하면,
이야기의 결말에 대한 정보가 텍스트에 포함되어 있지 않기 때문에
신데렐라가 어떻게 해피엔딩을 맞이하는지를 결정하는 것은 불가능하다.”
우리가 두 번째로 살펴보는 질문은
“이야기의 중심 주제는 무엇인가?”이며,
이는 전체 텍스트에 대한 총체적인 이해를 요구하는 주제적 질문이다.
이 질문에 대해 RAPTOR와 DPR이 검색한 텍스트는
표 13에 제시되어 있다.
RAPTOR가 검색한 텍스트는
이야기의 모든 주요 부분에 대한 짧은 설명들을 포함하는 반면,
DPR이 검색한 텍스트는
이야기의 좁은 일부에 대한 상세한 설명들을 포함한다.
또 다시, 검색 메커니즘의 차이는
질문에 답할 때 GPT-4의 성능에 영향을 미친다.
DPR의 컨텍스트가 주어졌을 때, GPT-4는 다음과 같이 출력한다.
“이야기의 중심 주제는 변화와 내면의 아름다움의 힘이며,
친절하고 겸손한 소녀인 신데렐라가
마법적으로 아름다운 공주로 변신하여
무도회에서 왕자와 다른 사람들의 관심과 찬사를 사로잡는 것이다.”
이 답변은 신데렐라가 처음으로 왕자를 만날 때까지의
이야기 초반부만을 고려한다.
반면에, RAPTOR의 컨텍스트가 주어졌을 때
GPT-4는 다음과 같이 출력한다.
“이야기의 중심 주제는 변화와 역경의 극복이며,
신데렐라는 요정 대모의 도움을 받아
학대받고 억눌린 소녀에서
아름답고 자신감 있는 젊은 여성으로 변신하고,
결국 왕자와 함께 행복과 사랑을 찾게 된다.”
이는 이야기에 대한 포괄적인 이해를 보여주는
보다 완전한 답변이다.
이 정성적 분석은
RAPTOR가 기존의 검색 메커니즘들보다 더 뛰어난 성능을 보인다는 것을 보여준다.
이는 RAPTOR가 검색하는 정보가 더 관련성이 높고 포괄적이기 때문에,
다운스트림 작업에서 더 나은 성능을 가능하게 하기 때문이다.
또한 우리는 그 서사(narrative)와 주제에 대한 질문들을 포함한
2,600단어 분량의 이야기를 새로 작성하였다.
이 이야기의 일부 발췌문은 아래에 제시되어 있으며,
이 이야기의 전체 PDF는 여기에 링크되어 있다.
“이야기의 중심 주제는 무엇인가?”와 같은 질문의 경우,
다음과 같은 문장을 포함하는 상위 레벨 노드가 검색된다:
“이 이야기는 인간적 연결의 힘에 관한 이야기이며…
서로의 열정을 추구하는 과정에서
서로를 고무하고 고양시킨다.”
이 요약은 원문 텍스트에는 명시적으로 존재하지 않지만,
거의 직접적으로 질문에 답하고 있다.
”The Eager Writer”에서 발췌:
“에단의 글쓰기에 대한 열정은 언제나 그의 일부였다.
어린 시절 그는 공책에 종종 이야기와 시를 끼적였고,
나이가 들수록 글쓰기에 대한 사랑은 더욱 강해졌다.
그의 저녁 시간은 종종 방 안의 희미한 불빛 아래에서
노트북을 두드리며 보내졌다.
그는 최근 생계를 유지하기 위해
온라인 마케팅 회사의 콘텐츠 작가로 일자리를 얻었지만,
그의 마음은 여전히 이야기의 세계를 갈망하고 있었다.
그러나 많은 예비 작가들처럼,
그는 업계에서 발판을 마련하는 데 어려움을 겪었다.
그는 온라인 마케팅 회사의 콘텐츠 작가로 일했지만,
이 길이 자신이 추구하고자 했던 길이 아니라는 사실이
점점 더 분명해졌다.
바로 이 시기에 그는 Pathways 앱을 알게 되었다.
이 앱은 비슷한 직업을 가진 사람들이
서로 연결되고 지식을 공유할 수 있는 플랫폼을 제공했으며,
에단은 이를 통해 마침내
자신과 같은 글쓰기에 대한 열정을 가진 사람들과
연결될 수 있는 기회로 보았다.
에단은 자신의 열정을 공유하고
지도와 멘토링을 제공해 줄 수 있는 사람들을
만날 수 있는 기회라고 느꼈다.
