[텍스트 마이닝] 14. Search 3 - Dense Retrieval 2
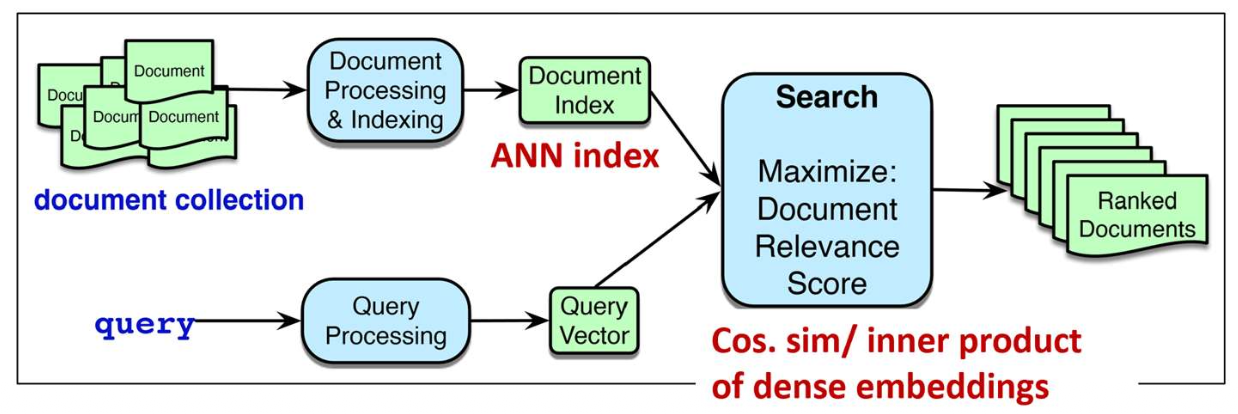
p3. 검색: 개요
- 우리는 실제(real-world) 검색 엔진을 작동시키는 핵심 기술들을 배우게 된다.
- 어휘 기반 검색 (Lexical retrieval)
- 쿼리와 문서를 단어 개수 기반의 희소 벡터(sparse vectors)로 표현한다.
- 쿼리와 문서 사이의 정확한 단어 일치(exact word matching)에 초점을 맞춘다.
- 고밀도 임베딩 검색 (Dense retrieval)
- 쿼리와 문서를 연속적인 벡터 공간에서 표현하기 위해 고밀도 임베딩(dense embeddings)을 사용한다.
- 의미적 유사성(semantic similarity)을 포착하여 키워드가 겹치지 않는 경우에도 검색이 가능하게 한다.
- LLM 기반 향상 검색 (LLM-enhanced retrieval)
- 대규모 언어 모델(LLMs)을 활용하여 검색 프로세스를 향상시킨다.

p8. 바이인코더가 가질 수 있는 잠재적 문제점은 무엇인가?
- 일반적인 밀집 검색기(dense retrievers)는
쿼리와 문서를 서로 독립적으로(independently) 벡터로 인코딩한다.- 이러한 접근 방식을 바이인코더(bi-encoder) 라고 부른다.
- 문서 벡터는 어떤 쿼리가 오더라도 항상 동일하게 유지된다.
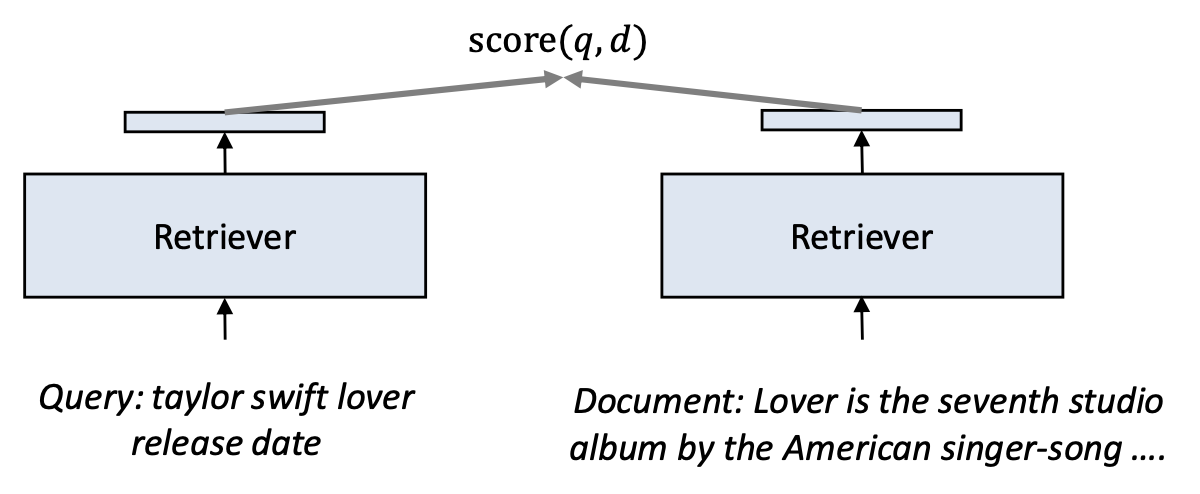
- 그러나 문서 안의 단어 중요도는 쿼리에 따라 달라질 수 있다.
- 바이인코더는 이러한 동적인 상호작용을 반영할 수 없다.
p9. 바이인코더가 가질 수 있는 잠재적 문제점은 무엇인가?
- 바이인코더는 각 문서마다 하나의 고정된 벡터(one fixed vector) 를 만든다.
- 이는 어떤 쿼리가 입력되더라도 문서 표현(document representation)은 절대 바뀌지 않는다는 뜻이다.
예시(Example):
Query 1:
taylor swift lover release dateDocument
Lover is the seventh studio album by the American singer-songwriter Taylor Swift, released on August 23, 2019.
The album features 18 tracks, including popular songs such as ‘Cruel Summer’, ‘Lover’, ‘The Archer’, and ‘The Man’.
‘Cruel Summer’ was produced by Jack Antonoff and Taylor Swift and is known for its upbeat synth-pop sound.Query 2:
taylor swift cruel summer producerDocument
Lover is the seventh studio album by the American singer-songwriter Taylor Swift, released on August 23, 2019.
The album features 18 tracks, including popular songs such as ‘Cruel Summer’, ‘Lover’, ‘The Archer’, and ‘The Man’.
‘Cruel Summer’ was produced by Jack Antonoff and Taylor Swift and is known for its upbeat synth-pop sound.- 두 예시는 서로 다른 정보를 요구하는 쿼리임에도,
문서 벡터는 동일하게 유지되며 쿼리별 중요도 변화가 반영되지 않음을 보여준다.
p10. 바이인코더가 가질 수 있는 잠재적 문제점은 무엇인가?
- 바이인코더는 각 문서마다 하나의 고정된 벡터(one fixed vector) 를 만든다.
- 즉, 어떤 쿼리가 입력되더라도 문서 표현(document representation)은 절대 바뀌지 않는다.
예시(Example):
Query 1:
taylor swift lover release dateDocument
Lover is the seventh studio album by the American singer-songwriter Taylor Swift, released on August 23, 2019.
The album features 18 tracks, including popular songs such as ‘Cruel Summer’, ‘Lover’, ‘The Archer’, and ‘The Man’.
‘Cruel Summer’ was produced by Jack Antonoff and Taylor Swift and is known for its upbeat synth-pop sound.Query 2:
taylor swift cruel summer producerDocument
Lover is the seventh studio album by the American singer-songwriter Taylor Swift, released on August 23, 2019.
The album features 18 tracks, including popular songs such as ‘Cruel Summer’, ‘Lover’, ‘The Archer’, and ‘The Man’.
‘Cruel Summer’ was produced by Jack Antonoff and Taylor Swift and is known for its upbeat synth-pop sound.- 이처럼 두 쿼리는 서로 다른 정보를 요구하지만,
바이인코더는 문서를 한 번만 인코딩하기 때문에 쿼리별 중요도 차이를 반영할 수 없다.
p10. 바이인코더가 가질 수 있는 잠재적 문제점은 무엇인가?
바이인코더는 각 문서마다 하나의 고정된 벡터(one fixed vector) 를 만든다.
- 그러나 같은 문서라도 서로 다른 쿼리는 문서의 서로 다른 부분에 주목한다.
- 사람은 쿼리에 따라 문서의 다른 부분을 읽게 된다.
- 하지만 바이인코더는 쿼리를 고려하지 않고 문서를 한 번만 인코딩하기 때문에 이를 반영할 수 없다.
- 그 결과,
바이인코더는 쿼리별로 필요한 정보(query-specific information)를 반영하지 못할 수 있다.
Document (예시 1)
Lover is the seventh studio album by the American singer-songwriter Taylor Swift, released on August 23, 2019.
The album features 18 tracks, including popular songs such as ‘Cruel Summer’, ‘Lover’, ‘The Archer’, and ‘The Man’.
‘Cruel Summer’ was produced by Jack Antonoff and Taylor Swift and is known for its upbeat synth-pop sound.
Document (예시 2)
Lover is the seventh studio album by the American singer-songwriter Taylor Swift, released on August 23, 2019.
The album features 18 tracks, including popular songs such as ‘Cruel Summer’, ‘Lover’, ‘The Archer’, and ‘The Man’.
