[텍스트 마이닝] 10. Text Classification 3
p5. 제한된 레이블로 학습하기 (Learning with limited labels)
지금까지 우리는 레이블이 있는 데이터(labeled data) 를 사용하여
분류기(classifier)를 학습하는 방법 에 대해 논의하였다.- 각 입력 텍스트 $x$ 마다, 해당하는 클래스 레이블 $y$ 가 주어진다고 가정하였다.
그러나 현실에서는 모든 데이터 인스턴스에 레이블이 존재할까?
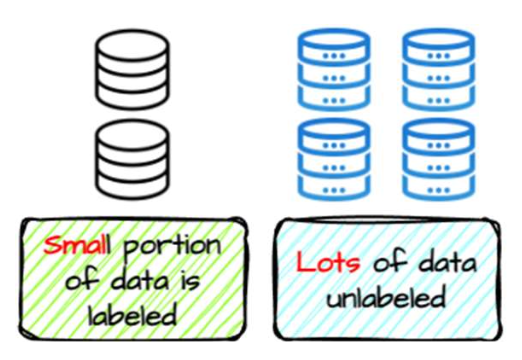
- 이제 우리는 레이블이 부족한 데이터(scarcity of labeled data) 를
어떻게 다루는지를 살펴볼 것이다.
- 준지도 학습(Semi-supervised learning)
- “레이블이 없는 데이터를 어떻게 효과적으로 활용할 수 있을까?”
(How can we effectively leverage unlabeled data?)
- “레이블이 없는 데이터를 어떻게 효과적으로 활용할 수 있을까?”
- 다중 작업 학습(Multi-task learning)
- “하나의 작업에 레이블이 부족하다면,
관련된 다른 작업으로부터 신호를 가져올 수 있을까?”
(If one task doesn’t have enough labels, can we borrow signals from related tasks?)
- “하나의 작업에 레이블이 부족하다면,
- 적대적 학습(Adversarial learning)
- “레이블이 있는 데이터와 없는 데이터가 서로 다른 분포에서 왔다면 어떻게 할까?”
(What if labeled and unlabeled data come from different distributions?)
- “레이블이 있는 데이터와 없는 데이터가 서로 다른 분포에서 왔다면 어떻게 할까?”
p6. 다중 과제 학습 (Multi-task Learning)
p7. 동기: 예시 (Motivation: example)
- 추천 시스템(recommender system)을 고려하자.
우리는 두 가지 예측 과제(two prediction tasks) 를 수행하고자 한다.- (1) 참여도(Engagement): 사용자가 아이템을 클릭(click)할지 여부
- (2) 만족도(Satisfaction): 사용자가 아이템에 높은 평점(high ratings)을 줄지 여부
- 우리는 각 과제마다 별도의 모델(separate models) 을 학습시킬 수 있다.
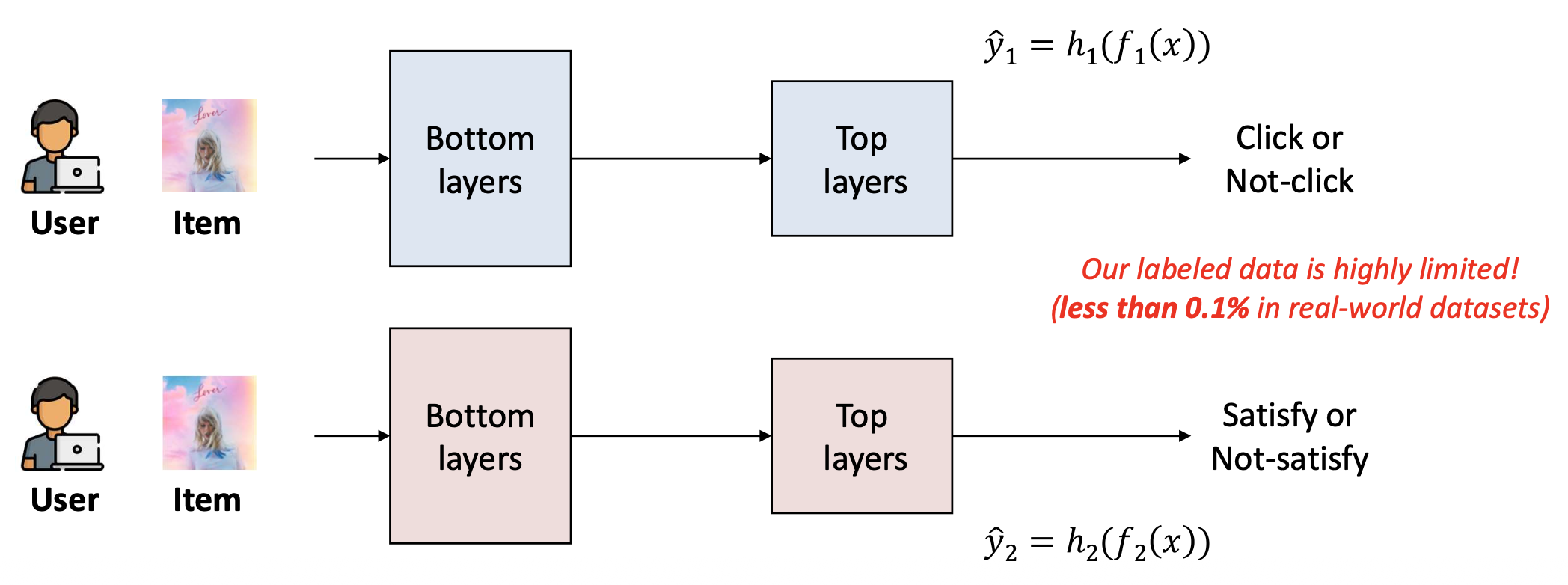
- 주의:
레이블된 데이터(labeled data) 는 매우 제한적이다.
(현실 세계의 데이터셋에서는 0.1% 미만이다.)
p8. 동기: 예시 (Motivation: example)
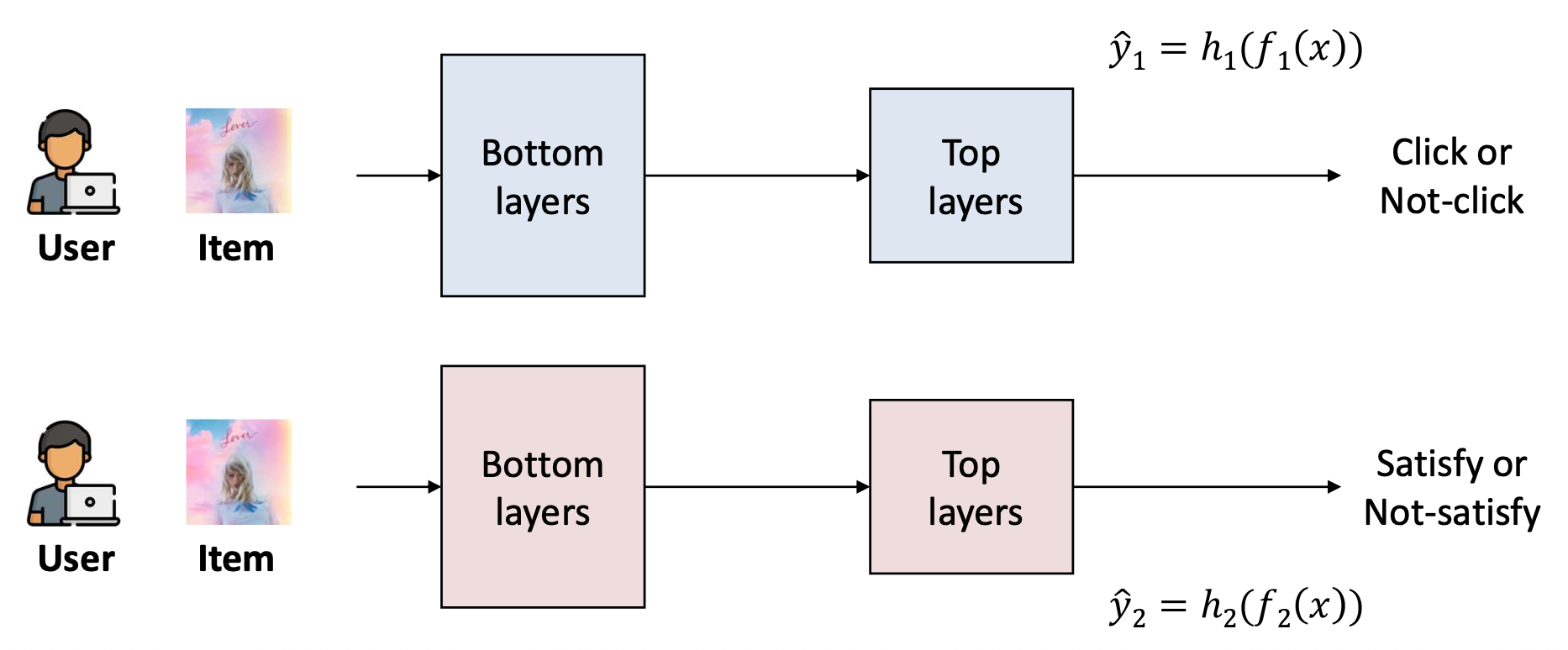
추천 시스템(recommender system)을 고려하자.
