[논문 번역] TranAD: Deep Transformer Networks for Anomaly Detection in Multivariate Time Series Data
논문 출처
Shreshth Tuli, Giuliano Casale, Nicholas R. Jennings.
TranAD: Deep Transformer Networks for Anomaly Detection in Multivariate Time Series Data.
Imperial College London / Loughborough University.
s.tuli20@imperial.ac.uk, g.casale@imperial.ac.uk, n.r.jennings@lboro.ac.uk
🔗 원문 링크 (arXiv: 2201.07284v6)
저자
- Shreshth Tuli
- Giuliano Casale
- Nicholas R. Jennings
(Imperial College London, Loughborough University)
초록 (Abstract)
다변량 시계열 데이터에서의 효율적인 이상 탐지와 진단은
현대 산업 응용에서 매우 중요한 문제이다.
그러나 이상 관측치를 빠르고 정확하게 식별할 수 있는 시스템을
구축하는 것은 도전적인 문제이다.
이는 이상 레이블의 부족, 데이터의 높은 변동성,
그리고 현대 응용에서 요구되는 초저지연 추론 시간 요구사항 때문이다.
최근 이상 탐지를 위한 딥러닝 접근법들이 개발되었음에도 불구하고,
이러한 모든 문제를 동시에 해결할 수 있는 방법은 소수에 불과하다.
본 논문에서는 TranAD를 제안하는데,
이는 데이터의 더 넓은 시간적 추세에 대한 지식을 바탕으로
어텐션 기반 시퀀스 인코더를 사용하여 신속하게 추론을 수행하는
딥 트랜스포머 네트워크 기반의 이상 탐지 및 진단 모델이다.
TranAD는 포커스 점수 기반 자기 조건화(self-conditioning)를
사용하여 강건한 멀티모달 특성 추출을 가능하게 하며,
적대적 학습을 통해 안정성을 확보한다.
자기 조건화(self-conditioning)는
모델이 이전 단계에서 생성한 예측이나 중간 출력을
다시 입력 조건으로 활용하여
이후 예측을 점진적으로 개선하는 학습 전략이다.
이를 통해 모델은 시간적 일관성과 예측 안정성을
스스로 강화할 수 있다.
또한 모델 비의존적 메타 학습(MAML, model-agnostic meta learning)을
적용하여 제한된 데이터만으로도 모델을 학습할 수 있도록 한다.
모델 비의존적 메타 학습(model-agnostic meta learning, MAML)은
여러 서로 다른 작업이나 환경을 고려하여,
새로운 작업에 대해 소량의 데이터와 몇 번의 업데이트만으로도
빠르게 적응할 수 있는 모델 파라미터의 출발점(initialization)을
사전에 학습하는 메타 학습 기법이다.
6개의 공개 데이터셋에 대한 광범위한 실험 결과를 통해,
TranAD는 데이터 효율적이고 시간 효율적인 학습을 유지하면서
탐지 및 진단 성능에서 최신 베이스라인 방법들을 능가함을 보였다.
구체적으로 TranAD는 베이스라인 대비 F1 점수를 최대 17%까지 향상시키고,
학습 시간을 최대 99%까지 감소시킨다.
1 서론 (Introduction)
현대 IT 운영 환경은
대규모 데이터셋의 지속적인 모니터링과 정상적인 동작을 위해 사용되는
막대한 양의 고차원 센서 데이터를 생성한다.
전통적으로 데이터 마이닝 전문가들은 결함(fault)을 보고하기 위해
일반적인 추세를 따르지 않는 데이터를 연구하고 강조하여 왔다.
이러한 보고들은
반응형 결함 허용(reactive fault tolerance)을 위한 시스템 관리 모델과
강건한 데이터베이스 설계에 있어 핵심적인 역할을 해왔다 [47].
반응형 결함 허용(reactive fault tolerance)은
시스템에서 결함(fault)이 발생한 이후에 이를 감지하고 대응하는 방식의 결함 처리 전략이다.
사전에 결함을 예측하거나 방지하기보다는,
장애 발생 시 재시도, 복구, 재구성 등의 메커니즘을 통해
시스템의 안정성과 연속적인 동작을 유지하는 데 초점을 둔다.
그러나 빅데이터 분석과 딥러닝의 등장으로 인해
이 문제는 데이터 마이닝 연구자들에게도 관심의 대상이 되었으며,
증가하는 데이터 양을 처리하는 데 있어 전문가들을 지원하는 방향으로 확장되었다.
특정 활용 사례 중 하나는
서비스 신뢰성(service reliability)에 중점을 둔
Industry-4.0 데이터베이스를 위한 인공지능 분야로,
현대 시스템에서의 결함 탐지, 복구 및 관리를 자동화하는 것을 목표로 한다 [38].
데이터 장애를 탐지하거나,
예상된 추세에 부합하지 않는 모든 형태의 행위를 탐지하는 것은
다변량 시계열에서의 이상 탐지라고 불리는 활발한 연구 분야이다 [11].
분산 컴퓨팅, 사물인터넷(Internet of Things, IoT), 로보틱스,
도시 자원 관리 [4, 46] 등 다양한 데이터 기반 산업 분야에서는
이상 탐지를 위해 머신러닝 기반 비지도 방법을 점점 더 널리 채택하고 있다.
도전 과제 (Challenges)
이상 탐지 문제는 데이터 모달리티의 증가로 인해
대규모 데이터베이스 환경에서 점점 더 어려워지고 있다 [18, 28, 54].
특히 현대 IoT 플랫폼에서 센서와 장치의 수가 증가하고 데이터 변동성이 커짐에 따라,
정확한 추론을 위해서는 상당한 양의 데이터가 요구된다.
그러나 지리적으로 분산된 클러스터를 전제로 한
연합 학습(federated learning) 패러다임의 부상으로 인해,
장치 간 데이터베이스를 동기화하는 비용이 커졌고
그 결과 학습을 위한 데이터 가용성이 제한되는 문제가 발생하고 있다 [48, 57].
연합 학습 패러다임(federated learning paradigm)이란
데이터를 중앙 서버로 모으지 않고,
지리적으로 분산된 여러 장치나 클러스터가
각자 로컬 데이터로 모델을 학습한 뒤
학습된 모델 파라미터만을 공유·집계하는 학습 방식이다.이 방식은 데이터 프라이버시와 통신 비용 측면에서 장점이 있지만,
장치 간 모델 동기화와 업데이트에 따른 비용이 커질 수 있으며
학습에 활용 가능한 데이터의 일관성과 가용성이 제한될 수 있다.
더 나아가 차세대 응용 시스템들은
빠른 복구와 최적의 서비스 품질(Quality of Service, QoS)을 달성하기 위해
초고속 추론 속도를 요구한다 [6, 49, 50].
시계열 데이터베이스는 환경, 인간, 또는 다른 시스템과 상호작용하는
여러 공학적 구성 요소들(서버, 로봇 등)에 의해 생성된다.
그 결과 데이터는 종종
확률적(stochastic) 특성과 시간적(temporal) 추세를 동시에 나타낸다 [45].
따라서 확률성(stochasticity)으로 인해 발생한 이상치(outliers)와
관측된 시간적(temporal) 추세를 따르지 않는 관측값(only pinpoint observation을
구분하여 식별하는 것이 중요해진다.
더욱이 레이블된 데이터의 부족과
이상의 다양성은 문제를 더욱 어렵게 만들며,
이는 다른 데이터 마이닝 영역에서 효과적임이 입증된
지도 학습 모델을 사용할 수 없기 때문이다 [12].
마지막으로, 이상을 탐지하는 것뿐만 아니라
비정상적인 행위를 유발한 근본 원인(root cause),
즉 구체적인 데이터 소스를 식별하는 것 또한 중요하다 [23].
이는 문제가 더욱 복잡해지는 원인이 되는데,
이상 여부를 판단하는 것뿐만 아니라
이상이 발생한 경우 그 원천이 무엇인지까지 판단해야 하는
다중 클래스 예측(multi-class prediction)이 필요하기 때문이다 [60].
기존 해법 (Existing solutions)
앞서 논의한 이러한 도전 과제들은 자동화된 이상 탐지를 위한
다양한 비지도 학습 기반 해법들의 개발로 이어졌다.
연구자들은 주로 시간적 추세를 포착하고
비지도 방식으로 시계열 데이터를 예측한 뒤,
예측값과 실제 데이터 간의 편차를 이상 점수로 사용하는
재구성(reconstruction) 기반 방법들을 개발해 왔다.
다양한 극값(extreme value) 분석 방법에 기반하여,
이러한 접근법들은 높은 이상 점수를 갖는 타임스탬프를
비정상으로 분류한다 [4, 10, 14, 20, 28, 29, 45, 60, 62].
기존 연구들이 주어진 시계열로부터 예측 시계열을 생성하는 방식은
연구마다 상이하다.
SAND [10]와 같은 전통적인 접근법은
클러스터링과 통계적 분석을 사용하여 이상을 탐지한다.
openGauss [30] 및 LSTM-NDT [20]와 같은 현대적인 방법들은,
입력 시계열을 기반으로 데이터를 예측하기 위해
LSTM 기반 신경망을 사용하고,
예측 오차로부터 이상을 탐지하기 위해
비모수적(non-parametric) 동적 임계값 설정 방식을 사용한다.
그러나 LSTM과 같은 순환 모델은 느리고 계산 비용이 크다는 한계가 있다 [4].
최근의 최첨단(state-of-the-art) 방법들인 MTAD-GAT [62]와 GDN [14]은
더 정확한 예측을 위해 시계열 윈도우(time-series window)를 입력으로 사용하는
딥 신경망을 활용한다.
그러나 입력이 점점 더 데이터 집약적으로 변함에 따라,
작은 고정 크기의 윈도우 입력은,
모델에 제공되는 국소적 문맥 정보가 제한되기 때문에 탐지 성능을 제한한다 [4].
따라서 계산 오버헤드를 크게 증가시키지 않으면서
고수준의 추세를 포착할 수 있고 빠르게 동작하는 모델이 요구된다.
새로운 통찰 (New insights)
앞서 언급했듯이, 기존 방법에 기반한 순환 모델들은
느리고 계산 비용이 클 뿐만 아니라,
장기 추세를 효과적으로 모델링하지 못한다 [4, 14, 62].
이는 순환 모델(recurrent model)의 경우
각 시점(timestamp)마다 다음 단계로 진행하기 전에
이전의 모든 시점들에 대해 먼저 추론을 수행해야 하기 때문이다.
최근 트랜스포머(transformer) 모델의 발전으로 인해
위치 인코딩(position encoding)을 활용하여
전체 입력 시계열에 대해 단일 단계(single-shot) 추론이 가능해졌다 [51].
트랜스포머를 사용하면 GPU 상에서 추론을 병렬화할 수 있어
순환 방법에 비해 훨씬 빠른 탐지가 가능하다 [19].
또한 트랜스포머는
시퀀스 길이에 거의 영향을 받지 않는 학습 및 추론 시간으로
대규모 시퀀스를 높은 정확도로 인코딩할 수 있다는 장점도 제공한다 [51].
따라서 우리는 계산 오버헤드를 크게 증가시키지 않으면서
이상 탐지기에 전달되는 시간적 문맥 정보를 확장하기 위해
트랜스포머를 사용한다.
우리의 기여 (Our contributions)
본 연구는 트랜스포머 신경망과
모델 비의존적 메타 학습(model-agnostic meta learning)을 포함한
다양한 도구들을 구성 요소로 사용한다.
그러나 이러한 각기 다른 기술들은 그대로는 직접 사용될 수 없으며,
이상 탐지를 위한 일반화 가능한 모델을 구축하기 위해
필요한 적절한 변형과 조정이 요구된다.
구체적으로 우리는 자기 조건화와 적대적 학습 과정을 사용하는
트랜스포머 기반 이상 탐지 모델 TranAD를 제안한다.
이 아키텍처는 대규모 입력 시퀀스에서도 안정성을 유지하면서
학습과 테스트를 빠르게 수행할 수 있도록 한다.
단순한 트랜스포머 기반 인코더–디코더 네트워크는 편차가 매우 작은 경우,
즉 정상 데이터와 비교적 가까운 경우에 이상을 놓치는 경향이 있다.
우리의 기여 중 하나는
재구성 오류를 증폭시킬 수 있는 적대적 학습 절차를 통해
이 문제를 완화할 수 있음을 보이는 것이다.
또한 강건한 멀티모달 특성 추출을 위한 자기 조건화는
학습 안정성을 높이고 일반화를 가능하게 한다 [32].
이는 모델 비의존적 메타 학습(model-agnostic meta learning, MAML)과 결합됨으로써
제한된 데이터 환경에서도 최적의 이상 탐지 성능을 유지하는 데 기여하며 [15],
이후 검증 결과에서 확인하듯이
단순한 트랜스포머 기반 방법들은 TranAD에 비해 11% 이상 성능이 저하됨을 보인다.
우리는 공개적으로 사용 가능한 데이터셋에 대해 광범위한 실증 실험을 수행하여,
TranAD를 최신 기법들과 비교·분석한다.
실험 결과, TranAD는
예측 점수를 최대 17%까지 향상시키는 동시에
학습 시간 오버헤드를 최대 99%까지 감소시켜
베이스라인 대비 우수한 성능을 보임을 확인하였다.
본 논문의 구성은 다음과 같다.
2장은 관련 연구를 개관한다.
3장은 다변량 이상 탐지 및 진단을 위한 TranAD 모델의 동작을 설명한다.
4장에서는 제안한 방법의 성능 평가를 제시한다.
5장은 추가 분석을 제공하며, 마지막으로 6장에서 결론을 맺는다.
2 관련 연구 (Related Work)
시계열 이상 탐지는 VLDB 커뮤니티에서 오랫동안 연구되어 온 문제이다.
VLDB 커뮤니티란
Very Large Data Bases(VLDB) 학회를 중심으로 형성된
대규모 데이터베이스 시스템, 데이터 관리, 데이터 마이닝 분야의
국제 연구자 및 실무자 공동체를 의미한다.
기존 문헌에서는 시계열 데이터를 단변량(univariate)과 다변량(multivariate)
두 가지 유형으로 구분하여 다루어 왔다.
전자의 경우에는
단일 데이터 소스를 갖는 시계열 데이터에서
이상을 분석하고 탐지하는 다양한 방법들이 제안되었으며 [34],
후자의 경우에는
여러 시계열을 함께 고려하는 방식들이 연구되어 왔다 [14, 45, 62].
고전적 방법 (Classical methods)
이상 탐지를 위한 고전적인 방법들은 일반적으로
k-평균 클러스터링, 서포트 벡터 머신(SVM), 또는 회귀 모델과 같은
다양한 고전적 기법들을 사용하여 시계열 분포를 모델링한다 [10, 28, 43, 52].
다른 방법들로는 웨이블릿(wavelet) 이론이나 힐버트 변환과 같은
신호 변환 기법을 사용하는 방식이 있다 [25].
웨이블릿 이론이나 힐버트 변환과 같은 신호 변환 기법은
시계열 데이터를 시간–주파수 영역으로 변환하여,
시간에 따라 변화하는 주기적 패턴이나 비정상적 신호 성분을
더 명확하게 분석하고 이상을 탐지하기 위해 사용된다.
또한 다른 계열의 방법들은 주성분 분석(PCA),
공정 회귀(process regression), 또는 은닉 마르코프 체인을 사용하여
시계열 데이터를 모델링한다 [41].
공정 회귀(process regression)는
시계열 데이터를 확률적 생성 과정으로 가정하고,
시간에 따른 연속적인 값의 변화를 회귀 방식으로 모델링하여
정상 패턴과의 편차를 통해 이상을 탐지하는 방법이다.은닉 마르코프 체인(Hidden Markov Chain)은
관측되지 않는 은닉 상태가 시간에 따라 전이된다고 가정하고,
각 상태에서 관측 데이터가 생성되는 확률 모델을 통해
상태 전이의 이상성이나 비정상적인 관측을 탐지하는 기법이다.
GraphAn 기법 [9]은 시계열 입력을 그래프로 변환하고,
그래프 거리 지표를 사용하여 이상치(outlier)를 탐지한다.
또 다른 기법인 Isolation Forest는
여러 개의 고립 트리(isolation tree)로 구성된 앙상블을 사용하여
특성 공간을 재귀적으로 분할함으로써 이상치(outlier)를 탐지한다 [5, 31].
마지막으로 고전적 방법들은
Auto-Regressive Integrated Moving Average(ARIMA)의
변형을 사용하여 이상 행위를 모델링하고 탐지한다 [56].
그러나 자기회귀 기반 접근법들은
변동성이 큰 시계열을 효율적으로 포착하지 못하기 때문에,
고차원 다변량 시계열에서의 이상 탐지에는 거의 사용되지 않는다 [1].
SAND [10], CPOD [47], Elle [28]과 같은 다른 방법들은
클러스터링과 데이터베이스 읽기–쓰기 이력을 활용하여 이상치(outlier)를 탐지한다.
시계열 디스코드(discord) 탐지는
최근 제안된 또 다른 장애(fault) 예측 방법이다 [16, 37, 58, 59].
시계열 디스코드란
동일한 시계열 내의 다른 모든 부분 시퀀스들과 비교했을 때
가장 이례적인 부분 시퀀스를 의미한다.
일부 하위 방법들은
매트릭스 프로파일링(matrix profiling) 또는 그 변형을 사용하여
시계열 디스코드(time series discord)를 탐지함으로써
이상(anomaly)과 모티프(motif)를 발견한다 [16, 35, 63].
매트릭스 프로파일링은 시계열 내 모든 부분 시퀀스 간의 유사도를 계산하여,
가장 비정상적인 부분(디스코드)은 이상으로,
반복적으로 나타나는 부분(모티프)은 정상 패턴으로 식별하는 기법이다.
매트릭스 프로파일링 기법을 데이터 및 시간 측면에서 더 효율적으로 만들기 위해
다양한 개선 방법들이 제안되어 왔다 [21].
다른 연구들은 매트릭스 프로파일링을
다양한 도메인에 적용 가능하도록 확장하는 데 초점을 맞추고 있다 [64].
그러나 매트릭스 프로파일링은 이상 탐지 외에도 다양한 용도로 사용되며,
순수 디스코드 탐지 알고리즘보다 느린 것으로 알려져 있다 [37].
