[논문 번역] Web Traffic Anomaly Detection Using Isolation Forest
논문 출처
Chua, W., Pajas, A. L. D., Castro, C. S., Panganiban, S. P., Pasuquin, A. J., Purganan, M. J., Malupeng, R., Pingad, D. J., Orolfo, J. P., Lua, H. H., & Velasco, L. C.
Web Traffic Anomaly Detection Using Isolation Forest.
MDPI, 2023.
🔗 원문 링크 (MDPI)
저자
- Wilson Chua¹
- Arsenn Lorette Diamond Pajas²
- Crizelle Shane Castro²
- Sean Patrick Panganiban²
- April Joy Pasuquin²
- Merwin Jan Purganan²
- Rica Malupeng²
- Divine Jessa Pingad²
- John Paul Orolfo²
- Haron Hakeen Lua³,*
- Lemuel Clark Velasco³⁴⁵
¹ Analytics Division, Future Gen International Pte. Ltd., Singapore 534260, Singapore
(wilson.chua@gmail.com)² 정보기술학과, 정보기술 및 공학대학(College of Information Technology and Engineering),
International School of Asia and the Pacific, Peñablanca, Cagayan 3502, Philippines
(diamondmoncespajas@gmail.com (A.L.D.P.); shanecastro620@gmail.com (C.S.C.);
seanpatrickpanganiban08@gmail.com (S.P.P.); pasuquinapriljoy@gmail.com (A.J.P.);
purgananmerwinjan@gmail.com (M.J.P.); ricamalupeng2424@gmail.com (R.M.);
divinepingad4@gmail.com (D.J.P.); paulj7521@gmail.com (J.P.O.))³ 정보기술학과, 컴퓨터학부(College of Computer Studies),
Mindanao State University–Iligan Institute of Technology, Iligan City 9200, Philippines
(lemuelclark.velasco@g.msuiit.edu.ph)⁴ 산업 및 정보관리학과, 경영대학(College of Management),
National Cheng Kung University, Tainan City 701, Taiwan⁵ 계산분석 및 모델링센터(Center for Computational Analytics and Modelling),
과학 및 수학 프리미어 연구소(Premier Research Institute of Science and Mathematics),
Mindanao State University–Iligan Institute of Technology, Iligan City 9200, Philippines* 교신 저자(Correspondence): haronhakeen.lua@g.msuiit.edu.ph
초록 (Abstract)
기업들이 점점 더 디지털 전환(digital transformation)을 진행함에 따라
데이터 자산의 가치도 함께 상승하고 있으며,
이로 인해 해커들에게 더욱 매력적인 공격 대상이 되고 있다.
웹 로그(web logs)의 방대한 양은
사이버보안 전문가들이 웹 트래픽 이상(anomaly)을 식별하기 위해
고급 분류(classification) 기법을 사용할 필요성을 제기한다.
본 연구의 목적은 비지도 학습(unsupervised machine learning) 방법론인
Isolation Forest를 구현하여,
비정상적(anomalous) 및 정상적(non-anomalous) 웹 트래픽을 식별하는 것이다.
공개된 전자상거래 웹사이트의 웹 로그 데이터셋은
데이터 수집(data ingestion), 데이터 유형 변환(data type conversion),
데이터 정제(data cleaning), 정규화(normalization) 등의
체계적인 처리 파이프라인을 거쳐 전처리되었다.
이 과정에서 학습용 데이터셋에는 파생 컬럼(derived columns)이 추가되었으며,
테스트용 데이터셋은 수동으로 라벨링(manually labeled)되어
사이버보안 전문가들이 식별한 결과와
Isolation Forest 모델의 이상 탐지 성능을 비교하는 데 사용되었다.
개발된 Isolation Forest 모델은 Python Scikit-learn 라이브러리를 이용해 구현되었으며,
정확도(Accuracy) 93%, 정밀도(Precision) 95%, 재현율(Recall) 90%,
그리고 F1 점수(F1-Score) 92%의 우수한 성능을 보였다.
적절한 데이터 준비(data preparation),
모델 개발(model development),
모델 구현(model implementation),
그리고 모델 평가(model evaluation)를 통해,
본 연구는 Isolation Forest가
웹 트래픽 이상 탐지에서 높은 정확도를 달성할 수 있는
실질적이고 유효한(suitable and viable) 솔루션이 될 수 있음을 보여준다.
Keywords:
anomaly detection; web traffic; web traffic anomaly detection; machine learning; isolation forest
1. 서론 (Introduction)
더 엄격한 데이터 프라이버시 법률이 시행됨에 따라,
보안 침해(security breach)는 데이터 유출에 대한 벌금,
평판 손실, 그리고 공격으로 인한 서비스 중단으로 인한 수익 손실 등으로 인해
웹사이트 소유자들에게 훨씬 더 큰 비용 부담이 되고 있다.
따라서 웹사이트 소유자와 보안 전문가들이
데이터 유출로 이어질 수 있는 웹 트래픽의 이상 징후(anomalous web traffic)를
조기에 신속하게 식별할 필요성이 대두되고 있다 [1–5].
연구자들은 정상(normal) 활동과 악의적(malicious) 활동 모두가
디지털 흔적(digital breadcrumbs)을 남긴다는 점에 착안하여
웹 로그(web logs) 데이터를 분석하였다 [2,3].
그러나 이러한 웹 로그를 이용한 이상 탐지는
네트워크 및 웹 서버 방화벽과 같은 전통적인 방어 수단이
점점 더 무력화되고 있다는 점에서 여러 도전에 직면해 있다.
이는 해커들이 웹 기반 공격(web-based attacks)에 더 집중하고 있기 때문이다 [1,3,6,7].
또한 해커들은 탐지를 피하기 위해
그들의 공격 방법을 자주 난독화(obfuscate)한다.
심지어 중간 정도의 트래픽을 가진 웹사이트에서도
웹 로그의 막대한 양 때문에 수작업 분석은 사실상 불가능하다 [3,5].
머신러닝(machine learning)은
이상 트래픽(anomalous traffic)의 식별을 가속화함으로써
생산성 향상 가능성을 제공한다 [3–6].
그러나 웹 트래픽 데이터는 일반적으로
전체 트래픽 중 이상치(anomaly)가 차지하는 비율이 매우 낮은,
심각한 클래스 불균형(class imbalance)을 보인다.
이러한 편차(deviation) 혹은 이상(anomaly)은
양성(benign) 또는 악성(malicious)으로 분류될 수 있다 [2,8].
양성 이상(benign anomalies)은
트래픽 패턴에서 무해한 변동(harmless fluctuation)을 나타낸다.
예를 들어, 사용자 활동의 계절적 변화(seasonal variation)는
양성 이상을 발생시킬 수 있다.
반면, 악성 이상(malicious anomalies)은
잠재적으로 해로운 활동을 의미한다.
이는 웹사이트 보안의 취약점을 악용하려는 사이버 공격(cyberattack),
사용자를 속이거나 조작하려는 사기성 활동(fraudulent activity),
또는 웹사이트의 기능을 고의로 방해하려는 시도일 수 있다.
악의적 행위자(malicious actors)는
자신들의 활동을 정상적인 웹 트래픽 흐름 속에 숨기려 하기 때문에,
이상 탐지는 온라인 보안을 유지하기 위한 핵심 도구로 간주된다 [1,4,8].
웹 트래픽 데이터에 얽혀 있는 복잡한 패턴을 분석함으로써,
웹 트래픽 분석은 웹사이트 성능 최적화를 가능하게 할 뿐만 아니라
온라인 보안과 이상 탐지 보장을 위해
매우 중요한 역할을 수행한다.
이전 연구들은 다양한 관점에서 웹 트래픽을 탐구해왔다.
예를 들어, 스택 아키텍처(stack architecture)의 사용은
웹 애플리케이션에서 이상(anomaly)을 탐지하기 위한
분류기 앙상블(classifier ensemble)을 결합하는 방법으로 검토되었으며,
이를 통해 웹 트래픽에서의 이상 탐지 성능 향상을 보여주었다 [4].
스택 아키텍처(stack architecture)는 여러 개의 분류기(classifier) 결과를
계층적으로 결합해 더 강력한 예측을 수행하는 방식이다.
즉, 단일 모델이 아닌 여러 모델의 판단을 종합하여
웹 트래픽의 비정상적인 패턴을 더 정확하게 식별하도록 한다.
추가 연구에서는 웹 트래픽 이상 탐지 기법에 대한
포괄적인 조사(comprehensive survey)를 제공하였으며,
이에는 통계적 방법(statistical methods),
머신러닝 접근법(machine learning approaches),
그리고 하이브리드(hybrid) 방법론이 포함되었다 [1–3,5,8].
빠르게 성장하고 있는 웹 트래픽 영역에서
이상을 탐지하기 위한 고급 기법을 구현하는 것은 필수적이다.
전통적인 규칙 기반(rule-based) 접근법은
이미 알려진 위협(known threats)을 식별하는 데 효과적이지만,
악의적 행위자(malicious actors)가 사용하는
지속적으로 변화하는 전술(tactics)을 따라잡는 데 어려움을 겪는다.
머신러닝은 이러한 문제를 해결하기 위한
유망한 접근법(promising approach)을 제공한다.
방대한 양의 웹 트래픽 데이터로부터 지속적으로 학습함으로써,
머신러닝 모델은 새로운 전술(novel tactics)을 사용하더라도
악의적 활동(malicious activity)을 나타낼 수 있는
패턴과 이상(anomaly)을 식별할 수 있다 [4,6].
이러한 지속적 학습 능력(continuous learning capability)은
머신러닝이 동적인 위협 환경(dynamic threat landscape)에
적응하도록 하며,
웹 트래픽 이상 탐지를 위한 강력한 도구로 만들어준다.
한 연구에서는 비지도 학습(unsupervised learning) 기법,
특히 Extended Isolation Forests를 사용하여
네트워크 트래픽 데이터에서 이상 탐지를 수행하였다.
Isolation Forest는 트리 기반(tree-based) 알고리즘으로,
데이터 포인트를 분리(isolate)하는 데 필요한 분할 횟수를 기준으로
이상치를 탐지한다.
즉, 적은 분할로 고립되는 데이터일수록
이상치(anomaly)일 가능성이 높다고 판단한다.
Extended Isolation Forest는 이러한 기본 원리를 확장하여
임의 분할(random split)이 아닌 더 다양한 분할 방향을 고려함으로써,
비선형적이고 복잡한 데이터 분포에서도
이상치를 더욱 정밀하게 탐지할 수 있도록 개선된 버전이다.
그 결과, 비지도 학습 방법은
라벨이 지정된 공격 데이터(labeled attack data)가 제한된 상황에서도
유효하고 설득력 있는 접근법(compelling approach)을 제공한다는
결과를 보여주었다 [7].
웹 트래픽 이상 탐지를 위한 머신러닝이
상당한 발전을 이루었음에도 불구하고,
여전히 여러 도전 과제(challenges)와 연구 격차(research gap)가 존재하여
그 잠재력이 완전히 실현되지 못하고 있다.
가장 중요한 장애물(critical hurdle)은
웹 트래픽 데이터의 본질적인 불균형(inherent imbalance)에 있다.
여러 머신러닝 기법들 가운데, Isolation Forest(IF)는
그 고유한 강점으로 인해 웹 트래픽 이상 탐지를 위한
매우 설득력 있는(compelling) 접근법으로 부상하였다.
