[텍스트 마이닝] 11. Text Classification 4
p3. 제한된 레이블로 학습하기 (Learning with limited labels)
지금까지 우리는 레이블이 있는 데이터(labeled data) 를 사용하여
분류기(classifier)를 학습하는 방법 에 대해 논의하였다.- 각 입력 텍스트 $x$ 마다, 해당하는 클래스 레이블 $y$ 가 주어진다고 가정하였다.
그러나 현실에서는 모든 데이터 인스턴스에 레이블이 존재할까?
- 이제 우리는 레이블이 부족한 데이터(scarcity of labeled data) 를
어떻게 다루는지를 살펴볼 것이다.
- 준지도 학습(Semi-supervised learning)
- “레이블이 없는 데이터를 어떻게 효과적으로 활용할 수 있을까?”
(How can we effectively leverage unlabeled data?)
- “레이블이 없는 데이터를 어떻게 효과적으로 활용할 수 있을까?”
- 다중 작업 학습(Multi-task learning)
- “하나의 작업에 레이블이 부족하다면,
관련된 다른 작업으로부터 신호를 가져올 수 있을까?”
(If one task doesn’t have enough labels, can we borrow signals from related tasks?)
- “하나의 작업에 레이블이 부족하다면,
- 적대적 학습(Adversarial learning)
- “레이블이 있는 데이터와 없는 데이터가 서로 다른 분포에서 왔다면 어떻게 할까?”
(What if labeled and unlabeled data come from different distributions?)
- “레이블이 있는 데이터와 없는 데이터가 서로 다른 분포에서 왔다면 어떻게 할까?”
p4. 동기: 예시 (Motivation: example)
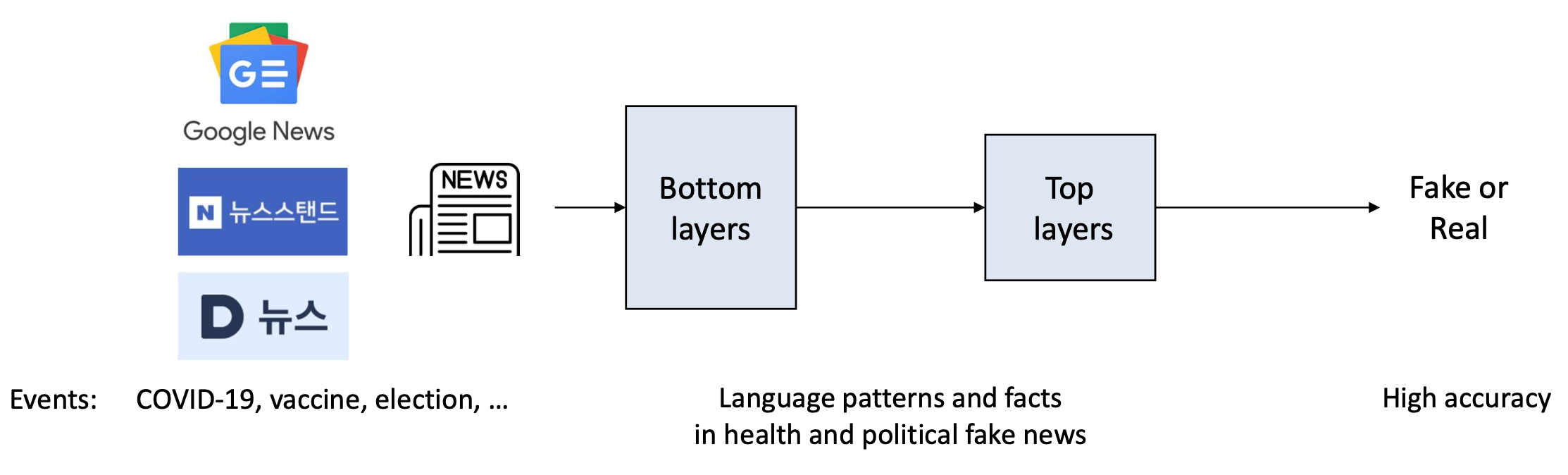
- 가짜 뉴스 탐지 시스템(fake news detection system)을 고려하자.
- 수집된 뉴스 데이터(news data) 와 레이블(labels) 을 사용하여
이진 분류(binary classification) 모델을 학습시킬 수 있다.
- 수집된 뉴스 데이터(news data) 와 레이블(labels) 을 사용하여
p5. 동기: 예시 (Motivation: example)
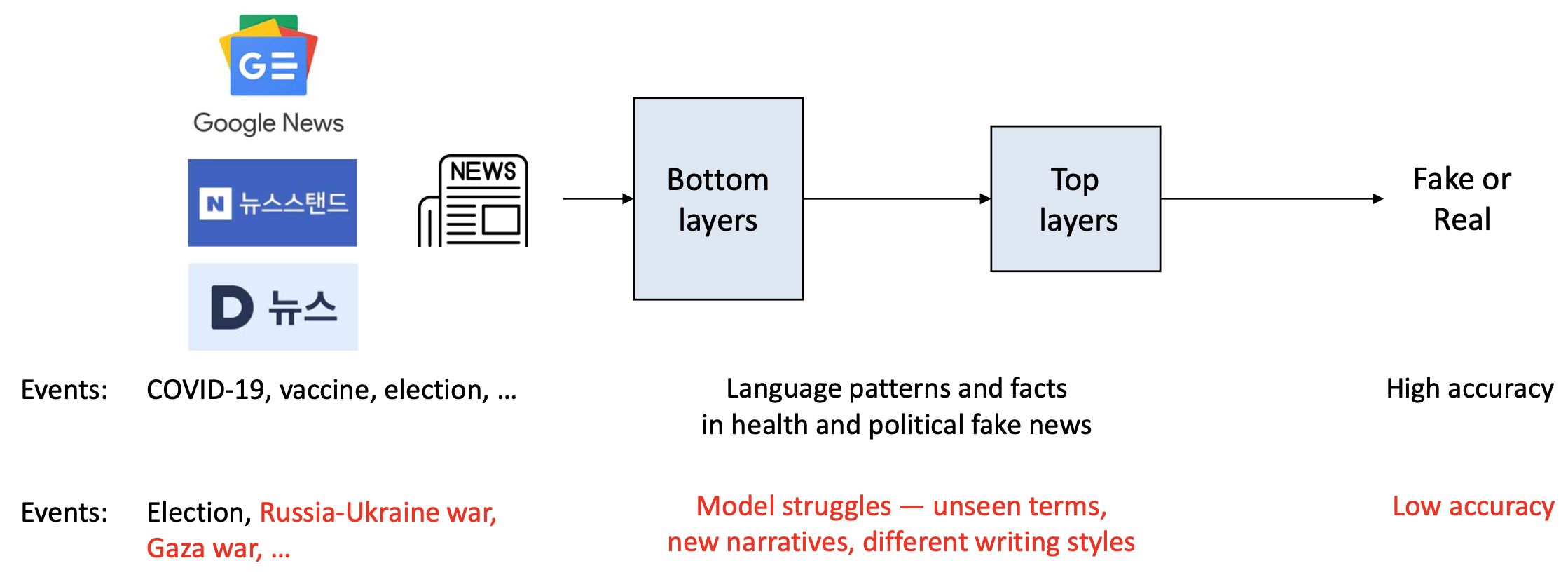
- 가짜 뉴스 탐지 시스템(fake news detection system)을 고려하자.
- 하지만 문제는… 새로운 사건들(new events) 이 계속 발생한다!
- 과거 데이터로 학습된 모델은 새로운 사건들(new events) 에 일반화(generalize) 되지 못할 수도 있다.
p6. 동기: 예시 (Motivation: example)
- 가짜 뉴스 탐지 시스템(fake news detection system)을 고려하자.
- 하지만 문제는… 새로운 사건들(new events) 이 계속 발생한다!
- 과거 데이터로 학습된 모델은 새로운 사건들(new events) 에 일반화(generalize) 되지 못할 수도 있다.
이 문제는 모든 새로운 뉴스 데이터(new news data) 에 대해 레이블(labels) 이 있다면 해결될 수 있지만,
그것은 비현실적이다(that’s infeasible).이러한 문제를 우리는 어떻게 해결할 수 있을까? (How do we cope with such a problem?)
p7. 문제: 도메인 적응 (Problem: domain adaptation)
- 이 문제는 도메인 적응(domain adaptation) 으로 알려져 있다.
- 형식적으로, 서로 다른 분포(도메인, domain)로부터 온 두 데이터 집합을 갖는다.
레이블된 소스 도메인 (Labeled source domain):
\[D_S = \lbrace (x_i^S, y_i^S) \rbrace_{i=1}^n \quad \text{from} \quad P_S(x, y)\]레이블되지 않은 타깃 도메인 (Unlabeled target domain):
\[D_T = \lbrace x_i^T \rbrace_{i=1}^m \quad \text{from} \quad P_T(x, y)\]
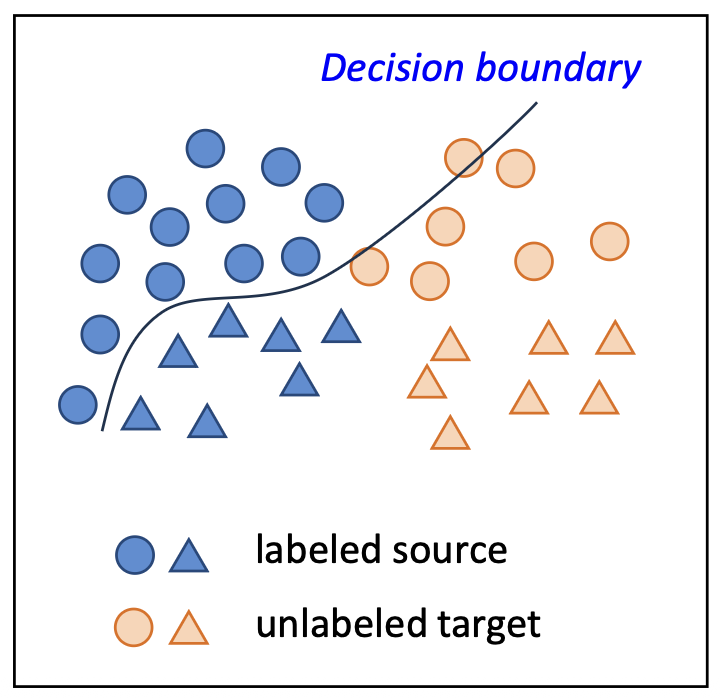
- 우리는 레이블된 소스 데이터(labeled source data) 에 대한 오차(error)를 최소화할 수 있다:
- 그러나 이 모델은 타깃 도메인(target domain) 에 대응하지 못한다.
