[텍스트 마이닝] 7. Representing Texts with Vectors 3
p11. 문맥적 표현 (Contextual representation?)
- 정적 임베딩(Static embeddings):
- 문맥과 상관없이 단어에 동일한 벡터를 할당한다.
- 예: Word2Vec
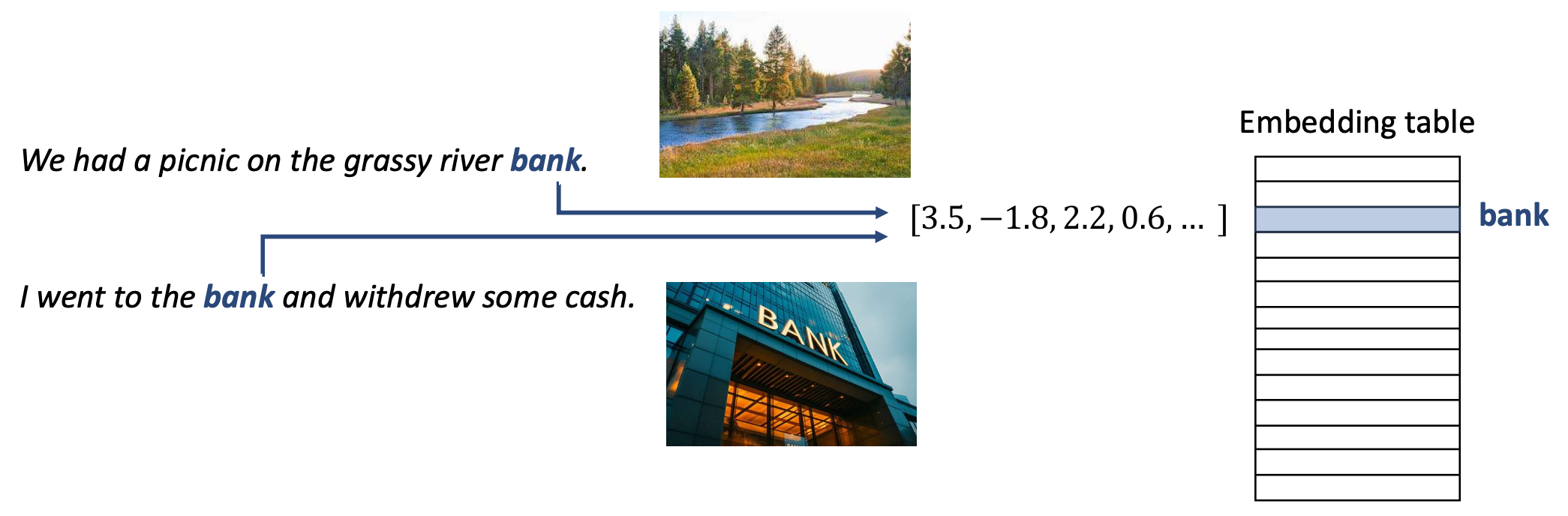
- 그러나 두 단어 모두 임베딩 테이블에서 동일한 벡터로 매핑된다.
p12. 문맥적 표현 (Contextual representation?)
- 정적 임베딩(Static embeddings):
- 문맥과 상관없이 단어에 동일한 벡터를 할당한다.
- 예: Word2Vec
- 문맥적 임베딩(Contextual embeddings):
- 단어의 벡터는 문맥(context)에 따라 동적으로 조정(dynamically adjusted) 된다.
- 예: BERT, 대규모 언어모델(LLM) 기반 임베딩
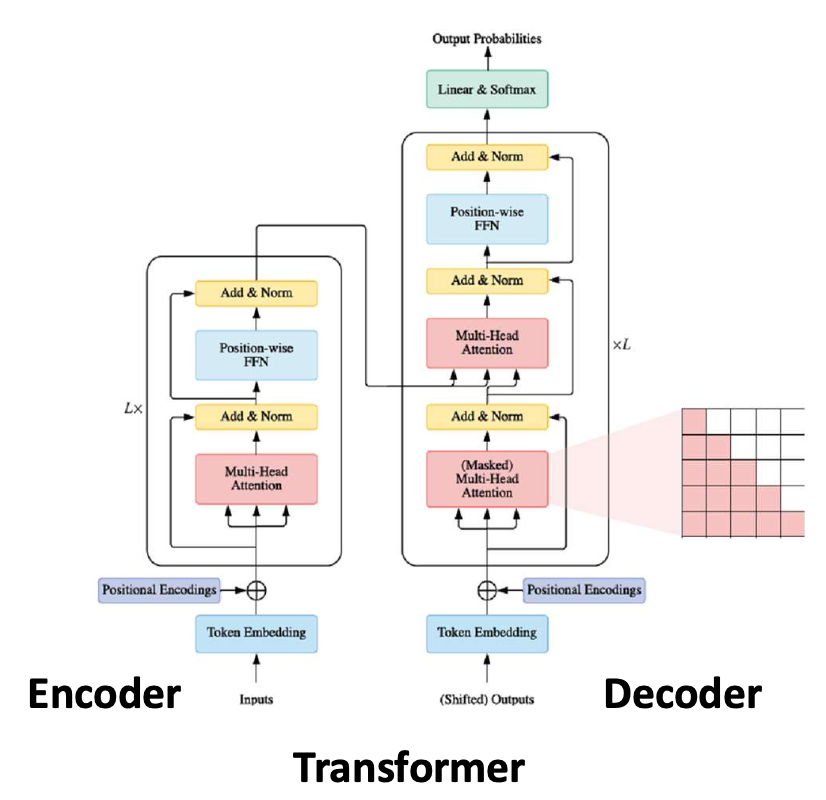
p13. 셀프-어텐션 (Self-attention)
Transformer에서 인코더(encoder)와 디코더(decoder)는
서로 다른 종류의 셀프-어텐션(self-attention) 을 사용한다.
이 강의에서는 인코더 부분(the encoder part) 에 초점을 맞춘다.
논문: Attention Is All You Need
저자:
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones,
Aidan N. Gomez, Łukasz Kaiser, Illia Polosukhin
p14. 문맥적 표현을 위한 트랜스포머
- 문맥적 임베딩(contextual embeddings)을 생성하기 위한 여러 시도가 있었다.
- 이 강의에서는 현대 NLP에서 가장 영향력 있는 구조인
트랜스포머(Transformer) 의 인코더(encoder) 부분에 초점을 맞춘다.
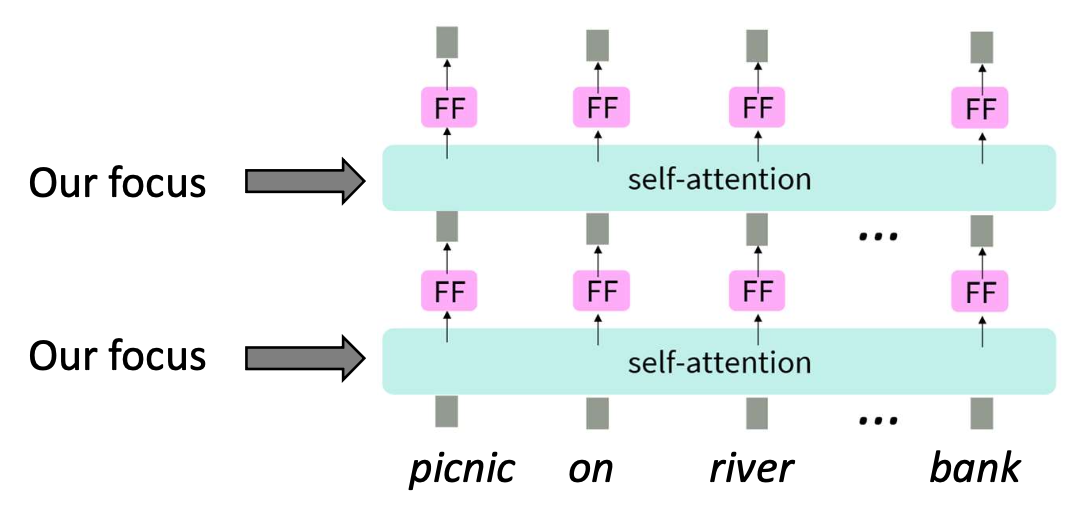
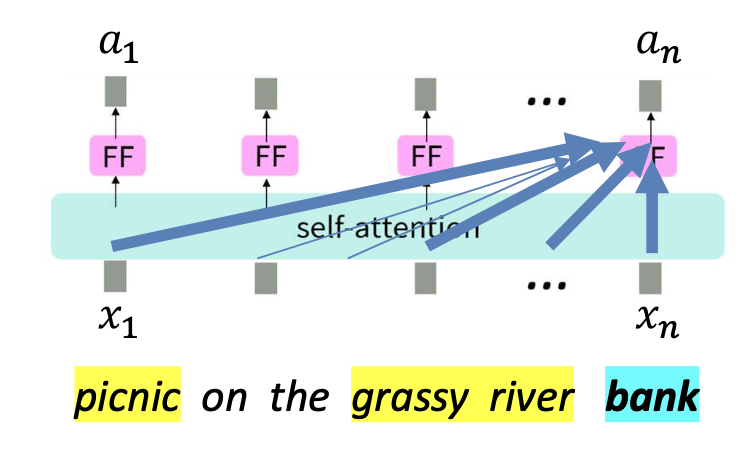
- 각 단어(예: picnic, on, river, bank)에 대해
셀프-어텐션(self-attention)과 피드포워드(FF, feed-forward) 층을 반복적으로 적용한다.
읽을거리:
https://web.stanford.edu/~jurafsky/slp3/8.pdf
참고:
- 우리의 목표는 트랜스포머의 모든 세부 사항을 다루는 것이 아니다.
- 이해해야 할 핵심은 다음과 같다:
- 트랜스포머가 문맥적 표현(contextual representations)을 어떻게 생성하는가
- 그것을 자신의 문제에 어떻게 활용할 수 있는가
p15. 셀프-어텐션: 전체 그림 (The big picture)
핵심 질문: 각 단어를 표현할 때 어떻게 문맥(context)을 반영할 수 있을까?
직관(Intuition):
주변 문맥에 있는 몇몇 단어들(some words in the surrounding context) 은
목표 단어(target word) 의 의미를 해석하는 데 도움을 준다.우리는 그러한 문맥 단어들(context words) 에 ‘주의(attention)’ 를 기울여야 한다.
그래야 목표 단어(target word) 를 이해할 수 있다.- 왜 ‘셀프(self)-어텐션’인가?
각 단어가 동일한 시퀀스(same sequence) 내의 다른 단어들에 주의를 기울이기 때문이다.
- 왜 ‘셀프(self)-어텐션’인가?
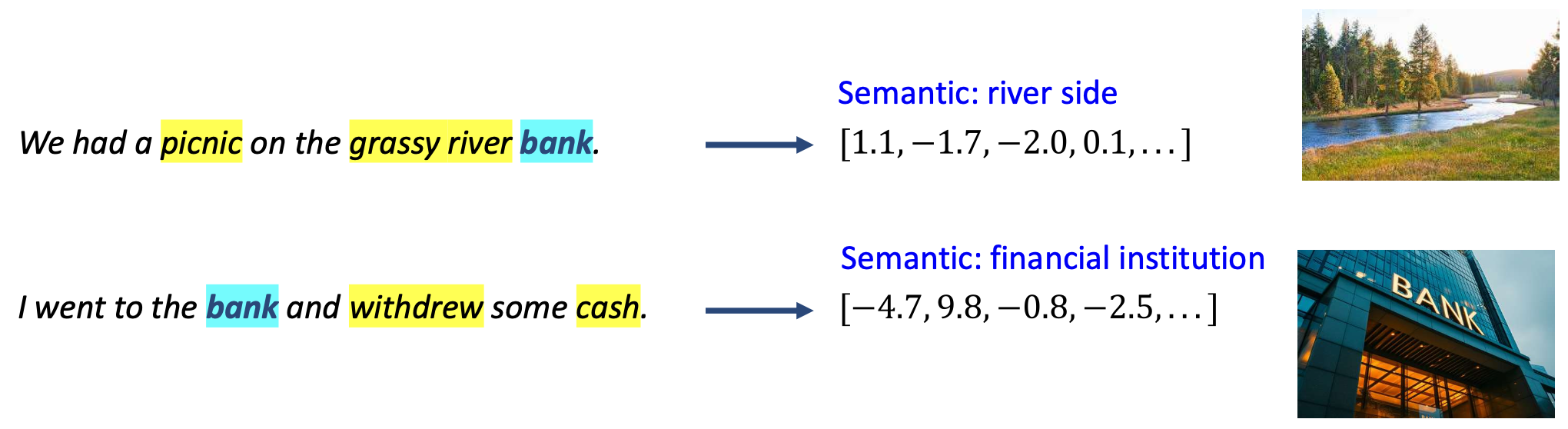
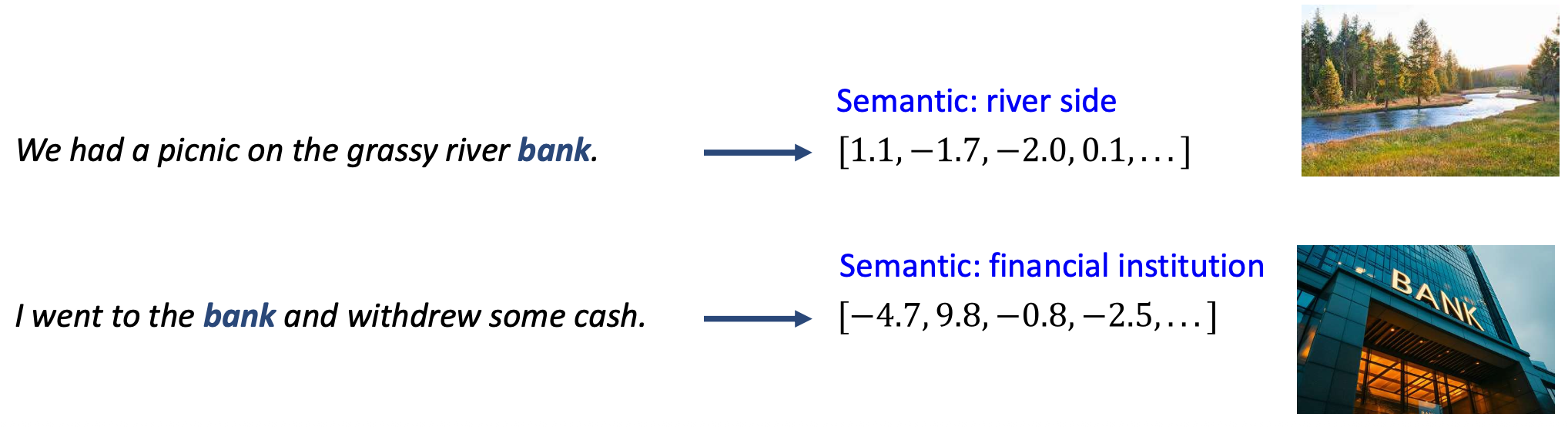
We had a picnic on the grassy river bank.