지도 학습(supervised learning) 방법이 학습을 위해
라벨이 지정된 데이터(labeled data)를 필요로 하는 것과 달리,
Isolation Forest는 비지도 학습(unsupervised learning) 패러다임을 활용하여,
라벨이 부족한(labeled anomaly data가 희소한) 상황에
특히 적합한 방법으로 평가된다 [7,9,10].
이러한 특성 덕분에 Isolation Forest는
대규모 데이터셋을 빠르게 분석할 수 있는 속도(speed)와
데이터셋의 부분 샘플링(subsampling)을 통해
모델을 생성할 수 있는 능력 덕분에,
보안 격차(security gap)를 줄이려는
네트워크 및 보안 관리자들에게 매우 유용한 도구가 될 잠재력을 가진다 [10–14].
Isolation Forest는 전체 데이터셋을 모두 사용하는 대신,
무작위로 선택된 일부 샘플(subsample)을 이용해
여러 개의 결정 트리(decision tree)를 학습시킨다.
이러한 부분 샘플링(subsampling)은 계산 효율성을 높이고,
과적합(overfitting)을 방지하며,
대규모 데이터셋에서도 빠른 학습과 탐지를 가능하게 한다.
Isolation Forest는 네트워크 트래픽 이상 탐지에서 사용되어 왔지만,
웹 트래픽 이상 탐지를 위해서는 아직 널리 구현되지 않았다.
따라서 본 연구는 웹 트래픽 맥락(context)에서
Isolation Forest의 구현을 통해
현재의 이상 탐지 기법, 동향, 및 방법론을 개선하는 것을 목표로 한다.
본 연구의 결과는 사이버보안 전문가(cybersecurity practitioners)와
데이터 과학자(data scientists)들에게
머신러닝, 특히 Isolation Forest를 활용하여
웹 트래픽 이상을 보다 정확하고 정밀하게 탐지하는 데 유용한 통찰(insight)을 제공하고자 한다.
이러한 이상(anomaly)들의 탐지는 또한
네트워크 및 웹사이트 관리자들이
네트워크 인프라 내의 숨겨진 취약점(hidden vulnerabilities)을 식별하고,
이상 현상의 발생을 방지하기 위한 대응책(countermeasures)을
개발하는 데 도움을 줄 것이다.
이 연구는 다음의 세 가지 연구 질문에 답하는 것을 목표로 한다.
Isolation Forest를 이용한 웹 트래픽 이상 탐지를 위해
필요한 데이터와 매개변수(parameters)는 무엇이며,
그것들은 어떻게 준비되는가?Isolation Forest는 웹 트래픽 이상 탐지에서
어떻게 구현되는가?Isolation Forest는 웹 트래픽의 이상을 탐지하는 데 있어
어떤 성능을 보이는가?
2. 방법론 (Methodology)
본 연구의 목적은 Isolation Forest를 구현함으로써
비정상적(anomalous) 및 정상적(non-anomalous) 웹 트래픽을 식별하고,
정확도(Accuracy), 정밀도(Precision), 재현율(Recall),
그리고 F1-점수(F1-score)와 같은 지표를 사용하여
그 성능을 평가하는 것이다.
이를 위해 정상 및 비정상 트래픽 패턴을 모두 포함하는
공개된 네트워크 트래픽 데이터셋(publicly available network traffic dataset)을 활용하였다 [15].
그림 1(Figure 1)에 제시된 바와 같이,
본 연구는 세 단계로 구성된다.
즉, 데이터 준비(Data Preparation),
모델 생성(Model Generation),
그리고 모델 평가(Model Evaluation)이다.
그림 1. 연구 설계의 개요.

2.1. 웹 트래픽 데이터 준비 (Web Traffic Data Preparation)
이상 탐지를 위해 사용되는 웹 트래픽 데이터는
Isolation Forest 모델에 대한 입력의 무결성(integrity)을 보장하기 위해
적절한 데이터 준비가 필요하다.
본 연구에서 사용된 데이터셋은
Farzin Zaker가 작성한 Harvard Dataverse의
2019 온라인 쇼핑 스토어(Online Shopping Store)—웹 서버 로그(Web Server Logs), V1이며,
연구자들은 이 데이터를 Kaggle 웹사이트로부터 확보하였다 [9,16].
표 1(Table 1)에 나타난 바와 같이,
Kaggle에서 획득한 이 3.3GB 크기의 데이터셋은
약 1,000만 개의 행(rows)을 포함하고 있으며,
이란의 전자상거래 웹사이트인 zanbil.ir의
Nginx 서버 접근 로그(server access logs)를
기본 로그 형식(native log format)으로 포함하고 있다.
표 1. 본 연구에서 사용된 웹 트래픽 데이터셋의 미리보기(Preveiw) [16].

정상적인 웹 트래픽(normal web traffic)은
사용자와 웹 서버 간의 상호작용(interaction) 중에 관찰되는
전형적인 패턴과 행동(typical patterns and behaviors)을 나타낸다.
정상 트래픽은 일반적인 웹 애플리케이션의
일관된 행동(consistent behaviors)을 보이는 경우가 많다.
비록 일반적인 웹 트래픽에서 벗어난(outliers) 트래픽이
자동적으로 비정상(anomalous)으로 분류되어서는 안 되지만,
이들은 이후 성공적인 공격(successful attacks)의
전조(harbinger)로 작용한 사례가 있다 [1,4,5,17].
이러한 트래픽은 또한 잠재적인 악의적 활동(malicious activity)의
가능성이 높으며, 추가적인 조사가 필요하다.
Isolation Forest를 이용한 이상 탐지(anomaly detection)는
예상되는 행동(expected behavior)에서
유의하게 벗어난(significantly differ) 데이터 포인트(data points)를
데이터셋 내에서 식별하는 것을 목표로 한다 [9,10,12].
이러한 이상(anomalies)은 추가적인 조사가 필요하며,
이는 임박한 문제(impending issues),
사기(fraud), 또는 기타 중요한 발견(important findings)을
예고할 수 있다.
표 2(Table 2)는 본 연구에서 사용된 웹 서버 로그(web server logs)가
각 사이트 방문(site visit) 또는 상호작용(interaction)에 대한
세부 정보(detailed information)를 포함하고 있음을 보여준다.
여기에는 방문자 정보(visitor details), 요청 방법(request methods),
프로토콜(protocol), 사용자 에이전트(user agents),
리퍼러(referrer), 사이트의 통합 자원 식별자(Uniform Resource Identifier, URI),
바이트(bytes), 그리고 응답 코드(response codes)가 포함된다.
리퍼러(referrer)는 사용자가 현재 페이지에 도달하기 직전에
방문했던 웹페이지의 URL을 의미한다.
예를 들어, A 사이트의 링크를 클릭해 B 사이트로 이동했다면,
B 사이트의 로그에는 A 사이트의 주소가 리퍼러로 기록된다.
이는 트래픽의 출처를 분석하거나
공격 경로를 추적하는 데 유용하게 활용된다.
표 2. 본 연구에서 사용된 원시 데이터셋의 스키마.

Scrip : Source IP Address
연구자들은 데이터 수집(data ingestion),
데이터 유형 변환(data type conversion),
데이터 정제(data cleansing)의 다양한 단계를 포함하는
체계적인 절차(systematic process)를 파이프라인(pipeline) 형태로 설계하였다.
이러한 절차는 데이터 준비(data preparation)와 정제(cleaning) 단계의 일부로 수행되었다.
데이터셋을 수집한 후,
그림 2(Figure 2)는 연구자들이 두 개의 데이터 세트를 추출했음을 보여준다.
그림 2. 본 연구에서 사용된 데이터 준비 과정의 파이프라인.
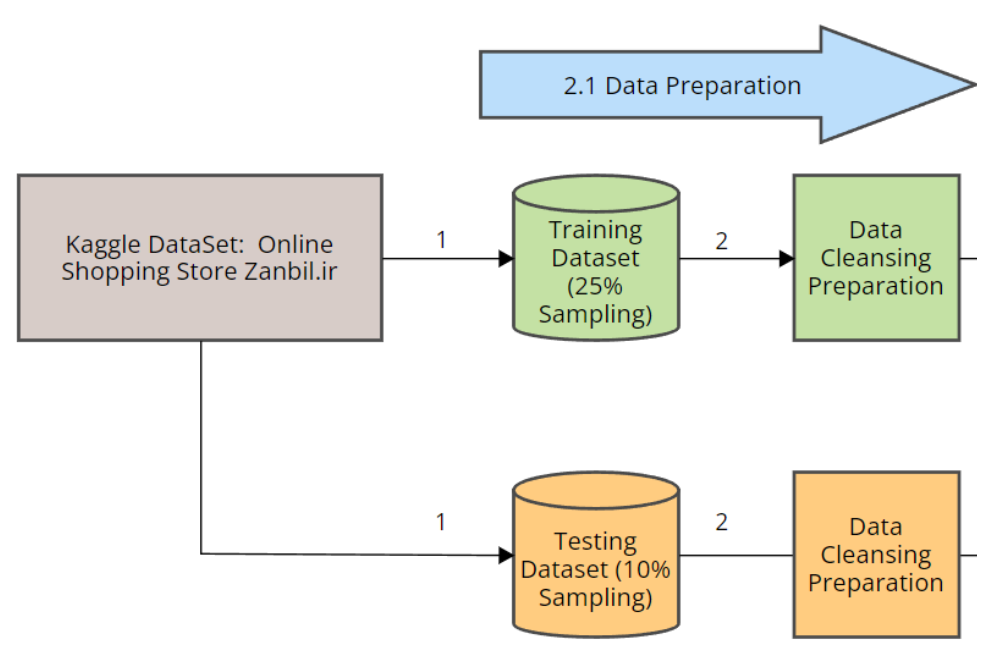
(1) 하나는 모델을 학습(training)하기 위한 세트이고,
다른 하나는 테스트(testing) 데이터셋으로 사용되었다 [18].
데이터 준비(data preparation)를 위해,
연구자들은 웹 로그의 25%를 샘플링(sampling)하여
학습용 데이터셋(training dataset)으로 사용하였다.
데이터 정제(data cleaning)의 일환으로,
연구자들은 결측 데이터(missing data)가 포함된
모든 행(row)을 삭제(drop)하였다 (2).
학습 세트(training set)를 위해,
연구자들은 매개변수(parameter) max_sampling = 25%로 설정하여,
전체 데이터셋의 25% 하위 집합(subset)에서
프로젝트가 수행되도록 하였다.
max_sampling은 Isolation Forest에서
트리(iTree)를 학습할 때 사용할 데이터의 비율을 지정하는 매개변수이다.
예를 들어max_sampling = 25%로 설정하면,
전체 데이터셋 중 25%만 무작위로 선택해 각 트리를 학습시킨다.
이는 계산 효율성을 높이고 과적합을 방지하는 데 도움을 준다.
연구자들은 이 과정에서 swamping과 masking 현상이
발생할 가능성을 예상하였다 [12,19,20].
Swamping은 정상(normal) 데이터 포인트가
잘못하여 이상치(anomaly) 또는 거짓 양성(false positive)으로
레이블링되는 현상이며,
반대로 Masking은 실제 이상치(anomaly)가
정상(normal) 데이터 포인트 또는 거짓 음성(false negative)으로
잘못 분류되는 현상이다 [12,20].