최근의 접근법인 MERLIN [37]은 길이가 서로 다른 부분 시퀀스를
인접한 이웃과 반복적으로 비교하는 방식의
파라미터-프리(parameter-free) 시계열 디스코드 탐지를 사용한다.
MERLIN은 낮은 오버헤드를 가지는 최신 디스코드 탐지 기법으로 간주되며,
따라서 본 연구의 실험에서 베이스라인 중 하나로 사용된다.
딥러닝 기반 방법 (Deep Learning based methods)
대부분의 현대적인 최첨단(state-of-the-art) 기법들은
어떤 형태로든 딥 신경망(deep neural network)을 활용한다.
LSTM-NDT [20] 방법은
입력 시퀀스를 학습 데이터로 사용하는 LSTM 기반 딥 신경망 모델에 의존하며,
각 입력 시점(timestamp)에 대해 다음 시점의 데이터를 예측하는 방식으로 동작한다.
LSTM은 자기회귀(auto-regressive) 신경망으로,
순차 데이터에서의 순서 의존성을 학습하며,
각 시점(timestamp)에서의 예측은 이전 시점의 출력으로부터 전달된 피드백을 사용한다.
이 연구에서는 또한
오차 시퀀스의 이동 평균을 이용하여 이상 라벨링을 위한 임계값을 설정하는
비모수적 동적 오차 임계값 설정(non-parametric dynamic error thresholding, NDT)
전략을 제안한다.
비모수적 동적 오차 임계값 설정(non-parametric dynamic error thresholding, NDT)은
오차 분포에 대한 특정 가정을 두지 않고,
시간에 따라 변화하는 오차 시퀀스의 이동 평균과 변동성을 기반으로
임계값을 동적으로 조정하는 방법이다.
이를 통해 데이터 분포나 잡음 수준이 변하더라도
고정 임계값보다 더 안정적으로 이상을 라벨링할 수 있다.
그러나 이러한 모델들은 순환(recurrent) 구조를 가지므로,
입력 시퀀스가 길어질 경우 학습 속도가 느려지는 한계를 지닌다.
또한 LSTM은 특히 데이터에 잡음이 많은 경우
장기적인 시간적 패턴을 모델링하는 데 비효율적인 경우가 많다 [62].
DAGMM [65] 방법은 특성 공간에서의 차원 축소를 위해
딥 오토인코딩 가우시안 혼합 모델을 사용하고,
시간적 모델링을 위해 순환 신경망을 활용한다.
이 방법은 각 가우시안의 파라미터를 딥 신경망으로부터 얻는
가우시안 혼합(a mixture of Gaussians)을 사용하여 출력을 예측한다.
오토인코더는 입력 데이터 포인트를 잠재 공간(latent space)으로 압축하며,
이 잠재 표현은 이후 순환 추정 네트워크(recurrent estimation network)에 의해
다음 데이터 포인트를 예측하는 데 사용된다.
두 네트워크를 분리하여 학습하는 방식은 모델을 더 강건하게 만들지만,
여전히 느리고 모달 간 상관관계를 명시적으로 활용하지 못한다 [14].
OmniAnomaly [45]는
확률적 순환 신경망(stochastic recurrent neural network)을 사용하며
이는 LSTM-변분 오토인코더(LSTM-Variational Autoencoder) [39]와 유사하다.
또한 평면 정규화 흐름(planar normalizing flow)을 결합하여
재구성 확률(reconstruction probability)을 생성한다.
확률적 순환 신경망이란
일반적인 순환 신경망이 각 시점의 상태를 하나의 값으로 결정하는 것과 달리,
은닉 상태를 확률 분포로 모델링하여
시계열 데이터에 내재된 불확실성과 잡음을 함께 표현하는 신경망 구조이다.즉, 같은 과거 관측이 주어지더라도
여러 가능한 미래 상태가 존재할 수 있음을 가정하며,
이는 변동성이 크고 예측이 불확실한 시계열을 다루는 데 유리하다.평면 정규화 흐름(planar normalizing flow)이란
단순한 확률 분포(예: 가우시안 분포)를
가역적이고 연속적인 비선형 변환을 통해
점점 더 복잡한 형태의 분포로 변형하는 기법이다.
또한 기존 NDT 접근법보다 성능이 우수한
자동화된 이상 임계값 선택을 위한
조정된 Peak Over Threshold(POT) 방법을 제안한다.
이는 기존 기법 대비 큰 성능 향상을 가져왔으나, 높은 학습 시간 비용을 요구한다.
극값 이론(extreme value theory, EVT)은
데이터 전체의 평균적인 분포가 아니라,
가장 큰 값이나 가장 작은 값처럼 극단적인 사건들의 통계적 특성을
이론적으로 분석하는 확률 이론이다.Peak Over Threshold(POT)는 EVT에 기반한 기법으로,
미리 정한 임계값(threshold)을 초과한 값들만 따로 모아
그 꼬리 분포(tail distribution)를 모델링한다.
이를 통해 정상 범위를 벗어난 극단적인 오차가
우연한 변동인지, 실제 이상(anomaly)인지를 구분할 수 있다.조정된 POT 방법은
이 임계값을 수동으로 정하지 않고 데이터로부터 자동으로 추정하여,
분포 변화나 잡음이 있는 환경에서도
이상 탐지를 보다 안정적이고 일관되게 수행하는 것을 목표로 한다.
Multi-Scale Convolutional Recursive Encoder-Decoder(MS-CRED) [60]는
입력 시퀀스 윈도우를 정규화된 이차원 이미지로 변환한 뒤,
이를 ConvLSTM 계층에 입력하여 처리한다.
ConvLSTM은 LSTM의 내부 연산에서
기존의 선형 변환(행렬 곱)을
합성곱(convolution) 연산으로 대체한 구조이다.일반 LSTM에서는
입력 $x_t$와 이전 은닉 상태 $h_{t-1}$를
완전연결층(행렬 곱)으로 처리하지만,ConvLSTM에서는
입력과 은닉 상태가 이미지나 2차원 격자 형태일 때
이들을 합성곱 필터로 처리한다.즉,
• 시간 축에서는 LSTM처럼 이전 시점의 정보를 기억하고
• 공간 축에서는 합성곱을 통해 국소적인 패턴을 포착한다.그 결과 ConvLSTM은
시간적 변화 + 공간적 구조가 동시에 중요한 데이터
(예: 시계열을 이미지로 변환한 경우, 비디오, 센서 맵 등)를
효과적으로 모델링할 수 있다.
이 방법은 보다 복잡한 모달 간 상관관계와 시간적 정보를 포착할 수 있지만,
학습 데이터가 부족한 환경에서는 일반화가 어렵다.
MAD-GAN [29]은 LSTM 기반의 GAN 모델을 사용하여
생성자(generator)를 통해 시계열 데이터의 분포를 모델링한다.
이 연구는 예측 오차뿐만 아니라 판별기 손실(discriminator loss) 또한
이상 점수(anomaly score)에 함께 활용한다.
MTAD-GAT [62]는 그래프 어텐션 네트워크를 사용하여
특성 간 상관관계와 시간적 상관관계를 동시에 모델링하고,
이를 경량화된 게이트 순환 유닛(GRU) 네트워크에 전달함으로써
과도한 연산 오버헤드 없이 이상 탐지를 수행한다.
전통적으로 어텐션(attention) 연산은
신경망에 의해 결정되는 가중치를 사용한 볼록 결합(convex combination)을 통해
입력을 압축하는 방식으로 수행된다.
GRU는 LSTM의 단순화된 버전으로,
더 적은 파라미터를 가지며, 제한된 데이터 환경에서도 학습이 가능하다.
CAE-M [61]은 MS-CRED와 유사한 구조의
합성곱(convolutional) 오토인코딩 메모리 네트워크를 사용한다.
시계열 데이터는 먼저 CNN을 통과한 뒤,
그 출력이 양방향(bidirectional) LSTM에 의해 처리되어
장기적인 시간적 추세를 포착한다.
이와 같은 순환 신경망 기반 모델들은 고차원 데이터셋에 대해
계산 비용이 높고 확장성이 낮다는 한계가 있음이 보고되어 왔다 [4].
USAD [4], GDN [14], openGauss [30]와 같은 보다 최근의 연구들은
연산 자원이 많이 소모되는 순환 모델을 사용하지 않고,
어텐션 기반 네트워크 구조만을 활용하여 학습 속도를 향상시킨다.
USAD 방법은 두 개의 디코더를 갖는 오토인코더를 사용하며,
적대적 게임(adversarial game) 방식의 학습 프레임워크를 적용한다.
이는 단순한 오토인코더를 사용하여
낮은 오버헤드에 초점을 맞춘 최초의 연구들 중 하나로,
기존 방법들에 비해 학습 시간을 수 배 이상 감소시킬 수 있음을 보인다.
그래프 편차 네트워크(Graph Deviation Network, GDN)는
데이터 모드들 간의 관계를 나타내는 그래프를 학습하고,
어텐션 기반 예측과 편차 점수 산정을 통해
이상 점수(anomaly score)를 출력하는 방법이다.
openGauss 접근법은
메모리 사용량과 계산 비용이 더 낮은 트리 기반 LSTM을 사용하며,
데이터에 잡음이 존재하는 경우에도
시간적 추세를 효과적으로 포착할 수 있도록 한다.
트리 기반 LSTM(tree-based LSTM)은
시간축을 따라 한 칸씩 처리하는 선형 LSTM과 달리,
여러 시점의 정보를 계층적으로 묶어 요약하는 구조를 가진 LSTM이다.예를 들어 연속된 여러 시점을
작은 구간 단위로 먼저 요약한 뒤,
그 요약 결과들을 다시 상위 단계에서 결합하는 방식으로
시간 정보를 처리한다.이때 각 요약·결합 단계가 트리의 노드처럼 연결되므로
전체 계산 구조가 트리 형태를 이루게 된다.그 결과, 매우 긴 시계열이라도
모든 시점을 순차적으로 처리하지 않고
중요한 정보만 단계적으로 전달할 수 있어
계산량과 메모리 사용이 줄고
잡음에 덜 민감한 시간적 추세 학습이 가능해진다.
그러나 입력으로 사용하는 윈도우가 작고
단순한 순환 모델을 사용하거나 아예 사용하지 않기 때문에,
최신 모델들은 장기적인 의존성(long-term dependency)을
효과적으로 포착하지 못하는 한계를 지닌다.
최근 제안된 HitAnomaly [19]는
바닐라 트랜스포머를 인코더–디코더 구조로 사용하지만,
자연어 로그 데이터에만 적용 가능하며
일반적인 연속 시계열 데이터에는 적합하지 않다.
실험에서는
TranAD를 최첨단(state-of-the-art) 방법들인
MERLIN, LSTM-NDT, DAGMM, OmniAnomaly, MSCRED,
MAD-GAN, USAD, MTAD-GAT, CAE-M, GDN과 비교한다.
이러한 방법들은 이상 탐지 및 진단에서 우수한 성능을 보여왔으나,
서로 다른 시계열 데이터셋 전반에 걸친 성능 측면에서는
상호 보완적인 특성을 지닌다.
이들 중에서 학습 시간 단축을 목표로 한 방법은 USAD뿐이지만,
그 효과는 제한적인 수준에 그친다.
재구성 기반 기존 연구들 [4, 29, 45, 60, 61]과 마찬가지로,
본 연구에서는 학습 데이터를 통해 전반적인 수준의 추세를 학습하고
이를 바탕으로 테스트 데이터에서 이상을 탐지하는
TranAD 모델을 개발한다.
본 연구에서는 이상 탐지 및 진단 성능을 향상시키는 동시에
학습 시간을 감소시키는 데 특히 중점을 둔다.
3 방법론 (Methodology)
3.1 문제 정의 (Problem Formulation)
우리는 다변량 시계열을 고려한다.
이는 크기 $T$를 갖는 관측값/데이터 포인트들의
타임스탬프가 부여된 시퀀스이다.
여기서 각 데이터 포인트 $x_t$는
특정 시점 $t$에서 수집되며,
모든 $t$에 대해 $x_t \in \mathbb{R}^m$이다.
이때 단변량 설정은 $m = 1$인 특수한 경우에 해당한다.
이제 우리는 이상 탐지(anomaly detection)와
진단(diagnosis)의 두 가지 문제를 정의한다.
이상 탐지(Anomaly Detection):
학습 입력 시계열 $\mathcal{T}$가 주어졌을 때,
길이가 $\hat{T}$이고 학습 시계열과 동일한 모달리티를 갖는
보지 못한 테스트 시계열 $\hat{\mathcal{T}}$에 대해
우리는
\[\mathcal{Y} = \lbrace y_1, \ldots, y_{\hat{T}} \rbrace\]를 예측해야 한다.
여기서 $y_t \in \lbrace 0, 1 \rbrace$는
테스트 집합에서 $t$번째 시점의 데이터 포인트가
이상인지 여부를 나타내며,
$1$은 해당 데이터 포인트가 이상임을 의미한다.
이상 진단(Anomaly Diagnosis):
위의 학습 및 테스트 시계열이 주어졌을 때,
우리는
\[\mathcal{Y} = \lbrace y_1, \ldots, y_{\hat{T}} \rbrace\]를 예측해야 하며,
이때 $y_t \in \lbrace 0, 1 \rbrace^{m}$은
$t$번째 시점의 데이터 포인트에서
어떤 모드(mode)들이 이상인지를 나타낸다.
이상 탐지(anomaly detection)는
다변량 시계열에서 $m$개의 차원을 하나의 묶음으로 보고,
특정 시점 $t$의 데이터 포인트가
전체적으로 이상인지 여부만을 판별하는 문제이다.이상 진단(anomaly diagnosis)는
동일한 시점 $t$에서
각 차원(또는 모드)별로 이상 여부를 판단하여,
어떤 차원이 이상 발생의 원인인지를 식별하는 문제이다.
3.2 데이터 전처리 (Data Preprocessing)
모델의 강건성을 높이기 위해,
학습과 테스트 모두에서 데이터를 정규화하고
이를 시계열 윈도우 형태로 변환한다.
시계열 데이터는 다음과 같이 정규화한다:
\[x_t \leftarrow \frac{x_t - \min(\mathcal{T})}{\max(\mathcal{T}) - \min(\mathcal{T}) + \epsilon'},\]여기서 $\min(\mathcal{T})$와 $\max(\mathcal{T})$는 학습 시계열에서
각 차원(mode)별 최소값과 최대값으로 이루어진 벡터를 의미한다.
$\epsilon’$는 0으로 나누는 상황을 방지하기 위한
작은 상수 벡터이다.
각 차원의 값 범위를 사전에 알고 있으므로,
이 정규화를 통해 데이터는 $[0, 1)$ 범위로 스케일링된다.
시점 $t$에서의 데이터 포인트 $x_t$의 의존성을 모델링하기 위해,
길이가 $K$인 국소 문맥 윈도우(local contextual window)를 다음과 같이 정의한다:
우리는 $t < K$인 경우에 대해 복제 패딩(replication padding)을 사용하고,
입력 시계열 $\mathcal{T}$를 슬라이딩 윈도우들의 시퀀스
로 변환한다.
복제 패딩은 각 $t < K$에 대해,
윈도우 $W_t$에 길이가 $K - t$인 상수 벡터
를 추가하여 모든 $t$에 대해 윈도우 길이가 $K$가 유지되도록 한다.
예를 들어 윈도우 길이가 $K = 5$이고,
현재 시점이 $t = 2$라고 가정하자.이때 실제로 존재하는 데이터는
$\lbrace x_1, x_2 \rbrace$ 두 개뿐이므로
그대로는 길이 5의 윈도우를 만들 수 없다.이 코드에서 사용하는 복제 패딩(replication padding)은
부족한 과거 데이터를
첫 시점 값 $x_1$로 반복해서 채우는 방식이다.즉, $W_2 = \lbrace x_1, x_1, x_1, x_1, x_2 \rbrace$와 같이
첫 값 $x_1$을 여러 번 복제하여
윈도우 길이를 항상 $K = 5$로 맞춘다.
학습 입력으로 $\mathcal{T}$를 직접 사용하는 대신,
모델 학습에는 $\mathcal{W}$를 사용하고,
테스트 시계열로는 $\hat{\mathcal{T}}$에 대응하는
$\hat{\mathcal{W}}$를 사용한다.
이와 같은 방식은 단일 벡터 대신
데이터 포인트에 국소 문맥을 함께 제공할 수 있으므로,
기존 연구 [4, 45]에서도 일반적으로 사용되는 관행이며
본 모델에서도 이를 채택한다.
또한 시계열 $\mathcal{T}$에서
현재 시점 $t$까지의 시간 구간을 고려하며,
이를 $C_t$로 표기한다.
이제 각 입력 윈도우 $W_t$에 대해
이상 라벨 $y_t$를 직접 예측하는 대신,
먼저 해당 윈도우에 대한 이상 점수 $s_t$를 예측한다.
이전 입력 윈도우들에 대한 이상 점수들을 이용하여
임계값 $D$를 계산하고,
이 값보다 큰 경우 입력 윈도우를 이상으로 라벨링한다.
즉, \(y_t = \mathbb{I}(s_t \ge D)\) 로 정의한다.
이상 점수 $s_t$를 계산하기 위해,
입력 윈도우를 $O_t$로 재구성하고
$W_t$와 $O_t$ 사이의 편차를 사용한다.
이후 논의를 단순화하고 일반성을 잃지 않기 위해,
앞으로는 $W$, $C$, $O$, $s$ 표기를 사용한다.
3.3 트랜스포머 모델 (Transformer Model)
트랜스포머(transformer)는
자연어 처리와 비전 처리 등 다양한 작업에서 활용되어 온
대표적인 딥러닝 모델이다 [51].
그러나 본 연구에서는
시계열 데이터에서의 이상 탐지 작업을 위해
트랜스포머 구조를 통찰력 있게 재구성하여 사용한다.
다른 인코더–디코더 모델들과 마찬가지로,
트랜스포머에서는 입력 시퀀스가
여러 단계의 어텐션 기반 변환을 거치게 된다.
그림 1은 TranAD에서 사용된 신경망 구조를 보여준다.
