[텍스트 마이닝] 14. Search 3 - Dense Retrieval 2 & LLM-enhanced IR
p4. 바이인코더가 가질 수 있는 잠재적 문제점은 무엇인가?
- 일반적인 밀집 검색기(dense retrievers)는
쿼리와 문서를 서로 독립적으로(independently) 벡터로 인코딩한다.- 이러한 접근 방식을 바이인코더(bi-encoder) 라고 부른다.
- 문서 벡터는 어떤 쿼리가 오더라도 항상 동일하게 유지된다.
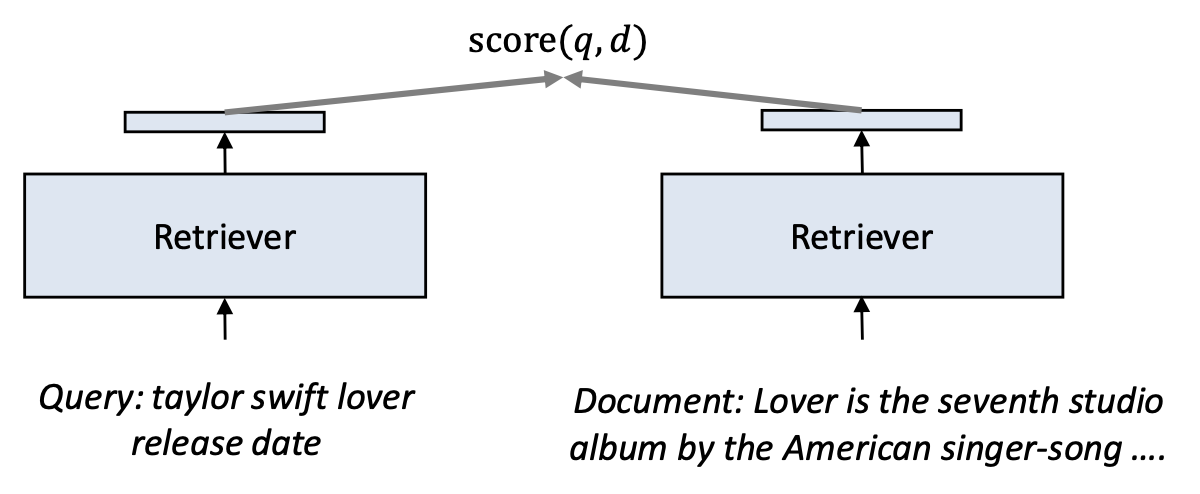
- 그러나 문서 안의 단어 중요도는 쿼리에 따라 달라질 수 있다.
- 바이인코더는 이러한 동적인 상호작용을 반영할 수 없다.
p5. 바이인코더가 가질 수 있는 잠재적 문제점은 무엇인가?
- 바이인코더는 각 문서마다 하나의 고정된 벡터(one fixed vector) 를 만든다.
- 이는 어떤 쿼리가 입력되더라도 문서 표현(document representation)은 절대 바뀌지 않는다는 뜻이다.
- 예시(Example):
Query 1:
taylor swift lover release date
Document
Lover is the seventh studio album by the American singer-songwriter Taylor Swift, released on August 23, 2019.
The album features 18 tracks, including popular songs such as ‘Cruel Summer’, ‘Lover’, ‘The Archer’, and ‘The Man’.
‘Cruel Summer’ was produced by Jack Antonoff and Taylor Swift and is known for its upbeat synth-pop sound.
Query 2:
taylor swift cruel summer producer
Document
Lover is the seventh studio album by the American singer-songwriter Taylor Swift, released on August 23, 2019.
The album features 18 tracks, including popular songs such as ‘Cruel Summer’, ‘Lover’, ‘The Archer’, and ‘The Man’.
‘Cruel Summer’ was produced by Jack Antonoff and Taylor Swift and is known for its upbeat synth-pop sound.
- 두 예시는 서로 다른 정보를 요구하는 쿼리임에도,
문서 벡터는 동일하게 유지되며 쿼리별 중요도 변화가 반영되지 않음을 보여준다.
p6. 바이인코더가 가질 수 있는 잠재적 문제점은 무엇인가?
바이인코더는 각 문서마다 하나의 고정된 벡터(one fixed vector) 를 만든다.
- 그러나 같은 문서라도 서로 다른 쿼리는 문서의 서로 다른 부분에 주목한다.
- 사람은 쿼리에 따라 문서의 다른 부분을 읽게 된다.
- 하지만 바이인코더는 쿼리를 고려하지 않고 문서를 한 번만 인코딩하기 때문에 이를 반영할 수 없다.
- 그 결과,
바이인코더는 쿼리별로 필요한 정보(query-specific information)를 반영하지 못할 수 있다.
Document (예시 1)
Lover is the seventh studio album by the American singer-songwriter Taylor Swift, released on August 23, 2019.
The album features 18 tracks, including popular songs such as ‘Cruel Summer’, ‘Lover’, ‘The Archer’, and ‘The Man’.
‘Cruel Summer’ was produced by Jack Antonoff and Taylor Swift and is known for its upbeat synth-pop sound.
Document (예시 2)
Lover is the seventh studio album by the American singer-songwriter Taylor Swift, released on August 23, 2019.
The album features 18 tracks, including popular songs such as ‘Cruel Summer’, ‘Lover’, ‘The Archer’, and ‘The Man’.
‘Cruel Summer’ was produced by Jack Antonoff and Taylor Swift and is known for its upbeat synth-pop sound.
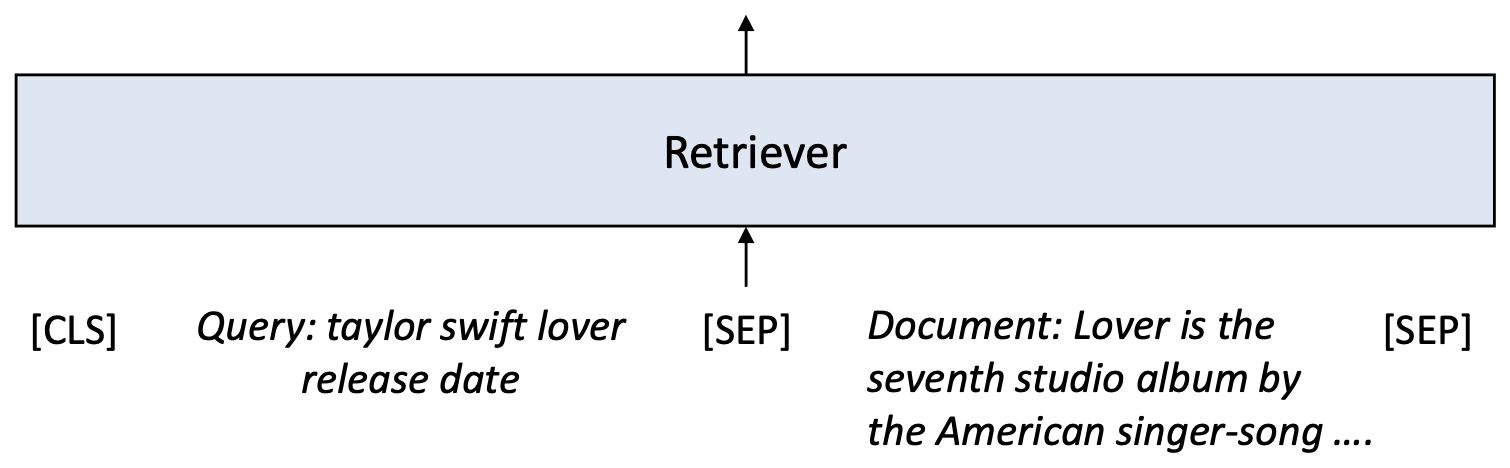
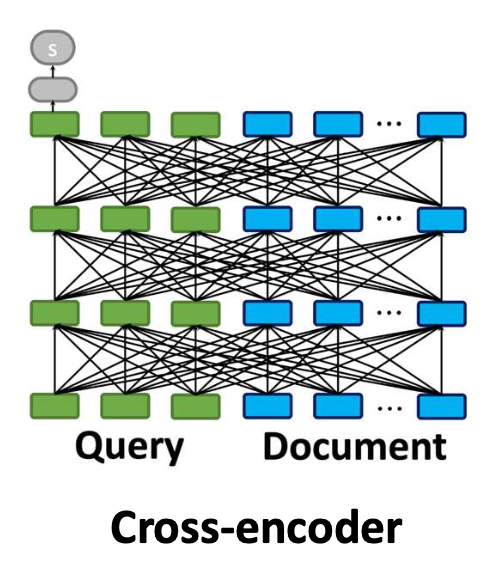
p7. 크로스-인코더(Cross-encoder)
- 크로스-인코더(cross-encoder) 는
쿼리와 문서를 하나의 입력 시퀀스로 연결(concatenate) 한다.- 이를 통해 모델은 양쪽의 모든 토큰을 동시에 공동으로(jointly) 주의를 기울일 수 있다(attend).
- 따라서 모델은 해당 쿼리에 대해 어떤 문서 단어가 중요한지 식별할 수 있다.
- 크로스-인코더는 이전에 다룬 순위 학습(learning-to-rank) 손실,
예: point-wise 손실로 파인튜닝(fine-tuning) 된다.
p9. 크로스인코더: 예시 (Cross-encoder: example)
- 크로스인코더는 쿼리와 문서를 토큰 단위(token-by-token)로 상호작용(interact) 하도록 만든다.
- 이를 통해 모델은 쿼리에 따라 동일한 문서의 서로 다른 부분을 강조(highlight) 할 수 있다.
Query 1:
[CLS] taylor swift lover release date [SEP] Taylor Swift, released on August 23, 2019 The album features [SEP]
Query 2:
[CLS] taylor swift cruel summer producer [SEP] ‘Cruel Summer’ was produced by Jack Antonoff and [SEP]
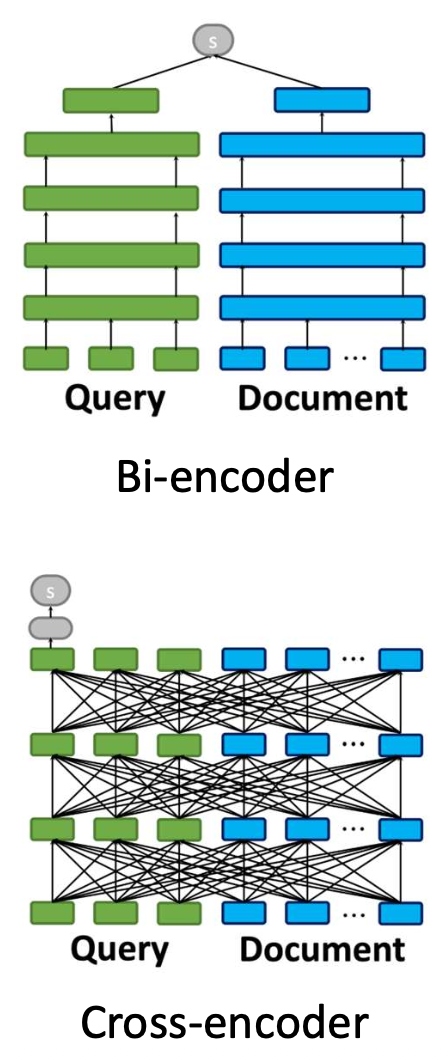
p10. 크로스인코더: 장점과 단점 (Cross-encoder: pros and cons)
- 장점(Pros):
- 바이인코더보다 더 강력한 관련성(relevance) 모델링을 수행한다.