이러한 이유로,
작은 샘플 크기(small sample size)는
swamping 및 masking 효과를 감소시켜
더 나은 iTree를 생성한다 [13,21,22].
정제 과정(cleaning process)은 처음에
연구자들이 직접 결측 데이터가 있는 행을 평가(evaluate)하고
삭제(delete)하는 수작업으로 시작되었으며,
그 다음으로 웹 트래픽 데이터 정제 프로토콜(cleaning protocols)을 따랐다.
데이터셋의 정제 절차(data cleaning procedure)는
Python의 Scikit 라이브러리에서 보완된(augmented) 코드(code)를 이용해 구현되었으며,
머신러닝을 위한 데이터 품질 향상을 위해
다양한 데이터 유형(data types)을 적절히 처리하였다.
연구자들은 웹 로그 데이터가 CSV 형식이 아닌
Apache 로그 형식(Apache log format)으로 존재함을 확인하였다.
따라서 로그 형식을 CSV 테이블 형식으로 변환하는 과정에서
일부 아티팩트(artifacts)가 남을 수 있으며,
이는 연구자들이 수정해야 할 부분이었다.
Apache 로그는 일반적으로 공백이나 기호로 구분된 비정형(unstructured) 텍스트 형식이다.
이를 CSV(쉼표로 구분된 값) 형태로 변환할 때,
잘못된 구분자 처리나 특수문자 인코딩 문제로 인해
일부 데이터가 깨지거나 비정상적인 잔여 정보(artifacts)가 생길 수 있다.
연구자들은 이러한 잔여 데이터를 정제(cleaning)하고
일관된 구조로 맞추기 위해 추가적인 수정 과정을 수행해야 했다.
이 정제 및 준비 과정은
Isolation Forest가 결측 데이터(missing data)나
잘못된 데이터 유형(incorrect data type)을 마주할 때
예외(exception)를 발생시키지 않도록
문제를 해결하기 위해 수행되었다.
2.2. Isolation Forest 모델 구현 (Isolation Forest Model Implementation)
웹 트래픽 데이터셋에 대해 적절한 데이터 준비 절차를 수행하여
데이터셋의 무결성(integrity)을 보장한 후,
Isolation Forest를 비지도 머신러닝(unsupervised machine learning) 모델로 구현하는 것이
연구자들이 설정한 파이프라인의 다음 단계였다.
그림 3(Figure 3)은 특징 생성(feature generation) 단계 (3)가
새로운 특징(feature)을 추가하는 결과를 낳았음을 보여준다.
그림 3. 본 연구에서 사용된 데이터 준비 및 모델 생성 과정의 파이프라인.
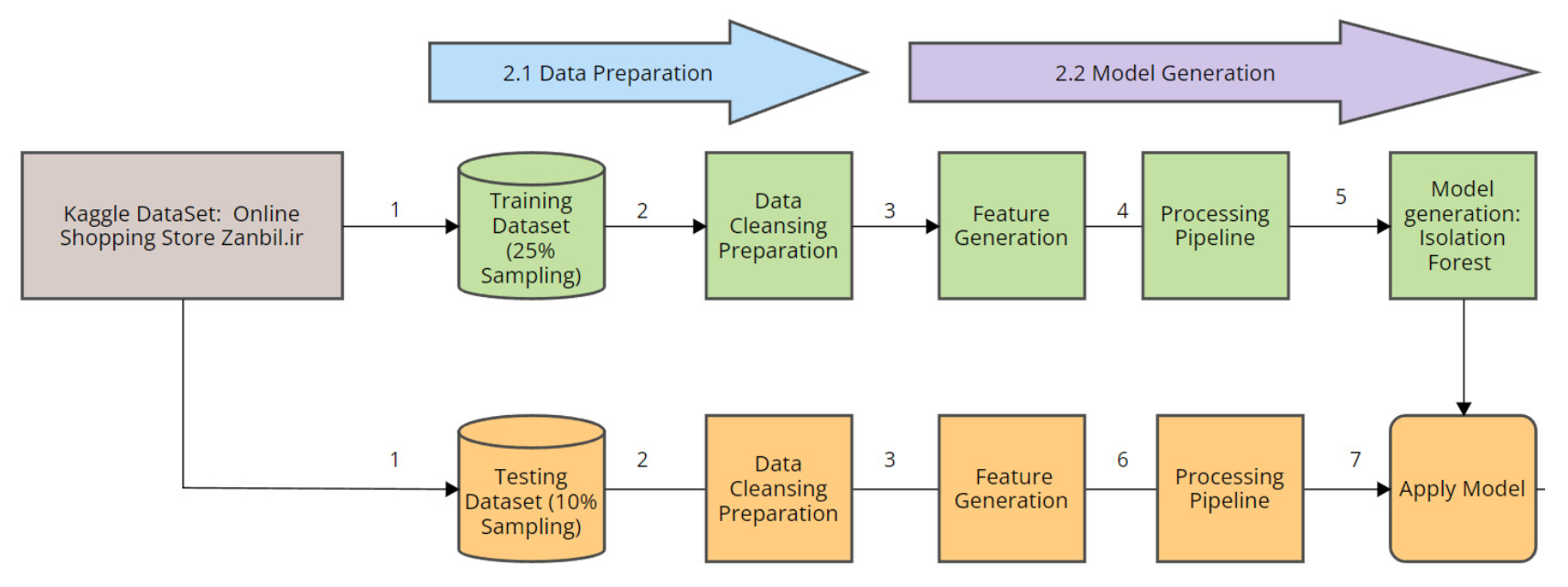
즉, URI_occurrences, IOC_occurrences, User-Agent_occurrences, URI_length,
UserAgentLength 등의 특징들이 생성되었으며,
이들은 URI, User-Agent, 그리고 Referrer 컬럼으로부터 파생되었다.
이렇게 생성된 특징들은 Source IP (Scrip) 주소,
Timestamp, Method, URIs, Protocol, Status, Bytes, Referrer, User-Agent 등의
입력 항목과 함께 추가되었다.
User-Agent 문자열(string)과 URI 문자열은
비정상적인 문자 집합(anomalous character sets) 및
침해 지표(Indicators of Compromise, IoCs)의 발생을 탐지하기 위해
생성된 특징 세트(generated feature set)를 사용하여 분석되었다.
User-Agent 문자열 또는 URI 내에서 IoC가 탐지되면,
이것은 이상(anomaly)을 유발할 수 있는데,
그 이유는 악의적 지표(malicious indicators)는
일반적인 합법적(User-Agent) 문자열이나
URI 내에는 일반적으로 존재하지 않기 때문이다.
URI는 인터넷상의 이름(name) 또는 자원(resource)을 식별하는
문자열(string)로,
이 자원들과 네트워크를 통해 상호작용(interaction)을 가능하게 한다 [3,23].
또한, URL(Uniform Resource Locator)은
URI의 하위 집합(subset)으로서
식별된 자원의 위치(location)와
이를 검색(retrieve)하기 위한 메커니즘을 지정하며,
이는 HTTP(Hypertext Transfer Protocol),
FTP(File Transfer Protocol) 등의 프로토콜을 통해 수행된다.
URL은 URI보다 더 구체적이며,
특정 웹페이지 또는 파일과 같은
최종 목적지(final destination)를 가리킨다.
이러한 필드(fields)로부터 생성된 특징들과
계산된 IoC 값들을 함께 활용함으로써,
Isolation Forest는 잠재적 위협(potential threats)을
더 효과적으로 탐지할 수 있으며,
특히 네트워크 트래픽이나 로그인 시도(login attempts)와 관련된
User-Agent 문자열과 URI 문자열에 집중한다.
데이터 처리 파이프라인(data processing pipeline) (4)는
Python의 Scikit-learn 패키지를 사용하여 구현되었으며,
그 후 비수치형(non-numeric) 객체 데이터 유형(object data type) 변수를
OneHotEncoder()를 사용하여 수치형(numerical) 값으로 변환하였다.
연구자들은 초기 단계에서 LabelEncoding 대신
OneHotEncoding을 선택하였다.
그 이유는 ‘bag of words’ 특징(feature)에서
각 단어가 고유한 “원-핫(one-hot)” 차원을 생성하기 때문이다.
즉, HTTP 세션에서 해당 단어가 포함되어 있으면 1로 표시되고,
그렇지 않으면 0으로 표시된다 [13,21].
그러나 대부분의 공격(attack)은
‘bag of words’에 포함되지 않은
의미 없는(nonsensible) 단어들을 사용하기 때문에
이러한 방식에는 한계가 있었다.
수치형 변수(numeric variables)에 대해서는
연구자들이 StandardScaler()를 적용하여
수치 데이터를 정규화(normalize)하고,
값의 크기가 지나치게 커져
내재된 편향(implicit bias)을 유발하는 것을 방지하였다.
이 파이프라인은 StandardScaler와,
StandardScaler와 함께 사용되는 OneHotEncoder를 모두 포함하고 있다.
StandardScaler는 모든 수치형 특징(numeric features)을
중심화(center)하고 스케일링(scale)하는 데 사용되며,
OneHotEncoder는 범주형 특징(categorical features)에 대해
상대적 차이에 초점을 맞춘 표준화(standardizing)된 특징으로 사용되었다.
그 후 ColumnTransformer 클래스가
다양한 변환(transformation)에 사용되었으며,
초기 변환 단계에서는
수치형 데이터를 평균 0, 표준편차 1로 조정하도록 설정되었다.
후처리 파이프라인(post-processing pipeline) 데이터를 완료한 후,
연구자들은 Isolation Forest 모델(5)을 생성하였다.
생성된 Isolation Forest 모델이 저장된 후,
연구자들은 동일한 파이프라인 처리를 테스트 데이터셋(testing dataset)에 적용하였다 (6).
그 다음, 생성된 Isolation Forest 모델을
후처리된 테스트 데이터셋(post-pipeline testing dataset)에 적용하였다 (7).
모델 적용(Apply the Model, 7) 단계에서
추가로 두 개의 필드(field)가 생성되었는데,
즉, Predict와 Anomaly_Score이다.
Predict 필드는 테스트 세트 내 데이터 인스턴스에 대한
모델의 예측(prediction) 또는 분류(classification)를 나타내며,
이 값은 이상치(outlier)에 대해 –1, 정상치(inlier)에 대해 +1을 가진다.
이 예측값은 각 데이터 포인트의 결과 또는 레이블에 대한
모델의 최적 추정(best estimate)을 의미한다.
반면, Anomaly_Score 열(column)은
모델이 학습한(expected) 패턴으로부터
각 데이터 포인트가 얼마나 비정상적인지(abnormality)
또는 벗어나 있는지(divergence)의 정도를 보여준다.
본 연구에서의 “격리(isolation)”의 정의는
특정 인스턴스를 나머지 인스턴스들로부터 분리하는 것을 의미한다.
즉, 격리 기반(isolation-based) 기법은
각 인스턴스가 격리되기 쉬운 정도의 민감도(sensitivity)를 측정하며,
이상치는 그 중에서도 격리되기 가장 쉬운(highest susceptibility) 인스턴스를 뜻한다 [10,11,20].
따라서 본 연구에서는 Isolation Forest를 사용하여
웹 로그(weblog) 데이터를 대상으로 격리 과정을 수행하였다.