→ 의미(Semantic): 강가(river side)
→ [1.1, −1.7, −2.0, 0.1, …]
I went to the bank and withdrew some cash.
→ 의미(Semantic): 금융기관(financial institution)
→ [−4.7, 9.8, −0.8, −2.5, …]
p16. 셀프-어텐션: 전체 그림 (The big picture)
핵심 질문: 각 단어를 표현할 때, 어떻게 문맥(context)을 반영할 수 있을까?
직관 (Intuition):
주변 문맥에 있는 몇몇 단어들(some words in the surrounding context) 이
목표 단어(target word) 의 의미를 해석하는 데 도움을 준다.구체화 (Instantiation):
목표 단어의 임베딩을 문맥 임베딩(context embeddings) 의
가중합(weighted sum) 으로부터 유도한다.
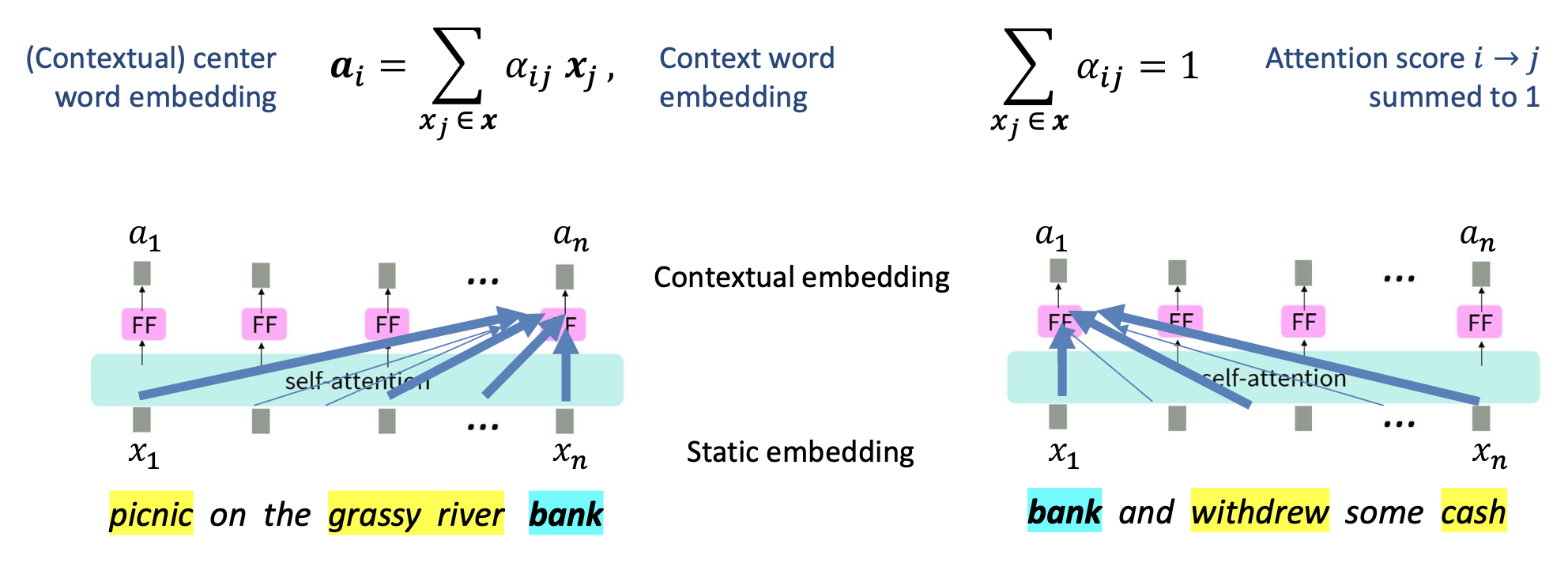
- $\alpha_{ij}$ : 단어 $i$가 단어 $j$에 주는 어텐션 점수(attention score) — 합이 1이 되도록 정규화됨
p17. 셀프-어텐션: 어텐션 점수 계산
- 어텐션 점수는 벡터 내적 에 대한 소프트맥스 함수 로 주어진다.
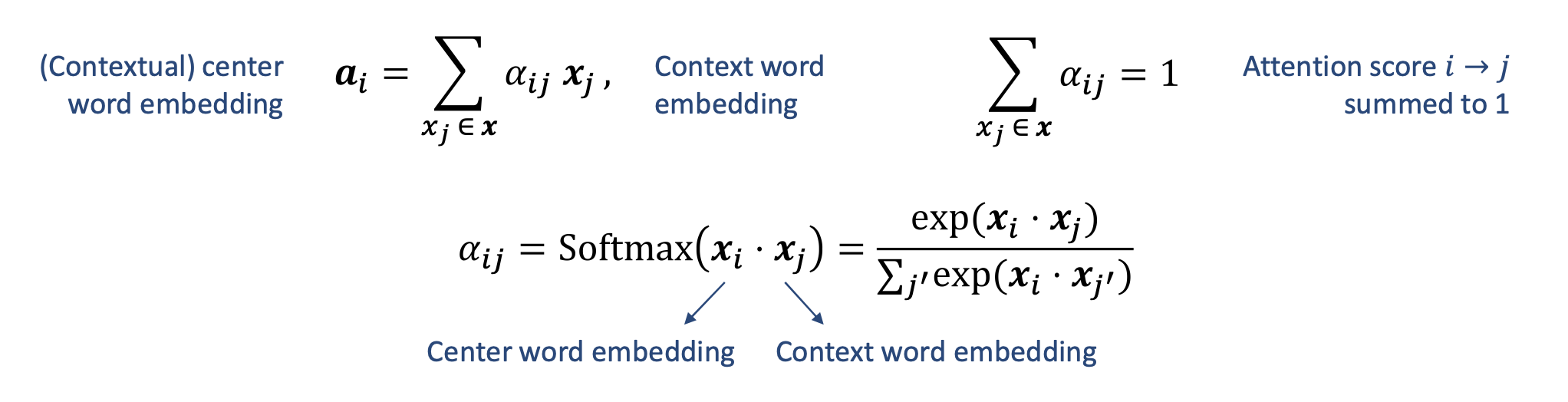
직관적으로(intuitively),
문맥적 임베딩(contextual embeddings)은
입력 문장에서 ‘유사한(similar)’ 단어들에 대한 더 많은 정보를 포함한다.이 가중합(weighted sum) 은 문장 내 모든 단어들에 적용된다.
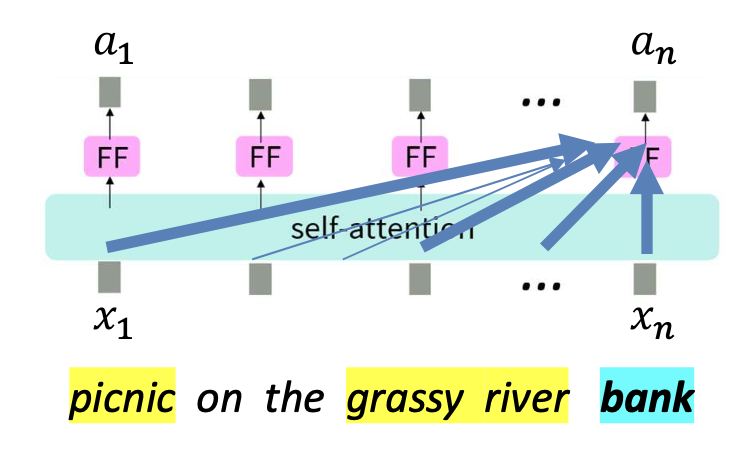
p18. 셀프-어텐션: 어텐션 점수 계산
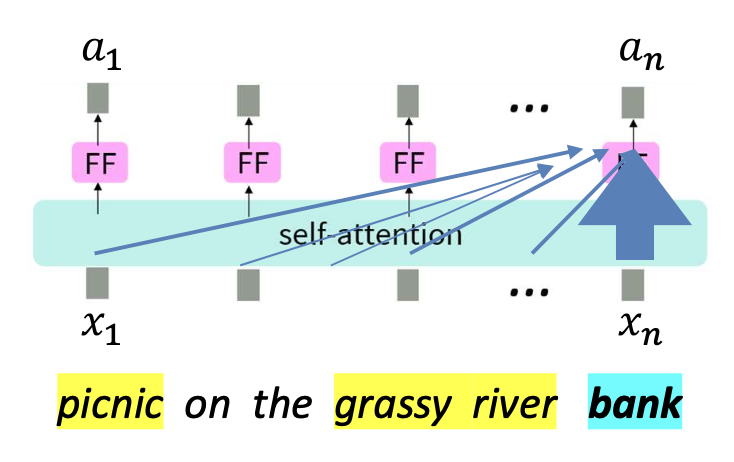
그러나 실제(practice)에서는 한 가지 세부 사항이 더 필요하다.
동일한 임베딩 $x$를 어텐션 계산에 그대로 사용하면,
단어는 자기 자신(self)에게 거의 항상 매우 강하게 주의를 기울이게(attend heavily) 된다.
이는 자기 자신과의 내적(dot product)이 매우 크기 때문이다.
p20. 셀프-어텐션: 쿼리, 키, 밸류 (Query, Key, and Value)
- 셀프-어텐션에서 각 단어는 세 가지 서로 다른 벡터 로 표현된다.
- Word2Vec에서 서로 다른 두 임베딩을 사용하는 것과 같은 철학.
- 다양한 관계 유형을 유연하게 포착할 수 있도록 한다.