인코더는 현재 시점 $C$까지의 전체 시퀀스를
포커스 점수(focus score)를 이용하여 인코딩한다
(이에 대한 자세한 설명은 이후에 제시한다).
윈도우 인코더는 이 정보를 활용하여
입력 윈도우 $W$의 인코딩된 표현을 생성하고,
이 표현은 이후 두 개의 디코더로 전달되어
입력 윈도우의 재구성을 수행한다.
그림 1. TranAD 모델
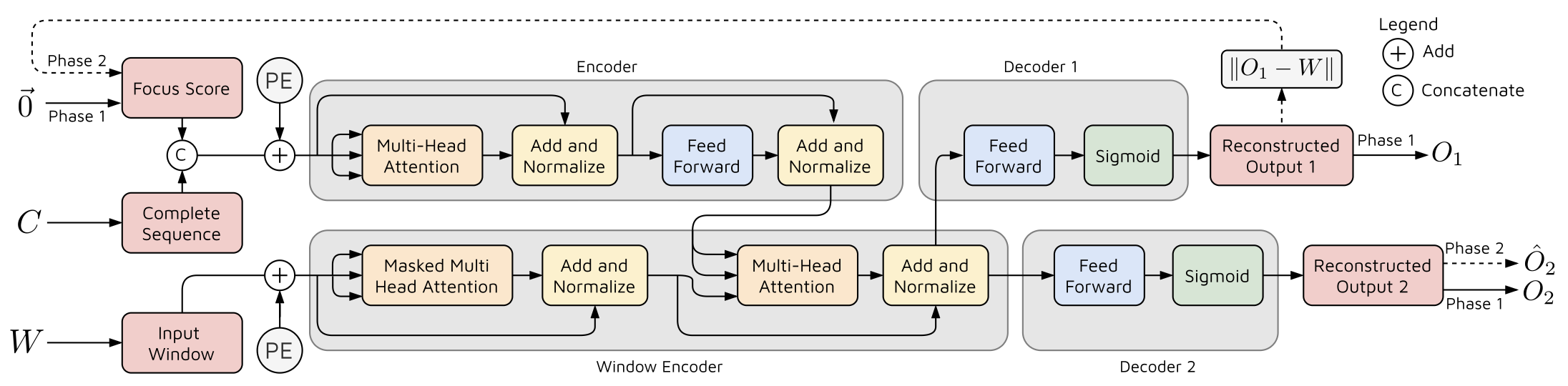
이제 TranAD의 동작 방식에 대한 세부 사항을 설명한다.
$W$ 또는 $C$와 같은 다변량 시퀀스는
먼저 모달리티 수가 $m$인 행렬 형태로 변환된다.
세 개의 행렬 $Q$(query), $K$(key), $V$(value)에 대해
스케일드 점곱 어텐션(scaled-dot product attention) [51]을 다음과 같이 정의한다:
여기서 softmax는
$V$에 포함된 값들에 대한 볼록 결합(convex combination)의 가중치를 형성하여,
행렬 $V$를 더 작은 대표 임베딩으로 압축할 수 있게 해주며,
이는 이후 신경망 연산에서 추론을 단순화하는 데 사용된다.
전통적인 어텐션 연산과 달리,
스케일드 점곱 어텐션은
가중치에 $\sqrt{m}$ 항으로 스케일링을 적용함으로써
가중치의 분산을 줄이고
보다 안정적인 학습을 가능하게 한다 [51].
입력 행렬 $Q$, $K$, $V$에 대해
우리는 멀티헤드 셀프 어텐션(multi-head self-attention) [51]을 적용한다.
이를 위해 먼저 $h$(헤드의 개수)개의 피드포워드 계층을 통과시켜
$i \in \lbrace 1, \ldots, h \rbrace$에 대해
$Q_i$, $K_i$, $V_i$를 얻고,
각각에 대해 스케일드 점곱 어텐션을 적용한다:
여기서 \(H_i = \mathrm{Attention}(Q_i, K_i, V_i).\)
멀티헤드 어텐션은
서로 다른 위치에서
서로 다른 표현 부분공간(sub-space)의 정보에
동시에 주의를 기울일 수 있도록 해준다.
추가적으로,
[51]에서 정의된 방식에 따라
입력 행렬에 위치 인코딩(position encoding)을 적용한다.
GAN 모델은
입력이 이상인지 여부를 판별하는 특성화 작업에서
우수한 성능을 보이는 것으로 알려져 있으므로,
본 연구에서는 시간 효율적인 GAN 스타일의
적대적 학습(adversarial training) 방법을 활용한다.
우리 모델은
두 개의 트랜스포머 인코더와
두 개의 디코더로 구성된다(그림 1).
모델의 추론 과정은 두 단계로 나누어 고려한다.
먼저 $W$와 $C$의 쌍을 입력으로 사용하고,
포커스 점수 $F$를 함께 사용한다.
$F$는 초기에는 $W$와 동일한 차원의 영 행렬이며,
이에 대한 자세한 내용은 다음 소절에서 설명한다.
이후 $F$를 $W$의 차원에 맞게 브로드캐스트하고,
적절한 제로 패딩을 적용한 뒤
두 행렬을 연결(concatenate)한다.
그 다음 위치 인코딩(position encoding)을 적용하여
첫 번째 인코더의 입력 $I_1$을 얻는다.
첫 번째 인코더는 다음과 같은 연산을 수행한다:
\[\begin{aligned} I_1^{(1)} &= \mathrm{LayerNorm}\!\bigl(I_1 + \mathrm{MultiHeadAtt}(I_1, I_1, I_1)\bigr), \\ I_1^{(2)} &= \mathrm{LayerNorm}\!\bigl(I_1^{(1)} + \mathrm{FeedForward}(I_1^{(1)})\bigr). \end{aligned} \tag{4}\]여기서 $\mathrm{MultiHeadAtt}(I_1, I_1, I_1)$는
입력 행렬 $I_1$에 대한 멀티헤드 셀프 어텐션 연산을 의미하며,
$+$는 행렬 덧셈을 나타낸다.
위 연산들은
입력 시계열 윈도우와 전체 시퀀스를 사용하여
어텐션 가중치를 생성함으로써
입력 시퀀스 내부의 시간적 추세를 포착한다.
이러한 연산들은
각 시점에서 신경망이 이전 시점의 출력에 의존하지 않기 때문에,
시계열 윈도우들의 여러 배치를 병렬로 추론할 수 있게 하며,
그 결과 제안된 방법의 학습 시간을 크게 단축시킨다.
윈도우 인코더의 경우,
입력 윈도우 $W$에 위치 인코딩을 적용하여
$I_2$를 얻는다.
또한 윈도우 인코더에서는
이후 위치의 데이터를 가리기 위해
셀프 어텐션에 마스킹을 적용한다.
이는 학습 시
병렬 처리를 위해 $W$와 $C$의 모든 데이터가
한 번에 주어지더라도,
디코더가 미래 시점의 데이터 포인트를
미리 참조하지 못하도록 하기 위함이다.
윈도우 인코더는 다음과 같은 연산을 수행한다:
\[\begin{aligned} I_2^{(1)} &= \mathrm{Mask}\!\bigl(\mathrm{MultiHeadAtt}(I_2, I_2, I_2)\bigr), \\ I_2^{(2)} &= \mathrm{LayerNorm}\!\bigl(I_2 + I_2^{(1)}\bigr), \\ I_2^{(3)} &= \mathrm{LayerNorm}\!\bigl(I_2^{(2)} + \mathrm{MultiHeadAtt}(I_2^{(2)}, I_1^{(2)}, I_1^{(2)})\bigr). \end{aligned} \tag{5}\]전체 시퀀스의 인코딩 결과인 $I_1^{(2)}$는
윈도우 인코더에서 어텐션 연산을 수행할 때
값(value)과 키(key)로 사용되며,
인코딩된 입력 윈도우는 질의(query) 행렬로 사용된다.
식 (5)에 나타난 연산의 동기는
식 (4)의 경우와 유사하지만,
여기서는 동일한 입력 배치 내에서
미래 시점에 해당하는 윈도우 시퀀스를 가리기 위해
윈도우 입력에 마스킹을 적용한다.
모델에는 $t$번째 시점까지의 전체 입력 시퀀스가
입력으로 주어지므로,
기존 연구 [4, 45, 62]에서와 같은
제한된 범위의 문맥보다 더 넓은 문맥을
포함하고 활용할 수 있다.
마지막으로, 우리는 동일한 구조의 두 개의 디코더를 사용하며,
각 디코더는 다음 연산을 수행한다:
여기서 $i \in \lbrace 1, 2 \rbrace$는
각각 첫 번째와 두 번째 디코더를 의미한다.
Sigmoid 활성화 함수는
정규화된 입력 윈도우와 범위를 맞추기 위해
출력을 $[0, 1]$ 구간으로 생성한다.
따라서 TranAD 모델은
입력 $C$와 $W$를 받아
두 개의 출력 $O_1$과 $O_2$를 생성한다.
3.4 오프라인 2단계 적대적 학습 (Offline Two-Phase Adversarial Training)
이제 알고리즘 1에 요약된 TranAD 모델의
적대적 학습 과정과
두 단계 추론(two-phase inference) 접근법을 설명한다.

단계 1 – 입력 재구성 (Phase 1 – Input Reconstruction)
트랜스포머 모델은 각 입력 시계열 윈도우의 재구성을 예측할 수 있게 해준다.
이는 각 시점에서 인코더–디코더 네트워크로 동작함으로써 이루어진다.
그러나 전통적인 인코더–디코더 모델은
단기적인 추세를 포착하지 못하는 경우가 많으며,
편차가 너무 작을 경우 이상을 놓치는 경향이 있다 [29].
이러한 문제를 해결하기 위해,
본 연구에서는 재구성된 윈도우를 두 단계로 예측하는
자기회귀(auto-regressive) 추론 방식을 개발한다.
첫 번째 단계에서 모델은
입력 윈도우의 근사적인 재구성을 생성하는 것을 목표로 한다.
이 추론으로부터의 편차는
앞서 언급한 포커스 점수(focus score)로 불리며,
트랜스포머 인코더 내부의 어텐션 네트워크가
편차가 큰 부분 시퀀스에 집중하여
시간적 추세를 추출하도록 돕는다.
따라서 두 번째 단계의 출력은
첫 번째 단계에서 생성된 편차에 조건화된다(conditioned).
즉, 첫 번째 단계에서 인코더는
입력 윈도우 \(W \in \mathbb{R}^{K \times m}\)
(포커스 점수 \(F = [0]_{K \times m}\)를 갖는 경우)을
일반적인 트랜스포머 모델과 동일하게
문맥 기반 어텐션을 사용하여
압축된 잠재 표현 $I_2^{(3)}$으로 변환한다.
이렇게 얻어진 압축 표현은
식 (6)을 통해 출력 $O_1$과 $O_2$를 생성하는 데 사용된다.
단계 2 – 포커스된 입력 재구성 (Phase 2 – Focused Input Reconstruction)
두 번째 단계에서는
첫 번째 디코더에 대한 재구성 손실을
포커스 점수로 사용한다.
두 번째 단계의 포커스 행렬을
\(F = L_1\)로 두고,
두 번째 디코더의 출력 $\hat{O}_2$를 얻기 위해
모델 추론을 다시 수행한다.
첫 번째 단계에서 생성된 포커스 점수는
주어진 입력으로부터 재구성된 출력의 편차를 나타낸다.
이는 두 번째 단계에서 어텐션 가중치를 수정하기 위한
사전 정보(prior)로 작용하며,
특정 입력 부분 시퀀스에 대해
더 높은 신경망 활성화를 부여하여
단기적인 시간적 추세를 추출할 수 있도록 한다.
본 논문에서는 이 접근 방식을
“자기-조건화(self-conditioning)”라고 부른다.
이러한 두 단계 자기회귀 추론 방식은
세 가지 이점을 가진다.
첫째,
재구성 오차가 그림 1의 인코더 내 어텐션 부분에서
활성화로 작용함으로써 편차를 증폭시켜,
이상 점수를 생성하고
결함 라벨링 작업을 단순화한다
(3.5절에서 논의됨).
둘째,
그림 1의 윈도우 인코더에서
단기적인 시간적 추세를 포착함으로써
거짓 양성(false positive)을 방지한다.
셋째,
적대적(adversarial) 스타일의 학습은
일반화 성능을 향상시키고,
다양한 입력 시퀀스에 대해
모델을 더욱 강건하게 만드는 것으로 알려져 있다 [4].
진화하는 학습 목적 함수 (Evolving Training Objective)
앞서 설명한 모델은
다른 적대적 학습 프레임워크와 유사한 문제들로 인해
필연적으로 어려움을 겪을 수 있다.
그중 하나의 핵심적인 문제는
학습 안정성을 유지하는 것이다.
이를 해결하기 위해,
본 연구에서는 두 개의 분리된 디코더
(그림 1의 디코더 1과 디코더 2)의 출력을 사용하는
적대적 학습 절차를 설계한다.
초기 단계에서 두 디코더는
입력 시계열 윈도우를
각각 독립적으로 재구성하는 것을 목표로 한다.
[45]와 [39]에서와 마찬가지로,
우리는 첫 번째 단계의 출력을 사용하여
각 디코더에 대한 재구성 손실을
$L_2$-노름으로 정의한다:
이제 두 번째 단계의 출력을 사용하는
적대적 손실(adversarial loss)을 도입한다.
여기서 두 번째 디코더는
첫 번째 단계에서 첫 번째 디코더가 생성한
후보 재구성(candidate reconstruction)과
입력 윈도우를 구별하는 것을 목표로 하며,
이를 위해 포커스 점수를 사용하여
다음 값의 차이를 최대화한다: \(\lVert \hat{O}_2 - W \rVert_2.\)
반면에 첫 번째 디코더는
입력을 완벽하게 재구성함으로써
(즉, $O_1 = W$)
퇴화된 포커스 점수(영 벡터)를 생성하는 것을 목표로 하여
두 번째 디코더를 속이려고 한다.
이 과정은 두 번째 단계에서
디코더 2가
첫 번째 단계에서 입력을 맞추려고 했던 출력 $O_2$와
동일한 출력을 생성하도록 유도한다.
따라서 학습 목적 함수는 다음과 같이 정의된다:
\[\min_{\text{Decoder1}} \; \max_{\text{Decoder2}} \; \lVert \hat{O}_2 - W \rVert_2. \tag{8}\]따라서 첫 번째 디코더의 목적은
이 자기-조건화(self-conditioned) 출력의 재구성 오차를
최소화하는 것이며,
두 번째 디코더의 목적은
동일한 오차를 최대화하는 것이다.
우리는 이를 다음과 같은 손실 함수를 사용하여 구현한다:
\[\begin{aligned} L_1 &= +\lVert \hat{O}_2 - W \rVert_2, \\ L_2 &= -\lVert \hat{O}_2 - W \rVert_2. \end{aligned} \tag{9}\]이제 두 단계 모두에 대한 손실 함수가 정의되었으므로,
각 디코더에 대한 누적 손실을 결정할 필요가 있다.
이를 위해 우리는 두 단계에서의
재구성 손실과 적대적 손실을 결합하는
진화형 손실 함수(evolutionary loss function)를 다음과 같이 사용한다.
여기서 $n$은 학습 에폭(epoch)을 의미하며,
$\epsilon$은 1에 가까운 학습 파라미터이다
(Algorithm 1의 7–8번째 줄).
초기에는 재구성 손실에 부여되는 가중치가 크다.
이는 디코더의 출력이 입력 윈도우를
아직 제대로 재구성하지 못하는 상황에서도
학습이 안정적으로 진행되도록 하기 위함이다.
재구성이 부정확한 경우,
두 번째 단계에서 사용되는 포커스 점수는 신뢰할 수 없으며,
따라서 입력 시퀀스와 크게 다른 재구성을
가리키는 사전 정보로 활용될 수 없다.
이로 인해 학습 초기에는
모델 학습의 불안정을 방지하기 위해
적대적 손실에 낮은 가중치를 부여한다.
재구성이 점차 입력 윈도우에 가까워지고,
포커스 점수가 더 정밀해짐에 따라,
적대적 손실에 대한 가중치는 점차 증가한다.
신경망 학습 과정에서의 손실 곡선이
일반적으로 지수 함수 형태를 따르므로,
우리는 작은 양의 상수 파라미터 $\epsilon$을 갖는
$\epsilon^{-n}$ 형태의 가중치를
학습 과정에서 사용한다.
학습 과정은 데이터가
온라인 과정과 같이 순차적으로 제공된다고 가정하지 않으므로,
전체 시계열은 $(W, C)$ 쌍으로 분할될 수 있으며
모델은 입력 배치를 사용하여 학습될 수 있다.
마스크된 멀티-헤드 어텐션은
여러 배치에 대해 이를 병렬로 수행할 수 있게 해주며,
그 결과 학습 과정을 가속화한다.
메타 러닝 (Meta Learning)
마지막으로, 본 연구의 학습 루프는
신경망의 빠른 적응을 위한 소수 샷(few-shot) 학습 모델인
모델 비의존적 메타 학습(model-agnostic meta learning, MAML)을 사용한다 [15].
이는 제한된 데이터만으로도
TranAD 모델이 입력 학습 시계열에서
시간적 추세를 학습할 수 있도록 돕는다.
각 학습 에폭마다,
신경망 가중치(일반성을 잃지 않고 $\theta$라 가정함)에 대한
그래디언트 업데이트는 다음과 같이 간단히 쓸 수 있다.
여기서 $\alpha$, $f(\cdot)$, $L(\cdot)$는 각각
학습률 및 신경망과 손실 함수의 추상적 표현을 의미한다.
이제 각 에폭의 끝에서
다음과 같은 메타 학습 단계를 수행한다.
메타 최적화는
메타 스텝 크기 $\beta$를 사용하여
모델 가중치 $\theta$에 대해 수행되며,
이때 목적 함수는
업데이트된 가중치 $\theta’$를 사용하여 평가된다.
기존 연구에서는
이러한 방식이 제한된 데이터 환경에서도
모델을 빠르게 학습할 수 있음을 보였다 [15].
본 연구에서는 이를
알고리즘 1의 한 줄(11번째 줄)로 요약하여 표현한다.