구체적으로, Isolation Forest의 구현은
이전 연구자들이 제시한 무작위 분할(random partitioning) 원리를 기반으로 하며,
데이터를 무작위로 선택된 속성(attributes)과 값(values)에 따라
재귀적으로(recursively) 분할하여 Isolation Trees를 생성한다 [9–13,20,21].
이 트리(tree)들의 경로 길이(path length)는
이상치를 분리하는 데 필요한 분할 횟수를 나타내며,
이는 이상 탐지(anomaly detection)의 측정 기준으로 사용된다 [11,15,20,24].
Isolation Forest의 원리는
이상치(outlier)가 데이터셋 내 대다수 인스턴스와 다른 패턴을 보이는 비정상 인스턴스라는 점에 있다.
이러한 이상치는 무작위 분할(random partitioning) 특성상
트리의 루트(root) 근처에 위치하게 되며,
이에 따라 더 짧은 경로(shorter paths)를 가진 트리가 생성된다.
만약 어떤 인스턴스가 트리의 짧은 가지(branch)에 위치한다면,
그 인스턴스는 이상치(outlier)로 간주된다 [18].
본 연구에서, 더 짧은 경로 길이(shorter path lengths)에 의해 식별된 이상치(anomalies)는
웹 로그 데이터셋 내의 정상 데이터 포인트들로부터
더 쉽게 격리될 수 있기 때문에,
더 높은 이상치 점수(anomaly scores)가 부여되었다.
연구자들은 그 후 Isolation Forest 알고리즘에
여러 매개변수(parameters)를 적용하였다.
‘contamination’ 매개변수의 값은 0.03으로 설정되었다.
Isolation Forest에서 contamination은
데이터셋 내에서 이상치(outlier)가 차지하는 비율을 나타내는 매개변수이다.
예를 들어 contamination = 0.03이면,
전체 데이터의 약 3%가 이상치일 것으로 가정하고 모델이 경계를 설정한다.
이 값은 결정 경계(threshold)를 조정하는 역할을 하며,
너무 높게 설정하면 정상 데이터가 이상치로 잘못 분류될 수 있고,
너무 낮게 설정하면 실제 이상치를 놓칠 가능성이 있다.
일반적으로 contamination은 0.10으로 설정되지만,
이 연구에서는 웹 로그 데이터셋의 특성에 따라 다르게 설정되었다.
초기 결과(initial results)에 따르면,
contamination 값은 0.0169 또는 1.6% 이하로 나타났으며,
이에 따라 연구자들은 contamination을 0.03 또는 3%로 설정하였다.
이 매개변수는 매우 민감(sensitive)하며,
실제 이상치 비율(actual outlier rate)을 얼마나 근사(approximate)하느냐에 따라
결과가 달라질 수 있다 [11,25–27].
재현성(reproducibility)을 보장하기 위해,
여러 번의 실행에서도 동일한 결과를 얻을 수 있도록 하는
‘random_state’ 매개변수는 42로 설정되었다.
또한, 분석의 속도(speed)와 확장성(scalability)을 높이기 위한
다중 프로세싱(multiprocessing)을 구현하기 위해,
컴퓨터의 16개 코어(processing cores)의 처리 능력을
최대한 활용할 수 있도록 n_jobs = 16이 적용되었다.
그 다음, max_samples는 0.25로 설정되었으며,
이는 전체 1천만(10 million) 레코드의 약 1/4,
즉 약 250만(2.5 million) 행(row)을 샘플링하는 결과를 낳는다.
이 크기 축소(reduction in size)는
성능(performance)에 부정적인 영향을 미치지 않으면서
더 빠른 처리 속도(faster processing)를 가능하게 하였다.
2.3. Isolation Forest 모델 평가 (Isolation Forest Model Evaluation)
준비된 웹 로그 데이터셋을 사용하여 Isolation Forest 모델을 구현한 후,
웹 이상 탐지(web anomalies)에서 모델의 분류 성능(classification power)을
측정하기 위해 모델 평가(model evaluation)가 수행되었다.
그림 4는 모델 평가 및 시각화 과정(8)에서,
Isolation Forest가 적용된 후 테스트 데이터셋이
총 17개의 열(columns)을 가지게 되었음을 보여준다.
그림 4. 본 연구에서 사용된 데이터 준비, 모델 생성, 그리고 모델 평가 과정의 파이프라인.
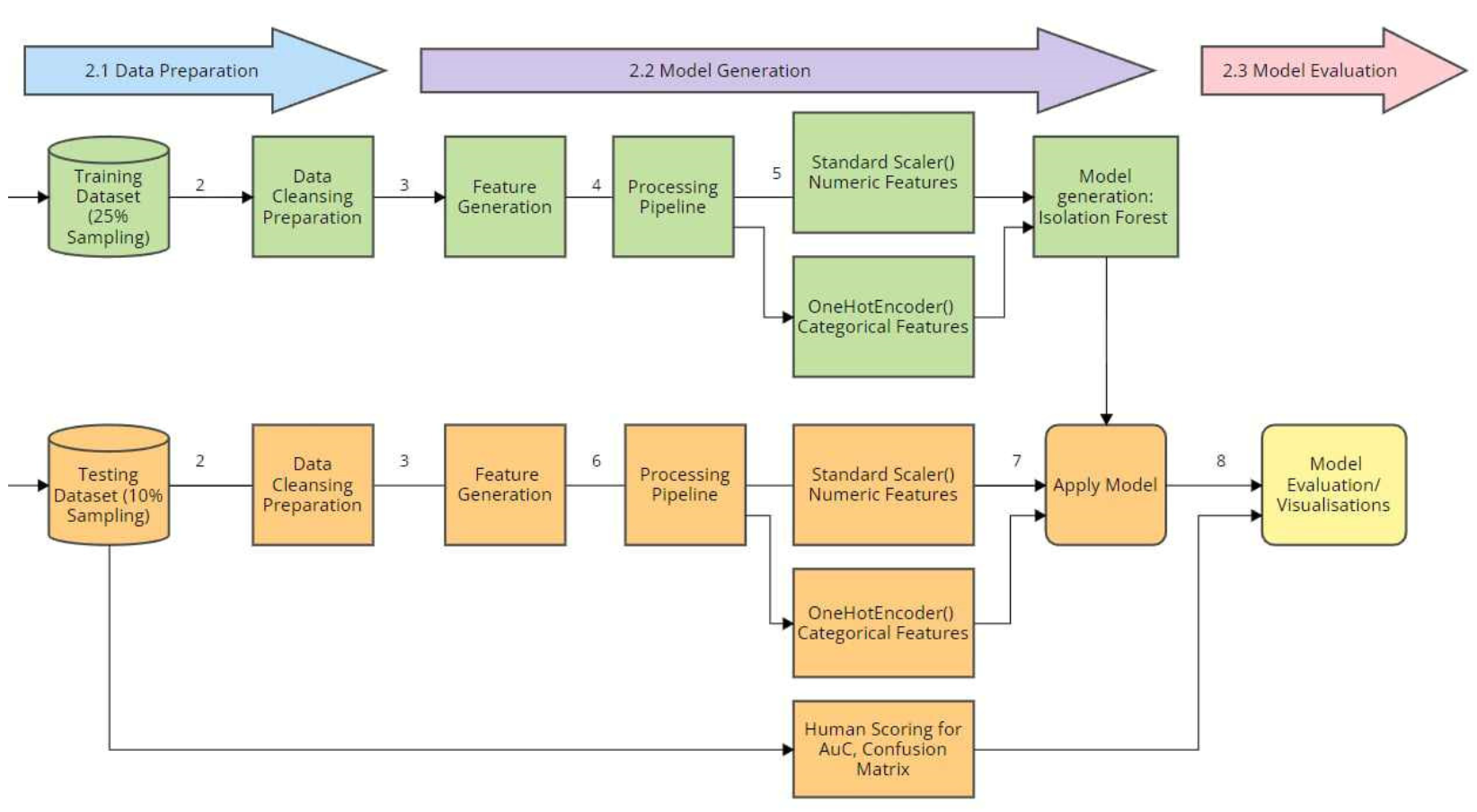
추가된 열에는 Predict와 Anomaly_Score가 포함되며,
또한 수동 인간 평가(manual human scoring)를 위한
두 개의 필드(field) — 즉, Human Rating과 Attack Type — 가 추가되었다.
이 두 필드는 이후 연구자들에 의해 모델 평가 단계에서
모델 성능(model performance)을 계산하는 기준으로 사용되었다.
Human Rating은 인간 평가자(human scorers)가 각 행(row)이
이상치(anomaly)를 나타내는지(-1로 표시),
또는 정상(normal)인지(+1로 표시)를 평가한 값을 포함하였다.
또한, Attack Type 필드에는
SQL 인젝션(SQL injection), 크로스 사이트 스크립팅(cross-site scripting),
프로브(probe), 연결 터널(connect tunnel)과 같은
특정 공격 유형(specific attack types)이 포함되어 있었다.
인간이 시각적 데이터(visual data)를 더 쉽게 처리한다는 점을 인식하고,
연구자들은 또한 예측된 결과(predicted outcomes)(8)을
여러 특징(feature)을 기반으로 시각화하여,
Isolation Forest 모델의 성능(performance)과 동작(behavior)에 대한
이해(comprehension)와 통찰(insight)을 향상시켰다.
그림 5는 연구자들이 여러 특징을 기반으로
예측된 결과를 시각화하여
Isolation Forest 모델의 성능과 동작에 대한
이해와 통찰을 강화한 모습을 보여준다.
그림 5. (a) 바이트(bytes)에서의 IOC 발생(occurrences)의 이상치(anomalies).
(b) 메서드(method)에서의 URI 발생의 이상치.
(c) User-Agent에서의 IOC 발생의 이상치.
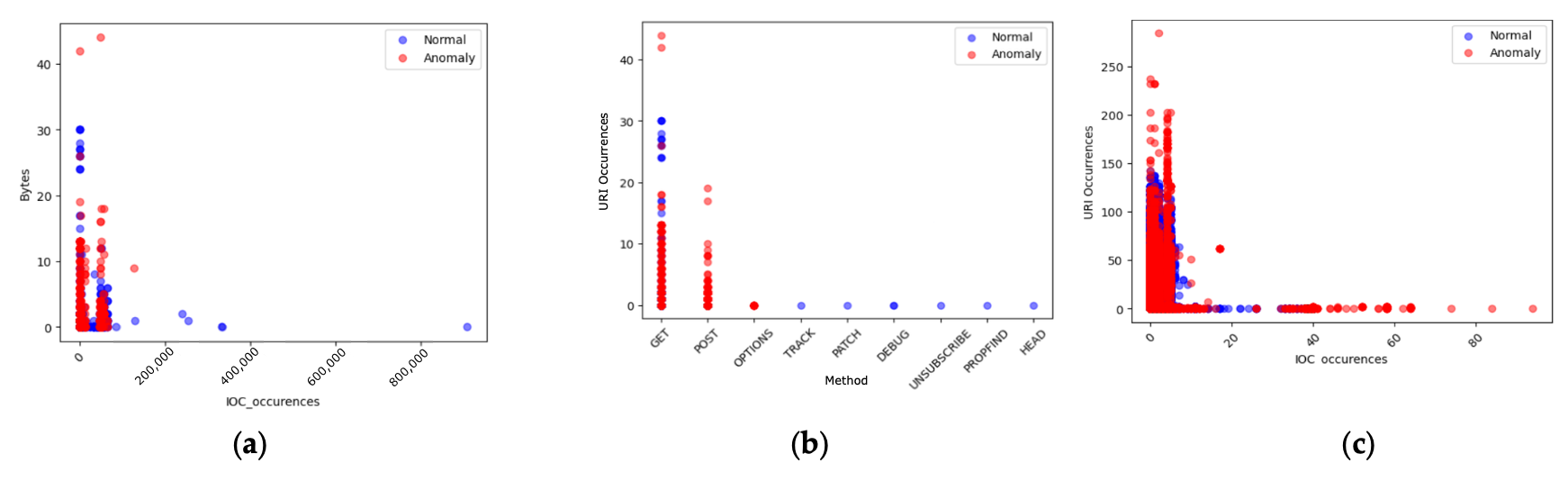
(a) Bytes vs IOC occurrences
- x축: IOC occurrences (IOC 발생 빈도)
- y축: Bytes (데이터 전송량)
대부분의 정상 요청은 IOC 발생 빈도와 데이터 전송량이 모두 낮은 영역에 분포한다.