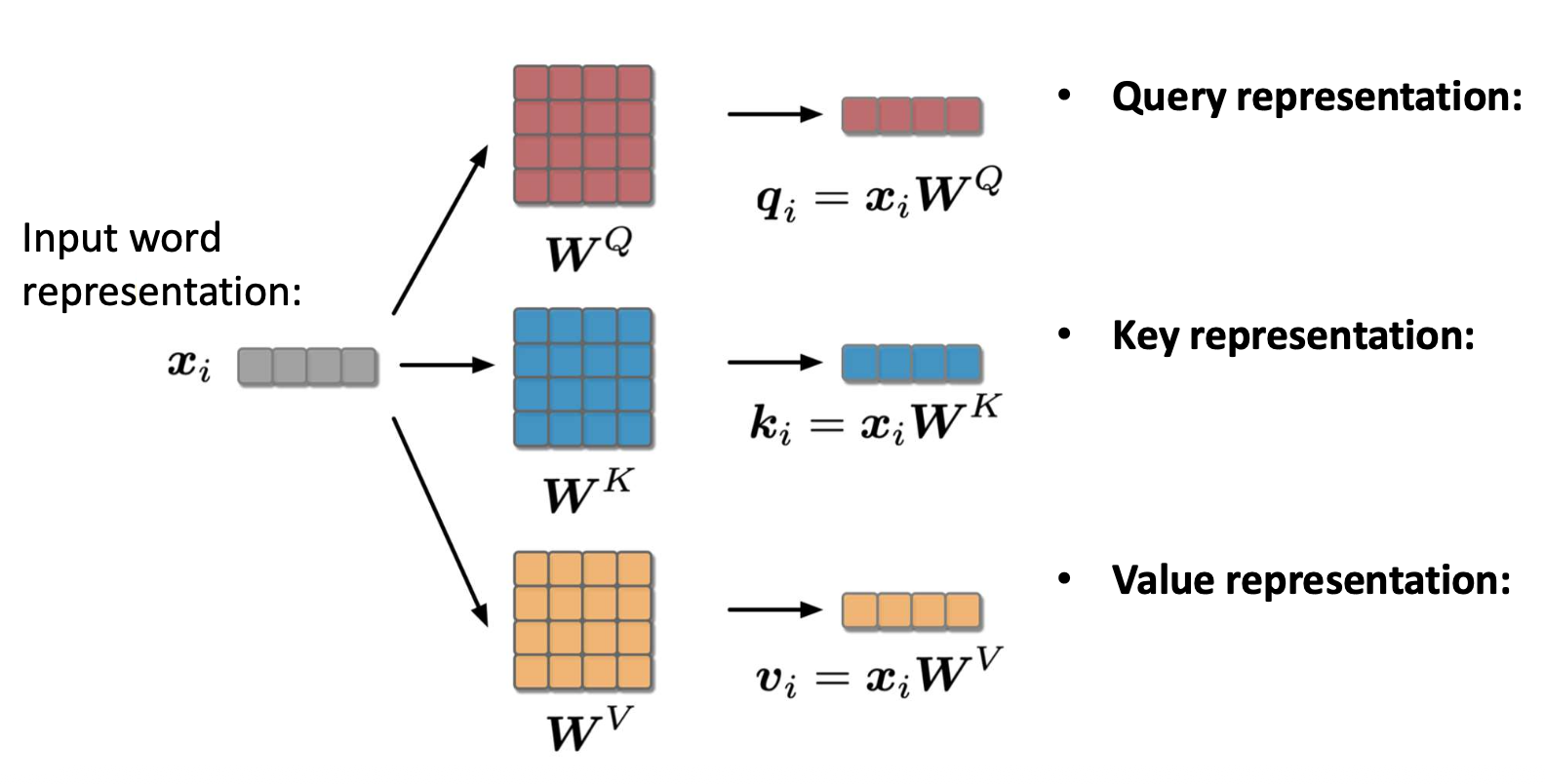
쿼리 표현(Query representation):
정보를 찾고자 하는 목표 단어(the target word) 를 나타낸다.키 표현(Key representation):
쿼리가 비교되는 문맥(the context) 을 나타낸다.밸류 표현(Value representation):
각 단어의 실제 정보(the actual information) 를 나타내며,
이는 어텐션 가중치(attention weights)에 따라 결합된다.
p21. 셀프-어텐션: 전체 계산 과정
- 입력: 각 단어 $x_i$ 의 단일 단어 벡터
1. 각 단어에 대해 Q, K, V 표현을 계산한다.
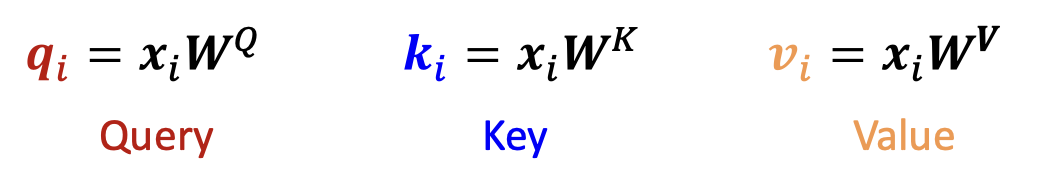
2. Q와 K를 사용하여 어텐션 점수를 계산한다.
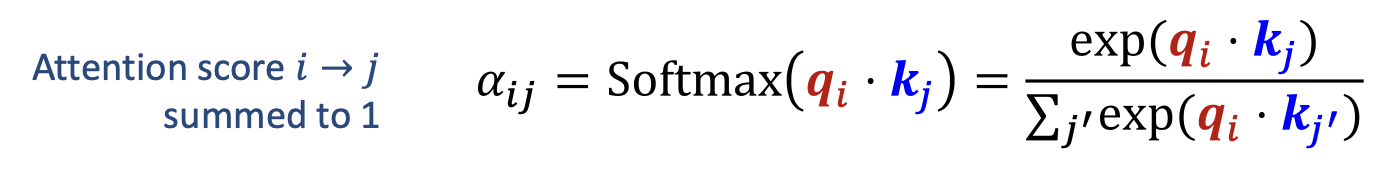
- 모든 점수의 합은 1로 정규화된다 (summed to 1).
3. 어텐션 점수로 가중된 밸류(Value) 벡터들의 합을 계산한다.
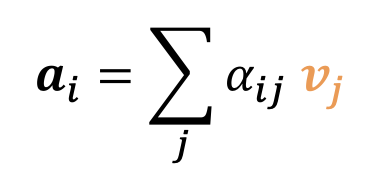
- 문맥(context)을 반영한 단어 표현(contextual embedding)을 생성한다.
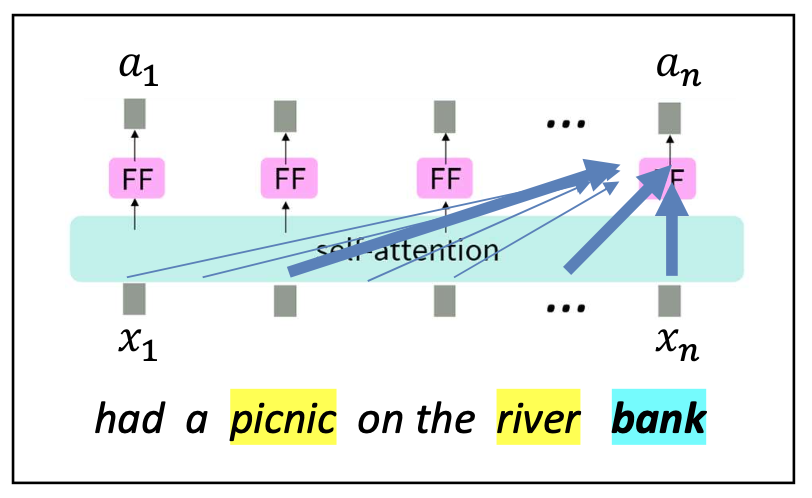
p24. 셀프-어텐션: 전체 계산 과정
예시:
세 개의 단어로 이루어진 입력 시퀀스
$[x_1, x_2, x_3]$이 그림은 $x_3$ 의 경우를 보여준다.
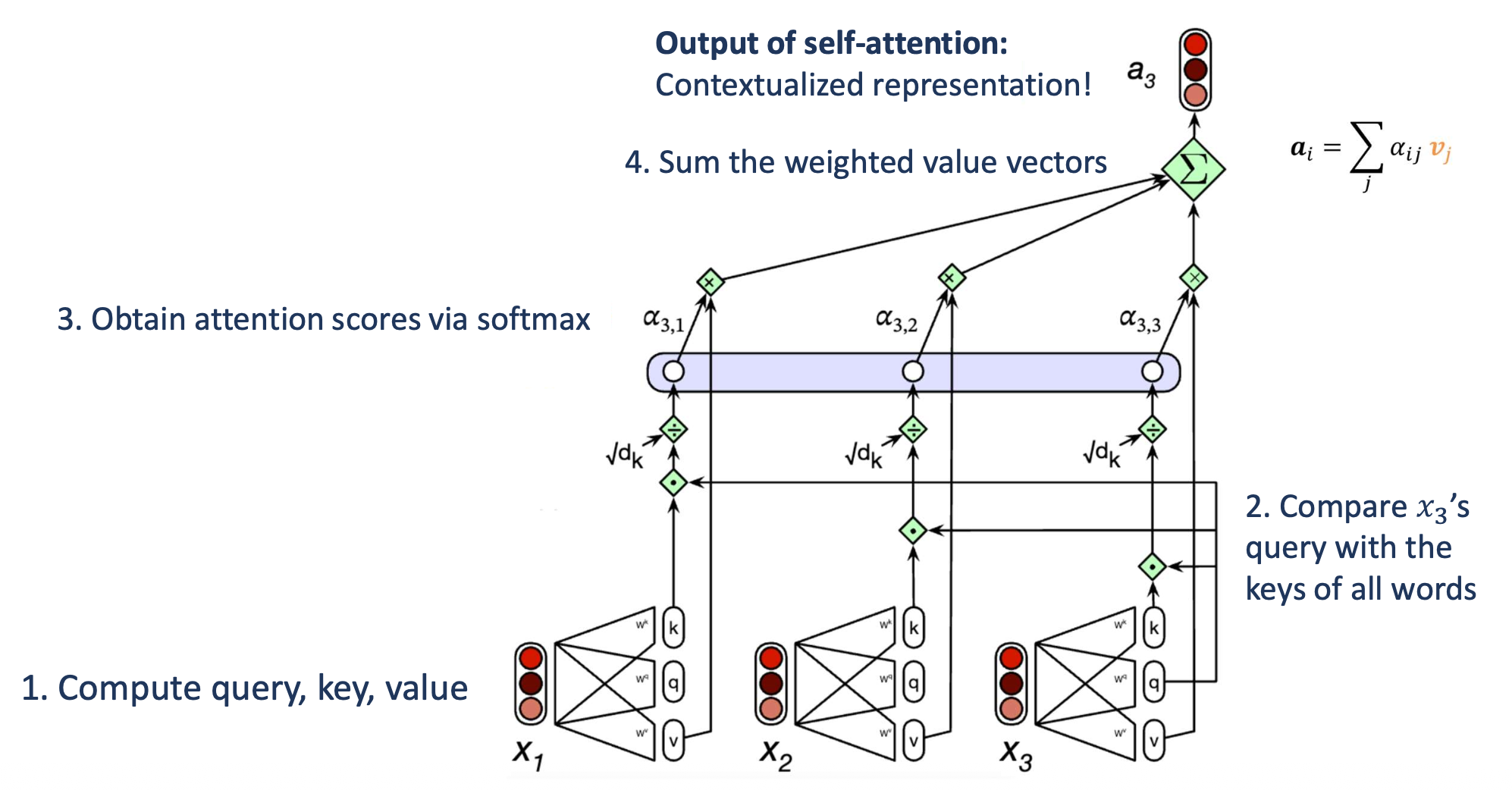
1. 쿼리(Query), 키(Key), 밸류(Value) 계산하기
각 입력 단어 $x_i$ 에 대해 $q_i$, $k_i$, $v_i$ 를 계산한다.
2. $x_3$의 쿼리(Query)를 모든 단어의 키(Key)와 비교하기
$q_3$ 와 각 $k_j$ 간의 내적(dot product)을 통해 유사도를 구한다.
3. 소프트맥스(softmax)를 통해 어텐션 점수를 계산
\(\alpha_{3,j} = \text{Softmax}\left(\frac{q_3 \cdot k_j}{\sqrt{d_k}}\right)\)
4. 가중된 밸류 벡터(weighted value vectors)를 합산
\(a_3 = \sum_j \alpha_{3,j} v_j\)
→ 출력:
문맥이 반영된 표현(contextualized representation) $a_3$
읽을거리:
https://web.stanford.edu/~jurafsky/slp3/8.pdf
p25. 셀프-어텐션 층의 적층 (Stacking self-attention layers)
하나의 셀프-어텐션 층은 문맥(context)을 포착하지만,
주로 얕은 수준(shallow level) 에서만 가능하다.- 유사도(similarity)는 정적 임베딩(static embeddings) 의
내적(inner product) 을 사용해 결정된다. - 즉, 정적 임베딩이 포착하지 못한 정보는 완전히 반영되지 않는다.
- 유사도(similarity)는 정적 임베딩(static embeddings) 의
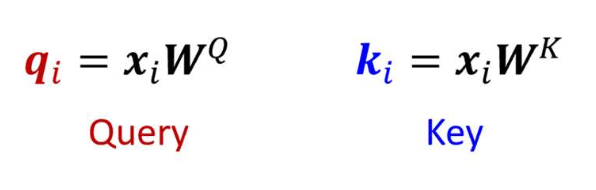
- 예를 들어,
“picnic”과 “bank”는 정적 임베딩에서 그다지 유사하지 않다.
따라서, 하나의 셀프-어텐션 층만으로는
이 두 단어를 크게 가깝게 만들 수 없다.
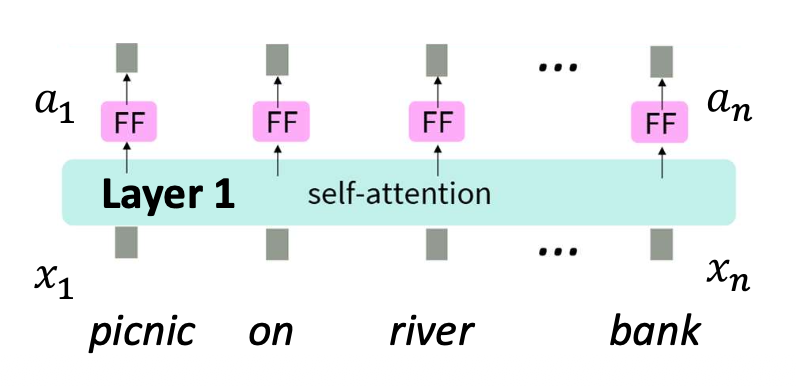
p26. 셀프-어텐션 층의 적층 (Stacking self-attention layers)
- 예를 들어,
- “picnic”과 “bank”는 정적 임베딩에서 그렇게 유사하지 않다.
- 그러면, 하나의 셀프-어텐션 층은 이 둘을 훨씬 더 가깝게 만들지 못할 것이다.