MAML(model-agnostic meta learning)은
개별 데이터나 특정 작업에서 바로 성능을 잘 내는 파라미터를 학습하는 것이 아니라,
아주 적은 데이터와 몇 번의 그래디언트 업데이트만으로도
빠르게 적응할 수 있는 파라미터의 출발점을 학습하는 메타 학습 방법이다.이를 위해 MAML은
먼저 현재 파라미터에서 한 번의 그래디언트 스텝을 수행하여
해당 데이터에 적응한 파라미터를 만들고,
그 결과가 얼마나 잘 작동했는지를 기준으로
다시 원래 파라미터를 업데이트한다.이 두 단계 업데이트 과정은
“조금 학습했을 때 성능이 얼마나 빨리 좋아지는가”를 직접적으로 고려하게 하며,
결과적으로 적은 데이터 환경에서도
빠른 학습과 안정적인 성능을 가능하게 한다.MAML은 모델의 구조나 형태에 대한 가정을 두지 않고,
기울기 기반 학습이 가능한 모델이면
어떤 아키텍처에도 그대로 적용할 수 있기 때문에
model-agnostic이라 불린다.따라서 MAML은
새로운 데이터나 환경이 주어졌을 때
처음부터 긴 학습 과정을 거치지 않고도
몇 번의 업데이트만으로 효과적으로 적응해야 하는 문제에 적합한 방법이다.
3.5 온라인 추론, 이상 탐지 및 진단
(Online Inference, Anomaly Detection and Diagnosis)
이제 학습된 트랜스포머 모델을 사용한
추론 절차를 설명한다(알고리즘 2에 요약되어 있다).

보지 못한 데이터 $(\hat{W}, \hat{C})$에 대해,
이상 점수(anomaly score)는 다음과 같이 정의된다.
테스트 시점에서의 추론 또한
두 단계로 다시 수행되며,
그 결과로 하나의 재구성 쌍
$(O_1, \hat{O}_2)$를 얻게 된다
(알고리즘 2의 2–3번째 줄).
테스트 시점에서는
현재 타임스탬프까지의 데이터만을 고려하므로,
이 연산은 온라인 방식으로
순차적으로 수행된다.
각 차원에 대해
해당 타임스탬프의 이상 점수 $s_i$가 계산되면,
이 점수가 임계값보다 클 경우
해당 타임스탬프를 이상으로 라벨링한다.
기존 연구 [9, 20, 45]에서 일반적으로 사용하는 방식과 동일하게,
공정한 비교를 위해
본 연구에서는 Peak Over Threshold(POT) [44] 방법을 사용하여
임계값을 자동적이고 동적으로 선택한다.
본질적으로 POT는
극값 이론(extreme value theory)을 사용하는 통계적 방법으로,
데이터 분포를 일반화 파레토 분포(Generalized Pareto Distribution)에 적합시키고,
동적으로 임계값을 결정하기 위한
적절한 위험 값(value at risk)을 식별한다.
또한 또 다른 대표적인 EVT 방법인
연간 최대값(annual maximum, AM) [7]도 함께 실험하였으나,
TranAD에서는 POT를 사용할 경우
AM 대비 평균적으로 7.2% 더 높은 F1 점수를 보였다.
각 차원 $i$에 대한 이상 진단 라벨 $y_i$와
이상 탐지 결과 $y$는 다음과 같이 정의된다.
즉, $m$개의 차원 중
하나라도 이상으로 판단되면
현재 타임스탬프 전체를 이상으로 라벨링한다
(알고리즘 2의 5–6번째 줄).
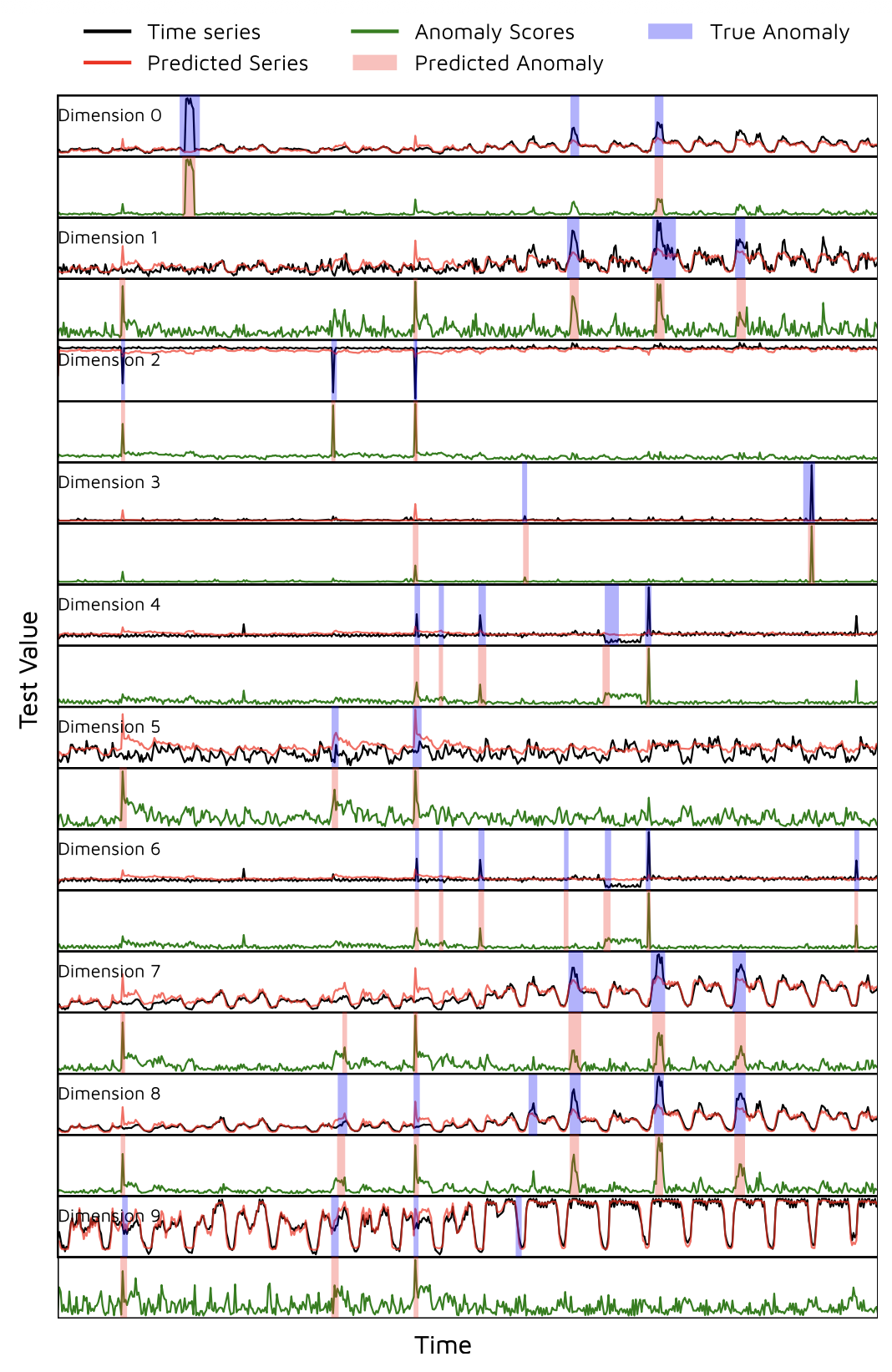
그림 2는
하나의 예제 시계열에 대해
이 과정을 시각적으로 보여준다.
그림 2: 이상 예측의 시각화.
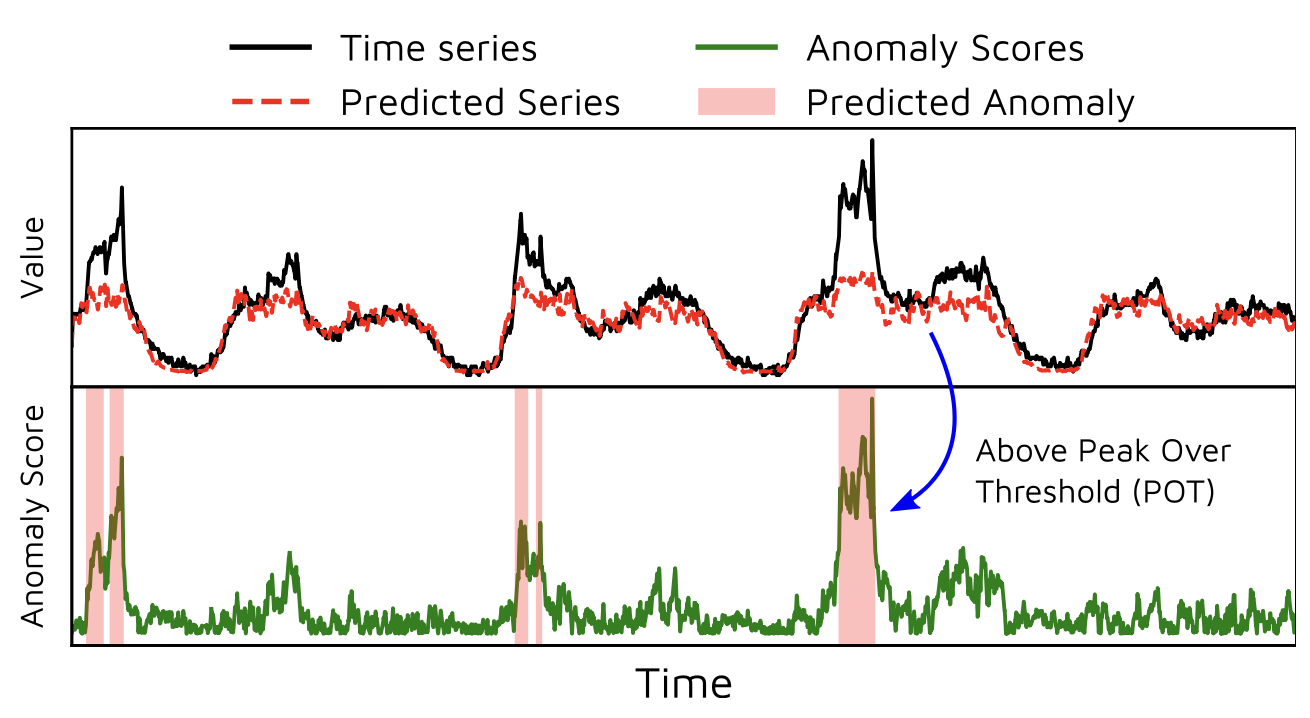
어텐션과 포커스 점수의 영향
(Impact of Attention and Focus Scores)
그림 3은 SMD 데이터셋으로 학습된 TranAD 모델의
어텐션과 포커스 점수를 시각화한다 (자세한 내용은 4.1절 참조).
그림 3: 포커스 점수와 어텐션 점수의 시각화.
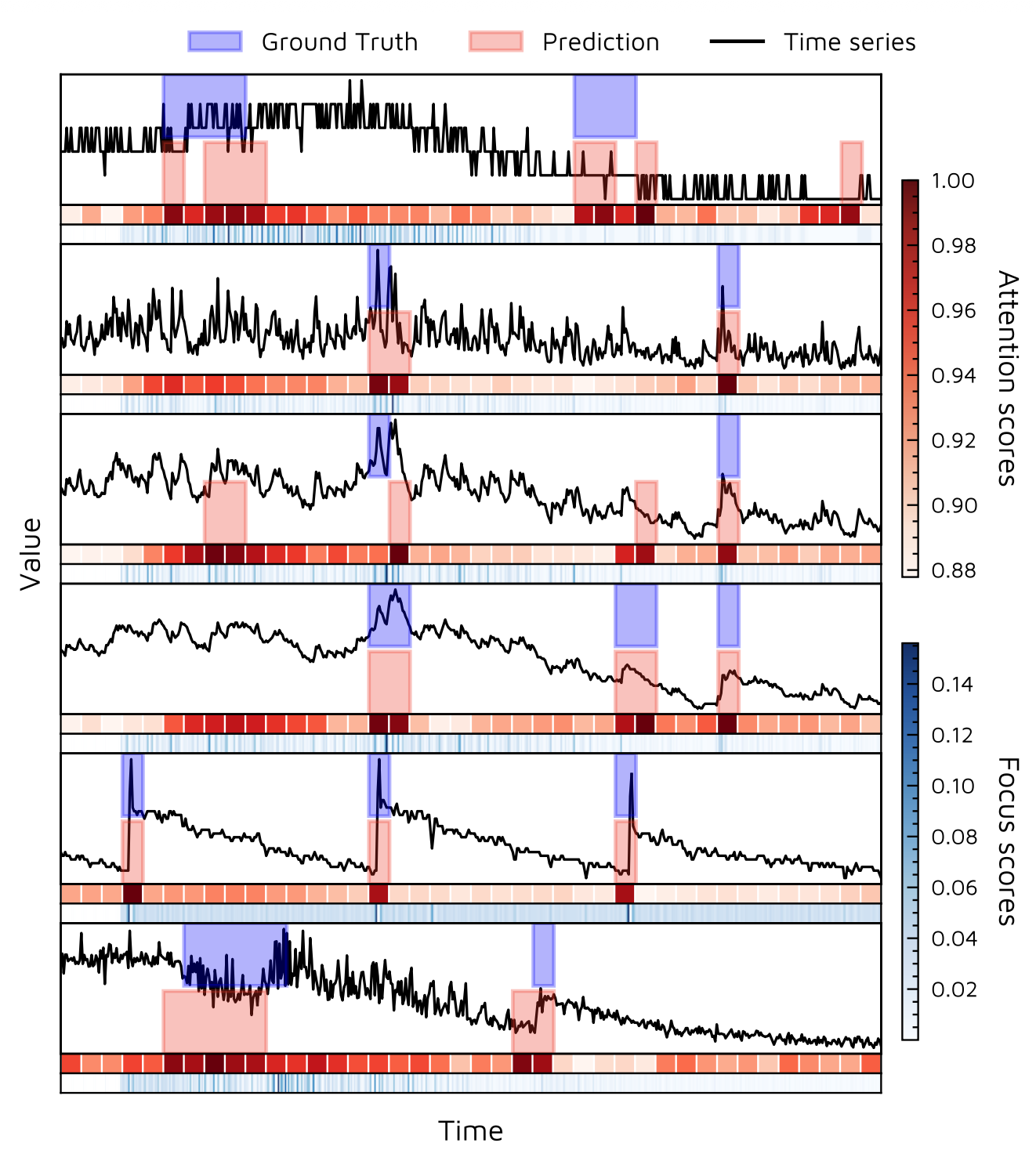
우리는 시계열, 각 윈도우에 대한 평균 어텐션 가중치
(여러 헤드에 대해 평균됨),
그리고 데이터셋의 처음 6개 차원에 대한
포커스 점수를 함께 제시한다.
포커스 점수는 데이터의 피크와 노이즈와
높은 상관관계를 가지는 것이 분명히 드러난다.
또한 차원 간 포커스 점수 역시 높은 상관관계를 보인다.
시계열에서 급격한 변화가 발생하는 타임스탬프에서는
포커스 점수가 더 크게 나타난다.
더 나아가, 모델은 편차가 큰 시계열의
특정 차원에 더 높은 어텐션 가중치를 부여한다.
이는 전체 시퀀스의 문맥적 추세를 사전 정보로 활용하여,
각 차원별 이상을 개별적으로 정밀하게 탐지할 수 있도록 한다.
4 실험 (Experiments)
우리는 MERLIN [37], LSTM-NDT [20] (openGauss [30]의 오토인코더 구현 사용),
DAGMM [65], OmniAnomaly [45], MSCRED [60], MAD-GAN [29], USAD [4],
MTAD-GAT [62], CAE-M [61], 그리고 GDN [14]
(GraphAn [9]의 그래프 임베딩 구현 사용) 등을 포함한
다변량 시계열 이상 탐지를 위한 최신(state-of-the-art) 모델들과
TranAD를 비교한다.
자세한 내용은 2.1절을 참고하라. 1
1 우리는 대부분의 베이스라인에 대해 공개된 코드 소스를 사용한다.
LSTM-NDT: https://github.com/khundman/telemanom
openGauss: https://gitee.com/opengauss/openGauss-AI
DAGMM: https://github.com/tnakae/DAGMM
OmniAnomaly: https://github.com/NetManAIOps/OmniAnomaly
MSCRED: https://github.com/7fantasysz/MSCRED
MAD-GAN: https://github.com/LiDan456/MAD-GANs다른 모델들은 우리가 직접 재구현하였다.
MERLIN 베이스라인의 구현에 대해서는 부록 A를 참고하라.
또한 Isolation Forest 방법도 실험하였으나,
F1 점수가 낮았기 때문에 해당 결과는 논의에 포함하지 않는다.
다른 고전적 방법들은 이전 연구 [4, 14, 62]에서
딥러닝 기반 접근법들이 이미 더 우수한 성능을 보였으므로 생략하였다.
우리는 각 베이스라인 모델의 하이퍼파라미터를
해당 논문에 제시된 설정 그대로 사용한다.
모든 모델은 PyTorch-1.7.1 [40] 라이브러리를 사용하여 학습한다.2
2병렬 트랜스포머 학습은 [51]을 따라 구현되었다.
모든 모델 학습 및 실험은 Intel i7-10700K CPU, 64GB RAM,
Nvidia RTX 3080, Windows 11 OS 환경에서 수행되었다.
우리는 AdamW [27] 옵티마이저를 사용하여
초기 학습률 0.01 (메타 학습률 0.02)과
스텝 크기 0.5의 스텝 스케줄러 [42]로 모델을 학습한다.
사용한 하이퍼파라미터 값은 다음과 같다.
- 윈도우 크기 = 10.
- 트랜스포머 인코더의 레이어 수 = 1
- 인코더 내 피드포워드 유닛의 레이어 수 = 2
- 인코더 레이어의 히든 유닛 수 = 64
- 인코더의 드롭아웃 = 0.1
윈도우 크기가 이상 탐지 성능에 미치는 영향은 5절에서 분석한다.
윈도우 크기를 제외한 다른 하이퍼파라미터들은
그리드 서치를 사용하여 선택하였다.
POT 파라미터의 경우,
모든 데이터셋에 대해 계수는 $10^{-4}$로 설정하였으며,
하위 분위수(low quantile)는
SMAP의 경우 0.07, MSL의 경우 0.01,
그 외 데이터셋의 경우 0.001로 설정하였다.