- 쿼리와 문서의 모든 토큰에 걸쳐 어텐션(attention)을 계산하여 더 정확한 매칭을 가능하게 한다.
- 미세한(fine-grained) 상호작용을 포착한다.
- 특정 쿼리에 대해 문서의 어떤 단어가 중요한지 정확히 집중(focused) 할 수 있다.
- 바이인코더보다 더 강력한 관련성(relevance) 모델링을 수행한다.
- 단점(Cons):
- 사전 인덱싱(pre-indexing)이 불가능하다.
- 추론 시점(inference time)마다 전체 쿼리–문서 쌍(full query–document pair) 을 처리해야 한다.
- 대규모 검색 환경에서는 확장성(scalability)이 떨어진다.
- 전체 크로스어텐션은 계산 비용이 매우 크므로
수백만 문서를 스코어링하는 것은 비현실적이다.
- 전체 크로스어텐션은 계산 비용이 매우 크므로
- 사전 인덱싱(pre-indexing)이 불가능하다.
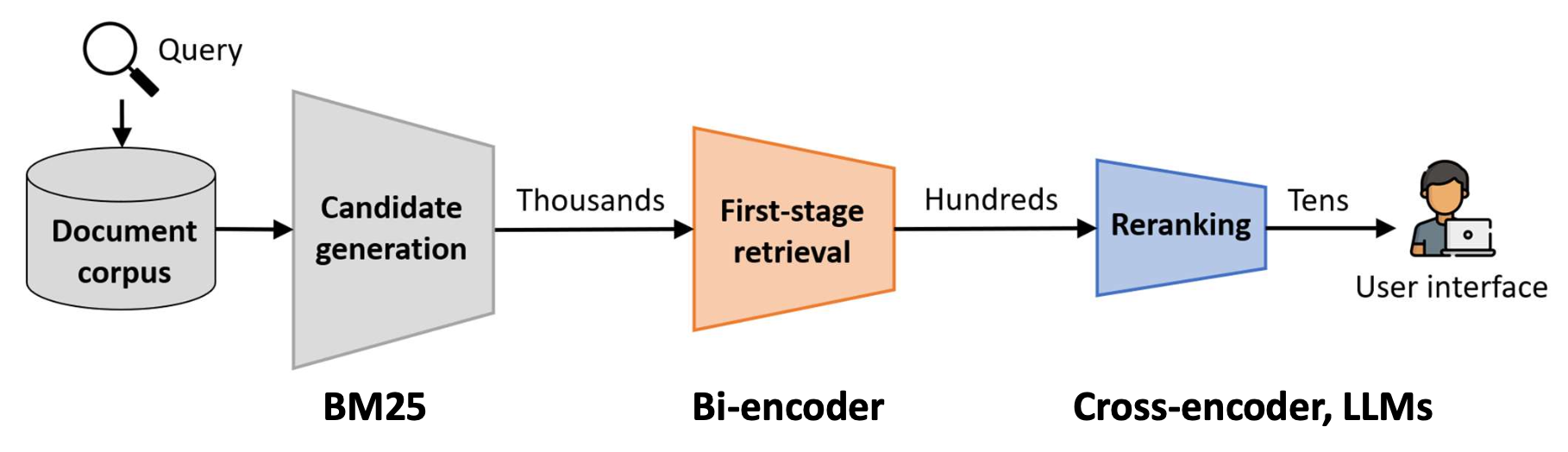
p11. 다단계 순위 매기기 파이프라인(Multi-stage ranking pipeline)
현대 검색 시스템은 효율성과 정확성을 균형 있게 유지하기 위해 다단계 파이프라인(multi-stage pipeline) 을 사용한다.
후보 생성(candidate generation) 은
BM25와 같은 빠른 방법을 사용하여 넓은 범위의 문서 집합을 검색한다.1단계 검색(first-stage retrieval) 은
보통 바이인코더를 사용하여 이 집합을 더 작고, 더 관련성 높은 부분집합으로 좁힌다.재순위화(reranking) 는
크로스인코더 혹은 LLM과 같은 강력하지만 비용이 큰 모델을 적용하여,
사용자에게 보여줄 최종 순위 리스트를 만든다.
p12. 바이인코더를 향상시키는 방법: Late interaction
CoLBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT
Omar Khattab
Stanford University
okhattab@stanford.edu
Matei Zaharia
Stanford University
matei@cs.stanford.edu
정보 검색 연구 및 개발을 위한 SIGIR 학회 2020에서 발표됨
p13. Late interaction: 동기(motivation)
사전 계산(precomputation)을 유지하면서도 세밀한(fine-grained) 쿼리–문서 상호작용을 가질 수 있을까?
원하는 속성(Desired properties):
- 독립적 인코딩 (효율성과 사전 인덱싱을 위해)
- 세밀한 쿼리–문서 상호작용 (효과성 향상을 위해)
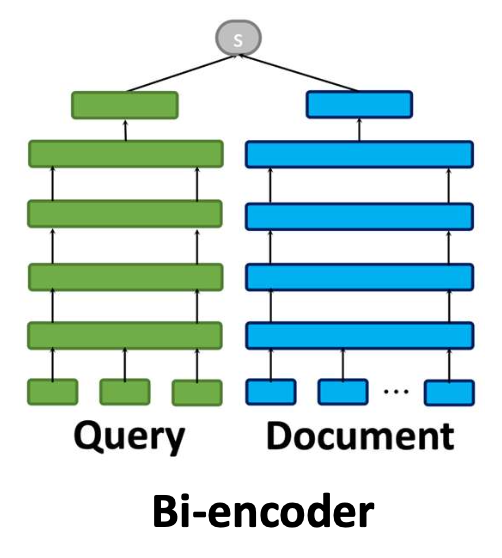
Bi-encoder
독립적인 쿼리–문서 인코딩
효과성은 제한되지만 효율적임
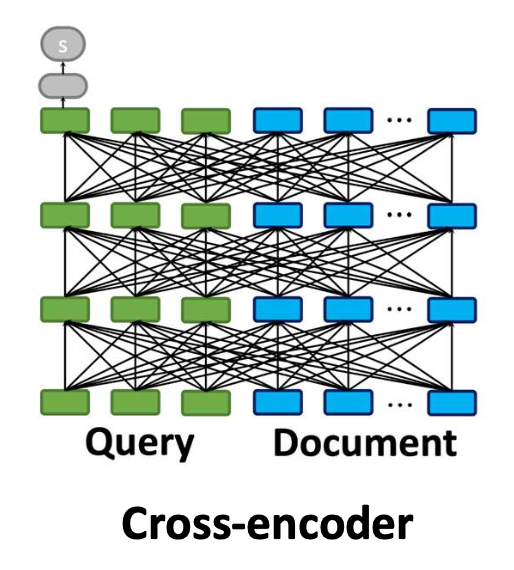
Cross-encoder
공동 쿼리–문서 인코딩
효과적이지만 비용이 큼
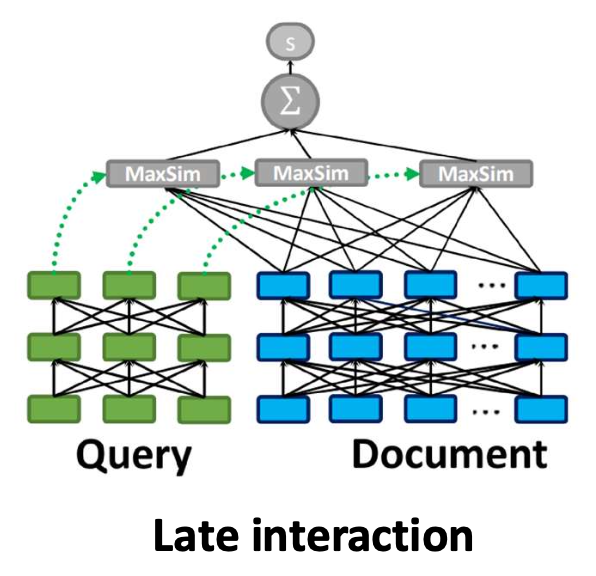
p14. Late interaction
Step 1: 문서를 토큰 벡터들의 시퀀스로 인코딩한다:
$e_{d_1}, e_{d_2}, \ldots, e_{d_L}$Step 2: 쿼리를 토큰 벡터들의 시퀀스로 인코딩한다:
$e_{q_1}, e_{q_2}, \ldots, e_{q_M}$Step 3: 관련도(relevance) 점수는 다음과 같이 계산한다:
\[\text{score}(q, d) = \sum_{m=1}^{M} \max_{1 \le l \le L} \left( e_{q_m}^{\top} e_{d_l} \right)\]
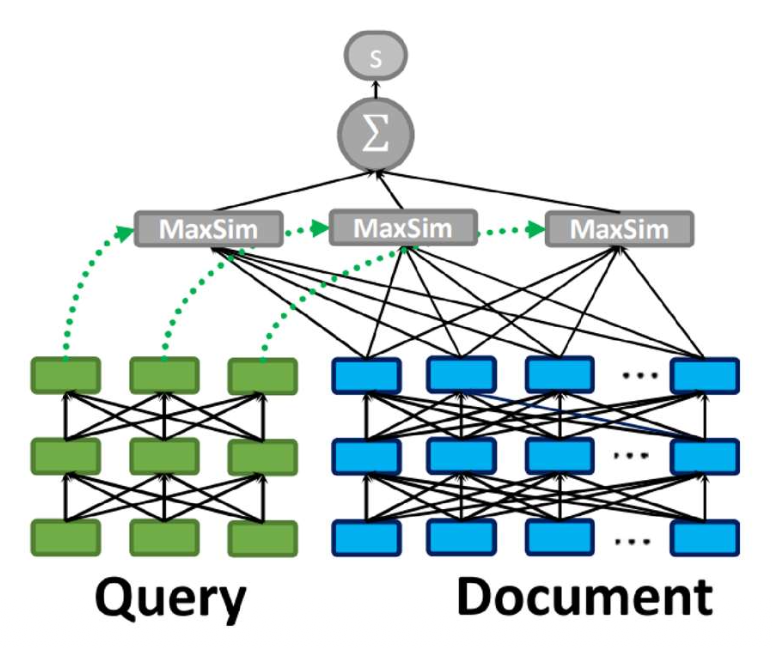
직관(Intuition):
각 쿼리 토큰(query token) 에 대해,
가장 유사한 문서 토큰(document token) 을 찾고,
이 유사도들을 모두 합하여 최종 점수를 만든다.쿼리와 문서는 먼저 서로 독립적으로 인코딩된다.