- 그러나, “picnic”이 “river”와 가깝고 “river”가 “bank”와 가깝다면,
여러 층(multiple layers) 을 적층(stacking)하면
이러한 문맥적 관계(contextual relations) 가 전파(propagate) 되도록 할 수 있다.
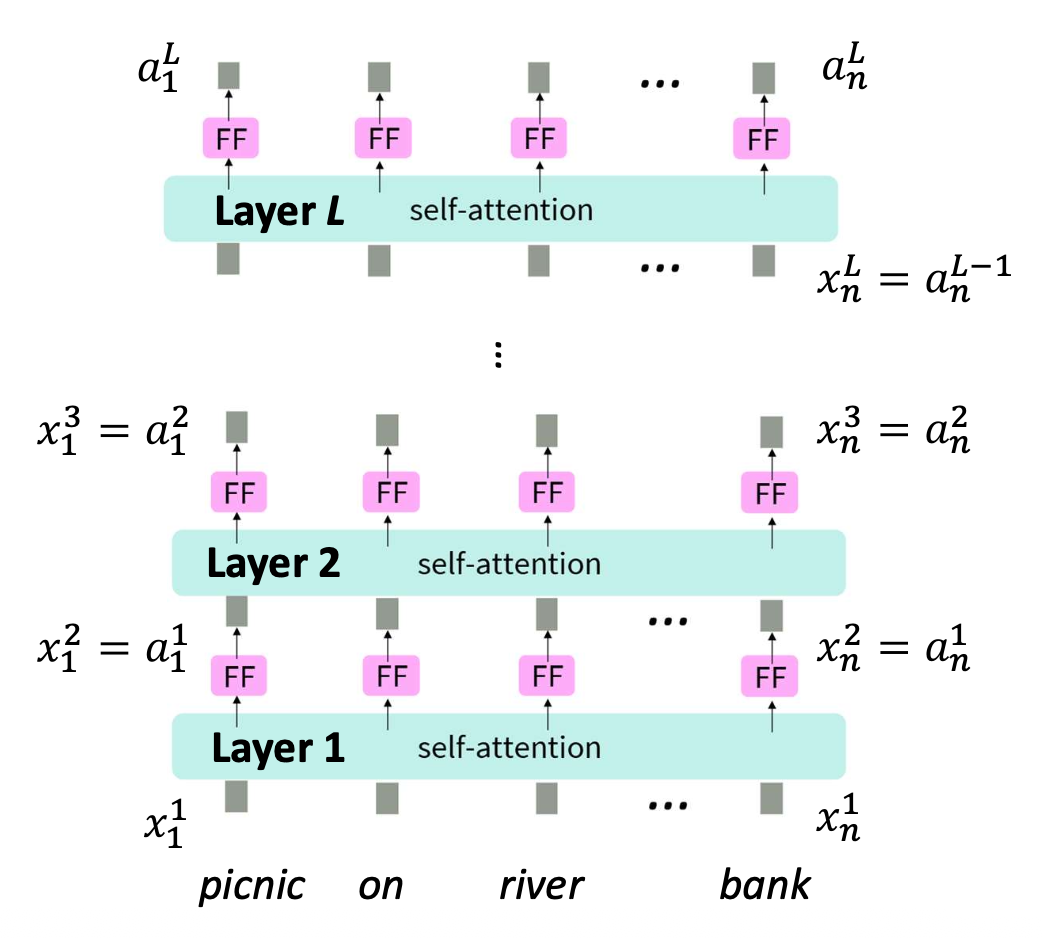
p27. 셀프-어텐션 층의 적층 (Stacking self-attention layers)
해결책(Solution): 여러 층(multiple layers)을 적층(stacking)하는 것
- 셀프-어텐션의 핵심은 시퀀스(sequence) 내에서
더 관련성 높은 부분(relevant parts)을 반영(reflect)하는 것이다. - 의미적으로 유사한 단어들의 임베딩은 점점 더 가까워지고,
관련 없는 단어들은 점점 멀어진다. - 문맥 정보(context information) 는 점진적으로 증폭(progressively amplified) 된다.
- 셀프-어텐션의 핵심은 시퀀스(sequence) 내에서
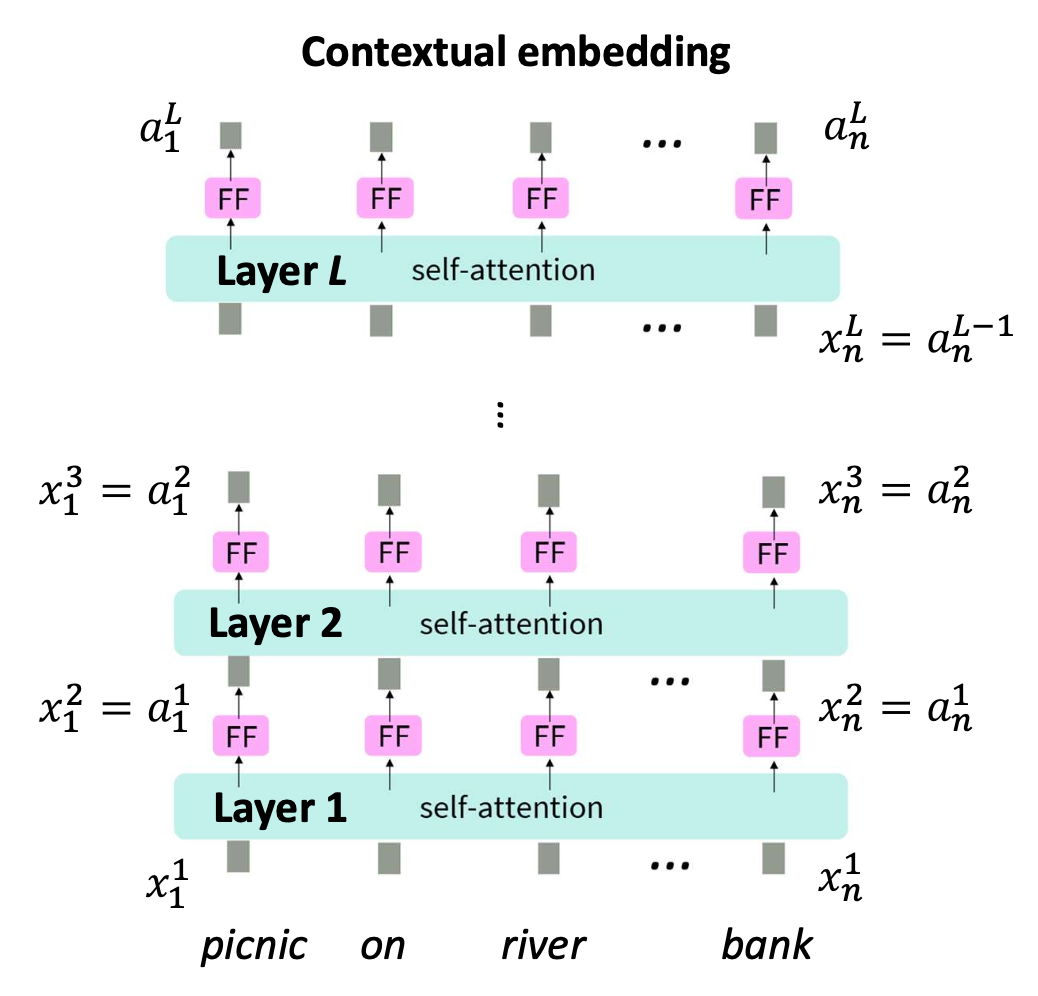
–
p28. 트랜스포머의 추가 구성 요소 (단, 우리의 관심사는 아님)
- 더 많은 변환 추가
- 피드포워드 네트워크(feed forward network, FF):
- 더 많은 층(변환 + 활성화)
- 다중 헤드 어텐션(Multi-head attention)
- 피드포워드 네트워크(feed forward network, FF):
- 최적화를 더 쉽게 만드는 방법
- 잔차 연결(residual connection)
- 층 정규화(layer normalization)
- 위치 정보 추가
- 위치 인코딩(positional encoding)
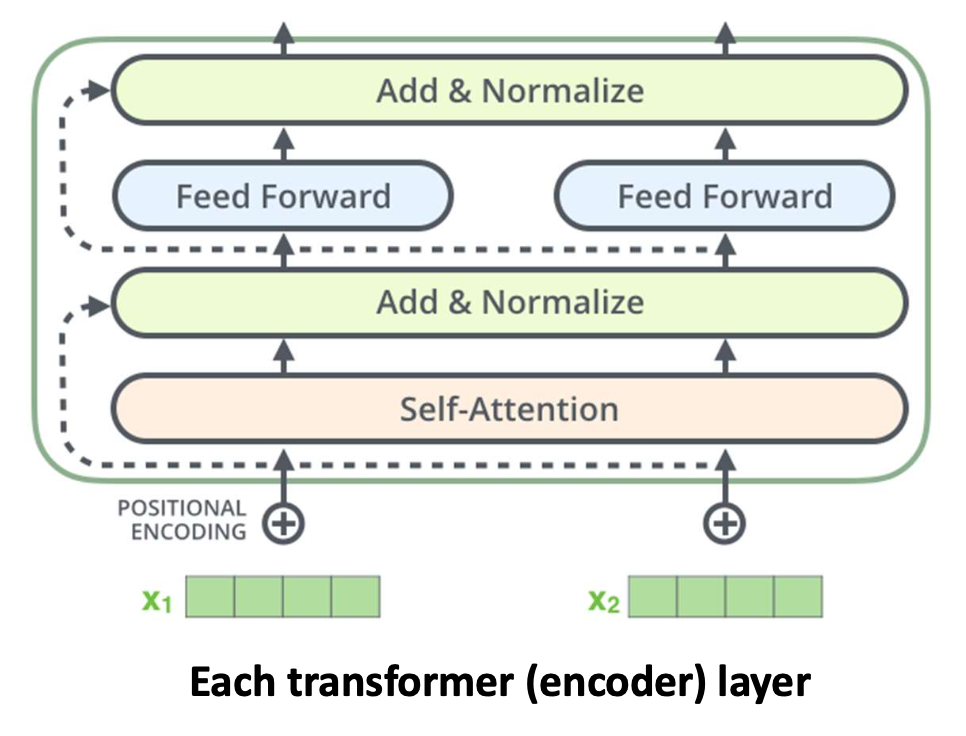
각 트랜스포머 인코더 층
셀프-어텐션(self-attention)과 피드포워드(feed forward)를 결합하며,
정규화(normalization)와 잔차 연결을 포함한다.
그림 출처:
https://jalammar.github.io/illustrated-transformer/
p29. 요약
우리의 질문:
각 단어를 표현할 때, 어떻게 문맥(context)을 반영할 수 있을까?핵심 아이디어 (Key idea):
특정 단어를 처리할 때, 시퀀스 내의 다양한 단어들의 중요도를
가중치로 조절(weigh the importance) 하여 반영한다.- 구현 방식 (Instantiation) — 셀프-어텐션
- 목표 단어 임베딩(target word embedding)을
문맥 임베딩(context embeddings) 의 가중합(weighted sum) 으로부터 도출한다. - 각 단어는 세 가지 벡터 로 표현된다.
- 쿼리(Query): 정보를 찾는 현재 단어(current word seeking information)
- 키(Key): 정보가 검색되는 문맥 단어(context word to be retrieved from)
- 밸류(Value): 새로운 단어 표현에 집약되는 의미 정보(semantic content aggregated as new representation)
- 목표 단어 임베딩(target word embedding)을
- 여러 셀프-어텐션 층 적층(Stacking)
→ 문맥 정보(context information)가 더욱 잘 반영된다.
읽을거리 (Reading materials):
https://web.stanford.edu/~jurafsky/slp3/8.pdf
p30. 다음 질문: 파라미터를 어떻게 최적화할까?
여러 개의 셀프-어텐션 층을 적층하면,
각 단어에 대해 풍부한 문맥 정보(rich context information) 를 반영할 수 있다.- 하지만 잠깐,
정말로 모든 것이 기대한 대로 작동한다고 확신할 수 있을까?분명히, 계산에는 많은 파라미터가 포함되어 있다.
\[\theta = \{ X, \{ W^Q, W^K, W^V \}_L, \ldots \}\]
- 이 파라미터들을 어떻게 최적화해야,
문맥적 표현(contextual representations) 을 생성할 수 있을까?
p31. 밀집 문맥 표현 (Dense contextual representation): BERT
논문 제목:
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
저자:
Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova
Google AI Language
{jacobdevlin, mingweichang, kentonl, kristout}@google.com
p32. BERT: 전체 구조 (The big picture)
- BERT (Bidirectional Encoder Representations from Transformers) 는
언어 이해(language understanding) 를 위해 최적화된 가중치(weights)를 갖는
사전학습된(pretrained) 트랜스포머 모델이다.- 단 몇 줄의 코드로 손쉽게 사용할 수 있다!
