[논문 번역] ARGOS: Agentic Time-Series Anomaly Detection with Autonomous Rule Generation via Large Language Models
논문 출처
Yile Gu, Yifan Xiong, Jonathan Mace, Yuting Jiang, Yigong Hu, Baris Kasikci, Peng Cheng.
ARGOS: Agentic Time-Series Anomaly Detection with Autonomous Rule Generation via Large Language Models.
University of Washington / Microsoft Research / Boston University.
🔗 원문 링크 (arXiv: 2501.14170v1)
저자
- Yile Gu
- Yifan Xiong
- Jonathan Mace
- Yuting Jiang
- Yigong Hu
- Baris Kasikci
- Peng Cheng
(University of Washington, Microsoft Research, Boston University)
초록
클라우드 인프라에서의 observability는 서비스 제공자에게 매우 중요하며,
이로 인해 모니터링 메트릭을 위한 anomaly detection 시스템이 널리 채택되고 있다.
그러나 기존 시스템들은 실제 운영 환경에서 필수적인 세 가지 특성인
설명 가능성(Explainability), 재현 가능성(Reproducibility), 자율성(Autonomy)를
동시에 달성하는 데 어려움을 겪고 있다.
본 논문에서는 대규모 언어 모델(LLM)을 활용하여
클라우드 인프라의 시계열 anomaly detection을 수행하는
agentic 시스템인 ARGOS를 제안한다.
ARGOS는 설명 가능하고 재현 가능한 anomaly rule을
intermediate representation으로 사용하며,
LLM을 이용해 이러한 규칙을 자율적으로 생성한다.
또한 시스템은 여러 협력 에이전트를 통해
오류 없고 정확도가 보장된 anomaly rule을 효율적으로 학습하며,
학습된 규칙을 저비용 온라인 anomaly detection에 배포한다.
평가 결과를 통해 ARGOS는 기존 state-of-the-art 방법들을 능가하였으며,
공개 anomaly detection 데이터셋과 Microsoft 내부 데이터셋에서
각각 최대 9.5%, 28.3%의 $F_1$ score 향상을 달성하였다.
1 서론
클라우드 서비스의 신뢰성과 가용성을 보장하는 것은
서비스 제공자에게 핵심적인 과제이다 [8, 19, 31, 32, 71].
서비스 중단(downtime)이나 장애(interruption)는
고객 경험과 비즈니스 운영 모두에 심각한 영향을 미칠 수 있기 때문이다.
2021년 12월에 autoscaling에 의해 촉발된
예기치 않은 연결성 급증(connectivity surge)으로 인해
Amazon Web Services(AWS)에서 대규모 장애가 발생하였으며,
이로 인해 하위 서비스들에 장애가 전파되었고
전 세계 수백만 명의 사용자에게 10시간 이상 영향을 미쳤다 [54].
서비스 중단의 부정적인 영향을 최소화하기 위해서는
메트릭 모니터링에서 anomaly를 조기에 탐지하는 것이 매우 중요하다.
이러한 메트릭들은 클라우드 서비스의 상태와 성능에 대한
실시간 통찰(real-time insight)을 제공하기 때문이다.
대규모 기업들은 실제 운영 환경(production environment)에서
anomaly detection 시스템을 개발하고 배포하는 경우가 많다 [49, 60, 69].
이러한 시스템들은 방대하고 동적인 인프라 구조의
규모(scale), 복잡성(complexity), 그리고 고유 요구사항(unique requirements)을 처리하도록 설계되어 있다.
예를 들어, Google의 Borg [60]는 작업 상태와 성능 메트릭을 추적하는 강력한 모니터링 도구를 제공하며,
실패한 작업을 자동으로 재시작하고 수만 대 규모의 머신으로 확장(scale-up)할 수 있다.
그러나 다양한 형태의 anomaly가 존재하기 때문에,
높은 정확도로 anomaly를 적시에 탐지하는 것은 매우 어려운 문제이다.
그림 1: 256개의 A100 GPU를 사용하는 분산 모델 학습 환경에서의 GPU utilization 및 memory usage 메트릭.
작업(job)이 시작된 이후 NCCL에서 hang 문제가 발생한 상황을 보여준다.
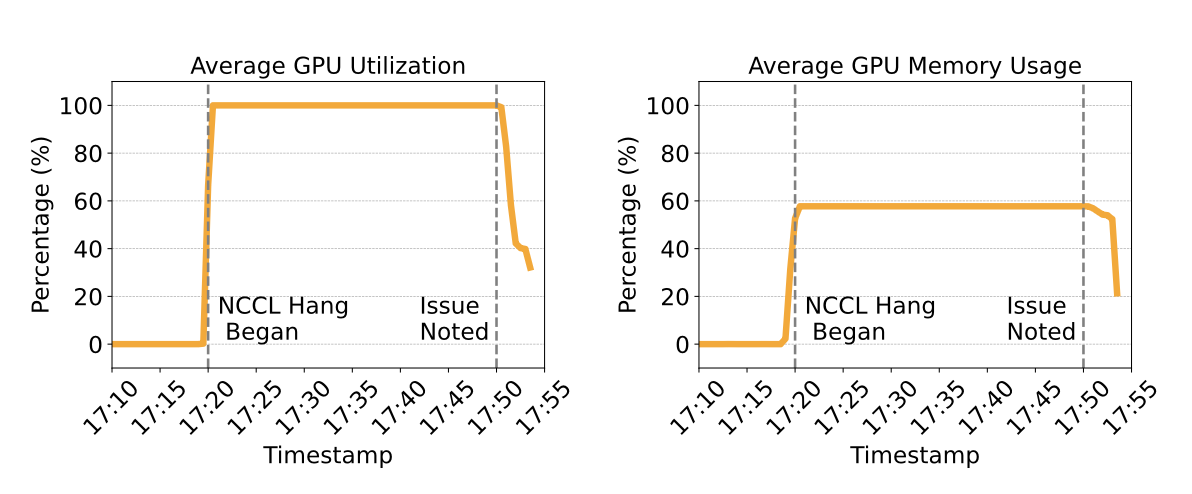
예를 들어 그림 1은 실제 서비스 중단 사례를 보여주는데,
256개의 A100 GPU를 사용하는 분산 모델 학습 환경에서 네트워크 hang 문제가 발생한 상황이다 [44].
timestamp 17:20에서 문제가 발생하였고, GPU들은 통신 재개를 기다리기 위해
busy wait 상태에 들어가면서 높은 utilization과 memory usage를 유지하였으며,
결과적으로 학습 과정이 정지(stall)되었다.
겉보기에는 GPU utilization이 포화(saturated) 상태이고
GPU memory가 효율적으로 사용되는 것처럼 보일 수 있으나,
정상적인 학습 과정에서는 GPU utilization과 GPU memory에 변동성(variation)이 존재해야 한다.
하지만 해당 그림에서는 이러한 변동성이 관찰되지 않는다.
수동으로 작성된 anomaly rule을 사용하는 모니터링 시스템들은
이 문제를 적시에 탐지하지 못하였으며,
결국 timestamp 17:50에서 사람이 직접 개입하여
학습을 종료한 이후에야 문제가 완화되었다.
그 결과 상당한 자원과 시간이 낭비되었다.
이와 같은 네트워크 hanging 문제는 여러 대형 기업들에서도 관찰된 바 있다 [14, 24, 66].
모니터링 시스템의 정확도를 향상시키기 위해 엔지니어들은
“모든 GPU가 15분 이상 지속적으로 100% utilization 상태로 동작하는 경우”와
같은 새로운 anomaly rule을 수동으로 추가해야 한다.
기존 연구들 [10, 28, 34, 46, 74]과
Microsoft에서 대규모 장애 관리(incident management)를 위한 이상 탐지 시스템을
실제로 배포하며 얻은 우리의 경험은,
이러한 시스템 설계에 필수적인 세 가지 핵심 특성을 강조한다:
(i) 설명 가능성(Explainability)
어떤 시스템도 완벽할 수는 없으며,
이상 탐지 시스템에서는 오탐(false alarm)이 불가피하게 발생한다.
알람이 발생했을 때
당직 엔지니어(on-call engineer, OCE)는
해당 결과가 발생한 근본 원인을 이해할 수 있어야 한다.
설명 가능한 이상 탐지 시스템은
OCE가 시스템의 부정확성을 쉽게 개선할 수 있도록 도와준다.
(ii) 재현 가능성(Reproducibility)
시스템은 동일한 입력 메트릭에 대해 항상 일관된 결과를 생성해야 한다.
이를 통해 실제 운영 환경(production)에서 알람이 발생했을 때
OCE는 다른 환경에서도 동일한 현상을 재현할 수 있으며,
추가적인 근본 원인 분석(root cause analysis)을 수행할 수 있다.
재현 가능한 이상 탐지 시스템은 비결정적(non-deterministic) 알람 또한 제거하여,
불필요한 엔지니어링 비용 낭비를 방지할 수 있다.
(iii) 자율성(Autonomy)
새로운 메트릭이나 주요 작업 부하(workload)가 도입되면 데이터 분포가 변화하기 때문에,
시스템은 지속적으로 업데이트되어야 한다 [5, 32].
자율적인 이상 탐지 시스템은 사람의 개입 없이도 이러한 데이터 분포 변화에 적응할 수 있다.
기존의 시계열 이상 탐지 연구는 크게 세 가지 방향으로 분류할 수 있지만,
이들 방법 중 어느 것도 설명 가능성, 재현 가능성, 자율성을 동시에 만족시키지는 못한다.
전통적인 딥러닝 기반 방법들 [38, 49, 51, 56, 59, 63, 67, 68, 70, 75]은
입력 데이터로부터 직접 이상 레이블을 생성하기 때문에
설명 가능성이 부족한 경우가 많다.
모델 정확도를 향상시키기 위해
엔지니어들은 일반적으로 하이퍼파라미터나 모델 구조를 조정하는데,
이로 인해 이러한 방법들은 부분적인 자율성만을 가진다.
LLM 기반 방법들 [4, 13, 18, 35]은
OCE가 이상 설명(anomaly description)을 기반으로 프롬프트를 입력할 수 있도록 하고,
데이터가 왜 이상으로 분류되었는지에 대한 설명과 함께
이상 레이블을 제공함으로써 설명 가능성과 자율성을 향상시킨다.
그러나 LLM의 본질적인 비결정성(non-determinism) [45, 57] 때문에,
이러한 방법들은 재현 가능성이 부족하며
동일한 데이터를 여러 번 입력하더라도 일관되지 않은 결과를 생성하는 경우가 많다.
결과적으로 규칙 기반 방법 [11, 37, 69]이 설명 가능성과 재현 가능성을 달성하기 위해
산업 현장에서 시계열 이상 탐지에 널리 사용되고 있다.
이러한 방법들은 개발자가 이해하기 쉬운 이상 탐지 규칙을 사용한다.
왜냐하면 정확한 모니터링 로직이 명시적으로 정의되어 있으며,
모니터를 배포하기 전과 실제로 모니터가 동작한 이후
모두에서 그 동작 방식을 이해할 수 있기 때문이다.
그러나 현재의 규칙 생성과 임계값 조정은 여전히 수작업에 크게 의존하고 있으며, 따라서 자율성이 부족하다.
그림 1의 예시에서 보인 것처럼,
이는 개발 리소스 부족이나 규칙 작성 과정에서의 인간 오류로 인해
모니터가 올바르게 설정되지 못하는 문제로 이어질 수 있다.
본 논문은 이상 탐지 시스템에서
설명 가능성, 재현 가능성, 자율성을 동시에 달성하는 방법을 탐구한다.
우리는 구조화된 탐지 규칙(structured detection rules)이
이러한 시스템을 위한 효과적인 중간 표현(intermediate representation)
역할을 수행한다는 점을 관찰하였다.
규칙 기반 방법은 탐지 규칙이 실행 가능한 코드 형태로 작성될 수 있음을 보여주며,
이는 재현 가능성과 설명 가능성을 모두 만족시킨다.
반면 LLM은 시계열 이상 탐지를 위한 규칙 생성을
자율적으로 수행하는 데 활용될 수 있다.
LLM은 시계열 작업 [18, 25, 47]에서 유망한 성능을 보여주었으며,
데이터 패턴에 대한 강력한 이해 능력을 입증하였다.
또한 LLM은 다양한 작업을 위한 실행 가능한 코드를 생성할 수 있다 [7, 12, 52].
이러한 특성들은 LLM을,
규칙을 자율적으로 생성하기 위한 이상적인 후보로 만든다.
우리 연구의 핵심 통찰 중 하나는
LLM이 생성한 규칙을 전통적인 규칙 기반 방법과 통합함으로써,
재현 가능성을 유지하면서도 자율성과 설명 가능성 사이의 간극을 줄일 수 있다는 점이다.
기존의 LLM 기반 방법들 [4, 13, 18, 35]은
런타임 탐지(runtime detection) 단계에서 LLM을 활용하는데,
이러한 방식은 종종 무작위성 문제와 재현 가능성 부족 문제를 겪는다.
반면 우리는 학습 단계에서 LLM을 사용하여 이상 탐지 규칙을 식별하고
이를 규칙 형태로 체계화(codify)한다.
이렇게 생성된 설명 가능하고 재현 가능한 규칙들은
이후 런타임 환경에서 이상을 탐지하는 데 활용된다.
그럼에도 불구하고, LLM을 이용해 이상 탐지 규칙을 생성하고
이를 실행 가능한 코드로 구현하는 과정에는 고유한 어려움이 존재한다.
첫째, LLM은 데이터 패턴을 잘못 이해하여
문법 오류(syntax error)가 있거나 부정확한 코드 및 규칙을 생성할 수 있다.
이러한 문법적 문제와 정확도 문제를 해결하는 것은 매우 어렵다.
둘째, LLM이 자율적으로 생성한 이상 규칙이
수년간의 운영 과정에서 충분히 튜닝된 기존 production 이상 탐지 시스템보다
더 높은 정확도를 가진다고 보장하기 어렵다.
마지막으로, LLM 동작의 본질적인 무작위성 때문에,
제한된 횟수의 시도만으로 정확한 이상 탐지 규칙을 생성하는 것은 여전히 어려운 문제이다.
(LLM 생성 비용은 매우 높기 때문이다.)
이러한 문제들을 해결하기 위해,
우리는 LLM을 이용하여 규칙을 자율적으로 생성하는
시계열 이상 탐지 시스템 ARGOS를 제안한다.
먼저 ARGOS는 피드백 루프를 포함한 에이전트 기반 파이프라인을 사용하여,
이상 탐지 규칙을 반복적으로 수정하고 정확도를 향상시킨다.
각 iteration 단계에서 여러 에이전트들은
규칙을 제안하고, 검증하고, 수정하고, 개선하는 작업을 협력적으로 수행하며,
이를 통해 문법 오류를 줄이고 정확도를 향상시킨다.
두 번째로, 더 높은 정확도를 보장하기 위해
ARGOS는 자신의 이상 탐지 규칙 예측 결과와
기존 이상 탐지 시스템의 예측 결과를 결합한다.
학습 과정에서 ARGOS는
기존 이상 탐지기가 잘못 분류한 샘플들을 중심으로 데이터 패턴을 학습한다.
실제 추론(runtime inference) 단계에서는
규칙 기반 예측과 기존 이상 탐지기의 예측을 통합하는
집계 알고리즘(aggregation algorithm)을 사용하여
최종 이상 예측 결과를 생성한다.
마지막으로, 정확한 이상 탐지 규칙을 생성하는 효율성을 높이기 위해
ARGOS는 각 iteration 단계마다 동시에 n개의 규칙 후보(rule candidate)를 생성하고,
그중 가장 우수한 k개의 규칙을 선택하여 다음 iteration 단계에서 추가적으로 개선한다.
우리는 ARGOS를 널리 사용되는 두 개의 공개 시계열 이상 탐지 데이터셋인
KPI [33], Yahoo [27], 그리고 Microsoft에서 수집한 내부 데이터셋에서 평가하였다.
최고 성능의 베이스라인과 비교했을 때,
제안한 시스템은 KPI [33]와 Yahoo [27] 데이터셋에서
평균 $F_1$ score를 각각 9.5%, 4.8% 향상시켰다.
또한 내부 데이터셋에서는 최대 28.3%의 $F_1$ score 향상을 달성하였다.
추가적으로 ARGOS는 KPI, Yahoo, 내부 데이터셋에서
각각 추론 속도를 3.0배, 34.3배, 1.5배 향상시켰다.
정리하면, 본 논문의 기여는 다음과 같다:
현재의 최신(state-of-the-art) 시계열 이상 탐지 시스템들이
설명 가능성, 재현 가능성, 자율성을 동시에 달성하는 데 한계가 있음을 보였다.LLM이 이상 탐지를 위한 설명 가능하고 재현 가능한 규칙을
자율적으로 생성하는 데 활용될 수 있음을 관찰하였다.LLM 기반 agentic 파이프라인을 통해
이상 탐지 규칙을 자율적으로 학습하고 배포하는 시계열 이상 탐지 시스템 ARGOS를 제안하였다.공개 및 내부 데이터셋에서 ARGOS를 평가하였으며,
최신 방법론들과 비교하여 그 효과성과 효율성을 입증하였다.