(즉, $ P_T(x, y) $ 가 $ P_S(x, y) $ 와 다를 때 문제 발생) - SSL 기법(예: pseudo-labeling) 을 적용할 수 있으나,
그들의 예측(predictions)은 종종 부정확하거나(inaccurate) 편향(biased) 되어 있다.
p8. 문제: 도메인 적응 (Problem: domain adaptation)
- 이 문제는 도메인 적응(domain adaptation) 으로 알려져 있다.
- 형식적으로, 서로 다른 분포(도메인, domain)로부터 온 두 데이터 집합을 갖는다.
레이블된 소스 도메인 (Labeled source domain):
$ D_S = \lbrace (x_i^S, y_i^S) \rbrace_{i=1}^n \quad \text{from} \quad P_S(x, y) $레이블되지 않은 타깃 도메인 (Unlabeled target domain):
$ D_T = \lbrace x_i^T \rbrace_{i=1}^m \quad \text{from} \quad P_T(x, y) $
하나의 가정 (An assumption):
두 도메인 사이에는 입력 $x$ 를 레이블 $y$ 로 매핑하는 공통된 결정 패턴(common decision pattern) 이 존재한다.
\[P_S(y \mid x) = P_T(y \mid x)\]- 다시 말해, 레이블링 규칙(labeling rule) 이 도메인 간에 공유된다.
- 이 가정은 항상 엄밀하게 참은 아니지만(not always strictly true),
많은 실제(real-world) 경우에서 꽤 잘 성립한다(holds reasonably well).
p9. 데이터 가중치 조정 (Data reweighting)
p10. 데이터 가중치 조정 (Data reweighting)
한 가지 해결책은 다음과 같다.
(1) 각 소스 샘플(source sample)이 타깃 도메인(target domain)에 얼마나 중요한지를 추정(estimate) 하고
(2) 이를 선택적으로 반영(reflect) 하는 것이다.핵심 아이디어 (Key idea):
타깃 분포 $P_T(x)$ 하에서 더 높은 확률(more likely) 을 가지는 소스 예시(source examples)의 가중치를 높인다(upweight).
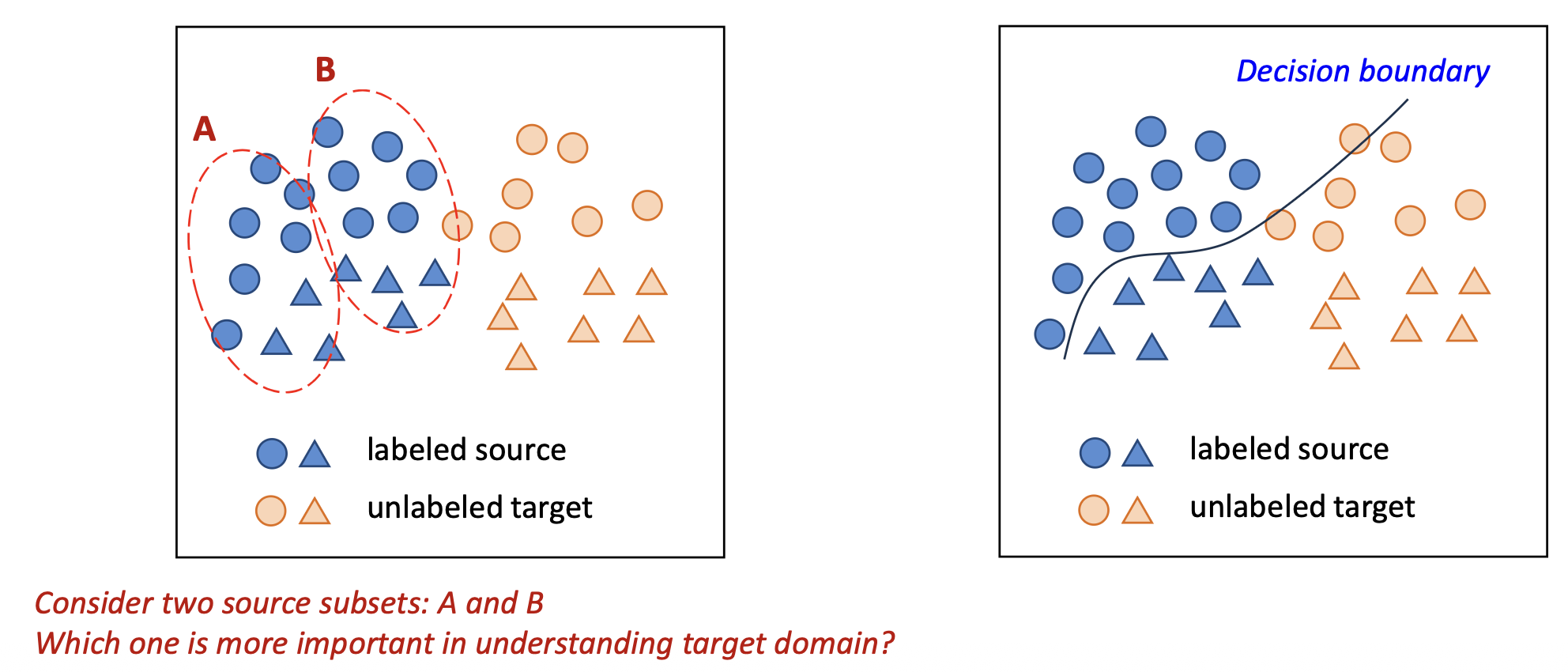
- 두 개의 소스 부분집합(subset) A와 B를 고려하자.
타깃 도메인을 이해하는 데 있어 어느 쪽이 더 중요할까?
p11. 데이터 가중치 조정 (Data reweighting)
한 가지 해결책은 다음과 같다.
(1) 각 소스 샘플(source sample)이 타깃 도메인(target domain)에 얼마나 중요한지를 추정(estimate) 하고
(2) 이를 선택적으로 반영(reflect) 하는 것이다.핵심 아이디어 (Key idea):
타깃 분포 $P_T(x)$ 하에서 더 높은 확률(more likely) 을 가지는 소스 예시(source examples)의 가중치를 높인다(upweight).
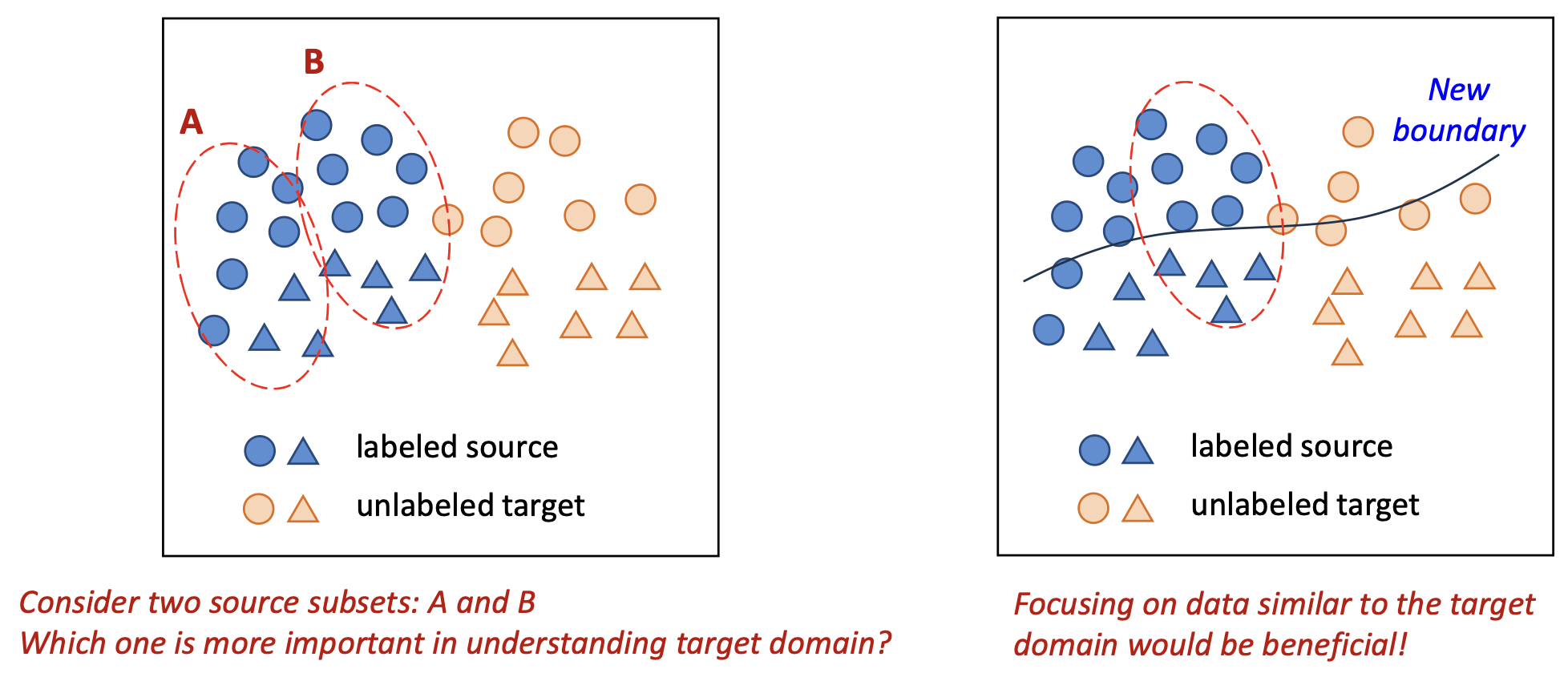
두 개의 소스 부분집합(subset) A와 B를 고려하자.