이는 OmniAnomaly 베이스라인 [45]의 구현을 따라 선택한 것이다.
데이터셋별로 다른 유일한 하이퍼파라미터는
멀티헤드 어텐션의 헤드 수이며,
이는 데이터셋의 차원 크기와 동일하게 설정하였다.
이 하이퍼파라미터에 대해 다른 설정을 사용하더라도
전반적인 추세는 유사하게 나타났다.
TranAD를 학습하기 위해,
학습 시계열을 80%의 학습 데이터와
20%의 검증 데이터로 분할한다.
모델 과적합을 방지하기 위해,
검증 정확도가 감소하기 시작하면 학습을 중단하는
조기 종료(early-stopping) 기준을 사용하여
TranAD를 학습한다.
4.1 데이터셋 (Datasets)
우리는 실험에서 공개적으로 사용 가능한
일곱 개의 데이터셋을 사용한다.
이들의 특성은 표 1에 요약되어 있다.
표 1: 데이터셋 통계
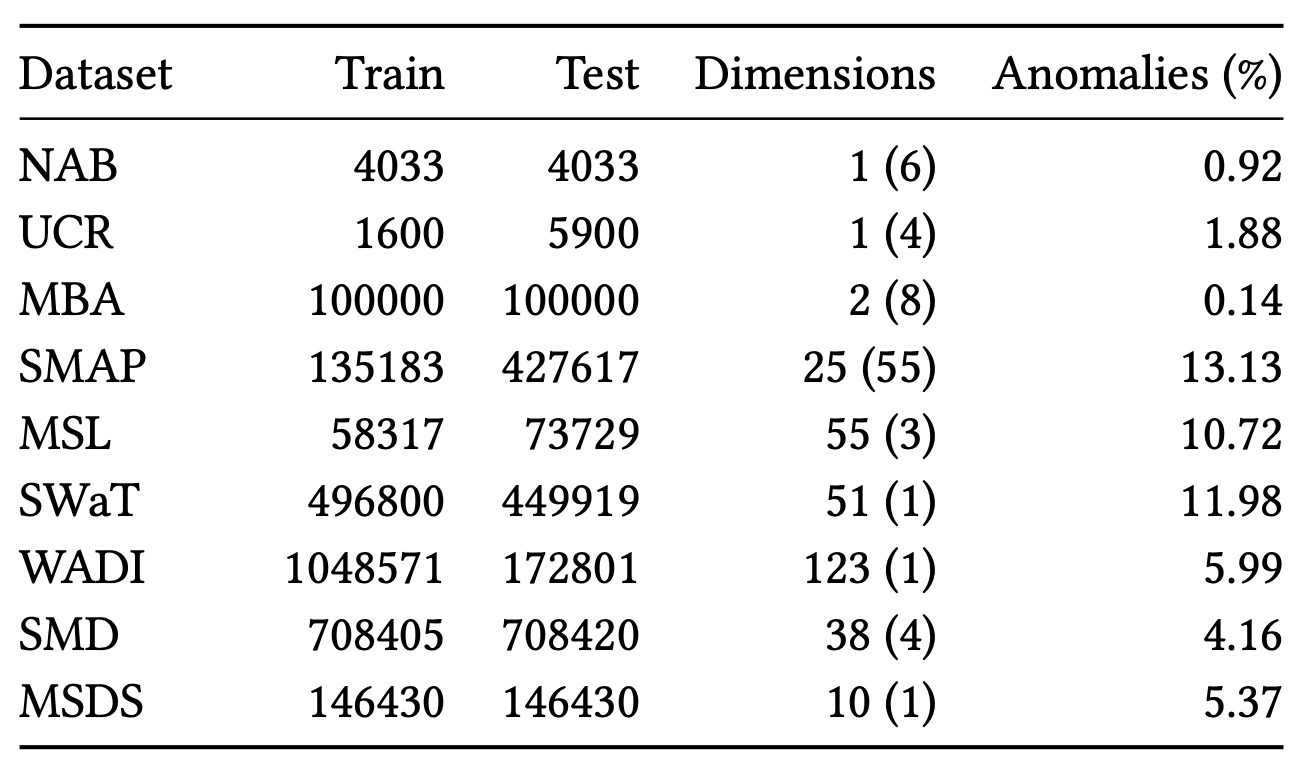
괄호 안의 값은
데이터셋 저장소에 포함된 시퀀스의 개수를 의미하며,
우리는 각 데이터셋에 포함된
모든 시퀀스에 대해 평균 점수를 보고한다
(NAB와 UCR은 단변량 데이터셋이며,
나머지는 모두 다변량 데이터셋이다).
예를 들어, SMAP 데이터셋은
각각 25개의 차원을 가지는 55개의 트레이스를 포함한다.
시계열 이상 탐지를 위한 고품질 벤치마크 데이터셋이 부족하다는 점에 대해
[55]에서 제기된 일부 우려에 공감하지만,
경쟁 방법들과의 직접적인 비교를 가능하게 하기 위해
여기서는 널리 사용되는 이러한 벤치마크 데이터셋들을 사용한다.
(1) Numenta Anomaly Benchmark (NAB):
온도 센서 측정값, 클라우드 머신의 CPU 사용률,
서비스 요청 지연 시간, 뉴욕시의 택시 수요 등을 포함하는
여러 실제(real-world) 데이터 트레이스로 구성된 데이터셋이다 [2].
그러나 이 데이터셋은 nyc-taxi 트레이스 [37]와 같이
이상 라벨이 잘못 지정된 시퀀스를 포함하는 것으로 알려져 있으며,
우리는 이러한 시퀀스를 실험에서 제외하였다.
(2) HexagonML (UCR) 데이터셋:
단변량 시계열로 구성된 여러 데이터셋의 모음으로, 완전성을 위해 포함되었으며
KDD 2021 컵 [13, 26]에서 사용되었다.
우리는 자연적인 출처에서 얻어진 데이터셋
(InternalBleeding 및 ECG 데이터셋)만 포함하고,
합성 시퀀스는 제외한다.
(3) MIT-BIH Supraventricular Arrhythmia Database (MBA):
네 명의 환자로부터 수집된 심전도(electrocardiogram) 기록의 모음으로,
두 가지 서로 다른 유형의 이상 (상심실 수축 또는 조기 심박동)을
여러 번 포함한다 [17, 36].
이는 데이터 관리 커뮤니티에서
널리 사용되는 대규모 데이터셋이다 [8, 10].
(4) Soil Moisture Active Passive (SMAP) 데이터셋:
NASA의 화성 탐사 로버를 이용해 수집된
토양 샘플과 원격 측정 정보로 구성된 데이터셋이다 [20].
(5) Mars Science Laboratory (MSL) 데이터셋:
SMAP과 유사하지만,
화성 로버 자체의 센서 및 액추에이터 데이터에 해당한다 [20].
그러나 이 데이터셋은
많은 자명한(trivial) 시퀀스를 포함하는 것으로 알려져 있으므로,
[37]에서 지적된 세 개의 비자명한 시퀀스 (A4, C2, T1)만을 고려한다.
(6) Secure Water Treatment (SWaT) 데이터셋:
실제 상수 처리 플랜트에서 수집된 데이터셋으로,
7일간의 정상 동작과 4일간의 비정상 동작을 포함한다 [33].
이 데이터셋은 센서 값(수위, 유량 등)과
액추에이터 동작(밸브 및 펌프)으로 구성된다.
(7) Water Distribution (WADI) 데이터셋:
SWaT 시스템의 확장 버전으로,
SWaT 모델보다 두 배 이상의 센서와 액추에이터를 포함한다 [3].
또한 이 데이터셋은
14일간의 정상 시나리오와 2일간의 공격 시나리오에 대해
더 긴 기간 동안 수집되었다.
(8) Server Machine Dataset (SMD):
이는 컴퓨트 클러스터에 속한 28대 머신의 자원 사용량에 대해
적층된 트레이스로 구성된, 총 5주 길이의 데이터셋이다 [45].
MSL과 유사하게, 우리는 이 데이터셋에서도
비자명한 시퀀스만을 사용하며, 구체적으로
machine-1-1, 2-1, 3-2, 3-7로 명명된 트레이스를 사용한다.
(9) Multi-Source Distributed System (MSDS) Dataset:
분산 트레이스, 애플리케이션 로그,
복잡한 분산 시스템에서 수집된 메트릭으로 구성된
최근의 고품질 다중 소스 데이터셋이다 [38].
이 데이터셋은 자동 이상 탐지, 근본 원인 분석,
그리고 복구(remediation)를 포함한
AI 운영을 위해 특별히 구축되었다.
우리는 라벨 오류 및 실패 시점 편향(run-to-failure bias)을
겪는 것으로 알려진 Yahoo 데이터셋 [53]에 대해서는
비교를 수행하지 않는다 [55].
4.2 평가 지표
4.2.1 이상 탐지
우리는 모든 모델의 탐지 성능을 평가하기 위해
정밀도(precision), 재현율(recall),
수신자 조작 특성 곡선 아래 면적(ROC/AUC),
그리고 F1 점수를 사용한다 [14, 62].
또한 제한된 데이터에서의 모델 성능을 측정하기 위해,
모든 모델을 학습 데이터의 20%만 사용하여 학습시키고
(검증 데이터셋과 나머지를 테스트 세트로 사용하는 80:20 분할을 다시 사용함),
이때의 AUC와 F1 점수를 각각 AUC와 F1로 표기한다.
통계적 유의성을 확보하기 위해,
우리는 다섯 개의 20% 학습 데이터 세트로 학습을 수행하고
그 평균 결과를 보고한다.
4.2.2 이상 진단
우리는 모든 모델의 진단 성능을 측정하기 위해
일반적으로 사용되는 지표들을 사용한다 [62].
HitRate@P%는 모델이 예측한 상위 후보들 중에
실제 정답(ground truth)에 해당하는 차원들이
얼마나 포함되어 있는지를 측정하는 지표이다 [45].
P%는 각 시점에서 실제 이상으로 라벨링된 차원들의 비율을 의미하며,
이를 기준으로 상위 예측 후보들을 고려한다.
예를 들어, 시점 $t$에서 실제로 2개의 차원이 이상으로 라벨링되어 있다면,
HitRate@100%는 상위 2개의 차원을 고려하고,
HitRate@150%는 상위 3개의 차원을 고려한다
(100과 150은 선행 연구 [62]를 기반으로 선택되었다).
또한 우리는 정규화 할인 누적 이득
(Normalized Discounted Cumulative Gain, NDCG) [24]도 측정한다.
NDCG@P%는 HitRate@P%와 동일한 개수의 상위 예측 후보들을 고려한다.
4.3 결과
이상 탐지
표 2와 표 3은 모든 데이터셋에 대해
TranAD와 베이스라인 모델들의
정밀도, 재현율, AUC, F1, AUC, F1 점수를 제공한다.
표 2: 전체 데이터셋에서 TranAD와 베이스라인 방법들의 성능 비교.
P: 정밀도(Precision), R: 재현율(Recall), AUC: ROC 곡선 아래 면적,
F1: 전체 학습 데이터를 사용했을 때의 F1 점수.
가장 높은 F1 및 AUC 점수는 표에서 강조되어 표시된다.
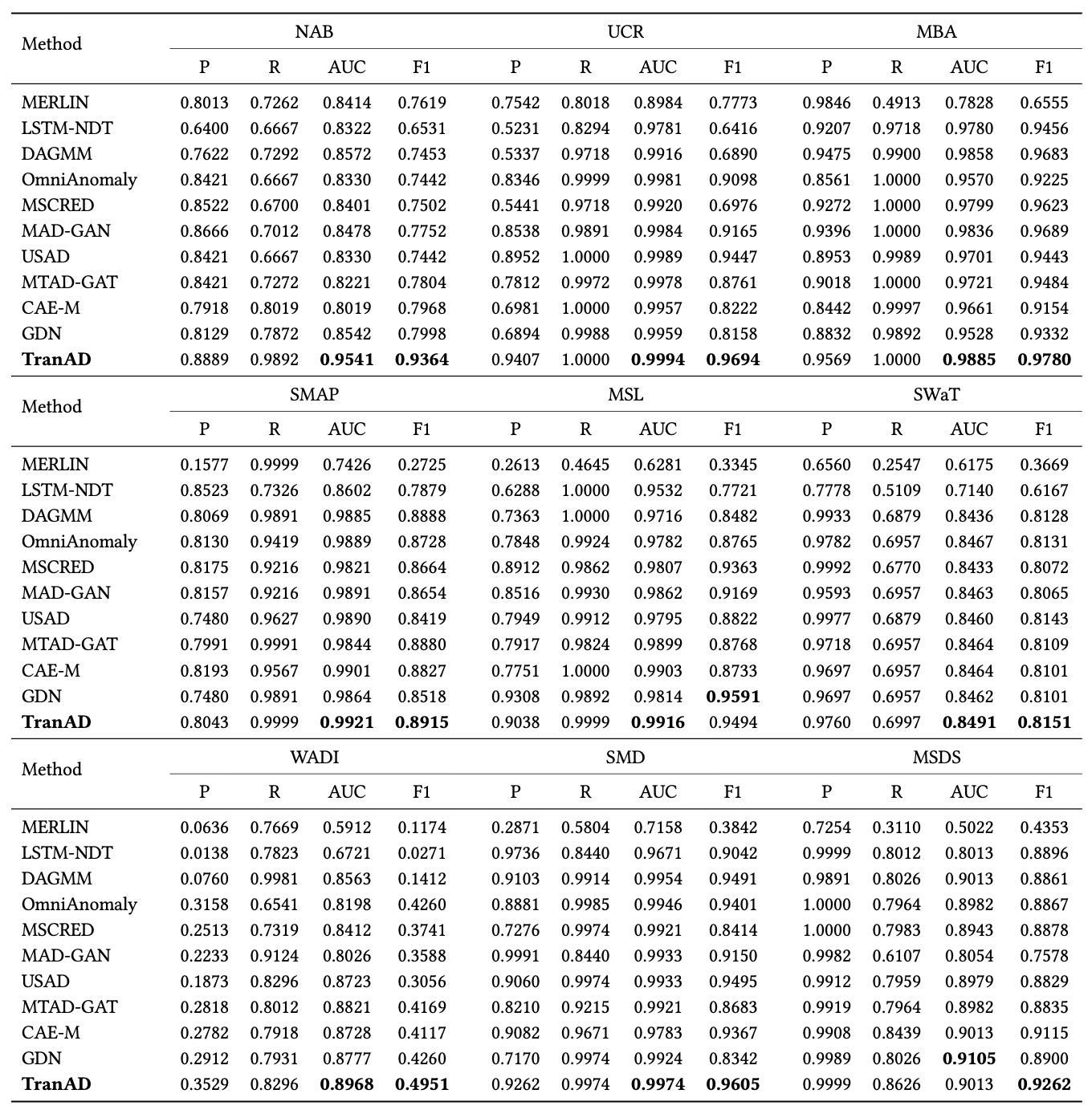
표 3: 학습 데이터의 20%만을 사용했을 때 TranAD와 베이스라인 방법들의 성능 비교.
AUC: 학습 데이터 20%를 사용했을 때의 AUC,
F1: 학습 데이터 20%를 사용했을 때의 F1 점수.
가장 높은 F1* 및 AUC* 점수는 표에서 강조되어 표시된다.
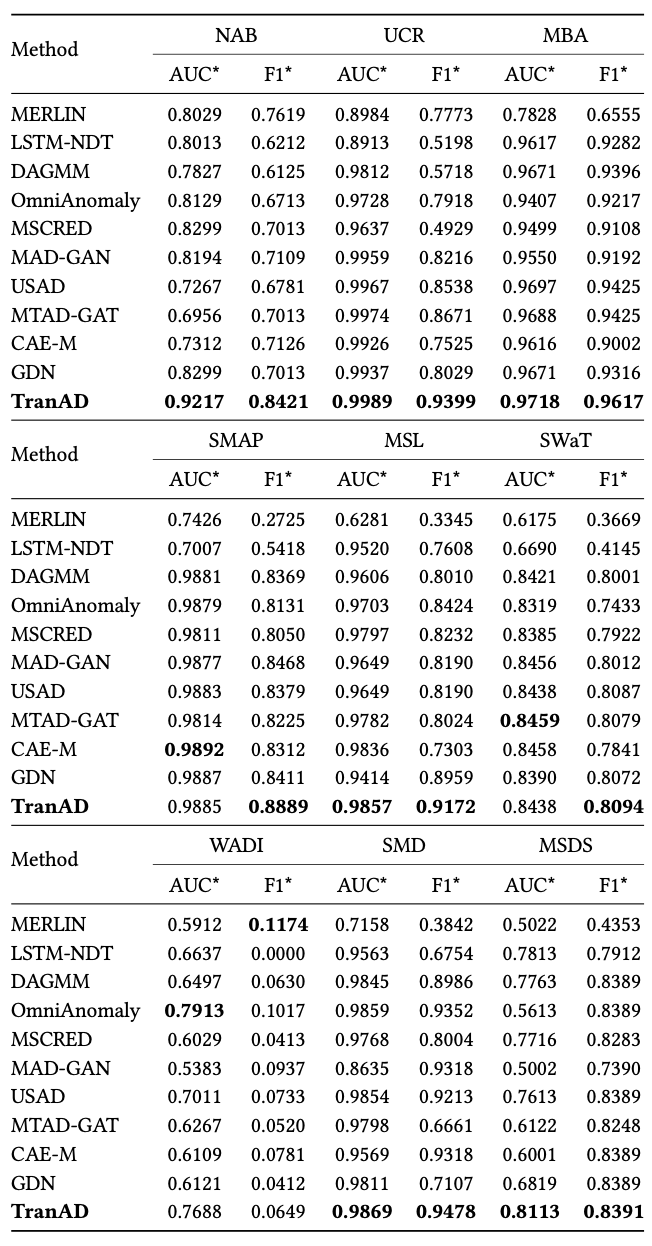
평균적으로 TranAD 모델의 F1 점수는 0.8802이며,
F1* 점수는 0.8012이다.
전체 데이터셋을 사용하여 모델을 학습한 경우,
TranAD는 MSL을 제외한 모든 데이터셋에서
F1 점수 기준으로 베이스라인을 능가한다.