2 동기와 도전 과제
2.1 기존 방법들은 왜 한계를 가지는가?
배경
클라우드 인프라에서는 CPU 사용량, 메모리 사용량, 네트워크 지연 시간(latency), 디스크 I/O 등
다양한 메트릭들이 주기적으로 수집되고 지속적으로 모니터링되며,
이를 통해 클라우드 서비스의 상태를 유지한다 [9, 48, 72].
이상은 정상 패턴으로부터 크게 벗어나는 주요 운영 메트릭의 변화를 의미하며,
실제 운영 환경(production)에서는 하드웨어 장애, 소프트웨어 버그, 자원 경합(resource contention) 등
다양한 원인에 의해 발생할 수 있다 [14, 21, 24, 64, 69].
실제 환경에서는 매우 다양한 형태의 이상 패턴이 존재하며,
클라우드 인프라의 각 애플리케이션이나 각 메트릭은 서로 다른 동작 특성을 보일 수 있다.
그림 2: KPI 데이터셋의 두 가지 예시 메트릭.
파란색 선은 메트릭 데이터를 나타내며, 주황색 십자 표시는 이상을 나타낸다.
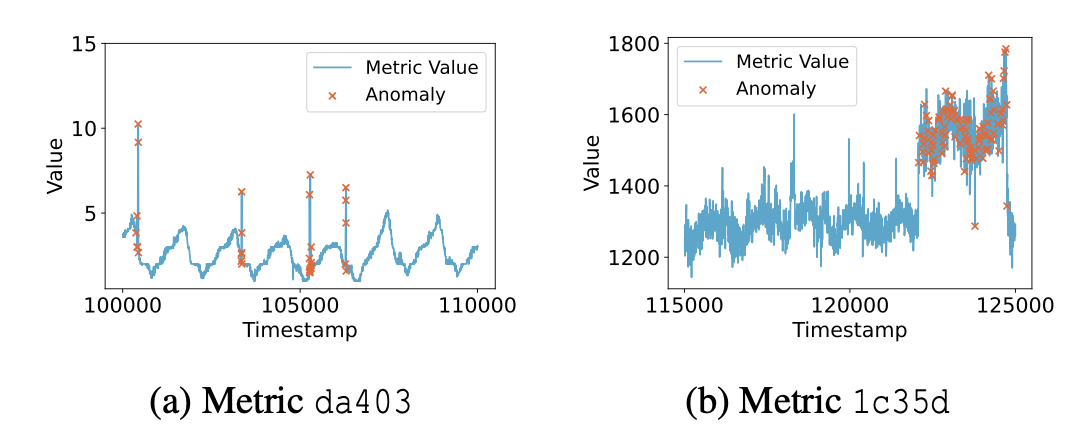
그림. 2는 KPI 데이터셋 [33]의 두 가지 예시 메트릭을 보여준다.
그림. 2a의 이상은 메트릭 값에서 여러 번의 급격한 스파이크가 발생하는 형태로 나타나며,
반면 그림. 2b의 이상은 지속적인 상승(shift-up) 형태로 나타난다.
규칙 기반 방법
모니터링 시스템에서는
엔지니어들이 모니터링 지표의 이상을 탐지하기 위한
규칙을 작성하는 것이 일반적인 관행이다 [11, 37, 69].
이러한 규칙들은 일반적으로 도메인 지식과 엔지니어들의 경험을 바탕으로 만들어진다.
그림 3: 사람이 작성하고 Python으로 구현한 규칙의 예시로, [37]의 규칙을 수정한 것이다.

그림 3은 시계열 데이터에서 이상을 탐지하기 위해
Python으로 구현된 이상 탐지 규칙의 예시를 보여주며,
이는 [37]에서 사용된 규칙을 기반으로 수정(adapted)된 것이다.
해당 rule 함수는 시계열 샘플과 임계값을 입력으로 받아,
각 데이터 포인트가 비정상인지 여부를 나타내는 labels 시퀀스를 반환한다.
표 1: 예시 metric에 대한 서로 다른 방법들의 $F_1$ 점수.
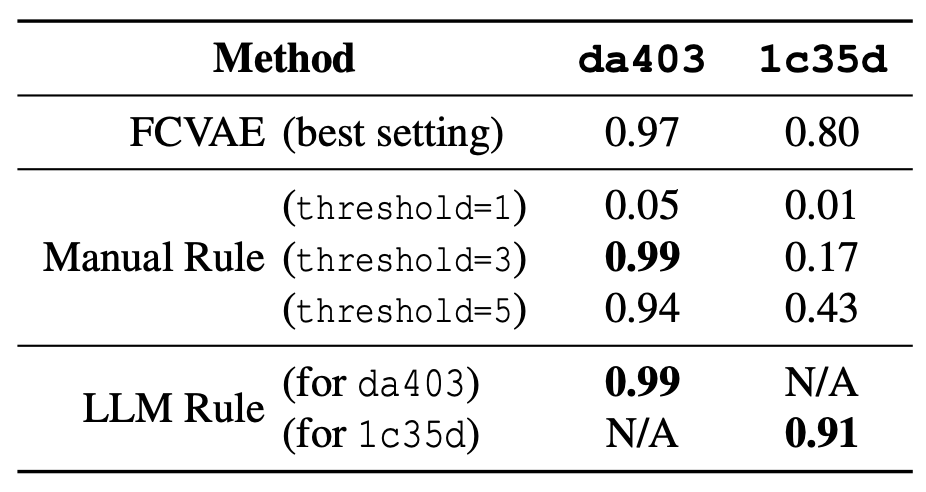
표 1은 최신(state-of-the-art) 딥러닝 기반 모델인 FCVAE 모델 [63]과
수동 규칙의 $F_1$ 점수($F_1$ score)를 비교한다.
비교는 그림 2에 제시된 두 개의 예시 metric에 대해
서로 다른 threshold를 적용하여 수행되었다.
우리는 수동 규칙의 결과가
각 metric에서 나타나는 이상 패턴의 특성에 매우 민감하다는 점을 관찰할 수 있었다.
따라서 특정 threshold를 적절히 설정하면 높은 $F_1$ 점수를 얻을 수 있다.
실제로 da403 metric에서는 수동 규칙이 FCVAE 모델과 유사한 성능을 보이지만,
1c35d metric에서는 다양한 threshold 전반에서 지속적으로 더 낮은 성능을 보인다.
이러한 차이는 두 metric이 서로 다른 이상 패턴을 가지기 때문에 발생하며,
모든 유형의 이상을 효과적으로 처리할 수 있는
단일한 “one-size-fits-all” 규칙은 존재하지 않음을 보여준다.
또한 클라우드 서비스 환경에서 새로운 이상이나 새로운 metric이 등장할 경우,
엔지니어들은 이상 탐지 규칙을 수동으로 설계하거나 수정해야 한다.
이러한 작업은 많은 시간이 소요되며 상당한 수준의 전문성을 요구한다 [69].
전통적인 딥러닝 기반 방법
딥러닝 모델은 데이터 레이블을 학습하여 이상을 분류함으로써
시계열 이상 탐지(time-series anomaly detection) 분야에서 유망한 성능을 보여주었다
[38, 49, 51, 56, 59, 63, 67, 68, 70, 75].
그러나 이러한 모델들은 설명 가능성이 부족하다는 문제를 가지며,
이는 실제 환경에서 엔지니어들에게 큰 어려움이 된다.
이러한 DL 모델들은 많은 하이퍼파라미터를 포함하고 있으며,
각 하이퍼파라미터가 이상 탐지 성능에 어떤 영향을 미치는지를 해석하기 어렵다.
그 결과 엔지니어들은 최적의 설정을 찾기 위해
매우 넓은 범위의 하이퍼파라미터에 대해 exhaustive grid search를 수행해야 하는 경우가 많으며,
이는 시간 소모가 크고 계산 비용 또한 매우 높다.
그림 4: KPI 데이터셋의 da403 metric에 대한 기존 방법들의 분석.
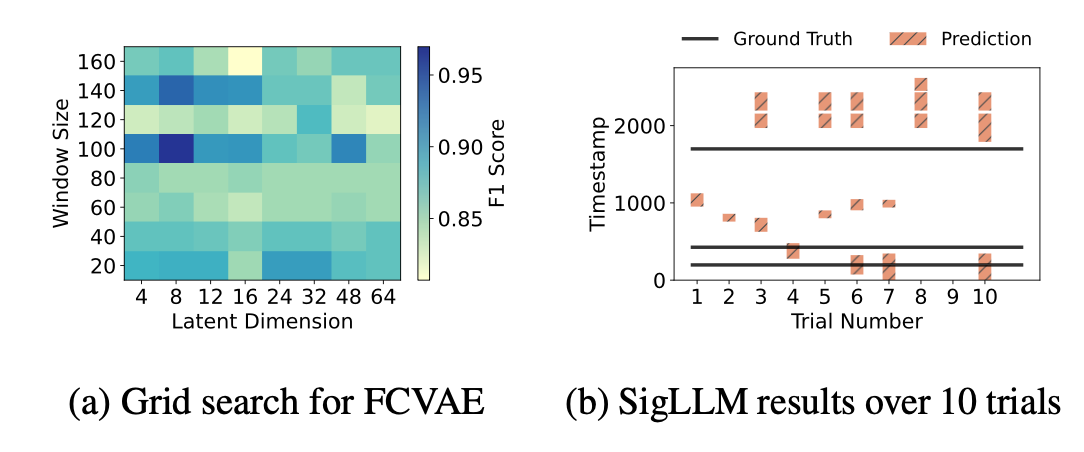
그림 4a는 KPI 데이터셋에서 da403 metric에 대해
FCVAE 모델 [63]의 grid search 결과를 보여준다.
여기서는 latent dimension과 window size라는 두 개의 하이퍼파라미터를 고려하였다.
latent dimension은 시계열 입력이 투영되는 hidden space의 차원을 의미하며,
window size는 모델이 예측에 사용하는 데이터 포인트의 개수를 결정한다.
우리는 모델의 $F_1$ 점수가
서로 다른 하이퍼파라미터 설정에 따라 크게 달라진다는 점을 관찰할 수 있었으며,
이는 모델에 대해 최적의 하이퍼파라미터를 찾는 일이 어렵다는 것을 보여준다.
더 큰 latent dimension은 hidden space 안에 더 많은 정보를 포함할 수 있게 하지만,
그렇다고 해서 항상 더 좋은 모델 성능으로 이어지는 것은 아니다.
또한 window size의 경우,
120으로 설정한 것보다 100 또는 140으로 설정했을 때 훨씬 더 좋은 성능을 보였지만,
이러한 성능 차이가 발생하는 이유에 대한 명확한 직관은 존재하지 않는다.
LLM 기반 방법
최근 대규모 언어 모델(LLM)의 발전은 시계열 이상 탐지 분야로
그 활용 범위를 확장시켰다 [4, 13, 18, 35].
이러한 방법들은 프롬프트를 통해 데이터를 입력받아 이상을 예측하고,
선택적으로 자연어 설명을 생성함으로써 결과의 설명 가능성을 향상시킨다.
그러나 LLM은 확률적 특성을 가지기 때문에,
서로 다른 실행 간 출력 결과의 분산이 매우 크게 나타날 수 있으며,
이는 재현 가능성을 저해한다.
그림 4b는 da403 metric에 대해 SigLLM 시스템 [4]을 10번 실행했을 때의 $F_1$ 점수를 보여준다.
우리는 LLM의 출력 label이 탐지된 이상(anomaly)의 개수와 위치 측면에서 크게 달라질 수 있으며,
어떤 두 실행도 동일한 예측(prediction)을 생성하지 않았다는 점을 관찰할 수 있었다.
10번의 실행 중 4개 실행(No. 4, 6, 7, 10)만이 하나의 이상을 부분적으로 탐지할 수 있었지만,
실제로 해당 metric에는 ground-truth anomaly가 3개 존재한다.
만약 이러한 여러 실행 결과로부터 일관된 최종 결과를 생성하기 위해
majority vote를 수행한다면 [61], 어떤 이상도 올바르게 탐지되지 못한다.
2.2 LLM은 규칙 생성에 어떻게 도움을 줄 수 있는가?
이상 탐지 규칙은 자율적으로 생성되지는 않지만,
설명 가능성과 재현 가능성을 모두 가진다.
예를 들어, 표 1의 수동 규칙은 설명 가능한 파라미터인 threshold를 제공하며,
이를 통해 엔지니어는 평균으로부터의 편차에 대한 규칙의 민감도를 조정할 수 있다.
또한 threshold는 배포(deployment) 중 고정되어 있으며
규칙의 로직이 결정론적이기 때문에, 탐지 결과의 재현 가능성 역시 보장된다.
규칙 생성에서의 자율성 부족 문제를 해결하기 위해,
우리의 직관은 LLM을 활용하여 시계열 데이터에 대한 이상 탐지 규칙을 생성하고 조정(tune)하며,
이를 실행 가능한 코드 형태로 구현하는 것이다.
이는 엔지니어들의 규칙 개발 과정을 모방(mimic)하는 방식이다.
비록 LLM이 시계열 이상 탐지 분야에서 사용되어 왔지만,
기존 연구들 [4, 13, 18, 35]은 배포 시점에 LLM을 직접 활용하여
시계열 데이터로부터 이상을 예측하는 데만 초점을 맞추고 있다.
반면 우리는 배포 이전에 LLM을 사용하여,
오프라인 환경에서 수집되고 레이블링된 시계열 데이터로부터 이상 탐지 규칙을 생성할 것을 제안한다.
이후 생성된 규칙들은 실제 운영 환경에 배포되어 metric을 모니터링하며,
이 과정에서 LLM은 실시간 탐지 과정에 관여하지 않는다.
2.3 LLM 적용에서의 기회와 어려움
그림 5: LLM이 생성한 이상 탐지 규칙과 코드.

그림 5는 두 개의 예시 metric에 대해 LLM이 생성한 이상 규칙과 코드의 유망한 결과를 보여준다.
우리는 시계열 데이터를 포함한 프롬프트를 LLM에 입력하고,
먼저 자연어 형태의 이상 탐지 규칙을 제안하도록 한 뒤,
이후 이를 Python 코드로 구현하도록 요청한다.
da403 metric의 경우, LLM은 수동 규칙과 기능적으로 동등한 규칙을 생성한다.
여기서는 z-score가 3보다 큰 데이터 포인트를 이상으로 판단한다.
반면 1c35d metric의 경우, LLM은 보다 복잡한 규칙을 생성하는데,
이는 metric 값에서 spike(Abnormal Rule 1)와
level shift(Abnormal Rule 2)를 모두 탐지한다.
표 1에 나타난 것처럼, 두 LLM 생성 규칙 모두 수동 규칙과 비교했을 때
유사하거나 더 높은 $F_1$ 점수를 달성하였다.
이는 설명 가능성, 재현 가능성, 자율성을 동시에 만족시키면서도,
시계열 이상 탐지를 위한 효과적인 규칙 생성에 LLM이 활용될 수 있는 잠재력을 보여준다.
그러나 초기 결과(initial result)는 유망하지만,
이상 탐지 규칙 생성에 LLM을 적용하는 과정에는 여전히 여러 고유한 어려움(challenge)이 존재한다.
정확성과 올바름 문제
이상 탐지 규칙은 코드 형태로 구현된다.
LLM은 수십억 줄 규모의 공개 소스 코드로 사전학습되었음에도 불구하고 [7],
여전히 문법 오류를 포함한 규칙 구현 코드를 생성할 수 있다.
또한 시계열 데이터 패턴에 대한 잘못된 이해는
이상 탐지 규칙의 설명 자체뿐만 아니라 실제 구현에서도 부정확성을 초래할 수 있다.
예를 들어 KPI 데이터셋의 각 메트릭에 대해 LLM을 사용하여 이상 탐지 규칙을 50번 생성했을 때,
전체 코드 구현 중 평균 4.8%의 문법 오류가 발생하는 것을 확인하였다.
추가적으로, 문법적으로 올바른 규칙들만 고려하더라도
모든 메트릭에 대한 평균 $F_1$ score는 단지 0.129에 불과했으며,
최고 성능의 딥러닝 기반 방법은 0.819의 점수를 달성하였다.
정확도 보장의 부재
실제 운영 환경의 성숙한 이상 탐지 시스템은
일반적으로 시간에 따라 각 메트릭에 대해 충분히 튜닝된 모델을 보유하고 있다.
설령 규칙 생성 과정의 정확성과 올바름 문제가 해결되더라도,
LLM이 생성한 규칙이 기존의 성숙한 이상 탐지 시스템보다
항상 더 우수한 성능을 보인다고 보장할 수는 없다.
예를 들어 KPI 데이터셋의 최고 성능 기존 모델과 비교했을 때,
최고의 LLM 생성 규칙조차도 전체 19개 메트릭 중 3개 메트릭에서는
$F_1$ score 성능 저하(regression)가 발생하였다.