‘Cruel Summer’ was produced by Jack Antonoff and Taylor Swift and is known for its upbeat synth-pop sound.
p11. 크로스-인코더(Cross-encoder)
- 크로스-인코더(cross-encoder) 는
쿼리와 문서를 하나의 입력 시퀀스로 연결(concatenate) 한다.- 이를 통해 모델은 양쪽의 모든 토큰을 동시에 공동으로(jointly) 주의를 기울일 수 있다(attend).
- 따라서 모델은 해당 쿼리에 대해 어떤 문서 단어가 중요한지 식별할 수 있다.
- 크로스-인코더는 이전에 다룬 순위 학습(learning-to-rank) 손실,
예: point-wise 손실로 파인튜닝(fine-tuning) 된다.
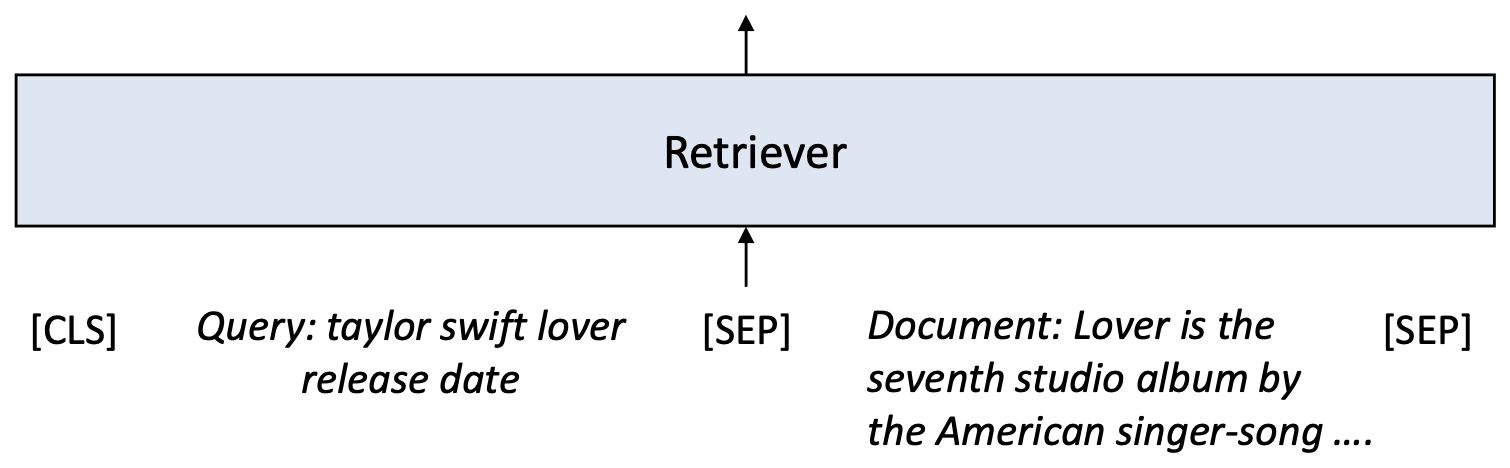
p13. 크로스인코더: 예시 (Cross-encoder: example)
- 크로스인코더는 쿼리와 문서를 토큰 단위(token-by-token)로 상호작용(interact) 하도록 만든다.
- 이를 통해 모델은 쿼리에 따라 동일한 문서의 서로 다른 부분을 강조(highlight) 할 수 있다.
Query 1:
[CLS] taylor swift lover release date [SEP] Taylor Swift, released on August 23, 2019 The album features [SEP]
Query 2:
[CLS] taylor swift cruel summer producer [SEP] ‘Cruel Summer’ was produced by Jack Antonoff and [SEP]
p14. 크로스인코더: 장점과 단점 (Cross-encoder: pros and cons)
- 장점(Pros):
- 바이인코더보다 더 강력한 관련성(relevance) 모델링을 수행한다.
- 쿼리와 문서의 모든 토큰에 걸쳐 어텐션(attention)을 계산하여 더 정확한 매칭을 가능하게 한다.
- 미세한(fine-grained) 상호작용을 포착한다.
- 특정 쿼리에 대해 문서의 어떤 단어가 중요한지 정확히 집중(focused) 할 수 있다.
- 바이인코더보다 더 강력한 관련성(relevance) 모델링을 수행한다.
- 단점(Cons):
- 사전 인덱싱(pre-indexing)이 불가능하다.
- 추론 시점(inference time)마다 전체 쿼리–문서 쌍(full query–document pair) 을 처리해야 한다.
- 대규모 검색 환경에서는 확장성(scalability)이 떨어진다.
- 전체 크로스어텐션은 계산 비용이 매우 크므로
수백만 문서를 스코어링하는 것은 비현실적이다.
- 전체 크로스어텐션은 계산 비용이 매우 크므로
- 사전 인덱싱(pre-indexing)이 불가능하다.
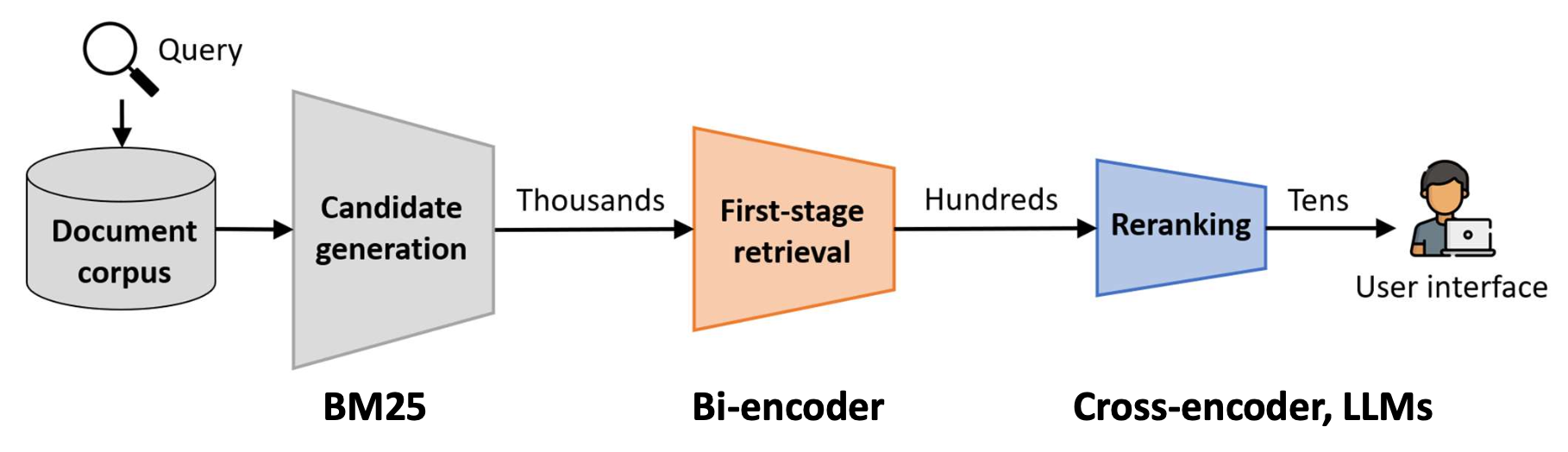
p15. 다단계 순위 매기기 파이프라인(Multi-stage ranking pipeline)
현대 검색 시스템은 효율성과 정확성을 균형 있게 유지하기 위해 다단계 파이프라인(multi-stage pipeline) 을 사용한다.
후보 생성(candidate generation) 은
BM25와 같은 빠른 방법을 사용하여 넓은 범위의 문서 집합을 검색한다.1단계 검색(first-stage retrieval) 은
보통 바이인코더를 사용하여 이 집합을 더 작고, 더 관련성 높은 부분집합으로 좁힌다.재순위화(reranking) 는
크로스인코더 혹은 LLM과 같은 강력하지만 비용이 큰 모델을 적용하여,
사용자에게 보여줄 최종 순위 리스트를 만든다.
p16. 바이인코더를 향상시키는 방법: Late interaction
CoLBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT
Omar Khattab
Stanford University
okhattab@stanford.edu
Matei Zaharia
Stanford University
matei@cs.stanford.edu
정보 검색 연구 및 개발을 위한 SIGIR 학회 2020에서 발표됨
p17. Late interaction: 동기(motivation)
사전 계산(precomputation)을 유지하면서도 세밀한(fine-grained) 쿼리–문서 상호작용을 가질 수 있을까?