우리는 두 가지 예측 과제(two prediction tasks) 를 수행하고자 한다.실제로, 두 과제는 독립적이지 않다(two tasks are not independent).
- 사용자는 일반적으로 이미 관심 있는 아이템을 클릭(click)하는데,
이러한 아이템이 나중에 좋아하게 되는 경우가 많다. - 하나의 과제를 해결하는 것이 다른 과제에 추가적인 단서(hints) 를 제공할 수 있다.
- 사용자는 일반적으로 이미 관심 있는 아이템을 클릭(click)하는데,
p9. 동기: 예시 (Motivation: example)
추천 시스템(recommender system)을 고려하자.
우리는 두 가지 예측 과제(two prediction tasks) 를 수행하고자 한다.실제로, 두 과제는 독립적이지 않다(two tasks are not independent).
따라서, 관련된 과제들(related tasks) 을 하나의 모델(single model) 로 처리하는 것은 타당하다.
- 과제들 간 지식을 공유(sharing knowledge across tasks) 함으로써,
모델은 레이블 희소성(label sparsity) 을 완화(alleviate)할 수 있다.
- 과제들 간 지식을 공유(sharing knowledge across tasks) 함으로써,
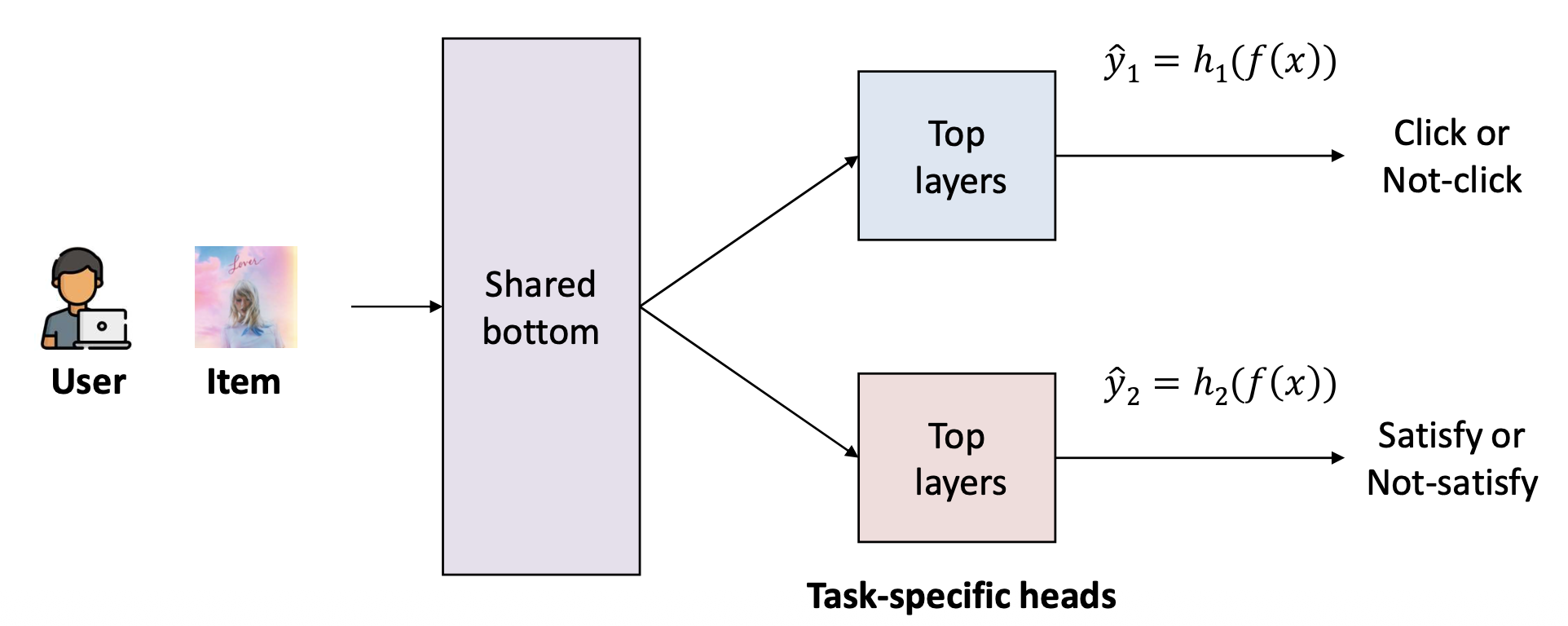
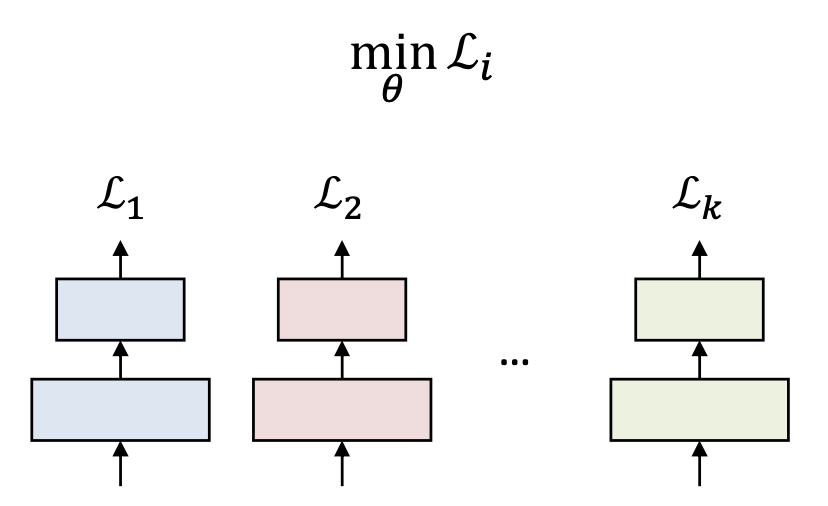
p10. 다중 과제 학습 (Multi-task learning, MTL)
다중 과제 학습(Multi-Task Learning) 은
하나의 모델(single model)이 여러 관련된 과제(multiple related tasks) 를
동시에(simultaneously) 수행하도록 학습되는 학습 패러다임이다.별도의 모델들을 구축하는 대신,
과제들 간에 유익한 지식(knowledge)을 공유(share) 할 수 있다.
단일 과제 학습(Single-task learning)
- 각 과제는 자신만의 손실(loss)을 독립적으로 최소화한다.
- 과제들 간 정보 공유는 없다.
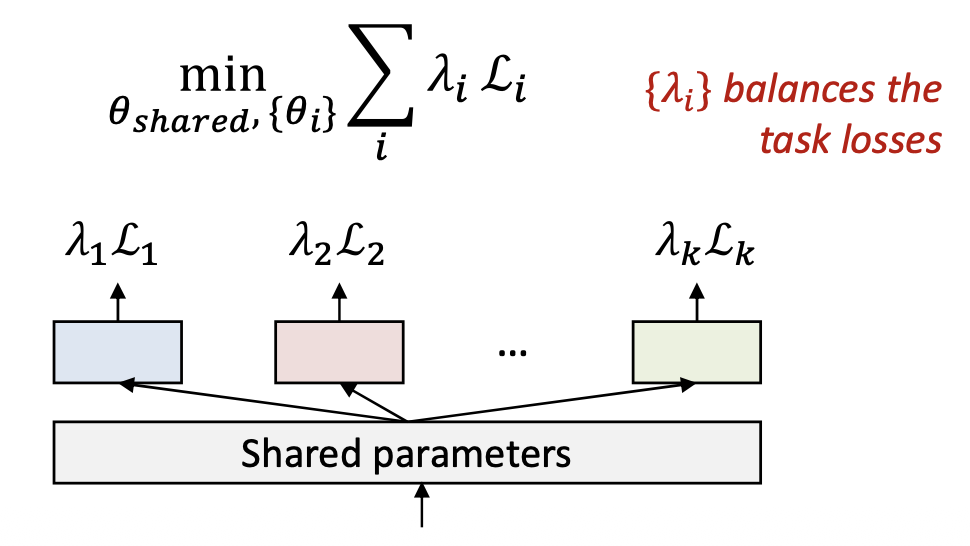
다중 과제 학습(Multi-task learning)
- 과제들은 일부 파라미터 $ \theta_{shared} $ 를 공유한다.