그는 곧바로 가입했고,
이미 업계에 자리 잡은 전문가들부터
막 이 일을 시작한 초보자들에 이르기까지,
플랫폼에서 발견한 수많은 작가들의 수에 놀라게 되었다.”
H 내러티브QA 평가 스크립트
우리는 평가 요구 사항에 더 잘 맞추기 위해
AllenNLP의 평가 스크립트3에 여러 가지 수정을 가했다.
3 docs.allennlp.org/models/main/models/rc/tools/narrativeqa/
스무딩 추가:
참조 텍스트에서 n-그램 일치가 발생하지 않는 경우로 인해
BLEU 점수가 0이 되는 상황을 처리하기 위해 스무딩을 도입하였다.
BLEU 점수가 0이 되면 결과가 왜곡되어,
드물거나 새로운 표현에 대해 지나치게 가혹한 평가로 이어진다.
스무딩 함수를 추가함으로써,
BLEU 점수가 0으로 떨어지는 것을 방지하고
보다 공정한 평가를 제공한다.수정된 BLEU-4 가중치:
기존 스크립트는 BLEU-4 계산에서
가장 높은 차수의 n-그램(4-그램)에 가중치 1을 적용하고,
나머지에는 0을 적용하였다
(즉, weights = (0, 0, 0, 1)).
이러한 접근은 낮은 차수의 일치를 무시한 채
4-그램 일치에 과도하게 집중할 수 있다.
보다 균형 잡힌 평가를 제공하기 위해,
우리는 모든 n-그램 수준에 걸쳐 가중치를 균등하게 분배하여
BLEU-4 계산의 가중치를
(0.25, 0.25, 0.25, 0.25)로 변경하였다.METEOR 계산에서 매핑하기 전에 토크나이제이션:
기존 스크립트는 METEOR 계산을 위해
단순한 분할 및 매핑 방법을 사용하였다.
우리는 먼저 텍스트를 토크나이즈한 다음
토큰을 매핑하는 방식으로 이를 수정하였다.
이러한 수정은 단어의 올바른 언어학적 경계를 고려함으로써
METEOR 계산의 정확도를 향상시킨다.
I RAPTOR 성능에 대한 서로 다른 레이어들의 분석
I.1 서로 다른 레이어들은 성능에 어떻게 영향을 미치는가?
이 절에서는 다양한 이야기들에 대해
계층적 트리 구조의 서로 다른 레이어들을 질의할 때의
RAPTOR의 검색 성능에 대한 상세한 분석을 제시한다.
이 표들은 다양한 질의 요구 사항에 대해
RAPTOR의 다층 구조가 가지는 유용성을 검증한다.
표 14: 이야기 2에 대해 트리의 서로 다른 레이어들을 질의할 때의 RAPTOR 성능

표 15: 이야기 3에 대해 트리의 서로 다른 레이어들을 질의할 때의 RAPTOR 성능
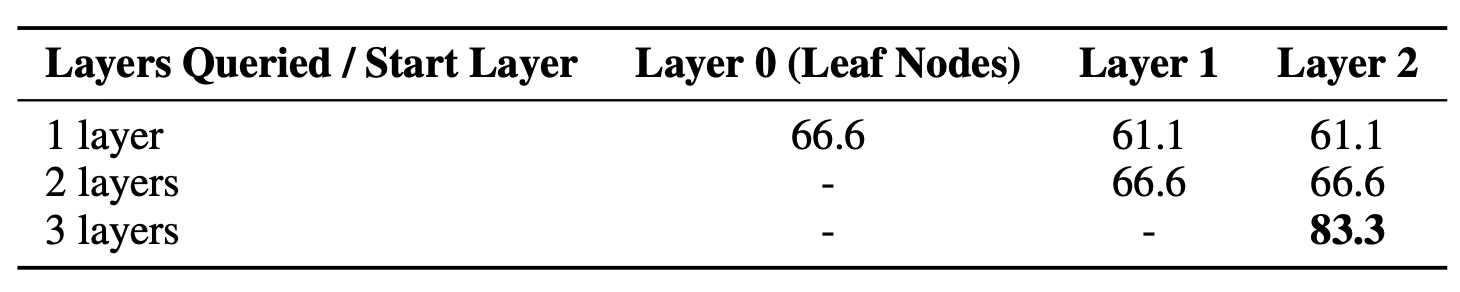
표 16: 이야기 4에 대해 트리의 서로 다른 레이어들을 질의할 때의 RAPTOR 성능

표 17: 이야기 5에 대해 트리의 서로 다른 레이어들을 질의할 때의 RAPTOR 성능

I.2 검색된 노드들은 어떤 레이어들에서 오는가?