또한 데이터셋의 20%만을 사용하여 학습한 경우(F1*),
WADI 데이터셋을 제외한 모든 데이터셋에서
베이스라인보다 우수한 성능을 보인다.
MSL의 경우, GDN 모델이 가장 높은 F1 점수(0.9591)를 보이며,
WADI 데이터셋에서는 OmniAnomaly가
가장 높은 F1* 점수(0.1017)를 보인다.
유사하게, AUC 점수 측면에서도
TranAD는 MSDS를 제외한 모든 데이터셋에서 베이스라인을 능가하며,
MSDS에서는 GDN이 가장 높은 AUC(0.9105)를 기록한다.
모든 모델은 시퀀스 길이와 데이터 모달리티 측면에서
규모가 큰 WADI 데이터셋에서 상대적으로 낮은 성능을 보인다.
구체적으로, TranAD는 최신 베이스라인 모델 대비
F1 점수에서 최대 17.06%,
F1* 점수에서 14.64%,
AUC 점수에서 11.69%,
AUC* 점수에서 11.06%의 개선을 달성한다.
MERLIN 베이스라인은 학습 데이터가 전혀 필요 없는
파라미터 프리 접근법이므로,
우리는 F1과 AUC를 각각 F1과 AUC 점수로 보고한다.
MERLIN은 단변량 데이터셋, 즉 NAB와 UCR에서만
상대적으로 양호한 성능을 보이며,
본 실험의 다변량 시계열 데이터에서는
효과적으로 확장되지 못한다.
베이스라인 방법인 LSTM-NDT는
MSL과 SMD 데이터셋에서는 좋은 성능을 보이지만,
다른 데이터셋들에서는 성능이 저조하다.
이는 다양한 시나리오에 대한 민감도와
NDT 임계값 설정 기법의 낮은 효율성 때문이다 [62].
TranAD와 OmniAnomaly 등에서 사용된 POT 기법은
데이터 시퀀스 내의 국소적인 피크 값들을 함께 고려함으로써
보다 정확한 임계값을 설정하는 데 도움을 준다.
DAGMM 모델은 UCR, NAB, MBA, SMAP과 같은
짧은 데이터셋에서는 매우 좋은 성능을 보이지만,
더 긴 시퀀스를 갖는 데이터셋에서는 점수가 크게 감소한다.
이는 시퀀스 윈도우를 사용하지 않고 단일 GRU 모델만을 사용하여
시간 정보를 명시적으로 매핑하지 않기 때문이다.
TranAD의 윈도우 인코더는
전체 시퀀스의 인코딩을 자기 조건(self-condition)으로 사용함으로써,
고차원·장기 시퀀스에서도 더 나은 성능을 달성할 수 있다.
OmniAnomaly, CAE-M, MSCRED 모델은
순차적인 관측값을 입력으로 사용하여
시간적 정보를 유지할 수 있도록 한다.
이러한 방법들은 이상 데이터 여부와 관계없이 재구성을 수행하므로,
정상 추세에 가까운 이상을 탐지하지 못하게 된다 [4].
TranAD는 적대적 학습을 사용하여
재구성 오차를 증폭시킴으로써 이 문제를 해결한다.
따라서 SMD와 같이 이상 데이터가 정상 데이터와 크게 다르지 않은 경우에도
미약한 이상을 탐지할 수 있다.
USAD, MTAD-GAT, GDN과 같은 최근 모델들은
데이터의 특정 모드에 집중하기 위해 어텐션 메커니즘을 사용한다.
또한 이러한 모델들은 신경망의 가중치를 조정함으로써
장기 추세를 포착하려고 시도하지만,
재구성을 위한 입력으로는 로컬 윈도우만을 사용한다.
GDN은 차원 간 데이터 상관관계에 대한 확장 가능한 그래프 기반 추론 덕분에,
MSL과 MSDS 데이터셋에서는 TranAD보다 약간 더 높은 점수를 보인다 [14].
TranAD는 셀프-어텐션을 사용하여 이를 수행하며,
전체 데이터셋에 걸쳐 전반적으로 GDN보다 더 우수한 성능을 보인다.
로컬 문맥 윈도우만을 관찰하는 한계로 인해,
USAD와 MTAD-GAT과 같은 방법들은
SMD나 WADI와 같이 장기 이상을 분류하는 데 어려움을 겪는다.
그러나 위치 인코딩이 적용된 전체 트레이스 임베딩에 대한 자기 조건화는,
TranAD의 트랜스포머 구조 덕분에 시간적 어텐션을 강화하는 데 도움을 준다.
이는 TranAD가 장기 추세를 보다 효과적으로 포착할 수 있게 한다.
또한 메타 러닝 덕분에, TranAD는 WADI 데이터셋에서
OmniAnomaly를 제외한 경우 제한된 학습 데이터 환경에서도
베이스라인 방법들보다 우수한 성능을 보이며,
이는 제한된 데이터 상황에서도 TranAD의 높은 효율성을 보여준다.
OmniAnomaly는 해당 데이터셋의 높은 노이즈와
전용(dedicated) 확률성 모델링으로 인해
WADI 데이터셋에서 가장 우수한 성능을 보인다 [45].
TranAD는 F1* 및 AUC* 측면에서는 이 방법보다 약간 뒤처지지만,
전체 데이터셋에 걸쳐 비교하거나 완전한 WADI 데이터셋이 주어졌을 때에는
해당 방법을 능가한다.
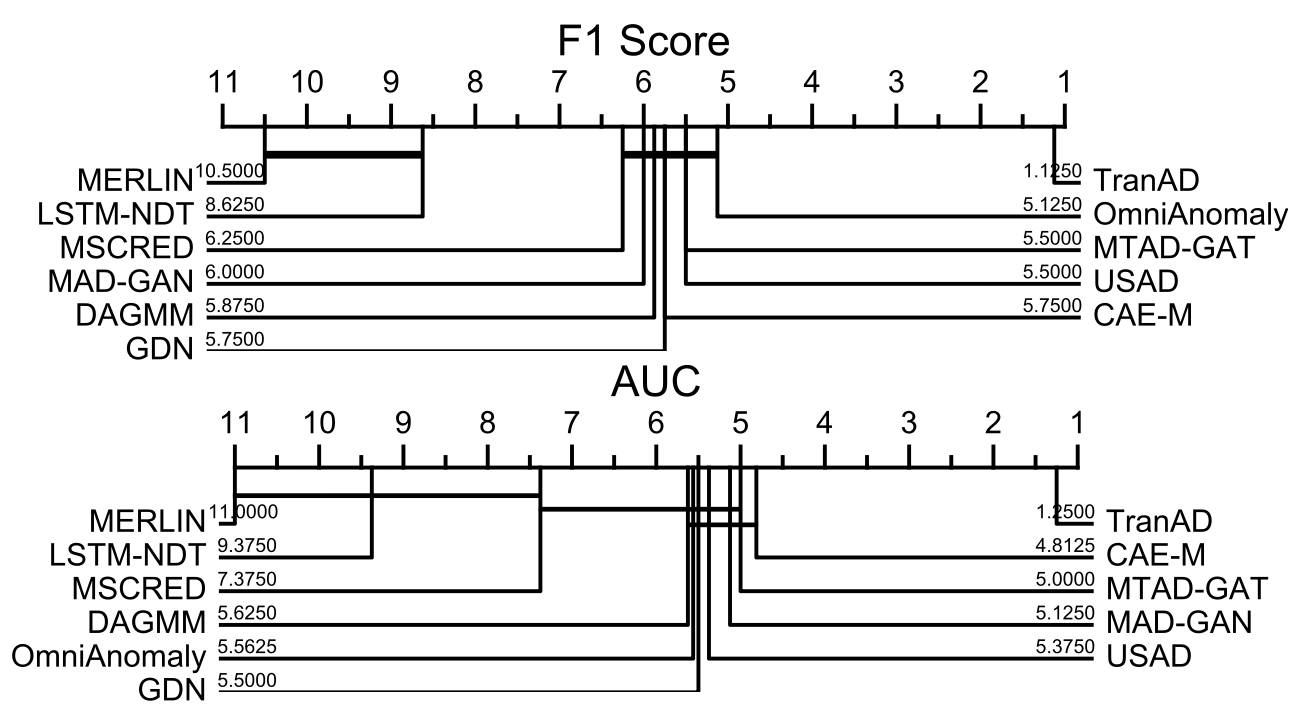
우리는 모델 성능 차이의 유의성을 평가하기 위해
임계 차이 분석(critical difference analysis)을 수행한다.
그림 4는 모든 데이터셋에 대해 Friedman 검정을 통해 귀무가설을 기각한 이후,
Wilcoxon 쌍대 부호 순위 검정 (pair-wised signed-rank test)
($\alpha = 0.05$)을 기반으로 한
F1 및 AUC 점수의 임계 차이 다이어그램을 나타낸다 [22].
TranAD는 모든 모델 중에서 통계적으로 유의미한 차이를 보이며
가장 높은 순위를 달성한다.
그림 4: 모든 데이터셋에 대해 Wilcoxon 쌍대 부호 순위 검정
($\alpha = 0.05$)을 사용하여 산출한
F1 및 AUC 점수의 임계 차이 다이어그램.
오른쪽에 위치한 방법일수록 더 높은 순위를 의미한다.
이상 진단
표 4는 이상 진단 결과를 제시하며,
여기서 H와 N은 각각 HitRate와 NDCG를 의미한다
(모델 테스트에는 전체 데이터가 사용됨).
표 4: 진단 성능
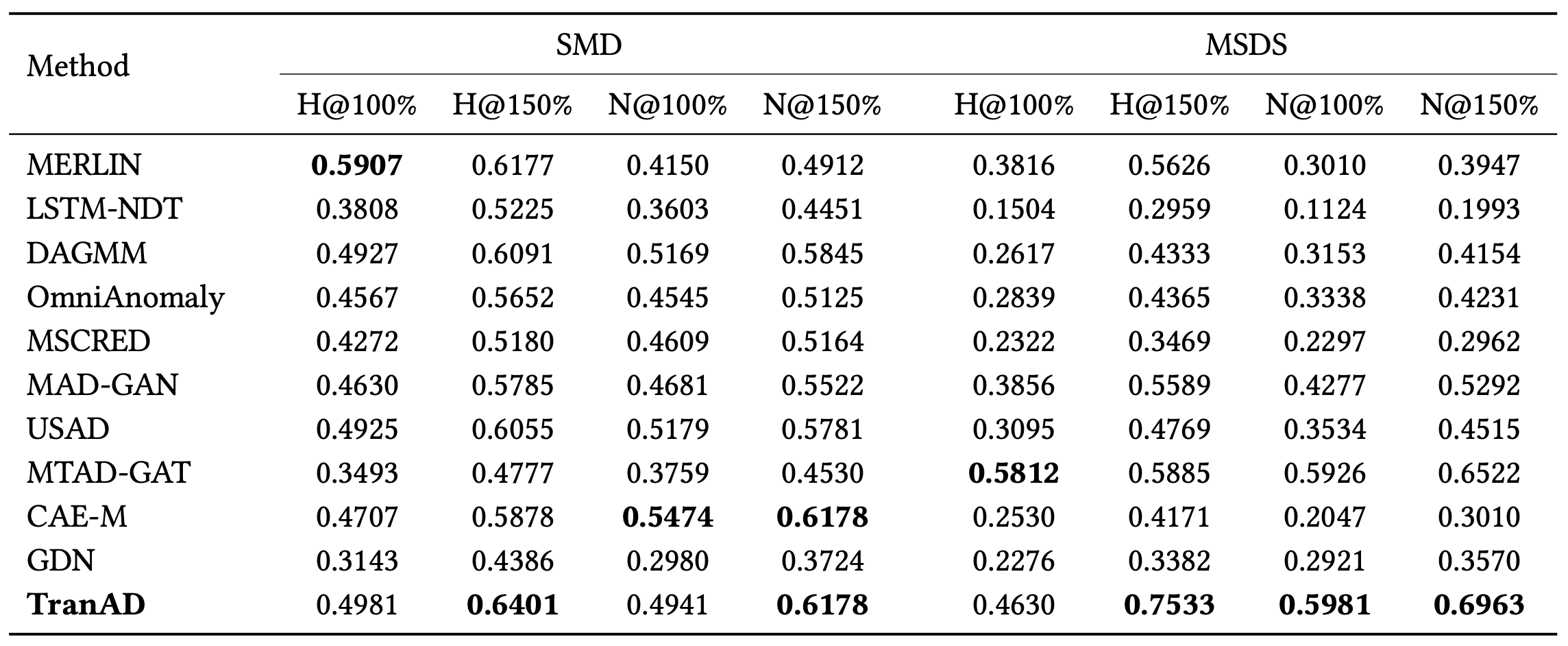
간결성을 위해 다변량 데이터셋인
SMD와 MSDS에 대해서만 결과를 제시한다
(TranAD는 다른 데이터셋에서도 더 나은 점수를 보임).
또한 각 차원별 이상 클래스 출력을
명시적으로 제공하지 않는 모델들은 제외한다.
TranAD의 멀티헤드 어텐션은
여러 모드를 동시에 주의할 수 있게 하여,
상호 연관된 이상에 더 적합하다.
이는 MSDS와 같은 분산 시스템 데이터셋에서 관찰되며,
한 모드의 이상 행동이 다른 모드의 이상으로 연쇄적으로 이어질 수 있다
(그림 5 참조).
그림 5: TranAD 모델을 사용한 MSDS 테스트 세트에 대한
예측 라벨과 실제 라벨(Ground Truth)
TranAD는 로컬 윈도우와 함께 전체 트레이스 정보를 활용하여,
이상 행동을 특정 모드로 정확히 지목할 수 있다.
표는 TranAD가 이상에 대한 근본 원인의 46.3%에서 75.3%까지를
탐지할 수 있음을 보여준다.
베이스라인 방법들과 비교했을 때, TranAD는 SMD 데이터셋에서는 최대 6%,
MSDS 데이터셋에서는 최대 30%까지 진단 점수를 향상시킬 수 있다.
진단 점수의 평균 개선 폭은 4.25%이다.
5 분석 (Analyses)
5.1 소거 분석 (Ablation Analysis)
모델의 각 구성 요소가 갖는 상대적인 중요성을 분석하기 위해,
우리는 주요 구성 요소를 하나씩 제거하고
각 데이터셋에 대해 F1 점수 관점에서 성능이 어떻게 변하는지를 관찰한다.
먼저, 트랜스포머 기반 인코더–디코더 구조를 제거하고
대신 피드포워드 네트워크를 사용한 TranAD 모델을 고려한다.
둘째, 자기 조건화(self-conditioning)을 제거한 모델을 고려하는데,
즉, 2단계에서 포커스 점수 $F = \mathbf{0}$으로 고정한다.
셋째, 적대적 손실(adversarial loss)을 제거한 모델을 분석하는데,
이는 단일 단계 추론만 수행하고 모델 학습에는 재구성 손실만 사용하는 경우에 해당한다.
마지막으로, 메타러닝을 사용하지 않는 모델을 고려한다.
그 결과는 표 6에 요약되어 있으며, 다음과 같은 관찰 결과를 제공한다.
표 6: 소거 분석 — TranAD와 각 소거된 변형 모델들의 F1 및 F1* 점수
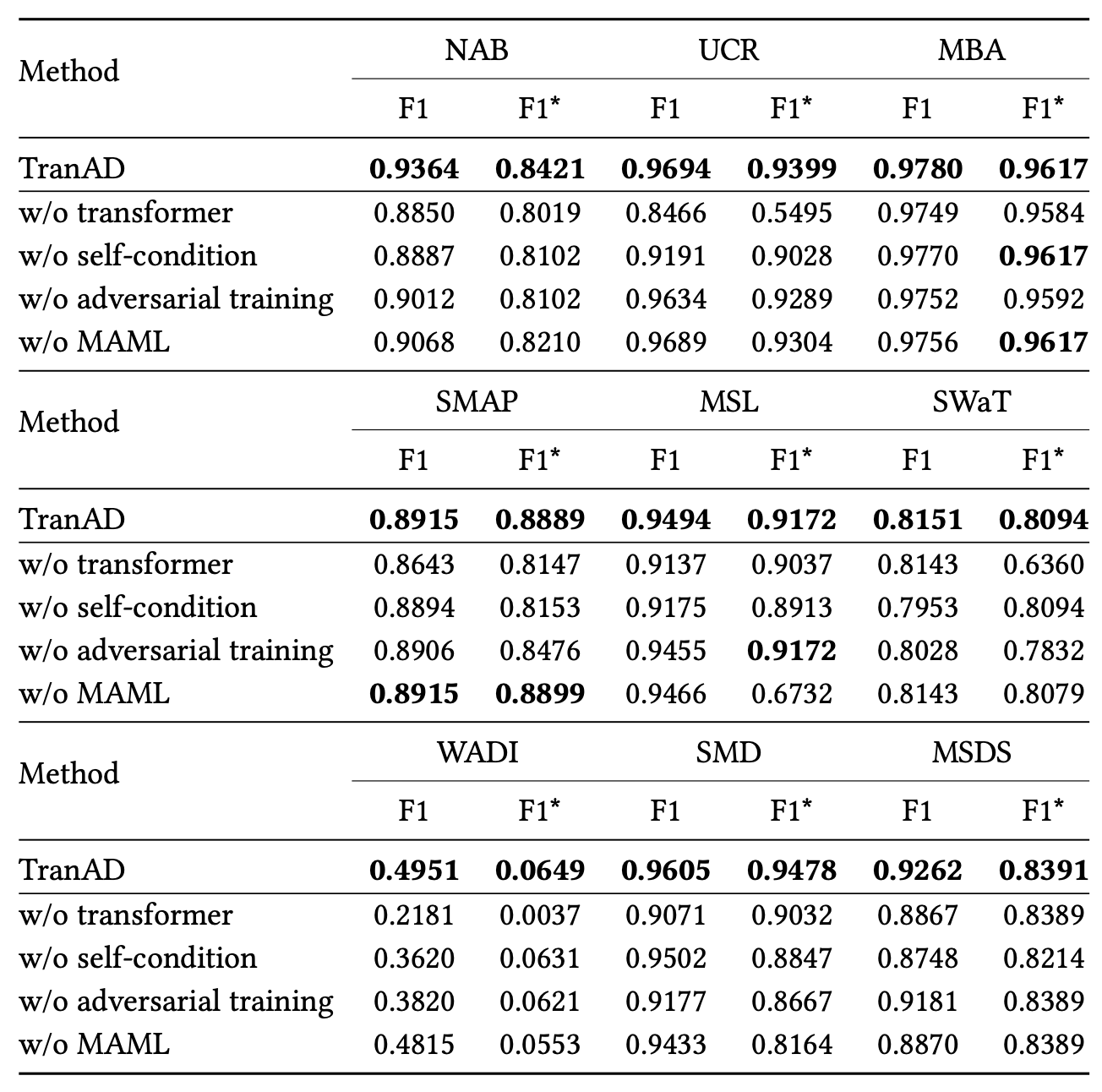
트랜스포머 기반 인코더–디코더를 제거할 경우,
F1 점수 기준으로 약 11%에 달하는 가장 큰 성능 저하가 발생한다.