타깃 도메인을 이해하는 데 있어 어느 쪽이 더 중요할까?타깃 도메인(target domain) 과 유사한 데이터(data) 에 집중하는 것이 더 유익하다(beneficial)!
p12. 데이터 가중치 조정: 개요 (Data reweighting: overview)
- 우리의 목표(goal)는 타깃 도메인(target domain) 에서의 오차(error)를 최소화하는 것이다.
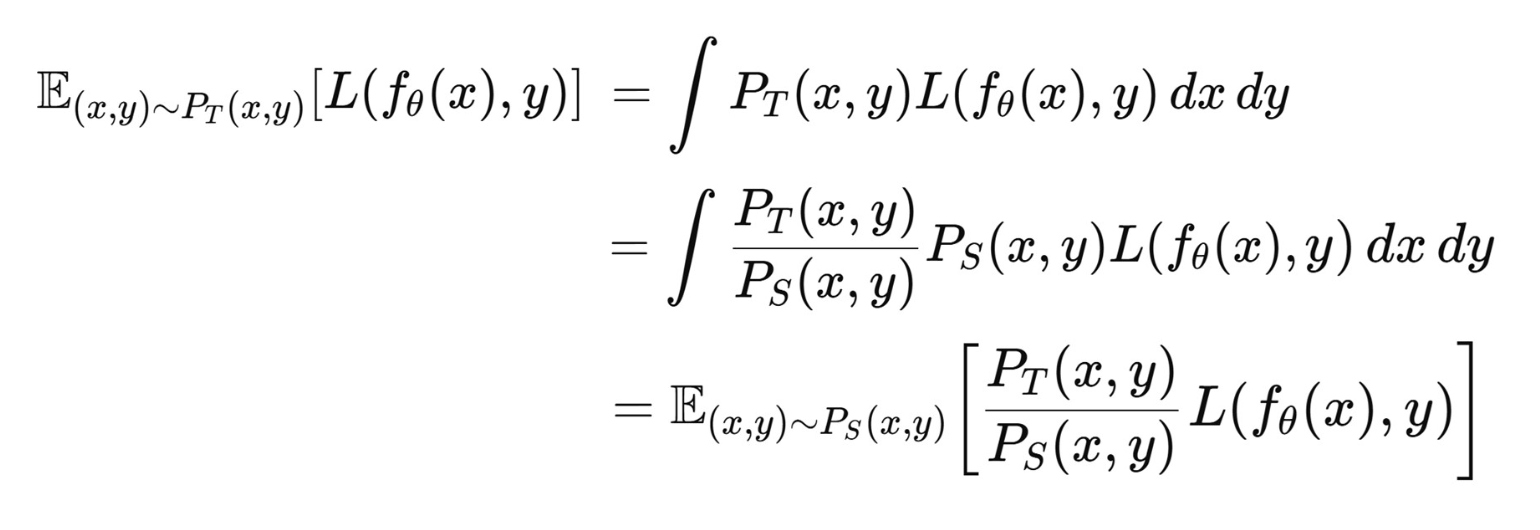
p13. 데이터 가중치 조정: 개요 (Data reweighting: overview)
- 우리의 목표(goal)는 타깃 도메인(target domain) 에서의 오차(error)를 최소화하는 것이다.

p14. 데이터 가중치 조정: 구체화 (Data reweighting: instantiation)
최종적으로, 우리의 목표(goal)는 다음과 같이 공식화(formulated)될 수 있다.
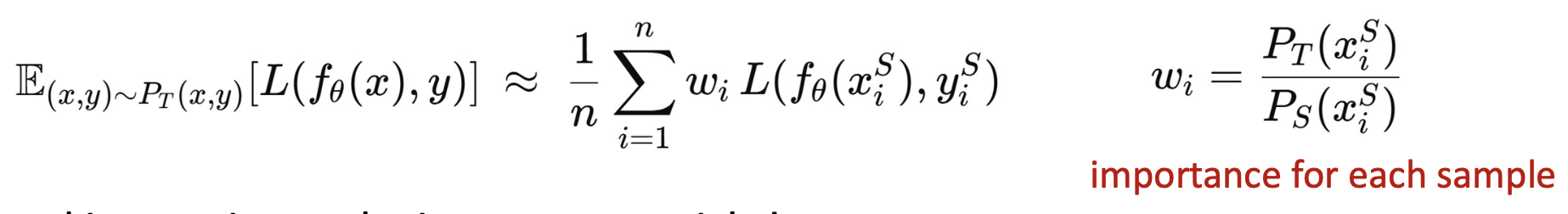
- 이제 우리가 해야 할 일은 중요도 가중치(importance weight) 를 추정(estimate) 하는 것이다!
베이즈 규칙(Bayes rule) 을 사용하면, 가중치(weight)는 다음과 같이 쓸 수 있다.

p15. 데이터 가중치 조정: 구체화 (Data reweighting: instantiation)
최종적으로, 우리의 목표(goal)는 다음과 같이 공식화될 수 있다.
- 이제 우리가 해야 할 일은 중요도 가중치(importance weight) 를 추정(estimate) 하는 것이다!
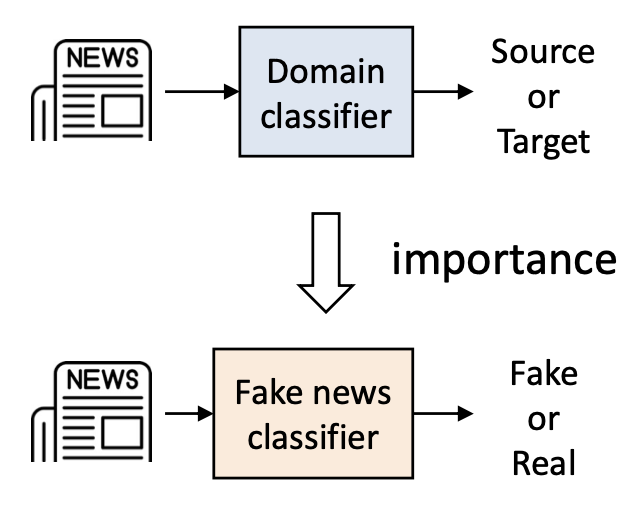
가중치는 별도의 도메인 분류기(separate domain classifier) 를 사용하여 추정된다.
- 즉, 우리는 소스(source) 와 타깃(target) 샘플을 구분하기 위한
이진 분류기(binary classifier) 를 학습시킨다.
- 즉, 우리는 소스(source) 와 타깃(target) 샘플을 구분하기 위한

p16. 데이터 가중치 조정: 요약 (Data reweighting: summary)
도메인 적응(domain adaptation) 문제에 대한 간단한 해결책:
(1) 각 소스 샘플(source sample)이 타깃 도메인(target domain)에
얼마나 중요한지를 추정(estimate) 하고,
(2) 이를 선택적으로 반영(reflect) 한다.절차 (Procedure):
- 이진 분류기(binary classifier) 를 학습시켜 소스 데이터와 타깃 데이터를 구분한다.
- 모든 소스 데이터 인스턴스에 대해 중요도 가중치(importance weight) 를 계산한다.
- 가중치가 적용된 손실 함수(weighted loss function)를 사용하여
타깃 분류기(target classifier) 를 학습시킨다.
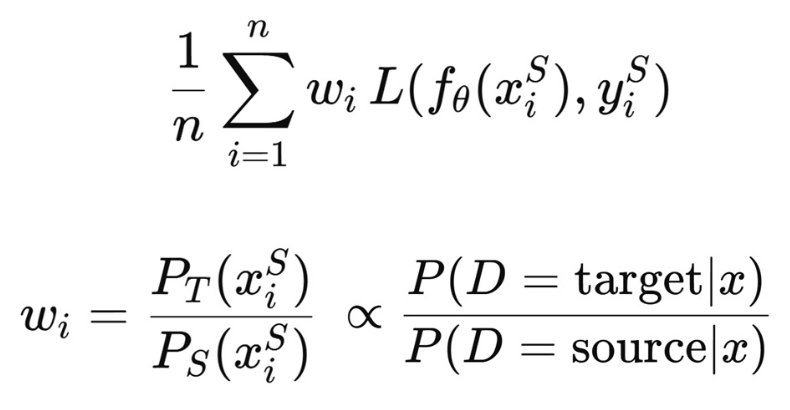
p17. 데이터 가중치 조정: 요약 (Data reweighting: summary)
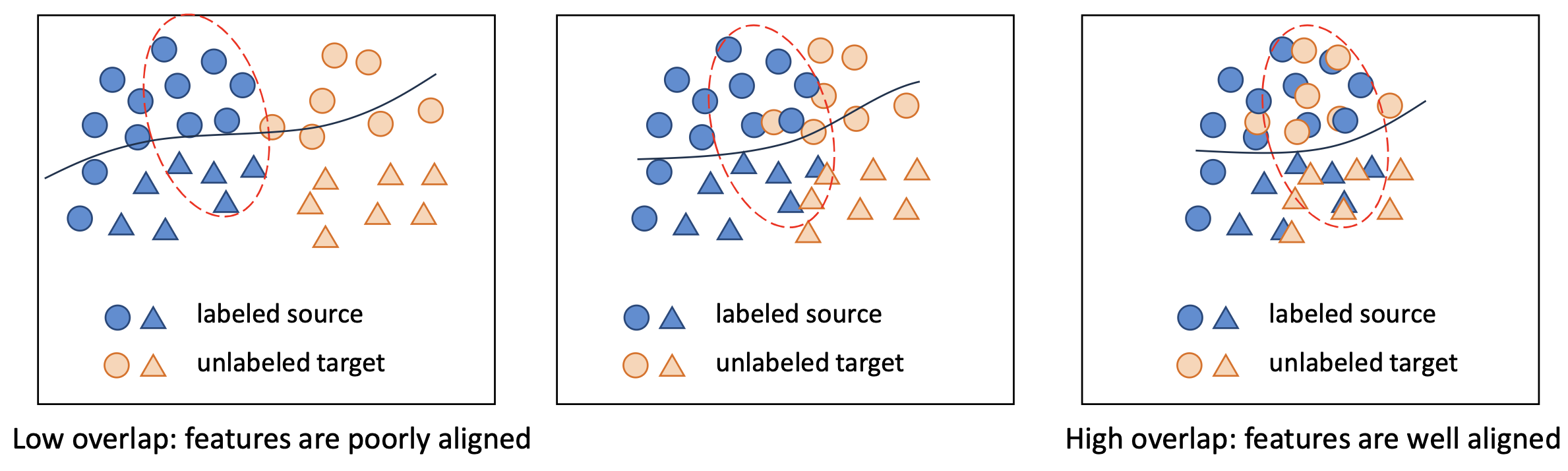
- 제한점 (Limitation):
- 여전히, 학습에는 소스 데이터(source data) 만 사용된다.