- 두 가지 모델 버전이 공개되었다:
- BERT-base: 12층(layers), 1억 1천만 개의 파라미터
- BERT-large: 24층(layers), 3억 4천만 개의 파라미터
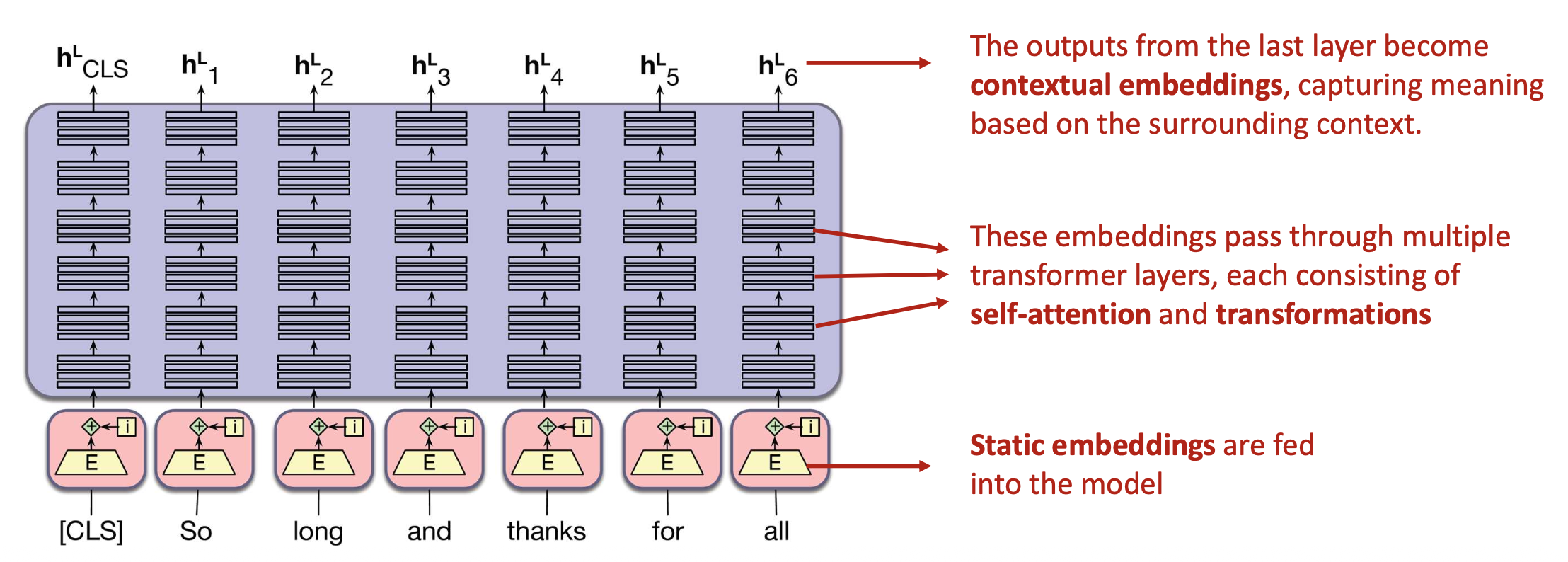
- 입력부:
- 정적 임베딩(static embeddings)이 모델에 입력된다.
- 중간 과정:
- 입력 임베딩들은 여러 트랜스포머 층(transformer layers) 을 통과하며,
각 층은 셀프-어텐션(self-attention) 과 변환(transformation) 으로 구성되어 있다.
- 입력 임베딩들은 여러 트랜스포머 층(transformer layers) 을 통과하며,
- 출력부:
- 마지막 층의 출력은 문맥 임베딩(contextual embeddings) 이 되어,
주변 문맥(context)에 기반한 의미를 포착한다.
- 마지막 층의 출력은 문맥 임베딩(contextual embeddings) 이 되어,
p33. BERT: 입력 (The input)
- “Thanks for all the”와 같은 문장이 주어졌을 때,
먼저 각 토큰을 어휘 인덱스(vocabulary indices) 로 변환한다.- 예를 들어, 결과는 다음과 같을 수 있다:
[5, 3000, 10532, 2224] - 이 과정을 토크나이즈(tokenization) 라고 하며,
사용된 토크나이저(tokenizer) 에 따라 결과가 달라진다.
- 예를 들어, 결과는 다음과 같을 수 있다:
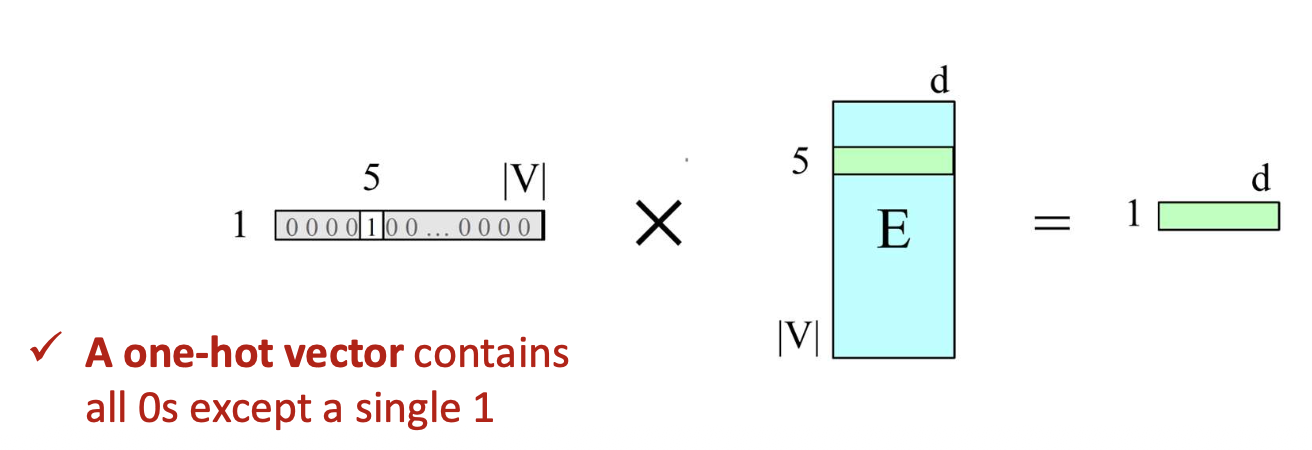
- 토크나이즈 이후, 각 토큰 인덱스는 임베딩 테이블(embedding table) 에서
벡터(vector) 로 매핑된다.- 이는 원-핫 벡터(one-hot vector) 와 임베딩 행렬(embedding matrix) 을 곱하는 것과 같다.
→ 해당 토큰에 대응되는 임베딩이 선택된다. - Word2Vec에서 학습된 임베딩을 사용할 수도 있지만,
BERT는 처음부터(scratch) 임베딩을 직접 학습하도록 설계되었다.
- 이는 원-핫 벡터(one-hot vector) 와 임베딩 행렬(embedding matrix) 을 곱하는 것과 같다.
원-핫 벡터(one-hot vector) 는
한 요소만 1이고 나머지는 모두 0으로 구성된다.- 예시:
토큰 #5에 해당하는 임베딩을 선택하는 경우를 생각해보자.
이는 임베딩 테이블(embedding table)을,
인덱스 5 위치에 1을 갖는 원-핫 벡터(one-hot vector) 와 곱하는 것으로 볼 수 있다.
p34. BERT: 입력 (The input)
- 이러한 과정을 통해,
문장 전체(the entire sentence) 는 임베딩 벡터들(즉 정적 임베딩) 로 변환되며,
이후 모델의 입력(input) 으로 사용된다.

정적 임베딩(static embeddings) 이 모델에 입력된다.
p35. BERT: 트랜스포머 층의 적층 (Stacking)
BERT는 여러 개의 트랜스포머(Transformer) 층을 적층(stacking)한다.
각 층은 셀프-어텐션(self-attention) 과 변환(transformations) 으로 구성되어 있다.이러한 층들을 적층함으로써,
각 단어에 대해 풍부한 문맥 정보(rich contextual information) 를 포착할 수 있다.
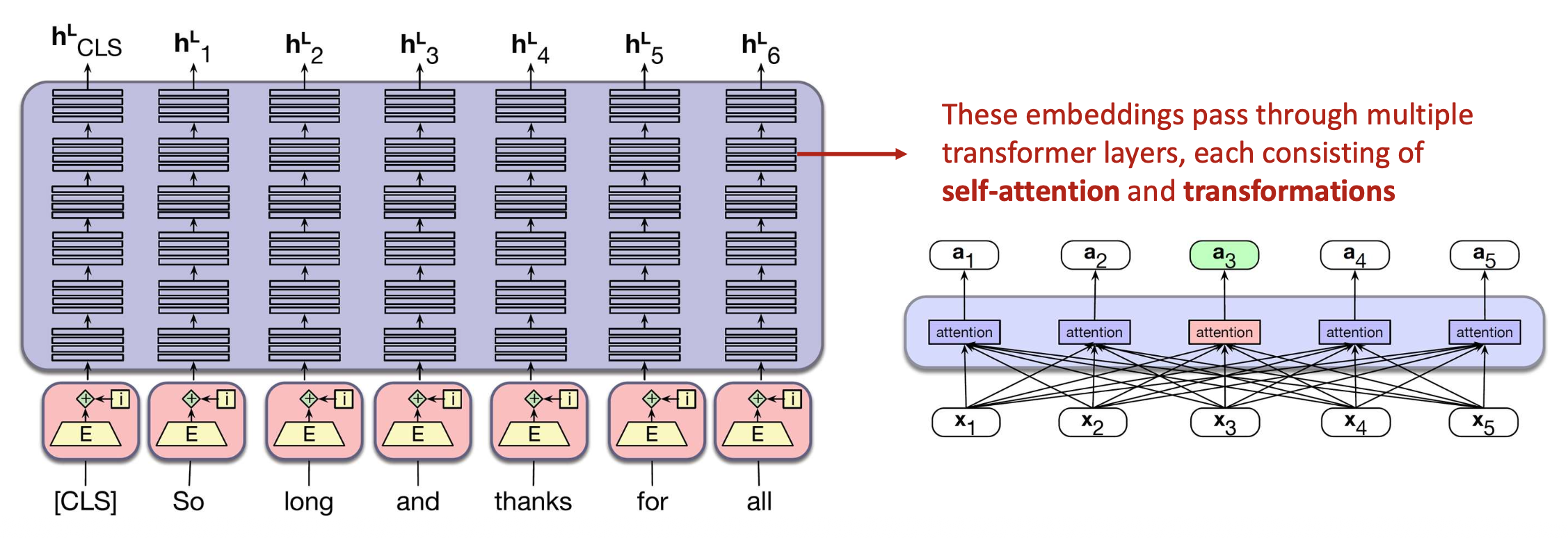
이러한 임베딩들은 여러 개의 트랜스포머 층을 통과하며,
각 층은 셀프-어텐션(self-attention) 과 변환(transformations) 으로 이루어져 있다.
p36. BERT: 트랜스포머 층의 적층 (Stacking)
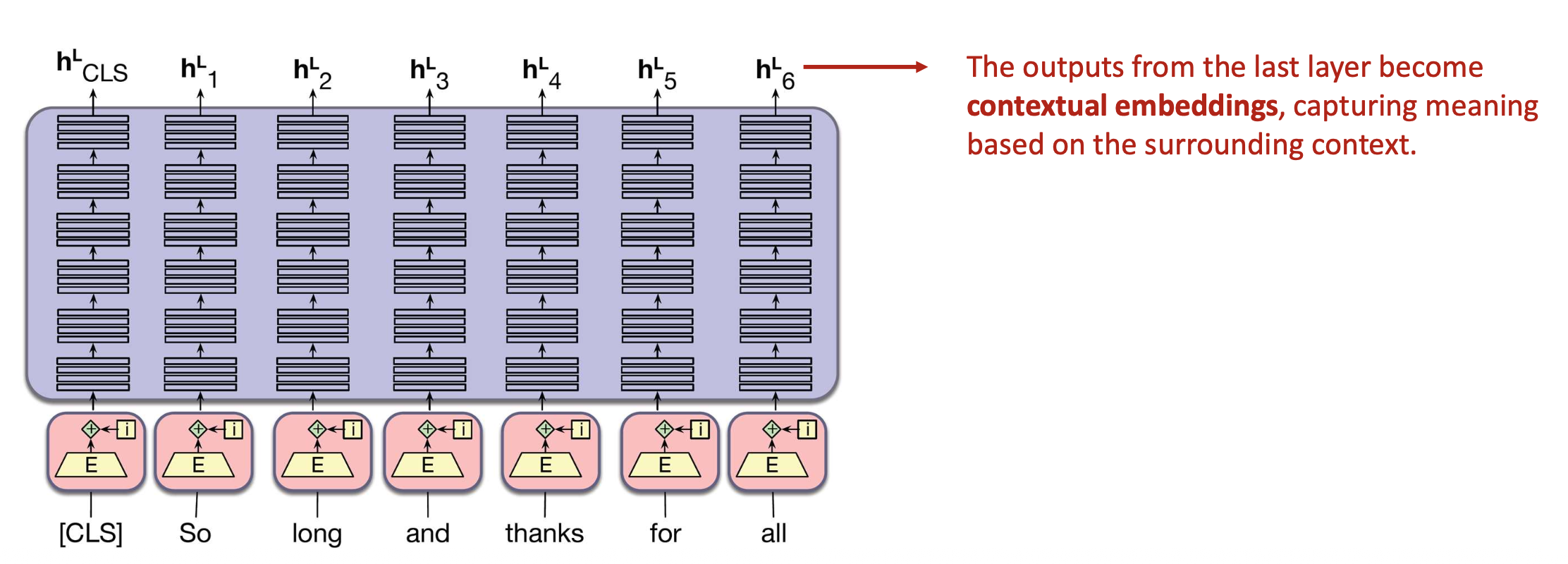
마지막 층의 출력(outputs from the last layer)은
주변 문맥(context)을 기반으로 의미를 포착하는
문맥 임베딩(contextual embeddings) 이 된다.
p37. BERT: 최적화 (Optimization)
- 원칙적으로, 최적화 문제(optimization problem) 를 정의하면,
경사하강법(gradient descent) 을 사용하여 이를 해결할 수 있다.- 따라서 우리의 질문은 다음과 같다:
→ “어떻게 하면 문맥(context)을 가장 잘 포착하는 최적화 문제를 정의할 수 있을까?”