이러한 성능 저하는 WADI 데이터셋에서 특히 두드러지며 (56% 감소),
대규모 데이터셋에서 어텐션 기반 트랜스포머가 필요함을 보여준다.자기 조건화를 제거하면 F1 점수가 평균적으로 6% 감소하는데,
이는 포커스 점수가 예측 성능 향상에 기여함을 보여준다.두 단계 적대적 학습을 제거하면
SMD와 WADI 데이터셋에서 성능 저하가 주로 발생한다.
이는 해당 시계열들이 완만한 이상(mild anomaly)의 비율이 높기 때문이며,
적대적 손실이 이상 점수를 증폭시키는 데 도움을 주기 때문이다.
이 경우 F1 점수의 평균 감소폭은 5%이다.메타러닝을 제거하더라도 F1 점수에는 큰 영향이 없으며 (약 1% 감소),
반면 F1* 점수는 거의 12%에 달하는 큰 감소를 보인다.
5.2 오버헤드 분석 (Overhead Analysis)
표 5는 모든 데이터셋에 대해 각 모델의 평균 학습 시간을 에폭당 초 단위로 보여준다.
표 5: 에폭(epoch)당 초 단위 학습 시간 비교
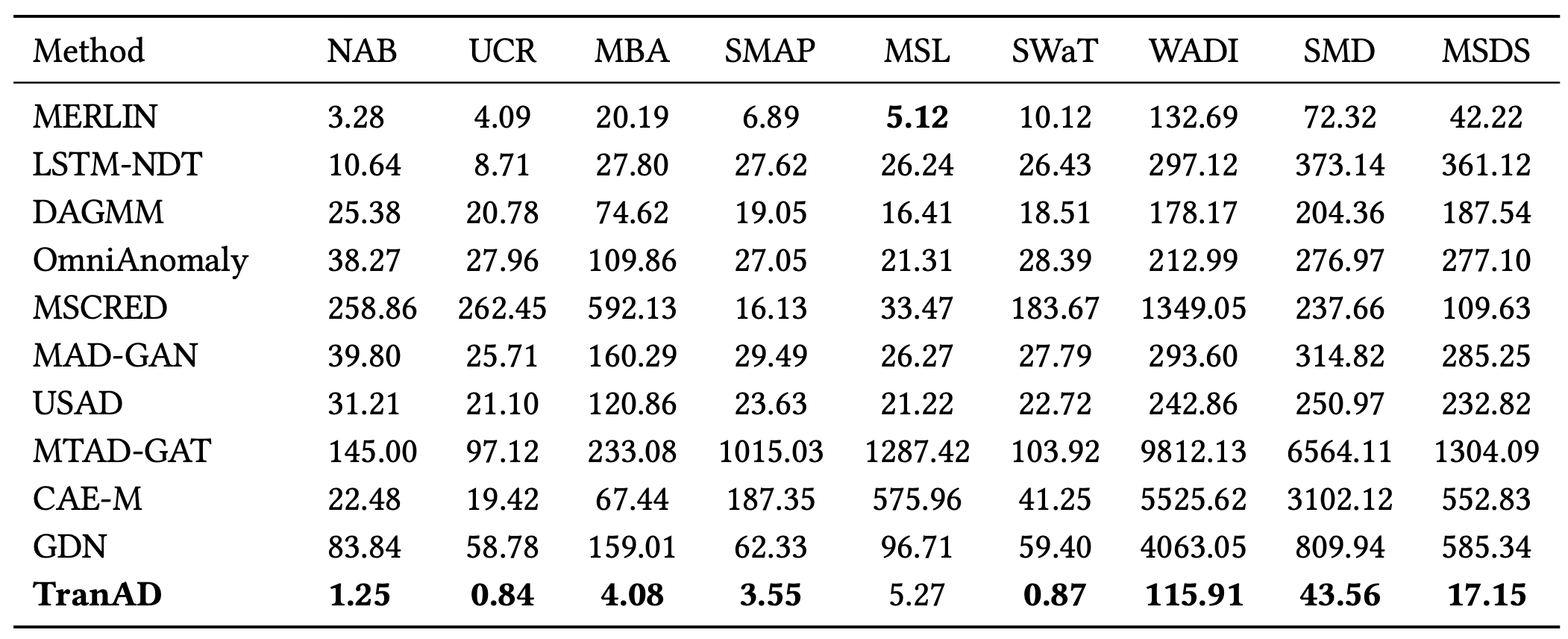
비교를 위해, MERLIN의 학습 시간은 테스트 데이터에서
불일치 부분 시퀀스(디스코드)를 탐지하는 데 소요되는 시간으로 보고한다.
TranAD의 학습 시간은 베이스라인 방법들에 비해 75%에서 99%까지 더 짧다.
이는 위치 인코딩을 갖춘 트랜스포머 모델을 사용하여
로컬 윈도우에 대해 순차적으로 추론하는 대신
전체 시퀀스를 입력으로 처리하는 방식이 갖는 장점을 분명하게 보여준다.
5.3 민감도 분석 (Sensitivity Analysis)
학습 데이터 크기에 대한 민감도
그림 6은 모든 데이터셋에 대해 평균을 낸 모든 모델의 F1 및 AUC 점수의 분산과,
학습에 사용된 데이터 비율(20%에서 100%)에 따른 학습 시간의 분산을 보여준다.
그림 6: 데이터셋 크기에 따른 F1 점수, ROC/AUC 점수, 그리고 학습 시간.
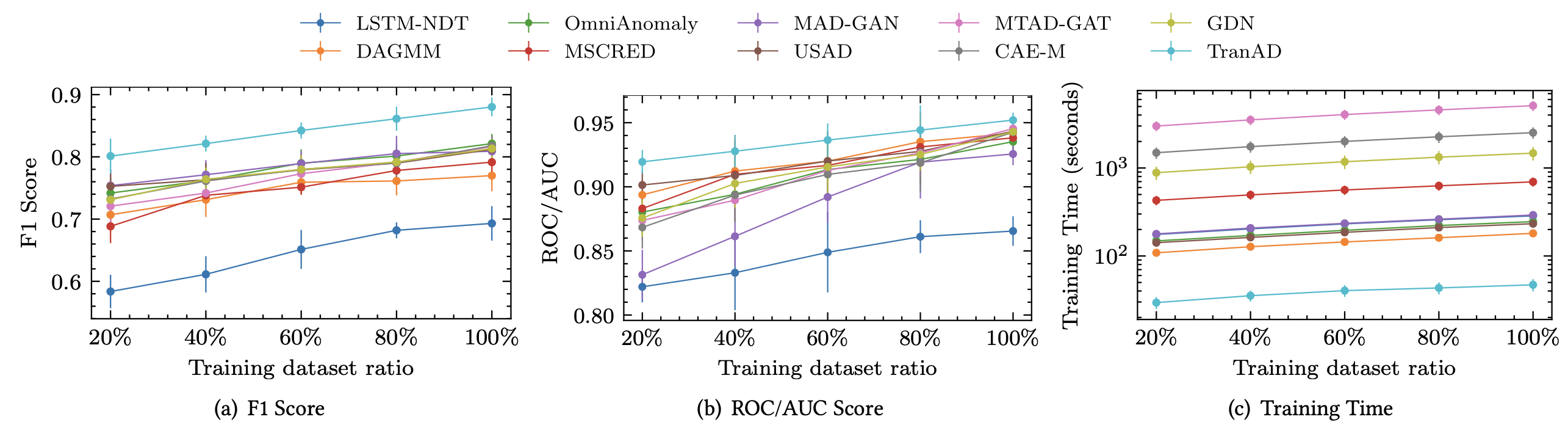
MERLIN은 학습 데이터를 사용하지 않기 때문에 민감도 결과를 보고하지 않는다.
다른 딥러닝 기반 재구성 모델들에는 학습 데이터로 사용된 것과 동일하게,
전체 데이터의 20%에서 100% 크기까지
무작위로 샘플링된 부분 시퀀스가 입력으로 주어진다.
그림 6에는 90% 신뢰 구간을 함께 보고한다.
분명하게도, 데이터셋 크기가 증가함에 따라
예측 성능은 향상되고 학습 시간은 증가한다.
우리는 모든 비율에 대해 TranAD 모델이
더 높은 F1 점수와 더 낮은 학습 시간을 보인다는 것을 관찰한다.
윈도우 사이즈에 대한 민감도
또한 그림 7에서는 서로 다른 윈도우 크기에 대해
TranAD 모델과 그 변형들의 성능을 보여준다.
그림 7: 윈도우 크기에 따른 F1 점수, ROC/AUC 점수, 그리고 학습 시간
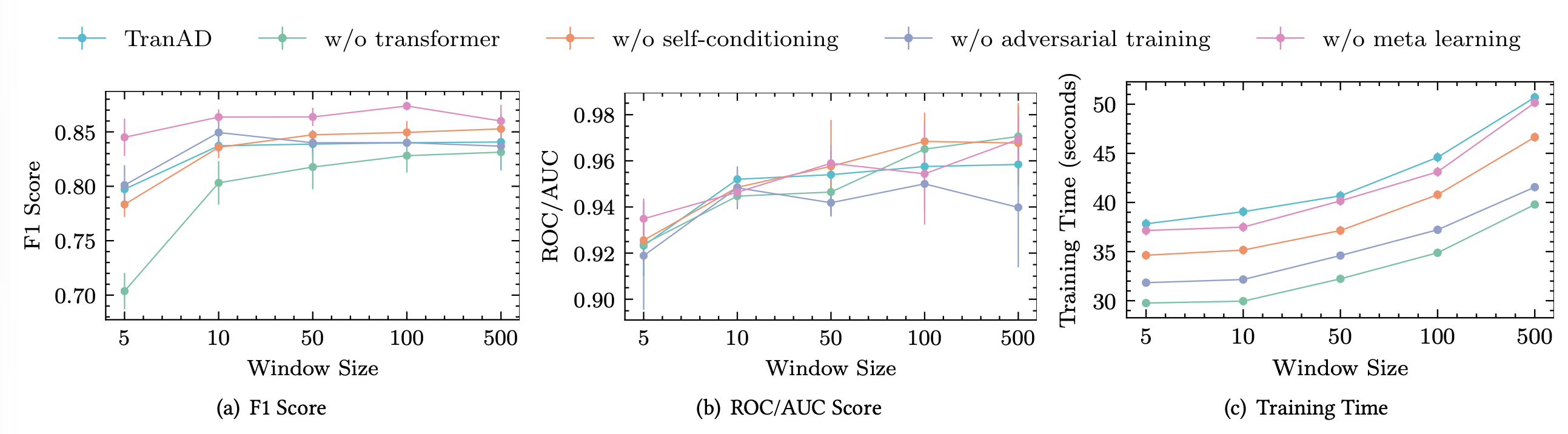
윈도우 크기는 이상 탐지 성능과 학습 시간 모두에 영향을 미친다.
입력 크기가 작아질수록 추론 시간이 줄어들기 때문에,
작은 윈도우를 사용할 경우 TranAD는 이상을 더 빠르게 탐지할 수 있다.
윈도우가 너무 작을 경우, 국소적인 문맥 정보를 충분히 표현하지 못한다.
반대로, 윈도우가 너무 크면
짧은 이상 패턴이 많은 데이터 포인트 속에 묻혀 탐지되지 않을 수 있다
(일부 모델에서 F1 점수가 감소하는 현상 참조).
윈도우 크기 10은
F1 점수와 학습 시간 사이에서 합리적인 균형을 제공하며,
이에 따라 본 연구의 실험에서 사용되었다.
6 결론 (Conclusions)
본 논문에서는
다변량 시계열 데이터에 대해 이상 탐지와 진단을 수행할 수 있는
트랜스포머 기반 이상 탐지 모델인 TranAD를 제안한다.
트랜스포머 기반 인코더–디코더 구조는
본 연구에서 고려한 다양한 데이터셋에 대해
빠른 모델 학습과 높은 이상 탐지 성능을 가능하게 한다.
TranAD는 자기 조건화(self-conditioning)와 적대적 학습을 활용하여
오차를 증폭시키고 학습 안정성을 확보한다.
또한 메타러닝을 통해 제한된 데이터 환경에서도 데이터의 추세를 식별할 수 있다.
구체적으로, TranAD는 전체 학습 데이터와 제한된 학습 데이터 환경에서
각각 F1 점수를 17%와 11% 향상시킨다.
또한 탐지된 이상 중 최대 75%에 대해 근본 원인을 정확히 식별할 수 있으며,
이는 기존 최신 기법들보다 높은 성능이다.
이러한 성능은 베이스라인 방법들에 비해
최대 99% 낮은 학습 시간으로 달성된다.
이는 TranAD가 정확하고 빠른 이상 예측이 요구되는 현대 산업 시스템에
이상적인 선택임을 의미한다.
향후 연구로는, 양방향 신경망과 같은 다른 트랜스포머 모델로 확장하여
다양한 시간적 추세에 대한 일반화 성능을 향상시키는 방향을 제안한다.
또한 배포 환경을 고려하여 과도한 계산 비용을 피하기 위해
각 모델 구성 요소에 대해 비용–효익 분석을 적용하는 방향도 탐구할 계획이다.
소프트웨어 제공 (Software Availability)
코드와 관련 학습 스크립트는
BSD-3 라이선스 하에 다음 GitHub 저장소에 공개되어 있다.
https://github.com/imperial-qore/TranAD
감사의 글 (Acknowledgements)
Shreshth Tuli는 Imperial College London의
총장 박사 장학금(President’s PhD scholarship)의 지원을 받았다.
원고 개선에 대해 건설적인 의견을 제공한 Kate Highnam에게 감사를 표한다.
또한 본 연구에서 사용된 모든 데이터셋의 제공자들에게 감사한다.
MERLIN 구현 (A MERLIN Implementation)
4장에서 제시된 비교 실험은
Python으로 구현한 MERLIN 베이스라인의 커스텀 구현을 사용한다.
표 7은 MATLAB3 기반의 원래 MERLIN 구현과 우리의 Python 구현을 비교한다.
3MERLIN:
https://sites.google.com/view/merlin-find-anomalies/
(documentation, Accessed: 30 January 2022, Last Updated: 23 June 2020)
표 7: 원래의 MERLIN 구현(MATLAB)과 우리의 구현(Python) 간의 비교.
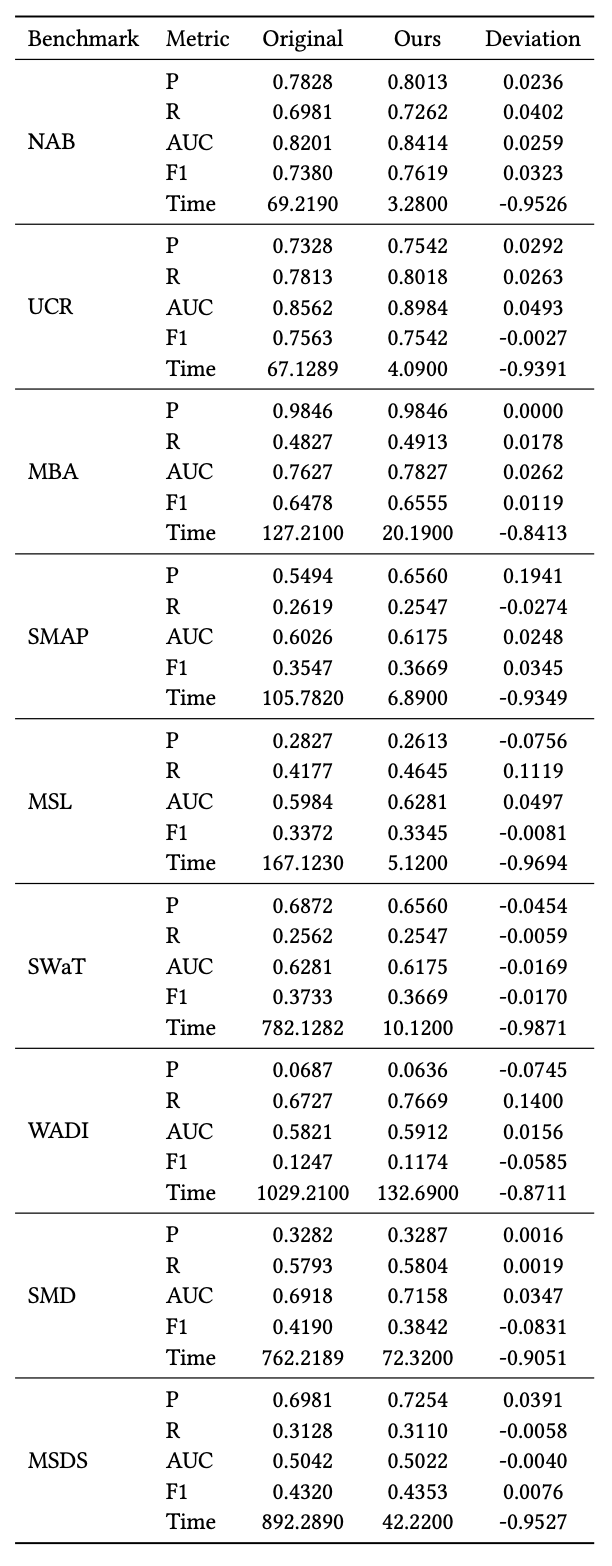
원래 코드에서는 불일치 부분 시퀀스(discord)의 길이에 대응하는 하이퍼파라미터,
즉 MinL과 MaxL을 어떻게 선택하는지가 제시되어 있지 않으므로,
우리는 F1 점수를 최대화하도록 그리드 서치를 사용하여 최적의 파라미터를 탐색한다.