- 효과성(effectiveness)은 소스와 타깃 도메인 간의 중첩 정도(degree of overlap) 에 크게 의존한다.
- 다시 말해, 두 도메인의 특성 공간(feature spaces) 은 잘 정렬되어야 한다(well aligned).
p18. 적대적 학습 (Adversarial learning)
논문:
Domain-Adversarial Training of Neural Networks
Journal of Machine Learning Research 17 (2016)
저자 (Authors):
Yaroslav Ganin, Evgeniya Ustinova
Skolkovo Institute of Science and Technology (Skoltech)
Skolkovo, Moscow Region, Russia
Hana Ajakan, Pascal Germain
Département d’informatique et de génie logiciel, Université Laval
Québec, Canada, G1V 0A6
Hugo Larochelle
Département d’informatique, Université de Sherbrooke
Québec, Canada, J1K 2R1
François Laviolette, Mario Marchand
Département d’informatique et de génie logiciel, Université Laval
Québec, Canada, G1V 0A6
Victor Lempitsky
Skolkovo Institute of Science and Technology (Skoltech)
Skolkovo, Moscow Region, Russia
p19. 적대적 학습: 동기 (Adversarial learning: motivation)
- 따라서, 두 도메인의 특징 공간(feature spaces) 이 잘 정렬(aligned)되어 있다면,
우리는 일반화 성능(generalization) 을 향상시킬 수 있다!
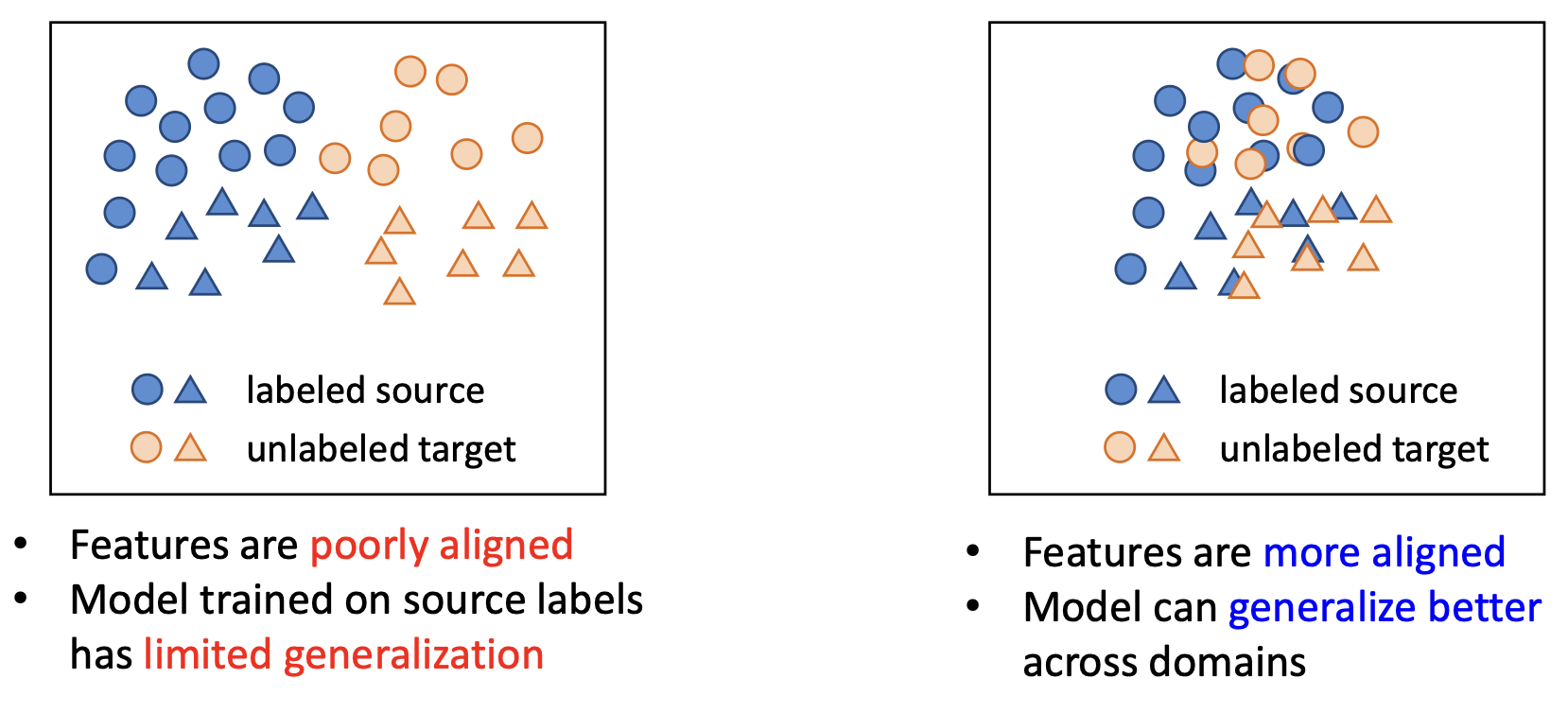
- (왼쪽)
- 특징(feature)들이 잘 정렬되지 않음(poorly aligned)
- 소스 레이블(source labels)로 학습된 모델은
제한된 일반화 성능(limited generalization) 만을 가짐
- (오른쪽)
- 특징(feature)들이 더 잘 정렬됨(more aligned)
- 모델은 도메인 간에서 더 나은 일반화(generalize better) 가 가능함
- 우리는 두 도메인 간의 특징 분포(feature distributions) 를
명시적으로 정렬하도록 모델을 학습시킬 수 있을까?
p22. 적대적 학습: 동기 (Adversarial learning: motivation)
- 이제 중간 층(intermediate layer) 의 출력(output) 에 인코딩된 정보를 생각해보자.
- 이것들은 학습된 특징(learned features) 으로, 원시 입력 특징(raw input features)을 기반으로 구축된다.
- 이들은 모델이 손실(loss)을 최소화하도록 돕는 정보를 인코딩한다.
(예: 가짜인지 아닌지 구분)
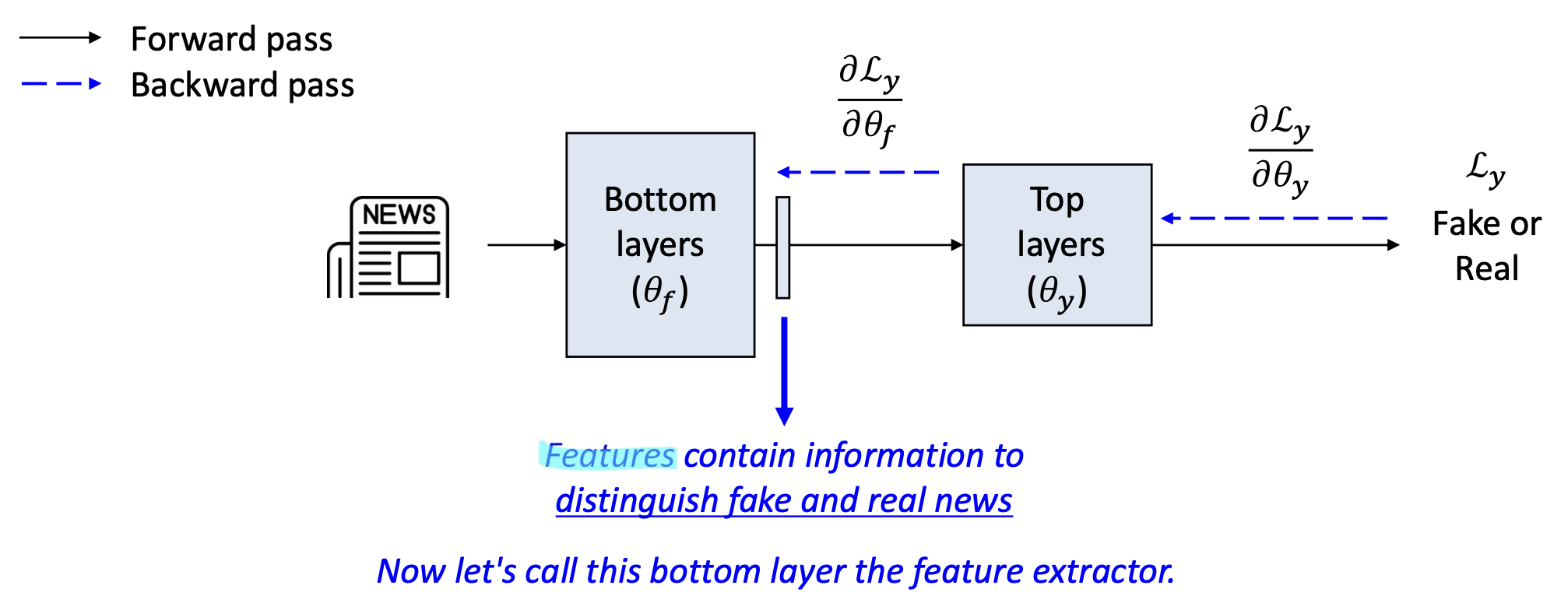
Features 는 가짜 뉴스와 진짜 뉴스를 구별(distinguish fake and real news) 하는 정보를 포함한다.