낮은 효율성
LLM은 동일한 입력이 주어지더라도 매우 다양한 응답을 생성할 수 있다.
그 결과 이상 탐지 시스템은 여러 번 반복적으로 LLM을 호출해야 하며,
각 시도(trial)는 입력 데이터에 대한 서로 다른 해석을 반영하게 된다.
이는 생성된 규칙의 정확도 변동성으로 이어진다.
LLM 출력 자체의 고유한 변동성 때문에,
적은 횟수의 시도만으로 정확한 규칙을 얻는 것은 매우 어려운 문제이다.
예를 들어 KPI 데이터셋에서 정확한 규칙에 수렴하기까지 평균적으로 113분이 소요되었다.
3 시스템 설계
3.1 개요
그림 6: ARGOS의 전체 시스템 설계 구조.
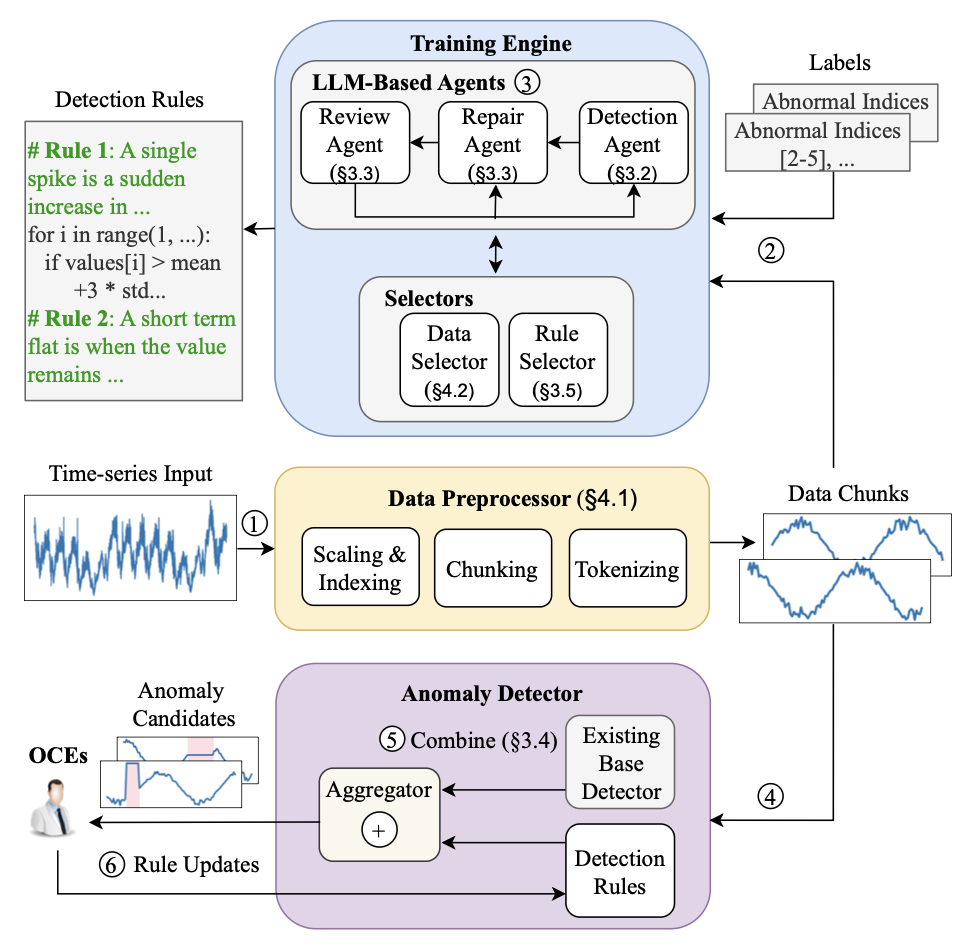
그림 6에서 보이는 것처럼, ARGOS는 데이터 전처리, 규칙 학습, 배포의
세 단계 접근 방식을 사용하여 시계열 데이터의 이상을 탐지한다.
1. 데이터 전처리
시계열 입력이 들어오면,
① Data Preprocessor는 먼저 입력 데이터를 더 작은 구간(chunk)으로 분할하고
scaling, indexing과 같은 데이터 전처리 기법을 적용한다.
2. 규칙 학습
규칙 학습 단계에서는,
② 데이터 chunk와 이에 대응하는 정답 레이블이 Training Engine으로 입력된다.
Training Engine은 전처리된 데이터 chunk와 레이블을 기반으로
agentic 파이프라인을 사용하여 이상 탐지 규칙을 반복적으로 학습한다.
이 파이프라인은 다음 세 가지 에이전트로 구성된다:
Detection Agent, Repair Agent, Review Agent
③ 각 iteration 단계에서 Detection Agent는
먼저 입력 데이터를 기반으로 이상 탐지 규칙 집합을 제안한다.
이후 Repair Agent는 제안된 규칙에 문법 오류가 있는지
검사하고 문제를 수정한다.
그 다음 Review Agent는 검증 데이터를 사용하여 제안된 규칙의 정확도를 평가한다.
문제가 발견되면 규칙은 다시 Repair Agent로 전달되며,
문제가 없다면 새로운 규칙을 반영하기 위해 Detection Agent로 다시 전달된다.
이 반복 루프는 정확도를 지속적으로 향상시킨다.
3. 배포
배포 단계에서는,
④ Anomaly Detector가 실제 실행 중인(runtime) 시계열 데이터로부터
처리된 데이터 chunk를 입력받는다.
⑤ Aggregator는 기존 시스템의 기본 탐지기(base detector) 출력과
이상 탐지 규칙의 출력을 결합하여 입력 데이터 chunk 내의 이상 여부를 판별한다.
이상이 탐지되면 Anomaly Detector는 incident를 보고하며,
이를 통해 당직 엔지니어(on-call engineer)는
근본 원인 분석(root cause analysis)과 장애 완화(incident mitigation)를 수행할 수 있다.
⑥ 또한 엔지니어는 incident 피드백을 기반으로
탐지 규칙을 수정하여 탐지 정확도를 향상시킬 수 있다.
3.2 자율적 규칙 생성
탐지 규칙(detection rule)은 LLM이 생성하기에 적합한 형식이어야 하며,
엔지니어가 쉽게 이해할 수 있고,
다양한 유형의 이상(anomaly)에 대해 일반화 가능해야 한다.
ARGOS는 이상 탐지 규칙 구현 언어로 Python을 선택하였다.
Python은 LLM 사전학습(pretraining)에 사용되는 데이터셋에서
가장 지배적으로 사용되는 프로그래밍 언어이며 [7],
코드 관련 작업을 위한 LLM 파인튜닝(finetuning)에서도
일반적으로 목표 언어(target language)로 사용된다 [52].
또한 Python은 튜링 완전(Turing-complete) 언어이므로,
시계열 데이터의 이상 탐지에 필요한 모든 계산을 수행할 수 있다.
(참고) 튜링 완전 언어(Turing-complete Language):
튜링 완전 언어란 이론적으로 계산 가능한 모든 알고리즘을 구현할 수 있는 프로그래밍 언어를 의미한다.
일반적으로:
- 조건문(if)
- 반복문(for, while)
- 변수 저장
- 함수 호출
등의 기능을 충분히 지원하면 튜링 완전성을 가진다.
Python은 튜링 완전 언어이므로,
시계열 데이터의 이상 탐지에 필요한:
- 통계 계산
- 조건 기반 규칙 검사
- 패턴 탐지
- 반복적 탐색
등의 다양한 연산을 모두 구현할 수 있다.
그림 7: ARGOS의 Detection Agent를 위한 코드 템플릿.

그림 7은 ARGOS의 Detection Agent를 위한 코드 템플릿을 보여준다.
Detection Agent는 입력 샘플을 기반으로 예측 레이블을 출력하는 Python 함수
inference(sample: np.ndarray) -> np.ndarray를 작성하는 역할을 수행한다.
우리는 Detection Agent가 먼저 주석 형태로 이상 규칙을 설명한 뒤,
그 규칙을 구현하는 Python 코드를 작성하도록 프롬프트한다.
이러한 단계별(step-by-step) 과정은
엔지니어가 쉽게 이해하고 검증할 수 있는 주석 기반 이상 탐지 규칙을 생성한다.
추가적으로 Detection Agent는 정상 데이터의 동작 방식 또한 주석으로 설명하도록 요구받으며,
이상 규칙 구현이 정상 규칙과 충돌하지 않도록 보장해야 한다.
Detection Agent에 사용된 전체 프롬프트는 Appendix A에서 확인할 수 있다.
3.3 피드백 루프를 통한 올바름 및 정확도 향상
프롬프트에 명확한 지시사항이 존재하더라도,
LLM은 여전히 문법 오류나 부정확성을 포함한 이상 탐지 규칙을 생성할 수 있으며,
이로 인해 규칙의 올바름과 정확도를 보장하기 어렵다.
ARGOS는 딥러닝 학습의 역전파 [30, 50]에서 영감을 받아,
Repair Agent와 Review Agent,
두 에이전트를 포함하는 반복적 피드백 루프를 도입하여 규칙을 반복적으로 학습한다.
Repair Agent는 생성된 이상 탐지 규칙의 문법 오류를 수정하며,
Review Agent는 validation set에서 해당 규칙의 정확도를 검증한다.
각 iteration 단계에서 두 에이전트는 협력하여 이상 탐지 규칙이 문법적으로 올바르며,
validation set에서의 성능이 최소한 이전 iteration 단계만큼 우수하도록 보장한다.
Repair Agent
Detection Agent로부터 이상 탐지 규칙을 전달받으면,
Repair Agent는 먼저 입력 데이터 형식을 모방한
더미 데이터에서 규칙을 실행하여 문법 오류 여부를 검사한다.
문법 오류가 발견되면 ARGOS는 오류 메시지와 call stack 정보를 Repair Agent에 제공하며,
Repair Agent는 새로운 프롬프트를 사용하여 수정된 규칙 버전을 제안하고,
모든 문법 오류가 해결될 때까지 이를 반복적으로 재검사한다.
Review Agent
Review Agent는 validation data에서 이상 탐지 규칙의 정확도를 평가한다.
현재 이상 탐지 규칙의 정확도가 이전 iteration보다 낮은 경우,
ARGOS는 두 버전 간의 정확도 지표와 코드 차이(code difference)를
Review Agent에 제공한다.
또한 ARGOS는 이전 iteration 단계에서는 올바르게 레이블링되었지만
새로운 규칙에서는 잘못 레이블링된 데이터 샘플 또한 제공한다.
이후 Review Agent는 이러한 관찰 결과를 기반으로 개선된 규칙 버전을 제안하고,
현재 iteration 단계에서 더 이상 정확도 저하가 발생하지 않을 때까지
정확도를 반복적으로 재평가한다.
만약 새로운 이상 탐지 규칙에 문법 오류가 존재한다면,
해당 규칙은 추가 수정을 위해 다시 Repair Agent로 전달된다.
실제 환경에서는 이러한 과정이 학습을 무한정 중단시키지는 않는다.
왜냐하면 Review Agent가 현재 반복 단계의 코드 변경 사항을 되돌려,
정확도를 이전 반복 단계 수준으로 복원할 수 있기 때문이다.
3.4 모델 융합을 통한 정확도 보장
도메인 지식의 부족으로 인해,
LLM은 실제 운영 환경에서 오랜 시간 동안 충분히 튜닝된
기존 이상 탐지기에 비해 성능이 떨어지는 이상 탐지 규칙을 생성할 수 있다.
LLM이 생성한 규칙을 직접 사용하는 대신,
ARGOS는 이러한 규칙과 실제 운영 환경에 배포된 기존의 안정적인 이상 탐지기를 결합하는
모델 융합 접근 방식을 제안하며, 이를 통해 정확도 보장을 달성한다.
학습 단계에서 ARGOS는 두 종류의 이상 탐지 규칙 집합을 별도로 학습한다.
하나는 기존 기본 탐지기가 출력한 false negative를 기반으로 하며,
다른 하나는 false positive를 기반으로 한다.
ARGOS는 false negative를
기본 탐지기가 정상으로 잘못 분류한 실제 이상 샘플로 정의한다.
마찬가지로 false positive는 기본 탐지기가 이상으로 잘못 분류한 정상 샘플이다.
false negative 샘플을 기반으로 이상 탐지 규칙 집합을 학습하기 위해,
ARGOS는 먼저 기존 기본 탐지기를 사용하여 학습 데이터에 대해 추론을 수행하고,
기본 탐지기의 예측 결과와 정답 레이블을 비교하여 false negative를 식별한다.
그 이후 false negative 샘플과 해당 정답 레이블을
Training Engine에 입력하여 이상 탐지 규칙을 학습한다.
false negative에 과적합되는 것을 방지하기 위해,
ARGOS는 샘플링된 true negative 데이터 또한 Training Engine에 제공하며,
Detection Agent는 true negative 샘플은 제외하면서
false negative 샘플의 이상만 탐지하는 규칙을 생성하도록 지시받는다.
각 iteration 단계에서 이상 탐지 규칙의 검증 정확도는
Aggregator를 사용하여 validation set에서의,
규칙에 의한 출력과 기존 기본 탐지기의 출력을 결합함으로써 평가된다.
ARGOS는 false positive에 대한 탐지 규칙 또한 동일한 방식으로 학습한다.
배포 단계에서는 Anomaly Detector가
runtime 시계열 데이터로부터 처리된 데이터 chunk를 입력받는다.
이후 Aggregator는 입력 시계열 데이터 chunk 내의 이상을 식별하기 위해,
false negative 및 false positive에 대한
기존 기본 탐지기의 출력 레이블과 이상 탐지 규칙의 출력 결과를 결합한다.
Aggregator

Algorithm 1은 ARGOS의 Aggregator를 위한 집계 알고리즘을 보여준다.
false negative를 위한 이상 탐지 규칙은
기본 탐지기의 정상 레이블을 효과적으로 수정하지만,
이상 레이블에는 영향을 주지 않는다.
마찬가지로 false positive를 위한 이상 탐지 규칙은
기본 탐지기의 이상 레이블을 수정하지만,
정상 레이블에는 영향을 미치지 않는다.
이는 이상 탐지 규칙 집합이 학습 과정 동안
한 번에 false negative 또는 false positive 예시 중 하나만을 다루기 때문이며,
그 결과 이상 탐지는 one-class classification task [53]가 된다.
3.5 효율성 향상
LLM의 자기회귀 과정은 확률적 특성을 가지기 때문에,
적은 횟수의 시도만으로 최적의 이상 탐지 규칙을 생성하지 못할 수 있다.
ARGOS는 beam search 알고리즘 [58]에서 영감을 받아,
최적의 규칙을 선택하고 부정확한 규칙을 조기에 제거하기 위해
top-k 선택 전략을 사용한다.
각 iteration 단계에서 Detection Agent는 동일한 입력을 사용하여 n개의 탐지 규칙을 생성하며,
이 규칙들은 Repair Agent와 Review Agent 모두에게 전달된다.
Review Agent가 생성된 n개의 규칙에서 정확도 저하가 존재하지 않음을 확인하면,
Rule Selector는 사용자 정의 기준에 따라 top-k 규칙을 선택한다.
현재 ARGOS는 검증 정확도를 기준으로 사용하며,
validation set에서 가장 높은 정확도를 가지는 k개의 규칙을 선택한다.
또한 Rule Selector는 이상 탐지 규칙의 추론 시간과 같은
추가 기준을 반영하도록 확장될 수도 있다.
4 구현
4.1 데이터 전처리
시계열 데이터는 연속적이며 길이에 제한이 없기 때문에(unbounded) 때문에,
우선 Training Engine이 처리할 수 있도록 더 작은 구간(chunk)으로 분할되어야 한다.
동시에 Data Preprocessor는
scaling, indexing, 토크나이저-specific preprocessing 또한 수행하는데,
이러한 과정들은 LLM이 데이터 패턴을 학습하는 데 필수적이다.
Scaling and Indexing
시계열 입력은 임의의 정밀도(precision)를 가질 수 있으며,
이는 LLM의 context window 안에 포함될 수 있는 데이터 양을 제한한다.
이를 해결하기 위해 Data Preprocessor는
입력 데이터를 지정된 유효 자릿수 수준으로 scaling한다.
마찬가지로 timestamp는 일반적으로 긴 숫자 값으로 표현되는데,
이는 LLM에게 큰 정보를 제공하지 못한다.
따라서 Data Preprocessor는 timestamp를 제거하고,
데이터 포인트의 순서를 기반으로 데이터를 다시 인덱싱한다.
ARGOS는 데이터 포인트가 고정된 시간 간격으로 수집된다고 가정한다.
Chunking
적절한 chunk 크기를 선택하는 것은
이상 탐지 규칙 학습에 매우 중요하다.
chunk 크기가 너무 작으면
LLM이 데이터 패턴을 학습하기 위한 충분한 문맥 정보를 얻지 못할 수 있으며,
반대로 chunk 크기가 너무 크면
LLM의 context window 크기를 초과하거나
지나치게 일반적인 규칙을 생성할 수 있다.