- 따라서 우리의 질문은 다음과 같다:
- BERT는 강력한 언어 이해(language understanding)를 구축하기 위해
두 가지 학습 목표(two learning objectives) 로 학습된다.
- 마스크드 언어 모델링 (Masked Language Modeling, MLM)
- 문맥(context)을 기반으로,
무작위로 가려진(masked) 단어를 예측한다.
- 문맥(context)을 기반으로,
- 다음 문장 예측 (Next Sentence Prediction, NSP)
- 한 문장이 논리적으로 다른 문장 다음에 오는지를 예측한다.
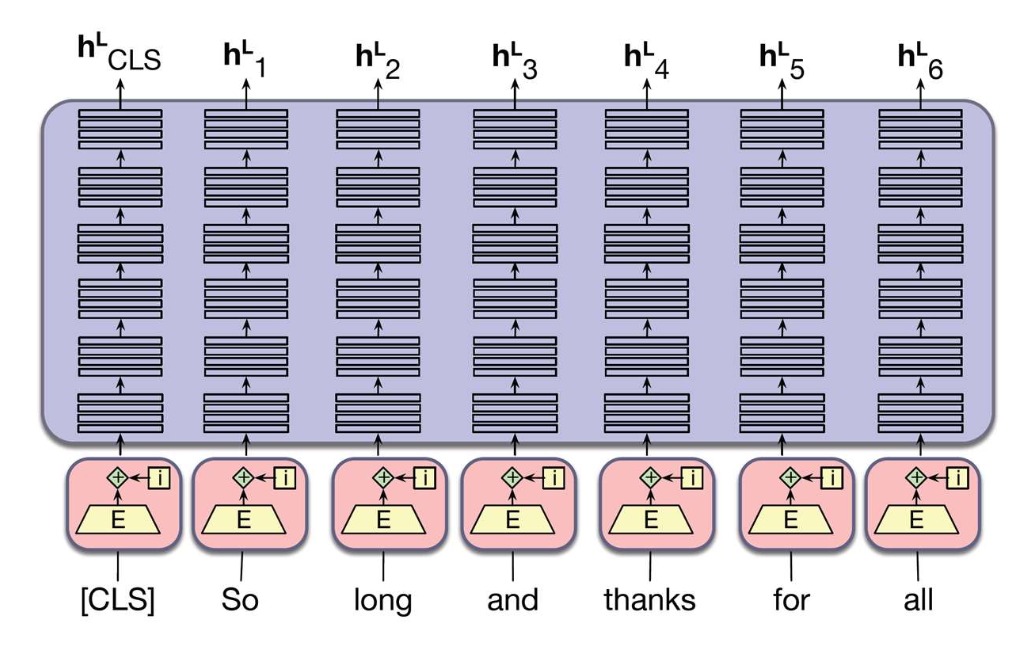
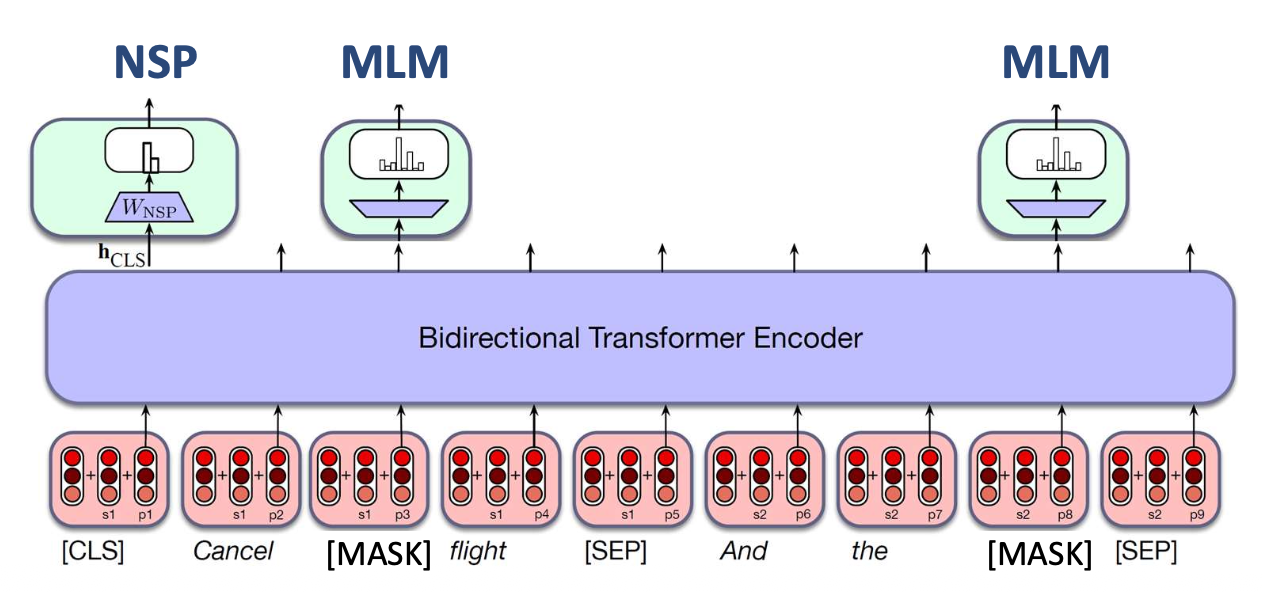
p39. 마스크드 언어 모델링 (Masked Language Modeling, MLM)
입력 텍스트(input text) 는
위키피디아(Wikipedia), 뉴스(News) 등 웹(web)에서 수집된다.Sentence #1
He had a picnic on the river bank일부 단어들은 무작위로 마스크(mask) 처리된다.
- He had a picnic on the river [MASK]
→ 예측해야 할 단어- money
- bank ✅
- beach
- river
- He had a picnic on the [MASK] bank
→ 예측해야 할 단어- money
- bank
- beach
- river ✅
Sentence #2
She deposited money in the bank- She deposited [MASK] in the bank
→ 예측해야 할 단어- money ✅
- bank
- beach
- river
- She deposited [MASK] in the bank
p40. 마스크드 언어 모델링 (Masked Language Modeling, MLM)
- 마스크된 단어 예측하기
모델은 원래 단어를 예측한다.
$M$: 마스크된 위치들의 집합
전체 토큰의 15%를
특수 토큰 [MASK]로 무작위하게 마스크한다.입력 문장:
So long and thanks for all the fish마스크된 문장:
So [MASK] and [MASK] for all the fish
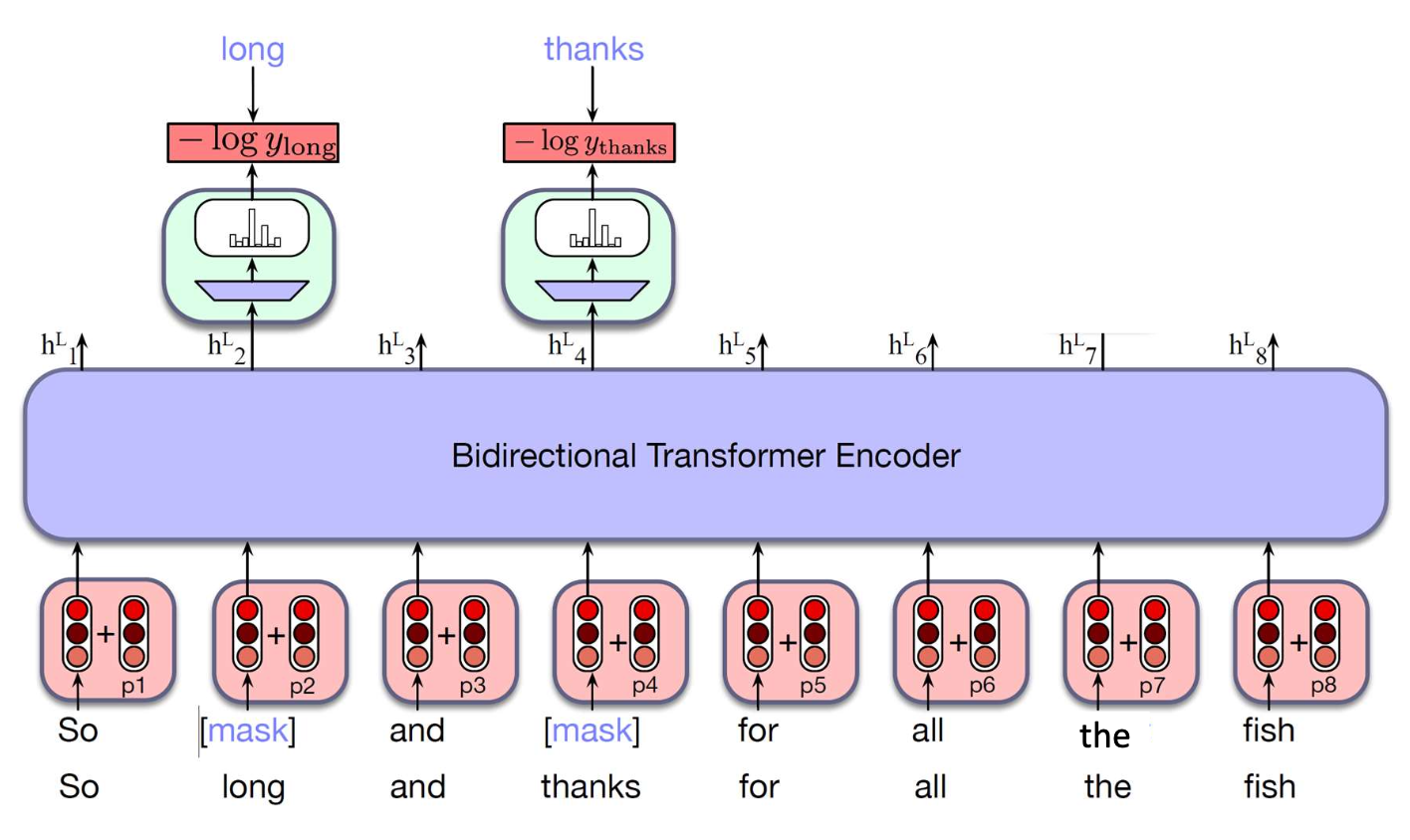
MLM 손실 함수의 의미
- $L_{MLM}$ 은 마스크드 언어 모델링(Masked Language Modeling) 을 학습하기 위한 손실 함수이다.
입력 문장에서 일부 토큰을 [MASK] 로 가리고,
\[L_{MLM} = -\frac{1}{|M|} \sum_{i \in M} \log P(x_i \mid h_i^L)\]
해당 위치의 정답 단어를 확률로 예측하도록 모델을 학습시킨다.- 이 식은 “마스크된 위치들의 평균 음의 로그 우도(negative log-likelihood)”를 의미한다.
정답 단어에 대해 모델이 높은 확률을 줄수록
$\log P(x_i \mid h_i^L)$ 이 커지고,
따라서 $L_{MLM}$ 은 작아진다.- 즉, $L_{MLM}$ 을 최소화한다는 것은
모델이 문맥(context) 을 더 잘 이해하여
마스크된 단어를 복원하도록 파라미터를 조정하는 과정이다.
p41. 마스크드 언어 모델링 (Masked Language Modeling, MLM)
- 확률은 어떻게 계산할까?
$M$: 마스크된 위치들의 집합
가장 단순한 방법은 선형 계층(linear layer) 과 소프트맥스(softmax) 를 사용하는 것이다.