이제 우리는 이 하위 계층(bottom layer) 을 특징 추출기(feature extractor) 라고 부르자.
p23. 적대적 학습: 동기 (Adversarial learning: motivation)
만약 우리가 도메인 분류 과제(domain classification task) 와 함께
다중 과제 학습(multi-task learning) 을 적용한다면 어떨까?- 과제 1 (Task 1): 가짜 vs. 진짜 분류 (주요 과제, main task)
- 과제 2 (Task 2): 소스 vs. 타깃 분류 (도메인 과제, domain task)
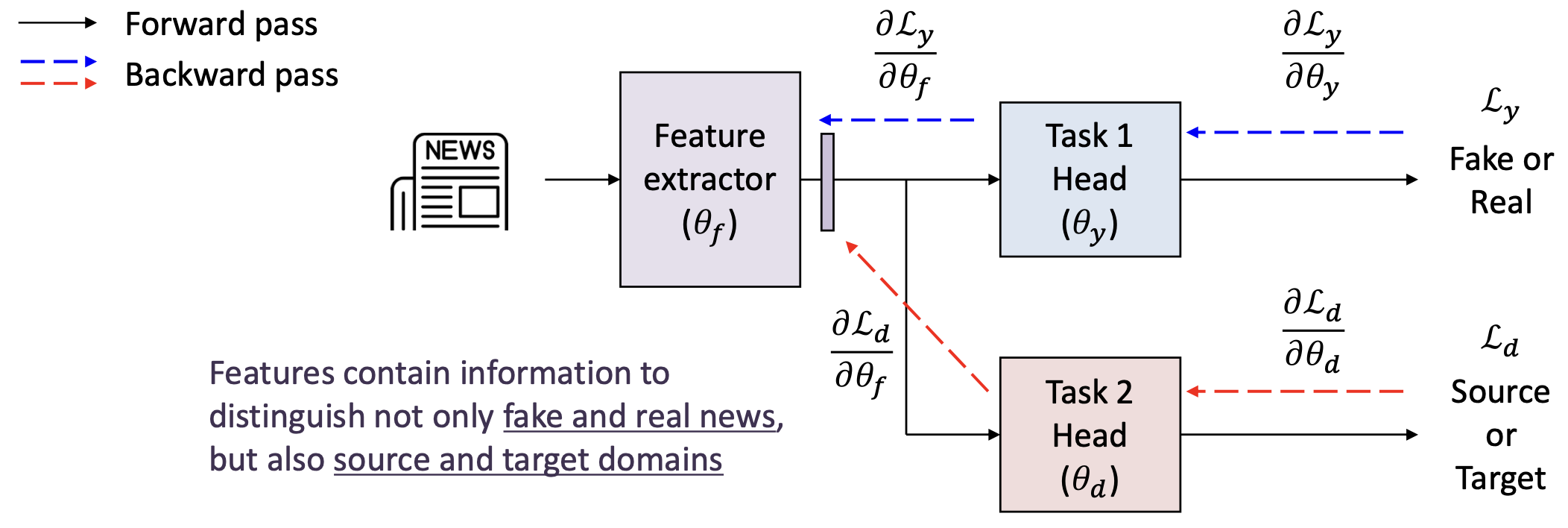
특징(Features) 은
가짜 뉴스(fake news) 와 진짜 뉴스(real news) 를 구분할 뿐만 아니라,
소스(source) 와 타깃(target) 도메인 역시 구분할 수 있는 정보를 포함한다.
p24. 적대적 학습: 동기 (Adversarial learning: motivation)
- 만약 우리가 도메인 분류 과제(domain classification task) 와 함께
다중 과제 학습(multi-task learning) 을 적용한다면 어떨까?
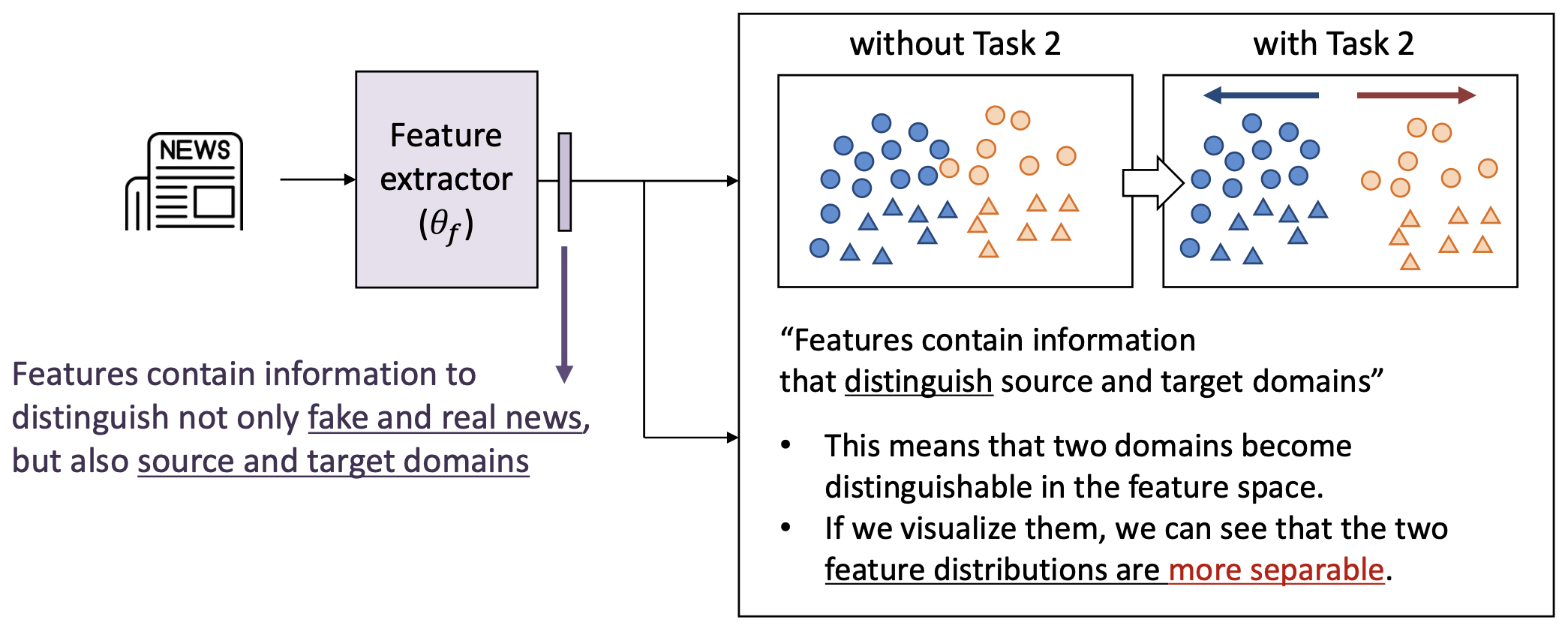
특징(Features) 은
가짜 뉴스(fake news) 와 진짜 뉴스(real news) 를 구분할 뿐만 아니라,
소스(source) 와 타깃(target) 도메인도 구분할 수 있는 정보를 포함한다.
(오른쪽 그림 설명)
- “특징들은 소스와 타깃 도메인을 구분하는 정보를 포함한다.”
- 이는 두 도메인이 특징 공간(feature space) 에서
구분 가능해진다는 것을 의미한다. - 시각화해보면, 두 도메인의 특징 분포(feature distributions) 가
더 분리되어 있음(more separable) 을 확인할 수 있다.
p25. 적대적 학습: 동기 (Adversarial learning: motivation)
- 만약 우리가 도메인 분류 과제(domain classification task) 와 함께
다중 과제 학습(multi-task learning) 을 적용한다면 어떨까?
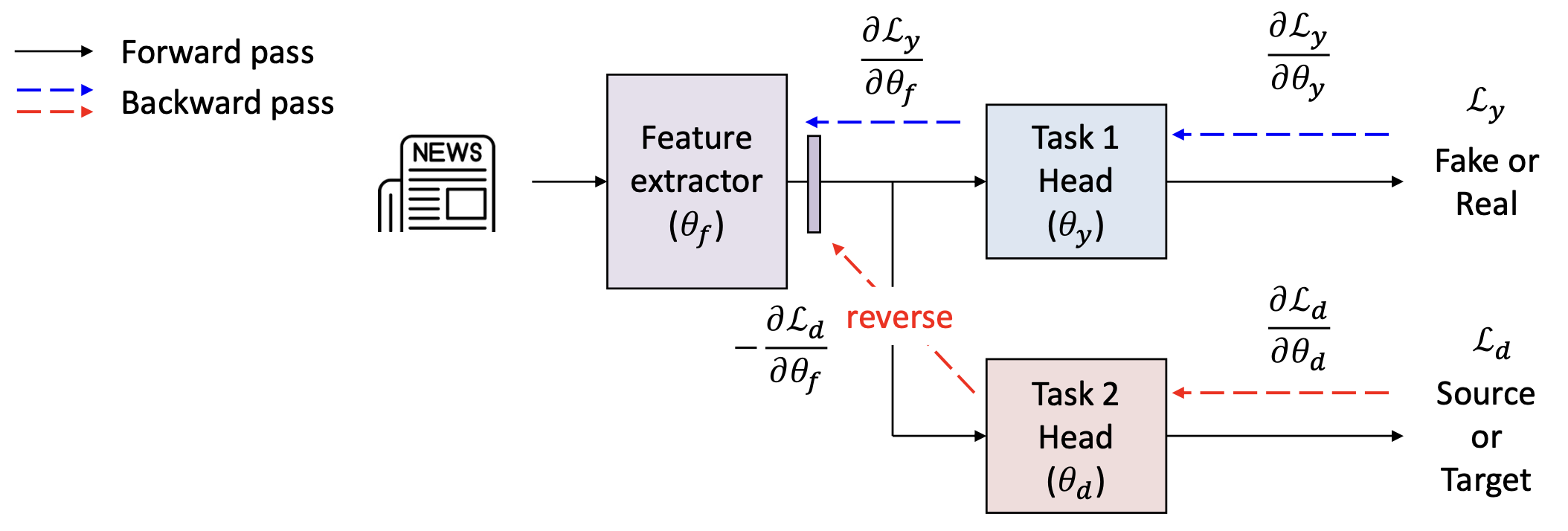
만약 도메인 분류 헤드(domain classification head) 로부터의
그래디언트(gradient)의 부호(sign)를 반전(reverse) 시킨다면 어떻게 될까?
- 특징 추출기(feature extractor)는 반대 방향으로 업데이트 된다.