- 여러 과제로부터의 감독(supervision)을 통합한다.
- 일반화(generalization)를 향상시키고 레이블 희소성(label sparsity)을 줄인다.
p11. 다중 과제 학습 (MTL): 도전 과제와 해결책 (challenge & solutions)
다중 과제 학습(Multi-Task Learning) 은
하나의 모델(single model)이 여러 관련된 과제(multiple related tasks) 를
동시에(simultaneously) 수행하도록 학습되는 학습 패러다임이다.도전 과제(Challenge): 부정적 전이(Negative transfer)
- MTL은 항상 도움이 되는 것은 아니다.
때로는 과제들을 독립적으로 학습시키는 것이 더 잘 작동한다. - 부정적 전이(negative transfer)는
과제들 간 지식 공유(sharing knowledge between tasks) 가
성능(performance)을 해치는(harms) 현상을 의미한다.
- MTL은 항상 도움이 되는 것은 아니다.
p12. 다중 과제 학습 (MTL): 도전 과제와 해결책 (challenge & solutions)
- 도전 과제(Challenge): 부정적 전이(Negative transfer)
- MTL은 항상 도움이 되는 것은 아니다.
때때로 과제들을 독립적으로 학습시키는 것이 더 잘 작동한다. - 부정적 전이(negative transfer)는
과제들 간 지식 공유(sharing knowledge between tasks) 가
성능(performance)을 해치는(harms) 현상을 의미한다.
- MTL은 항상 도움이 되는 것은 아니다.
- 왜 이런 일이 발생하는가? (Why does this happen?)
- 과제 불일치(Task discrepancy):
과제들이 서로 관련되어 있더라도,
여전히 차이점(differences) 이 존재한다.- 이러한 차이가 큰 경우,
이들을 함께 학습하는 것은 이로울 수 없다(not be beneficial).
- 이러한 차이가 큰 경우,
- 과제 불일치(Task discrepancy):
- 과제 예시 (Tasks):
- 과제 1: 사용자가 아이템을 클릭(click the item) 할지 여부
- 과제 2: 사용자가 그것에 높은 평점(rate it highly) 을 줄지 여부
- 과제 3: 사용자가 그것을 친구에게 공유(share it with friends) 할지 여부
p13. 과제 불일치(task discrepancy) 해결: 다중 게이트 전문가 혼합 (Multi-gate Mixture-of-Experts)