- 인코딩 과정에서는 아무 상호작용도 일어나지 않는다.
- 상호작용은 맨 마지막 단계에서만 발생한다.
p16. 지연 상호작용(Late interaction): 연습(Exercise)
- 예시(Example):
- 쿼리 표현(query representation):
$[0.9, 0.1],\ [0.2, 0.8]$ - 문서 표현(document representation):
$[0.7, 0.3],\ [0.4, 0.9],\ [0.1, 0.6],\ [0.8, 0.2]$
- 쿼리 표현(query representation):
관련도 점수(relevance score)는 무엇인가?
\[\text{score}(q, d) = \sum_{m=1}^{M} \max_{1 \le l \le L} \left( e_{q_m}^{\top} e_{d_l} \right)\]
쿼리 토큰 1:
$e_{q_1} = [0.9, 0.1]$
$e_{q_1}^{\top} e_{d_1} = 0.9(0.7) + 0.1(0.3) = 0.66$
$e_{q_1}^{\top} e_{d_2} = 0.9(0.4) + 0.1(0.9) = 0.45$
$e_{q_1}^{\top} e_{d_3} = 0.9(0.1) + 0.1(0.6) = 0.15$
$e_{q_1}^{\top} e_{d_4} = 0.9(0.8) + 0.1(0.2) = 0.74$
$\max = 0.74$
쿼리 토큰 2:
$e_{q_2} = [0.2, 0.8]$
$e_{q_2}^{\top} e_{d_1} = 0.2(0.7) + 0.8(0.3) = 0.38$
$e_{q_2}^{\top} e_{d_2} = 0.2(0.4) + 0.8(0.9) = 0.80$
$e_{q_2}^{\top} e_{d_3} = 0.2(0.1) + 0.8(0.6) = 0.50$
$e_{q_2}^{\top} e_{d_4} = 0.2(0.8) + 0.8(0.2) = 0.24$
$\max = 0.80$
최종 점수:
$\text{score}(q, d) = 0.74 + 0.80 = 1.54$
p17. 지연 상호작용(Late interaction): 매칭 예시
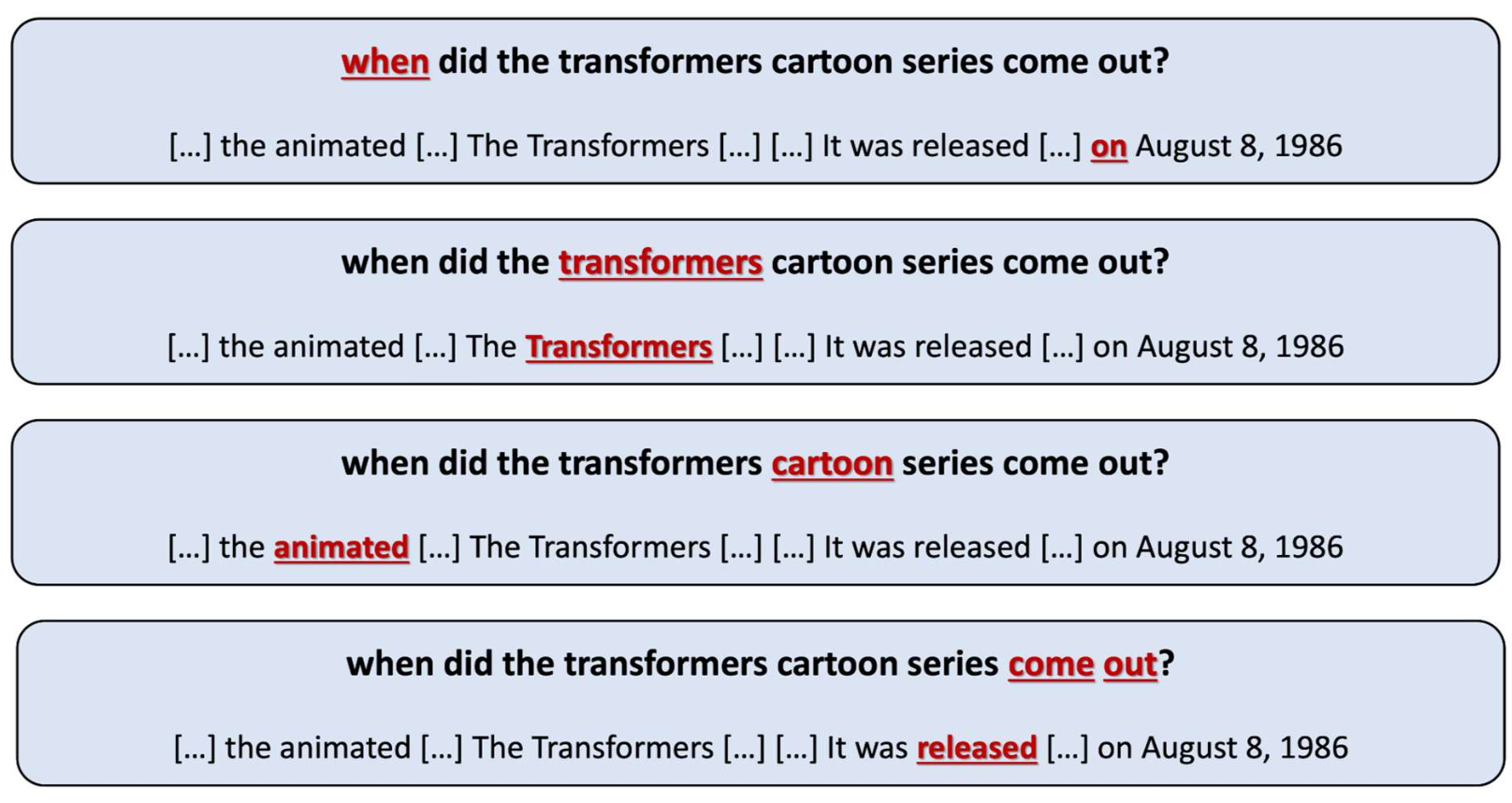
- 지연 상호작용에서는, 각 쿼리 토큰(query token) 이
문서에서 가장 유사한 토큰(most similar token) 을 찾는다.- 각 쿼리 단어는 의미적으로 가장 강한 매칭을 제공하는 문서 단어와 정렬된다.
- 최종 점수는 이러한 가장 좋은 매칭(best matches)의 합(sum) 으로 계산되며,
미세한 쿼리–문서 상호작용(fine-grained q-d interactions)을 포착한다.
p18. 지연 상호작용(Late interaction): 인덱싱
- 일반적인 바이인코더에서는 문서 하나당 하나의 벡터(one vector per document) 를 저장한다.
- 지연 상호작용에서는 문서 하나당 여러 개의 토큰 벡터(multiple token vectors per document) 를 저장한다.
- 모든 문서 토큰 임베딩을 저장해야 하므로 → 훨씬 더 큰 저장 공간(much larger storage) 이 필요하다.
- ANN을 사용할 수는 있으나, 문서 단위 벡터가 아니라 토큰 단위 벡터(token-level vectors) 에 대해 동작해야 한다.
- 후보 생성(candidate generation)은 바이인코더보다 더 느리다(slower).
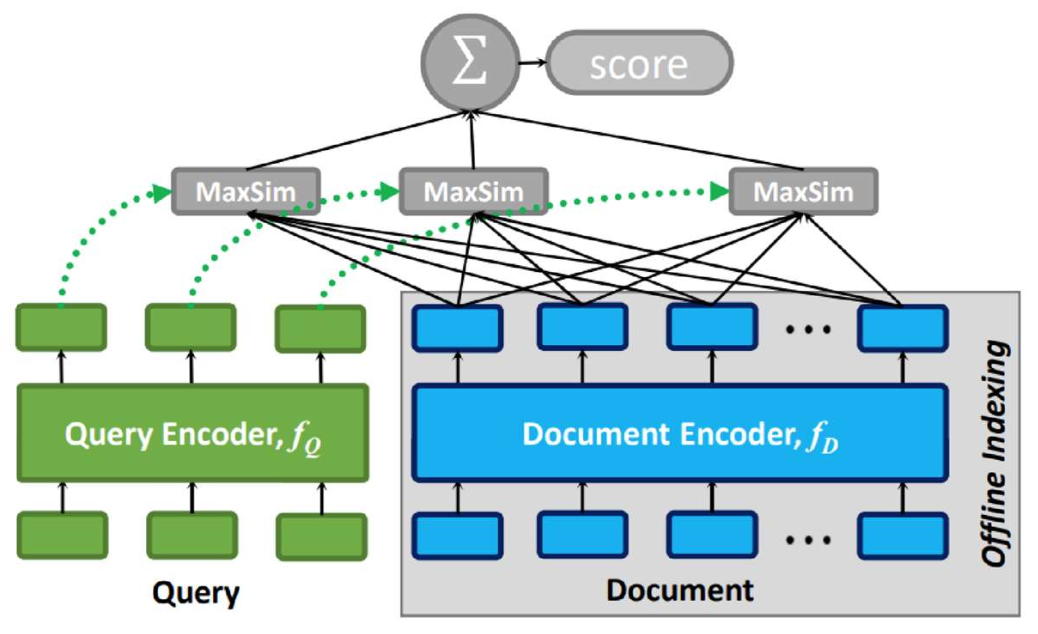
p19. 실험 결과(파인튜닝됨)
설정(Setup):
주어진 코퍼스에 대해, 모든 검색기(retrievers)는 (q, d) 쌍을 사용해 파인튜닝된다.관찰(Observation):
지연 상호작용(late interaction)은 바이인코더와 크로스인코더 사이에서 좋은 균형을 보여준다.