적절한 chunk 크기를 결정하기 위해,
ARGOS는 주어진 데이터셋의 특정 메트릭에 대해 chunk 크기 조정(calibration) 을 수행한다.
ARGOS는 Detection Agent만을 사용하여
해당 메트릭에 대해 반복적으로 이상 탐지 규칙을 생성하고,
학습 데이터에서 가장 높은 $F_1$ score를 얻는 chunk 크기를 선택한다.
토크나이저별 전처리
최근 연구들은 서로 다른 토크나이저가 수치 값을
서로 다른 방식으로 처리한다는 점을 보여주었으며 [4, 18, 43],
이는 LLM이 데이터를 해석하는 방식에 영향을 미친다.
동일한 수치 값이라 하더라도
토크나이저는 각 숫자 자릿수와 일치하지 않는 방식으로
값을 여러 chunk로 분할할 수 있다.
이 문제를 해결하기 위해 Data Preprocessor는
Training Engine에서 사용되는 LLM 종류에 따라
토크나이저별 전처리를 데이터에 적용한다.
GPT 기반 모델의 경우,
Data Preprocessor는 기존 연구 [4]에서 사용된 기법과 유사하게
시계열 값의 각 숫자 자릿수 사이에 공백을 추가한다.
4.2 데이터 선택
자동 메트릭 선택
시계열 데이터셋이 주어지면,
Data Selector는 데이터셋을 어떻게 분할할지와
학습 과정에서 어떤 분할을 사용할지를 결정한다.
Data Selector는 두 가지 데이터셋 모드인
one-for-one과 one-for-all을 지원한다.
one-for-one 모드는 연속적인 메트릭이 많은 데이터셋에 적합하며,
Training Engine이 각 메트릭의 패턴을 개별적으로 학습하는 데 집중할 수 있도록 한다.
one-for-all 모드는 여러 메트릭에 걸쳐 일반화될 수 있는
이상 탐지 규칙 집합을 학습하려는 경우에 유용하다.
ARGOS는 먼저 Data Preprocessor가 결정한 chunk 크기를 사용하여
데이터셋의 각 메트릭을 분할한다.
최소 10개의 데이터 chunk를 가진 메트릭
(즉, 최소 10회의 학습 반복을 수행할 수 있는 경우)에 대해서는,
ARGOS는 one-for-one 모드를 사용하여 해당 메트릭을 학습한다.
그 외의 메트릭에 대해서는 ARGOS가 one-for-all 모드를 사용한다.
또한 ARGOS는 사용자가 데이터셋 모드를 직접 지정할 수 있도록 한다.
one-for-one 모드에서는 Data Selector가
연속적인 시계열 메트릭의 개수에 따라 데이터셋을 분할한다.
각 학습 반복(training trial)에서 Data Selector는
데이터셋으로부터 하나의 연속적인 메트릭을 선택하여 이상 탐지 규칙 집합을 학습한다.
one-for-all 모드에서는 Data Selector가
사용자가 제공한 그룹 식별자를 기준으로 데이터셋을 분할한다.
각 그룹은 여러 개의 연속적인 시계열 메트릭 집합으로 구성된다.
각 학습 반복(training trial)에서 Data Selector는
데이터셋으로부터 하나의 그룹을 선택하여 이상 탐지 규칙 집합을 학습한다.
이 모드는 각 연속 메트릭의 길이가 짧은 경우
데이터 증강(data augmentation) 기법으로도 활용된다.
대조 예제 검색 (Contrastive Example Retrieval)
기존 이상 탐지 모델의 거짓 음성 또는 거짓 양성 예제로부터 이상 탐지 규칙을 학습할 때,
Data Selector는 검색된 대조 예제(즉, 진짜 음성 또는 진짜 양성)가
거짓 음성 또는 거짓 양성 예제와 유사한 분포에서 추출되도록 보장해야 한다.
이는 서로 다른 데이터 분포에서 진짜 음성 또는 진짜 양성 예제를 선택할 경우,
데이터 패턴에 대한 잘못된 가정을 유도할 수 있으며,
그 결과 부정확한 이상 탐지 규칙이 생성될 수 있기 때문이다.
one-for-one 모드에서는 모든 데이터 샘플이 동일한 분포에서 생성되므로,
Data Selector가 진짜 음성 또는 진짜 양성 예제를 무작위로 선택한다.
one-for-all 모드에서는 Data Selector가 먼저
거짓 음성 또는 거짓 양성 예제들의 평균과 표준편차를 계산한다.
그 다음 거짓 음성 또는 거짓 양성 예제의 평균 및 표준편차와의 유클리드 거리를 기준으로 정렬하여,
진짜 음성 또는 진짜 양성 예제를 검색한다.
우리는 임베딩 유사도에 기반한 보다 발전된 검색 기법이
검색 품질을 더욱 향상시킬 수 있다고 생각하며,
이는 향후 연구 과제로 남겨 둔다.
5 평가 (Evaluation)
5.1 실험 설정 (Experiment Setup)
평가 지표 (Metrics)
ARGOS는 베이스라인 모델들과 비교할 때 $F_1$ 점수를 주요 평가 지표로 사용한다.
$F_1$ 점수는 정밀도(Precision)와 재현율(Recall)의 조화평균(harmonic mean)으로 계산된다.
정밀도는 참 양성(TP)을 참 양성과 거짓 양성(FP)의 합으로 나눈 비율이며,
재현율은 참 양성을 참 양성과 거짓 음성(FN)의 합으로 나눈 비율이다.
수식으로 표현하면 $F_1$ 점수는 다음과 같다.
\[F_1 = 2 \times \frac{\text{Precision} \times \text{Recall}} {\text{Precision} + \text{Recall}} \tag{1}\]여기서,
\[\text{Precision} = \frac{TP}{TP + FP}\] \[\text{Recall} = \frac{TP}{TP + FN}\]이다.
시계열 이상 탐지에서는 응용 환경의 맥락에서
양성 샘플과 음성 샘플을 정의하는 것이 매우 중요하다 [55].
클라우드 인프라 모니터링에서는 각 이상(anomaly)을 하나의 사건(incident)으로 간주하며,
이 사건은 시간 축상에서 여러 데이터 포인트에 걸쳐 나타날 수 있다.
표 2: 시계열 이상 탐지에서 사용되는 다양한 평가 지표의 예시.
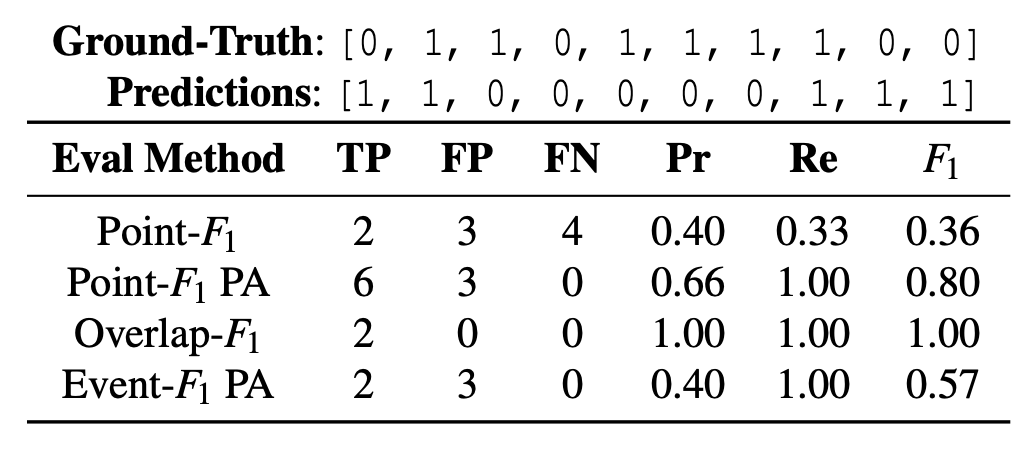
예를 들어, 표 2의 정답 레이블(Ground Truth, GT)에는 두 개의 사건이 포함되어 있다.
하나는 인덱스 1~2 구간에 걸쳐 있으며,
다른 하나는 인덱스 4~7 구간에 걸쳐 있다.
예측 레이블은 두 사건 모두를 올바르게 탐지했지만,
정답 구간과는 일부만 겹친다.
표 2에서 볼 수 있듯이,
기존 연구들은 이러한 예측 결과에 대한 $F_1$ 점수를 계산하기 위해 네 가지 평가 방식을 사용한다.
포인트 기반 $F_1$ 점수 (Point-Based $F_1$ Score, Point-$F_1$) [26]
각 데이터 포인트를 독립적인 개별 샘플로 취급한다.
따라서 일반적으로 매우 낮은 $F_1$ 점수가 계산되는 경우가 많다.
포인트 보정 기반 포인트 $F_1$ 점수 (Point-Based $F_1$ Score with Point Adjustment, Point-$F_1$ PA) [70]
하나의 이상 구간(segment) 안에서 단 하나의 포인트라도 탐지되면,
해당 구간 전체가 탐지된 것으로 간주한다.따라서 일반적으로 높은 $F_1$ 점수가 계산된다.
중첩 기반 $F_1$ 점수 (Overlap $F_1$ Score, Overlap-$F_1$) [3]
각 사건을 하나의 개별 샘플로 취급하지만,
예측 결과의 거짓 양성(False Positive)을 무시한다.따라서 비현실적으로 높은 $F_1$ 점수가 계산되는 경우가 많다.
포인트 보정 기반 이벤트 $F_1$ 점수 (Event-Based $F_1$ Score with Point Adjustment, Event-$F_1$ PA) [16]
각 사건을 하나의 개별 샘플로 취급한다.
또한 정답 사건 구간 밖에 존재하는 각 데이터 포인트를 거짓 양성으로 간주하여 정밀도를 감소시킨다.
따라서 보다 균형 잡힌 $F_1$ 점수를 제공한다.
ARGOS에서는 $F_1$ 점수를 계산하기 위한 주요 평가 방법으로 Event-$F_1$ PA를 사용한다.
베이스라인
우리는 제안한 ARGOS를 다양한 최신(state-of-the-art) 방법들과 비교한다.
비교 대상에는 EasyTSAD 프레임워크 [55]에 포함된 5개의 딥러닝 기반 방법과 2개의 LLM 기반 방법이 포함된다.
AnomalyTransformer [68]
정상 데이터 포인트와 이상 데이터 포인트 사이의 연관 패턴(association pattern) 차이를 활용하여
이상을 탐지하는 Anomaly-Attention 메커니즘 기반의 비지도 학습 모델이다.AutoRegression [51]
여러 개의 선형 계층(linear layer)을 사용하여
입력 데이터를 입력과 동일한 길이의 이상 점수 로짓(anomaly score logits)으로 변환하는 지도 학습 모델이다.FCVAE [63]
시계열의 유사하면서도 서로 다른 주기 패턴과 세부 추세를 포착하기 위해
전역 주파수 특성과 지역 주파수 특성을 함께 통합하는 비지도 학습 모델이다.LSTMAD [38]
정상 데이터만을 사용해 학습하며,
관측 데이터의 예측 오차에 기반한 통계적 전략을 이용해 이상을 탐지하는 지도 학습 기반 LSTM 모델이다.TFAD [70]
시계열 분해를 이용해 입력 데이터를 주파수 영역으로 변환하고,
주파수 영역 특성과 시간 영역 특성을 모두 활용하여 이상을 탐지하는 지도 학습 모델이다.LLMAD [35]
이상 탐지를 위해 시계열 데이터, In-Context Learning 예제,
그리고 추가적인 문맥 정보를 함께 LLM에 입력하는 LLM 기반 방법이다.SigLLM [4]
Detector 모드와 Prompter 모드로 구성된 LLM 기반 방법이다.
Detector 모드에서는 LLM에게 시계열의 다음 시점을 예측하도록 한 뒤,
예측값과 실제 출력값을 비교하여 이상을 탐지한다.반면 Prompter 모드는 이상 인덱스를 식별하기 위해
시계열 데이터를 직접 LLM에 프롬프트로 제공한다.
데이터셋
우리는 제안한 ARGOS를 세 개의 데이터셋(KPI, Yahoo, Internal)에서 평가한다.
KPI 데이터셋 [33]
다섯 개의 대형 인터넷 기업으로부터 수집된
수작업 라벨링 사건(incident)을 포함하는 실제 데이터셋이다.수개월 동안 수집된 27개의 연속 메트릭(continuous metrics)으로 구성된다.
일부 메트릭에서는 이상치가 매우 적기 때문에,
이러한 메트릭은 제외하고 나머지 19개의 메트릭을 평가에 사용한다.Yahoo 데이터셋 [27]
이 데이터셋은 A1 ~ A4의 네 개 파티션에 걸쳐 존재하는
367개의 실제(real) 및 합성(synthetic) 시계열을 포함한다.이상치는 스파이크(spike), 추세(trend), 계절성 변화(seasonal change) 등 다양한 특성을 가진다.
Internal 데이터셋
이 데이터셋은 Microsoft의 AI 학습 플랫폼에서 수집되었으며,
GPU 사용률, GPU 메모리 사용량, CPU 사용률, 디스크 사용량,
네트워크 트래픽과 같은 20개의 하드웨어 메트릭을 포함한다.
각 데이터셋의 메트릭 또는 파티션에 대해
학습 세트와 테스트 세트 간의 이상치 비율이 유사하도록
분할 비율(split ratio)을 0.7로 설정하였다.
Yahoo 데이터셋의 A2 파티션에 대해서는
두 세트 모두 이상치 샘플을 포함하도록 하기 위해 0.5의 분할 비율을 사용하였다.
청크 크기는 KPI 데이터셋의 경우 2500, Yahoo 데이터셋의 경우 500,
Internal 데이터셋의 경우 1000으로 설정하였다.
KPI 데이터셋에는 one-for-one 데이터셋 모드를 사용하였으며,
이 모드에서는 ARGOS가 각 메트릭마다 하나의 이상 탐지 규칙 집합을 학습한다.
Yahoo 데이터셋과 Internal 데이터셋에는 one-for-all 데이터셋 모드를 사용하였으며,
이 모드에서는 ARGOS가 각각의 파티션과 각각의 하드웨어 메트릭에 대해 하나의 규칙 집합을 학습한다.
Test Machines.
모든 LLM 실험은 16개의 vCPU와 64 GiB 메모리를 갖춘
Azure Standard_D16as_v4 VM [41]에서 수행되었다.
반면 모든 모델 학습 및 평가는 96개의 vCPU와 8개의 NVIDIA A100 GPU를 갖춘
Azure Standard_ND96amsr_A100_v4 VM [42]에서 수행되었다.
LLM Endpoints.
우리는 Azure OpenAI 서비스 [40]를 사용하여
GPT-3.5 [6], GPT-4-32k [1], GPT-4o [22]를 포함한 LLM 모델의 엔드포인트 [39]에 접근하였다.
이들 모델은 베이스라인과 ARGOS 모두의 모든 LLM 실험에 사용되었다.
5.2 정확성과 성능 향상 (Correctness and Accuracy Improvement)
Repair Agent와 Review Agent를 포함한 피드백 루프가
이상 탐지 규칙의 정확성(correctness)과 성능(accuracy)을 어떻게 향상시키는지 보여주기 위해,
우리는 Training Engine을 두 가지 설정에서 평가한다.
첫 번째는 Detection Agent만 사용하는 설정이고,
두 번째는 Detection Agent, Repair Agent, Review Agent를 모두 포함하는 설정이다.
데이터셋의 각 메트릭 또는 파티션에 대해 50회의 trial을 수행하였으며,
각 trial은 20회의 iteration으로 구성된다.
Detection Agent만 사용하는 설정에서는
각 iteration마다 에이전트가 시계열 데이터와 이전 iteration에서 생성된 이상 탐지 규칙을 함께 입력받는다.
정확성(correctness rate)의 경우,
각 trial에서 생성된 이상 탐지 규칙 중 문법 오류(syntax error)가 없는 규칙의 수를 측정한다.
성능(accuracy)의 경우,
모든 iteration과 모든 trial에서 생성된 이상 탐지 규칙에 대해 테스트 세트에서의 평균 $F_1$ 점수를 계산한다.