그러나 일부 요청은 IOC 발생이 거의 없거나 매우 낮음에도
데이터 전송량(Bytes)이 비정상적으로 크다.
이는 정상처럼 보이는 세션이 대규모 데이터를 송수신하는 경우로,
데이터 유출(exfiltration)이나 비인가 다운로드 같은 공격 행위를 의미할 수 있다.
Isolation Forest는 이러한 “IOC 발생이 거의 없는 대용량 트래픽”을 주요 이상치로 탐지한다.
(b) Method vs URI occurrences
- x축: HTTP Method (요청 방식, 예: GET, POST, PUT 등)
- y축: URI occurrences (URI 발생 빈도)
정상 요청은 대부분 GET과 POST 요청에 분포하며,
URI 발생 빈도도 일정한 수준에서 안정적으로 유지된다.
반면, 비정상 요청은 동일한 메서드(GET, POST) 내에서도
특정 URI가 과도하게 반복 호출되거나
비정상적인 URI 문자열을 포함한 요청으로 나타난다.
이는 정상 요청 형태를 가장한 자동화된 공격(예: SQL Injection, XSS 등)의
반복적 접근 시도로 해석될 수 있다.
(c) IOC occurrences vs URI occurrences
- x축: IOC occurrences (IOC 발생 빈도)
- y축: URI occurrences (URI 발생 빈도)
대부분의 정상 요청은 IOC와 URI 발생 빈도가 모두 낮거나 안정된 범위에 있다.
그러나 일부 요청은 IOC 발생 빈도가 낮더라도
동일한 URI가 과도하게 반복 호출되는 패턴을 보인다.
이는 특정 자동화 스크립트나 봇(bot)이
제한된 URI를 지속적으로 호출하며 공격을 시도하는 행위를 반영한다.
Isolation Forest는 이러한 “IOC와 URI의 비정상적 조합”을
이상 행동으로 감지한다.
이와 함께, 연구자들은 또한 산점도(scatter diagram)(7)와
혼동 행렬(confusion matrix)을 사용하였으며,
높은 이상치 점수(anomaly score)는
데이터 포인트가 정상(norm)에 비해
이상치(outlier)일 가능성이 더 높거나
드물게(uncommon) 나타난다는 것을 의미한다고 지적하였다.
모델 평가 단계에서, 연구자들은 Isolation Forest 모델이
거짓 양성(false positives)과 거짓 음성(false negatives)을 최소화함으로써
웹 트래픽의 이상(anomaly)을 얼마나 정확하게 식별하는지를 결정하였다.
이 분석은 Isolation Forest가 비이상적(non-anomalous) 트래픽과 이상 트래픽을
정확하게 분류함으로써 웹 트래픽 분류 알고리즘으로서
얼마나 효과적인지를 보여주기 때문에 중요하다.
정확도(Accuracy)는 모델이 비정상적 혹은 정상 트래픽을
정확히 예측할 수 있는 능력을 나타내는 중요한 지표이지만,
데이터셋이 불균형한 경우에는 성능을 과대평가할 수 있다.
예를 들어, 모델이 대부분의 클래스를 다수 클래스로 예측하는 경향이 있다면,
소수 클래스(minority categories)가 완전히 무시되더라도
정확도는 상대적으로 높은 값을 가질 수 있다.
이로 인해, 이러한 평가지표는 소수 클래스의 분류 성능을 반영하지 못하고,
평가의 편향(bias)을 초래하게 된다.
게다가, 정확도 지표는 모델의 소수 클래스에 대한 분류 성능이 낮더라도,
다수 클래스의 정확도가 높으면 불균형을 인식하지 못할 수 있다.
따라서, 본 연구에서는 모델의 전반적인 분류 성능의 다양한 측면을 평가하기 위해
정확도와 함께 정밀도(Precision), 재현율(Recall),
그리고 F1-점수(F1-score)와 같은 다른 지표들도 사용하였다.
이러한 지표들은 Isolation Forest 구현의 성능을 평가하는 데 활용될 수 있는
분류 성능의 여러 측면을 보여준다【15,21,24,27,29】.
정확도(Accuracy)는 모델의 결과를 예측하는 능력을 측정한다【14,21,30,31】.
식 (1)은 정확도가 어떻게 계산되는지를 보여주며,
True Positive (TP)는 모델이 웹 트래픽의 이상(anomalies)을
정확하게 식별한 경우를 나타내고,
True Negative (TN)은 모델이 정상 인스턴스를 정확히 식별한 경우를 나타낸다.
False Positive (FP)는 모델이 정상 데이터를 이상치로 잘못 식별한 경우이며,
False Negative (FN)는 실제 이상 데이터를 모델이 식별하지 못한 경우를 의미한다.
정확도가 모델의 전체 예측이 얼마나 올바른지를 측정하는 반면,
정밀도(Precision)는 Isolation Forest 모델이 예측한
모든 양성(positive) 중 실제 양성의 비율을 계산한다【14,21,32,33】.
식 (2)는 높은 정밀도(precision)가
모델이 양성 클래스(positive class)를 예측할 때를 나타낸다는 것을 보여준다.
재현율(Recall)은 Isolation Forest 모델이
웹 트래픽의 실제 이상치(positive instance)를 얼마나 잘 식별하는지를 측정한다.
즉, 전체 실제 이상치 중 모델이 올바르게 예측한 비율을 나타낸다【14,21,30,32,33】.
식 (3)은 재현율이 실제 이상치에 대한 모델의 민감도를 나타내며,
참양성(True Positive)의 비율로 계산된다.
F1-점수(F1-score)는 정밀도(Precision)와 재현율(Recall)을
하나의 값으로 결합하여 시스템 성능을 균형 있게 평가하는 지표이다.
이 지표는 특히 클래스 불균형이 존재하는 상황에서 유용하다【14,21,31,32】.
식 (4)는 F1-점수가 정밀도와 재현율 간의 상충 관계를 조화시키며,
두 값의 조화평균(harmonic mean)을 사용하여 계산된다는 것을 보여준다.
이 지표는 불균형한 상황에서 시스템의 전체적인 효율성을 평가하기 위한
통합적인 척도를 제공한다.
3. 결과 및 논의 (Results and Discussions)
3.1 웹 트래픽 데이터 준비 결과 (Web Traffic Data Preparation Results)
모델 구현을 위한 학습 데이터셋을 적절히 준비하기 위해,
연구자들은 Isolation Forest가 웹 로그(weblog) 데이터셋과 함께 작동할 수 있도록
확인할 필요가 있었다.
Isolation Forest는 null 값이 없어야 하며 정수(integer) 데이터 유형을 요구하므로,
null 값을 포함한 모든 행은 학습 데이터셋에서 삭제되었다.
모든 비수치(non-numerical) 필드는 숫자 값(numeric values)으로 변환되었으며,
이 값들은 대부분 데이터 유형(Data Type, D-type) 열에서
객체(object) 데이터 유형으로 유지되었다.
이는 이 열이 다양한 데이터 유형을 포함할 수 있음을 의미하며,
숫자형(int64I) 열처럼 숫자로만 제한되지 않는다는 점에서 차이가 있다.
표 3은 학습 데이터셋에서
웹 로그 데이터셋이 열 1부터 8까지 표준으로 제공되었으며,
Bytes를 위한 열 7만이 Isolation Forest의 일반적인 구현에서
숫자형(numeric) 데이터로 사용되었음을 보여준다 [9].
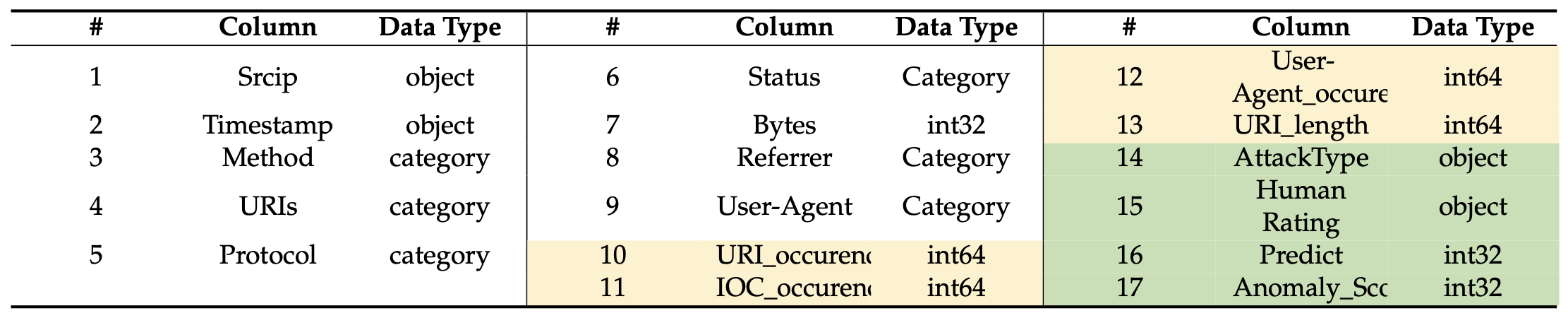
표 3. 본 연구에서 사용된 준비된 학습 데이터셋의 스키마(schema).

이와 함께, 연구자들은 특성 공학(feature engineering)을 사용하여
파생된 특성(derived features)을 생성하고,
열 10에서 13(밝은 금색으로 강조 표시됨)에 대한 계산을 수행하였다.
즉, URI_occurrences, IOC_occurrences, User-Agent_occurrences, 그리고 URI_length이다.
연구자들은 숫자형 열의 int64 데이터를 StandardScaler에 포함시켰으며,
나머지 D-type 데이터는 OneHotEncoding에 포함시켰다.
표 4는 추가 열들이 존재함을 보여준다.
즉, Attack Type, Human Rating, Predict, 그리고 Anomaly_Score (녹색으로 강조 표시됨)이다.
표 4. 본 연구에서 사용된 준비된 테스트 데이터셋의 스키마(schema).
연구자들은 이후 테스트 데이터셋에 대해
학습 데이터셋에서 사용된 동일한 정제(cleaning) 및
특성 생성(feature generation) 절차를 적용하였다.
또한, 연구자들은 Isolation Forest 모델을
테스트 데이터셋에 적용하고,
그 결과를 Predict와 Anomaly_Score라는 이름의 열에 각각 저장하였다.