원하는 속성(Desired properties):
- 독립적 인코딩 (효율성과 사전 인덱싱을 위해)
- 세밀한 쿼리–문서 상호작용 (효과성 향상을 위해)
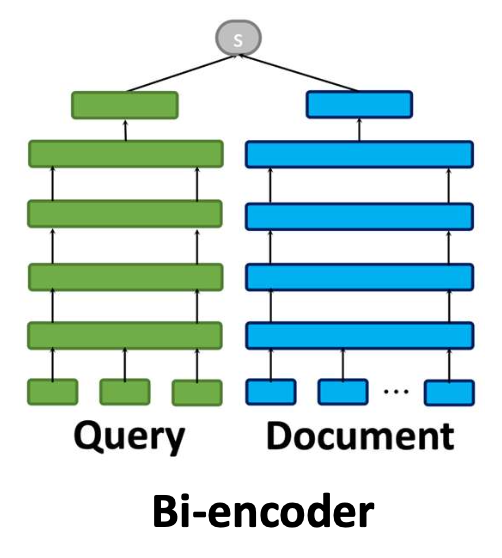
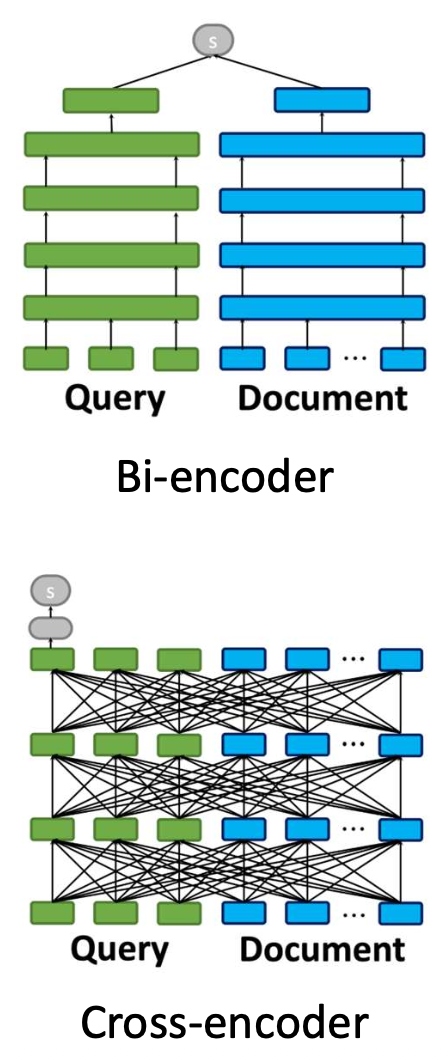
Bi-encoder
독립적인 쿼리–문서 인코딩
효과성은 제한되지만 효율적임
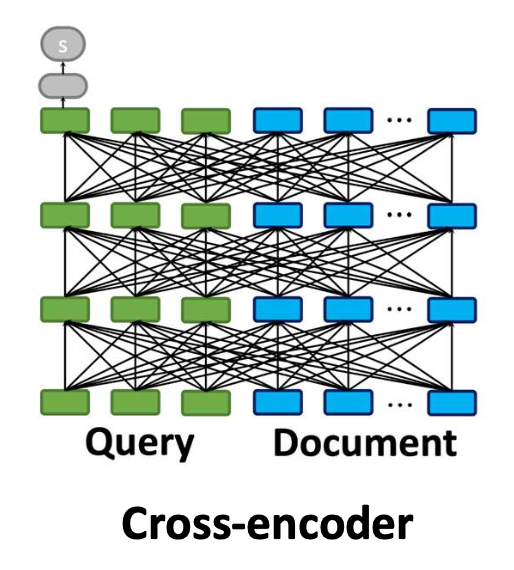
Cross-encoder
공동 쿼리–문서 인코딩
효과적이지만 비용이 큼
p18. Late interaction
Step 1: 문서를 토큰 벡터들의 시퀀스로 인코딩한다:
$e_{d_1}, e_{d_2}, \ldots, e_{d_L}$Step 2: 쿼리를 토큰 벡터들의 시퀀스로 인코딩한다:
$e_{q_1}, e_{q_2}, \ldots, e_{q_M}$Step 3: 관련도(relevance) 점수는 다음과 같이 계산한다:
\[\text{score}(q, d) = \sum_{m=1}^{M} \max_{1 \le l \le L} \left( e_{q_m}^{\top} e_{d_l} \right)\]
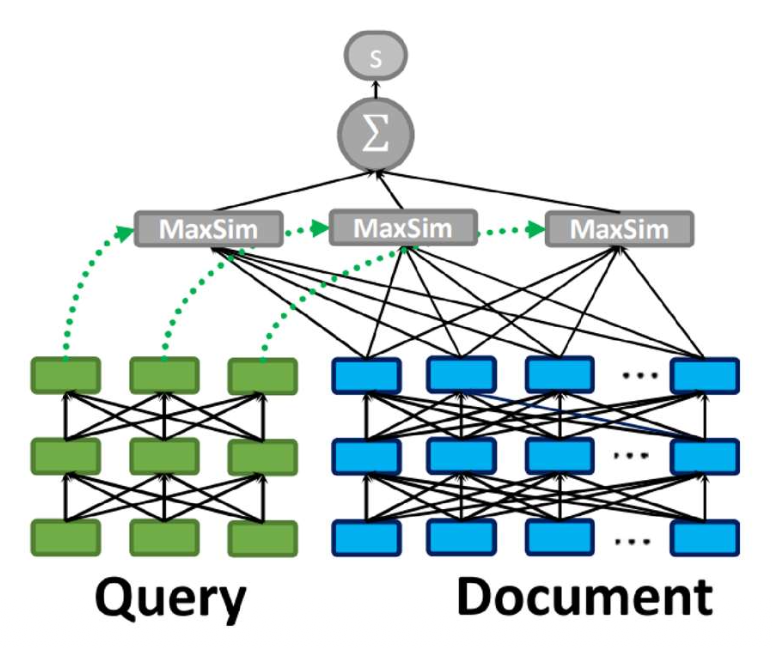
직관(Intuition):
각 쿼리 토큰(query token) 에 대해,
가장 유사한 문서 토큰(document token) 을 찾고,
이 유사도들을 모두 합하여 최종 점수를 만든다.쿼리와 문서는 먼저 서로 독립적으로 인코딩된다.
- 인코딩 과정에서는 아무 상호작용도 일어나지 않는다.
- 상호작용은 맨 마지막 단계에서만 발생한다.
p20. 지연 상호작용(Late interaction): 연습(Exercise)
- 예시(Example):
- 쿼리 표현(query representation):
$[0.9, 0.1],\ [0.2, 0.8]$ - 문서 표현(document representation):
$[0.7, 0.3],\ [0.4, 0.9],\ [0.1, 0.6],\ [0.8, 0.2]$
- 쿼리 표현(query representation):
관련도 점수(relevance score)는 무엇인가?
\[\text{score}(q, d) = \sum_{m=1}^{M} \max_{1 \le l \le L} \left( e_{q_m}^{\top} e_{d_l} \right)\]
쿼리 토큰 1:
$e_{q_1} = [0.9, 0.1]$
$e_{q_1}^{\top} e_{d_1} = 0.9(0.7) + 0.1(0.3) = 0.66$
$e_{q_1}^{\top} e_{d_2} = 0.9(0.4) + 0.1(0.9) = 0.45$
$e_{q_1}^{\top} e_{d_3} = 0.9(0.1) + 0.1(0.6) = 0.15$
$e_{q_1}^{\top} e_{d_4} = 0.9(0.8) + 0.1(0.2) = 0.74$
$\max = 0.74$
쿼리 토큰 2:
$e_{q_2} = [0.2, 0.8]$
$e_{q_2}^{\top} e_{d_1} = 0.2(0.7) + 0.8(0.3) = 0.38$
$e_{q_2}^{\top} e_{d_2} = 0.2(0.4) + 0.8(0.9) = 0.80$
$e_{q_2}^{\top} e_{d_3} = 0.2(0.1) + 0.8(0.6) = 0.50$
$e_{q_2}^{\top} e_{d_4} = 0.2(0.8) + 0.8(0.2) = 0.24$
$\max = 0.80$
최종 점수:
$\text{score}(q, d) = 0.74 + 0.80 = 1.54$
p21. 지연 상호작용(Late interaction): 매칭 예시
- 지연 상호작용에서는, 각 쿼리 토큰(query token) 이
문서에서 가장 유사한 토큰(most similar token) 을 찾는다.- 각 쿼리 단어는 의미적으로 가장 강한 매칭을 제공하는 문서 단어와 정렬된다.
- 최종 점수는 이러한 가장 좋은 매칭(best matches)의 합(sum) 으로 계산되며,
미세한 쿼리–문서 상호작용(fine-grained q-d interactions)을 포착한다.
p22. 지연 상호작용(Late interaction): 인덱싱
- 일반적인 바이인코더에서는 문서 하나당 하나의 벡터(one vector per document) 를 저장한다.
- 지연 상호작용에서는 문서 하나당 여러 개의 토큰 벡터(multiple token vectors per document) 를 저장한다.
- 모든 문서 토큰 임베딩을 저장해야 하므로 → 훨씬 더 큰 저장 공간(much larger storage) 이 필요하다.
- ANN을 사용할 수는 있으나, 문서 단위 벡터가 아니라 토큰 단위 벡터(token-level vectors) 에 대해 동작해야 한다.
- 후보 생성(candidate generation)은 바이인코더보다 더 느리다(slower).