논문:
Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts
Jiaqi Ma¹, Zhe Zhao², Xinyang Yi², Jilin Chen², Lichan Hong², Ed H. Chi²
¹미시간 대학교 정보학부 (School of Information, University of Michigan, Ann Arbor)
²Google Inc.
발표 장소:
ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), 2018
과제 불일치(Task discrepancy) 해결:
다중 게이트 전문가 혼합(Multi-gate Mixture-of-Experts)
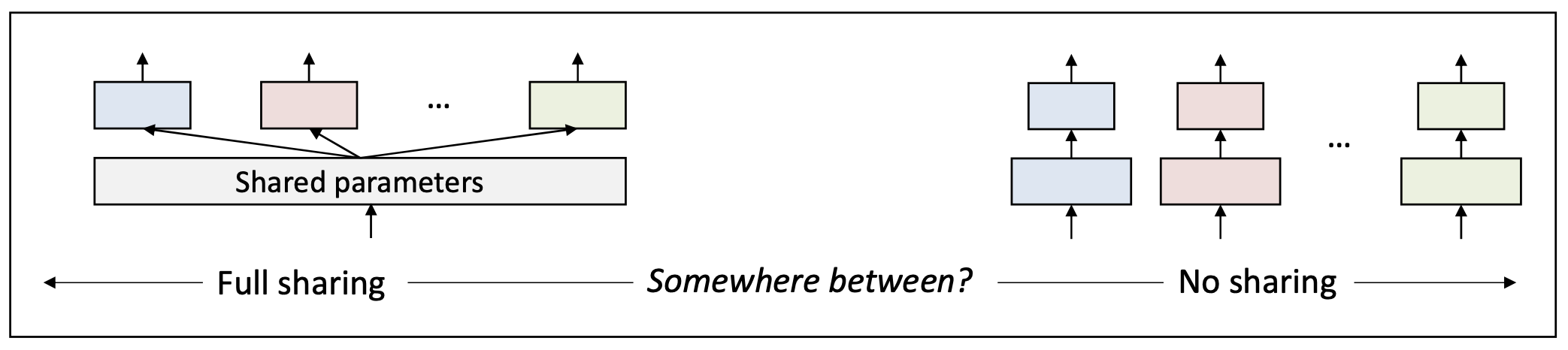
p14. 다중 게이트 전문가 혼합 (Multi-gate Mixture-of-Experts, MMoE)
다중 게이트 전문가 혼합(Multi-gate Mixture-of-Experts)은
과제 불일치(task discrepancy) 를 해결하기 위한
가장 영향력 있는 해결책 중 하나이다.- 문제(Problem): 과제 불일치(Task discrepancy)
- 과제들이 서로 관련되어 있더라도,
여전히 그들 간에는 차이(differences) 가 존재한다.
- 과제들이 서로 관련되어 있더라도,
- 목표(Objective):
과제 유사도(task similarity) 에 따라
파라미터 공유 정도(degree of parameter sharing) 를 제어한다.
- 질문:
우리는 공유 정도(sharing degree) 를
자동으로(automatically) 어떻게 조정할 수 있을까?
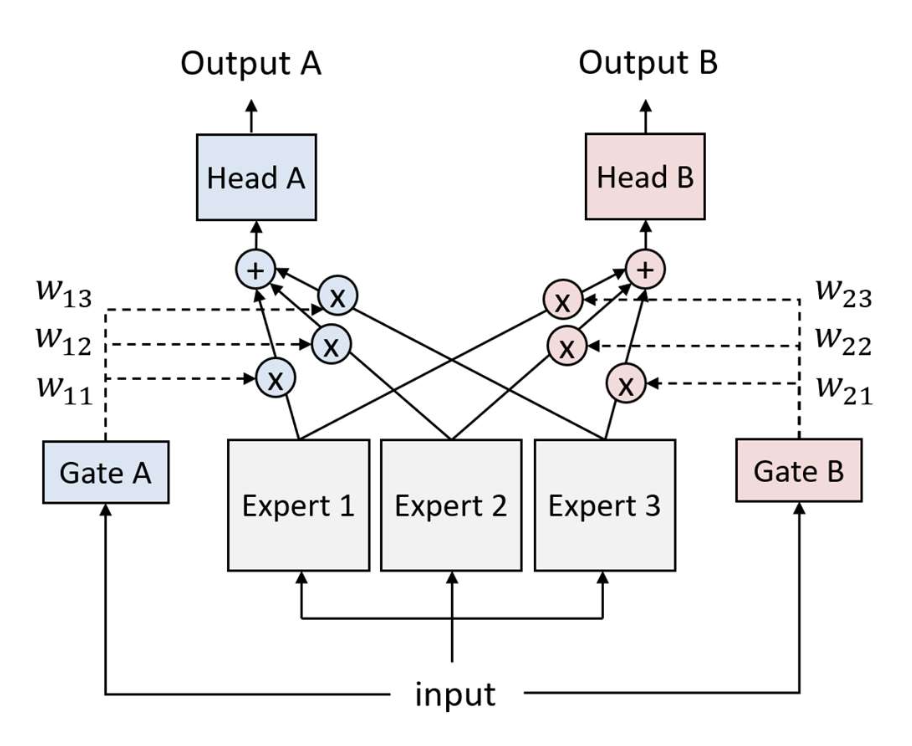
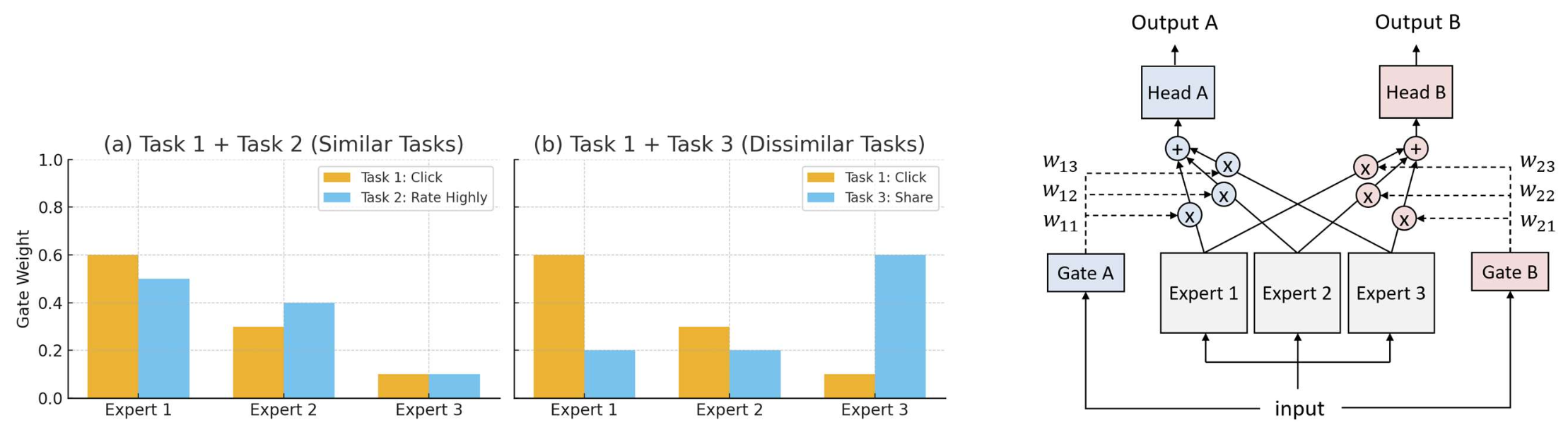
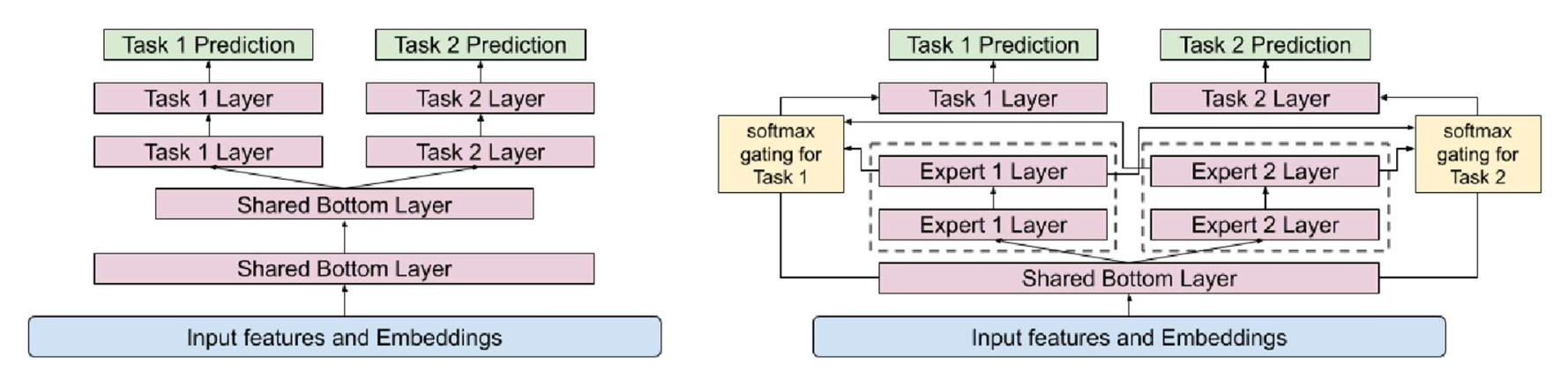
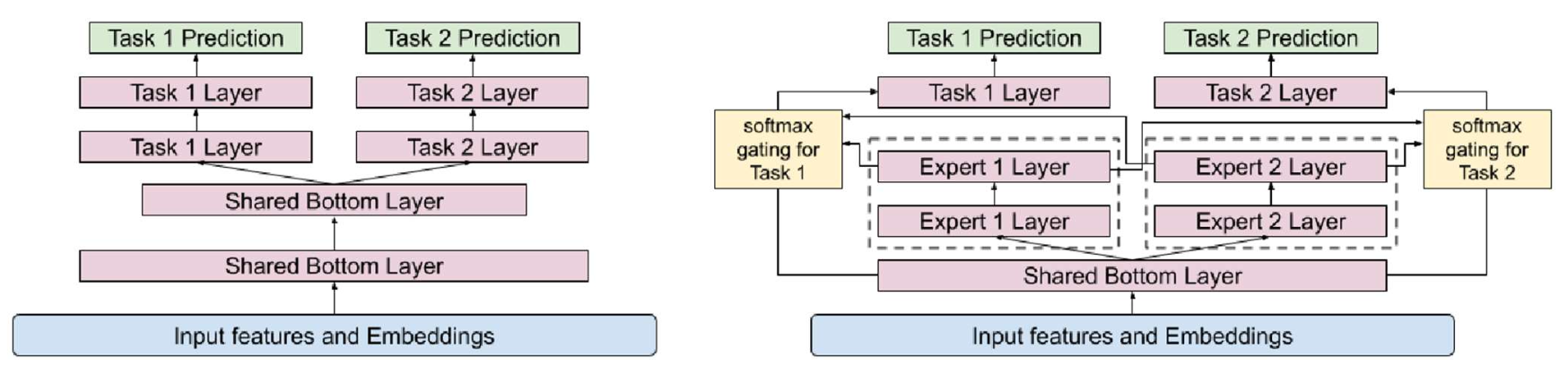
p16. MMoE: 구조 (architecture)
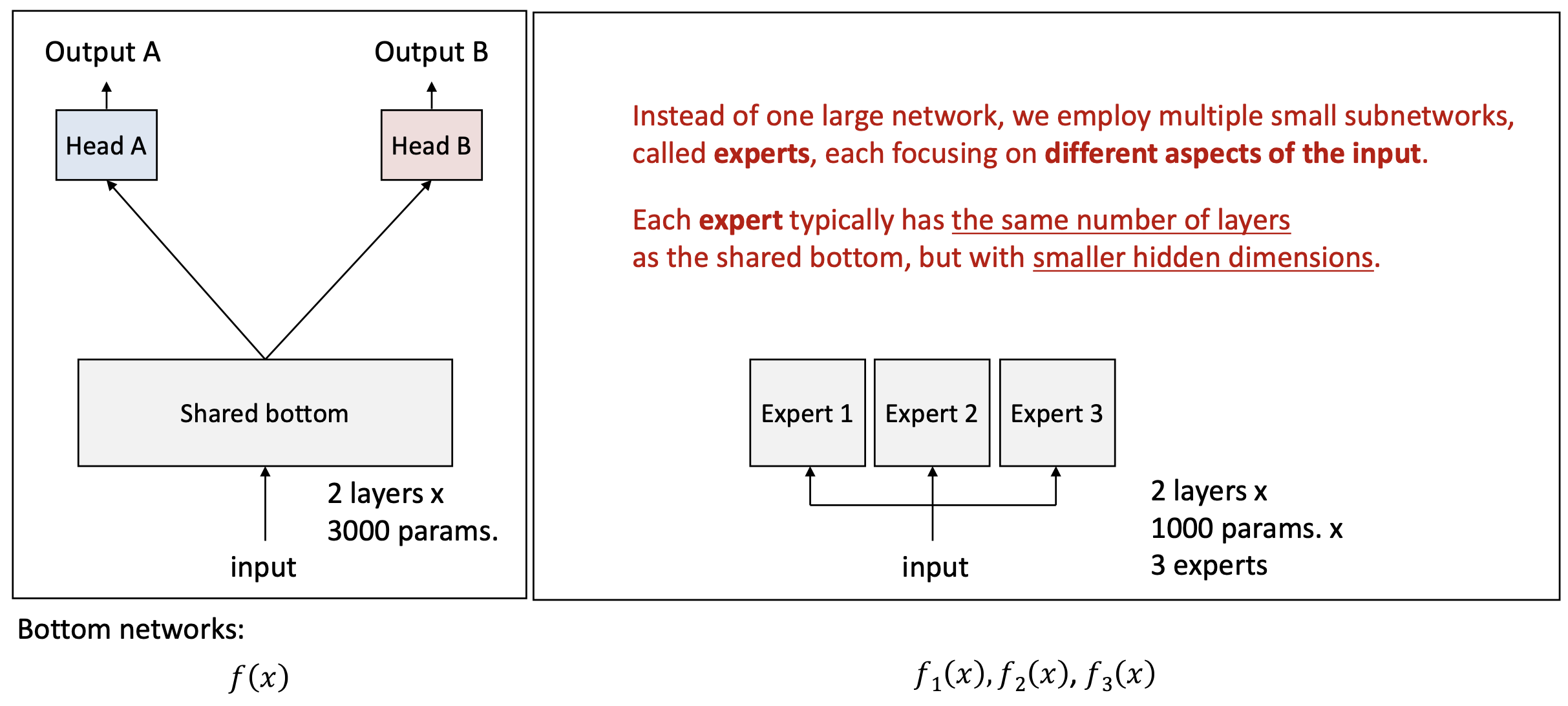
왼쪽 그림:
- 공유 하단(Shared bottom) 을 기반으로
두 개의 출력 (Output A, Output B)을 생성한다. - 입력(input)은 공유 하단으로 들어가며,
두 개의 층(layers)과 3000개의 파라미터(params)를 가진다. - 이후, 각각의 출력 헤드(Head A, Head B)로 전달된다.