우리는 검색된 노드들이 어떤 레이어들에서 기원하는지를 조사하기 위해,
collapsed tree 검색을 사용하는 RAPTOR를 대상으로
세 가지 데이터셋 전체와 세 가지 서로 다른 검색기 전반에 걸쳐
추가적인 소거 실험(ablation study)을 수행한다.
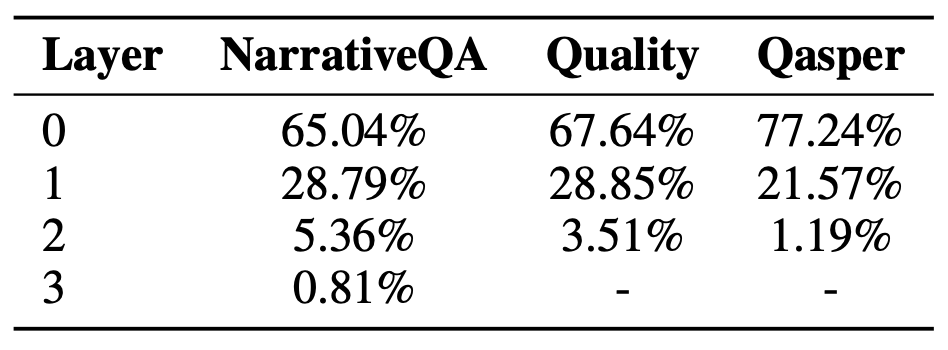
우리는 검색된 노드들 중 18.5%에서 57% 사이가
리프 노드가 아닌 노드들로부터 나온다는 것을 관찰한다.
그림 7에 나타난 바와 같이,
레이어 전반에 걸친 검색 패턴은
RAPTOR의 다중 레이어 트리 구조의 중요성을 드러낸다.
특히, NarrativeQA 데이터셋에 대해 DPR 검색기를 사용하는 RAPTOR가
검색한 노드들 중 상당한 비율이
리프 노드가 아니라 트리의 첫 번째 및 두 번째 레이어에서 나온다.
이러한 패턴은 다른 데이터셋들과 검색기들 전반에서도
비율에는 차이가 있으나 일관되게 관찰된다.
그림 7: 세 가지 검색기(SBERT, BM25, DPR)를 사용하여
세 가지 데이터셋(NarrativeQA, Quality, Qasper)에 걸쳐