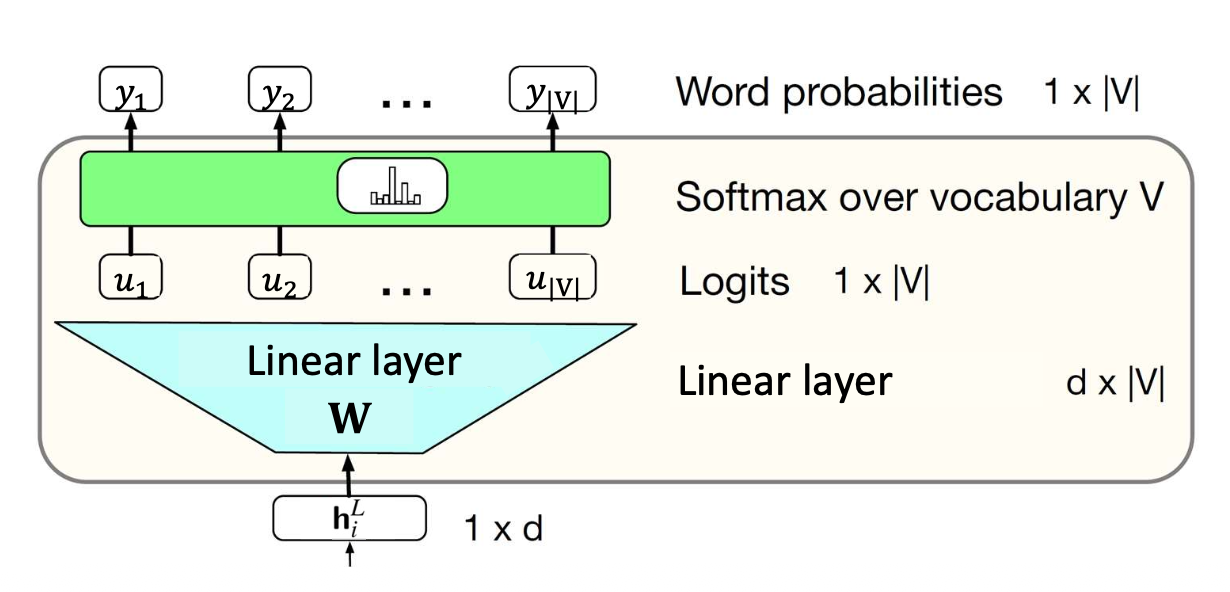
- 핵심 통찰 (Key insight):
각 로짓(logit)은 문맥(contextual) 임베딩($h_i^L$) 과
어휘 내 각 단어(행렬 $W$의 열) 의 내적(inner product) 으로 계산된다.
p42. 마스크드 언어 모델링 (Masked Language Modeling, MLM)
- 확률을 어떻게 계산하는가?
$M$: 마스크된 위치들의 집합
실제 구현에서는, 이 선형층(linear layer) 은
입력 시의 정적 임베딩 행렬(static embedding matrix) $\mathbf{E}$ 을
그대로 사용하는 가중치 결합(weight-tying) 방식으로 구현된다.
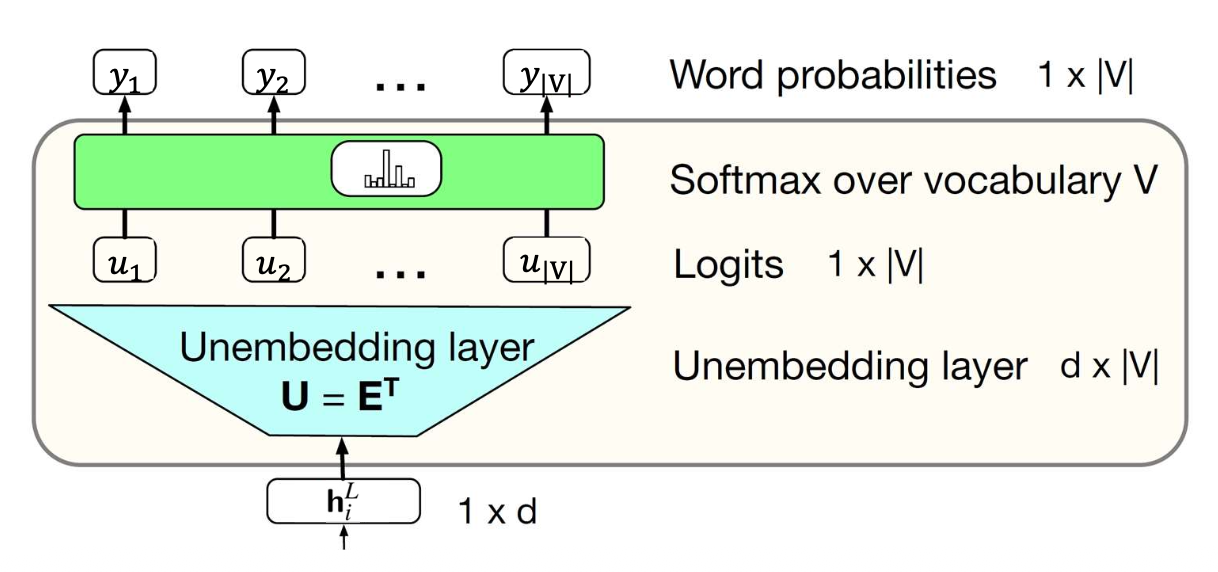
핵심 통찰 (Key insight):
각 로짓(logit)은 문맥 임베딩(contextual embedding) $h_i^L$ 과
어휘집의 각 단어(행렬 $\mathbf{E}^\top$의 열) 간의 내적(inner product) 으로 계산된다.가중치 결합(weight-tying) 은 모델의 크기를 줄이고
불필요한 중복을 방지한다.
Weight-tying의 개념과 목적
- Weight-tying(가중치 결합)은 입력 임베딩(embedding) 행렬과
출력층의 가중치(unembedding) 행렬을 하나로 공유하는 기법이다.- 일반적인 언어 모델에서는
- 입력 단어를 벡터로 바꾸기 위한 임베딩 행렬 $\mathbf{E}$
- 단어 분포를 예측하기 위한 출력 가중치 행렬 $\mathbf{W}$
를 별도로 사용한다.그러나 두 행렬은 모두 어휘집 크기 $|V|$ × 임베딩 차원 $d$ 형태이므로
\[\mathbf{u} = h_i^L \mathbf{E}^\top, \qquad \mathbf{y} = \text{softmax}(\mathbf{u})\]
둘을 따로 두면 동일한 형태의 파라미터를 중복해서 학습하게 된다.- Weight-tying은 $\mathbf{W} = \mathbf{E}^\top$ 로 설정하여
동일한 행렬을 입력 임베딩과 출력층에서 함께 사용한다.- 이를 통해
- 불필요한 파라미터를 줄이고(parameter reduction)
- 모델의 일반화 성능을 높이며
- 단어 임베딩과 출력 확률 계산 간의 의미적 일관성을 확보한다.
- BERT, GPT 등 대부분의 현대 NLP 모델에서 사용되는 표준 기법이다.
p43. 다음 문장 예측 (Next Sentence Prediction, NSP)
입력 텍스트:
웹에서 수집한 문장 (Wikipedia, 뉴스 등)- Sentence #1
He had a picnic on the river bank
→ Many people were sitting on the grass
이 문장이 다음 문장인가?- 예 (Yes)
- 아니오 (No)
- Sentence #2
He had a picnic on the river bank
→ Stock market closed higher on Monday
이 문장이 다음 문장인가?- 예 (Yes)
- 아니오 (No)
(무작위로 선택된 문장)
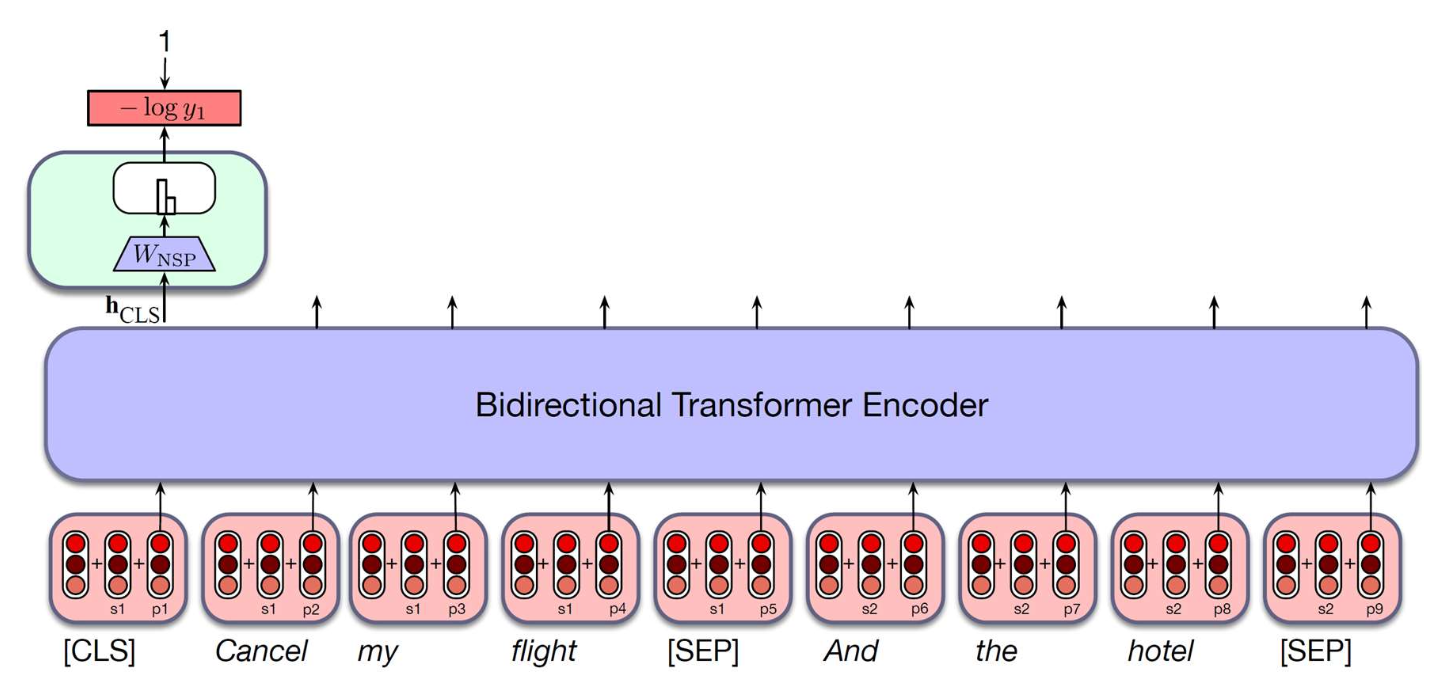
p44. 다음 문장 예측 (Next Sentence Prediction, NSP)
- 아이디어:
- 두 문장을 하나의 입력으로 모델에 동시에 넣되,
그 사이를 특수 토큰 [SEP] 으로 구분한다. - 입력의 맨 앞에는 전체 입력 정보를 요약하기 위한
특수 토큰 [CLS] 를 추가한다. - 모델은 두 번째 문장이 실제로 첫 번째 문장 뒤에 오는지 여부 를 예측한다.
- 두 문장을 하나의 입력으로 모델에 동시에 넣되,
- 이것이 문맥(context) 학습에 도움이 되는 이유?
- 모델이 단어 수준(token-level)이 아닌
문장 간의 연결성(coherence) 을 학습하도록 유도한다. - 이후의 일부 연구에서는 NSP가 필수적이지 않다고 주장했지만,
이 설계는 이후의 많은 모델에 영감을 주었다.
- 모델이 단어 수준(token-level)이 아닌
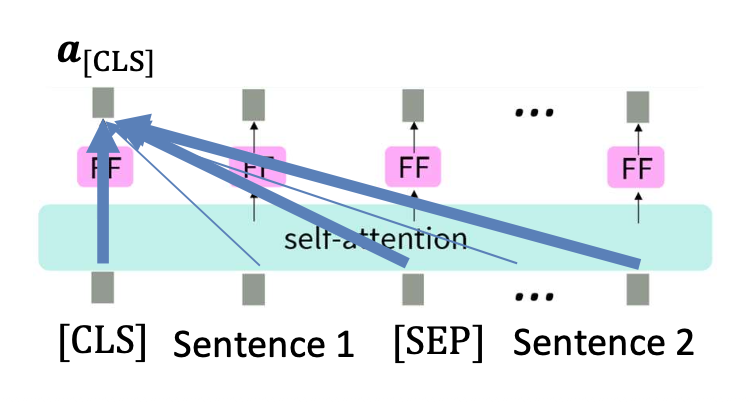
p45. 다음 문장 예측 (Next Sentence Prediction, NSP)
- 다음 문장 예측:
$y$: 두 문장이 연속인지 아닌지를 나타내는 이진 분류 변수
[CLS] 토큰 은 개별 단어가 아니라
전체 입력(whole input) 으로부터 정보를 집약(aggregate)한다.
따라서 [CLS]를 사용하여
두 문장이 실제로 연속(consecutive)인지 여부 를 예측한다.입력 문장:
두 문장을 함께 입력하고,
이 둘을 구분하기 위해 특수 토큰 [SEP] 을 문장 사이에 둔다.
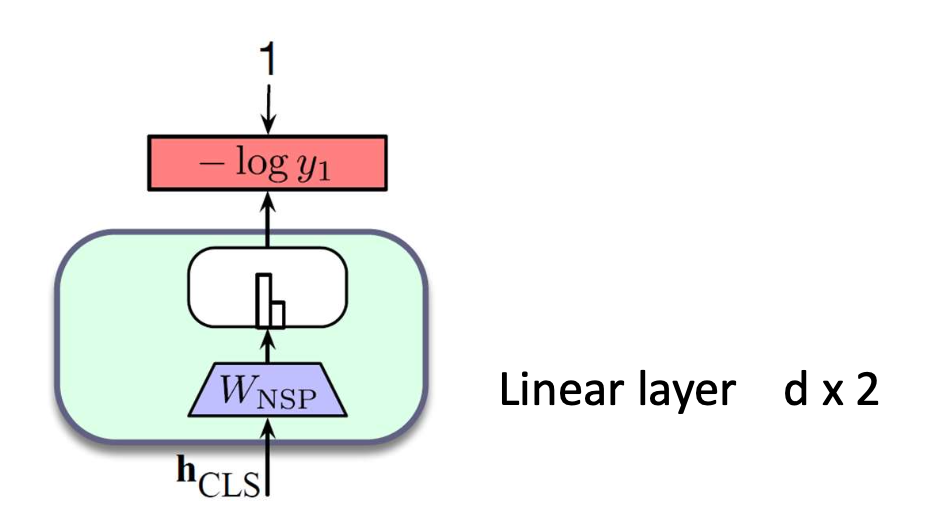
p46. 다음 문장 예측 (Next Sentence Prediction, NSP)
- 확률은 어떻게 계산되는가?