이렇게 생성된 결과 데이터셋은
이후 CSV 파일로 저장되었다.
학습 데이터셋과 테스트 데이터셋의 경우,
연구자들은 각각 25%와 10%의 통계적 샘플링(statistical sampling)을 사용하였다.
Isolation Forest는 비지도(unsupervised) 학습이므로,
연구자들은 데이터셋을 공식적으로 분할하지 않고
무작위 샘플링(random sampling) 테스트를 사용하였다 [11,15,24].
본 연구에서 웹 로그(weblog) 데이터셋은
null이 아닌(non-null) 값의 개수와 데이터 유형(D-type)에 따라
학습과 테스트용으로 분할되었다.
표 5에 나타난 바와 같이,
Isolation Forest 모델 구현에 사용된 웹 로그 데이터셋은
전체의 25%, 즉 2,591,287개의 레코드가 학습 데이터셋에,
10%, 즉 1,035,020개의 레코드가 테스트 데이터셋에 사용되었다.
표 5. 데이터 준비 후 Isolation Forest 모델 구현에 사용된 데이터셋.

이는 테스트 데이터셋 내 100만 개 이상의 레코드가
인간 평가자(human raters)에 의해 채점되어,
실제 웹 트래픽 이상(anomalies)과
기계 학습 분류 결과를 비교하는 데 사용되었음을 의미한다.
이후 데이터셋은 모델 생성을 위한 정규화(normalization) 및
스케일링(scaling) 과정을 거쳤다.
정규화(normalization)는 OneHotEncoding과 StandardScaler를 사용하여 수행되었으며,
데이터는 테스트 데이터셋의 경우 0에서 10,365,151까지의 범위 인덱스로 스케일링되었다.
또한 테스트 데이터셋 역시 0에서 10,365,151까지의 범위 인덱스로 스케일링되었다.
본 연구는 Isolation Forest를 사용한 네트워크 이상(anomaly) 분류 연구들과
거의 유사한 데이터 준비 결과를 보여준다 [12–15,21].
Isolation Forest를 구현하기 전에 데이터 준비를 위해
OneHotEncoding과 StandardScaling을 사용하는 것은 일반적이지만,
본 연구에서는 테스트 데이터셋의 인간 레이블 인코딩(human label encoding)을 사용하여
실제 사이버 보안 전문가들이 웹 트래픽 이상을 분류하는 방식과
기계 학습 분류의 방식을 비교할 수 있도록 하였다.
이 연구에서 탐구된 또 다른 차이점은
학습 데이터셋과 테스트 데이터셋 모두에 추가된
파생 열(derived columns)의 도출이다.
연구자들의 실제 웹 트래픽 이상 탐지에 대한 전문 지식을 바탕으로,
이러한 파생 열들은 Isolation Forest 구현에 유용한 것으로 간주되었다.
3.2. Isolation Forest 모델 구현 및 평가 결과
분류(metric) 점수들은 웹 트래픽 이상(anomaly) 탐지에서
Isolation Forest 모델 구현에 대한 균형 잡힌 분석을 이해하기 위해 사용되었다.
표 6은 테스트 데이터셋으로부터 계산된
Accuracy, Precision, Recall, 그리고 F1-score의 비교를 제시한다.
Isolation Forest 모델은 93%의 Accuracy와 95%의 Precision을 달성하였으며,
이는 모델이 양성(positive) 사례를 얼마나 잘 예측하는지를 나타낸다.
실제 양성 비율(true positive rate)에 초점을 맞춘 Recall은 90%이며,
이는 실제 양성 사례 중 얼마나 많은 비율이 정확하게 식별되었는지를 측정한다.
F1-score는 92%이며, 이는 Precision과 Recall을 균형 있게 맞춘다.
표 6. Isolation Forest 모델의 분류 metric 점수들.

그림 6은 생성된 true positives, true negatives,
false positives, 그리고 false negatives의 관점에서
Isolation Forest 모델의 성능에 대한 추가적인 통찰을 제공하는
혼동 행렬(confusion matrix)을 보여준다.
그림 6. Isolation Forest 모델 구현의 혼동 행렬(confusion matrix).
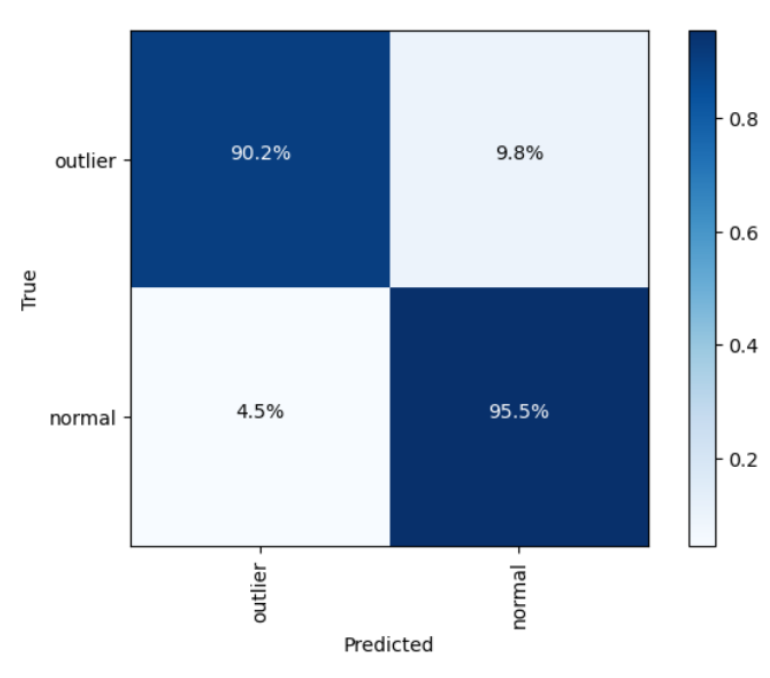
true positive 결과는 예측의 90.2%가 올바르게 분류되었음을 보여주며,
false negative 결과는 실제 클래스가 positive일 때
9.8%의 경우에서 모델이 그것을 negative로 예측했음을 보여준다.
또한, false positive 결과는 실제 클래스가 negative였을 때
4.5%의 경우에서 모델이 그것을 positive로 예측했음을 보여주며,
true negative 결과는 예측의 95.5%가
Isolation Forest 모델에 의해 올바르게 negative로 분류되었음을 보여준다.
이 모델 성능은 데이터 과학자나 머신러닝 전문가에게는
평균적으로 보일 수 있으나,
웹 트래픽 이상(web traffic anomalies)의 탐지자로서는
혼동 행렬이 이미 사이버보안 및
네트워크 보안 응용 분야에서
평균 이상의 훌륭한 성능을 보여준다 [2,5,6,14,17,18,27,29,34,35].
이는 해당 머신러닝 성능이
사이버보안 전문가가 잠재적인 웹 트래픽 공격자를
탐지하기에 이미 충분하기 때문이다.
Isolation Forest 모델의 제시된 Accuracy, Precision, Recall, 그리고 F1-score 덕분에
사이버보안 전문가는 이미 공격자의 Source IP Address (Srcip)를
매칭할 수 있으며
모델이 포착하지 못한 부분을 추가로 밝혀낼 수 있다.
또한, 이러한 공격자들의 모든 트래픽을 찾아내는 것은
나머지 숨겨진 이상 징후까지
더 명확하게 드러나게 할 것이다.
그림 7은 정상 또는 inlier와 비정상 또는 outlier 데이터의
3D 표현을 추가로 보여준다.
그림 7. URI_Occurrences, URI_Length, 그리고 User-Agent_Occurrences의 3D 플롯.
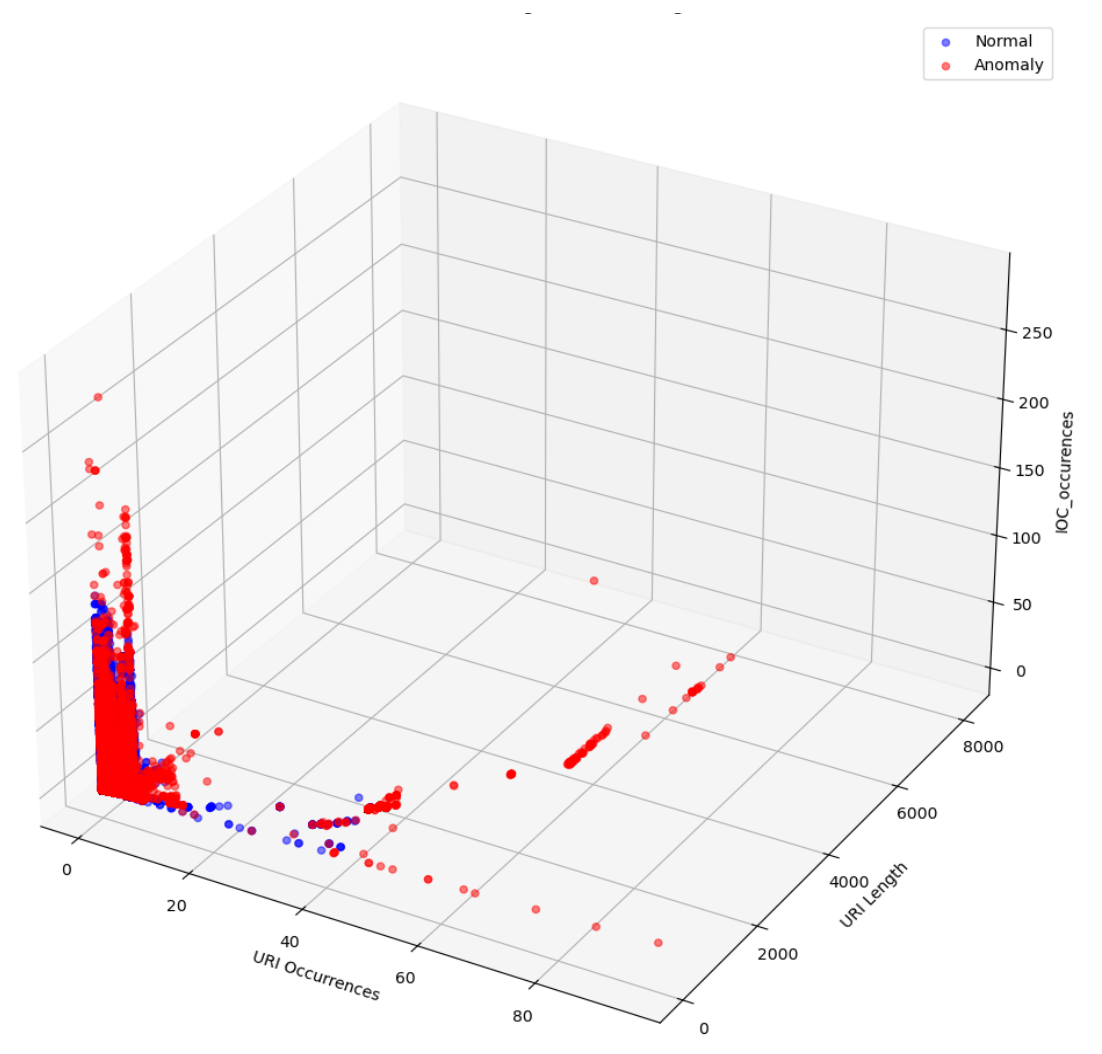
각 점(dot)은 본 연구의 특정 데이터 인스턴스에 해당하며,
이는 웹 요청(web request) 또는 사용자 세션(user session)이 될 수 있다.