오른쪽 그림:
하나의 큰 네트워크 대신,
여러 개의 작은 서브네트워크(subnetworks)를 사용한다.
이들을 전문가(experts) 라고 부르며,
각 전문가는 입력의 서로 다른 측면(different aspects of the input) 에 집중한다.각 전문가는 일반적으로
공유 하단(shared bottom) 과 동일한 층 수(the same number of layers) 를 가지지만,
더 작은 은닉 차원(smaller hidden dimensions) 을 갖는다.입력(input)은 3개의 전문가에게 전달된다.
각 전문가는 2개의 층과 1000개의 파라미터를 가진다.
p17. MMoE: 구조 (architecture)
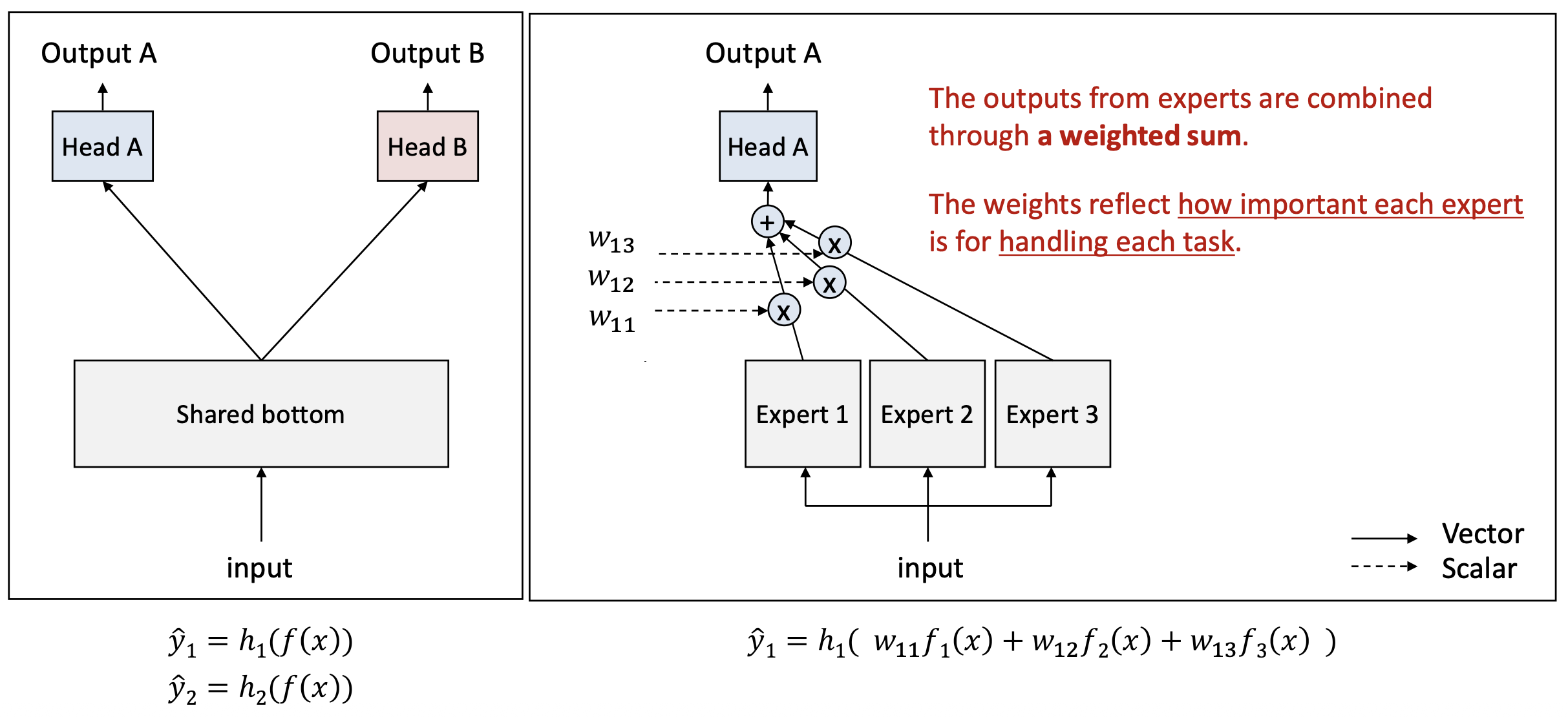
오른쪽 그림:
- 전문가(experts) 들의 출력은 가중합(weighted sum) 을 통해 결합된다.
- 각 가중치(weights) 는
각 전문가가 각 과제를 처리하는 데 얼마나 중요한지(how important each expert is for handling each task) 를 반영한다.
p18. MMoE: 구조 (architecture)
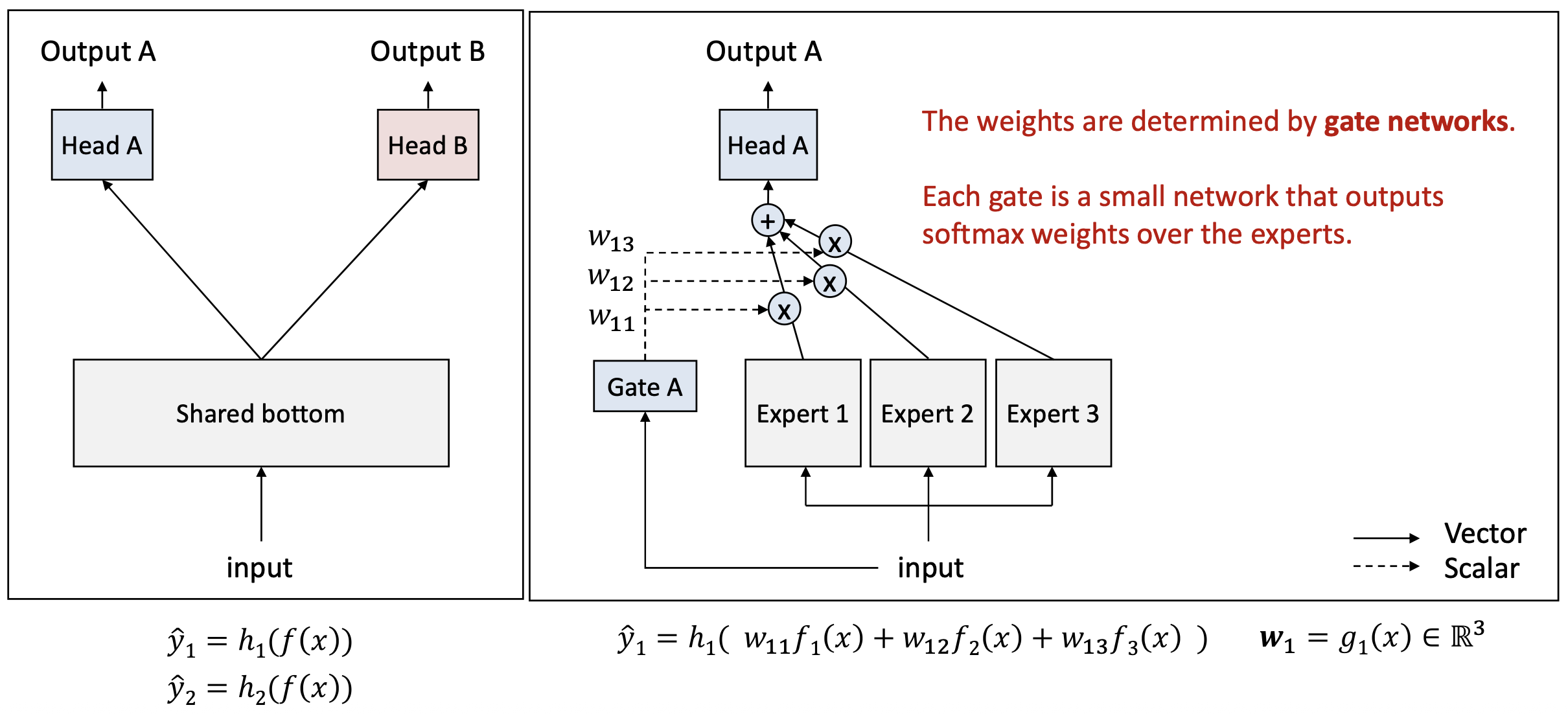
오른쪽 그림:
- 가중치(weights) 는 게이트 네트워크(gate networks) 에 의해 결정된다.