$y$: 두 문장이 연속(consecutive)인지 아닌지를 나타내는 이진 분류 변수
가장 단순한 방법, linear layer + softmax 을 사용한다.
- 선형 계층(linear layer)은 $d \times 2$ 차원을 갖는다.
(두 클래스: 연속 / 비연속)
p47. BERT의 최적화 = MLM + NSP
- BERT는 사전학습(pretraining)된 트랜스포머로,
두 가지 학습 목표 로 학습된다.
- 이 두 목적함수는 동시에 적용된다.
- 마스크드 언어 모델링 (Masked Language Modeling, MLM)
- 주변 문맥(context)으로부터
무작위로 마스크된 단어를 예측한다.
- 주변 문맥(context)으로부터
- 다음 문장 예측 (Next Sentence Prediction, NSP)
- 하나의 문장이 다른 문장 뒤에 논리적으로 이어지는지 예측한다.
p48. BERT의 최적화 = MLM + NSP
- BERT는 사전학습(pretrained)된 트랜스포머로,
두 가지 학습 목표 로 학습된다.
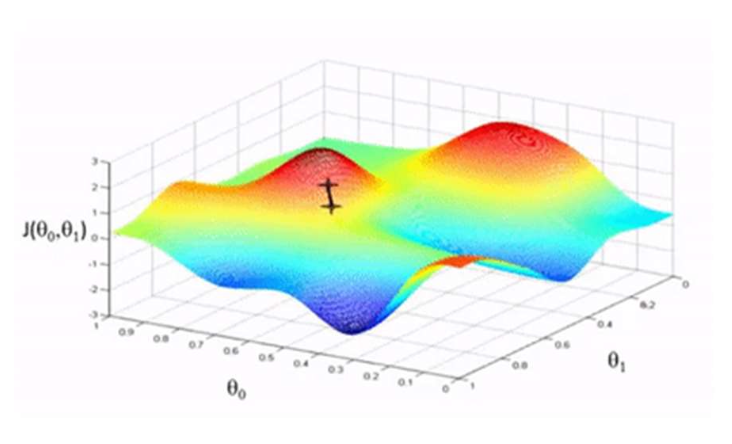
어떻게 최적화할까?
→ 경사하강법(gradient descent) 을 사용한다.- 그래디언트(∇θℒ(θ))는
학습 손실(training loss)을 가장 크게 증가시키는 방향이다.
- 그래디언트(∇θℒ(θ))는
알고리즘
- 파라미터 θ를 무작위로 초기화한다.
- 수렴할 때까지 반복한다:
- θ: 학습 파라미터(learning parameters)
- η: 학습률(learning rate, step size) — 하이퍼파라미터(hyperparameter)
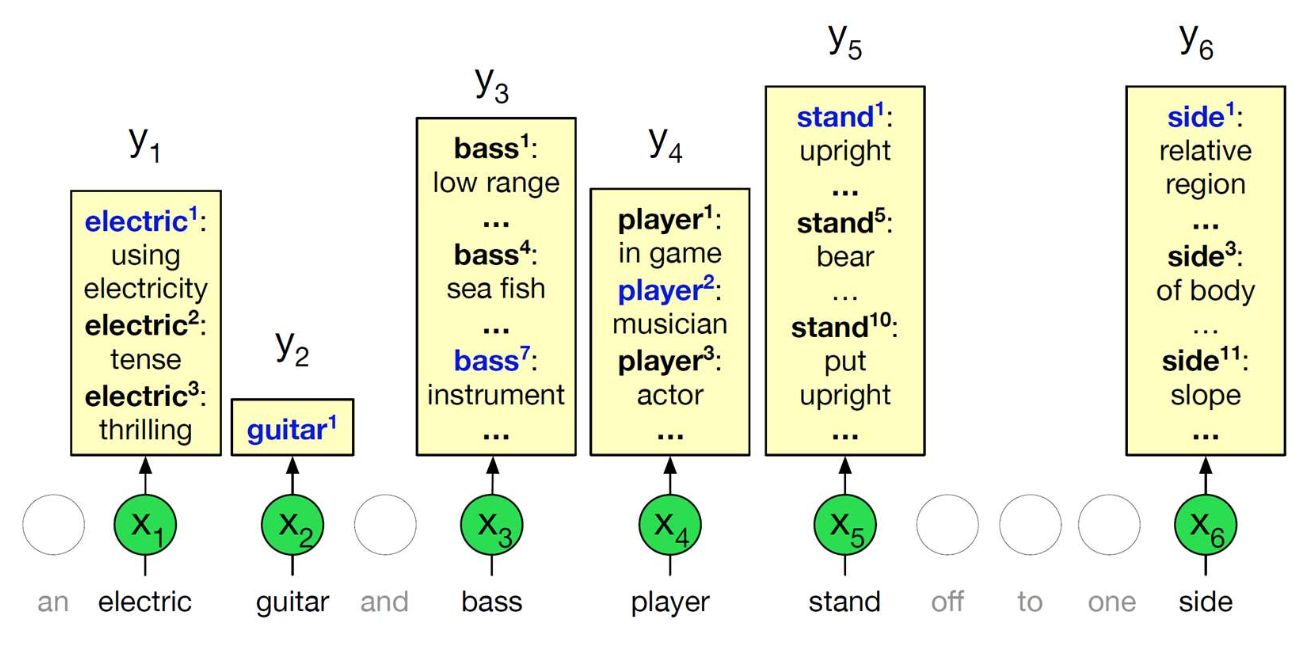
p49. 문맥 임베딩: 단어 의미 중의성 해소 (Word Sense Disambiguation)
- 하나의 단어는 여러 가지 가능한 의미를 가질 수 있으며,
문맥 임베딩(contextual embeddings) 은
문맥(context)에 따라 올바른 의미를 식별할 수 있게 해준다.
1. 각 단어의 가능한 모든 의미를 벡터로 인코딩한다.
(예: ‘find’라는 단어가 문맥에 따라 여러 의미 벡터로 표현됨)
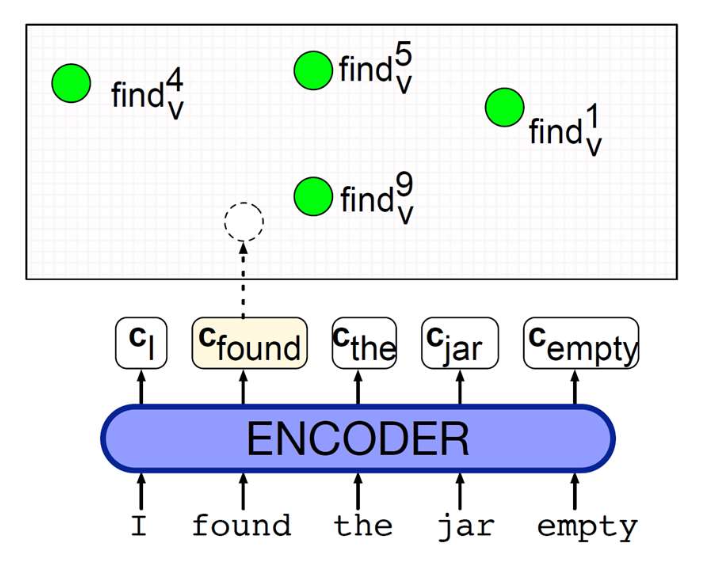
2. 벡터 공간에서 가장 가까운 이웃(nearest neighbor)을 찾는다.
→ 올바른 의미는 가장 가까운 벡터로 결정된다.
올바른 가장 가까운 이웃(corresponding nearest neighbor)은
파란색으로 표시된다(blue).
p50. 요약: 밀집 문맥 표현 (Dense Contextual Representations)
- 문맥 임베딩 (Contextual embeddings)
- 단어 벡터는 주변 문맥(context) 에 따라 동적으로 조정(dynamically adjusted) 된다.
- 문맥화는 어떻게 이뤄지는가? → 셀프 어텐션(Self-Attention)!
- 목표 단어의 임베딩을 문맥 임베딩들의 가중합(weighted sum) 으로 도출한다.
- 이를 위한 특화된 구조가 바로 트랜스포머(Transformer) 이다.
- 파라미터는 어떻게 최적화되는가? → MLM & NSP!
- 언어 이해를 향상시키기 위해 설계된 두 가지 과제(task)를 사용한다.
- 가장 널리 쓰이는 모델 중 하나가 BERT이다.
- 최종 출력은 문맥적 표현(contextual representations) 으로서
다양한 다운스트림 과제(task)에 활용된다.
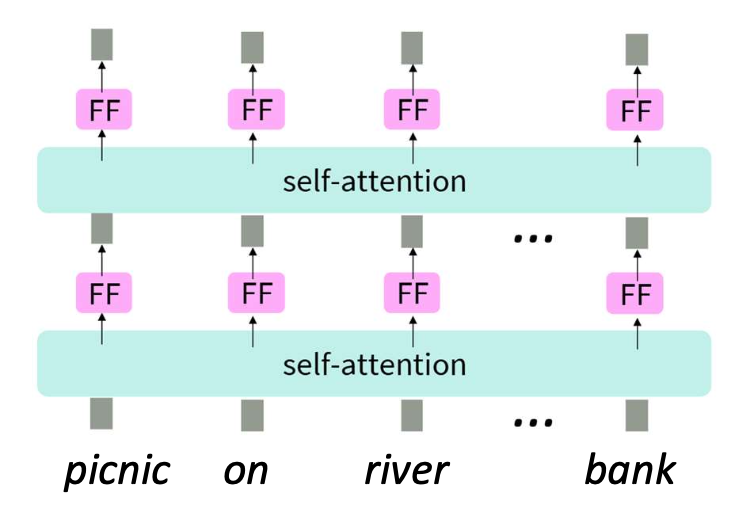
p51. 이 수업에서 다루지 않는 내용
- 셀프 어텐션(Self-Attention)의 다양한 유형
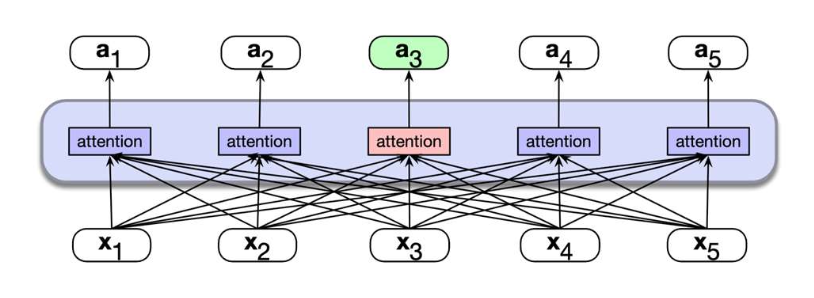
1. 양방향(Bi-directional) 셀프-어텐션
- 트랜스포머 인코더(Transformer Encoder)에 사용된다.
- 예시: BERT, RoBERTa 등
- 각 토큰(token)은 양쪽 방향의 모든 토큰을 참조(attend) 할 수 있어,
문맥 전체를 포착할 수 있다. - 자연어 이해(NLU) 과제에 적합하다.
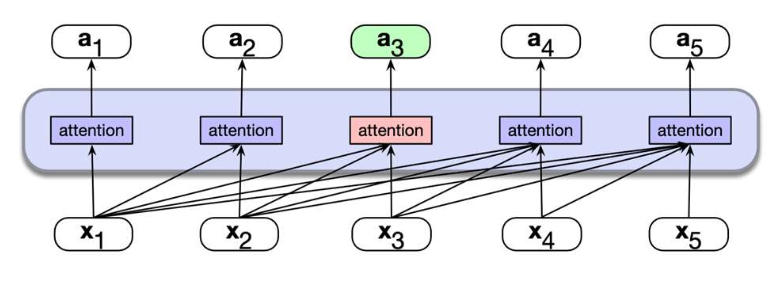
2. 인과적(Causal) 셀프-어텐션
- 트랜스포머 디코더(Transformer Decoder)에 사용된다.
- 예시: GPT 시리즈와 같은 대규모 언어 모델(LLM)
- 각 토큰은 이전 토큰들만 참조(attend) 하며,
미래 정보가 유출되는 것을 방지한다. - 자연어 생성(NLG) 과제에 적합하다.
p52. 참고 자료 (Recommended Readings)
BERT의 직관적 시각화:
https://jalammar.github.io/illustrated-bert/Speech and Language Processing
- Chapter 8: Transformers
- Chapter 9: Masked Language Models