RAPTOR 트리의 서로 다른 레이어들로부터 검색된 노드들의 비율을 보여주는 히스토그램.
이 데이터는 최종 검색 결과에 기여하는 노드들의 상당 부분이
리프 노드가 아닌 레이어들에서 비롯되며,
특히 첫 번째 및 두 번째 레이어에서 나온 노드들의 비율이 두드러짐을 보여준다.
이는 검색 과정에서 RAPTOR의 계층적 요약(hierarchical summarization)의 중요성을 강조한다.
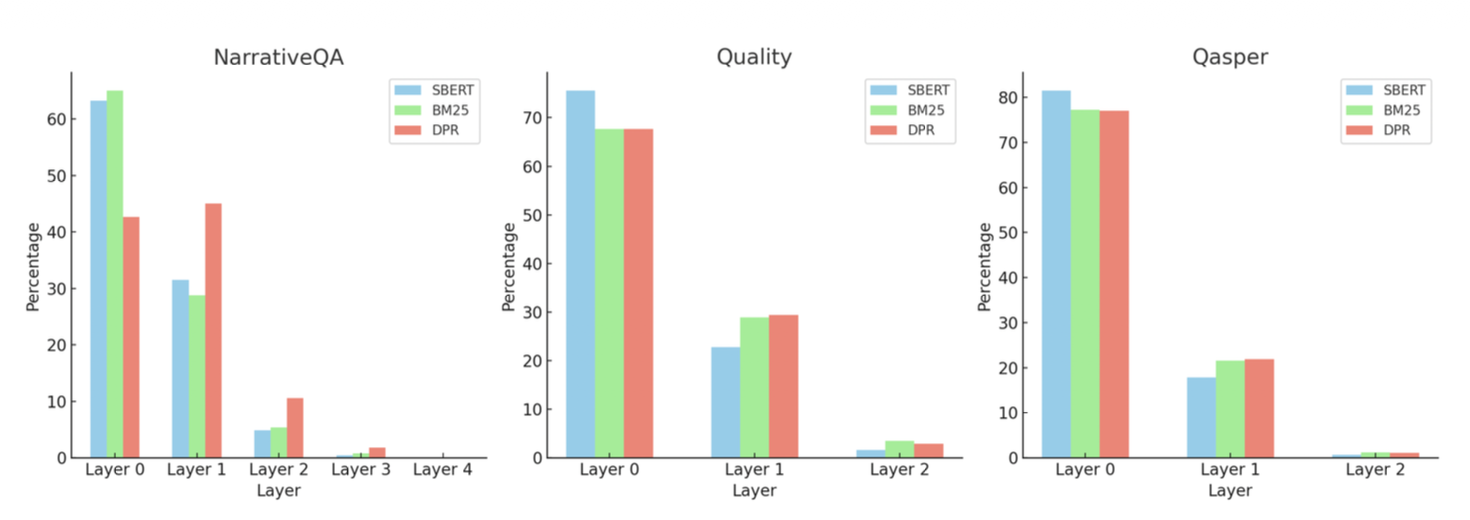
표 18: 서로 다른 데이터셋과 검색기들에 걸쳐
리프 노드가 아닌 노드들로부터 나온 노드들의 비율
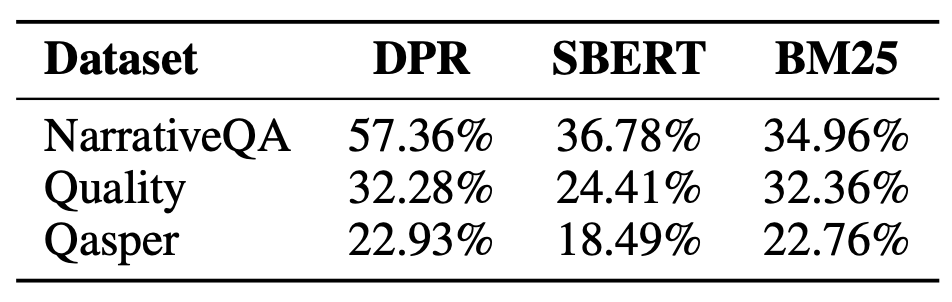
표 19: DPR을 검색기로 사용했을 때
서로 다른 레이어들로부터 나온 노드들의 비율
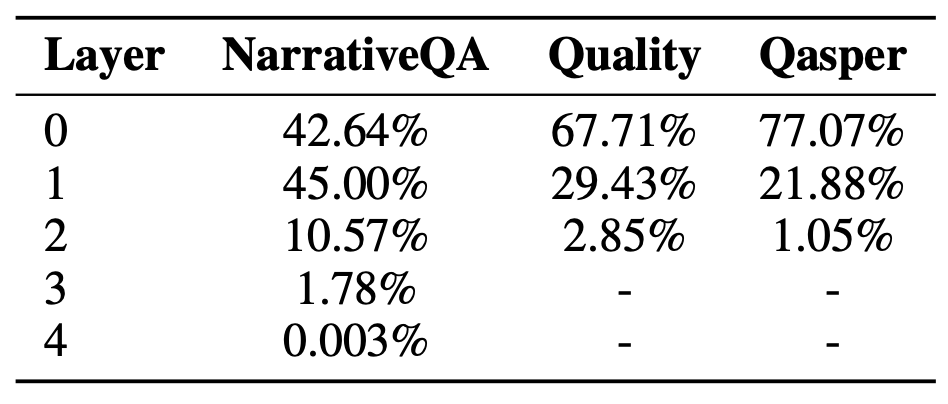
표 20: SBERT를 검색기로 사용했을 때
서로 다른 레이어들로부터 나온 노드들의 비율
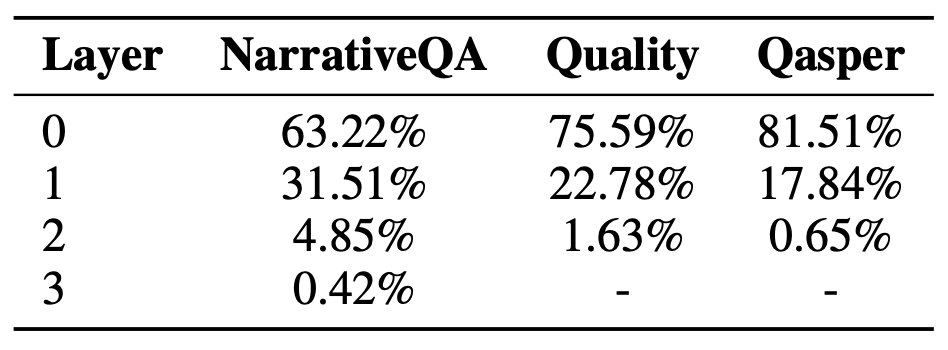
표 21: BM25를 검색기로 사용했을 때
서로 다른 레이어들로부터 나온 노드들의 비율