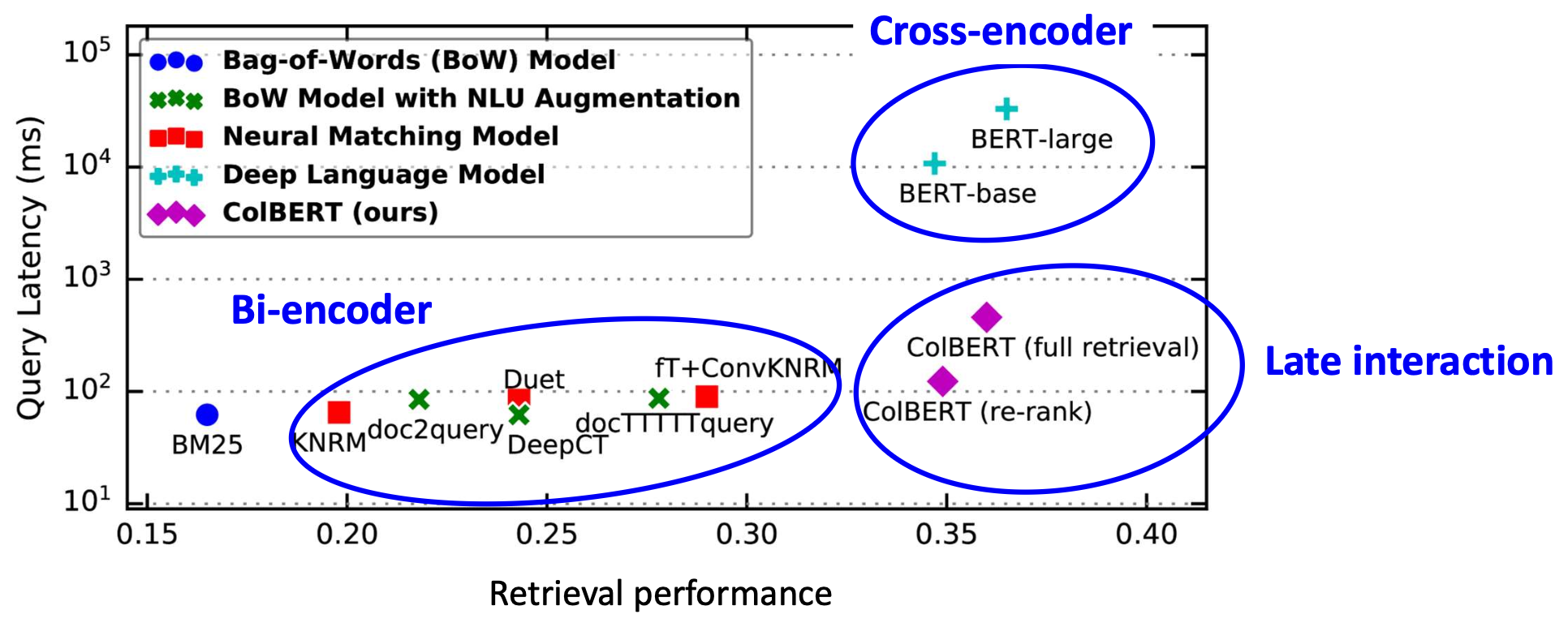
p20. 실험 결과(파인튜닝 없음)
(Results from BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models)
설정(Setup):
검색기(retriever)들은 다른 코퍼스에서 파인튜닝된 후,
타깃 코퍼스에 직접 적용된다.관찰(Observations):
- BM25는 어떤 파인튜닝도 없이 매우 강력한 베이스라인으로 남아 있다.
- 크로스인코더와 지연 상호작용(late-interaction) 모델은 더 잘 일반화된다.
이는 세밀한 토큰 상호작용(fine-grained token interaction) 덕분이다. - 바이인코더는 더 약한 일반화 성능을 보인다.
순수한 표현 유사도 기반 방법은 작업 특화 튜닝(task-specific tuning) 없이 종종 성능이 떨어진다.
p21. 요약: 지연 상호작용(late interaction)
- 지연 상호작용은 토큰 수준 매칭(token-level matching) 을 제공하며,
효율적인 바이인코더(bi-encoder)와 정확하지만 비용이 큰 크로스인코더(cross-encoder) 사이의
중간 지점(middle ground) 을 제공한다.
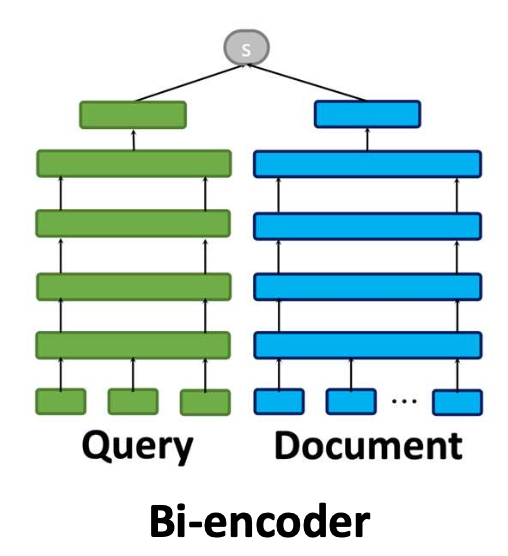
Bi-encoder
- 쿼리와 문서를 독립적으로(independently) 인코딩한다.
- 빠르고 효율적이지만, 상호작용은 제한적이다.
지연 상호작용(late interaction)
- 쿼리와 문서를 별도로(separately) 인코딩하지만, 토큰 수준(token level) 에서 매칭한다.
- 적당한 비용(moderate cost) 으로 높은 효과를 달성한다.
Cross-encoder
- 쿼리/문서를 공동으로(jointly) 인코딩한다.
- 가장 효과적이지만, 계산 비용이 매우 크다.
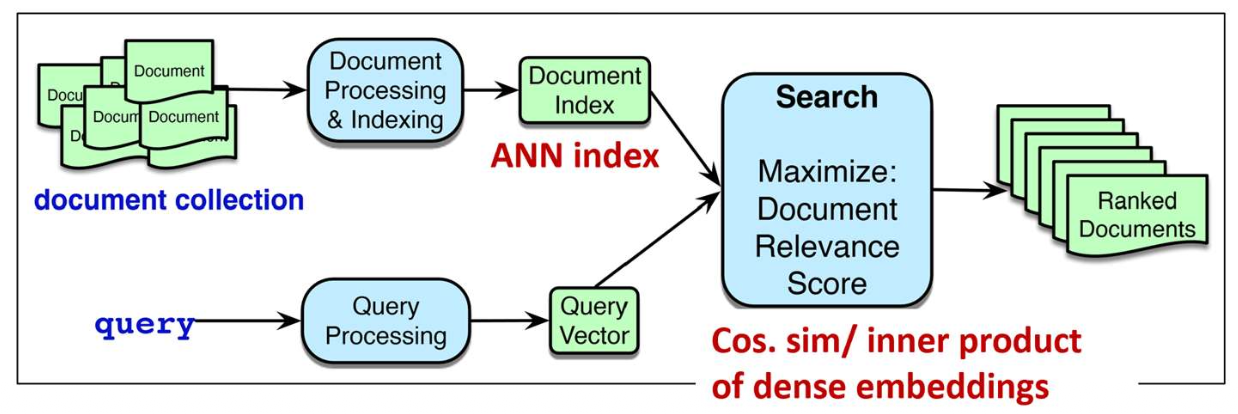
p22. 요약: 밀집 검색(dense retrieval)
- 밀집 검색(dense retrieval)
- 쿼리와 문서를 연속 벡터 공간에서 표현하기 위해 밀집 임베딩(dense embeddings) 을 사용한다.
- 의미적 유사도(semantic similarity) 를 포착하여, 키워드 중복을 넘는 검색을 가능하게 한다.
- 이번 강의에서 배운 내용:
- 전체 검색 과정: ANN 인덱스 + 밀집 임베딩 유사도
- 밀집 검색기를 파인튜닝하는 방법: 랭킹 학습(learning to rank)
- 핵심 한계점과 해결 방법: 지연 상호작용(late interaction), 사용자-관심 속성 주입(user-interested aspects)
p24. 검색: 개요
- 우리는 실제(real-world) 검색 엔진을 작동시키는 핵심 기술들을 배우게 된다.
- 어휘 기반 검색 (Lexical retrieval)
- 쿼리와 문서를 단어 개수 기반의 희소 벡터(sparse vectors)로 표현한다.
- 쿼리와 문서 사이의 정확한 단어 일치(exact word matching)에 초점을 맞춘다.
- 고밀도 임베딩 검색 (Dense retrieval)
- 쿼리와 문서를 연속적인 벡터 공간에서 표현하기 위해 고밀도 임베딩(dense embeddings)을 사용한다.
- 의미적 유사성(semantic similarity)을 포착하여 키워드가 겹치지 않는 경우에도 검색이 가능하게 한다.
- LLM 기반 향상 검색 (LLM-enhanced retrieval)
- 대규모 언어 모델(LLMs)을 활용하여 검색 프로세스를 향상시킨다.

p25. LLM 기반 검색 향상: 개요
LLM은 현대 검색 시스템을 빠르게 변화시키고 있으며,
더 정확하고, 문맥을 이해하며, 사용자 적응형 검색을 가능하게 한다.이 강의에서는 LLM이 검색을 크게 향상시키는 세 가지 주요 방향을 다룬다:
1. LLM을 랭커(ranker)로 사용
- LLM이 어떤 문서가 더 관련 있는지를 직접 판단한다 (LLM 기반 재랭킹)
2. LLM을 문맥 강화(context enhancer)로 사용
- 누락된 문맥을 생성하고, 의미적 신호를 강화하며, 검색기가 더 잘 매칭하도록 돕는다
3. LLM을 사용자 시뮬레이터(user simulator)로 사용
- 실제 사용자 행동을 닮은 합성 쿼리를 생성한다
p26. LLM을 랭커(ranker)로 사용
p27. LLM을 랭커(ranker)로 사용
- 초기 아이디어: 쿼리와 모든 후보 문서를 LLM에 입력하고, LLM이 최종 랭킹을 출력하도록 한다.

p28. LLM을 랭커(ranker)로 사용
- 이 아이디어를 1,000개 또는 1,000,000개의 후보 문서로 일반화할 수 있을까?
- 불가능하다! LLM은 엄격한 입력 길이 제한과 높은 계산 비용을 가진다.
- 실제로 LLM은 다단계 파이프라인의 최종 재랭킹 단계에서 사용된다.
p29. LLM을 이용한 리스트 기반 랭킹(Listwise ranking)
- 지시(Instruction): 질의 $q$ 와 후보 문서 $d_1, d_2, \ldots, d_N$ 이 주어졌을 때, 랭킹 목록을 출력한다.

p30. LLM을 이용한 리스트 기반 랭킹의 한계(Limitation)
- 우리가 무한한 비용을 사용할 수 있다고 해도(물론 아니다),
LLM 기반 랭킹이 항상 최선의 결과를 줄까?- 아니다 — 단순히 비용 때문이 아니라, LLM 자체의 구조적 한계 때문이다.
- 핵심 한계점: 중간 위치 정보 손실 (Lost-in-the-middle)
- LLM은 시퀀스 중간에 위치한 정보를 잘 활용하지 못하는 경향이 있다.
- 검색(Search)에서는, 관련 문서가 어느 위치에 놓이느냐가 정확도에 큰 영향을 미친다.
- LLM이 5개 이하의 후보 문서에 대해서는 강력하지만,
20개의 문서를 랭킹하도록 만들려면 어떻게 해야 할까?