그림 8: Detection Agent만 사용하는 Training Engine과,
Repair Agent 및 Review Agent를 포함한 전체 Training Engine의 정확성 및 평균 테스트 $F_1$ 점수 비교
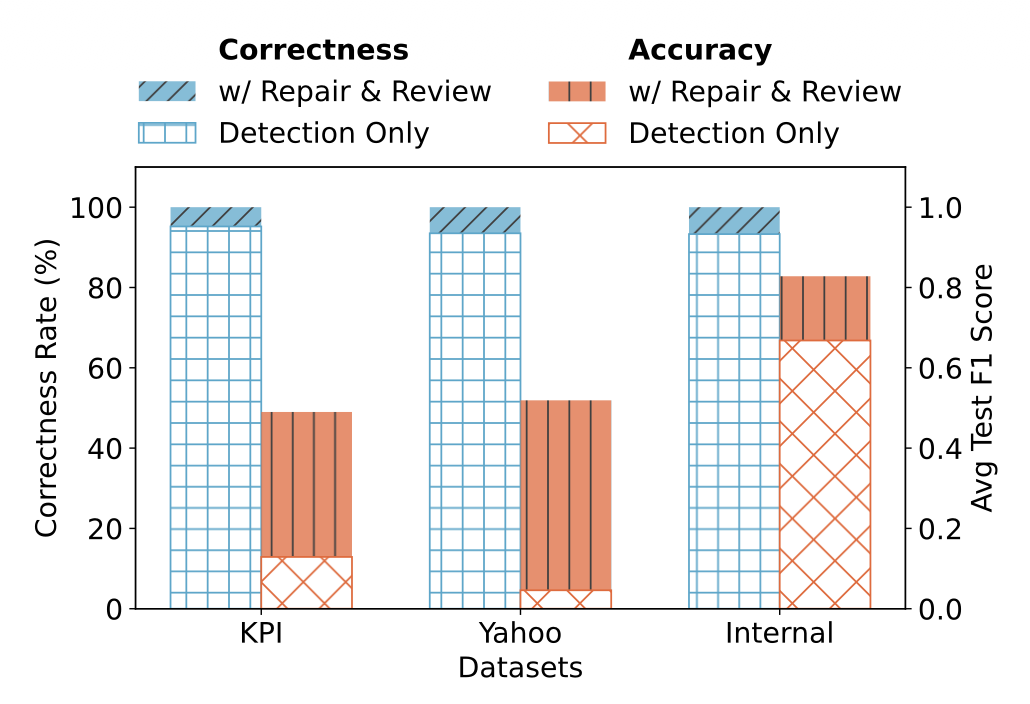
그림 8은 두 설정 간의 정확성과 평균 테스트 $F_1$ 점수를 비교한 결과를 보여준다.
Detection Agent만 사용하는 설정의 정확성은
KPI 데이터셋에서 95.2%, Yahoo 데이터셋에서 93.5%, Internal 데이터셋에서 93.3%로 나타났다.
Repair Agent의 도움을 통해 Training Engine이 생성한 모든 이상 탐지 규칙은 문법 오류를 포함하지 않게 되었다.
또한 Review Agent는 이상 탐지 규칙의 평균 테스트 $F_1$ 점수를
KPI 데이터셋에서 3.8배, Yahoo 데이터셋에서 11.3배, Internal 데이터셋에서 1.2배 향상시켰다.
이는 Training Engine에서 피드백 루프가 효과적으로 작동함을 명확하게 보여준다.
5.3 정확도 보장 (Accuracy Guarantee)
모델 융합(model fusion)이 이상 탐지 규칙에 대해 어떻게 정확도 보장을 제공하는지 보여주기 위해,
우리는 Aggregator 모듈이 없는 ARGOS와 Aggregator 모듈이 있는 ARGOS 두 가지 버전을 비교한다.
Aggregator가 없는 버전에서는
각 데이터셋의 학습 세트에 포함된 모든 시계열 데이터로 규칙을 학습하며,
추론 시에는 규칙으로부터 직접 예측 레이블을 생성한다.
Aggregator가 있는 버전에서는
먼저 각 데이터셋에 대해 학습 세트에서 가장 높은 $F_1$ 점수를 기록한 딥러닝 모델을 기본 탐지기로 선택한다.
그 다음, 이 기본 탐지기로부터 학습 세트 내의 거짓 양성과 거짓 음성을 수집하여 이상 탐지 규칙을 학습한다.
표 3: Aggregator를 제거한 ARGOS가 베이스라인 모델 대비 성능 저하를 보인 모든 메트릭에 대한 $F_1$ 점수 비교
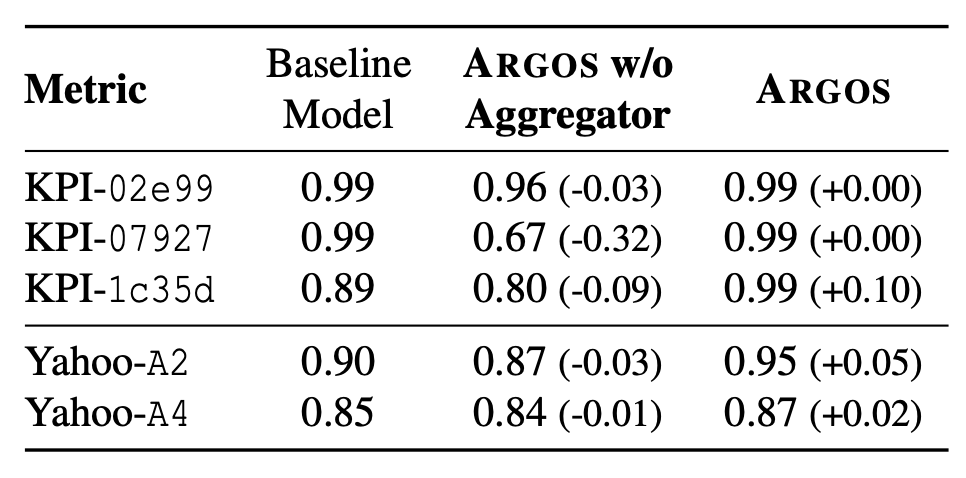
표 3은 Aggregator가 없는 ARGOS가
베이스라인과 비교하여 정확도 저하를 보인 세 데이터셋의 모든 메트릭을 보여준다.
KPI 데이터셋과 Yahoo 데이터셋에서 Aggregator가 없는 ARGOS는
각각 3개와 2개의 메트릭에서 정확도 저하를 보였으며, 최대 32%의 성능 하락이 발생하였다.
반면, Aggregator가 있는 ARGOS는 세 데이터셋 전체의 모든 메트릭에서 어떠한 정확도 저하도 발생하지 않았다.
5.4 효율성 향상 (Efficiency Enhancement)
top-$k$ 규칙 선택의 효율성을 측정하기 위해,
우리는 ARGOS와 규칙 선택을 사용하지 않는 ARGOS의 정확도를 비교한다.
규칙 선택을 사용하지 않는 설정에서는
Detection Agent가 각 iteration마다 하나의 규칙을 제안하고,
이후 Repair Agent와 Review Agent가 이를 검증한다.
top-$k$ 규칙 선택에서는
Detection Agent가 5개의 규칙을 병렬로 제안하며,
이들 모두가 검증된 후 가장 성능이 우수한 규칙이 선택된다.
다음 iteration에서는
Detection Agent가 이전 iteration에서 선택된 최적의 규칙을 기반으로 새로운 5개의 규칙을 제안한다.
평가를 위해 GPT-4-32k를 LLM 백엔드로 사용하였으며,
각 메트릭 또는 파티션에 대해 5회의 trial을 수행하였다.
두 설정 모두 Aggregator가 없는 ARGOS에서 수행하였으며,
모든 trial에 걸쳐 생성된 규칙들의 학습 세트 평균 $F_1$ 점수를 비교하였다.
그림 9: top-$k$ 규칙 선택과 규칙 선택을 사용하지 않는 경우 사이의 학습 세트 평균 $F_1$ 점수 비교
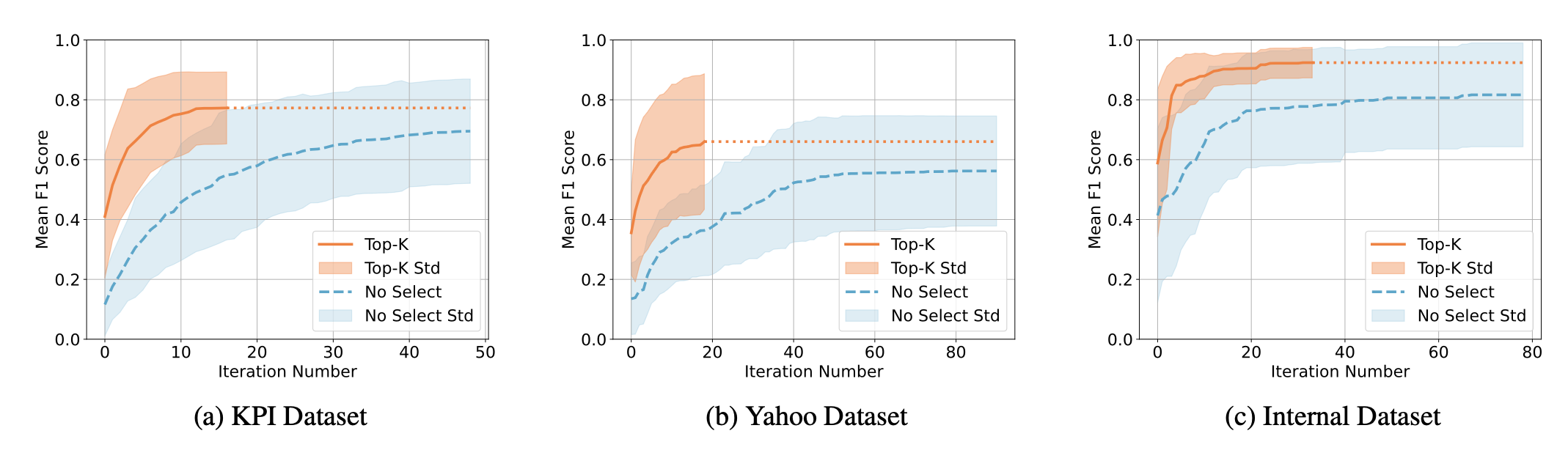
그림 9은 각 데이터셋에 대해 학습 세트에서 모든 trial과 모든 메트릭에 걸친 평균 $F_1$ 점수를 보여준다.
공정한 비교를 위해, top-$k$ 규칙 선택은 iteration마다 5개의 규칙을 생성하므로,
no-selection의 iteration 수가 top-$k$ 규칙 선택의 5배가 되는 지점에서 평균 $F_1$ 점수를 평가하였다.
KPI 데이터셋에서 top-$k$ 규칙 선택은 iteration 8에서 $F_1$ 점수 0.736을 기록하였으며,
이는 iteration 40의 no-selection이 기록한 0.682보다 높다.
Yahoo 데이터셋에서 top-$k$ 규칙 선택은 iteration 8에서 $F_1$ 점수 0.597을 기록하였으며,
이는 iteration 40의 no-selection이 기록한 0.523보다 높다.
Internal 데이터셋에서 top-$k$ 규칙 선택은 iteration 8에서 $F_1$ 점수 0.870을 기록하였으며,
이는 iteration 40의 no-selection이 기록한 0.795보다 높다.
또한 우리는 학습 종료 시 수렴된 $F_1$ 점수가
모든 데이터셋에서 no-selection보다 top-$k$ 규칙 선택에서 일관되게 더 높다는 것을 확인하였다.
이는 top-$k$ 규칙 선택이 학습을 가속화하고 생성된 규칙의 정확도를 향상시킨다는 것을 보여준다.
5.5 종단간(End-to-End) 결과
종단간 결과를 평가하기 위해, 우리는 세 개의 데이터셋에 대해 ARGOS와 모든 베이스라인을 비교하고,
테스트 세트에서 각 방법의 평균 정밀도(precision), 재현율(recall), 그리고 $F_1$ 점수를 계산한다.
딥러닝 기반 방법의 경우,
각 데이터셋에 대해 하이퍼파라미터 그리드 탐색(grid search)을 수행하고,
학습 세트에서 가장 높은 $F_1$ 점수를 생성하는 설정을 선택한다.
LLM 기반 방법의 경우,
테스트 세트에서 각 메트릭마다 10회의 시행(trial)을 수행하고,
모든 시행 중 가장 높은 정확도를 보고한다.
원 논문의 설정과 일치시키기 위해, 베이스라인에서
LLMAD는 GPT-4-32k를 LLM 백엔드로 사용하며 [35],
SigLLM은 GPT-3.5를 사용한다 [4].
ARGOS의 경우 먼저,
학습 세트에서 가장 높은 $F_1$ 점수를 보인 베이스라인 모델을 기본 탐지기로 선택한다.
이후 이 기본 탐지기의 거짓 음성 샘플(ARGOS w/ FN Rules Only)과
거짓 양성 샘플(ARGOS w/ FP Rules Only)로부터 이상 탐지 규칙을 학습한다.
이후 이 두 규칙 집합은 Algorithm 1을 사용하여
기본 탐지기와 융합되며 최종 결과를 생성한다.
각 메트릭에 대해 5회의 시행을 수행하고, 모든 시행 중 가장 높은 정확도를 보고한다.
ARGOS에서는 GPT-4o를 LLM 백엔드로 사용한다.
표 4: 세 개의 데이터셋에서 다양한 이상 탐지 방법들의 정확도 비교
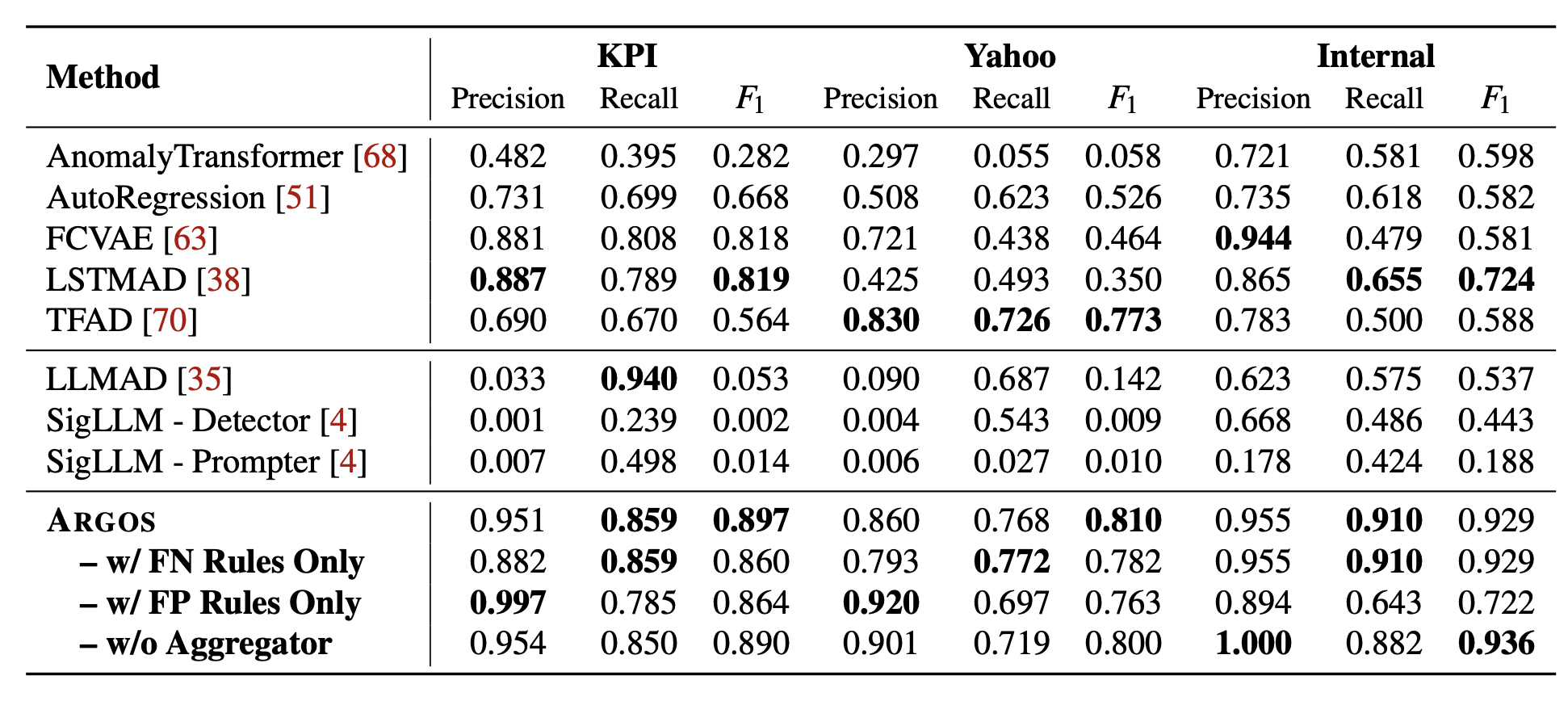
표 4는 세 개의 데이터셋에 대한 모든 방법의 전체 정확도 비교 결과를 보여준다.
ARGOS는 모든 데이터셋에서 모든 베이스라인보다 우수한 성능을 보인다.
KPI 데이터셋에서 ARGOS는 $F_1$ 점수 0.897을 달성하며,
이는 최고 베이스라인인 LSTMAD보다 9.5% 높다.
Yahoo 데이터셋에서 ARGOS는 $F_1$ 점수 0.810을 달성하며,
이는 최고 베이스라인인 TFAD보다 4.8% 높다.