따라서 여전히 가짜 뉴스와 진짜 뉴스를 구별(distinguish fake and real news)
하는 정보는 유지하지만,
소스(source) 와 타깃(target) 도메인을 구별하지 않게(not to distinguish) 된다.
p26. 적대적 학습: 동기 (Adversarial learning: motivation)
- 만약 우리가 도메인 분류 과제(domain classification task) 와 함께
다중 과제 학습(multi-task learning) 을 적용한다면 어떨까?
만약 도메인 분류 헤드(domain classification head) 로부터의
그래디언트(gradient)의 부호(sign) 를 반전(reverse) 시킨다면 어떻게 될까?
- 특징 추출기(feature extractor)는 반대 방향으로 업데이트 된다.
따라서 여전히 가짜 뉴스(fake) 와 진짜 뉴스(real) 를 구별하는 정보는 유지하지만,
소스(source) 와 타깃(target) 도메인을 구별하지 않게(not to distinguish) 된다.
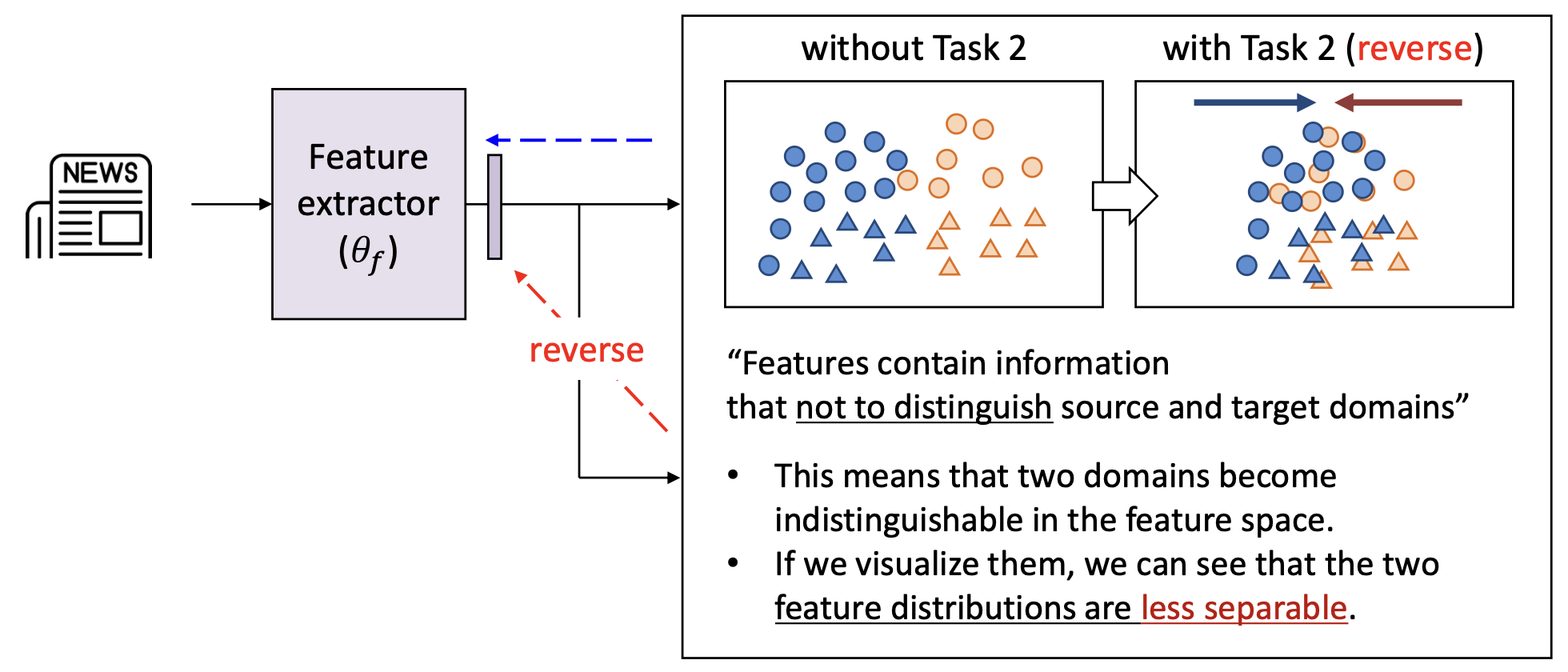
(오른쪽 그림 설명)
- “특징들은 소스와 타깃 도메인을 구별하지 않게(not to distinguish) 하는 정보를 포함한다.”
- 이는 두 도메인이 특징 공간(feature space) 에서 구별 불가능해짐(indistinguishable) 을 의미한다.
- 이를 시각화하면, 두 도메인의 특징 분포(feature distributions) 가
덜 분리됨(less separable) 을 확인할 수 있다.
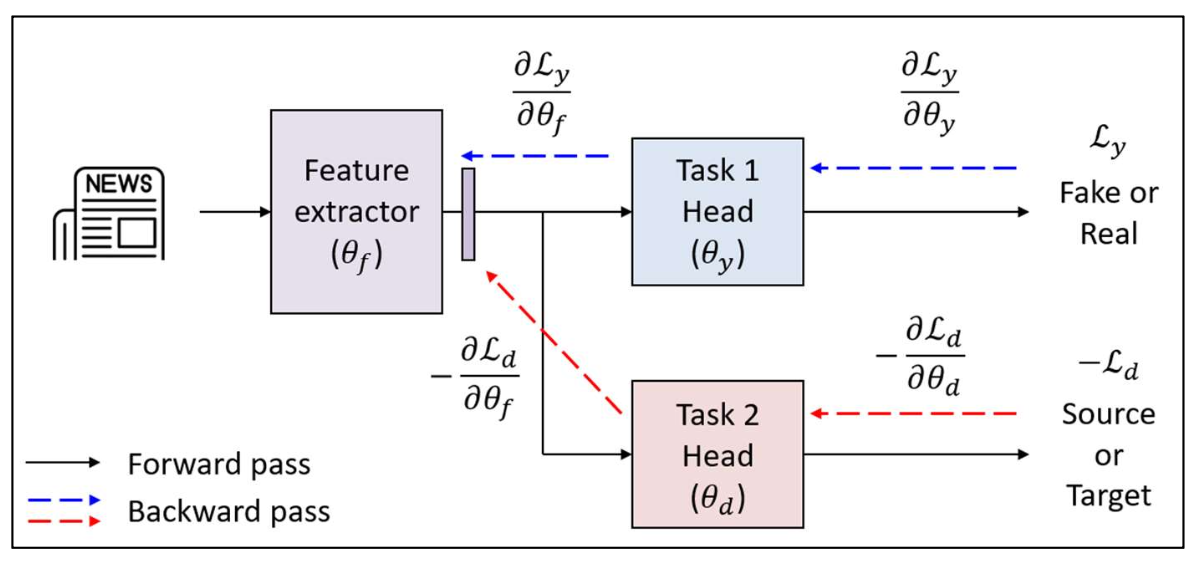
p27. 적대적 학습: 그래디언트 반전 (Adversarial learning: gradient reversal)
- 이 메커니즘은 그래디언트 반전 층(Gradient Reversal Layer, GRL) 이라고 불린다.
- GRL은 도메인 분류기(domain classifier)로부터의 그래디언트(gradient) 를 반전(reverse) 시켜,
하위 계층(bottom layers)이 도메인을 구별하지 못하는 특징(features that cannot distinguish domains) —
즉, 도메인 불변 특징(domain-invariant features) 을 생성하도록 강제한다.
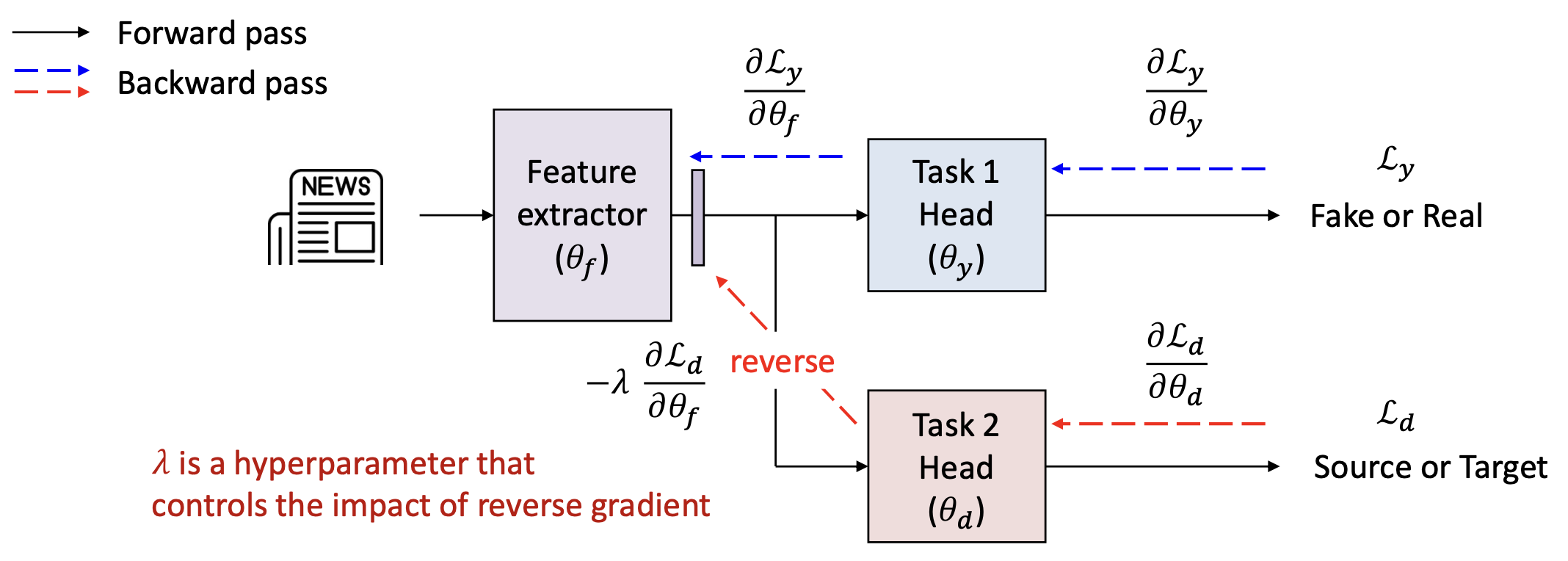
$\lambda$ 는 역전파된 그래디언트(reverse gradient) 의 영향을 조절하는 하이퍼파라미터(hyperparameter) 이다.