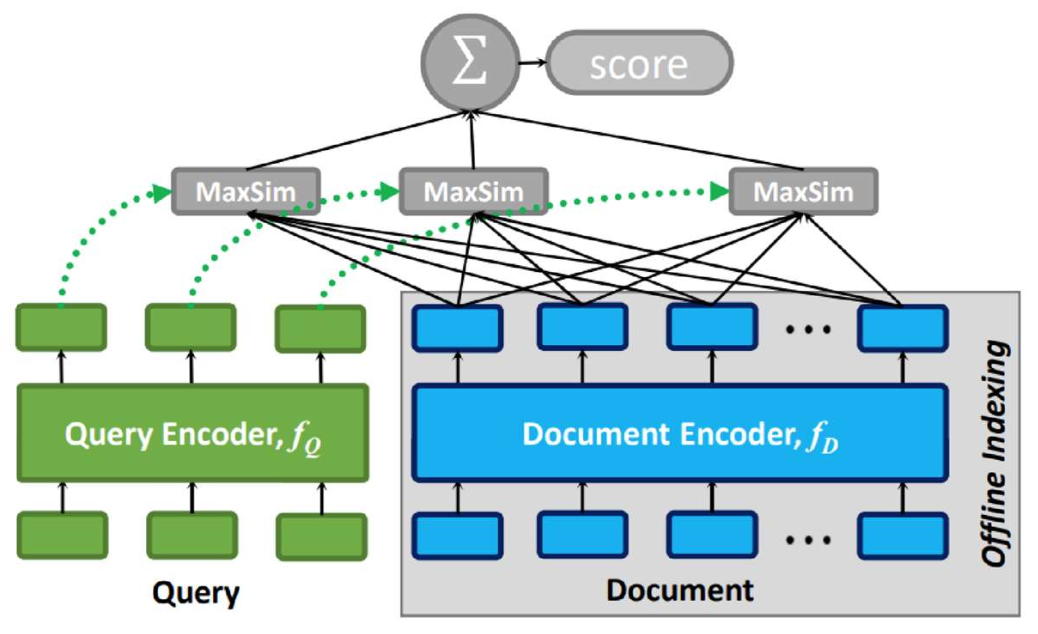
p23. 실험 결과(파인튜닝됨)
설정(Setup):
주어진 코퍼스에 대해, 모든 검색기(retrievers)는 (q, d) 쌍을 사용해 파인튜닝된다.관찰(Observation):
지연 상호작용(late interaction)은 바이인코더와 크로스인코더 사이에서 좋은 균형을 보여준다.
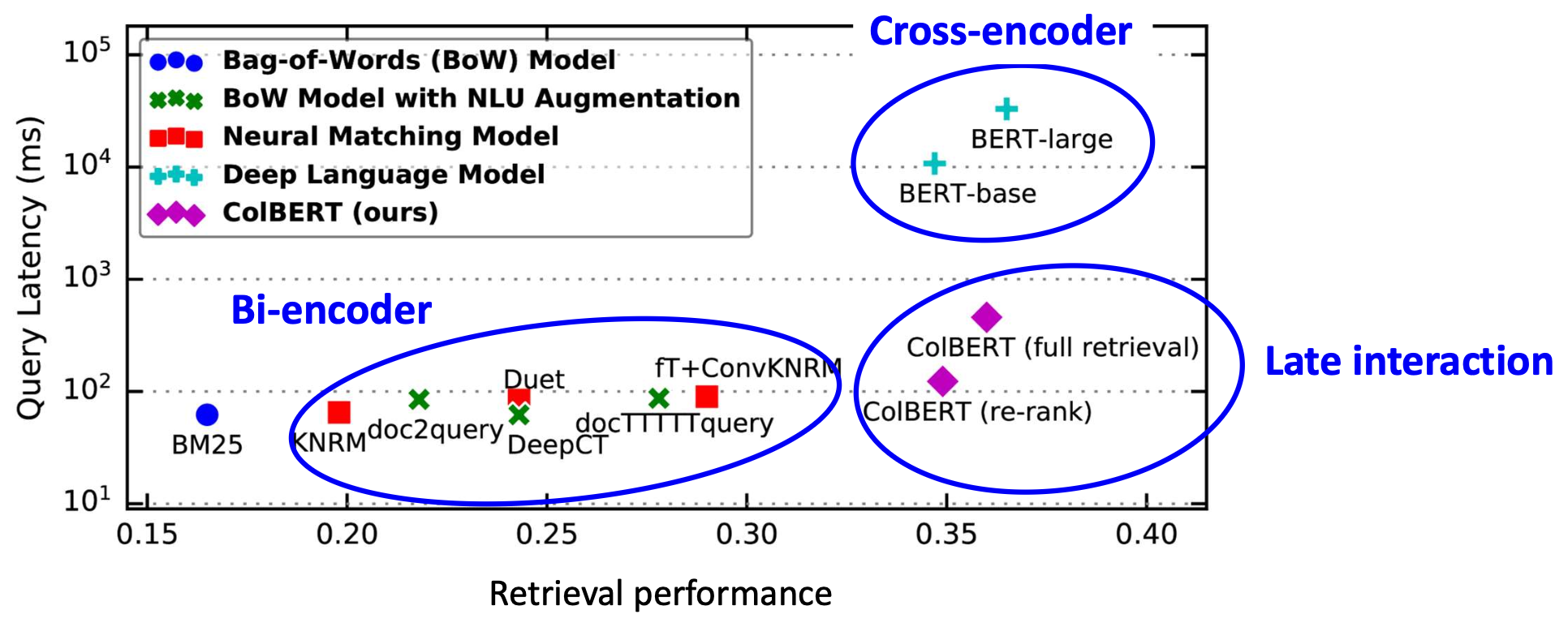
p24. 실험 결과(파인튜닝 없음)
(Results from BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models)
설정(Setup):
검색기(retriever)들은 다른 코퍼스에서 파인튜닝된 후,
타깃 코퍼스에 직접 적용된다.관찰(Observations):
- BM25는 어떤 파인튜닝도 없이 매우 강력한 베이스라인으로 남아 있다.
- 크로스인코더와 지연 상호작용(late-interaction) 모델은 더 잘 일반화된다.
이는 세밀한 토큰 상호작용(fine-grained token interaction) 덕분이다. - 바이인코더는 더 약한 일반화 성능을 보인다.
순수한 표현 유사도 기반 방법은 작업 특화 튜닝(task-specific tuning) 없이 종종 성능이 떨어진다.
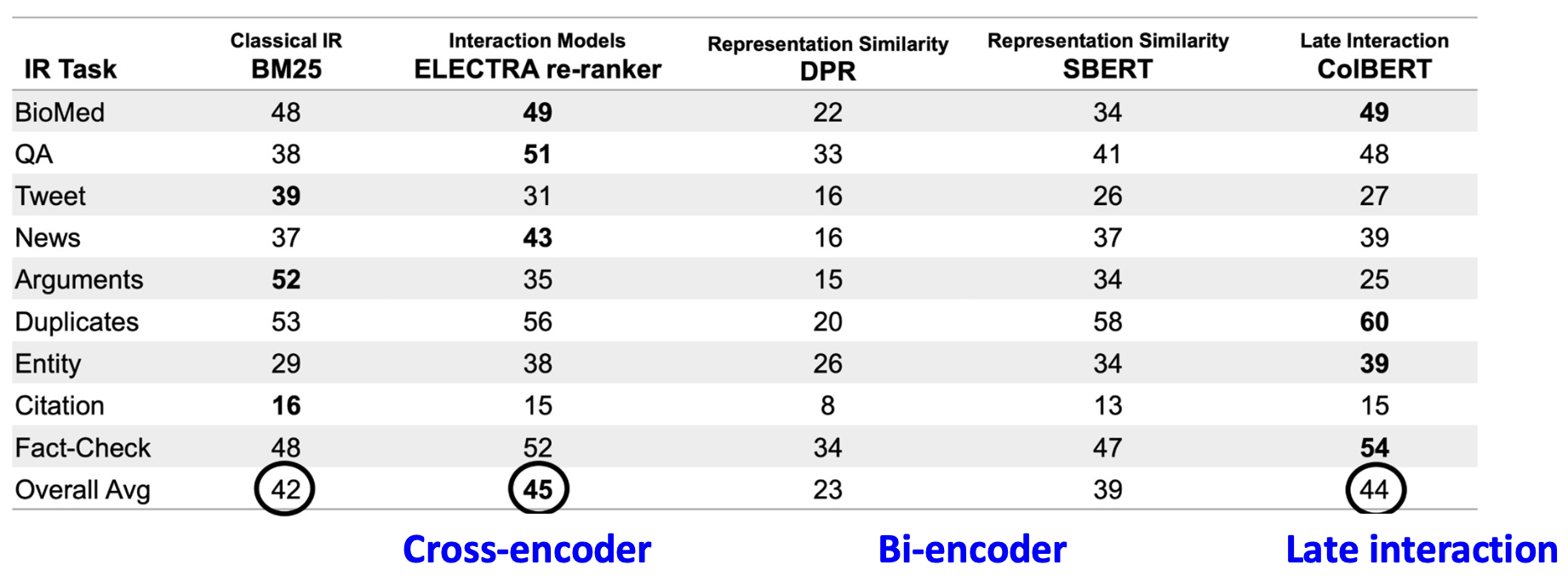
p25. 요약: 지연 상호작용(late interaction)
- 지연 상호작용은 토큰 수준 매칭(token-level matching) 을 제공하며,
효율적인 바이인코더(bi-encoder)와 정확하지만 비용이 큰 크로스인코더(cross-encoder) 사이의
중간 지점(middle ground) 을 제공한다.
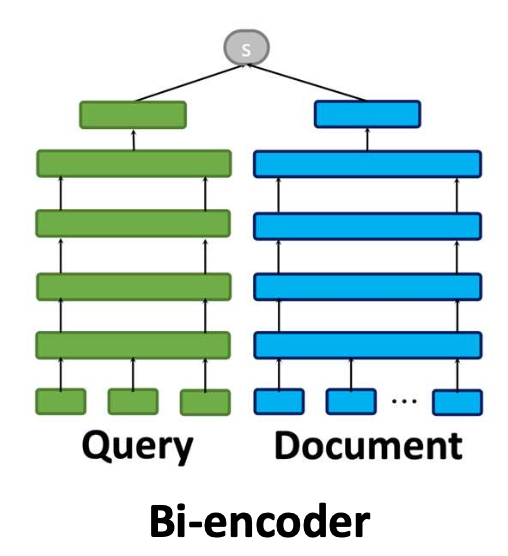
Bi-encoder
- 쿼리와 문서를 독립적으로(independently) 인코딩한다.