빨간 점(red points)은 예측된 anomaly 인스턴스를 나타내며,
파란 점(blue points)은 예측된 normal 인스턴스를 나타낸다.
보여지는 고립된(isolated) 특성은
고립된 빨간 점들과 섞여 있는 일부 파란 점들에서 나타나는
비정상성(abnormalities) 때문에 발생한 것이다.
(The isolated nature shown is due to abnormalities
with some of the blue dots mixed with the isolated red dots.)
Isolation Forest 모델 구현의 성능을
웹 트래픽 이상(anomaly) 탐지에 대해 평가하는 것은
거의 유사한 사용 사례에 대한 응용에서
얼마나 잘 수행되는지를 기반으로 또한 평가될 수 있다.
그림 8에서 보여지듯이,
Isolation Forest를 사용하는 다른 논문들과 비교하여,
본 연구의 구현된 방법론은
비교 가능한 성능과 더 빠른 처리 시간을 보여준다 [21,22].
그림 8. 다른 Isolation Forest 모델 구현들[21,22]에 대한 본 연구의 성능 비교
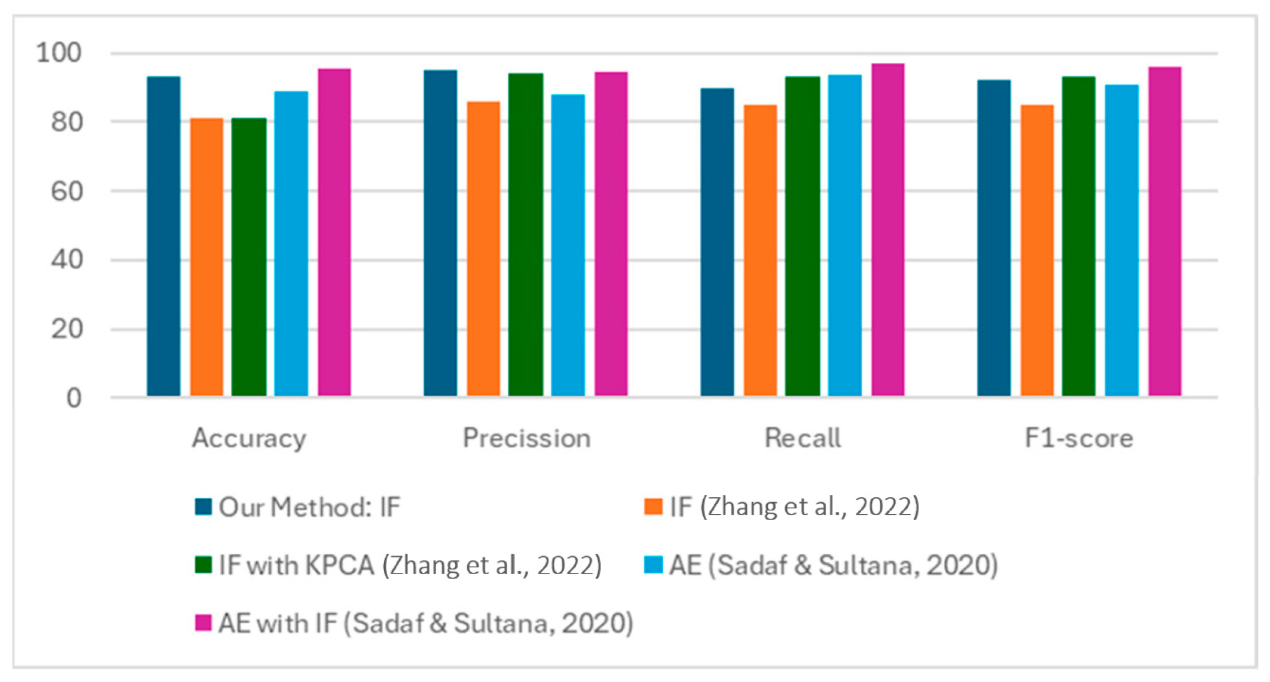
숫자형(numerical) 값과 명목형(nominal) 값을 포함하는
데이터셋을 또한 정규화(normalize)한 뒤
Isolation Forest를 구현한 유사 연구는
Accuracy 95.4%, Precision 94.81%, Recall 97.25%,
그리고 F1-score 96.01%를 보였다 [21].
또 다른 유사 연구는 Isolation Forest만을 구현하여
Isolation Forest와 커널 주성분 분석(KPCA)을 비교하였다 [22].
307,510개의 행과 122개의 열로 구성된 데이터셋을 처리한 이 연구는
Isolation Forest with KPCA 구현에서
Accuracy 87.3%, Precision 93.7%, Recall 92.5%,
그리고 F1-score 93.1%를 보였다.
Isolation Forest 단독 모델 구현의 경우,
Accuracy 80.9%, Precision 86.0%, Recall 85.5%,
그리고 F1-score 85.2%를 기록하였다.
이 성능 비교는
본 연구가 웹 트래픽 이상 탐지를 위해
Isolation Forest 모델을 최적으로 구현했음을 보여준다.
또한 Isolation Forest는
심하게 불균형한 데이터(highly imbalanced data)에서도
잘 동작하기 때문에,
전통적인 머신러닝 기법 및 앙상블 기법에 대한
유망한 대안을 제공한다 [18].
더욱이, 모델을 적용하는 데 걸리는 전체 시간은
모델이 그 알고리즘을 적용하고 결과를 산출하는 데 소요된 기간을 나타낸다.
본 연구에서 기록된 시간은 23.620082초인데,
이는 비교적 빠른 응답으로,
빠른 예측이 중요할 때
웹 트래픽 이상(anomaly) 탐지에서
더 시기 적절한 결정을 내릴 수 있음을 의미한다 [6,32,34,36].
그러나 모델 적용 속도가
결과의 품질을 훼손해서는 안 된다는 점을
기억하는 것도 똑같이 중요하다.
속도와 정확성을 모두 균형 있게 유지하는 것은
Isolation Forest 구현뿐 아니라
데이터 분석 및 머신러닝의 일반적인 분야에서도
핵심적인 과제로 남아 있다.
웹 트래픽에서 이상을 탐지하기 위해
Isolation Forest 모델을 사용하는 것은
데이터 준비, 모델 구현, 그리고 성능 평가를 포함한다.
Kaggle 데이터셋은 학습용 25%와 테스트용 10% 샘플로 분할되었다.
Method, Status, Protocol과 같은 비숫자(non-numeric) 필드는
OneHotEncoding을 사용해 인코딩되었으며,
URI, Referrer, User-Agent(예: user-agent 문자열 길이)와 같은 필드에 대해
추가 특징(feature)이 도출되었다.
비지도(unsupervised)임에도 불구하고,
약 250만 행 중에서
약 100만 건의 레코드로 구성된 테스트 데이터셋은
검증을 위해 수동으로 레이블링되었다.
모델은 Accuracy 0.93, Precision 0.95, Recall 0.90,
F1-score 0.92를 달성했으며,
실행 시간은 23.620082초였다.
본 연구는 PCA(주성분 분석), Autoencoder, Ensemble 등
다른 이상 탐지 기법을 사용하지 않고
Isolation Forest 모델만을 단독으로 구현하였다.
또한 이 연구는 HTTP 데이터로 구성된
웹 트래픽의 이상 탐지에만 초점을 두며,
전송 계층(segment)이나 네트워크 계층 패킷과 같은
애플리케이션 계층 아래의 데이터는 포착하지 않는다.
4. 결론 및 제언 (Conclusions and Recommendations)
본 연구는 웹 트래픽에서 이상(anomalies)을 탐지하기 위한
Isolation Forest의 개발, 구현, 그리고 평가를 탐구한다.
데이터 준비는 최적의 모델 구현을 보장하기 위해
데이터 수집(data ingestion), 데이터 유형 변환(data type conversion),
그리고 데이터 정제(data cleansing) 단계를 포함하는
체계적인 파이프라인을 통해
공개적으로 사용 가능한 데이터셋에서 수행되었다.
이는 학습 데이터셋에 2,591,287개의 레코드를 처리하기 위해
다양한 파생 열(derived columns)을 추가하도록 했으며,
테스트 세트의 1,035,020개의 웹로그 레코드를 처리하기 위해
추가적인 파생 열과 레이블이 지정된 열들도 포함하였다.
구현된 비지도(unsupervised) Isolation Forest 모델은
Accuracy 93%, Precision 95%, Recall 90%,
그리고 F1-Score 92%라는 뛰어난 성능을 보였다.
결과는 Isolation Forest가
네트워크 관리자/방어자 및 보안 연구자들이
웹 트래픽의 이상을 신속하게 식별하는 데 크게 도움을 줄 수 있음을 보여준다.
이러한 이상들은 방어자들이
웹사이트를 대상으로 실행될 가능성이 있는
공격을 가리키도록(point) 할 수 있다.
23.620082초에 불과한 더 빠른 실행 속도를 고려할 때,
본 연구에서 구현된 Isolation Forest 모델은
네트워크 방어자들의 더 빠른 반응 및 대응 시간을 가능하게 한다.
이러한 더 짧은 반응 시간은,
대부분의 공격 벡터가 식별되는 즉시 무력화될 수 있으므로,
성공적인 침해 가능성을 줄이는 데 도움을 준다.
Isolation Forest 모델 구현에 대한 향후 연구는
웹로그 트래픽을
최근에 발표된 Common Vulnerabilities and Exposures(CVEs)에 매핑함으로써
그 예측 능력을 더욱 향상시킬 수 있다.
새로운 CVE들의 고유한 지문(fingerprint)을 이해하고
그것들을 특성 생성(feature generation)에 통합하는 것은
Isolation Forest의 최적 기계 학습 모델 성능을
향상시킬 수 있다.
향후 연구들은 또한 Isolation Forest가
제로데이(zero-day) 공격을 탐지하는 데 얼마나 효과적인지를
탐구할 수 있는데,
희귀한 발생(rare occurrences)을 강조하는 그 능력이
정상적인 트래픽 패턴 속에서
이들의 탐지를 잠재적으로 용이하게 할 수 있기 때문이다.
새로운 위협 탐지를 위한 CVE의 통합은
Isolation Forest 알고리즘이
네트워크 및 웹사이트 관리 도구와
침입 방지 시스템에 통합될 수 있게 하며,
이는 해당 시스템들이
최근 익스플로잇(exploit), 패치 취약점(patch gaps),
그리고 특정 공격 벡터와 관련된 트래픽을
사전에(proactively) 인식할 수 있도록 하기 때문이다.
이는 웹사이트 소유자들을 위한
사이버보안 조치의 모니터링, 평가,
그리고 개선을 향상시킬 것이다.
Isolation Forest와 함께
다른 머신러닝 기법을 통합하는 것은
분류 성능을 더욱 최적화하기 위해
탐구될 수도 있다.
또한, 웹 트래픽 이상 탐지에서
Isolation Forest의 비교 성능을 설정하기 위해,
SMOTE(합성 소수 클래스 오버샘플링 기법),
Local Outlier Factor,
Support Vector Machine(SVM),
그리고 기타 앙상블(ensemble) 기법과 같은 방법들이
탐구될 수 있다.