p28. 적대적 학습: 그래디언트 반전 (Adversarial learning: gradient reversal)
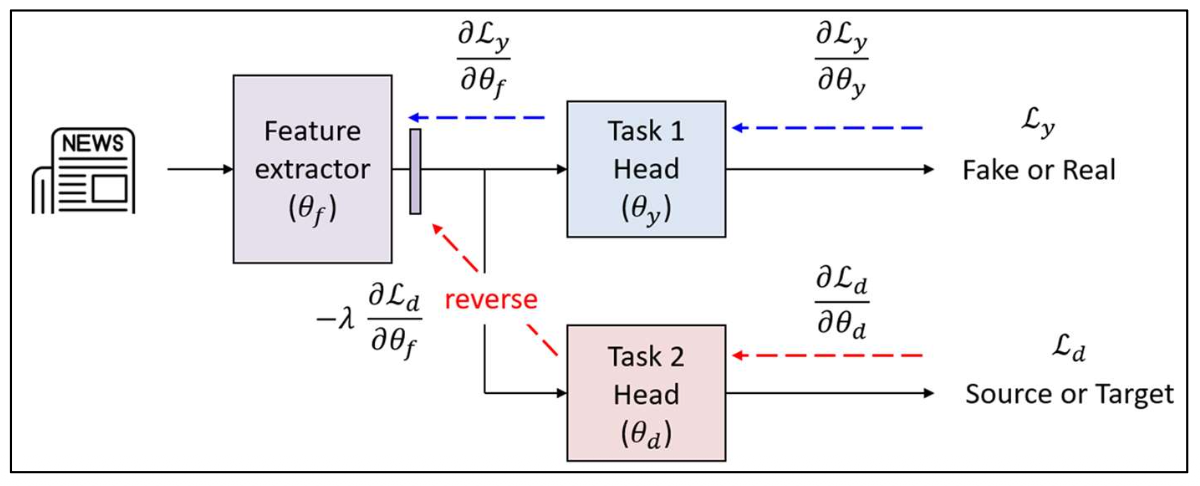
- GRL을 사용하면, 학습 목표는 다음과 같이 공식화된다:
$\lambda$ 는 역전된 그래디언트(reverse gradient) 의 영향을 조절하는 하이퍼파라미터(hyperparameter) 이다.
$\mathcal{L}_y(\theta_f, \theta_y)$: 레이블 분류 손실(label classification loss) —
모델이 주된 과제를 올바르게 예측하도록 유도한다.$\mathcal{L}_d(\theta_f, \theta_d)$: 도메인 분류 손실(domain classification loss) —
소스(source)와 타깃(target) 도메인을 구별하도록 시도한다.
$\theta_f$ 는 음의 $\mathcal{L}_d$ (즉, $\mathcal{L}_d$ 최대화) 를 최소화하도록 학습되어
도메인 혼동(domain confusion)을 촉진한다.$\theta_d$ 는 음의 $\mathcal{L}_d$ (즉, $\mathcal{L}_d$ 최소화) 를 최대화하도록 학습되어
도메인 분류(domain classification)를 촉진한다.
p29. 적대적 학습: 그래디언트 반전 (Adversarial learning: gradient reversal)
- GRL을 사용하면, 학습 목표는 다음과 같이 공식화된다:
$\lambda$ 는 역전된 그래디언트(reverse gradient) 의 영향을 조절하는 하이퍼파라미터(hyperparameter) 이다.
$\mathcal{L}_y(\theta_f, \theta_y)$: 레이블 분류 손실(label classification loss) —
모델이 주된 과제를 올바르게 예측하도록 유도한다.$\mathcal{L}_d(\theta_f, \theta_d)$: 도메인 분류 손실(domain classification loss) —
소스(source)와 타깃(target) 도메인을 구별하려고 시도한다.
$\theta_f$ 는 음의 $\mathcal{L}_d$ (즉, $\mathcal{L}_d$ 최대화) 를 최소화하도록 학습되어
도메인 혼동(domain confusion)을 촉진한다.$\theta_d$ 는 음의 $\mathcal{L}_d$ (즉, $\mathcal{L}_d$ 최소화) 를 최대화하도록 학습되어
도메인 분류(domain classification)를 촉진한다.
✓ 특징 추출기(feature extractor) 와 도메인 분류기(domain classifier) 는
적대적 게임(adversarial game) 을 수행한다 —
하나는 혼란(confuse) 을 일으키려 하고,
다른 하나는 도메인을 구별(discriminate) 하려 한다.
p30. 적대적 학습: 그래디언트 반전 (Adversarial learning: gradient reversal)
- GRL을 사용하면, 학습 목표는 다음과 같이 공식화된다:
$\lambda$ 는 역전된 그래디언트(reverse gradient) 의 영향을 조절하는 하이퍼파라미터(hyperparameter) 이다.
💻 알고리즘: GRL을 이용한 SGD
- $\theta_f, \theta_y, \theta_d$ 를 무작위로 초기화한다.
- 수렴할 때까지 반복한다:
- 무작위로 샘플링한다: $(x^S, y^S) \in D_S$ 그리고 $x^T \in D_S$
- $\mathcal{L}_y(\theta_f, \theta_y)$ 와 $\mathcal{L}_d(\theta_f, \theta_d)$ 를 계산한다.
- 파라미터를 다음과 같이 갱신한다:
$\eta$: 단계 크기(step size) 또는 학습률(learning rate)
$\lambda$: 역전된 그래디언트의 영향을 조절한다.
p31. 적대적 학습: 그래디언트 반전 (Adversarial learning: gradient reversal)
여러분은 이렇게 궁금해할 수 있다 —
“왜 단순히 도메인 분류 손실(domain classification loss)을 최대화하지 않는가?”만약 우리가 단순히 도메인 손실을 최대화한다면,
전체 학습 과정이 붕괴된다(the whole training collapse).- 가장 중요한 점은, $\theta_d$ 가 잘못된 방향(wrong direction) 으로 이동하여
빠르게 무의미해진다(useless). - 이때 도메인 분류기는 특징 추출기에 유의미한 그래디언트를 전달하지 못한다.
- 결과적으로 특징 추출기는 정보가 없는 그래디언트(uninformative gradients) 만 받아
특징 붕괴(feature collapse) 가 발생한다.
- 가장 중요한 점은, $\theta_d$ 가 잘못된 방향(wrong direction) 으로 이동하여
만약 특징 추출기(feature extractor)가 모든 0인 특징(all-zero features) 을 출력한다면,
도메인 분류기(domain classifier)는 도메인을 전혀 구별할 수 없다(cannot distinguish domains at all)!이는 도메인 분류 손실(domain classification loss)을 완벽하게 최대화하지만,
주요 과제(main task) 에 필요한 모든 유용한 정보(all useful information) 를 파괴한다.
✓ 적대적 학습(adversarial learning) 은
유용한 정보를 잃지 않으면서도 도메인 혼동(domain confusion) 을 달성한다.
p32. 적대적 학습: 특징 정렬 (Adversarial learning: feature alignment)
적대적 학습(adversarial learning) 은
특징 추출기(feature extractor)가 도메인 불변 표현(domain-invariant representations) 을
생성하도록 유도한다.- 적대적 학습(GRL) 을 사용하면,
두 도메인은 특징 공간(feature space) 에서 잘 정렬(well aligned)되어,
모델이 보지 못한 타깃 데이터(unseen target data)에 대해
더 잘 일반화(generalize)할 수 있게 된다.
- 적대적 학습(GRL) 을 사용하면,

p33. 적대적 학습: 응용 (가짜 뉴스 탐지)
(Adversarial learning: applications — fake news detection)
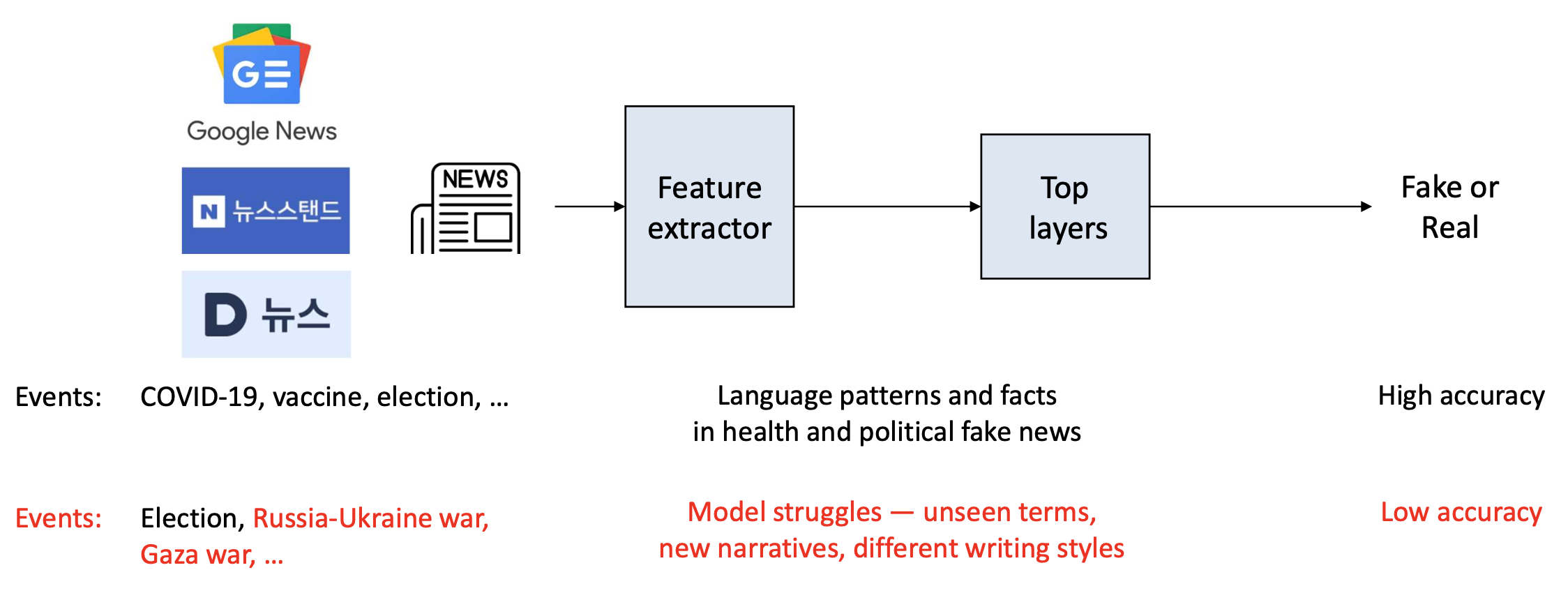
가짜 뉴스 탐지 시스템을 생각해보자.