- 빠르고 효율적이지만, 상호작용은 제한적이다.
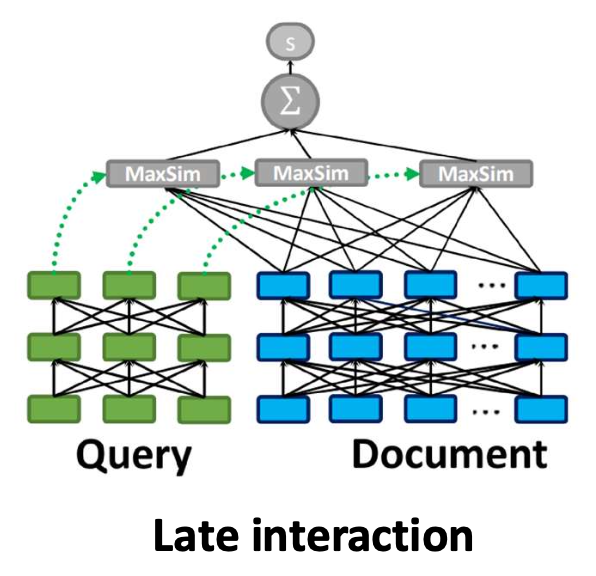
지연 상호작용(late interaction)
- 쿼리와 문서를 별도로(separately) 인코딩하지만, 토큰 수준(token level) 에서 매칭한다.
- 적당한 비용(moderate cost) 으로 높은 효과를 달성한다.
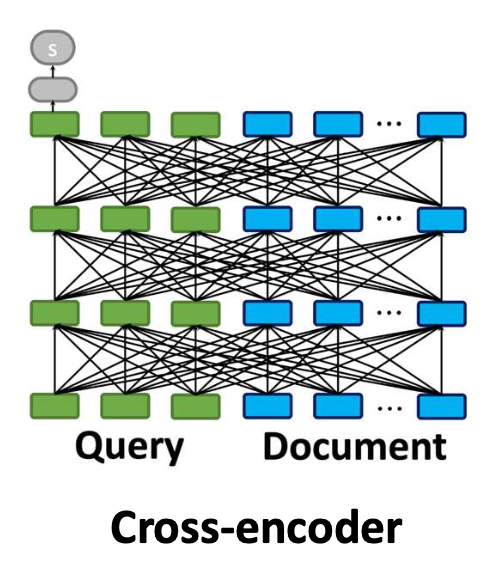
Cross-encoder
- 쿼리/문서를 공동으로(jointly) 인코딩한다.
- 가장 효과적이지만, 계산 비용이 매우 크다.
p26. 바이인코더를 향상시키는 방법: 사용자 관심 기반 요소 주입
Multi-Aspect Dense Retrieval
Weize Kong — weize@google.com — Google
Shaleen Kumar Gupta — shaleng@google.com — Google
Swaraj Kadanga — khadanga@google.com — Google
Mingyang Zhang — mingyang@google.com — Google
Michael Bendersky — bemike@google.com — Google
Cheng Li — chgli@google.com — Google
Wensong Xu — asong@google.com — Google
Presented at SIGKDD Conference on Knowledge Discovery and Data Mining 2022
Taxonomy-guided Semantic Indexing for Academic Paper Search
SeongKu Kang¹, Yunyi Zhang¹, Pengcheng Jiang¹, Dongha Lee²,
Jiawei Han¹, Hwanjo Yu³*
¹University of Illinois at Urbana Champaign
²Yonsei University
³Pohang University of Science and Technology
Empirical Methods in Natural Language Processing 2024
Presented at Conference on Empirical Methods in Natural Language Processing 2024
p27. 동기: 사용자 관심 요소 주입 (infusing user-interested aspects)
- 우리가 배운 것:
- 표준 바이인코더는 전체 텍스트를 하나의 벡터(one vector) 로 압축하며,
이는 종종 미세한 신호(fine-grained signals)를 잃게 만든다. - 지연 상호작용(Late interaction)은 토큰 수준 매칭(token-level matching) 을 가능하게 하지만,
무거운 인덱싱 비용(heavy indexing costs) 을 동반한다.
- 표준 바이인코더는 전체 텍스트를 하나의 벡터(one vector) 로 압축하며,
- 많은 도메인에서는 사용자가 어떤 측면(aspects)에 관심을 가지는지 이미 알고 있다:
- 전자상거래: category, brand, color
- 학술 도메인: background, method, findings

- 우리는 이러한 사용자 관심 요소들을 명시적으로 주입함으로써
바이인코더를 강화할 수 있을까?
p28. 사용자 관심 요소 추출 (범위 외 내용)
- 각 문서로부터 사용자 관심 요소(user-interested aspects) 를 추출할 수 있다.
- 규칙 기반 도구(rule-based tools)나 대규모 언어 모델(large language models)을 사용할 수 있으나,
이는 본 강의의 범위를 벗어난다.
- 규칙 기반 도구(rule-based tools)나 대규모 언어 모델(large language models)을 사용할 수 있으나,

p29. 이러한 관심 요소를 바이인코더에 주입하는 방법은?
문제 설정
- 우리는 말뭉치(corpus) $D = \lbrace d_1, d_2, \dots, d_N \rbrace$ 와
미리 정의된(predefined) 관심 요소 타입 집합 $\mathcal{A}$ 를 갖고 있다.- 예: $\mathcal{A} = \lbrace \text{brand},\ \text{category},\ \text{color},\ \dots \rbrace$
- 각 관심 요소 타입 $a \in \mathcal{A}$ 에 대해
고정된 단어 집합(fixed vocabulary)
\(\mathcal{V}_a = \lbrace v^{(a)}_1,\ v^{(a)}_2,\ \dots,\ v^{(a)}_{|\mathcal{V}_a|} \rbrace\) 를 정의한다.- 예: 타입 ‘brand’의 경우
$\lbrace \text{adidas},\ \text{nike},\ \dots \rbrace$
- 예: 타입 ‘brand’의 경우
각 문서 $d_i$ 는
원본 텍스트(raw text) $x_i$ 와
관심 요소 주석(aspect annotations)
$y_i = \lbrace y_i^{(a)} \mid a \in \mathcal{A} \rbrace$ 를 포함한다.
각 $y_i^{(a)} \in \mathcal{V}_a$ 이다.
- 우리는 말뭉치(corpus) $D = \lbrace d_1, d_2, \dots, d_N \rbrace$ 와
p30. 순진한(naïve) 접근법: 추가 입력 문맥
- 간단한 아이디어는
각 문서에 관심 요소 주석(aspect annotations)을 추가 입력 문맥(additional input context) 으로 덧붙이는 것이다.- 이러한 정보를 입력에 직접 주입하면,
밀집 벡터(dense vector)가 사용자가 관심을 가지는 신호(user-interested signals) 를 더 잘 포착할 수 있다.
- 이러한 정보를 입력에 직접 주입하면,
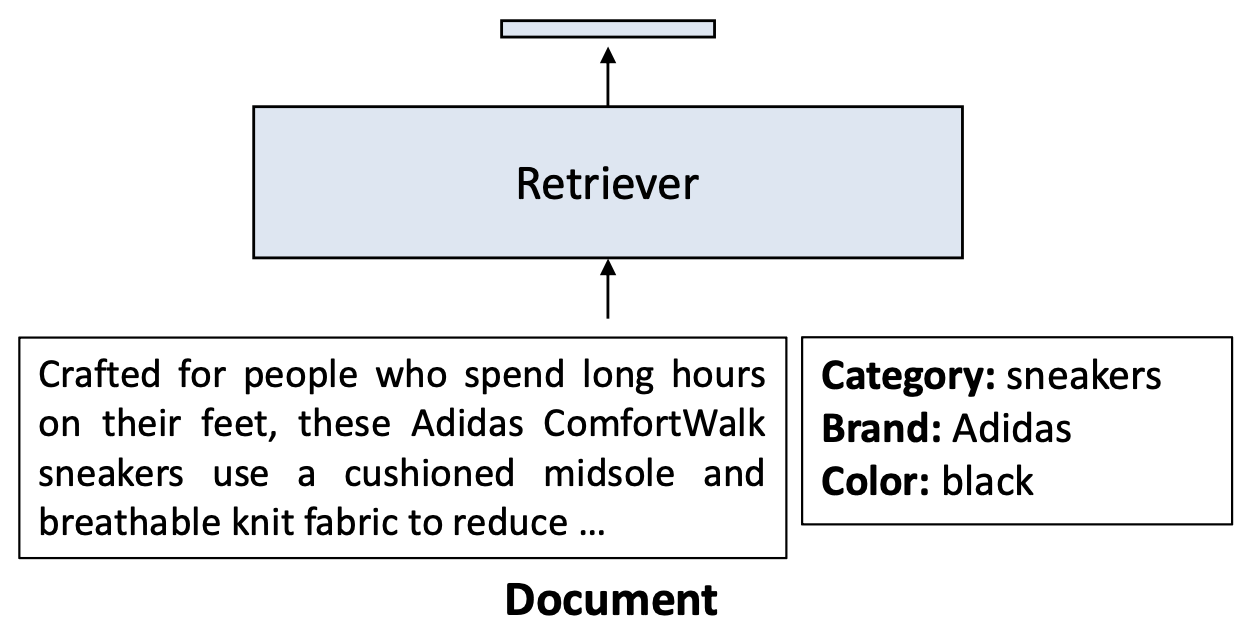
- 이 접근법을 쿼리 측(query-side) 에도 적용할 수 있을까?
p31. 순진한(naïve) 접근법: 추가 입력 문맥
- 사용자 쿼리는 서비스 시점(serving time) 에 도착하므로,
그 쿼리에 대한 관심 요소(aspect)를 미리 주석(annotate) 하는 것은 불가능하다.- 도구나 LLM을 이용해 실시간(on the fly) 으로 관심 요소를 주석하면
속도가 느려지고 검색 효율(retrieval efficiency) 이 떨어진다.