Internal 데이터셋에서 ARGOS는 $F_1$ 점수 0.936을 달성하며,
이는 최고 베이스라인인 LSTMAD보다 28.3% 높다.
ARGOS w/ FN Rules Only는 모든 데이터셋에서 가장 높은 재현율(recall)을 달성하는데,
이는 재현율이 거짓 음성률(False Negative Rate)과 관련된 지표이므로
기본 모델의 거짓 음성을 보완하는 효과가 있음을 보여준다.
마찬가지로, ARGOS w/ FP Rules Only는 두 공개 데이터셋에서 가장 높은 정밀도(precision)를 달성한다.
5.6 비용 분석(Cost Analysis)
학습을 위한 API 예산(API Budget for Training).
표 5: 반복(iteration)당 규칙 학습 비용 분석
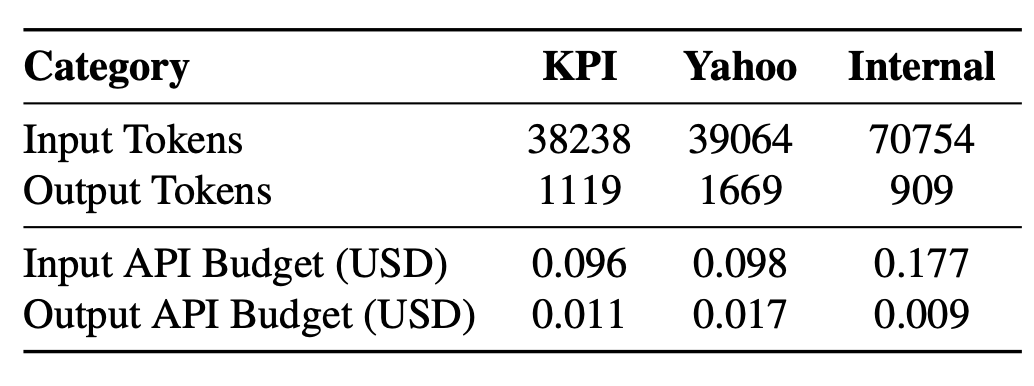
표 5는 각 데이터셋에 대한 입력 토큰 수와 출력 토큰 수를 보여준다.
우리는 거짓 음성 및 거짓 양성 샘플을 사용하여 이상 탐지 규칙을 학습하는 과정에서 이러한 통계를 수집한다.
데이터셋별로 모든 시행(trial)에 대한 반복(iteration)당 평균 토큰 수를 계산한다.
LLM 백엔드로 GPT-4o를 사용할 경우,
반복당 입력 토큰 비용은 최대 0.177 달러이며,
출력 토큰 비용은 반복당 최대 0.017 달러이다.
총 50회의 반복을 수행하더라도,
모든 데이터셋을 대상으로 이상 탐지 규칙을 학습하는 비용은 총 10 달러 미만이다.
추론을 위한 실행 지연 시간(Runtime Latency for Inference).
표 6: 다양한 방법들의 추론 지연 시간(초) 비교
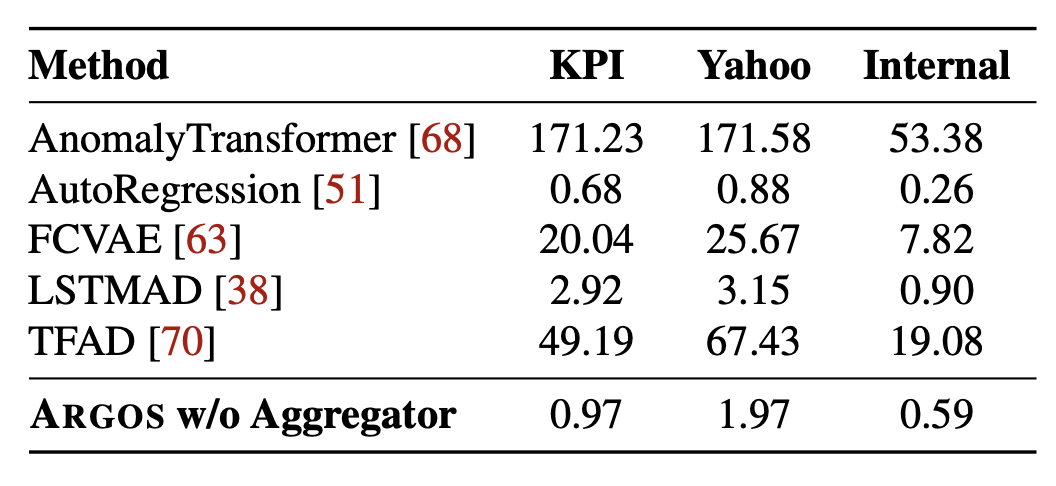
표 6은 세 개의 데이터셋에 대해 ARGOS와 베이스라인들의 추론 지연 시간을 비교한다.
우리는 테스트 세트에서 추론을 수행하고,
데이터셋 내 모든 메트릭 또는 파티션에 대한 평균 지연 시간을 계산한다.
모든 베이스라인과 ARGOS는 CPU를 사용하는 Standard_D16as_v4 VM 환경 [41]에서 실행된다.
Python으로 구현된 이상 탐지 규칙은 경량(lightweight)이기 때문에,
ARGOS는 베이스라인 대비 낮은 추론 지연 시간을 달성한다.
각 데이터셋에서 평균 $F_1$ 점수가 가장 높은 베이스라인과 비교했을 때,
ARGOS는 KPI 데이터셋에서 3.0배, Yahoo 데이터셋에서 34.3배,
Internal 데이터셋에서 1.5배의 속도 향상을 달성한다.
5.7 사례 연구
이 사례 연구에서는, 기존 이상 탐지 모델을 기반으로 ARGOS가 학습한 이상 탐지 규칙이
어떻게 모델의 정확도를 향상시키는지를 보여준다.
예시로 KPI 데이터셋의 e0770 메트릭을 선택하였다.
이 메트릭에서 최고의 베이스라인 모델인 LSTMAD는
테스트 세트에서 0.33이라는 낮은 재현율(recall)을 보인다.
그림 10: KPI 데이터셋의 e0770 메트릭에서 ARGOS의 출력과 LSTMAD 베이스라인의 출력 비교.
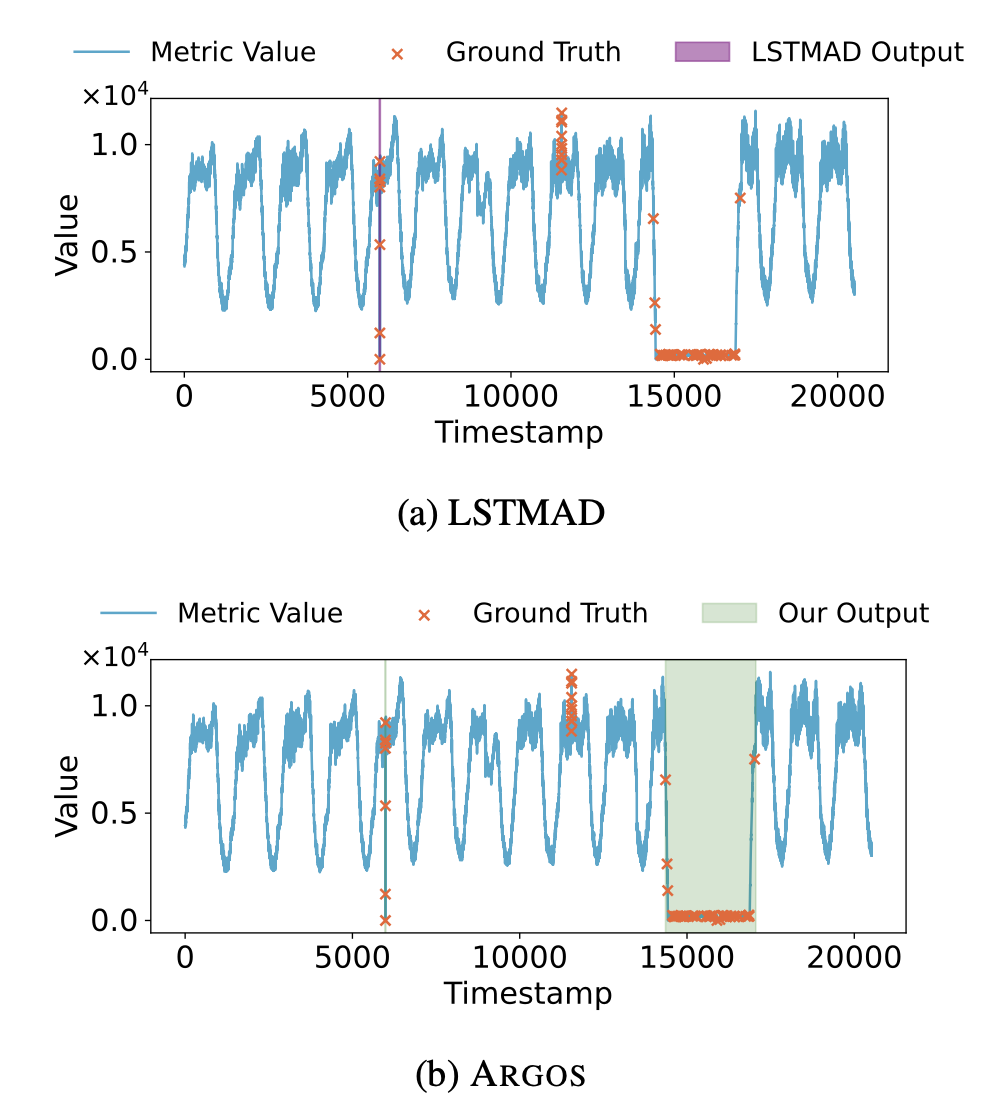
그림 10a는 테스트 세트에 대한 LSTMAD의 출력을 보여준다.
정답(ground-truth) 이상은 총 3개로,
두 개의 스파이크(spike)와 하나의 장기간 지속되는 극단값 구간으로 구성되어 있다.
반면 LSTMAD는 타임스탬프 5,000 부근의 스파이크만 탐지하고,
나머지 두 개의 이상은 탐지하지 못한다.
그림 11: KPI 데이터셋의 e0770 메트릭에서 LSTMAD의 거짓 음성 샘플로부터 학습된 이상 탐지 규칙.

우리는 ARGOS에서 학습 세트의 LSTMAD가 생성한 거짓 음성 샘플을 사용하여 이상 탐지 규칙을 학습한다.
그림 11은 ARGOS가 생성한 규칙을 보여주는데, 이 규칙은 두 개의 조건으로 구성된다.
첫 번째 조건은 급격한 스파이크 또는 하락을 탐지하고,
두 번째 조건은 장기간 지속되는 극단값 구간을 식별한다.
그림 10b는 테스트 세트에 대한 ARGOS의 출력을 보여준다.
여기서 결과는 Aggregator 모듈을 사용하여 LSTMAD의 결과와 규칙의 결과를 집계한 것이다.
특히 두 번째 조건은 타임스탬프 15,000 부근에서 누락되었던 이상을 탐지하는 데 도움을 주며,
재현율을 0.33에서 0.67로 향상시킨다.
또한 타임스탬프 12,000 부근에서는 여전히 거짓 음성이 ARGOS의 출력에 남아 있음을 확인할 수 있다.
이는 해당 샘플의 작은 편차(deviation) 패턴이 학습 세트에 존재하지 않았거나,
규칙에서 스파이크를 탐지하기 위한 임계값이 추가적인 튜닝을 필요로 하기 때문일 수 있다.
6 관련 연구
시계열 이상 탐지
시계열 이상 탐지에 관한 기존 연구들은 주로
딥러닝 기반 방법들 [38,49,51,56,59,63,67,68,70,75] 과 규칙 기반 방법들 [11,37,69] 로 구성된다.
초기의 딥러닝 기반 모델은 현재 윈도우의 관측값을 바탕으로 다음 값을 직접 예측하는 데 초점을 맞추었다 [38,51].
이후 인코더-디코더와 변분 오토인코더(variational encoder)가 도입되면서,
후속 모델들은 입력을 복원(denoising)하는 방식으로 시계열 신호를 재구성하고,
관측된 신호가 재구성된 신호와 크게 다를 경우 이상으로 판별한다 [49,59,63,67,68,70].
딥러닝 기반 방법과 비교했을 때,
규칙 기반 방법은 설명 가능성(explainability) 때문에 산업 현장에서 더욱 널리 사용된다.
Resin [37]은 메모리 사용량을 추적하고,
현재 구간의 사용량이 이전 구간 평균에 표준편차의 세 배를 더한 값보다 클 경우 이상을 보고한다.
마찬가지로 FBDetect [69]는 사용자가 탐지 임계값을 설정할 수 있도록 하며,
메트릭 편차의 크기가 해당 임계값을 초과하면 이상으로 분류한다.
이상 탐지를 위한 LLM
최근에는 LLM의 등장으로 인해 이상 탐지 분야에도 LLM을 활용하는 연구가 진행되고 있다.
로그 기반 이상 탐지에 LLM을 활용하는 연구들이 존재한다 [15,20,29,36].
예를 들어, NeuralLog [29]는 로그 메시지를 의미 벡터(semantic vector)로 변환하고
Transformer 기반 모델을 사용하여 이상을 분류한다.
LogLLM [20]은 정규표현식을 사용해 로그를 전처리하고,
의미 추출을 위해 BERT를 활용하며, 시퀀스 분류를 위해 LLM을 사용한다.
또한 일부 연구는 시계열 이상 탐지에 LLM을 활용하는 방법을 연구하였다 [4,13,35].
이들은 시계열 데이터를 기반으로 LLM을 파인튜닝하거나,
출력 레이블을 얻기 위해 LLM에 직접 프롬프트를 제공한다.
우리가 아는 한, 본 연구는 시계열 이상 탐지를 위해 설명 가능하고
재현 가능한 탐지 규칙을 생성하는 데 LLM을 활용한 최초의 연구이다.
클라우드 신뢰성을 위한 LLM
클라우드 모니터링 외에도, LLM은 근본 원인 분석(root cause analysis)부터
장애 완화(incident mitigation)에 이르기까지
클라우드 신뢰성의 다양한 영역에 활용되고 있다 [2,8,17,23,62,65,73].
RCACopilot [8]은 자동화된 클라우드 장애 근본 원인 분석을 위한 온콜(on-call) 시스템으로,
사용자 정의 가능한 장애 처리 워크플로우와 LLM 기반 근본 원인 예측을 결합하여
진단 데이터 수집을 간소화(streamline)한다.
[73]은 파인튜닝 없이 LLM을 사용하여 근본 원인 분석을 수행하는 in-context learning 방법을 제안하였다.
이 방법은 과거 장애 사례를 예시로 활용하여 모델에 정보를 제공하며,
정확도와 활용성 측면에서 파인튜닝된 모델보다 우수한 성능을 보인다.
Atlas [65]는 대규모 언어 모델을 활용하여
비정형 시스템 정보를 구조화된 인과 그래프(causal graph)로 자동 변환하는 도구로,
고품질 인과 표현(causal representation)을 구축함으로써
클라우드 시스템에서의 장애 위치 파악(fault localization)을 향상시킨다.
7 결론
실제 운영 환경의 이상 탐지 시스템은
설명 가능성(explainability), 재현 가능성(reproducibility), 그리고 자율성(autonomy)이라는
세 가지 필수 속성을 동시에 만족해야 한다.
본 논문에서는 이상을 탐지하기 위해
LLM을 통해 규칙을 자율적으로 생성하는 시계열 이상 탐지 시스템 ARGOS를 제안하였다.
시계열 이해와 코드 생성에 대한 LLM의 능력을 활용함으로써,
ARGOS는 생성된 규칙이 설명 가능하면서도 재현 가능하도록 보장한다.
ARGOS는 에이전트 기반 파이프라인으로 구성되어 있으며,
이상 탐지 규칙을 반복적으로 제안(propose), 수정(repair), 검토(review)하여 규칙의 품질을 보장한다.
또한 ARGOS는 정확도를 보장하기 위해 모델 융합(model fusion)을 도입하고,
효율성을 향상시키기 위해 top-k 규칙 선택을 수행한다.
공개 데이터셋과 내부 데이터셋을 대상으로 한 실험 결과,
ARGOS는 최신(state-of-the-art) 시계열 이상 탐지 방법들을 능가하는 성능을 보였으며,
최대 28.3%의 $F_1$ 점수 향상을 달성하였다.
참고문헌
[1] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023.
GPT-4 technical report.
(GPT-4 기술 보고서.)
arXiv preprint arXiv:2303.08774.[2] Toufique Ahmed, Supriyo Ghosh, Chetan Bansal, Thomas Zimmermann, Xuchao Zhang, and Saravan Rajmohan. 2023.
Recommending root-cause and mitigation steps for cloud incidents using large language models.
(대규모 언어 모델을 이용한 클라우드 장애의 근본 원인 및 대응 방안 추천.)
Proceedings of the IEEE/ACM International Conference on Software Engineering (ICSE), 1737–1749.[3] Sarah Alnegheimish, Dongyu Liu, Carles Sala, Laure Berti-Equille, and Kalyan Veeramachaneni. 2022.