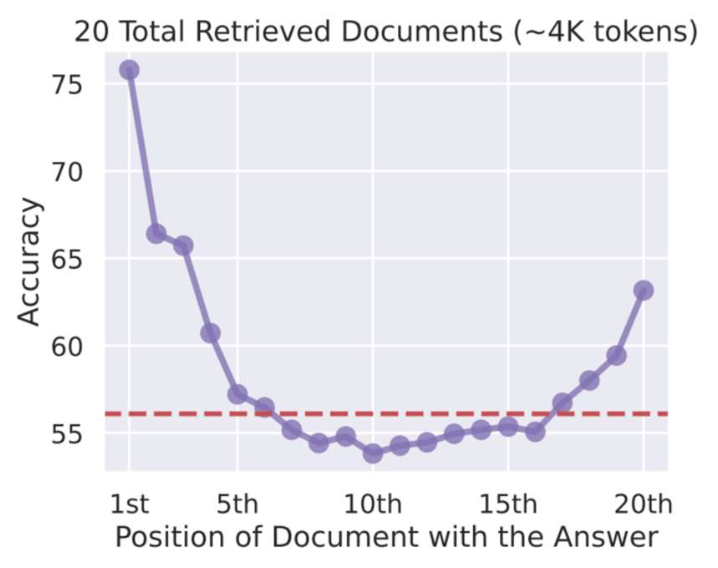
정확도는 관련 문서가 처음에 등장할 때는 높지만,
중간에 위치하면 크게 떨어지고,
마지막에 가까워질 때 약간만 회복된다.
p31. 슬라이딩 윈도우(sliding window)를 이용한 해결책
- 아이디어:
- LLM은 한 번에 $w$개의 문서만 랭킹한다 (예: $w = 4$)
- LLM은 슬라이딩 윈도우(sliding window) 를 이용하여 뒤에서 앞으로(back-to-first) 순서로 모든 후보 문서를 랭킹한다
- 이전 윈도우에서 상위 $s$개 문서는 다음 윈도우에도 포함된다 (예: $s = 2$)
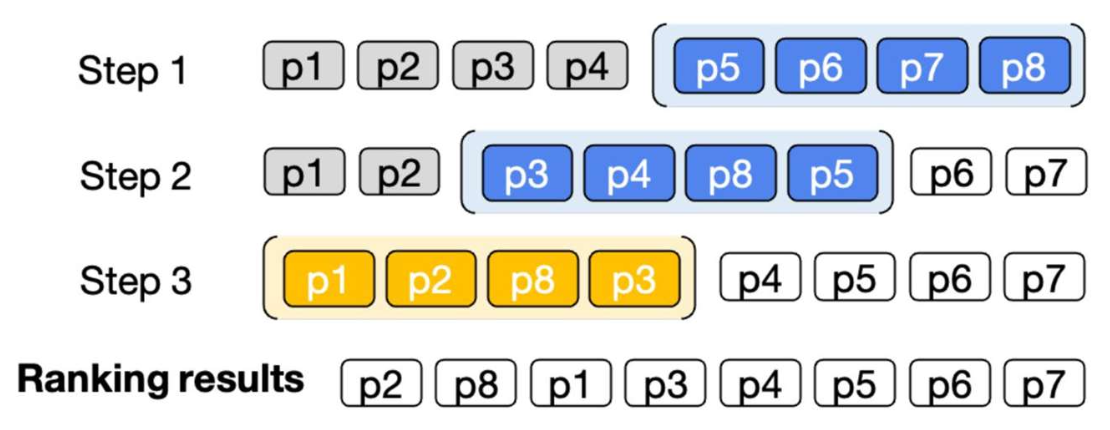
- 왜 back-to-first인가?
- 랭킹 목록의 상단 부분(top portion) 이 더 정확하도록 보장하기 위함이며,
마지막 부분의 정렬은 상대적으로 덜 중요하기 때문이다.
- 랭킹 목록의 상단 부분(top portion) 이 더 정확하도록 보장하기 위함이며,
Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agents, EMNLP’23
p32. 또 다른 해결책: 압축 문서 표현(compact document representation)
- 전체 문서를 그대로 LLM에 넣는 대신,
가장 중요한 의미적 요소들만 추출하여 사용할 수 있다
(LLM과 텍스트 마이닝 기법 활용)

- 전체 문서를 핵심 의미 요소들로 대체함으로써,
LLM이 각 문서를 더 효과적으로 소화(digest)할 수 있다.
CoRank: LLM-Based Compact Reranking with Document Features for Scientific Retrieval, Arxiv’25
p33. 실험 결과 (Experiment results)
- Retriever Only (1단계 검색)
- 재정렬(reranking)을 적용하지 않기 때문에 모든 데이터셋에서 가장 낮은 성능을 보인다.
- 전체 재정렬(Full Reranking) vs. 슬라이딩 재정렬(Sliding Reranking)
- 전체 재정렬은 긴 문맥(long-context) 문제(예: 중간 위치 정보 손실)에 취약하다.
- 슬라이딩 재정렬은 작은 윈도우를 처리함으로써 긴 문맥 실패를 피한다.
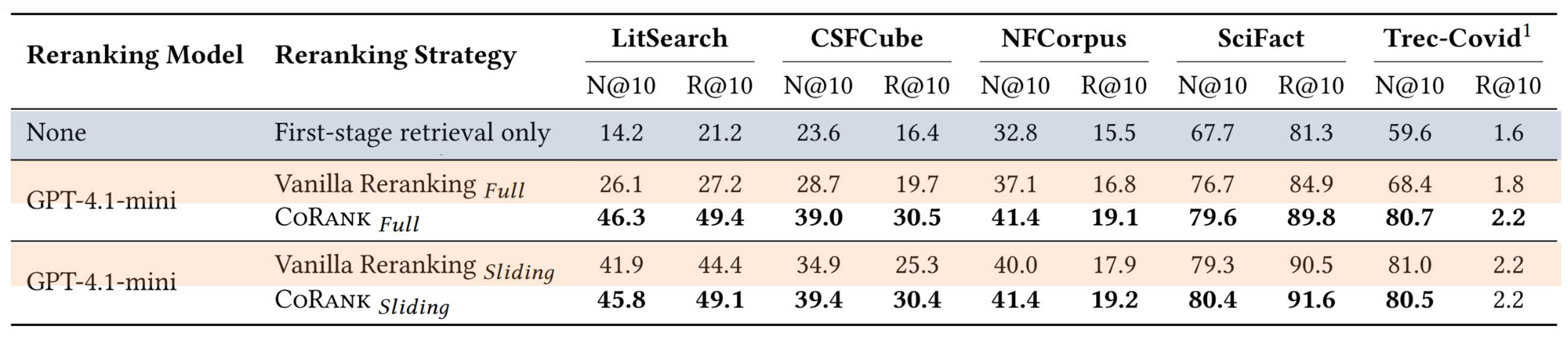
CoRank: LLM-Based Compact Reranking with Document Features for Scientific Retrieval, Arxiv’25
p34. 실험 결과
요약 문서 표현(Compact document representation) 을 사용할 때와 사용하지 않을 때의 재정렬 성능 비교(CoRANK)
- 요약 문서 표현 은 LLM이 핵심 의미 요소 에 더 집중하도록 도와주어,
전체 재정렬(full reranking)이 긴 문맥 입력 문제를 더 효과적으로 처리하게 만들며