- 각 게이트(gate) 는 작은 신경망(small network)으로,
전문가들(experts) 에 대한 softmax 가중치(softmax weights) 를 출력한다.
p19. MMoE: 구조 (architecture)
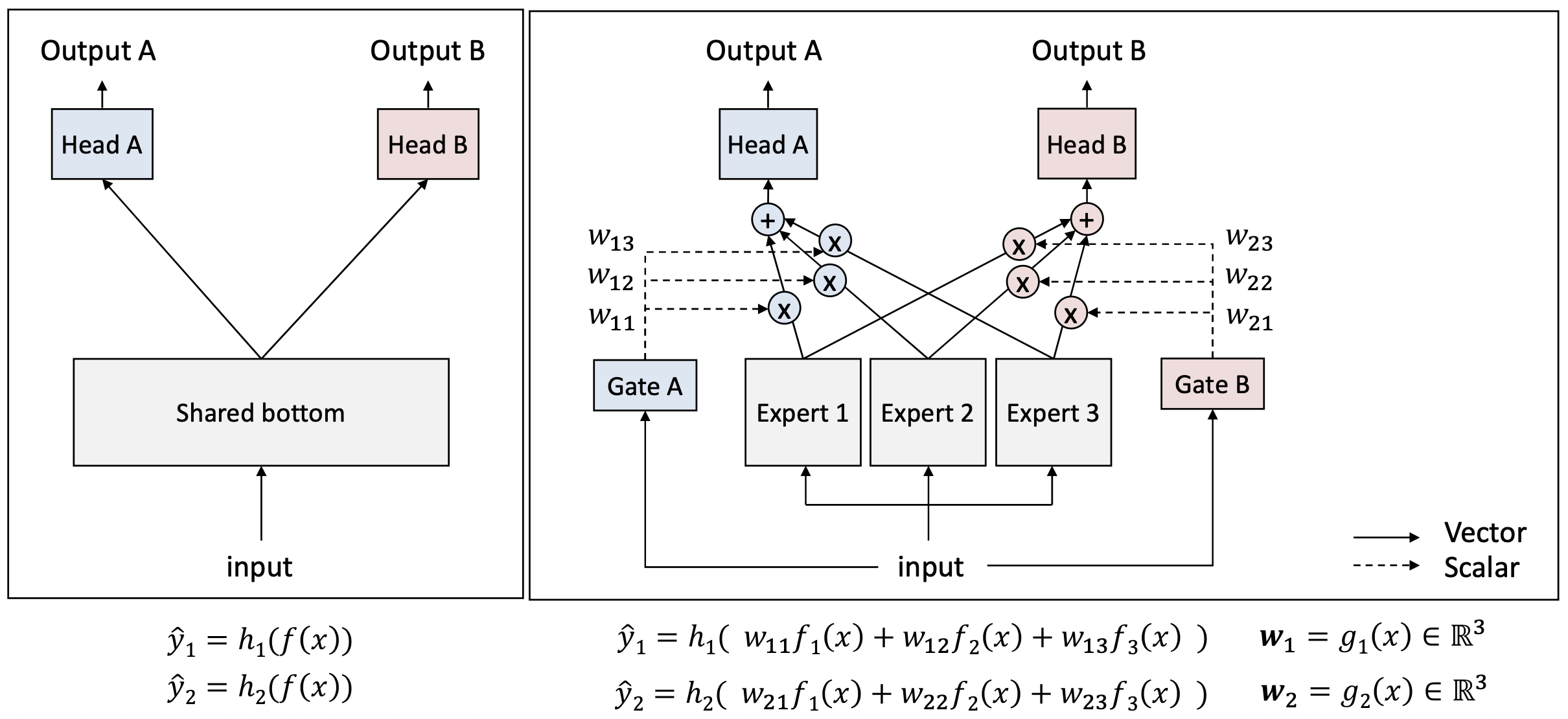
오른쪽 그림:
- 각 게이트(Gate A, Gate B) 는
입력(input) 을 받아
각 과제(Task)에 맞는 전문가(experts) 들의 가중치(weights) 를 생성한다. - 각 과제는 서로 다른 가중치 세트
$(w_{11}, w_{12}, w_{13})$ 와 $(w_{21}, w_{22}, w_{23})$ 를 사용하여
전문가들의 출력을 결합한다.
p20. MMoE: 구조 (architecture)
- MMoE의 순전파(forward propagation) (K개의 과제에 대해)
알고리즘 2
MMoE에서의 순전파 (Forward Propagation in MMoE)
- 입력 (Input): 입력 특징 $x$, 전문가 수 $M$, 과제 수 $K$
- 출력 (Output): 과제별 예측값 $\lbrace\hat{y}_1, \hat{y}_2, \dots, \hat{y}_K\rbrace$
- 전문가 \(\lbrace f_i(\cdot)\rbrace_{i=1}^{M}\), 게이트 \(\lbrace g_k(\cdot)\rbrace_{k=1}^{K}\), 과제별 헤드 \(\lbrace h_k(\cdot)\rbrace_{k=1}^{K}\) 초기화
- 전문가 출력 계산: $f_i(x)$, for $i = 1, \dots, M$
- for 각 과제 $k = 1, \dots, K$ do
- 게이팅 가중치 계산: \(w_k = g_k(x) \in \mathbb{R}^M\)
- 결합 표현(combined representation) 계산: \(z_k(x) = \sum_{i=1}^{M} w_{ki} f_i(x)\)
- 과제별 출력 계산: \(\hat{y}_k = h_k(z_k(x))\)
- end for
- 반환 (Return): $\lbrace\hat{y}_1, \hat{y}_2, \dots, \hat{y}_K\rbrace$
- 최적화(Optimization) 는 공유 하단(shared bottom) 과 정확히 동일한 손실(loss) 을 사용하여 수행된다.
- 예시: 각 과제(헤드)에 대해 교차 엔트로피(cross-entropy) 사용
p21. MMoE: 통찰 (insights)
통찰 1 (Insight 1):
MMoE는 어떻게 과제 불일치(task discrepancy)를 처리할 수 있을까?- 각 전문가(expert) 는 입력의 서로 다른 측면(different aspects of the input) 에 집중한다.
각 과제별 게이트(task-specific gate) 는
각 과제에 대해 전문가가 얼마나 유용한지(how useful they are for each task) 에 따라
전문가 출력을 결합한다.- 이는 동적인 공유 행동(dynamic sharing behavior) 을 만든다.
- 두 과제가 유사하다(similar) 면,
그들의 게이트는 유사한 가중치 분포(similar weight distributions) 를 생성한다 → 더 많이 공유(sharing more) - 두 과제가 덜 유사하다(less similar) 면,
그들의 게이트는 전문가들에게 서로 다른 가중치(different weights) 를 할당한다 → 덜 공유(sharing less)
- 두 과제가 유사하다(similar) 면,
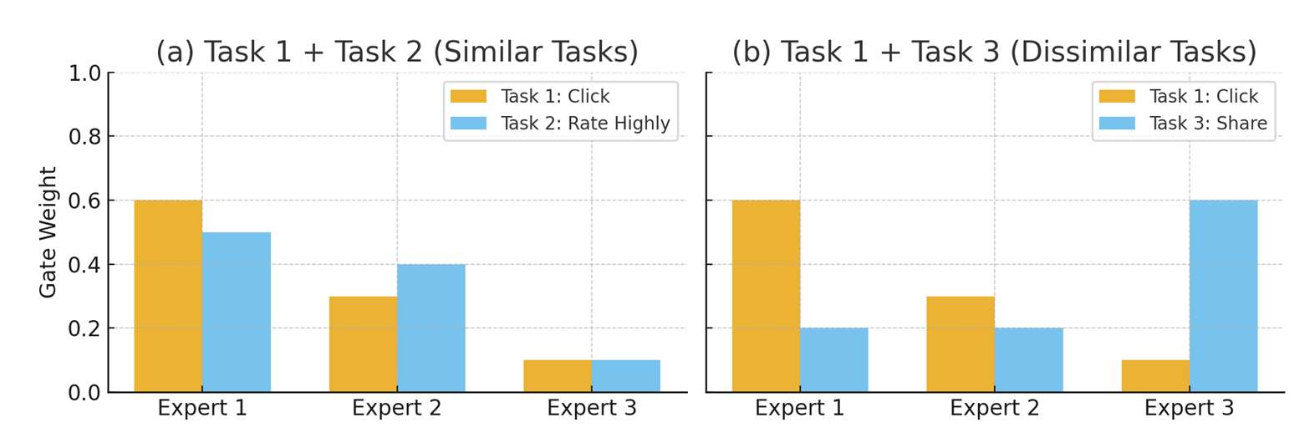
- 사용자가 다음을 수행할지 여부:
- 과제 1: 아이템을 클릭(click the item)할지
- 과제 2: 높은 평점을 줄지(rate it highly)
- 과제 3: 친구와 공유할지(share it with friends)
p22. MMoE: 통찰 (insights)
통찰 1 (Insight 1):
MMoE는 어떻게 과제 불일치(task discrepancy)를 처리할 수 있을까?- 각 전문가(expert) 는 입력의 서로 다른 측면(different aspects of the input) 에 집중한다.