Sintel: A machine learning framework to extract insights from signals.
(신호 데이터로부터 인사이트를 추출하기 위한 머신러닝 프레임워크 Sintel.)
Proceedings of the ACM SIGMOD Conference, 1855–1865.[4] Sarah Alnegheimish, Linh Nguyen, Laure Berti-Equille, and Kalyan Veeramachaneni. 2024.
Large language models can be zero-shot anomaly detectors for time series?
(대규모 언어 모델은 시계열 이상 탐지기를 제로샷으로 수행할 수 있는가?)
arXiv preprint arXiv:2405.14755.[5] Dan Ardelean, Amer Diwan, and Chandra Erdman. 2018.
Performance analysis of cloud applications.
(클라우드 애플리케이션의 성능 분석.)
15th USENIX Symposium on Networked Systems Design and Implementation (NSDI), 405–417.[6] Tom B. Brown. 2020.
Language models are few-shot learners.
(언어 모델은 소수 예제(Few-shot) 학습자이다.)
arXiv preprint arXiv:2005.14165.[7] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021.
Evaluating large language models trained on code.
(코드로 학습된 대규모 언어 모델 평가.)
arXiv preprint arXiv:2107.03374.[8] Yinfang Chen, Huaibing Xie, Minghua Ma, Yu Kang, Xin Gao, Liu Shi, Yunjie Cao, Xuedong Gao, Hao Fan, Ming Wen, Jun Zeng, Supriyo Ghosh, Xuchao Zhang, Chaoyun Zhang, Qingwei Lin, Saravan Rajmohan, Dongmei Zhang, and Tianyin Xu. 2024.
Automatic root cause analysis via large language models for cloud incidents.
(대규모 언어 모델을 활용한 클라우드 장애 자동 근본 원인 분석.)
Proceedings of EuroSys 2024, 674–688.[9] Qian Cheng, Doyen Sahoo, Amrita Saha, Wenzhuo Yang, Chenghao Liu, Gerald Woo, Manpreet Singh, Silvio Saverese, and Steven C. H. Hoi. 2023.
AI for IT operations (AIOps) on cloud platforms: Reviews, opportunities and challenges.
(클라우드 플랫폼의 AIOps: 현황, 기회 및 과제.)
arXiv preprint arXiv:2304.04661.[10] Ludmila Cherkasova, Kivanc Ozonat, Ningfang Mi, Julie Symons, and Evgenia Smirni. 2009.
Automated anomaly detection and performance modeling of enterprise applications.
(엔터프라이즈 애플리케이션의 자동 이상 탐지 및 성능 모델링.)
ACM Transactions on Computer Systems 27(3).[11] Mike Chow, Yang Wang, William Wang, Ayichew Hailu, Rohan Bopardikar, Bin Zhang, Jialiang Qu, David Meisner, Santosh Sonawane, Yunqi Zhang, Rodrigo Paim, Mack Ward, Ivor Huang, Matt McNally, Daniel Hodges, Zoltan Farkas, Caner Gocmen, Elvis Huang, and Chunqiang Tang. 2024.
ServiceLab: Preventing tiny performance regressions at hyperscale through pre-production testing.
(사전 테스트를 통한 초대규모 환경의 미세 성능 저하 방지 시스템 ServiceLab.)
18th USENIX Symposium on Operating Systems Design and Implementation (OSDI), 545–562.[12] Yinlin Deng, Chunqiu Steven Xia, Haoran Peng, Chenyuan Yang, and Lingming Zhang. 2023.
Large language models are zero-shot fuzzers: Fuzzing deep-learning libraries via large language models.
(대규모 언어 모델을 활용한 제로샷 퍼징 기법.)
Proceedings of the ACM SIGSOFT International Symposium on Software Testing and Analysis, 423–435.[13] Manqing Dong, Hao Huang, and Longbing Cao. 2024.
Can LLMs serve as time series anomaly detectors?
(LLM은 시계열 이상 탐지기로 활용될 수 있는가?)
arXiv preprint arXiv:2408.03475.[14] Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024.
The Llama 3 herd of models.
(Llama 3 모델 계열.)
arXiv preprint arXiv:2407.21783.[15] Chris Egersdoerfer, Di Zhang, and Dong Dai. 2023.
Early exploration of using ChatGPT for log-based anomaly detection on parallel file systems logs.
(병렬 파일 시스템 로그 기반 이상 탐지에 ChatGPT를 활용하기 위한 초기 연구.)
Proceedings of HPDC 2023, 315–316.[16] Astha Garg, Wenyu Zhang, Jules Samaran, Ramasamy Savitha, and Chuan-Sheng Foo. 2022.
An evaluation of anomaly detection and diagnosis in multivariate time series.
(다변량 시계열에서의 이상 탐지 및 진단 평가.)
IEEE Transactions on Neural Networks and Learning Systems 33(6), 2508–2517.[17] Drishti Goel, Fiza Husain, Aditya Singh, Supriyo Ghosh, Anjaly Parayil, Chetan Bansal, Xuchao Zhang, and Saravan Rajmohan. 2024.
X-lifecycle learning for cloud incident management using LLMs.
(LLM 기반 클라우드 장애 관리용 X-Lifecycle Learning.)
Companion Proceedings of FSE 2024, 417–428.[18] Nate Gruver, Marc Finzi, Shikai Qiu, and Andrew G. Wilson. 2024.
Large language models are zero-shot time series forecasters.
(대규모 언어 모델을 활용한 제로샷 시계열 예측.)
Advances in Neural Information Processing Systems (NeurIPS) 36.[19] Jiawei Tyler Gu, Xudong Sun, Wentao Zhang, Yuxuan Jiang, Chen Wang, Mandana Vaziri, Owolabi Legunsen, and Tianyi Xu. 2023.
Acto: Automatic end-to-end testing for operation correctness of cloud system management.
(클라우드 시스템 관리의 운영 정확성을 위한 자동 종단간 테스트 시스템 Acto.)
Proceedings of the ACM Symposium on Operating Systems Principles (SOSP).[20] Wei Guan, Jian Cao, Shiyou Qian, and Jianqi Gao. 2024.
LogLLM: Log-based anomaly detection using large language models.
(대규모 언어 모델을 활용한 로그 기반 이상 탐지.)
2024.[21] Yigong Hu, Gongqi Huang, and Peng Huang. 2020.
Automated reasoning and detection of specious configuration in large systems with symbolic execution.
(심볼릭 실행을 이용한 대규모 시스템의 잘못된 설정 자동 탐지.)
14th USENIX Symposium on Operating Systems Design and Implementation (OSDI), 719–734.[22] Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. 2024.
GPT-4o system card.
(GPT-4o 시스템 카드.)
arXiv preprint arXiv:2410.21276.[23] Yuxuan Jiang, Chaoyun Zhang, Shilin He, Zhihao Yang, Minghua Ma, Si Qin, Yu Kang, Yingnong Dang, Saravan Rajmohan, Qingwei Lin, et al. 2024.
Xpert: Empowering incident management with query recommendations via large language models.
(대규모 언어 모델 기반 질의 추천을 활용한 장애 관리 지원 시스템 Xpert.)
Proceedings of the IEEE/ACM International Conference on Software Engineering (ICSE), 1–13.[24] Ziheng Jiang, Haibin Lin, Yinmin Zhong, Qi Huang, Yangrui Chen, Zhi Zhang, Yanghua Peng, Xiang Li, Cong Xie, Shibiao Nong, et al. 2024.
MegaScale: Scaling large language model training to more than 10,000 GPUs.
(1만 개 이상의 GPU로 확장 가능한 대규모 언어 모델 학습 시스템 MegaScale.)
21st USENIX Symposium on Networked Systems Design and Implementation (NSDI), 745–760.[25] Ming Jin, Shiyu Wang, Lintao Ma, Zhixuan Chu, James Y. Zhang, Xiaoming Shi, Pin-Yu Chen, Yuxuan Liang, Yuan-Fang Li, Shirui Pan, et al. 2023.
Time-LLM: Time series forecasting by reprogramming large language models.
(대규모 언어 모델 재프로그래밍을 통한 시계열 예측.)
arXiv preprint arXiv:2310.01728.[26] Siwon Kim, Kukjin Choi, Hyun-Soo Choi, Byunghan Lee, and Sungroh Yoon. 2022.
Towards a rigorous evaluation of time-series anomaly detection.
(시계열 이상 탐지의 엄격한 평가를 위한 연구.)
Proceedings of the AAAI Conference on Artificial Intelligence 36(7) (2022), 7194–7201.[27] Nikolay Laptev, Saeed Amizadeh, and Youssef Billawala. 2015.
A benchmark dataset for time series anomaly detection.
(시계열 이상 탐지를 위한 벤치마크 데이터셋.)
Yahoo Research (2015).[28] Nikolay Laptev, Saeed Amizadeh, and Ian Flint. 2015.
Generic and scalable framework for automated time-series anomaly detection.
(자동화된 시계열 이상 탐지를 위한 범용적이고 확장 가능한 프레임워크.)
Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ’15) (2015), 1939–1947.[29] Van-Hoang Le and Hongyu Zhang. 2021.
Log-based anomaly detection without log parsing.
(로그 파싱 없이 수행하는 로그 기반 이상 탐지.)
2021 36th IEEE/ACM International Conference on Automated Software Engineering (ASE) (2021), 492–504.[30] Yann LeCun, Léon Bottou, Genevieve B. Orr, and Klaus-Robert Müller. 2002.
Efficient backprop.
(효율적인 역전파 학습.)
In Neural Networks: Tricks of the Trade, 9–50.[31] Sebastien Levy, Randolph Yao, Youjiang Wu, Yingnong Dang, Peng Huang, Zheng Mu, Pu Zhao, Tarun Ramani, Naga Govindaraju, Xukun Li, Qingwei Lin, Gil Lapid Shafriri, and Murali Chintalapati. 2020.
Predictive and adaptive failure mitigation to avert production cloud VM interruptions.
(프로덕션 클라우드 VM 중단을 방지하기 위한 예측 및 적응형 장애 완화 기법.)
14th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’20) (2020), 1155–1170.[32] Ze Li, Qian Cheng, Ken Hsieh, Yingnong Dang, Peng Huang, Pankaj Singh, Xinsheng Yang, Qingwei Lin, Youjiang Wu, Sebastien Levy, and Murali Chintalapati. 2020.
Gandalf: An intelligent, End-To-End analytics service for safe deployment in Large-Scale cloud infrastructure.
(대규모 클라우드 인프라의 안전한 배포를 위한 지능형 엔드투엔드 분석 서비스 Gandalf.)
17th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’20) (2020), 389–402.[33] Zeyan Li, Nengwen Zhao, Shenglin Zhang, Yongqian Sun, Pengfei Chen, Xidao Wen, Minghua Ma, and Dan Pei. 2022.
Constructing large-scale real-world benchmark datasets for aiops.
(AIOps를 위한 대규모 실제 벤치마크 데이터셋 구축.)
arXiv preprint arXiv:2208.03938 (2022).[34] Zhong Li, Yuxuan Zhu, and Matthijs Van Leeuwen. 2023.
A survey on explainable anomaly detection.
(설명 가능한 이상 탐지에 대한 서베이.)
ACM Transactions on Knowledge Discovery from Data 18(1) (2023).[35] Jun Liu, Chaoyun Zhang, Jiaxu Qian, Minghua Ma, Si Qin, Chetan Bansal, Qingwei Lin, Saravan Rajmohan, and Dongmei Zhang. 2024.
Large language models can deliver accurate and interpretable time series anomaly detection.
(대규모 언어 모델을 활용한 정확하고 해석 가능한 시계열 이상 탐지.)
arXiv preprint arXiv:2405.15370 (2024).[36] Yilun Liu, Shimin Tao, Weibin Meng, Feiyu Yao, Xiaofeng Zhao, and Hao Yang. 2024.
Logprompt: Prompt engineering towards zero-shot and interpretable log analysis.
(제로샷 및 해석 가능한 로그 분석을 위한 프롬프트 엔지니어링.)
ICSE Companion Proceedings (2024), 364–365.[37] Chang Lou, Cong Chen, Peng Huang, Yingnong Dang, Si Qin, Xinsheng Yang, Xukun Li, Qingwei Lin, and Murali Chintalapati. 2022.
RESIN: A holistic service for dealing with memory leaks in production cloud infrastructure.
(프로덕션 클라우드 인프라의 메모리 누수를 해결하기 위한 통합 서비스 RESIN.)
16th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’22) (2022), 109–125.[38] Pankaj Malhotra, Lovekesh Vig, Gautam Shroff, and Puneet Agarwal. 2015.
Long short term memory networks for anomaly detection in time series.
(시계열 이상 탐지를 위한 LSTM 네트워크.)
(2015).[39] Microsoft. 2024.
Azure OpenAI Service Models.
(Azure OpenAI 서비스 모델 문서.)
Microsoft Documentation.[40] Microsoft. 2024.
Azure OpenAI Service – Advanced Language Models.
(Azure OpenAI 서비스 소개.)
Microsoft Documentation.[41] Microsoft. 2024.
Dasv4 Size Series – Azure Virtual Machines.
(Azure Dasv4 가상 머신 사양.)
Microsoft Documentation.[42] Microsoft. 2024.
NDM_A100_v4 Sizes Series – Azure Virtual Machines.
(Azure NDM A100 v4 가상 머신 사양.)
Microsoft Documentation.[43] Rodrigo Nogueira, Zhiying Jiang, and Jimmy Lin. 2021.
Investigating the limitations of transformers with simple arithmetic tasks.
(간단한 산술 문제를 통한 Transformer의 한계 분석.)
arXiv preprint arXiv:2102.13019 (2021).[44] NVIDIA. 2024.
How to detect which node causes a NCCL hang.
(NCCL Hang을 유발한 노드를 탐지하는 방법.)
NVIDIA GitHub Issue Documentation.[45] Shuyin Ouyang, Jie M. Zhang, Mark Harman, and Meng Wang. 2024.
An empirical study of the non-determinism of ChatGPT in code generation.
(코드 생성에서 ChatGPT 비결정성에 대한 실증 연구.)
ACM Transactions on Software Engineering and Methodology (2024).[46] Guansong Pang and Charu Aggarwal. 2021.
Toward explainable deep anomaly detection.
(설명 가능한 딥러닝 기반 이상 탐지를 향하여.)
Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining (2021), 4056–4057.[47] Kashif Rasul, Arjun Ashok, Andrew Robert Williams, Arian Khorasani, George Adamopoulos, Rishika Bhagwatkar, Marin Biloš, Hena Ghonia, Nadhir Hassen, Anderson Schneider, et al. 2023.
Lag-Llama: Towards foundation models for time series forecasting.
(시계열 예측을 위한 파운데이션 모델 Lag-Llama.)
R0-FoMo Workshop (2023).[48] Youcef Remil, Anes Bendimerad, Romain Mathonat, and Mehdi Kaytoue. 2024.
AIOps solutions for incident management: Technical guidelines and a comprehensive literature review.
(사고 관리를 위한 AIOps 솔루션: 기술 가이드라인 및 종합 문헌 조사.)
arXiv preprint arXiv:2404.01363 (2024).[49] Hansheng Ren, Bixiong Xu, Yujing Wang, Chao Yi, Congrui Huang, Xiaoyu Kou, Tony Xing, Mao Yang, Jie Tong, and Qi Zhang. 2019.
Time-series anomaly detection service at Microsoft.
(마이크로소프트의 시계열 이상 탐지 서비스.)
KDD ’19 (2019), 3009–3017.[50] Herbert Robbins and Sutton Monro. 1951.
A stochastic approximation method.
(확률적 근사 방법.)
The Annals of Mathematical Statistics (1951), 400–407.[51] Peter J. Rousseeuw and A. Leroy. 2005.
Robust regression and outlier detection.
(강건 회귀와 이상치 탐지.)
Wiley Series in Probability and Statistics (2005).[52] Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, et al. 2023.
Code Llama: Open foundation models for code.
(코드를 위한 오픈 파운데이션 모델 Code Llama.)
arXiv preprint arXiv:2308.12950 (2023).[53] Lukas Ruff, Robert Vandermeulen, Nico Goernitz, Lucas Deecke, Shoaib Ahmed Siddiqui, Alexander Binder, Emmanuel Müller, and Marius Kloft. 2018.
Deep one-class classification.
(딥 원클래스 분류.)
Proceedings of the 35th International Conference on Machine Learning (ICML) (2018), 4393–4402.[54] Amazon Web Services. 2021.
Summary of the AWS service event in the Northern Virginia (us-east-1) region.
(AWS 북버지니아 리전 장애 사건 요약.)
AWS Incident Report.[55] Haotian Si, Jianhui Li, Changhua Pei, Hang Cui, Jingwen Yang, Yongqian Sun, Shenglin Zhang, Jingjing Li, Haiming Zhang, Jing Han, et al. 2024.