슬라이딩 재정렬과의 성능 격차를 줄여준다.
- 요약 문서 표현 은 LLM이 핵심 의미 요소 에 더 집중하도록 도와주어,
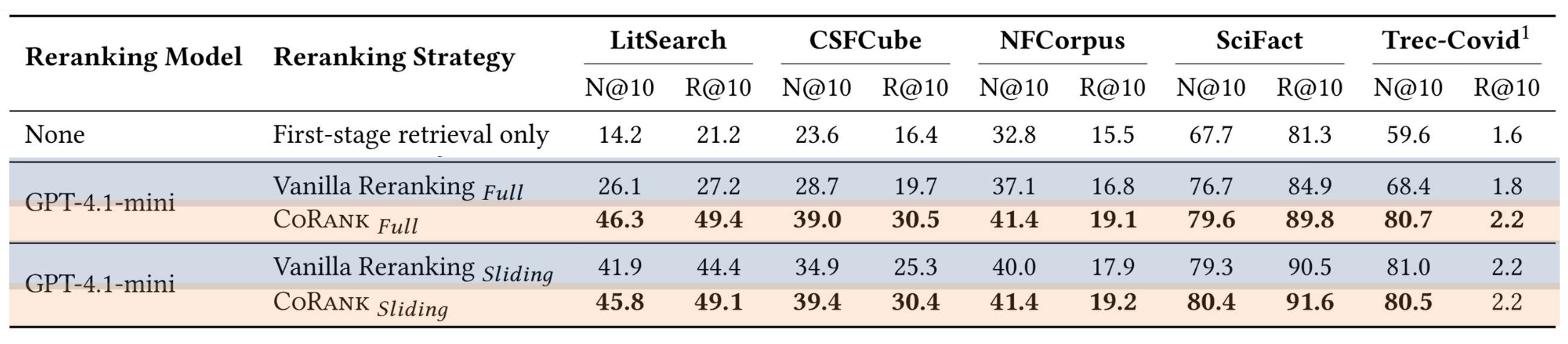
CoRank: LLM-Based Compact Reranking with Document Features for Scientific Retrieval, Arxiv’25
35. LLM을 문맥 강화(context enhancer)로 사용
p36. 질의에서 누락된 문맥 생성하기
사용자 질의는 종종 핵심 문맥(essential context) 이 부족하다
(예: 누락된 키워드, 배경 정보 등)LLM은 원래 질의를 기반으로 이러한 공백을 메워주는 보완 정보(complementary information) 를 생성할 수 있다
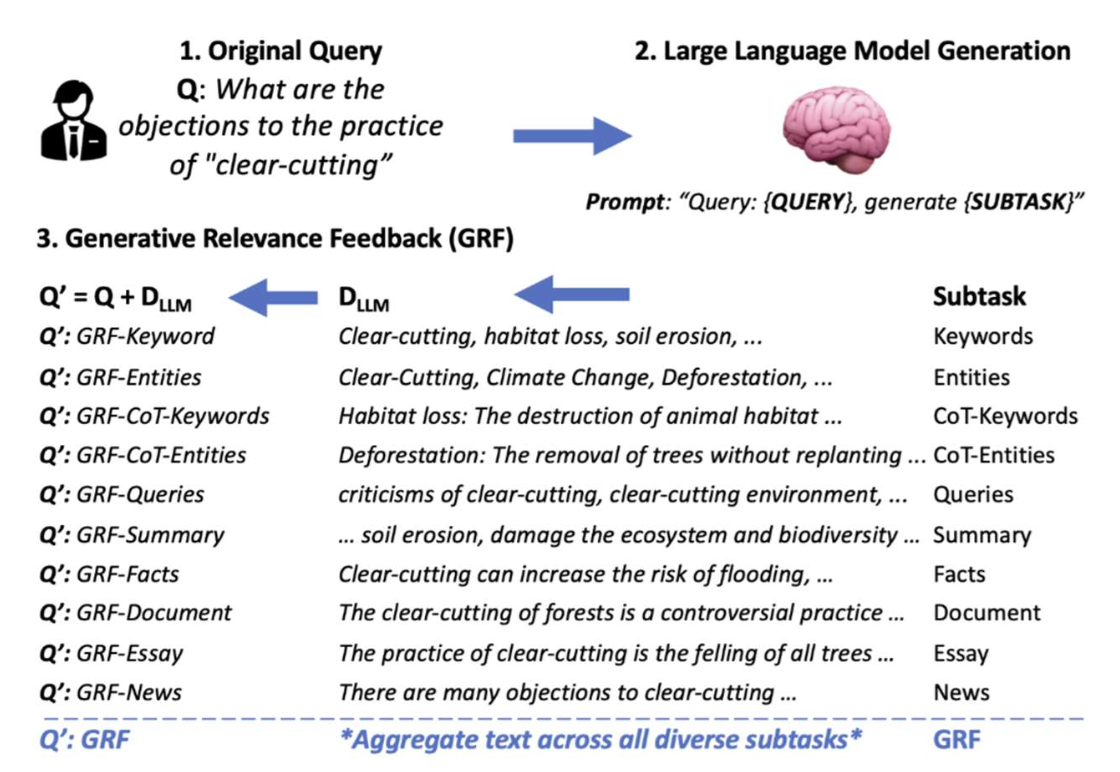
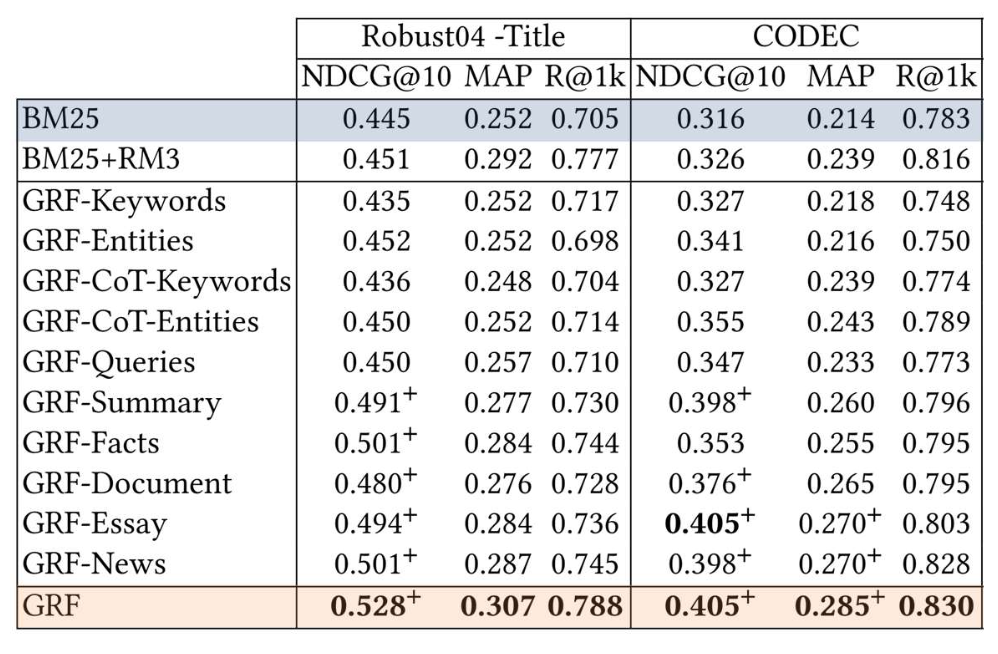
Generative Relevance Feedback with Large Language Models, SIGIR’23
p37. 질의를 문서 수준으로 확장하기
- 사용자 질의는 말뭉치(corpus) 내 문서 수준 정보와 매칭하기에 충분한 세부 정보를 담지 못하는 경우가 많다.
- LLM은 질의를 유사 문서(pseudo-document) 로 확장할 수 있으며,
이는 LLM이 질의에 대해 답하거나 설명을 덧붙여 생성한 하나의 단락이다. - 생성된 단락은 더 풍부한 문맥을 포함하며, 문서와 유사한 서술 구조를 갖는다.
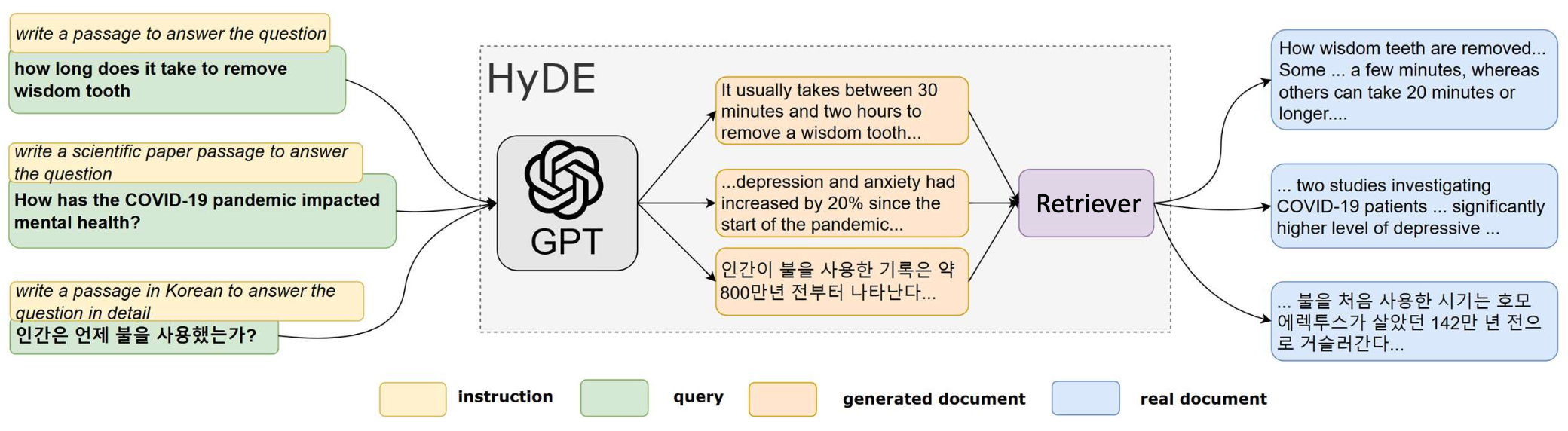
Precise Zero-Shot Dense Retrieval without Relevance Labels, ACL’23
p38. 검색 시스템을 위한 질의 재작성(Rewriting queries for search system)
- 사용자 질의는 종종 문서의 문체나 표현과 일치하지 않는다.
- 사용자는 짧고, 모호하고, 노이즈가 많은 질의를 작성한다.
- 문서는 길고, 잘 작성되어 있으며, 도메인 특화 용어를 포함한다.
- LLM은 사용자의 질의를 코퍼스와 더 잘 맞는 형태로 재작성할 수 있다.
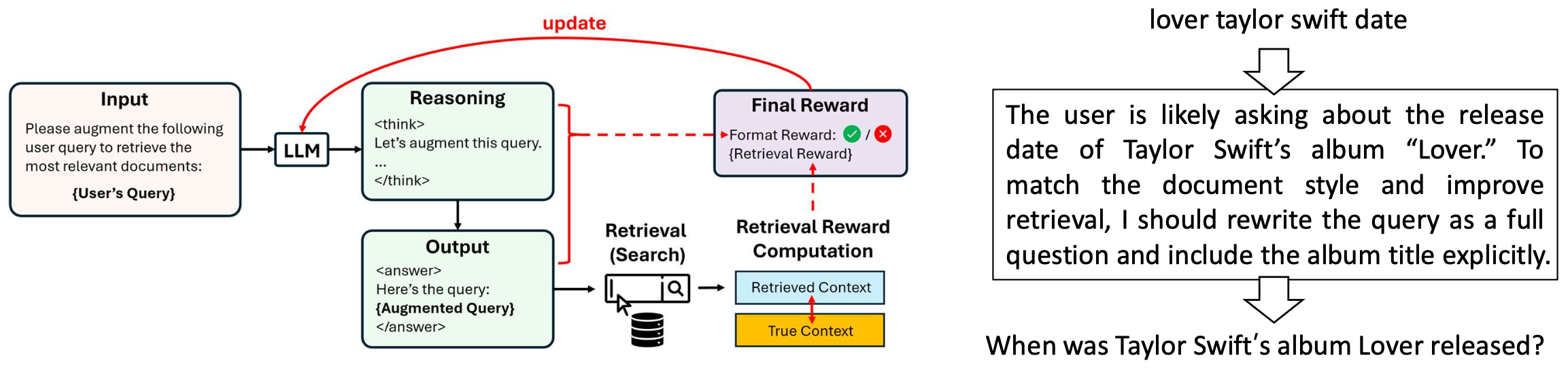
DeepRetrieval: Hacking Real Search Engines and Retrievers with Large Language Models via Reinforcement Learning, COLM’25
p39. 의미 기반 인덱서로서의 LLM(LLM as a semantic indexer)
문서를 원시 텍스트나 임베딩만으로 인덱싱하는 대신,
LLM은 각 문서에서 핵심 의미 요소(semantic components)—주제, 개념, 핵심 구절—를 식별할 수 있다.이러한 의미 요소들은 오프라인에서 추출되어
개념 기반 의미 인덱스(concept-based semantic index)로 저장된다.