- 도구나 LLM을 이용해 실시간(on the fly) 으로 관심 요소를 주석하면
- 그렇다면 이 문제를 어떻게 해결할 수 있을까?
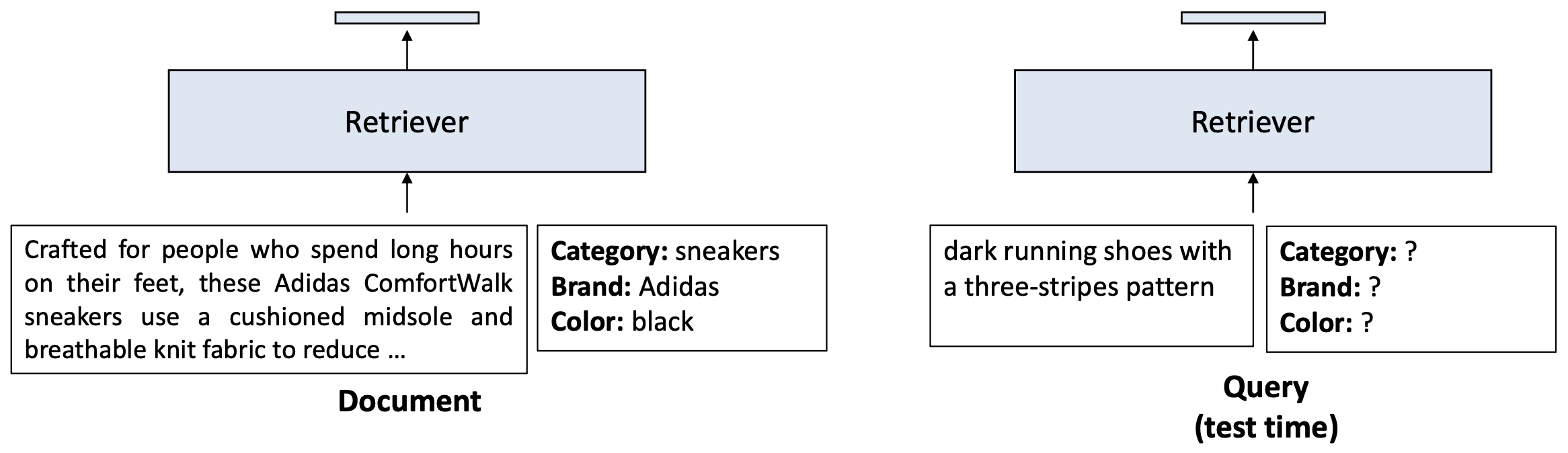
p32. 분류(classification)를 통해 검색 성능을 향상시킬 수 있음
우리는 보지 못한 임의의 텍스트에 대해 속성(aspect) 값을 부여하고자 한다.
이 작업을 분류(classification) 라고 부른다.최근 시도들은
aspect 분류 작업을 포함한 다중 작업 학습(multi-task learning) 에 초점을 맞추고 있다.
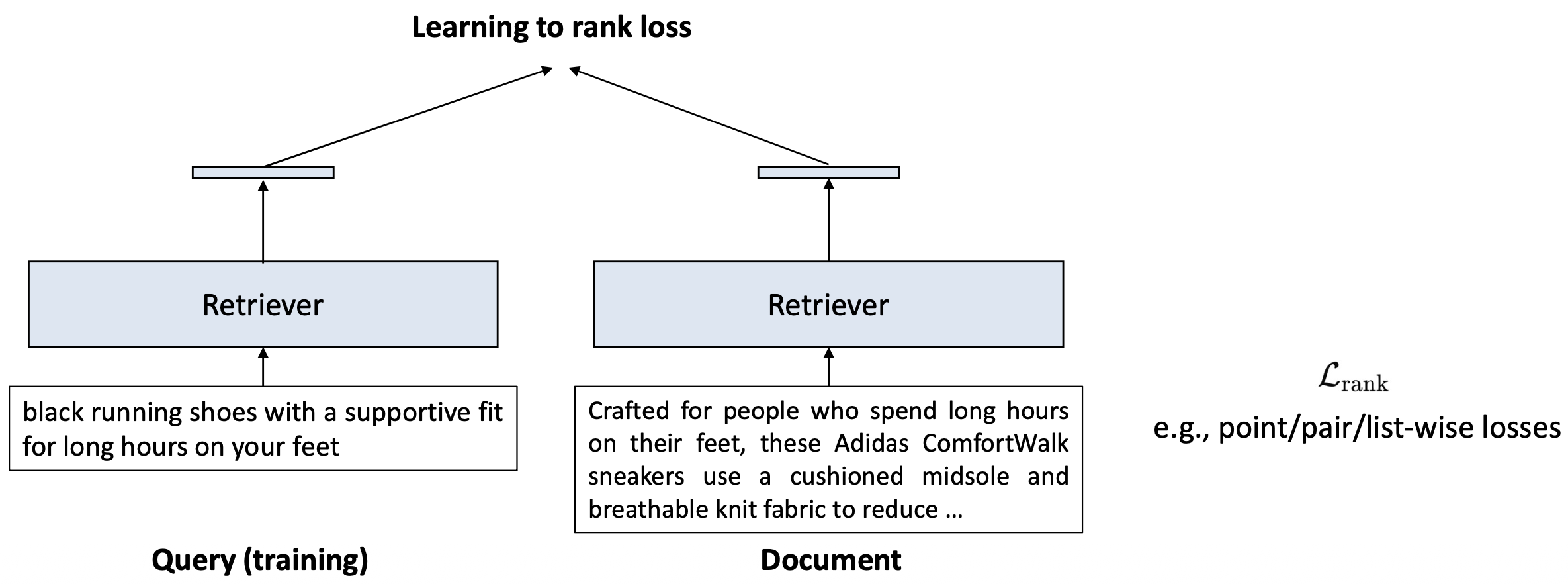
p33. 분류(classification)를 통해 검색 성능을 향상시킬 수 있음
우리는 보지 못한 임의의 텍스트에 대해 속성(aspect) 값을 부여하고자 한다.
이 작업을 분류(classification) 라고 부른다.최근 시도들은
aspect 분류 작업을 포함한 다중 작업 학습(multi-task learning) 에 초점을 맞추고 있다.