TimeseriesBench: An industrial-grade benchmark for time series anomaly detection models.
(산업 수준의 시계열 이상 탐지 벤치마크 TimeseriesBench.)
arXiv preprint arXiv:2402.10802 (2024).[56] Alban Siffer, Pierre-Alain Fouque, Alexandre Termier, and Christine Largouet. 2017.
Anomaly detection in streams with extreme value theory.
(극단값 이론을 이용한 스트림 이상 탐지.)
KDD ’17 (2017), 1067–1075.[57] Yifan Song, Guoyin Wang, Sujian Li, and Bill Yuchen Lin. 2024.
The good, the bad, and the greedy: Evaluation of LLMs should not ignore non-determinism.
(LLM 평가에서 비결정성을 무시해서는 안 된다는 연구.)
arXiv preprint arXiv:2407.10457 (2024).[58] Ilya Sutskever, Oriol Vinyals, and Quoc V. Le. 2014.
Sequence to sequence learning with neural networks.
(신경망을 이용한 시퀀스-투-시퀀스 학습.)
Advances in Neural Information Processing Systems (NIPS ’14) (2014), 3104–3112.[59] Shreshth Tuli, Giuliano Casale, and Nicholas R. Jennings. 2022.
TranAD: Deep transformer networks for anomaly detection in multivariate time series data.
(다변량 시계열 데이터 이상 탐지를 위한 Transformer 기반 모델 TranAD.)
arXiv preprint arXiv:2201.07284 (2022).[60] Abhishek Verma, Luis Pedrosa, Madhukar Korupolu, David Oppenheimer, Eric Tune, and John Wilkes. 2015.
Large-scale cluster management at Google with Borg.
(Google Borg를 이용한 대규모 클러스터 관리.)
Proceedings of the Tenth European Conference on Computer Systems (EuroSys ’15) (2015).[61] Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2022.
Self-consistency improves chain of thought reasoning in language models.
(언어 모델의 Chain-of-Thought 추론을 향상시키는 Self-Consistency.)
arXiv preprint arXiv:2203.11171 (2022).[62] Zefan Wang, Zichuan Liu, Yingying Zhang, Aoxiao Zhong, Jihong Wang, Fengbin Yin, Lunting Fan, Lingfei Wu, and Qingsong Wen. 2024.
RCAgent: Cloud root cause analysis by autonomous agents with tool-augmented large language models.
(도구 증강 LLM 기반 자율 에이전트를 활용한 클라우드 장애 원인 분석.)
Proceedings of the 33rd ACM International Conference on Information and Knowledge Management (CIKM ’24) (2024), 4966–4974.[63] Zexin Wang, Changhua Pei, Minghua Ma, Xin Wang, Zhihan Li, Dan Pei, Saravan Rajmohan, Dongmei Zhang, Qingwei Lin, Haiming Zhang, et al. 2024.
Revisiting VAE for unsupervised time series anomaly detection: A frequency perspective.
(주파수 관점에서 재조명한 VAE 기반 비지도 시계열 이상 탐지.)
Proceedings of The ACM Web Conference 2024 (2024), 3096–3105.[64] Lingmei Weng, Yigong Hu, Peng Huang, Jason Nieh, and Junfeng Yang. 2023.
Effective performance issue diagnosis with value-assisted cost profiling.
(Value-assisted Cost Profiling을 이용한 성능 문제 진단.)
Proceedings of the Eighteenth European Conference on Computer Systems (EuroSys ’23) (2023), 1–17.[65] Zhiqiang Xie, Yujia Zheng, Lizi Ottens, Kun Zhang, Christos Kozyrakis, and Jonathan Mace. 2024.
Cloud Atlas: Efficient fault localization for cloud systems using language models and causal insight.
(언어 모델과 인과 분석을 활용한 클라우드 시스템 장애 위치 추적.)
arXiv preprint arXiv:2407.08694 (2024).[66] Yifan Xiong, Yuting Jiang, Ziyue Yang, Lei Qu, Guoshuai Zhao, Shuguang Liu, Dong Zhong, Boris Pinzur, Jie Zhang, Yang Wang, et al. 2024.
SuperBench: Improving cloud AI infrastructure reliability with proactive validation.
(사전 검증을 통한 클라우드 AI 인프라 신뢰성 향상.)
2024 USENIX Annual Technical Conference (USENIX ATC ’24) (2024), 835–850.[67] Haowen Xu, Wenxiao Chen, Nengwen Zhao, Zeyan Li, Jiahao Bu, Zhihan Li, Ying Liu, Youjian Zhao, Dan Pei, Yang Feng, et al. 2018.
Unsupervised anomaly detection via variational auto-encoder for seasonal KPIs in web applications.
(웹 애플리케이션의 계절성 KPI를 위한 VAE 기반 비지도 이상 탐지.)
Proceedings of the 2018 World Wide Web Conference (2018), 187–196.[68] Jiehui Xu, Haixu Wu, Jianmin Wang, and Mingsheng Long. 2021.
Anomaly Transformer: Time series anomaly detection with association discrepancy.
(Association Discrepancy를 활용한 시계열 이상 탐지 모델.)
arXiv preprint arXiv:2110.02642 (2021).[69] Dong Young Yoon, Yang Wang, Miao Yu, Elvis Huang, Juan Ignacio Jones, Abhinay Kukkadapu, Osman Kocas, Jonathan Wiepert, Kapil Goenka, Sherry Chen, Yanjun Lin, Zhihui Huang, Jocelyn Kong, Michael Chow, and Chunqiang Tang. 2024.
FBDetect: Catching tiny performance regressions at hyperscale through in-production monitoring.
(대규모 서비스 환경에서 미세한 성능 저하를 탐지하는 FBDetect.)
Proceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles (SOSP ’24) (2024), 522–540.[70] Chaoli Zhang, Tian Zhou, Qingsong Wen, and Liang Sun. 2022.
TFAD: A decomposition time series anomaly detection architecture with time-frequency analysis.
(시간-주파수 분석 기반 시계열 이상 탐지 아키텍처 TFAD.)
Proceedings of the 31st ACM International Conference on Information and Knowledge Management (CIKM ’22) (2022), 2497–2507.[71] Chaoyun Zhang, Randolph Yao, Si Qin, Ze Li, Shekhar Agrawal, Binit R. Mishra, Tri Tran, Minghua Ma, Qingwei Lin, Murali Chintalapati, and Dongmei Zhang. 2024.
Deoxys: A causal inference engine for unhealthy node mitigation in large-scale cloud infrastructure.
(대규모 클라우드 인프라의 비정상 노드 완화를 위한 인과 추론 엔진.)
Proceedings of the 2024 ACM Symposium on Cloud Computing (SoCC ’24) (2024), 361–379.[72] Lingzhe Zhang, Tong Jia, Mengxi Jia, Yifan Wu, Aiwei Liu, Yong Yang, Zhonghai Wu, Xuming Hu, Philip S. Yu, and Ying Li. 2024.
A survey of AIOps for failure management in the era of large language models.
(대규모 언어 모델 시대의 장애 관리를 위한 AIOps 서베이.)
arXiv preprint arXiv:2406.11213 (2024).[73] Xuchao Zhang, Supriyo Ghosh, Chetan Bansal, Rujia Wang, Minghua Ma, Yu Kang, and Saravan Rajmohan. 2024.
Automated root causing of cloud incidents using in-context learning with GPT-4.
(GPT-4 기반 In-Context Learning을 활용한 클라우드 장애 원인 분석.)
Companion Proceedings of the 32nd ACM International Conference on the Foundations of Software Engineering (FSE ’24) (2024), 266–277.[74] Yue Zhao. 2024.
Towards reproducible, automated, and scalable anomaly detection.
(재현 가능하고 자동화되며 확장 가능한 이상 탐지를 향하여.)
AAAI Conference on Artificial Intelligence (2024).[75] Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang. 2021.
Informer: Beyond efficient transformer for long sequence time-series forecasting.
(장기 시계열 예측을 위한 Informer.)
Proceedings of the AAAI Conference on Artificial Intelligence 35 (2021), 11106–11115.
부록 (Appendices)
A 프롬프트
A.1 Detection Agent
그림 12는 ARGOS에서 Detection Agent가 사용하는 프롬프트 템플릿을 보여준다.
이 템플릿은 먼저 Detection Agent를 위한 상위 수준의 작업 요약으로 시작하며,
그 다음에는 데이터 형식과 함수 불변식(function invariants)에 대한 단계별 지침이 이어진다.
마지막으로, 이상 탐지 규칙의 정확도를 향상시키기 위해
Detection Agent가 따르는 것이 유용하다고 경험적으로 확인한 중요한 주의사항들을 제공한다.
Function invariants(함수 불변식)은 함수가 항상 만족해야 하는 조건이나 규칙을 의미한다.
즉, 입력이 달라지더라도 함수의 동작 방식, 입력·출력 형식, 반환값의 의미 등은 항상 동일하게 유지되어야 한다.
그림 12: ARGOS의 Detection Agent에서 사용되는 프롬프트 템플릿.
Detection Agent를 위한 프롬프트 템플릿
작업 요약(Task Summary):
당신은 시계열 데이터의 한 조각이 이상(negative)인지 아닌지(positive)를 판단하기 위한 탐지 규칙을 작성하도록 사람들을 돕는 AI 어시스턴트이다.
이 시계열 데이터는 클라우드 서비스 작업 중에 수집된다 …
단계별 지침(Step-by-step Instructions):
다음 단계에 따라 작업을 수행해야 한다:
다음 형식의 데이터 샘플이 제공된다: …
주어진 negative/abnormal 샘플의 패턴을 설명하고, 주어진 모든 positive/normal 샘플을 제외하기 위한 다양한 규칙을 작성할 수 있도록 Python 함수
inference(sample: np.ndarray) -> labels: np.ndarray를 제공해야 한다.이 함수는 shape이
(X, 2)인 numpy 배열 샘플을 입력으로 받으며, 각 행은(value, index)튜플이다.반환값은 shape이
(X,)인np.ndarray형태의 labels여야 하며,각 index에 대해
value=1은 해당 index의 데이터가 이상임을 의미하고,value=0은 해당 index의 데이터가 정상임을 의미한다.이상(anomaly)뿐만 아니라 정상 데이터가 어떻게 동작하는지도 주석(comments)으로 설명할 수 있으며, 형식은
"Normal Rule 1 \n Normal Rule 2 ..."와 같다.이상적으로는
inference함수가 어떠한 이상 index도 반환하지 않는 경우, 데이터는 주석에 설명한 모든 정상 규칙을 반드시 만족해야 한다.반드시 다음 형식을 사용해야 한다: …
중요 참고 사항(Important Notes):
코드에는 예제 데이터에서 제공된 레이블에 대한 어떠한 정보도 하드코딩해서는 안 된다.
이상 데이터의 인덱스를 하드코딩해서는 안 된다.
Python 코드가 올바르며 어떠한 오류 없이 실행될 수 있도록 해야 한다.
코드가 외부 라이브러리를 사용하는 경우, 해당 라이브러리의 import 문을 코드에 포함해야 한다.
A.2 Repair Agent
그림 13은 ARGOS에서 Repair Agent가 사용하는 프롬프트 템플릿을 보여준다.
코드에 문법 오류(syntax errors)가 포함되어 있는 경우, Repair Agent에는 오류 메시지와 잘못된 규칙이 제공된다.
Repair Agent는 모든 문법 오류가 수정될 때까지 규칙의 수정된 버전을 제안한다.
그림 13: ARGOS의 Repair Agent에서 사용되는 프롬프트 템플릿.
Repair Agent를 위한 프롬프트 템플릿
작업 요약(Task Summary):
당신은 Python 코드의 문법 오류(syntax errors)와 실행 시간 오류(runtime errors)를 수정하는 AI 어시스턴트이다.
문법 오류 및/또는 실행 시간 오류에 대한 세부 정보를 포함하는 오류 메시지와 함께 Python 코드 조각이 제공된다.
당신은 코드의 오류를 수정하고, 코드가 어떠한 오류 없이 실행될 수 있도록 해야 한다 …
단계별 지침(Step-by-step Instructions):
다음 단계에 따라 작업을 수행해야 한다:
다음 형식의 데이터 샘플이 제공된다: …
주어진 negative/abnormal 샘플의 패턴을 설명하고 기억하며, 주어진 모든 positive/normal 샘플을 제외하기 위한 다양한 규칙을 작성하는 Python 함수
inference(sample: np.ndarray) -> labels: np.ndarray가 제공된다.이 함수는 shape이
(X, 2)인 numpy 배열 샘플을 입력으로 받는다 …
중요 참고 사항(Important Notes):
입력 코드와 동일한 형식을 따르도록 수정된 코드를 출력해야 하며, 코드의 첫 번째 줄에는
*** python begin ***을, 마지막 줄에는*** python end ***를 사용하여 코드를 감싸야 한다.수정된 코드를 감쌀 때는
*** python begin ***과*** python end ***를 단 한 번만 사용해야 하며, 다른 용도로 사용해서는 안 된다.코드의 오류를 수정하고 코드가 어떠한 오류 없이 실행될 수 있도록 하는 데만 집중해야 한다.
오류와 관련되지 않은 코드의 다른 로직은 변경해서는 안 된다.
A.3 Review Agent
그림 14는 ARGOS에서 Review Agent가 사용하는 프롬프트 템플릿을 보여준다.
코드가 이전 반복(iteration)과 비교하거나 기존 이상 탐지 모델과 비교했을 때
정확도 저하(accuracy regression)를 보이는 경우,
Review Agent에는 현재 코드,
존재하는 경우 이전 반복과의 코드 차이(code difference), 그리고 성능 지표 비교 결과가 제공된다.
추가적으로, Review Agent에는 현재 코드가 잘못 예측한 반면
이전 코드 또는 모델은 올바르게 예측한 오류 사례들도 제공된다.
Review Agent는 성능 저하가 완화될 때까지 새로운 규칙 집합을 제안한다.
그림 14: ARGOS의 Review Agent가 사용하는 프롬프트 템플릿.
Review Agent를 위한 프롬프트 템플릿
작업 요약(Task Summary):
당신은 Python 코드의 변경 사항을 검토하고 수정 사항을 제안하는 AI 어시스턴트이다.
주어진 negative/abnormal 샘플의 패턴을 설명하고 기억하며, 주어진 모든 positive/normal 샘플을 제외하기 위한 다양한 이상 탐지 규칙이 포함된 Python 코드가 제공된다.
이 Python 코드의 규칙들은 이상 탐지를 수행하는 이상 탐지 모델과 함께 사용된다.
규칙과 이상 탐지 모델은 모두 이상 레이블을 생성하며, 최종 성능은 양쪽에서 생성된 이상 레이블을 결합한 결과를 정답 레이블(ground-truth labels)과 비교하여 평가된다 …
단계별 지침(Step-by-step Instructions):
다음 단계에 따라 작업을 수행해야 한다:
다음 형식의 데이터 샘플이 제공된다: …
주어진 negative/abnormal 샘플의 패턴을 설명하고 기억하며, 주어진 모든 positive/normal 샘플을 제외하기 위한 다양한 규칙을 작성하는 Python 함수
inference(sample: np.ndarray) -> labels: np.ndarray가 제공된다 …검토 과정은 규칙 생성(rule generation)의 단계에 따라 달라진다.
이전 코드가 존재하지 않는다면, 이는 규칙에 대한 첫 번째 반복(iteration)임을 의미한다.
규칙을 위한 현재 코드가 제공되며, 현재 코드와 이상 탐지 모델을 결합한 성능 지표, 그리고 이상 탐지 모델만 실행했을 때의 기준 성능(baseline performance)이 함께 제공된다 …
이전 코드가 존재한다면, 이는 규칙에 대해 반복적으로 개선을 수행하는 과정임을 의미한다.
현재 코드와 이전 코드를 비교한 코드 차이(code difference)가 추가로 제공된다.
우리의 목표는 현재 코드의 성능 지표가 이전 코드보다 더 좋아지도록 만드는 것이다.
현재 코드의 성능 지표와, 기준 성능 또는 이전 코드의 성능 중 하나가 다음 형식으로 제공된다 … …
이전 코드가 존재하는 경우, 다음 형식으로 코드 차이(code difference)가 제공된다 …
또한 현재 코드가 잘못 예측했지만 이전 코드 또는 이상 탐지 모델은 올바르게 예측한 오답 사례들이 제공된다 …
중요 참고 사항(Important Notes):
입력 코드와 동일한 형식을 따르도록 수정된 코드를 출력해야 하며, 코드의 첫 번째 줄에는
*** python begin ***을, 마지막 줄에는*** python end ***를 사용하여 코드를 감싸야 한다.수정된 코드를 감쌀 때는
*** python begin ***과*** python end ***를 단 한 번만 사용해야 하며, 다른 용도로 사용해서는 안 된다.Python 코드가 올바르며 어떠한 오류 없이 실행될 수 있도록 해야 한다.
코드에서 외부 라이브러리를 사용하는 경우, 해당 라이브러리의 import 문을 코드에 포함해야 한다.