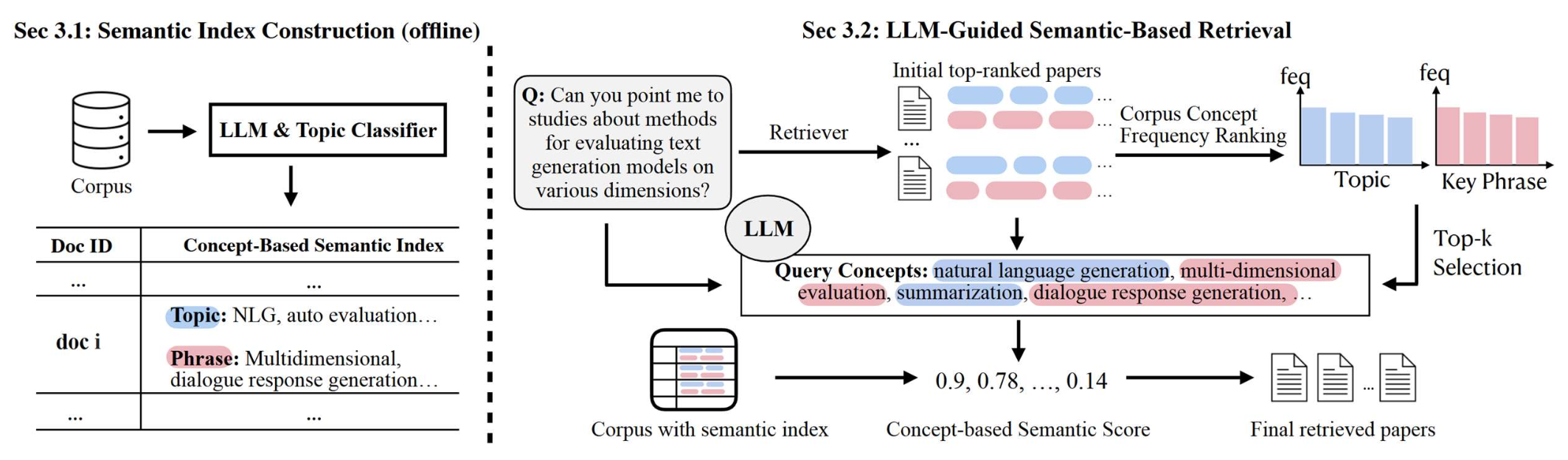
Scientific Paper Retrieval with LLM-Guided Semantic-Based Ranking, EMNLP’25
p40. 문서 확장자로서의 LLM(LLM as a document expander)
원시 문서를 그대로 사용하는 대신,
LLM은 각 문서와 관련된 사용자의 잠재적 정보 요구(potential information needs)를 추론(infer)할 수 있다.검색 과정에서는 원래 문서 텍스트 자체가 아니라,
이러한 시나리오 표현(scenario representations)과 질의를 비교한다.
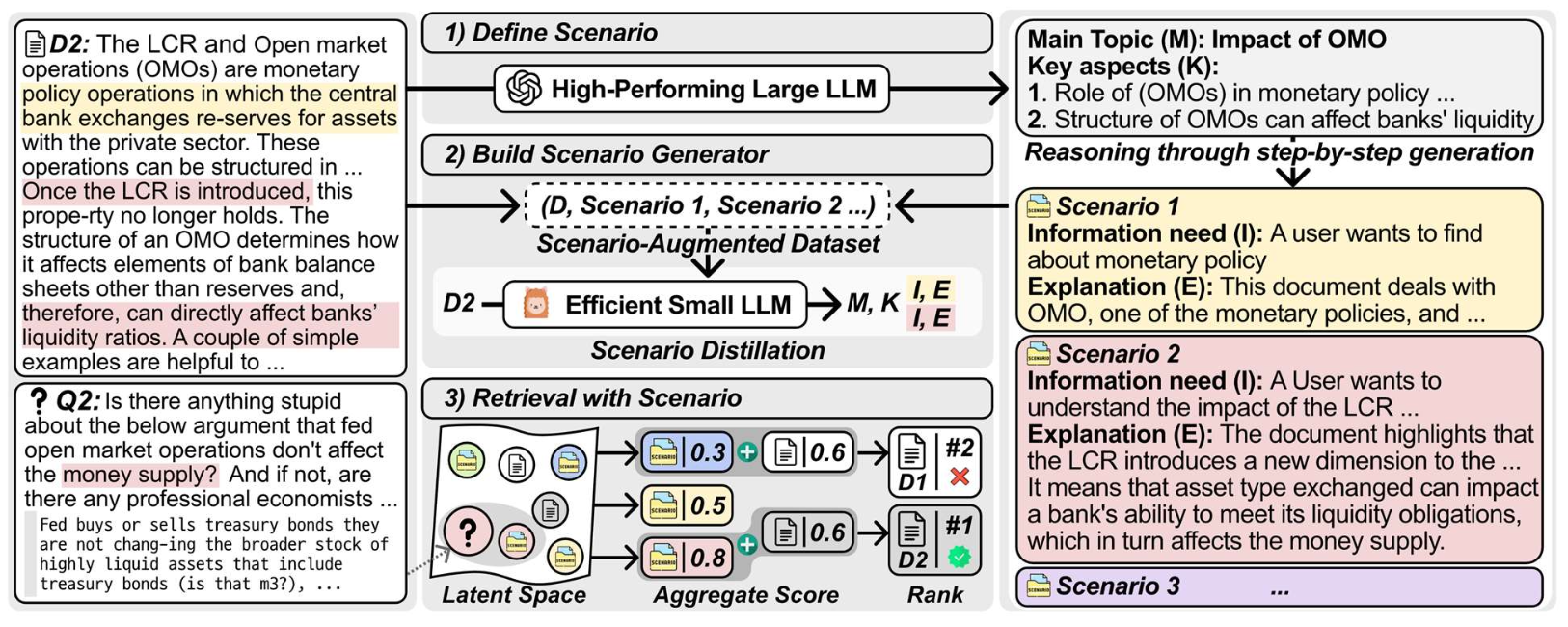
Imagine All The Relevance: Scenario-Profiled Indexing with Knowledge Expansion for Dense Retrieval, COLM’25
p41. LLM을 사용자 시뮬레이터(user simulator)로 사용
p44. 이러한 학습 데이터는 어디에서 얻을까?
- 실제 사용자 질의(검색 로그)
- 데이터 품질은 높지만, 프라이버시, 접근 제한, 새로운 도메인 등의 이유로
실제로는 종종 이용 불가능(often unavailable)하다.
- 데이터 품질은 높지만, 프라이버시, 접근 제한, 새로운 도메인 등의 이유로
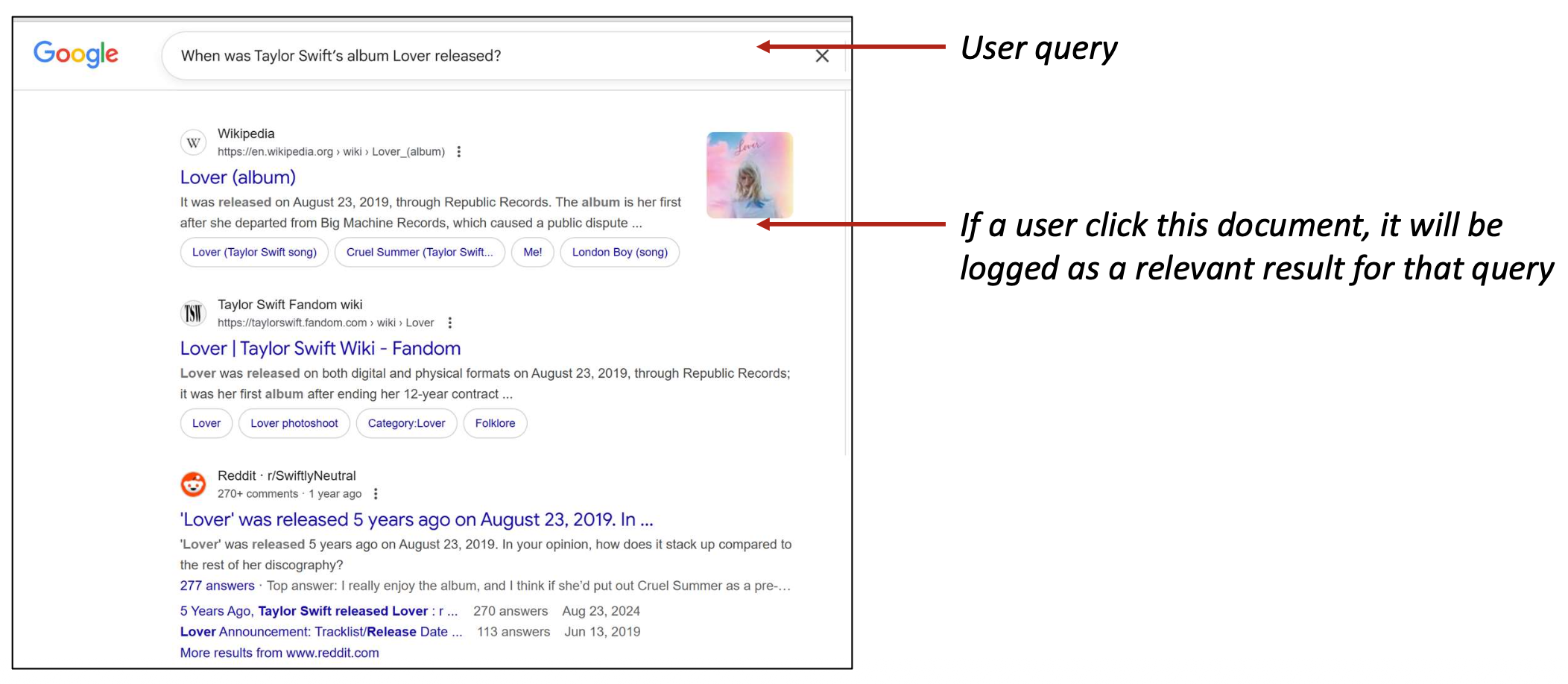
p45. 이러한 학습 데이터는 어디에서 얻을까?
- 휴리스틱 또는 규칙 기반 질의 생성(Heuristic or rule-based query generation)
- 키워드 추출, 템플릿, 기존 제목·설명 재작성 등을 활용한다.
- 품질이 제한적(Limited quality)이며, 실제 사용자 질의를 잘 모방하지 못하는 경우가 많다.

p46. 이러한 학습 데이터는 어디에서 얻을까?
- LLM 기반 질의 생성(LLM-based query generation)
- LLM이 사용자를 시뮬레이션하여 문서로부터 합성 질의를 생성한다.
- 더 고품질이고 자연스러운 질의를 만들어낼 수 있다.