표 7에서 사용한 하이퍼파라미터 값은
$(MinL, MaxL) = {(10,40), (50,60), (60,100), (70,100), (30,60), (10,20), (60,100), (100,140), (5,10)}$이며,
이는 각각 NAB, UCR, MBA, SMAP, MSL, SWaT, WADI, SMD, MSDS 데이터셋에 대응한다.
각 벤치마크에 대해
Precision (P), Recall (R), ROC 곡선 아래 면적 (AUC),
F1 점수 (F1), 학습 시간 (Time)을
MATLAB 코드 $(x)$와 우리의 구현 $(y)$에 대해 계산한다.
편차는 $(y - x) / x$로 계산한다.
표는 우리의 구현이 원래 구현과 매우 유사한 점수를 제공하면서도,
학습 시간은 최대 96%까지 개선됨을 보여준다.
참고문헌 (References)
Hossein AbbasiMehr, Mostafa Shabani, and Mohsen Yousefi. 2020.
An optimized model using LSTM network for demand forecasting.
(LSTM 네트워크를 이용한 수요 예측을 위한 최적화된 모델.)
Computers & Industrial Engineering 143 (2020), 106435.Subutai Ahmad, Alexander Lavin, Scott Purdy, and Zuha Ghahramani. 2017.
Unsupervised real-time anomaly detection for streaming data.
(스트리밍 데이터를 위한 비지도 실시간 이상 탐지.)
Neurocomputing 262 (2017), 134–147.Chaudhry Mujeeb Ahmed, Venkata Reddy Palleti, and Aditya P. Mathur. 2017.
WADI: A water distribution testbed for research in the design of secure cyber physical systems.
(보안 사이버-물리 시스템 설계를 위한 수자원 분배 테스트베드 WADI.)
In Proceedings of the 3rd International Workshop on Cyber-Physical Systems for Smart Water Networks, 25–28.Julien Audibert, Pietro Michiardi, Frédéric Guérin, Sébastien Marti, and Maria A. Zuluaga. 2020.
USAD: UnSupervised Anomaly Detection on Multivariate Time Series.
(다변량 시계열에서의 비지도 이상 탐지 USAD.)
In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 3395–3404.Tharindu R. Bandaragoda, Kai Ming Ting, David Albrecht, Fei Tony Liu, and Jonathan R. Wells. 2014.
Efficient anomaly detection by isolation using nearest neighbour ensemble.
(최근접 이웃 앙상블을 이용한 고립 기반 효율적 이상 탐지.)
In IEEE International Conference on Data Mining Workshop, 698–705.Julian Bellendorf and Zoltán Ádám Mann. 2020.
Classification of optimization problems in fog computing.
(포그 컴퓨팅에서의 최적화 문제 분류.)
Future Generation Computer Systems 107 (2020), 158–176.Nejib Bezak, Mitja Brilly, and Mojca Šraj. 2014.
Comparison between peaks-over-threshold method and the annual maximum method for flood frequency analysis.
(홍수 빈도 분석에서 임계값 초과 기법과 연최대 기법의 비교.)
Hydrological Sciences Journal 59, 5 (2014), 959–977.Paul Boniol, Michele Linardi, Federico Roncalli, and Themis Palpanas. 2020.
Automated anomaly detection in large sequences.
(대규모 시퀀스에서의 자동 이상 탐지.)
In Proceedings of the 36th IEEE International Conference on Data Engineering (ICDE), 1834–1837.Paul Boniol, Themis Palpanas, Mohammed Meftah, and Emmanuel Remy. 2020.
Graph-based subsequence anomaly detection.
(그래프 기반 부분 시퀀스 이상 탐지.)
Proceedings of the VLDB Endowment 13, 12 (2020), 2941–2944.Paul Boniol, John Paparrizos, Themis Palpanas, and Michael J. Franklin. 2021.
SAND: Streaming Subsequence Anomaly Detection.
(스트리밍 부분 시퀀스 이상 탐지 SAND.)
Proc. VLDB Endow. 14, 10 (2021), 1717–1729.Saikiran Bulusu, Bhavya Kaushik, Bo Li, Pramod K. Varshney, and Dawn Song. 2020.
Anomalous example detection in deep learning: A survey.
(딥러닝에서의 이상 샘플 탐지에 대한 서베이.)
IEEE Access 8 (2020), 132330–132347.Raghavendra Chalapathy and Sanjay Chawla. 2019.
Deep learning for anomaly detection: A survey.
(이상 탐지를 위한 딥러닝: 서베이.)
arXiv preprint arXiv:1901.03407.
URL: https://arxiv.org/abs/1901.03407Hoang Anh Dau, Eamonn Keogh, Kaveh Kamgar, Chin-Chia Michael Yeh, Yan Zhu, Shaghayegh Gharghabi, Chotirat Ann Ratanamahatana, Yiping Ding, Núrián Begum, Anthony Bagnall, Abdullah Mueen, Gustavo Batista, and Hexagon-ML. 2018.
The UCR Time Series Classification Archive.
(UCR 시계열 분류 아카이브.)
URL: https://www.cs.ucr.edu/~eamonn/time_series_data_2018/Ailin Deng and Bryan Hooi. 2021.
Graph neural network-based anomaly detection in multivariate time series.
(다변량 시계열에서의 그래프 신경망 기반 이상 탐지.)
In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 35, 4027–4035.Chelsea Finn, Pieter Abbeel, and Sergey Levine. 2017.
Model-agnostic meta-learning for fast adaptation of deep networks.
(딥 네트워크의 빠른 적응을 위한 모델 비의존 메타 학습.)
In International Conference on Machine Learning (ICML), 1126–1135.Shaghayegh Gharghabi, Shima Imani, Anthony Bagnall, Amirali Darvishzadeh, and Eamonn Keogh. 2018.
Matrix profile XII: MPDIST: a novel time series distance measure to allow data mining in more challenging scenarios.
(어려운 환경에서의 데이터 마이닝을 위한 새로운 시계열 거리 척도 MPDIST.)
In IEEE ICDM, 965–970.Ary L. Goldberger et al. 2000.
PhysioBank, PhysioToolkit, and PhysioNet.
(PhysioBank, PhysioToolkit, PhysioNet: 복잡 생리 신호를 위한 자원.)
Circulation 101, 23 (2000), e215–e220.Xin He, Kaiyong Zhao, and Xiaowen Chu. 2021.
AutoML: A survey of the state-of-the-art.
(AutoML 최신 동향 서베이.)
Knowledge-Based Systems 212 (2021), 106622.Shaohan Huang et al. 2020.
HitAnomaly: Hierarchical Transformers for Anomaly Detection in System Log.
(시스템 로그 이상 탐지를 위한 계층적 트랜스포머.)
IEEE Transactions on Network and Service Management 17, 4 (2020), 2064–2076.Kyle Hundman et al. 2018.
Detecting spacecraft anomalies using LSTMs and non-parametric dynamic thresholding.
(LSTM과 비모수 동적 임계값을 이용한 우주선 이상 탐지.)
In KDD, 387–395.Shima Imani et al. 2018.
Matrix profile XIII: Time series snippets.
(시계열 스니펫을 위한 매트릭스 프로파일.)
In IEEE ICDM, 332–339.Hassan Ismail Fawaz et al. 2019.
Deep learning for time series classification: A review.
(시계열 분류를 위한 딥러닝 리뷰.)
Data Mining and Knowledge Discovery 33, 4 (2019), 917–963.Vincent Jacob et al. 2020.
Exathlon: A benchmark for explainable anomaly detection over time series.
(설명 가능한 시계열 이상 탐지를 위한 벤치마크 Exathlon.)
Proceedings of the VLDB Endowment (2020).Eamonn Keogh et al. 2021.
Multi-dataset time-series anomaly detection competition.
(다중 데이터셋 시계열 이상 탐지 대회.)
In KDD.
URL: https://competitions.codalab.org/competitions/39137Diederik P. Kingma and Jimmy Ba. 2014.
Adam: A method for stochastic optimization.
(확률적 최적화를 위한 Adam 알고리즘.)
arXiv preprint arXiv:1412.6980.Kyle Kingsbury and Peter Alvaro. 2020.
Elle: Inferring isolation anomalies from experimental observations.
(실험 관측을 통한 격리 이상 추론.)
Proceedings of the VLDB Endowment 14, 3 (2020), 268–280.Dan Li et al. 2019.
MAD-GAN: Multivariate anomaly detection for time series data with generative adversarial networks.
(GAN 기반 다변량 시계열 이상 탐지.)
In International Conference on Artificial Neural Networks, 703–716.Guoliang Li et al. 2021.
OpenGauss: An autonomous database system.
(자율 데이터베이스 시스템 OpenGauss.)
Proceedings of the VLDB Endowment 14, 12 (2021), 3028–3042.Fei Tony Liu, Kai Ming Ting, and Zhi-Hua Zhou. 2008.
Isolation Forest.
(Isolation Forest.)
In ICDM, 413–422.Steven Liu et al. 2020.
Diverse image generation via self-conditioned GANs.
(자기 조건부 GAN을 통한 다양한 이미지 생성.)
In ECCV, 1486–14295.Gideon Midanyan et al. 2020.
Univariate Time Series Anomaly Labelling Algorithm.
(단변량 시계열 이상 라벨링 알고리즘.)
In ICMLA, 586–599.Stefano Monteiro and Forrest Landola. 2016.
MPOPS: Statistical Techniques for Optimizing and Modeling Performance of Blocked Sparse Matrix Vector Multiplication.
(희소 행렬 벡터 곱의 성능 모델링과 최적화를 위한 통계 기법.)
In SBAC-PAD, 93–100.George B. Moody and Roger G. Mark. 2001.
The impact of the MIT-BIH arrhythmia database.
(MIT-BIH 부정맥 데이터베이스의 영향.)
IEEE Engineering in Medicine and Biology Magazine 20, 3 (2001), 45–50.Takashi Nakamura et al. 2020.
MERLIN: Parameter-Free Discovery of Arbitrary Length Anomalies in Massive Time Series Archives.
(대규모 시계열 아카이브에서 임의 길이 이상을 파라미터 없이 탐색.)
In ICDM, 1190–1195.Sasho Nedelkoski et al. 2020.
Multi-source distributed system data for AI-powered analytics.
(AI 기반 분석을 위한 다중 소스 분산 시스템 데이터.)
In European Conference on Service-Oriented and Cloud Computing, 161–176.Daehyung Park et al. 2018.
A multimodal anomaly detector for robot-assisted feeding.
(로봇 보조 급식을 위한 다중 모달 이상 탐지기.)
IEEE Robotics and Automation Letters 3, 3 (2018), 1544–1551.Adam Paszke et al. 2019.
PyTorch: An Imperative Style, High-Performance Deep Learning Library.
(고성능 딥러닝 라이브러리 PyTorch.)
Advances in Neural Information Processing Systems 32 (2019), 8026–8037.Animesh Patcha and Jung-Min Park. 2007.
An overview of anomaly detection techniques.
(이상 탐지 기법 개요.)
Computer Networks 51, 12 (2007), 3448–3470.Noorshan Saleh and Maggie Mashaly. 2019.
A Dynamic Simulation Environment for Container-based Cloud Data Centers using ContainerCloudSim.
(컨테이너 기반 클라우드 데이터 센터를 위한 동적 시뮬레이션 환경.)
In ICICIS, 332–336.Osman Salem et al. 2014.
Anomaly detection in medical wireless sensor networks using SVM and linear regression models.
(의료 무선 센서 네트워크에서의 SVM 및 선형 회귀 기반 이상 탐지.)
International Journal of E-Health and Medical Communications 5, 1 (2014), 20–45.Alban Siffer, Pierre-Alain Fouque, Alexandre Termier, and Christine Largouet. 2017.
Anomaly detection in streams with extreme value theory.
(극값 이론을 이용한 스트림 데이터 이상 탐지.)
In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 1067–1075.Ya Su, Youjian Zhao, Chenhao Niu, Rong Liu, Wei Sun, and Dan Pei. 2019.
Robust anomaly detection for multivariate time series through stochastic recurrent neural network.
(확률적 순환 신경망을 이용한 다변량 시계열 강건 이상 탐지.)
In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2828–2837.Srikanth Thudumu, Philip Branch, Jiong Jin, and Jugdutt Jack Singh. 2020.
A comprehensive survey of anomaly detection techniques for high dimensional big data.
(고차원 빅데이터를 위한 이상 탐지 기법 종합 서베이.)
Journal of Big Data 7, 1 (2020), 1–30.Luan Tran, Min Y. Mun, and Cyrus Shahabi. 2020.
Real-time distance-based outlier detection in data streams.
(데이터 스트림에서의 실시간 거리 기반 이상치 탐지.)
Proceedings of the VLDB Endowment 14, 2 (2020), 141–153.Shreshth Tuli, Giuliano Casale, and Nicholas R. Jennings. 2022.
PreGAN: Preemptive Migration Prediction Network for Proactive Fault-Tolerant Edge Computing.
(사전적 마이그레이션 예측을 통한 선제적 장애 허용 엣지 컴퓨팅.)
In IEEE Conference on Computer Communications (INFOCOM).Shreshth Tuli, Shivananda Poojara, Satish Narayana Srirama, Giuliano Casale, and Nick Jennings. 2021.
COSCO: Container Orchestration using Co-Simulation and Gradient Based Optimization for Fog Computing Environments.
(포그 컴퓨팅 환경을 위한 공동 시뮬레이션 및 경사 기반 최적화 컨테이너 오케스트레이션.)
IEEE Transactions on Parallel and Distributed Systems (2021).Shreshth Tuli, Shikhar Tuli, Ruchi Verma, and Rakesh Tuli. 2020.
Modelling for prediction of the spread and severity of COVID-19 and its association with socioeconomic factors and virus types.
(사회경제적 요인과 바이러스 유형을 고려한 COVID-19 확산 및 심각도 예측 모델링.)
Biomedical Research and Clinical Reviews (2020), Issue 3.Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones,
Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017.
Attention is all you need.
(어텐션만으로 충분하다.)
In Proceedings of the 31st International Conference on Neural Information Processing Systems, 6000–6010.Yiyang Wang, Neda Masoud, and Anahita Khojandi. 2020.
Real-time sensor anomaly detection and recovery in connected automated vehicle sensors.
(연결 자율주행 차량 센서에서의 실시간 이상 탐지 및 복구.)
IEEE Transactions on Intelligent Transportation Systems 22, 3 (2020), 1411–1421.Webscope. [n.d.].
S5-A Labeled Anomaly Detection Dataset, Version 1.0.
(S5-A 라벨된 이상 탐지 데이터셋.)
URL: https://webscope.sandbox.yahoo.com/catalog.php?datatype=s&did=70
Accessed: 2021-08-31.Krzysztof Witkowski. 2017.
Internet of things, big data, industry 4.0—innovative solutions in logistics and supply chains management.
(물류 및 공급망 관리에서의 IoT, 빅데이터, 인더스트리 4.0 혁신 솔루션.)
Procedia Engineering 182 (2017), 763–769.Renjie Wu and Eamonn J. Keogh. 2020.
Current Time Series Anomaly Detection Benchmarks are Flawed and are Creating the Illusion of Progress.
(현재 시계열 이상 탐지 벤치마크의 한계와 진보의 착시.)
arXiv preprint arXiv:2009.13807.Asrul H. Yaacob, Ian K. T. Tan, Su Fong Chien, and Hon Khi Tan. 2010.
ARIMA-based network anomaly detection.
(ARIMA 기반 네트워크 이상 탐지.)
In IEEE International Conference on Communication Software and Networks, 205–209.Qiang Yang, Yang Liu, Tianjian Chen, and Yongxin Tong. 2019.
Federated machine learning: Concept and applications.
(연합 학습: 개념과 응용.)
ACM Transactions on Intelligent Systems and Technology 10, 2 (2019), 1–19.Dragomir Yankov, Eamonn Keogh, and Umaa Rebbapragada. 2008.
Disk aware discord discovery: Finding unusual time series in terabyte sized datasets.
(디스크 인지 기반 디스코드 탐색.)
Knowledge and Information Systems 17, 2 (2008), 241–262.Chin-Chia Michael Yeh et al. 2016.
Matrix profile I: All pairs similarity joins for time series.
(시계열 전체 쌍 유사도 조인을 위한 매트릭스 프로파일.)
In IEEE ICDM, 1317–1322.Chuxu Zhang et al. 2019.
A deep neural network for unsupervised anomaly detection and diagnosis in multivariate time series data.
(다변량 시계열 비지도 이상 탐지 및 진단을 위한 딥 신경망.)
In AAAI Conference on Artificial Intelligence, Vol. 33, 1409–1416.Yuxin Zhang et al. 2021.
Unsupervised Deep Anomaly Detection for Multi-Sensor Time-Series Signals.
(다중 센서 시계열 신호를 위한 비지도 딥 이상 탐지.)
IEEE Transactions on Knowledge and Data Engineering (2021).Hang Zhao et al. 2020.
Multivariate time-series anomaly detection via graph attention network.
(그래프 어텐션 네트워크 기반 다변량 시계열 이상 탐지.)
In International Conference on Data Mining.Chin-Chia Michael Yeh et al. 2018.
Matrix profile XI: SCRIMP++: Time series motif discovery at interactive speeds.
(대화형 속도의 시계열 모티프 탐색 SCRIMP++.)
In IEEE ICDM, 837–846.Zachary Zimmerman et al. 2019.
Matrix profile XVIII: Time series mining in the face of fast moving streams using a learned approximate matrix profile.
(빠르게 변화하는 스트림에서의 근사 매트릭스 프로파일.)
In IEEE ICDM, 936–945.Bo Zong et al. 2018.
Deep autoencoding gaussian mixture model for unsupervised anomaly detection.
(비지도 이상 탐지를 위한 딥 오토인코딩 가우시안 혼합 모델.)
In International Conference on Learning Representations.