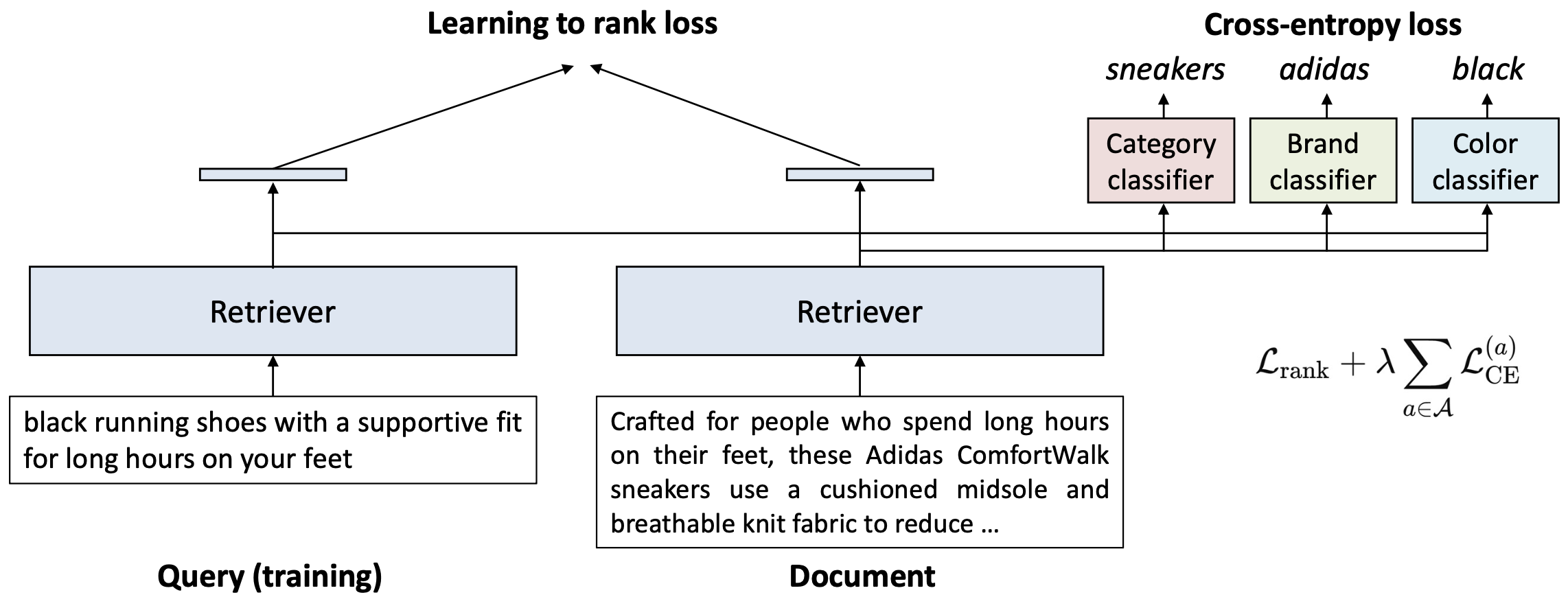
p34. 분류(classification)를 통해 검색 성능을 향상시킬 수 있음
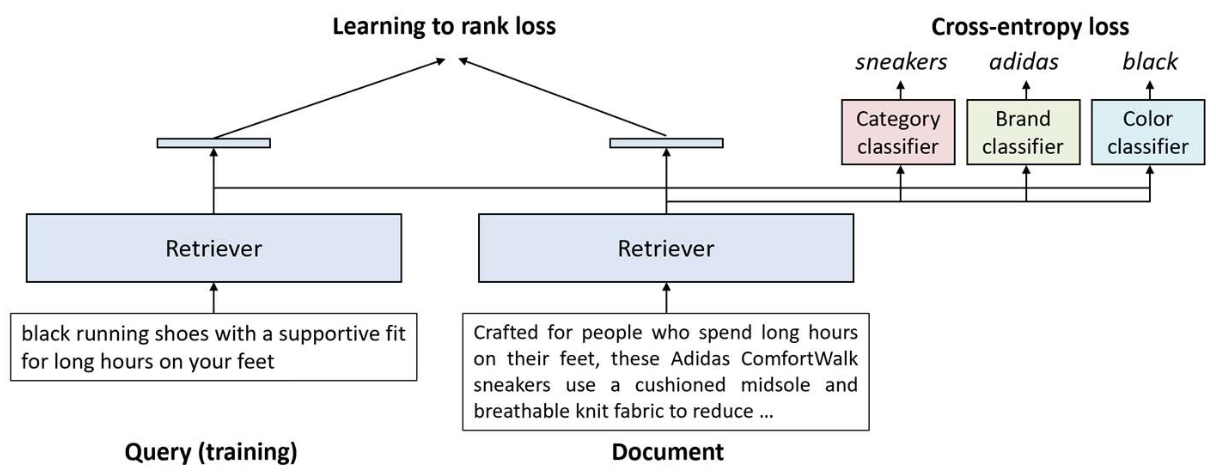
속성 분류(aspect classification)가 추가되면, 검색 모델(retriever)은 이제 두 가지를 학습하게 된다.
- 관련성(Relevance)
- learning-to-rank 손실을 통해
쿼리–문서 유사도를 인코딩한다.
- learning-to-rank 손실을 통해
- 속성 구분(Aspect discrimination)
- cross-entropy 손실을 통해
예: sneakers, adidas, black 같은 속성 값을 구분한다.
- cross-entropy 손실을 통해
- 관련성(Relevance)
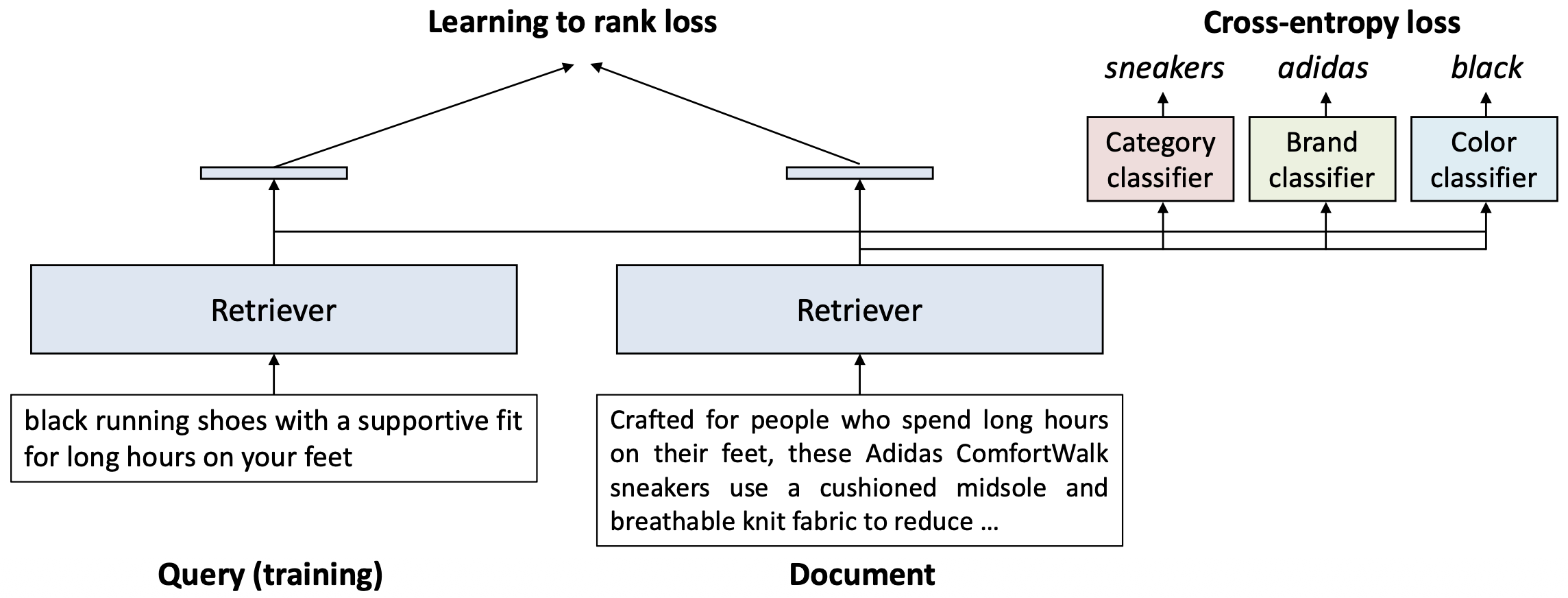
p35. 분류(classification)를 통해 검색 성능을 향상시킬 수 있음
테스트 시점(test time)에는 이 설계가 두 가지 핵심 이점을 제공한다.
- 어떤 텍스트가 주어지더라도, 검색 모델(retriever)은 해당 텍스트의 속성(aspect) 정보를 추출할 수 있다.
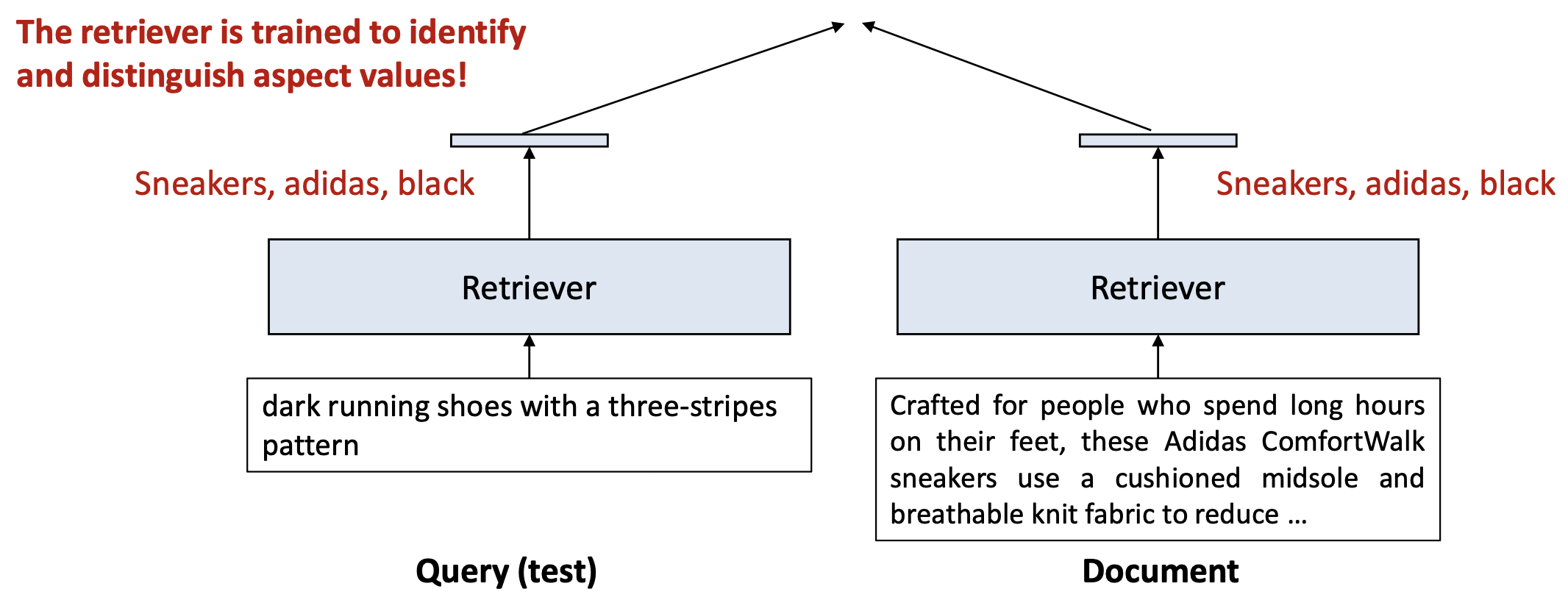
retriever는 ‘속성 값’을 식별하고 구분하도록 학습되어 있다!
p36. 분류(classification)를 통해 검색 성능을 향상시킬 수 있음
테스트 시점(test time)에는 이 설계가 두 가지 핵심 이점을 제공한다.