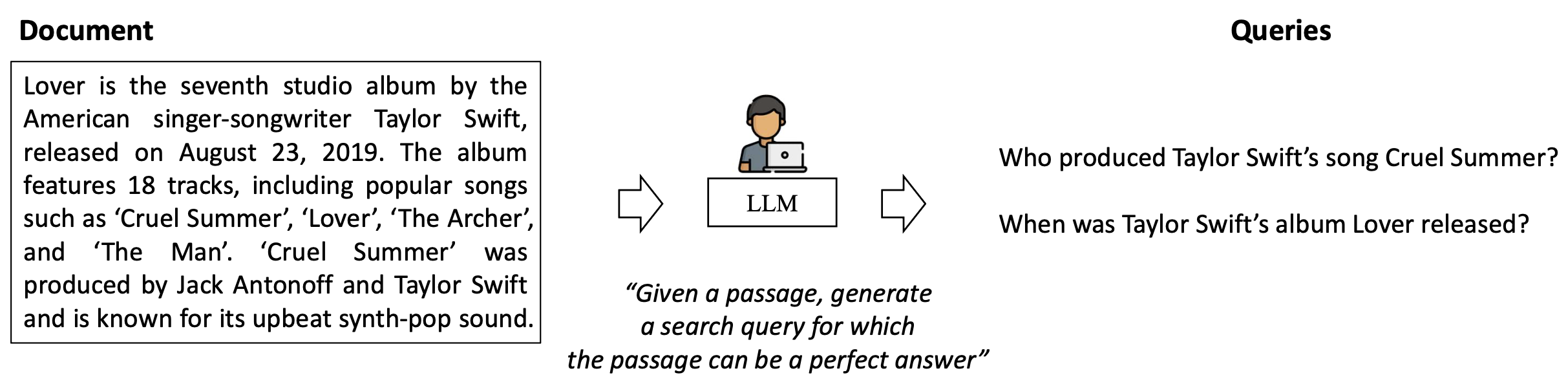
p47. 질의 시뮬레이터로서의 LLM
- Papers:
- Promptagator: Few-shot Dense Retrieval From 8 Examples, ICLR’23
- It’s All Relative! – A Synthetic Query Generation Approach for Improving Zero-Shot Relevance Prediction, NACCL’24
- Improving Scientific Document Retrieval with Concept Coverage-based Query Set Generation, WSDM’25
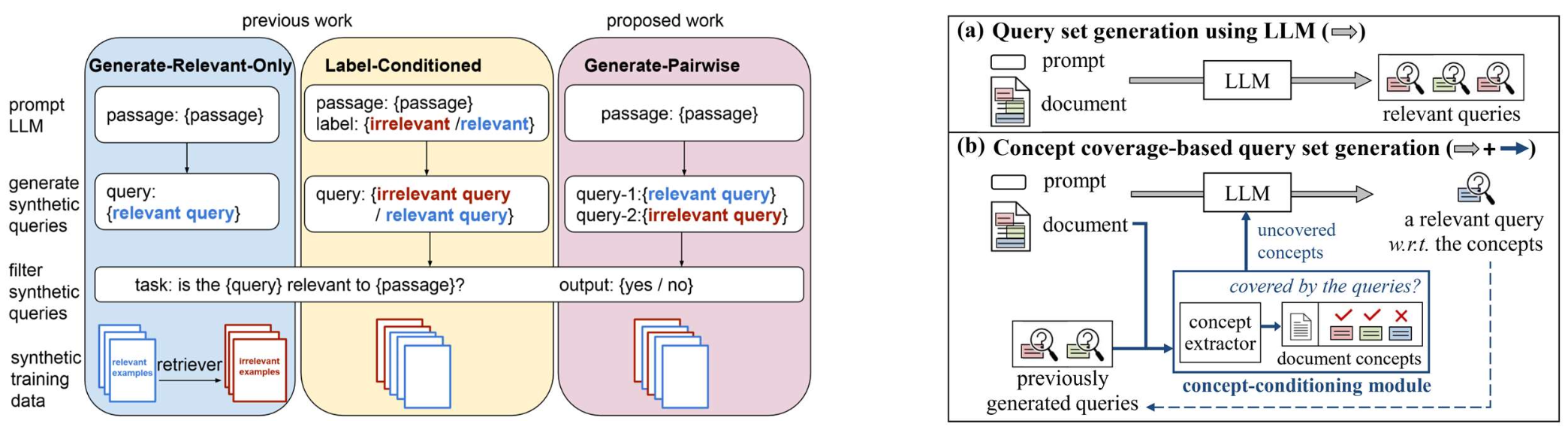
p48. 개인화된 질의 이해를 위한 LLM
- 동일한 질의라도 사용자의 맥락에 따라 다른 의미를 가질 수 있다.
- 예: “bumblebee costume”은 벌 의상을 의미할 수도 있고 Transformers 캐릭터 범블비를 의미할 수도 있다.
- 사용자가 최근에 “Transformers movie”를 검색했다면, LLM은 질의를 개인화하여
“Bumblebee Transformers cosplay costume”처럼 다시 작성할 수 있다.
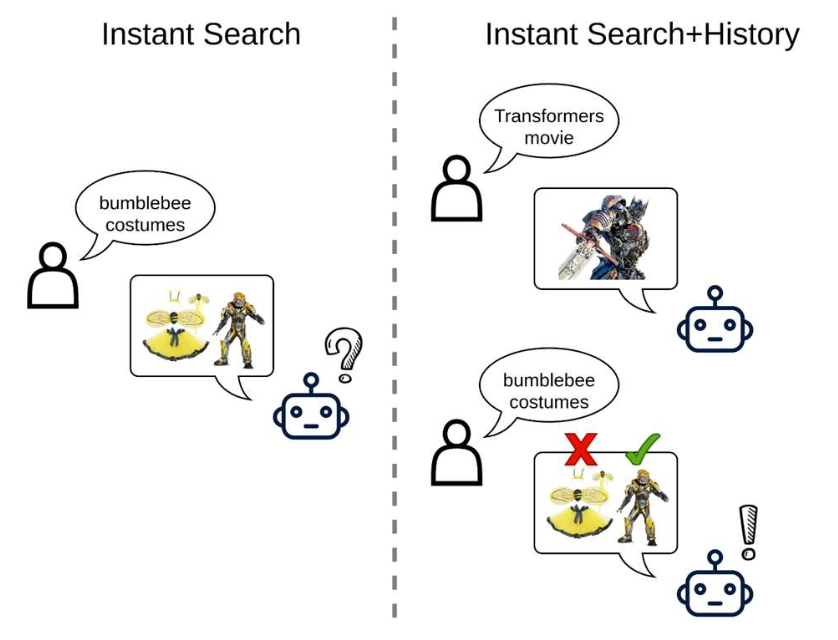
Context-Aware Query Rewriting for Improving Users’ Search Experience on E-commerce Websites, ACL’23
p49. 개인화된 질의 이해를 위한 LLM
- 사용자의 선호도(user’s preferences)를 모델링하고 활용함으로써,
LLM은 개인화된 질의(personalized queries)를 생성하고
사용자 맞춤형 검색 결과를 제공할 수 있다.
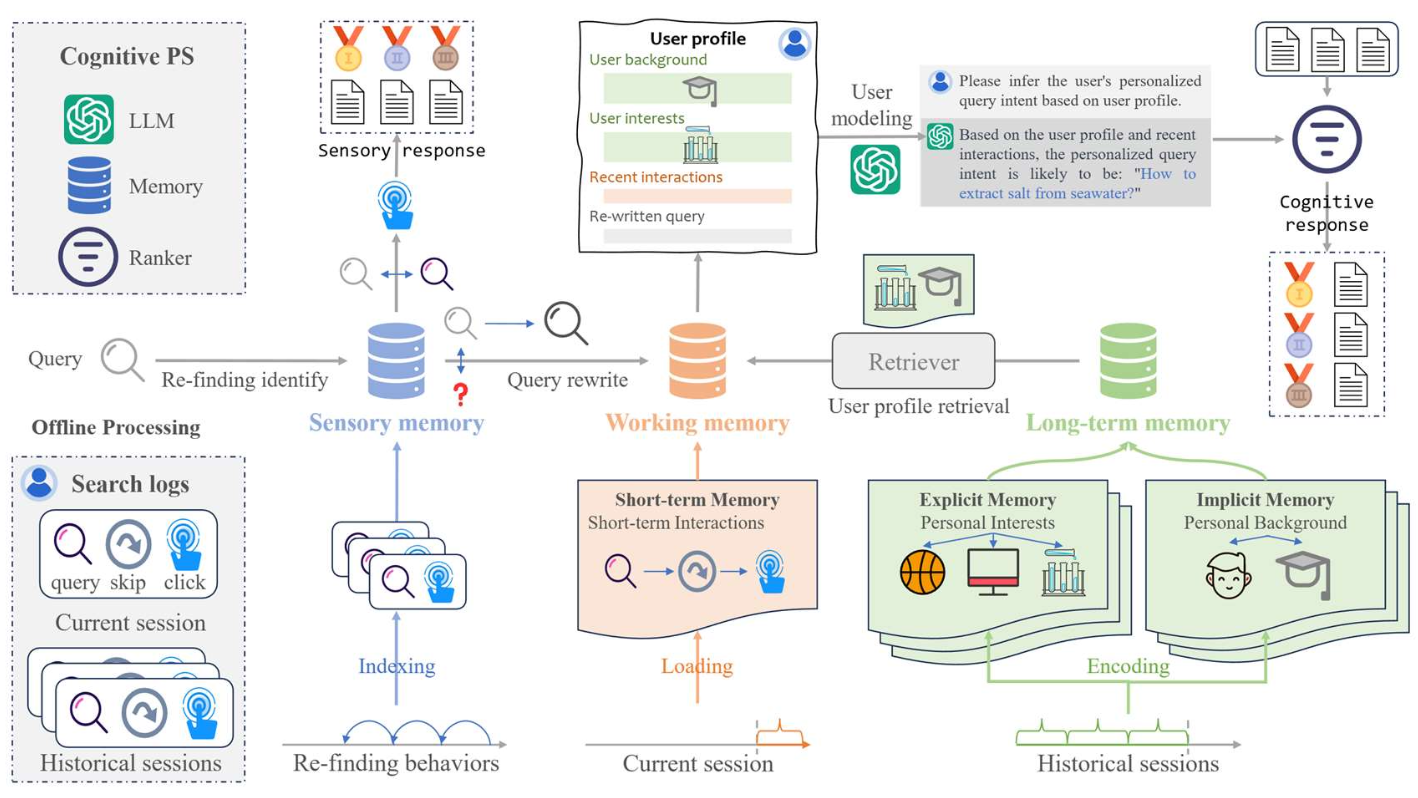
Cognitive Personalized Search Integrating Large Language Models with an Efficient Memory Mechanism, WWW’24
p50. LLM 기반 검색 강화: 요약
- 이번 강의에서는 LLM이 검색을 크게 향상시키는 세 가지 주요 방향을 다루었다.
- 랭커로서의 LLM
- LLM이 어떤 문서가 더 관련성이 높은지 직접 판단한다 (LLM 기반 재랭킹).
- Full reranking, Sliding reranking, Compact document representation
- 컨텍스트 강화자로서의 LLM
- 부족한 컨텍스트를 생성하고, 의미적 신호를 강화하여 더 나은 매칭을 돕는다.
- Query augmentation/rewriting/expansion, Document semantic indexing/expansion
- 사용자 시뮬레이터로서의 LLM
- 실제 사용자 행동을 닮은 합성 질의를 생성한다.
- Training query generation, Personalized search
- 그 외에도 수많은 활발한 연구 주제들이 있다!
p51. 검색: 요약
- 실제 검색 엔진을 구성하는 핵심 기술들을 다루었다.
- 어휘 기반 검색(Lexical retrieval)
- TF-IDF, BM25, Inverted index
- 밀집 검색(Dense retrieval)
- ANN index, Learning to rank, Bi-encoder, Cross-encoder, Late interaction
- LLM 기반 검색(LLM-enhanced retrieval)
- LLM을 랭커/컨텍스트 강화자/사용자 시뮬레이터로 활용