새로운 사건(new events)은 계속해서 발생한다!문제점: 과거 데이터로 학습된 모델은
새로운 사건(new events)에 일반화(generalize) 하지 못할 수 있다.
p34. 적대적 학습: 응용 (가짜 뉴스 탐지)
(Adversarial learning: applications — fake news detection)
문제(Problem):
과거 데이터로 학습된 모델은
새로운 사건(new events)에 일반화(generalize) 하지 못할 수 있다.해결책(Solution):
적대적 학습(adversarial learning)을 통해
사건 간에 구별되지 않는(event-invariant) 특징들을 학습한다.
(즉, 사건들이 구별 불가능하게(indistinguishable) 된다.)
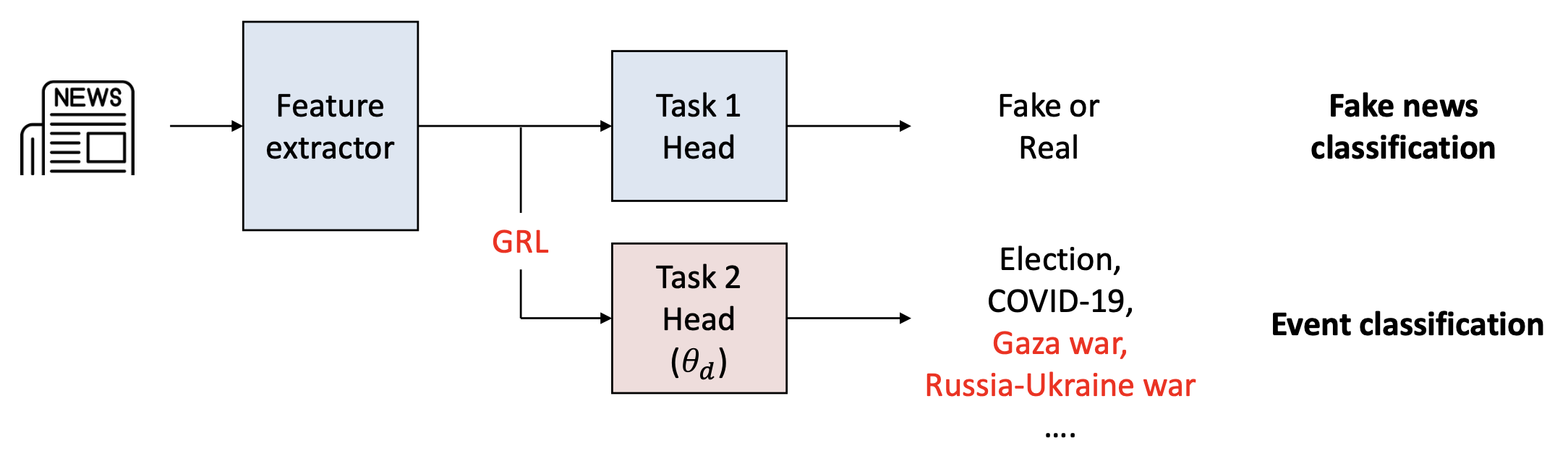
참고(Note):
새로운 사건(new events)에 대해 가짜/진짜 레이블(fake/real labels) 은 필요하지 않다.
이미 알려진 사건 유형(event type) 만을 사용하여
사건 불변 표현(event-invariant representations) 을 학습하도록 유도한다.
p35. 적대적 학습: 응용 (가짜 뉴스 탐지)
(Adversarial learning: applications — fake news detection)
- 해결책(Solution):
적대적 학습(adversarial learning)을 통해
사건 간 구별 불가능(event-invariant)한 특징들을 학습한다.
(즉, 사건들이 서로 구별되지 않게(indistinguishable) 된다.)
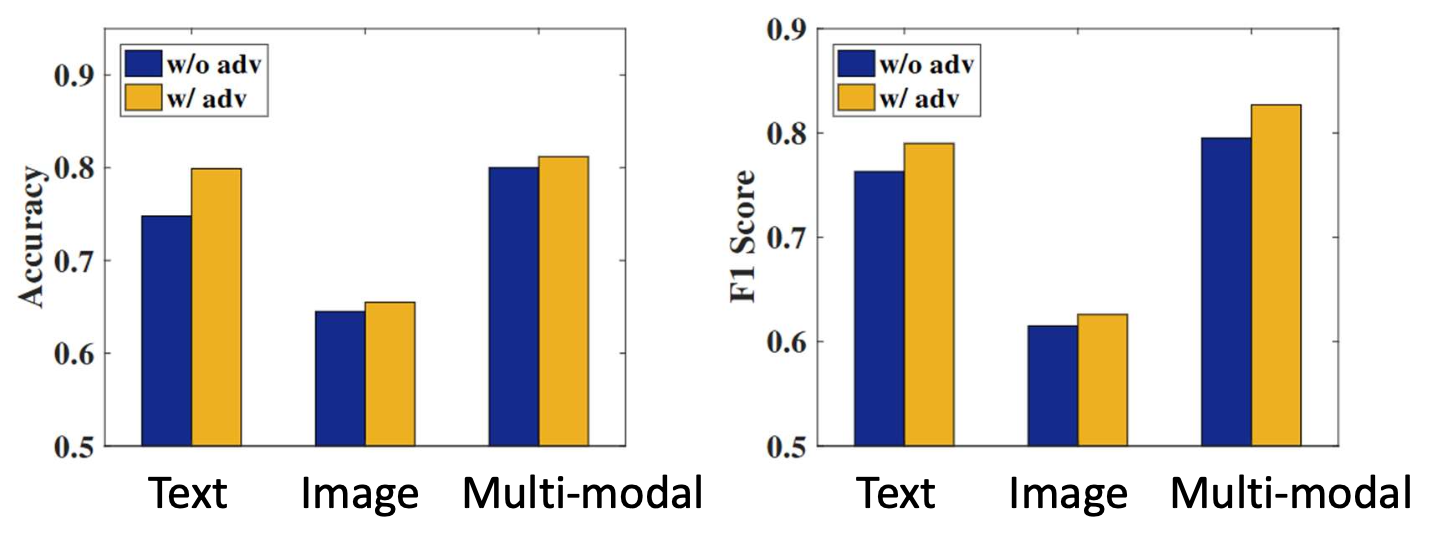
EANN: Event Adversarial Neural Networks for Multi-Modal Fake News Detection, KDD’18
p36. 적대적 학습: 요약
(Adversarial learning: summary)
- 적대적 학습(adversarial learning)은
도메인 간 특징을 정렬(alignment)함으로써
도메인 불변 표현(domain-invariant representations) 을 학습한다.- 이는 레이블이 있는(labeled) 데이터와 레이블이 없는(unlabeled) 데이터 분포 간
일반화(generalization) 를 촉진한다.
- 이는 레이블이 있는(labeled) 데이터와 레이블이 없는(unlabeled) 데이터 분포 간
- 장점(Pros):
- 단순하고 효과적(Simple and effective) —
GRL(Gradient Reversal Layer)을 통해 기존 네트워크에 쉽게 통합 가능하다. - 데이터 재가중(data reweighting)에 비해
소스–타깃 간 중첩(source–target overlap) 에 덜 의존한다.- 사전 존재하는 중첩(pre-existing overlap)에 의존하지 않고,
특징 분포(feature distributions) 를 정렬하도록 학습한다.
- 사전 존재하는 중첩(pre-existing overlap)에 의존하지 않고,
- 단순하고 효과적(Simple and effective) —
- 단점(Cons):
- 전역 정렬(Global alignment):
클래스 구조(class structure)를 무시하고 도메인을 전역적으로 정렬한다.- 이는 클래스 불일치(class misalignment) 를 유발할 수 있다.
(서로 다른 클래스가 섞이게 됨)
- 이는 클래스 불일치(class misalignment) 를 유발할 수 있다.
- 전역 정렬(Global alignment):

- 주의:
정렬 후에도 클래스들이 잘 분리된 상태로 남는다는
보장은 없다. (No guarantee that classes remain well separated after alignment.)
(Figure credit):
Prototypical Cross-domain Self-supervised Learning for Few-shot Unsupervised Domain Adaptation, CVPR’21
p37. 제한된 레이블로 학습하기: 요약
(Learning with limited labels: summary)
- 우리는 레이블이 지정된 데이터의 부족(scarcity of labeled data)을
어떻게 다룰 수 있는지를 살펴보았다.
- 반지도 학습 (Semi-supervised learning)
- “레이블이 없는 데이터(unlabeled data) 를 어떻게 효과적으로 활용(leverage)할 수 있을까?”
- Pseudo-label, Self-training, Consistency regularization, Temporal ensemble
- 다중 과제 학습 (Multi-task learning)
- “만약 한 과제(task)에 충분한 레이블이 없다면,
관련된 과제(related tasks) 로부터 신호를 빌려올 수 있을까?” - MMoE, GradNorm
- “만약 한 과제(task)에 충분한 레이블이 없다면,
- 적대적 학습 (Adversarial learning)
- “레이블이 있는 데이터와 없는 데이터가
서로 다른 분포(different distributions) 에서 온다면 어떻게 될까?” - Data reweighting, GRL (Gradient Reversal Layer)
- “레이블이 있는 데이터와 없는 데이터가
p38. 추천 읽기 자료
(Recommended readings)
- 논문(Papers):
- Domain-Adversarial Training of Neural Networks, JMLR’16
- EANN: Event Adversarial Neural Networks for Multi-Modal Fake News Detection, KDD’18