- 어떤 텍스트가 주어지더라도, 검색 모델(retriever)은 해당 텍스트의 속성 정보를 추출할 수 있다.
- 문서 표현(document representation)은 사전에 계산하여 인덱싱(ANN index)할 수 있다.
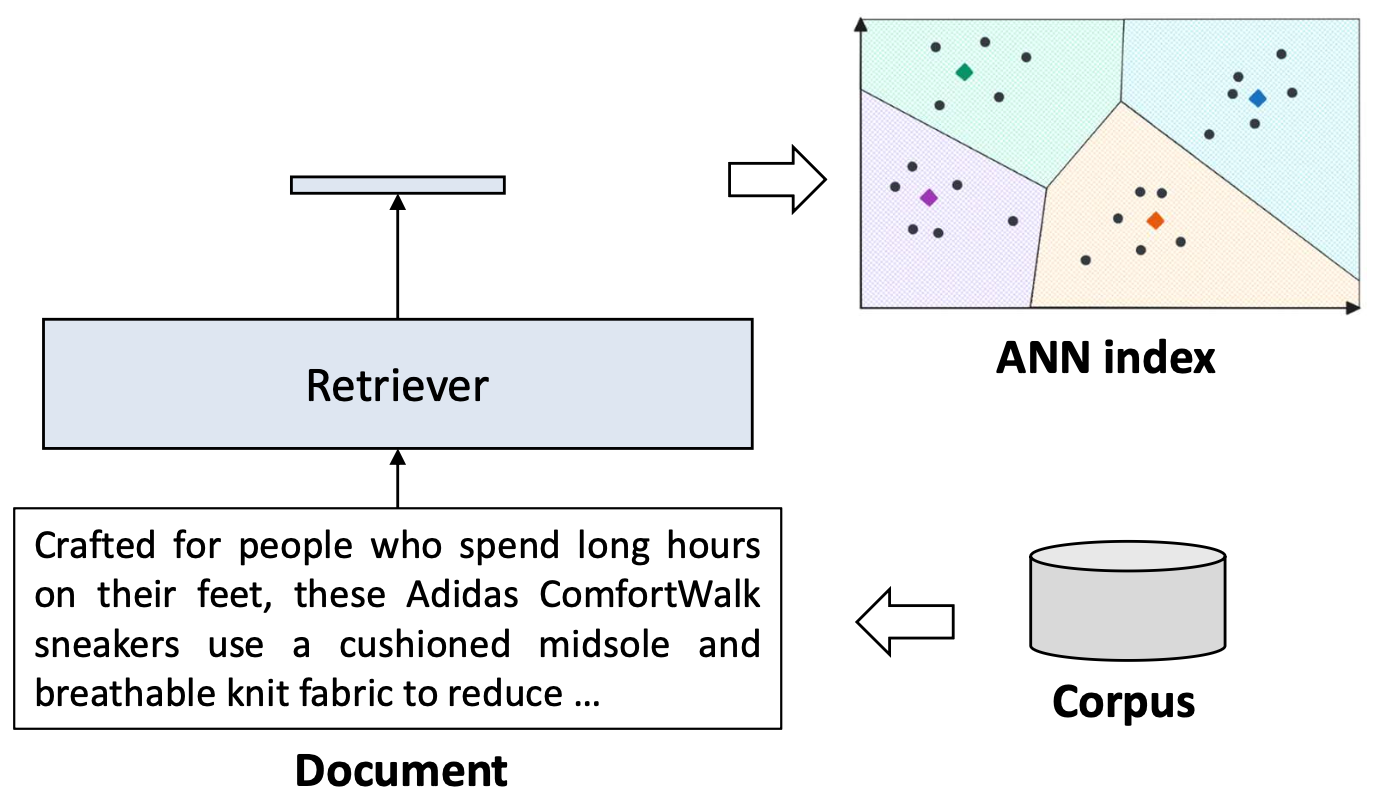
p37. 실험 결과
- 최신(state-of-the-art) 기법들은 구현에 여러 추가 세부 사항을 포함한다.
- 여기서는 속성 기반 강화(aspect-enhanced) 검색기를
표준 바이인코더(bi-encoder) 와 단순 비교한다.
표 1. Multi-Aspect Dense Retrieval, KDD’22 결과
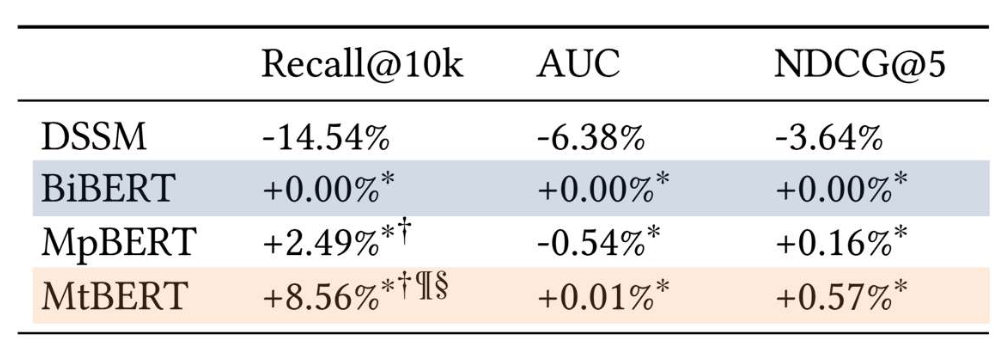
- BiBERT: 바이인코더
- MtBERT: 속성 분류를 포함한 멀티태스크 학습
Taxonomy-guided Semantic Indexing for Academic Paper Search, EMNLP’24 결과
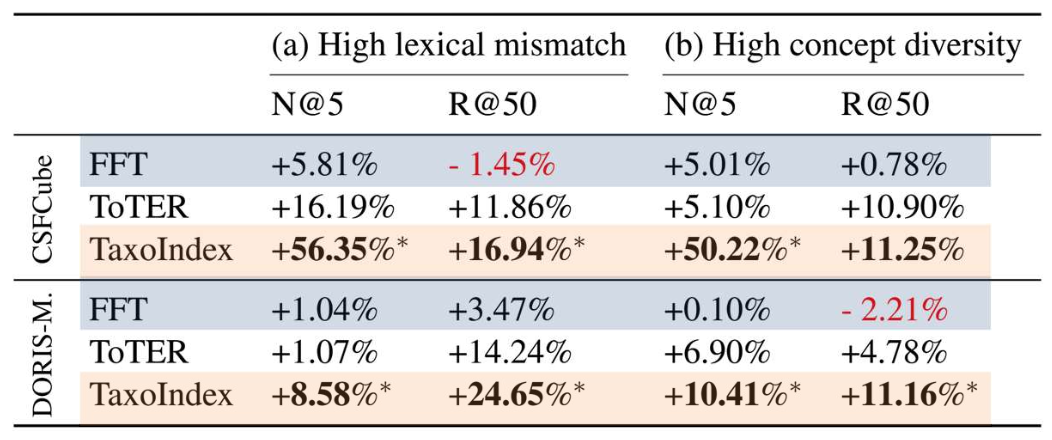
- FFT: 바이인코더
- TaxoIndex: 속성 분류를 포함한 멀티태스크 학습
p38. 요약: 사용자-관심 속성 주입하기
- 배경(Backgrounds):
- 바이인코더는 효율적이지만 표현력이 부족하다
- 전체 텍스트를 하나의 벡터(one vector) 로 압축하며, 이 과정에서 세밀한 신호(fine-grained signals) 를 잃는다.
- 지연 상호작용(late interaction)은 표현력은 높지만 비효율적이다
- 토큰 수준 매칭(token-level matching) 이 가능하지만, 높은 인덱싱 비용(heavy indexing costs) 이 든다.
- 바이인코더는 효율적이지만 표현력이 부족하다
- 핵심 요점(Key takeaways):
- 바이인코더는 사용자-관심 속성(user-interested aspects) 을 명시적으로 주입함으로써 강화될 수 있다.
- 분류(classification)는 이러한 속성을 더욱 강화할 수 있으며, 이 외에도 다양한 연구가 활발히 진행되고 있다.
p39. 요약: 밀집 검색(dense retrieval)
- 밀집 검색(dense retrieval)
- 쿼리와 문서를 연속 벡터 공간에서 표현하기 위해 밀집 임베딩(dense embeddings) 을 사용한다.
- 의미적 유사도(semantic similarity) 를 포착하여, 키워드 중복을 넘는 검색을 가능하게 한다.
- 이번 강의에서 배운 내용:
- 전체 검색 과정: ANN 인덱스 + 밀집 임베딩 유사도
- 밀집 검색기를 파인튜닝하는 방법: 랭킹 학습(learning to rank)
- 핵심 한계점과 해결 방법: 지연 상호작용(late interaction), 사용자-관심 속성 주입(user-interested aspects)
p40. 추천 읽을거리
- 책(Books):
- Chapter 11: Information Retrieval and Retrieval-Augmented Generation, Speech and Language Processing
- 논문(Papers):
- ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT, SIGIR’20
- Multi-Aspect Dense Retrieval, KDD’22
- Taxonomy-guided Semantic Indexing for Academic Paper Search, EMNLP’24