이와 함께, 이상 탐지에서의
머신러닝 활용에 대한 향후 연구는
사이버보안 실무자와 데이터 과학자 모두에게
향상된 통찰과 중요한 도구를 제공하기 위해
웹 트래픽 응용에서 Isolation Forest 방법론을
확장하고 정교화하는 데 초점을 맞추어야 한다.
저자 기여(Author Contributions):
개념화, W.C.; 방법론, W.C. 그리고 L.C.V.; 소프트웨어, W.C.;
검증, H.H.L.; 형식 분석, W.C., A.L.D.P., C.S.C., S.P.P., A.J.P., M.J.P., R.M., D.J.P., J.P.O., H.H.L. 그리고 L.C.V.;
조사, W.C., A.L.D.P., C.S.C., S.P.P., A.J.P., M.J.P., R.M., D.J.P., J.P.O. 그리고 H.H.L.;
자원, W.C.;
데이터 큐레이션, W.C., A.L.D.P., C.S.C., S.P.P., A.J.P., M.J.P., R.M., D.J.P. 그리고 J.P.O.;
글쓰기—원고 초안 준비, W.C., A.L.D.P., C.S.C., S.P.P., A.J.P., M.J.P., R.M., D.J.P., J.P.O. 그리고 L.C.V.;
글쓰기—검토 및 편집, W.C., H.H.L. 그리고 L.C.V.;
시각화, W.C., A.L.D.P., C.S.C., S.P.P., A.J.P., M.J.P., R.M., D.J.P. 그리고 J.P.O.;
감독, W.C. 그리고 L.C.V.;
프로젝트 관리, W.C.;
자금 확보, H.H.L.
모든 저자는 본 원고의 출판된 버전을 읽고 동의하였다.
자금 지원(Funding):
APC는 미나다오 주립대학교-일리간 기술대학교(Mindanao State University–Iligan Institute of Technology)의
연구 및 기업부총장실(Office of the Vice Chancellor for Research and Enterprise)의
연구관리실(Office of Research Management)에 의해 지원되었다.
기관생명윤리위원회 성명(Institutional Review Board Statement):
해당 사항 없음(Not applicable).
연구 참여자 동의(Informed Consent Statement):
해당 사항 없음(Not applicable).
데이터 가용성 성명(Data Availability Statement):
이 연구는 2019 Online Shopping Store—Web Server Logs, Harvard Dataverse, V1
(Farzin Zaker 제공)의 공개 데이터셋을 사용하였다.
해당 데이터셋은 https://doi.org/10.7910/DVN/3QBYB5 에서 확인 가능하며,
2024년 5월 28일에 접속되었다.
감사의 말(Acknowledgments):
연구자들은 Online Shopping Store—Web Server Logs 데이터셋을 제공해 준 Farzin Zaker에게 감사를 표한다.
연구자들은 본 연구 수행에 이 데이터셋을 사용하였다.
이해 상충(Conflicts of Interest):
저자 Wilson Chua는 현재 Future Gen International Pte. Ltd.의 애널리틱스 부서에서 근무 중이다.
나머지 저자들은 이 연구가 잠재적인 이해 상충으로 해석될 수 있는
상업적 또는 재정적 관계 없이 수행되었음을 선언한다.
참고문헌 (References)
[1] Trivedi, J.; Shah, M. 웹 트래픽 예측을 위한 머신러닝 및 딥러닝 모델에 관한 체계적이고 종합적인 연구. Arch. Comput. Methods Eng. 2024, 31, 3171–3195.
[2] Lu, Y.; Wang, L.; Zhao, X. 데이터 스트림을 위한 이상 탐지 알고리즘 리뷰. Appl. Sci. 2023, 13, 6353.
[3] Ji, H.H.; Lee, J.H.; Kang, M.J.; Park, W.J.; Jeon, S.H.; Seo, J.T. 인공지능 기반 이상 탐지 기술을 활용한 암호화 트래픽: 체계적 문헌 리뷰. Sensors 2024, 24, 898.
[4] Tama, B.A.; Nkenguyeze, L.; Islam, S.M.R.; Kwak, K.-S. 분류기 앙상블 스택을 활용한 웹 트래픽 이상 탐지를 위한 향상된 이상 탐지. IEEE Access 2020, 8, 24120–24134.
[5] Kim, T.-Y.; Cho, S.-B. LSTM 신경망을 활용한 웹 트래픽 이상 탐지. Expert Syst. Appl. 2018, 106, 66–76.
[6] Nassif, A.B.; Talib, M.A.; Nasir, Q.; Dakalbaf, F.M. 이상 탐지를 위한 머신러닝: 체계적 리뷰. IEEE Access 2021, 9, 78658–78700.
[7] Carrera, F.; Dentamaro, V.; Galantucci, S.; Iannacone, A.; Impedovo, D.; Pirlo, G. 실시간 웹 트래픽 이상 탐지를 위한 지도학습 접근법 결합. Appl. Sci. 2022, 12, 1759.
[8] Inuwa, M.M.; Das, R. IoT 사이버 공격에 대한 이상 탐지를 위한 다양한 머신러닝 방법 비교 분석. Internet Things 2024, 26, 101162.
[9] Li, X.; Liang, B.; Li, X.; Huang, J.; Wu, J.; Gou, H. Isolation Forest 기반 잔차 이상 탐지를 통한 실시간 PPP 서비스 품질 모니터링. GPS Solut. 2024, 28, 118.
[10] Gatka, L.; Karczmarek, P.; Tokovarov, M. 최소 스패닝 트리를 기반으로 한 Isolation Forest. IEEE Access 2022, 10, 74175–74186.
[11] Liu, F.T.; Ting, K.M.; Zhou, Z.-H. Isolation Forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 413–422.
[12] Ding, Z.; Fei, M. 스트리밍 데이터 이상 탐지를 위한 Isolation Forest 접근법: 슬라이딩 윈도우 구현. IFAC Proc. Vol. 2013, 46, 12–17.
[13] Karev, D.; McCubbin, C.; Vaulin, R. Isolation Forest 사용을 통한 사이버 위협 헌팅. In CompSysTech ’17; ACM: New York, 2017; pp. 163–170.
[14] Rupian, R.C.; Sarker, I.H.; Anwar, M.F.; Murad, M.H.; Rahat, F.; Hoque, M.M.; Sarfraz, M. Isolation Forest 기반 Outlier Detector를 활용한 사이버 이상 탐지. In Hybrid Intelligent Systems; Springer, 2021; pp. 270–279.
[15] Castillo, O.; Gandhi, N.; Rios, T.N.; Hong, T.-P. Local Outlier Factor와 Isolation Forest 기반 신용카드 사기 탐지. Int. J. Comput. Sci. Eng. 2019, 7, 1060–1064.
[16] Zaker, F. Online Shopping Store—Web Server Logs. Harvard Dataverse 2019.
[17] Gabryel, M.; Lada, D.; Filutowicz, Z.; Patora-Wysocka, Z.; Kisiel-Dorohinicki, M.; Chen, G.Y. 오토인코더 변형을 활용한 광고 웹 트래픽 이상 탐지. J. Artif. Intell. Soft Comput. Res. 2022, 12, 255–256.
[18] Al-Shehri, T.; Al-Razgan, M.; Alfakhi, T.; Alswaeil, R.A.; Pandiaraj, S. Insider Threat Detection을 위한 이상 탐지: Isolation Forest 기반. IEEE Access 2023, 11, 118170–118185.
[19] Franklin, R.J.; Mohammed Dabbagol, V. 비디오 감시 영상에서 이상 탐지를 위한 신경망 기반 접근. 2020 International Conference on Investigative Systems; 2020; pp. 632–637.
[20] Liu, F.T.; Ting, K.M.; Zhou, Z.-H. Isolation-Based Anomaly Detection. ACM Trans. Knowl. Discov. Data 2012, 6, 1–39.
[21] Sadaf, K.; Sultana, J. Autoencoder와 Isolation Forest 기반 Fog Computing 이상 탐지. IEEE Access 2020, 8, 167059–167068.
[22] Zhang, Y.F.; Hu, L.; Lin, H.F.; Qiao, X.C.; Zheng, H. 불균형 신용카드 사기 탐지 데이터셋을 위한 최적화된 이상 탐지 모델. Mob. Inf. Syst. 2022, 2022, 8027093.
[23] Hamon, V. HTTP 문서에서 악성 URL 처리. J. Comput. Virol. Hacking Tech. 2019, 4, 95–76.
[24] Chabchoub, Y.; Togbe, M.U.; Boly, A.; Chiky, R. Isolation Forest 개선 및 심층 분석. IEEE Access 2022, 10, 10219–10227.
[25] Aldrich, C.; Liu, X. Isolation Forest를 이용한 광물 처리 공정 모니터링. Minerals 2024, 14, 76.
[26] Zhang, Q.; Liang, Z.; Liu, W.; Peng, W.; Huang, H.; Zhang, S.; Chen, L.; Jiang, K.; Liu, L. Isolation Forest 기반 산사태 민감도 예측. Sustainability 2022, 14, 16692.
[27] Priyanto, C.Y.; Hendry; Purnomo, H.D. Isolation Forest와 LSTM Autoencoder 결합을 통한 이상 탐지. Proceedings of ICITech 2021; pp. 35–38.
[28] Chen, W.; Yang, K.; Yu, Z.; Shi, Y.; Chen, P. 불균형 학습에 관한 최신 연구와 응용. Artif. Intell. Rev. 2024, 57, 137.
[29] Madhukar Rao, G.; Ramesh, D. IoT, 스마트 시티, 애플리케이션에서의 이상 탐지를 위한 Isolation Forest 하이브리드 개선 알고리즘. Proceedings of IFML 2021; Springer; pp. 589–598.
[30] Foody, G.M. 현실 세계의 분류 정확도 측정의 문제점: ROC, Matthews 상관계수까지. PLoS ONE 2023, 18, e0291908.
[31] Sokolova, M.; Japkowicz, N.; Szpakowicz, S. 정확도, F-Score, ROC를 넘어: 판별 성능 평가를 위한 기준. AI 2006; pp. 1015–1021.
[32] Yacouby, R.; Axman, D. Precision, Recall, F1 평가의 확률적 확장. EVAL4NLP 2020.
[33] Powers, D.M.W. Precision, recall, F-measure에서 ROC 등까지. J. Mach. Learn. Technol. 2011, 2, 37–63.
[34] Naseer, S.; Saleem, Y.; Khalid, S.; Bashir, M.K.; Han, J.; Iqbal, M.M.; Han, K. 딥러닝 기반 향상된 네트워크 이상 탐지. IEEE Access 2018, 6, 48231–48246.
[35] Benova, L.; Hudec, L. 웹 서버 로그에서의 이상 사용자 활동 종합 분석 및 평가. Sensors 2024, 24, 746.
[36] Sharova, E. Isolation Forest를 이용한 비지도 이상 탐지. PyData London 2018 발표자료.
Disclaimer/Publisher’s Note:
모든 출판물에 포함된 진술, 의견, 그리고 데이터는
전적으로 개별 저자(들)과 기여자(들)의 것이며,
MDPI 및/또는 편집자(들)의 것이 아니다.
MDPI 및/또는 편집자(들)는
본 콘텐츠에 언급된 어떠한 아이디어, 방법, 지침 또는 제품으로 인해
사람이나 재산에 발생할 수 있는 어떠한 피해에 대해서도 책임을 부인한다.