각 과제별 게이트(task-specific gate) 는
각 과제에 대해 전문가가 얼마나 유용한지(how useful they are for each task) 에 따라
전문가 출력을 결합한다.- 이는 동적인 공유 행동(dynamic sharing behavior) 을 만든다.
- 두 과제가 유사하다(similar) 면,
그들의 게이트는 유사한 가중치 분포(similar weight distributions) 를 생성한다 → 더 많이 공유(sharing more) - 두 과제가 덜 유사하다(less similar) 면,
그들의 게이트는 전문가들에게 서로 다른 가중치(different weights) 를 할당한다 → 덜 공유(sharing less)
- 두 과제가 유사하다(similar) 면,
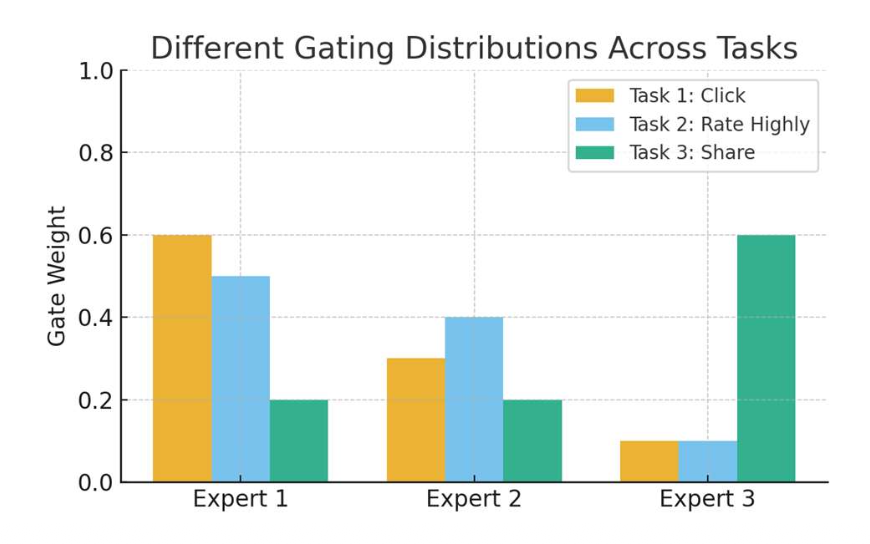
- 사용자가 다음을 수행할지 여부:
- 과제 1: 아이템을 클릭(click the item)할지
- 과제 2: 높은 평점을 줄지(rate it highly)
- 과제 3: 친구와 공유할지(share it with friends)
p23. MMoE: 통찰 (insights)
통찰 2 (Insight 2):
왜 전문가(experts)들은 학습 과정에서 점점 더 특화(specialized)되는가?- 학습 중, 파라미터들은 손실(losses)을 최소화하도록 업데이트된다.
- 각 과제별 게이트(task-specific gate) 는
해당 과제의 손실을 줄이는 데 가장 효과적인(experts that are most effective in reducing its task loss)
전문가들에게 더 높은 가중치(higher weights) 를 할당하도록 업데이트된다. - 학습이 진행됨에 따라, 특정 전문가들(certain experts) 은
특정 과제들(specific tasks) 에 의해 점점 더 많이 사용되어(increasingly utilized),
그 과제들과 가장 관련된 패턴에 특화(specialize) 되게 된다.
p24. MMoE: 응용 (YouTube)
- 목표 (Goal):
YouTube에서 다음에 시청할 동영상(what to watch next) 을 추천하는 것
- 참고 논문:
Recommending What Video to Watch Next: A Multitask Ranking System, RecSys’19
p25. MMoE: 응용 (YouTube)
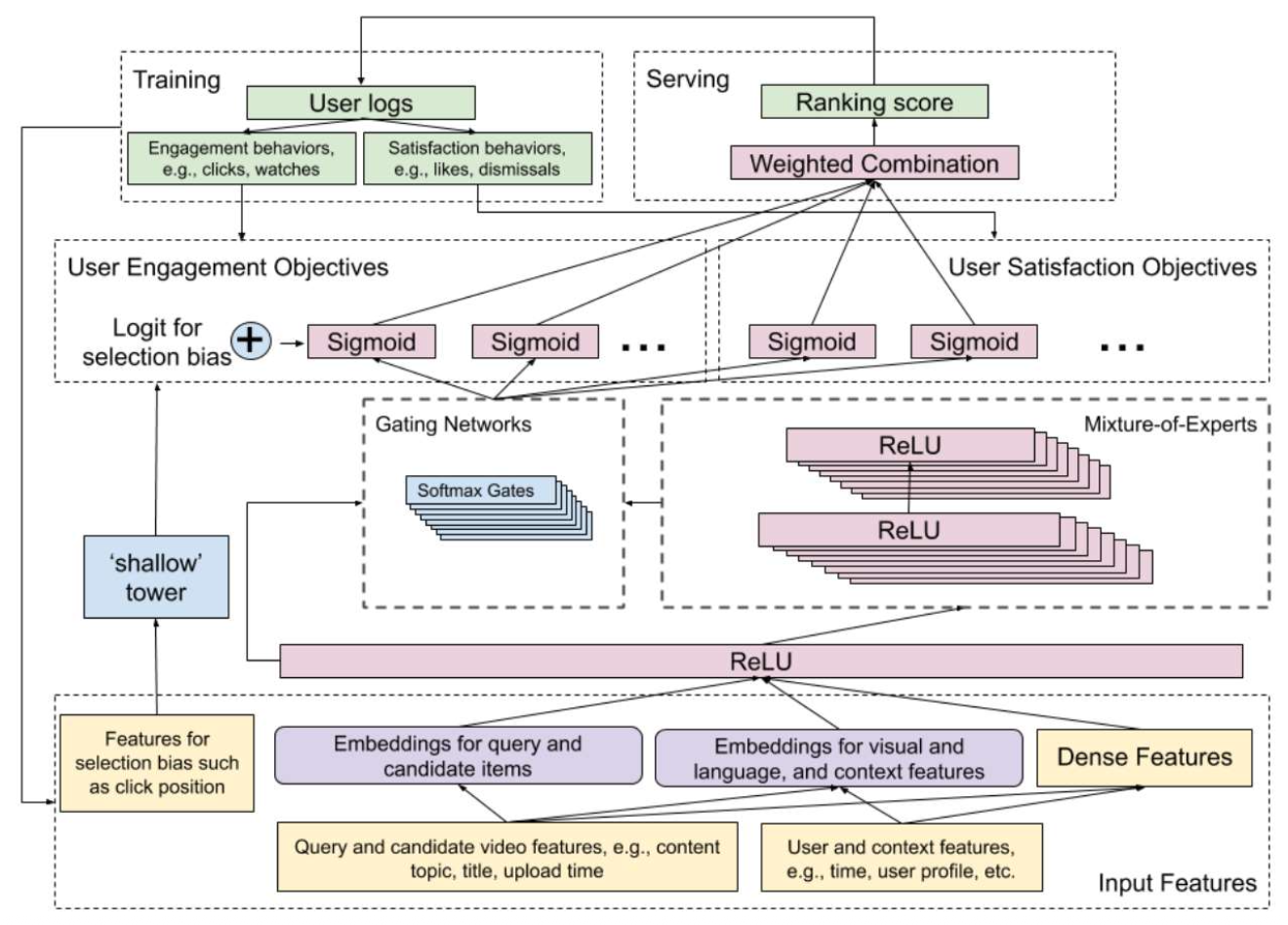
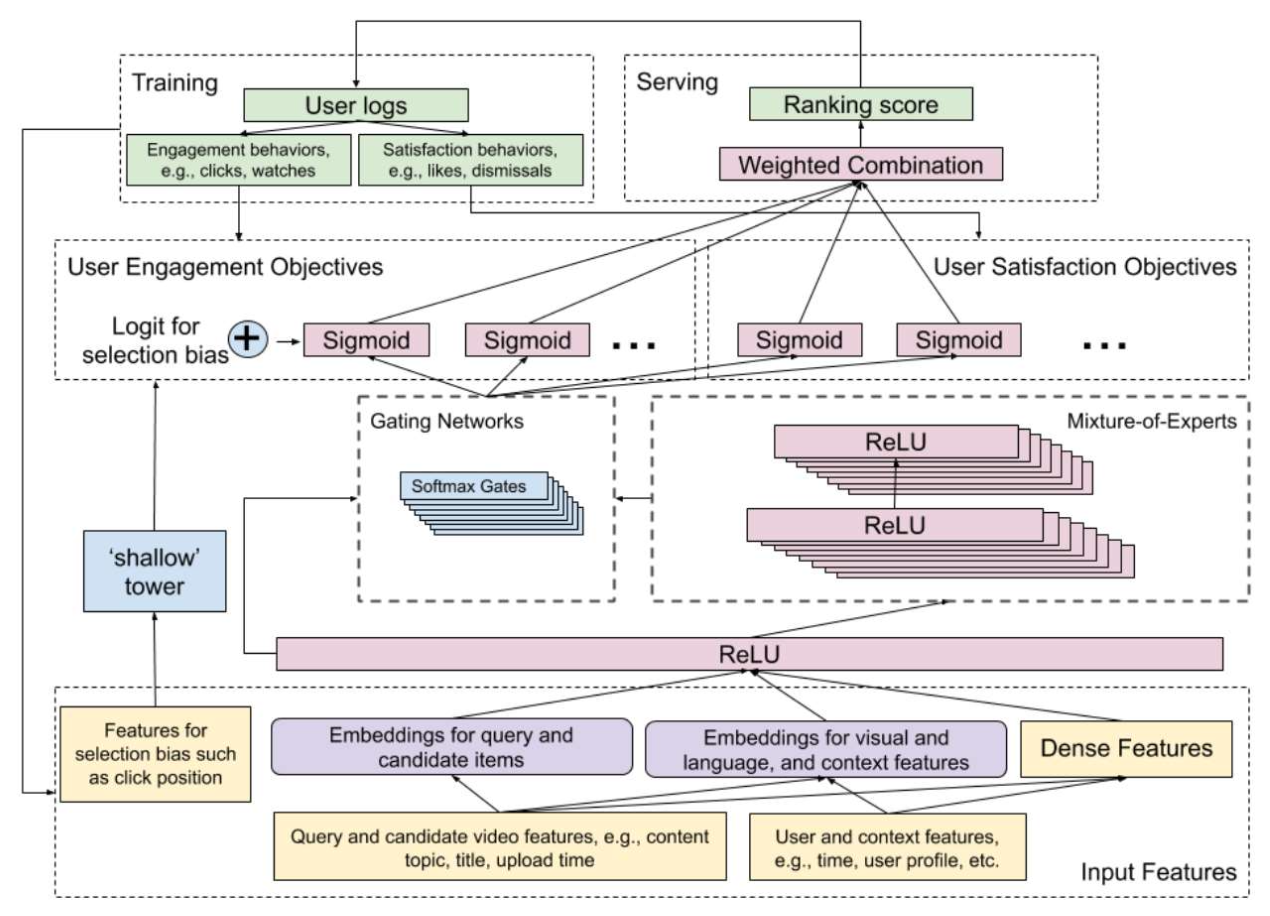
각 동영상의 최종 점수(The final score of each video) 는
모든 과제별 점수(task-specific scores) 의 가중합(weighted sum) 으로 계산된다.
(가중치는 Google이 수동으로 정의함)- 출력 (Output, 두 가지 목표 유형):
- 참여도 과제(Engagement tasks)
- 클릭(click), 시청(watch), 나중에 시청(watch later) 등
- 만족도 과제(Satisfaction tasks)
- 좋아요(like), 구독(subscribe), 공유(share) 등
- 참여도 과제(Engagement tasks)
- 입력 (Input):
- 쿼리 동영상(Query video): 사용자가 현재 시청 중인 동영상
- 후보 동영상(Candidate videos): 쿼리 동영상과 함께 자주 시청된 동영상들
- 기타 특성(Other features): 예) 나이, 위치, 시간 등
- 참고 논문:
Recommending What Video to Watch Next: A Multitask Ranking System, RecSys’19
p26. MMoE: 응용 (YouTube)
- 문제 (Problem):
- 우리는 클릭(click), 좋아요(like), 공유(share) 등 여러 과제 점수(task scores) 를 가지고 있으며,
이는 최종 예측(final predictions)에 영향을 미친다. - 각 과제의 레이블(task label) 은 충분하지 않기 때문에,
과제 간 지식을 공유(share knowledge across tasks) 하기를 원한다. - 그러나, 과제 간 불일치(discrepancies among tasks) 가 존재한다.
이를 어떻게 처리할 수 있을까?
- 우리는 클릭(click), 좋아요(like), 공유(share) 등 여러 과제 점수(task scores) 를 가지고 있으며,
- 해결책 (Solution): MMoE는 과제 간의 공유 정도(degree of sharing) 를 자동으로 조정한다.
- 과제별 게이트(task-specific gates)는 각 과제가 공유된 전문가(shared experts)를
얼마나 사용할지 동적으로 제어한다(dynamically control).
- 과제별 게이트(task-specific gates)는 각 과제가 공유된 전문가(shared experts)를
- 참고 논문:
Recommending What Video to Watch Next: A Multitask Ranking System, RecSys’19
p27. MMoE: 응용 (YouTube)
- 해결책 (Solution): MMoE는 과제 간의 공유 정도(degree of sharing)를 자동으로 조정한다.
| 모델 구조 (Model Architecture) | 곱셈 연산 수 (Number of Multiplications) | 참여도 지표 (Engagement Metric) | 만족도 지표 (Satisfaction Metric) |
|---|---|---|---|
| Shared-Bottom | 3.7M | / | / |
| Shared-Bottom | 6.1M | +0.1% | +1.89% |
| MMoE (4명의 전문가) | 3.7M | +0.20% | +1.22% |
| MMoE (8명의 전문가) | 6.1M | +0.45% | +3.07% |
MMoE는 파라미터 수를 증가시키지 않고도,
두 측면(aspects) 모두에서 성능 향상(improvements) 을 가져온다.참고 논문:
Recommending What Video to Watch Next: A Multitask Ranking System, RecSys’19
p28. MMoE: 응용 (YouTube)
- 해결책 (Solution): MMoE는 과제 간의 공유 정도(degree of sharing)를 자동으로 조정한다.
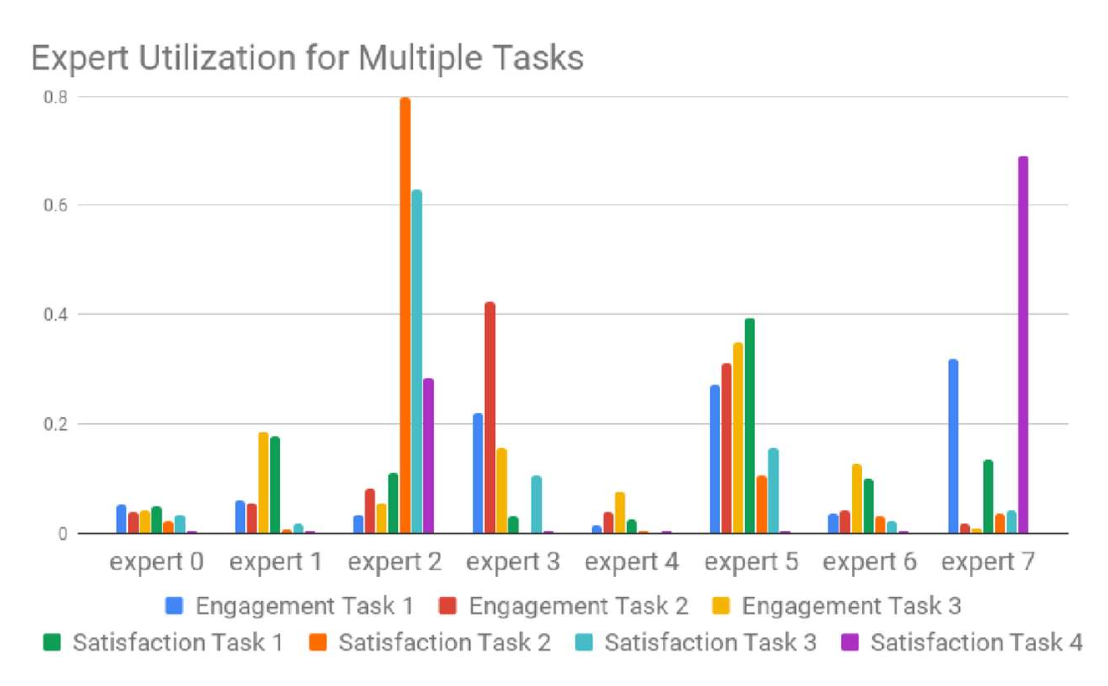
- 각 전문가(expert)는 입력의 특정 측면(aspect)에 특화되어 있으며,
주로 특정 과제(specific tasks)에 의해 활용된다.
- 참고 논문:
Recommending What Video to Watch Next: A Multitask Ranking System, RecSys’19
p29. 추천 읽을거리 (Recommended readings)
- 논문 (Papers):
- Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts, KDD’18
- Recommending What Video to Watch Next: A Multitask Ranking System, RecSys’19